Embed Size (px)
DESCRIPTION
Hierarchical Mixture of Experts. Presented by Qi An Machine learning reading group Duke University 07/15/2005. Outline. Background Hierarchical tree structure Gating networks Expert networks E-M algorithm Experimental results Conclusions. Background. The idea of mixture of experts - PowerPoint PPT Presentation
Citation preview

Hierarchical Mixture of Experts
Presented by Qi AnMachine learning reading groupDuke University07/15/2005

Outline Background Hierarchical tree structure Gating networks Expert networks E-M algorithm Experimental results Conclusions

Background The idea of mixture of experts
First presented by Jacobs and Hintons in 1988 Hierarchical mixture of experts
Proposed by Jordan and Jacobs in 1994 Difference from previous mixture mod
el Mixing weights depends on both the input and t
he output

Example (ME)

One-layer structure
Expert Network
Expert Network
Expert Network
Gating Network
x
x x x
μ
μ1 μ2 μ3
g1 g2 g3
Ellipsoidal Gating function

Example (HME)

Hierarchical tree structure
Linear Gating function

Expert network
At the leaves of treesfor each expert:
Uxij linear predictor
)( ijij f output of the expert
link function
For example: logistic function for binary classification

Gating network
At the nonterminal of the treetop layer: other lay
er:xvTii
kk
iig )exp(
)exp(
xvTijij
kik
ijijg )exp(
)exp(|

Output
At the non-leaves nodestop node: other
nodes:
j
ijiji μgμ |i
iiμgμ

Probability model For each expert, assume the true output y is
chosen from a distribution P with mean μij
Therefore, the total probability of generating y from x is given by
),( ijxyP
i j
ijijijii xyPvxgvxgxyP ),(),(),(),( |

Posterior probabilities Since the gij and gi are computed based only
on the input x, we refer them as prior probabilities.
We can define the posterior probabilities with the knowledge of both the input x and the output y using Bayes’ rule
i jijiji
jijiji
i yPgg
yPgg
h)(
)(
|
|
jijij
ijijij yPg
yPgh
)(
)(
|
||

E-M algorithm Introduce auxiliary variables zij which have
an interpretation as the labels that corresponds to the experts.
The probability model can be simplified with the knowledge of auxiliary variables
i j
ztij
tij
ti
tij
tij
ti
ttij
ttijyPggyPggxzyP
)(
)()(),,( )()(|
)()()(|
)()()()(

E-M algorithm Complete-data likelihood:
The E-step
t i j
tij
tij
ti
tijc yPggzyl )(lnlnln);( )()(
|)()(
t i j
tij
tij
ti
tijcz
p yPgghylEQ )(lnlnln));((),( )()(|
)()()(

E-M algorithm The M-step
t
tij
tij
pij yPh
ij
)(lnmaxarg )()(1
t k
tk
tk
v
pi ghv
i
)()(1 lnmaxarg
t k l
tkl
tkl
tk
v
pij ghhv
ij
)(|
)(|
)(1 lnmaxarg

IRLS Iteratively reweighted least squares al
g. An iterative algorithm for computing the
maximum likelihood estimates of the parameters of a generalized linear model
A special case for Fisher scoring method
llE
Trr
1
1

Algorithm
E-step
M-step

Online algorithm This algorithm can be used for online regres
sion
For Expert network:
where Rij is the inverse covariance matrix for EN(i,j)
( 1) ( ) ( ) ( ) ( ) ( ) ( ) ( )| ( )t t t t t t t T t
ij ij i j i ij ijU U h h y x R
( 1) ( ) ( ) ( 1)( ) 1 ( 1) 1
( ) 1 ( ) ( 1) ( )[ ]
t t t T tij ijt t
ij ij t t T t tij ij
R x x RR R
h x R x

Online algorithm For Gating network:
where Si is the inverse covariance matrix
and
where Sij is the inverse covariance matrix
( 1) ( ) ( ) ( ) ( ) ( ) ( )|(ln )t t t t t t t
ij ij ij i j i ijv v S h h x
( 1) ( ) ( ) ( ) ( ) ( )(ln )t t t t t ti i i i iv v S h x
( 1) ( ) ( ) ( 1)( ) 1 ( 1) 1
( ) 1 ( ) ( 1) ( )[ ]
t t t T tij ijt t
ij ij t t T t ti ij
S x x SS S
h x S x
( 1) ( ) ( ) ( 1)( ) 1 ( 1) 1
( ) ( 1) ( )
t t t T tt t i ii i t T t t
i
S x x SS S
x S x

Results Simulated data of a four-joint robot arm
moving in three-dimensional space
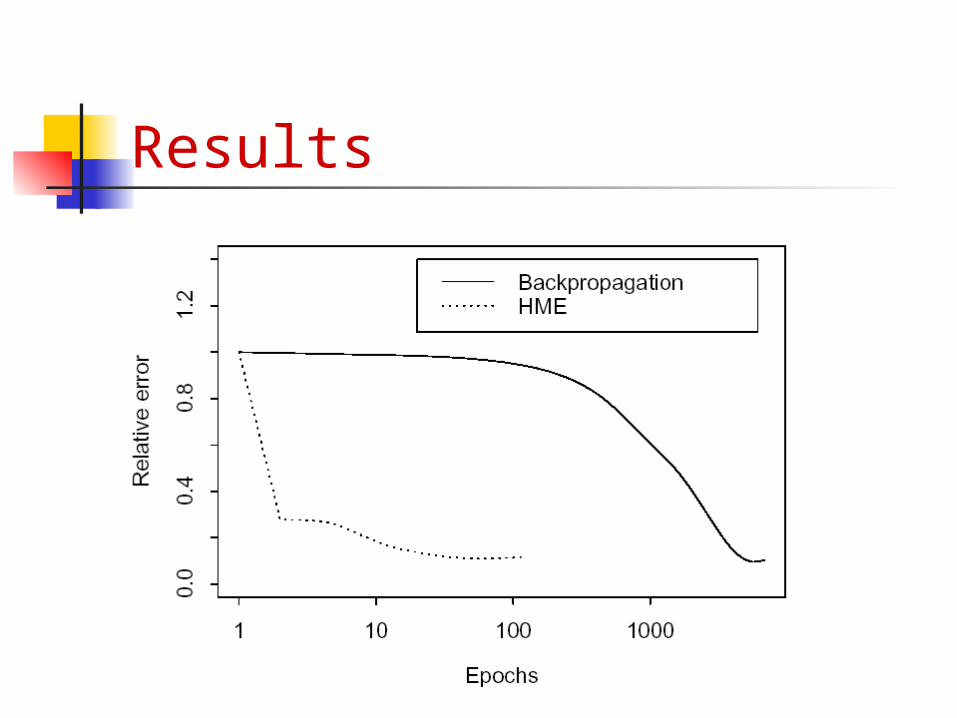
Results

Conclusions Introduce a tree-structured
architecture for supervised learning
Much faster than traditional back-propagation algorithm
Can be used for on-line learning

Thank you
Questions?





















![Speech Enhancement using a Deep Mixture of Experts · The Mixture of Experts (MoE) approach, which was intro-arXiv:1703.09302v1 [cs.SD] 27 Mar 2017. 2 duced more than twenty years](https://img.dokumen.tips/doc/110x75/604c00628a7a1a1c6760bc1f/speech-enhancement-using-a-deep-mixture-of-experts-the-mixture-of-experts-moe.jpg)







