Embed Size (px)
Citation preview

IBM Deep Learning Solutions
Reference Architecture for Deep Learning on POWER8, P100, and NVLink
October, 2016

2
How do you teach a computer to Perceive?

3
Deep Learning: teaching “Siri” to recognize a bicycle

4
Deep Learning: a tale of two infrastructures
Deep Learning / Training
Focused on perceptive tasks
• Teach a computer to recognize and categorize images (cross industry)
• Develop a model for natural language processing, real time translation, and/or interactive voice response (cross industry)
• Discover patterns of behavior and potential preferences (retail, entertainment)
Deep Learning / Inference
Act upon a trained model
• Autonomous vehicle: move through the physical world
• System of engagement: simplify access for users and provide a more familiar human / computer interface
• Better meet client needs by delivering recommendations, suggestions, or alternatives
Focus:: Datacenter infrastructure System on Chip, low power device,
partner solutions

5
Accelerated AI / Deep Learning Strategy for Power
• Modify open-source DL frameworks to add innovations, optimizations, new algorithms
• Add system-level optimizations. For example: take advantage of NVLink on Power platform, better network (scale-out) performance
• Build differentiated GPU-accelerated system solutions, using NVLink
IBM Version of DL Frameworks
Deep Learning Frameworks
New algorithmic techniques, optimizations
Power / NVLink specific optimizations

6
Introducing Deep Learning on POWER8 and NVLink
• A software distribution of Deep Learning frameworks optimized for the POWER8 S822LC for HPC server and for large scale cluster scaling, enabling much faster training of deep learning models
• Software frameworks are made available at:
– launchpad.net for stabilized and ported versions of Deep Learning frameworks and supporting libraries, in open source and binary distribution
– ibm.com for binary distribution of optimized packages containing neural network optimizations from IBM Research
• Systems are available through IBM direct and Business Partner channels globally, and are provided as a recommended configuration (reference architecture)
• Binary distribution of optimized Deep Learning frameworks will be supported through IBM Technical Support Services in the coming months
• Targeted availability for the initial software frameworks is October 31, 2016

7
Simplify Access and Installation
• Tested, binary builds of common Deep Learning frameworks for ease of implementation
• Simple, complete installation process documented on IBM OpenPOWER
– http://openpowerfoundation.org/blogs/ and search Deep Learning
• Future focus on optimizing specific packages for POWER: NVIDIA Caffe, TensorFlow, and Torch
Already ported Future focusOS Ubuntu 14.04 Ubuntu 16.04CUDA 7.5 8.0cuDNN 5.1 5.1Built w/ MASS Yes YesOpenBLAS 0.2.18 OptimizeCaffe 1.0 rc3NVIDIA Caffe 0.14.5 OptimizeNVIDIA DIGITS 3.2Torch 7 OptimizeTheano 0.8.2TensorFlow 0.9(*) OptimizeCNTK Nov 2015(*)DL4J 0.5.0(*)ChainerGPU 2x K80 4 x P100Base System 822LC Minsky* Ported; not released as binary

8
• NVLink between CPUs and GPUs enables fast memory access to large data sets in system memory
• Two NVLink connections between each GPU and CPU-GPU leads to faster data exchange
• First to market: volume shipments starting September, 2016
POWER8+P100+NVLink for increases system bandwidth
P100GPU
Power8CPU
GPUMemory
System Memory
P100GPU
80 GB/s
GPUMemory
NVLink
115 GB/s
P100GPU
Power8CPU
GPUMemory
System Memory
P100GPU
80 GB/s
GPUMemory
NVLink
115 GB/s
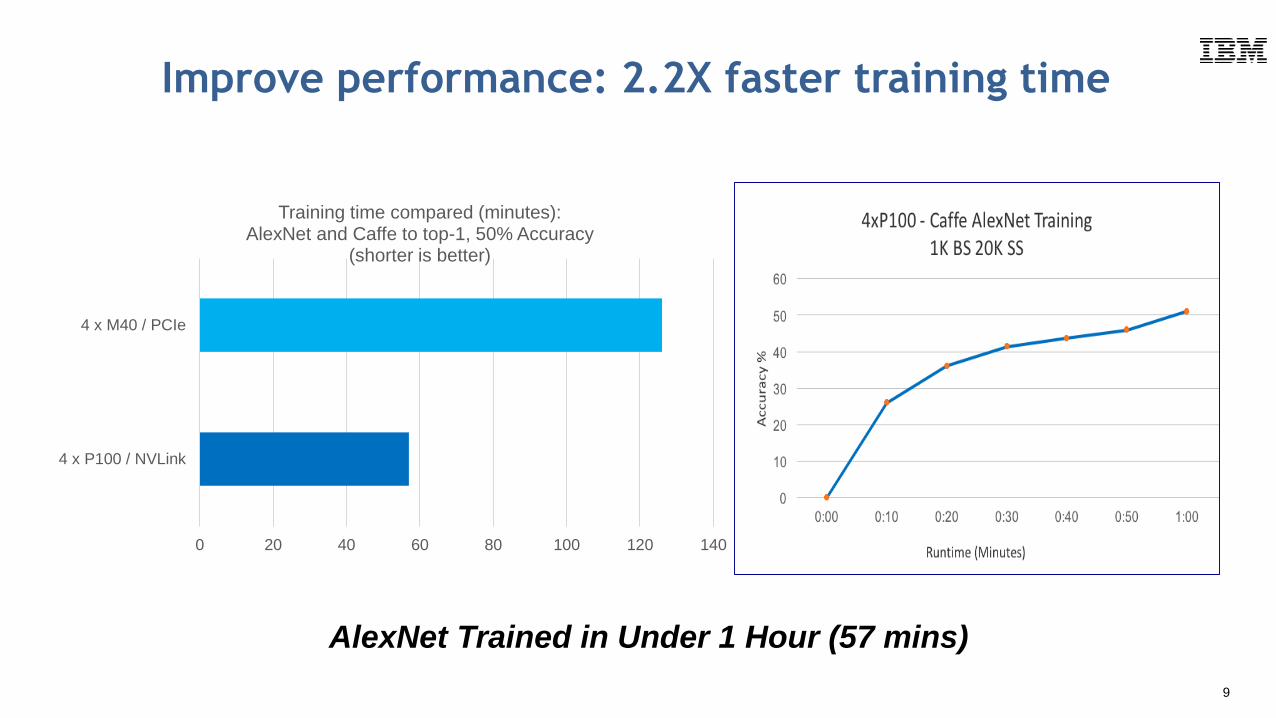
9
AlexNet Trained in Under 1 Hour (57 mins)
0 20 40 60 80 100 120 140
4 x P100 / NVLink
4 x M40 / PCIe
Training time compared (minutes): AlexNet and Caffe to top-1, 50% Accuracy
(shorter is better)
Improve performance: 2.2X faster training time

10
Improve Performance: Reduce Communication Overhead
• NVLink reduces communication time and overhead
• Data gets from GPU-GPU, Memory-GPU faster, for shorter training times
Digits devbox
POWER8+P1
00+NVLink
ImageNet / Alexnet: Minibatch size = 128
170 ms
78 ms
NVLink advantage: data
communication

11
Message – Deep Learning
Business Value– Increased Efficiency of Data Scientist – reduced training time allows the scientist to iterate and improve models
– Improved Inference (end product) – higher performance allows for more training runs that improves accuracy
Why IBM?– Cost Effective - two S822LC for HPC is less than price of the NVIDIA DGX-1 offering, and fully configurable
– OpenPOWER Deep Learning Software Distribution
• Ease of implementation – tested and build frameworks, IBM documented installation process
• Single source for applications, libraries, and other system components for faster time to compute.
– First to market - Competitors are selling last years’ model, OpenPOWER is first to market with P100 GPUs… the fastest GPU for Deep Learning.

12
Required:• 2 POWER8 10 Core CPUs
• 4 NVIDIA P100 ”Pascal” GPUs
• 256 GB System Memory
• 2 SSD storage devices
• High-speed interconnect (IB or Ethernet, depending on infrastructure)
Optional:• Up to 1 TB System Memory
• PCIe attached NVMe storage
S822LC for HPC: System Requirements for Deep Learning2 Socket, 4 GPU System with NVLink

13
Backup
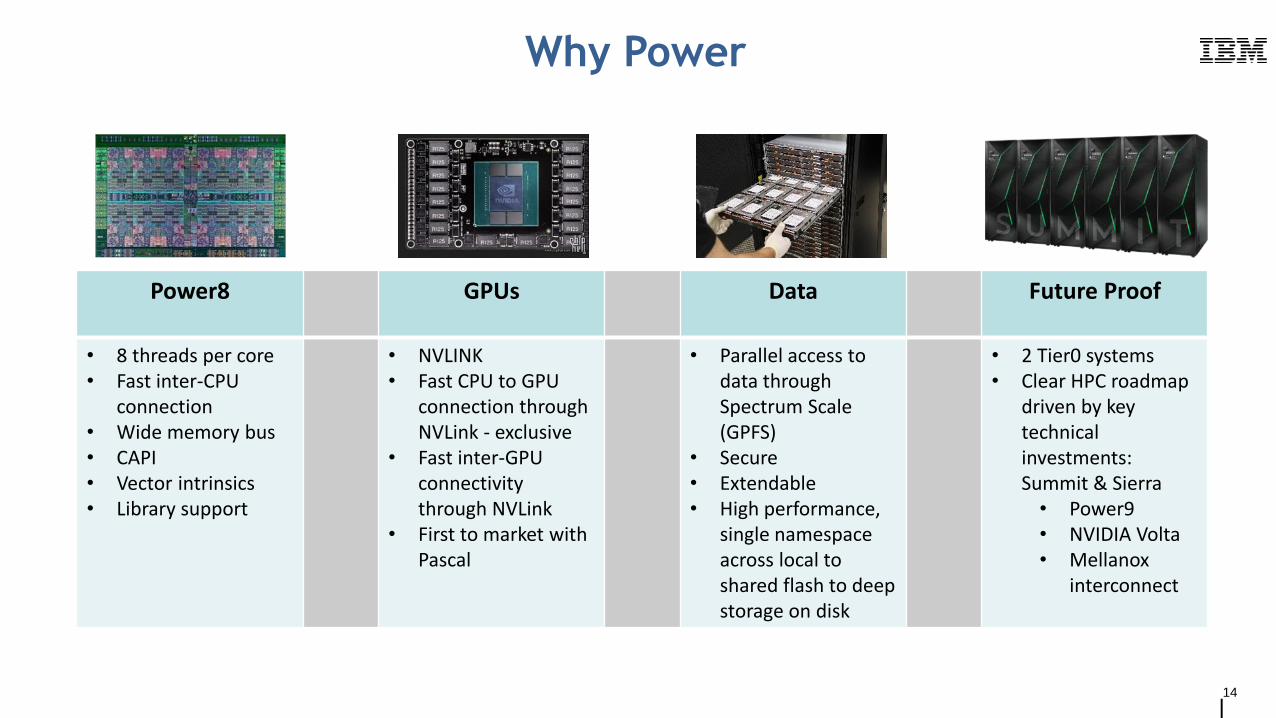
14
Why Power
|
Power8 GPUs Data Future Proof
• 8 threads per core• Fast inter-CPU
connection• Wide memory bus• CAPI• Vector intrinsics• Library support
• NVLINK• Fast CPU to GPU
connection through NVLink - exclusive
• Fast inter-GPU connectivity through NVLink
• First to market with Pascal
• Parallel access to data throughSpectrum Scale (GPFS)
• Secure• Extendable• High performance,
single namespace across local to shared flash to deep storage on disk
• 2 Tier0 systems• Clear HPC roadmap
driven by key technical investments: Summit & Sierra• Power9• NVIDIA Volta• Mellanox
interconnect

15
Model details
• AlexNet Model.
– Batch size 1024.
– Step size – 20K
– Rest of the hyper parameters remain default (base_lr : 0.01, wd – 0.0005)
• ImageNet 2012 Dataset

16
System configuration Details
– Minsky (g217l)
• 16 cores (8 cores/socket )
• 4.025 GHz
• 512 GB memory
• OS – Ubuntu 16.04.1
• Endian – LE
• Kernel version – 4.4.0-34-generic
– SW details.
• G++ - 5.3.1
• Gfortran – 5.3.1
• OpenBlas - 0.2.18
• Boost – 1.58.0
• CUDA 8.0 Toolkit
• Lapack – 3.6.0
• Hdf5 – 1.8.16
• Opencv – 2.4.9
• NVCaffe 0.14.5
• BVLC-Caffe :
f28f5ae2f2453f42b5824723efc326a04d
d16d85
– TurboTrainer (t1)
• 20 cores (10 cores/socket )
• 3.694 GHz
• 512 GB memory
• OS – Ubuntu 16.04
• Endian – LE
• Kernel version – 4.4.0-36-generic
– SW details.
• G++ - 5.3.1
• Gfortran – 5.3.1
• OpenBlas - 0.2.18
• Boost – 1.58.0
• CUDA 8.0 Toolkit
• Lapack – 3.6.0
• Hdf5 – 1.8.16
• Opencv – 2.4.9
• NVCaffe 0.14.5
• BVLC-Caffe :
f28f5ae2f2453f42b5824723efc326a04
dd16d85
– Intel (Haswell)
• 24 cores (12 cores/socket )
• 2.60 GHz
• 252 GB memory
• OS – Ubuntu 14.04
• Endian – LE
• Kernel version – 3.13.0-74-generic.
– SW details.
• G++ - 4.8.4
• Gfortran – 4.8.4
• MKL - 11.3.1 (2016 update 1)
• ATLAS - 3.10.2
• Boost – 1.58.0
• CUDA 7.5 Toolkit
• Lapack – 3.5.0
• Hdf5 – 1.8.14
• Opencv – 2.4.11
• Gmock – 1.7.0
• BVLC-Caffe :
f28f5ae2f2453f42b5824723efc326a0
4dd16d85

17
IBM Power Systems Server Codename “Minsky” & NVIDIA Tesla P100
|
2 POWER8 CPUs
Up to 1TB DDR4 memory
Up to 4 Tesla P100 GPUs(2x the density)
1st Server with POWER8 with
NVLink Technology
Only architecture with
CPU:GPU NVlink





























