Embed Size (px)
Citation preview

GPUs in Computational Science
Matthew Knepley1
1Computation InstituteUniversity of Chicago
ColloquiumSimula Research
Oslo, Norway, September 1, 2010
M. Knepley GPU 9/1/10 1 / 63

Collaborators
Chicago Automated Scientific Computing Group:
Prof. Ridgway ScottDept. of Computer Science, University of ChicagoDept. of Mathematics, University of Chicago
Peter Brune, (biological DFT)Dept. of Computer Science, University of Chicago
Dr. Andy Terrel, (Rheagen)Dept. of Computer Science and TACC, University of Texas at Austin
M. Knepley GPU 9/1/10 2 / 63

Introduction
Outline
1 Introduction
2 Tools
3 FEM on the GPU
4 PETSc-GPU
5 Conclusions
M. Knepley GPU 9/1/10 3 / 63

Introduction
New Model for Scientific Software
Simplifying Parallelization of Scientific Codesby a Function-Centric Approach in Python
Jon K. Nilsen, Xing Cai, Bjorn Hoyland, and Hans Petter Langtangen
Python at the application levelnumpy for data structurespetsc4py for linear algebra and solversPyCUDA for integration (physics) and assembly
M. Knepley GPU 9/1/10 4 / 63

Introduction
New Model for Scientific Software
Application
FFC/SyFieqn. definitionsympy symbolics
numpyda
tast
ruct
ures
petsc4py
solve
rs
PyCUDA
integration/assembly
PETScCUDA
OpenCL
Figure: Schematic for a generic scientific applicationM. Knepley GPU 9/1/10 5 / 63

Introduction
What is Missing from this Scheme?
Unstructured graph traversalIteration over cells in FEM
Use a copy via numpy, use a kernel via Queue
(Transitive) Closure of a vertexUse a visitor and copy via numpy
Depth First SearchHell if I know
Logic in computationLimiters in FV methods
Can sometimes use tricks for branchless logic
Flux Corrected Transport for shock capturingMaybe use WENO schemes which can be branchless
Boundary conditionsRestrict branching to PETSc C numbering and assembly calls
Audience???M. Knepley GPU 9/1/10 6 / 63

Introduction
What is Missing from this Scheme?
Unstructured graph traversalIteration over cells in FEM
Use a copy via numpy, use a kernel via Queue
(Transitive) Closure of a vertexUse a visitor and copy via numpy
Depth First SearchHell if I know
Logic in computationLimiters in FV methods
Can sometimes use tricks for branchless logic
Flux Corrected Transport for shock capturingMaybe use WENO schemes which can be branchless
Boundary conditionsRestrict branching to PETSc C numbering and assembly calls
Audience???M. Knepley GPU 9/1/10 6 / 63

Introduction
What is Missing from this Scheme?
Unstructured graph traversalIteration over cells in FEM
Use a copy via numpy, use a kernel via Queue
(Transitive) Closure of a vertexUse a visitor and copy via numpy
Depth First SearchHell if I know
Logic in computationLimiters in FV methods
Can sometimes use tricks for branchless logic
Flux Corrected Transport for shock capturingMaybe use WENO schemes which can be branchless
Boundary conditionsRestrict branching to PETSc C numbering and assembly calls
Audience???M. Knepley GPU 9/1/10 6 / 63

Introduction
What is Missing from this Scheme?
Unstructured graph traversalIteration over cells in FEM
Use a copy via numpy, use a kernel via Queue
(Transitive) Closure of a vertexUse a visitor and copy via numpy
Depth First SearchHell if I know
Logic in computationLimiters in FV methods
Can sometimes use tricks for branchless logic
Flux Corrected Transport for shock capturingMaybe use WENO schemes which can be branchless
Boundary conditionsRestrict branching to PETSc C numbering and assembly calls
Audience???M. Knepley GPU 9/1/10 6 / 63

Introduction
What is Missing from this Scheme?
Unstructured graph traversalIteration over cells in FEM
Use a copy via numpy, use a kernel via Queue
(Transitive) Closure of a vertexUse a visitor and copy via numpy
Depth First SearchHell if I know
Logic in computationLimiters in FV methods
Can sometimes use tricks for branchless logic
Flux Corrected Transport for shock capturingMaybe use WENO schemes which can be branchless
Boundary conditionsRestrict branching to PETSc C numbering and assembly calls
Audience???M. Knepley GPU 9/1/10 6 / 63

Introduction
What is Missing from this Scheme?
Unstructured graph traversalIteration over cells in FEM
Use a copy via numpy, use a kernel via Queue
(Transitive) Closure of a vertexUse a visitor and copy via numpy
Depth First SearchHell if I know
Logic in computationLimiters in FV methods
Can sometimes use tricks for branchless logic
Flux Corrected Transport for shock capturingMaybe use WENO schemes which can be branchless
Boundary conditionsRestrict branching to PETSc C numbering and assembly calls
Audience???M. Knepley GPU 9/1/10 6 / 63

Introduction
What is Missing from this Scheme?
Unstructured graph traversalIteration over cells in FEM
Use a copy via numpy, use a kernel via Queue
(Transitive) Closure of a vertexUse a visitor and copy via numpy
Depth First SearchHell if I know
Logic in computationLimiters in FV methods
Can sometimes use tricks for branchless logic
Flux Corrected Transport for shock capturingMaybe use WENO schemes which can be branchless
Boundary conditionsRestrict branching to PETSc C numbering and assembly calls
Audience???M. Knepley GPU 9/1/10 6 / 63

Introduction
What is Missing from this Scheme?
Unstructured graph traversalIteration over cells in FEM
Use a copy via numpy, use a kernel via Queue
(Transitive) Closure of a vertexUse a visitor and copy via numpy
Depth First SearchHell if I know
Logic in computationLimiters in FV methods
Can sometimes use tricks for branchless logic
Flux Corrected Transport for shock capturingMaybe use WENO schemes which can be branchless
Boundary conditionsRestrict branching to PETSc C numbering and assembly calls
Audience???M. Knepley GPU 9/1/10 6 / 63
Tools
Outline
1 Introduction
2 Toolsnumpypetsc4pyPyCUDAFEniCS
3 FEM on the GPU
4 PETSc-GPU
5 Conclusions
M. Knepley GPU 9/1/10 7 / 63

Tools numpy
Outline
2 Toolsnumpypetsc4pyPyCUDAFEniCS
M. Knepley GPU 9/1/10 8 / 63

Tools numpy
numpy
numpy is ideal for building Python data structures
Supports multidimensional arraysEasily interfaces with C/C++ and FortranHigh performance BLAS/LAPACK and functional operationsPython 2 and 3 compatibleUsed by petsc4py to talk to PETSc
M. Knepley GPU 9/1/10 9 / 63

Tools petsc4py
Outline
2 Toolsnumpypetsc4pyPyCUDAFEniCS
M. Knepley GPU 9/1/10 10 / 63

Tools petsc4py
petsc4py
petcs4py provides Python bindings for PETSc
Provides ALL PETSc functionality in a Pythonic wayLogging using the Python with statement
Can use Python callback functionsSNESSetFunction(), SNESSetJacobian()
Manages all memory (creation/destruction)
Visualization with matplotlib
M. Knepley GPU 9/1/10 11 / 63

Tools petsc4py
petsc4py Installation
Automaticpip install -install-options=-user petscp4yUses $PETSC_DIR and $PETSC_ARCHInstalled into $HOME/.localNo additions to PYTHONPATH
From Sourcevirtualenv python-envsource ./python-env/bin/activateNow everything installs into your proxy Python environmenthg clone https://petsc4py.googlecode.com/hgpetsc4py-devARCHFLAGS="-arch x86_64" python setup.py sdistARCHFLAGS="-arch x86_64" pip installdist/petsc4py-1.1.2.tar.gzARCHFLAGS only necessary on Mac OSX
M. Knepley GPU 9/1/10 12 / 63
Tools petsc4py
petsc4py Examples
externalpackages/petsc4py-1.1/demo/bratu2d/bratu2d.py
Solves Bratu equation (SNES ex5) in 2D
Visualizes solution with matplotlib
src/ts/examples/tutorials/ex8.py
Solves a 1D ODE for a diffusive process
Visualize solution using -vec_view_draw
Control timesteps with -ts_max_steps
M. Knepley GPU 9/1/10 13 / 63

Tools PyCUDA
Outline
2 Toolsnumpypetsc4pyPyCUDAFEniCS
M. Knepley GPU 9/1/10 14 / 63

Tools PyCUDA
PyCUDA and PyOpenCL
Python packages by Andreas Klöcknerfor embedded GPU programming
Handles unimportant details automaticallyCUDA compile and caching of objectsDevice initializationLoading modules onto card
Excellent Documentation & Tutorial
Excellent platform for MetaprogrammingOnly way to get portable performanceRoad to FLAME-type reasoning about algorithms
M. Knepley GPU 9/1/10 15 / 63

Tools PyCUDA
Code Template
<%namespace name=" pb " module=" performanceBenchmarks " / >$ { pb . globalMod ( isGPU ) } vo id kerne l ( $ { pb . g r i dS ize ( isGPU ) } f l o a t * output ) {
$ { pb . g r idLoopSta r t ( isGPU , load , s to re ) }$ { pb . threadLoopStar t ( isGPU , blockDimX ) }f l o a t G[ $ { dim * dim } ] = { $ { ’ , ’ . j o i n ( [ ’ 3.0 ’ ] * ( dim * dim ) ) } } ;f l o a t K [ $ { dim * dim } ] = { $ { ’ , ’ . j o i n ( [ ’ 3.0 ’ ] * ( dim * dim ) ) } } ;f l o a t product = 0 . 0 ;const i n t Oof fse t = g r i d I d x *$ { numThreads } ;
/ / Cont ract G and K% f o r n i n range ( numLocalElements ) :% f o r alpha i n range ( dim ) :% f o r beta i n range ( dim ) :<% gIdx = ( n* dim + alpha ) * dim + beta %><% kIdx = alpha * dim + beta %>
product += G[ $ { gIdx } ] * K [ $ { k Idx } ] ;% endfor% endfor% endfor
output [ Oof fse t+ idx ] = product ;$ { pb . threadLoopEnd ( isGPU ) }$ { pb . gridLoopEnd ( isGPU ) }r e t u r n ;
} M. Knepley GPU 9/1/10 16 / 63

Tools PyCUDA
Rendering a Template
We render code template into strings using a dictionary of inputs.
args = { ’ dim ’ : s e l f . dim ,’ numLocalElements ’ : 1 ,’ numThreads ’ : s e l f . threadBlockSize }
kernelTemplate = s e l f . getKernelTemplate ( )gpuCode = kernelTemplate . render ( isGPU = True , * * args )cpuCode = kernelTemplate . render ( isGPU = False , * * args )
M. Knepley GPU 9/1/10 17 / 63

Tools PyCUDA
GPU Source Code
__global__ vo id kerne l ( f l o a t * output ) {const i n t g r i d I d x = b lock Idx . x + b lock Idx . y * gr idDim . x ;const i n t i dx = th read Idx . x + th read Idx . y * 1 ; / / This i s ( i , j )f l o a t G[ 9 ] = { 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 } ;f l o a t K [ 9 ] = { 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 } ;f l o a t product = 0 . 0 ;const i n t Oof fse t = g r i d I d x * 1 ;
/ / Cont ract G and Kproduct += G[ 0 ] * K [ 0 ] ;product += G[ 1 ] * K [ 1 ] ;product += G[ 2 ] * K [ 2 ] ;product += G[ 3 ] * K [ 3 ] ;product += G[ 4 ] * K [ 4 ] ;product += G[ 5 ] * K [ 5 ] ;product += G[ 6 ] * K [ 6 ] ;product += G[ 7 ] * K [ 7 ] ;product += G[ 8 ] * K [ 8 ] ;ou tput [ Oof fse t+ idx ] = product ;r e t u r n ;
}
M. Knepley GPU 9/1/10 18 / 63

Tools PyCUDA
CPU Source Code
vo id kerne l ( i n t numInvocations , f l o a t * output ) {f o r ( i n t g r i d I d x = 0; g r i d I d x < numInvocations ; ++ g r i d I d x ) {
f o r ( i n t i = 0 ; i < 1 ; ++ i ) {f o r ( i n t j = 0 ; j < 1 ; ++ j ) {
const i n t i dx = i + j * 1 ; / / This i s ( i , j )f l o a t G[ 9 ] = { 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 } ;f l o a t K [ 9 ] = { 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 , 3 . 0 } ;f l o a t product = 0 . 0 ;const i n t Oof fse t = g r i d I d x * 1 ;
/ / Cont ract G and Kproduct += G[ 0 ] * K [ 0 ] ;product += G[ 1 ] * K [ 1 ] ;product += G[ 2 ] * K [ 2 ] ;product += G[ 3 ] * K [ 3 ] ;product += G[ 4 ] * K [ 4 ] ;product += G[ 5 ] * K [ 5 ] ;product += G[ 6 ] * K [ 6 ] ;product += G[ 7 ] * K [ 7 ] ;product += G[ 8 ] * K [ 8 ] ;ou tput [ Oof fse t+ idx ] = product ;
}}
}r e t u r n ;
}
M. Knepley GPU 9/1/10 19 / 63

Tools PyCUDA
Creating a Module
CPU:
# Output kerne l and C support codes e l f . outputKernelC ( cpuCode )s e l f . w r i t e M a k e f i l e ( )out , er r , s ta tus = s e l f . executeShellCommand ( ’make ’ )\ end { minted }
\ b i gsk ip
GPU:\ begin { minted } { python }from pycuda . compi ler impor t SourceModule
mod = SourceModule ( gpuCode )s e l f . ke rne l = mod. ge t_ func t i on ( ’ ke rne l ’ )s e l f . kerne lRepor t ( s e l f . kernel , ’ ke rne l ’ )
M. Knepley GPU 9/1/10 20 / 63

Tools PyCUDA
Executing a Module
impor t pycuda . d r i v e r as cudaimpor t pycuda . a u t o i n i t
blockDim = ( s e l f . dim , s e l f . dim , 1)s t a r t = cuda . Event ( )end = cuda . Event ( )g r i d = s e l f . c a l c u l a t e G r i d (N, numLocalElements )s t a r t . record ( )f o r i i n range ( i t e r s ) :
s e l f . ke rne l ( cuda . Out ( output ) ,b lock = blockDim , g r i d = g r i d )
end . record ( )end . synchronize ( )gpuTimes . append ( s t a r t . t i m e _ t i l l ( end ) *1 e−3/ i t e r s )
M. Knepley GPU 9/1/10 21 / 63

Tools FEniCS
Outline
2 Toolsnumpypetsc4pyPyCUDAFEniCS
M. Knepley GPU 9/1/10 22 / 63

Tools FEniCS
Weak Form DefinitionLaplacian
# $P^k$ elementelement = F in i teE lement ( " Lagrange " , domains [ s e l f . dim ] , k )v = TestFunct ion ( element )u = T r i a l F u n c t i o n ( element )f = C o e f f i c i e n t ( element )
a = inner ( grad ( v ) , grad ( u ) ) * dxL = v * f * dx
M. Knepley GPU 9/1/10 23 / 63

Tools FEniCS
Form Decomposition
Element integrals are decomposed into analytic and geometric parts:
∫T ∇φi(x) · ∇φj(x)dx (1)
=∫T∂φi (x)∂xα
∂φj (x)∂xα dx (2)
=∫Tref
∂ξβ∂xα
∂φi (ξ)∂ξβ
∂ξγ∂xα
∂φj (ξ)∂ξγ|J|dx (3)
=∂ξβ∂xα
∂ξγ∂xα |J|
∫Tref
∂φi (ξ)∂ξβ
∂φj (ξ)∂ξγ
dx (4)
= Gβγ(T )K ijβγ (5)
Coefficients are also put into the geometric part.
M. Knepley GPU 9/1/10 24 / 63

Tools FEniCS
Weak Form Processing
from f f c . ana l ys i s impor t analyze_formsfrom f f c . compi ler impor t compute_ir
parameters = f f c . defau l t_parameters ( )parameters [ ’ r ep resen ta t i on ’ ] = ’ tensor ’ana l ys i s = analyze_forms ( [ a , L ] , { } , parameters )i r = compute_ir ( ana lys is , parameters )
a_K = i r [ 2 ] [ 0 ] [ ’AK ’ ] [ 0 ] [ 0 ]a_G = i r [ 2 ] [ 0 ] [ ’AK ’ ] [ 0 ] [ 1 ]
K = a_K . A0 . astype (numpy . f l o a t 3 2 )G = a_G
M. Knepley GPU 9/1/10 25 / 63

FEM on the GPU
Outline
1 Introduction
2 Tools
3 FEM on the GPU
4 PETSc-GPU
5 Conclusions
M. Knepley GPU 9/1/10 26 / 63

FEM on the GPU
Form Decomposition
Element integrals are decomposed into analytic and geometric parts:
∫T ∇φi(x) · ∇φj(x)dx (6)
=∫T∂φi (x)∂xα
∂φj (x)∂xα dx (7)
=∫Tref
∂ξβ∂xα
∂φi (ξ)∂ξβ
∂ξγ∂xα
∂φj (ξ)∂ξγ|J|dx (8)
=∂ξβ∂xα
∂ξγ∂xα |J|
∫Tref
∂φi (ξ)∂ξβ
∂φj (ξ)∂ξγ
dx (9)
= Gβγ(T )K ijβγ (10)
Coefficients are also put into the geometric part.
M. Knepley GPU 9/1/10 27 / 63

FEM on the GPU
Form Decomposition
Additional fields give rise to multilinear forms.
∫T φi(x) ·
(φk (x)∇φj(x)
)dA (11)
=∫T φ
βi (x)
(φαk (x)
∂φβj (x)∂xα
)dA (12)
=∫Trefφβi (ξ)φ
αk (ξ)
∂ξγ∂xα
∂φβj (ξ)
∂ξγ|J|dA (13)
=∂ξγ∂xα |J|
∫Trefφβi (ξ)φ
αk (ξ)
∂φβj (ξ)
∂ξγdA (14)
= Gαγ(T )K ijkαγ (15)
The index calculus is fully developed by Kirby and Logg inA Compiler for Variational Forms.
M. Knepley GPU 9/1/10 28 / 63

FEM on the GPU
Form Decomposition
Isoparametric Jacobians also give rise to multilinear forms
∫T ∇φi(x) · ∇φj(x)dA (16)
=∫T∂φi (x)∂xα
∂φj (x)∂xα dA (17)
=∫Tref
∂ξβ∂xα
∂φi (ξ)∂ξβ
∂ξγ∂xα
∂φj (ξ)∂ξγ|J|dA (18)
= |J|∫TrefφkJβαk
∂φi (ξ)∂ξβ
φlJγαl
∂φj (ξ)∂ξγ
dA (19)
= Jβαk Jγαl |J|∫Trefφk
∂φi (ξ)∂ξβ
φl∂φj (ξ)∂ξγ
dA (20)
= Gβγkl (T )K
ijklβγ (21)
A different space could also be used for Jacobians
M. Knepley GPU 9/1/10 29 / 63

FEM on the GPU
Element Matrix Formation
Element matrix K is now made up of small tensorsContract all tensor elements with each the geometry tensor G(T )
3 00 0
0 -10 0
1 10 0
-4 -40 0
0 40 0
0 00 0
0 0-1 0
0 00 3
0 01 1
0 00 0
0 04 0
0 0-4 -4
1 01 0
0 10 1
3 33 3
-4 0-4 0
0 00 0
0 -40 -4
-4 0-4 0
0 00 0
-4 -40 0
8 44 8
0 -4-4 -8
0 44 0
0 04 0
0 40 0
0 00 0
0 -4-4 -8
8 44 8
-8 -4-4 0
0 00 0
0 -40 -4
0 0-4 -4
0 44 0
-8 -4-4 0
8 44 8
M. Knepley GPU 9/1/10 30 / 63

FEM on the GPU
Mapping GαβK ijαβ to the GPU
Problem Division
For N elements, map blocks of NL elements to each Thread Block (TB)Launch grid must be gx × gy = N/NL
TB grid will depend on the specific algorithmOutput is size Nbasis × Nbasis × NL
We can split a TB to work on multiple, NB, elements at a timeNote that each TB always gets NL elements, so NB must divide NL
M. Knepley GPU 9/1/10 31 / 63

FEM on the GPU
Mapping GαβK ijαβ to the GPU
Kernel Arguments
__global__vo id in teg ra teJacob ian ( f l o a t * elemMat ,
f l o a t * geometry ,f l o a t * a n a l y t i c )
geometry: Array of G tensors for each element
analytic: K tensor
elemMat: Array of E = G : K tensors for each element
M. Knepley GPU 9/1/10 32 / 63

FEM on the GPU
Mapping GαβK ijαβ to the GPU
Memory Movement
We can interleave stores with computation, or wait until the endWaiting could improve coalescing of writes
Interleaving could allow overlap of writes with computation
Also need toCoalesce accesses between global and local/shared memory(use moveArray())
Limit use of shared and local memory
M. Knepley GPU 9/1/10 33 / 63

FEM on the GPU
Memory Bandwidth
Superior GPU memory bandwidth is due to both
bus width and clock speed.
CPU GPUBus Width (bits) 64 512Bus Clock Speed (MHz) 400 1600Memory Bandwidth (GB/s) 3 102Latency (cycles) 240 600
Tesla always accesses blocks of 64 or 128 bytes
M. Knepley GPU 9/1/10 34 / 63

FEM on the GPU
Mapping GαβK ijαβ to the GPU
Reduction
Choose strategies to minimize reductions
Only reductions occur in summation for contractionsSimilar to the reduction in a quadrature loop
Strategy #1: Each thread uses all of K
Strategy #2: Do each contraction in a separate thread
M. Knepley GPU 9/1/10 35 / 63

FEM on the GPU
Strategy #1TB Division
Each thread computes an entire element matrix, so that
blockDim = (NL/NB,1,1)
We will see that there is little opportunity to overlap computation andmemory access
M. Knepley GPU 9/1/10 36 / 63

FEM on the GPU
Strategy #1Analytic Part
Read K into shared memory (need to synchronize before access)
__shared__ f l o a t K [ $ { dim * dim * numBasisFuncs * numBasisFuncs } ] ;
$ { fm . moveArray ( ’K ’ , ’ a n a l y t i c ’ ,dim * dim * numBasisFuncs * numBasisFuncs , ’ ’ , numThreads ) }
__syncthreads ( ) ;
M. Knepley GPU 9/1/10 37 / 63

FEM on the GPU
Strategy #1Geometry
Each thread handles NB elementsRead G into local memory (not coalesced)Interleaving means writing after each thread does a singleelement matrix calculation
f l o a t G[ $ { dim * dim * numBlockElements } ] ;
i f ( i n t e r l e a v e d ) {const i n t Gof fse t = ( g r i d I d x *$ { numLocalElements } + idx ) * $ { dim * dim } ;f o r n i n range ( numBlockElements ) :
$ { fm . moveArray ( ’G ’ , ’ geometry ’ , dim * dim , ’ Gof fse t ’ ,blockNumber = n* numLocalElements / numBlockElements ,localBlockNumber = n , isCoalesced = False ) }
endfor} e lse {
const i n t Gof fse t = ( g r i d I d x *$ { numLocalElements / numBlockElements } + idx )*$ { dim * dim * numBlockElements } ;
$ { fm . moveArray ( ’G ’ , ’ geometry ’ , dim * dim * numBlockElements , ’ Gof fse t ’ ,isCoalesced = False ) }
}
M. Knepley GPU 9/1/10 38 / 63

FEM on the GPU
Strategy #1Output
We write element matrices out contiguously by TB
const i n t matSize = numBasisFuncs * numBasisFuncs ;const i n t Eo f f se t = g r i d I d x * matSize * numLocalElements ;
i f ( i n t e r l e a v e d ) {const i n t elemOff = idx * matSize ;__shared__ f l o a t E [ matSize * numLocalElements / numBlockElements ] ;
} e lse {const i n t elemOff = idx * matSize * numBlockElements ;__shared__ f l o a t E [ matSize * numLocalElements ] ;
}
M. Knepley GPU 9/1/10 39 / 63

FEM on the GPU
Strategy #1Contraction
matSize = numBasisFuncs * numBasisFuncsi f i n t e r l ea v eS t o re s :
f o r b i n range ( numBlockElements ) :# Do 1 c o n t r a c t i o n f o r each thread__syncthreads ( ) ;fm . moveArray ( ’E ’ , ’ elemMat ’ ,
matSize * numLocalElements / numBlockElements ,’ Eo f f se t ’ , numThreads , blockNumber = n , isLoad = 0)
e lse :# Do numBlockElements co n t r ac t i ons f o r each thread__syncthreads ( ) ;fm . moveArray ( ’E ’ , ’ elemMat ’ ,
matSize * numLocalElements ,’ Eo f f se t ’ , numThreads , isLoad = 0)
M. Knepley GPU 9/1/10 40 / 63

FEM on the GPU
Strategy #2TB Division
Each thread computes a single element of an element matrix, so that
blockDim = (Nbasis,Nbasis,NB)
This allows us to overlap computation of another element in the TBwith writes for the first.
M. Knepley GPU 9/1/10 41 / 63

FEM on the GPU
Strategy #2Analytic Part
Assign an (i , j) block of K to local memoryNB threads will simultaneously calculate a contraction
const i n t Kidx = th read Idx . x + th read Idx . y *$ { numBasisFuncs } ; / / This i s ( i , j )const i n t i dx = Kidx + th read Idx . z *$ { numBasisFuncs * numBasisFuncs } ;const i n t Ko f f se t = Kidx *$ { dim * dim } ;f l o a t K [ $ { dim * dim } ] ;
% f o r alpha i n range ( dim ) :% f o r beta i n range ( dim ) :<% kIdx = alpha * dim + beta %>K[ $ { k Idx } ] = a n a l y t i c [ Ko f f se t +$ { k Idx } ] ;% endfor% endfor
M. Knepley GPU 9/1/10 42 / 63

FEM on the GPU
Strategy #2Geometry
Store NL G tensors into shared memoryInterleaving means writing after each thread does a singleelement calculation
const i n t Gof fse t = g r i d I d x *$ { dim * dim * numLocalElements } ;__shared__ f l o a t G[ $ { dim * dim * numLocalElements } ] ;
$ { fm . moveArray ( ’G ’ , ’ geometry ’ , dim * dim * numLocalElements ,’ Gof fse t ’ , numThreads ) }
__syncthreads ( ) ;
M. Knepley GPU 9/1/10 43 / 63

FEM on the GPU
Strategy #2Output
We write element matrices out contiguously by TBIf interleaving stores, only need a single productOtherwise, need NL/NB, one per element processed by a thread
const i n t matSize = numBasisFuncs * numBasisFuncs ;const i n t Eo f f se t = g r i d I d x * matSize * numLocalElements ;
i f ( i n t e r l e a v e d ) {f l o a t product = 0 . 0 ;const i n t elemOff = idx * matSize ;
} e lse {f l o a t product [ numLocalElements / numBlockElements ] ;const i n t elemOff = idx * matSize * numBlockElements ;
}
M. Knepley GPU 9/1/10 44 / 63

FEM on the GPU
Strategy #2Contraction
i f i n t e r l ea v eS t o re s :f o r n i n range ( numLocalElements / numBlockElements ) :
# Do 1 c o n t r a c t i o n f o r each thread__syncthreads ( )# Do coalesced w r i t e o f element mat r i xelemMat [ Eo f f se t + idx + n* numThreads ] = product
e lse :# Do numLocalElements / numBlockElements c on t r ac t i ons# save r e s u l t s i n product [ ]f o r n i n range ( numLocalElements / numBlockElements ) :
elemMat [ Eo f f se t + idx + n* numThreads ] = product [ n ]
M. Knepley GPU 9/1/10 45 / 63

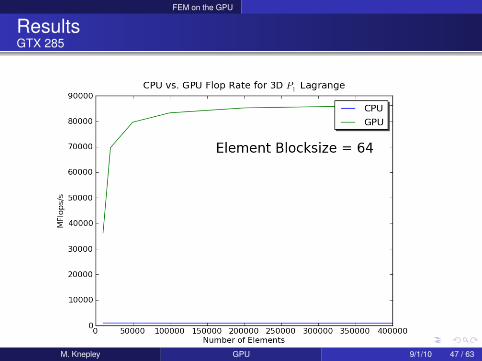
FEM on the GPU
ResultsGTX 285
M. Knepley GPU 9/1/10 46 / 63

FEM on the GPU
ResultsGTX 285
M. Knepley GPU 9/1/10 46 / 63

FEM on the GPU
ResultsGTX 285, 2 Simultaneous Elements
M. Knepley GPU 9/1/10 46 / 63

FEM on the GPU
ResultsGTX 285, 2 Simultaneous Elements
M. Knepley GPU 9/1/10 46 / 63
FEM on the GPU
ResultsGTX 285
M. Knepley GPU 9/1/10 47 / 63

FEM on the GPU
ResultsGTX 285
M. Knepley GPU 9/1/10 47 / 63

FEM on the GPU
ResultsGTX 285, 2 Simultaneous Elements
M. Knepley GPU 9/1/10 47 / 63

FEM on the GPU
ResultsGTX 285, 2 Simultaneous Elements
M. Knepley GPU 9/1/10 47 / 63

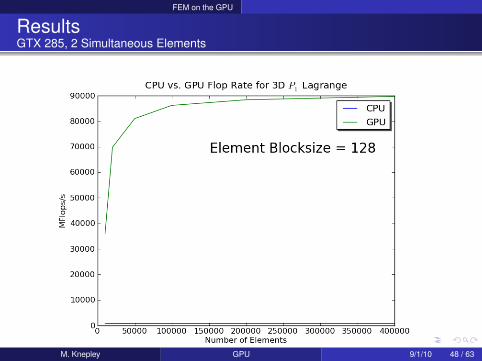
FEM on the GPU
ResultsGTX 285
M. Knepley GPU 9/1/10 48 / 63

FEM on the GPU
ResultsGTX 285
M. Knepley GPU 9/1/10 48 / 63
FEM on the GPU
ResultsGTX 285, 2 Simultaneous Elements
M. Knepley GPU 9/1/10 48 / 63

FEM on the GPU
ResultsGTX 285, 2 Simultaneous Elements
M. Knepley GPU 9/1/10 48 / 63

FEM on the GPU
ResultsGTX 285, 2 Simultaneous Elements
M. Knepley GPU 9/1/10 49 / 63
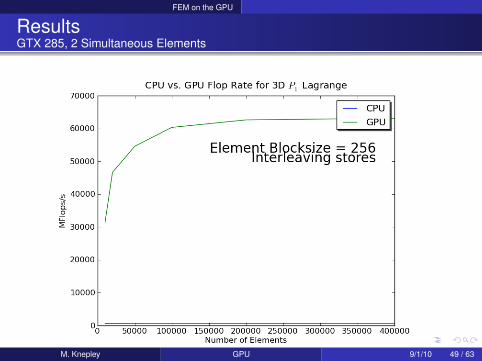
FEM on the GPU
ResultsGTX 285, 2 Simultaneous Elements
M. Knepley GPU 9/1/10 49 / 63

FEM on the GPU
ResultsGTX 285, 4 Simultaneous Elements
M. Knepley GPU 9/1/10 49 / 63

FEM on the GPU
ResultsGTX 285, 4 Simultaneous Elements
M. Knepley GPU 9/1/10 49 / 63

PETSc-GPU
Outline
1 Introduction
2 Tools
3 FEM on the GPU
4 PETSc-GPU
5 Conclusions
M. Knepley GPU 9/1/10 50 / 63

PETSc-GPU
Thrust
Thrust is a CUDA library of parallel algorithms
Interface similar to C++ Standard Template Library
Containers (vector) on both host and device
Algorithms: sort, reduce, scan
Freely available, part of PETSc configure (-with-thrust-dir)
Included as part of CUDA 4.0 installation
M. Knepley GPU 9/1/10 51 / 63

PETSc-GPU
Cusp
Cusp is a CUDA library forsparse linear algebra and graph computations
Builds on data structures in Thrust
Provides sparse matrices in several formats (CSR, Hybrid)
Includes some preliminary preconditioners (Jacobi, SA-AMG)
Freely available, part of PETSc configure (-with-cusp-dir)
M. Knepley GPU 9/1/10 52 / 63

PETSc-GPU
VECCUDA
Strategy: Define a new Vec implementation
Uses Thrust for data storage and operations on GPU
Supports full PETSc Vec interface
Inherits PETSc scalar type
Can be activated at runtime, -vec_type cuda
PETSc provides memory coherence mechanism
M. Knepley GPU 9/1/10 53 / 63

PETSc-GPU
Memory Coherence
PETSc Objects now hold a coherence flag
PETSC_CUDA_UNALLOCATED No allocation on the GPUPETSC_CUDA_GPU Values on GPU are currentPETSC_CUDA_CPU Values on CPU are currentPETSC_CUDA_BOTH Values on both are current
Table: Flags used to indicate the memory state of a PETSc CUDA Vec object.
M. Knepley GPU 9/1/10 54 / 63

PETSc-GPU
MATAIJCUDA
Also define new Mat implementations
Uses Cusp for data storage and operations on GPU
Supports full PETSc Mat interface, some ops on CPU
Can be activated at runtime, -mat_type aijcuda
Notice that parallel matvec necessitates off-GPU data transfer
M. Knepley GPU 9/1/10 55 / 63

PETSc-GPU
Solvers
Solvers come for FreePreliminary Implementation of PETSc Using GPU,
Minden, Smith, Knepley, 2010
All linear algebra types work with solvers
Entire solve can take place on the GPUOnly communicate scalars back to CPU
GPU communication cost could be amortized over several solves
Preconditioners are a problemCusp has a promising AMG
M. Knepley GPU 9/1/10 56 / 63

PETSc-GPU
Installation
PETSc only needs# Turn on CUDA--with-cuda# Specify the CUDA compiler--with-cudac=’nvcc -m64’# Indicate the location of packages# --download-* will also work soon--with-thrust-dir=/PETSc3/multicore/thrust--with-cusp-dir=/PETSc3/multicore/cusp# Can also use double precision--with-precision=single
M. Knepley GPU 9/1/10 57 / 63

PETSc-GPU
ExampleDriven Cavity Velocity-Vorticity with Multigrid
ex50 -da_vec_type seqcusp-da_mat_type aijcusp -mat_no_inode # Setup types-da_grid_x 100 -da_grid_y 100 # Set grid size-pc_type none -pc_mg_levels 1 # Setup solver-preload off -cuda_synchronize # Setup run-log_summary
M. Knepley GPU 9/1/10 58 / 63

Conclusions
Outline
1 Introduction
2 Tools
3 FEM on the GPU
4 PETSc-GPU
5 Conclusions
M. Knepley GPU 9/1/10 59 / 63

Conclusions
How Will Algorithms Change?
Massive concurrency is necessaryMix of vector and thread paradigmsDemands new analysis
More attention to memory managementBlocks will only get largerDeterminant of performance
M. Knepley GPU 9/1/10 60 / 63

Conclusions
Results9400M
M. Knepley GPU 9/1/10 61 / 63

Conclusions
Results9400M
M. Knepley GPU 9/1/10 61 / 63

Conclusions
Results9400M
M. Knepley GPU 9/1/10 61 / 63

Conclusions
Results9400M
M. Knepley GPU 9/1/10 61 / 63

Conclusions
Results9400M
M. Knepley GPU 9/1/10 62 / 63

Conclusions
Results9400M
M. Knepley GPU 9/1/10 62 / 63

Conclusions
Results9400M
M. Knepley GPU 9/1/10 63 / 63

Conclusions
Results9400M
M. Knepley GPU 9/1/10 63 / 63





























