Embed Size (px)
Citation preview

Identifying prokaryotic consortia that live in close
interaction with algae
Assia SALTYKOVA
Master’s dissertation submitted to obtain the degree of
Master of Science in Biochemistry and Biotechnology
Major Bioinformatics and Systems Biology
Academic year 2014-2015
Promoter: Prof. Dr. Kathleen Marchal
Scientific supervisors: Stephane Rombauts and Sergio Pulido Tamayo
UGent - Department Information Technology
UGent - Department Plant Biotechnology and Bioinformatics
VIB - Department Plant Systems Biology
Research Group Data Integration and Biological Networks


Acknowledgements
i
Acknowledgements
It is a great pleasure to thank those who made this work possible. I am grateful to Prof. Dr.
Kathleen Marshal for giving me the opportunity to make this thesis and to Sergio Pulido for
valuable advices and for revising the manuscript. Special thanks go to Stephane Rombauts who
has provided the data and who with endless patience has guided me through the practical part
of this work. It was also an adorable experience to join the Biocomp group with its absolutely
unique atmosphere and people.

Acknowledgements
ii

Table of contents
iii
Table of contents
Acknowledgements .............................................................................................................. i
Table of contents ................................................................................................................ iii
List of abbreviations .......................................................................................................... vii
Samenvatting ..................................................................................................................... ix
Abstract ............................................................................................................................. xi
1. Introduction .................................................................................................................... 1
1.1 Algae and the associated bacteria. ............................................................................. 3
1.1.1 Beneficial interactions between algae and bacteria. .................................................. 4
1.1.2 Detrimental interactions and defense. ........................................................................ 6
1.1.3 Structure of algal-associated bacterial communities. ................................................. 7
1.1.4 Future perspectives. ..................................................................................................... 9
1.2 Studying algal-bacterial interactions using whole-genome sequencing data. ............. 10
1.2.1 Illumina sequencing and NGS data assembly. ........................................................... 11
1.2.2 Binning of the data. ................................................................................................... 13
1.2.3 Using CONCOCT for binning of algal-bacterial assemblies. ...................................... 17
1.2.4 Estimating cluster quality. ......................................................................................... 18
2. Aim ............................................................................................................................... 21
3. Results .......................................................................................................................... 23
3.1 Assembly of non-algal reads within O. tauri sequencing data and CONCOCT-assisted
binning. ......................................................................................................................... 24
3.2 Assessing the possibility to better delineate the eukaryote target genome from
contaminants. ............................................................................................................... 28
3.3 Binning of O. mediterraneus data. ............................................................................ 29
3.4 Binning of filtered P. crispa assembly. ...................................................................... 31
3.5 Binning of C. braunii data ......................................................................................... 35
3.4.1 Binning of German C. braunii assembly .................................................................... 36
3.4.2 Binning of Japanese C. braunii assembly ................................................................... 38
4. Discussion ..................................................................................................................... 47
4.1 Performance of the binning method. ........................................................................ 47
4.2 Biology of the observed bacteria. ............................................................................. 48
4.2.1 Proteobacteria and Bacteroidetes. ............................................................................ 48

Table of contents
iv
4.2.2 Actinobacteria, Acidobacteria and Bacteroidetes. .................................................... 52
4.3 Origin of contamination ........................................................................................... 55
4.4 Future perspectives .................................................................................................. 56
5. Discussie ........................................................................................................................ 56
5.1 Beoordeling van de gebruikte methode. ................................................................... 57
5.2 Biologie van de waargenomen bacteriën .................................................................. 58
5.2.1 Proteobacteria en Bacteroidetes ............................................................................... 58
5.2.2 Actinobacteria, Acidobacteria en Planctomycetes. ................................................... 60
5.3 Toekomstperspectieven ........................................................................................... 61
6. Conclusion ..................................................................................................................... 63
7. Materials and methods .................................................................................................. 65
7.1 Sequencing data and assemblies. ............................................................................. 65
7.1.1 O. tauri and O. mediterraneus. ................................................................................. 65
7.1.2 P. crispa. ..................................................................................................................... 66
7.1.3 C. braunii. ................................................................................................................... 66
7.2 Preparation of the data prior to binning. .................................................................. 67
7.2.1 De novo assembly of non-algal contigs from O.tauri genome sequencing data using
CLC-assembly cell. ............................................................................................................... 67
7.2.2 Filtering of P. crispa assembly prior to binning. ........................................................ 68
7.2.3 Combining two German C. braunii draft assemblies using Newbler. ....................... 68
7.3 Binning of contigs with CONCOCT. ............................................................................ 69
7.6 Binning evaluation using taxonomic labels provided by MEGAN5. ............................ 69
7.7 Binning evaluation using single-copy core genes. ...................................................... 70
7.6 Isolation of bacterial genomes and scaffolding with Sspace. ..................................... 71
7.7 Aligning isolated genomes to reference using MUMmer. .......................................... 71
7.8 Evaluation of CONCOCT-assisted binning for separating prokaryotic and eukaryotic
sequences. ..................................................................................................................... 72
8. References ..................................................................................................................... 74
9. Addendum ..................................................................................................................... 92
9.1 Scripts ...................................................................................................................... 92
9.1.1 CONFPLOT.R ................................................................................................................. 92
9.1.2 CLUSTERPLOT.R .............................................................................................................. 92

Table of contents
v
9.1.3 MEGAN_TO_CONCOCT.PY ................................................................................................ 94
9.1.4 MEGAN_CONCAT_TAXON.PY ............................................................................................ 94
9.1.5 CUT_FASTA.PY ............................................................................................................... 99
9.1.6 SCAFFOLD2CONTIGS.PL .................................................................................................. 100
9.1.7 COUNT_FRAGMENTS.SH ................................................................................................. 101
9.1.8 MFASTA_TOOLS.PL ....................................................................................................... 103
9.2 Supplementary figures ............................................................................................... 119

Table of contents
vi

List of abbreviations
vii
List of abbreviations
BCC Banyuls-sur-mer Culture Collection
BIC Bayesian Information Criterion
bp base pairs
CCALA Culture Collection of Autotrophic Organisms
CDD Conserved Domain Database
COG Clusters of Orthologous Group
DGGE Denaturing Gradient Gel Electrophoresis
ENA European Nucleotide Archive
Gbp Giga base pairs
kbp kilo base pairs
LCA Lowest Common Ancestor
Mbp Mega base pairs
NGS New Generation Sequencing
PCA Principal Component Analysis
PES Provasoli Enriched Seawater
RCC Roscoff Culture Collection
RPS-BLAST Reversed Position Specific BLAST
SCG Single Copy Core Gene
T-RFLP Terminal Restriction Fragment Length Polymorphisms (T-RFLP)

List of abbreviations
viii

Samenvatting
ix
Samenvatting
Algen ondergaan talrijke interacties met bacteriën, die belangrijk zijn voor hun metabolisme,
groei en verdediging tegen pathogenen. De geassocieerde bacteriële gemeenschappen zijn
vaak complex en dynamisch, wat het bestuderen van de relaties tussen de organismen
bemoeilijkt. Dit probleem kan worden omzeild door het bestuderen van algen in
cultuurcollecties die een verminderde bacteriën diversiteit vertonen door een gedeeltelijke
sterilisatie en groei in laboratorium condities gedurende een lange termijn. Dergelijke culturen
worden vaak aangewend in genoom sequeneringsprojecten van algen. De gegenereerde
datasets omschrijven alle organismen die in de culturen aanwezig zijn, inclusief de prokaryoten,
en kunnen worden gebruikt om de geselecteerde prokaryote gemeenschappen te bestuderen.
In het kader van dit project werden bacteriële consortia onderzocht die vertegenwoordigd zijn
in het genoom-sequeneringsdata van vier algensoorten: Ostreococcus tauri, Ostreococcus
mediterraneus, Prasiola crispa en Chara braunii. De analyse bestond uit het segregeren van
geassembleerde contigs in groepen (bins) op basis van abundantie- en samenstelling, en
taxonomische affiliatie van de verkregen bins via een similariteit-gebaseerde methode. Dit liet
toe om de bacteriële populaties die in elke cultuur aanwezig waren in kaart te brengen, en om
in totaal 15 vrijwel volledige bacteriële genomen te reconstrueren. Sommige van de
genomische sequenties kwamen van soorten die nog niet beschreven zijn in publieke
databanken, waaronder die van de phyla Actinomycetes, Acidobacteria en Planctomycetes. De
biologie van de waargenomen bacteriën kwam goed overeen met de levensstijl van de
gastheren. Onder andere, de bacteriële partners van zoetwater alg C. braunii behoorden
meestal tot groepen typisch voor grond- en zoetwater habitats, terwijl ostreococci en P. crispa
interageerden met soorten die in mariene en kustmilieu voorkomen.
Onze resultaten suggereren dat de niet-axenische laboratoriumculturen van algen bacteriën
bevatten die relevant zijn voor de ecologie van de eukaryote gastheer. Het beperkt aantal
bacteriële soorten die in de culturen aanwezig zijn, laat toe sequeneringsdata afkomstig van
bacteriën binnen zulke culturen, tot kwalitatief goede genoomsequenties te reconstrueren.
Afhankelijk van de onderzochte eukaryoot, kunnen op die manier genoomsequenties worden
verkregen van onbeschreven bacteriën, waaronder ook moeilijk kweekbare soorten.

Samenvatting
x

Abstract
xi
Abstract
Algae experience numerous interactions with bacteria, which are important for algal
metabolism, growth and defense. The associated bacterial communities are often complex and
dynamic, making it difficult to study the relationships between the organisms. This problem can
be circumvented by analyzing samples with a limited bacterial diversity, for example cultures of
algae that have lost a substantial fraction of their microbial flora due to long-term growth
under laboratory conditions and partial sterilization. When such cultures are utilized in algal
genome sequencing projects, generated datasets typically capture the associated microbiome
and can be subjected to metagenomic analyses to study the prokaryotic community.
In this thesis, we have analyzed bacterial contaminants present in whole-genome shotgun
sequencing datasets of four algal species, Ostreococcus tauri, Ostreococcus mediterraneus,
Prasiola crispa and Chara braunii. The analysis involved abundance- and composition based
binning of preassembled sequencing data, combined with similarity-based identification of the
bins. The method allowed to characterize bacterial populations associated with the different
algal species and to reconstruct a total of 15 nearly complete bacterial genomes. Some of the
genomic sequences belonged to species not yet described in public databases, including those
from the phyla Actinomycetes, Acidobacteria and Planctomycetes. Members of these
taxonomic clades are known to be difficult to cultivate in laboratory conditions. Biology of the
observed bacteria corresponded well with the lifestyle of the host species. Among other, the
bacterial partners of freshwater algal C. braunii mostly contained bacteria found in soil- and
freshwater habitats, while ostreococci and P. crispa interacted with species thriving in marine
and coastal environment.
Our findings suggest that non-axenic laboratory cultures of algae mostly contain bacteria that
are relevant for the ecology of the eukaryotic host. Given a limited number of bacterial species,
the sequencing data of such cultures permits reconstruction of good quality assemblies of
bacterial genomes. Depending on the studied alga, the data can contain sequences of
undescribed bacteria, including difficultly cultivable species.

Abstract
xii

Introduction
1
1. Introduction
Organisms don't live alone in nature, and interactions between different species are common.
The interactions can be symbiotic, commensalistic or parasitic, although many relationships are
complex and do not fit neatly into one category (Dimijian, 2000). Symbiosis between
eukaryotes and prokaryotes is very widespread, laying even at the origin of the eukaryotic cell.
Mitochondria and plastids have evolved from endosymbiosis between primitive protists and an
ancient alpha-proteobacterium and cyanobacterium, respectively, giving rice to different
eukaryotic lineages (Kutschera & Niklas, 2005). Regarding a limited metabolic potential of many
eukaryotic groups, a popular theme is for an eukaryotic host to outsource metabolic processes
to a prokaryote. This increases the fitness of the host, or allows it to colonize new ecological
niches, while the microbial partner can benefit from the provided protection and/or nutrients
(Moran, 2007). Ecologically significant examples of this form of mutualism include symbiotic
polymer degradation in the gastrointestinal tracts of vertebrates (Mackie, 2002) and insects
(Dillon & Dillon, 2004) and symbiotic nitrogen fixation by bacteria associated with plants
(Denison & Toby Kiers, 2004). In aquatic ecosystems, symbiosis between bacteria and
eukaryotes is particularly widespread, which is not surprising regarding the often nutrient-poor
and highly variable conditions found in both marine and freshwater environments (Egan et al,
2013a; Muscatine & Porter, 1977). Interesting symbiotic consortia have been reported in
marine sponges (Lee et al, 2001) and corals (Lema et al, 2012), where the biomass of the
associated microbes may constitute up to 40% of the host’s volume (Lee et al, 2009). Also algae
are known to harbor numerous extra- and intracellular symbionts (Egan et al, 2013b).
Close observation of the marine eukaryote-microbe consortia have revealed that they often
function and evolve as single biological entities, which has led to the introduction of the
holobiont concept (Rohwer et al, 2002b). Holobionts are communities of closely interacting and
mutually dependent organisms belonging to different species that coexist sustainably. There is
a growing interest in approaching studied organisms as holobionts, i.e. considering the tightly
associated bacteria and microorganisms, as it produces a more complete picture on the
biology, ecology and evolution of the participants (Singh et al, 2013). With the development of
increasingly powerful molecular and bioinformatics tools, this approach has become technically
and financially feasible.

Introduction
2
A number of studies have been published using metagenomics to analyze whole symbiotic
communities of different eukaryotes, including microbiota associated with honey bees (Cox-
Foster et al, 2007), the guts of mice (Turnbaugh et al, 2008) and humans (Booijink et al, 2007),
marine sponges (Schmitt et al, 2007), oligochaetes (Woyke et al, 2006) and plant-rhizobacteria
(Leveau, 2007). However, not only samples collected with the aim to perform metagenomics
are potentially useful to study symbiotic associations. Datasets from genome projects targeting
a single eukaryotic organism typically reveal a rich body of contaminating sequences,
originating from bacteria and other microorganisms. While such collateral data is usually
discarded, the sequences potentially belong to species which coexist sustainably with the
studied host, and can be used to obtain additional information on the flora of the organism.
Several studies have addressed the composition of the contaminating sequences of genome
projects and were able to identify putative symbionts and extract nearly complete genomes of
previously unknown bacteria (Gouin et al, 2015; Poinar et al, 2006; Qi et al, 2009).
In this thesis, we analyze prokaryotic sequences present in whole-genome sequencing data of
four ubiquitous green algal species: O. tauri, O. mediterraneus, P. crispa and C. braunii (Figure
1). Ostreococcus is a genus of unicellular algae, reported to thrive in the illuminated waters of
oceans and seas (Subirana et al, 2013b). Both studied species originate from the Mediterranean
Sea and have been maintained in the same culture collection prior to sequencing (Blanc-
Mathieu et al, 2014; Subirana et al, 2013a). The genus Prasiola entails small multicellular algae
found in terrestrial, marine and fresh water environments (Holzinger et al, 2006). P. crispa is
terrestrial, often found in moist nitrogen-rich habitats, and the studied P. crispa culture has
been isolated from penguin benches of Antarctica. Finally Chara is a genus of fresh-water
weeds with plant-like appearance (Kufel & Kufel, 2002). The C. braunii individual used in this
study originates from a freshwater habitat in Japan (Kato et al, 2008). For that alga, we analyze
two sequencing datasets obtained from an algal culture that has been split and maintained
separately for some time prior to sequencing.

Introduction
3
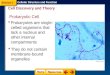
Figure 1. Morphology of the studied algal species. Left: micrograph of Ostreococcus tauri strain OTH95 (Hervé
Moreau, Laboratoire Arago). All Ostreococci share similar morphological characteristics, consisting of non-motile
nearly 1-micron cells with a single chloroplast and mitochondrion (Subirana et al, 2013b). Middle: micrograph of
filamentous Prasiola crispa (Nicolas Dauchot, Université de Namur). Besides growing in the filamentous form, P.
crispa can exhibit leafy morphology. Right: photograph of Chara braunii gametophyte with stem-like and leaf-like
structures (modified from (Ryu, 2009)).
100 μm
The aim of the study is to identify the bacteria which were co-sequenced with the algae,
compare them between the different algal species and cultures, and if possible to obtain (in
silico) the genomes of the bacteria.
1.1 Algae and the associated bacteria.
Algae are oxygenic photosynthetic eukaryotes, but as commonly used, the term artificially
excludes land plants (Brodie & Lewis, 2007). They show a remarkable morphological variation,
ranging from the smallest known free-living eukaryote O. tauri to giant kelps, which can be up
to 70 m long. Algae originate from the primary endosymbiotic event involving incorporation of
a cyanobacterium by a heterotrophic eukaryote, and subsequent evolution of the
cyanobacterium into a plastid (Kutschera & Niklas, 2005). Diversification of the ancient
photosynthetic eukaryotic lineage gave rice to green algae (including land plants), red algae and
glaucophytes. From there, photosynthesis has spread among diverse eukaryotes via secondary
and tertiary endosymbioses between algae and heterotrophic eukaryotic protists, generating
additional photosynthetic lineages including for example dinoflagellates and diatoms (Keeling,
2010). Together with land plants, algae mediate the bulk global production of fixed carbon and
oxygen on earth (Dunne et al, 2007; Field et al, 1998). They form the base of most aquatic food
chains and are important to structurally shape aquatic ecosystems, in the same way as green
plants shape the land (Agrawal & Gopal, 2013). Besides being found in marine and freshwater

Introduction
4
environments algae occur in an impressive range of habitats, including desert soils (Hu et al,
2002), frigid Antarctic lakes (Cathey et al, 1981; Seckbach, 2007) and edges of hot springs (Koch
et al, 1999), although in more limited diversity. Most algae are phototrophic (use light as the
only energy source), but some unicellular species are mixotrophic, combining photosynthesis
with uptake of dissolved organic substrates, and/or phagotrophy (ingestion of other protists)
(Thingstad et al, 1996). Other algae, such as the green algae of the genus Prototheca have
become heterotrophic parasites of free-living species (Pore et al, 1983).
1.1.1 Beneficial interactions between algae and bacteria.
Scientists working with algae have long been aware that like their unicellular ancestors, modern
algae closely interact with microorganisms. First descriptive studies of bacteria isolated from
the surface of macroalgae date from as early as 1875 (Johansen et al, 1999). Phycologists have
quickly discovered the difficulties associated with obtaining axenic (bacteria-free) algal cultures
(1896), leading to anticipations on existence of symbiotic relationships between the organisms
(reviewed by Hollants et al, 2013). Nowadays, the availability of vast laboratory-based evidence
points to profound effects, both beneficial and detrimental, which prokaryotic microorganisms
can have on algal growth, reproduction, performance and physiology (Singh & Reddy, 2014).
Bacteria can be found living free in the phycosphere, attached to the cell surfaces, or as
endosymbionts inside thalli or cells. Phycosphere is the area around algal cells where bacteria
feed on extracellular products of the eukaryotes (Sapp et al, 2007b). The strong effect which
bacteria can have on algal growth is illustrated by green algae of the genera Monostroma and
Ulva. These seaweeds fail to develop normal morphology if grown axenically, requiring the
presence of thallusin, a potent inducer of differentiation produced by Cytophaga species
(Wichard, 2015). Many other bacteria associated with algae are known to produce cytokinin-
type and auxin-type hormones modulating algal growth and morphogenesis (Goecke et al,
2010).
Besides the production of growth factors, advantageous effects of bacteria on algal growth rely
on nutrient exchange between the organisms, including vitamin supply, carbon cycling and
nutrient re-mineralization (Hollants et al, 2013; Singh & Reddy, 2014). Algae are known to
benefit from the presence of bacteria if grown under iron-deficient conditions, presumably
profiting from bacterial iron-chelating molecules (siderophores), which increase iron solubility

Introduction
5
(Amin, 2010; Jermy, 2009). Many studies describe algae that require B-group vitamins like
biotin (B7), thiamine (B1) and cobalamine (B12) (Croft et al, 2006). While biotin and thiamine
can be released into the water by other algae or eukaryotes, cobalamin synthesis is restricted
to prokaryotes, and has to be supplied by bacteria or archaea (Hollants et al, 2013; Rodionov et
al, 2003). Under natural circumstances another profitable factor is bacterial nitrogen fixation.
Seaweed-associated bacteria that have been identified as important nitrogen contributors for
their hosts include endosymbiotic Agrobacterium-Rhizobium group members (Chisholm et al,
1996), some epiphytic Azotobacter species (Villa et al, 2014), and cyanobacteria like Nostoc,
Calothrix, and Anabaena (Ariosa et al, 2004). In addition, microbes play a role in the protection
of the algae from toxic compounds in oligotrophic and contaminated environments, as for
example by degradation of crude oil (Semenova et al, 2009), and detoxification of heavy metals
(Dimitrieva et al, 2006; Riquelme et al, 1997).
In exchange for growth factors, minerals and vitamins, algae provide bacteria with nutrients
(Armstrong et al, 2001; Hehemann et al, 2012; Lane & Kubanek, 2008; Legendre &
Rassoulzadegan, 1995; Rosenstock & Simon, 2001). In natural environments, release of
dissolved organic carbon by seaweeds and planktonic species can reach up to 80% of
photosynthates (Hulatt & Thomas, 2010; Hulatt et al, 2009). Besides excreting direct products
of photosynthesis such as organic acids and sugars (Bertilsson et al, 2003; Nguyen et al, 2005),
algae synthesize and release other organics, including amino acids, proteins, nucleic acids,
lipids, phosphoric esters and polymers composed of lipids, proteins, and/or sugars (Cardozo et
al, 2007; Crawford et al, 1974; Hoagland et al, 1993; Markell & Trench, 1993; Rosenstock &
Simon, 2001). Aerobic re-mineralization of these substances by bacteria is an important part of
the global carbon cycle: while about one-third of the CO2 that is photosynthetically reduced on
Earth is fixed in the oceans by photoautotrophic organisms, most of it is rapidly re-oxidized by
marine heterotrophic microorganisms (Duarte et al, 2005; Field et al, 1998). During re-
mineralization of algal exudates, bacteria consume oxygen, which if present in high
concentrations can slow down photosynthesis, and release carbon dioxide, keeping conditions
favorable for the algae during periods of intensive carbon fixation (Bai et al, 2015; Fenchel,
2008; Mouget et al, 1995; Subashchandrabose et al, 2011). On the other hand, overwhelming
growth of algae can also inhibit bacterial activity by releasing toxic metabolites and keeping
high O2 levels (Skulberg, 2000). Besides feeding on released organic substances, a number of

Introduction
6
bacterial genera associated with algae possess enzymatic activities allowing to degrade
polysaccharides found on algal cell walls such as cellulases, alginases, fucoidanases, pectinases
and agarases (reviewed by Goecke et al, 2010). These abilities are necessary for
biotransformation of senescent algal tissues into minerals, and have been proposed as another
reason for specific macroalgal-bacterial interactions (Goecke et al, 2010; Lu et al, 2008; Polne-
Fuller & Gibor, 1987). In laboratory conditions, bacterial mineralization of algal detritus leads to
enhanced algal growth, facilitating release of carbon dioxide, nitrogen, phosphorus and
minerals (Boyd et al, 2010; Grossart, 1999).
1.1.2 Detrimental interactions and defense.
While being beneficial to algae for mineral recycling, polymer degradation can obviously have a
detrimental impact on the host, if not controlled. At least some of the bacteria able to degrade
algal cell walls can be pathogens, rather than commensals or symbionts (Potin et al, 2002;
Weinberger & Friedlander, 2000). In addition to direct damage, they can provide entry points
for opportunistic and pathogenic bacteria, causing secondary infection and further
disintegration of algal tissue (Ivanova et al, 2005). Besides, parasitic bacteria can harm the algal
host in other ways, including induction of abnormal tissue growth (galls) (Ashen & Goff, 2000),
formation of unwanted biofilms leading to decreased gaseous exchange and light availability
(Dworjanyn et al, 2006; Mindl et al, 2005; Wahl, 1989) or can directly damage the eukaryote by
production of toxins and waste products (Ivanova et al, 2002; Patel et al, 2003; Rao et al, 2006;
Weinberger et al, 1997).
Being continuously challenged by all sorts of organisms, algae have to tightly control their
associated communities (Armstrong et al, 2001; Hollants et al, 2013). Because algae lack cell-
based immunity, they mainly rely on chemical defense to prevent undesired bacterial growth
(Engel et al, 2002; Goecke et al, 2010; Steinberg et al, 1997). A number of studies have shown
that both crude macroalgal extracts, as well as specific excreted metabolites can strongly alter
the composition of a microbiotic community and prevent biofilm formation in both laboratory
studies and field (Nylund et al, 2010b) conditions (Engel et al, 2006; Hellio et al, 2002; Hellio et
al, 2001; Lam et al, 2008; Nylund et al, 2010b). Furthermore, multicellular algae are known to
possess a non-specific defense response similar to oxidative burst process found in higher
plants (Kupper et al, 2002; Lesser, 2006), and can inhibit quorum sensing signaling (QC) of

Introduction
7
bacteria (Maximilien et al, 1998; S et al, 1997; Steinberg & de Nys, 2002a), preventing massive
colonization. Besides deterring undesired prokaryotes, algal primary secretion products can
induce, together with cell-wall components, specific interactions with beneficial bacteria (Egan
et al, 2013a; Steinberg & De Nys, 2002b; Uppalapati & Fujita, 2000; Wahl et al, 1994). Once
established, beneficial bacterial communities contribute to host defense by competing for
space and nutrients with potential pathogen and commensal species, and by producing QC
inhibitors and antimicrobial compounds (Hollants et al, 2013 and references therein; Lemos et
al, 1985; Rao et al, 2007).
1.1.3 Structure of algal-associated bacterial communities.
Phycologists generally agree that bacterial communities associated with algae are non-random,
suggesting that the composition of the adhering flora is determined by physiological and
biochemical properties of the hosting algae (Beleneva & Zhukova, 2006; Goecke et al, 2010;
Morrow et al, 2012; Nylund et al, 2010b; Sapp et al, 2007a). Various culturing and microscopy
surveys as well as studies using molecular methods confirm that bacterial populations found on
algal surfaces and within microalgal blooms diverge strongly from those in the surrounding
water, both in terms of density and composition (Bolinches et al, 1988; Burke et al, 2011b;
Cundell et al, 1977b; Goecke et al, 2013; Goecke et al, 2010; Nylund et al, 2010b). In addition,
interspecific variation of the algal flora is generally higher than the intraspecific one for algae
growing both in the same, or in different habitats (reviewed in Egan et al, 2013a). This has been
illustrated by Lachnit et al (2009) who used 16S rRNA gene-based denaturing gradient gel
electrophoresis (DGGE) to study bacterial communities associated with Delesseria
sanguinea, Fucus vesiculosus, Saccharina latissima and U. compressa found in the Baltic and
North Seas. Also Nylund et al (2010a) confirmed the observations with terminal restriction
fragment length polymorphisms (T-RFLP) of the epiphytic bacteria found on the three red algal
species Bonnemaisonia asparagoides, Lomentaria clavellosa and Polysiphonia stricta sampled
on two locations on the west coast of Sweden. Similarly, bacteria-phytoplankton associations
have been shown to exhibit some specificity using molecular fingerprinting methods (Jasti et al,
2005).
However, algal-associated bacterial communities are not stable, varying with the season
(Lachnit et al, 2011; Tujula et al, 2010), particular parts of the algal thallus (Ariosa et al, 2004;

Introduction
8
Cundell et al, 1977a; Staufenberger et al, 2008) and with life cycle stage of the host (Laycock,
1974; Staufenberger et al, 2008). While molecular fingerprinting methods suggest host-
specificity and existence of a core-community that is stable over space and time (Jasti et al,
2005; Lachnit et al, 2009; Longford et al, 2007; Tujula et al, 2010), high resolution techniques
such as 16S rRNA sequencing indicate that the host specificity is mostly observed at higher
bacterial taxonomic levels (‘phylum’). At a more detailed phylogenetic level (‘species’) large
differences exist between bacteria populations associated with a single algal species (Lachnit et
al, 2011; Longford et al, 2007). This has for instance been illustrated in a survey analyzing the
bacterial flora of Fucus vesiculosus, Gracilaria vermiculophylla and Ulva intestinalis. The algae-
associated bacterial communities were sampled in the winter and summer over two years using
DGGE and 16S rRNA gene libraries. The study demonstrated that at phylum level, bacterial
populations were more similar within species than between species and exhibited strong
reproducible seasonal shifts over the different years (Lachnit et al, 2011). At the level of
bacterial species however, intra-specific and intra-seasonal similarity was considerably lower:
for the studied algal species, a core community represented by only 7-16% of 16S rRNA
sequences (grouped at 99% sequence identity) remained unchanged over the different
sampling years. Authors concluded that marine macroalgae harbor species-specific and
temporally adapted epiphytic bacterial biofilms on their surfaces. Another study, conducted on
U. lactuca based on 16S rRNA libraries identified an even smaller bacterial core community
present on the algal surface. Authors demonstrated that only only six bacterial species from a
total of 528 were commonly found between six U. lactuca individuals (Burke et al, 2011a).
However, subsequent analysis of the transcriptome of U. lactuca microbiome has shown that
despite the phylogenetic differences, the algal-associated bacterial communities contained a
core set of gene functions, which could be retrieved from all algal samples while being absent
from samples of seawater. These functions were consistent with the ecology of surface- and
host-associated bacteria, including detection and movement toward the host surface,
attachment and biofilm formation, response to the algal host environment, defense, and lateral
gene transfer (Burke et al, 2011c).
Endophytic seaweed-associated bacterial are less investigated than the epiphytic ones. It is
known that many coenocytic green algae (for which the entire thallus is a single multinucleate
cell) such as Caulerpa, Codium, Bryopsis and Penicillus spp. contain endosymbionts (Burr &

Introduction
9
West, 1970; Turner & Friedmann, 1974; Dawes & Lohr, 1978; Rosenberg & Paerl, 1981; Aires et
al., 2013). Studies using 16S rRNA gene-based DGGE with subsequent sequencing of 16S rRNA
bands of the endophytic communities of the genera Caulerpa (4 species studied) and Bryopsis
(2 species studied) have shown the bacterial flora to be relatively uncomplicated, entailing a
limited number of bacterial species from different phyla, stable over time and distinct from the
epiphytic flora of the same algae (Delbridge et al, 2004; Hollants et al, 2011a; Hollants et al,
2011b). The communities differed between the various algal species, and were for Bryopsis sp.
reproducible at species level over the different locations sampled along the Mexican coast.
Finally one study has been conducted on O. tauri microbiome (Abby et al, 2014). It has been
noted by the authors that despite extensive antibiotic treatments, and plating out of single
algal cells, cultures of unicellular algae do not become axenic, suggesting tight associations
between algae and bacteria, possibly involving physical contact. In order to investigate the
nature of the bacterial contaminants, authors performed metagenomic sequencing of 13 O.
tauri cultures from different locations of the Mediterranean. All cultures harbored bacterial
contaminants, but no ubiquitous bacterial groups were present. The most prevalent group was
Flavobacteriia, found in 10 out of 13 cultures.
1.1.4 Future perspectives.
Although some of the bacterial–algal interactions have been discussed earlier, the ecological
relevance of many naturally occurring bacterial communities associated with algae remains
unclear and in most cases the involved bacterial species have not yet been identified (Egan et
al, 2013b; Singh & Reddy, 2014). There is however an increasing interest to study algal-bacterial
interactions that arises from the growing applied importance of algae (Hollants et al, 2013).
Algae are currently mostly used in food industry, and for the production of various poly-and
monosaccharides, including agars, carrageenans and alginates (Cardozo et al, 2007; Gupta &
Abu-Ghannam, 2011; MacArtain et al, 2007). Macro- and microalgal biomass is regarded as an
alternative to plant biomass for the production of biofuel, as it lacks the difficult to degrade
lignocellulose, does not require land cultivation and shows a high carbohydrate- and oil content
(Pittman et al, 2011; Vasudevan et al, 2012). Knowledge of algal pathogens, and symbionts
would benefit the expanding algal farming in aquaculture and bioreactors. An interesting
application involving algal-bacterial symbiosis has been demonstrated by Ortiz-Marquez and

Introduction
10
colleagues (Ortiz-Marquez et al, 2012), who have established an artificial symbiosis between a
mutant Azotobacter vinelandii strain producing increased levels of ammonium and
nondiazotrophic microalgae allowing to obtain oil-rich microalgal biomass using atmospheric
carbon and nitrogen. Another example of the use of algal-bacterial cooperation involves the
application of algal-bacterial self-aerating systems for wastewater remediation. In such
systems, bacterial growth and degradation of organic material present in wastewater is
promoted by oxygen produced by the co-cultivated algae (De Godos et al, 2014; McGinn et al,
2011). Finally, algal holobionts are an interesting source of new bacterial species (Fernandes et
al, 2011b), secondary metabolites with various biological activities (Penesyan et al, 2009; Yung
et al, 2011) and industrially important enzymes (Kim et al, 2009; WANG et al, 2006).
1.2 Studying algal-bacterial interactions using whole-genome sequencing data.
Current sequencing and bioinformatics techniques allow accessing the phylogenetic and
functional composition of complex metagenomic samples. However, assembly and analysis of
individual genomes from datasets showing the full environmental bacterial diversity is still a
challenging task (Howe et al, 2014; Zepeda Mendoza et al, 2015). With the lowering cost of the
new generation sequencing (NGS), studies on algae now more often involve sequencing of the
whole genome (Bhattacharya et al, 2015). Typically in those projects, no attention is paid to the
microbiotic contaminants. But even when no specific effort is done to study the associated
bacteria, collateral bacterial genomes are captured inadvertently within the genomic data. Prior
to sequencing, an alga is usually grown in the presence of antibiotics for a short period of time
and then subjected to multiple rounds of washing with sterile growth medium (macroalgae)
(Fernandes et al, 2011a) or subcloning (microalgae) (Abby et al, 2014) in order to eliminate
natural bacterial flora. These procedures allow to limit the number of species present in the
cultures, but seldom lead to complete removal of contaminants (Abby et al, 2014). Available
DNA sample preparation methods also do not permit to specifically enrich algal DNA. Therefore
nucleic acid samples generated from algal cultures often represent a mixture of bacterial and
eukaryotic sequences. Because of the relatively low complexity of the data, sequencing
datasets from such samples potentially allow detailed metagenomic analysis of the embodied
bacteria, including reconstruction of individual genomes (Tyson et al, 2004). This approach is
suitable to study bacterial species that are not amenable to individual culturing, including for

Introduction
11
example obligate endosymbionts. Only 99% of all environmental bacteria can be cultured in
laboratory conditions (Vartoukian et al, 2010), making the substantial fraction of the earth’s
microbiome inaccessible for culture-based techniques. Presence of algae can help to obtain the
necessary conditions for successful cultivation of such bacteria, bypassing the culturing
bottleneck.
1.2.1 Illumina sequencing and NGS data assembly.
All datasets used in the current study have been obtained with Illumina sequencing technology,
which is now the most widely adopted NGS technology on the market (reviewed by Mardis,
2013). Illumina sequencing entails massive parallel sequencing by synthesis based on the use of
fluorescent reversible terminator nucleotides (dNTP’s): as each dNTP is added, fluorescently
labeled reversible terminator is imaged, and then cleaved to allow incorporation of the next
base. Illumina sequencing library is constructed by fragmentation of medium molecular weight
DNA, and ligation of partially complementary adapters to both ends of the fragments, ensuring
that each strand of the fragment receives a different adapter sequence at either end (Figure 2).
Next, size selection of the fragments (200-500 base pairs (bp)) and sample clean-up are carried
out, and the library is amplified by PCR (1) to enrich for template strands which have received
an adapter at both ends, (2) to increase the size of the library available for sequencing and (3)
to elongate template strands with oligonucleotides that will later allow hybridization to the
flow cell surface. The denaturated library is loaded on an Illumina flow cell, which is decorated
with oligonucleotides complementary to the library adapters. Library fragments are amplified
on the surface of the flow cell by bridge amplification resulting in generation of clonal fragment
clusters. One of the flow cell’s primers is cleaved prior to sequencing, resulting in selective
removal of one strand and generation of single stranded clusters. The strands are primed with
the first primer, and the clusters are sequenced in parallel, with up to 300 nucleotide addition
reactions carried out during the whole sequencing round.
In paired-end sequencing protocols, a second sequencing round is performed. Therefore, the
hybridized strands are washed away and the clusters are regenerated by a limited bridge
hybridization. Now the opposite ends of the fragments are released by chemical cleavage, the
fragments are primed with a second primer and sequenced from the opposite end. Resulting
paired-end data consists of two reads of up to 300 bp separated by a distance which can be

Introduction
12
Figure 2. Schematic representation of (A) paired-end and (B) mate-pair sequencing library-construction
processes. See text for details. Figure modified from (Mardis, 2013).
B A
deduced from the average length of the used DNA fragments. Availability of paired-end reads
facilitates assembly of genomic rearrangements and repeats, as it provides short-range spatial
information (Yang et al, 2014).
In addition, long-range spatial information can be obtained with mate-pair sequencing (Figure
2). For mate-pair sequencing, genomic DNA is fragmented to generate long (up to 20 kilo base
pairs (kbp)) pieces, which are circularized and, upon enzymatic digestion of the non-linearized
fragments, re-fragmented into shorter sequences (200-500 bp). The junction-site is labelled
using a biotin tag allowing enriching the fragments containing the junction from the library.
Alternatively, a sequence tag can be incorporated at the junction site, allowing recognizing it in
silico afterwards (Mardis, 2013). The generated libraries are sequenced using paired-end
sequencing protocol. The ends of the fragments containing the junction site correspond to DNA
regions that are located at a long known distance from each other, providing information for

Introduction
13
assembly and scaffolding (Boetzer & Pirovano, 2014).
The reads obtained from Illumina sequencing technology are short compared to the classical
Sanger sequencing and Pyrosequencing technologies that generate reads of around 900 and
700 bp respectively (Liu et al, 2012). This is compensated by the huge amount of data produced
(for example, an Illumina HiSeq machine yields up to 600 Giga base pairs (Gbp) of sequence per
run (Dröge & McHardy, 2012)). Most assemblers developed for longer reads apply overlap-
based algorithms, involving computation of all pairwise overlaps between the reads (Pop et al,
2002). This method is not usable for Illumina data because of the huge number of reads.
Instead, most established short read assemblers use deBrujin graph-based methods (Compeau
et al, 2011). Here, a hash is made of all k-mers of a particular length (typically between 30 and
60 bp) found in the dataset, and a deBrujin graph is constructed with nodes representing the k-
1 overlaps between the found k-mers, and edges representing the k-mer sequences. The
running time of the algorithm is limited because the pairwise search for overlaps is replaced by
hash-based exact matching of k-mers. The graph is then simplified by melting linear stretches of
nodes, and by resolving ambiguities based on the coverage of the branches and information
from paired-end and mate pair reads. Typically, not all regions of the sequenced genome(s) can
be reconstructed or resolved due to the presence of repeats, and complex genomic regions.
Therefore the final assembly is composed of contigs (long continuous stretches of sequence),
which can be oriented and ordered into scaffolds using paired-end and mate-pair information
(Boetzer & Pirovano, 2014).
1.2.2 Binning of the data.
The next step in both normal and metagenomic assemblies is to trace back, to which organisms
the assembled contigs or scaffolds belong. For a non-metagenomic assembly, this step is
necessary to allow removal of contaminating sequences, while for a metagenomic assembly,
grouping sequences according to species or broader phylogenetic groups is essential for many
of the downstream analyses (Leung et al, 2014). The process of segregating metagenomic
sequences into groups corresponding to biological entities is called binning.
While older binning techniques were designed to handle the longer reads obtained with Sanger
sequencing and Pyrosequencing, information contained in the shorter Illumina reads is

Introduction
14
insufficient to deduce the taxonomic origin (Wang et al, 2014). Therefore, binning of NGS data
is most often performed on contigs or scaffolds. Features which can be used for binning of long
reads, contigs and scaffolds include (a) sequence similarity to previously described taxa
(similarity-based binning), (b) compositional patterns of sequences (composition-based binning)
and (c) differential abundance of sequenced DNA molecules in a sample (abundance-based
binning) (Albertsen et al, 2013; Dröge & McHardy, 2012; Mande et al, 2012). There is a huge
number of tools which utilize one, or a combination of these possibilities.
Similarity-based binning
Similarity-based algorithms work by searching reads or contigs against databases of nucleotide
or amino-acid sequences of known organisms. The search can be performed with alignment
programs like BLAST (Camacho et al, 2009) and BLAT (Kent, 2002). Databases addressed for this
approach include NCBI RefSeq, a non-redundant nucleotide and protein collection; NCBI whole
genomes, a collection of sequenced genomes; NCBI nucleotides, a large nucleotide collection;
and NCBI proteins, a large non-redundant protein collection (2013). The choice depends on the
computational resources, and on the representation of related organisms in the repositories.
To convert the retrieved hits into taxonomic assignment, different methods are employed. In
the simplest form, the query sequence can be assigned to its respective best hit (Mande et al,
2012). Alternatively, a lowest common ancestor (LCA) assignment strategy can be applied,
where the sequence is affiliated to the lowest ranking phylum common to all sequences in a set
of significant hits (Patil et al, 2011). This strategy is adopted in the metagenomic analysis
software MEGAN5, which will be used in this work. Differences among the sequence similarity-
based methods lay mainly in the identification of the ‘significant’ hits, used as LCA input. To
judge whether a hit is significant, MEGAN5 uses (1) bit-score: a log-transformed score
representing alignment quality, (2) e-value: expectation value, a probability that the observed
match occurred by chance (3) and top percent: a maximal allowed difference of the bit-score of
a significant hit from the best hit observed for the sequence (Huson et al, 2007). Other tools,
such as SOrt-ITEMS (Monzoorul Haque et al, 2009), MetaPhyler (Liu et al, 2010) and MARTA
(Horton et al, 2010) improve the specificity/accuracy of the assignment procedure by
determining an appropriate level of taxonomic assignment based on the number of identities,
positives and gaps observed in an alignments. The assignment is then done at the allowed level

Introduction
15
or above it using the LCA procedure. Main weakness of alignment-based methods is the high
computational cost associated with searching each entry in the assembly or read set against the
large sequence repositories. In addition, the success of the approach depends strongly on the
presence of sequences of closely related organisms in the database. In cases when a protein or
gene database is searched, contigs containing no core genes shared by the related species will
not be classified (Dröge & McHardy, 2012).
Composition-based binning
Composition-based methods utilize compositional properties of sequences such as GC
percentage, codon usage and oligonucleotide frequencies to group or classify contigs or
scaffolds. These features, also called genomic signatures, are generally characteristic for the
different evolutionary lineages and can be used to discriminate between species, genera, or
higher taxa (Bentley & Parkhill, 2004; Pride et al, 2003). Supervised composition-based tools
make use of available genomes and genomic sequences to build a model, which is then applied
for classification of unknown sequences. For example PhyloPythia (McHardy et al, 2007) and
the NBC classifier (Rosen et al, 2011) train Support Vector Machine and Naive-Bayesian
classification models respectively on oligonucleotide usage patterns of various genomes or
taxonomic clades.
In unsupervised composition-based methods contigs are clustered according to the observed
internal compositional properties of the sequences (Chen et al, 2009). Many unsupervised
binning methods use tetra-nucleotide patterns, based on the observation that tetramers have
the highest taxonomic discriminating ability (Pride et al, 2003). For example, TETRA (Teeling et
al, 2004) clusters contigs based on pairwise correlations between tetra-nucleotides usage
patterns, while SOMs (Ultsch & Mörchen, 2005) performs neural network-based clustering of
tetra-nucleotide frequencies. Alternatively, CompostBin (Chatterji et al, 2008) computes
frequencies of k-mers of different lengths and use weighted Principal Component Analysis
(PCA) to pick the right combination of features for optimal clustering. The final taxonomic
assignment of the obtained bins can be made using either a small amount of reference
sequence to link observed genomic signatures to taxa (Patil et al, 2012), or by taxonomic
classification of conserved marker-genes including 16S rRNA genes (Chakravorty et al, 2007),
DNA polymerase genes (Monier et al, 2008), and the 31 marker genes defined by Ciccarelli et al

Introduction
16
(2006) contained within each bin. In addition, composition-based methods can be combined
with similarity-based methods to evaluate the efficiency of binning, and to assign obtained
clusters to a particular biological entity (Alneberg et al, 2014; Brady & Salzberg, 2009a).
Because composition-based methods require sequences of sufficient length for optimal binning
performance, they are mainly applicable for binning contigs instead of reads (Mande et al,
2012). PhyloPythia has for example been shown to be effective for DNA fragments of 3000 bp
and longer, while for 1000 bp sequences, sensitivity drops strongly, allowing only 7.1% of
correct classifications at the genus level (Brady & Salzberg, 2009b). While newer methods can
have an improved performance, the limit of ∼1 kbp will be difficult to break, because of the
high noise caused by local variation of DNA composition (Bentley & Parkhill, 2004). Advantages
of composition-based methods are the lower computational cost compared to methods
requiring sequence alignment, and the ability to bin contigs that have no close homologs in the
databases (Mande et al, 2012). Also supervised composition-based binning methods can bin
organisms for which no genomic sequences are available, circumventing the problem by
priming the binning with an unsupervised method and using the obtained bins to train more
precise models (Saeed et al, 2012; Strous et al, 2012).
Among the huge variety of developed binning algorithms, a number of methods combine both
composition and similarity in order to improve binning efficiency or time. An interesting novel
tool is MetaCluster-TA (Wang et al, 2014), which is developed to bin NGS reads using a three-
step approach: first, so-called virtual contigs are constructed in a process similar to NGS data
assembly. These virtual contigs are then grouped into clusters based on composition properties
(q-mer distribution with q = 4 or 5), and the clusters are annotated using a BLAST-assisted
procedure.
Abundance-based binning
Finally, several recent binning techniques utilize the frequencies of the different genomes in a
single or multiple DNA samples to make species-specific bins. Such methods have received the
name differential abundance- or differential coverage binning, and show a very high efficiency
when working with samples composed of bacterial populations of different sizes (Mande et al,
2012). These methods rely on the fact that all contigs originating from a genome of the same

Introduction
17
species will have similar coverage, with some variation resulting from the bias introduced by
sample handling and sequencing. While some abundance-based methods, such as
AbundanceBin (Tanaseichuk et al, 2012) and MaxBin (Wu et al, 2014) utilize abundance
differences observed within a single sample, binning can be improved if multiple samples are
available containing sequences of the same species at varying frequencies. Methods designed
to use multiple samples assume that contigs for which the coverage co-varies across different
samples are likely to originate from the same organisms. Examples of tools based on the
described principle include Canopy (Nielsen et al, 2014), CONCOCT (Alneberg et al, 2014),
GroopM (Imelfort et al, 2014) and MetaBAT (Kang et al, 2014). Besides coverage, all tools utilize
composition based binning to improve performance.
1.2.3 Using CONCOCT for binning of algal-bacterial assemblies.
For every studied organism, we had several sequencing datasets, some of which were produced
from independent biological sampling likely showing different composition of the species. For
O. tauri two sequencing datasets were available from DNA samples extracted at different years
from subcultures sharing the same origin. For O. mediterraneus and P. crispa respectively two
and four sequencing datasets were available of different libraries constructed using a single
DNA extraction sample of the organism. Finally for C. braunii a total of nine different
sequencing datasets were available, produced from libraries constructed from three DNA
samples. Because of the availability of independent datasets for two out of four studied
organisms we decided to apply a method binning sequences according to co-variation of
abundances observed across different samples and k-mer composition. Depending on the
applied algorithms, most co-abundance based methods also take into account the abundance
differences observed within each sample, making them applicable for binning of datasets
containing a single biological replica (i.e. obtained from a single DNA extraction sample). The
final choice was made in favor of CONCOCT, as this package provides several ways of estimating
binning efficiency. While authors of the package used a higher number of independent samples
(11 and more) to illustrate binning efficiency, tests with a smaller number of samples (2-4) also
yielded satisfactory results (Alneberg et al, 2014).
In this method, contigs are first fragmented into pieces of 10 kbp to give more statistical weight
to longer sequences. Abundance is estimated from coverage of the contig fragments, which can

Introduction
18
be obtained with any of the available read mapping tools. Coverage is determined individually
for every read-set, and, upon removal of PCR duplicates with a dedicated tool, provided to
CONCOCT together with the sequence fragments. CONCOCT generates for each fragment a
profile containing normalized coverages observed for the different sequencing datasets, and
the normalized k-mer frequencies for each of the possible k-mers and their complements. The
package allows choosing between tetra- or pentamers. The resulting set of multidimensional
profile vectors of all fragments is subjected to a PCA, reducing the dimensionality so as to keep
a user-defined percentage of information (we use a 90% limit). To cluster contig fragments into
bins Gaussian mixture model is applied. The model regards the data as a set of points from a
mixture of Gaussian (normal) distributions, with each distribution being characterized by a
mean vector and a standard deviation. Each distribution corresponds to a cluster. To fit the
mixture-of-Gaussian models to the available data, an expectation-maximization algorithm is
used. The optimal cluster number is determined by constructing a range of models with
different numbers of clusters and scoring these based on Bayesian Information Criterion (BIC).
BIC is a model quality measure accounting for both the fitting quality of the model, as well as
the number of parameters used to explain the data, this way penalizing for model overfitting.
1.2.4 Estimating cluster quality.
The package allows to estimate clustering quality by two approaches, which are universally
applicable: by comparing each cluster with taxonomic assignments obtained from similarity-
based methods and by monitoring the presence of a set of single-copy core genes (SCG’s) in the
isolated clusters. To obtain the taxonomic assignments, we used similarity-based binning with
MEGAN5. The attained contig labels were provided to CONCOCT to calculate statistics
evaluating the binning, namely (1) recall - the number of contigs from each taxon that are
clustered together, summarized over all taxons and divided by the total number of contigs, (2)
precision - the number of contigs in each cluster that derive from the same taxon, summarized
over all clusters and divided by the total number of contigs and (3) Rand and Adjusted Rand
indices, which summarize precision and recall. The Rand Index can have a value between 0 and
1, and is calculated as the number of correct pairs of contigs (i.e. number of contigs
representing the same genome which were placed in one cluster, and contigs from different
genomes placed in different clusters), divided by the total number of pairs possible. Because

Introduction
19
even a random clustering would produce a nonzero Rand Index just by chance, the Adjusted
Rand Index is also reported, which is calculated by subtracting the expected value for the given
taxon- and cluster sizes and normalizing the value to lay between 0 and 1. The second method
applied to estimate cluster purity and completeness was monitoring of the presence of 36
SCG’s. The SCG’s have been selected from Clusters of Orthologous Groups (COG’s) based on the
criteria to be present in 97% of 525 genomes of species from different bacterial genera, and to
have an average copy number of 1.03 per genome. COG’s are entries of the COG protein
database corresponding to clusters of orthologous microbial proteins found across multiple
lineages and likely representing an ancient conserved domain (Tatusov et al, 2000).

Introduction
20

Aim
21
2. Aim
The aim of this thesis is to study algae-associated bacterial communities starting from the
genome sequencing data of targeted algal eukaryotes. Such datasets are typically generated
with DNA from as axenic as possible algal cultures, and therefore contain a restricted set of
bacterial ‘contaminants’. Because the embodied bacterial communities are less complex than
the ones observed in the environment, corresponding sequencing samples are amenable for
metagenomic analysis. The studied sets, and methods used, are a way to obtain complete
bacterial genomes that are otherwise hard to culture. The identified (complete) bacterial
genomes are also a resource for the more extended meta-genomic projects going around
studying the ocean’s microscopic biodiversity like the Sargasso Sea expedition (Bork et al, 2015)
or the TARA-project (Hingamp et al, 2013).
The difficulty associated with producing axenic algal cultures, as well as the slower growth of
algae in the absence of prokaryotes suggests that at least some of the represented bacteria can
exhibit beneficial interactions with the hosting algae. Alternatively, the cultures can harbor
commensal and opportunistic species. The methods applied will allow to delineate the most
prevalent species, and presumably to isolate nearly complete genomic sequences of bacteria.
While falling outside the scope of the thesis, the genome sequences can be used to shed light
on genetic toolboxes available to the bacteria and permit identifying features possibly
responsible for maintenance of the association with the alga. Together with information
available in the literature on the origin and lifestyle of observed bacteria, this data can help to
deduce the nature of the relationship between the bacterial species found and the algal host.
The available datasets can also help to better describe the bacterial populations present in algal
cultures. All Ostreococcus cultures have been maintained in the same collection prior to
sequencing. Therefore, comparison of the associated bacteria could allow detecting collection-
specific contamination. Comparison of the two C. braunii, and of the two O. tauri datasets, both
generated by sub-cloning of a single algal culture, can illustrate how composition of bacterial
community is affected by handling the cultures.

Aim
22

Results
23
3. Results
In this study, we have analyzed bacterial contaminants present in the whole-genome shotgun-
sequencing datasets of four algal species. For each species, a slightly different strategy was
adopted with regard to removal or retainment of algal sequences, depending on the availability
of a reference genome. For O. tauri, a reference genome sequence was accessible, allowing to
filter out non-algal reads and re-assemble them to obtain bacterial-only scaffolds. For O.
mediterraneus, P. crispa and C. braunii, no bacteria-free genomic sequence was available.
Therefore, the analysis was carried out on unfiltered scratch genome assemblies that have
been constructed in the course of ongoing genome projects. Other small differences in pre-
processing of the data were present. These will be discussed in more detail below.
The binning consisted of the following steps: the scaffolded assemblies were fragmented into
pieces between 10 and 20 kbp while keeping track of the original scaffold identifiers. For every
organism, the available read-sets were mapped independently on the fragmented contigs to
determine coverage, and the data was binned according to coverage and composition using
CONCOCT. To calculate binning quality statistics and assign taxonomic labels to the bins,
fragments were aligned to NCBI proteins database using BLASTx and taxonomic affiliation was
carried out with MEGAN5. The presence of a set of 36 SCG’s genes was monitored to assess
completeness and purity of the clustered genomes.
The clusters containing relatively full sets of SCG’s were isolated, and manually enhanced by
adding sequences with correct taxonomic assignment, while removing contaminant sequences.
The scaffolds were reconstructed by retrieving the original sequences for which over 50% of the
fragments were present in a bin. An additional scaffolding round was performed for each
isolated sequence-bin to improve the quality. The assemblies for which a reference genome
could be identified based on MEGAN5 output were aligned with the reference using NUCmer
alignment tool from MUMmer 1.2 at default parameters. To confirm the taxonomic labels
assigned to the assemblies, 16S RNA sequences were retrieved using online RNAmmer 1.2
Server and classified with the online SINA service provided by Silva database.

Results
24
3.1 Assembly of non-algal reads within O. tauri sequencing data and CONCOCT-
assisted binning.
For O. tauri, two sequencing datasets were available. The datasets have been generated from
DNA samples extracted in 2001 and 2009 from clonal O. tauri strains obtained independently
from a single O. tauri liquid culture. To isolate non-algal sequences, we have mapped both
sequencing datasets simultaneously on the O. tauri genome v2.2 and assembled only those
reads that didn’t map using the CLC de novo assembler. Optimal assembly was obtained with a
k-mer length of 30 nucleotides, yielding 147595 contigs with a total size of 58.0 Mbp (N50 = 595
bp, max size 407214 bp, min size 100 bp). Subsequent scaffolding and removal of sequences
shorter than 500 bp reduced the assembly to 24.4 Mega base pairs (Mbp), contained in 3184
scaffolds (N50 22137 bp, max size 740848 bp, min size 500 bp, N% 1.87). N% is the percentage
of unidentified nucleotides (N) present in an assembly, and N50 is a that allows assessing the
quality of an assembly. Given a subset of the longest sequences containing 50% of an assembly,
N50 of the assembly equals the length of the shortest sequence from this subset.
Out of 5468 contig fragments, 3265 could be assigned a taxonomic label at genus level (Figure
4). Optimal binning was obtained with 10 clusters, with a precision of 0.71, a recall of 0.68 and
an Adjusted Rand Index of 0.45 for the genus level. Despite the intermediate binning statistics,
it was possible to identify two well-resolved clusters (cluster 1 and cluster 5, Figure 3A)
harboring 36 and 33 SCG’s out of 36 (Figure 3B), and consisting mostly of contigs assigned to a
single bacterial genus, being Marinobacter (Alteromonadaceae, Alteromonadales,
Gammaproteobacteria) and Kordia (Flavobacteriaceae, Flavobacteriales, Flavobacteriia)
respectively (Figure 3C). Upon retrieval of additional Alteromonadales fragments, removal of
contaminant sequences and scaffold reconstruction, the bin corresponding to Marinobacter
contained 52 scaffolds with a total size of 4.70 Mbp (N50 233014 bp, max size 729230 bp, min
size 1039 bp, N% 0.01). The final Kordia cluster obtained similarly consisted of 113 scaffolds,
with a total of 4.71 Mbp of sequence (N50 293332 bp, max size 740848 bp, min size 1000 bp,
N% 0.004). The majority of the fragments assigned to species level within Marinobacter and
Kordia clusters were labelled as respectively Marinobacter adhaerens HP15 and Kordia algicida
OT-1. NUCmer-assisted alignment of the isolated Marinobacter scaffolds to the genome of
Marinobacter adhaerens HP15 showed a very high correspondence between the two sequence

Figure 3. Binning of O. tauri data according to coverage and composition with CONCOCT. (A) Visualization of fragmented contigs from O. tauri assembly. The assembly was constructed from reads filtered against O. tauri v2.2 genome to remove algal sequences. The fragmented contigs were plotted in the first two PCA dimensions in the space of tetramer frequencies and relative fragment coverages across 2 read sets. Contig fragments were clustered, and labelled by cluster for an optimal model with 10 bins. (B) A heatmap visualization of the number of single-copy core genes in each cluster for the optimal model with 10 clusters. Only clusters with at least one SCG are shown. (C) A heatmap visualization of the confusion matrix comparing CONCOCT clustering of the sequence fragments with genus assignment by MEGAN5. The intensities are weighted by fragment length. Each column is a cluster, and the intensities reflect the proportion of each cluster deriving from each genus (D) Alignment of genomic sequence of Marinobacter adhaerens HP15 (GenBank accession number: GCA_000166295.1, 3 scaffolds, 4651725 bp, 97.14% aligned) with the putative Marinobacter adhaerens sequences from cluster 1 (52 scaffolds, 4696466 bp, 95.63% aligned). Average identity for a 1-to-1 alignment: 99.90%. (E) Alignment of genomic sequence of Kordia algicida OT-1 (GenBank accession number: GCA_000154725.1, 20 scaffolds, 4762297 bp, 31.34% aligned) with the putative Kordia sequences from cluster 5 (137 contigs, 4711118 bp, 31.54% aligned). Contigs are aligned instead of scaffolds to aid the alignment. Average identity for a 1-to-1 alignment: 84.11%. Red dots: matches between sequences, Blue dots: reverse complement matches.
C
Cluster
A P
CA
2
PCA1
B
SCG count
s
Clu
ster
Single-copy core gene (SCG)
Reference: Marinobacter adhaerens HP15
Clu
ste
r 1
Clu
ste
r 5
Reference: Kordia algicida OT-1
D E

Results
26
sets (Figure 3D, Table 1), with the similarity levels comparable to those typical for strains of the
same bacterial species. According to Kim et al (2014b), individual bacterial species usually show
less than 95-96% average nucleotide identity between genomes, and less than 98.65% 16S
rRNA gene sequence similarity.
Contigs from the Kordia clusters displayed limited similarity to the genomic sequences of Kordia
algicida OT-1, with only 31.54% of the query sequence being aligned to the reference genome
at 84.07% identity (Figure 3E, Table 1). Similar alignment statistics were observed with Kordia
jejudonensis SSK3-3 (22.70% aligned at 83.84% similarity) and Kordia sp. MCCC 1A00726
(18.15% aligned at 83.70% similarity), and between the genomes of the three different Kordia
species (data not shown). This indicates that the retrieved genomic sequence likely belongs to a
Figure 4. Taxonomic profile of a fragmented O. tauri assembly generated with MENAG5. The assembly was
constructed from whole-genome sequencing data of O. tauri filtered against O. tauri v2.2 genome to remove algal
sequences. Contigs exceeding 20 kbp were fragmented into pieces of 10 kbp, the fragmented assembly was
filtered to exclude sequences shorter that 999 bp and classified using MEGAN5 (database: NCBI protein,
MinScore=60.0, MaxExpected=1.0E-5, TopPercent=10.0). Minimal number of fragments assigned to a node for
the node to be displayed is 25. Node size corresponds linearly to the total number of fragments terminally
assigned to the node. Because of the variable fragment size, the number of fragments can differ significantly from
their cumulative length.

Results
27
new Kordia species. However, no 16S rRNA could be isolated from the assembly to confirm the
results.
Clusters 3 and 7 (figure 3A) could be assigned to Hyphomonadaceae family (Rhodobacterales,
Alphaproteobacteria) and Hyphomonas genus (Hyphomonadaceae, Rhodobacterales,
Alphaproteobacteria) respectively based on majority votes of the constituting scaffolds (Figure
3C). Because of the less complete SCG set (figure 3B), and the shorter scaffold lengths, the bins
were not further analyzed. Clusters 0 and 9 contained fragments from Rhodobacteraceae
family (Rhodobacterales, Alphaproteobacteria), with the main genera being Ruegeria and
Roseovarius (Figure 3C). Cumulatively, the two clusters enclosed at least 2 partial genomic
fractions according to SCG content (Figure 3B). Finally, a small number of Thalassobacter
(Rhodobacteraceae, Rhodobacterales, Alphaproteobacteria) contigs was present in cluster 4
and 129 sequences were assigned to Viridiplantae lineage, including the genus Ostreococcus
(cluster 6 and 2, Figure 3A,C).
To identify which organisms were represented in each of the two datasets used to construct
the assembly, contig coverages were compared across the two 2001 and 2009 sequencing sets.
The contigs from clusters 1, 3, 4, and 5 corresponding to respectively Marinobacter, an
unknown genus from the Hyphomonadaceae family, Thalassobacter, and Kordia had a high
coverage with reads from the 2001 sequencing dataset, and coverages approaching zero with
reads from O. tauri 2009 data. Clusters 0, 8 and 9 corresponding mainly to Rhodobacteraceae
sequences were exclusively composed of reads from 2009. As expected, clusters containing O.
tauri fragments were covered by reads from both datasets, and also Hyphomonas genus
contained in cluster 7 showed an equal coverage in both read sets (Table 2).

Results
28
3.2 Assessing the possibility to better delineate the eukaryote target genome from
contaminants.
Besides identification and retrieval of bacterial sequences present in a whole-genome
sequencing dataset of an eukaryote, we were interested in the applicability of the binning
method for isolation of the targeted eukaryotic contigs from the original assembly. To assess
this possibility, we have fragmented the genome of O. tauri in pieces of 1kb, added them to the
fragmented assembly constructed in the previous step and repeated the analysis. Setting the
maximal number of clusters to two allowed to retrieve all but two of the 12908 chromosome
fragments generated from O.tauri genome within a single bin (cluster 0, Figure 5A,B). From the
5468 contig fragments originating from the prokaryotic assembly, only 22 were retrieved within
the same bin; 21 of these were assigned as Viridiplantae. All other sequences were places in the
second bin, including the remaining O. tauri sequences found back in the prokaryotic assembly.
Figure 5. Binning of fragmented O. tauri genome and prokaryotic contigs with CONCOCT according to coverage and
composition. (A) Visualization of the cumulative sequence set consisting of 1kbp fragments of O. tauri genome and
bacterial contigs constructed using O. tauri sequencing data. The data was plotted in the first two PCA dimensions in
the space of tetramer frequencies and relative fragment coverages across 2 read sets. Fragments were clustered, and
labelled by cluster for a model with 2 bins. (B) A heatmap visualization of the confusion matrix comparing CONCOCT
clustering of the sequences with genus assignment by MEGAN5. The intensities are weighted by fragment length. Each
column is a cluster, and the intensities reflect the proportion of each cluster deriving from each genus.

Results
29
3.3 Binning of O. mediterraneus data.
For O. mediterraneus, no reference genome sequence was available. We have used the same
binning procedure as described above for the analysis of the unfiltered draft target-genome
assembly containing 111 scaffolds with a total of 17.9 Mbp of sequence (N50 806365 bp, max
size 3668993 bp, min size 1037 bp, N% 1.26). Out of 1831 generated fragments, 1524 could be
assigned at genus level (Figure 7). Optimal binning statistics were obtained with 4 clusters,
yielding a recall of 0.93, a precision of 0.90 and an Adjusted Rand Index of 0.74. The assembly
appeared to be very clean, containing only one bin corresponding to an Alcanivorax bacterium
(Alcanivoraceae, Oceanospirillales, Gammaproteobacteria), with a relatively full genomic
sequence according to the SCG content (cluster 0, Figure 6A-C). The majority of the sequences
belonging to Viridiplantae were grouped within a single cluster (cluster 1, Figure 6A), which was
clean from contamination according to MEGAN5 taxonomic labelling (Figure 6C). However, a
smaller fraction of algal sequences was spread over the two remaining clusters (cluster 2, 3,
Figure 6A), along with bacterial and viral fragments (Figure 6C). BLASTn comparison of the
assembly with available O. mediterraneus organelle genomes performed previously allowed to
label scaffolds corresponding to chloroplast and mitochondrion genomes. All 25 scaffolds
originating from organelles were, after scaffolds reconstruction, retrieved within a single cluster
(cluster 3, Figure 6A), forming the majority of Ostreococcus sequences present in that cluster
(25 out of 26, data not shown). The same bin was enriched in scaffolds labelled as dsDNA
viruses, containing 7 out of 10 viral sequences.
Isolation of Alcanivorax cluster yielded 3.80 Mbp of sequence in 6 scaffolds (N50 3668993 bp,
max size 3668993 bp, min size 1109 bp, N% 0.7). Alignment of the scaffolds to the genome of
Alcanivorax sp. DG881 using NUCmer showed good correspondence between the two
sequences (Figure 6D, Table 1). The 16S rRNA gene was 100% identical to the 16S rRNA gene of
Alcanivorax sp. Shm-2 strain ((Syutsubo et al, 2001), Table 1).

Results
30
A
PC
A2
PCA1
Reference: Alcanivorax sp. DG881
Clu
ster
0
D C
Cluster
B
Clu
ster
Single-copy core gene (SCG)
SCG counts
Figure 6. Binning of O. mediterraneus data according to coverage and composition with CONCOCT. (A)
Visualization of fragmented contigs from unfiltered O. mediterraneus assembly plotted in the first two PCA
dimensions in the space of tetramer frequencies and relative contig coverages across 2 read sets. Contig
fragments were clustered, and labelled by cluster for an optimal model with 4 bins. (B) A heatmap visualization of
the number of single-copy core genes in each cluster for the optimal model with 4 clusters. (C) A heatmap
visualization of the confusion matrix comparing CONCOCT clustering of the contig fragments with genus
assignment by MEGAN5. The intensities are weighted by fragment length. Each column is a cluster, and the
intensities reflect the proportion of each cluster deriving from each genus. (D) Alignment of genomic sequence of
Alcanivorax sp. DG881 (GenBank accession number: GCA_000155615.1, 4 scaffolds, 3804728 bp, 90.66% aligned)
with the putative Alcanivorax sequences contained within cluster 0 (6 scaffolds, 3799333 bp, 90.62% aligned).
Average identity for a 1-to-1 alignment: 97.78%. Red dots: matches between sequences, Blue dots: reverse
complement matches.

Results
31
While the fragmented and size-filtered O. tauri assembly did not contain sequences assigned to
Alcanivorax, MEGAN5 analysis of the non-fragmented dataset identified 2930 short contigs
with a total size of 502.5 kbp (N50 169 bp, max size 608 bp, min size 102 bp) which were
labelled as Alcanivorax (Figures 14 and 15, addendum). A substantial fraction was further
assigned to Alcanivorax sp. DG881. None of these contigs was included in the binned dataset
because of the smaller size. Alignment of the Alcanivorax scaffolds from the O. tauri dataset
(547454 bp, 92.14% aligned) to the Alcanivorax scaffolds isolated from O. mediterraneus data
(3799333 bp, 13.25% aligned) with NUCmer showed exceptionally high correspondence
between the two sequence sets, with an average 1-to-1 alignment identity of 99.90%,
indicating that the sequences belonged to a single or two closely related strains.
3.4 Binning of filtered P. crispa assembly.
For P. crispa, no reference genome sequence was available. Regarding the large size of the draft
assembly (188.1 Mbp in 52528 scaffolds, N50 8152 bp, max size 1727554 bp, min size 500 bp,
N% 48.7) we have performed a pre-filtering, excluding scaffolds which gave strong
unambiguous BLASTx hits with proteins of algae and/or plants. This resulted in removal of 5872
Figure 7. Taxonomic profile of fragmented O. mediterraneus assembly generated with MENAG5. Contigs exceeding
20 kbp were fragmented into pieces of 10 kbp, the fragmented assembly was filtered to exclude sequences shorter
that 999 bp and classified using MEGAN5 (database: NCBI protein, MinScore=60.0, MaxExpected=1.0E-5,
TopPercent=10.0). Minimal number of fragments assigned to a node for the node to be displayed is 25. Node size
corresponds linearly to the total number of fragments terminally assigned to the node. Because of the variable
fragment size, the number of fragments can differ significantly from their cumulative length.

Results
32
Figure 8. Binning of P. crispa data according to coverage and composition using CONCOCT. P. crispa genomic
assembly was filtered to remove scaffolds giving unambiguous BLASTx hits with algae and plants, fragmented and
binned using a two-step approach. (A-C): 1st
binning round: binning of P. crispa genomic assembly. (A)
Visualization of contig fragments plotted in the first two PCA dimensions in the space of tetramer frequencies and
relative contig coverages across 4 read sets. Contig fragments were clustered, and labelled by cluster for an optimal
model with 4 bins. (B) A heatmap visualization of the number of single-copy core genes in each cluster for the
optimal model with 4 clusters. (C) A heatmap visualization of the confusion matrix comparing CONCOCT clustering
of the fragments with phylum assignment by MEGAN5. The intensities are weighted by fragment length. Each
column is a cluster, and the intensities reflect the proportion of each cluster deriving from each phylum. (D-F): 2nd
binning round: further binning of cluster 3. (D) Idem to A for the contig fragments contained within cluster 3 from
the 1st
binning round for a model with 3 clusters. (E) A heatmap visualization of the confusion matrix comparing
CONCOCT clustering of the contig fragments with genus assignment by MEGAN5. (F) Idem to B for the contig
fragments contained within cluster 3 for a model with 3 clusters. (G) Alignment of genomic sequence of Gramella
portivictoriae DSM 23547 (GenBank accession number: GCA_000423045.1, 11 scaffolds, 3264369 bp, 76.38%
aligned) with the putative Gramella sequences contained within cluster 2 from the second binning round (3
scaffolds, 3313579 bp, 75.34% aligned). Average alignment identity for a 1-to-1 alignment: 86.18%. (H) Alignment
of genomic sequence of Flavobacterium sp. 83 JQMS01 (GenBank assembly accession: GCA_000744835.1, 1
scaffold, 3790620 bp, 10.56 % aligned) with the putative Flavobacterium sequences contained within cluster 1 from
the second binning round (88 contigs, 3599094 bp, 9.95 % aligned). Contigs are aligned instead of scaffolds to aid
the alignment. Average identity for a 1-to-1 alignment: 84.93 %. Red dots: matches between sequences, Blue
dots: reverse complement matches.
scaffolds with a total size of 36.4 Mbp. Remaining scaffolds were broken down to individual
contigs, fragmented, and binned with CONCOCT as described.
Out of 22307 fragments exceeding the 999 bp limit, only 1690 could be assigned at genus level
(Figure 9). The represented bacterial phyla were again Bacteroidetes, with the class
Flavobacteriia and Proteobacteria, with the classes Alphaproteobacteria and to a smaller extent
Gammaproteobacteria (Table 2). Plotting the binned contigs along the first two PCA dimensions
exposed presence of 3 separated groups of sequences (Figure 8A). Setting the maximal number
of clusters to 4 allowed to optimally retrieve each group in one or two bins, revealing their
correspondence to three phyla present in the dataset, namely Bacteroidetes, Proteobacteria
and Chlorophyta (8A,C). Evaluation of binning results at phylum level using the 4784 labelled
contigs yielded a precision of 0.75, a recall of 0.92 and an Adjusted Rand Index on 0.48.
The two bins corresponding to Chlorophyta (cluster 0 and 2, 8A,C) contained a minor fraction of
sequences belonging Opisthokonta (a broad phylogenetic group including the animal and
fungus kingdom). Increasing the number of bins did not allow to isolate the contaminating
sequences into separate bins.

PC
A2
PCA1
B
Clu
ster
Single-copy core gene (SCG)
SCG counts 3
0
2
1
A C
Cluster
1st binning round (A-C)
1
2
2nd
binning round (cluster 3, D-F)
EE
D
F
Cluster
SCG
cou
nts
Clu
ster
Reference: Gramella portivictoriae DSM 23547
Clu
ste
r 2
C
lust
er
1
Reference: Flavobacterium sp. 83 JQMS01
H
G
Isolation of bacterial genomes (G,H)

Results
34
Within the cluster corresponding to Proteobacteria, (cluster 1, Figure 8A) the majority of
sequences was assigned to the Rhodobacteraceae family from the order Rhodobacterales
(Alphaproteobacteria) and a smaller number belonged to the order Rhizobiales
(Alphaproteobacteria) (Figure 8C, Figure 9). Approximately 25% of sequences could be
identified up to genus level with the two main represented genera being Sulfitobacter (19.5%,
Rhodobacteraceae) and Oceanibulbus (2.9%, Rhodobacteraceae). SCG content indicated
presence of two incomplete sets of single copy core genes (Figure 8B). Retrieving contigs
according to the described scheme yielded a highly fragmented dataset of 5.67 Mbp and 2829
sequences (N50 = 2124 bp), which was not further processed.
Sequences in the Bacteroidetes cluster (cluster 3, Figure 8A) belonged mainly to two distinct
genera, Gramella (Flavobacteriaceae, Flavobacteriales, Flavobacteriia) and Flavobacterium
(Flavobacteriaceae, Flavobacteriales, Flavobacteriia) (Figure 8C,E), and contained two nearly
complete sets of single copy core genes (Figure 8B). Increasing the number of clusters did not
Figure 9. Taxonomic profile of fragmented, pre-filtered P. crispa assembly generated with MENAG5. The genomic
assembly of P. crispa was pre-filtered to partially remove sequences of algae and plants. Contigs exceeding 20 kbp were
fragmented into pieces of 10 kbp, the fragmented assembly was filtered to exclude sequences shorter that 999 bp and
classified using MEGAN5 (database: NCBI protein, MinScore=60.0, MaxExpected=1.0E-5, TopPercent=10.0). Minimal
number of fragments assigned to a node for the node to be displayed is 25. Node size corresponds linearly to the total
number of fragments terminally assigned to the node. Because of the variable fragment size, the number of fragments
can differ significantly from their cumulative length.

Results
35
allow separate the individual genera. Instead, the larger Chlorophyta bins were further
subdivided. Therefore we isolated the cluster and re-binned it individually, which allowed
segregating the sequences of Gramella and Flavobacterium into two distinct bins (Figure 8D-F)
at a precision of 0.86, a recall of 0.66 and an Adjusted Rand Index of 0.43 at genus level. The
binning statistics were compromised by the presence of sequences assigned to related bacterial
genera from the Flavobacteriaceae family in the clusters. These were most probably miss-
assignments of MEGAN5, as the labels were never confirmed by other fragments from the
same contigs and scaffolds. Final assemblies contained resp. 3.72 Mbp in 16 scaffolds (N50
592880 bp, max size 917057 bp, min size 2187 bp, N% 3.27) and 3.60 Mbp in 3 scaffolds (N50
1727554 bp, max size 1727554 bp, min size 665776 bp, N% 1.44). The isolated Gramella
assembly enclosed a large fraction of contigs assigned to Gramella portivictoriae, and could be
neatly aligned to Gramella portivictoriae DSM 23547 genome assembly (Figure 8. G). The
alignment quality and the level of 16S rRNA sequence similarity indicated that the retrieved
sequences belonged to a distinct Gramella species than Gramella portivictoriae (Table 1). The
sequences from the Flavobacterium bin were largely unassigned at species level. Examination
of the BLASTx hits of the fragments showed that for many contigs, Flavobacterium sp. 83
proteins were retrieved in the top 3 hits. While alignment of contigs with Flavobacterium sp. 83
JQMS01 genomic sequence indicated some correspondence between the sequences (Figure
8H), it was still less similar than observed for cases with other bins (Table 1). The 16srRNA was
assigned to the genus Flavobacterium with the closest neighbors being Flavobacterium sp. R-
40838 (97.54% sequence similarity, European Nucleotide Archive (ENA) accession number
FR682718) and Flavobacterium sp. R-40949 (97.54%, ENA accession number FR772055) isolated
respectively from soil, and a terrestrial microbial mat in Antarctica (Peeters and Willems, 2011).
The closest neighbor with a sequenced genome was Flavobacterium succinans (96.06%,
AM230493), but genome alignment with Flavobacterium succinans LMG 10402 was even less
complete than that with Flavobacterium sp. 83 JQMS01 (data not shown).
3.5 Binning of C. braunii data.
For C. braunii, two sequencing datasets of the same strain were obtained at different
laboratories. For the smaller German dataset, two previously produced assemblies were
combined with Newbler, yielding 31.0 Mbp of sequence in 10050 contigs (N50 6785 bp, max

Results
36
size 173266 bp, min size 500 bp). Scaffolding of the assembly decreased the number of
sequences to 2972, giving a total size of 35.0 Mbp (N50=43452, max size 813864, min size 500
bp, N% 17.3). The assembly from the larger Japanese dataset contained 2.0 Gbp in 28091
scaffolds (N50 2217102 bp, max size 142228587 bp, min size 885 bp, N% 17.59).
Regarding the promising results for segregation of eukaryotic and prokaryotic sequences
obtained for the assemblies of P. crispa and O. mediterraneus as well as for the mixture of O.
tauri genomic sequence and O. tauri prokaryotic contigs, the filtering step was skipped despite
the large size of the Japanese C. braunii assembly. The scaffolds were broken down to contigs,
while keeping track of the scaffolds from which they originated, fragmented and binned. For
coverage determination, we performed an additional cross-mapping of the Japanese
sequencing data on the German assembly and vice versa.
3.4.1 Binning of German C. braunii assembly.
Out of 7725 fragments from the German assembly, 3412 were assigned at genus and species
levels (Figure 11). Besides the previously observed phyla Bacteroidetes and Proteobacteria, the
assembly contained Actinobacteria and Planctomycetes (Table 2). The most popular classes
were: the class Actinobacteria from the phyla Actinobacteria, Sphingobacteriia from
Bacteroidetes, Planctomycetia from Planctomycetes, and Alpha- Beta- and
Gammaproteobacteria from Proteobacteria. Optimal binning was obtained with 7 clusters, with
a precision of 0.65, a recall of 0.66 and an Adjusted Rand Index of 0.30 for the genus level
(Figure 10). Surprisingly, the fragmented assembly contained only 45 fragments assigned to
Eukaryota (Figure 11), out of which only 16 were Viridiplantae.
Two clusters enclosed relatively full genomic fractions (clusters 5 and 2, Figure 10B). For cluster
5 corresponding to Streptomyces (Figure 10C) the final assembly contained 226 scaffolds with a
total size of 8.32 Mbp (N50 64105 bp, max size 179263 bp, min size 1013 bp, N% 0.83). The
assembly could be accurately aligned with the genome of Streptomyces griseoflavus Tu4000,
the major bacterial species represented within the cluster (Figure 10D, Table 1). The average
identity with the reference genome lay above the threshold for delineation of individual
bacterial species, but the assembly lacked a 16S rRNA gene, preventing to confirm the

Clu
ste
r 2
Reference: Gemmata obscuriglobus UQM 2246
E
Reference: Streptomyces griseoflavus Tu4000
Clu
ste
r 5
D
A P
CA
2
PCA1
B
Clu
ster
Single-copy core gene (SCG)
SCG counts
C
Cluster
Figure 10. Binning of the unfiltered fragmented German C.
braunii assembly according to coverage and composition
with CONCOCT. (A) Visualization of contig fragments plotted
in the first two PCA dimensions in the space of tetramer
frequencies and relative contig coverages across 9 read sets
(3 German and 7 Japanese). Contig fragments were clustered,
and labelled by cluster for an optimal model with 7 bins. (B)
A heatmap visualization of the number of single-copy core
genes in each cluster for the optimal model with 7 clusters.
Only clusters with at least one SCG are shown. (C) A heatmap
visualization of the confusion matrix comparing CONCOCT
clustering of the contig fragments with genus assignment by
MEGAN5. Only genera with more than 25 assigned fragments
are shown. The intensities are weighted by fragment length.
Each column is a cluster, and the intensities reflect the
proportion of each cluster deriving from each genus (D)
Alignment of the genomic sequence of Streptomyces
griseoflavus Tu4000 (GenBank accession number:
GCA_000158975.1, 1 scaffold, 8047042 bp, 77.91% aligned)
with the putative Streptomyces sequences from cluster 5 (226
scaffolds, 8319752 bp, 75.62% aligned). Average alignment
identity for a 1-to-1 alignment: 98.87 % (E) Alignment of the
genomic sequence of Gemmata obscuriglobus UQM 2246
(GenBank assembly accession: GCA_000171775.1, 922
scaffolds, 9161847 bp, 13.91% aligned) with the putative
Gemmata sequences from cluster 2 (69 scaffolds, 9311387
bp, 13.30% aligned). Average alignment identity for a 1-to-1
alignment: 84.20%.

Results
38
Figure 11. Taxonomic profile of fragmented German C. braunii assembly generated with MENAG5. The genomic assembly of C. braunii was fragmented, cutting contigs exceeding 20 kbp into pieces of 10 kbp, the fragmented assembly was filtered to exclude sequences shorter that 999 bp and classified using MEGAN5 (database: NCBI proteins, MinScore=60.0, MaxExpected=1.0E-5, TopPercent=10.0). Minimal number of fragments assigned to a node for the node to be displayed is 25. Node size corresponds linearly to the total number of fragments terminally assigned to the node. Because of the variable fragment size, the number of fragments can differ significantly from their cumulative length.
taxonomic affiliation. The final assembly for cluster 2 corresponded to Gemmata according to
the taxonomic labels provided by MEGAN5 (Figure 10C), and more precisely to Gemmata
obscuriglobus UQM 2246. It enclosed 9.31 Mbp in 56 scaffolds (N50 281865, max size 978387,
min size 1227, N% 1.91). Alignment quality of the sequence with the genome of Gemmata
obscuriglobus UQM 2246 (Figure 10E, Table 1) was below the species threshold, and the
isolated 16S rRNA gene showed 99.73% identity with the 16S rRNA of Gemmata-related strain
JW3-8s0 isolated from Australian soil. The latter strain has been identified as being closely
related to Gemmata obscuriglobus (Wang et al, 2002).
3.4.2 Binning of Japanese C. braunii assembly.
For the Japanese assembly, 39150 contig fragments could be assigned at genus level out of
319269. The same bacterial phyla were represented as for the German C. braunii assembly,
except for an extra phylum, Acidobacteria and traces of Cyanobacteria and Firmicutes (Figure
13, Table 2). The Japanese assembly contained all the classes observed in the German

Results
39
Figure 12. Binning of unfiltered fragmented Japanese C. braunii data according to coverage and composition using CONCOCT. Japanese C. braunii genomic assembly was fragmented and binned using a two-step approach. (A-C): 1
st
binning round: binning of C. braunii genomic assembly. (A) Visualization of contig fragments plotted in the first two PCA dimensions in the space of tetramer frequencies and relative contig coverages across 9 read sets (3 German and 7 Japanese). Contig fragments were clustered, and labelled by cluster for a model with 3 bins. (B) A heatmap visualization of the number of single-copy core genes in each cluster for the optimal model with 3 clusters. (C) A heatmap visualization of the confusion matrix comparing CONCOCT clustering of the contig fragments with phylum assignment by MEGAN5. The intensities are weighted by fragment length. Each column is a cluster, and the intensities reflect the proportion of each cluster deriving from each phylum. (D-F): 2
nd binning round: further
binning of cluster 2. (D) Idem to A for the contig fragments contained within cluster 2 from the 1st
binning round for a model with 45 clusters. (E) Idem to B for the contig fragments contained within cluster 2 for a model with 45 clusters. (F) A heatmap visualization of the confusion matrix comparing CONCOCT clustering of the contig fragments with genus assignment by MEGAN5. Only genera with more than 25 assigned fragments are shown.
assembly, being the class Actinobacteria from the Actinobacteria phylum, Spingobacteriia from
Bacteroidetes, Planctomycetia from Planctomycetes, and Alpha- Beta- and
Gammaproteobacteria from Proteobacteria, and a few additional classes, including Cytophagia
and Flavobacteriia from Bacteroidetes and Acidobacteriia and Solibacteres from Acidobacteria.
Also eukaryotes were richly represented: besides Viridiplantae, the assembly contained
sequences of Alveolata (a major superphylum of protists), Oomycetes (fungus-like eukaryotic
microorganisms) and a large number of Opisthokonta. Within Opisthokonta, both Fungi and
Metazoa were present.
To segregate different bacterial taxa, the same strategy was used as for P. crispa: in the first
binning round, eukaryotic and prokaryotic contigs were separated (Figure 12A,B), and in the
second binning round, the bacterial sequences were further subdivided into individual genera
(Figure 12C-E). Best isolation of bacterial contigs was achieved with a maximal cluster number
of 3, giving a recall of 0.78, a precision of 0.72 and an Adjusted Rand Index of 0.19 evaluated at
phylum level.
Some cross-contamination of bacterial and eukaryotic sequences was still observed (Figure
12B). Therefore, prior to the second binning round, cluster 2 was enhanced as described
previously removing the contaminating eukaryotic sequences (2325), adding bacterial
sequences (1782) and retrieving all scaffolds fragments, which yielded a total of 38629
fragments and 231.7 Mbp of sequence. Setting the maximal number of bins to 60 resulted in an
optimal model with 45 clusters (Figure 12A), out of which 4 contained nearly full sets of SCG’s
(figure 12B). Upon scaffold reconstruction the SCG content of the clusters was yet improved
resulting in 6 nearly complete sets of single copy core genes (Figure 16A, addendum). No
manual enhancement of the clusters was performed because of the larger size of the dataset,

Results
40
PC
A2
PCA1
Cluster
PC
A2
PCA1
1st
binning round 2nd
binning round (binning of cluster 2)
SCG counts
Clu
ster
Single-copy core gene (SCG)
A
B
C
D
E
Cluster

as well as its higher complexity which often prevented to delineate precisely the taxonomy of
the isolated genome.
None of the 6 clusters could be unambiguously labelled at genus or species level based on
MEGAN5 output (Figure 12, C-E). Instead, different species, genera, families, orders and even
classes were represented, even for fragments derived from a single scaffold. This can originate
from inaccurate taxonomy determination by MEGAN5 because of the small representation of
neighboring organisms in the database, and/or from chimerization of contigs belonging to
different bacterial classes during assembly or scaffolding. However, in the latter case, the SCG
content would likely be inconsistent. 16S rRNA’s were isolated from each sequence set and
classified with SINA to better delineate the taxonomy of the clusters (Table 1).
Figure 13. Taxonomic profile of fragmented Japanese C. braunii assembly generated with MENAG5. The genomic
assembly of C. braunii was fragmented, cutting contigs exceeding 20 kbp into pieces of 10 kbp, the fragmented
assembly was filtered to exclude sequences shorted that 885 bp and classified using MEGAN5 (database: NCBI
proteins, MinScore=60.0, MaxExpected=1.0E-5, TopPercent=10.0). Contigs exceeding 20 kbp were fragmented into
pieces of 10 kbp, the fragmented assembly was filtered to exclude sequences shorter that 999 bp and classified using
MEGAN5 (database: NCBI protein, MinScore=60.0, MaxExpected=1.0E-5, TopPercent=10.0). Minimal number of
fragments assigned to a node for the node to be displayed is 50. Node size corresponds linearly to the total number of
fragments terminally assigned to the node. Because of the variable fragment size, the number of fragments can differ
significantly from their cumulative length.

Results
42
Cluster 0 (Figure 14C) contained 2 scaffolds with a total size of 4.20 Mbp (max size 4156444 bp,
min size 45979 bp, N% 1.09). Majority of sequences were assigned to the phylum
Actinobacteria, but two different sequence classes, namely Rubrobacteridae and
Actinobacteria were present. The isolated 16S rRNA gene showed a single hit at 89.72%
similarity to an uncultured bacterium from the order Gaiellales (Thermoleophilia,
Actinobacteria) isolated from soil diseased with banana fursarium wilt in China (European
Nucleotide Archive (ENA) accession number JX133582.1, no reference provided).
Cluster 2 (Figure 12C) corresponded to Proteobacteria with a single scaffold of 7432413 bp (N%
0.42). The unique 16S rRNA gene was classified as belonging to the order Xanthomonadales
(Gammaproteobacteria), and showed a 100.0% similarity to the 16S rRNA sequence of an
uncultured eubacterium WD2124 from the order Xanthomonadales isolated during a study of
the bacterial community of polychlorinated biphenyl-polluted soil (Nogales et al, 2001).
Fragments of the scaffold gave hits to Alpha, Beta- and Gammaproteobacteria classes.
For cluster 3 (Figure 12C, 6.90 Mbp in 4 scaffolds ranging from 6818177 to 7267 bp, N% 0.48),
the 16S rRNA gene was classified as Bryobacter (Unknown family, subgroup 3 (candidate class
Solibacteres), Acidobacteria) and corresponded most closely to an uncultured Bryobacter from
a permafrost core of Qinghai-Tibet Plateau (93.75%, ENA accession number KF494505, no
reference). The individual fragments were assigned to different classes of the phylum
Acidobacteria, including Solibacteres and Acidobacteria class.
Cluster 8 (Figure 15C, 11.19 Mbp in 4 scaffolds, ranging from 10926697 to 12101 bp, N% 0.42)
was enriched in sequences labelled as Singulisphaera acidiphila DSM 18658 (Singulisphaera,
Planctomycetaceae, Planctomycetales, Planctomycetia, Planctomycetes) but alignment to a
reference assembly (GenBank accession number: GCA_000242455.3) with NUCmer showed
very low correspondence between the genomic sequences: 3.05% of the reference could be
aligned to 2.35% of the isolated sequence. The 16S rRNA belonged to the genus Singulisphaera,
and showed a 100.0% sequence identity with an uncultured planctomycete strain from the
genus Singulisphaera (ENA accession number AJ231192, (Griepenburg et al, 1999)).
The 16S rRNA of cluster 10 (Figure 16C, 4.79 Mbp of sequence in 139 scaffolds, N50 3506533
bp, max size 3506533 bp, min size 1101 bp, N% 0.58) was labelled as belonging to

Results
43
Sediminibacterium (Chitinophagaceae, Sphingobacteriales, Sphingobacteriia, Bacteroidetes) and
showed closest neighborhood (92.36%) with a 16S rRNA sequence from the same taxonomic
clade isolated from biological soil crust of copper mine tailings wastelands in China (ENA
accession number JQ769640, no reference provided).
Finally cluster 34 (Figure 17C) with 78 scaffolds of 3.42 Mbp (N50 65109 bp, max size 332430
bp, min size 2801 bp, N% 0) did not possess any 16S rRNA sequences, but MEGAN5 output
assigned most fragments to Bradyrhizobiaceae family (Rhizobiales, Alphaproteobacteria,
Proteobacteria).
In addition to the 6 clusters with a nearly complete SCG content, a number of less complete
bins were retrieved and analyzed (Figure 18C-E). Clusters 30 (7.51 Mbp, 359 scaffolds, N50
29294 bp) and 35 (5.83 Mbp, 738 scaffolds, N50 10087 bp) corresponded respectively to
Variovorax (Comamonadaceae, Burkholderiales, Betaproteobacteria) and Gemmata
(Planctomycetaceae, Planctomycetales, Planctomycetia, Planctomycetes) as judged from the
MEGAN5 taxonomic assignments. Cluster 38 contained sequences from Chlorobi, with the
largest scaffold (5.98 Mbp, N% 0.56) giving hits with Niastella (Chitinophagaceae,
Sphingobacteriales, Sphingobacteriia).
Also Alphaproteobacteria were richly represented in the Japanese dataset. Clusters 5 (6.64 Mbp
and 887 scaffolds, N50 8939 bp), 31 (8.08 Mbp in 148 scaffolds, N50 89325) and 40 (11.36 Mbp
in 1174 scaffolds, N50 12151 bp) could be assigned to Alphaproteobacteria based on MEGAN5
output, respectively to Caulobacter (Caulobacteraceae, Caulobacterales, Alphaproteobacteria),
Reyanella (unclassified Rhodospirillaceae, Rhodospirillales, Alphaproteobacteria) and
Rhizobiales (Alphaproteobacteria) (Figure 19C,E). Besides, two scaffolds of sufficient length to
represent a substantial part of a bacterial genome were retrieved from clusters 16. Both
scaffolds 5 (8.72 Mbp, N% 0.051) and scaffold 40 (4.86 Mbp, N% 0.04) possessed a full set of
SCG’s (Figure 16B, addendum). 16S rRNA of scaffold 40 showed highest correspondence to an
uncultured Bradyrhizobium bacterium isolated from boreal pine forest soil (99.32%, ENA
accession number FJ625376, no reference). Scaffold 5 did not contain a 16S rRNA, but could be
affiliated to Bradyrhizobium genus using MEGAN5 fragment labels.

Results
44
Table 1. Nearly complete genomic sequences of bacteria isolated from whole-genome sequencing datasets of algae.
Algal culture/Bacterial Class size
(Mbp) N50
(kbp) SCG's Reference genome
size reference (Mbp)
% aligned
% identity
16S rRNA best hit %
identity %
aligned
O. tauri (2001)
Gammaproteobacteria 4.70 233 36/36 Marinobacter
adhaerens HP15 4.65 95.62 99.90 Marinobacter adhaerens 100.0 99.15
Flavobacteriia 4.71 293 33/36 Kordia algicida OT-1 4.76 31.54 84.11 gene absent
O. mediterraneus
Gammaproteobacteria 3.80 547 36/36 Alcanivorax sp. DG881 3.80 90.62 97.78 Alcanivorax sp. Shm-2 100.0 99.15
P. crispa
Flavobacteriia 3.72 593 36/36 Gramella portivictoriae
DSM 23547 3.26 75.34 86.18
Gramella portivictoriae DSM 23547
97.02 100.0
Flavobacteriia 3.60 1728 35/36
Flavobacterium sp. R-40838
97.54 100.0
C. braunii German
Actinobacteria 8.32 64 35/36 Streptomyces
griseoflavus Tu4000 8.05 75.65 98.87 gene absent
Planctomycetia 9.31 232 35/36 Gemmata obscuriglobus
UQM 2246 9.16 13.30 84.20
Gemmata-like str. JW3-8s0
99.73 99.17
C. braunii Japan
Actinobacteria 4.20 4156 36/36
uncultured Gaiellales 89.72 100.0
Gammaproteobacteria 7.43 7432 36/36
uncultured Xanthomonadales
100.0 100.0
Acidobacteria/Solibacteres 6.90 6818 36/36
uncultured Bryobacter 93.75 99.20
Planctomycetes 11.19 10927 35/36
planctomycete str. 394 (Singulisphaera)
100.0 100.0
Sphingobacteriia 4.79 3507 36/36
uncultured Sediminibacterium
92.36 99.60
Alphaproteobacteria 3.42 64 35/36
gene absent
Alphaproteobacteria 8.72 8723 36/36
gene absent
Alphaproteobacteria 4.86 4859 36/36
uncultured Bradyrhizobium
99.32 98.66
Mbp: Mega base pairs, kbp: kilo base pairs, SCG: number of single-copy core genes observed within the isolated genomic sequence, % aligned: percentage of the isolated genomic sequences that could be aligned to a reference genome in a 1-to-1 alignment, % identity: percentage of nucleotide similarity of the isolated genomic sequences with the reference genome in a 1-to-1 alignment. Genomic sequences were aligned using NUCmer program from MUMmer v3.23 at default parameters. 16S rRNA best hit: best matching 16SrRNA sequence identified by SINA search and classification tool from SILVA database. % identity and % alignment: respective parameters for query 16S rRNA alignment with the best matching 16S rRNA gene reported by SINA.

Results
45
Table 2. Most represented bacterial genera and families observed in the different algal assemblies.
Bacterial taxon/alga O. tauri 2001 O. tauri 2009 O. mediterraneus P. crispa German C. braunii Japanese C. braunii Bacteroidetes Kordia Gramella Flavobacterium
Niastella Niastella Chitinophaga
Sediminibacterium
Proteobacteris -Gammaproteobacteria
Marinobacter
Alcanivorax ? Alcanivorax ? Alcanivorax Pseudomonas Pseudomonas Xanthomonadales Xanthomonadales Proteobacteria - Alphaproteobacteria
Hyphomonas * Hyphomonas *
Hyphomonadaceae * Thalassobacter * Ruegeria * Roseovarius * Sulfitobacter * Oceanibulbus * Bosea ** Bosea ** Bradyrhizobium ** Bradyrhizobiaceae ** Hyphomicrobium ** Hyphomicrobium ** Mesorhizobium ** Mesorhizobium ** Rhizobiales ** Rhizobiales ** Sphingomonas Reyanella Caulobacter Phenylobacterium Proteobacteria -Betaproteobacteria
Burkholderaceae Burkholderia
Pelomonas Pelomonas
Variovorax Actinomycetes Rhodococcus

Results
46
Streptomyces Streptomyces Gaiellales/ Solirubrobacter Planctomycetes Gemmata Gemmata Zavarzinella Zavarzinella Singulisphaera Acidobacteria Bryobacter/ Solibacter
Most represented bacterial genera and families in algal datasets were identified from MEGAN5 taxonomic profiles and from 16s rRNA affiliation of isolated bacterial genomic sequences. (*) Rhodobacterales; (**) Rhizobiales. Genera separated by ‘/’ represent a set of sequences possibly originating from a single organism that have been affiliated to different closely related genera by MEGAN5.

Discussion
47
4. Discussion
Metagenomic analyses have been carried out on genomic sequencing data of six algal cultures
obtained from four algal species. The assemblies of the data were fragmented and binned
according to coverage and composition. Taxonomic assignment of the bins was performed
using a similarity-based labelling of the fragments, while bin-quality and completeness were
assessed by monitoring the presence of single copy genes (SCG’s).
4.1 Performance of the binning method.
The adopted binning method was efficient in segregating eukaryotic and prokaryotic contigs.
This was both the case for the artificial dataset containing fragmented O. tauri chromosomes
and bacterial assembly from filtered O. tauri sequencing data, as well as whole-genome
assemblies of O. mediterraneus, P. crispa and C. braunii. Further subdivision of the eukaryotic
fraction, however, did not allow putting the different eukaryotic taxa (ex. Viridiplantae and
Ophisthokonta) into individual bins. Also whenever bacterial and eukaryotic contigs were
binned together, the method failed to form correct subdivisions within the bacterial data. The
problem has been circumvented by isolating the bins corresponding to bacterial fractions and
re-binning these separately.
For every dataset, the method allowed to make a number of species-specific bins containing
substantial fractions of individual bacterial genomes despite the lower number of biological
replicates available for the datasets compared to what was recommended by the authors of
CONCOCT (Alneberg et al, 2014). However, cross-contamination of the sequences as well as
completely unresolved groups were often present, requiring manual improvement of the
clusters where possible.
The adopted method for reconstruction of original scaffolds, together with the fact that the
genomes of most prevalent bacteria were assembled into very long scaffolds, allowed to
retrieve a number of nearly complete genomes from every studied algal species (Table 1). It
should be noted that while monitoring the presence of SCG’s allows to approximately evaluate
the completeness of the isolated genomic fractions, the results are not conclusive. The selected
core genes mainly encode ribosomal proteins (Table 3, addendum) known to be located in a

Discussion
48
restricted part of bacterial genomes (Lecompte et al, 2002). Another concern is the possible
presence of chimeric sequences, which could have arisen during assembly or scaffolding. Such
erroneous contigs and scaffolds can be identified using an approach adopted by Albertsen et al
(2013) that involves tracking paired-end read connections between sequences. The original
reads are mapped to the genomes, and the resulting mapping is used to visualize the linkage
between the isolated sequences as well as their coverage. This allows to identify problematic
regions, but also to associate additional scaffolds and repeat regions such as 16S rRNA genes
with the correct bins and to remove scaffolds wrongly included in bins.
Besides the sequences with a nearly complete set of SCG’s, a number of less complete
assemblies could be isolated. Such assemblies can be improved by mapping the original
sequencing data to the contigs and reassembling the mapping reads, followed by scaffolding
and gap filling. Because of the availability of paired-end information, more reads can be
retrieved by mapping than were originally used to construct the contigs, and the assembly can
be performed more efficiently because of the lower complexity of the dataset. Using this
approach, it might also be possible to reconstruct the 16S rRNA sequences absent from some of
the isolated assemblies.
4.2 Biology of the observed bacteria.
4.2.1 Proteobacteria and Bacteroidetes.
Cultures of all algal species contained representatives of Proteobacteria, with the most
occurring classes being Alphaproteobacteria and Gammaproteobacteria (Table 2). Four cultures
out of six also enclosed bacteria from the phylum Bacteroidetes. Members of these bacterial
clades are typically found living in the phycosphere of phytoplankton and macroalgae, often
representing the major fraction of the associated bacterial communities (Hollants et al, 2013
and references therein; Kaczmarska et al, 2005; Methé et al, 1998; Sapp et al, 2007c and
references therein; Wu et al, 2007).
Ostreococcus cultures harbored species from the orders Oceanospirillales and Alteromonadales
(Gammaproteobacteria), mainly occurring in marine water (Kassabgy, 2011; Williams et al,
2010) (Table 2). Members of these orders are often encountered within phytoplankton blooms

Discussion
49
and on surfaces of macroalgae, and contain heterotrophs responsible for rapid degradation of
the more accessible fraction of organic matter (Bowman & McMeekin, 2005; Garrity et al,
2005a). Some authors describe marine Gammaproteobacteria as copiotrophs, i.e. organisms
adapted to high levels of nutrients (Gauthier et al, 1992; Newton et al, 2011). Their associations
with algae likely rely on bacterial degradation of various organic substrates released by the
eukaryotic hosts (Yakimov et al, 2007). The isolated genomic sequence of a Marinobacter
species showed very high similarity to the genome of the M. adhaerens H15 strain, which has
received the name because of its ability to specifically attach to diatom cells (Gardes et al,
2010). Another closely related species, M. algicola, has been described from dinoflagellate
cultures (Gardes et al, 2010; Green et al, 2006). The second isolated genomic sequence
belonged to the genus Alcanivorax, which are known for their ability to degrade and live
predominately on alkanes, quickly becoming the dominant microbes in oil-contaminated areas
(Yakimov et al, 2007).
In contrast to mostly marine Oceanospirillales and Alteromonadales, orders Xanthomonadales
and Pseudomonadales (Gammaproteobacteria), whose representatives have been observed in
C. braunii cultures, are mainly known as ubiquitous soil bacteria able to utilize a large number
of carbon and energy sources (Garrity et al, 2005b; Saddler & Bradbury, 2005). Terrestrial
representatives of these orders are relatively well studied because of their ability to degrade
aromatic-hydrocarbons (Erkelens et al, 2012; Kersters et al, 1996), and because of the
numerous pathogenic (Ryan et al, 2011; Xin & He, 2013) and beneficial (Berg & Martinez, 2015;
Preston, 2004) interactions with plants. Besides soil, both groups have also been observed in
aquatic habitats (Gutierrez et al, 2013; Kim et al, 2014a; Methé & Zehr, 1999; Renders et al,
1996; Wand et al, 1997). One well assembled genomic sequence assigned to Xanthomonadales
could be isolated from the Japanese C. braunii dataset, showing a 100% 16S rRNA similarity to
an uncultured soil bacterium.
Different Alphaproteobacteria orders were represented in analyzed cultures, including the
ubiquitous classes Rhizobiales and Rhodobacterales but also less common classes
Caulobacterales, Sphingomonadales and Rhodospirillales (Williams et al, 2007).
Rhodobacterales are typically found in association with phytoplankton and macroalgae, being
richly represented within the flora of marine eukaryotic hosts (reviewed by Buchan et al, 2005).

Discussion
50
Rhodobacterales, and especially Roseobacter clade members are characterized as metabolically
diverse surface-colonizing bacteria, encountered mostly in marine or saline environments
(Dang et al, 2008), but also coastal biofilms (Dang & Lovell, 2000; Dang & Lovell, 2002) and
polar sea ice (Brinkmeyer et al, 2003; Brown & Bowman, 2001). This is confirmed in our
findings, where Rhodobacterales species were retrieved within Ostreococcus and P. crispa
cultures but not within the C. braunii cultures (Table 2, marked with *). Although roles of most
Rhodobacterales bacteria remain unknown, studied members of this order often form close
and potentially obligate mutualistic interactions with algae (Dang et al, 2008; Hahnke et al,
2013; Piekarski et al, 2009). Some Rhodobacterales have changed the balance from symbiosis
to opportunism and pathogenesis, producing algicidal compounds (Amaro et al, 2005) and
inducing gall formation (Ashen & Goff, 1998).
While C. braunii cultures lacked Rhodobacterales species, another group of
Alphaproteobacteria, namely Rhizobiales, was abundantly present within the two cultures
(Table 2, marked with **). In contrast to Rhodobacterales which thrive in saline habitats, this
group of bacteria is equally often found in soil, freshwater and in marine environments
(Dobbelaere et al, 2003; Hollants et al, 2011c; Jordan et al, 2007; Ruger & Hofle, 1992;
Schaechter, 2009; Suss et al, 2006). Organisms from this group form beneficial interactions with
plants based on the production of various nutrients, phytohormones and precursors for
essential plant metabolites (Delmotte et al, 2009; Ivanova et al, 2000; Verginer et al, 2010).
Mutual beneficial effects of Rhizobiales on algal growth are well documented (Do Nascimento
et al, 2013; Kim et al, 2014a; Rivas et al, 2010). One of the main advantage provided by
members of Rhizobiales to algae and plants is thought to be nitrogen fixation (Garrity et al,
2005c; Jourand et al, 2004; Vance et al, 2002). Diazotrophic bacteria capable of nitrogen
fixation have been identified, among others, in the families Bradyrhizobiaceae,
Hyphomicrobiaceae and Rhizobiaceae (Vance et al, 2002) all of which were present in the C.
braunii cultures (Table 2).
Despite being present in all but one algal cultures, the genomic sequences belonging
Alphaproteobacteria were generally less well assembled and poorly segregated into individual
bins compared to other bacteria. This might be a result of a lower genome numbers in the
initial samples, and the consequent lower sequencing coverage. Also presence of a large

Discussion
51
number of sequences of related species in the dataset can interfere with assembly. The deeply
sequenced Japanese dataset of C. braunii did allow retrieving three partial Alphaproteobacteria
assemblies. Two of the assemblies lacked a 16S rRNA gene, while the third assembly showed a
relatively high 16S rRNA similarity (99.32%) to an uncultured Bradyrhizobium species isolated
from boreal pine forest soil.
The third phylum typically found associated with algae, and observed within the analyzed
cultures is Bacteroidetes. Bacteroidetes are globally distributed in terrestrial, freshwater and
marine habitats (reviewed in Fernández-Gómez et al, 2013). The trophic strategy of
Bacteroidetes differs strongly from that of Gammaproteobacteria and Alphaproteobacteria:
members of the group typically specialize in processing polymeric organic matter, for example
in soil (Cytophaga) and in the mammalian gut (for example, Bacteroides spp.) (Thomas et al,
2011). Available evidence suggests that in the oceans, a common lifestyle of Bacteroidetes is
attachment to particles and surfaces of living organisms, such as corals (Rohwer et al, 2002a)
and algae (Gomez-Pereira et al, 2010; Mann et al, 2013; Teeling et al, 2012b) and degradation
of high molecular weight compounds (Cottrell & Kirchman, 2000; Fernández-Gómez et al,
2013). While Bacteroidetes are generally degraders, their association with algae can take form
of pathogenesis and facultative pathogenesis (Correa & McLachlan, 1994; Craigie & Correa,
1996; Goecke et al, 2010).
We have retrieved three Bacteroidetes assemblies, one belonging to a well-studied genus
Flavobacteria, and two additional, showing similarity to the less well characterized genera
Kordia and Gramella, each genus containing only three sequenced genomes (NCBI whole
genomes). One representative of the genus Kordia, Krodia algicida, possesses the ability to lyse
cells of several marine microalgae (Sohn et al, 2004). The isolated assembly displayed only an
intermediate similarity to the genomes of other Kordia species, but it lacked a 16S rRNA gene,
preventing a more detailed taxonomic assignment. However, it might be still possible to
retrieve the 16S rRNA using one of the two approaches described in 4.1. Another isolated
genome belonged to the genus Gramella. The genome of one Gramella representative,
Gramella forsetii KT0803 was the first genome of a marine Bacteroidetes to be studied, and has
revealed adaptations of the bacterium to degradation of high molecular weight compounds
(Bauer et al, 2006).

Discussion
52
One more class of Proteobacteria observed during the analysis, Betaproteobacteria, was
present only in C. braunii cultures. Similarly to Alphaproteobacteria, Betaproteobacteria can fix
nitrogen and induce nodulation in plants (Gyaneshwar et al, 2011). Whereas
Alphaproteobacteria are common in both marine as well as freshwater habitats,
Betaproteobacteria often form a numerically important group in fresh water but are nearly
absent from salt water environment (Glockner et al, 1999; Gyaneshwar et al, 2011; Likens,
2010; Shade et al, 2007). Aquatic Betaproteobacteria are frequently retrieved from
phycosphere of algae and Cyanobacteria (Šimek et al, 2011). In the dataset, sequences of the
genera Pelomonas and Variovorax have been identified. These bacterial genera belong to the
Burkerholderiales family, harboring numerous plant-interacting members, both pathogens, and
epi- and endophytic symbionts, some of which are capable of nitrogen fixation (reviewed by
Compant et al, 2008).
As it becomes apparent from the discussed physiologies of the observed bacterial groups, the
bacterial populations associated with algae might have complementary roles.
Gammaproteobacteria and Alphaproteobacteria metabolize readily accessible organic
molecules released by algae. While some of the associated bacteria, such as members if
Gammaproteobacteria, can be commensal organisms, ‘grazing’ on algal metabolites, other such
as members of Alphaproteobacteria and Betaproteobacteria might form more close mutually
beneficial interactions with algae. By contrast Bacteroidetes are master degraders. While
retaining the ability to feed on polymers of living algal cells, these bacteria are essential for re-
mineralization of algal detritus, allowing to recycle nutrients and minerals. Besides algae,
Bacteroidetes can potentially cooperate with other bacteria. For example members of the
Roseobacter clade have been shown to grow on by-products from the flavobacterial
decomposition of algal biomass (Mou et al, 2008; Teeling et al, 2012a).
4.2.2 Actinobacteria, Acidobacteria and Planctomycetes.
Besides the two phyla represented in most of the studied cultures, a number of bacterial phyla
were exclusively encountered in C. braunii samples, including Actinobacteria, Acidobacteria and
Planctomycetes. Actinobacteria are ubiquitously present in terrestrial and aquatic
environments, where they play an important role in decomposition of organic material (Cuesta
et al, 2012; Goodfellow & Williams, 1983; Hong et al, 2009; Ramesh & Mathivanan, 2009; Sousa

Discussion
53
et al, 2008). This group is produces a huge diversity of organic compounds: from more than
22000 known microbial secondary metabolites, 70% are synthesized by Actinobacteria (Berdy,
2005; Tiwari & Gupta, 2012). Many of these compounds possess antibiotic or other biological
activities. Aquatic Actinobacteria are less well characterized compared to terrestrial
representatives because of the difficulties associated with culturing (Berdy, 2005; Subramani &
Aalbersberg, 2012). Screening of rare Actinobacteria, such as the under-represented genera
from unexplored environments is considered to be a very promising strategy for discovery of
novel antibiotics (Tiwari & Gupta, 2012). In this study we were able to isolate two genomes
belonging to the Actinobacteria (Table 1). The first sequence did not contain a 16S rRNA, but
showed over 98% nucleotide identity with the genome Streptomyces griseoflavus (Subramani &
Aalbersberg, 2012). The 16S rRNA of the second isolated genomic sequence showed closest
similarity (89.72%) to a 16S rRNA of an uncultured Gaiellales. While genomes of Streptomyces
species are widely available, no genomic sequences of Gaiellales have been reported yet (NCBI
whole genomes). Gaiellales is a deeply branching family from the class Actinobacteria. The low
similarity of the 16S rRNA sequence with any sequences deposited in SILVA database indicates
that the assembly likely belongs to a yet uncharacterized species, or even a novel genus
(Albuquerque et al, 2011).
The phylum Acidobacteria is also abundantly distributed in the major types of habitats (Quaiser
et al, 2003). For example these bacteria typically form from 10% to 50% of the total bacterial
population represented in 16S rRNA gene libraries from soil (Quaiser et al, 2008). Despite that,
less than 15 genera have been formally described from this phylum, and several isolates have
been given candidate names (Huber et al, 2014). The reason for that is the difficulties
associated with isolation and culturing of Acidobacteria (Foesel et al, 2014). Across the small
collection of isolates, most are heterotrophs (Davis et al, 2005; Eichorst et al, 2007; Joseph et al,
2003; Ward et al, 2009), and some Acidobacteria have been shown to form a dominant and
metabolically active population in rhizosphere soil (Lee et al, 2008) The C. braunii assembly
contained a genomic sequence of an organism with 93.75% 16S rRNA similarity to an
uncultured Bryobacter species (Table 1). MEGAN5 labelled the constituting sequences as
originating from two closely related genera Bryobacter and Solibacter from the class
Solibacteres. Solibacteres is a newly established and highly unstudied candidate class of

Discussion
54
Actinobacteria, containing only two characterized members with available genomic sequences
(Kulichevskaya et al, 2010).
The last phylum, Planctomycetes contains bacteria with unusual characteristics, such as
absence of peptidoglycan in the cell walls and presence of endomembranes
compartmentalizing the cells (Fuerst & Sagulenko, 2012). Like Actinobacteria and
Acidobacteria, Planctomycetes have been identified in many different habitats with 16S rRNA-
based surveys (Gade et al, 2004; Janssen, 2006; Neef et al, 1998), but relatively few species
have been described from this phylum. Only 24 sequenced genomes are available for the entire
bacterial group. Planctomycetes have been isolated from soil, and different aquatic
environments (Lage & Bondoso, 2014), and from diverse eukaryotes, including the rhizosphere
of plants (Jensen et al, 2007; Zhang et al, 2012) and the phycosphere of different marine algae
(Bengtsson & Ovreas, 2010; Lachnit et al, 2011; Lage & Bondoso, 2011b). Aquatic
Planctomycetes have been shown to degrade various poly- and monosaccharides produced by
algae (Glöckner et al, 2003; Lage et al, 2013; Lage & Bondoso, 2011a). We have isolated two
nearly complete genomes of Planctomycetes species. The 16S rRNA gene of one of the isolated
genomes showed a high similarity to 16S rRNA of a Gemmata-like str. JW3-8s0 from an
environmental sample, while demonstrating only an intermediate similarity to the two
genomes available for the genus (NCBI whole genomes). The second isolated genomic sequence
showed highest similarity to the 16S rRNA of the Planctomycete str. 394 assigned to the genus
Singulisphaera. For Singulisphaera, only a single genome from Singulisphaera acidiphila is
available (Guo et al, 2012).
Presence of the difficultly cultivable bacterial species in algal cultures in interesting. The fact
that the retrieved organisms are not well sustained in pure cultures while be successfully co-
cultivated with algae suggests that algae play an important role in the ecology of the retrieved
species. This role is probably related to provision of nutrients, either in the form of released
metabolites, or organic molecules present in algal cell walls and senescent parts. These finding
demonstrate the direct benefit of performing metagenomics on sequencing datasets of
eukaryotes, as it allows to obtain genomic sequences of rare or difficultly cultivable organisms.

Discussion
55
4.3 Origin of contamination
One of the aims of this study was to obtain more information on the origin of bacteria present
within algal cultures. For this purpose we have compared the identified bacterial species
between the cultures (Table 2).
The datasets of the two O. tauri cultures obtained by subcloning a single liquid culture shared
only one bacterial species out of at least seven present in the cumulative assembly. The
substantial differences between the subcloned cultures can be explained by the specific
method of isolation. The method consists of an antibiotic treatment of the microalgal culture to
reduce bacterial population followed by growing the cells on solid medium and picking up of
individual colonies (Abby et al, 2014). The bacterial species that are retained upon the
procedure are likely the species that were physically associated with the individual eukaryotic
cells forming the colony. Because Ostreococcus cells are small, this results in a random
subsample of the original bacterial community. Further, one or both O. tauri sequencing
datasets contained a small number of sequences belonging to the same or very similar
Alcanivorax species as observed in the O. mediterraneus culture. This single bacterium can be a
member of the natural flora of the two algae or alternatively represent a contaminating
organism acquired during culturing in the same collection.
C. braunii cultures contained highly similar bacterial populations, sharing the majority fractions
of representatives. A small number of species present in the Japanese sample were absent from
the German data. Such situation is not surprising: the larger size of the Japanese sequencing
sets should have allowed to reconstruct sequences of a larger number of species. On the other
hand, the German culture has possibly passed through a bottleneck during sub-cloning and
transportation. A less well explainable difference between the cultures was the absence of
Rhodococcus and nearly complete absence of Streptomycetes from Japanese assembly, while
those genera were well represented in German assembly. Both genera are commonly found in
the environment and could have been introduced to the culture during maintenance in the
laboratory. Alternatively, they could have been present in the Japanese culture at negligible
frequencies, but gained more importance due to changes associated with transporting the
culture between laboratories.

Discussion
56
4.4 Future perspectives
We were able to isolate a number of high-quality assemblies of bacterial genomic sequences,
including those from representatives of poorly studied bacterial groups. The logical next step
would be annotation of the isolated assemblies. Studying the gene content and structure of the
genomes would allow to gain more information on the lifestyle and physiology of the bacteria.
Besides looking at the genomic sequences of less characterized organisms, sequences of the
well-studied bacterial groups retrieved in the course of the analysis could be surveyed for
presence of specific features, such as the biological marker gene for nitrogen fixation nifH
(Dedysh et al, 2004) or various enzymatic activities.
The obtained data directly suggests an interesting application associated with non-axenic algal
laboratory cultures. As our analysis has demonstrated, such cultures might be useful for
cultivation of bacterial species for which no pure cultures can be obtained otherwise. If the
number of other associated bacteria can be limited, this would allow to study the difficultly
approachable species in a relatively detailed way. Additional information on the bacterial
organism could be obtained with other omics techniques, such as transcriptomics and
metabolomics.

Discussie
57
5. Discussie
In deze studie werden metagenomische analyses uitgevoerd op genoom-sequentie data
verkregen van zes algenculturen behorende tot vier verschillende algensoorten. De
bestudeerde soorten waren Ostreococcus tauri en O. mediterraneus, beide uit de Middenlandse
Zee, de Antarctische alg Prasiola crispa en Chara braunii uit rijstvelden in Japen. Het doel van
de analyse was om de aanwezige bacteriële populaties te bestuderen en eventueel bacteriële
genoomsequenties te isoleren. De geassembleerde sequeneringsdata werd gefragmenteerd en
geclusterd volgens de abundantie- en de sequentie compositie. De groepen werden
taxonomisch geïdentificeerd via similariteit van de sequentiefragmenten met proteïnen uit de
NCBI proteïnendatabank en door middel van classificatie van de aanwezige 16S rRNA genen. De
kwaliteit en volledigheid van de bacteriële genoomsequenties opgenomen in individuele
clusters werden geëvalueerd op basis van de aanwezigheid van uniek voorkomende essentiële
genen.
5.1 Beoordeling van de gebruikte methode.
De gebruikte methodologie was succesvol in het scheiden van eukaryote en prokaryote contigs.
Verdere onderverdeling van de eukaryotische fractie liet echter niet toe om verschillende taxa
(ex. Viridiplantae en Ophisthokonta) in afzonderlijke clusters onder te brengen. Ook wanneer
bacteriële en eukaryotische contigs samen werden geanalyseerd, slaagde de methode er niet
altijd in om de bacteriële data te onderverdelen in groepen overeenkomend met individuele
species. Het probleem werd omzeild door de prokaryotische fractie te isoleren en deze
afzonderlijk te analyseren. Deze benadering was wel succesvol om prokaryotische species-
specifieke clusters te verkrijgen, en liet toe om een aantal nagenoeg complete bacteriële
genomen te isoleren uit elke dataset (Tabel 1). Het moet worden opgemerkt dat geen terminale
conclusies kunnen worden getrokken over de volledigheid van een genoom sequentie aan de
hand van unieke essentiële genen. De geselecteerde genen coderen voornamelijk voor
ribosomale eiwitten (Tabel 3, addendum) waarvan bekend is dat ze in een beperkt deel van het
bacteriële genoom gegroepeerd zijn (Lecompte et al, 2002). Aan de hand van aligneringen, met
gebruik van NUCmer, van de geïsoleerde bacteriële genomen met referentie genomen

Discussie
58
voorhanden in de NCBI databanken, kan men echter aantonen dat de bekomen genomen
inderdaad dikwijls heel volledig blijken te zijn
5.2 Biologie van de waargenomen bacteriën
5.2.1 Proteobacteria en Bacteroidetes
Culturen van alle algensoorten bevatten Proteobacteria, met de meest voorkomende klassen
Alphaproteobacteria en Gammaproteobacteria. Ook Bacteroidetes waren vertegenwoordigd in
vier van de zes culturen. Leden van deze bovengenoemde taxa worden vaak teruggevonden in
de bacteriële gemeenschappen geassocieerd met fytoplankton en macroalgen, waar ze het
grootste deel kunnen uitmaken van de geobserveerde diversiteit (Hollants et al, 2013 and
references therein; Kaczmarska et al, 2005; Methé et al, 1998; Sapp et al, 2007c and references
therein; Wu et al, 2007).
Ostreococcus culturen bevatten soorten uit de orders Oceanospirillales en Alteromonadales
(Gammaproteobacteria), die vooral in zeewater worden aangetroffen (Bowman & McMeekin,
2005; Garrity et al, 2005a). Oceanospirillales en Alteromonadales huizen heterotrofen,
verantwoordelijk voor een snelle afbraak van de meer toegankelijke fractie van opgeloste
organische verbindingen. Andere orders van Gammaproteobacteria, namelijk
Xanthomonadales en Pseudomonadales waren vertegenwoordigd in C. braunii culturen. Beide
taxa staan bekend als heel courante bodembacteriën (Garrity et al, 2005b; Saddler & Bradbury,
2005), die onder andere verschillende pathogene (Ryan et al, 2011; Xin & He, 2013) en
symbiotische (Berg & Martinez, 2015; Preston, 2004) interacties aangaan met planten. Hoewel
veel van de terrestrische Xanthomonadales beschreven zijn, is er weinig informatie
beschikbaar over aquatische soorten (Gutierrez et al, 2013; Kim et al, 2014a; Methé & Zehr,
1999; Renders et al, 1996; Wand et al, 1997). Een goed geassembleerd genoomsequentie van
een Xanthomonadales species kon worden geïsoleerd uit de Japanse C. braunii dataset. De 16S
rRNA uit deze genoomsequentie vertoonde een 100% overeenkomst met de 16S rRNA van een
niet beschreven Xanthomonadales bodembacterie.
Een abundant vertegenwoordigde klasse in de culturen van O. tauri, C. braunii en P. crispa was
die van de Alphaproteobacteria, met onder andere de orders Rhizobiales en Rhodobacterales.

Discussie
59
Rhodobacterales en vooral de Roseobacter subgroep worden beschreven als metabolisch
diverse oppervlakte-koloniserende bacteriën, meestal aangetroffen in mariene en zoutige
milieus (Dang et al, 2008), maar ook op kust biofilms (Dang & Lovell, 2000; Dang & Lovell, 2002)
en zee-ijs op de polen (Brinkmeyer et al, 2003; Brown & Bowman, 2001). Dit wordt bevestigd in
onze observaties: Roseobacterales werden teruggevonden in de datasets van de ostreococci en
P. crispa, maar niet in de datasets van C. braunii (Tabel 2, gemarkeerd met *). Hoewel de rol
van de meeste Roseobacteraceae onbekend blijft, komen symbiotische en potentieel obligate
interacties van deze organismen met algen vaak voor (Dang et al, 2008; Hahnke et al, 2013;
Piekarski et al, 2009).
De tweede orde van Alphaproteobacteria, Rhizobiales, was prominent aanwezig in C. braunii
culturen (Tabel 2, gemarkeerd met **). In tegenstelling tot Rhodobacterales die voornamelijk
gedijen in mariene habitats, worden Rhizobiales bacteriën even vaak teruggevonden in de
bodem en in zoetwater- en mariene omgevingen (Dobbelaere et al, 2003; Hollants et al, 2011c;
Jordan et al, 2007; Ruger & Hofle, 1992; Schaechter, 2009; Suss et al, 2006). Organismen uit
deze groep vormen gunstige interacties met planten gebaseerd op de productie van
fytohormonen, precursoren voor essentiële plantenmetabolieten en stikstofixatie (Delmotte et
al, 2009; Ivanova et al, 2000; Vance et al, 2002; Verginer et al, 2010). De diep gesequeneerde
Japanse C. braunii dataset liet toe om drie gedeeltelijke Alphaproteobacteria genomen te
isoleren (Tabel 1).
De derde grote groep van bacteriën waargenomen in meeste datasets, was Bacteroidetes. De
organismen uit deze groep zijn gespecialiseerd in de verwerking van polymere organische
stoffen, bijvoorbeeld in bodems en in de darmen van zoogdieren (Thomas, et al., 2011). We
hebben drie volledige genomische sequenties van Bacteroidetes geïsoleerd, waarvan één van
de goed bestudeerde genus Flavobacteria kwam en twee die overeenkomsten vertoonden met
de minder goed gekarakteriseerde genera Kordia en Gramella.
Een andere groep van bacteriën die vaak in associatie met planten worden teruggevonden, en
die in staat zijn om stikstoffixatie uit te voeren is Betaproteobacteria (Gyaneshwar, et al., 2011).
Betaproteobacteria vormen een belangrijke groep in zoet water, maar zijn nagenoeg afwezig in
mariene omgevingen (Glockner, et al., 1999; Gyaneshwar, et al., 2011; Likens, 2010; Shade, et

Discussie
60
al., 2007). In overeenstemming met deze observatie werden Betaproteobacteria enkel
teruggevonden in C. braunii culturen (Tabel 2).
De geobserveerde bacteriëngroepen kunnen complementaire rollen vervullen in de alg-
geassocieerde gemeenschap. Gammaproteobacteria en Alphaproteobacteria metaboliseren
gemakkelijk toegankelijk organische moleculen die door algen worden geproduceerd. Sommige
van deze bacteriën, zoals bepaalde Gammaproteobacteria, zijn eerder commensalen die op
algale metabolieten ‘grazen’. Andere, zoals leden van Alphaproteobacteria en
Betaproteobacteria kunnen daarentegen wederzijds voordelige interacties ondergaan met de
gastheer. Deze interacties kunnen zich baseren op uitwisseling van nutriënten en verdediging
tegen parasitaire bacteriën (Egan et al, 2013b). Bacteroidetes daarentegen zijn meester
afbrekers, die essentieel zijn voor re-mineralisatie van algale detritus, waardoor
voedingsstoffen en mineralen worden gerecycleerd.
5.2.2 Actinobacteria, Acidobacteria en Planctomycetes.
Naast Proteobacteria en Bacteroidetes, bevatten de culturen van C. braunii de phyla
Actinobacteria, Acidobacteria en Planctomycetes. Leden van deze phyla maken een belangrijke
deel uit van de bacteriële populatie in verschillende milieus (Cuesta et al, 2012; Gade et al,
2004; Quaiser et al, 2003; Subramani & Aalbersberg, 2012). Acidobacteria en Planctomycetes
zijn grotendeels onbeschreven door een bijna volledige afwezigheid van gekweekte isolaten.
Voor Acidobacteria zijn minder dan 15 genera formeel beschreven, en enkele bijkomende
isolaten hebben kandidaat namen (Huber, et al., 2014). Er zijn 24 genomen van Acidobacteria
gedeponeerd in NCBI whole genomes databank. De C. braunii assembly bevatte een
genoomsequentie van een organisme met 93,75% 16S rRNA gelijkenis met een onbeschreven
Bryobacter species uit de klasse Solibacteres. Solibacteres is een nieuw gevestigde kandidaat
klasse van Actinobacteria, met slechts twee gekarakteriseerde leden met de beschikbare
genoomsequenties (Kulichevskaya, et al., 2010). Voor de phylum Planctomycetes zijn slechts 22
verschillende genomen beschikbaar in NCBI whole genomes databank. In deze studie werden
twee vrijwel complete genomen van Planctomycetes species geïsoleerd. Ook aquatische
Actinobacteria zijn minder goed gekarakteriseerd. In deze studie werd een Actinobacteria
genoom sequenties geïsoleerd waarvan de 16S rRNA gen het dichts verwant (89.72% identiteit)

Discussie
61
was met een 16S rRNA van een isolaat uit de Gaiellales familie. Voor deze familie waren nog
geen genoomsequenties beschikbaar (Albuquerque et al, 2011).
Aanwezigheid van de moeilijk kweekbare bacteriesoorten in algenculturen in interessant. Het
feit dat organismen die niet goed kunnen worden bijgehouden in zuivere culturen toch met
succes kunnen worden gekweekt in aanwezigheid van algen, suggereert een belangrijke rol van
de eukaryoten in de ecologie van deze organismen. Deze rol is waarschijnlijk gerelateerd aan
het voorzien van voedingsstoffen, hetzij onder de vorm van vrije metabolieten of als
organische moleculen uit algale celwanden of van afgestorven delen. Deze bevindingen
demonstreren het directe voordeel van het uitvoeren van metagenomiche analyses op
sequeneringsdatasets bedoeld om eukaryootgenomen te bekomen, omdat hiermee
genoomsequenties van zeldzame of moeilijk kweekbare organismen kunnen worden verkregen.
5.3 Toekomstperspectieven
Het was mogelijk om een aantal hoge kwaliteit assemblages van bacteriële genomen te
recupereren, waaronder die van moeilijk te bestuderen bacteriële groepen. De logische
volgende stap zou annotatie zijn van de geïsoleerde genoomsequenties. Het bestuderen van de
gen inhoud en de structuur van het genoom maakt het mogelijk om meer informatie over de
levensstijl en de fysiologie van de bacterie te verkrijgen. Bovendien kunnen de sequenties
specifiek worden gescreend op de aanwezigheid van de biologische merker-gen voor
stikstofbinding nifH (Dedysh, et al., 2004) of verschillende andere enzymatische activiteiten en
functies.
De verkregen gegevens suggereren een interessante toepassing van niet-axenische
laboratorium culturen van algen. Zoals aangetoond in de loop van dit werk, kunnen dergelijke
culturen nuttig blijken voor de teelt van bacteriële soorten waarvoor geen zuivere culturen
kunnen worden verkregen op klassieke manieren.

Discussie
62

Conclusion
63
6. Conclusion
In this thesis we have studied bacterial populations captured within whole-genome sequencing
data obtained from six cultures of four algal species. The composition of bacterial communities
observed in different algal cultures corresponded well with what would be expected regarding
the natural growth conditions of the algae. Bacterial species associated with P. crispa, O. tauri
and O. mediterraneus belonged mostly to typically marine and coastal lineages. Bacteria from
C. braunii cultures contained a high number of representatives of groups usually encountered
in soil and freshwater. Besides, most of the bacterial species originated from bacterial phyla
often found on algal surfaces and within phytoplankton communities, and many of the
identified organisms contained close relatives known to interact with algae and plants.
Comparison of two clonal cultures of the microalga O. tauri obtained by subcloning of a single
liquid culture has revealed little similarities between represented bacteria, which could be
explained by the specificity of the used subculturing technique. By contrast, cultures of the
macroalga C. braunii sharing the same origin did show clear resemblances with respect to
bacterial flora, suggesting relative insusceptibility of the associated bacterial community to
subculturing.
The adopted binning method allowed to isolate a total of 15 bacterial genomic sequences with
nearly complete SCG content. These sequences belonged to both well-studied as well as almost
uncharacterized bacterial groups. Upon checking for the presence of chimeric sequences, and
possibly an additional round of sequence improvement, the isolated assemblies can be used for
gene prediction and annotation. This can permit to find potentially interesting traits revealing
the possible roles of the bacteria in the algal associated communities.
Because the applied binning method appeared to perform well for separating eukaryotic and
prokaryotic sequences, it can be used in the future for cleaning up of newly obtained eukaryotic
assemblies.

Conclusion
64

Materials and methods
65
7. Materials and methods
7.1 Sequencing data and assemblies.
The analysis was performed on whole-genome shotgun sequencing datasets of four algal
species, Ostreococcus tauri, Ostreococcus mediterraneus, Prasiola crispa and Chara braunii. All
datasets were obtained previously at different laboratories with Illumina sequencing
technology (Illumina, San Diego, CA, USA).
7.1.1 O. tauri and O. mediterraneus.
For O. tauri, two Illumina genomic sequencing datasets with accession numbers SRX026855 and
SRX030853 were retrieved from the SRA archive. The corresponding O. tauri culture, currently
kept at Roscoff Culture Collection (RCC) under accession number RCC 4221, has been isolated in
1995 in Thau Lagoon, and maintained at Banyuls-sur-mer Culture Collection (BCC) in liquid
medium until 2005, when it has been subcloned and further maintained on agar plates (Blanc-
Mathieu et al, 2014). The sequencing data originates from two DNA libraries prepared in 2001
and 2009, and containing respectively 43 million and 41 million 76 bp paired-end reads with an
average insert size of 250 nucleotides. For filtering out non-bacterial reads, we used the O. tauri
genome version 2.2 (Genbank accession numbers CAID01000001 to CAID01000020, (Alneberg
et al, 2014)), which consists of 20 chromosomes with a total size of 12.91 Mbp.
For the whole-genome sequencing project of O. mediterraneus, the BCC 102000 strain has been
used. This strain, now deposited at Roscoff Culture Collection as RCC 2590, has been isolated in
Gulf of Lion in 2009 and maintained at BCC prior to sequencing. The sequencing dataset used in
this project consists of paired-end Illumina reads (10.3 million 101 bp reads generated from 270
bp DNA fragments) and mate-paired reads (13.5 million 101 bp reads generated from 5230 bp
DNA fragments). The analysis was performed on an unfiltered, scaffolded draft assembly
generated previously with ALL-PATHS-LG genome assembler (Butler et al, 2008) by GENSCOPE
(http://www.genoscope.cns.fr) containing of 111 scaffolds with a cumulative size of 17.9 Mbp
(N50 800924 bp, max size 3668993 bp, min size 1037 bp, N% 2.51).

Materials and methods
66
7.1.2 P. crispa.
The terrestrial alga P. crispa, currently deposited at Culture Collection of Autotrophic Organisms
(CCALA) as CCALA 1053, has been isolated from a penguin rookery on Saunders Island, Falkland
Islands in 2010. The culture has been maintained in the Provasoli Enriched Seawater (PES S/2
liquid medium, (Starr & Zeikus, 1993)). Illumina sequencing dataset obtained from this strain in
2012 entails three paired-end read sets (119.0 million 101 bp reads with an insert size of 350
bp), and one mate-pair library (141.2 million 101 bp reads with an insert size of 2200 bp)
obtained with DNA from a single DNA extraction event.
Analysis was carried out on an unfiltered draft genome assembly generated previously using
CLC-assembly cell (CLC bio, Aarhus, Denmark) for read processing and assembly. Sspace
(Boetzer et al, 2011) was then used for scaffolding. The assembly contains 52528 scaffolds with
a total size of 188.1 Mbp (N50 8152 bp, max size 1727554 bp, min size 500 bp, N% 40.0).
7.1.3 C. braunii.
The C. braunii strain used for whole-genome shotgun sequencing has been isolated in Japan in
2008 and maintained in soil-water medium in laboratory conditions (Kato et al, 2008). Two
distinct genome sequencing projects were started, one in Japan and one in Germany to obtain
the genome of the strain. The first sequencing dataset generated in Japan contained 1.05 billion
Illumina 150 bp paired-end reads in seven DNA libraries with varying insert sizes. The analysis
was carried out on an unfiltered assembly obtained with ALL-PATHS-LG, containing 2.00 Gbp of
sequence in 28091 scaffolds (N50 2217102 bp, max size 14228587 bp, min size 885 bp, N%
17.6). The second dataset produced in Germany entailed two extra Illumina datasets, the first
of 58.0 million of 51 bp paired-end reads with an insert size of 250 bp and 40 million of 101 bp
single-end reads, and the second of 193 million of 51 bp of paired-end reads with an insert size
of 250 bp encompassing approximately 10% of mate pair reads with an insert size of 3000 bp.
From these libraries, two separate assemblies had been generated previously using CLC-
assembly cell, holding respectively 322685 contigs with a total size of 76.7 Mbp (N50 242 bp,
max size 167358 bp, min size 100 bp) and 325720 contigs with a total size of 90.1 Mbp (N50 373
bp, max size 172440 bp, min size 100 bp).

Materials and methods
67
7.2 Preparation of the data prior to binning.
Every dataset was pre-processed differently prior to metagenomic analysis, because of the
different sorts of data available for each of the studied organisms. For O. tauri, a reference
genomic sequence was accessible, which allowed to remove algal reads from the sequencing
dataset, simplifying the data. The non-algal reads were reassembled, and the obtained
assembly was subjected to binning. For P. crispa binning was performed on the draft assembly
constructed previously, but an initial filtering was carried out discarding a fraction of eukaryotic
sequences which gave strong unambiguous hits with algae and plants to limit the complexity of
the dataset. Because binning of P. crispa data has showed that the presence of eukaryotic
sequences does not interfere with the analysis, O. mediterraneus and C. braunii draft genomes
assemblies were binned without a preliminary filtering. The two German C. braunii assemblies
were combined and re-assembled with Newbler (Roche Applied Science, Penzberg, Germany)
before the analysis.
7.2.1 De novo assembly of non-algal contigs from O.tauri genome sequencing data using CLC-
assembly cell.
CLC-assembly cell is an integrated software suite that allows efficient processing of raw NGS
data, including removal of low quality nucleotides and adapter sequences. It contains a read-
mapper for placing reads on reference sequences, and a de novo assembly software based on
the deBruijn-graph algorithm.
Raw reads in FASTQ format were quality trimmed with CLC_QUALITY_TRIM program from the CLC-
assembly cell v. 4.3 with a minimum phred score of 20, a minimal length fraction of good
quality bases of 0.6, and allowing up to 10% of bad quality bases. To select non-algal reads, the
pre-processed sequencing data was mapped on O. tauri genome with the CLC_READ_MAPPER
using default mapping parameters. CLC_READ_MAPPER maps reads to the contigs by representing
the contigs as a uncompressed Suffix-Array and finding for each read up to 100 longest
ungapped matches with the reference starting at any position of the read. Identified seeds are
extended using a banded Smith-Waterman algorithm and one best matching position is chosen
based on the quality of the obtained alignments. Reads which did not map to the chromosomes
were extracted as unpaired reads with CLC_UNMAPPED_READS function with a minimal output

Materials and methods
68
length of 30 bp, and assembled with CLC’s de novo assembler. Bubble size was kept constant at
47 bp while sampling K-mer sizes from 30 to 65 in steps of 5 to determine the optimal
parameter value. Generated assemblies were compared on N50, N75 and N90 values and on
the total number of contigs longer than 100 kb. The optimal assembly was scaffolded with
Sspace, using a minimal limit of 15 links for contig joining, a maximal ratio of 0.6 for the
resolution of ambiguous links, allowing contig extension if a minimum overlap of 50 bp and a
20X coverage can be achieved, and allowing to trim up to 20 bases to retry extension.
7.2.2 Filtering of P. crispa assembly prior to binning.
Prior to binning, P. crispa assembly was aligned to NCBI proteins database with BLASTx (E-value
<1e-6) to assess the composition. BLASTx output was then used to carry out an initial filtering,
removing sequences with strong similarity to algae and plants. This was achieved with
FILTER_CONTIGS.PY script (scripts can be found in the addendum) which parses BLASTx output,
discarding sequences that show similarity with the Prasiola entries within the 10 best hits, and
sequences giving over 2/3 hits with algae and plants within the 20 best hits.
7.2.3 Combining two German C. braunii draft assemblies using Newbler.
Newbler is an assembly software developed for longer reads generated with Roche/454 Life
Science sequencing technology (Roche Applied Science, Penzberg, Germany), which has been
adapted to use other read types, including Sanger reads, paired-end and mate-pair Illumina
reads, and any sequences in fasta format with a maximum length of 2000 bp. The program
utilizes seed-based alignment to assemble contigs and longer paired-end reads.
The two German C. braunii assemblies were combined by fragmenting the contigs into pieces of
1800 bp with 300 bp overhangs with MFASTA_TOOLS.PL script, and re-assembled with Newbler
v2.8.1 using default alignment parameters, allowing to extend tips with single reads, and
outputting each read in only one contig. The obtained assembly was further scaffolded with
Sspace v2.0, using identical parameters as explained before.

Materials and methods
69
7.3 Binning of contigs with CONCOCT.
For each organism, the available or constructed assemblies were binned with CONCOCT v0.4
(Alneberg et al, 2014), a tool which segregates contigs according to coverage and composition.
In order to use CONCOCT, scaffolds were first disassembled into contigs using the
SCAFFOLD2CONTIGS.PL script which removes stretches of N (unassigned nucleotides) longer than 5,
while tagging fragments with the scaffold name to allow subsequent reconstruction. Contigs
were filtered by length, retaining entries longer than 999 nucleotides. Contigs exceeding 10 kbp
were fragmented as suggested by the developers of the CONCOCT package to ensure that they
were given more statistical weight. This was performed with CUT_FASTA.PY script, which cuts
sequences exceeding 20 kbp into pieces of 10 kbp or longer while keeping a reference to the
original contig name. To determine coverage, reads were mapped on the corresponding
fragmented assemblies using CLC_READ_MAPPER tool as described. For C. braunii, the reads were
also cross-mapped between German and Japanese assemblies. PCR duplicate reads were
removed from the resulting mapping files using MARKDUPLICATES function provided within Picard
Tools 1.129 package using default parameters. Coverage of each fragment was calculated with
COVERAGEBED utility from BEDTools 2.22.0. The output of COVERAGEBED was provided to
CONCOCT. Binning was performed using a k-mer length of 4 bp, minimal contig length of 999
bp, and the number of iterations of the expectation maximization algorithm of 500. The
algorithm performs iterative fitting of a mixture-of-Gaussian models to the available data. For
each assembly, the maximal number of clusters was determined individually based on the
taxonomical composition of the assembly provided by MEGAN5 and on precision and recall
values obtained for each number of clusters (see below). In some cases, cleaner bins could be
obtained by applying an iterative binning procedure, where bins corresponding to multiple
bacterial species were isolated and re-clustered separately. Results were visualized by
projecting the contigs in the first two PCA dimensions in R using CLUSTERPLOT.R script.
7.6 Binning evaluation using taxonomic labels provided by MEGAN5.
In order to evaluate the binning quality, and label the clusters, we performed taxonomic
classification of the fragmented contigs using MEGAN5. MEGAN5 is a package for compositional
and functional analysis of metagenomic datasets based on BLAST comparison of reads or

Materials and methods
70
contigs to nucleotide or protein databases. Contigs were searched against NCBI proteins
database using BLASTx at an E-value cut-off of 1e^-3 and reporting 100 best hits. MEGAN5 was
used to extract taxonomic assignments from the BLASTx output files according to the internal
LCA procedure with following parameters: minimum bit-score of 60, a maximum permitted E-
value of 1e^-5 and the Top Percent score of 10.0%. The assigned NCBI taxon identifiers were
converted to taxon labels at a chosen taxonomic level using MEGAN_TO_CONCOCT.PY and
MEGAN_CONCAT_TAXON.PY scripts from CONCOCT package (the latter is a script from CONCOCT
adapted to accept MEGAN5 output; modified scripts from the package can be found in the
addendum). Obtained taxonomic labels were provided to the VALIDATE.PL script from CONCOCT
to calculate clustering statistics, being recall, precision and Rand and Adjusted Rand indices.
Confusion plots were generated with CONFPLOT.R script from CONCOCT.
7.7 Binning evaluation using single-copy core genes.
To find the COG (Cluster of Orthologous Groups) representing a selected single copy core gene
in a set of sequences, RPS-BLAST (Reversed Position Specific BLAST) was used. RPS-BLAST
compares amino acid or translated nucleotide sequences to a collection of position-specific
score matrices of conserved protein domains from CDD (Conserved Domain Database), which
also contains COG entries.
To limit the running time of downstream applications, open reading frames were first predicted
and extracted from the fragmented assemblies using the metagenome version of Prodigal 2.5
(Hyatt et al, 2010), a tool which predicts bacterial and archaeal genes using a dynamic
programming algorithm. The open reading frames were scored against the NCBI CDD database
with RPS-BLAST at an E-value cut-off of 1e^-3. The output of RPS-BLAST was provided to
COG_TABLE.PY script from CONCOCT package to generate counts for the 36 COG’s with each
cluster. To ensure that fragmented COG’s are not over-counted, the script only considers COG’s
representing the major length fraction of the gene. Generated COG tables were visualized in R
using COGPLOT.R script.

Materials and methods
71
7.6 Isolation of bacterial genomes and scaffolding with Sspace.
To isolate bacterial genomes, fragments assigned to the cluster of interest were retrieved.
Because each fragment was tagged with the name of its parent contig and scaffold, the original
non-fragmented contigs and scaffolds could be reconstructed using COUNT_FRAGMENTS.SH script.
Only contigs for which 50% or more of the fragments were present in the bin were retained. An
identical rule was adopted to retrieve the scaffolds. Manual refinement of the clusters was
performed involving examination of scaffolds for which one or more fragments were assigned
to a distinct taxonomic lineage. If an inconsistent taxonomy was confirmed for the larger
fraction of the fragments, the scaffold was removed. In addition, the bins were augmented with
all scaffolds assigned to the correct taxonomic group which were not retrieved within the bin.
To improve the quality of the isolated genomes, a final scaffolding round was performed with
paired-end and mate-pair reads, when available, using Sspace with the same parameters as
listed above.
7.7 Aligning isolated genomes to reference using MUMmer.
16S rRNA genes were isolated from the sequences using online RNAmmer 1.2 Server (Lagesen
et al, 2007). This software utilizes a two-level Hidden Markov Model-based approach for finding
ribosomal RNA genes. The retrieved sequences were provided to SINA Alignment Service within
Silva database for classification (Pruesse et al, 2012). SINA is a comprehensive on-line resource
containing quality checked and aligned ribosomal RNA sequence data and providing a search
service for taxonomic identification of unknown 23s and 16S rRNA’s. Reference genomes,
identified from the MEGAN5 assignments of the sequences within each bin, were retrieved
from NCBI whole genomes. In cases when no species could be assigned to the majority of
sequences, closely related organisms were identified using 16S rRNA-based approach. Contigs
were aligned against the reference genome using NUCmer from MUMmer v3.23 (Delcher et al,
1999) using a minimum exact-match seed size of 30 bp and a minimum combined anchor
length of 65 bp per cluster. MUMmer is a system allowing rapid alignment of entire genomes,
either complete or in fragments, using a suffix-tree based algorithm. The NUCmer program
within the package is adapted for alignment of two large sets of contigs corresponding to two
draft genomes.

Materials and methods
72
7.8 Evaluation of CONCOCT-assisted binning for separating prokaryotic and eukaryotic
sequences.
In order to access the ability of the approach to discriminate between eukaryotic and
prokaryotic sequences, we have fragmented the O. tauri genome v2.2 into pieces of 1 kbp,
avoiding generation of fragments shorter than 2 kbp using CUT_FASTA.PL. The chromosome
fragments were combined with the fragmented bacterial O. tauri assembly, coverage was
determined, and the sequences were binned with CONCOCT as described.


References
74
8. References
(2013) Database resources of the National Center for Biotechnology Information. Nucleic acids research 41: D8-d20 Abby S, Touchon M, DE JODE A, Grimsley N, Piganeau G (2014) Bacteria in Ostreococcus tauri Cultures – Friends, Foes or Hitchhikers? Frontiers in Microbiology 5 Agrawal A, Gopal K (2013) Biomass Production in Food Chain and Its Role at Trophic Levels. In Biomonitoring of Water and Waste Water, pp 59-70. Springer Albertsen M, Hugenholtz P, Skarshewski A, Nielsen KL, Tyson GW, Nielsen PH (2013) Genome sequences of rare, uncultured bacteria obtained by differential coverage binning of multiple metagenomes. Nature biotechnology 31: 533-538 Albuquerque L, França L, Rainey FA, Schumann P, Nobre MF, da Costa MS (2011) Gaiella occulta gen. nov., sp. nov., a novel representative of a deep branching phylogenetic lineage within the class Actinobacteria and proposal of Gaiellaceae fam. nov. and Gaiellales ord. nov. Systematic and Applied Microbiology 34: 595-599 Alneberg J, Bjarnason BS, de Bruijn I, Schirmer M, Quick J, Ijaz UZ, Lahti L, Loman NJ, Andersson AF, Quince C (2014) Binning metagenomic contigs by coverage and composition. Nat Meth 11: 1144-1146 Amaro AM, Fuentes MS, Ogalde SR, Venegas JA, Suarez-Isla BA (2005) Identification and characterization of potentially algal-lytic marine bacteria strongly associated with the toxic dinoflagellate Alexandrium catenella. The Journal of eukaryotic microbiology 52: 191-200 Amin SA. (2010) The role of siderophores in algal-bacterial interactions in the marine environment. Ariosa Y, Quesada A, Aburto J, Carrasco D, Carreres R, Leganes F, Fernandez Valiente E (2004) Epiphytic cyanobacteria on Chara vulgaris are the main contributors to N(2) fixation in rice fields. Applied and environmental microbiology 70: 5391-5397 Armstrong E, Yan L, Boyd KG, Wright PC, Burgess JG (2001) The symbiotic role of marine microbes on living surfaces. Hydrobiologia 461: 37-40 Ashen JB, Goff LJ (1998) Galls on the marine red alga Prionitislanceolata (Halymeniaceae): specific induction and subsequentdevelopment of an algal-bacterial symbiosis. American journal of botany 85: 1710-1721 Ashen JB, Goff LJ (2000) Molecular and ecological evidence for species specificity and coevolution in a group of marine algal-bacterial symbioses. Applied and environmental microbiology 66: 3024-3030 Bai X, Lant P, Pratt S (2015) The contribution of bacteria to algal growth by carbon cycling. Biotechnology and bioengineering 112: 688-695 Bauer M, Kube M, Teeling H, Richter M, Lombardot T, Allers E, Wurdemann CA, Quast C, Kuhl H, Knaust F, Woebken D, Bischof K, Mussmann M, Choudhuri JV, Meyer F, Reinhardt R, Amann RI, Glockner FO (2006) Whole genome analysis of the marine Bacteroidetes'Gramella forsetii' reveals adaptations to degradation of polymeric organic matter. Environmental microbiology 8: 2201-2213 Beleneva IA, Zhukova NV (2006) Bacterial communities of some brown and red algae from Peter the Great Bay, the Sea of Japan. Microbiology 75: 348-357 Bengtsson MM, Ovreas L (2010) Planctomycetes dominate biofilms on surfaces of the kelp Laminaria hyperborea. BMC microbiology 10: 261 Bentley SD, Parkhill J (2004) Comparative genomic structure of prokaryotes. Annual review of genetics 38: 771-792

References
75
Berdy J (2005) Bioactive microbial metabolites. The Journal of antibiotics 58: 1-26 Berg G, Martinez JL (2015) Friends or foes: can we make a distinction between beneficial and harmful strains of the Stenotrophomonas maltophilia complex? Frontiers in Microbiology 6: 241 Bertilsson S, Jones J, Findlay S, Sinsabaugh R (2003) Supply of dissolved organic matter to aquatic ecosystems: autochthonous sources. Bhattacharya D, Qiu H, Price DC, Yoon HS (2015) Why we need more algal genomes. Journal of Phycology 51: 1-5 Blanc-Mathieu R, Verhelst B, Derelle E, Rombauts S, Bouget FY, Carre I, Chateau A, Eyre-Walker A, Grimsley N, Moreau H, Piegu B, Rivals E, Schackwitz W, Van de Peer Y, Piganeau G (2014) An improved genome of the model marine alga Ostreococcus tauri unfolds by assessing Illumina de novo assemblies. BMC genomics 15: 1103 Boetzer M, Henkel CV, Jansen HJ, Butler D, Pirovano W (2011) Scaffolding pre-assembled contigs using SSPACE. Bioinformatics (Oxford, England) 27: 578-579 Boetzer M, Pirovano W (2014) SSPACE-LongRead: scaffolding bacterial draft genomes using long read sequence information. BMC bioinformatics 15: 211 Bolinches J, Lemos ML, Barja JL (1988) Population dynamics of heterotrophic bacterial communities associated withFucus vesiculosus andUlva rigida in an estuary. Microbial ecology 15: 345-357 Booijink CC, Zoetendal EG, Kleerebezem M, de Vos WM (2007) Microbial communities in the human small intestine: coupling diversity to metagenomics. Future microbiology 2: 285-295 Bork P, Bowler C, de Vargas C, Gorsky G, Karsenti E, Wincker P (2015) Tara Oceans. Tara Oceans studies plankton at planetary scale. Introduction. Science (New York, NY) 348: 873 Bowman J, McMeekin T (2005) Alteromonadales ord. nov. In Bergey’s Manual® of Systematic Bacteriology, Brenner D, Krieg N, Staley J, Garrity G, Boone D, De Vos P, Goodfellow M, Rainey F, Schleifer K-H (eds), 10, pp 443-491. Springer US Boyd P, Ibisanmi E, Sander S, Hunter K, Jackson G (2010) Remineralization of upper ocean particles: Implications for iron biogeochemistry. Limnology and Oceanography 55: 1271-1288 Brady A, Salzberg SL (2009a) Phymm and PhymmBL: metagenomic phylogenetic classification with interpolated Markov models. Nat Methods 6: 673-676 Brady A, Salzberg SL (2009b) Phymm and PhymmBL: Metagenomic Phylogenetic Classification with Interpolated Markov Models. Nature methods 6: 673-676 Brinkmeyer R, Knittel K, Jürgens J, Weyland H, Amann R, Helmke E (2003) Diversity and Structure of Bacterial Communities in Arctic versus Antarctic Pack Ice. Applied and environmental microbiology 69: 6610-6619 Brodie J, Lewis J (2007) Unravelling the algae: the past, present, and future of algal systematics: CRC Press. Brown MV, Bowman JP (2001) A molecular phylogenetic survey of sea-ice microbial communities (SIMCO). FEMS microbiology ecology 35: 267-275 Buchan A, González JM, Moran MA (2005) Overview of the Marine Roseobacter Lineage. Applied and environmental microbiology 71: 5665-5677 Burke C, Steinberg P, Rusch D, Kjelleberg S, Thomas T (2011a) Bacterial community assembly based on functional genes rather than species. Proceedings of the National Academy of Sciences 108: 14288-14293

References
76
Burke C, Thomas T, Lewis M, Steinberg P, Kjelleberg S (2011b) Composition, uniqueness and variability of the epiphytic bacterial community of the green alga Ulva australis. The ISME Journal 5: 590-600 Burke C, Thomas T, Lewis M, Steinberg P, Kjelleberg S (2011c) Composition, uniqueness and variability of the epiphytic bacterial community of the green alga Ulva australis. Isme j 5: 590-600 Butler J, MacCallum I, Kleber M, Shlyakhter IA, Belmonte MK, Lander ES, Nusbaum C, Jaffe DB (2008) ALLPATHS: de novo assembly of whole-genome shotgun microreads. Genome research 18: 810-820 Camacho C, Coulouris G, Avagyan V, Ma N, Papadopoulos J, Bealer K, Madden TL (2009) BLAST+: architecture and applications. BMC bioinformatics 10: 421 Cardozo KH, Guaratini T, Barros MP, Falcão VR, Tonon AP, Lopes NP, Campos S, Torres MA, Souza AO, Colepicolo P (2007) Metabolites from algae with economical impact. Comparative Biochemistry and Physiology Part C: Toxicology & Pharmacology 146: 60-78 Cathey D, Parker B, Simmons Jr G, Yongue Jr W, Van Brunt M (1981) The microfauna of algal mats and artificial substrates in Southern Victoria Land lakes of Antarctica. Hydrobiologia 85: 3-15 Chakravorty S, Helb D, Burday M, Connell N, Alland D (2007) A detailed analysis of 16S ribosomal RNA gene segments for the diagnosis of pathogenic bacteria. Journal of microbiological methods 69: 330-339 Chatterji S, Yamazaki I, Bai Z, Eisen J (2008) CompostBin: A DNA Composition-Based Algorithm for Binning Environmental Shotgun Reads. In Research in Computational Molecular Biology, Vingron M, Wong L (eds), Vol. 4955, 3, pp 17-28. Springer Berlin Heidelberg Chen Y, Garcia EK, Gupta MR, Rahimi A, Cazzanti L (2009) Similarity-based Classification: Concepts and Algorithms. J Mach Learn Res 10: 747-776 Chisholm JRM, Dauga C, Ageron E, Grimont PAD, Jaubert JM (1996) 'Roots' in mixotrophic algae. Nature 381: 382-382 Ciccarelli FD, Doerks T, von Mering C, Creevey CJ, Snel B, Bork P (2006) Toward automatic reconstruction of a highly resolved tree of life. Science (New York, NY) 311: 1283-1287 Compant S, Nowak J, Coenye T, Clément C, Ait Barka E (2008) Diversity and occurrence of Burkholderia spp. in the natural environment, Vol. 32. Compeau PEC, Pevzner PA, Tesler G (2011) How to apply de Bruijn graphs to genome assembly. Nat Biotech 29: 987-991 Correa JA, McLachlan J (1994) Endophytic algae of Chondrus crispus (Rhodophyta). V. Fine structure of the infection by Acrochaete operculata (Chlorophyta). European Journal of Phycology 29: 33-47 Cottrell MT, Kirchman DL (2000) Natural Assemblages of Marine Proteobacteria and Members of the Cytophaga-Flavobacter Cluster Consuming Low- and High-Molecular-Weight Dissolved Organic Matter. Applied and environmental microbiology 66: 1692-1697 Cox-Foster DL, Conlan S, Holmes EC, Palacios G, Evans JD, Moran NA, Quan PL, Briese T, Hornig M, Geiser DM, Martinson V, vanEngelsdorp D, Kalkstein AL, Drysdale A, Hui J, Zhai J, Cui L, Hutchison SK, Simons JF, Egholm M, Pettis JS, Lipkin WI (2007) A metagenomic survey of microbes in honey bee colony collapse disorder. Science (New York, NY) 318: 283-287 Craigie JS, Correa JA (1996) Etiology of infectious diseases in cultivated Chondrus crispus (Gigartinales, Rhodophyta). In Fifteenth International Seaweed Symposium, pp 97-104.

References
77
Crawford CC, Hobbie J, Webb K (1974) The utilization of dissolved free amino acids by estuarine microorganisms. Ecology: 551-563 Croft MT, Warren MJ, Smith AG (2006) Algae Need Their Vitamins. Eukaryotic Cell 5: 1175-1183 Cuesta G, García-de-la-Fuente R, Abad M, Fornes F (2012) Isolation and identification of actinomycetes from a compost-amended soil with potential as biocontrol agents. Journal of environmental management 95: S280-S284 Cundell AM, Sleeter TD, Mitchell R (1977a) Microbial populations associated with the surface of the brown algaAscophyllum nodosum. Microbial ecology 4: 81-91 Cundell AM, Sleeter TD, Mitchell R (1977b) Microbial populations associated with the surface of the brown algaAscophyllum nodosum. Microbial ecology 4: 81-91 Dang H, Li T, Chen M, Huang G (2008) Cross-Ocean Distribution of Rhodobacterales Bacteria as Primary Surface Colonizers in Temperate Coastal Marine Waters. Applied and environmental microbiology 74: 52-60 Dang H, Lovell CR (2000) Bacterial Primary Colonization and Early Succession on Surfaces in Marine Waters as Determined by Amplified rRNA Gene Restriction Analysis and Sequence Analysis of 16S rRNA Genes. Applied and environmental microbiology 66: 467-475 Dang H, Lovell CR (2002) Seasonal dynamics of particle-associated and free-living marine Proteobacteria in a salt marsh tidal creek as determined using fluorescence in situ hybridization. Environmental microbiology 4: 287-295 Davis KER, Joseph SJ, Janssen PH (2005) Effects of Growth Medium, Inoculum Size, and Incubation Time on Culturability and Isolation of Soil Bacteria. Applied and environmental microbiology 71: 826-834 De Godos I, Vargas V, Guzmán H, Soto R, García B, García P, Muñoz R (2014) Assessing carbon and nitrogen removal in a novel anoxic–aerobic cyanobacterial–bacterial photobioreactor configuration with enhanced biomass sedimentation. Water research 61: 77-85 Dedysh SN, Ricke P, Liesack W (2004) NifH and NifD phylogenies: an evolutionary basis for understanding nitrogen fixation capabilities of methanotrophic bacteria. Microbiology 150: 1301-1313 Delbridge L, Coulburn J, Fagerberg W, Tisa LS (2004) Community profiles of bacterial endosymbionts in four species of Caulerpa. Symbiosis 37: 335-344 Delcher AL, Kasif S, Fleischmann RD, Peterson J, White O, Salzberg SL (1999) Alignment of whole genomes. Nucleic acids research 27: 2369-2376 Delmotte N, Knief C, Chaffron S, Innerebner G, Roschitzki B, Schlapbach R, von Mering C, Vorholt JA (2009) Community proteogenomics reveals insights into the physiology of phyllosphere bacteria. Proceedings of the National Academy of Sciences of the United States of America 106: 16428-16433 Denison RF, Toby Kiers E (2004) Why are most rhizobia beneficial to their plant hosts, rather than parasitic? Microbes and Infection 6: 1235-1239 Dillon R, Dillon V (2004) The gut bacteria of insects: nonpathogenic interactions. Annual Reviews in Entomology 49: 71-92 Dimijian GG (2000) Evolving together: the biology of symbiosis, part 1. Proceedings (Baylor University Medical Center) 13: 217-226 Dimitrieva GY, Crawford RL, Yuksel GU (2006) The nature of plant growth-promoting effects of a pseudoalteromonad associated with the marine algae Laminaria japonica and linked to catalase excretion. Journal of applied microbiology 100: 1159-1169

References
78
Do Nascimento M, Dublan MdlA, Ortiz-Marquez JCF, Curatti L (2013) High lipid productivity of an Ankistrodesmus–Rhizobium artificial consortium. Bioresource Technology 146: 400-407 Dobbelaere S, Vanderleyden J, Okon Y (2003) Plant growth-promoting effects of diazotrophs in the rhizosphere. Critical Reviews in Plant Sciences 22: 107-149 Dröge J, McHardy AC (2012) Taxonomic binning of metagenome samples generated by next-generation sequencing technologies. Briefings in bioinformatics Duarte CM, Middelburg JJ, Caraco N (2005) Major role of marine vegetation on the oceanic carbon cycle. Biogeosciences 2: 1-8 Dunne JP, Sarmiento JL, Gnanadesikan A (2007) A synthesis of global particle export from the surface ocean and cycling through the ocean interior and on the seafloor. Global Biogeochemical Cycles 21 Dworjanyn S, De Nys R, Steinberg P (2006) Chemically mediated antifouling in the red alga Delisea pulchra. Marine Ecology Progress Series 318: 153-163 Egan S, Harder T, Burke C, Steinberg P, Kjelleberg S, Thomas T (2013a) The seaweed holobiont: understanding seaweed–bacteria interactions, Vol. 37. Egan S, Harder T, Burke C, Steinberg P, Kjelleberg S, Thomas T (2013b) The seaweed holobiont: understanding seaweed–bacteria interactions. FEMS microbiology reviews 37: 462-476 Eichorst SA, Breznak JA, Schmidt TM (2007) Isolation and Characterization of Soil Bacteria That Define Terriglobus gen. nov., in the Phylum Acidobacteria. Applied and environmental microbiology 73: 2708-2717 Engel S, Jensen PR, Fenical W (2002) Chemical ecology of marine microbial defense. Journal of chemical ecology 28: 1971-1985 Engel S, Puglisi MP, Jensen PR, Fenical W (2006) Antimicrobial activities of extracts from tropical Atlantic marine plants against marine pathogens and saprophytes. Marine Biology 149: 991-1002 Erkelens M, Adetutu EM, Taha M, Tudararo-Aherobo L, Antiabong J, Provatas A, Ball AS (2012) Sustainable remediation–The application of bioremediated soil for use in the degradation of TNT chips. Journal of environmental management 110: 69-76 Fenchel T (2008) The microbial loop–25 years later. Journal of Experimental Marine Biology and Ecology 366: 99-103 Fernandes DR, Yokoya NS, Yoneshigue-Valentin Y (2011a) Protocol for seaweed decontamination to isolate unialgal cultures. Revista Brasileira de Farmacognosia 21: 313-316 Fernandes N, Case RJ, Longford SR, Seyedsayamdost MR, Steinberg PD, Kjelleberg S, Thomas T (2011b) Genomes and virulence factors of novel bacterial pathogens causing bleaching disease in the marine red alga Delisea pulchra. PloS one 6: e27387-e27387 Fernández-Gómez B, Richter M, Schüler M, Pinhassi J, Acinas SG, González JM, Pedrós-Alió C (2013) Ecology of marine Bacteroidetes: a comparative genomics approach. The ISME Journal 7: 1026-1037 Field CB, Behrenfeld MJ, Randerson JT, Falkowski P (1998) Primary production of the biosphere: integrating terrestrial and oceanic components. Science (New York, NY) 281: 237-240 Foesel BU, Nägele V, Naether A, Wüst PK, Weinert J, Bonkowski M, Lohaus G, Polle A, Alt F, Oelmann Y, Fischer M, Friedrich MW, Overmann J (2014) Determinants of Acidobacteria activity inferred from the relative abundances of 16S rRNA transcripts in German grassland and forest soils. Environmental microbiology 16: 658-675

References
79
Fuerst JA, Sagulenko E (2012) Keys to eukaryality: planctomycetes and ancestral evolution of cellular complexity. Frontiers in microbiology 3 Gade D, Schlesner H, Glöckner F, Amann R, Pfeiffer S, Thomm M (2004) Identification of planctomycetes with order-, genus-, and strain-specific 16S rRNA-targeted probes. Microbial ecology 47: 243-251 Gardes A, Kaeppel E, Shehzad A, Seebah S, Teeling H, Yarza P, Glockner FO, Grossart HP, Ullrich MS (2010) Complete genome sequence of Marinobacter adhaerens type strain (HP15), a diatom-interacting marine microorganism. Standards in genomic sciences 3: 97-107 Garrity G, Bell J, Lilburn T (2005a) Oceanospirillales ord. nov. In Bergey’s Manual® of Systematic Bacteriology, Brenner D, Krieg N, Staley J, Garrity G, Boone D, De Vos P, Goodfellow M, Rainey F, Schleifer K-H (eds), 8, pp 270-323. Springer US Garrity G, Bell J, Lilburn T (2005b) Pseudomonadales Orla-Jensen 1921, 270AL. In Bergey’s Manual® of Systematic Bacteriology, Brenner D, Krieg N, Staley J, Garrity G, Boone D, De Vos P, Goodfellow M, Rainey F, Schleifer K-H (eds), 9, pp 323-442. Springer US Garrity GM, Bell JA, Lilburn T (2005c) Class I. Alphaproteobacteria class. nov. In Bergey’s Manual® of Systematic Bacteriology, pp 1-574. Springer Gauthier MJ, Lafay B, Christen R, Fernandez L, Acquaviva M, Bonin P, Bertrand JC (1992) Marinobacter hydrocarbonoclasticus gen. nov., sp. nov., a new, extremely halotolerant, hydrocarbon-degrading marine bacterium. International journal of systematic bacteriology 42: 568-576 Glockner FO, Fuchs BM, Amann R (1999) Bacterioplankton compositions of lakes and oceans: a first comparison based on fluorescence in situ hybridization. Applied and environmental microbiology 65: 3721-3726 Glöckner FO, Kube M, Bauer M, Teeling H, Lombardot T, Ludwig W, Gade D, Beck A, Borzym K, Heitmann K, Rabus R, Schlesner H, Amann R, Reinhardt R (2003) Complete genome sequence of the marine planctomycete Pirellula sp. strain 1. Proceedings of the National Academy of Sciences 100: 8298-8303 Goecke F, Thiel V, Wiese J, Labes A, Imhoff JF (2013) Algae as an important environment for bacteria – phylogenetic relationships among new bacterial species isolated from algae. Phycologia 52: 14-24 Goecke FR, Labes A, Wiese J, Imhoff JF (2010) Chemical interactions between marine macroalgae and bacteria. Marine Ecology Progress Series 409: 267-299 Gomez-Pereira PR, Fuchs BM, Alonso C, Oliver MJ, van Beusekom JE, Amann R (2010) Distinct flavobacterial communities in contrasting water masses of the north Atlantic Ocean. Isme j 4: 472-487 Goodfellow M, Williams S (1983) Ecology of actinomycetes. Annual Reviews in Microbiology 37: 189-216 Gouin A, Legeai F, Nouhaud P, Whibley A, Simon JC, Lemaitre C (2015) Whole-genome re-sequencing of non-model organisms: lessons from unmapped reads. Heredity 114: 494-501 Green DH, Bowman JP, Smith EA, Gutierrez T, Bolch CJ (2006) Marinobacter algicola sp. nov., isolated from laboratory cultures of paralytic shellfish toxin-producing dinoflagellates. International journal of systematic and evolutionary microbiology 56: 523-527 Griepenburg U, Ward-Rainey N, Mohamed S, Schlesner H, Marxsen H, Rainey FA, Stackebrandt E, Auling G (1999) Phylogenetic diversity, polyamine pattern and DNA base composition of members of the order Planctomycetales. International journal of systematic bacteriology 49 Pt 2: 689-696 Grossart H-P (1999) Interactions between marine bacteria and axenic diatoms (Cylindrotheca fusiformis, Nitzschia laevis, and Thalassiosira weissflogii) incubated under various conditions in the lab. Aquatic Microbial Ecology 19: 1-11

References
80
Guo M, Han X, Jin T, Zhou L, Yang J, Li Z, Chen J, Geng B, Zou Y, Wan D, Li D, Dai W, Wang H, Chen Y, Ni P, Fang C, Yang R (2012) Genome Sequences of Three Species in the Family Planctomycetaceae. Journal of Bacteriology 194: 3740-3741 Gupta S, Abu-Ghannam N (2011) Bioactive potential and possible health effects of edible brown seaweeds. Trends in Food Science & Technology 22: 315-326 Gutierrez T, Green DH, Nichols PD, Whitman WB, Semple KT, Aitken MD (2013) Polycyclovorans algicola gen. nov., sp. nov., an Aromatic-Hydrocarbon-Degrading Marine Bacterium Found Associated with Laboratory Cultures of Marine Phytoplankton. Applied and environmental microbiology 79: 205-214 Gyaneshwar P, Hirsch AM, Moulin L, Chen WM, Elliott GN, Bontemps C, Estrada-de Los Santos P, Gross E, Dos Reis FB, Sprent JI, Young JP, James EK (2011) Legume-nodulating betaproteobacteria: diversity, host range, and future prospects. Molecular plant-microbe interactions : MPMI 24: 1276-1288 Hahnke S, Brock NL, Zell C, Simon M, Dickschat JS, Brinkhoff T (2013) Physiological diversity of Roseobacter clade bacteria co-occurring during a phytoplankton bloom in the North Sea. Systematic and Applied Microbiology 36: 39-48 Hehemann J-H, Correc G, Thomas F, Bernard T, Barbeyron T, Jam M, Helbert W, Michel G, Czjzek M (2012) Biochemical and structural characterization of the complex agarolytic enzyme system from the marine bacterium Zobellia galactanivorans. Journal of Biological Chemistry 287: 30571-30584 Hellio C, Berge JP, Beaupoil C, Le Gal Y, Bourgougnon N (2002) Screening of marine algal extracts for anti-settlement activities against microalgae and macroalgae. Biofouling 18: 205-215 Hellio C, De La Broise D, Dufosse L, Le Gal Y, Bourgougnon N (2001) Inhibition of marine bacteria by extracts of macroalgae: potential use for environmentally friendly antifouling paints. Marine environmental research 52: 231-247 Hingamp P, Grimsley N, Acinas SG, Clerissi C, Subirana L, Poulain J, Ferrera I, Sarmento H, Villar E, Lima-Mendez G (2013) Exploring nucleo-cytoplasmic large DNA viruses in Tara Oceans microbial metagenomes. The ISME journal 7: 1678-1695 Hoagland KD, Rosowski JR, Gretz MR, Roemer SC (1993) Diatom extracellular polymeric substances: function, fine structure, chemistry, and physiology. Journal of Phycology 29: 537-566 Hollants J, Decleyre H, Leliaert F, De Clerck O, Willems A (2011a) Life without a cell membrane: challenging the specificity of bacterial endophytes within Bryopsis (Bryopsidales, Chlorophyta). BMC microbiology 11: 255 Hollants J, Leliaert F, De Clerck O, Willems A (2013) What we can learn from sushi: a review on seaweed–bacterial associations. FEMS microbiology ecology 83: 1-16 Hollants J, Leroux O, Leliaert F, Decleyre H, De Clerck O, Willems A (2011b) Who Is in There? Exploration of Endophytic Bacteria within the Siphonous Green Seaweed <italic>Bryopsis</italic> (Bryopsidales, Chlorophyta). PloS one 6: e26458 Hollants J, Leroux O, Leliaert F, Decleyre H, De Clerck O, Willems A (2011c) Who is in there? Exploration of endophytic bacteria within the siphonous green seaweed Bryopsis (Bryopsidales, Chlorophyta). PloS one 6: e26458 Holzinger A, Karsten U, Lütz C, Wiencke C (2006) Ultrastructure and photosynthesis in the supralittoral green macroalga Prasiola crispa from Spitsbergen (Norway) under UV exposure. Phycologia 45: 168-177 Hong K, Gao A-H, Xie Q-Y, Gao HG, Zhuang L, Lin H-P, Yu H-P, Li J, Yao X-S, Goodfellow M (2009) Actinomycetes for marine drug discovery isolated from mangrove soils and plants in China. Marine drugs 7: 24-44

References
81
Horton M, Bodenhausen N, Bergelson J (2010) MARTA: a suite of Java-based tools for assigning taxonomic status to DNA sequences. Bioinformatics (Oxford, England) 26: 568-569 Howe AC, Jansson JK, Malfatti SA, Tringe SG, Tiedje JM, Brown CT (2014) Tackling soil diversity with the assembly of large, complex metagenomes. Proceedings of the National Academy of Sciences 111: 4904-4909 Hu C, Liu Y, Song L, Zhang D (2002) Effect of desert soil algae on the stabilization of fine sands. Journal of Applied Phycology 14: 281-292 Huber KJ, Wust PK, Rohde M, Overmann J, Foesel BU (2014) Aridibacter famidurans gen. nov., sp. nov. and Aridibacter kavangonensis sp. nov., two novel members of subdivision 4 of the Acidobacteria isolated from semiarid savannah soil. International journal of systematic and evolutionary microbiology 64: 1866-1875 Hulatt CJ, Thomas DN (2010) Dissolved organic matter (DOM) in microalgal photobioreactors: a potential loss in solar energy conversion? Bioresource technology 101: 8690-8697 Hulatt CJ, Thomas DN, Bowers DG, Norman L, Zhang C (2009) Exudation and decomposition of chromophoric dissolved organic matter (CDOM) from some temperate macroalgae. Estuarine, Coastal and Shelf Science 84: 147-153 Huson DH, Auch AF, Qi J, Schuster SC (2007) MEGAN analysis of metagenomic data. Genome research 17: 377-386 Hyatt D, Chen GL, Locascio PF, Land ML, Larimer FW, Hauser LJ (2010) Prodigal: prokaryotic gene recognition and translation initiation site identification. BMC bioinformatics 11: 119 Imelfort M, Parks D, Woodcroft BJ, Dennis P, Hugenholtz P, Tyson GW (2014) GroopM: an automated tool for the recovery of population genomes from related metagenomes. PeerJ 2: e603 Ivanova E, Bakunina IY, Sawabe T, Hayashi K, Alexeeva Y, Zhukova N, Nicolau D, Zvaygintseva T, Mikhailov V (2002) Two species of culturable bacteria associated with degradation of brown algae Fucus evanescens. Microbial ecology 43: 242-249 Ivanova EG, Doronina NV, Shepeliakovskaia AO, Laman AG, Brovko FA, Trotsenko Iu A (2000) [Facultative and obligate aerobic methylobacteria synthesize cytokinins]. Mikrobiologiia 69: 764-769 Ivanova EP, Christen R, Sawabe T, Alexeeva YV, Lysenko AM, Chelomin VP, Mikhailov VV (2005) Presence of ecophysiologically diverse populations within Cobetia marina strains isolated from marine invertebrate, algae and the environments. Microbes and environments 20: 200-207 Janssen PH (2006) Identifying the Dominant Soil Bacterial Taxa in Libraries of 16S rRNA and 16S rRNA Genes. Applied and environmental microbiology 72: 1719-1728 Jasti S, Sieracki ME, Poulton NJ, Giewat MW, Rooney-Varga JN (2005) Phylogenetic diversity and specificity of bacteria closely associated with Alexandrium spp. and other phytoplankton. Applied and environmental microbiology 71: 3483-3494 Jensen SI, Kuhl M, Prieme A (2007) Different bacterial communities associated with the roots and bulk sediment of the seagrass Zostera marina. FEMS microbiology ecology 62: 108-117 Jermy A (2009) Symbiosis: A partnership cast in iron. Nat Rev Micro 7: 760-760 Johansen JE, Nielsen P, Sjoholm C (1999) Description of Cellulophaga baltica gen. nov., sp. nov. and Cellulophaga fucicola gen. nov., sp. nov. and reclassification of [Cytophaga] lytica to Cellulophaga lytica gen. nov., comb. nov. International journal of systematic bacteriology 49 Pt 3: 1231-1240

References
82
Jordan EM, Thompson FL, Zhang XH, Li Y, Vancanneyt M, Kroppenstedt RM, Priest FG, Austin B (2007) Sneathiella chinensis gen. nov., sp. nov., a novel marine alphaproteobacterium isolated from coastal sediment in Qingdao, China. International journal of systematic and evolutionary microbiology 57: 114-121 Joseph SJ, Hugenholtz P, Sangwan P, Osborne CA, Janssen PH (2003) Laboratory Cultivation of Widespread and Previously Uncultured Soil Bacteria. Applied and environmental microbiology 69: 7210-7215 Jourand P, Giraud E, Bena G, Sy A, Willems A, Gillis M, Dreyfus B, de Lajudie P (2004) Methylobacterium nodulans sp. nov., for a group of aerobic, facultatively methylotrophic, legume root-nodule-forming and nitrogen-fixing bacteria. International journal of systematic and evolutionary microbiology 54: 2269-2273 Kaczmarska I, Ehrman JM, Bates SS, Green DH, Léger C, Harris J (2005) Diversity and distribution of epibiotic bacteria on Pseudo-nitzschia multiseries (Bacillariophyceae) in culture, and comparison with those on diatoms in native seawater. Harmful Algae 4: 725-741 Kang DD, Froula J, Egan R, Wang Z (2014) A robust statistical framework for reconstructing genomes from metagenomic data. Kassabgy M (2011) Diversity and abundance of Gammaproteobacteria during the winter-spring transition at station Kabeltonne-Helgoland. Kato S, Sakayama H, Sano S, Kasai F, Watanabe MM, Tanaka J, Nozaki H (2008) Morphological variation and intraspecific phylogeny of the ubiquitous species Chara braunii (Charales, Charophyceae) in Japan. Phycologia 47: 191-202 Keeling PJ (2010) The endosymbiotic origin, diversification and fate of plastids. Philosophical Transactions of the Royal Society B: Biological Sciences 365: 729-748 Kent WJ (2002) BLAT--the BLAST-like alignment tool. Genome research 12: 656-664 Kersters K, Ludwig W, Vancanneyt M, De Vos P, Gillis M, Schleifer K-H (1996) Recent Changes in the Classification of the Pseudomonads: an Overview. Systematic and Applied Microbiology 19: 465-477 Kim B-H, Ramanan R, Cho D-H, Oh H-M, Kim H-S (2014a) Role of Rhizobium, a plant growth promoting bacterium, in enhancing algal biomass through mutualistic interaction. biomass and bioenergy 69: 95-105 Kim DE, Lee EY, Kim HS (2009) Cloning and characterization of alginate lyase from a marine bacterium Streptomyces sp. ALG-5. Marine biotechnology 11: 10-16 Kim M, Oh HS, Park SC, Chun J (2014b) Towards a taxonomic coherence between average nucleotide identity and 16S rRNA gene sequence similarity for species demarcation of prokaryotes. International journal of systematic and evolutionary microbiology 64: 346-351 Koch I, Feldmann J, Wang L, Andrewes P, Reimer KJ, Cullen WR (1999) Arsenic in the Meager Creek hot springs environment, British Columbia, Canada. Science of the total environment 236: 101-117 Kufel L, Kufel I (2002) Chara beds acting as nutrient sinks in shallow lakes—a review. Aquatic Botany 72: 249-260 Kulichevskaya IS, Suzina NE, Liesack W, Dedysh SN (2010) Bryobacter aggregatus gen. nov., sp. nov., a peat-inhabiting, aerobic chemo-organotroph from subdivision 3 of the Acidobacteria. International journal of systematic and evolutionary microbiology 60: 301-306 Kupper FC, Muller DG, Peters AF, Kloareg B, Potin P (2002) Oligoalginate recognition and oxidative burst play a key role in natural and induced resistance of sporophytes of laminariales. Journal of chemical ecology 28: 2057-2081 Kutschera U, Niklas KJ (2005) Endosymbiosis, cell evolution, and speciation. Theory in Biosciences 124: 1-24

References
83
Lachnit T, Blumel M, Imhoff JF, Wahl M (2009) Specific epibacterial communities on macroalgae: phylogeny matters more than habitat. Aquatic Biology 5: 181-186 Lachnit T, Meske D, Wahl M, Harder T, Schmitz R (2011) Epibacterial community patterns on marine macroalgae are host-specific but temporally variable. Environmental microbiology 13: 655-665 Lage O, Bondoso J, Lobo-da-Cunha A (2013) Insights into the ultrastructural morphology of novel Planctomycetes. Antonie van Leeuwenhoek 104: 467-476 Lage OM, Bondoso J (2011a) Planctomycetes diversity associated with macroalgae, Vol. 78. Lage OM, Bondoso J (2011b) Planctomycetes diversity associated with macroalgae. FEMS microbiology ecology 78: 366-375 Lage OM, Bondoso J (2014) Planctomycetes and macroalgae, a striking association. Frontiers in microbiology 5 Lagesen K, Hallin P, Rødland EA, Stærfeldt H-H, Rognes T, Ussery DW (2007) RNAmmer: consistent and rapid annotation of ribosomal RNA genes. Nucleic acids research 35: 3100-3108 Lam C, Grage A, Schulz D, Schulte A, Harder T (2008) Extracts of North Sea macroalgae reveal specific activity patterns against attachment and proliferation of benthic diatoms: a laboratory study. Biofouling 24: 59-66 Lane AL, Kubanek J (2008) Secondary metabolite defenses against pathogens and biofoulers. In Algal chemical ecology, pp 229-243. Springer Laycock RA (1974) DETRITAL FOOD-CHAIN BASED ON SEAWEEDS .1. BACTERIA ASSOCIATED WITH SURFACE OF LAMINARIA FRONDS. Marine Biology 25: 223-231 Lecompte O, Ripp R, Thierry JC, Moras D, Poch O (2002) Comparative analysis of ribosomal proteins in complete genomes: an example of reductive evolution at the domain scale. Nucleic acids research 30: 5382-5390 Lee OO, Wong YH, Qian P-Y (2009) Inter-and intraspecific variations of bacterial communities associated with marine sponges from San Juan Island, Washington. Applied and environmental microbiology 75: 3513-3521 Lee S-H, Ka J-O, Cho J-C (2008) Members of the phylum Acidobacteria are dominant and metabolically active in rhizosphere soil, Vol. 285. Lee YK, Lee J-H, Lee HK (2001) Microbial symbiosis in marine sponges. JOURNAL OF MICROBIOLOGY-SEOUL- 39: 254-264 Legendre L, Rassoulzadegan F (1995) Plankton and nutrient dynamics in marine waters. Ophelia 41: 153-172 Lema KA, Willis BL, Bourne DG (2012) Corals form characteristic associations with symbiotic nitrogen-fixing bacteria. Applied and environmental microbiology 78: 3136-3144 Lemos ML, Toranzo AE, Barja JL (1985) Antibiotic activity of epiphytic bacteria isolated from intertidal seaweeds. Microbial ecology 11: 149-163 Lesser MP (2006) Oxidative stress in marine environments: biochemistry and physiological ecology. Annual review of physiology 68: 253-278 Leung HC, Wang Y, Yiu S, Chin FY (2014) Next-Generation Sequencing on Metagenomic Data: Assembly and Binning. In Encyclopedia of Metagenomics, pp 1-7. Springer Leveau JH (2007) The magic and menace of metagenomics: prospects for the study of plant growth-promoting rhizobacteria. European Journal of Plant Pathology 119: 279-300

References
84
Likens GE (2010) Plankton of inland waters: Academic Press. Liu B, Gibbons T, Ghodsi M, Pop M (2010) MetaPhyler: Taxonomic profiling for metagenomic sequences. In Bioinformatics and Biomedicine (BIBM), 2010 IEEE International Conference on, pp 95-100. Liu L, Li Y, Li S, Hu N, He Y, Pong R, Lin D, Lu L, Law M (2012) Comparison of next-generation sequencing systems. BioMed Research International 2012 Longford SR, Tujula NA, Crocetti GR, Holmes AJ, Holmström C, Kjelleberg S, Steinberg PD, Taylor MW (2007) Comparisons of diversity of bacterial communities associated with three sessile marine eukaryotes. Aquatic Microbial Ecology 48: 217-229 Lu K, Lin W, Liu J (2008) The characteristics of nutrient removal and inhibitory effect of Ulva clathrata on Vibrio anguillarum 65. Journal of applied phycology 20: 1061-1068 MacArtain P, Gill CI, Brooks M, Campbell R, Rowland IR (2007) Nutritional value of edible seaweeds. NUTRITION REVIEWS-WASHINGTON- 65: 535 Mackie RI (2002) Mutualistic fermentative digestion in the gastrointestinal tract: diversity and evolution. Integrative and Comparative Biology 42: 319-326 Mande SS, Mohammed MH, Ghosh TS (2012) Classification of metagenomic sequences: methods and challenges. Briefings in bioinformatics 13: 669-681 Mann AJ, Hahnke RL, Huang S, Werner J, Xing P, Barbeyron T, Huettel B, Stüber K, Reinhardt R, Harder J, Glöckner FO, Amann RI, Teeling H (2013) The Genome of the Alga-Associated Marine Flavobacterium Formosa agariphila KMM 3901T Reveals a Broad Potential for Degradation of Algal Polysaccharides. Applied and environmental microbiology 79: 6813-6822 Mardis ER (2013) Next-generation sequencing platforms. Annual review of analytical chemistry 6: 287-303 Markell DA, Trench RK (1993) MACROMOLECULES EXUDED BY SYMBIOTIC DINOFLAGELLATES IN CULTURE: AMINO ACID AND SUGAR COMPOSITION1. Journal of phycology 29: 64-68 Maximilien R, de Nys R, Holmstrom C, Gram L, Givskov M, Crass K, Kjelleberg S, Steinberg PD (1998) Chemical mediation of bacterial surface colonisation by secondary metabolites from the red alga Delisea pulchra. Aquatic Microbial Ecology 15: 233-246 McGinn PJ, Dickinson KE, Bhatti S, Frigon JC, Guiot SR, O'Leary SJ (2011) Integration of microalgae cultivation with industrial waste remediation for biofuel and bioenergy production: opportunities and limitations. Photosynthesis research 109: 231-247 McHardy AC, Martin HG, Tsirigos A, Hugenholtz P, Rigoutsos I (2007) Accurate phylogenetic classification of variable-length DNA fragments. Nat Methods 4: 63-72 Methé BA, Hiorns WD, Zehr JP (1998) Contrasts between marine and freshwater bacterial community composition: Analyses of communities in Lake George and six other Adirondack lakes. Limnology and Oceanography 43: 368-374 Methé BA, Zehr JP (1999) Diversity of bacterial communities in Adirondack lakes: do species assemblages reflect lake water chemistry? In Molecular Ecology of Aquatic Communities, Zehr JP, Voytek MA (eds), Vol. 138, 7, pp 77-96. Springer Netherlands Mindl B, Sonntag B, Pernthaler J, Vrba J, Psenner R, Posch T (2005) Effects of phosphorus loading on interactions of algae and bacteria: reinvestigation of the ‘phytoplankton–bacteria paradox’in a continuous cultivation system. Aquat Microb Ecol 38: 203-213

References
85
Monier A, Claverie JM, Ogata H (2008) Taxonomic distribution of large DNA viruses in the sea. Genome biology 9: R106 Monzoorul Haque M, Ghosh TS, Komanduri D, Mande SS (2009) SOrt-ITEMS: Sequence orthology based approach for improved taxonomic estimation of metagenomic sequences. Bioinformatics (Oxford, England) 25: 1722-1730 Moran NA (2007) Symbiosis as an adaptive process and source of phenotypic complexity. Proceedings of the National Academy of Sciences of the United States of America 104 Suppl 1: 8627-8633 Morrow KM, Ritson-Williams R, Ross C, Liles MR, Paul VJ (2012) Macroalgal Extracts Induce Bacterial Assemblage Shifts and Sublethal Tissue Stress in Caribbean Corals. PloS one 7: e44859 Mou X, Sun S, Edwards RA, Hodson RE, Moran MA (2008) Bacterial carbon processing by generalist species in the coastal ocean. Nature 451: 708-711 Mouget J-L, Dakhama A, Lavoie MC, de la Noüe J (1995) Algal growth enhancement by bacteria: is consumption of photosynthetic oxygen involved? FEMS microbiology ecology 18: 35-43 Muscatine L, Porter JW (1977) Reef corals: mutualistic symbioses adapted to nutrient-poor environments. Bioscience 27: 454-460 Neef A, Amann R, Schlesner H, Schleifer K-H (1998) Monitoring a widespread bacterial group: in situ detection of planctomycetes with 16S rRNA-targeted probes. Microbiology 144: 3257-3266 Newton RJ, Jones SE, Eiler A, McMahon KD, Bertilsson S (2011) A Guide to the Natural History of Freshwater Lake Bacteria. Microbiology and Molecular Biology Reviews : MMBR 75: 14-49 Nguyen M-L, Westerhoff P, Baker L, Hu Q, Esparza-Soto M, Sommerfeld M (2005) Characteristics and reactivity of algae-produced dissolved organic carbon. Journal of Environmental Engineering 131: 1574-1582 Nielsen HB, Almeida M, Juncker AS, Rasmussen S, Li J, Sunagawa S, Plichta DR, Gautier L, Pedersen AG, Le Chatelier E, Pelletier E, Bonde I, Nielsen T, Manichanh C, Arumugam M, Batto J-M, Quintanilha dos Santos MB, Blom N, Borruel N, Burgdorf KS, Boumezbeur F, Casellas F, Dore J, Dworzynski P, Guarner F, Hansen T, Hildebrand F, Kaas RS, Kennedy S, Kristiansen K, Kultima JR, Leonard P, Levenez F, Lund O, Moumen B, Le Paslier D, Pons N, Pedersen O, Prifti E, Qin J, Raes J, Sorensen S, Tap J, Tims S, Ussery DW, Yamada T, Meta HITC, Renault P, Sicheritz-Ponten T, Bork P, Wang J, Brunak S, Ehrlich SD (2014) Identification and assembly of genomes and genetic elements in complex metagenomic samples without using reference genomes. Nat Biotech 32: 822-828 Nogales B, Moore ER, Llobet-Brossa E, Rossello-Mora R, Amann R, Timmis KN (2001) Combined use of 16S ribosomal DNA and 16S rRNA to study the bacterial community of polychlorinated biphenyl-polluted soil. Applied and environmental microbiology 67: 1874-1884 Nylund GM, Persson F, Lindegarth M, Cervin G, Hermansson M, Pavia H (2010a) The red alga Bonnemaisonia asparagoides regulates epiphytic bacterial abundance and community composition by chemical defence. FEMS microbiology ecology 71: 84-93 Nylund GM, Persson F, Lindegarth M, Cervin G, Hermansson M, Pavia H (2010b) The red alga Bonnemaisonia asparagoides regulates epiphytic bacterial abundance and community composition by chemical defence, Vol. 71. Ortiz-Marquez JC, Do Nascimento M, Dublan Mde L, Curatti L (2012) Association with an ammonium-excreting bacterium allows diazotrophic culture of oil-rich eukaryotic microalgae. Applied and environmental microbiology 78: 2345-2352 Patel P, Callow ME, Joint I, Callow JA (2003) Specificity in the settlement–modifying response of bacterial biofilms towards zoospores of the marine alga Enteromorpha. Environmental microbiology 5: 338-349

References
86
Patil KR, Haider P, Pope PB, Turnbaugh PJ, Morrison M, Scheffer T, McHardy AC (2011) Taxonomic metagenome sequence assignment with structured output models. Nature methods 8: 191-192 Patil KR, Roune L, McHardy AC (2012) The PhyloPythiaS Web Server for Taxonomic Assignment of Metagenome Sequences. PloS one 7: e38581 Penesyan A, Marshall-Jones Z, Holmstrom C, Kjelleberg S, Egan S (2009) Antimicrobial activity observed among cultured marine epiphytic bacteria reflects their potential as a source of new drugs. FEMS microbiology ecology 69: 113-124 Piekarski T, Buchholz I, Drepper T, Schobert M, Wagner-Doebler I, Tielen P, Jahn D (2009) Genetic tools for the investigation of Roseobacter clade bacteria. BMC microbiology 9: 265 Pittman JK, Dean AP, Osundeko O (2011) The potential of sustainable algal biofuel production using wastewater resources. Bioresource Technology 102: 17-25 Poinar HN, Schwarz C, Qi J, Shapiro B, Macphee RD, Buigues B, Tikhonov A, Huson DH, Tomsho LP, Auch A, Rampp M, Miller W, Schuster SC (2006) Metagenomics to paleogenomics: large-scale sequencing of mammoth DNA. Science (New York, NY) 311: 392-394 Polne-Fuller M, Gibor A (1987) Microorganisms as digestors of seaweed cell walls. In Twelfth International Seaweed Symposium, Ragan M, Bird C (eds), Vol. 41, 60, pp 405-409. Springer Netherlands Pop M, Salzberg SL, Shumway M (2002) Genome sequence assembly: Algorithms and issues. Computer 35: 47-54 Pore R, Barnett E, Barnes Jr W, Walker J (1983) Prototheca ecology. Mycopathologia 81: 49-62 Potin P, Bouarab K, Salaün J-P, Pohnert G, Kloareg B (2002) Biotic interactions of marine algae. Current opinion in plant biology 5: 308-317 Preston GM (2004) Plant perceptions of plant growth-promoting Pseudomonas. Philosophical Transactions of the Royal Society B: Biological Sciences 359: 907-918 Pride DT, Meinersmann RJ, Wassenaar TM, Blaser MJ (2003) Evolutionary Implications of Microbial Genome Tetranucleotide Frequency Biases. Genome research 13: 145-158 Pruesse E, Peplies J, Glockner FO (2012) SINA: accurate high-throughput multiple sequence alignment of ribosomal RNA genes. Bioinformatics (Oxford, England) 28: 1823-1829 Qi W, Nong G, Preston JF, Ben-Ami F, Ebert D (2009) Comparative metagenomics of Daphnia symbionts. BMC genomics 10: 172 Quaiser A, López‐García P, Zivanovic Y, Henn MR, Rodriguez‐Valera F, Moreira D (2008) Comparative analysis of genome fragments of Acidobacteria from deep Mediterranean plankton. Environmental microbiology 10: 2704-2717 Quaiser A, Ochsenreiter T, Lanz C, Schuster SC, Treusch AH, Eck J, Schleper C (2003) Acidobacteria form a coherent but highly diverse group within the bacterial domain: evidence from environmental genomics. Molecular microbiology 50: 563-575 Ramesh S, Mathivanan N (2009) Screening of marine actinomycetes isolated from the Bay of Bengal, India for antimicrobial activity and industrial enzymes. World J Microbiol Biotechnol 25: 2103-2111 Rao D, Webb JS, Holmstrom C, Case R, Low A, Steinberg P, Kjelleberg S (2007) Low densities of epiphytic bacteria from the marine alga Ulva australis inhibit settlement of fouling organisms. Applied and environmental microbiology 73: 7844-7852

References
87
Rao D, Webb JS, Kjelleberg S (2006) Microbial colonization and competition on the marine alga Ulva australis. Applied and environmental microbiology 72: 5547-5555 Renders N, Römling Y, Verbrugh H, van Belkum A (1996) Comparative typing of Pseudomonas aeruginosa by random amplification of polymorphic DNA or pulsed-field gel electrophoresis of DNA macrorestriction fragments. Journal of clinical microbiology 34: 3190-3195 Riquelme C, Rojas A, Flores V, Correa JA (1997) Epiphytic bacteria in a copper-enriched environment in northern Chile. Marine pollution bulletin 34: 816-820 Rivas MO, Vargas P, Riquelme CE (2010) Interactions of Botryococcus braunii cultures with bacterial biofilms. Microbial ecology 60: 628-635 Rodionov DA, Vitreschak AG, Mironov AA, Gelfand MS (2003) Comparative genomics of the vitamin B12 metabolism and regulation in prokaryotes. Journal of Biological Chemistry 278: 41148-41159 Rohwer F, Seguritan V, Azam F, Knowlton N (2002a) Diversity and distribution of coral-associated bacteria. Marine Ecology Progress Series 243: 1-10 Rohwer F, Seguritan V, Azam F, Knowlton N (2002b) Diversity and distribution of coral-associated bacteria. Marine Ecology Progress Series 243 Rosen GL, Reichenberger ER, Rosenfeld AM (2011) NBC: the Naive Bayes Classification tool webserver for taxonomic classification of metagenomic reads. Bioinformatics (Oxford, England) 27: 127-129 Rosenstock B, Simon M (2001) Sources and sinks of dissolved free amino acids and protein in a large and deep mesotrophic lake. Limnology and Oceanography 46: 644-654 Ruger HJ, Hofle MG (1992) Marine star-shaped-aggregate-forming bacteria: Agrobacterium atlanticum sp. nov.; Agrobacterium meteori sp. nov.; Agrobacterium ferrugineum sp. nov., nom. rev.; Agrobacterium gelatinovorum sp. nov., nom. rev.; and Agrobacterium stellulatum sp. nov., nom. rev. International journal of systematic bacteriology 42: 133-143 Ryan RP, Vorhölter F-J, Potnis N, Jones JB, Van Sluys M-A, Bogdanove AJ, Dow JM (2011) Pathogenomics of Xanthomonas: understanding bacterium–plant interactions. Nature Reviews Microbiology 9: 344-355 Ryu S (2009) Chara braunii. S K, P S, M G, L G, M M, R dN (1997) Do marine natural products interfere with prokaryotic AHL regulatory systems? Aquatic Microbial Ecology 13: 85-93 Saddler G, Bradbury J (2005) Xanthomonadales ord. nov. In Bergey’s Manual® of Systematic Bacteriology, Brenner D, Krieg N, Staley J, Garrity G, Boone D, De Vos P, Goodfellow M, Rainey F, Schleifer K-H (eds), 3, pp 63-122. Springer US Saeed I, Tang SL, Halgamuge SK (2012) Unsupervised discovery of microbial population structure within metagenomes using nucleotide base composition. Nucleic acids research 40: e34 Sapp M, Schwaderer A, Wiltshire K, Hoppe H-G, Gerdts G, Wichels A (2007a) Species-Specific Bacterial Communities in the Phycosphere of Microalgae? Microbial ecology 53: 683-699 Sapp M, Schwaderer AS, Wiltshire KH, Hoppe H-G, Gerdts G, Wichels A (2007b) Species-specific bacterial communities in the phycosphere of microalgae? Microbial ecology 53: 683-699 Sapp M, Wichels A, Gerdts G (2007c) Impacts of cultivation of marine diatoms on the associated bacterial community. Applied and environmental microbiology 73: 3117-3120

References
88
Schaechter M (2009) Encyclopedia of microbiology: Academic Press. Schmitt S, Wehrl M, Bayer K, Siegl A, Hentschel U (2007) Marine sponges as models for commensal microbe-host interactions. Symbiosis 44: 43-50 Seckbach J (2007) Algae and cyanobacteria in extreme environments, Vol. 11: Springer Science & Business Media. Semenova E, Shlykova D, Semenov A, Ivanov M, Shelyakov O, Netrusov A (2009) Bacteria-epiphytes of brown macro alga in oil utilization in north sea ecosystems. Moscow University biological sciences bulletin 64: 107-110 Shade A, Kent AD, Jones SE, Newton RJ, Triplett EW, McMahon KD (2007) Interannual dynamics and phenology of bacterial communities in a eutrophic lake. Limnology and Oceanography 52: 487-494 Šimek K, Kasalický V, Zapomělová E, Horňák K (2011) Alga-Derived Substrates Select for Distinct Betaproteobacterial Lineages and Contribute to Niche Separation in Limnohabitans Strains. Applied and environmental microbiology 77: 7307-7315 Singh RP, Reddy CRK (2014) Seaweed–microbial interactions: key functions of seaweed-associated bacteria, Vol. 88. Singh Y, Ahmad J, Musarrat J, Ehtesham NZ, Hasnain SE (2013) Emerging importance of holobionts in evolution and in probiotics. Gut pathogens 5: 1-8 Skulberg OM (2000) Microalgae as a source of bioactive molecules–experience from cyanophyte research. Journal of Applied Phycology 12: 341-348 Sohn JH, Lee JH, Yi H, Chun J, Bae KS, Ahn TY, Kim SJ (2004) Kordia algicida gen. nov., sp. nov., an algicidal bacterium isolated from red tide. International journal of systematic and evolutionary microbiology 54: 675-680 Sousa CdS, Soares ACF, Garrido MdS (2008) Characterization of streptomycetes with potential to promote plant growth and biocontrol. Scientia Agricola 65: 50-55 Starr RC, Zeikus JA (1993) UTEX—THE CULTURE COLLECTION OF ALGAE AT THE UNIVERSITY OF TEXAS AT AUSTIN 1993 LIST OF CULTURES1. Journal of phycology 29: 1-106 Staufenberger T, Thiel V, Wiese J, Imhoff JF (2008) Phylogenetic analysis of bacteria associated with Laminaria saccharina. FEMS microbiology ecology 64: 65-77 Steinberg PD, de Nys R (2002a) Chemical mediation of colonization of seaweed surfaces. Journal of Phycology 38: 621-629 Steinberg PD, De Nys R (2002b) CHEMICAL MEDIATION OF COLONIZATION OF SEAWEED SURFACES1. Journal of Phycology 38: 621-629 Steinberg PD, Schneider R, Kjelleberg S (1997) Chemical defenses of seaweeds against microbial colonization. Biodegradation 8: 211-220 Strous M, Kraft B, Bisdorf R, Tegetmeyer HE (2012) The Binning of Metagenomic Contigs for Microbial Physiology of Mixed Cultures. Frontiers in Microbiology 3: 410 Subashchandrabose SR, Ramakrishnan B, Megharaj M, Venkateswarlu K, Naidu R (2011) Consortia of cyanobacteria/microalgae and bacteria: biotechnological potential. Biotechnology advances 29: 896-907 Subirana L, Péquin B, Michely S, Escande M-L, Meilland J, Derelle E, Marin B, Piganeau G, Desdevises Y, Moreau H (2013a) Morphology, genome plasticity, and phylogeny in the genus Ostreococcus reveal a cryptic species, O. mediterraneus sp. nov.(Mamiellales, Mamiellophyceae). Protist 164: 643-659

References
89
Subirana L, Pequin B, Michely S, Escande ML, Meilland J, Derelle E, Marin B, Piganeau G, Desdevises Y, Moreau H, Grimsley NH (2013b) Morphology, genome plasticity, and phylogeny in the genus ostreococcus reveal a cryptic species, O. mediterraneus sp. nov. (Mamiellales, Mamiellophyceae). Protist 164: 643-659 Subramani R, Aalbersberg W (2012) Marine actinomycetes: An ongoing source of novel bioactive metabolites. Microbiological Research 167: 571-580 Suss J, Schubert K, Sass H, Cypionka H, Overmann J, Engelen B (2006) Widespread distribution and high abundance of Rhizobium radiobacter within Mediterranean subsurface sediments. Environmental microbiology 8: 1753-1763 Syutsubo K, Kishira H, Harayama S (2001) Development of specific oligonucleotide probes for the identification and in situ detection of hydrocarbon‐degrading Alcanivorax strains. Environmental microbiology 3: 371-379 Tanaseichuk O, Borneman J, Jiang T (2012) A Probabilistic Approach to Accurate Abundance-Based Binning of Metagenomic Reads. In Algorithms in Bioinformatics, Raphael B, Tang J (eds), Vol. 7534, 32, pp 404-416. Springer Berlin Heidelberg Tatusov RL, Galperin MY, Natale DA, Koonin EV (2000) The COG database: a tool for genome-scale analysis of protein functions and evolution. Nucleic acids research 28: 33-36 Teeling H, Fuchs BM, Becher D, Klockow C, Gardebrecht A, Bennke CM, Kassabgy M, Huang S, Mann AJ, Waldmann J (2012a) Substrate-controlled succession of marine bacterioplankton populations induced by a phytoplankton bloom. Science (New York, NY) 336: 608-611 Teeling H, Fuchs BM, Becher D, Klockow C, Gardebrecht A, Bennke CM, Kassabgy M, Huang S, Mann AJ, Waldmann J, Weber M, Klindworth A, Otto A, Lange J, Bernhardt J, Reinsch C, Hecker M, Peplies J, Bockelmann FD, Callies U, Gerdts G, Wichels A, Wiltshire KH, Glockner FO, Schweder T, Amann R (2012b) Substrate-controlled succession of marine bacterioplankton populations induced by a phytoplankton bloom. Science (New York, NY) 336: 608-611 Teeling H, Waldmann J, Lombardot T, Bauer M, Glockner FO (2004) TETRA: a web-service and a stand-alone program for the analysis and comparison of tetranucleotide usage patterns in DNA sequences. BMC bioinformatics 5: 163 Thingstad TF, Havskum H, Garde K, Riemann B (1996) On the strategy of" eating your competitor": A mathematical analysis of algal mixotrophy. Ecology: 2108-2118 Thomas F, Hehemann J-H, Rebuffet E, Czjzek M, Michel G (2011) Environmental and Gut Bacteroidetes: The Food Connection. Frontiers in Microbiology 2: 93 Tiwari K, Gupta RK (2012) Rare actinomycetes: a potential storehouse for novel antibiotics. Critical reviews in biotechnology 32: 108-132 Tujula NA, Crocetti GR, Burke C, Thomas T, Holmstrom C, Kjelleberg S (2010) Variability and abundance of the epiphytic bacterial community associated with a green marine Ulvacean alga. Isme j 4: 301-311 Turnbaugh PJ, Backhed F, Fulton L, Gordon JI (2008) Diet-induced obesity is linked to marked but reversible alterations in the mouse distal gut microbiome. Cell host & microbe 3: 213-223 Tyson GW, Chapman J, Hugenholtz P, Allen EE, Ram RJ, Richardson PM, Solovyev VV, Rubin EM, Rokhsar DS, Banfield JF (2004) Community structure and metabolism through reconstruction of microbial genomes from the environment. Nature 428: 37-43 Ultsch A, Mörchen F (2005) ESOM-Maps: tools for clustering, visualization, and classification with Emergent SOM. Uppalapati SR, Fujita Y (2000) Carbohydrate regulation of attachment, encystment, and appressorium formation by Pythium porphyrae (Oomycota) zoospores on Porphyra yezoensis (Rhodophyta). Journal of Phycology 36: 359-366

References
90
Vance CP, Waisel Y, Eshel A, Kafkafi U (2002) Root-bacteria interactions: symbiotic N2 fixation. Plant roots: the hidden half: 839-868 Vartoukian SR, Palmer RM, Wade WG (2010) Strategies for culture of ‘unculturable’ bacteria. FEMS Microbiology Letters 309: 1-7 Vasudevan V, Stratton RW, Pearlson MN, Jersey GR, Beyene AG, Weissman JC, Rubino M, Hileman JI (2012) Environmental performance of algal biofuel technology options. Environmental science & technology 46: 2451-2459 Verginer M, Siegmund B, Cardinale M, Muller H, Choi Y, Miguez CB, Leitner E, Berg G (2010) Monitoring the plant epiphyte Methylobacterium extorquens DSM 21961 by real-time PCR and its influence on the strawberry flavor. FEMS microbiology ecology 74: 136-145 Villa JA, Ray EE, Barney BM (2014) Azotobacter vinelandii siderophore can provide nitrogen to support the culture of the green algae Neochloris oleoabundans and Scenedesmus sp. BA032. FEMS microbiology letters 351: 70-77 Wahl M (1989) Marine epibiosis. I. Fouling and antifouling: some basic aspects. Marine Ecology Progress Series 58: 175-189 Wahl M, Jensen PR, Fenical W (1994) Chemical control of bacterial epibiosis on ascidians. Marine Ecology Progress Series 110: 45-57 Wand H, Laht T, Peters M, Becker PM, Stottmeister U, Heinaru A (1997) Monitoring of Biodegradative Pseudomonas putida Strains in Aquatic Environments Using Molecular Techniques. Microbial ecology 33: 124-133 Wang J, Jenkins C, Webb RI, Fuerst JA (2002) Isolation of Gemmata-like and Isosphaera-like planctomycete bacteria from soil and freshwater. Applied and environmental microbiology 68: 417-422 Wang Y, Leung HC, Yiu SM, Chin FY (2014) MetaCluster-TA: taxonomic annotation for metagenomic data based on assembly-assisted binning. BMC genomics 15: S12 WANG YH, YU GL, WANG XM, LV ZH, Zhao X, WU ZH, JI WS (2006) Purification and characterization of alginate lyase from marine Vibrio sp. YWA. Acta biochimica et biophysica Sinica 38: 633-638 Ward NL, Challacombe JF, Janssen PH, Henrissat B, Coutinho PM, Wu M, Xie G, Haft DH, Sait M, Badger J, Barabote RD, Bradley B, Brettin TS, Brinkac LM, Bruce D, Creasy T, Daugherty SC, Davidsen TM, DeBoy RT, Detter JC, Dodson RJ, Durkin AS, Ganapathy A, Gwinn-Giglio M, Han CS, Khouri H, Kiss H, Kothari SP, Madupu R, Nelson KE, Nelson WC, Paulsen I, Penn K, Ren Q, Rosovitz MJ, Selengut JD, Shrivastava S, Sullivan SA, Tapia R, Thompson LS, Watkins KL, Yang Q, Yu C, Zafar N, Zhou L, Kuske CR (2009) Three Genomes from the Phylum Acidobacteria Provide Insight into the Lifestyles of These Microorganisms in Soils. Applied and environmental microbiology 75: 2046-2056 Weinberger F, Friedlander M (2000) RESPONSE OF GRACILARIA CONFERTA (RHODOPHYTA) TO OLIGOAGARS RESULTS IN DEFENSE AGAINST AGAR-DEGRADING EPIPHYTES. Journal of Phycology 36: 1079-1086 Weinberger F, Hoppe H-G, Friedlander M (1997) Bacterial induction and inhibition of a fast mecrotic response in Gracilaria conferta (Rhodophyta). Journal of applied phycology 9: 277-285 Wichard T (2015) Exploring bacteria-induced growth and morphogenesis in the green macroalga order Ulvales (Chlorophyta). Frontiers in Plant Science 6: 86 Williams KP, Gillespie JJ, Sobral BWS, Nordberg EK, Snyder EE, Shallom JM, Dickerman AW (2010) Phylogeny of Gammaproteobacteria. Journal of Bacteriology 192: 2305-2314 Williams KP, Sobral BW, Dickerman AW (2007) A Robust Species Tree for the Alphaproteobacteria. Journal of Bacteriology 189: 4578-4586

References
91
Woyke T, Teeling H, Ivanova NN, Huntemann M, Richter M, Gloeckner FO, Boffelli D, Anderson IJ, Barry KW, Shapiro HJ, Szeto E, Kyrpides NC, Mussmann M, Amann R, Bergin C, Ruehland C, Rubin EM, Dubilier N (2006) Symbiosis insights through metagenomic analysis of a microbial consortium. Nature 443: 950-955 Wu X, Xi W, Ye W, Yang H (2007) Bacterial community composition of a shallow hypertrophic freshwater lake in China, revealed by 16S rRNA gene sequences, Vol. 61. Wu YW, Tang YH, Tringe SG, Simmons BA, Singer SW (2014) MaxBin: an automated binning method to recover individual genomes from metagenomes using an expectation-maximization algorithm. Microbiome 2: 26 Xin X-F, He SY (2013) Pseudomonas syringae pv. tomato DC3000: a model pathogen for probing disease susceptibility and hormone signaling in plants. Annual review of phytopathology 51: 473-498 Yakimov MM, Timmis KN, Golyshin PN (2007) Obligate oil-degrading marine bacteria. Current opinion in biotechnology 18: 257-266 Yang R, Chen L, Newman S, Gandhi K, Doho G, Moreno CS, Vertino PM, Bernal-Mizarchi L, Lonial S, Boise LH, Rossi M, Kowalski J, Qin ZS (2014) Integrated analysis of whole-genome paired-end and mate-pair sequencing data for identifying genomic structural variations in multiple myeloma. Cancer informatics 13: 49-53 Yung PY, Burke C, Lewis M, Kjelleberg S, Thomas T (2011) Novel antibacterial proteins from the microbial communities associated with the sponge Cymbastela concentrica and the green alga Ulva australis. Applied and environmental microbiology 77: 1512-1515 Zepeda Mendoza ML, Sicheritz-Ponten T, Gilbert MT (2015) Environmental genes and genomes: understanding the differences and challenges in the approaches and software for their analyses. Briefings in bioinformatics Zhang W, Wu X, Liu G, Chen T, Zhang G, Dong Z, Yang X, Hu P (2012) Pyrosequencing Reveals Bacterial Diversity in the Rhizosphere of Three Phragmites australis Ecotypes. Geomicrobiology Journal 30: 593-599

Addendum
92
9. Addendum
9.1 Scripts
9.1.1 CONFPLOT.R
(Adapted from CONCOCT)
#!/usr/bin/Rscript
#load libraries
library(gplots)
library(getopt)
spec =
matrix(c('verbose','v',0,"logical",'help','h',0,"logical",'confile','c',1,"character",'ofile','o',1,"ch
aracter"),byrow=TRUE,ncol=4)
opt=getopt(spec)
# if help was asked for print a friendly message
# and exit with a non-zero error code
if( !is.null(opt$help)) {
cat(getopt(spec, usage=TRUE));
q(status=1);
}
confFile <- opt$confile
Conf <- read.csv(confFile,header=TRUE,row.names=1)
Conf.t <- t(Conf)
ConfP <- Conf.t/rowSums(Conf.t)
crp <- colorRampPalette(c("blue","red","orange","yellow"))(100)
ConfP[is.na(ConfP)] <- 0
pdf(opt$ofile)
heatmap.2 (as.matrix(t(ConfP)),col=crp,trace="none", dendrogram="none",Rowv=FALSE,lwid = c(1,4.5),lhei
= c(1,4.5),cexRow=1.2,margin = c(10,10))
dev.off()
9.1.2 CLUSTERPLOT.R
(Adapted from CONCOCT)
#!/usr/bin/Rscript
#load libraries
library(ggplot2)
library(ellipse)
library(getopt)

Addendum
93
library(grid)
spec =
matrix(c('verbose','v',0,"logical",'help','h',0,"logical",'cfile','c',1,"character",'pcafile','p',1,"ch
aracter",'mfile','m',1,"character",'proot','r',1,"character",'ofile','o',1,"character",'legend','l',0,"
logical"),byrow=TRUE,ncol=4)
opt=getopt(spec)
# if help was asked for print a friendly message
# and exit with a non-zero error code
if( !is.null(opt$help)) {
cat(getopt(spec, usage=TRUE));
q(status=1);
}
clusterFile <- opt$cfile
pcaFile <- opt$pcafile
meanFile <- opt$mfile
pcaRoot <- opt$proot
PCA <- read.csv(pcaFile,header=TRUE,row.names=1)
Clusters <- read.csv(clusterFile,header=FALSE,row.names=1)
means <- read.csv(meanFile,header=FALSE)
PCA.df <- data.frame(x=PCA[,1],y=PCA[,2],c=Clusters$V2)
PCA.df$c <- factor(PCA.df$c)
df_ell <- data.frame()
for(c in levels(PCA.df$c))
{
filename = sprintf("%s%s.csv",pcaRoot,c);
print(filename)
temp <- read.csv(filename,header=FALSE)
temp2 <- as.matrix(temp[1:2,1:2])
elt <- as.data.frame(ellipse(temp2,centre=c(means[strtoi(c) + 1,1],means[strtoi(c) + 1,2])))
eltc <- cbind(elt,group=c)
df_ell <- rbind(df_ell,eltc)
rm(temp)
rm(temp2)
}
colnames(df_ell)[1] <- "x"
colnames(df_ell)[2] <- "y"
colours <- c("#F0A3FF", "#0075DC",
"#993F00","#4C005C","#2BCE48","#FFCC99","#808080","#94FFB5","#8F7C00","#9DCC00","#C20088","#003380","#F
FA405","#FFA8BB","#426600","#FF0010","#5EF1F2","#00998F","#740AFF","#990000","#FFFF00");
shapes <- c(15,16,17,18)
nC <- length(colours);
nS <- length(shapes);
nClust <- length(levels(PCA.df$c))
valuesC <- vector()
valuesS <- rep(16,nClust);
for(i in 1:nClust){
valuesC[i] <- colours[i %% nC + 1]
valuesS[i] <- 15 + i %/% nC
}

Addendum
94
print(valuesC);
print(valuesS);
# Order the factor levels
valuesS <- valuesS[as.integer(factor(PCA.df$c, levels = sort(unique(PCA.df$c))))]
pdf(opt$ofile)
theme_set(theme_bw(20))
p <- ggplot(data=PCA.df, aes(x=x, y=y,colour=c)) + geom_point(size=1.0, alpha=.3) + xlab("PCA1") +
ylab("PCA2") + scale_colour_manual(values=valuesC) + scale_shape_manual(values=valuesS) +
geom_path(data=df_ell, aes(x=x, y=y,colour=as.factor(group)), size=0.5, linetype=2)
if( !is.null(opt$legend)){ p + theme(legend.key.size = unit(0.3, "cm")) + guides(col =
guide_legend(ncol = 2,override.aes = list(alpha = 1)))+ opts(legend.text=theme_text(size=4));}else{p +
theme(legend.position="none");}
dev.off()
9.1.3 MEGAN_TO_CONCOCT.PY
import re, sys
[input, output, taxon] = sys.argv[1:4]
taxonsearch = re.compile('(.*)\t.*;(.*):' + taxon)
contigsearch = re.compile('(.*)\t.*')
with open(input,'r') as i, open(output,'wr') as o:
for line in i:
taxon_search = taxonsearch.match(line)
if taxon_search:
o.write(taxon_search.group(1)+','+taxon_search.group(2)+'\n')
else:
contig_search=contigsearch.match(line)
if contig_search:
o.write(contig_search.group(1)+',unclassified\n')
9.1.4 MEGAN_CONCAT_TAXON.PY
(modified from CONCOCT)
#!/usr/bin/env python
# ***************************************************************
# Name: megan_concat_taxon.py
# Purpose: This scripts takes a megan output file, extracts the
# gid and appends taxonomic path
#
#
# This script can filter megan output files generated through the
# the following command:
#
# select > select all
# file > export > CSV format > read-name,taxon-id in comma-delimited format
#
# Dependencies: BioSQL
# Download BioSQL from http://biosql.org/DIST/biosql-1.0.1.tar.gz. Once the software is
installed,
# setup a database and import the BioSQL schema. The following command line should create
a new database
# on your own computer called bioseqdb, belonging to the root user account:

Addendum
95
# mysqladmin -u root create bioseqdb
# We can then tell MySQL to load the BioSQL scheme we downloaded above. Change to the
scripts subdirectory
# from the unzipped BioSQL download, then use the command:
# mysql -u root bioseqdb < biosqldb-mysql.sql
# To update the NCBI taxonomy, change to the scripts subdirectory from the unzipped BioSQL
download, then use
# the command (output is also shown):
# ./load_ncbi_taxonomy.pl --dbname bioseqdb --driver mysql --dbuser root --
download true
# Loading NCBI taxon database in taxdata:
# ... retrieving all taxon nodes in the database
# ... reading in taxon nodes from nodes.dmp
# ... insert / update / delete taxon nodes
# ... (committing nodes)
# ... rebuilding nested set left/right values
# ... reading in taxon names from names.dmp
# ... deleting old taxon names
# ... inserting new taxon names
# ... cleaning up
# Done.
#
# You can also use sqlite3 to store the database in case you don't want to go for
MySQL server option.
# Last time I checked BioSQL didn't have any option to load database schema in
sqlite directly or loading data with load_ncbi_taxonomy.pl script
# A work around is to dump your MySQL database to sqlite3 and place the database
as db.sqlite in the database folder.
# You can then edit the parameters section below and set use_MySQL=False. The
section is as follows
#
# # Parameters #########################################
# use_MySQL=True
# #MySQL server settings for BioSQL
# MySQL_server='localhost'
# MySQL_user='root'
# MySQL_password=''
# MySQL_database='bioseqdb'
# #sqlite3 database
# sqlite3_database=os.getcwd()+"/../database/db.sqlite"
# #####################################################
#
# There are several conversion scripts out there to export data from MySQL to
sqlite3 but not all of them work. The only thing that worked for me
# was ruby-gem. The commands are as follows:
#
# sudo gem install sequel
# sudo gem install sqlite3
# sudo gem install mysql
# sequel mysql://root@localhost/bioseqdb -C sqlite://db.sqlite
#
# Make sure that you have development version of both sqlite3 and MySQL
installed.
#
# **************************************************************/
import re,urllib,sys,time,getopt
from xml.dom import minidom
import MySQLdb as mdb
import os
import sqlite3 as lite
def print_record(record,cur):
ncbi_taxon_id=[]
ncbi_taxon_ids=record.split(",")[1]
for ncbi_taxon_id in ncbi_taxon_ids.split(";"):
taxonomy=[]
#We only have the ncbi_taxon_id so use it to get the first bioSQL taxon_id
#then iterate up through the taxonomy

Addendum
96
status=cur.execute("""SELECT taxon_name.name, taxon.node_rank, taxon.parent_taxon_id FROM
taxon, taxon_name WHERE taxon.taxon_id=taxon_name.taxon_id AND taxon_name.name_class='scientific name'
AND taxon.ncbi_taxon_id = %s""" % (ncbi_taxon_id,))
if status:
name, rank, parent_taxon_id = cur.fetchone()
taxonomy.append(name+":"+rank)
taxon_id = parent_taxon_id
while taxon_id:
cur.execute("""SELECT taxon_name.name, taxon.node_rank, taxon.parent_taxon_id
FROM taxon, taxon_name WHERE taxon.taxon_id=taxon_name.taxon_id AND taxon_name.name_class='scientific
name' AND taxon.taxon_id = %s""" % (taxon_id,))
name, rank, parent_taxon_id = cur.fetchone()
if taxon_id == parent_taxon_id:
break
taxonomy.insert(0,name+":"+rank)
taxon_id=parent_taxon_id
print record.split(",")[0]+"\t"+";"+";".join(taxonomy)
def usage():
print 'Usage:'
print '\tpython megan_concat_taxon.py -m <megan_file> > <output_file>'
def main(argv):
# Parameters #########################################
use_MySQL=True
#MySQL server settings for BioSQL
MySQL_server='psbsql05'
MySQL_user='bioseq'
MySQL_password='aUfup6RGEB5XTbeL'
MySQL_database='bioseqdb'
#sqlite3 database
sqlite3_database=os.getcwd()+"/../database/db.sqlite"
#####################################################
#either a megan file or a single megan record
megan_file=''
try:
opts, args = getopt.getopt(argv,"hm:",["megan_file="])
except getopt.GetoptError:
usage()
exit(2)
for opt, arg in opts:
if opt == '-h':
usage()
exit()
elif opt in ("-m", "--megan_file"):
megan_file = arg
if (megan_file==""):
usage()
exit()
#required for MySQL
con = None
cur = None
if use_MySQL:
#connect to MySQL server
try:
con = mdb.connect(MySQL_server,MySQL_user,MySQL_password,MySQL_database);
cur = con.cursor()
except mdb.Error, e:
print "Error %d: %s" % (e.args[0],e.args[1])
sys.exit(1)
else:
con=lite.connect(sqlite3_database)
cur=con.cursor()
#check if it is a single record or a file
if re.findall(r'gi\|(\w.*?)\|',megan_file):
print_record(megan_file,cur)

Addendum
97
else:
ins=open(megan_file,"r")
for line in ins:
print_record(line,cur)
ins.close()
if con:
con.close();
if __name__ == '__main__':
main(sys.argv[1:])
FILTER_CONTIGS.PL # Usage: python extract_blast_hits.py <blast output NCBI format> <list>
# with <list> = list of contigs which should be processed
# if no list given: outputs all queries
# contigs with more than 1/3 algal and plant hits are written to <blast output NCBI format>_plant
# remaining contigs are written to <blast output NCBI format>_prok
#!/bin/csh
import sys
import re
blast_file = sys.argv[1]
data_dict = {}
list_queries = []
# search commands:
entry_search = re.compile('Query= (.*)')
alignment_search = re.compile('>gi')
orgname_search = re.compile('\[(.*)\]')
length_search = re.compile('\((.*)\)')
evalue_search = re.compile('Expect.* = (.*)')
position_search = re.compile('Query:\s*(\d*)\s*')
#filling in {data_dict}ionary
continue_search = False
continue_length = False
continue_evalue = False
continue_position = False
with open(blast_file) as f:
for line in f:
if continue_search: #4. continue searching for org name
line = previous_line+line.lstrip()
org_name = orgname_search.search(line)
continue_search = False
if org_name:
data_dict[entry_name].append(org_name.group(1).rstrip())
continue_evalue = True
elif continue_length: #5. continue search for length of new contig
length = length_search.search(line)
continue_length = False
if length:
data_dict[entry_name].append(length.group(1).rstrip())
continue_length = False
elif continue_evalue: #6. continue searching for evalue
evalue = evalue_search.search(line)
if evalue:
data_dict[entry_name].append(evalue.group(1).rstrip())
continue_evalue = False
continue_position = True
elif continue_position: #7. continue searching for position
position = position_search.match(line)
if position:
data_dict[entry_name].append(position.group(1).rstrip())
continue_position = False

Addendum
98
else:
new_entry = entry_search.match(line) #START
if new_entry: #1. new query?
entry_name = new_entry.group(1)
data_dict[entry_name] = list()
list_queries.append(entry_name)
continue_length = True
else:
alignm = alignment_search.match(line)
if alignm: #2. alignment?
org_name = orgname_search.search(line)
if org_name: #3. organism name on same line?
data_dict[entry_name].append(org_name.group(1))
continue_evalue = True
else:
previous_line = line.rstrip()+' '
continue_search = True
plant_names = {'Heleocharis':'plant',
'Husnotiella':'plant',
'Polypremum':'plant',
'Castalia':'plant',
'Rhetinolepis':'plant',
'Dolichomitra':'plant',
'Odontostelma':'plant',
'Leucospora':'plant',
'Helogyne':'plant',
'Pycnanthemum':'plant',
'Marsupiomonadaceae':'alga',
...(plant and algal genera names from NCBI taxonomy)}
search_genus = re.compile('([A-Za-z]*)')
def test_plant_print_out(name):
count_plants = 0
count_other = 0
output_string =''
output_string += "\n"+">"+line+"\t"+data_dict[name][0]+"\n"
for i in range (1, len(data_dict[name])-1,3):
genus = search_genus.search(data_dict[name][i]).group(1)
if genus in plant_names:
if i <= 10 and (genus == 'Prasiolopsis' or genus == 'Prasiola') :
count_plants +=50
elif i <=20 and plant_names[genus]=='alga':
count_plants +=2
output_string +=
data_dict[line][i]+"\t"+data_dict[line][i+1]+"\t\t\t\t"+data_dict[line][i+2]+"\t\t\t\t"+plant_names[gen
us]+ "\n"
else:
if i < 120:
count_other +=1
output_string +=
data_dict[line][i]+"\t"+data_dict[line][i+1]+"\t\t\t\t"+data_dict[line][i+2]+"\t\t\t\t"+"\n"
if count_plants >= count_other and (count_plants >= 3):
return (output_string, True)
else:
return (output_string, False)
contig_list = []
if len(sys.argv) >= 3:
file = sys.argv[2]
with open(file) as f:
for line in f:
contig_list.append(line.rstrip())
else:
contig_list = list_queries

Addendum
99
with open (sys.argv[1]+"_plantoralga", 'w') as pl:
with open(sys.argv[1]+"_prok", 'w') as pr:
for line in contig_list:
print line
if line in data_dict:
(output_string,plant) = test_plant_print_out(line)
if plant:
pl.write(output_string)
else:
pr.write(output_string)
9.1.5 CUT_FASTA.PY
import sys
import re
fi = sys.argv[1]
searchname = re.compile('(>[A-Za-z0-9\-_]*)')
writing_seq = False
sequence = ""
name = ""
with open (fi, 'r') as fi:
for line in fi:
namesearch = searchname.match(line)
if namesearch: #next sequence?
#processing previous name and sequence
i = 0
nameindex = 1
while i < len(sequence) and len(sequence) >= 1000:
if i + 20000 <= len(sequence):
print name+"-"+ str(nameindex)
print sequence[i:i+10000]
i += 10000
nameindex += 1
else:
print name+"-"+ str(nameindex)
print sequence[i:]
break
#writing new name and starting new seq search
name = namesearch.group(1).rstrip()
sequence = ''
else: # writing sequence
line = line.upper()
sequence += line.rstrip()
i = 0
nameindex = 1
while i < len(sequence) and len(sequence) >= 1000:
if i + 20000 <= len(sequence):
print name+"-"+ str(nameindex)
print sequence[i:i+10000]
i += 10000

Addendum
100
nameindex += 1
else:
print name+"-"+ str(nameindex)
print sequence[i:]
break
9.1.6 SCAFFOLD2CONTIGS.PL
(Stephane Rombauts)
#!/usr/bin/env perl
=head1 Description
perl scaffold2contigs.pl -f <fasta file with scaffolds>
scaffolds have stretches of N and sequences will be split in contigs according to these.
(stretches are 5 or longer
Created by Stephane Rombauts on 24/03/2015
=cut
use strict;
use warnings;
use Getopt::Long;
use lib "/scratch/algae/chara/ASSAL/script/";
use bioutils_strom;
#========================================================================================
sub usage ( $ )
{
print STDERR "$_[0]\n";
system("pod2text $0");
exit(1);
}
#-----------------------------------------------------------------------------------------
my ($fasta) = ('');
#get file from argument-array
GetOptions(
"f=s" => \$fasta
) or &usage("not enough parameters");
&usage("not enough parameters") if($fasta eq '');
chomp $fasta;
my $dir = `dirname $fasta`;
my $basename = `basename $fasta`; #extract the name of the file (no path anymore)
chomp($dir,$basename);
my %scaffolds = &fasta2hash($fasta);
my $file_out = ${basename}.'_contigs';
open(FOUT, "> $file_out"); #open output file
warn(" writing to file $file_out\n");
my $y = 0;
foreach my $ID (sort keys(%scaffolds)) #read the file line by line
{
my $i =1;my @contigs = (); #count the reads included
my $sequence = $scaffolds{$ID}{'sequence'};
if($sequence =~ m/N{5,}/)
{
@contigs = ( $sequence =~ m/([ACGT]+)/g );

Addendum
101
} else {
push(@contigs, $sequence);
}
foreach my $contig (@contigs)
{
my $contig_ID = 'contig_'.sprintf("%04d",$y);
$y++;
print FOUT '>'.$contig_ID.'_'.$ID."\n";
print FOUT $contig."\n";
}
}
close(FOUT);
9.1.7 COUNT_FRAGMENTS.SH
fastafile='/scratch/algae/ostreococcus/assal/mapping_filtered/OtauriV2.2_unmapped_4730.fasta_prok.cut_n
ew.fasta'
fastaname2=`basename $fastafile .2_unmapped_4730.fasta_prok.cut_new.fasta`
###qsub -l h_vmem=10G /scratch/algae/chara/ASSAL/script/taxassign/scripts/count_fragments.sh
../../../sspace_stringent/OtauriV2.2_unmapped_4730.fasta_prok.cut_new_renamed.fasta
../../../sspace_stringent/OtauriV2.2_unmapped_4730_renamed.fasta
../../../sspace_stringent/OtauriV2.2_sspace.final.scaffolds_renamed.fasta 1
../../OtauriV2.2_unmapped_4730.fasta_prok.cut_new.fasta
rm -r new_clustering_gt999.csv
END=$4
for i in $(seq 0 $END); do
name='cluster'
name+=$i
grep ",$i" clustering_gt999.csv | grep -o 'contig_[0-9]*-[0-9]*' > $name
module load python/x86_64/2.7.2
python /scratch/algae/chara/ASSAL/script/sspace_contigs_rename.py
../../../sspace/DUST_Newbler4_sspace.final.evidence $name > ${name}_ren
name+='_ren'
declare -i countincluster
declare -i counttotal
rm -r ${name}_contigs ${name}_scaffolds
rm -r ${name}_contig.list ${name}_scaffold.list
grep -o 'contig_[0-9]*_scaffold[0-9]*' ${name} | sort -V | uniq > ${name}_contig.list
FILE=${name}_contig.list
while read line; do
countincluster=`grep -c "$line" ${name}`
let countincluster=countincluster+countincluster
counttotal=`grep -c "$line" $1`
#echo $A
#echo $countincluster
#echo $counttotal
if ((counttotal<=countincluster)); then
echo $line >> ${name}_contigs
fi

Addendum
102
done < $FILE
grep -o 'scaffold[0-9]*' ${name} | sort -V | uniq > ${name}_scaffold.list
FILE=${name}_scaffold.list
while read line; do
A="$line"
A+="-"
countincluster=`grep -c "$A" ${name}`
let countincluster=countincluster+countincluster
counttotal=`grep -c "$A" $1`
#echo $A
#echo $countincluster
#echo $counttotal
if ((counttotal<=countincluster)); then
echo $line >> ${name}_scaffolds
fi
done < $FILE
module load perl
perl /scratch/algae/chara/ASSAL/script/Mfasta.pl $1 -SAMPLE=${name} > ${name}.fasta
perl /scratch/algae/chara/ASSAL/script/Mfasta.pl $2 -SAMPLE=${name}_contigs > ${name}_contigs.fasta
perl /scratch/algae/chara/ASSAL/script/Mfasta.pl $3 -SAMPLE=${name}_scaffolds > ${name}_scaffolds.fasta
rm -r contig_fragments
FILE=${name}_scaffolds
while read line; do
A="$line"
A+="-"
grep "$A" $1 | grep -o 'contig_[0-9]*' | sort | uniq >> contig_fragments
done < $FILE
sort contig_fragments -o contig_fragments
FILE=contig_fragments
while read line; do
A="$line"
A+="-"
grep "$A" $fastafile | sed 's/>//' | sed 's/ //' > tmp
cat tmp | awk '{print $1",$i"}' | sort >> new_clustering_gt999.csv
done < $FILE
done
module load R/x86_64/2.15.1
module load python/x86_64/2.7.2
perl /home/assal/CONCOCT-0.4.0/scripts/Validate.pl --cfile=../concoct-output/new_clustering_gt999.csv -
-sfile=../../megan/${fastaname2}_ASSIGNMENTS_TAXON.csv --ofile=../evaluation-
output/new_clustering_gt999_conf.csv --ffile=$fastafile
Rscript /home/assal/CONCOCT-0.4.0/scripts/ConfPlot.R -c ../evaluation-
output/new_clustering_gt999_conf.csv -o ../evaluation-output/new_clustering_gt999_conf.pdf
python /home/assal/CONCOCT-0.4.0/scripts/COG_table.py -b ../../annotations/cog-
annotations/${fastaname2}.out \
-m /home/assal/CONCOCT-0.4.0/scgs/scg_cogs_min0.97_max1.03_unique_genera.txt \
-c new_clustering_gt999.csv \
--cdd_cog_file /home/assal/CONCOCT-0.4.0/scgs/cdd_to_cog.tsv > ../evaluation-
output/new_clustering_gt999_scg.tab
Rscript /home/assal/CONCOCT-0.4.0/scripts/COGPlot.R -s ../evaluation-
output/new_clustering_gt999_scg.tab -o ../evaluation-output/new_clustering_gt999_scg.pdf

Addendum
103
9.1.8 MFASTA_TOOLS.PL
(Stephane Rombauts)
#!/usr/bin/env perl
=head1 Description
Takes as input a (multi-)fasta file or a directory of fasta files as first argument
with those sequences one of the following is possible:
-LEN = length of the sequence
-FIND=<string> = find back the sequence having a match in the description line with <string>
-FETCH=<string> = find back exactly 1 sequence by Acnr <string>
-TRANSLATE = translate DNA sequence to AA sequence
-6FRAMETRANS = translate 6 frames of DNA sequence to AA sequence
-FORMAT = formats a fasta file according to the 60char/line rule
-REV_COMP = return the reverse complement of a DNA sequence
-REVERSE = return the reverse of a DNA sequence (not complemented!!)
-COMPLEMENT = return the complement of a DNA sequence (not reversed!!)
-ORF = return the longest ORF from a DNA sequence (transcript)
-UTR5 = returns the 5' UTR from a transcript (based on longest ORF)
-UTR3 = returns the 3' UTR from a transcript (based on longest ORF)
-LENGTH=<number> = return a sequence of length <number> from the beginning, downstream
-LARGER=<number> = only output sequences of minimum <number> length
-SIZE=<number> = return a sequence of length <number> from the end, upstream
-ORDER=<file> = order a multi-fasta file according to a given list <file>
-SPLIT=<number> = split a multi-fasta file in <number> new (multi)-fasta files
-SPLITsize=<number> = split a multi-fasta file in <number> new (multi)-fasta files (based on file
size!)
-SINGLE = split a multi-fasta file in files with each 1 sequence in fasta format (multi->single fasta)
-CHOP=<number1>[,<number2>] = chops a sequence in sequences of length <number1> (not overlapping)
<number2> => with overlap <number2>
-GC calculate %GC
-SAMPLE=<file> = fetch fasta sequences according to a given list <file>
-EXTRACT=<integer>,<integer> extract piece of sequence from,to
-MEXTRACT=<file> => tab-delimited file with "ACnr from to"
-NR make a multi-fasta file non-redundant using MD5 key generation based on the sequences

Addendum
104
-REMOVE=<file> = remove entries from a fasta file according to a given list in <file>
(added by liste)
-MERGE merge multi fasta file into 1 large sequence (simple sort on ACnr) with 1000xN spacers
-MD5 : generate MD5 key for sequence
-CLIP : clip header or tailing 'N' from a sequence.
-CLEAN : cleans also internal repeats of N or X and limits them to 20char
created by Stephane Rombauts (strom)
=cut
use POSIX;
use strict;
use Digest::MD5;
#========================================================================================
sub makeNR ( $ )
{
my $file=$_[0];
my %fasta_hash = ();
my @existing_keys =();
my $x='';
my $md5 = Digest::MD5->new;
my $key='';
my $comment='';
my $sequence='';
my $id='';
open (IN,$file) || die "problem with $file\n";
while (<IN>)
{
chomp;
if (/^>(\S+)\s*(.*)/)
{
if($sequence ne '')
{
$sequence =~ s/\*$//;
$md5->add(uc($sequence));
$id = $md5->hexdigest;
$fasta_hash{$id}{'AC'}.=$key .' ';
$fasta_hash{$id}{'comment'}=$comment;
$fasta_hash{$id}{'sequence'}=$sequence;
$key='';
$comment='';
$sequence='';
}
my @ids = split(m/\|/,$1);
$key=$ids[-1];
$comment=$2;
}
else
{
$key || die "File $file is not a fasta file!";
s/\s+//g;
$sequence.=$_;
} #else
} #while (<IN>)
if($sequence ne '')
{
$sequence =~ s/\*$//;
$md5->add(uc($sequence));
$id = $md5->hexdigest;
$fasta_hash{$id}{'AC'}.=$key .' ';
$fasta_hash{$id}{'comment'}=$comment;
$fasta_hash{$id}{'sequence'}=$sequence;
$key='';
$comment='';
$sequence='';
}

Addendum
105
close IN;
return (%fasta_hash);
} #fasta2hash ( $ )
#============================================================================
sub flat2fasta ( $ $ )
{
my($seq, $line_length) = @_;
my $new_seq = '';
for (my $i=0; $i < length($seq); $i += $line_length)
{
$new_seq .= sprintf ("%s\n", substr($seq,$i,$line_length));
}
return($new_seq);
}
#------------------------------------------------------------
sub fasta2hash ( $ )
{
my ($file,$key,$value,$comment);
my (%fasta_hash);
$file=$_[0];
if($file =~ m/\.gz$/)
{
open(IN,"gunzip -c $file |");
}
elsif($file =~ m/\.bz2$/)
{
open(IN,"bunzip2 -c $file |");
}
else
{
open (IN,$file) || die "problem with $file\n";
}
while (<IN>)
{
chomp;
if (/^>(\S+)\s*(.*)/)
{
$key=$1;
$comment=$2;
if($key =~ m/\|/)
{
my @ids = split(m/\|/,$key);
$key=$ids[-1];
}
#$key =~ s/\|//g;
$fasta_hash{$key}{"comment"}=$comment;
#if(defined($fasta_hash{$key}{"sequence"}) || $fasta_hash{$key}{"sequence"} ne '')
#{
# print STDERR "sequence $key already exists\n";
$fasta_hash{$key}{"sequence"}='';
#}
} #if (/^>(\w)$/)
else
{
$key || die "File $file is not a fasta file!";
s/\s+//g;
$fasta_hash{$key}{"sequence"}.=$_;
} #else
} #while (<IN>)
close IN;
return (%fasta_hash);
} #fasta2hash ( $ )
#-----------------------------------------------------------------------------------------
sub translate ( $ )
{
my($seq) = @_;
my($i,$len,$output) = (0,0,'');

Addendum
106
my($codon) = "";
for($len=length($seq),$seq = uc($seq),$i=0; $i<($len-2) ; $i+=3) {
$codon = substr($seq,$i,3);
# would this be easier with a hash system (?) EB
if ($codon =~ /^TC/) {$output .= 'S'; } # Serine
elsif($codon =~ /^TT[TCY]/) {$output .= 'F'; } # Phenylalanine
elsif($codon =~ /^TT[AGR]/) {$output .= 'L'; } # Leucine
elsif($codon =~ /^TA[TCY]/) {$output .= 'Y'; } # Tyrosine
elsif($codon =~ /^TA[AGR]/) {$output .= '*'; } # Stop
elsif($codon =~ /^TG[TCY]/) {$output .= 'C'; } # Cysteine
elsif($codon =~ /^TGA/) {$output .= '*'; } # Stop
elsif($codon =~ /^TGG/) {$output .= 'W'; } # Tryptophan
elsif($codon =~ /^CT/) {$output .= 'L'; } # Leucine
elsif($codon =~ /^CC/) {$output .= 'P'; } # Proline
elsif($codon =~ /^CA[TCY]/) {$output .= 'H'; } # Histidine
elsif($codon =~ /^CA[AGR]/) {$output .= 'Q'; } # Glutamine
elsif($codon =~ /^CG/) {$output .= 'R'; } # Arginine
elsif($codon =~ /^AT[TCAH]/){$output .= 'I'; } # Isoleucine
elsif($codon =~ /^ATG/) {$output .= 'M'; } # Methionine
elsif($codon =~ /^AC/) {$output .= 'T'; } # Threonine
elsif($codon =~ /^AA[TCY]/) {$output .= 'N'; } # Asparagine
elsif($codon =~ /^AA[AGR]/) {$output .= 'K'; } # Lysine
elsif($codon =~ /^AG[TCY]/) {$output .= 'S'; } # Serine
elsif($codon =~ /^AG[AGR]/) {$output .= 'R'; } # Arginine
elsif($codon =~ /^GT/) {$output .= 'V'; } # Valine
elsif($codon =~ /^GC/) {$output .= 'A'; } # Alanine
elsif($codon =~ /^GA[TCY]/) {$output .= 'D'; } # Aspartic Acid
elsif($codon =~ /^GA[AGR]/) {$output .= 'E'; } # Glutamic Acid
elsif($codon =~ /^GG/) {$output .= 'G'; } # Glycine
else {$output .= 'X'; } # Unknown Codon
}
return $output;
}
#-----------------------------------------------------------------------------------------
sub speedy_translate ( $ )
{
my $stops = 0;
my($seq) = @_;
my($i,$len,$output) = (0,0,'');
my($codon) = "";
for($len=length($seq),$seq = uc($seq),$i=0; $i<($len-2) ; $i+=3)
{
$codon = substr($seq,$i,3);
# would this be easier with a hash system (?) EB
if ($codon =~ /^TC/) {$output .= 'S'; } # Serine
elsif($codon =~ /^TT[TCY]/) {$output .= 'F'; } # Phenylalanine
elsif($codon =~ /^TT[AGR]/) {$output .= 'L'; } # Leucine
elsif($codon =~ /^TA[TCY]/) {$output .= 'Y'; } # Tyrosine
elsif($codon =~ /^TA[AGR]/) {$output .= '*'; $stops++;} # Stop
elsif($codon =~ /^TG[TCY]/) {$output .= 'C'; } # Cysteine
elsif($codon =~ /^TGA/) {$output .= '*'; $stops++;} # Stop
elsif($codon =~ /^TGG/) {$output .= 'W'; } # Tryptophan
elsif($codon =~ /^CT/) {$output .= 'L'; } # Leucine
elsif($codon =~ /^CC/) {$output .= 'P'; } # Proline
elsif($codon =~ /^CA[TCY]/) {$output .= 'H'; } # Histidine
elsif($codon =~ /^CA[AGR]/) {$output .= 'Q'; } # Glutamine
elsif($codon =~ /^CG/) {$output .= 'R'; } # Arginine
elsif($codon =~ /^AT[TCAH]/){$output .= 'I'; } # Isoleucine
elsif($codon =~ /^ATG/) {$output .= 'M'; } # Methionine
elsif($codon =~ /^AC/) {$output .= 'T'; } # Threonine
elsif($codon =~ /^AA[TCY]/) {$output .= 'N'; } # Asparagine
elsif($codon =~ /^AA[AGR]/) {$output .= 'K'; } # Lysine
elsif($codon =~ /^AG[TCY]/) {$output .= 'S'; } # Serine
elsif($codon =~ /^AG[AGR]/) {$output .= 'R'; } # Arginine
elsif($codon =~ /^GT/) {$output .= 'V'; } # Valine

Addendum
107
elsif($codon =~ /^GC/) {$output .= 'A'; } # Alanine
elsif($codon =~ /^GA[TCY]/) {$output .= 'D'; } # Aspartic Acid
elsif($codon =~ /^GA[AGR]/) {$output .= 'E'; } # Glutamic Acid
elsif($codon =~ /^GG/) {$output .= 'G'; } # Glycine
else {$output .= 'X'; } # Unknown Codon
last if ($stops == 2);
}
return $output;
}
#-----------------------------------------------------------------------------------------
sub translate3frames ( $ $ )
{
my $stops = 0;
my $seq = uc($_[0]); # sequence to translate
my $strand = $_[1]; # both strand yes or no (1/0)
my $rev_seq = '';
$rev_seq = &reverseComplement($seq) if($strand);
my $len = length($seq);
my @translations = ();
my($output,$CDS) = ('','');
my %codon = ("TCA"=>"S","TCC"=>"S","TCG"=>"S","TCT"=>"S","TCN"=>"S",
# Serine
"TTT"=>"F","TTC"=>"F","TTY"=>"F",
# Phenylalanine
"TTA"=>"L","TTG"=>"L","TTR"=>"L",
# Leucine
"TAT"=>"Y","TAC"=>"Y","TAY"=>"Y",
# Tyrosine
"TAA"=>"*","TAG"=>"*","TAR"=>"*",
# Stop
"TGT"=>"C","TGC"=>"C","TGY"=>"C",
# Cysteine
"TGA"=>"*",
# Stop
"TGG"=>"W",
# Tryptophan
"CTA"=>"L","CTC"=>"L","CTG"=>"L","CTT"=>"L","CTN"=>"L",
# Leucine
"CCA"=>"P","CCC"=>"P","CCG"=>"P","CCT"=>"P","CCN"=>"P",
# Proline
"CAT"=>"H","CAC"=>"H","CAY"=>"H",
# Histidine
"CAA"=>"Q","CAG"=>"Q","CAR"=>"Q",
# Glutamine
"CGA"=>"R","CGC"=>"R","CGG"=>"R","CGT"=>"R","CGN"=>"R",
# Arginine
"ATA"=>"I","ATC"=>"I","ATT"=>"I","ATH"=>"I",
# Isoleucine
"ATG"=>"M",
# Methionine
"ACA"=>"T","ACC"=>"T","ACG"=>"T","ACT"=>"T","ACN"=>"T",
# Threonine
"AAT"=>"N","AAC"=>"N","AAY"=>"N",
# Asparagine
"AAA"=>"K","AAG"=>"K","AAR"=>"K",
# Lysine
"AGT"=>"S","AGC"=>"S","AGY"=>"S",
# Serine
"AGA"=>"R","AGG"=>"R","AGR"=>"R",
# Arginine
"GTA"=>"V","GTC"=>"V","GTG"=>"V","GTT"=>"V","GTN"=>"V",
# Valine
"GCA"=>"A","GCC"=>"A","GCG"=>"A","GCT"=>"A","GCN"=>"A",
# Alanine
"GAT"=>"D","GAC"=>"D","GAY"=>"D",
# Aspartic Acid
"GAA"=>"E","GAG"=>"E","GAR"=>"E",
# Glutamic Acid
"GGA"=>"G","GGC"=>"G","GGG"=>"G","GGT"=>"G","GGN"=>"G",
# Glycine

Addendum
108
);
foreach my $dna ($seq,$rev_seq)
{
next if($dna eq '');
foreach my $frame (0..2)
{
for( my $i=(0+$frame); $i<($len-2) ; $i+=3)
{
if(exists $codon{substr($dna,$i,3)})
{
$output .= $codon{substr($dna,$i,3)};
}
else
{
$output .= 'X';
# Unknown Codon
# printf STDERR " no translation for: " . substr($seq,$i,3) . "\n";
}
}
push(@translations, $output);
$output = ();
}
}
return (\@translations);
}
#-----------------------------------------------------------------------------------------
sub longestORF ( $ )
{
my $cDNA = $_[0];
my $ATG_pos = 0;
my $STOP_pos = 0;
my @ATG = ();
my @STOP = ();
my @temp = ();
$cDNA = uc($cDNA);
while($ATG_pos > -1)
{
push(@ATG, index($cDNA, "ATG", $ATG_pos));
$ATG_pos = index($cDNA, "ATG", ($ATG_pos+1));
}
$STOP_pos = 0;
while($STOP_pos > -1)
{
push(@temp, index($cDNA, "TAA", $STOP_pos)+3);
$STOP_pos = index($cDNA, "TAA", ($STOP_pos+1));
}
$STOP_pos = 0;
while($STOP_pos > -1)
{
push(@temp, index($cDNA, "TGA", $STOP_pos)+3);
$STOP_pos = index($cDNA, "TGA", ($STOP_pos+1));
}
$STOP_pos = 0;
while($STOP_pos > -1)
{
push(@temp, index($cDNA, "TAG", $STOP_pos)+3);
$STOP_pos = index($cDNA, "TAG", ($STOP_pos+1));
}
@STOP = sort {$b <=> $a} @temp;
my $ORFlength=0;
my $temp_start = 0;
my $temp_end = 0;
my $CDS = "";
my $UTR5 = "";
my $UTR3 = "";
my $temp_pep = "";
my $final_start = 0;
my $final_end = 0;
foreach my $start (@ATG)
{
foreach my $end (@STOP)

Addendum
109
{
# print $end ."\n";
last if ($end < ($start + $ORFlength));
next if (($end-$start) % 3 != 0);
$temp_pep = &speedy_translate(substr($cDNA,$start,($end-$start))) if(($end-
$start) > 0);
$temp_pep =~ s/\*$/+/;
if(($end-$start) % 3 == 0 && ($end-$start) > 0 && $temp_pep !~ m/\*/)
{
$temp_start = $start;
$temp_end = $end;
}
}
if(($temp_end-$temp_start) > $ORFlength)
{
print SUM length($cDNA) ."\t". $temp_start ."\t". $temp_end ."\t". ($temp_end-
$temp_start) ."\t". (($temp_end-$temp_start) % 3) ."\n";
$ORFlength = $temp_end-$temp_start;
$final_start = $temp_start;
$final_end = $temp_end;
}
}
$CDS = substr($cDNA,$final_start,$ORFlength) if(($final_start+$ORFlength) <= length($cDNA) &&
$final_end>0);
$UTR5 = substr($cDNA,0,$final_start) if(($final_start) <= length($cDNA) && $final_end>0);
$UTR3 = substr($cDNA,$final_end) if(($final_end) <= length($cDNA) && $final_end>0);
return "$UTR5\t$CDS\t$UTR3";
}
#-----------------------------------------------------------------------------------------
sub reverseComplement ( $ )
{
my $tmp_sequence = $_[0];
my %complement = ("A" => "T",
"T" => "A",
"C" => "G",
"G" => "C",
"a" => "t",
"t" => "a",
"c" => "g",
"g" => "c",
"M" => "K",
"R" => "Y",
"W" => "W",
"S" => "S",
"Y" => "R",
"K" => "M",
"V" => "B",
"H" => "D",
"D" => "H",
"B" => "V",
"m" => "k",
"r" => "y",
"w" => "w",
"s" => "s",
"y" => "r",
"k" => "m",
"v" => "b",
"h" => "d",
"d" => "h",
"b" => "v",
"N" => "N",
"X" => "X",
"n" => "n",
"x" => "x",
"-" => "-");
my $CDS_comp = "";
my $Len = length($tmp_sequence);
$tmp_sequence = reverse($tmp_sequence);

Addendum
110
for (my $j=0; $j < $Len ; $j++)
{
if(!exists $complement{substr($tmp_sequence,$j,1)}) { printf STDERR " no complement for:
" . substr($tmp_sequence,$j,1) . "\n"; }
$CDS_comp .= $complement{substr($tmp_sequence,$j,1)};
}
return($CDS_comp);
}
#-----------------------------------------------------------------------------------------
sub complement ( $ )
{
my $tmp_sequence = $_[0];
my %complement = ("A" => "T",
"T" => "A",
"C" => "G",
"G" => "C",
"a" => "t",
"t" => "a",
"c" => "g",
"g" => "c",
"M" => "K",
"R" => "Y",
"W" => "W",
"S" => "S",
"Y" => "R",
"K" => "M",
"V" => "B",
"H" => "D",
"D" => "H",
"B" => "V",
"m" => "k",
"r" => "y",
"w" => "w",
"s" => "s",
"y" => "r",
"k" => "m",
"v" => "b",
"h" => "d",
"d" => "h",
"b" => "v",
"N" => "N",
"X" => "X",
"n" => "n",
"x" => "x",
"-" => "-");
my $CDS_comp = "";
my $Len = length($tmp_sequence);
for (my $j=0; $j < $Len ; $j++)
{
if(!exists $complement{substr($tmp_sequence,$j,1)}) { printf STDERR " no complement for:
" . substr($tmp_sequence,$j,1) . "\n"; }
$CDS_comp .= $complement{substr($tmp_sequence,$j,1)};
}
return($CDS_comp);
}
#========================================================================================
sub usage ( $ )
{
print STDERR "$_[0]\n";
system("pod2text $0");
exit(1);
}
#-----------------------------------------------------------------------------------------
#========================================================================================
#-----------------------------------------------------------------------------------------
&usage("not enough parameters") if(scalar(@ARGV)<1);

Addendum
111
my $params = join(' ',@ARGV);
if (scalar(@ARGV) <1 || $params =~ m/-HELP/i)
{
die "usage:\n\nparam1 = sequence file in FASTA format,\n"
. "\n";
}
else
{
my $fasta_dir = "";
my @fasta_files = glob("$ARGV[0]");
# ($params) = @ARGV;
print STDERR "@ARGV\n" if($params !~ m/-QUIET/i);
if (scalar(@fasta_files) < 1)
{
die "no FASTA files (*.tfa) in $fasta_dir";
}
else
{
print STDERR scalar(@fasta_files) ."\n" if($params !~ m/-QUIET/i);
}
foreach my $f (@fasta_files)
{
# $f =~ s/\\/\//g;
print "\n-----------------------------------$f\n" if($params =~ m/-VERB/ );
my $j = 1;
my $split = 1;
my %sequence_file = &fasta2hash($f) if($params !~ m/-NR/i );
my @seq_keys=sort(keys(%sequence_file)) if($params !~ m/-NR/i );
my $count = scalar(@seq_keys) if($params !~ m/-NR/i );
my $ACnr = '';
my $fasta_sequence = '';
my $comment_line = '';
my @seq_array = ();
my $seq_length = 0;
my $A = 0;
my $C = 0;
my $G = 0;
my $T = 0;
my $N = 0;
my $temp = '';
print STDERR $count if($params !~ m/-QUIET/i);
print STDERR "the parameters: $params\n" if($params !~ m/-QUIET/i);
if($params =~ m/-MERGE/i && $ACnr !~ m/_comment/)
{
my $new_seq = '';
foreach my $key (sort keys (%sequence_file))
{
$new_seq .= $sequence_file{$key}{'sequence'}.'N'x1000;
}
print ">merge0001 merge of ".scalar(keys (%sequence_file)).' contigs length:'.
length($new_seq) . "\n";
print "$new_seq\n";
}
elsif($params !~ m/-ORDER=/i && $params !~ m/-SAMPLE=(\S+)/i && $params !~ m/-NR/i &&
$params !~ m/-MAKE_NR/i && $params !~ m/-REMOVE=/i )
{
foreach my $key (sort keys (%sequence_file))
{
if($key !~ m/_comment/)
{
$ACnr = $key;
$fasta_sequence = $sequence_file{$key}{'sequence'};
$comment_line = $sequence_file{$key}{'comment'};
}
else

Addendum
112
{
next;
}
if($params =~ m/-GC/i && $ACnr !~ m/_comment/)
{
my $_A=0;
my $_C=0;
my $_G=0;
my $_T=0;
my $N=0;
@seq_array = ();
$seq_length = length($fasta_sequence);
@seq_array = split('',$fasta_sequence);
for(my $x=0; $x<$seq_length; $x++)
{
if(uc($seq_array[$x]) eq "A") { $A++ ; $_A++;}
elsif(uc($seq_array[$x]) eq "C") { $C++ ; $_C++ ;}
elsif(uc($seq_array[$x]) eq "G") { $G++ ; $_G++ ;}
elsif(uc($seq_array[$x]) eq "T") { $T++ ; $_T++ ;}
else
{
if(ord($seq_array[$x]) ne 13 ||
ord($seq_array[$x]) ne 0 ) {$N++;}
}
}
print STDOUT "$ACnr\t";
print STDOUT
"$seq_length\t\#A=$_A\t\#C=$_C\t\#G=$_G\t\#T=$_T\t\#N=$N\t\%GC:". ($_C+$_G)/($_A+$_C+$_G+$_T+$N)
."\t\%N:". ($N)/($_A+$_C+$_G+$_T+$N) ."\n";
}
if($params =~ m/-MD5/i && $ACnr !~ m/_comment/)
{
my $md5 = Digest::MD5->new;
$md5->add($fasta_sequence);
my $id = $md5->hexdigest;
print "$ACnr\t";
print $id . "\n";
}
if($params =~ m/-LEN/i && $ACnr !~ m/_comment/)
{
print STDOUT "$ACnr\t";
print STDOUT length($fasta_sequence) . "\n";
}
if(($params =~ m/-CLIP/i || $params =~ m/-CLEAN/i) && $ACnr !~
m/_comment/)
{
my $new_seq = $fasta_sequence;
if($fasta_sequence =~ m/^[NX]{10,}(.*?)[NX]{10,}$/i)
{
$new_seq = $1;
}
if($params =~ m/-CLEAN/i && $new_seq =~ m/([NX]{20,})/i)
{
my @gap_chars = split('',$1);
my $ii = sprintf("%.0f", scalar(@gap_chars)/2);
my $gap_char = $gap_chars[$ii];
my $gap = $gap_char x 20;
$new_seq =~ s/$gap_char{20,}/$gap/i;
}
if(length($fasta_sequence) ne length($new_seq))
{
print STDERR "clipped: $ACnr\n" if($params !~ m/-
QUIET/i);;
print STDOUT ">$ACnr $comment_line
(".length($fasta_sequence).' clipped to '.length($new_seq).")\n";
print STDOUT "$new_seq\n";
}
else
{
print STDOUT ">$ACnr $comment_line\n";
print STDOUT "$new_seq\n";
}

Addendum
113
}
if($params =~ m/-FIND=(\S+)/i)
{
$temp=$1;
if("$ACnr $comment_line" =~ m/$temp/)
{
print STDOUT ">$ACnr $comment_line ".
length($fasta_sequence) . "\n";
print STDOUT "$fasta_sequence\n";
}
}
if($params =~ m/-FETCH=(\S+)/i)
{
$temp=$1;
print ">$temp $sequence_file{$temp}{'comment'} ".
length($sequence_file{$temp}{'sequence'}) . "\n";
print "$sequence_file{$temp}{'sequence'}\n";
exit;
}
if($params =~ m/-TRANSLATE/i)
{
my $pep_sequence = &translate($fasta_sequence);
print ">$ACnr $comment_line ". length($pep_sequence) . "\n";
print "$pep_sequence\n";
}
if($params =~ m/-6FRAMETRANS/i)
{
my $a = 0;
my $pep_sequence = &translate3frames($fasta_sequence,1);
foreach my $p (@$pep_sequence)
{
print ">$ACnr.$a $comment_line ". length($pep_sequence) .
"\n";
print "$p\n";
$a++;
}
}
if($params =~ m/-FORMAT/i)
{
my $form_sequence = &flat2fasta($fasta_sequence,60);
print ">$ACnr $comment_line ". length($fasta_sequence) . "\n";
print "$form_sequence\n";
}
if($params =~ m/-REV_COMP/i)
{
my $rev_sequence = &reverseComplement($fasta_sequence);
print ">$ACnr $comment_line ". length($rev_sequence) . "\n";
print "$rev_sequence\n";
}
if($params =~ m/-REVERSE/i)
{
my $rev_sequence = reverse($fasta_sequence);
print ">$ACnr $comment_line ". length($rev_sequence) . "\n";
print "$rev_sequence\n";
}
if($params =~ m/-COMPLEMENT/i)
{
my $rev_sequence = &complement($fasta_sequence);
print ">$ACnr $comment_line ". length($rev_sequence) . "\n";
print "$rev_sequence\n";
}
if($params =~ m/-ORF/i)
{
my $ORF_sequence = &longestORF($fasta_sequence);
my ($UTR5, $ORF, $UTR3) = split("\t", $ORF_sequence);
print ">$ACnr $comment_line ". length($ORF) . "\n";
print "$ORF\n";
}
if($params =~ m/-UTR5/i) #added by liste 6/9/05
{
my $ORF_sequence = &longestORF($fasta_sequence);
my ($UTR5, $ORF, $UTR3) = split("\t", $ORF_sequence);

Addendum
114
if ($UTR5 ne '')
{
print ">$ACnr $comment_line ". length($UTR5) . "\n";
print "$UTR5\n";
}
}
if($params =~ m/-UTR3/i) #added by liste 6/9/05
{
my $ORF_sequence = &longestORF($fasta_sequence);
my ($UTR5, $ORF, $UTR3) = split("\t", $ORF_sequence);
if ($UTR3 ne '')
{
print ">$ACnr $comment_line ". length($UTR3) . "\n";
print "$UTR3\n";
}
}
if($params =~ m/-SIZE=(\d+)/i) #length from end of seq upstream
{
my $size=$1;
my $short_seq = '';
if(length($fasta_sequence)>$size)
{
$short_seq =
substr($fasta_sequence,(length($fasta_sequence)-$size));
print ">$ACnr $comment_line ". length($short_seq) . "\n";
print "$short_seq\n";
}
else
{
print ">$ACnr $comment_line ". length($fasta_sequence) .
"\n";
print "$fasta_sequence\n";
}
}
if($params =~ m/-LENGTH=(\d+)/i) # length from beginning of seq
downstream
{
my $size=$1;
my $short_seq = '';
if(length($fasta_sequence)>=$size)
{
$short_seq = substr($fasta_sequence,0,$size);
print ">$ACnr $comment_line ". length($short_seq) . "\n";
print "$short_seq\n";
}
else
{
print ">$ACnr $comment_line ". length($fasta_sequence) .
"\n";
print "$fasta_sequence\n";
}
}
if($params =~ m/-LARGER=(\d+)/i) # only output sequence of minimum
<number> length
{
my $size=$1;
my $short_seq = '';
if(length($fasta_sequence)>=$size)
{
print ">$ACnr $comment_line ". length($fasta_sequence) .
"\n";
print "$fasta_sequence\n";
}
}
if($params =~ m/-ENDS/i) # length from beginning of seq downstream
{
my $short_seq5 = '';
my $short_seq3 = '';
if(substr($fasta_sequence,(length($fasta_sequence)-3)) eq "ATG")
{
$short_seq5 = substr($fasta_sequence,0,20);

Addendum
115
$short_seq3 =
substr($fasta_sequence,(length($fasta_sequence)-20));
print "$ACnr\t";
print "$short_seq5 .. $short_seq3\n";
}
}
if($params =~ m/-CHOP=(\d+)\,?(\d*)/i) # length from beginning of seq
downstream
{
my $size=$1;
my $overlap = $2;
my $chop_from=0;
my $short_seq = '';
my $counter=1;
if(length($fasta_sequence)>=$size)
{
while($chop_from <= length($fasta_sequence))
{
$short_seq =
substr($fasta_sequence,$chop_from,$size);
if(length($short_seq) > 0)
{
print ">". sprintf("%03d", $counter)
."_${ACnr} $comment_line [".$chop_from .','.$size .'] '. length($short_seq) . "\n";
print "$short_seq\n";
}
$chop_from += ($size - $overlap);
$counter++;
}
}
else
{
print ">$ACnr $comment_line ". length($fasta_sequence) .
"\n";
print "$fasta_sequence\n";
}
}
if($params =~ m/-EXTRACT=(\d+)\,(\d+)/i) # length from,to extraction of
part of sequence
{
my $size= $2 - $1 + 1;
my $chop_from=$1-1;
my $short_seq = '';
if((length($fasta_sequence) - $chop_from)>=$size)
{
$short_seq = substr($fasta_sequence,$chop_from,$size);
print ">$ACnr $comment_line ". length($short_seq) . "\n";
print "$short_seq\n";
}
else
{
$short_seq = substr($fasta_sequence,$chop_from);
print ">$ACnr $comment_line ". length($short_seq) . "\n";
print "$short_seq\n";
}
}
if($params =~ m/-MEXTRACT=(\S+)/i) # file with ACnr, from,to extraction
of part of sequence
{
open(FIN, "< $1");
while(<FIN>)
{
chomp;
my ($ACnr,$from,$to) = split(m/\t/,$_);
my $size= $to - $from + 1;
my $chop_from=$from-1;
my $short_seq = '';
if((length($sequence_file{$ACnr}{'sequence'}) -
$chop_from)>=$size)
{

Addendum
116
$short_seq =
substr($sequence_file{$ACnr}{'sequence'},$chop_from,$size);
print ">$ACnr $comment_line ". length($short_seq)
. " $ACnr,[$from,$to]\n";
print "$short_seq\n";
}
elsif(exists($sequence_file{$ACnr}{'sequence'}))
{
$short_seq =
substr($sequence_file{$ACnr}{'sequence'},$chop_from);
print ">$ACnr $comment_line ". length($short_seq)
. " $ACnr,[$from,$to] ".length($sequence_file{$ACnr}{'sequence'})."\n";
print "$short_seq\n";
}
}
close(FIN);
last;
}
if($params =~ m/-SPLIT=(\d+)/i)
{
my $i = $1;
if($split <= ceil($count/$i))
{
open(OUT, ">> ${f}_${j}");
print OUT ">$ACnr $comment_line ". length($fasta_sequence) .
"\n";
print OUT "$fasta_sequence\n";
close(OUT);
$split++;
}
else
{
$j++;
open(OUT, ">> ${f}_${j}");
print OUT ">$ACnr $comment_line ". length($fasta_sequence) .
"\n";
print OUT "$fasta_sequence\n";
close(OUT);
$split =2;
}
}
if($params =~ m/-SINGLE/i)
{
open(OUT, "> ${ACnr}.fasta");
print OUT ">$ACnr $comment_line ". length($fasta_sequence) .
"\n";
print OUT "$fasta_sequence\n";
close(OUT);
}
if($params =~ m/-SPLITsize=(\d+)/i)
{
my $sizeF = (-s $f);
#print $sizeF ."\n";
my $sizeP = (-s "${f}_${j}");
#print $sizeP ."\n";
my $i = $1;
if ($sizeP < ($sizeF/$i) ){
open(OUT, ">> ${f}_${j}");
print OUT ">$ACnr $comment_line ". length($fasta_sequence)
. "\n";
print OUT "$fasta_sequence\n";
close(OUT);
} else {
$j++;
open(OUT, ">> ${f}_${j}");
print OUT ">$ACnr $comment_line ". length($fasta_sequence)
. "\n";
print OUT "$fasta_sequence\n";
close(OUT);

Addendum
117
}
}
}#foreach $ACnr (keys (%sequence_file))
if($params =~ m/-GC/i && $ACnr !~ m/_comment/)
{
print "overall:\t";
print "\%A: ". $A/($A+$C+$G+$T) ."\t\%C: ". $C/($A+$C+$G+$T) ."\t\%G: ".
$G/($A+$C+$G+$T) ."\t\%T: ". $T/($A+$C+$G+$T) ."\n";
print"\%GC: ". ($C+$G)/($A+$C+$G+$T) ."\n";
print"\%AT: ". ($A+$T)/($A+$C+$G+$T) ."\n";
}
}
elsif($params =~ m/-ORDER=(\S+)/i || $params =~ m/-SAMPLE=(\S+)/i)
{
my $list_file = $1;
my @sample_data = ();
print STDERR "list: $list_file\n" if($params !~ m/-QUIET/i);;
open(LIST, "< $list_file");
print STDERR ">$list_file\n" if($params !~ m/-QUIET/i);;
while(my $AC = <LIST>)
{
chomp($AC);
my $ACnr = $AC;
# ($ACnr, $ID1, $ID2) = split("\t",$_);
# if($ACnr ne '' && $ID1 ne '' && $ID2 ne 'N/A')
# if($ACnr =~ m/^\d+/)
# my @clefs = keys(%sequence_file);
# my @ACnrs = grep(m/^$AC$/i,@clefs);
# foreach my $ACnr (@ACnrs)
# {
$fasta_sequence = $sequence_file{$ACnr}{'sequence'};
$comment_line = $sequence_file{$ACnr}{'comment'};
if(!length($fasta_sequence)>1)
{
$fasta_sequence =
$sequence_file{uc($ACnr).'.1'}{'sequence'};
$comment_line = $sequence_file{uc($ACnr).'.1'}{'comment'};
if(!length($fasta_sequence)>1)
{
print STDERR "no sequence for $ACnr\n" if($params
!~ m/-QUIET/i);
}
}
if(length($fasta_sequence)>1)
{
push(@sample_data, ">$ACnr $comment_line");
push(@sample_data,"$fasta_sequence");
if(scalar(@sample_data) > 10000)
{
print join("\n",@sample_data) ."\n";
@sample_data = ();
print STDERR '.';
}
}
# }
}
print join("\n",@sample_data) ."\n";
print STDERR ".\n";
}
elsif ($params =~ m/-REMOVE=(\S+)/i )
{
my $list_file = $1;
my %remove = ();
my $cc = 0;
print STDERR "list: $list_file\n" if($params !~ m/-QUIET/i);;
open(LIST, "< $list_file");
print STDERR ">$list_file\n" if($params !~ m/-QUIET/i);;
while(<LIST>)
{
chomp $_;

Addendum
118
$remove{$_} = 1;
}
close LIST;
foreach my $ACnr (sort keys %sequence_file)
{
if (defined $remove{$ACnr} )
{
$cc++;
next;
}
else
{
$fasta_sequence = $sequence_file{$ACnr}{'sequence'};
$comment_line = $sequence_file{$ACnr}{'comment'};
if(length($fasta_sequence)>1)
{
print ">$ACnr $comment_line\n";
print "$fasta_sequence\n";
}
}
}
print STDERR "\nremoved $cc entrie(s)\n" if($params !~ m/-QUIET/i);;
}
elsif($params =~ m/-NR/i)
{
my %nr_seq = makeNR($f);
print STDERR "output file will be nr_${f}\n" if($params !~ m/-QUIET/i);;
open(OUT, "> nr_${f}");
foreach my $skey (sort {$nr_seq{$a}{'AC'} cmp $nr_seq{$b}{'AC'}} keys(%nr_seq))
{
# my $tmp_comment = substr($nr_seq{$skey}{'comment'},0,50);
print OUT ">". $nr_seq{$skey}{'AC'} ." ". length($nr_seq{$skey}{'sequence'})
." ". $nr_seq{$skey}{'comment'} . "\n";
print OUT $nr_seq{$skey}{'sequence'} ."\n";
}
close(OUT);
}
elsif($params =~ m/-MD5/i)
{
my %nr_seq = makeNR($f);
foreach my $skey (sort {$nr_seq{$a}{'AC'} cmp $nr_seq{$b}{'AC'}} keys(%nr_seq))
{
print STDOUT $nr_seq{$skey}{'AC'} ." ". $skey ."\n" ;
}
}
}#foreach $f (@fasta_files)
}
print "\n";

Addendum
119
9.2 Supplementary figures
Figure 20. MEGAN5 taxonomic profile of the fragmented O. tauri assembly (hiding nodes with less than 15 assigned
contigs). The assembly was constructed from whole-genome sequencing data of O. tauri filtered against O. tauri v2.2
genome to remove algal sequences. Contigs exceeding 20 kbp were fragmented into pieces of 10 kbp, the fragmented
assembly was filtered to exclude sequences shorter that 999 bp and classified using MEGAN5 (database: NCBI protein,
MinScore=60.0, MaxExpected=1.0E-5, TopPercent=10.0). Node size corresponds linearly to the total number of fragments
terminally assigned to the node. Because of the variable fragment size, the number of fragments can differ significantly
from their cumulative length.

Addendum
120
Figure 21 MEGAN5 taxonomic profile of the non-fragmented O. tauri assembly (hiding nodes with less than 500
assigned contigs). The assembly was constructed from whole-genome sequencing data of O. tauri filtered against O. tauri
v2.2 genome to remove algal sequences. Contigs were classified using MEGAN5 (database: NCBI protein, MinScore=60.0,
MaxExpected=1.0E-5, TopPercent=10.0). Node size as well as digits represent the total number of fragments terminally
assigned to the node. Because of the variable fragment length, the number of fragments can differ significantly from the
cumulative length of the fragments.

Addendum
121
Figure 22. Single-copy core gene content of Japanese C. braunii assembly upon scaffold reconstruction. (A) A heatmap
visualization of the number of single-copy core genes in each cluster for the optimal model with 45 clusters upon retrieval
of scaffolds for which over 50% of the fragments were co-clustered. Only clusters with at least one SCG are shown. (B) A
heatmap visualization of the number of single-copy core genes in a set of long scaffolds from the Japanese C. braunii
assembly. Scaffolds 5 and 40 originate from cluster 16.
Single-copy core gene (SCG)
Single-copy core gene (SCG)
Scaf
fold
Clu
ste
r
A B

Addendum
122
Table 3. The list of single-copy core genes (SCGs)
SCG’s used for evaluating cluster completeness and purity, the percentage of genomes in which they are present, and
their mean frequencies within genomes. The genes have been identified by Alneberg et al (2014). Calculations have been
carried out using 525 microbial genomes, each representing a unique genus.





![[PPT]Bacteria and Algae - Hatboro-Horsham School District / … · Web viewChapters 6-7 Marine bacteria Small, prokaryotic cells Reproduce asexually via binary fission 3 forms Chemosynthetic](https://img.dokumen.tips/doc/110x75/5ac91f257f8b9a51678cf165/pptbacteria-and-algae-hatboro-horsham-school-district-viewchapters-6-7.jpg)