Embed Size (px)
Citation preview

1
Optimizing a Parallel Video Encoder with Message Passing and a Shared
Memory ArchitectureGU Junli
SUN Yihe

2
Introduction & Related work Parallel encoder implementation Test results and Analysis Conclusions
Outline

3
Parallel processing◦Real time
Parallel processing type◦Cluster[5], MPP[4]◦ Shared memory[6]
Introduction & Related work #1

4
MPI (message passing interface)◦Communicate by passing message
Inefficient Shared memory◦ Share the same data space
Efficient
Introduction & Related work #2

5
Most MPI codes adopt master-slave standard which has one master and couples of slaves to do different jobs.◦Workload imbalance◦Communication cost is high
On a typical shared memory CMP◦ Each code has a private L1 cache◦ Shared a large L2 cache
Introduction & Related work #3

6
Balanced parallel scheme◦A strip-wise balanced parallel scheme
Parallel encoder implementation #1

7
◦ Each process take one strip.◦ Each strip contains a number of slices
Sn = Frame_size/P◦ If Sn is not integer -> workload problem
Data dependency◦Message passing
Parallel encoder implementation #2
8
Hybrid communication
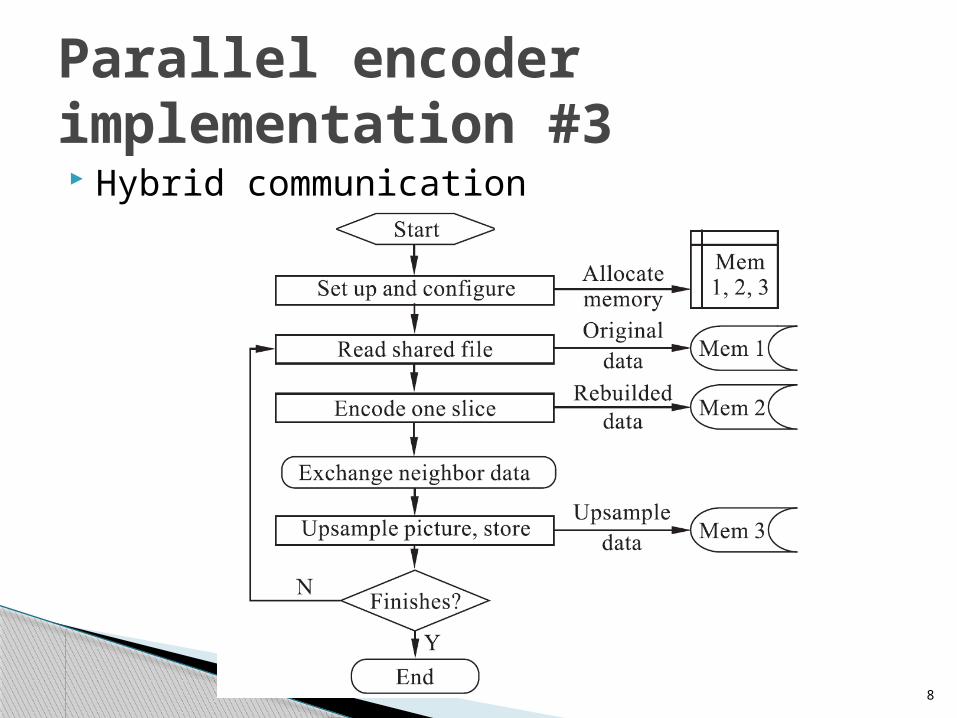
Parallel encoder implementation #3

9
Hybrid communication◦Combine MPI and shared memory
To reduce the communication cost
◦ Ex. It takes 54.5ms to read a file and send the data to others process by MPI but 9ms by shared memory.
The memory allocation scheme has one global shared memory area to store the original video data from where all processes read the original strip data.
Parallel encoder implementation #4

10
Three dedicated memory spaces kept by each process including one for original data, a second for reconstructed data and the last for up-sampled data.
Parallel encoder implementation #5

11
Environment◦ Two Intel Xeon E5310 @1.6 GHz processors, each with 4
cores. Test case◦HD, VGA, SD, CIF and QCIF
Version◦H264 JM10.2
Test results and Analysis #1
12
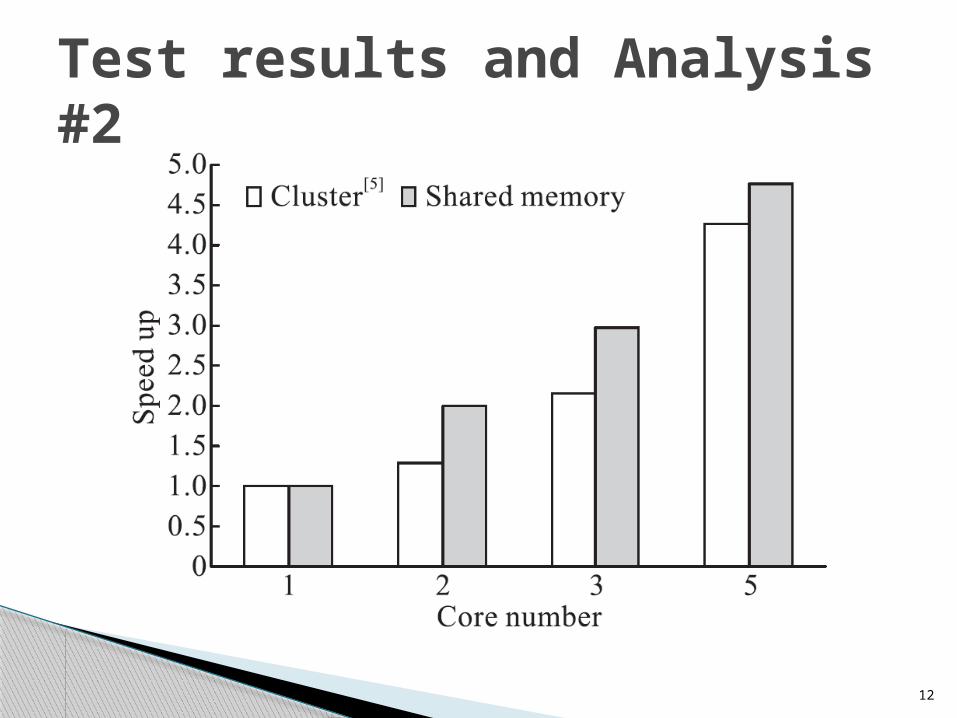
Test results and Analysis #2

13
25% higher speed improvement for the shared memory architecture as Compared to the case of cluster[5].
Test results and Analysis #3
14
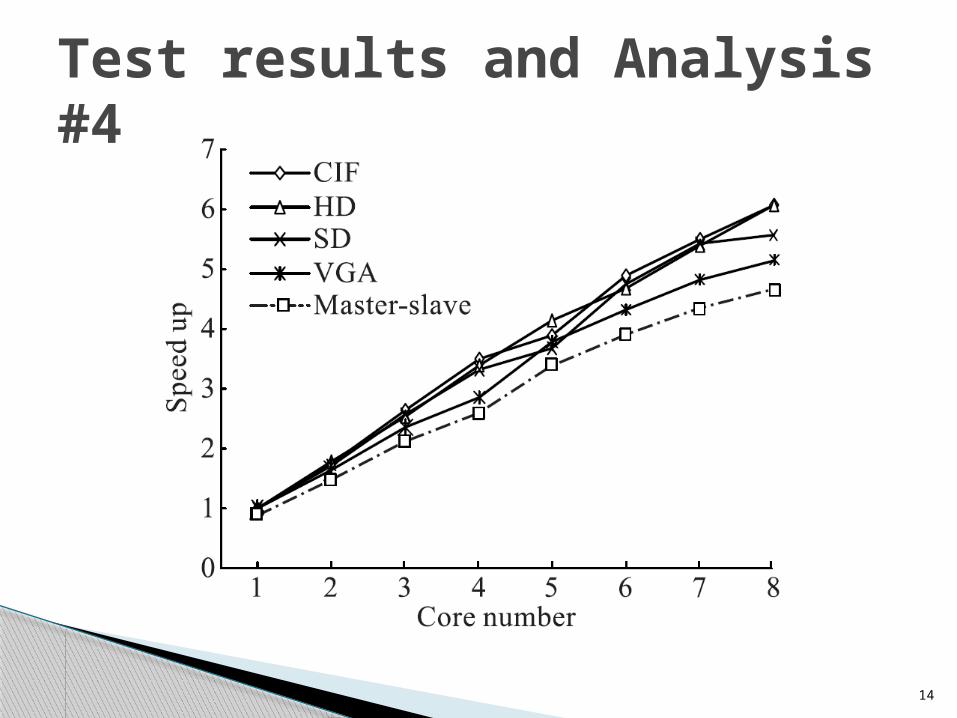
Test results and Analysis #4
15
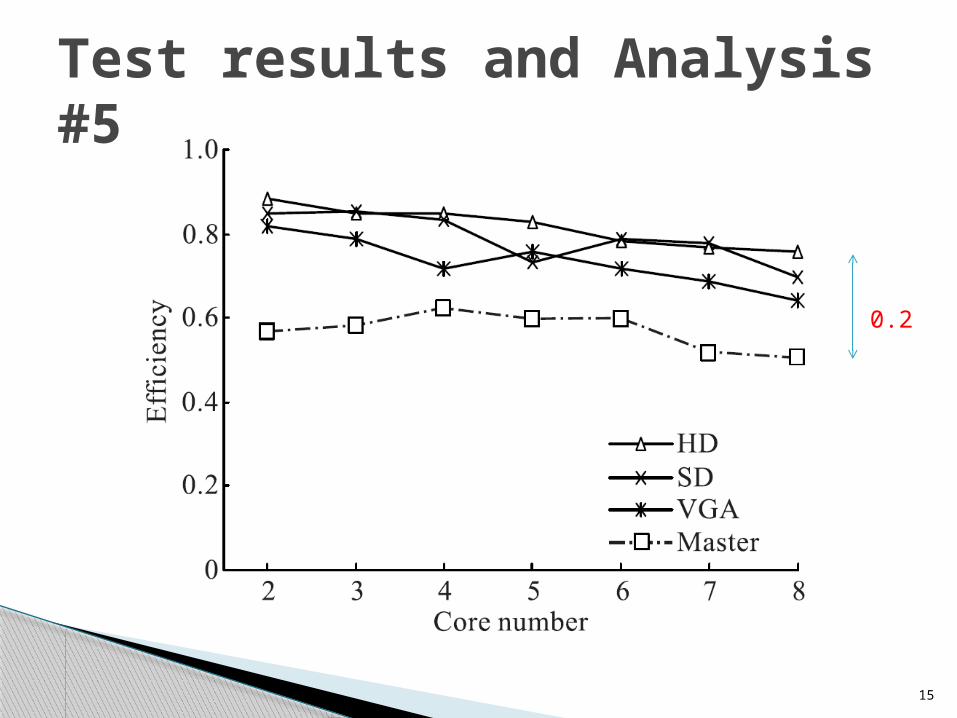
Test results and Analysis #5
0.2
16
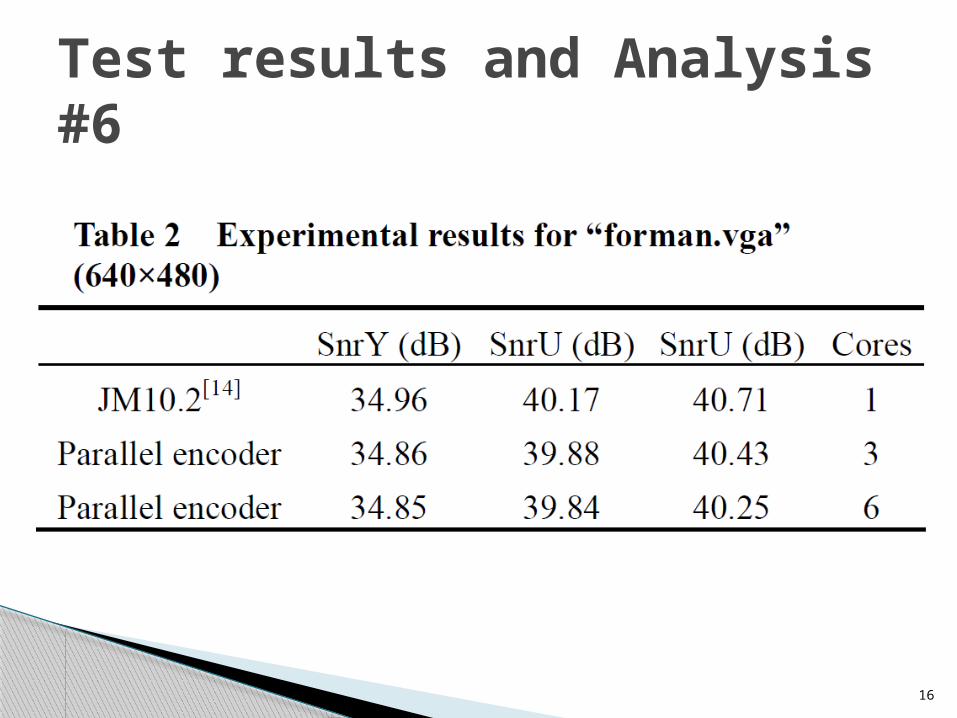
Test results and Analysis #6
17
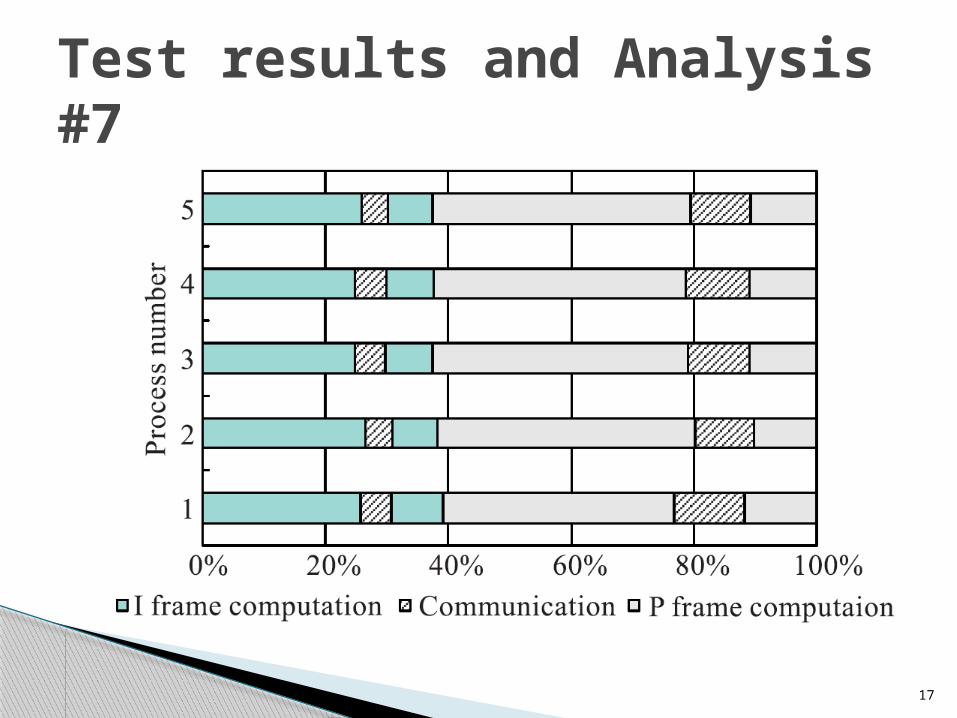
Test results and Analysis #7
18
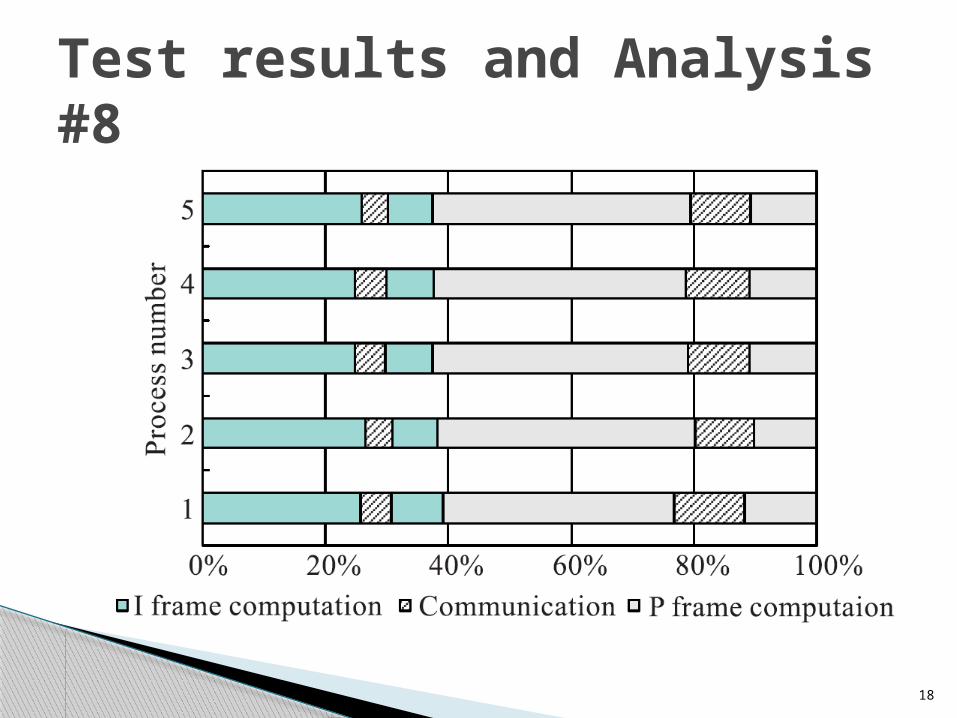
Test results and Analysis #8

19
Test results and Analysis #9

20
Upgrading legacy MPI applications to the class of shared memory architectures can provide significant performance improvements.
Optimizing the communication mechanism and further enhancements to the hybrid shared-memory and message-passing multi-core processor design can be expected to raise performance to still higher levels.
Conclusion #1









![XiaoMa,Shen-YiZhaoandWu-JunLi ...withtheoreticalguarantee. InfiniteMDPs,E3 [15],R-Max[6]andUCRL[3]allmakeuseofstate-actioncountsandareactivated bytheideaofoptimismunderuncertainty](https://img.dokumen.tips/doc/110x75/6009e0e86935ee13bd57fbc7/xiaomashen-yizhaoandwu-junli-withtheoreticalguarantee-ininitemdpse3-15r-max6anducrl3allmakeuseofstate-actioncountsandareactivated.jpg)



















