Embed Size (px)
Citation preview

Image and Video Retrieval and Visual Analytics:
Opportunities for Collaboration
Mike Christel, [email protected]
Entertainment Technology Center, Carnegie Mellon University

Talk Outline
(Heavy on demonstrations, light on slides….)• Introduction to two test corpora on my demo laptop• Very quick overview of CMU Informedia research
• Speech recognition; text alignment• Image processing; visual concept classification• Language processing; named entity detection
• Lessons Learned• Opportunities

CMU Informedia Video Research• Details at: http://www.informedia.cs.cmu.edu• Speech recognition and alignment; image processing;
named entity tagging • Synchronized metadata for search and navigation• Fast, direct video access to oral histories, news, etc.• Demonstration oral history corpus: 913 hours of
interviews from 400 individuals, 18,254 interview story segments (average story segment length of 3 minutes)
• Demonstration news corpus: NIST TRECVID 2006 test set (165 hours of U.S., Arabic, and Chinese news with 79,484 reference shots)

The HistoryMakers Oral History Archive
• http://www.thehistorymakers.com• The world’s largest African American oral history archive
with accomplished African Americans • Purpose:
• To educate and show the breadth and depth of this important American history as told by the first person
• To highlight the accomplishments of individual African Americans across a variety of disciplines
• To preserve this material for generations to come• Committed to exposing the archive to the widest audience
possible, making use of new technologies as appropriate

The HistoryMakers Intellectual Property
• The set of 400 interviewees I will show today is in a corpus with planned growth to 5000
• The work is in beta test, with strict limitations on copying and distribution:“All content is the property of The HistoryMakers™: all proposed uses must be submitted in a proposal in advance to The HistoryMakers for approval before anything can be used and approval is totally at our discretion.” – Julieanna Richardson, Founder & Executive Director, The HistoryMakers, Chicago, IL

A Theme for Today: User Involvement
• User Correction: Corrective action for metadata errors (analogous to Harry Shum’s vision at Microsoft for human-assisted computer vision success)
• User Control: Driving the interface to overcome metadata errors
• User Context: More useful interfaces driven implicitly by context

Speech Recognition Functions
• Generates transcript (if one is not given) to enable text-based retrieval from spoken language documents
• Improves text synchronization to audio/video in presence of scripts (align speech with text)
• Supplies necessary information for library segmentation and multimedia abstractions (e.g., break stories apart at silence points rather than in the middle of sentences)

Image Understanding Functions
• Scene segmentation• Similarity matching • Camera motion determination and object tracking• Optical Character Recognition (OCR) on video text and
titles• Face detection and recognition• Ongoing research work in object identification and scene
characterization, e.g., indoor/outdoor, road, building, etc.

Images Containing Similar Colors…
Image search with tropical rainforest image leads to…

Images Containing Similar Colors

Images Containing Similar Shapes

Images Containing Similar Content

Shots
Camera
Objects
Action
Captions
Scenery
Yellowstone
Static
Adult Female
Head Motion
CNN LIVE
Studio
Static
Animal
Left Motion
CNN
Outdoor
Zoom
Two adults
None
An Online First
Indoor
Goal: Automatic Video Characterization

Shots
Camera
Objects
Action
Captions
Scenery
Yellowstone
Static
Adult Female
Head Motion
CNN LIVE
Studio
Static
Animal
Left Motion
CNN
Outdoor
Zoom
Two adults
None
An Online First
Indoor
Goal: Automatic Video Characterization

Automated Video Processing
• Produces descriptive metadata for video libraries• Metadata has errors greater than metadata produced by a
careful, human-provided annotation• Errors in metadata can be reduced – examples to follow…

Camera and Motion Detection
Pan
Right object motion (not
pan left)

Text and Face Detection
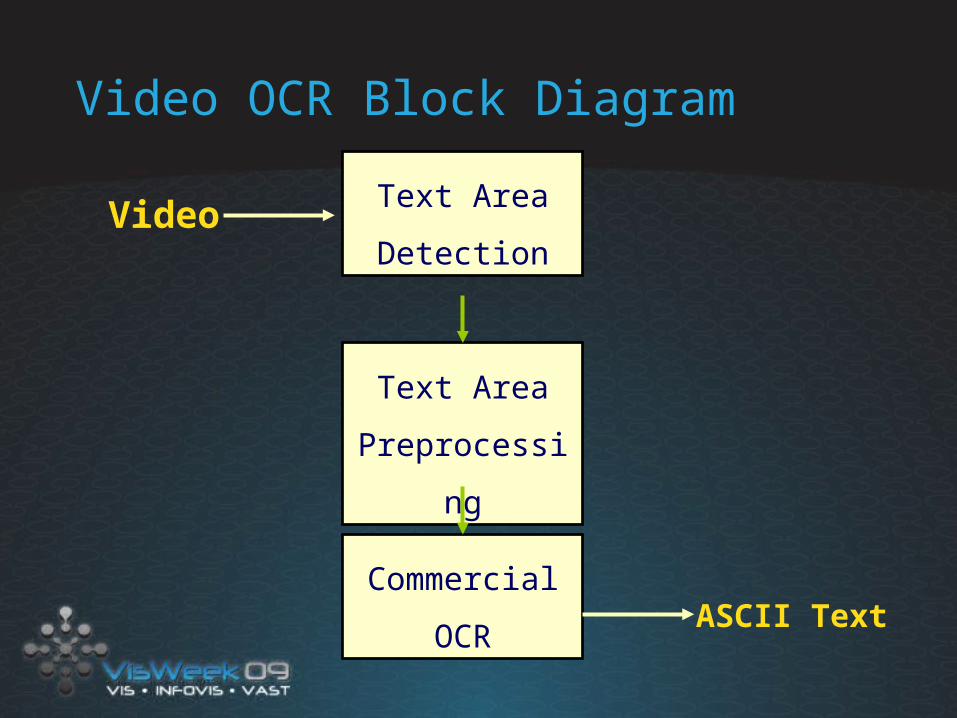
Video OCR Block Diagram
Text Area
Detection
Text Area
Preprocessing
Commercial
OCR
Video
ASCII Text

(1/2 sec. intervals)
Video Frames Filtered Frames AND-ed Frames

VOCR Preprocessing Problems

Augmenting VOCR with Dictionary Look-up

Named Entity Extraction
CNN national correspondent John Holliman is at Hartsfield International Airport in Atlanta. Good morning, John. …But there was one situation here at Hartsfield where one airplane flying from Atlanta to Newark, New Jersey yesterday had a
mechanical problem and it caused a backup that spread throughout the whole system because even though there were a lot of planes flying to the New York area from the Atlanta
area yesterday, ….
Key: Place, Time, Organization/Person
F. Kubala, R. Schwartz, R. Stone, and R. Weischedel, “Named Entity Extraction from Speech”, Proc. DARPA Workshop on Broadcast News Understanding Systems, Lansdowne, VA, February 1998.

Improving the Interface via Usage ContextExample: query-based thumbnail selection

Improving Utility through End-User ControlExample: filtering storyboard based on visual
concepts with user controlling precision and recall

Improving the Metadata via User Interaction
• Example: collecting positive and implicit negative sets of labeled shot data for visual concepts
• Reference: Ming-yu Chen, et al., ACM Multimedia 2005

Automated Video Processing• Produces descriptive metadata for video libraries
• Metadata has errors greater than metadata produced by a careful, human-provided annotation
• Errors in metadata can be reduced:• By more computation-intensive algorithms• By taking advantage of video frame-to-frame redundancy• By folding in context, e.g., probable text sizes in video• By folding in extra sources of knowledge, e.g., a dictionary for
cleaning up VOCR, or labeled data revealing patterns for named entity detection
• By human review and correction, which can generate additional labeled data for machine learning

Storyboards: TRECVID Search Success
• For the shot-based directed search information retrieval task evaluated at TRECVID, storyboards have consistently and overwhelmingly produced top scores
• Motivated users can navigate through thousands of shot thumbnails in storyboards, better even than with “extreme video retrieval” interfaces: 2487 shots on average per 15 minute topic for TRECVID 2006 (Christel & Yan, CIVR 2007)
• Storyboard benefits: packed visual overview, trivial interactive control needed for “overview, zoom and filter, details on demand” – Shneiderman’s Visual Information-Seeking Mantra

Beyond Fact-Finding• CACM (April 2006), Info. Processing and Mgt (March 2008),
etc., have special issues on this topic• G. Marchionini (“Exploratory Search: From Finding to
Understanding,” CACM 49, April 2006) breaks down 3 types of search activities:• Lookup (fact-finding; solving stated/understood need)• Learn• Investigate
• Computer scientists and information retrieval specialists emphasize evaluation of lookup activities (NIST TREC)
• Real world interest in learn/investigate: for an oral history collection, State Univ. New York at Buffalo Workshop library science and humanities participants quite interested in learn/investigate activities

Exploratory Search• Examples where storyboards still useful: visual review• Where storyboards fail:
• Showing other facets like time, space, co-occurrence, named entities (When did disasters occur? Where?)
• Providing collection understanding, holistic view of what’s in 100s of segments of 1000s of shots
• Providing window into visually homogenous results, e.g., results from color search perhaps, or a corpus of just lectures, or head-and-shoulder interview shots
• Claim: Storyboards are not sufficient, but are part of a useful suite of tools/interfaces for interactive video search

Anecdotal Support for Claim• Collected 2006-2007 from:
• Government analysts with news data• History students and faculty with oral history data
• Views Tested: • Timeline• Visual Info Browsing Environment (VIBE) Plot • Map View• Named Entity view (people, places, organizations)• Text-dominant views:
• Nested Lists (pre-defined clusters by contributor)• Common Text (on-the-fly grouping of common phrases)

Anecdotal Results
• 38 HistoryMakers corpus users (mostly students, 15 female, average age 24), experienced web searchers, modest digital video experience
• 6 intelligence analysts (1 female; 2 older than 40, 3 in their 30s, 1 in 20s), very experienced text searchers, experienced web searchers, novice video searchers
• View use minimal aside from Common Text• Text titling and text transcripts used frequently• A bit of evidence for collection understanding (e.g., diffs in
topic between New York and Chicago), but overall, cautious use of default settings for initial trial(s).

Evaluation Hurdles• How does one evaluate information visualization for
promoting exploratory video search?• Low level simple tasks vs. complex real-world tasks• Traditional effectiveness, efficiency, satisfaction are
even problematic: is “fast” interface for exploration good or bad?
• HCI discount usability techniques offer some support, but ecological validity may limit impact of conclusions (e.g., HCII students found Common Text well suited for History students)
• Look to HCI+Visual Analytics for help, e.g., Plaisant• “First hour with system” studies, or “developer as user”
insights too limiting. Rather, consider Multi-dimensional In-depth Long-term Case-studies (MILC)

Reflections –Informedia Successes
• Open benchmarking to gauge progress in digital video libraries and video information retrieval
• NIST TREC Spoken Document Retrieval• NIST TRECVID
• Application of machine learning techniques for visual classification; addressing “semantic gap” through visual concepts (Rong Yan, Wei-Hao Lin, Jun Yang, Robert Chen with Alex Hauptmann as PhD thesis advisor in LTI)
• User studies to empirically drive interface development (see http://www.morganclaypool.com/toc/icr/1/1 - Morgan & Claypool Synthesis Lectures on Information Concepts, Retrieval, and Services)

Reflections – Opportunities Missed
• Foreseeing growth of the Web in 1994• Limited use and dissemination via work with broadcasters
and intellectual property concerns• Significant shifts in environment, e.g., from $1,000,000 for
a terabyte of storage in 1994 to $100 (or less) today• Emphasis on information retrieval in traditional sense
(lookup tasks)

Conclusions to Build Upon - 1
• “Interactive” allows human direction to compensate for automation shortcomings and varying needs• Interactive fact-finding better than automated fact-
finding in visual shot retrieval (TRECVID)• Interactive computer vision has successes (Harry Shum
at Microsoft, Michael Brown et al. at NUS)• Interactive view/facet control == ??? (too early to tell)
• Users need scaffolding/support to get started• Evaluations need to run longer term, in depth, with case
studies to see what has benefit (MILC)

Conclusions to Build Upon - 2
• Storyboards work well for visual overview• Video surrogates can be made more effective, efficient,
and satisfying when tailored to user activity (leverage context)
• Interface should provide easy tuning of precision vs. recall• As cheap storage and transmission is producing a wealth
of digital video, exploratory search will gain emphasis regarding video repositories
• Augment automatically produced metadata with human-provided descriptors (take advantage of what users are willing to volunteer, and in fact solicit additional feedback from humans through motivating games that allow for human computation, a research focus of Luis von Ahn at Carnegie Mellon University)

CreditsMany members of the Informedia Project, CMU research community, and The HistoryMakers contributed to this work, including:
Informedia Project Director: Howard Wactlar
The HistoryMakers Executive Director: Julieanna Richardson
Informedia User Interface: Ron Conescu, Neema Moraveji
Informedia Processing: Alex Hauptmann, Ming-yu Chen, Wei-Hao Lin, Rong Yan, Jun Yang
Informedia Library Essentials: Bob Baron, Bryan Maher
This work supported by the National Science Foundation under Grant Nos. IIS-0535056 and IIS-0705491





























