Embed Size (px)
Citation preview

Improved Mesh PartitioningImproved Mesh Partitioning F Foror Parallel S Parallel Substructure Finite Element Computationsubstructure Finite Element Computations
Shang-Hsien Hsieh, Yuan-Sen Yang and Po-Liang TsaiShang-Hsien Hsieh, Yuan-Sen Yang and Po-Liang Tsai
Department of Civil EngineeringDepartment of Civil Engineering
National Taiwan UniversityNational Taiwan University
Taipei, Taiwan, R.O.C.Taipei, Taiwan, R.O.C.
Sponsored by the National Science Council of R.O.C.Sponsored by the National Science Council of R.O.C.

ObjectiveObjective
To improve the efficiency of the parallel substructure To improve the efficiency of the parallel substructure
finite element method through investigation on mesh finite element method through investigation on mesh
partitioning.partitioning.

Parallel Substructure MethodParallel Substructure Method
((a) Mesh partitioning (preprocessed by a single processor)a) Mesh partitioning (preprocessed by a single processor) (b) Concurrent substructure condensation(b) Concurrent substructure condensation (c) Solution of condensed system equations associated with the (c) Solution of condensed system equations associated with the
interface d.o.f.’s using a single processor interface d.o.f.’s using a single processor (d) Concurrent solution of the substructure internal d.o.f.’s (d) Concurrent solution of the substructure internal d.o.f.’s
((a)a) ((b)b) ((c)c) ((d)d)

Parallel Substructure Method Parallel Substructure Method (Cont’d)(Cont’d)
• Major difficultyMajor difficulty– Workloads are not well balanced.Workloads are not well balanced.
• ReasonReason– Insufficient mesh partitioning criteriaInsufficient mesh partitioning criteria
0 50 100 150 200 250 300
4
3
2
1Pr
oc ID
Time (sec.)
Read
Stiff
Condn
Data
Wait
Com+asm
Solv
UpdatBLD30-145,480 BC elms 152,400 D.O.F.‘s

Common criteria used by most of mesh Common criteria used by most of mesh partitioning algorithms:partitioning algorithms:
– Balance of number of elements among Balance of number of elements among substructuressubstructures
– Minimization of total number of interface nodesMinimization of total number of interface nodes
Mesh PartitioningMesh Partitioning

Mesh Partitioning Mesh Partitioning (Cont’d)(Cont’d)
New criteriaNew criteria
– Balance of the total element weights among Balance of the total element weights among substructuressubstructures
– Minimization of number of interface nodesMinimization of number of interface nodes

An iterative approachAn iterative approach– Mesh partitioning kernel – Mesh partitioning kernel –
METIS METIS (Karypis and Kumar, 1995)(Karypis and Kumar, 1995)
– Evaluation of performance Evaluation of performance indicatorsindicators
– Adjustment of element Adjustment of element weights based on the weights based on the number of substructure number of substructure interface nodesinterface nodes
Improved Mesh PartitioningImproved Mesh Partitioning
M E T I S
P o te n t ia l fo rim p r o v e m e n t
A d ju s t in gE le m e n tw e ig h ts
N o
Y e s
E v a lu a t in gp e r fo r m a n c e
in d ic a to r s
F in ite e le m e n tm e s h
P a r t it io n e d m e s h

Improved Mesh Partitioning Improved Mesh Partitioning (Cont’d)(Cont’d)
Tuning factor F of iteration Tuning factor F of iteration i i ::
NNiiIN, IN, jj
Min(NNiiIN, IN, jj , for each substructure j)
Fii jj =
88/13/13
Fi i 11 = 6/6=1.0
Fii 3 3 = 7/6=1.17
Fii 2 2 = 6/6=1.0

Improved Mesh Partitioning Improved Mesh Partitioning (Cont’d)(Cont’d)
Indicator E:Indicator E:
– Indicator of efficiency of iteration Indicator of efficiency of iteration ii
– EEii = max(E = max(Eii1,1,
jj for each substructure for each substructure jj) + E) + Eii
22
– EEii1, 1, jj : condensation time indicator of substructure : condensation time indicator of substructure jj
– EEii1, 1, jj = [(I = [(Iii
1, 1, jj )) 2.52.5+(I+(Iii
2, 2, j j )) 2.52.5 ] / [(I ] / [(I00
1, 1, jj )) 2.52.5+(I+(I00
2, 2, j j )) 2.52.5 ] ]
– IIii1, 1, jj : N: Nii
ELM, ELM, jj / N/ NELMELM
– IIii2, 2, jj : N: Nii
IN, IN, jj / N / N00IN, IN, jj
– Interface solution time factor - EInterface solution time factor - E2,2,ii ::
– EEii22 = (N = (Nii
IN IN / N/ N00IN IN ))
33

Improved Mesh Partitioning Improved Mesh Partitioning (Cont’d)(Cont’d)
Indicator E vs. Total elapsed time TIndicator E vs. Total elapsed time T
Model: 4E123072solid(B20) elements 48,975 D.O.F.‘s
(Tsai, 1999)
0
0.2
0.4
0.6
0.8
1
1.2
0 1 2 3 4 5 6
E
TN
orm
aliz
ed E
or
T
Iteration i

CPU: Intel Pentium II-CPU: Intel Pentium II-350350Memory: NEC Memory: NEC 128MB128MB PC100 SDRAM PC100 SDRAMNetwork: ACCTON 10/Network: ACCTON 10/100 Mbps100 Mbps
D-Link D-Link 100100 Mbps Hub Mbps HubOS: OS: LinuxLinux Redhat 5.2 Redhat 5.2
CPU: Intel Pentium II-CPU: Intel Pentium II-350350Memory: NEC Memory: NEC 128MB128MB PC100 SDRAM PC100 SDRAMNetwork: ACCTON 10/Network: ACCTON 10/100 Mbps100 Mbps
D-Link D-Link 100100 Mbps Hub Mbps HubOS: OS: LinuxLinux Redhat 5.2 Redhat 5.2
PC Cluster
Computing EnvironmentComputing Environment

Numerical ExperimentsNumerical Experiments
BLADE944 solid(B20) elements 18,180 D.O.F.‘s
i Max/Min ( Ni
IN, j ) Ni
IN Ei
0 1.82 580 2.0 1 1.51 506 1.54 2 1.95 498 1.49 3 1.59 556 1.84
Improved mesh partitioning iterationsImproved mesh partitioning iterations
(Wawrzynek, 1991)
Nsub ( number of substructures) = 4
CPU time: 1.6 sec.

•METIS without iteration
•Improved mesh partitioning (with 2 iterations)
BLADE944 solid(B20) elements 18,180 D.O.F.‘s
0 20 40 60 80
1
2
3
4 Read
Stiff
Condn
Data
Wait
Com+asm
Solv
Updat
Np = 4Hardware: PC cluster ( P II 350)OS : Linux Redhat 5.2
0 20 40 60 80
1
2
3
4ReadStiffCondnDataWaitCom+asmSolvUpdat
Numerical Experiments Numerical Experiments (Cont’d)(Cont’d)
67.4 sec.
45.4 sec.
Additional 1.6 sec. for iterative mesh partitioning
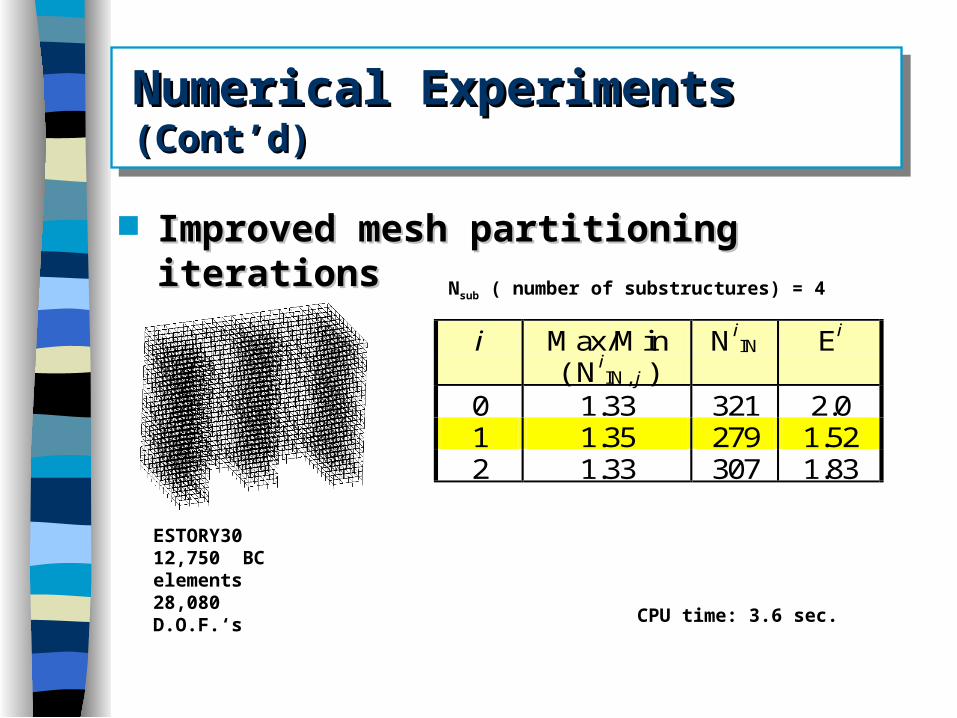
Numerical Experiments Numerical Experiments (Cont’d)(Cont’d)
i Max/Min ( Ni
IN, j ) Ni
IN Ei
0 1.33 321 2.0 1 1.35 279 1.52 2 1.33 307 1.83
Improved mesh partitioning iterationsImproved mesh partitioning iterations
ESTORY3012,750 BC elements 28,080 D.O.F.‘s
CPU time: 3.6 sec.
Nsub ( number of substructures) = 4

•METIS without iteration
•Improved mesh partitioning (with 1 iteration)ESTORY3012,750 BC elements 28,080 D.O.F.‘s
Np = 4Hardware: PC cluster ( P II 350)OS : Linux Redhat 5.2
0 20 40 60 80
1
2
3
4
Proc
Sec
Read
Stiff
Condn
Data
Wait
Com+asm
Solv
Updat
Numerical Experiments Numerical Experiments (Cont’d)(Cont’d)
89.2 sec.
56.5 sec.
Additional 3.6 sec. for iterative mesh partitioning
0 20 40 60 80
1
2
3
4
Proc
Sec
Read
Stiff
Condn
Data
Wait
Com+asm
Solv
Updat64.5 sec.

ConclusionsConclusions
The iterative mesh partitioning approach can The iterative mesh partitioning approach can effectively improve the efficiency of parallel effectively improve the efficiency of parallel substructure finite element computations.substructure finite element computations.
Better mesh partitioning is still needed.Better mesh partitioning is still needed. A parallel equation solver becomes more A parallel equation solver becomes more
important.important.





























