Embed Size (px)
Citation preview

UNIVERSIDAD DE COSTA RICA
SISTEMA DE ESTUDIOS DE POSGRADO
INTEGRACIÓN DE ETIQUETADORES GRAMATICALES PARA
ESPAÑOL COMO UN SERVICIO
Trabajo final de investigación aplicada sometido a la
consideración de la Comisión del Programa de Estudios de
Posgrado en Computación e Informática para optar al grado
y título de Maestría Profesional en Computación e
Informática
MARCO ANTONIO GONZÁLEZ ROESCH
Ciudad Universitaria Rodrigo Facio, Costa Rica
2014

ii
“Este trabajo final de investigación aplicada fue aceptado por la
Comisión del Programa de Estudios de Posgrado en Computación e
Informática de la Universidad de Costa Rica, como requisito parcial
para optar al grado y título de Maestría Profesional en
Computación e Informática.”
Dr. Jorge Leoni de León
Representante de la Decana Sistema de Estudios de Posgrado
M.Sc. Edgar Casasola Murillo Profesor Guía
Dr. Vladimir Lara Villagrán
Director Programa de Posgrado en Computación e Informática
Marco Antonio González Roesch
Sustentante

iii
Tabla de contenidos
Resumen ........................................................................................................................................ vi
Lista de figuras .............................................................................................................................. vii
Lista de ilustraciones ..................................................................................................................... vii
Lista de abreviaturas .................................................................................................................... viii
Introducción .................................................................................................................................. 1
Problema ................................................................................................................................... 1
Justificación ............................................................................................................................... 1
Objetivos ....................................................................................................................................... 2
Objetivo general ........................................................................................................................ 2
Objetivos específicos .................................................................................................................. 2
Lista de actividades ........................................................................................................................ 2
Etiquetado gramatical .................................................................................................................... 3
Conjuntos de etiquetas gramaticales ............................................................................................. 3
Implementación ............................................................................................................................. 4
Diseño de la arquitectura ........................................................................................................... 4
Algoritmo de agregación ............................................................................................................ 7
Pools .......................................................................................................................................... 9
Evaluación y resultados .................................................................................................................11
Rendimiento .............................................................................................................................11
Calidad ......................................................................................................................................13
Conclusiones .................................................................................................................................16
Anexo A. Artículo ..........................................................................................................................17
Anexo B. Conjunto de etiquetas EAGLES/PAROLE ..........................................................................27
Adjetivos ...................................................................................................................................28
Adverbios ..................................................................................................................................29
Determinantes ..........................................................................................................................29
Nombres ...................................................................................................................................30
Verbos ......................................................................................................................................30
Pronombres ..............................................................................................................................31
Conjunciones ............................................................................................................................32

iv
Interjecciones ...........................................................................................................................32
Preposiciones ............................................................................................................................33
Puntuación ................................................................................................................................33
Numerales ................................................................................................................................34
Fechas y horas ..........................................................................................................................34
Anexo C. Resultados de prueba de calidad ....................................................................................35
Anexo D. Código fuente ................................................................................................................41
cr.ac.ucr.sentimetro.postagging.factories.Factory<T> ...............................................................42
cr.ac.ucr.sentimetro.postagging.factories.FreelingTaggerFactory ..............................................42
cr.ac.ucr.sentimetro.postagging.factories.GsonFactory .............................................................42
cr.ac.ucr.sentimetro.postagging.factories.OpenNlpMaxentTaggerFactory .................................42
cr.ac.ucr.sentimetro.postagging.factories.OpenNlpPerceptronTaggerFactory ...........................43
cr.ac.ucr.sentimetro.postagging.factories.PatternTaggerFactory ...............................................43
cr.ac.ucr.sentimetro.postagging.factories.PatternWordNormalizerFactory ...............................43
cr.ac.ucr.sentimetro.postagging.factories.WordNormalizerFactory ...........................................44
cr.ac.ucr.sentimetro.postagging.managers.FreelingTaggerManager ..........................................44
cr.ac.ucr.sentimetro.postagging.managers.OpenNlpMaxentTaggerManager .............................45
cr.ac.ucr.sentimetro.postagging.managers.OpenNlpPerceptronTaggerManager .......................46
cr.ac.ucr.sentimetro.postagging.managers.PatternTaggerManager ...........................................47
cr.ac.ucr.sentimetro.postagging.managers.TaggerManager ......................................................48
cr.ac.ucr.sentimetro.postagging.normalizers.PatternWordNormalizer ......................................49
cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer ..................................................49
cr.ac.ucr.sentimetro.postagging.taggers.FreelingTagger ............................................................52
cr.ac.ucr.sentimetro.postagging.taggers.OpenNlpTagger ..........................................................55
PatternTagger.py ......................................................................................................................56
cr.ac.ucr.sentimetro.postagging.taggers.Tagger ........................................................................57
cr.ac.ucr.sentimetro.postagging.Main .......................................................................................57
cr.ac.ucr.sentimetro.postagging.OriginalWord ..........................................................................60
cr.ac.ucr.sentimetro.postagging.PojoWord ...............................................................................61
cr.ac.ucr.sentimetro.postagging.Pool<T> ..................................................................................61
cr.ac.ucr.sentimetro.postagging.TaggerResource ......................................................................63
cr.ac.ucr.sentimetro.postagging.TaggerSummarizer ..................................................................67

v
cr.ac.ucr.sentimetro.postagging.Word ......................................................................................68
cr.ac.ucr.sentimetro.postagging.WordSummary........................................................................68
Anexo E. Scripts de instalación ......................................................................................................72
run-file.sh .................................................................................................................................73
run-server.sh.............................................................................................................................73
setup.sh ....................................................................................................................................73
setup-scripts/freeling-install.sh .................................................................................................74
setup-scripts/freeling-java-api-compile.sh .................................................................................75
setup-scripts/java-compile.sh....................................................................................................76
setup-scripts/pattern-install.sh .................................................................................................76
setup-scripts/requirements.sh ..................................................................................................77
uninstall.sh ...............................................................................................................................80

vi
Resumen El siguiente trabajo final de investigación aplicada se deriva del curso de laboratorio de
Programación en Java para Ambientes para Ambientes Distribuidos impartido por el profesor
Édgar Casasola Murillo en el segundo semestre del 2013.
De este trabajo surgió un artículo científico, el cual será enviado a una conferencia internacional
para optar por la posibilidad de formar parte de ella. El presente documento se presenta como un
acompañamiento del artículo presentado, puesto que contiene más detalles que no se pudieron
desarrollar en el artículo por motivos de longitud.
El trabajo consistió en implementar una arquitectura de servicio web tipo REST (Representational
State Transfer) en Java, que combina múltiples bibliotecas de código abierto de etiquetado
gramatical creadas en lenguajes de programación heterogéneos, tomando en cuenta
compatibilidad, rendimiento y extensibilidad.
Para comprobar la funcionalidad del prototipo se realizaron dos evaluaciones: una orientada a
rendimiento y la otra en calidad. Los resultados de ambas evaluaciones son alentadores.
El servicio fue escrito completamente en Java y puede ser portado a cualquier sistema operativo
que soporte Java, sin embargo, al día de hoy sólo se probó en Ubuntu Linux.
Al final de este documento se encuentran anexos: el texto completo del artículo, el detalle de los
resultados de la evaluación de calidad, el código fuente del prototipo y los scripts de instalación
del mismo.

vii
Lista de figuras Figura 1 - Algoritmo de agregación para la palabra “El” .................................................................. 8
Figura 2 - Algoritmo de agregación para la palabra “come” ............................................................ 8
Figura 3 - Resultados de rendimiento de primera solicitud ............................................................12
Figura 4 - Resultados de rendimiento de solicitudes 2-4 ................................................................13
Lista de ilustraciones Ilustración 1 - Resumen del problema ............................................................................................ 4
Ilustración 2 - Diseño de la arquitectura a alto nivel del prototipo .................................................. 5
Ilustración 3 - Creación de FreelingTagger en segundo plano ........................................................10
Ilustración 4 - Comportamiento de Pool<T> ..................................................................................10
Ilustración 5 - Concepto detrás de la prueba de calidad.................................................................14

viii
Lista de abreviaturas EAGLES: Expert Advisory Group on Language Engineering Standards.
NLP: Natural Language Processing.
REST: Representational State Transfer.
PoS: Part of speech.

1
Introducción
Problema Se desea crear una arquitectura de servicio web tipo REST (Representational State Transfer) en
Java, que combine múltiples bibliotecas de código abierto de etiquetado gramatical creadas en
lenguajes de programación heterogéneos, tomando en cuenta compatibilidad, rendimiento y
extensibilidad.
Justificación El etiquetado gramatical (o PoS tagging), es una actividad básica necesaria para la mayoría de las
tareas de procesamiento de lenguaje natural. Cualquier aplicación de procesamiento de lenguaje
natural (como reconocimiento del habla, traducción, análisis de sentimiento, entre otros)
normalmente requiere de esta actividad. El etiquetado gramatical consiste en: dada una oración,
asignar a cada palabra su categoría gramatical (adjetivo, sustantivo, verbo, entre otros). La
complejidad de este problema consiste en que la categoría gramatical de una palabra puede
cambiar según el contexto, puesto que existen palabras con más de un significado. Aunque existen
varias bibliotecas de código abierto de etiquetado gramatical con soporte para español, son
relativamente nuevas y no probadas cuando se les compara con sus homólogas en inglés.
Para contrarrestar la limitación presentada anteriormente, un abordaje útil sería utilizar varias
bibliotecas de etiquetado gramatical y agregar los resultados de las mismas en un único resultado
con un indicador porcentual de consenso. De esta manera, se podría mejorar la calidad del
proceso de etiquetado gramatical. Sin embargo, la complejidad de instalar, configurar e integrar
estas bibliotecas a múltiples plataformas y lenguajes de programación, sin mencionar las
consideraciones de rendimiento asociadas para dicha integración, pueden resultar abrumadoras.
Es por esto, que un servicio web tipo REST podría facilitar enormemente esta situación, puesto
que podría ser consumido fácilmente por cualquier lenguaje de programación que tenga soporte
para servicios web REST.

2
Objetivos
Objetivo general Implementar un servicio en Java de etiquetado gramatical para el lenguaje español, utilizando
varias bibliotecas de código abierto.
Objetivos específicos 1. Integrar las bibliotecas de etiquetado gramatical: Freeling, Pattern for Python y Apache
OpenNLP a Java.
2. Crear un esquema de agregación para retornar un único resultado derivado de los
resultados de las bibliotecas de etiquetado gramatical.
3. Publicar el servicio mediante un servicio web REST utilizando la biblioteca Jersey.
4. Evaluar la efectividad del servicio desarrollado.
Lista de actividades Para llevar a cabo la creación de este trabajo de investigación, las siguientes tareas se llevaron a
cabo:
1. Se hizo una revisión bibliográfica de las bibliotecas de etiquetado gramatical: Freeling,
Pattern for Python y Apache OpenNLP con respecto a su uso e integración con Java.
2. Se implementó una pequeña prueba de concepto con cada biblioteca para verificar la
integración de las mismas con Java.
3. Se creó un esquema de normalización de los resultados de las bibliotecas para poder
comparar los resultados.
4. Se creó un algoritmo para agregar los resultados de las bibliotecas.
5. Se diseñó una arquitectura de un servicio REST que utilice las bibliotecas de etiquetado
gramatical orientado a compatibilidad, extensibilidad y rendimiento.
6. Se hizo una selección de tecnologías para implementar el servicio y se procederá a su
implementación.
7. Se validó el funcionamiento del servicio publicado mediante una prueba de concepto.
8. Se realizó una evaluación empírica del servicio en términos de calidad y rendimiento.

3
Etiquetado gramatical El etiquetado gramatical es una actividad básica del procesamiento de lenguaje natural (NLP).
Consiste en asignar a cada palabra en una oración, una etiqueta que desambigua su gramática
(sustantivo, verbo, adjetivo, entre otros) en un contexto.
Aunque inicialmente el etiquetado gramatical se realizaba manualmente por lingüistas, ha sido
remplazado por métodos estadísticos y basados en reglas, usando un corpus etiquetado
previamente para entrenamiento.
Conjuntos de etiquetas gramaticales A una notación de etiquetas gramaticales se le llama un conjunto de etiquetas gramaticales. Una
buena práctica, es que las etiquetas gramaticales denoten la gramática de una manera consistente
y jerárquica.
En 1996 el Expert Advisory Group on Language Engineering Standards (EAGLES) publicó un
documento con recomendaciones para anotaciones morfosintácticas, entre ellas, conjuntos de
etiquetas gramaticales. Este estándar fue utilizado en un proyecto de la Unión Europea llamado
PAROLE. El estándar EAGLES/PAROLE es utilizado normalmente por las bibliotecas de etiquetado
gramatical en español y es el utilizado también por el prototipo. En los anexos del trabajo se puede
consultar el conjunto de etiquetas completo.
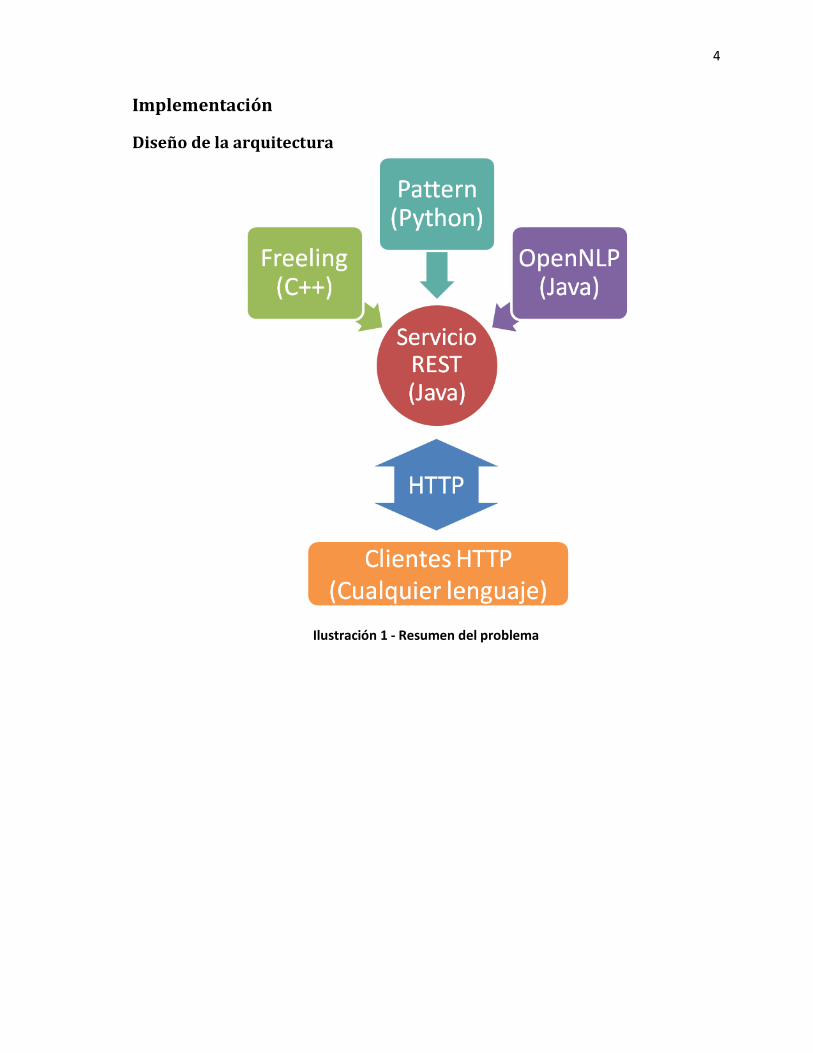
4
Implementación
Diseño de la arquitectura
Ilustración 1 - Resumen del problema
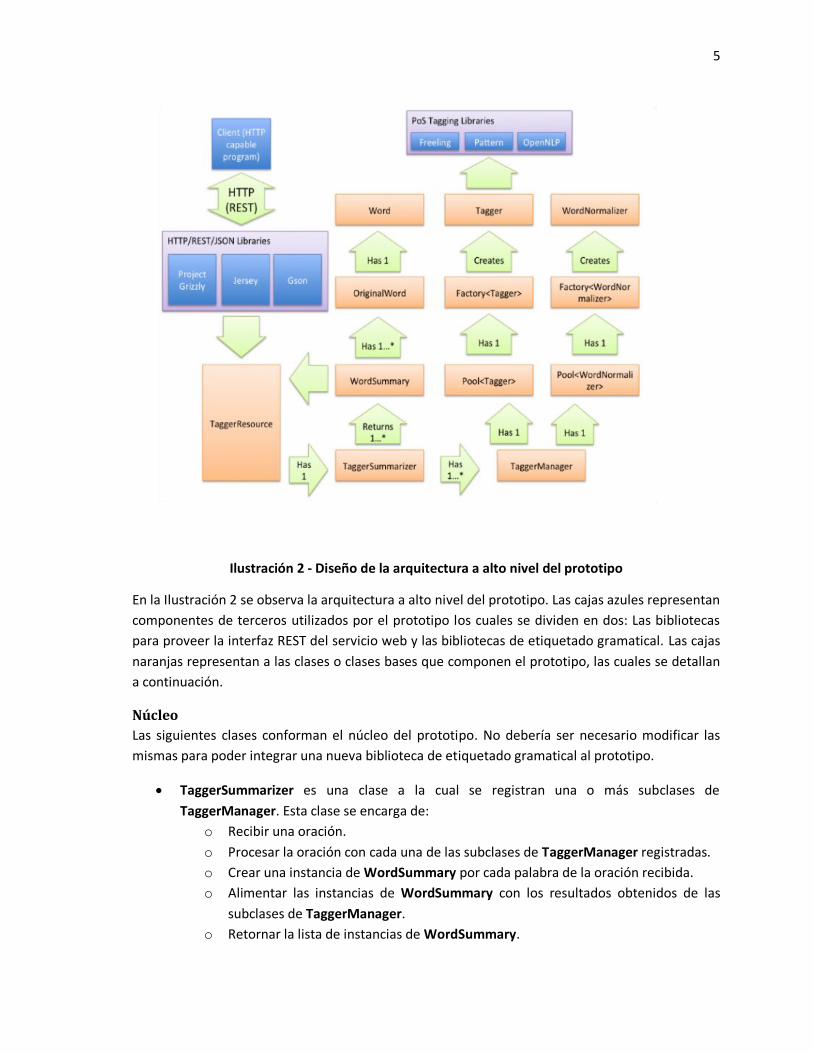
5
Ilustración 2 - Diseño de la arquitectura a alto nivel del prototipo
En la Ilustración 2 se observa la arquitectura a alto nivel del prototipo. Las cajas azules representan
componentes de terceros utilizados por el prototipo los cuales se dividen en dos: Las bibliotecas
para proveer la interfaz REST del servicio web y las bibliotecas de etiquetado gramatical. Las cajas
naranjas representan a las clases o clases bases que componen el prototipo, las cuales se detallan
a continuación.
Núcleo
Las siguientes clases conforman el núcleo del prototipo. No debería ser necesario modificar las
mismas para poder integrar una nueva biblioteca de etiquetado gramatical al prototipo.
TaggerSummarizer es una clase a la cual se registran una o más subclases de
TaggerManager. Esta clase se encarga de:
o Recibir una oración.
o Procesar la oración con cada una de las subclases de TaggerManager registradas.
o Crear una instancia de WordSummary por cada palabra de la oración recibida.
o Alimentar las instancias de WordSummary con los resultados obtenidos de las
subclases de TaggerManager.
o Retornar la lista de instancias de WordSummary.

6
WordSummary es una de las clases principales del prototipo puesto que contiene el
algoritmo de agregación, el cual será descrito más adelante. Esta clase contiene una
instancia de OriginalWord por cada subclase de TaggerManager que se haya registrado
con el TaggerSummarizer. Finalmente, esta clase es serializada al formato JSON
(JavaScript Object Notation) por medio de la biblioteca Gson y se retorna como respuesta
al cliente del servicio REST.
OriginalWord contiene una instancia de Word y el nombre de la biblioteca de etiquetado
gramatical utilizada para crear la instancia de Word.
Pool<T> es una clase que se utiliza para mejorar el rendimiento del servicio web. El
funcionamiento de la misma será descrito más adelante. Un Pool<T> siempre requiere un
Factory<T> para su funcionamiento.
PojoWord es la implementación por defecto de la interfaz Word.
Extensibilidad
Las siguientes clases e interfaces conforman el punto de extensibilidad el prototipo, en otras
palabras, se utilizan para poder incorporar nuevas bibliotecas de etiquetado gramatical al
prototipo.
TaggerResource es una clase que en conjunto con las bibliotecas Jersey y Grizzly, provee
el punto de entrada y procesamiento de las solicitudes del servicio REST. Aquí es donde se
registran las subclases de TaggerManager al TaggerSummarizer.
Factory<T> es una interfaz de Java que denota el patrón de arquitectura de software
Factory. La implementación de esta interfaz es trivial en la mayoría de los casos,
simplemente debe poder crear instancias de T.
TaggerManager es una clase abstracta que utiliza a una instancia de Tagger y una
instancia de WordNormalizar para etiquetar a una oración y luego normalizar el resultado.
El resultado de este proceso se representa con una lista de instancias de Word. Para
incorporar una nueva biblioteca de etiquetado gramatical, se debe extender esta clase. La
implementación de la misma es trivial si se utilizan instancias de Pool<T>.
WordNormalizer es una clase que se encarga de normalizar un resultado de
procesamiento de una biblioteca de etiqueta gramatical de forma que se pueda aplicar el
algoritmo de agregación. Para incorporar una nueva biblioteca de etiquetado gramatical,
se debe extender esta clase sólo si hay particularidades adicionales a las implementadas
en WordNormalizer.
Tagger es la interfaz de Java más importante del prototipo en cuanto a extensibilidad. Una
implementación de esta interfaz recibe una oración y debe retornar una lista de instancias
de Word. Es aquí donde se debe poner todo el código de integración con la biblioteca de
etiquetado gramatical que se desee incorporar.
Word es una interfaz de Java que para su implementación requiere exponer: una forma,
un lema y una etiqueta gramatical. Esta interfaz es implementada por las clases que
representan los resultados de las bibliotecas gramaticales. En la mayoría de los casos no es

7
necesario crear una implementación puesto que la implementación por defecto
(PojoWord) es suficiente.
Por ejemplo, para integrar a la biblioteca de etiquetado gramatical Freeling fue necesario crear las
siguientes clases:
FreelingTaggerFactory, la cual implementa la interfaz Factory<FreelingTagger>.
FreelingTaggerManager, la cual extiende a la clase TaggerManager.
FreelingTagger, la cual implementa la interfaz Tagger.
No fue necesario crear nuevas implementaciones para WordNormalizer o Word puesto que las
implementaciones del núcleo eran suficientes.
Algoritmo de agregación La mejor manera de explicar el algoritmo de agregación utilizado para retornar un único resultado
de las bibliotecas de etiquetado gramatical es más fácil de entender con un ejemplo. Antes de ver
ejemplo, asegúrese que conoce y entiende conjunto de etiquetas gramaticales EAGLES/PAROLE
presentado en los anexos.
Para una oración como “El perro come.”, el algoritmo daría un resultado como el siguiente:
El perro Come .
DA, 100% NC, 100% VMI, 75% Fp, 100%
Para cada palabra, el algoritmo obtiene la etiqueta gramatical de cada una de las bibliotecas y
calcula todas las posibles formas de etiquetas, desde su forma más específica hasta su forma más
general. Dado que las etiquetas de EAGLES/PAROLE son jerárquicas por naturaleza, calcular las
formas consiste en ir quitando un carácter cada vez hasta quedar un único carácter, de derecha a
izquierda.
Una vez que se tienen todas las formas de las etiquetas, el algoritmo cuenta la cantidad de
apariciones de cada forma de etiqueta y selecciona la forma que tenga una mayor cantidad de
apariciones. Si la cantidad de apariciones para dos formas es igual, se escoge la que tenga una
longitud más larga, puesto que es la más específica y da más información al usuario.
Finalmente, una vez que se tiene seleccionada una forma de etiqueta seleccionada, se calcula el
consenso porcentual, que consiste en dividir la cantidad de apariciones entre la cantidad de
bibliotecas utilizadas.
Por ejemplo, para la palabra “El”, el procesamiento se vería así:
Biblioteca Resultado nativo
Formas de etiquetas
Palabra Formas de etiquetas
Cantidad de apariciones
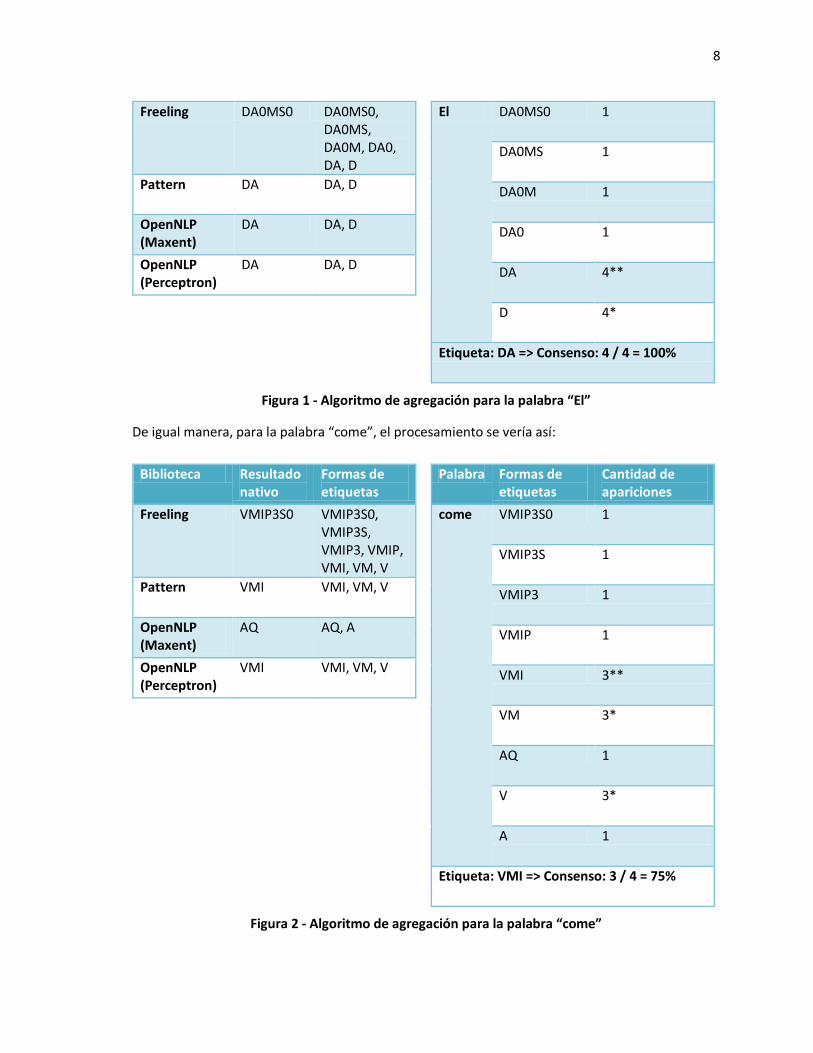
8
Freeling DA0MS0 DA0MS0, DA0MS, DA0M, DA0, DA, D
Pattern DA DA, D
OpenNLP (Maxent)
DA DA, D
OpenNLP (Perceptron)
DA DA, D
El DA0MS0 1
DA0MS 1
DA0M 1
DA0 1
DA 4**
D 4*
Etiqueta: DA => Consenso: 4 / 4 = 100%
Figura 1 - Algoritmo de agregación para la palabra “El”
De igual manera, para la palabra “come”, el procesamiento se vería así:
Biblioteca Resultado nativo
Formas de etiquetas
Freeling VMIP3S0 VMIP3S0, VMIP3S, VMIP3, VMIP, VMI, VM, V
Pattern VMI VMI, VM, V
OpenNLP (Maxent)
AQ AQ, A
OpenNLP (Perceptron)
VMI VMI, VM, V
Palabra Formas de etiquetas
Cantidad de apariciones
come VMIP3S0 1
VMIP3S 1
VMIP3 1
VMIP 1
VMI 3**
VM 3*
AQ 1
V 3*
A 1
Etiqueta: VMI => Consenso: 3 / 4 = 75%
Figura 2 - Algoritmo de agregación para la palabra “come”

9
Llama la atención en el procesamiento anterior que una de las bibliotecas etiqueto la palabra
come como un adjetivo calificativo y no un verbo. Una posible explicación de porqué sucedió esto
es porque el conjunto de entrenamiento utilizado para entrenar el modelo utilizado por OpenNLP
tenía más ocurrencias en las que un sustantivo (perro) iba inmediatamente acompañado de un
adjetivo y no un verbo (come).
El algoritmo implementado en el código fuente es un poco diferente al ejemplificado
anteriormente, aunque el resultado final de ambos algoritmos es igual, el implementado es más
eficiente. A continuación se detallan las particularidades del algoritmo implementado en código:
No se calculan todas las formas de las etiquetas.
La primera etiqueta entera se ingresa en una colección con una coincidencia de 1 y ésta se
convierte automáticamente en la etiqueta seleccionada.
Para las demás etiquetas:
o Si la coincidencia es exacta con alguna en la colección, se incrementa el contador
de coincidencias.
o De lo contrario, se intenta obtener la coincidencia parcial más larga posible.
Si la coincidencia parcial ya existe en la colección, se incrementa el
contador de coincidencias.
Si la coincidencia parcial no existe en la colección, se ingresa con una
coincidencia de 1.
o Si no hay coincidencia del todo, la etiqueta entera se ingresa con una coincidencia
de 1.
o Finalmente, se recalcula la etiqueta seleccionada: la que tiene más coincidencias y
que tiene la mayor longitud en caso de que tengan la misma cantidad de
coincidencias.
Pools Crear una instancia de un etiquetador en Java es una operación costosa en términos de tiempo y
memoria. Por ejemplo, crear una instancia de FreelingTagger puede tomar alrededor de 175 Mb
de RAM y hasta 5 segundos en un equipo con Ubuntu 13.04 y un Intel Core i3 U 330 (1.33 GHz) y 4
GB de RAM. Este costo es prohibitivo para un servicio web que tiene que servir cientos de
solicitudes.

10
Ilustración 3 - Creación de FreelingTagger en segundo plano
Para resolver el problema, se implementó una clase llamada Pool<T>. El objetivo principal de la
clase es reutilizar instancias para incrementar el rendimiento del sistema. Como se puede observar
en la Ilustración 3, cuando se instancia un Pool<T> por primera vez, ésta automáticamente crea
una nueva instancia de T en un hilo en segundo plano.
Ilustración 4 - Comportamiento de Pool<T>
Como se puede observar en la Ilustración 4, si un hilo solicita una instancia al Pool, bloquea el hilo
que hace la solicitud y lo desbloquea hasta que haya una instancia disponible. Para prevenir el
bloqueo al máximo, si un hilo solicita la última instancia en el Pool, se empieza a crear una nueva
instancia en un hilo en segundo plano. El hilo que solicita la instancia tiene la responsabilidad de
retornar la instancia al Pool cuando ya no la necesita.

11
Evaluación y resultados Para comprobar la funcionalidad del prototipo, se hicieron dos evaluaciones. Una centrada en
rendimiento y la otra en calidad.
Rendimiento La evaluación de rendimiento consistió en lo siguiente:
Ambiente
Se utilizó un equipo con las siguientes características:
Sistema operativo: Lubuntu 13.10.
Procesador: Intel Core i3 U 330 (1.33 GHz).
Memoria RAM: 4 GB DDR3 RAM.
Se utilizó Mozilla Firefox 28.0 con RESTClient 2.0.3 para hacer las solicitudes y medir los tiempos
de respuesta. Los tiempos de respuesta se midieron en milisegundos.
Experimento
Se utilizó una oración de 42 palabras. Para cada biblioteca de etiquetado gramatical y para el
prototipo, se hicieron cuatro corridas. Cada corrida consiste en lo siguiente:
Se inició el servicio web.
Se hizo una solicitud al mismo recurso con los mismos parámetros cuatro veces, se
midieron los tiempos de respuesta para cada solicitud.
El servicio web se detuvo.
Luego de que las corridas se completaron, se calcularon los promedios para cada solicitud y los
promedios de las solicitudes 2-4. La razón de esto es porque la primera solicitud siempre tiene un
costo muy alto debido a la carga de las clases a memoria, entre otros.
Resultados

12
Figura 3 - Resultados de rendimiento de primera solicitud
Como se puede observar en la Figura 3, en la primera solicitud el prototipo queda muy por detrás
de cualquier biblioteca por sí sola. Esto es de esperar puesto que el prototipo debe cargar todas
las bibliotecas a memoria.
14164,3 791,7 926,3
11168,3 5422
0 5000 10000 15000
Solicitud 1
Tiempo de ejecución (menor es mejor)
Freeling Pattern
OpenNLP (Maxent) OpenNLP (Perceptron)
Prototipo (con Pools)
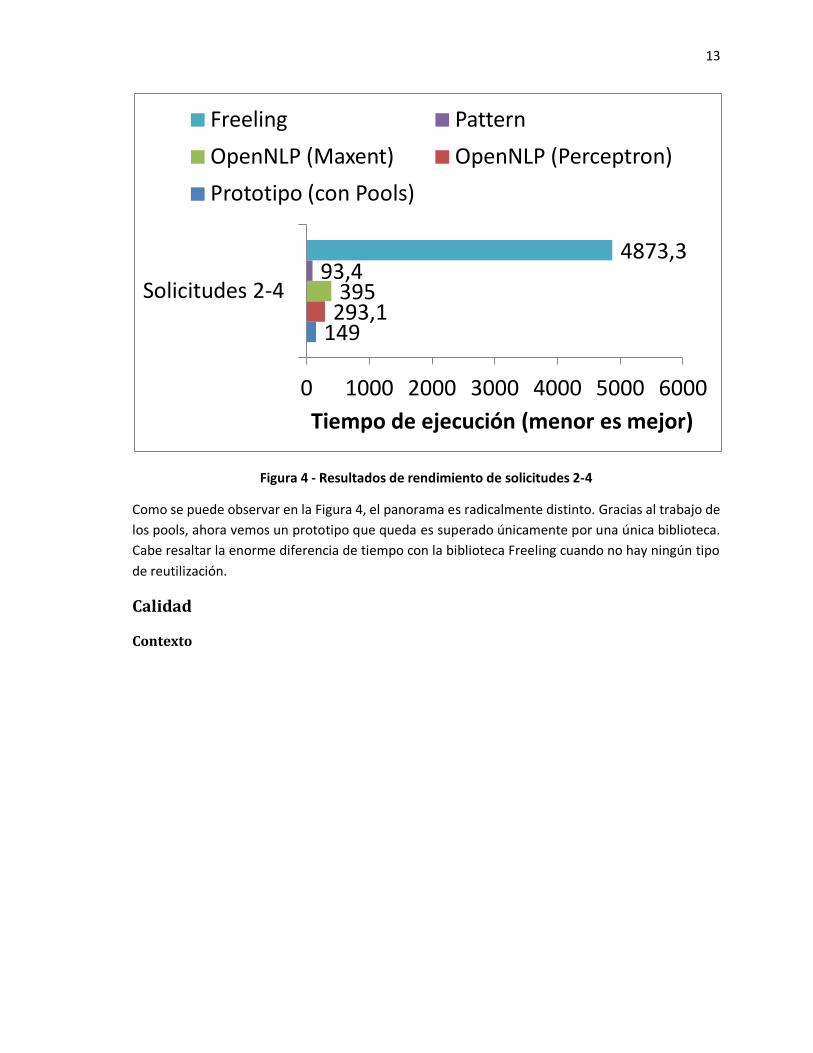
13
Figura 4 - Resultados de rendimiento de solicitudes 2-4
Como se puede observar en la Figura 4, el panorama es radicalmente distinto. Gracias al trabajo de
los pools, ahora vemos un prototipo que queda es superado únicamente por una única biblioteca.
Cabe resaltar la enorme diferencia de tiempo con la biblioteca Freeling cuando no hay ningún tipo
de reutilización.
Calidad
Contexto
149 293,1 395
93,4 4873,3
0 1000 2000 3000 4000 5000 6000
Solicitudes 2-4
Tiempo de ejecución (menor es mejor)
Freeling Pattern
OpenNLP (Maxent) OpenNLP (Perceptron)
Prototipo (con Pools)

14
Ilustración 5 - Concepto detrás de la prueba de calidad
La prueba de calidad busca comprobar que exista suficiente varianza entre los resultados de las
bibliotecas para comprobar que existe un beneficio en retornar un único valor agregando los
resultados de las bibliotecas.
La Ilustración 5 muestra el concepto detrás de la prueba. Las cajas de color verde representan una
respuesta correcta mientras que las cajas de color rojo representan una respuesta incorrecta. Al
buscar varianza, se busca que ocurra algo como los primeros dos casos. En estos casos el error de
una biblioteca es absorbido por las respuestas correctas de las demás. Si no hay varianza entre las
bibliotecas como se puede observar en el tercer y cuarto caso, no hay utilidad en el prototipo. En
estos casos todas las bibliotecas siempre están correctas o incorrectas.
Por último, las cajas de color naranja representan un caso especial. Hablando más estrictamente,
esta prueba es más una prueba de utilidad que de calidad. En el quinto caso, todas las bibliotecas
dan respuestas diferentes entre sí, sin embargo, todas son incorrectas. Este caso sería
erróneamente catalogado por el experimento como algo positivo cuando en realidad no lo es. No
obstante, la evaluación de la calidad de las bibliotecas como tales ha quedado fuera del ámbito de
este trabajo.
Experimento
Para realizar esta prueba, se utilizó un corpus de 1.4 millones de publicaciones de Facebook de
páginas de Costa Rica. De este corpus, se escogieron 10 grupos de 20 publicaciones cada uno.
Para cada muestra de texto se calculó la cantidad de resultados que eran iguales al resultado del
prototipo (el resultado aplicando el algoritmo de agregación) de forma nominal y porcentual. Los
datos de este experimento se pueden consultar en los anexos.

15
Resultados
Una vez obtenidos los datos, se hizo un análisis ANOVA, obteniendo una diferencia de menos de
0.05 como se esperaba. Este resultado dejó así en evidencia la utilidad del prototipo más allá de
un simple envoltorio de bibliotecas de etiquetado gramatical, sino que puede que arroje
resultados de mejor calidad que al utilizar las bibliotecas por si solas.

16
Conclusiones Tal y como se presentó en este trabajo escrito, se creó una arquitectura en Java, que combina
múltiples bibliotecas de etiquetado gramatical, programados en lenguajes heterogéneos.
La utilidad del prototipo en cuanto a rendimiento y calidad ha quedado evidenciada por los
experimentos realizados y los resultados obtenidos. El servicio fue escrito completamente en Java
y puede ser portado a cualquier sistema operativo que soporte Java, sin embargo, al día de hoy
sólo se probó en Ubuntu Linux.
Uno de los beneficios del servicio, es la capacidad de mejorar la calidad de los etiquetados al
agregar más bibliotecas. La calidad aumenta puesto que el servicio actúa como un sistema de
votación. Al ser de código abierto y estar pensado para su extensibilidad, integrar nuevas
bibliotecas es una tarea relativamente simple.

17
Anexo A.
Artículo

Integration of Heterogeneous Open-Source SpanishPart of Speech Taggers as a Service
Edgar CasasolaECCI-CITIC
Universidad de Costa RicaEmail: [email protected]
Marco GonzalezMaestrıa en ComputacionUniversidad de Costa Rica
Email: [email protected]
Gabriela Marın RaventosECCI-CITIC
Universidad de Costa RicaEmail: [email protected]
Abstract—Part-of-speech tagging is a basic activity neededfor most natural language processing tasks. Although there arevarious open-source part-of-speech tagging libraries with Spanishsupport, they are relatively new and untested when compared totheir English counterparts. Thus, using several tagging librariessimultaneously may enhance the quality of the tagging process. ARepresentational State Transfer web service architecture writtenin Java, that combines multiple open-source Spanish part-of-speech tagging libraries created with heterogeneous programminglanguages, is presented. The design is made with compatibility,performance and extensibility in mind.
keywords PoS Tagging, Spanish, Natural Language Pro-cessing
I. INTRODUCTION
Part-of-speech (PoS) tagging is a basic activity neededfor most natural language (NL) processing tasks. Althoughthere are various open-source (OS) PoS tagging libraries withSpanish support, they are relatively new and untested whencompared to their English counterparts. One useful approachseems to be the use of various libraries and aggregate theresults from the libraries into a single result with a percentageconsensus indicator. However, the complexity of installing,configuring, and integrating these libraries on multiple plat-forms and programming languages, not to mention the perfor-mance considerations that will have to be taken into accountfor such integration, can be overwhelming.
To solve the problems mentioned earlier, a RepresentationalState Transfer (REST) web service architecture written inJava, that combines multiple OS Spanish PoS tagging librariescreated with heterogeneous programming languages, is pre-sented. The design was done trying to improve the overallexecution time and to overcome the overhead of executingmore than one tagger per request. Moreover, the architectureand programming were realized such that new taggers couldbe easily included in the future (extensibility).
The paper is organized as follows. Section II describes PoStagging, PoS tag-sets and the PoS tagging libraries used in theweb service prototype. Section III describes the architectureand details of implementation. Section IV presents executionresults, both from the quality and performance standpoint.Finally, section V presents the conclusions and further work.
II. PART OF SPEECH TAGGING
PoS tagging is a basic activity of NL processing, whichconsists on assigning each word in a corpus (or text) with
a tag that disambiguates its part of speech (e.g. noun, verb,adjective) within a context. This is necessary because the PoSof a word on its own is ambiguous, and requires a context to bedisambiguated. Although, initially PoS tagging was performedmanually [1], it was later replaced by statistical methods [2],[3] and rule-based (e.g. finite-state) methods [4], by using acorpora (or a set of corpus) for training.
Table I presents an example of PoS tagging using theFreeling library [5], [6], [7], [8]. In this example, the wordtail is used twice with different meanings: the first time, it’sused as a noun and refers to a part of the dog’s body; thesecond time, it’s used as a verb and refers to the action of thedog following the cat.
PoS tagging is a language dependent activity becausegrammatical structures differ from one language to another.This means that the number of PoS types and sub-types variesby language. However, efforts have been made to overcomethis limitation [9]. The meaning of each tag is defined as partof a speech tag-set.
A. Part-of-speech tag-sets
A PoS tag-set is a set of tags used to perform PoS tagginguniformly in a corpus. A PoS tag normally identifies the type(e.g. noun, verb) and sub-type (e.g. common noun, propernoun) of a PoS.
The most widely used tag-set for the English languageis the PENN TREEBANK tag-set [10]. For other languages,particularly Spanish, several alternatives exist, but the mostwidely used tag-set on Open Source (OS) PoS tagging librariesis the EAGLES/PAROLE tag-set [5], [6], [11], [7], [8].
In 1996, the Expert Advisory Group on Language Engi-neering Standards (EAGLES) published a document titled Rec-ommendations for the Morphosyntactic Annotation of Corpora.This document provided a set of recommendations for variousmorphosyntatic annotations, including PoS tag-sets [12]. Therecommendations became very popular in the European Union,especially for non-English languages thanks to the support oftwo projects known as MULTEXT and PAROLE [13].
Between 1994 and 1997, the European Union subsidizedtwo projects called MLAP-PAROLE or PAROLE, and LE-PAROLE or PAROLE-2 [14], [15], [16], [17], [18], whichconsisted among other things on:
... the compilation of large, generic, and re-usable

TABLE I. POS TAGGING EXAMPLE USING THE FREELING LIBRARY
The dog has to stop wagging its tail , if it wants to tail the cat .
the dog have to stop wag its tail , if it want to tail the cat .DT NN VBZ TO VB VBG PRP$ NN Fc IN PRP VBZ TO VB DT NN Fp
Written Language Resources for all EU languages ...[18]
On these projects, a part of the captured corpora was annotatedusing a tag-set compliant with the EAGLES tag-set recom-mendations which later became known as the PAROLE tag-set[13], [16], [18]. This is why the terms PAROLE tag-set andEAGLES tag-set are sometimes used interchangeably whenworking with the PoS tagging software libraries for naturallanguage processing.
B. PoS tagging libraries
A PoS tagging library is a software component used toperform PoS tagging on a corpus. A PoS tagging libraryusually performs the following actions:
• Tokenizes the corpus into words.
• Splits the words into sentences.
• Performs morphosyntactic analysis.
• Performs PoS tagging.
Several PoS tagging libraries supporting Spanish exist. Wedescribe the most popular which have been incorporated toour web service.
1) Freeling: Freeling, as presented in [6], [5], [7], [8] isan Open Source (OS) library consisting of a set of NaturalLanguage (NL) analyzers that provide various NL relatedservices (PoS tagging among them) for multiple languages,including Spanish.
On the technical side, Freeling is written entirely in C++.It is compiled as a library, and has three basic ways to interactwith the user:
1) by using a console program called analyzer,2) by using two console programs called analyzer and
analyzer client in a client/server paradigm,3) by using the C++ library directly with C/C++ or
indirectly by using a wrapper in another programminglanguage (e.g. Java’s JNI, CPython Native Exten-sions).
For performing PoS tagging in Spanish, Freeling uses bydefault the statistical method proposed by [3] and its ownSpanish tag-set based on the EAGLES tag-set recommen-dations [6] (see http://nlp.lsi.upc.edu/freeling/doc/tag-sets/tag-set-es.html for details).
2) Pattern for Python: Pattern for Python as presented in[11], is an OS package for Python 2.4+ that provides multi-ple functionality, PoS tagging included. Initially, it only hadsupport for English and Danish. Spanish and other languageswere included in later releases [19].
Regarding user interaction, Pattern for python can only beused directly with the Python language, or some mechanismto connect Python with other programming languages.
For performing PoS tagging in Spanish, Pattern uses areduced version of the EAGLES/PAROLE tag-set used byFreeling [7] and the rule-based method proposed by [4].
3) Apache OpenNLP: Apache OpenNLP is an OS li-brary for Natural Language processing. It is written inJava and supports PoS tagging among other NL process-ing tasks. For PoS tagging, Apache OpenNLP providestwo statistical machine learning methods: maximum entropyas defined in [20] and [21], and perceptron as definedin [21]. Unlike Freeling and Pattern for Python, ApacheOpenNLP does not include any Spanish PoS Tagger mod-els by default. These models have to be obtained by thirdparties or created manually with data. The REST webservice prototype presented in this paper uses two mod-els obtained from https://github.com/utcompling/OpenNLP-Models/tree/master/lang/es/pos. The models were created us-ing the CoNLL 2002 shared task data [22]. Not coincidentally,the models use the EAGLES/PAROLE tag-set used by Freel-ing, since the tagging of the data was provided by XavierCarreras, the co-creator of Freeling. As a result, to differentmodel implementations using OpenNLP are included in thispaper.
4) Other PoS taggers : Other PoS taggers like Fibs [23]exist and there are versions available with Web online accessfor user queries as in like http://latl.unige.ch/. At this momentthe aggregation here does API’s integration. Invocation ofremote sites or Web services are not implemented since theygo beyond the scope of this paper.
The service we created gives a simplified access to thepreviously described PoS Tag libraries. A description of theaggregation mechanism and results merging strategy is givenin the next section.
III. TAGGER INTEGRATION AS A SERVICE
A. Architecture requirements
The architecture and prototype of the web service weremade with the following requirements in mind:
1) Integrate the OS PoS tagging libraries: Freeling,OpenNLP and Pattern for Python to Java.
2) Implement a mechanism to normalize the PoS taggingresults returned by the libraries.
3) Create a mechanism for aggregating the results andindicate consensus with the usage of a percentageindicator.
4) Allow the inclusion of additional PoS tagging li-braries to the web service.
5) Provide easy access to consume the web service usinga REST like Application Program Interface (API).

Fig. 1. Web Service Architecture Design. The design shows existing the relation among classes.
B. Architecture design
We decided to implement the Web service itself usingJava and use Java technology as the base integration platform,that is why the first design goal was the integration oflibraries to Java. The second requirement was intended tobe able to compare the results and evaluate the consensus.The third requirement exists to facilitate the usage of theweb service by the end user. In this way the user will notneed to choose manually a result from one of the libraries.The fourth requirement is desired, since it allows developersand researchers to extend the functionality of the web serviceby supporting other libraries. The last one seeks to facilitateinteroperability with any programming language the user wantsto use to consume the service, since REST APIs are verysimple by nature. The development processes was guided bythe following methodology.
C. Development process
In order to create the REST web service architecture andprototype, the following tasks were executed:
1) A bibliographical revision of PoS tagging was con-ducted. A selection of three PoS tagging libraries wasmade, based on popularity and easiness of integrationwith Java.
2) A proof-of-concept of integration with Java for eachlibrary was built.
3) A set of technologies for implementing the webservice in Java was selected, based on popularity andperformance.
4) The PoS tagging output of each library was analyzed,in order to design the normalization mechanism.
5) The architecture of the web service was developed,taking into account compatibility, performance andextensibility and the web service was implemented.
Figure 1 shows the architecture of the REST web service.The use of Factories provide easy extensibility while thePools of components were included for performance reasons.It consists of the following types of classes:
1) Taggers: Perform the PoS tagging using a library.Each tagger must implement the Tagger interface.
2) Word normalizers: Responsible for normalizing theoutputs of a PoS tagging library in order to becomparable with the other libraries. The outputs mustuse the EAGLES/PAROLE tag-set as specified byFreeling. Each factory must extend the WordNormal-izer class.
3) Tagger managers: Are responsible for providingTaggers and Normalizers with the help of the Poolclass to perform a normalized PoS tagging. Eachfactory must extend the TaggerManager class.
4) Factories: Are responsible for creating new instancesof Taggers and Normalizers. Each factory must im-plement the Factory interface.

[{
” form ” : ” example ” , / / The form of t h e word i n t h e t e x t .” t a g ” : ”NC” , / / The PoS t a g wi th h i g h e s t c o u n t o f c o i n c i d e n c e s .” c o n s e n s u s ” : 1 . 0 , / / The p e r c e n t a g e o f c o n s e n s u s .” o r i g i n a l W o r d s ” : [{
” taggerName ” : ” F r e e l i n g ” , / / The name of t h e PoS t a g g i n g l i b r a r y .” word ” : { / / The o r i g i n a l PoS t a g g i n g l i b r a r y word d a t a .
” form ” : ” example ” ,” lemma” : ” example ” ,” t a g ” : ”NCMS000”
}} ,{
. . . / / Same c o n t e n t s a s p r e v i o u s e n t r y f o r each PoS t a g g i n g l i b r a r y .}
]} ,{
. . . / / Same c o n t e n t s a s p r e v i o u s e n t r y f o r each t a g g e d word .}
]
Fig. 2. JSON result structure returned by the REST web service
Support for a PoS tagging library is achieved by cre-ating a concrete implementation of each of these classes.For example, support for the Freeling library consists of thefollowing classes: FreelingTagger, FreelingWordNormalizer,FreelingTaggerManager, FreelingTaggerFactory and Freeling-WordNormalizerFactory.
D. Implementation details
The web service prototype was implemented in the Javaprogramming language with the help of the following tech-nologies:
1) Apache Maven (see http://maven.apache.org/), forthe build process automation.
2) Project Grizzly (see https://grizzly.java.net/), for theHypertext Transfer Protocol (HTTP) server.
3) Jersey (see https://jersey.java.net/), for the REST webservice framework.
4) SWIG (see http://www.swig.org/) and JNI (seehttp://docs.oracle.com/javase/7/docs/technotes/guides/jni/),for integrating Java with Freeling.
5) Jython (see http://www.jython.org/), for integratingJava with Pattern for Python.
6) Google Gson (see http://code.google.com/p/google-gson/), for JavaScript Object Notation (JSON) serial-ization.
The web service consists of a single resource with the follow-ing Uniform Resource Locator (URL):
http://server-name/tagger/summary
The service expects a POST request with a corpus to betagged. The server responds in return a JSON result with thestructure shown in Figure 2.
Creating an instance of a tagger is an expensive operationin both time and memory terms. For example, creating a newFreelingTagger instance can take up to 175 Mb of RAM and upto 5 seconds on a Ubuntu 13.04 system with and Intel Core i3U 330 (1.33 Ghz) and 4 Gb of RAM. This cost is prohibitivefor a web service that has to serve hundreds of requests. Asolution is proposed as follows.
E. Object Pools
To solve the problems mentioned earlier, a Pool<T> classwas implemented. It’s main objective is to reuse instances inorder to save memory and increment the program’s perfor-mance.
When a Pool<T> class is first instantiated, it automaticallystarts creating a new instance of T in a background thread. If athread requests for an instance to the pool, it blocks the callingthread and unblocks it as soon as an instance is available. Inorder to prevent blocking to the maximum, the pool tries toalways maintain at least one instance available. If a thread asksfor the last instance of the pool, it automatically starts creatinga new one in a background thread. When the thread that askedfor the instance no longer needs it, it has the responsibility toreturn it to the pool, in order to be available for other threads.
F. Tag Aggregation and consensus mechanism
Each PoS tagged word returned by the web service has asingle PoS tag and a consensus in the form of a percentage.These values are the result of the aggregation algorithm usedby the web service.
The proposed algorithm first calculates the tag forms ofeach PoS tag returned by each PoS tagging library.

TABLE II. AGREGATION OF RESULTS PROCESS
============================================================================WORD: ElL i b r a r y N a t i v e r e s u l t Tag forms============================================================================F r e e l i n g DA0MS0 DA0MS0, DA0MS, DA0M, DA0, DA, DP a t t e r n DA DA, DOpenNLP ( Maxent ) DA DA, DOpenNLP ( P e r c e p t r o n ) DA DA, D
Tag form Appearance c o u n t============================================================================DA0MS0 1DA0MS 1DA0M 1DA0 1DA 4∗∗D 4∗
TAG: DA => CONSENSUS: 4 / 4 = 1============================================================================WORD: p e r r oL i b r a r y N a t i v e r e s u l t Tag forms============================================================================F r e e l i n g NCMS000 NCMS000 , NCMS00, NCMS0, NCMS, NCM, NC, NP a t t e r n NC0S NC0S , NC0 , NC, NOpenNLP ( Maxent ) NC NC, NOpenNLP ( P e r c e p t r o n ) NC NC, N
Tag form Appearance c o u n t============================================================================NCMS000 1NCMS00 1NCMS0 1NCMS 1NC0S 1NCM 1NC0 1NC 4∗∗N 4∗
TAG: NC => CONSENSUS: 4 / 4 = 1============================================================================WORD: comeL i b r a r y N a t i v e r e s u l t Tag forms============================================================================F r e e l i n g VMIP3S0 VMIP3S0 , VMIP3S , VMIP3 , VMIP , VMI , VM, VP a t t e r n VMI VMI, VM, VOpenNLP ( Maxent ) AQ AQ, AOpenNLP ( P e r c e p t r o n ) VMI VMI, VM, V
Tag form Appearance c o u n t============================================================================VMIP3S0 1VMIP3S 1VMIP3 1VMIP 1VMI 3∗∗VM 3∗AQ 1V 3∗A 1
TAG: VMI => CONSENSUS: 3 / 4 = 0 . 7 5============================================================================WORD: .L i b r a r y N a t i v e r e s u l t Tag forms============================================================================F r e e l i n g Fp Fp , FP a t t e r n Fp Fp , FOpenNLP ( Maxent ) Fp Fp , FOpenNLP ( P e r c e p t r o n ) Fp Fp , F
Tag form Appearance c o u n t============================================================================Fp 4∗∗F 4∗
TAG: Fp => CONSESNSUS : 4 / 4 = 1============================================================================RESULT :El p e r r o come .Da,100% NC,100% VMI,75% Fp ,100%

Calculation of the tag forms is done by taking a PoS tagand creating a new PoS tag by removing the last letter of thePoS tag until a PoS tag of a single letter is created.
Since the EAGLES/PAROLE tagset tags are represented ina hierarchical manner, the longer the tag is, the more specificthe tag is and viceversa. For example, the tag forms for thePoS tag ”VMI” are: ”VMI”, ”VM” and ”V”.
After all the tag forms are calculated for each PoS tag, thetag forms are grouped by counting the number the tag formrepeats. The tag form with the highest count is then selected.
If two tags forms have the same count then the mostspecific (or longest one) is preferred. If two tag forms have thesame count and the same length, then the first created tag formis preferred. For example, the tag forms ”VMI”, ”VM”, ”V”,”VM” and ”V” have the following counts: ”VMI,1”, ”VM,2”and ”V,2”. In this case the tag form ”VM” is preferred sinceit’s more specific than ”V”.
The consensus is calculated simply dividing the countnumber of the selected tag form by the number of PoS tagginglibraries used.
An easy to understand version of the aggregation algorithmfor the sentence ”El perro come.” (”The dog eats.”) is presentedin Table II.
For performance reasons, at the latest implementation ofthe algorithm not all tag forms are calculated. It was improved,and the final result is the same.
IV. RESULTS
The main objetive of this section is to demonstrate theperformance of the integrated web service in terms of qualityof results and of execution time.
In order to have a glance of the potential performance gainsfrom using this web service prototype, a performance test casestudy was made. This test case study was done on a systemwith the following characteristics:
• Operating system: Lubuntu 13.10.
• Processor: Intel Core i3 U 330 (1.33 GHz).
• Ram: 4 GB DDR3.
The Mozilla Firefox 28.0 browser with the RESTClient2.0.3 was used to query and measure response times. The testcase procedure was as follows:
1) A text sample was selected.2) For each PoS Tagging library, three runs were made.
Each run consists of the following:a) The web service is started.b) A request to the same resource whith the
same parameters is done four times, the re-sponse times are measured for each request.
c) The web service is stopped.3) After the runs for each PoS Tagging library are
completed, the averages for each request and theaverage of the averages of the requests from 2 to4 are calculated (the rst request is ignored since itsan outlier case for the loading overhead).
All the response times are were measured in milliseconds.Freeling has a lot of overhead on the first request caused by theloading/creation of the tagging model and the creation of theJNI objects. JNI is the mechanism in which Java talks to C++.The next requests has the overhead of loading and creating thetagging model every time.
Fig. 3. Time comparison between libraries and Web Service implementation
The added overhead of the REST web server and the JSONserialization for the responses affected equally all the results,the elimination of such overhead could imply a small timereduction of little significance. Results are shown in Figure 3.
Pattern has a lot of overhead on the first request causedby the Jython compilation of the Python code. Jython is themechanism in which Java talks to Python. OpenNLP is Javanative, its overhead is caused by the loading of the taggingmodel every time.
Fig. 4. Selection of data to compare percentage of aggreement between API’s
Notice how the aggregated Web Service identified as MoS

PoS produces a significant improvement because the Poolreduces the overhead other API’s like Freeling have by theirown. Pattern seems to be a much lighter implementation andits time is the lowest of all.
To evaluate the existence of differences among API’s apseudo experiment was designed. As shown in Figure 4, 200sample texts were randomly selected from a pool related topolitical candidates at the 2014 Costa Rica presidential electionprocess.
Those postings are part of the a Costa Rica corpus contain-ing 1.4 million Facebook posts in Spanish downloaded fromthe most popular news profiles at this country [24].
Five random groups of 20 postings were created. We willrefer to this as the sample data. Using this sample data thecreated Web service was used to tag all texts.
Individual API’s results were stored for evaluation pur-poses. Table III shows the first 10 and the last 5 results ofthose 200 sample texts.
Notice that each entry has the score asociated to the fractionof hits (tags in common) that each API’s share with the tagobtained by the consensus average. The consensus averagefor each text was calculated using the procedure previouslydescribed. Then the precision obtained by each individual APIwith respect to the consensus results is calculated and it isexpressed as a real value.
Since the consensus average is calculated from the API’s,differences are expected to be lower than the ones that canbe obtain if we compare API results against each other. Thepurpose of this study is to measure if there is a significantdifference with regard to the average API consensus.
Fig. 5. ANOVA results obtained confirms signifitive differences amongdifferent API results
The existence of differences amongst the results obtainedby API’s was evaluated using an ANOVA and we confirm sig-nificance differences among consensus averages. The ANOVAresults are shown in Figure 5, notice how the significace islower than 0.05 as expected. Data analysis showed that allrequirements for the application of the ANOVA apply.
When comparing the average consensus amongst API’sFigure 6 presents that Pattern results are significantly differentfrom the others.
It was interesting to analyze individual cases. Table IVshows one case were the lighter implementation Pattern hada 100 percent coincidence with the consensus. At the sen-tence ”Asesoramiento de como robar y quedar impune ?”that correspond to a question that translates to ”advise ofhow to get away with robbery ?” the tags effectively match
Fig. 6. Average consensus obtained from the sample data. The mayordifference among API’s is shown by Pattern. It means that Patterns results aredifferent from the ones provided by the others. Their results were comparedagainst the Web Service selected tags.
with the tags and subtags: NC,SP,CS,VMN,CC,VMN,NC andFit accordingly. Individual results for text sample id 177are: Freeling 87.50% (7/8), Pattern 100.00% (8/8), OpenNLP(Maxent), 75.00% (6/8) and OpenNLP (Perceptron) 87.50%(7/8).
The sentence shown in Table V corresponds to the postingnumber 10 from the sample data. It is a misspelled sentence.It translates to something like ”Amelia I respect you” but theword used for respect is ”respecto” and the correct should be”respetos” (notice the extra c and the lack of the ending s).What makes this and interesting case is that the individual term”respecto” means ”concerning” but the error can be identifyas an error because of its lack of concordance that produces anon grammatical phrase.
Other PoS taggers like Fibs, previously mentioned inSection II-B4 are affected by the misspelling and consider”respecto” to be a preposition and the conjunction ”para” tobe a verb phrase instead. The tagging obtained as part ofthe consensus voting produced by the Web Service producea ”different” closer to the real answer or tag assignment.
V. CONCLUSIONS AND FURTHER WORK
A REST web service architecture written in Java, thatcombines multiple OS Spanish PoS tagging libraries createdwith heterogeneous programming languages, was presented.
The web service prototype is completely written in Javaand can be ported to any operating system platform supportingJava, however it was only tested in Ubuntu Linux and Windowsat the moment. Useful scripts for testing and installing the webservice on Ubuntu Linux were created.
One benefit of the REST web service is its capability toimprove the quality of the PoS tagging by adding more API’s.The quality is improved because the web service acts as a typeof ”voting tagger”, since the web service returns the PoS tagwith the highest appearance count:

TABLE III. TOTAL NUMBER OF TAGGED WORDS WITH SAME TAG AS AGGREGATED TAG. THE FRACTION NUMBER REPRESENTS THE PROPORTION OFTAGS CORRESPONDING TO COINCIDENCES, THE REAL NUMBERS ARE THE PERCENTAGE OF CONSENSUS OBTAINED
Text sample Freeling Pattern OpenNLP-Maxent OpenNLP-Perceptron
1 97.62 (41/42) 54.76 (23/42) 90.48 (38/42) 90.48 (38/42)2 96.97 (32/33) 87.88 (29/33) 100.00 (33/33) 100.00 (33/33)3 77.78 (14/18) 77.78 (14/18) 94.44 (17/18) 94.44 (17/18)4 93.94 (31/33) 90.91 (30/33) 93.94 (31/33) 90.91 (30/33)5 100.00 (07/07) 100.00 (07/07) 85.71 (06/07) 85.71 (06/07)6 100.00 (29/29) 75.86 (22/29) 100.00 (29/29) 96.55 (28/29)7 94.87 (37/39) 92.31 (36/39) 94.87 (37/39) 94.87 (37/39)9 87.50 (14/16) 81.25 (13/16) 100.00 (16/16) 100.00 (16/16)
10 100.00 (05/05) 60.00 (03/05) 80.00 (04/05) 80.00 (04/05)...
196 91.67 (11/12) 91.67 (11/12) 83.33 (10/12) 91.67 (11/12)197 90.00 (18/20) 70.00 (14/20) 100.00 (20/20) 95.00 (19/20)198 85.71 (6/7) 100.00 (7/7) 71.43 (5/7) 100.00 (7/7)199 90.91 (30/33) 93.94 (31/33) 100.00 (33/33) 96.97 (32/33)200 100.00 (05/05) 100.00 (05/05) 100.00 (05/05) 100.00 (05/05)
Total 93.81 (4032/4298) 86.02 (3697/4298) 92.69 (3984/4298) 92.39 (3971/4298)
TABLE IV. SAMPLE INDIVIDUAL RESULT FOR THE SENTENCE WITH ID 177 ” ASESORAMIENTO DE COMO ROBAR Y QUEDAR IMPUNE ? ”
Asesoramiento de como robar y quedar impune ?
Consensus NC SP CS VMN CC VMN NC FitFreeling NCMS000 SPS00 CS VMN0000 CC VMN0000 AQ0CS0 FitPattern NC0S SP CS VMN CC VMN NC0S Fit
OpenNLP-Maxent NC SP CS NC VMN CC VMI FitOpenNLP-Perceptron NC SP CS NC CC VMN NC Fit
TABLE V. SAMPLE INDIVIDUAL RESULT FOR THE MISSPELLED SENTENCE 10 ” AMELIA MIS RESPECTO PARA USTED ”
Amelia mis respecto para usted
Consensus NC DP NC SP PPFreeling NCFS000 DP1CPS NCMS000 SPS00 PP2CS00PPattern NP DP SP SP PP
OpenNLP-Maxent NC DP NC SP NCOpenNLP-Perceptron NC DP NC SP VMN
...comparisons of approaches that can be trainedon corpora ...have shown that in most cases statisticalapproaches ... yield better results than finite-state,rule-based, or memory-based taggers ... They areonly surpassed by combinations of different sys-tems, forming a voting tagger... ( on PoS taggingapproaches)[3]
Moreover, the execution time of the integrated consensustagger is also enhanced by the use of the Web Servicearchitecture. Several taggers can be run using REST moreefficiently than using the original taggers.
Adding support for other PoS tagging libraries could beuseful for researches who need to use libraries other thanthe ones included in the prototype. Finally, its design forextensibility is a plus.
REFERENCES
[1] W. N. Francis and H. Kucera, “Brown corpus manual,” Brown Univer-sity Department of Linguistics, 1979.
[2] D. Cutting, J. Kupiec, J. Pedersen, and P. Sibun, “A practical part-of-speech tagger,” in Proceedings of the third conference on Applied nat-ural language processing. Association for Computational Linguistics,1992, pp. 133–140.
[3] T. Brants, “Tnt: a statistical part-of-speech tagger,” in Proceedings of thesixth conference on Applied natural language processing. Associationfor Computational Linguistics, 2000, pp. 224–231.
[4] E. Brill, “A simple rule-based part of speech tagger,” in Proceedingsof the workshop on Speech and Natural Language. Association forComputational Linguistics, 1992, pp. 112–116.
[5] X. Carreras, I. Chao, L. Padro, and M. Padro, “Freeling: An open-sourcesuite of language analyzers.” in LREC, 2004.
[6] J. Atserias, B. Casas, E. Comelles, M. Gonzalez, L. Padro, andM. Padro, “Freeling 1.3: Syntactic and semantic services in an open-source nlp library,” in LREC, vol. 6, 2006, pp. 48–55.
[7] L. Padro, M. Collado, S. Reese, M. Lloberes, I. Castellon et al.,“Freeling 2.1: Five years of open-source language processing tools,” in7th International Conference on Language Resources and Evaluation,2010.
[8] L. Padro and E. Stanilovsky, “Freeling 3.0: Towards wider multilin-guality,” in 7th International Conference on Language Resources andEvaluation, 2012.
[9] S. Petrov, D. Das, and R. McDonald, “A universal part-of-speechtagset,” arXiv preprint arXiv:1104.2086, 2011.
[10] M. P. Marcus, M. A. Marcinkiewicz, and B. Santorini, “Building alarge annotated corpus of english: The penn treebank,” Computationallinguistics, vol. 19, no. 2, pp. 313–330, 1993.
[11] T. De Smedt and W. Daelemans, “Pattern for python,” The Journal ofMachine Learning Research, vol. 98888, pp. 2063–2067, 2012.
[12] G. Leech and A. Wilson, “Eagles recommendations for the morphosyn-tactic annotation of corpora,” 1996.
[13] M. Monachini and N. Calzolari, “Eagles synopsis and comparison of

morphosyntactic phenomena encoded in lexicons and corpora,” 1996.[14] C. Research and D. I. S. CORDIS, “Parole,” 1995.[15] ——, “LE-PAROLE,” 1996.[16] A. Zampolli, “Le parole,” 1996.[17] P. Baroni, “Parole,” 2007.[18] ——, “Parole-2,” 2007.[19] C. Linguistics and P. R. C. CLIPS, “pattern.es.”[20] A. L. Berger, V. J. D. Pietra, and S. A. D. Pietra, “A maximum entropy
approach to natural language processing,” Computational linguistics,vol. 22, no. 1, pp. 39–71, 1996.
[21] C. D. Manning and H. Schutze, Foundations of statistical naturallanguage processing. MIT press, 1999.
[22] E. F. Tjong Kim Sang, “Introduction to the conll-2002 shared task:Language-independent named entity recognition,” in Proceedings ofCoNLL-2002. Taipei, Taiwan, 2002, pp. 155–158.
[23] E. Wehrli, “Fips, a deep linguistic multilingual parser,” in Proceedingsof the Workshop on Deep Linguistic Processing. Association forComputational Linguistics, 2007, pp. 120–127.
[24] J. L. Arce, “Medios de comunicacion de masas en Costa Rica: Entre ladigitalizacion, la convergencia y el auge de los ”new media”,” in Haciala Sociedad de la Informacion y el Conocimiento. Programa Sociedadde la Informacion y el Conocimiento, Universidad de Costa Rica, 2012,ch. Medios de Comunicacion de Masas en Costa Rica, pp. 283–308.

27
Anexo B.
Conjunto de etiquetas EAGLES/PAROLE

28
El siguiente conjunto de etiquetas es tomado del sitio web de la biblioteca de etiquetado
gramatical Freeling [http://nlp.lsi.upc.edu/freeling/doc/tagsets/tagset-es.html].
Las etiquetas consisten en un conjunto de caracteres alfanuméricos en los cuales, entre más a la
izquierda se denota algo más general, y entre más a la derecha se denota algo más específico. Las
tablas que se muestran a continuación tienen el siguiente formato:
ETIQUETAS
Posición Atributo Valor Código
Columna 1 Columna 2 Columna 3 Columna 4
La columna indica la posición del carácter en la etiqueta. La columna 2 indica el atributo de la
etiqueta que representa la posición. La columna 3 indica los posibles valores que puede tener cada
atributo. Finalmente la columna 4 representa que carácter alfanumérico se utiliza para
representar el valor del atributo. Cuando un atributo no aplica o se desconoce para una etiqueta
se utiliza un cero. Un ejemplo de una etiqueta con estas características es VMSI1S0, que significa:
verbo principal subjuntivo imperfeto en primera persona singular.
Adjetivos
ADJETIVOS
Pos. Atributo Valor Código
1 Categoría Adjetivo A
2 Tipo Calificativo Q
Ordinal O
3 Grado Aumentativo A
Diminutivo D
Comparativo C
Superlativo S
4 Género Masculino M
Femenino F
Común C
5 Número Singular S
Plural P
Invariable N
6 Función - 0
Participio P
Ejemplo
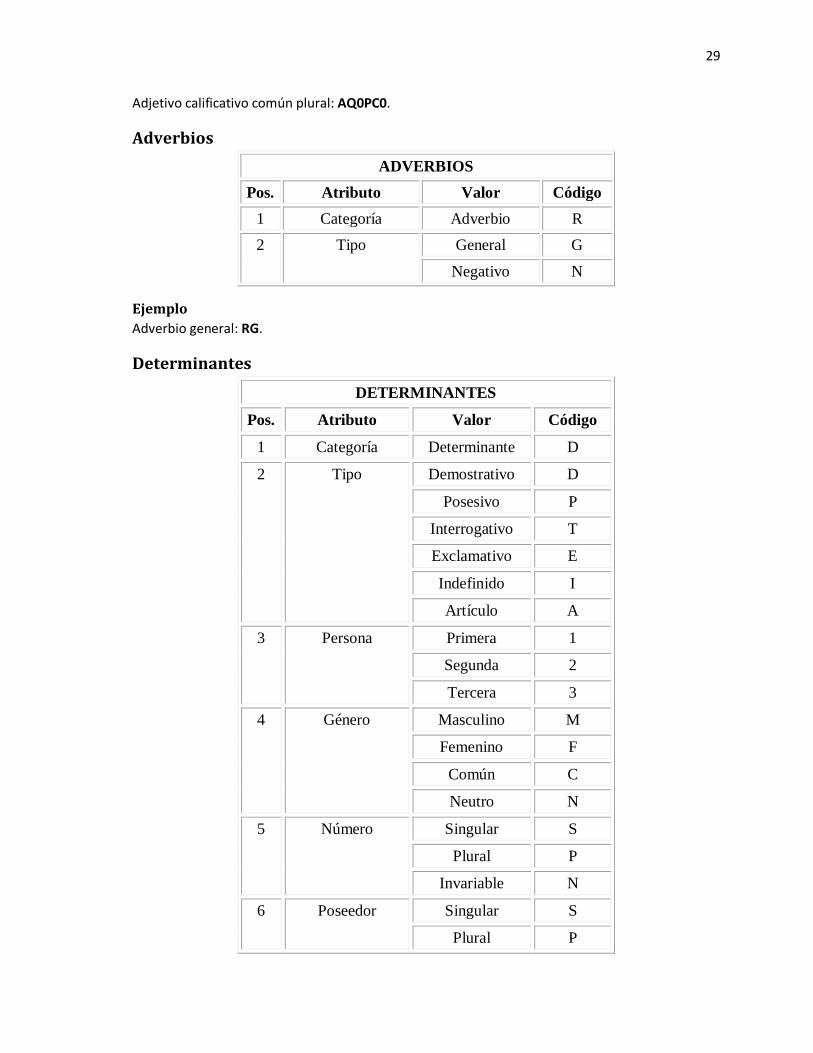
29
Adjetivo calificativo común plural: AQ0PC0.
Adverbios
ADVERBIOS
Pos. Atributo Valor Código
1 Categoría Adverbio R
2 Tipo General G
Negativo N
Ejemplo
Adverbio general: RG.
Determinantes
DETERMINANTES
Pos. Atributo Valor Código
1 Categoría Determinante D
2 Tipo Demostrativo D
Posesivo P
Interrogativo T
Exclamativo E
Indefinido I
Artículo A
3 Persona Primera 1
Segunda 2
Tercera 3
4 Género Masculino M
Femenino F
Común C
Neutro N
5 Número Singular S
Plural P
Invariable N
6 Poseedor Singular S
Plural P

30
Ejemplo
Determinante artículo masculino plural: DA0MP0.
Nombres
NOMBRES
Pos. Atributo Valor Código
1 Categoría Nombre N
2 Tipo Común C
Propio P
3 Género Masculino M
Femenino F
Común C
4 Número Singular S
Plural P
Invariable N
5-6 Clasificación
semántica
Persona SP
Lugar G0
Organización O0
Otros V0
7 Grado Aumentativo A
Diminutivo D
Ejemplo
Nombre común masculino singular diminutivo: NCMS00D.
Verbos
VERBOS
Pos. Atributo Valor Código
1 Categoría Verbo V
2 Tipo Principal M
Auxiliar A
Semiauxiliar S
3 Modo Indicativo I
Subjuntivo S
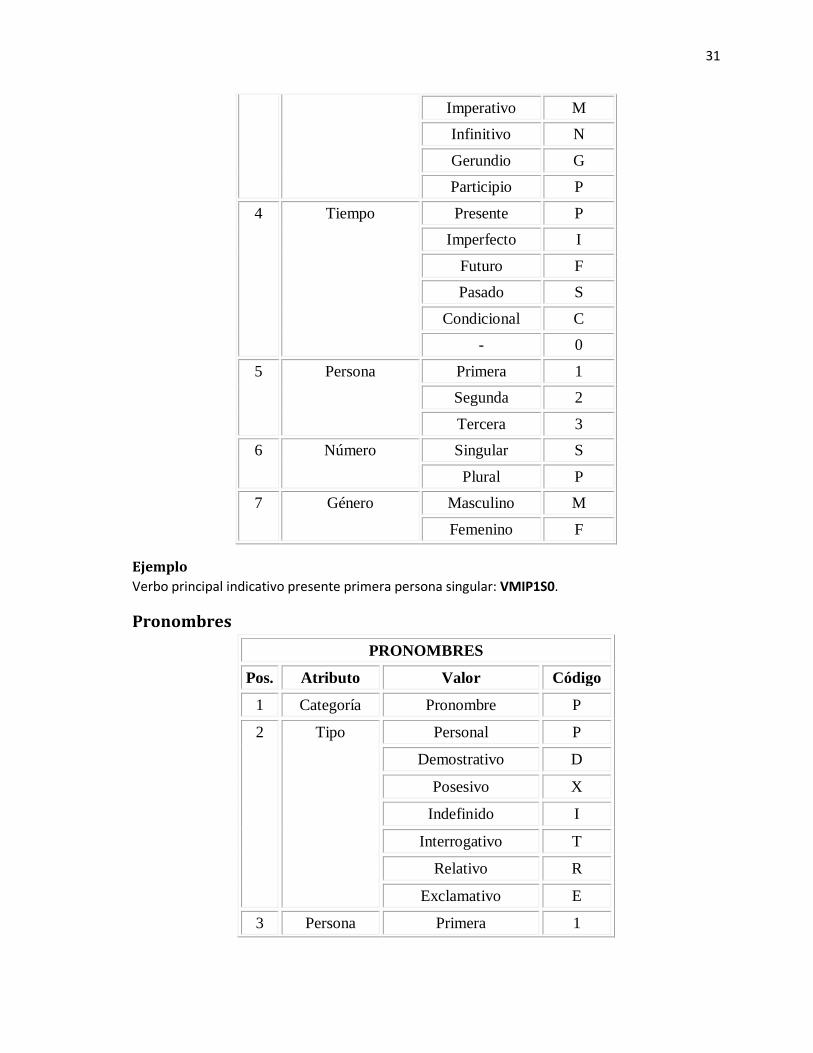
31
Imperativo M
Infinitivo N
Gerundio G
Participio P
4 Tiempo Presente P
Imperfecto I
Futuro F
Pasado S
Condicional C
- 0
5 Persona Primera 1
Segunda 2
Tercera 3
6 Número Singular S
Plural P
7 Género Masculino M
Femenino F
Ejemplo
Verbo principal indicativo presente primera persona singular: VMIP1S0.
Pronombres
PRONOMBRES
Pos. Atributo Valor Código
1 Categoría Pronombre P
2 Tipo Personal P
Demostrativo D
Posesivo X
Indefinido I
Interrogativo T
Relativo R
Exclamativo E
3 Persona Primera 1
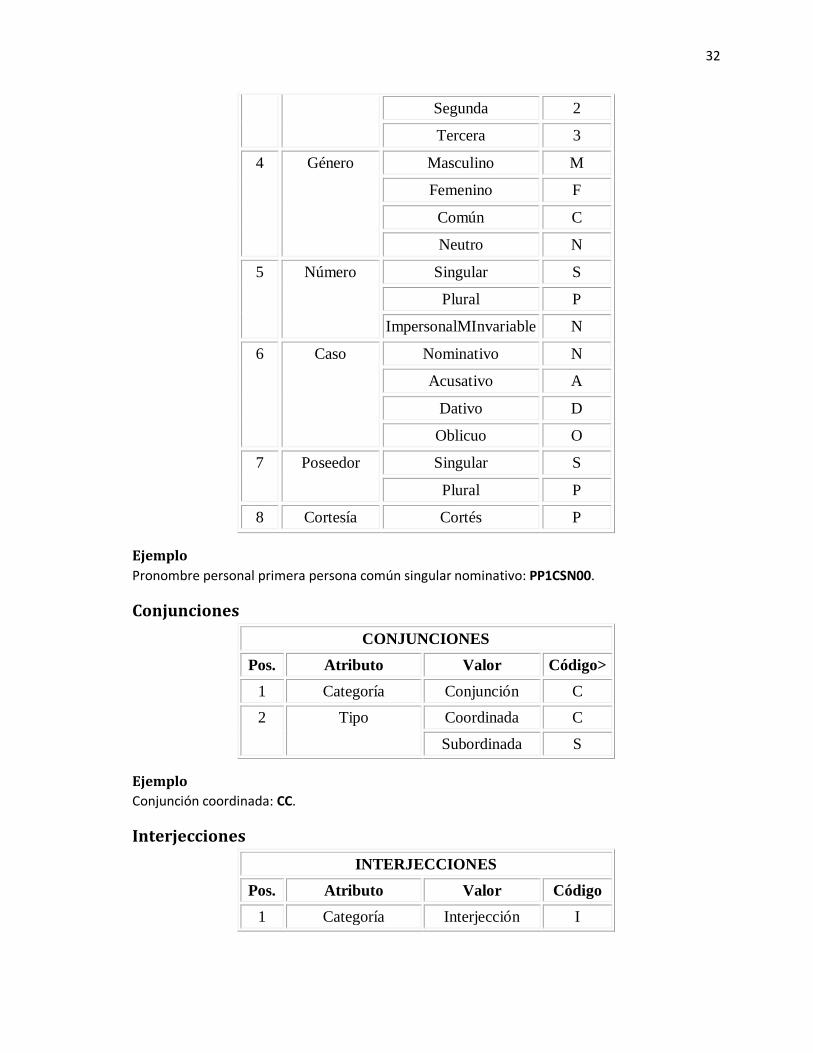
32
Segunda 2
Tercera 3
4 Género Masculino M
Femenino F
Común C
Neutro N
5 Número Singular S
Plural P
ImpersonalMInvariable N
6 Caso Nominativo N
Acusativo A
Dativo D
Oblicuo O
7 Poseedor Singular S
Plural P
8 Cortesía Cortés P
Ejemplo
Pronombre personal primera persona común singular nominativo: PP1CSN00.
Conjunciones
CONJUNCIONES
Pos. Atributo Valor Código>
1 Categoría Conjunción C
2 Tipo Coordinada C
Subordinada S
Ejemplo
Conjunción coordinada: CC.
Interjecciones
INTERJECCIONES
Pos. Atributo Valor Código
1 Categoría Interjección I

33
Ejemplo
Interjección: I.
Preposiciones
PREPOSICIONES
Pos. Atributo Valor Código
1 Categoría Adposición S
2 Tipo Preposición P
3 Forma Simple S
Contraída C
3 Género Masculino M
4 Número Singular S
Ejemplo
Adposición preposición contraída masculino singular: SPCMS.
Puntuación
SIGNOS DE PUNTUACIÓN
Pos. Atributo Valor Código
1 Categoría Puntuación F
Ejemplo
Forma Lema Etiqueta
¡ ¡ Faa
! ! Fat
, , Fc
[ [ Fca
] ] Fct
: : Fd
" " Fe
- - Fg
/ / Fh
¿ ¿ Fia
? ? Fit
{ { Fla
} } Flt
. . Fp
( ( Fpa
) ) Fpt
« « Fra
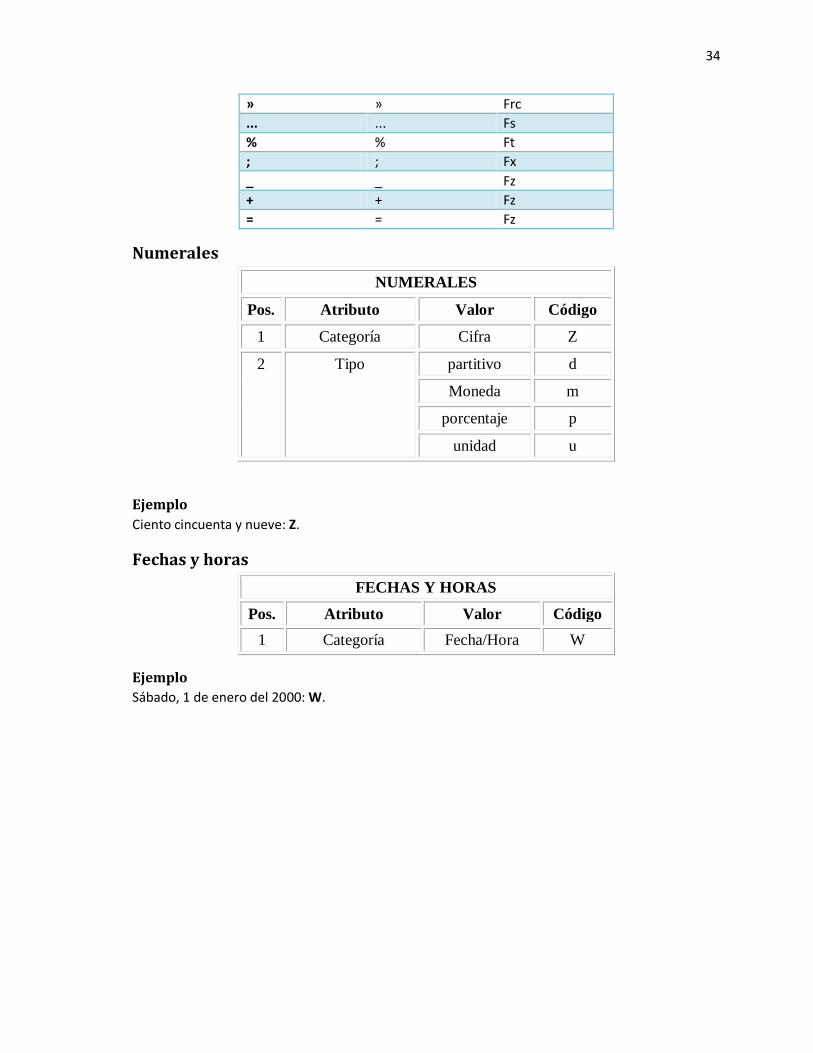
34
» » Frc
... ... Fs
% % Ft
; ; Fx
_ _ Fz
+ + Fz
= = Fz
Numerales
NUMERALES
Pos. Atributo Valor Código
1 Categoría Cifra Z
2 Tipo partitivo d
Moneda m
porcentaje p
unidad u
Ejemplo
Ciento cincuenta y nueve: Z.
Fechas y horas
FECHAS Y HORAS
Pos. Atributo Valor Código
1 Categoría Fecha/Hora W
Ejemplo
Sábado, 1 de enero del 2000: W.

35
Anexo C.
Resultados de prueba de calidad

36
Muestra de texto
Freeling Pattern OpenNLP (Maxent)
OpenNLP (Perceptron)
[1] 97.62% (41/42) 54.76% (23/42) 90.48% (38/42) 90.48% (38/42)
[2] 96.97% (32/33) 87.88% (29/33) 100.00% (33/33) 100.00% (33/33)
[3] 77.78% (14/18) 77.78% (14/18) 94.44% (17/18) 94.44% (17/18)
[4] 93.94% (31/33) 90.91% (30/33) 93.94% (31/33) 90.91% (30/33)
[5] 100.00% (7/7) 100.00% (7/7) 85.71% (6/7) 85.71% (6/7)
[6] 100.00% (29/29) 75.86% (22/29) 100.00% (29/29) 96.55% (28/29)
[7] 94.87% (37/39) 92.31% (36/39) 94.87% (37/39) 94.87% (37/39)
[8] 100.00% (15/15) 80.00% (12/15) 100.00% (15/15) 93.33% (14/15)
[9] 87.50% (14/16) 81.25% (13/16) 100.00% (16/16) 100.00% (16/16)
[10] 100.00% (5/5) 60.00% (3/5) 80.00% (4/5) 80.00% (4/5)
[11] 94.44% (34/36) 83.33% (30/36) 94.44% (34/36) 94.44% (34/36)
[12] 100.00% (14/14) 92.86% (13/14) 85.71% (12/14) 71.43% (10/14)
[13] 91.67% (11/12) 91.67% (11/12) 91.67% (11/12) 100.00% (12/12)
[14] 99.11% (111/112) 97.32% (109/112) 97.32% (109/112) 97.32% (109/112)
[15] 100.00% (12/12) 91.67% (11/12) 91.67% (11/12) 66.67% (8/12)
[16] 95.35% (82/86) 94.19% (81/86) 94.19% (81/86) 94.19% (81/86)
[17] 100.00% (14/14) 85.71% (12/14) 100.00% (14/14) 100.00% (14/14)
[18] 76.92% (10/13) 61.54% (8/13) 100.00% (13/13) 100.00% (13/13)
[19] 100.00% (19/19) 84.21% (16/19) 94.74% (18/19) 94.74% (18/19)
[20] 100.00% (5/5) 80.00% (4/5) 80.00% (4/5) 100.00% (5/5)
[21] 90.00% (18/20) 85.00% (17/20) 95.00% (19/20) 95.00% (19/20)
[22] 100.00% (9/9) 77.78% (7/9) 88.89% (8/9) 77.78% (7/9)
[23] 100.00% (3/3) 66.67% (2/3) 100.00% (3/3) 33.33% (1/3)
[24] 100.00% (9/9) 100.00% (9/9) 100.00% (9/9) 100.00% (9/9)
[25] 95.12% (39/41) 95.12% (39/41) 97.56% (40/41) 95.12% (39/41)
[26] 60.00% (9/15) 60.00% (9/15) 100.00% (15/15) 100.00% (15/15)
[27] 80.00% (8/10) 80.00% (8/10) 90.00% (9/10) 90.00% (9/10)
[28] 80.00% (4/5) 80.00% (4/5) 80.00% (4/5) 80.00% (4/5)
[29] 100.00% (47/47) 89.36% (42/47) 93.62% (44/47) 97.87% (46/47)
[30] 97.44% (38/39) 94.87% (37/39) 94.87% (37/39) 94.87% (37/39)
[31] 80.00% (4/5) 60.00% (3/5) 100.00% (5/5) 100.00% (5/5)
[32] 100.00% (34/34) 91.18% (31/34) 91.18% (31/34) 97.06% (33/34)
[33] 94.44% (17/18) 83.33% (15/18) 72.22% (13/18) 77.78% (14/18)
[34] 100.00% (5/5) 100.00% (5/5) 100.00% (5/5) 100.00% (5/5)
[35] 96.80% (121/125) 94.40% (118/125) 92.00% (115/125) 92.00% (115/125)
[36] 100.00% (6/6) 100.00% (6/6) 100.00% (6/6) 83.33% (5/6)
[37] 77.78% (7/9) 66.67% (6/9) 88.89% (8/9) 88.89% (8/9)
[38] 100.00% (9/9) 66.67% (6/9) 100.00% (9/9) 88.89% (8/9)
[39] 100.00% (20/20) 85.00% (17/20) 100.00% (20/20) 100.00% (20/20)
[40] 100.00% (5/5) 60.00% (3/5) 100.00% (5/5) 100.00% (5/5)
[41] 100.00% (93/93) 94.62% (88/93) 94.62% (88/93) 92.47% (86/93)
[42] 100.00% (15/15) 86.67% (13/15) 100.00% (15/15) 100.00% (15/15)
[43] 77.78% (7/9) 88.89% (8/9) 100.00% (9/9) 100.00% (9/9)

37
[44] 100.00% (7/7) 85.71% (6/7) 100.00% (7/7) 100.00% (7/7)
[45] 0.00% (0/1) 0.00% (0/1) 100.00% (1/1) 100.00% (1/1)
[46] 97.78% (44/45) 84.44% (38/45) 93.33% (42/45) 93.33% (42/45)
[47] 96.55% (28/29) 93.10% (27/29) 93.10% (27/29) 89.66% (26/29)
[48] 100.00% (8/8) 75.00% (6/8) 87.50% (7/8) 87.50% (7/8)
[49] 100.00% (10/10) 100.00% (10/10) 90.00% (9/10) 90.00% (9/10)
[50] 91.30% (21/23) 78.26% (18/23) 86.96% (20/23) 82.61% (19/23)
[51] 100.00% (2/2) 100.00% (2/2) 50.00% (1/2) 0.00% (0/2)
[52] 100.00% (14/14) 85.71% (12/14) 100.00% (14/14) 85.71% (12/14)
[53] 96.97% (32/33) 100.00% (33/33) 90.91% (30/33) 90.91% (30/33)
[54] 100.00% (8/8) 75.00% (6/8) 100.00% (8/8) 100.00% (8/8)
[55] 93.33% (14/15) 93.33% (14/15) 93.33% (14/15) 86.67% (13/15)
[56] 91.67% (22/24) 87.50% (21/24) 91.67% (22/24) 95.83% (23/24)
[57] 100.00% (16/16) 93.75% (15/16) 93.75% (15/16) 87.50% (14/16)
[58] 100.00% (5/5) 100.00% (5/5) 100.00% (5/5) 80.00% (4/5)
[59] 9.09% (1/11) 27.27% (3/11) 81.82% (9/11) 81.82% (9/11)
[60] 100.00% (10/10) 90.00% (9/10) 100.00% (10/10) 100.00% (10/10)
[61] 84.21% (16/19) 84.21% (16/19) 94.74% (18/19) 89.47% (17/19)
[62] 90.20% (46/51) 80.39% (41/51) 82.35% (42/51) 90.20% (46/51)
[63] 100.00% (18/18) 100.00% (18/18) 100.00% (18/18) 100.00% (18/18)
[64] 93.55% (29/31) 74.19% (23/31) 93.55% (29/31) 93.55% (29/31)
[65] 85.71% (12/14) 78.57% (11/14) 100.00% (14/14) 92.86% (13/14)
[66] 80.00% (4/5) 80.00% (4/5) 100.00% (5/5) 100.00% (5/5)
[67] 100.00% (24/24) 87.50% (21/24) 87.50% (21/24) 100.00% (24/24)
[68] 100.00% (10/10) 100.00% (10/10) 100.00% (10/10) 100.00% (10/10)
[69] 100.00% (14/14) 100.00% (14/14) 92.86% (13/14) 92.86% (13/14)
[70] 88.89% (16/18) 83.33% (15/18) 100.00% (18/18) 100.00% (18/18)
[71] 100.00% (38/38) 86.84% (33/38) 100.00% (38/38) 97.37% (37/38)
[72] 100.00% (26/26) 88.46% (23/26) 100.00% (26/26) 92.31% (24/26)
[73] 100.00% (21/21) 90.48% (19/21) 85.71% (18/21) 80.95% (17/21)
[74] 100.00% (21/21) 90.48% (19/21) 90.48% (19/21) 90.48% (19/21)
[75] 100.00% (3/3) 66.67% (2/3) 100.00% (3/3) 100.00% (3/3)
[76] 50.00% (1/2) 50.00% (1/2) 100.00% (2/2) 50.00% (1/2)
[77] 100.00% (15/15) 73.33% (11/15) 86.67% (13/15) 93.33% (14/15)
[78] 98.46% (64/65) 89.23% (58/65) 95.38% (62/65) 93.85% (61/65)
[79] 66.67% (4/6) 33.33% (2/6) 100.00% (6/6) 83.33% (5/6)
[80] 88.00% (22/25) 96.00% (24/25) 96.00% (24/25) 96.00% (24/25)
[81] 100.00% (8/8) 75.00% (6/8) 87.50% (7/8) 100.00% (8/8)
[82] 100.00% (12/12) 83.33% (10/12) 91.67% (11/12) 91.67% (11/12)
[83] 90.91% (20/22) 95.45% (21/22) 86.36% (19/22) 95.45% (21/22)
[84] 100.00% (18/18) 83.33% (15/18) 88.89% (16/18) 94.44% (17/18)
[85] 100.00% (9/9) 100.00% (9/9) 100.00% (9/9) 100.00% (9/9)
[86] 100.00% (20/20) 90.00% (18/20) 95.00% (19/20) 95.00% (19/20)
[87] 92.75% (64/69) 34.78% (24/69) 98.55% (68/69) 94.20% (65/69)
[88] 100.00% (13/13) 84.62% (11/13) 100.00% (13/13) 92.31% (12/13)
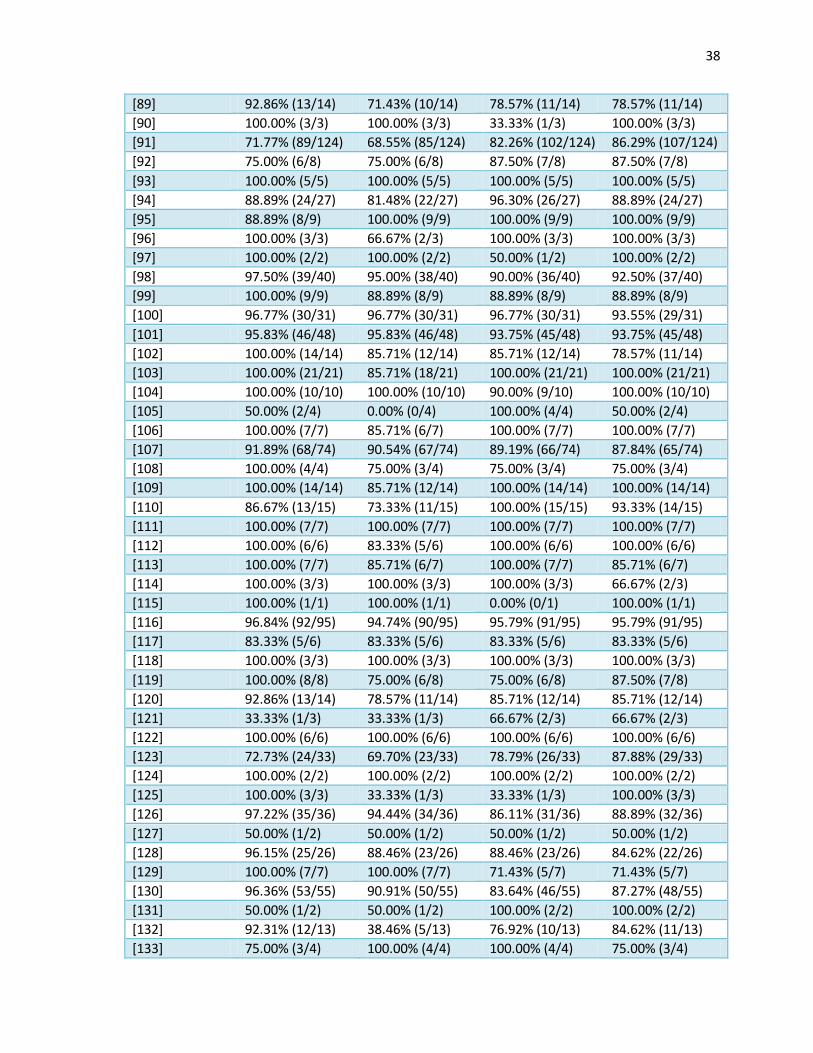
38
[89] 92.86% (13/14) 71.43% (10/14) 78.57% (11/14) 78.57% (11/14)
[90] 100.00% (3/3) 100.00% (3/3) 33.33% (1/3) 100.00% (3/3)
[91] 71.77% (89/124) 68.55% (85/124) 82.26% (102/124) 86.29% (107/124)
[92] 75.00% (6/8) 75.00% (6/8) 87.50% (7/8) 87.50% (7/8)
[93] 100.00% (5/5) 100.00% (5/5) 100.00% (5/5) 100.00% (5/5)
[94] 88.89% (24/27) 81.48% (22/27) 96.30% (26/27) 88.89% (24/27)
[95] 88.89% (8/9) 100.00% (9/9) 100.00% (9/9) 100.00% (9/9)
[96] 100.00% (3/3) 66.67% (2/3) 100.00% (3/3) 100.00% (3/3)
[97] 100.00% (2/2) 100.00% (2/2) 50.00% (1/2) 100.00% (2/2)
[98] 97.50% (39/40) 95.00% (38/40) 90.00% (36/40) 92.50% (37/40)
[99] 100.00% (9/9) 88.89% (8/9) 88.89% (8/9) 88.89% (8/9)
[100] 96.77% (30/31) 96.77% (30/31) 96.77% (30/31) 93.55% (29/31)
[101] 95.83% (46/48) 95.83% (46/48) 93.75% (45/48) 93.75% (45/48)
[102] 100.00% (14/14) 85.71% (12/14) 85.71% (12/14) 78.57% (11/14)
[103] 100.00% (21/21) 85.71% (18/21) 100.00% (21/21) 100.00% (21/21)
[104] 100.00% (10/10) 100.00% (10/10) 90.00% (9/10) 100.00% (10/10)
[105] 50.00% (2/4) 0.00% (0/4) 100.00% (4/4) 50.00% (2/4)
[106] 100.00% (7/7) 85.71% (6/7) 100.00% (7/7) 100.00% (7/7)
[107] 91.89% (68/74) 90.54% (67/74) 89.19% (66/74) 87.84% (65/74)
[108] 100.00% (4/4) 75.00% (3/4) 75.00% (3/4) 75.00% (3/4)
[109] 100.00% (14/14) 85.71% (12/14) 100.00% (14/14) 100.00% (14/14)
[110] 86.67% (13/15) 73.33% (11/15) 100.00% (15/15) 93.33% (14/15)
[111] 100.00% (7/7) 100.00% (7/7) 100.00% (7/7) 100.00% (7/7)
[112] 100.00% (6/6) 83.33% (5/6) 100.00% (6/6) 100.00% (6/6)
[113] 100.00% (7/7) 85.71% (6/7) 100.00% (7/7) 85.71% (6/7)
[114] 100.00% (3/3) 100.00% (3/3) 100.00% (3/3) 66.67% (2/3)
[115] 100.00% (1/1) 100.00% (1/1) 0.00% (0/1) 100.00% (1/1)
[116] 96.84% (92/95) 94.74% (90/95) 95.79% (91/95) 95.79% (91/95)
[117] 83.33% (5/6) 83.33% (5/6) 83.33% (5/6) 83.33% (5/6)
[118] 100.00% (3/3) 100.00% (3/3) 100.00% (3/3) 100.00% (3/3)
[119] 100.00% (8/8) 75.00% (6/8) 75.00% (6/8) 87.50% (7/8)
[120] 92.86% (13/14) 78.57% (11/14) 85.71% (12/14) 85.71% (12/14)
[121] 33.33% (1/3) 33.33% (1/3) 66.67% (2/3) 66.67% (2/3)
[122] 100.00% (6/6) 100.00% (6/6) 100.00% (6/6) 100.00% (6/6)
[123] 72.73% (24/33) 69.70% (23/33) 78.79% (26/33) 87.88% (29/33)
[124] 100.00% (2/2) 100.00% (2/2) 100.00% (2/2) 100.00% (2/2)
[125] 100.00% (3/3) 33.33% (1/3) 33.33% (1/3) 100.00% (3/3)
[126] 97.22% (35/36) 94.44% (34/36) 86.11% (31/36) 88.89% (32/36)
[127] 50.00% (1/2) 50.00% (1/2) 50.00% (1/2) 50.00% (1/2)
[128] 96.15% (25/26) 88.46% (23/26) 88.46% (23/26) 84.62% (22/26)
[129] 100.00% (7/7) 100.00% (7/7) 71.43% (5/7) 71.43% (5/7)
[130] 96.36% (53/55) 90.91% (50/55) 83.64% (46/55) 87.27% (48/55)
[131] 50.00% (1/2) 50.00% (1/2) 100.00% (2/2) 100.00% (2/2)
[132] 92.31% (12/13) 38.46% (5/13) 76.92% (10/13) 84.62% (11/13)
[133] 75.00% (3/4) 100.00% (4/4) 100.00% (4/4) 75.00% (3/4)

39
[134] 96.05% (73/76) 84.21% (64/76) 94.74% (72/76) 94.74% (72/76)
[135] 100.00% (22/22) 90.91% (20/22) 95.45% (21/22) 90.91% (20/22)
[136] 84.62% (11/13) 84.62% (11/13) 76.92% (10/13) 76.92% (10/13)
[137] 100.00% (3/3) 66.67% (2/3) 100.00% (3/3) 100.00% (3/3)
[138] 86.67% (13/15) 73.33% (11/15) 86.67% (13/15) 73.33% (11/15)
[139] 93.33% (14/15) 80.00% (12/15) 93.33% (14/15) 93.33% (14/15)
[140] 100.00% (25/25) 88.00% (22/25) 88.00% (22/25) 92.00% (23/25)
[141] 94.74% (36/38) 89.47% (34/38) 92.11% (35/38) 92.11% (35/38)
[142] 95.96% (95/99) 96.97% (96/99) 93.94% (93/99) 94.95% (94/99)
[143] 93.33% (14/15) 73.33% (11/15) 100.00% (15/15) 93.33% (14/15)
[144] 100.00% (2/2) 0.00% (0/2) 100.00% (2/2) 100.00% (2/2)
[145] 95.24% (20/21) 85.71% (18/21) 100.00% (21/21) 100.00% (21/21)
[146] 96.43% (27/28) 96.43% (27/28) 92.86% (26/28) 96.43% (27/28)
[147] 95.00% (19/20) 75.00% (15/20) 95.00% (19/20) 90.00% (18/20)
[148] 90.00% (9/10) 80.00% (8/10) 90.00% (9/10) 90.00% (9/10)
[149] 100.00% (25/25) 76.00% (19/25) 92.00% (23/25) 100.00% (25/25)
[150] 100.00% (8/8) 100.00% (8/8) 100.00% (8/8) 100.00% (8/8)
[151] 83.33% (20/24) 75.00% (18/24) 100.00% (24/24) 95.83% (23/24)
[152] 100.00% (21/21) 80.95% (17/21) 95.24% (20/21) 95.24% (20/21)
[153] 80.00% (4/5) 80.00% (4/5) 80.00% (4/5) 100.00% (5/5)
[154] 88.24% (30/34) 61.76% (21/34) 85.29% (29/34) 79.41% (27/34)
[155] 100.00% (6/6) 100.00% (6/6) 100.00% (6/6) 100.00% (6/6)
[156] 98.75% (79/80) 97.50% (78/80) 98.75% (79/80) 97.50% (78/80)
[157] 96.72% (59/61) 83.61% (51/61) 85.25% (52/61) 90.16% (55/61)
[158] 93.33% (14/15) 100.00% (15/15) 93.33% (14/15) 100.00% (15/15)
[159] 92.86% (13/14) 78.57% (11/14) 85.71% (12/14) 100.00% (14/14)
[160] 100.00% (42/42) 90.48% (38/42) 92.86% (39/42) 88.10% (37/42)
[161] 100.00% (20/20) 95.00% (19/20) 85.00% (17/20) 85.00% (17/20)
[162] 100.00% (9/9) 100.00% (9/9) 100.00% (9/9) 100.00% (9/9)
[163] 95.65% (22/23) 82.61% (19/23) 100.00% (23/23) 95.65% (22/23)
[164] 91.67% (22/24) 87.50% (21/24) 95.83% (23/24) 100.00% (24/24)
[165] 97.06% (33/34) 91.18% (31/34) 97.06% (33/34) 94.12% (32/34)
[166] 91.67% (11/12) 91.67% (11/12) 66.67% (8/12) 66.67% (8/12)
[167] 100.00% (7/7) 100.00% (7/7) 85.71% (6/7) 85.71% (6/7)
[168] 100.00% (6/6) 100.00% (6/6) 83.33% (5/6) 83.33% (5/6)
[169] 83.33% (25/30) 93.33% (28/30) 93.33% (28/30) 93.33% (28/30)
[170] 83.33% (5/6) 100.00% (6/6) 100.00% (6/6) 83.33% (5/6)
[171] 85.71% (6/7) 85.71% (6/7) 100.00% (7/7) 85.71% (6/7)
[172] 100.00% (6/6) 100.00% (6/6) 66.67% (4/6) 83.33% (5/6)
[173] 100.00% (10/10) 100.00% (10/10) 100.00% (10/10) 100.00% (10/10)
[174] 82.54% (52/63) 92.06% (58/63) 93.65% (59/63) 93.65% (59/63)
[175] 93.10% (27/29) 79.31% (23/29) 96.55% (28/29) 96.55% (28/29)
[176] 97.65% (83/85) 95.29% (81/85) 94.12% (80/85) 94.12% (80/85)
[177] 87.50% (7/8) 100.00% (8/8) 75.00% (6/8) 87.50% (7/8)
[178] 95.24% (20/21) 85.71% (18/21) 90.48% (19/21) 90.48% (19/21)

40
[179] 88.89% (8/9) 88.89% (8/9) 100.00% (9/9) 100.00% (9/9)
[180] 90.91% (30/33) 84.85% (28/33) 96.97% (32/33) 96.97% (32/33)
[181] 88.24% (15/17) 82.35% (14/17) 100.00% (17/17) 100.00% (17/17)
[182] 100.00% (10/10) 100.00% (10/10) 80.00% (8/10) 90.00% (9/10)
[183] 100.00% (27/27) 81.48% (22/27) 100.00% (27/27) 100.00% (27/27)
[184] 100.00% (11/11) 81.82% (9/11) 81.82% (9/11) 63.64% (7/11)
[185] 100.00% (3/3) 100.00% (3/3) 100.00% (3/3) 66.67% (2/3)
[186] 100.00% (14/14) 85.71% (12/14) 100.00% (14/14) 100.00% (14/14)
[187] 100.00% (1/1) 0.00% (0/1) 100.00% (1/1) 100.00% (1/1)
[188] 96.30% (26/27) 81.48% (22/27) 96.30% (26/27) 88.89% (24/27)
[189] 100.00% (14/14) 100.00% (14/14) 92.86% (13/14) 92.86% (13/14)
[190] 100.00% (24/24) 83.33% (20/24) 95.83% (23/24) 91.67% (22/24)
[191] 100.00% (6/6) 100.00% (6/6) 83.33% (5/6) 66.67% (4/6)
[192] 92.31% (12/13) 76.92% (10/13) 84.62% (11/13) 92.31% (12/13)
[193] 64.71% (22/34) 73.53% (25/34) 85.29% (29/34) 82.35% (28/34)
[194] 92.86% (13/14) 85.71% (12/14) 100.00% (14/14) 92.86% (13/14)
[195] 96.67% (29/30) 96.67% (29/30) 93.33% (28/30) 96.67% (29/30)
[196] 91.67% (11/12) 91.67% (11/12) 83.33% (10/12) 91.67% (11/12)
[197] 90.00% (18/20) 70.00% (14/20) 100.00% (20/20) 95.00% (19/20)
[198] 85.71% (6/7) 100.00% (7/7) 71.43% (5/7) 100.00% (7/7)
[199] 90.91% (30/33) 93.94% (31/33) 100.00% (33/33) 96.97% (32/33)
[200] 100.00% (5/5) 100.00% (5/5) 100.00% (5/5) 100.00% (5/5)
Total 93.81% (4032/4298)
86.02% (3697/4298)
92.69% (3984/4298)
92.39% (3971/4298)

41
Anexo D.
Código fuente

42
cr.ac.ucr.sentimetro.postagging.factories.Factory<T>
package cr.ac.ucr.sentimetro.postagging.factories;
public interface Factory<T> {
public T create() throws Exception;
}
cr.ac.ucr.sentimetro.postagging.factories.FreelingTaggerFactory
package cr.ac.ucr.sentimetro.postagging.factories;
import cr.ac.ucr.sentimetro.postagging.taggers.FreelingTagger;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
public final class FreelingTaggerFactory implements Factory<Tagger> {
@Override
public final Tagger create() {
return new FreelingTagger("es");
}
}
cr.ac.ucr.sentimetro.postagging.factories.GsonFactory
package cr.ac.ucr.sentimetro.postagging.factories;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
public final class GsonFactory implements Factory<Gson> {
@Override
public final Gson create() {
return new
GsonBuilder().excludeFieldsWithoutExposeAnnotation().create();
}
}
cr.ac.ucr.sentimetro.postagging.factories.OpenNlpMaxentTaggerFactory
package cr.ac.ucr.sentimetro.postagging.factories;
import cr.ac.ucr.sentimetro.postagging.taggers.OpenNlpTagger;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
import java.io.IOException;
public final class OpenNlpMaxentTaggerFactory implements Factory<Tagger>
{
@Override
public final Tagger create() throws IOException {
return new OpenNlpTagger(OpenNlpTagger.Type.MAXENT);
}

43
}
cr.ac.ucr.sentimetro.postagging.factories.OpenNlpPerceptronTaggerFacto
ry
package cr.ac.ucr.sentimetro.postagging.factories;
import cr.ac.ucr.sentimetro.postagging.taggers.OpenNlpTagger;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
import java.io.IOException;
public final class OpenNlpPerceptronTaggerFactory implements
Factory<Tagger> {
@Override
public final Tagger create() throws IOException {
return new OpenNlpTagger(OpenNlpTagger.Type.PERCEPTRON);
}
}
cr.ac.ucr.sentimetro.postagging.factories.PatternTaggerFactory
package cr.ac.ucr.sentimetro.postagging.factories;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
import org.python.core.PyObject;
import org.python.util.PythonInterpreter;
public final class PatternTaggerFactory implements Factory<Tagger> {
private final PyObject patternTaggerClass;
public PatternTaggerFactory() {
PythonInterpreter i = new PythonInterpreter();
i.exec("from PatternTagger import PatternTagger");
this.patternTaggerClass = i.get("PatternTagger");
}
@Override
public final Tagger create() {
PyObject o = this.patternTaggerClass.__call__();
Tagger t = (Tagger)o.__tojava__(Tagger.class);
return t;
}
}
cr.ac.ucr.sentimetro.postagging.factories.PatternWordNormalizerFactory
package cr.ac.ucr.sentimetro.postagging.factories;

44
import cr.ac.ucr.sentimetro.postagging.normalizers.PatternWordNormalizer;
import cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer;
public final class PatternWordNormalizerFactory implements
Factory<WordNormalizer> {
@Override
public final WordNormalizer create() {
return new PatternWordNormalizer();
}
}
cr.ac.ucr.sentimetro.postagging.factories.WordNormalizerFactory
package cr.ac.ucr.sentimetro.postagging.factories;
import cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer;
public final class WordNormalizerFactory implements
Factory<WordNormalizer> {
@Override
public final WordNormalizer create() {
return new WordNormalizer();
}
}
cr.ac.ucr.sentimetro.postagging.managers.FreelingTaggerManager
package cr.ac.ucr.sentimetro.postagging.managers;
import cr.ac.ucr.sentimetro.postagging.Pool;
import cr.ac.ucr.sentimetro.postagging.factories.FreelingTaggerFactory;
import cr.ac.ucr.sentimetro.postagging.factories.WordNormalizerFactory;
import cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
public final class FreelingTaggerManager extends TaggerManager {
private static final Pool<Tagger> FREELING_TAGGER_POOL
= new Pool<Tagger>(new FreelingTaggerFactory());
private static final Pool<WordNormalizer>
FREELING_WORD_NORMALIZER_POOL = new Pool<WordNormalizer>(new
WordNormalizerFactory());
@Override
public final String getTaggerName() {
return "Freeling";
}
@Override
protected final Tagger takeTaggerInstance() throws
InterruptedException {
return FreelingTaggerManager.FREELING_TAGGER_POOL.takeInstance();
}

45
@Override
protected final WordNormalizer takeWordNormalizerInstance() throws
InterruptedException {
return
FreelingTaggerManager.FREELING_WORD_NORMALIZER_POOL.takeInstance();
}
@Override
protected final void putTaggerInstance(final Tagger tagger) throws
InterruptedException {
FreelingTaggerManager.FREELING_TAGGER_POOL.putInstance(tagger);
}
@Override
protected final void putWordNormalizerInstance(final WordNormalizer
wordNormalizer) throws InterruptedException {
FreelingTaggerManager.FREELING_WORD_NORMALIZER_POOL.putInstance(wordNorma
lizer);
}
}
cr.ac.ucr.sentimetro.postagging.managers.OpenNlpMaxentTaggerManage
r
package cr.ac.ucr.sentimetro.postagging.managers;
import cr.ac.ucr.sentimetro.postagging.Pool;
import
cr.ac.ucr.sentimetro.postagging.factories.OpenNlpMaxentTaggerFactory;
import cr.ac.ucr.sentimetro.postagging.factories.WordNormalizerFactory;
import cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
public final class OpenNlpMaxentTaggerManager extends TaggerManager {
private static final Pool<Tagger> OPENNLP_TAGGER_POOL
= new Pool<Tagger>(new OpenNlpMaxentTaggerFactory());
private static final Pool<WordNormalizer>
OPENNLP_WORD_NORMALIZER_POOL = new Pool<WordNormalizer>(new
WordNormalizerFactory());
@Override
public final String getTaggerName() {
return "OpenNLP (Maxent)";
}
@Override
protected final Tagger takeTaggerInstance() throws
InterruptedException {
return
OpenNlpMaxentTaggerManager.OPENNLP_TAGGER_POOL.takeInstance();
}

46
@Override
protected final WordNormalizer takeWordNormalizerInstance() throws
InterruptedException {
return
OpenNlpMaxentTaggerManager.OPENNLP_WORD_NORMALIZER_POOL.takeInstance();
}
@Override
protected final void putTaggerInstance(final Tagger tagger) throws
InterruptedException {
OpenNlpMaxentTaggerManager.OPENNLP_TAGGER_POOL.putInstance(tagger);
}
@Override
protected final void putWordNormalizerInstance(final WordNormalizer
wordNormalizer) throws InterruptedException {
OpenNlpMaxentTaggerManager.OPENNLP_WORD_NORMALIZER_POOL.putInstance(wordN
ormalizer);
}
}
cr.ac.ucr.sentimetro.postagging.managers.OpenNlpPerceptronTaggerMan
ager
package cr.ac.ucr.sentimetro.postagging.managers;
import cr.ac.ucr.sentimetro.postagging.Pool;
import
cr.ac.ucr.sentimetro.postagging.factories.OpenNlpPerceptronTaggerFactory;
import cr.ac.ucr.sentimetro.postagging.factories.WordNormalizerFactory;
import cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
public final class OpenNlpPerceptronTaggerManager extends TaggerManager {
private static final Pool<Tagger> OPENNLP_TAGGER_POOL
= new Pool<Tagger>(new OpenNlpPerceptronTaggerFactory());
private static final Pool<WordNormalizer>
OPENNLP_WORD_NORMALIZER_POOL = new Pool<WordNormalizer>(new
WordNormalizerFactory());
@Override
public final String getTaggerName() {
return "OpenNLP (Perceptron)";
}
@Override
protected final Tagger takeTaggerInstance() throws
InterruptedException {
return
OpenNlpPerceptronTaggerManager.OPENNLP_TAGGER_POOL.takeInstance();
}

47
@Override
protected final WordNormalizer takeWordNormalizerInstance() throws
InterruptedException {
return
OpenNlpPerceptronTaggerManager.OPENNLP_WORD_NORMALIZER_POOL.takeInstance(
);
}
@Override
protected final void putTaggerInstance(final Tagger tagger) throws
InterruptedException {
OpenNlpPerceptronTaggerManager.OPENNLP_TAGGER_POOL.putInstance(tagger);
}
@Override
protected final void putWordNormalizerInstance(final WordNormalizer
wordNormalizer) throws InterruptedException {
OpenNlpPerceptronTaggerManager.OPENNLP_WORD_NORMALIZER_POOL.putInstance(w
ordNormalizer);
}
}
cr.ac.ucr.sentimetro.postagging.managers.PatternTaggerManager
package cr.ac.ucr.sentimetro.postagging.managers;
import cr.ac.ucr.sentimetro.postagging.Pool;
import cr.ac.ucr.sentimetro.postagging.factories.PatternTaggerFactory;
import
cr.ac.ucr.sentimetro.postagging.factories.PatternWordNormalizerFactory;
import cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
public final class PatternTaggerManager extends TaggerManager {
private static final Pool<Tagger> PATTERN_TAGGER_POOL
= new Pool<Tagger>(new PatternTaggerFactory());
private static final Pool<WordNormalizer>
PATTERN_WORD_NORMALIZER_POOL = new Pool<WordNormalizer>(new
PatternWordNormalizerFactory());
@Override
public final String getTaggerName() {
return "Pattern";
}
@Override
protected final Tagger takeTaggerInstance() throws
InterruptedException {
return PatternTaggerManager.PATTERN_TAGGER_POOL.takeInstance();
}
@Override

48
protected final WordNormalizer takeWordNormalizerInstance() throws
InterruptedException {
return
PatternTaggerManager.PATTERN_WORD_NORMALIZER_POOL.takeInstance();
}
@Override
protected final void putTaggerInstance(final Tagger tagger) throws
InterruptedException {
PatternTaggerManager.PATTERN_TAGGER_POOL.putInstance(tagger);
}
@Override
protected final void putWordNormalizerInstance(final WordNormalizer
wordNormalizer) throws InterruptedException {
PatternTaggerManager.PATTERN_WORD_NORMALIZER_POOL.putInstance(wordNormali
zer);
}
}
cr.ac.ucr.sentimetro.postagging.managers.TaggerManager
package cr.ac.ucr.sentimetro.postagging.managers;
import cr.ac.ucr.sentimetro.postagging.Word;
import cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer;
import cr.ac.ucr.sentimetro.postagging.taggers.Tagger;
import java.util.List;
public abstract class TaggerManager {
public List<Word> process(final String text) throws
InterruptedException {
Tagger tagger = this.takeTaggerInstance();
WordNormalizer wordNormalizer =
this.takeWordNormalizerInstance();
List<Word> result =
wordNormalizer.normalize(tagger.analyze(text));
this.putTaggerInstance(tagger);
this.putWordNormalizerInstance(wordNormalizer);
return result;
}
public abstract String getTaggerName();
protected abstract Tagger takeTaggerInstance() throws
InterruptedException;
protected abstract WordNormalizer takeWordNormalizerInstance() throws
InterruptedException;
protected abstract void putTaggerInstance(final Tagger tagger) throws
InterruptedException;

49
protected abstract void putWordNormalizerInstance(final
WordNormalizer wordNormalizer) throws InterruptedException;
}
cr.ac.ucr.sentimetro.postagging.normalizers.PatternWordNormalizer
package cr.ac.ucr.sentimetro.postagging.normalizers;
import cr.ac.ucr.sentimetro.postagging.PojoWord;
import cr.ac.ucr.sentimetro.postagging.Word;
public final class PatternWordNormalizer extends WordNormalizer {
@Override
protected final Word normalizeSplittedWord(final String formPart,
final Word word) {
return new PojoWord(formPart, word.getLemma(),
PatternWordNormalizer.normalizeTag(word.getTag()));
}
@Override
protected final Word normalizeWord(final Word word) {
return new PojoWord(word.getForm(), word.getLemma(),
PatternWordNormalizer.normalizeTag(word.getTag()));
}
private static final String normalizeTag(final String tag) {
switch (tag) {
case "NCS":
return "NC0S";
case "NCP":
return "NCP";
default:
return tag;
}
}
}
cr.ac.ucr.sentimetro.postagging.normalizers.WordNormalizer
package cr.ac.ucr.sentimetro.postagging.normalizers;
import cr.ac.ucr.sentimetro.postagging.PojoWord;
import cr.ac.ucr.sentimetro.postagging.Word;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Pattern;
public class WordNormalizer {
private static final String PUNCTUATION_MARKS =
"\\¡|\\!|\\,|\\[|\\]|\\:|\\\"|\\-
|\\/|\\¿|\\?|\\{|\\}|\\.|\\(|\\)|\\«|\\»|\\%|\\;|\\_|\\+|\\=";
private static final Pattern PUNCTUATION_MARKS_SPLITTER =

50
Pattern.compile(String.format("(?<=%1$s)|(?=%1$s)",
WordNormalizer.PUNCTUATION_MARKS));
private static final Pattern PUNCTUATION_MARKS_DETECTOR =
Pattern.compile(String.format("^%s$", WordNormalizer.PUNCTUATION_MARKS));
public final List<Word> normalize(final List<Word> words) {
List<Word> normalizedWords = new ArrayList<Word>(words.size());
for (Word word : words) {
String form = word.getForm();
if
(WordNormalizer.PUNCTUATION_MARKS_DETECTOR.matcher(form).matches()) {
normalizedWords.add(WordNormalizer.tagPunctuationMark(form));
} else {
String[] formParts =
WordNormalizer.PUNCTUATION_MARKS_SPLITTER.split(form);
if (formParts.length > 1) {
for (int i = 0; i < formParts.length; ++i) {
if (!formParts[i].isEmpty()) {
if
(WordNormalizer.PUNCTUATION_MARKS_DETECTOR.matcher(formParts[i]).matches(
)) {
if (".".equals(formParts[i]) &&
i < formParts.length - 2 &&
".".equals(formParts[i + 1]) &&
".".equals(formParts[i + 1])) {
normalizedWords.add(WordNormalizer.tagPunctuationMark("..."));
i += 2;
} else {
normalizedWords.add(WordNormalizer.tagPunctuationMark(formParts[i]));
}
} else {
normalizedWords.add(this.normalizeSplittedWord(formParts[i], word));
}
}
}
} else {
normalizedWords.add(this.normalizeWord(word));
}
}
}
return normalizedWords;
}
protected Word normalizeSplittedWord(final String formPart, final
Word word) {
return new PojoWord(formPart, word.getLemma(), word.getTag());
}

51
protected Word normalizeWord(final Word word) {
return word;
}
private static final Word tagPunctuationMark(final String
punctuationMark) {
switch (punctuationMark) {
case "¡":
return new PojoWord(punctuationMark, punctuationMark,
"Faa");
case "!":
return new PojoWord(punctuationMark, punctuationMark,
"Fat");
case ",":
return new PojoWord(punctuationMark, punctuationMark,
"Fc");
case "[":
return new PojoWord(punctuationMark, punctuationMark,
"Fca");
case "]":
return new PojoWord(punctuationMark, punctuationMark,
"Fct");
case ":":
return new PojoWord(punctuationMark, punctuationMark,
"Fd");
case "\"":
return new PojoWord(punctuationMark, punctuationMark,
"Fe");
case "-":
return new PojoWord(punctuationMark, punctuationMark,
"Fg");
case "/":
return new PojoWord(punctuationMark, punctuationMark,
"Fh");
case "¿":
return new PojoWord(punctuationMark, punctuationMark,
"Fia");
case "?":
return new PojoWord(punctuationMark, punctuationMark,
"Fit");
case "{":
return new PojoWord(punctuationMark, punctuationMark,
"Fla");
case "}":
return new PojoWord(punctuationMark, punctuationMark,
"Flt");
case "...":
return new PojoWord(punctuationMark, punctuationMark,
"Fs");
case ".":
return new PojoWord(punctuationMark, punctuationMark,
"Fp");
case "(":
return new PojoWord(punctuationMark, punctuationMark,
"Fpa");

52
case ")":
return new PojoWord(punctuationMark, punctuationMark,
"Fpt");
case "«":
return new PojoWord(punctuationMark, punctuationMark,
"Fra");
case "»":
return new PojoWord(punctuationMark, punctuationMark,
"Frc");
case "%":
return new PojoWord(punctuationMark, punctuationMark,
"Ft");
case ";":
return new PojoWord(punctuationMark, punctuationMark,
"Fx");
case "_":
case "+":
case "=":
return new PojoWord(punctuationMark, punctuationMark,
"Fz");
default:
throw new IllegalArgumentException("Unrecognized
punctuation mark.");
}
}
}
cr.ac.ucr.sentimetro.postagging.taggers.FreelingTagger
package cr.ac.ucr.sentimetro.postagging.taggers;
import cr.ac.ucr.sentimetro.postagging.PojoWord;
import edu.upc.freeling.HmmTagger;
import edu.upc.freeling.ListSentence;
import edu.upc.freeling.ListSentenceIterator;
import edu.upc.freeling.ListWord;
import edu.upc.freeling.ListWordIterator;
import edu.upc.freeling.Maco;
import edu.upc.freeling.MacoOptions;
import edu.upc.freeling.Sentence;
import edu.upc.freeling.Splitter;
import edu.upc.freeling.Tokenizer;
import edu.upc.freeling.Util;
import edu.upc.freeling.Word;
import java.util.ArrayList;
import java.util.List;
public final class FreelingTagger implements Tagger {
private static final String DATA_PATH = "/usr/local/share/freeling/";
private static boolean libraryLoaded;
private final Tokenizer tokenizer;
private final Splitter splitter;

53
private final Maco maco;
private final HmmTagger hmmTagger;
public FreelingTagger(final String lang) {
if (!FreelingTagger.libraryLoaded) {
System.loadLibrary("freeling_javaAPI");
Util.initLocale("default");
FreelingTagger.libraryLoaded = true;
}
if (lang == null) {
throw new IllegalArgumentException("'lang' cannot be null.");
}
this.tokenizer = new Tokenizer(FreelingTagger.getFilePath(lang,
"/tokenizer.dat"));
this.splitter = new Splitter(FreelingTagger.getFilePath(lang,
"/splitter.dat"));
MacoOptions macoOptions = new MacoOptions(lang);
macoOptions.setActiveModules(
false, // UserMap
true, // AffixAnalysis (e.g. "perrazo")
false, // MultiwordsDetection (e.g. "una vez que")
false, // NumbersDetection (e.g. "ciento ciencuenta")
true, // PunctuationDetection
false, // DatesDetection (e.g. "12 de diciembre del 2012")
false, // QuantitiesDetection (e.g. "milimetro cuadrado")
true, // DictionarySearch
true, // ProbabilityAssignment
false); // NERecognition (e.g. "Charlie Chaplin")
macoOptions.setDataFiles(
"", //
UserMapFile
"", //
LocutionsFile
"", //
QuantitiesFile
FreelingTagger.getFilePath(lang, "/afixos.dat"), //
AffixFile
FreelingTagger.getFilePath(lang, "/probabilitats.dat"), //
ProbabilityFile
FreelingTagger.getFilePath(lang, "/dicc.src"), //
DictionaryFile
"", //
NPdataFile
FreelingTagger.getFilePath("", "common/punct.dat")); //
PunctuationFile
// Avoids retokenization of contractions (e.g. "al" retokenized
as "a" & "el").
macoOptions.setRetokContractions(false);

54
this.maco = new Maco(macoOptions);
this.hmmTagger = new HmmTagger(
FreelingTagger.getFilePath(lang, "/tagger.dat"), // The HMM
file, which containts the model parameters.
false, // A boolean
stating whether words that carry retokenization information (e.g. set by
the dictionary or affix handling modules) must be retokenized (that is,
splitted in two or more words) after the tagging.
2); // An
integer stating whether and when the tagger must select only one analysis
in case of ambiguity. Possbile values are: FORCE_NONE (or 0): no
selection forced, words ambiguous after the tagger, remain ambiguous.
FORCE_TAGGER (or 1): force selection immediately after tagging, and
before retokenization. FORCE_RETOK (or 2): force selection after
retokenization.
}
@Override
public final List<cr.ac.ucr.sentimetro.postagging.Word> analyze(final
String text) {
// Split the text in words.
ListWord words = this.tokenizer.tokenize(text);
// Split the words in sentences.
ListSentence sentences = this.splitter.split(
words,
true); // The boolean states if a buffer flush has to be
forced (true) or some words may remain in the buffer (false) if the
splitter needs to wait to see what is coming next.
// Analyze morphologically.
this.maco.analyze(sentences);
// Analyze PoS.
this.hmmTagger.analyze(sentences);
// Build results.
List<cr.ac.ucr.sentimetro.postagging.Word> result = new
ArrayList<cr.ac.ucr.sentimetro.postagging.Word>();
ListSentenceIterator sIt = new ListSentenceIterator(sentences);
while (sIt.hasNext()) {
Sentence sentence = sIt.next();
ListWordIterator wIt = new ListWordIterator(sentence);
while (wIt.hasNext()) {
Word word = wIt.next();
result.add(new PojoWord(word.getForm(), word.getLemma(),
word.getTag()));
}
}
return result;

55
}
private static final String getFilePath(final String lang, final
String file) {
return FreelingTagger.DATA_PATH + lang + file;
}
}
cr.ac.ucr.sentimetro.postagging.taggers.OpenNlpTagger
package cr.ac.ucr.sentimetro.postagging.taggers;
import cr.ac.ucr.sentimetro.postagging.PojoWord;
import cr.ac.ucr.sentimetro.postagging.Word;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.SimpleTokenizer;
public final class OpenNlpTagger implements Tagger {
public static enum Type {
PERCEPTRON,
MAXENT
}
private static final String PERCEPTRON_MODEL_PATH = "../opennlp-es-
perceptron-pos-es.bin";
private static final String MAXENT_MODEL_PATH = "../opennlp-es-
maxent-pos-es.bin";
private final POSTaggerME tagger;
public OpenNlpTagger(final OpenNlpTagger.Type type) throws
IOException {
String modelPath = OpenNlpTagger.resolveModelPath(type);
try (InputStream is = new FileInputStream(modelPath)) {
POSModel model = new POSModel(is);
this.tagger = new POSTaggerME(model);
}
}
@Override
public final List<Word> analyze(final String text) {
String[] tokens = SimpleTokenizer.INSTANCE.tokenize(text);
String[] tags = this.tagger.tag(tokens);
List<Word> words = new ArrayList<Word>(tokens.length);
for (int i = 0; i < tokens.length; ++i) {

56
words.add(new PojoWord(tokens[i], tokens[i], tags[i]));
}
return words;
}
private static final String resolveModelPath(final OpenNlpTagger.Type
type) {
if (type == OpenNlpTagger.Type.PERCEPTRON) {
return OpenNlpTagger.PERCEPTRON_MODEL_PATH;
}
return OpenNlpTagger.MAXENT_MODEL_PATH;
}
}
PatternTagger.py
# Java interfaces.
from cr.ac.ucr.sentimetro.postagging import Word
from cr.ac.ucr.sentimetro.postagging.taggers import Tagger
# Make pattern module visible.
import os
import sys
sys.path.insert(0,
os.path.join(os.path.dirname(os.path.abspath(__name__)), '..'))
# Import pattern.
import pattern.es
class PatternTagger(Tagger):
def analyze(self, text):
result = []
sentences = pattern.es.parse(
text,
tokenize = True, # Split punctuation marks from
words.
tags = True, # Parse, part-of-speech
tagging.
chunks = False, # Parse chunks.
relations = False, # Parse chunk relations.
lemmata = True, # Parse lemmata.
encoding = 'utf-8', # Input string encoding.
tagset = 'parole').split() # Tagset.
for sentence in sentences:
for word in sentence:
result.append(PatternWord(word[0], word[2], word[1]))
return result
class PatternWord(Word):

57
def __init__(self, wordForm, wordLemma, wordTag):
self.wordForm = wordForm
self.wordLemma = wordLemma
self.wordTag = wordTag
def getForm(self):
return self.wordForm
def getLemma(self):
return self.wordLemma
def getTag(self):
return self.wordTag
cr.ac.ucr.sentimetro.postagging.taggers.Tagger
package cr.ac.ucr.sentimetro.postagging.taggers;
import cr.ac.ucr.sentimetro.postagging.Word;
import java.util.List;
public interface Tagger {
public List<Word> analyze(final String text);
}
cr.ac.ucr.sentimetro.postagging.Main
package cr.ac.ucr.sentimetro.postagging;
import cr.ac.ucr.sentimetro.postagging.managers.FreelingTaggerManager;
import
cr.ac.ucr.sentimetro.postagging.managers.OpenNlpMaxentTaggerManager;
import
cr.ac.ucr.sentimetro.postagging.managers.OpenNlpPerceptronTaggerManager;
import cr.ac.ucr.sentimetro.postagging.managers.PatternTaggerManager;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.net.URI;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.glassfish.grizzly.http.server.HttpServer;
import org.glassfish.jersey.grizzly2.httpserver.GrizzlyHttpServerFactory;
import org.glassfish.jersey.server.ResourceConfig;
/**
* Main class.
*/
public final class Main {

58
// Base URI the Grizzly HTTP server will listen on.
private static final String BASE_URI = "http://localhost:8080/";
// The cached thread pool used for executing parallel tasks.
static final ExecutorService EXECUTOR_SERVICE =
Executors.newCachedThreadPool();
public static final void main(final String[] args) throws Exception {
if (args.length == 0) {
Main.serverMain();
} else {
Main.fileMain(args);
}
// Cleanup.
Main.EXECUTOR_SERVICE.shutdown();
}
private static final void fileMain(final String[] args) throws
Exception {
String filePath = args[0];
char separator = args.length > 1 ? args[1].charAt(0) : '|';
try (FileReader fileIn = new FileReader(filePath)) {
try (BufferedReader reader = new BufferedReader(fileIn)) {
try (FileWriter fileOut = new FileWriter(filePath +
".tag")) {
try (BufferedWriter writer = new
BufferedWriter(fileOut)) {
TaggerSummarizer sum = new TaggerSummarizer();
sum.addTaggerManager(new
FreelingTaggerManager());
sum.addTaggerManager(new PatternTaggerManager());
sum.addTaggerManager(new
OpenNlpMaxentTaggerManager());
sum.addTaggerManager(new
OpenNlpPerceptronTaggerManager());
String nextLine = reader.readLine();
while (nextLine != null) {
String text = null;
// Get the current line.
do {
if (nextLine != null && nextLine.length()
> 0) {
if (text != null) {
text += " ";
} else {
text = "";
}
if (nextLine.charAt(0) == separator)
{
text += nextLine.substring(1);

59
} else {
text += nextLine;
}
}
nextLine = reader.readLine();
} while (nextLine != null &&
(nextLine.length() == 0 || nextLine.charAt(0) != separator));
if (text != null && text.trim().length() > 0)
{
List<WordSummary> taggedWords =
sum.process(text);
for (WordSummary taggedWord :
taggedWords) {
String tagText = taggedWord.getForm()
+ " ( " + taggedWord.getTag() + " ";
for (OriginalWord originalWord :
taggedWord.getOriginalWords()) {
switch
(originalWord.getTaggerName()) {
case "Freeling":
tagText += "F";
break;
case "OpenNLP (Maxent)":
tagText += "OM";
break;
case "OpenNLP (Perceptron)":
tagText += "OP";
break;
case "Pattern":
tagText += "P";
break;
}
tagText += ": " +
originalWord.getWord().getTag() + " ";
}
tagText += ")";
writer.write(tagText);
writer.newLine();
}
writer.newLine();
}
}
}
}
}
}
}

60
private static final void serverMain() throws IOException {
final HttpServer server = Main.startServer();
System.out.println(String.format("Jersey app started with WADL
available at %sapplication.wadl\nHit enter to stop it...",
Main.BASE_URI));
System.in.read();
server.stop();
}
/**
* Starts Grizzly HTTP server exposing JAX-RS resources defined in
this application.
* @return Grizzly HTTP server.
*/
private static final HttpServer startServer() {
// Create a resource config that scans for JAX-RS resources and
providers in cr.ac.ucr.sentimetro.pos package.
final ResourceConfig rc = new
ResourceConfig().packages("cr.ac.ucr.sentimetro.postagging");
// Create and start a new instance of grizzly http server
exposing the Jersey application at BASE_URI.
return
GrizzlyHttpServerFactory.createHttpServer(URI.create(Main.BASE_URI), rc);
}
}
cr.ac.ucr.sentimetro.postagging.OriginalWord
package cr.ac.ucr.sentimetro.postagging;
import com.google.gson.annotations.Expose;
public final class OriginalWord {
@Expose
private final String taggerName;
@Expose
private final Word word;
public OriginalWord(final String taggerName, final Word word) {
this.taggerName = taggerName;
this.word = word;
}
public final String getTaggerName() {
return this.taggerName;
}
public final Word getWord() {
return this.word;
}
}

61
cr.ac.ucr.sentimetro.postagging.PojoWord
package cr.ac.ucr.sentimetro.postagging;
import com.google.gson.annotations.Expose;
public final class PojoWord implements Word {
@Expose
private final String form;
@Expose
private final String lemma;
@Expose
private final String tag;
public PojoWord(final String form, final String lemma, final String
tag) {
this.form = form;
this.lemma = lemma;
this.tag = tag;
}
public PojoWord(final Word word) {
this(word.getForm(), word.getLemma(), word.getTag());
}
@Override
public final String getForm() {
return this.form;
}
@Override
public final String getLemma() {
return this.lemma;
}
@Override
public final String getTag() {
return this.tag;
}
}
cr.ac.ucr.sentimetro.postagging.Pool<T>
package cr.ac.ucr.sentimetro.postagging;
import cr.ac.ucr.sentimetro.postagging.factories.Factory;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;

62
public final class Pool<T> {
private final BlockingQueue<T> instances;
private final Factory<T> factory;
// Flag to avoid starvation on race condition.
private boolean creatingInstance;
public Pool(final Factory<T> factory) {
this.instances = new LinkedBlockingQueue<T>();
this.factory = factory;
this.createInstance();
}
public final void putInstance(final T instance) throws
InterruptedException {
this.instances.put(instance);
}
public final T takeInstance() throws InterruptedException {
T result = this.instances.take();
if (this.instances.size() == 0) {
boolean shouldCreateInstance;
synchronized (this) {
shouldCreateInstance = !this.creatingInstance;
}
if (shouldCreateInstance) {
this.createInstance();
}
}
return result;
}
private final void createInstance() {
Main.EXECUTOR_SERVICE.submit(new Runnable() {
@Override
public final void run() {
synchronized (Pool.this) {
Pool.this.creatingInstance = true;
}
try {
Pool.this.instances.put(Pool.this.factory.create());
}
catch (Throwable ex) {
System.err.println("Error creating instance.");
ex.printStackTrace();
}
synchronized (Pool.this) {
Pool.this.creatingInstance = false;
}

63
}
});
}
}
cr.ac.ucr.sentimetro.postagging.TaggerResource
package cr.ac.ucr.sentimetro.postagging;
import com.google.gson.Gson;
import cr.ac.ucr.sentimetro.postagging.factories.GsonFactory;
import cr.ac.ucr.sentimetro.postagging.factories.PatternTaggerFactory;
import cr.ac.ucr.sentimetro.postagging.managers.FreelingTaggerManager;
import
cr.ac.ucr.sentimetro.postagging.managers.OpenNlpMaxentTaggerManager;
import
cr.ac.ucr.sentimetro.postagging.managers.OpenNlpPerceptronTaggerManager;
import cr.ac.ucr.sentimetro.postagging.managers.PatternTaggerManager;
import cr.ac.ucr.sentimetro.postagging.managers.TaggerManager;
import cr.ac.ucr.sentimetro.postagging.taggers.FreelingTagger;
import cr.ac.ucr.sentimetro.postagging.taggers.OpenNlpTagger;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.ws.rs.GET;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.container.AsyncResponse;
import javax.ws.rs.container.Suspended;
import javax.ws.rs.core.MediaType;
@Path("/tagger")
public final class TaggerResource {
private static final Pool<Gson> GSON_POOL = new Pool<Gson>(new
GsonFactory());
@POST
@Path("/freeling")
@Produces(MediaType.APPLICATION_JSON)
public final void freeling(
final String text,
@Suspended final AsyncResponse ar) {
Main.EXECUTOR_SERVICE.submit(new Runnable() {
@Override
public final void run() {
try {
Gson gson = TaggerResource.GSON_POOL.takeInstance();
TaggerManager mgr = new FreelingTaggerManager();
ar.resume(gson.toJson(mgr.process(text)));

64
TaggerResource.GSON_POOL.putInstance(gson);
}
catch (Throwable ex) {
ar.resume(ex);
}
}
});
}
@POST
@Path("/freeling-slow")
@Produces(MediaType.APPLICATION_JSON)
public final String freelingSlow(final String text) {
FreelingTagger t = new FreelingTagger("es");
return new Gson().toJson(t.analyze(text));
}
@POST
@Path("/open-nlp-maxent")
@Produces(MediaType.APPLICATION_JSON)
public final void openNlpMaxent(
final String text,
@Suspended final AsyncResponse ar) {
Main.EXECUTOR_SERVICE.submit(new Runnable() {
@Override
public final void run() {
try {
Gson gson = TaggerResource.GSON_POOL.takeInstance();
TaggerManager mgr = new OpenNlpMaxentTaggerManager();
ar.resume(gson.toJson(mgr.process(text)));
TaggerResource.GSON_POOL.putInstance(gson);
}
catch (Throwable ex) {
ar.resume(ex);
}
}
});
}
@POST
@Path("/open-nlp-maxent-slow")
@Produces(MediaType.APPLICATION_JSON)
public final String openNlpMaxentSlow(final String text) {
try {
OpenNlpTagger t = new
OpenNlpTagger(OpenNlpTagger.Type.MAXENT);
return new Gson().toJson(t.analyze(text));
}
catch (IOException ex) {
return "Error: " + ex.getMessage();
}
}

65
@POST
@Path("/open-nlp-perceptron")
@Produces(MediaType.APPLICATION_JSON)
public final void openNlpPerceptron(
final String text,
@Suspended final AsyncResponse ar) {
Main.EXECUTOR_SERVICE.submit(new Runnable() {
@Override
public final void run() {
try {
Gson gson = TaggerResource.GSON_POOL.takeInstance();
TaggerManager mgr = new
OpenNlpPerceptronTaggerManager();
ar.resume(gson.toJson(mgr.process(text)));
TaggerResource.GSON_POOL.putInstance(gson);
}
catch (Throwable ex) {
ar.resume(ex);
}
}
});
}
@POST
@Path("/open-nlp-perceptron-slow")
@Produces(MediaType.APPLICATION_JSON)
public final String openNlpPerceptronSlow(final String text) {
try {
OpenNlpTagger t = new
OpenNlpTagger(OpenNlpTagger.Type.PERCEPTRON);
return new Gson().toJson(t.analyze(text));
}
catch (IOException ex) {
return "Error: " + ex.getMessage();
}
}
@POST
@Path("/pattern")
@Produces(MediaType.APPLICATION_JSON)
public void pattern(
final String text,
@Suspended final AsyncResponse ar) {
Main.EXECUTOR_SERVICE.submit(new Runnable() {
@Override
public final void run() {
try {
Gson gson = TaggerResource.GSON_POOL.takeInstance();
TaggerManager mgr = new PatternTaggerManager();
ar.resume(gson.toJson(mgr.process(text)));

66
TaggerResource.GSON_POOL.putInstance(gson);
}
catch (Throwable ex) {
ar.resume(ex);
}
}
});
}
@POST
@Path("/pattern-slow")
@Produces(MediaType.APPLICATION_JSON)
public final String patternSlow(final String text) {
List<Word> result = new ArrayList<Word>();
PatternTaggerFactory p = new PatternTaggerFactory();
for (Word w : p.create().analyze(text)) {
result.add(new PojoWord(w.getForm(), w.getLemma(),
w.getTag()));
}
return new Gson().toJson(result);
}
@POST
@Path("/summary")
@Produces(MediaType.APPLICATION_JSON)
public final void summary(
final String text,
@Suspended final AsyncResponse ar) {
Main.EXECUTOR_SERVICE.submit(new Runnable() {
@Override
public final void run() {
try {
Gson gson = TaggerResource.GSON_POOL.takeInstance();
TaggerSummarizer sum = new TaggerSummarizer();
sum.addTaggerManager(new FreelingTaggerManager());
sum.addTaggerManager(new PatternTaggerManager());
sum.addTaggerManager(new
OpenNlpMaxentTaggerManager());
sum.addTaggerManager(new
OpenNlpPerceptronTaggerManager());
ar.resume(gson.toJson(sum.process(text)));
TaggerResource.GSON_POOL.putInstance(gson);
}
catch (Throwable ex) {
ar.resume(ex);
}
}
});
}
@GET
@Path("/test")
@Produces(MediaType.TEXT_HTML)

67
public final String test() {
try (FileReader fileReader = new
FileReader("src/main/html/test.html")) {
StringBuffer buff = new StringBuffer();
int i;
while ((i = fileReader.read()) != -1) {
char ch = (char)i;
buff.append(ch);
}
return buff.toString();
}
catch (IOException ex) {
return "<!DOCTYPE html><html><head><meta charset=\"utf-8\"
/></head><body><strong>Error:</strong> " + ex.getMessage() +
"</body></html>";
}
}
}
cr.ac.ucr.sentimetro.postagging.TaggerSummarizer
package cr.ac.ucr.sentimetro.postagging;
import cr.ac.ucr.sentimetro.postagging.managers.TaggerManager;
import java.util.ArrayList;
import java.util.List;
public final class TaggerSummarizer {
private final ArrayList<TaggerManager> taggerManagers;
public TaggerSummarizer() {
this.taggerManagers = new ArrayList<TaggerManager>();
}
public final void addTaggerManager(final TaggerManager taggerManager)
{
this.taggerManagers.add(taggerManager);
}
public final List<WordSummary> process(final String text) throws
InterruptedException {
List<WordSummary> result = new ArrayList<WordSummary>();
if (!this.taggerManagers.isEmpty()) {
Word[][] allWords = new Word[this.taggerManagers.size()][];
// The base tagger wil be the one who tokenized the minimum
quantity of words.
int baseTaggerIndex = 0;
// Store the words in a matrix and calculate the base tagger.
for (int i = 0; i < this.taggerManagers.size(); ++i) {

68
List<Word> words =
this.taggerManagers.get(i).process(text);
allWords[i] = words.toArray(new Word[words.size()]);
if (allWords[i].length <
allWords[baseTaggerIndex].length) {
baseTaggerIndex = i;
}
}
// Create a word summary for each word of the base tagger.
for (int wordIndex = 0; wordIndex <
allWords[baseTaggerIndex].length; ++wordIndex) {
WordSummary wordSummary = new
WordSummary(allWords[baseTaggerIndex][wordIndex].getForm());
for (int taggerIndex = 0; taggerIndex < allWords.length;
++taggerIndex) {
wordSummary.addOriginalWord(
this.taggerManagers.get(taggerIndex).getTaggerName(),
allWords[taggerIndex][wordIndex]);
}
result.add(wordSummary);
}
}
return result;
}
}
cr.ac.ucr.sentimetro.postagging.Word
package cr.ac.ucr.sentimetro.postagging;
public interface Word {
public String getForm();
public String getLemma();
public String getTag();
}
cr.ac.ucr.sentimetro.postagging.WordSummary
package cr.ac.ucr.sentimetro.postagging;
import com.google.gson.annotations.Expose;
import java.util.ArrayList;
import java.util.List;
public final class WordSummary {
@Expose

69
private final String form;
@Expose
private final List<OriginalWord> originalWords;
private final List<TagCoincidence> tagCoincidences;
@Expose
private double consensus;
@Expose
private String tag;
public WordSummary(final String form) {
this.form = form;
this.originalWords = new ArrayList<OriginalWord>();
this.tagCoincidences = new ArrayList<TagCoincidence>();
}
public final double getConsensus() {
return this.consensus;
}
public final String getForm() {
return this.form;
}
public List<OriginalWord> getOriginalWords() {
return this.originalWords;
}
public final String getTag() {
return this.tag;
}
public final void addOriginalWord(final String taggerName, final Word
word) {
this.originalWords.add(new OriginalWord(taggerName, word));
this.process(word);
}
private final void addOrUpdateTagCoincidence(final Word word) {
String largestTagCoincidence = null;
double largestTagCoincidenceCount = 0.0;
for (TagCoincidence tagCoincidence : this.tagCoincidences) {
if (word.getTag().equals(tagCoincidence.tag)) {
// Found an exact tag coincidence: increment the
coincidence counter and return.
++tagCoincidence.coincidences;
return;
} else if (word.getTag().length() <=
tagCoincidence.tag.length()) {
int index = 0;

70
while (index < word.getTag().length() &&
word.getTag().charAt(index) == tagCoincidence.tag.charAt(index)) {
++index;
}
if (index > 0 && (largestTagCoincidence == null ||
largestTagCoincidence.length() <= index)) {
largestTagCoincidence =
tagCoincidence.tag.substring(0, index);
largestTagCoincidenceCount =
tagCoincidence.coincidences;
}
}
}
if (largestTagCoincidence != null) {
for (TagCoincidence tagCoincidence : this.tagCoincidences) {
if (largestTagCoincidence.equals(tagCoincidence.tag)) {
// Found an existing partial tag coincidence:
increment the coincidence counter and return.
++tagCoincidence.coincidences;
return;
}
}
// Found a non-existing partial tag coincidence: add it with
the coincidence count incremented by one.
this.tagCoincidences.add(new
TagCoincidence(largestTagCoincidence, largestTagCoincidenceCount + 1.0));
} else {
// No tag coincidence found at all: add the current tag.
this.tagCoincidences.add(new TagCoincidence(word.getTag(),
1.0));
}
}
private final void process(final Word word) {
this.addOrUpdateTagCoincidence(word);
// Get the best coincidence.
TagCoincidence bestCoincidence = null;
for (TagCoincidence tagCoincidence : this.tagCoincidences) {
if (bestCoincidence == null ||
bestCoincidence.coincidences <
tagCoincidence.coincidences ||
(bestCoincidence.coincidences ==
tagCoincidence.coincidences && bestCoincidence.tag.length() <
tagCoincidence.tag.length())) {
bestCoincidence = tagCoincidence;
}
}
// Update the consensus and the tag.
this.consensus = bestCoincidence.coincidences /
this.originalWords.size();
this.tag = bestCoincidence.tag;

71
}
private static class TagCoincidence {
public final String tag;
public double coincidences;
public TagCoincidence(final String tag, final double
coincidences) {
this.tag = tag;
this.coincidences = coincidences;
}
}
}

72
Anexo E.
Scripts de instalación

73
run-file.sh
#!/bin/bash
echo "======================";
echo "sentimetro-pos (v1.0)";
echo "======================";
BASEDIR=$(pwd);
if [ -d ./sentimetro-pos/target ]; then
# Environment variables.
export LD_LIBRARY_PATH=/usr/local/lib:$BASEDIR/freeling-
3.1/APIs/java;
# Run sentimetro-pos.
cd $BASEDIR/sentimetro-pos;
mvn exec:java -Dfreeling.jar=$BASEDIR/freeling-
3.1/APIs/java/freeling.jar -Dexec:args="%1 %2";
else
echo "Cannot run sentimetro-pos because it's not installed. Please
run setup.sh first."
fi;
run-server.sh
#!/bin/bash
echo "======================";
echo "sentimetro-pos (v1.0)";
echo "======================";
BASEDIR=$(pwd);
if [ -d ./sentimetro-pos/target ]; then
# Environment variables.
export LD_LIBRARY_PATH=/usr/local/lib:$BASEDIR/freeling-
3.1/APIs/java;
# Run sentimetro-pos.
cd $BASEDIR/sentimetro-pos;
mvn exec:java -Dfreeling.jar=$BASEDIR/freeling-
3.1/APIs/java/freeling.jar;
else
echo "Cannot run sentimetro-pos because it's not installed. Please
run setup.sh first."
fi;
setup.sh
#!/bin/bash

74
echo "===========================" | tee ./setup.log;
echo "sentimetro-pos setup (v1.0)" | tee -a ./setup.log;
echo "===========================" | tee -a ./setup.log;
echo "For more information, consult the setup.log file.";
DISTRIBUTION=`lsb_release -is`;
VERSION=`lsb_release -rs`;
if [ $DISTRIBUTION = "Ubuntu" ] && [ $VERSION = 13.04 -o $VERSION = 13.10
]; then
# Ask if continue with setup
[http://stackoverflow.com/questions/3231804/in-bash-how-to-add-are-you-
sure-y-n-to-any-command-or-alias].
read -r -p "Are you sure you want to perform the setup? [y/n] "
response;
response=${response,,}; # tolower.
if [[ $response =~ ^(yes|y)$ ]]; then
# requirements.sh
echo "" | tee -a ./setup.log;
./setup-scripts/requirements.sh;
# freeling-install.sh
echo "" | tee -a ./setup.log;
./setup-scripts/freeling-install.sh;
# freeling-java-api-compile.sh
echo "" | tee -a ./setup.log;
./setup-scripts/freeling-java-api-compile.sh;
# pattern-install.sh
echo "" | tee -a ./setup.log;
./setup-scripts/pattern-install.sh;
# java-compile.sh
echo "" | tee -a ./setup.log;
./setup-scripts/java-compile.sh;
echo "";
echo "Setup completed! For more information, consult the
setup.log file.";
else
echo "Setup canceled." | tee -a ./setup.log;
fi;
else
echo "ERROR: Cannot perform setup. Only Ubuntu 13.04 or 13.10 are
supported." | tee -a ./setup.log;
fi;
setup-scripts/freeling-install.sh
#!/bin/bash
BASEDIR=$(pwd);

75
echo "======================" | tee -a $BASEDIR/setup.log;
echo "Installing freeling..." | tee -a $BASEDIR/setup.log;
echo "======================" | tee -a $BASEDIR/setup.log;
VERSION=`lsb_release -rs`;
if [ ! -d $BASEDIR/freeling-3.1 ]; then
echo "1. Extracting freeling..." | tee -a $BASEDIR/setup.log;
cd $BASEDIR;
tar xzvf freeling-3.1.tar.gz >> $BASEDIR/setup.log;
if [ $VERSION = 13.10 ]; then
echo -e "\t1.1. Extracting Ubuntu 13.10 specific freeling
files..." | tee -a $BASEDIR/setup.log;
tar xzvf freeling-3.1-ubuntu-13.10.tar.gz >> $BASEDIR/setup.log;
fi;
echo "2. Compiling and installing freeling (this make a while, please
be patient, also don't worry about the notes or warnings)..." | tee -a
$BASEDIR/setup.log;
cd $BASEDIR/freeling-3.1;
./configure >> $BASEDIR/setup.log;
make >> $BASEDIR/setup.log;
sudo make install >> $BASEDIR/setup.log;
else
echo "Freeling is already installed." | tee -a $BASEDIR/setup.log;
fi;
setup-scripts/freeling-java-api-compile.sh
#!/bin/bash
BASEDIR=$(pwd);
echo "===============================" | tee -a $BASEDIR/setup.log;
echo "Installing freeling java api..." | tee -a $BASEDIR/setup.log;
echo "===============================" | tee -a $BASEDIR/setup.log;
if [ ! -d $BASEDIR/freeling-3.1/APIs/java/edu ]; then
# Detect java folder.
if [ -d /usr/lib/jvm/java-7-openjdk-i386 ]; then
JAVADIR=/usr/lib/jvm/java-7-openjdk-i386;
fi;
if [ -d /usr/lib/jvm/java-7-openjdk-amd64 ]; then
JAVADIR=/usr/lib/jvm/java-7-openjdk-amd64;
fi;
if [ -d /usr/lib/jvm/default-java ]; then
JAVADIR=/usr/lib/jvm/default-java;
fi;
# Compile java api.

76
echo "1. Compiling freeling java api..." | tee -a $BASEDIR/setup.log;
cd $BASEDIR/freeling-3.1/APIs/java;
make FREELINGDIR=/usr/local SWIGDIR=/usr/share/swig2.0
JAVADIR=$JAVADIR >> $BASEDIR/setup.log;
else
echo "Freeling java api is already installed." | tee -a
$BASEDIR/setup.log;
fi;
setup-scripts/java-compile.sh
#!/bin/bash
BASEDIR=$(pwd);
echo "===========================" | tee -a $BASEDIR/setup.log;
echo "Compiling sentimetro-pos..." | tee -a $BASEDIR/setup.log;
echo "===========================" | tee -a $BASEDIR/setup.log;
if [ ! -d $BASEDIR/sentimetro-pos/target ]; then
# Compile sentimetro-pos.
echo "1. Compiling sentimetro-pos..." | tee -a $BASEDIR/setup.log;
cd $BASEDIR/sentimetro-pos;
mvn clean compile -Dfreeling.jar=$BASEDIR/freeling-
3.1/APIs/java/freeling.jar >> $BASEDIR/setup.log;
else
echo "sentimetro-pos is already compiled." | tee -a
$BASEDIR/setup.log;
fi;
setup-scripts/pattern-install.sh
#!/bin/bash
BASEDIR=$(pwd);
echo "================================" | tee -a $BASEDIR/setup.log;
echo "Installing pattern for python..." | tee -a $BASEDIR/setup.log;
echo "================================" | tee -a $BASEDIR/setup.log;
if [ ! -d $BASEDIR/pattern ]; then
# Install pattern for python.
echo "1. Extracting pattern for python..." | tee -a
$BASEDIR/setup.log;
cd $BASEDIR;
unzip pattern-2.6.zip pattern-2.6/pattern/* -d pattern-tmp >>
$BASEDIR/setup.log;
mv pattern-tmp/pattern-2.6/pattern pattern;
rm -r pattern-tmp;
else
echo "Pattern for python is already installed." | tee -a
$BASEDIR/setup.log;

77
fi;
setup-scripts/requirements.sh
#!/bin/bash
BASEDIR=$(pwd);
echo "==================================================" | tee -a
$BASEDIR/setup.log;
echo "Checking and installing the system requirements..." | tee -a
$BASEDIR/setup.log;
echo "==================================================" | tee -a
$BASEDIR/setup.log;
#
# Update the apt-get database.
echo "1. Updating the apt-get database (this make a while, please be
patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get update >> $BASEDIR/setup.log;
#
# Install C++ compiler tools.
echo "2. Installing C++ compiler tools..." | tee -a
$BASEDIR/setup.log;
# build-essential.
C=$(dpkg-query -W --showformat='${Status}\n' build-essential | grep
"install ok installed");
echo -e "\t2.1. Checking for build-essential package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tbuild-essential package not found, installing
package (this make a while, please be patient)..." | tee -a
$BASEDIR/setup.log;
sudo apt-get -y install build-essential >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
# automake.
C=$(dpkg-query -W --showformat='${Status}\n' automake | grep "install
ok installed");
echo -e "\t2.2. Checking for automake package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tautomake package not found, installing package (this
make a while, please be patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get -y install automake >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
# autoconf.

78
C=$(dpkg-query -W --showformat='${Status}\n' autoconf | grep "install
ok installed");
echo -e "\t2.2. Checking for autoconf package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tautoconf package not found, installing package (this
make a while, please be patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get -y install autoconf >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
#
# Install freeling dependencies.
echo "3. Installing freeling dependencies..." | tee -a
$BASEDIR/setup.log;
# libboost-dev.
C=$(dpkg-query -W --showformat='${Status}\n' libboost-dev | grep
"install ok installed");
echo -e "\t3.1. Checking for libboost-dev package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tlibboost-dev package not found, installing package
(this make a while, please be patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get -y install libboost-dev >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
# libboost-regex-dev.
C=$(dpkg-query -W --showformat='${Status}\n' libboost-regex-dev |
grep "install ok installed");
echo -e "\t3.2. Checking for libboost-regex-dev package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tlibboost-regex-dev package not found, installing
package (this make a while, please be patient)..." | tee -a
$BASEDIR/setup.log;
sudo apt-get -y install libboost-regex-dev >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
# libicu-dev.
C=$(dpkg-query -W --showformat='${Status}\n' libicu-dev | grep
"install ok installed");
echo -e "\t3.3. Checking for libicu-dev package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tlibicu-dev package not found, installing package
(this make a while, please be patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get -y install libicu-dev >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;

79
# libboost-system-dev.
C=$(dpkg-query -W --showformat='${Status}\n' libboost-system-dev |
grep "install ok installed");
echo -e "\t3.4. Checking for libboost-system-dev package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tlibboost-system-dev package not found, installing
package (this make a while, please be patient)..." | tee -a
$BASEDIR/setup.log;
sudo apt-get -y install libboost-system-dev >>
$BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
# libboost-program-options-dev.
C=$(dpkg-query -W --showformat='${Status}\n' libboost-program-
options-dev | grep "install ok installed");
echo -e "\t3.5. Checking for libboost-program-options-dev package..."
| tee -a $BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tlibboost-program-options-dev package not found,
installing package (this make a while, please be patient)..." | tee -a
$BASEDIR/setup.log;
sudo apt-get -y install libboost-program-options-dev >>
$BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
# libboost-thread-dev.
C=$(dpkg-query -W --showformat='${Status}\n' libboost-thread-dev |
grep "install ok installed");
echo -e "\t3.6. Checking for libboost-thread-dev package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tlibboost-thread-dev package not found, installing
package (this make a while, please be patient)..." | tee -a
$BASEDIR/setup.log;
sudo apt-get -y install libboost-thread-dev >>
$BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
# zlib1g-dev.
C=$(dpkg-query -W --showformat='${Status}\n' zlib1g-dev | grep
"install ok installed");
echo -e "\t3.7. Checking for zlib1g-dev package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tzlib1g-dev package not found, installing package
(this make a while, please be patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get -y install zlib1g-dev >> $BASEDIR/setup.log;
else

80
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
#
# Install freeling java api dependencies.
echo "4. Installing freeling java api dependencies..." | tee -a
$BASEDIR/setup.log;
# openjdk-7-jdk.
C=$(dpkg-query -W --showformat='${Status}\n' openjdk-7-jdk | grep
"install ok installed");
echo -e "\t4.1. Checking for openjdk-7-jdk package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\topenjdk-7-jdk package not found, installing package
(this make a while, please be patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get -y install openjdk-7-jdk >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
# swig.
C=$(dpkg-query -W --showformat='${Status}\n' swig | grep "install ok
installed");
echo -e "\t4.1. Checking for swig package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tswig package not found, installing package (this
make a while, please be patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get -y install swig >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
#
# Install java dependencies.
echo "5. Installing java dependencies..." | tee -a
$BASEDIR/setup.log;
# maven.
C=$(dpkg-query -W --showformat='${Status}\n' maven | grep "install ok
installed");
echo -e "\t4.1. Checking for maven package..." | tee -a
$BASEDIR/setup.log;
if [ "" = "$C" ]; then
echo -e "\t\tmaven package not found, installing package (this
make a while, please be patient)..." | tee -a $BASEDIR/setup.log;
sudo apt-get -y install maven >> $BASEDIR/setup.log;
else
echo -e "\t\tok!" | tee -a $BASEDIR/setup.log;
fi;
uninstall.sh

81
#!/bin/bash
echo "===============================";
echo "sentimetro-pos uninstall (v1.0)";
echo "===============================";
BASEDIR=$(pwd);
# Ask if continue with setup
[http://stackoverflow.com/questions/3231804/in-bash-how-to-add-are-you-
sure-y-n-to-any-command-or-alias].
read -r -p "Are you sure you want to perform the uninstall? [y/n] "
response;
response=${response,,}; # tolower.
if [[ $response =~ ^(yes|y)$ ]]; then
# Uninstall freeling.
if [ -d $BASEDIR/freeling-3.1 ]; then
cd $BASEDIR/freeling-3.1;
sudo make uninstall;
cd $BASEDIR;
rm -rf $BASEDIR/freeling-3.1;
fi;
# Uninstall pattern for python.
if [ -d $BASEDIR/pattern ]; then
rm -rf $BASEDIR/pattern;
fi;
# Uninstall sentimetro-pos.
if [ -d $BASEDIR/sentimetro-pos/target ]; then
rm -rf $BASEDIR/sentimetro-pos/target;
fi;
echo "Uninstall completed!";
fi;





























