Embed Size (px)
Citation preview


The “New” Moore’s Law
• Computers no longer get faster, just wider
• You must re-think your algorithms to be parallel !
• Data-parallel computing is most scalable solution

The “New” Moore’s Law

Enter the GPU
• Massive economies of scale
• Massively parallel

5
Graphical processors
• The graphics processing unit (GPU) on commodity video cards has evolved into an extremely flexible and powerful processor Programmability Precision Power
• GPGPU: an emerging field seeking to harness GPUs for general-purpose computation

Parallel Computing on a GPU
• 8-series GPUs deliver 25 to 200+ GFLOPSon compiled parallel C applications Available in laptops, desktops, and clusters
• GPU parallelism is doubling every year• Programming model scales transparently
• Multithreaded SPMD model uses application data parallelism and thread parallelism
GeForce 8800
Tesla S870
Tesla D870

7
Computational Power
• GPUs are fast… 3.0 GHz dual-core Pentium4: 24.6 GFLOPS NVIDIA GeForceFX 7800: 165 GFLOPs 1066 MHz FSB Pentium Extreme Edition : 8.5 GB/s ATI Radeon X850 XT Platinum Edition: 37.8 GB/s
• GPUs are getting faster, faster CPUs: 1.4× annual growth GPUs: 1.7×(pixels) to 2.3× (vertices) annual growth

CPU vs GPU

9
Flexible and Precise
• Modern GPUs are deeply programmable Programmable pixel, vertex, video engines Solidifying high-level language support
• Modern GPUs support high precision 32 bit floating point throughout the pipeline High enough for many (not all) applications

10
GPU for graphics
• GPUs designed for & driven by video games Programming model unusual Programming idioms tied to computer graphics Programming environment tightly constrained
• Underlying architectures are: Inherently parallel Rapidly evolving (even in basic feature set!) Largely secret

11
General purpose GPUs
• The power and flexibility of GPUs makes them an attractive platform for general-purpose computation
• Example applications range from in-game physics simulation to conventional computational science
• Goal: make the inexpensive power of the GPU available to developers as a sort of computational coprocessor

Previous GPGPU Constraints• Dealing with graphics API
Working with the corner cases of the graphics API
• Addressing modes Limited texture size/dimension
• Shader capabilities Limited outputs
• Instruction sets Lack of Integer & bit ops
• Communication limited Between pixels
Input Registers
Fragment Program
Output Registers
Constants
Texture
Temp Registers
per threadper Shaderper Context
FB Memory

Enter CUDA
• Scalable parallel programming model
• Minimal extensions to familiar C/C++ environment
• Heterogeneous serial-parallel computing

Sound Bite
GPUs + CUDA =
The Democratization of Parallel Computing
Massively parallel computing has become a commodity technology

MOTIVATION
146X
Interactive visualization of
volumetric white matter connectivity
36X
Ionic placement for molecular dynamics simulation on GPU
19X
Transcoding HD video stream to H.264
17X
Fluid mechanics in Matlab using .mex file
CUDA function
100X
Astrophysics N-body simulation
149X
Financial simulation of LIBOR model with
swaptions
47X
GLAME@lab: an M-script API for GPU
linear algebra
20X
Ultrasound medical imaging for cancer
diagnostics
24X
Highly optimized object oriented
molecular dynamics
30X
Cmatch exact string matching to find
similar proteins and gene sequences

Cell Phone RF Simulation
Computational Chemistry
Neurological Modeling
3D CTUltrasound
4.6 Days
27 Minutes
2.7 Days
30 Minutes
8 Hours
13 Minutes16 Minutes
3 Hours
CPU Only Heterogeneous with Tesla GPU

GPUs: Turning Point in Supercomputing
Tesla Personal Supercomputer
$10,000CalcUA
$5 Million
Source: University of Antwerp, Belgium
Desktop beats Cluster
4 GPUsvs
256 CPUs

CUDA: ‘C’ FOR PARALLELISMvoid saxpy_serial(int n, float a, float *x, float *y)
{
for (int i = 0; i < n; ++i)
y[i] = a*x[i] + y[i];
}
// Invoke serial SAXPY kernel
saxpy_serial(n, 2.0, x, y);
__global__ void saxpy_parallel(int n, float a, float *x, float *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
// Invoke parallel SAXPY kernel with 256 threads/block
int nblocks = (n + 255) / 256;
saxpy_parallel<<<nblocks, 256>>>(n, 2.0, x, y);
Standard C Code
Parallel C Code

So far, today..
• GPU – powerful coprocessors• CUDA – programming model for GPU
• Easier to parallelize on GPUs• CUDA extends GPU to general purpose computing
• Now we shall look at the thread programming and memory structure on GPU

Hierarchy of concurrent threads
• Parallel kernels composed of many threads all threads execute the same sequential program
• Threads are grouped into thread blocks threads in the same block can cooperate
• Threads/blocks have unique IDs
Thread t
t0 t1 … tBBlock b
Kernel foo()
. . .

Hierarchical organizationThread
per-threadlocal memory
Block
per-blockshared
memory
Kernel 0
. . .per-device
globalmemory
. . .
Kernel 1
. . .Global barrier
Local barrier

Heterogeneous Programming• CUDA = serial program with parallel kernels, all in C Serial C code executes in a CPU thread Parallel kernel C code executes in thread blocks
across multiple processing elementsSerial Code
. . .
. . .
Parallel Kernelfoo<<< nBlk, nTid
>>>(args);Serial Code
Parallel Kernel bar<<<nBlk, nTid>>>(args);

What is a thread?
• Independent thread of execution has its own PC, variables (registers), processor state,
etc. no implication about how threads are scheduled
• CUDA threads might be physical threads as on NVIDIA GPUs
• CUDA threads might be virtual threads might pick 1 block = 1 physical thread on multicore
CPU

What is a thread block?
• Thread block = virtualized multiprocessor freely choose processors to fit data freely customize for each kernel launch
• Thread block = a (data) parallel task all blocks in kernel have the same entry point but may execute any code they want
• Thread blocks of kernel must be independent tasks program valid for any interleaving of block executions

Blocks must be independent
• Any possible interleaving of blocks should be valid presumed to run to completion without pre-emption can run in any order can run concurrently OR sequentially
• Blocks may coordinate but not synchronize shared queue pointer: OK shared lock: BAD … can easily deadlock
• Independence requirement gives scalability

Levels of parallelism
• Thread parallelism each thread is an independent thread of execution
• Data parallelism across threads in a block across blocks in a kernel
• Task parallelism different blocks are independent independent kernels

Block = virtualized multiprocessor
• Provides programmer flexibility freely choose processors to fit data freely customize for each kernel launch
• Thread block = a (data) parallel task all blocks in kernel have the same entry point but may execute any code they want
• Thread blocks of kernel must be independent tasks program valid for any interleaving of block executions

Scalable Execution ModelKernel launched by host
. . .
SP
SharedMemory
MT IU
SP
SharedMemory
MT IU
SP
SharedMemory
MT IU
SP
SharedMemory
MT IU
SP
SharedMemory
MT IU
SP
SharedMemory
MT IU
SP
SharedMemory
MT IU
SP
SharedMemory
MT IU
. . .
Device Memory
Blocks Run on Multiprocessors

Synchronization & Cooperation
• Threads within block may synchronize with barriers… Step 1 …__syncthreads();… Step 2 …
• Blocks coordinate via atomic memory operations e.g., increment shared queue pointer with atomicInc()
• Implicit barrier between dependent kernelsvec_minus<<<nblocks, blksize>>>(a, b, c);vec_dot<<<nblocks, blksize>>>(c, c);

CUDA Memories

31
G80 Implementation of CUDA Memories
• Each thread can: Read/write per-thread registers Read/write per-thread local
memory Read/write per-block shared
memory Read/write per-grid global
memory Read/only per-grid constant
memory• The host can R/W global,
constant, and texture memories
Grid
Global Memory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host
Constant Memory

32
Thread
Local Memory
Grid 0
. . .Global
Memory
. . .
Grid 1SequentialGridsin Time
Block
SharedMemory

Memory model
Device 0memory
Device 1memory
Host memory

34
A Common Programming Strategy• Global memory resides in device memory (DRAM) - much
slower access than shared memory• So, a profitable way of performing computation on the device is
to tile data to take advantage of fast shared memory: Partition data into subsets that fit into shared memory Handle each data subset with one thread block by:
Loading the subset from global memory to shared memory, using multiple threads to exploit memory-level parallelism
Performing the computation on the subset from shared memory; each thread can efficiently multi-pass over any data element
Copying results from shared memory to global memory

35
A Common Programming Strategy (Cont.)
• Constant memory also resides in device memory (DRAM) - much slower access than shared memory But… cached! Highly efficient access for read-only data
• Carefully divide data according to access patterns R/Only constant memory (very fast if in cache) R/W shared within Block shared memory (very fast) R/W within each thread registers (very fast) R/W inputs/results global memory (very slow)

Is that all??
• No!!• Memory Coalescing• Bank conflicts

Memory Coalescing
• When accessing global memory, peak performance utilization occurs when all threads access continuous memory locations.
Md Nd
WID
TH
WIDTH
Thread 1Thread 2
Not coalesced coalesced

M2,0
M1,1
M1,0M0,0
M0,1
M3,0
M2,1 M3,1
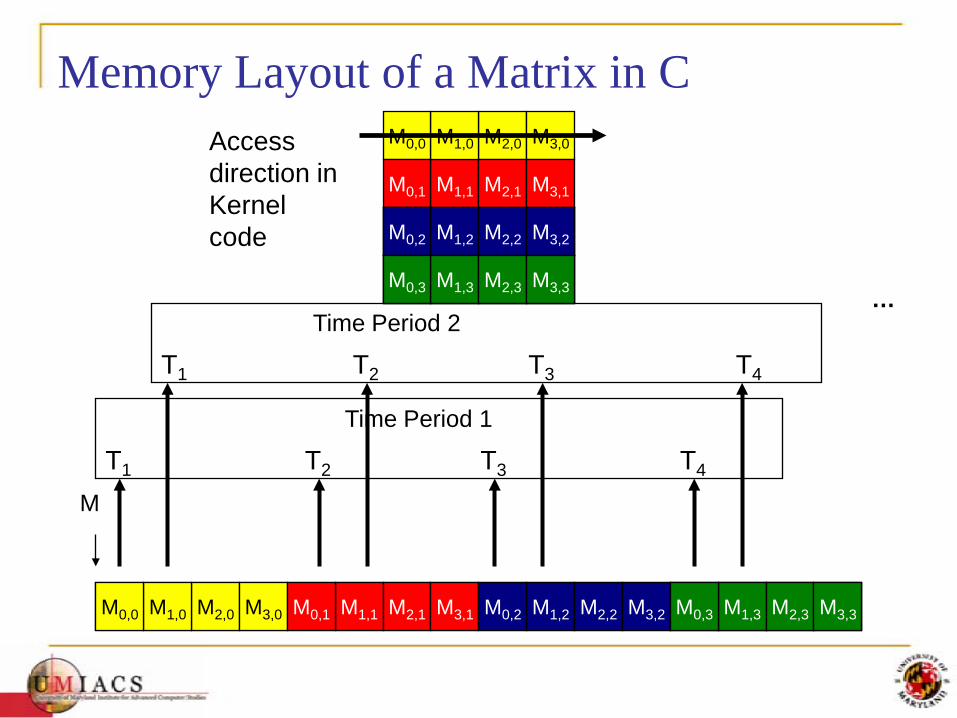
Memory Layout of a Matrix in C
M2,0M1,0M0,0 M3,0 M1,1M0,1 M2,1 M3,1 M1,2M0,2 M2,2 M3,2
M1,2M0,2 M2,2 M3,2
M1,3M0,3 M2,3 M3,3
M1,3M0,3 M2,3 M3,3
M
T1 T2 T3 T4
Time Period 1
T1 T2 T3 T4
Time Period 2
Access direction in Kernel code
…
M2,0
M1,1
M1,0M0,0
M0,1
M3,0
M2,1 M3,1
Memory Layout of a Matrix in C
M2,0M1,0M0,0 M3,0 M1,1M0,1 M2,1 M3,1 M1,2M0,2 M2,2 M3,2
M1,2M0,2 M2,2 M3,2
M1,3M0,3 M2,3 M3,3
M1,3M0,3 M2,3 M3,3
M
T1 T2 T3 T4
Time Period 1
T1 T2 T3 T4
Time Period 2
Access direction in Kernel code
…

Parallel Memory Architecture for Shared memory• In a parallel machine, many threads access memory Therefore, memory is divided into banks Essential to achieve high bandwidth
• Each bank can service one address per cycle A memory can service as many simultaneous
accesses as it has banks
• Multiple simultaneous accesses to a bankresult in a bank conflict Conflicting accesses are serialized
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0

Bank Addressing Examples
• No Bank Conflicts Linear addressing
stride == 1
• No Bank Conflicts Random 1:1 Permutation
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0

Bank Addressing Examples• 2-way Bank Conflicts
Linear addressing stride == 2
• 8-way Bank Conflicts Linear addressing
stride == 8
Thread 11Thread 10Thread 9Thread 8
Thread 4Thread 3Thread 2Thread 1Thread 0
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0
Bank 9Bank 8
Bank 15
Bank 7
Bank 2Bank 1Bank 0x8
x8

Summary of CUDA programming tips
• Divide the overall task between concurrent non-communicating threads.
• Design a coalesced access of global memory• Avoid bank-conflicts when accessing shared memory

Programming on CUDA

Basic steps
• Transfer data from CPU to GPU • Explicitly call the GPU kernel designed CUDA will implicitly assign threads to each
multiprocessor, and assign resources for computations• Transfer results back from GPU to CPU

CPU vs GPU
• CPU – operation intensive Goal: reduce number of operations performed at the
expense of additional memory access• GPU – memory intensive Goal: reduce the number of memory accesses at the
expense of additional operations.

Memory model
Device 0memory
Device 1memory
Host memory cudaMemcpy()

CUDA: Minimal extensions to C/C++• Declaration specifiers to indicate where things live
__global__ void KernelFunc(...); // kernel callable from host__device__ void DeviceFunc(...); // function callable on device__device__ int GlobalVar; // variable in device memory__shared__ int SharedVar; // in per-block shared memory
• Extend function invocation syntax for parallel kernel launchKernelFunc<<<500, 128>>>(...); // 500 blocks, 128 threads each
• Special variables for thread identification in kernelsdim3 threadIdx; dim3 blockIdx; dim3 blockDim;
• Intrinsics that expose specific operations in kernel code__syncthreads(); // barrier synchronization

CUDA: Features available on GPU• Standard mathematical functions
sinf, powf, atanf, ceil, min, sqrtf, expf
erfc
And many more standard mathematical functions

CUDA: Runtime support• Explicit memory allocation returns pointers to GPU memory
cudaMalloc(), cudaFree()
• Explicit memory copy for host ↔ device, device ↔ devicecudaMemcpy(), cudaMemcpy2D(), ...
• Texture managementcudaBindTexture(), cudaBindTextureToArray(), ...
• OpenGL & DirectX interoperabilitycudaGLMapBufferObject(), cudaD3D9MapVertexBuffer(), …

Example: Vector Addition Kernel// Compute vector sum C = A+B
// Each thread performs one pair-wise addition
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// Run N/256 blocks of 256 threads each
vecAdd<<< N/256, 256>>>(d_A, d_B, d_C);
}

Example: Host code for vecAdd// allocate and initialize host (CPU) memoryfloat *h_A = …, *h_B = …;
// allocate device (GPU) memoryfloat *d_A, *d_B, *d_C;cudaMalloc( (void**) &d_A, N * sizeof(float));cudaMalloc( (void**) &d_B, N * sizeof(float));cudaMalloc( (void**) &d_C, N * sizeof(float));
// copy host memory to devicecudaMemcpy( d_A, h_A, N * sizeof(float),
cudaMemcpyHostToDevice) );cudaMemcpy( d_B, h_B, N * sizeof(float),
cudaMemcpyHostToDevice) );
// execute the kernel on N/256 blocks of 256 threads eachvecAdd<<<N/256, 256>>>(d_A, d_B, d_C);

CUDA libraries – CUFFT & CUBLAS

CUBLAS and CUFFT
• Standard libraries with development kit• CUBLAS CUDA version of blas Available for single- and double- precision for real and
complex numbers Double version – slower
• CUFFT FFT & IFFT on CUDA Faster than the fastest CPU algorithm

CUBLAS
• 3 classes1. Vector operations Vector addition, norm, dot-product, etc
2. Matrix-vector operations Matrix-vector product for symmetric and normal
matrices, etc3. Matrix-matrix operations Matrix multiplication, etc

Advantage
• Highly optimized design• Usable as standard C/C++/Fortran libraries
• Caters the needs in many scientific computing tasks

OpenCL
CUDA: An Architecture for Massively Parallel Computing
ATI’s Compute “Solution”

OpenCL vs. C for CUDA
Shared back-end compiler & optimization technology
OpenCL
C for CUDA
PTX
GPU
Entry point for developers who prefer high-level C
Entry point for developers who
want low-level API


Recall: GPU and CUDA
• GPU – developed for accelerating graphics• CUDA – developed to harness the power of GPUs for
general purpose applications Like C in syntax
• GPU – not a panacea Used in a master-slave scenario with CPU (host) as
master

62
Recall: GPU memories• Each thread can: Read/write per-thread registers Read/write per-thread local memory Read/write per-block shared memory Read/write per-grid global memory Read/only per-grid constant memory
• Divide data according to accesspatterns R/Only constant memory (very fast
if in cache) R/W shared within Block shared
memory (very fast) R/W within each thread registers
(very fast) R/W inputs/results global memory
(very slow)
Grid
Global Memory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host
Constant Memory

63
Thread
Local Memory
Grid 0
. . .Global
Memory
. . .
Grid 1SequentialGridsin Time
Block
SharedMemory
Recall: Thread organization

Recall: Heterogeneous programming \\ CPU codescudaMalloc() \\ allocate memories on device
cudaMemcpy() \\ transfer input data to device
Kernel<<blocks,threads>>() \\ call cuda kernels
\\ kernels are functions evaluated on a single thread
cudaMemcpy() \\ transfer results from device
Keywords: __global__, __shared__, __device__Special math functions: sinf, expf, min, etc

Case Study: Matrix Multiplication

Matrix Multiplication Kernel using Multiple Blocks
__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width){// Calculate the row index of the Pd element and Mint Row = blockIdx.y*TILE_WIDTH + threadIdx.y;// Calculate the column idenx of Pd and Nint Col = blockIdx.x*TILE_WIDTH + threadIdx.x;
float Pvalue = 0;// each thread computes one element of the block sub-matrixfor (int k = 0; k < Width; ++k)Pvalue += Md[Row*Width+k] * Nd[k*Width+Col];
Pd[Row*Width+Col] = Pvalue;
}

Grid
Global Memory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host
Constant Memory
How about performance on G80?
• All threads access global memory for their input matrix elements Two memory accesses (8 bytes) per
floating point multiply-add 4B/s of memory bandwidth/FLOPS 4*346.5 = 1386 GB/s required to
achieve peak FLOP rating 86.4 GB/s limits the code at 21.6
GFLOPS• The actual code runs at about 15
GFLOPS• Need to drastically cut down memory
accesses to get closer to the peak 346.5 GFLOPS

68
Use Shared Memory to reuse global memory data• Each input element is
read by Width threads.• Load each element into
Shared Memory and have several threads use the local version to reduce the memory bandwidth Tiled algorithms
M
N
P
WID
TH
WID
TH
WIDTH WIDTH
ty
tx

Md
Nd
Pd
Pdsub
TILE_WIDTH
WIDTHWIDTH
TILE_WIDTHTILE_WIDTH
bx
tx01 TILE_WIDTH-12
0 1 2
by ty 210
TILE_WIDTH-1
2
1
0
TIL
E_W
IDT
HT
ILE
_WID
TH
TIL
E_W
IDT
HE
WID
TH
WID
TH
Tiled Multiply
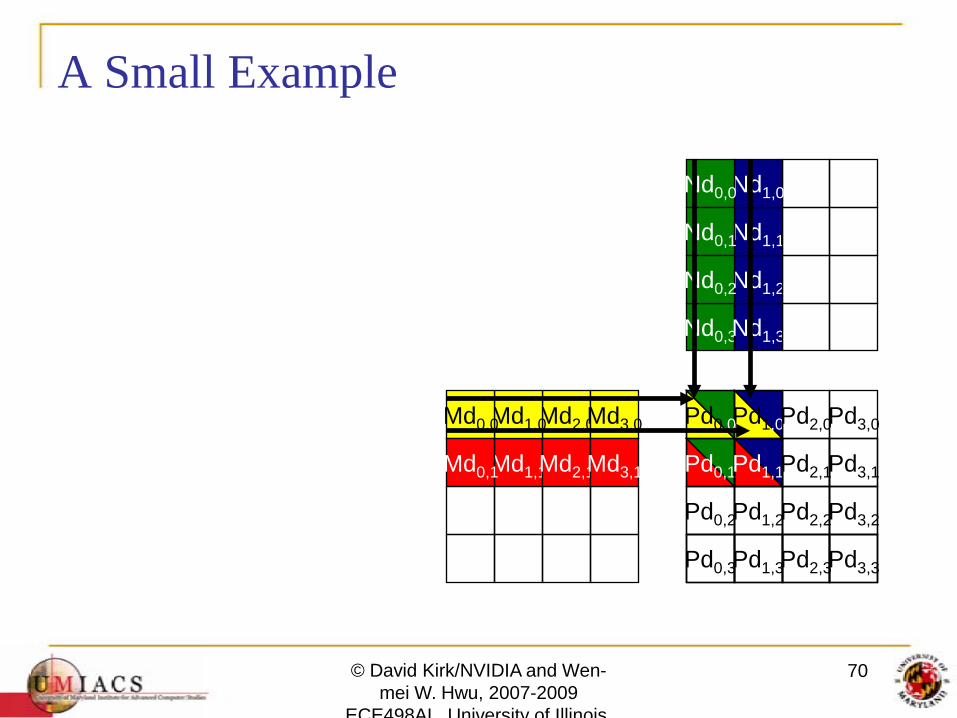
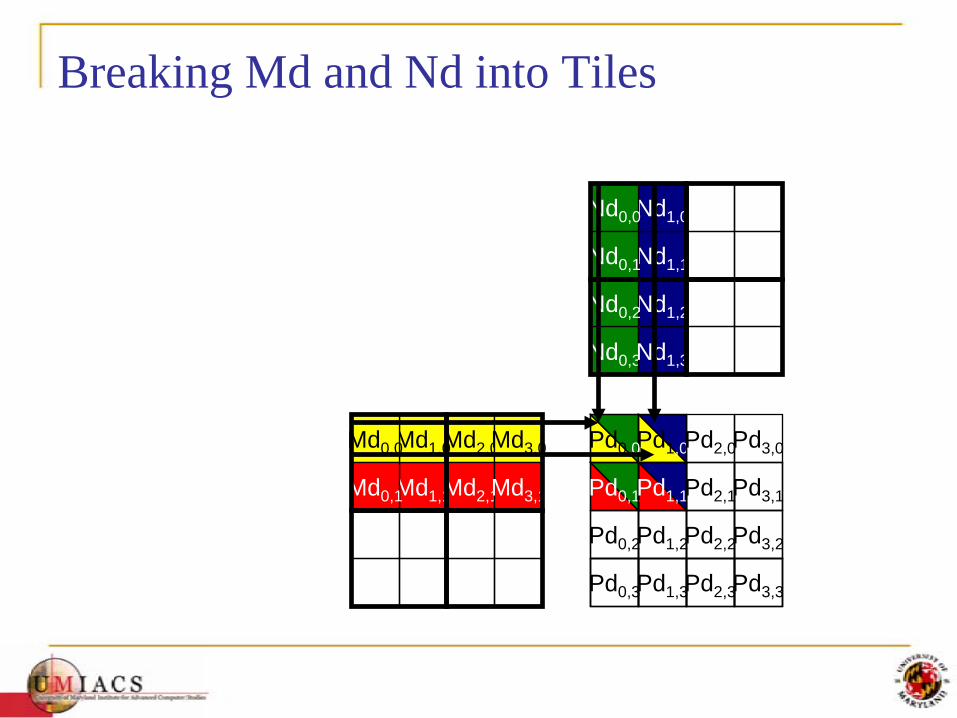
• Break up the execution of the kernel into phases so that the data accesses in each phase is focused on one subset (tile) of Md and Nd
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2009
ECE498AL University of Illinois
70
Pd1,0
A Small Example
Md2,0
Md1,1
Md1,0Md0,0
Md0,1
Md3,0
Md2,1
Pd0,0
Md3,1 Pd0,1
Pd2,0Pd3,0
Nd0,3Nd1,3
Nd1,2
Nd1,1
Nd1,0Nd0,0
Nd0,1
Nd0,2
Pd1,1
Pd0,2 Pd2,2Pd3,2Pd1,2
Pd3,1Pd2,1
Pd0,3 Pd2,3Pd3,3Pd1,3

Every Md and Nd Element is used exactly twice in generating a 2X2 tile of P
P0,0
thread0,0
P1,0
thread1,0
P0,1
thread0,1
P1,1
thread1,1
M0,0 * N0,0 M0,0 * N1,0 M0,1 * N0,0 M0,1 * N1,0
M1,0 * N0,1 M1,0 * N1,1 M1,1 * N0,1 M1,1 * N1,1
M2,0 * N0,2 M2,0 * N1,2 M2,1 * N0,2 M2,1 * N1,2
M3,0 * N0,3 M3,0 * N1,3 M3,1 * N0,3 M3,1 * N1,3
Accessorder
Pd1,0Md2,0
Md1,1
Md1,0Md0,0
Md0,1
Md3,0
Md2,1
Pd0,0
Md3,1 Pd0,1
Pd2,0Pd3,0
Nd0,3Nd1,3
Nd1,2
Nd1,1
Nd1,0Nd0,0
Nd0,1
Nd0,2
Pd1,1
Pd0,2 Pd2,2Pd3,2Pd1,2
Pd3,1Pd2,1
Pd0,3 Pd2,3Pd3,3Pd1,3
Breaking Md and Nd into Tiles

First-order Size Considerations in G80
• Each thread block should have many threads TILE_WIDTH of 16 gives 16*16 = 256 threads
• There should be many thread blocks A 1024*1024 Pd gives 64*64 = 4096 Thread Blocks
• Each thread block perform 2*256 = 512 float loads from global memory for 256 * (2*16) = 8,192 mul/add operations. Memory bandwidth no longer a limiting factor

CUDA Code – Kernel Execution Configuration
// Setup the execution configuration
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH);dim3 dimGrid(Width / TILE_WIDTH,
Width / TILE_WIDTH);

Tiled Matrix Multiplication Kernel__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width){1. __shared__float Mds[TILE_WIDTH][TILE_WIDTH];2. __shared__float Nds[TILE_WIDTH][TILE_WIDTH];
3. int bx = blockIdx.x; int by = blockIdx.y;4. int tx = threadIdx.x; int ty = threadIdx.y;
// Identify the row and column of the Pd element to work on5. int Row = by * TILE_WIDTH + ty;6. int Col = bx * TILE_WIDTH + tx;
7. float Pvalue = 0;// Loop over the Md and Nd tiles required to compute the Pd element8. for (int m = 0; m < Width/TILE_WIDTH; ++m) {// Coolaborative loading of Md and Nd tiles into shared memory9. Mds[ty][tx] = Md[Row*Width + (m*TILE_WIDTH + tx)];10. Nds[ty][tx] = Nd[Col + (m*TILE_WIDTH + ty)*Width];11. __syncthreads();
11. for (int k = 0; k < TILE_WIDTH; ++k)12. Pvalue += Mds[ty][k] * Nds[k][tx];13. Synchthreads();14. }13. Pd[Row*Width+Col] = Pvalue;}

Md
Nd
Pd
Pdsub
TILE_WIDTH
WIDTHWIDTH
TILE_WIDTHTILE_WIDTH
bx
tx01 TILE_WIDTH-12
0 1 2
by ty 210
TILE_WIDTH-1
2
1
0
TIL
E_W
IDT
HT
ILE
_WID
TH
TIL
E_W
IDT
HE
WID
TH
WID
TH
Tiled Multiply
• Each block computes one square sub-matrix Pdsub of size TILE_WIDTH
• Each thread computes one element of Pdsub
m
kbx
by
k
m

77
G80 Shared Memory and Threading• Each SM in G80 has 16KB shared memory
SM size is implementation dependent! For TILE_WIDTH = 16, each thread block uses 2*256*4B = 2KB of
shared memory. Can potentially have up to 8 Thread Blocks actively executing
This allows up to 8*512 = 4,096 pending loads. (2 per thread, 256 threads per block)
The next TILE_WIDTH 32 would lead to 2*32*32*4B= 8KB shared memory usage per thread block, allowing only up to two thread blocks active at the same time
• Using 16x16 tiling, we reduce the accesses to the global memory by a factor of 16 The 86.4B/s bandwidth can now support (86.4/4)*16 = 347.6 GFLOPS!
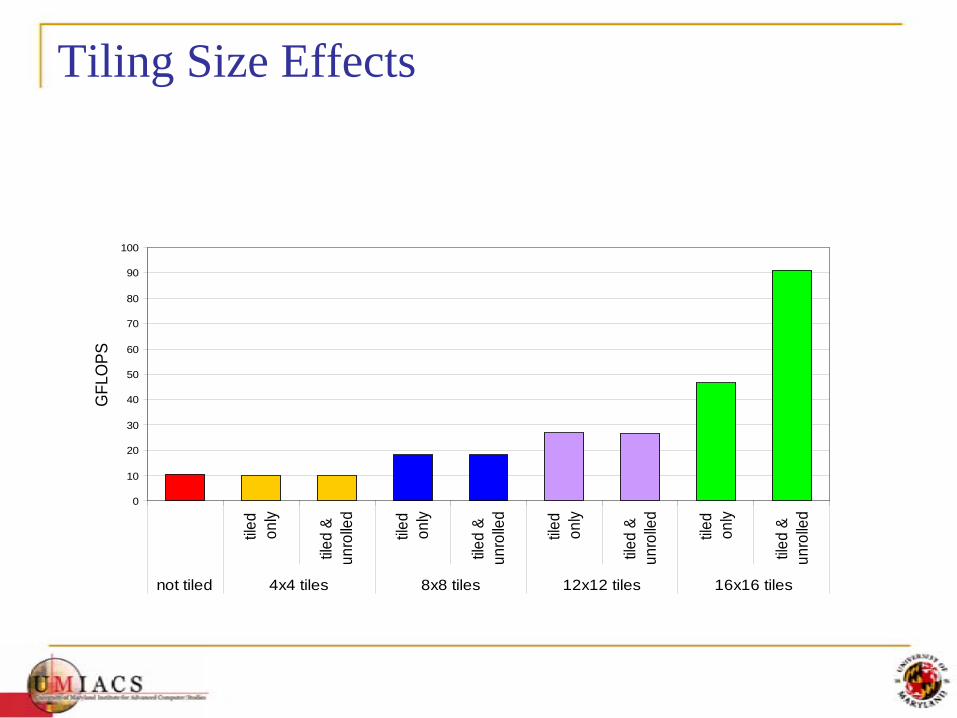
Tiling Size EffectsG
FLO
PS
0
10
20
30
40
50
60
70
80
90
100tile
don
ly
tiled
&un
rolle
d
tiled
only
tiled
&un
rolle
d
tiled
only
tiled
&un
rolle
d
tiled
only
tiled
&un
rolle
d
not tiled 4x4 tiles 8x8 tiles 12x12 tiles 16x16 tiles

• Global variables declaration __host__ __device__... __global__, __constant__, __texture__
• Function prototypes __global__ void kernelOne(…) float handyFunction(…)
• Main () allocate memory space on the device – cudaMalloc(&d_GlblVarPtr, bytes ) transfer data from host to device – cudaMemCpy(d_GlblVarPtr, h_Gl…) execution configuration setup kernel call – kernelOne<<<execution configuration>>>( args… ); transfer results from device to host – cudaMemCpy(h_GlblVarPtr,…) optional: compare against golden (host computed) solution
• Kernel – void kernelOne(type args,…) variables declaration - __local__, __shared__
automatic variables transparently assigned to registers or local memory syncthreads()…
• Other functions float handyFunction(int inVar…);
Typical Structure of a CUDA Program
repeatas needed

GPU for Machine learning

Machine learning
• With improved sensors, the amount of data availablehas increased by several folds over the past decade.
• Also, more robust and sophisticated learningalgorithms have been developed to extractmeaningful information from the data
• This has resulted in the application of thesealgorithms in many areas: Geostatistics, astronomical predictions, weather data
assimilations, computational finance.

Extracting information from the data• “Extracting information from the data” means converting the
raw data to an interpretable version For example, given a face image, it would desirable to
extract the identity of the person, the face pose, etc• Information extraction categories Regression – [fitting a continuous function] Classification – [classify into one of the predefined classes] Density estimation – [evaluating the class membership] Ranking – [preference relationships between classes]
• Bottom-line: Infer the relationships based on the data Build the relationship model from the data

Relationship modeling• There are two primary categories of the models Parametric Non-parametric
• Parametric model: Assumes a known parametric form of the “relationship” Estimates the parameters of this “form” from the data
• Non-parametric model Do not make any assumptions on the form of the
underlying function. “Letting the data speak for itself”

Kernel methods• A class of robust non-parametric learning methods• Projects the data into a higher dimensional space• Formulates the problem such that only the inner product of the higher
dimension features are required• The inner-products are given by the kernel functions• For example the Gaussian kernel is given by:

Scalable learning methods• Most of these kernel based learning approaches scale O(N2) or O(N3) in
time with respect to data
• There is also O(N2) memory requirement in many of these• This is undesirable for very large datasets• We would like to develop a parallelized version on GPU

Kernel methods on GPUs• There are problems where summations of kernel
functions need to be evaluated Algorithm must map summation to multiple threads
• Some problems require the solution of linear systeminvolving kernel matrices Possibly use the kernel summation before with popular
iterative approaches like conjugate gradient• There also exist problems where popular matrix
decompositions like LU needed to performed forkernel matrices Number of approaches already exist on GPUs

Solving Ky=b
• Can use iterative methods Conjugate Gradient
• Over each iteration, to evaluate Kx
• We will discuss the matrix-vector product now

Kernel matrix – special structure
• O(N) dependence N x N matrix depends on O(N)-length vector
• Need only O(N) space
• Need to exploit this to minimize space requirements

Kernel summation on GPU• Data:
Source points xi, i=1,…,N, Evaluation points yj, j=1,…,M $
• Each thread evaluates the sum corresponding to one evaluation point:• Algorithm:
1. Load evaluation point corresponding to the current thread in to alocalregister.
2. Load the first chunk of source data to the shared memory.3. Evaluate part of kernel sum corresponding to sourcedata in the shared
memory.4. Store the result in a local register.5. If all the source points have not been processed yet, load the next chunk,
go to Step 3.6. Write the sum in the local register to the global memory.

Gaussian kernel on GPUfloat sum=0.0; __shared__ float hs[DIM]; volatile float yr[DIM];
for (int k=0;k<DIM;k++){
int indexM=k+(blockIdx.x*BLOCK_SIZE + threadIdx.x)*DIM;
yr[k]=y[indexM];}
// load ‘h’
for (int b=0;b<N;b+=BLOCK_SIZE){
__shared__ float qs[BLOCK_SIZE];
__shared__ float Xs[BLOCK_SIZE][DIM];
// load X & q
for (int i=0;i<BLOCK_SIZE;i++){
float dist=0.0;
if ((b+i)<N){
for (int k=0;k<DIM;k++){
float tempDiff=yr[k]-Xs[i][k];
dist+=(tempDiff*tempDiff)/(hs[k]*hs[k]);
}
sum+=__expf(-dist)*qs[i];
}}
__syncthreads();
}
if ((blockIdx.x*BLOCK_SIZE + threadIdx.x)<M)
f[blockIdx.x*BLOCK_SIZE + threadIdx.x] = sum;
}

Kernels tested:
Gaussian
Matern
Periodic
Epanechnikov

Raw speedups across dimension

Applications
• Kernel density estimation• Gaussian process regression• Meanshift clustering• Ranking• And many more…

Kernel Density Estimation
• Non-parametric way of estimating probability densityfunction of a random variable
• Two popular kernels: Gaussian and Epanechnikov
• Accelerated with GPU based algorithm: Speed up ~ 450X

Results on standard distributions• Performed KDE on 15 normal mixture densities from [1]
[1] J. S. Marron and M. P. Wand 'Exact Mean Integrated SquaredError' The Annals of Statistics, 1992, Vol. 20, No. 2, 712-736

Gaussian Process Regression• Non-parametric regression
Kernel regression Robust in non-linear modeling
• For ; given y and x, need to model ‘f’• Given
• Data D = {xi, yi}, i=1..N• Test point x*, need to find f(x*) or f*
• GPR model f*=k*(x) x (K+σ2I)-1 x y K = kernel matrix of training data k* = kernel vector of test point w.r.t all training data

Gaussian Process Regression
• GPR model f*=k*(x) x (K+σ2I)-1 x y• Complexity – O(N3) due to the inversion of the kernel
matrix (can be made O(N2) using Conjugate Gradient A popular iterative krylov algorithm
• Popular kernels that are used in GPR are: Gaussian Matern Periodic

Gaussian Process Regression
102
103
104
105
10-2
10-1
100
101
102
Performance of Gaussian Proces Regression with Gaussian kernel
Size of data
Tim
e ta
ken
CPUGPU

GPR on standard datasets

GPU based kernel summation
• Still O(N2)! • A linear approximation algorithm can beat this
beyond “some” N• FMM – based Gaussian kernel (FIGTREE) vs GPU
version

FIGTREE vs GPU 1

FIGTREE vs GPU 2

FIGTREE vs GPU 3

Further :
• More interesting: FMM on GPU• Issues on data structures• Need to consider many factors.
• Will be discussed next class by Dr. Nail Gumerov

Quotes

GPUs have evolved to the point where many real world applications are easily implemented on them and run significantly faster than on multi-core systems.
Future computing architectures will be hybrid systems with parallel-core GPUs working in tandem with multi-core CPUs.
Jack DongarraProfessor, University of TennesseeAuthor of Linpack

We’ve all heard ‘desktop supercomputer’ claims in the past, but this time it’s for real: NVIDIA and its partners will be delivering outstanding performance and broad applicability to the mainstream marketplace.
Heterogeneous computing is what makes such a breakthrough possible.
Burton SmithTechnical Fellow, MicrosoftFormerly, Chief Scientist at Cray

























![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://img.dokumen.tips/doc/110x75/543d7a678d7f72ee598b58d3/harvard-cs264-03-introduction-to-gpu-computing-cuda-basics.jpg)




