Embed Size (px)
Citation preview

MolMed Course “Genetics for Dummies”
Rotterdam, 1 November, 2017
Introduction to Complex Genetics:
Concepts and Tools André G Uitterlinden
Genetic Laboratory
Department of Internal Medicine Department of Epidemiology
Department of Clinical Chemistry
www.glimdna.org
Professor Trifonius Zonnebloem
Professor Cuthbert Calculus
Professeur Tryphon Tournesol
Our website…

ROTTERDAM – OLDEBARNEVELDSTRAAT - MULTATULI
Portret gemaakt door Mathieu Ficheroux, 1974
Viewed from the moon we are all equal

DNA Differences
cause
Phenotype Differences

AGING RESEARCH

Genetics of Ageing……
1953 1990 James Watson : 1928- Francis Crick : 1916-2004

exon
mRNA
Protein
Gene structure
DNA
base pair
sequence
A A C C G C A T A A G G
T T G G C G T A T T C C
.
.
.
.
.
.
.
.
From DNA to RNA to Protein....
“Genetics”
“Genomics”
“Proteomics”

Why do we study DNA variation ?
*Biology:
- Mechanism: understand cause of disease
- Treatment: finding new potential drug targets
*Prediction:
- (Early) diagnostics with a stable marker:
understand how DNA variation contributes to variation in:
- Risk of disease (vulnarability):
“personalized medicine”
- “Response-to-treatment” (medication, diet):
“pharmacogenetics”

“The Human Genome Project”
* 26 Juni 2000: Press conference Bill Clinton & Tony Blair:
"working draft“, 95% gesequenced
* 14 april 2003: finished: 99% gesequenced.
>>Cheaper and Faster!!
Costs: $ 2.7 miljard (instead of $ 3 billion estimated costs)
Timing: 1990 - 2003 (instead of 2005)
Bill Clinton Tony Blair Craig Venter Francis Collins
What will DNA
tell about this
stain in a dress

AGGAGTCTGACTGACCATTGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATT
AGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGAC
GTGCAGTGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGAT
CGATGCTAGTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTA
GTCATCTGTGGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGGGAGTCTGACTGACCATTGGAC
TAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGC
GATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGAGTCT
GACTGACCATTGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGA
CGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTG
CGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTA
GTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGT
GGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGGGAGTCTGACTGACCATTGGACTAGGGGATT
GACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGA
CTGAACGCCCCTCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGAGGAGTCTGACTGACCATTGGACTA
GGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGA
TGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGTGCTTAC
CTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGATC
GATCATCGATAACCGTATAAGGGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATGC
GATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGA
TCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAAGGAGTCTGACTGACCATTGGACTAGGGGATTGACCAGTAGGCTG
CGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCC
CGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGT
CGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAGC
TAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAAC
AAAATAGCGGTATTTTGGAGGAGTCTGACTGACCATTGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGAC
GATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCT
GACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTA
GCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATC
GATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGGCTA
GCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGG
GGGTTAAATGCACACACACACACACACACACACACACACACACAGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGGGT
GCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAG
CTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTT
AAATGCGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGAGGAGTCTGACTGACCATTGGACTAGGGGATTGACCAGTAGG
CTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCC
CCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCA
GTCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGATCGA
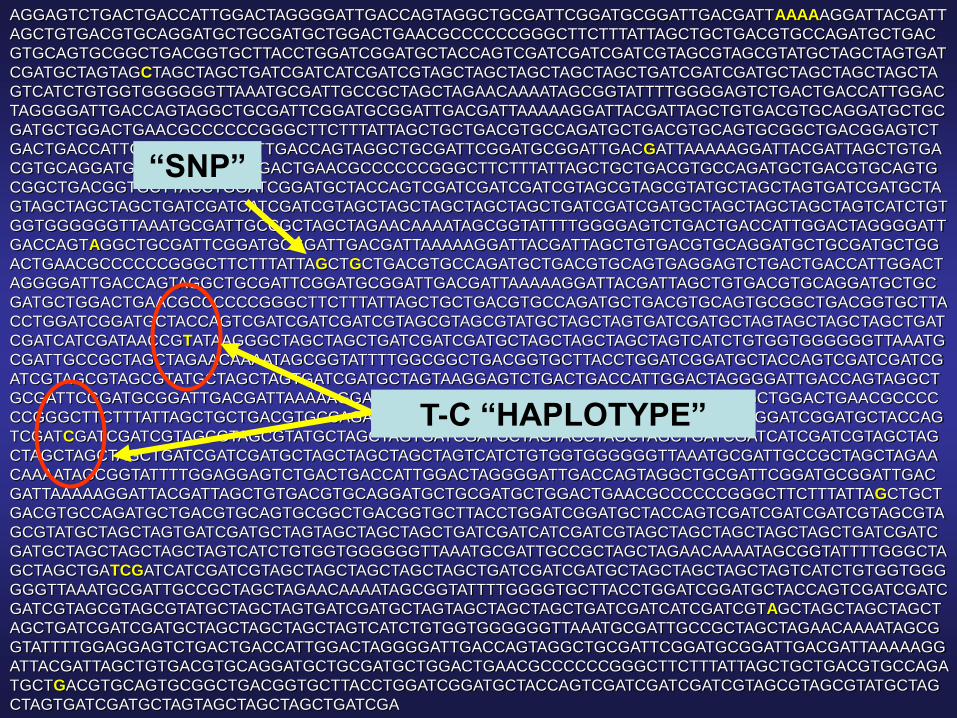
“SNP=Single Nucleotide Polymorphism” DNA Variants are:
*Frequent in the Genome (50k WGS/250k WES):
- >150 million variable loci in genome (~3%)
- “SNPs” , in/del, CNV, VNTR
- dbSNP, HapMap, 1KG, “local” NGS efforts,..
*Frequent in the Population:
> 5 % = common polymorphism
1 – 5 % = less common variant
< 1 % = rare variant/mutation
HUMAN DNA IS HIGHLY VARIABLE
“IN/DEL=Insertion Deletion”
“CNV=Copy Number Variation”
“VNTR=Variable Nunber of Repeats”
AGGAGTCTGACTGACCATTGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATT
AGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGAC
GTGCAGTGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGAT
CGATGCTAGTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTA
GTCATCTGTGGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGGGAGTCTGACTGACCATTGGAC
TAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGC
GATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGAGTCT
GACTGACCATTGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGA
CGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTG
CGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTA
GTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGT
GGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGGGAGTCTGACTGACCATTGGACTAGGGGATT
GACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGG
ACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGAGGAGTCTGACTGACCATTGGACT
AGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGC
GATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGTGCTTA
CCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGAT
CGATCATCGATAACCGTATAAGGGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATG
CGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCG
ATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAAGGAGTCTGACTGACCATTGGACTAGGGGATTGACCAGTAGGCT
GCGATTCGGATGCGGATTGACGATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCC
CCGGGCTTCTTTATTAGCTGCTGACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAG
TCGATCGATCGATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAG
CTAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAA
CAAAATAGCGGTATTTTGGAGGAGTCTGACTGACCATTGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGAC
GATTAAAAAGGATTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCT
GACGTGCCAGATGCTGACGTGCAGTGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTA
GCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATC
GATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGGCTA
GCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCTAGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGG
GGGTTAAATGCGATTGCCGCTAGCTAGAACAAAATAGCGGTATTTTGGGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATC
GATCGTAGCGTAGCGTATGCTAGCTAGTGATCGATGCTAGTAGCTAGCTAGCTGATCGATCATCGATCGTAGCTAGCTAGCTAGCT
AGCTGATCGATCGATGCTAGCTAGCTAGCTAGTCATCTGTGGTGGGGGGTTAAATGCGATTGCCGCTAGCTAGAACAAAATAGCG
GTATTTTGGAGGAGTCTGACTGACCATTGGACTAGGGGATTGACCAGTAGGCTGCGATTCGGATGCGGATTGACGATTAAAAAGG
ATTACGATTAGCTGTGACGTGCAGGATGCTGCGATGCTGGACTGAACGCCCCCCGGGCTTCTTTATTAGCTGCTGACGTGCCAGA
TGCTGACGTGCAGTGCGGCTGACGGTGCTTACCTGGATCGGATGCTACCAGTCGATCGATCGATCGTAGCGTAGCGTATGCTAG
CTAGTGATCGATGCTAGTAGCTAGCTAGCTGATCGA
“SNP”
T-C “HAPLOTYPE”

SNPs, alleles, genotypes and haplotypes
A
C
G
T
A
G
C
A
A
C
G
T
A
G
C
A
SNP= Single Nucleotide Polymorphism
Genotype
Allele
Haplotype Allele
+
+
strand Chromosomes:
from Father
from Mother

Single Nucleotide Polymorphisms (SNPs)
are common and have subtle effects
..AACCGCATAAGG..
..TTGGCGTATTCC..
..AACCGTATAAGG..
..TTGGCATATTCC..
Codon 222 Codon 222
Alanine Valine
Ala Val
DNA: C677T
protein: Ala222Val
Population frequency:
65% 35%
c u
enzyme activity
Hcy level
Disease risk

“Simple” versus “Complex” Disease
Simple/Monogenic Disease
• severe phenotype
• early onset
• rare
• Mendelian inheritance
• e.g.: cystic fibrosis,
osteogenesis imperfecta
Complex Disease
• mild phenotype
• late onset
• common
• complex inheritance
• e.g.: diabetes, asthma,
osteoporosis
Mutations (< 1%)
Polymorphisms ( 1%)
Cause:

DNA polymorphisms as markers
Pro:
- DNA (essentially) does not change with age (=stable) and so
allows risk analysis at very early stage (=prognostic)
- DNA is (essentially) identical in all tissues (=accessible)
- Allows risk analysis for many characteristics (=comprehensive)
Contra:
- Individual effects of most common variants are small
- Not all contributing variants (common or rare) are known

This is what happens
when there are NO POLYMORPHISMS
Why is the study of polymorphisms important ?
-Human History
-Evolution
-Forensics
-Social
Sciences
-Disease
-Ageing
-Normal
variation
Slide stolen from Prof Axel Themmen

Quantitating the Genetic Contribution
to Complex Traits using Twins
Monozygotic
Dizygotic
100%
50%
Genes
Shared
H2 bone phenotypes
• BMD 50-80%
• Turnover 40-70%
• Geometry 70-85%
• QUS ~80%
• Fracture:
• Hip fx 3-70%
• Wrist fx 54%
Resemblance
MZ
Tw
in 1
Twin 2
r2 = 0.7
DZ
Tw
in 1
Twin 2
r2 = 0.3
• Height 80-90%
• Menopause 60%
• BMI 60-70%
H2 bone-related phenotypes
H2 ~ 2x (r2MZ – r2
DZ)

Diabetes
Breast cancer
Osteoarthrosis
Menopause
Height
Infidelity
Entrepreneurship
Paget’s Disease
Depression
Eye colour
Osteoporosis
Longevity
Eye diseases
Telomere length
Etc.
Twin Studies Demonstrate Heritability
Heritable diseases and traits:
Rheumatoid arthritis
Lung cancer
BMI
Weight
Menarche
cholesterol
Uric acid
Infectious disease susceptibility
Ankylosing spondylitis
Myocardial Infarction
Skin colour
Stroke
Baldness
Smoking behaviour
Etc.

Clinical Expression:
Risk Factors:
Fracture Risk
Bone Strength Impact Force Fall Risk
DNA mutations and polymorphisms
BMD Quality Geometry
Osteoporotic fracture is a “complex” phenotype:
Environmental factors: diet, exercise, sun exposure, ...
Hip fx
Wrist fx
Vertebral fx
etc.
Age, Sex, Age-at-Menopause, Height, OA, etc.

Environmental influences can differ between populations !
HOLLAND BELGIUM
> 1100 mg/day < 500 mg/day Dietary Calcium intake
Geographical distance: <100km
Foto: Barbara Obermayer-Pietsch Foto: Stuart Ralston

Time needed for analysing 1 SNP in 7.000 DNA samples
1996 6 months: RFLP, Epp tubes
1999 3 months: RFLP, 96-well plates
2001 1 week: SBE, 384-well plates
2003 1 day: Taqman (manual)
2004 6 hrs: Taqman, Caliper pipetting robot
2005 3 hrs: Taqman, Deerac, “Fast” PCR
2007 6 sec: Illumina 550K array, 600 DNAs/week
2010 < 0.0006 sec: Illumina HiSeq2000 Sequencers
The influence of “technology-push”
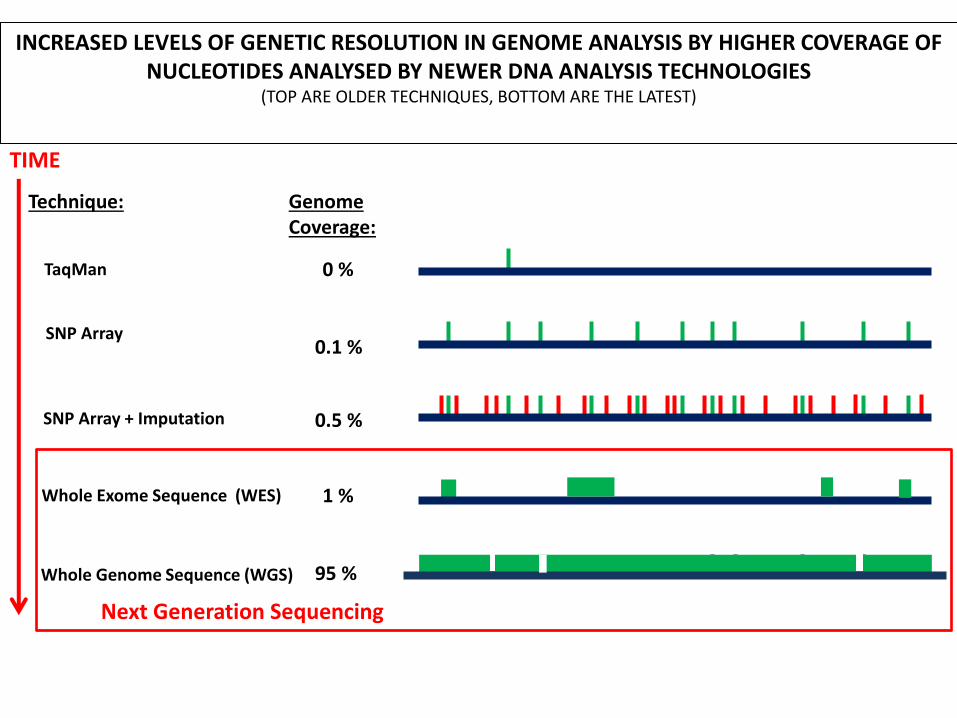
INCREASED LEVELS OF GENETIC RESOLUTION IN GENOME ANALYSIS BY HIGHER COVERAGE OF NUCLEOTIDES ANALYSED BY NEWER DNA ANALYSIS TECHNOLOGIES
(TOP ARE OLDER TECHNIQUES, BOTTOM ARE THE LATEST)
Technique: Genome Coverage:
0 %
0.1 %
0.5 %
1 %
95 %
TaqMan
SNP Array
SNP Array + Imputation
Whole Exome Sequence (WES)
Whole Genome Sequence (WGS)
TIME
Next Generation Sequencing

TTIME
TVISIBILITY
and/or
ACTIVITY
NGS, SEQUENCING
ARRAYS
Progres (in DNA research) is technology driven:

Human Genomics-Facility (HuGe-F), Genetic Lab, Ee 575
Samples/month
~ 1,000 - 2,000
~ 2,500 – 20,000
~ 4,600
~ 600
~ 1,000
~ 500
Service Biobanking:
• DNA isolation (5 ml blood)
Arrays (a few examples):
• SNP GWAS Array (e.g., GSA)
• DNA Methylation Array (450K)
NGS:
• DNA Full Exome (WES; MedExome)
(60X; Nimblegen/Agilent/Illumina)
• RNA Seq Transcriptome
(30 mio reads)
* Microbiome (16S)
~ Cost/sample *
€ 10
€ 32 - 350
€ 217
€ 350
€ 317
€ 40
*Prices October 2017; subject to change by project volume and date; costs are all-in and include running and QC, but excl VAT
WWW.GLIMDNA.ORG

Price of SNP arrays has gone down…
>> much more GWAS data in DNA collections
>> but content has also been enriched with “goodies”
0
100
200
300
400
500
600
700
800
2007 2008 2009 2010 2011 2012 2013 2014 2015 2016
32 euro for GSA array (consortium price, including running)
Human Genomics Facility (HuGeF), ErasmusMC www.glimdna.org
Euro’s
Time

EU-GSA project time line at the
Human Genomics Facility, Erasmus MC
-Okt 2015: introduction of GSA concept by Illumina at ASHG
-Nov 2015 – feb 2016: Illumina invites genotyping centres with their offer
(order minimum 150k samples!!…)
-Dec 2015 – March 2016: HuGeF approaches people through its network
-March 2016: Collaboration with Bonn and Paris to place single order
-April 2016: HuGeF places first order of 150k (initial approval RvB)
-Jan 2016 – July 2016: contact more people to reach 500k samples
-Sept 2016: Final order of 500k samples (final approval Exec Board)
-Dec 2016: Lab is optimized for running high throughput and data
production can start
-Sept 2017: Many more orders >185 signed contracts (134
studies/cohorts)
The hunt for more
samples
began……

Samples processed at HuGeF for GSA:
9th January – September 4th 2017
142,205 samples: ~20.000/month

Some large GSA datasets:
LifeLines UMCG 40k samples
Qskin Australia 20k samples
Estonia Biobank 35K samples
MoBa cohort Norway 27k samples
AROS Denmark 70k samples
…..
Under negotiation for array typing:
Sardinia 70K samples
Biobank 1 Scandinavia 400K samples
Scandinavian projects 20K and 70K samples
Biobank 2 Scandinavia 1000k samples
…..

Illumina EU-GSA consortium 130 groups; 685k samples (September 2017)
(coordinated by HuGeF, Genetic lab, Erasmus MC)
By mid 2018 there will be many GWAS datasets..
Existing:
academic data 1 million samples (global)
UK Biobank 0.5 mio samples (UK)
Millions Veterans Program 1 million samples (USA)
23andme >1 mio samples (USA centricl)
Kaiser Permanente 0.2 mio samples (USA)
New:
GSA sales 2016/2017 >6 million samples (USA centric)
EU-GSA 0.7 million samples (global)
Under negotiation:
National biobanks (Scandinavia) 1.5 mio samples (EU)
TOTAL ~12 million samples with GWAS……

Gene
Regulatory
sequences
But not only for more GWAS….a shift from attention to regulatory variants to clinical/coding variants ?
Efforts with a focus on
genes/coding variants:
-WES/WGS
-exome chip
-new arrays with
enhanced cinical content
(e.g., GSA, PMRA)

New SNP arrays have a very “ rich” content: the goodies

Eff
ect
Siz
e
Frequency Genetic Variant
rare, monogenic common, complex
Next-Generation
High-Throughput
Sequencing
rare common
sm
all
big
Genetic Architecture of Diseases/Traits : Study designs to identify “risk” alleles
Linkage
Analysis
in pedigrees
Genome-Wide
Association
Study (GWAS)
(very) few “big” effects
(ApoE, CFH)
Exome Sequencing

“Top-down” / hypothesis free
* Genome Wide Linkage Analysis
- Pedigrees
- Sib-pairs
- Human, mouse
* Genome Wide Association (GWA) Analysis
- 100K – 2000K SNP analysis in cases/controls
* Genome Wide Sequencing
- full exome and full genome
“Bottom-up” / up-front hypothesis
* Association Analyses of Candidate
Gene Polymorphisms (based on biology)
* Candidate Sequencing
- Selected regions (e.g., exons, gene regions)
Effectiveness Type of Approach
-
+/-
+
Resolution
5-20 million bp
5k-50k bp
1 bp
+ 1 bp
+/- 1 bp
Common risk alleles Rare risk alleles
+/-
+/-
-
+
+/-

Grades of Evidence
Level Method Science disciplines
- Large scale collaborative prospective
meta-analysis of individual level data in
consortia
- Meta-analysis of published data
- >2 large studies (n > 1000 each)
- 1-3 smaller studies
- 1 small study (n<500), NO replication
- Expert Opinion…
Very Good
Not so Good
-Complex Genetics
-Physics
-Astronomy
-Sociology
-Psychology
-Medicine
Cell Biology
-The biomedical community publishes 2,5 mio papers per year
-Not all papers describe results that can be replicated (the “reproducibility crisis”)

Collaboration doesn’t come easy….. >> Donald Trump’s view on EUROPE…. ?
(From: Yanko Tsvetkov, alphadesigner.com)
Wall !!
Wall !!
Wall !!
Wall !!

A “Culture” Change in doing Research:
GLOBAL COLLABORATIONS IN COMPLEX GENETICS
Example: the “GIANT” consortium:
>1,000,000 participants…

AA→
BB→
AB→ . . .
AB→
SNP1
SNP2
SNP3 . . .
SNP550,000
1 2 3 4 5 6 7 8 14 18 X
Chromosomes
10 12
AA AB BB
AA
BB
AB
DATA ANALYSIS (e.g., PLINK):
Replication
Illumina Affymetrix
Genome-Wide Association Study (GWAS)
Select SNPs
DNA collection: e.g. 1000 cases vs. 1000 controls
Each dot is one SNP in, e.g, 2000 subjects
Meta-Analysis of all data
Combine GWAS
- Effects per SNP are usually small
- We are looking at common variants

NHGRI GWA Catalog www.genome.gov/GWAStudies www.ebi.ac.uk/fgpt/gwas/
Published Genome-Wide Associations through 12/2012 Published GWA at p≤5X10-8 for 17 trait categories
With GWAS for common variants we have:
*Genotyped only 1 mio (0.3%) nucleotides in the human genome
*By imputation to reference data: ~50 mio nucleotides
*Selected for “Universal/Cosmopolitan” variants
*Explained 2-30% of genetic variance per disease (some exceptions)
*analysed not all phenotypes…
As of 11/19/13, the catalog includes 1751 publications and 11,912 SNPs.

Per 19 sept 2017:
• 3,128 publications
• 51,054 unique SNP-trait associations.
(www.ebi.ac.uk/GWAS )
GWAS ….drinking from the firehose

HERC2/OCA2 gene
12 kb on Chr. 15q11
Rotterdam Study: Kayser et al, Am J Hum Genet, 2008
A “Dubai”plot: GWAS of human iris colour
Chromosome / position
P -
valu
e (
-lo
g 1
0)
P < 1.10-206
n = 5974

A “Holland”plot: GWAS for BMD in the Rotterdam Study
N=5,000
5 x 10-8
• Rotterdam Study
• ERF Study
• Twins UK
• deCODE Genetics
• Framingham Study
LUMBAR SPINE BMD
Rivadeneira et al., Nat Genet., 2009

A real Manhattan plot: “height” in the GIANT consortium
5 x 10-8
Lango, Estrada, Rivadeneira et al., Nature, 2010
- 180,000 subjects
- 180 loci identified
- 10-15% variance explained

Choice of Biobanks: Bone as an Example...
ERGO/Rotterdam Study
Age (yr)
BMD
Bone
growth
Peak BMD Bone Loss
50 75 25 100
EPOS
GenR
CALEUR AGGO
Osteoporosis:
Low BMD, fractures
men
women
DNA collections
bone endpoints
Maternal genotype
Paternal genotype
Environmental factors
Ageing

! OPTIMAL EPIDEMIOLOGICAL DESIGN:
A single-centre, longitudinal population-based cohort study of normal elderly Dutch,
started in 1990, with 25 years of follow-up
! LARGE:
Total = 15,000 men and women of age 45 yrs
! VERY DEEP PHENOTYPING:
5 Follow-up measurements with ~1,500 per
subject each time : height, bmi, brain MRI,
DXA, cholesterol level, blood pressure,
glucose, etc. etc. etc.
! ETHNICALLY HOMOGENEOUS:
99% White Caucasian
! EXTENSIVE GENOMICS DATA AVAILABLE:
GWAS, RNA expression (array+ NGS), DNA methylation (450K), Whole Exome
Sequencing, 16S microbiome, telomeres, mitochondrial DNA,
“ERGO: Erasmus Rotterdam Gezondheid Ouderen”
“The Rotterdam Study”

The Rotterdam Study comprises three cohorts
(RS-I,-II,-III), examined every three to four years
GWAS
Exome
Methylation
GWAS
Methylation
GWAS
RNA
Methylation

current health status
medical history
physical activity.
current drug use (ATC-classification)
use of medical facilities
dietary habits
smoking habits
socio-economic status
Questionnaire Visits at the research centre
Anthropometry, limited physical examination, venous blood sample, glucose tolerance test
Cardiovascular diseases
- ultrasound assessment of cardiac dimensions, diameter of the abdominal aorta, carotid arterial wall thickness and plaques thickness
- computerized ECG
Neurological diseases
- cognitive function
- indicators for Parkinson's disease
- MRI (3T)
Locomotor diseases
- Dual-Energy X-ray Absorptiometry (DEXA)
- X-rays of hands, thoraco-lumbar spine, hips, knees
Opthalmologic diseases
- extensive ophthalmologic examination
New phenotypes:
Sleep patterns
Skin Aging
Gait
Pain Sensitivity
Stool , nose(Meta-genomics)

Biomaterials available
- base line + several follow-up !
- Blood :
genomic DNA (“Native” DNA is advantage over “cell line” DNA )
DNA methylation
RNA
-DNA and RNA is from mixed blood cells !
- Serum + Plasma
>Proteins: measuring ~50 “classic” serum markers in all cohorts
- Urine
- Sputum (cortisol only)
- In progress: MICROBIOME
- Stool, Nose swap >> meta-genomics/micro-biome
- Skin
- Eye
Bio-banking in Genomic Epidemiology:
the Rotterdam Study

The “CHARGE” consortium “Cohorts for Heart and Aging Research in Genomic Epidemiology”
Approved by participating cohort studies jan 31, 2008, Boston, USA
Cohort Acronym Contact (RSC) N Genotyping platform
Age, Gene/Environment,
Susceptibility-Reykjavik
AGES Tamara Harris
Vilmundur Gudnason
5.000 Illumina 317K
Atherosclerosis Risk in
Communities
ARIC Eric Boerwinkle 15.000 Affymetrix 6.0
Cardiovascular Health Study CHS Bruce Psaty 5.000 Illumina 317K
Framingham Heart Study FHS Chris O’Donell 10.000 Affymetrix 550K
Rotterdam Study RS Albert Hofman
André Uitterlinden
12.000 Illumina 550K, 610K
TOTAL N GWA 47.000
-Join GWA data for meta-analysis
-Many “Phenotype Working Groups (PWG)” (>45)
-Analyses/Publications arranged at PWG level; RSC oversees

JAMA. 2013;309(18):1912-1920
2 cohorts, 10,938 individuals
GWAS for Helicobacter pylori serological status host
susceptibility
Clinical relevance: Helicobacter pylori is a major cause of gastritis and
gastroduodenal ulcer disease and can cause cancer
=TLR1
=FcGR2A

EU-FP7 project: GEFOS (2008-2012)
Number of subjects:
GENOMOS: >150,000
of which GWAS: 40,000
www.gefos.org
= GENOMOS study population
= idem + GWAS
= idem, under negotiation / in development

population
frequency
of BMD
value
Monogenic
Mutations with
large effects
Polymorphisms with subtle effects Rare Rare Common
Monogenic
Mutations with
large effects
BMD value
LRP5
SOST
ClCN7
TCIRG1
CATK
OSTM1
RANKL
RANK
COLIA1
COLIA2
CRTAP
LEPRE
LRP5
CYP17
ESR1
PLS3
Low High
LINKAGE IN
PEDIGREES+ EXOME
SEQUENCING
GWAS + GEFOS + GENOMOS
ANALYTICAL
APPROACHES: EXOME + GENOMESEQUENCING EXOME + GENOME SEQUENCING
LINKAGE IN
PEDIGREES + EXOME
SEQUENCING
Genetic “architecture” of human BMD
ANXA11 LIN7C RSPH10B TNFAIP8L3 ARHGAP1 LRP3 RTDR1 TNFRSF11B
BBOX1 LRP4 RUNX2 TNFSF11 BCR LRP5 SERPINE2 TOE1
CDC5L LSM12 SETD4 TOP2B CDK5 LYRM5 SFTPD TSGA10IP CLIP4 MAP3K11 SHFM1 TSPYL6
COL11A1 MAP3K12 SIRT3 TSR1 CTNNB1 MBL2 SLC25A13 TTC21B
CYLD MEF2C SLC45A1 UNKL DAB2IP MEOX1 SNX20 USHBP1 DCDC1 MEPE SOX4 WDFY1 DLX5 MKKS SOX6 WDR43 DLX6 MPP2 SOX9 WDR86
DYDC1 MPP3 SP1 WDR88 ERC1 MYO9B SP7 WFIKKN1 ESR1 NAB1 SPIRE1 WNT1
FOXC2 PAX6 SPP1 WNT10B FOXF1 PIGC SPTBN1 WNT16 GPR141 PKD2L1 STARD3NL WNT3 GPR177 PLAC9 STK38L WNT4 GRB10 PTPRN2 SUPT3H WNT4 HDAC5 QRFP SUV420H1 WNT5B IBSP RAB18 TIPARP WNT9B
IGFBP6 RADIL TLR5 XKR9 INSIG2 RBMS3 TMEM16J ZBTB40 ITGA2B RIC8B TMEM175 ZCCHC2
JAG1 RPE65 TMEM87B ZDHHC23
Expl. variance :
5% >> 20%? EN1
LGR4
PLS3

GWAS identifies “drugable targets”
in bone metabolism
10-23
10-15
10-12
10-13
10-12
10-10
10-7
10-3
10-3
10-2
1. RANKL 13q14 2. OPG 8q24 3. GPR177 1p31 4. MEF2C 5q14 5. FLJ42280(?) 7q21 6. ESR1 6q25 - - x. SOST 17q21 - x. FDPS 1q22 x. PTH 11p15 x. CATK 1q21
P value GEFOS
GWAS*
Rank/Gene/location*
Yes, denosumab Yes, denosumab No No No Yes; HRT, SERMS Yes, anti-SOSTAb Yes; bisphosphonates Yes; teriparatide Yes; odanacatib
Existing Drug Target?
Estrada et al, unpublished *Ranking based on GEFOS 1 data; Rivadeneira et al. NatGenet 2009
>> “Selecting genetically supported targets could double success rate in
clinical development”
Nelson et al, Nat Genet vol 47, 8, 856-602, august 2015

Pharmaco-Genetics and –Genomics in Bone Research
> Relevant when there is substantial inter-individual variation in
response of expensive drugs, and/or serious side effects
-Bisphosphonates:
Not much inter-individual variation in response, but side-effects:
~ osteonecrosis (small GWAS: CYP2C8 variant)
~ atypical fractures
-PTH:
Expensive and inter-individual variation in response…

Pharmaco-Genetics and –Genomics
* Candidate gene analyses:
TPMT ~ azathioprine (FDA approved; dose)
UGT1A1 ~ irinotecan (FDA approved; dose)
HLA-B*5701 ~ abacavir FDA approved; ADR)
•Drug n cases lowest p-value genes discovered
•GWAS Drug response:
-Warfarin/acenocoumarol 181-1451 6.10-13 – 2.10-123 VKORC1, CYP2C9,
CYP4F2, CYP2C18
-Interferon-alpha 293-1137 9.10-9 – 1.10-25 IL28B
-Clopidogrel 429 4.10-11 CYP2C19
-Methotrexate 434 1.7.10-10 SLCO1B1
* GWAS Adverse Drug Reactions (ADR):
Simvastatin ~ myopathy 85/90 4.10-9 SLCO1B1
Flucloxacillin ~ liver injury 51/282 8.7.10-33 HLA-B*5701
Bisphosphon. ~ ostenecrosis 25/65 1.10-6 CYP2C8
Daly et al., Nat Rev Genet 2010, 241-246

Next Gen Sequencing will:
-Assess (almost) ALL nucleotides in the human genome
-Find more variants:
-rare variants
-functional variants
-other types of variants
-Enrich existing GWAS datasets by imputation
-Link Mendelian genetics with Complex genetics
-Change the focus to the complete genome of an
individual, rather than on one gene

Eff
ect
Siz
e
Frequency Genetic Variant
rare, monogenic common, complex
Next-Generation
High-Throughput
Sequencing
rare common
sm
all
big
Genetic Architecture of Diseases/Traits : Study designs to identify “risk” alleles
Linkage
Analysis
in pedigrees
Genome-Wide
Association
Study (GWAS)
(very) few “big” effects
(ApoE, CFH)
Exome Sequencing

DNA Sequence Data in the Rotterdam Study A historical perspective : 1995 - 2014
Analysis: Genome coverage: Samples Genotyped:
-Candidate polymorphisms - n = 300 bp 1995-2005 12,000
-SNP arrays 550K/610K 0.1% n = 3,000,000 bp 2006 12,000
-Exome Sequencing (WES) 1% n = 38,000,000 bp 2014 3,000
-Full Genome sequencing (WGS) ~100% n = 3,300,000,000 bp ?

Human Complex Genetics
The Next Frontiers:
>>> NEXT GEN SEQUENCING:
- EXOME SEQUENCING
- FULL GENOME SEQUENCING
- RNA SEQUENCING
- MICROBIOME SEQUENCING
>> Full genome sequencing of individual cells…..(cancer, brain, immunology,..)
>> Full genome sequencing of several cells from a subject
>> Coupling of genomic levels: DNA > methylation> RNA > protein
>> Microbiome Sequencing (100x more bacterial cells than human cells per subject):
> Flora of Intestine, Skin, Nose, Eye, Mouth, etc.

DISCOVERY meta-analysis:
7,257 whole blood samples
(6 cohorts)
Differential expression with age: Linear model adjusted for sex, smoking, fasting status, blood
cell counts, RNA quality (RIN), batch effects, family structure
EGCUT, FHS (gen1), InCHIANTI, KORA, RS, and SHIP
REPLICATION meta-analysis:
8,009 whole blood samples
(7 cohorts)
Differential expression with age: Linear model adjusted for sex, smoking, fasting status, blood
cell counts, RNA quality (RIN), batch effects, family structure
BSGS, DILGOM, FEHRMANN, FHS (gen3), GTP, HVH, and
NIDDK/PHOENIX
GENERALIZATION:
4,644 samples
(8 other tissues/cell types)
Differential expression with age in other tissues: Brain (cerebellum + frontal cortex) (n=394),
CD4+ cells (n=515), CD8+ cells (n=299)
CD14+ cells / monocytes (n=567), LCLs (n=869),
lymphocytes (n=1,244), and PBMCs (n=362)
EGCUT, GARP, GENOA, BOSTON COHORT, MESA,
NABEC-UKBEC, and SAFS
In total,
19,910 samples analyzed
CHARGE consortium Working Group
RNA expression array data : TWAS by Age
Peters M,…van Meurs JB. Nat. Communic., Sept 2015
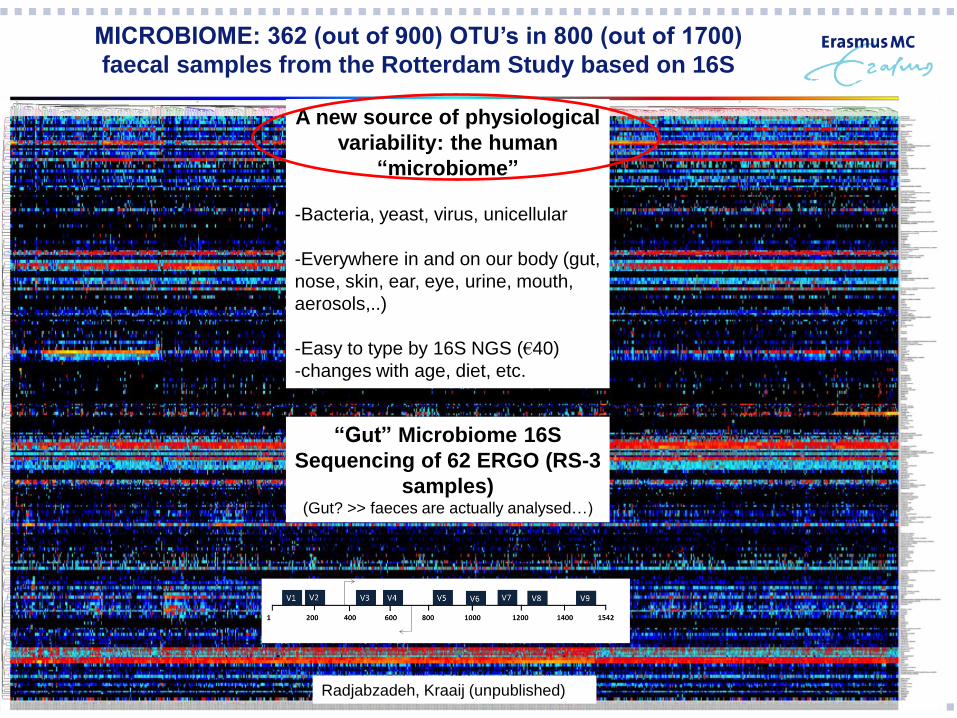
MICROBIOME: 362 (out of 900) OTU’s in 800 (out of 1700)
faecal samples from the Rotterdam Study based on 16S
“Gut” Microbiome 16S
Sequencing of 62 ERGO (RS-3
samples) (Gut? >> faeces are actually analysed…)
Radjabzadeh, Kraaij (unpublished)
A new source of physiological
variability: the human
“microbiome”
-Bacteria, yeast, virus, unicellular
-Everywhere in and on our body (gut,
nose, skin, ear, eye, urine, mouth,
aerosols,..)
-Easy to type by 16S NGS (€40)
-changes with age, diet, etc.

“Translational Genomics” Progress of translating DNA Research into the Hospital…..
We are here….





























