Embed Size (px)
Citation preview

1
GPGPU facile avec JavaCL...... et trivial avec ScalaCL
by Olivier Chafik@ochafik

Monstres de puissance
2

Répartition inéquitable
3
•

4
Mettons les GPUs au travail !
• Concepts de base d’OpenCL
• JavaCL en quelques lignes de code
• Pour les paresseux et les pressés : ScalaCL

5
Speaker
Olivier Chafik (@ochafik)
•Développeur C++ / Java (3D, finance)
•Hobby = interopérabilité
• JNAerator, BridJ : des bindings en 1 minute-chrono
• JavaCL, ScalaCL

6
OpenCL =
OpenGL pour calculs généralistes

7
OpenCL =
environnement d’exécution multi-plateforme

8
Pourquoi OpenCL ?
• Puissance gratuite (x10 à x100)
• Standard multi-vendeur, CPU + GPU
• Close-to-metal : parallélisme boucles + SIMDPousse les multi-coeurs à bout !
• Interaction DirectX / OpenGL

9
Charge utile d’OpenCL
• Task : appel unique
• Kernel : appels massivement parallèles N-dimensions

10
Orienté événement
• Opérations asynchrones & enchaînables
• Renvoient events, en attendre d’autres
Écriture buffer Exec 1 Exec 2 Lecture buffer
• Files d’exécutions attachées à un device

Exemple de boucle C
Calcul de sinus & cosinus en boucle
void scos( const double* params, double* out, int length) { for (int i = 0; i < length; i++) { double param = params[i]; out[2 * i] = sin(param); out[2 * i + 1] = cos(param); }}
11

Kernel OpenCL équivalent
Calcul de sinus & cosinus parallèle (simplifié)
#pragma OpenCL EXTENSION cl_khr_fp64 : enablekernel void scos( global const double* params, global double2* out, int length) { int i = get_global_id(0); // indice parallèle if (i >= length) return; // dépassements possibles { double param = params[i]; double c, s = sincos(param, &c); // calcul sin & cos rapide out[i] = (double2)(s, c); }}
12

13
Kernels
• Dialecte du C
• Fonctions math vectorielles (SIMD sur float4, int8…)
• Code connait sa position d’exécution
• Lecture / écriture buffers / images
• Synchronisation avec voisins (working group)

14
Code hôte
• Choix devices + création contexte
• Création file d’exécution
• Compilation kernels
• Allocation buffers / images
• Scheduling des exécutions
• Lecture / écriture buffers

JavaCL (BSD)
15
• 1ers bindings OpenCL
• API orientée-objet
• Maven Central (jar unique)
• Communauté active

16
DémoHello World

17
Sous le capot…
OpenCL bindings générés par JNAerator :
BridJ fournit la “colle” à l’exécution

Plus que des bindings
• Gestion mémoire débrayable
• Cache automatique des binaires
• Inclusion depuis URLs
• Générateur de wrappers typés
• Parallel Reduction (min, max, sum, product)
18

Plus que des bindings (2)
• FFT complexe d'un tableau de primitives :
DoubleFFTPow2 fft = new DoubleFFTPow2();double[] transformed = fft.transform(data);
• Chargement (+ conversion) d'une image :
CLImage2D img = context.createImage2D(Usage.Input, ImageIO.read(file));
• Multiplication de matrices UJMP :
Matrix a = new CLDenseFloatMatrix2D(n, m), Matrix b = new CLDenseFloatMatrix2D(m, q);Matrix c = a.times(b);
19

20
DémoInteractive Image Editor

Les pièges d’OpenCL
• Coût des transferts RAM / GPU
• Contextes mixtes CPU / GPU : seulement sur APU AMD
• Branchements conditionnels lents sur GPU
• Besoin de tests d’arrêt
21

Encore des pièges
• Peu de formats d’image garantis
• Endianness parfois différente entre hôte & device
• Apple ne supporte qu’OpenCL 1.0
22

Chasse à la performance sur GPU
• Groupes d’exécution : memoire locale, barrières…
• Répartition de charge multi-GPU
• Exécutions pyramidales pour réductions associatives
23

JavaCL 1.0.0-RC2
• 32 & 64 bits / Windows, Linux, MacOS X
• NVIDIA, AMD, Intel & Apple
• OpenCL 1.0 / 1.1 (1.2 peu répandu)
24

Rendre OpenCL plus facile ?
• Éviter d’écrire les kernels en C
• Cacher l’asynchronicité
• Accepter performance sub-optimale (> 10x plus rapide que Java)
25

OpenCL “traduit”
• Apapapi (AMD)
• Java
• Cache beaucoup (trop ?) de détails
• ScalaCL (votre serviteur)
26

ScalaCL
• Collections Scala asynchrones
• Stockage + Opérations OpenCL (map, filter, sum…)
• Traduction Scala / OpenCL
27

Qu'est-ce que Scala ?
• Saint-Graal des langages (impératif, fonctionnel, objet…)
• Tuples + Collections mutables / immutables
• Syntaxe familière
• JVM
28

Quelques lignes de Scala…
val intervalle = (0 until 100000)
val cosSinCol = intervalle.map(i => { val f = 0.2 (cos(i * f), sin(i * f))})
val sum = cosSinCol.map({ case (c, s) => c * s }).sum
29

Les mêmes lignes sur GPUimport scalacl._implicit val context = Context.best(DoubleSupport)val intervalle = (0 until 100000).cl
val cosSinCol = intervalle.map(i => { val f = 0.2 (cos(i * f), sin(i * f))})
val sum = cosSinCol.map({ case (c, s) => c * s }).sum
30

31
DémoConsole GPU

Comment ça marche
• Conversion fonctions Scala => code OpenCL
• 3 collections
• CLRange : intervalle
• CLArray : tableau de tuploïdes
• CLFilteredArray : tableau filtré, compactable en parallèle
32

Des collections asynchrones
• Contrainte : les collections Scala ont l’air synchrones
• Principe : single writer, multiple reader
33

Des collections asynchrones
val tab = Array(1, 2, 3, 4).cl
val resultat = tab.map(x => x * 2).map(x – 5)
// resultat pas encore calculé
resultat(i) = 10 // attente avant écriture
34
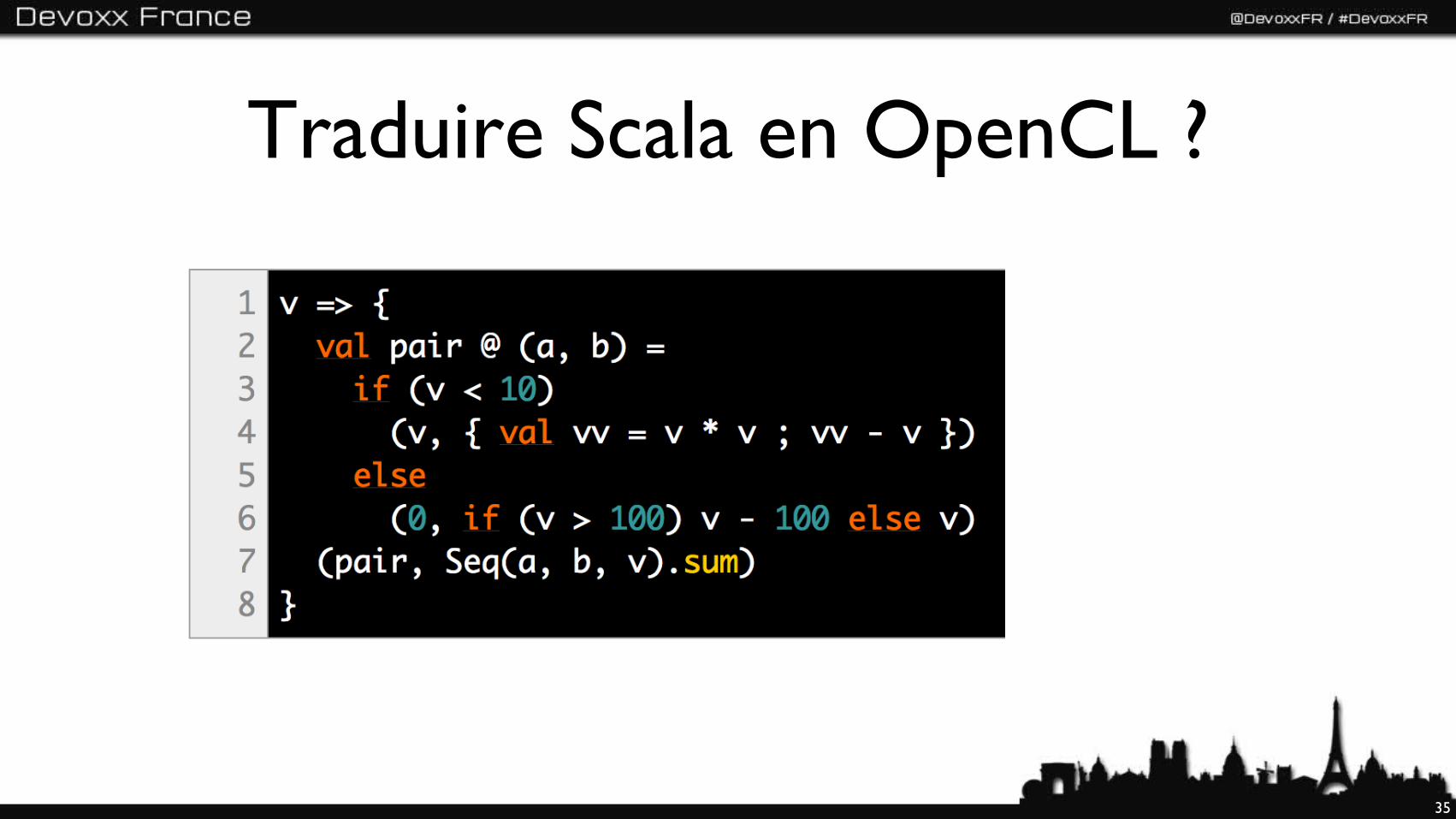
Traduire Scala en OpenCL ?
35

Traduire Scala en OpenCL ?
• Limitations (pas de classes)
• Élimination des tuples
• Élimination du code “objet”
36

Ceci est du code objet
for (i <- 0 until 100) {
…
}
37

Une lambda peut en cacher une autre
(0 until 100).foreach(i => {
…
})
38

Des boucles 5x plus rapides
var i = 0while (i < 100) {
…
}
39
(0 until 100).foreach(i => {
…
})

Aller plus vite : flot d’opérations
col.map(f).filter(g).map(h).reduceLeft(i)
•Collections intermédiaires + lambdas
•f, g, h sans effet de bord ?
40

ScalaCL : encore un prototype
• Scalaxy : spin-off généraliste plutôt stable
• Fonctionalités expérimentales :captures, random, reduce
•Macros Scala 2.10
41

OpenCL
•Votre GPU se tourne les pouces
•Write once, run (almost) everywhere
http://javacl.googlecode.comhttp://scalacl.googlecode.com
42

43
Questions

44

CLFilteredArray[T]
• Tableau de valeurs + Bitmap de présence
• Compactage :
• Somme préfixée
• Recopie aux incréments
• Exemple : filtrage pairsf: x => ((x % 2) == 0)
45

46
JavaCL : générateur de code
LinearAlgebraKernels.cl :
LinearAlgebraKernels.java :

JavaCL : hôte minimaliste
• Choix d'un contexte + file d'exécution :CLContext context = JavaCL.createBestContext(DoubleSupport);CLQueue queue = context.createDefaultQueue();
• Création de tableaux :DoubleBuffer values = ...;CLDoubleBuffer params = context.createDoubleBuffer(Usage.Input, values);
• Compilation du programme :CLKernel scos = context.createProgram(src).createKernel("scos");
• Exécution parallèle :scos.setArgs(params, out, length);CLEvent evt = scos.enqueueNDRange(queue, new int[] { length });
47


![Librería Thrust - Argentina.gob.ar · [koltona@gpgpu-fisica clase_thrust]$ nvcc xxxxx.cu [koltona@gpgpu-fisica clase_thrust]$ qsub submit.sh [koltona@gpgpu-fisica ejemplos]$ more](https://img.dokumen.tips/doc/110x75/5f0f52177e708231d4439434/librera-thrust-koltonagpgpu-fisica-clasethrust-nvcc-xxxxxcu-koltonagpgpu-fisica.jpg)


























