Embed Size (px)
Citation preview

Available online at www.sciencedirect.com
44 (2008) 870–882www.elsevier.com/locate/dss
Decision Support Systems
Improving customer complaint management by automatic emailclassification using linguistic style features as predictors
Kristof Coussement, Dirk Van den Poel ⁎
Ghent University, Faculty of Economics and Business Administration, Department of Marketing, Tweekerkenstraat 2, 9000 Ghent, Belgium
Received 12 January 2007; received in revised form 19 September 2007; accepted 14 October 2007Available online 24 October 2007
Abstract
Customer complaint management is becoming a critical key success factor in today's business environment. This studyintroduces a methodology to improve complaint-handling strategies through an automatic email-classification system thatdistinguishes complaints from non-complaints. As such, complaint handling becomes less time-consuming and more successful.The classification system combines traditional text information with new information about the linguistic style of an email. Theempirical results show that adding linguistic style information into a classification model with conventional text-classificationvariables results in a significant increase in predictive performance. In addition, this study reveals linguistic style differencesbetween complaint emails and others.© 2007 Elsevier B.V. All rights reserved.
Keywords: Customer Complaint Handling; Call-center email; Voice of customers (VOC); Singular Value Decomposition (SVD); Latent SemanticIndexing (LSI); Automatic email classification
1. Introduction
Due to the rapid development of information tech-nology and Internet, new opportunities arise for market-ing analysts nowadays. For instance, companies caneasily advertise through the email channel [10] or offerproducts in an electronic commerce [14]. This studyfocuses on the usefulness of client/company interactionsthrough email as the basis for improved customer com-plaint management. Nowadays, companies receive daily
⁎ Corresponding author. Tel.: +32 9 264 89 80; fax: +32 9 264 42 79.E-mail addresses: [email protected]
(K. Coussement), [email protected] (D. Van den Poel).URL: http://www.crm.UGent.be (D. Van den Poel).
0167-9236/$ - see front matter © 2007 Elsevier B.V. All rights reserved.doi:10.1016/j.dss.2007.10.010
huge amounts of emails due to the fact that their clientsbecome more used to sending emails as a substitute fortraditional communication methods [29]. Growingly,efficient email handling is becoming a critical key suc-cess factor in today's business environment. Recently,companies start to outsource their customer-email man-agement by relying on customer-call centers to addressthe voice of customers — i.e. customer complaints andservice-information requests [20].
Indeed, Internet enables customers to easily expresstheir problems with a product or a service. Consequently,customer complaint management and service recoveryare becoming key drivers for improved customer rela-tionships. Several studies have shown the positive fi-nancial impact of investments in efficient complainthandling in a wide range of industries [13,28]. It is

871K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
crucial that service-recovery efforts are forceful andeffective [4], because ample research has shown thatfailed service-recovery actions have a significantinfluence on customer-switching behaviour [26].
A tool to support efficient processing of customercomplaint emails is the use of an automatic email-clas-sification system. Automatic text-classification labelsincoming emails into predefined categories — i.e. com-plaints versus non-complaints in this study. As a con-sequence, customer complaint management becomesmore successful in mainly two ways: (i) In contrast tomanual text classification, automatic text classification istime-saving and thus less expensive in terms of laborcosts. It makes the email-handling process more efficient.(ii) By classifying incoming emails into complaints andnon-complaints, one can optimize the complaint-handlingprocess. By making a distinction between complaintemails and other email types (e.g. information requests onpromotional deals), the company is able to set up aseparate complaint-handling department with specially-trained complaint handlers. One can create a separatetreatment procedure for complaint emails. Consequently,call centers can react more helpful on occurring problemsor service failures. In general, the consistency in the waycomplaint emails are handled increases due to the fact thatnot every employee in the call center needs to be trainedfor all email types. In summary, building an automaticemail-classification system that distinguishes complaintsfrom non-complaints is necessary for optimizing thecomplaint-handling process within a call center.
Automatic text-classification systems are typicallybuilt using the conventional vector-space approach pro-posed by Salton [24] (e.g. [16,6,1]). This means thatevery email is converted into a vector that contains astream of words or terms. This is often a very high-dimensional vector due to the many distinct terms in theemail corpus. This study employs Latent Semantic In-dexing by means of Singular Value Decomposition asproposed by Deerweester et al. [7] to reduce the di-mensionality. Consequently, textual information isrepresented as k distinct concepts or explanatory var-iables. Within this study, linguistic style information isintroduced as a new type of textual information. More-over, linguistic style differences between complaintemails and other emails are explored. Furthermore, thebeneficial effect of adding linguistic style character-istics to a traditional complaint-classification system isinvestigated.
This study offers marketing managers a valuablesystem for automatic email classification in order to en-able them to optimize the client/company relationshipthrough efficient and effective complaint handling. More-
over, it introduces linguistic style characteristics of anemail as a new type of textual information in a customercomplaint setting. Accordingly, this study contributes tothe existing literature in two ways: (i) it shows that addingthese linguistic style features into a conventional email-classification model results in an additional increase inpredictive performance in distinguishing complaints fromnon-complaints. (ii) Moreover, this study proves that lin-guistic style differences exist between complaints andothers.
This paper is organized as follows. Section 2 de-scribes the methodology used throughout this study.Section 3 describes how the proposed framework isapplied and evaluated within a real-life call-centersetting. In the last section, the findings of this study aresummarized, while also some shortcomings and direc-tions for further research are given.
2. Methodology
This section describes the methodology used through-out this study. In Section 2.1 the content-based approachwhich is often used in traditional text-classification prob-lems is explained. In this study, a new type of informationis used to predict whether the incoming email is a com-plaint or not — i.e. linguistic style information of anemail. Section 2.2 gives an overview how the linguisticstyle features are extracted from the email corpus. Section2.3 gives an overview of the classification technique. Inorder to compare the performance of the differentclassification models, some objective evaluation criteriaare needed. The evaluation criteria used throughout thisstudy are covered in Section 2.4.
2.1. Vector-space approach
This section gives an overview of the conventionaltext-classification approach using the vector-spaceapproach proposed by Salton [24]. Original documentsare converted into a vector in a feature space based onthe weighted term frequencies. Each vector componentreflects the importance of the corresponding term bygiving it a weight if the term is present or zero otherwise.The purpose is to select the most informative terms fromthe number of distinct terms in the corpus dictionary. Alldocuments are traditionally converted from the originalformat to word vectors following the steps as shown inFig. 1.
2.1.1. Pre-processingRaw text cleaning converts documents into a form
which is more suitable for subsequent processing. In this

Fig. 1. An overview of the conventional vector-space approach for text classification.
872 K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
step, special characters and punctuations are separatedfrom words, while spelling errors are handled by com-paring all words in the document with a referencedictionary.
During the tokenization step, documents are dividedinto tokens or words, by which white space charactersare used as separators. Once the text field is divided intowords, words are converted to lower case — i.e. caseconversion.
All words are tagged a part of speech based on theirsyntactic category. All words are summarized intoinformative and non-informative parts of speech. Thenon-informative parts of speech contain determiners,conjunctions, auxiliaries, prepositions, pronouns, nega-tive articles or possessive markers, interjections, propernouns, abbreviations and numbers. On the other hand,words can be part of an informative part of speech likenouns, verbs, adjectives and adverbs.
The next step in the text-preprocessing phase isstemming or lemmatization. Word variations are con-flated into a single representative form, called the stem.A typical example of a stem is the word ‘connect’ whichis the stem for the variants ‘connected’, ‘connecting’,‘connection’ and ‘connections’. Stemming has two ad-vantages: it reduces the corpus dictionary enormously[3] and it increases the retrieval performance signifi-
cantly [15]. A dictionary-based stemmer is usedthroughout this study. The huge advantage is that allmorphological variations are treated naturally bycomparing them with a reference dictionary. When acorpus term is unrecognizable, the stemmer applies somestandard decision rules to give the term the correct stem.
In order to reduce the number of irrelevant terms inthe corpus dictionary, a number of term filtering tasks areperformed. Firstly, rare words are left out from furtheranalysis because they are unable to aid in future clas-sification. Consequently, all words appearing less thenthree times over the entire document corpus are elim-inated for further analysis. Additionally, overly commonwords like for instance ‘a’ or ‘the’ are also removed fromthe corpus dictionary. These type of words or stopwordsappear so often that they are not discriminative anymore.A stoplist is language and domain specific, as a con-sequence a standard stoplist is often manually adapted toavoid the risk of removing relevant words. Furthermore,only words that are part of an informative part of speechare included, because these words contain relevantinformation to aid in future classification. In the end, thetemporary dictionary is manually checked and irrelevantwords are removed from the dictionary.
The result is a high-dimensional term-by-documentmatrix where each cell in the matrix represents the raw

873K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
frequency of appearance of a term in a document. Tocorrect for the importance of a term in a document andits importance in the corpus dictionary, the term vectorsin the term-by-document matrix are weighted.
2.1.2. Term-vector weightingIn the term vector weighting phase, a weighted term
vector for every document in the document collectionis constructed. Right now, the values in the term-by-document matrix are simply the raw frequencies ofappearance for a term in a document. Term-vectorweighting is often done by determining the product ofthe term frequency (tf) and the inverse document fre-quency (idf) [27,21–23].
The tf measures the frequency of occurrence of anindex term in the document text [23]. The more a term ispresent in a document, the more important this term is incharacterizing the content of that document. As such thefrequency of occurrence of a content word is used toindicate term importance for content representation e.g.[21] and [22]. In this study, the tf is obtained by taking alogarithmic transformation of the original term fre-quency. Taking the logarithmic transformation reducesthe importance of the raw tf, which is important fordocument collections with a varying length. The termfrequency of term i in document j (tfij) is given by
tf ij ¼ log 2 nij þ 1� � ð1Þ
with nij equal to the frequency of term i in document j.The idf takes into account that the more rarely a term
occurs in a document collection, the more discriminatingthat term is. Therefore, the weight of a term is inverselyrelated to the number of documents in which the termoccurs — i.e. the document frequency of the term[21,22,27]. The logarithm of the idf is taken to decreasethe effect of the raw idf-factor. The inverse documentfrequency of term i (idfi) is given by
idf i ¼ log2ndf i
� �þ 1 ð2Þ
with n equal to the total number of documents in theentire document collection and dfi equal to the number ofdocuments where term i is present.
Finally, the weight of term i in document j (wij) isgiven by
wij ¼ tf ijidf i ð3Þ
with tfij equal to the term frequency of term i in documentj, idfi equal to the inverse document frequency of term i.
2.1.3. Dimensionality reductionThis weighted term-by-document matrix is a high-
dimensional matrix due to the many distinct corpusterms. Moreover, this matrix is very sparse – i.e. itcontains a lot of zeros – since not all documents containall corpus terms. In order to reduce the dimensionality ofthe feature space, this study employs Latent SemanticIndexing by using Singular Value Decomposition (SVD)as proposed by Deerweester [7]. Latent Semantic In-dexing projects documents from the high-dimensionalterm space to an orthonormal, semantic latent subspaceby grouping together similar terms into several distinctconcepts k. All textual information can be summarizedinto k concepts. Furthermore, these k concepts or SVDvariables are often used as explanatory variables in atraditional text-classification model. In summary, oneconcludes that Latent Semantic Indexing approximatesthe original weighted term-by-document matrix in asmaller rank k – i.e. k concepts or variables that sum-marizes the emails content – which makes it workablefrom a prediction point of view. Factor-analytic literatureproposes an operational criterion to find the optimalvalue for k [7].
2.2. Linguistic style features
The linguistic style features are introduced as anew set of text-classification predictors. These variablesare created using Linguistic Inquiry and Word Count[19,30]. This program searches individual text files,while it computes the percentage of words that wereearlier judged to reflect the linguistic categories. Thesecategories are described using an extensive dictionary.The word counts on the different categories are usedas an additional set of features in the text-classificationsystem. In sum, a detailed overview of the linguisticstyle categories is given in Table 1.
2.3. Classification technique
Boosting is used as the main classification techniquefor discriminating complaints from non-complaintsthroughout this study (see Sections 3.3 and 3.4). It isa relatively young, yet extremely powerful machinelearning technique. The main idea behind boosting algo-rithms is to combine the outputs of many “weak” clas-sifiers to produce a powerful “committee” or ensemble ofclassifiers [12]. Several studies show that ensemblesgenerally achieve a significantly lower error rate than thebest single model (e.g. [18]). Although being refinedsubsequently, the main idea of all boosting algorithms canbe traced back to the first practical boosting algorithm,

Table 1Overview of the linguistic style features extracted from the call-centeremails
Abbreviation Dimension Examples Number ofwords
WC Word CountWPS Words per sentenceQmarks Sentences
ending with ?Unique Unique words
(type/token ratio)Sixltr % words longer
than 6 lettersPronoun Total pronouns I, our, they,
you're38
I 1st person singular I, my, me 7We 1st person plural we, our, us 6Self Total first person I, we, me 13You Total second
personYou, you'll 7
Other Total third person She, their, them 12Negate Negations No, never, not 36Assent Assents Yes, OK,
mmhmm50
Article Articles A, an, the 3Preps Prepositions On, to, from 48Number Numbers One, thirty, million 107Time Time indication Hour, day, o'clock 269Past Past tense verb Walked, were, had 1773Present Present tense verb Walk, is, be 1886Future Future tense verb Will, might, shall 19
Table 2Overview of the data characteristics
Number of emails Relative percentage
Training setComplaint emails 1890 36.37Others 3306 63.63Total 5196 100
Test setComplaint emails 838 37.61Others 1390 62.39Total 2228 100
Validation setComplaint emails 571 32.59Others 1181 67.41Total 1752 100
874 K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
Adaboost [9]. Adaboost and related algorithms produceextremely competitive results to other classification algo-rithms in many settings, most notably for text classifica-tion (e.g. [25]).
This study concisely describes Adaboost for a twoclass classification problem. For more details aboutAdaboost, we refer to Hastie et al. [12]. Consider atraining set T={(xi,yi)} with i={1,2,…, N}; the input dataxi ∈ Rn and corresponding binary target labels coded asyi ∈ {−1,1}. The final classifier of the Adaboost pro-cedure is given by
F xð Þ ¼XMm¼1
cm fm xð Þ ð4Þ
with m the number of iterations, fm(x) the classifierpredicting values ±1 during the mth round and cm theweight of the contribution of each fm(x) in the finalclassifier. The purpose of Adaboost is to train classifiersfm(x) onweighted versions of the training data obtained bymodifying the data at each boosting step by applyingweights w1, w2,…, wN to each of the training observations(xi,yi) with i={1,2,…, N}. Initially all the weights are setto wi ¼ 1
N ; so the first step simply trains the classifier on
the data in the usual manner. For each successive iterationm=2,3,… M, (i) the weights are individually modifiedgiving a higher weight to cases that are currently mis-classified and (ii) the classifier is reapplied to theweightedobservations. Thus as the iterations proceed, observationsthat are difficult to classify receive ever-increasing in-fluence due to the higher weight assigned. So each suc-cessive classifier is thereby forced to concentrate on thosetraining observations that are missed by previous ones inthe sequence. In the end when the maximum number ofiterationsM is reached, predictions from all classifiers arecombined through a weighted majority vote to producethe final classifier F(x).
In order to give the reader more insights into thelinguistic style differences between complaints and otheremail types (see Section 3.2), a stepwise logisticregression that differentiates between complaint emailsand other email types is run using the linguistic stylevariables as described in Table 1. This technique is usedbecause it is a conceptually simple binary classifier [5],while it provides standardized parameter estimates forthe explanatory variables.
2.4. Evaluation criteria
In order to evaluate the performance of different pre-dictive models, two criteria are used: the percentagecorrectly classified (PCC) and the area under the re-ceiving operating curve (AUC). The PCC compares the aposteriori probability of being a complaint email with thetrue type of the email. If TP, FP, TN and FN are re-spectively the number of complaints that are correctlypredicted (True Positives), the number of non-complaintsthat are predicted as complaints (False Positives), thenumber of non-complaints that are classified correctly

Table 3Standardized parameter estimates
Linguistic style Standardizedparameterestimates a
Abbreviation Dimension
Article Articles 0.1438Future Future tense verb −0.0897I 1st person singular −0.1225Negate Negations 0.4886Number Numbers 0.1078Other Total third person −0.0548Past Past tense verb 0.1009Preps Prepositions −0.4739Present Present tense verb 0.0628Qmarks Sentences ending with? −0.0833Sixltr % words longer than 6 letters −0.1295Time Time indication 0.2122WC Word count 0.1758You Total second person 0.0759a All parameter estimates are significant at 95% confidence level.
875K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
(True Negatives) and the number of complaints that arepredicted as non-complaints (False Negatives), the PCCis defined as (TP+TN) / (TP+FP+TN+FN). The PCCshould be benchmarked to the proportional chancecriterion (= percentageevent
2 + (1−percentageevent)2) inorder to confirm the predictive capabilities of a clas-sifier [17]. A disadvantage of the PCC is that it is notvery robust concerning the chosen cut-off value on the a
Fig. 2. The AUC performance on the test set of A
posteriori probabilities [2]. In order to equally comparedifferent classification models on PCC, the cut-off valuefor classifying emails into complaints or non-complaints ischosen so that the a posteriori incidence equals the a priorioccurrence of complaints. For instance, 35% of the emailshaving the highest complaint probability will be classifiedas complaints when the a priori frequency of complaints is35%. In contrast to PCC, AUC takes into account allpossible thresholds on the a posteriori probabilities. Forall the different levels, it considers the sensitivity (TP/(TP+FN)) and 1 minus the specificity (TN/(TN+FP))in a two-dimensional graph, named the receiving operat-ing curve (ROC). The area under the ROC curve is used toevaluate the performance of a binary classifier [11].DeLong et al. [8] propose a non-parametric test to com-pare the performance of different classification models.
3. Empirical results
This section applies the proposed framework in areal-life call-center setting. In the first section, detailedinformation concerning the call-center setting is given.Section 3.2 explores the linguistic style differencesbetween complaint emails and other email types, whileSection 3.3 investigates the beneficial effect of includ-ing linguistic predictors into a traditional text-classifica-tion setting. In the last section, the robustness of theproposed methodology is investigated.
DA_SVD, ADA_SVD_LS and ADA_LS.

876 K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
3.1. Corpus construction
In this study, emails sent to the call center of a largeBelgian newspaper company are used. Subscribers ofthis newspaper have the possibility to send their concernsor complaints and information requests to the call centervia email.When an email message comes in, themessageis manually encoded into a complaint or another emailtype. The former email type reports all different servicefailures (e.g. newspaper not delivered, financial com-plaints…), while the latter type consists of informationrequests like subscription related questions or informa-tion on promotional actions. Manually encoding emailmessages is a very time-consuming and very inefficienttask. Moreover, all types of emails are treated equallywithin the same department, while in fact complaintemails need a different treatment by specialized peopleduring email handling. The email-classification problemin this context comes down to predicting whether theincoming email is a complaint or not. Consequently,complaint handling becomes more efficient due to afaster detection of the emails at risk.
All emails from July 2004 till December 2004 are usedwithin this study. Consequently, it is possible to derivethe dependent and the explanatory variables. Becausehistorical data is used, all email messages are alreadymanually encoded by the staff of the call center. Thedependent variable is encoded as ‘1’ when the email is acomplaint and ‘−1’ otherwise. There are two types of
Fig. 3. The PCC on the test set of ADA_S
independent variables. The first type of explanatory var-iables is extracted using the methodology of the vector-space approach. Email messages are converted into ahigh-dimensional term-by-document matrix. However,this matrix is unworkable from a prediction point of viewdue to the large number of terms or variables. Conse-quently, several reduced rank-k models (with k={10,20,…, 200}) are obtained by applying Latent SemanticIndexing using SVD. The second type of independentvariables is derived by processing all emails throughLinguistic Inquiry and Word Count. These independentvariables represent word counts for the different cate-gories derived from the linguistic program. These var-iables which contain information about the linguisticstyles are used to explore their beneficial effect on top ofthe traditionally-used SVD variables.
Intended to methodologically correctly predictwhether an email is complaint or not, the data set isdivided into training, test and validation set. Emailsbetween July 2004 and November 2004 are randomlyassigned using a 70–30 split to the training and test set.The former one is used to generate and train theclassifiers, while the test set is used to test the classifieron an unseen data sample. In this study, all emailsof December 2004 are assigned to the validation setor out-of-period set. This dataset is used to verifythe robustness of the proposed methodology. Table 2summarizes the characteristics of the different datasets.
VD, ADA_SVD_LS and ADA_LS.

877K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
As such, one is able to explain differences in linguisticstyle between complaint emails and other email typesusing a traditional stepwise logistic regression (see Sec-tion 3.2). Furthermore, a comparison is made in pre-dictive performance between the models built with the kconcepts (with k={10,20,…, 200}) extracted usingthe SVD procedure (i.e. Adaboost model with SVDvariables or ADA_SVD), the model using only thelinguistic style predictors (i.e. Adaboost model withlinguistic style feature or ADA_LS) and the modelusing both types of information or ADA_SVD_LS (seeSection 3.3).
3.2. Linguistic style differences between complaint emailsand other email types
This section explores if linguistic style differencesexist between a complaint email and another emailtype. Table 3 shows the standardized parameterestimates of the linguistic style variables kept duringthe stepwise logistic regression whereby one tries topredict whether the received email involves a com-plaint or not using only the linguistic style variables asdescribed in Table 1.
Table 3 clearly indicates that the more words (WC),the more articles (Article) and the less prepositions(Preps) are found in an email; the more likely, the emailis classified as a complaint. In contrast to other types ofemails (e.g. an information request), the probability ofbeing a complaint increases when more time indications(Time) are found in an email. Moreover, the likelihoodof being a complaint is positively related with thepresent tense (Present) – e.g. Hopefully, you can fix themisdelivery of my newspaper today (Present, Time) –and the past tense (Past) – e.g.Moreover, the newspaperwas not delivered last week either (Past, Time, Time) –while the possibility of classifying an email as aninformation request increases when more future tenses(Future) and questions (Qmarks) are used – e.g. Willthere be a reduction on my next subscription? (Future,Qmarks). When the tone of an email is more ‘aggres-sive’ – i.e. it contains more negations (Negate), morenumbers (Numbers) and more clenched words (Sixltr) –the chance of having a complaint increases. Further-more, complainants often directly blame the companyfor the service failure (I, Other, You) – e.g. Dear, thenewspaper is not delivered today. It is already the sixthtime this month. You must have noticed already somedelivery problems. You have to fix this problem as soonas possible.(Negate, Numbers, You, You). These resultsindicate that differences in linguistic style exist betweencomplaints and non-complaints.
3.3. Comparing predictive performance of ADA_SVD,ADA_LS and ADA_SVD_LS
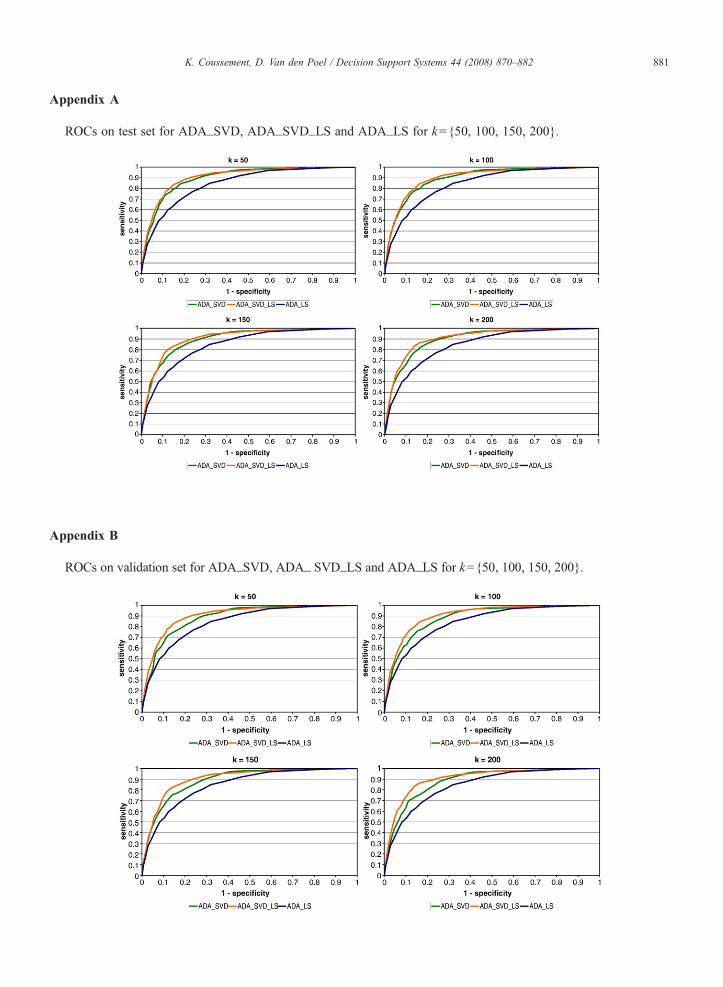
This section compares the predictive performance ofADA_SVD, ADA_SVD_LS and ADA_LS in terms ofAUC and PCC. Fig. 2 shows the predictive performanceof the different models on the test set in terms of AUC,while a comparison in terms of PCC is shown in Fig. 3.The number of SVD concepts is represented on theX-axis, while on the Y-axis, the performance measureis shown. As a remark; (i) ADA_LS is a horizontal linebecause its performance is independent of the number ofSVD concepts, but it is incorporated in the figures forcomparison reasons only, (ii) Appendix A includesROCs on the test set for the models with k={50, 100,150, 200} in order to provide the reader with more in-depth information.
As one observes from Figs. 2 and 3, all modelsperform enormously well in distinguishing complaintemails from non-complaint emails. Indeed, the AUCperformance of all models lies between 84.55 and 91.32,while the PCC lies in the range of 77.02 and 84.65 whichclearly outperforms the proportional chance criterion of53.07 (= 0.37612+(1−0.3761)2) [17]. These resultsclearly indicate that all models – i.e. ADA_SVD,ADA_SVD_LS and ADA_LS – have predictive cap-abilities in distinguishing complaints from other emails.
Figs. 2, 3 and Table 4 give an answer to the questionif adding additional linguistic style predictors to thetraditional SVD dimensions is beneficial from a text-classification point of view. In other words, doesADA_SVD_LS significantly outperform ADA_SVDand ADA_LS?
Table 4 indicates that ADA_SVD_LS significantlyoutperforms ADA_LS and ADA_SVD on all SVD di-mensions [8]. Fig. 2 confirms these results graphically interms of AUC. Furthermore, the PCC of ADA_SVD_LSis always higher then ADA_SVD and ADA_LS as can beseen in Fig. 3. These results indicate the highly beneficialimpact of combining traditional SVD predictors withlinguistic style indicators into one text-classificationmodel. As such, predictive modelers are able to buildbetter email-classification models by incorporating thisnew type of information.
3.4. Out-of-period validation
In order to verify the robustness of the proposedmethodology, all models are scored on an out-of-periodvalidation set. This is necessary because in a realistic call-center environment, the incoming emails lie by definitionin another timeframe than the ones used during model
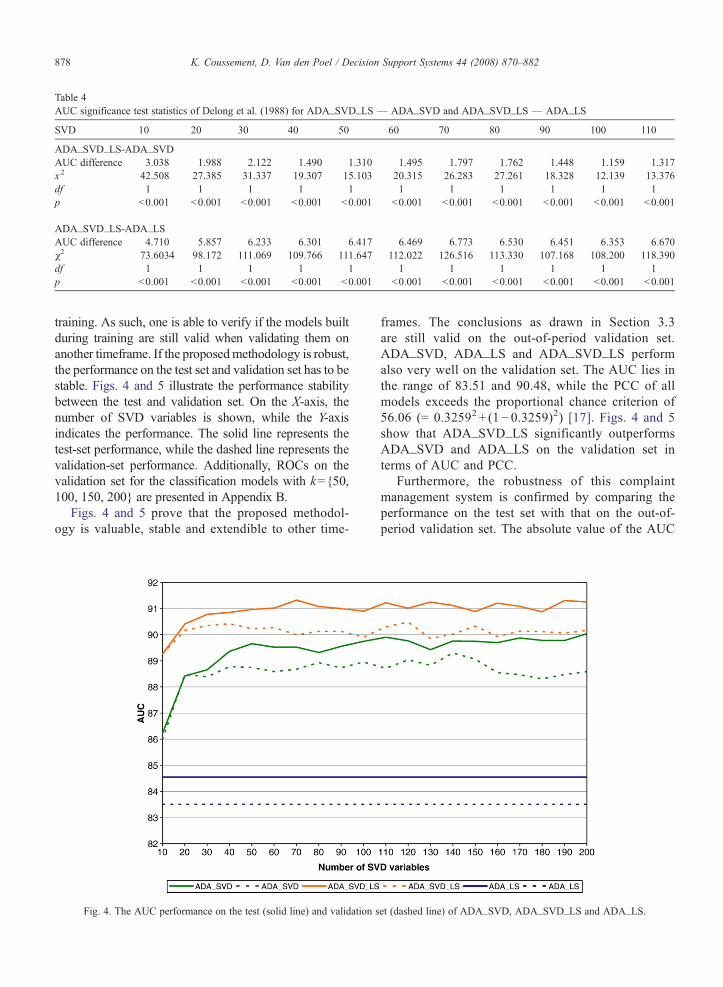
Table 4AUC significance test statistics of Delong et al. (1988) for ADA_SVD_LS — ADA_SVD and ADA_SVD_LS — ADA_LS
SVD 10 20 30 40 50 60 70 80 90 100 110
ADA_SVD_LS-ADA_SVDAUC difference 3.038 1.988 2.122 1.490 1.310 1.495 1.797 1.762 1.448 1.159 1.317x2 42.508 27.385 31.337 19.307 15.103 20.315 26.283 27.261 18.328 12.139 13.376df 1 1 1 1 1 1 1 1 1 1 1p b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001
ADA_SVD_LS-ADA_LSAUC difference 4.710 5.857 6.233 6.301 6.417 6.469 6.773 6.530 6.451 6.353 6.670χ2 73.6034 98.172 111.069 109.766 111.647 112.022 126.516 113.330 107.168 108.200 118.390df 1 1 1 1 1 1 1 1 1 1 1p b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001
878 K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
training. As such, one is able to verify if the models builtduring training are still valid when validating them onanother timeframe. If the proposedmethodology is robust,the performance on the test set and validation set has to bestable. Figs. 4 and 5 illustrate the performance stabilitybetween the test and validation set. On the X-axis, thenumber of SVD variables is shown, while the Y-axisindicates the performance. The solid line represents thetest-set performance, while the dashed line represents thevalidation-set performance. Additionally, ROCs on thevalidation set for the classification models with k={50,100, 150, 200} are presented in Appendix B.
Figs. 4 and 5 prove that the proposed methodol-ogy is valuable, stable and extendible to other time-
Fig. 4. The AUC performance on the test (solid line) and validation s
frames. The conclusions as drawn in Section 3.3are still valid on the out-of-period validation set.ADA_SVD, ADA_LS and ADA_SVD_LS performalso very well on the validation set. The AUC lies inthe range of 83.51 and 90.48, while the PCC of allmodels exceeds the proportional chance criterion of56.06 (= 0.32592 + (1−0.3259)2) [17]. Figs. 4 and 5show that ADA_SVD_LS significantly outperformsADA_SVD and ADA_LS on the validation set interms of AUC and PCC.
Furthermore, the robustness of this complaintmanagement system is confirmed by comparing theperformance on the test set with that on the out-of-period validation set. The absolute value of the AUC
et (dashed line) of ADA_SVD, ADA_SVD_LS and ADA_LS.

120 130 140 150 160 170 180 190 200
1.250 1.820 1.365 1.143 1.512 1.214 1.093 1.528 1.21714.104 29.678 15.290 11.127 19.811 12.028 10.442 18.294 12.7961 1 1 1 1 1 1 1 1
b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001
6.466 6.699 6.571 6.341 6.659 6.537 6.326 6.756 6.705109.018 116.827 114.625 102.791 115.494 112.497 106.401 119.710 118.2431 1 1 1 1 1 1 1 1
b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001 b0.001
879K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
difference between the test set and the out-of-periodvalidation set fluctuates between 0.008 and 1.476 AUCpoints over all different models (see Fig. 4). This in-dicates that the models are robust over the proposedtime period. These results are confirmed when having alook at the absolute value of the difference in PCC (seeFig. 5). This difference fluctuates between 0.063 and1.535 PCC points.
In summary, applying these classifiers to a newtimeframe does not result in a drastic drop in performance.Contrary, implementing the proposed methodologywithin a call-center environment is a valuable strategyto improve customer complaint management.
Fig. 5. The PCC on the test (solid line) and validation set (das
4. Conclusions and direction for further research
Due to the strong increase in Internet penetration, a lotof customers write an email as a substitute for traditionalcommunication methods as for instance a letter or atelephone call. As a consequence, companies receivedaily a huge amount of emails. Nowadays, companiesoutsource their internal email management to a specia-lized call-center environment. Efficient email handlingbecomes one of the major key challenges in business.This study focuses on how a company can optimize itscomplaint-handling strategies through an automaticemail-classification system. Indeed, practitioners and
hed line) of ADA_SVD, ADA_SVD_LS and ADA_LS.

Table 5Real-life call-center example
Call-center setting Discounted Cost per Year(in Euro)
Total Cost after 5 year(in Euro)
Additional savings over manuallabeling after 5 year (in Euro)
Year
1 2 3 4 5
Manual labeling 7250 6971 6703 6445 6197 33,567Automatic email classification 1813 1743 1676 1611 1549 8392 25,175
880 K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
academics feel the need for an efficient and successfulcomplaint-handling strategy, because recovering servicefailures as quick as possible results in additional benefits.
This study offers an automatic email-classificationsystem that distinguishes complaints fromnon-complaints.In contrast to manually encoding the incoming emails, thisstudy offers a feasible methodology to automate thisprocess. As a result, email handling becomes less time-consuming and less expensive due to the lower labor costs.Table 5 indicates that implementing the current methodol-ogy in a real-life call-center setting saves a lot of resourceswithin this specific case.
Suppose that in the current situation, an employeelabels an incoming email at a realistic 45 s per email or 80email messages per hour, whereas the explicit cost of re-labeling falsely called complaints as non-complaints orvisa versa is similar. Moreover, the call center receivesabout 20,000 emails a year. Table 5 shows that the totalcosts over 5 years with 20,000 email messages a year formanually labeling is about 33,567Euros having a discountrate of 4% and a gross employee cost of 29 Euros per hour.If the call center implements the proposed methodology,resources are saved. Knowing that the email-classificationsystem easily succeeds in classifying 83% of the emailmessages correctly, the call center saves approximately25,175 Euros over a 5-year period supposing a labelingefficiency gain of 75%. Indeed, the employee's time-consuming labeling task gives way to a less expensiverearranging task of the correctly classified email set.
Furthermore, there is a possibility to treat incomingcomplaints in a separate way than other email typesduring the email-handling process. Transferring com-plaints to a separate complaint-handling departmentwith well-trained complaint handlers should result in amore successful and faster complaint treatment whichresults in an overall increase of customer satisfaction.
Moreover, this study explores the differences inlinguistic style between complaints and non-complaints.The probability of having a complaint email increaseswhen more words and time indications are used. Incontrast to for instance an information request, the
likelihood of being a complaint is positively related withthe present and past tense, while it decreases when morefuture tenses and question marks are used. Furthermore,the possibility of classifying an incoming email as acomplaint increases when the tone of email becomesmore antagonistic — i.e. it contains more negations,more numbers and more clenched words. Offending thecompany by using a lot of second person pronouns –e.g. you are responsible for the misdelivery of thenewspaper – increases the chance of having a complaint.
Furthermore, this study proves that adding linguisticstyle features as an additional set of predictors in atraditional text-classification model significantlyincreases the predictive performance. In addition, therobustness of the proposed methodology is confirmedby validating the text-classification models on an out-of-period dataset.
While we believe that this study contributes to today'sliterature, some shortcomings and directions for futureresearch are given. First of all, it is not clear whetheradding linguistic style predictors in other text-classifica-tion tasks will result in the same highly beneficialincrease in predictive performance. Additional experi-ments need to be done to answer this question.Moreover,additional efforts can be done to refine the proposedmethodology. For instance, automatically detecting dif-ferent types of complaints (e.g. delivery problems, fi-nancial problems…) would give us valuable and in-depthinformation on the occurring problems and servicefailures that customer encounter.
Acknowledgments
We would like to thank (1) the anonymous Belgiancompany for providing us with data for testing ourresearch questions, (2) Ghent University for funding thePhD project of Kristof Coussement (BOF 01D26705),(3) Bart Larivière, Jonathan Burez and Ilse Bellinck fortheir insights during this project. This project wasrealized using SAS v9.1.3, SAS Text Miner v2.3 andMatlab v7.0.4.
881K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
Appendix A
ROCs on test set for ADA_SVD, ADA_SVD_LS and ADA_LS for k={50, 100, 150, 200}.
Appendix B
ROCs on validation set for ADA_SVD, ADA_ SVD_LS and ADA_LS for k={50, 100, 150, 200}.

882 K. Coussement, D. Van den Poel / Decision Support Systems 44 (2008) 870–882
References
[1] C.Aasheim,G.J.Koehler, Scanningworldwidewebdocumentswiththe vector space model, Decision Support Systems 42 (2) (2006).
[2] B. Baesens, S. Viaene, D. Van den Poel, J. Vanthienen, G.Dedene, Bayesian neural network learning for repeat purchasemodeling in direct marketing, European Journal of OperationalResearch 138 (1) (2002).
[3] C. Bell, K.P. Jones, Toward everyday language informationretrieval systems via minicomputers, Journal of the AmericanSociety for Information Science 30 (1979).
[4] R. Bougie, R. Pieters, M. Zeelenberg, Angry customers don'tcome back, they get back: the experience and behaviouralimplications of anger and dissatisfaction in services, Journal ofthe Academy of Marketing Science 31 (4) (2003).
[5] R.E. Bucklin, S. Gupta, Brand Choice, purchase incidence andsegmentation: an integrated modeling approach, Journal ofMarket-ing Research 29 (1992).
[6] R.C. Chen, C.H. Hsieh, Web page classification based on asupport vector machine using a weighted vote schema, ExpertSystems with Applications 31 (2) (2006).
[7] S. Deerweester, S. Dumais, G. Furnas, T. Landauer, R. Harsh-man, Indexing by latent semantic analysis, Journal of theAmerican Society for Information Science 41 (6) (1990).
[8] E.R. DeLong, D.M. DeLong, D.L. Clarke-Pearson, Comparing theareas under two or more correlated receiver operating characteristiccurves: a nonparametric approach, Biometrics 44 (3) (1988).
[9] Y. Freund, R.E. Schapire, A decision-theoretic generalization ofon-line learning and an application to boosting, Journal ofComputer and System Sciences 55 (1) (1997).
[10] R.D. Gopal, A.K. Tripathi, Z.D. Walter, Economics of first-contactemail advertising, Decision Support Systems 42 (3) (2006).
[11] J.A. Hanley, B.J. McNeil, The meaning and use of the area under areceiver operating characteristic (ROC) curve, Radiology 143 (1)(1982).
[12] T. Hastie, R. Tibshirani, J. Friedman, The elements of statisticallearning: data mining, inference and prediction, Springer Seriesin Statistics, Springer-Verlag, New York, 2003.
[13] J.L. Heskett, T.O. Jones, G.W. Loveman, W.E. Sasser, L.A.Schlesinger, Putting the service-profit chain to work, HarvardBusiness Review 72 (March–April 1994).
[14] M.Y. Kiang, T.S. Raghu, K.H.M. Shang, Marketing on theInternet— who can benefit from an online marketing approach?Decision Support Systems 27 (4) (2000).
[15] W. Kraaij, R. Pohlmann, Viewing stemming as recall enhance-ment, Proceedings of the 19th Annual International ACM SIGIRConference on Research and Development in InformationRetrieval (Zurich Switzerland), 1996.
[16] C.Y. Liang, L. Guo, Z.H. Xia, F.G. Nie, X.X. Li, L.A. Su, Z.Y.Yang, Dictionary-based text categorization of chemical webpages, Information Processing and Management 42 (4) (2006).
[17] D.G. Morrison, On the interpretation of discriminant analysis,Journal of Marketing Research 6 (1969).
[18] P. Mangiameli, D. West, R. Rampal, Model selection for medicaldiagnosis decision support systems, Decision Support Systems36 (3) (2004).
[19] J.W. Pennebaker, M.E. Francis, R.J. Booth, Linguistic Inquiry andWord Count (LIWC), Erlbaum Publishers, Mahwah, N.J., 2001.
[20] M. Pontes, C. Kelly, The identification of inbound call centeragents' competencies that are related to callers' repurchaseintentions, Journal of Interactive Marketing 14 (2000).
[21] G. Salton, ATheory of Indexing, J.W. Arrowsmith, Bristol, UK,1975.
[22] G. Salton, Automatic Text Processing: The Transformation,Analysis and Retrieval of Information by Computer, Addison-Wesley, Reading, MA, 1989.
[23] G. Salton, C. Buckley, Term-weighting approaches in automatic textretrieval, Information Processing and Management 24 (5) (1988).
[24] G. Salton,TheSMARTRetrieval System:Experiments inAutomaticDocument Processing, Prentice Hall, Englewood Cliffs, NJ, 1971.
[25] R.E. Schapire, Y. Singer, BoosTexter: a boosting-based systemfor text categorization, Machine Learning 39 (2–3) (2000).
[26] A.K. Smith, R.N. Bolton, The effect of customers' emotionalresponses to service failures on their recovery effort evaluationsand satisfaction judgments, Journal of the Academy of MarketingScience 30 (2002).
[27] K. Sparck Jones, Index term weighting, Information Storage andRetrieval 9 (11) (1973).
[28] S.S. Tax, S.W. Brown, Recovering and learning from servicefailures, Sloan Management Review 40 (1) (1998).
[29] S.S.Weng, C.K. Liu, Using text classification andmultiple conceptsto answer emails, Expert Systems with Applications 26 (4) (2004).
[30] H. Zijlstra, T. van Meerveld, H. van Middendorp, J.W.Pennebaker, R. Geenen, Dutch version of the Linguistic Inquiryand Word Count (LIWC); a computerized text analysis program,Behaviour and Health (Dutch journal) 32 (2004).
Kristof Coussement is a Customer Intelli-gence researcher in the Faculty of AppliedEconomics and Business Administration atGhent University, (Belgium). He received hisMaster degree inAppliedEconomics aswell ashis Master after Master degree in MarketingAnalysis at Ghent University (Belgium).During his research project, he investigatesthe impact of client/company interactionsthrough verbalized information sources on
Customer Relationship Marketing (churn ana-lysis, customer complaint management, etc.).
Dirk Van den Poel is professor of marketingat the Faculty of Economics and BusinessAdministration ofGhentUniversity, Belgium.He heads a competence center on analyticalcustomer relationship management (aCRM).He received his degree of management/busi-ness engineer as well as his PhD from K.U.Leuven (Belgium).Hismain interest fields arethe quantitative analysis of consumer beha-vior (CRM), data mining (genetic algorithms,
neural networks, random forests, randommultinomial logit: RMNL), text mining, optimal marketing resourceallocation (DIMAROPT) and operations research.





























