Embed Size (px)
Citation preview

High-Performance Graph Primitives on the GPU: Design andImplementation of Gunrock
Yangzihao Wang
University of California, Davis
March 24, 2014
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 1 / 17
Problem Overview
There is a significant demand for efficient parallel framework for processing and analytics onlarge-scale graphs.
Applications in fields such as: Social Media, Science and Simulation, Advertising, and Web.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 2 / 17

Graph Processing on the CPU
Hig
her
Leve
l of
Per
form
ance
Higher Level of Programmability
GaloisLigra
PowerGraph
Pregel
PBGL
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 3 / 17

Graph Processing on the GPU
Initial results show that GPU computing is promising for future processing of large-scalegraphs. Most current research on GPU graph processing focuses on the challenge of irregularmemory accesses and work distribution. However, two gaps in graph computation on the GPUare overlooked.
I Algorithmic and Implementation Gap: few algorithms have efficient single-node GPUimplementations when compared to the state of the art on CPUs, and multi-node GPUimplementations are even rarer.
I Programmability Gap: the implementations of these algorithms are complex and requireexpert programmers. The resulting code couples graph computation to parallel graphtraversal, and is difficult to maintain and extend.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 4 / 17

Graph Processing on the GPU
Initial results show that GPU computing is promising for future processing of large-scalegraphs. Most current research on GPU graph processing focuses on the challenge of irregularmemory accesses and work distribution. However, two gaps in graph computation on the GPUare overlooked.
I Algorithmic and Implementation Gap: few algorithms have efficient single-node GPUimplementations when compared to the state of the art on CPUs, and multi-node GPUimplementations are even rarer.
I Programmability Gap: the implementations of these algorithms are complex and requireexpert programmers. The resulting code couples graph computation to parallel graphtraversal, and is difficult to maintain and extend.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 4 / 17

Graph Processing on the GPU
Initial results show that GPU computing is promising for future processing of large-scalegraphs. Most current research on GPU graph processing focuses on the challenge of irregularmemory accesses and work distribution. However, two gaps in graph computation on the GPUare overlooked.
I Algorithmic and Implementation Gap: few algorithms have efficient single-node GPUimplementations when compared to the state of the art on CPUs, and multi-node GPUimplementations are even rarer.
I Programmability Gap: the implementations of these algorithms are complex and requireexpert programmers. The resulting code couples graph computation to parallel graphtraversal, and is difficult to maintain and extend.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 4 / 17

Graph Processing on the GPU
The main goal of Gunrock’s programming model is to enable end-users to express, develop,and refine iterative graph algorithms with a high-level, programmable, and high-performanceabstraction.
I Programmability: To be expressive enough to represent a wide variety of graphcomputations.
I Performance: To leverage the highest-performing GPU computing primitives.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 5 / 17

Graph Processing on the GPU
The main goal of Gunrock’s programming model is to enable end-users to express, develop,and refine iterative graph algorithms with a high-level, programmable, and high-performanceabstraction.
I Programmability: To be expressive enough to represent a wide variety of graphcomputations.
I Performance: To leverage the highest-performing GPU computing primitives.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 5 / 17

Graph Processing on the GPU
The main goal of Gunrock’s programming model is to enable end-users to express, develop,and refine iterative graph algorithms with a high-level, programmable, and high-performanceabstraction.
I Programmability: To be expressive enough to represent a wide variety of graphcomputations.
I Performance: To leverage the highest-performing GPU computing primitives.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 5 / 17

Common Characteristics of Graph Problems
I Large-Scale: Facebook has over 1 billion nodes, 144 billion friendships and Twitter has500 million nodes and over 15 billion follower edges.
I Heterogenous Node Degree Distribution: Several real-world graphs have suchscale-free structure whose degree distribution follows a power law, at least asymptotically,which brings challenge on load-balancing.
I Iterative Convergent Process: Start with a working queue contains a subset of thegraph, iteratively do the computation, will finally converge.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 6 / 17

Common Characteristics of Graph Problems
I Large-Scale: Facebook has over 1 billion nodes, 144 billion friendships and Twitter has500 million nodes and over 15 billion follower edges.
I Heterogenous Node Degree Distribution: Several real-world graphs have suchscale-free structure whose degree distribution follows a power law, at least asymptotically,which brings challenge on load-balancing.
I Iterative Convergent Process: Start with a working queue contains a subset of thegraph, iteratively do the computation, will finally converge.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 6 / 17

Common Characteristics of Graph Problems
I Large-Scale: Facebook has over 1 billion nodes, 144 billion friendships and Twitter has500 million nodes and over 15 billion follower edges.
I Heterogenous Node Degree Distribution: Several real-world graphs have suchscale-free structure whose degree distribution follows a power law, at least asymptotically,which brings challenge on load-balancing.
I Iterative Convergent Process: Start with a working queue contains a subset of thegraph, iteratively do the computation, will finally converge.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 6 / 17

Common Characteristics of Graph Problems
I Large-Scale: Facebook has over 1 billion nodes, 144 billion friendships and Twitter has500 million nodes and over 15 billion follower edges.
I Heterogenous Node Degree Distribution: Several real-world graphs have suchscale-free structure whose degree distribution follows a power law, at least asymptotically,which brings challenge on load-balancing.
I Iterative Convergent Process: Start with a working queue contains a subset of thegraph, iteratively do the computation, will finally converge.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 6 / 17

Design Choices
I Bulk Synchronous Parallel (BSP) Model: Large amount of independent computationscan be parallelized when traverse the graph. Programming simplicity and scalabilityadvantages.
I Queue-based Iterative Method: Workload efficient. Small cost of keeping a compactworking queue with GPU primitives: scan + stream compact. Could easily expand tosupport priority scheduling.
I Hybrid Push-vs-Pull style of graph traversal: Start graph traversing step from eitherthe current frontier (push) or the unvisited set (pull) to achieve the highest performance.
I Idempotent Operation: Whether to permit a vertex to appear multiple times infrontier(s) from one or more iterations.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 7 / 17

Design Choices
I Bulk Synchronous Parallel (BSP) Model: Large amount of independent computationscan be parallelized when traverse the graph. Programming simplicity and scalabilityadvantages.
I Queue-based Iterative Method: Workload efficient. Small cost of keeping a compactworking queue with GPU primitives: scan + stream compact. Could easily expand tosupport priority scheduling.
I Hybrid Push-vs-Pull style of graph traversal: Start graph traversing step from eitherthe current frontier (push) or the unvisited set (pull) to achieve the highest performance.
I Idempotent Operation: Whether to permit a vertex to appear multiple times infrontier(s) from one or more iterations.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 7 / 17

Design Choices
I Bulk Synchronous Parallel (BSP) Model: Large amount of independent computationscan be parallelized when traverse the graph. Programming simplicity and scalabilityadvantages.
I Queue-based Iterative Method: Workload efficient. Small cost of keeping a compactworking queue with GPU primitives: scan + stream compact. Could easily expand tosupport priority scheduling.
I Hybrid Push-vs-Pull style of graph traversal: Start graph traversing step from eitherthe current frontier (push) or the unvisited set (pull) to achieve the highest performance.
I Idempotent Operation: Whether to permit a vertex to appear multiple times infrontier(s) from one or more iterations.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 7 / 17

Design Choices
I Bulk Synchronous Parallel (BSP) Model: Large amount of independent computationscan be parallelized when traverse the graph. Programming simplicity and scalabilityadvantages.
I Queue-based Iterative Method: Workload efficient. Small cost of keeping a compactworking queue with GPU primitives: scan + stream compact. Could easily expand tosupport priority scheduling.
I Hybrid Push-vs-Pull style of graph traversal: Start graph traversing step from eitherthe current frontier (push) or the unvisited set (pull) to achieve the highest performance.
I Idempotent Operation: Whether to permit a vertex to appear multiple times infrontier(s) from one or more iterations.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 7 / 17

Design Choices
I Bulk Synchronous Parallel (BSP) Model: Large amount of independent computationscan be parallelized when traverse the graph. Programming simplicity and scalabilityadvantages.
I Queue-based Iterative Method: Workload efficient. Small cost of keeping a compactworking queue with GPU primitives: scan + stream compact. Could easily expand tosupport priority scheduling.
I Hybrid Push-vs-Pull style of graph traversal: Start graph traversing step from eitherthe current frontier (push) or the unvisited set (pull) to achieve the highest performance.
I Idempotent Operation: Whether to permit a vertex to appear multiple times infrontier(s) from one or more iterations.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 7 / 17

Graph Data Representation
Gunrock uses compressed sparse row (CSR) format for vertex-centric operations and edge listfor edge-centric operations.
0
1 2 3
4 5
6
0 3 6 9 11 14 15 15
1 2 3 0 4 2 3 4 5 5 6 2 5 6 6
Row offsets:
Column indices:
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 8 / 17

Workload Mapping Strategies (What makes Gunrock traversal fast?)
I The Problem: Write various-length neighbor lists of vertices into an output queue.
I Per-thread+Per-warp and Per-CTA: Develop specialized workload mapping strategiesaccording to neighbor list’s size.
t0
t0 t1 t2 t3 t4 t31... one warp (t4 is the controlling thread)
t1 t2 t3 t4 t5 t6 t7 t8 t9 t42 t255... ...one block (256 threads, with t42 is the controlling thread)
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 9 / 17

Workload Mapping Strategies (What makes Gunrock traversal fast?)
I Partitioned Load-balancing: Organize groups of edges into equal-length chunks andassigning each chunk to a block.
t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t255...
t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t255...Block 0
Block 1
.
.
.t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t255... Block n
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 10 / 17

Workload Mapping Strategies (What makes Gunrock traversal fast?)
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 11 / 17
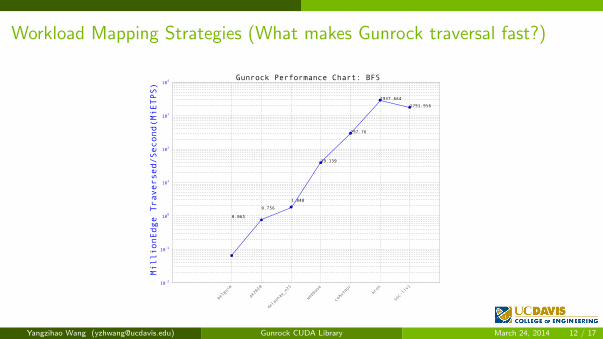
Workload Mapping Strategies (What makes Gunrock traversal fast?)
belguim
ak2010
delaunay_n21
webbase
coAuthor
kron
soc-livj
10-2
10-1
100
101
102
103
104
MillionEdge Traversed/Second(MiETPS)
0.065
0.756
1.848
39.139
297.76
2937.664
1791.956
Gunrock Performance Chart: BFS
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 12 / 17

A High-Level View of Programming Model
Bulk iterative processes which iterate between graph traversal and computation usingoperators and functors.
above the abstraction
below the abstraction
Enactor(CUDA Kernel Entry)
Functor(Problem-spec Computation)
Graph Traverse Operator:Workload mapping strategiesIdempotent operation switch
Push-vs-Pull based operation switch
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 13 / 17

Graph Primitive Example: BFSA breadth-first search (BFS) algorithm takes a graph and a source vertex s, and computes abreadth-first search tree rooted at s containing all vertices reachable from s. Ourimplementation will compute the predecessor and the distance from source vertex for eachvertex.
0
1 2 3
4 5
6
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 14 / 17

Graph Primitive Example: BFSA breadth-first search (BFS) algorithm takes a graph and a source vertex s, and computes abreadth-first search tree rooted at s containing all vertices reachable from s. Ourimplementation will compute the predecessor and the distance from source vertex for eachvertex.
0
1 2 3
4 5
6
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 14 / 17

Graph Primitive Example: BFSA breadth-first search (BFS) algorithm takes a graph and a source vertex s, and computes abreadth-first search tree rooted at s containing all vertices reachable from s. Ourimplementation will compute the predecessor and the distance from source vertex for eachvertex.
0
1 2 3
4 5
6
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 14 / 17
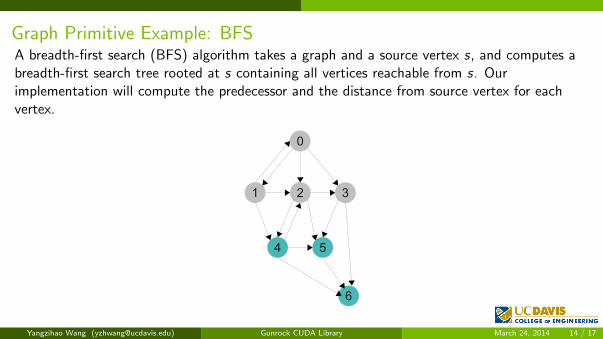
Graph Primitive Example: BFSA breadth-first search (BFS) algorithm takes a graph and a source vertex s, and computes abreadth-first search tree rooted at s containing all vertices reachable from s. Ourimplementation will compute the predecessor and the distance from source vertex for eachvertex.
0
1 2 3
4 5
6
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 14 / 17

Graph Primitive Example: BFSA breadth-first search (BFS) algorithm takes a graph and a source vertex s, and computes abreadth-first search tree rooted at s containing all vertices reachable from s. Ourimplementation will compute the predecessor and the distance from source vertex for eachvertex.
0
1 2 3
4 5
6
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 14 / 17

Performance: Speedup
Primitive webbase1M coAuthor socLiveJournal Kron g500
BFS NA(GPU:0.001s) 4 27 22CC 3 10 13 NA(GPU:0.253s)BC 2 5 10 10SSSP 2 15 10 16PR 13 NA(GPU:0.1s) NA(GPU:3.4s) NA(GPU:29.6s)
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 15 / 17

What’s Next?
I More flexible operator set;
I More graph types and data structures;
I External memory and multi-node GPUs support;
I Non-regular Graph Operations/Advanced graph primitives.
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 16 / 17

Acknowledgement
I This work is done with Yuechao Pan and my advisor Prof. John Owens.
I Thanks to Andrew Davidson for his help with SSSP implementation.
I Thanks to Erich Elsen and Vishal Vaidyanathan from Royal Caliber.
I Thanks to Duane Merrill and Sean Baxter from NVIDIA Research.
I Thanks to Dr. Chris White and DARPA XDATA funding.
Thank you!
Yangzihao Wang ([email protected]) Gunrock CUDA Library March 24, 2014 17 / 17





























