Embed Size (px)
Citation preview

HTCondor at the RAL Tier-1
Andrew LahiffSTFC Rutherford Appleton Laboratory
European HTCondor Site Admins Meeting 2014

Outline
• Overview of batch system at RAL• HTCondor setup & configuration• Multi-core jobs• Monitoring• Virtual machines• Clouds
2

Introduction
• RAL is a Tier-1 for all 4 LHC experiments– In terms of Tier-1 computing requirements, RAL provides
• ALICE 2%• ATLAS 13%• CMS 8%• LHCb 32%
– Also support ~12 non-LHC experiments, including non-HEP– All access is via the grid
• No local submission to HTCondor by any users
• Computing resources– 784 worker nodes, over 14K cores– Generally have 40-60K jobs submitted per day
3

Introduction
• Torque / Maui had been used for many years– Many issues– Severity & number of problems increased as size of farm increased– In 2012 decided it was time to start investigating moving to a new
batch system– HTCondor became a production service in August 2013
• Experience over past 1.5 years with HTCondor– Very stable operation
• Generally just ignore the batch system & everything works fine• Staff don’t need to spend all their time fire-fighting problems
– No changes needed as the HTCondor pool increased in size from ~1000 to >10000 cores
– Job start rate much higher than Torque / Maui even when throttled• Farm utilization much better
– Very good support
4

• Currently have 6 CEs, condor_schedd on each– 4 ARC CEs– 2 CREAM CEs
• Hope to decommission CREAM CEs soon– Only significant usage now is from a single non-LHC VO
Computing elements
5
End of LHCb CREAM usage ALICE started using ARC

Setup
• Overview of the HTCondor pool & associated middleware
6
ARC CEscondor_schedd
CREAM CEscondor_schedd
HA central managers
worker nodes
condor_gangliad,other monitoring &
accounting
APEL glite-CLUSTER

Future setup
• Soon
7
ARC CEscondor_schedd
CREAM CEscondor_schedd
HA central managers
worker nodes
condor_gangliad,other monitoring &
accounting
APEL glite-CLUSTER
Configuration
• Basics– Partitionable slots, hierarchical accounting groups, …– All configuration in Quattor
• Putting users in boxes– MOUNT_UNDER_SCRATCH + lcmaps-plugins-mount-under-scratch
• Jobs have their own /tmp, /var/tmp– PID namespaces
• Jobs can’t see system processes or processes from other jobs• Problem: ATLAS pilots accidently kill themselves after payload has finished
– CPU cgroups• In production for > 4 months
– Memory limits via cgroups• Testing on one worker node tranche for a few months• Will enable on all worker nodes soon
8

Multi-core jobs
• Current situation– ATLAS have been running multi-core jobs since Nov 2013– CMS started submitting multi-core jobs in early May 2014
• What we did– Added accounting groups for multi-core jobs– Specified GROUP_SORT_EXPR so that multi-core jobs considered
before single-core jobs– Defrag daemon enabled, configured so that:
• Drain 8 cores, not whole nodes• Pick WNs to drain based on how many cores they have that can be freed
– Demand for multi-core jobs not known by defrag daemon• By default defrag daemon will constantly drain same number of WNs• Simple cron to adjust defrag daemon configuration based on demand
– Uses condor_config_val to change DEFRAG_MAX_CONCURRENT_DRAINING
9

Multi-core jobs
10
Draining machines over past year
Wasted cores due to draining
(past week)
Before we added cron

Multi-core jobs
• Multi-core running jobs over the past year– So far no need to make any further improvements
11
ATLAS CMS

Worker node health check
• Want to ignore worker nodes as much as possible– Problems shouldn’t affect new jobs
• Startd cron– Script checks for problems on worker nodes
• Disk full or read-only• CVMFS• Swap• …
– Prevents jobs from starting in the event of problems• If problem with ATLAS CVMFS, then only prevents ATLAS jobs from
starting– Information about problems made available in machine ClassAds
• Can easily identify WNs with problems, e.g.# condor_status –constraint 'NODE_STATUS =!= "All_OK”’ -af Machine NODE_STATUS
lcg0980.gridpp.rl.ac.uk Problem: CVMFS for alice.cern.ch
lcg0981.gridpp.rl.ac.uk Problem: CVMFS for cms.cern.ch Problem: CVMFS for lhcb.cern.ch
lcg1675.gridpp.rl.ac.uk Problem: Swap in use, less than 25% free
12
Worker node health check
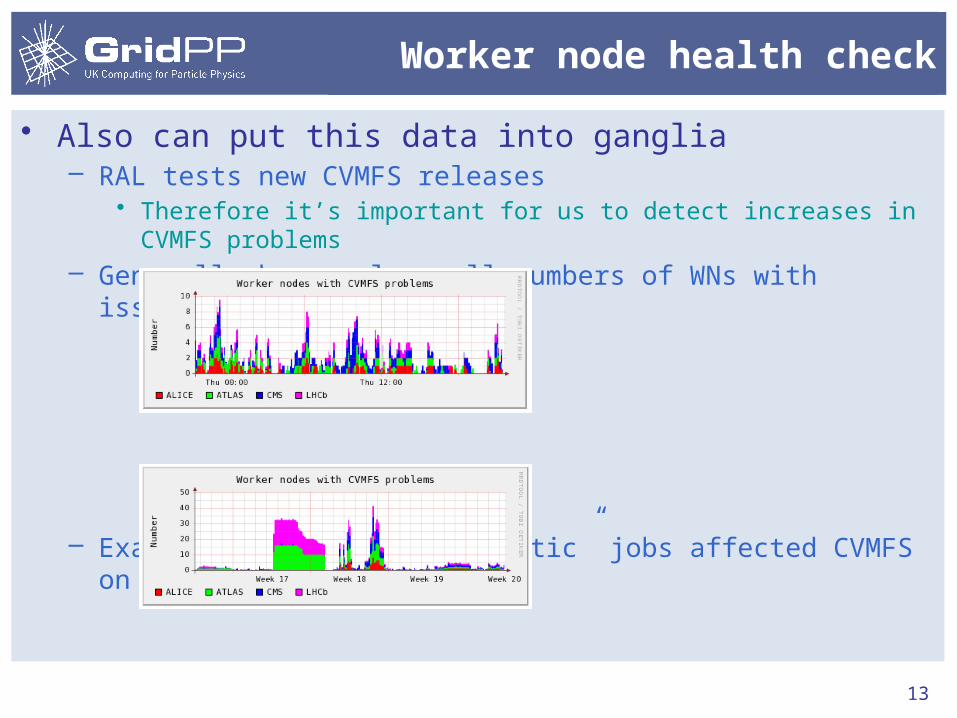
• Also can put this data into ganglia– RAL tests new CVMFS releases
• Therefore it’s important for us to detect increases in CVMFS problems– Generally have only small numbers of WNs with issues:
– Example: a user’s “problematic” jobs affected CVMFS on many WNs:
13

Monitoring using ELK
• Elasticsearch ELK stack– Logstash: parses log files– Elasticsearch: search & analyze data in real-time– Kibana: data visualization
• Adding HTCondor– Wrote config file for Logstash to enable history files to be parsed– Add Logstash to machines running schedds
14

Monitoring using ELK
15
• Minimal resources used– < 60,000 documents, < 400 MB per day

Monitoring using ELK
• Search for information about completed jobs (faster than using condor_history)
16
ARC job id

• Custom plots– E.g. completed jobs by VO
Monitoring using ELK
17

Virtual machines
• Make use of the VM universe• Instantiating a micro CernVM; example submit file:
universe = vmexecutable = CernVM3vm_type = kvmvm_memory = 3000request_memory = 3000vm_disk = ucernvm-prod.1.18-2.cernvm.x86_64.iso:hda:r:rawvm_no_output_vm = falsetransfer_input_files= root.pub,ucernvm-prod.1.18-2.cernvm.x86_64.iso,user_data+PublicKey = "root.pub"+UserData = "user_data"+HookKeyword = ”CernVM3”
queue
• CernVM3 job hook– Base64 encodes user data– Creates context.sh, context.iso required for contextualization– Creates 20 GB sparse disk for CVMFS cache– Updates vm_disk to include context.iso & the sparse disk
18

Vacuum model in HTCondor
• “Vacuum” model becoming popular in the UK– No centrally submitted pilot jobs or requests for VMs by the
experiments– VMs run appropriate pilot framework to pull down jobs
• HTCondor implementation of “vacuum” model– Local universe job which runs permanently & submits jobs (VMs) as
necessary• Different contextualization for each VO• If no work or an error, only submit 1-2 VMs every hour• If VMs are running real work, more VMs submitted• Fairshares are maintained since the negotatior decides what jobs to run
19

Vacuum model in HTCondor
• Uses job hooks similar to CernVM3 hook, but also– Prepare job hook: sets up NFS mount so that pilot log files are written
to the hypervisor’s disk– Job exit hook: condor_chip puts information about payload into job
ClassAd
-bash-4.1$ condor_history -const 'Cmd=="VAC-GRIDPP"' -af ClusterId QDate ShutdownCode ShutdownMessage
43838 1418107303 300 Nothing to do
43836 1418107243 300 Nothing to do
43834 1418104298 300 Nothing to do
43832 1418104238 200 Success
43826 1418101233 300 Nothing to do
43828 1418101293 300 Nothing to do
43822 1418098288 300 Nothing to do
43820 1418098228 300 Nothing to do
43816 1418095223 300 Nothing to do
20

Clouds
• Clouds at RAL– Last year we had a StratusLab cloud– Recently an OpenNebula cloud has become available for testing
• Aims– Integrate batch system with the cloud– First step: allow the batch system to expand into the cloud
• Avoid running additional third-party and/or complex services• Leverage existing functionality in HTCondor as much as possible
– Proof-of-concept testing carried out with StratusLab cloud• Tried using
– condor_rooster to instantiate VMs– HIBERNATE expression to shutdown idle VMs
• Ran around 11,000 LHC jobs over a week of testing– Restarting this work with the OpenNebula cloud
21

Summary
• Due to scalability problems with Torque / Maui, migrated to HTCondor last year
• We are happy with the choice we made based on our requirements
• Multi-core jobs working well• Future plans
– Soft limits with memory cgroups– Look into expanding use of Elasticsearch– Integration with our private cloud
22





























