Embed Size (px)
Citation preview

Geospatial Data Mining at University of Texas at Dallas
Dr. Bhavani Thuraisingham (Computer Science)
Dr. Latifur Khan (Computer Science)
Dr. Fang Qiu (GIS)
Students
Shaofei Chen (GIS)
Mohammad Farhan (CS)
Shantnu Jain (GIS),
Lei Wang (CS)
Post Doc:
Dr. Chuanjun Li
This Research is Partly Funded by Raytheon

Outline Ontology-driven Modeling and Mining of Geospatial Data
- Ontology Case Study: Dataset Aster Dataset Process of Our Approach
- SVM Classifiers
- Region Growing
- Graph of Regions: Near Neighboring Regions
- Ontology Driven Rule Mining High Level Concept Detection
Output Related Work Future Work

Ontology-Driven Modeling and Mining of Geospatial Data
- Ontology will be represented as a directed acyclic graph (DAG). Each node in DAG represents a concept
- Interrelationships are represented by labeled arcs/links. Various kinds of interrelationships are used to create an ontology such as specialization (Is-a), instantiation (Instance-of), and component membership (Part-of).
Residential
Apartment Single Family Home
Multi-family Home
IS-AUrban
Part-of

Ontology-Driven Modeling and Mining of Geospatial Data
We will develop domain-dependent ontologies
- Provide for specification of fine grained concepts
- USGS taxonomy can be extended by adding concepts to facilitate finer grained classification
- Concept, “Residential” can be further categorized into concepts, “Apartment”, “Single Family House” and “Multi-family House”
Generic ontologies provide concepts in coarser grain

Case Study: Dataset
ASTER (Advanced Spaceborne Thermal Emission and Reflection Radiometer)
- To obtain detailed maps of land surface temperature, reflectivity and elevation.
ASTER obtains high-resolution (15 to 90 square meters per pixel) images of the Earth in 14 different wavelengths of the electromagnetic spectrum, ranging from visible to thermal infrared light.
ASTER data is used to create detailed maps of land surface temperature, emissivity, reflectivity, and elevation.

Case Study: Dataset & Features
Remote sensing data used in this study is ASTER image acquired on 31 December 2005.
- Covers northern part of Dallas with Dallas-Fort Worth International Airport located in southwest of the image.
ASTER data has 14 channels from visible through the thermal infrared regions of the electromagnetic spectrum, providing detailed information on surface temperature, emissive, reflectance, and elevation.
ASTER is comprised of the following three radiometers :
- Visible and Near Infrared Radiometer (VNIR --band 1 through band 3) has a wavelength range from 0.56~0.86μm.

Case Study: Dataset & Features
Short Wavelength Infrared Radiometer (SWIR-- band 4 through band 9) has a wavelength range from 1.60~2.43μm.
- Mid-infrared regions. Used to extract surface features. Thermal Infrared Radiometer (TIR --band 10 through band 14)
covers from 8.125~11.65μm.
- Important when research focuses on heat such as identifying mineral resources and observing atmospheric condition by taking advantage of their thermal infrared characteristics.

ASTER Dataset: Technical Challenges
Testing will be done based on pixels Goal: Region-based classification and identify high level
concepts Solution
- Grouping adjacent pixels that belong to same class
- Identify high level concepts using ontology-based rule mining

Process of Our Approach
Testing Image Pixels
SVM Classifier
Region Growing
Shortest Path Tree
Ontology Driven Rule Mining
Classified Pixels
Graph of Regions
Graph of Near Neighboring Regions
High Level Concept
Training Image Pixels

Process of Our Approach
Testing Image Pixels
SVM Classifier
Region Growing
Shortest Path Tree
Ontology Driven Rule Mining
Classified Pixels
Graph of Regions
Graph of Near Neighboring Regions
High Level Concept
Training Image Pixels
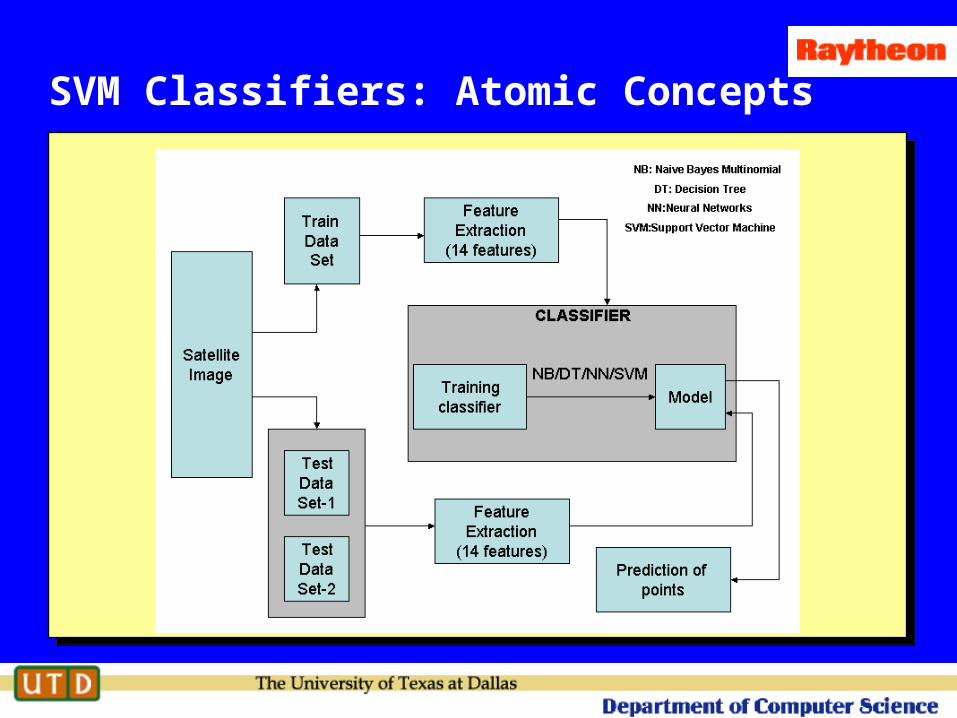
SVM Classifiers: Atomic Concepts

SVM Classifiers: Atomic Concepts
Classes Train set Test set-1 Test set-2
Water 85,463 7,520 210
Bare Lands 11,767 1,746 1,043
Grass 452 830 568
Forests 3,153 438 652
Buildings 668 193 50
Open Places 1,503 297 888
Roads 70 166 89
# of instances 1,14,392 11,190 3,500
Different Class Distribution of Training and Test Set

SVM Classifiers: Atomic Concepts
Classifier Test set-1 Test set-2
ML 90% 40.09%
SVM-Linear 91% 67.5%
SVM-Polynomial 89.3% 50.7%
SVM-RBF 89.6% 54.7%
Accuracy of Various Classifiers

Process of Our Approach
Testing Image Pixels
SVM Classifier
Region Growing
Shortest Path Tree
Ontology Driven Rule Mining
Classified Pixels
Graph of Regions
Graph of Near Neighboring Regions
High Level Concept
Training Image Pixels

Region Growing

Region Growing

Region Growing

Region Growing

Process of Our Approach
Testing Image Pixels
SVM Classifier
Region Growing
Shortest Path Tree
Ontology Driven Rule Mining
Classified Pixels
Graph of Regions
Graph of Near Neighboring Regions
High Level Concept
Training Image Pixels

Graph of Regions: Near Neighbor Regions
After region growing- We generate a graph by treating each region as a
node - Distance between two regions as edge between two
nodes. Generate Shortest Path Tree (SPT) of this graph for
each source.- Near Neighboring regions will be determined

Shortest Path Tree
…… …

Process of Our Approach
Testing Image Pixels
SVM Classifier
Region Growing
Shortest Path Tree
Ontology Driven Rule Mining
Classified Pixels
Graph of Regions
Graph of Near Neighboring Regions
High Level Concept
Training Image Pixels

Ontology Driven Rule Mining
RootNode
CountrySide CityDeepForest
GrassForest BareLand Road BuildingWater OpenPlaces
Athletic Field Garden Park WaterCross
Lake Reservoir

Ontology-Driven Modeling and Mining of Geospatial Data
Ontology-based Pruning and Retrieval:
- Ontology will facilitate mining of information at various level of abstraction.
- Using ontology and a set of atomic concepts we will infer a set of high level concepts (i.e., apartment, single family house, multi-level house).
We will exploit the possible influence relations between concepts based on the given ontology hierarchy.

Ontology-Driven Modeling and Mining of Geospatial Data
- To determine or to improve the accuracy of high level concept classifier learning, two forms of influence are taken into consideration: boosting, and confusion.
Boosting factor is Co-occurrence of regions based on topology (spatial relationship) such as adjacency, connectivity, orientation, hierarchy, or combinations thereof embedded in the ontology. For a certain concept, “City”, specific concepts “Building,” “Road” and “Open Space” will co-exist.
Confusion factor is the influence between concepts that cannot be coexistent.

Rules: From Ontology
Class(A1)=Building ^ Class(A2) = Road ^ Class(A3) =Open Place ^ NextTo (A1,A2, Distance) ^ NextTo (A2, A3, D)=>
City (A1 U A2 U A3) Class(A1)=Forest ^ Class(A2)=Water ^ Class(A3) =Bare Land ^
NextTo (A1,A2, Distance) ^ NextTo (A2, A3, D)=>
Deep Forest (A1 U A2 U A3) Class(A1)=Forest ^ Class(A2)=Water ^ NextTo (A1,A2, D)=>
Deep Forest(A1 U A2) Class(A1)=Forest ^ Class(A2)=Bare Land ^ NextTo(A1,A2,D)=>
Deep Forest(A1 U A2) Class(A1)=Building ^ Class(A2)=Open Place ^ NextTo(A1,A2,D)=>
City (A1 U A2)
Note that D is for Distance; Ai is a Region & Class (Ai)= Concept of the Region

Ontology Driven Rule Mining: Psudocode

Implementation
Software:
- ArcGIS 9.1 software.
- For programming, we use Visual Basic 6.0 embedded in the software.
As of Today
- 8 rules
- Two levels Taxonomy

Output:Training set

Output:Test set

Output:City Concept

Output:Deep Forest Concept

Related Work Classification
- ML
Wilson, Gina M. 2004. Landcover classification of the City of Rocks, National
Reserve using ASTER satellite imagery. Upper Columbia Basin Network,
Inventory and Monitoring Program. Project Number UCBN-000001, National
Park Service. Moscow, ID. 19 Pages.
- SVM
Farid Melgani, Lorenzo Bruzzone, Classification of hyperspectral remote-
sensing images with support vector machines.
Zhu, G. and D.G. Blumberg. (2002). Classification using ASTER data and SVM
algorithms - The case study of Beer Sheva, Israel.
Huang C.; Davis L. S.; Townshend J. R. G. (2002) An assessment of support
vector machines for land cover classification.

Rules: From Ontology
Technical Challenges
- Sparse Test Dataset Difficult to determine adjacency
- Size of Area should be included in Rules
- Finer grain classification is required Concepts like Lake, River Rather than Water Concept
- Ordering of Rules will play a role

Future Work Develop Full Fledged Prototype (By January 31, 2007) Improve Accuracy of SVM classification (By January 31,
2007)
- Hierarchical SVM Generate Rules automatically (By June 30, 2007)
- Ripper –Semi-automatically
- Association Rule mining

Water 23392 0 0 0 1 0 0
Bare Lands 0 3685 10 5 1 3 3
Grass 0 10 407 76 0 2 0
Forests 3 5 46 1022 1 2 0
Buildings 0 1 4 3 218 2 0
Open Places 0 13 1 5 4 638 7
Roads 0 0 0 0 0 6 63
Water Bare Lands Grass Forests Buildings Open Places Roads
PredictedActual
Confusion Matrix (7 Classes)

Observations: Hierarchical SVM
Different Classes have different true recognition rates (TR) and different false recognition rates (FR)
If there is one class for which TR is HIGH and FR is LOW:
- Classification to this class can be accepted with high confidence
- Classes with low TR and high FR can be considered for a NEW and possibly better classifier

Bare Lands 3685 10 5 1 3 3
Grass 10 407 76 0 2 0
Forests 5 46 1022 1 2 0
Buildings 1 4 3 218 2 0
Open Places 13 1 5 4 638 7
Roads 0 0 0 0 6 63
Bare Lands Grass Forests Buildings Open Places Roads
PredictedActual
Confusion Matrix (6 Classes)

Bare Lands 3685 10 5 3 3
Grass 10 407 76 2 0
Forests 5 46 1022 2 0
Open Places 13 1 5 638 7
Roads 0 0 0 6 63
Bare Lands Grass Forests Open Places Roads
PredictedActual
Confusion Matrix (5 Classes)

Suppose k classes ONE multi-class Classifier
- Originally k(k-1)/2 binary SVMs
K(k-1)/2 binary SVMs
Class 1
……
Class 2
Class 3
Class k
Class with HIGH TR and LOW FR

Suppose k classes ONE multi-class Classifier
- Originally k(k-1)/2 binary SVMs
- Then (k-1)(k-2)/2 binary SVMs
K(k-1)/2 binary SVMs
Class 1
…… (k-1)(k-2)/2 binary SVMs
Class 2
Class 3
Class k
……
Class 2
Class 3
Class k
…
First Classifier:Second Classifier:
High TR and Low FR

Challenges: Hierarchical SVM
Same set of parameters will not yield the same classification rates for classifiers at different levels
Classification accuracy might not be sensitive to parameters How to achieve High TR and Low FR for some classes?





























