Embed Size (px)
Citation preview

General Purpose Processors as Processor Arrays
Peter Cappello
UC, Santa Barbara

VLSI Design Forces in 1986
“Nature, to be commanded, must be obeyed.” – Sir Francis Bacon
• High performance parallelism

VLSI Design Forces in 1986
• High performance parallelism

VLSI Design Forces in 1986
• Power is scarce limit resistive delay

VLSI Design Forces in 1986
• Power is scarce limit resistive delay
limit long communication

VLSI Design Forces in 1986
• Power is scarce limit resistive delay
limit long communication
• Area is scarce limit wire crossing

VLSI Design Forces in 1986
• Power is scarce limit resistive delay
limit long communication
• Area is scarce limit wire crossing
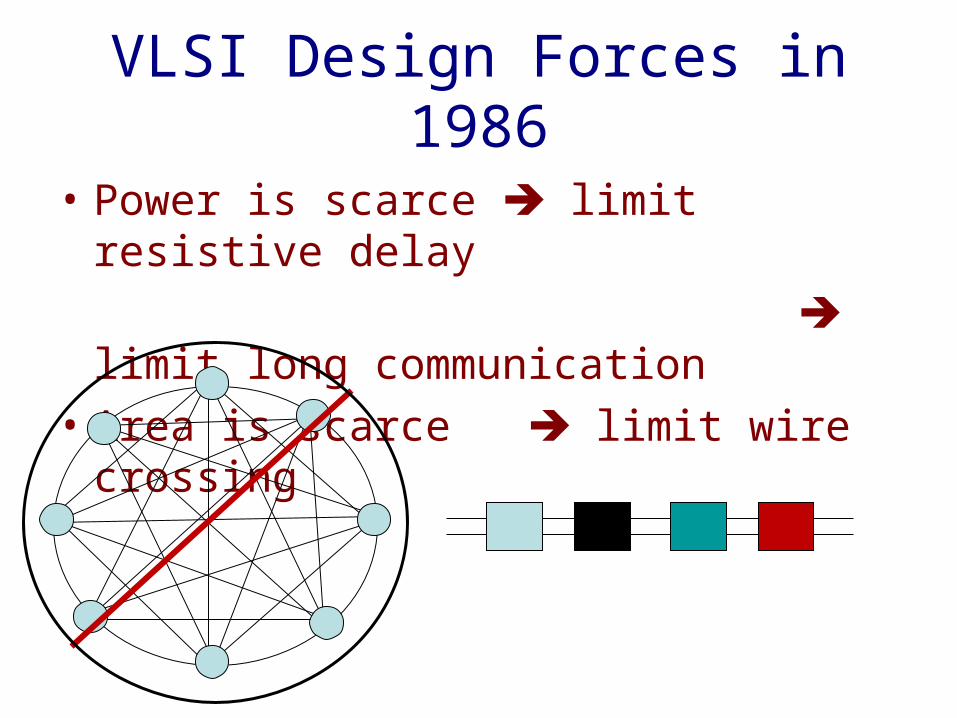
VLSI Design Forces in 1986
• Power is scarce limit resistive delay
limit long communication
• Area is scarce limit wire crossing

VLSI Design Forces in 1986
• $$ are scarce design is expensive

VLSI Design Forces in 1986
• $$ are scarce design is expensive
reuse components

VLSI Design Forces in 1986
• $$ are scarce design is expensive
reuse components

VLSI Design Forces in 1986
• $$ are scarce design is expensive
reuse components

VLSI Design Forces in 1986
• $$ are scarce design is expensive
reuse components

VLSI Design Forces in 1986
• $$ are scarce design is expensive
reuse components

VLSI Design Forces in 1986
In 2D systolic arrays, clock skew is an issue wavefront arrays
Islands of synchrony inan ocean of asynchrony
Processor Array Properties
1. Have multiple processors
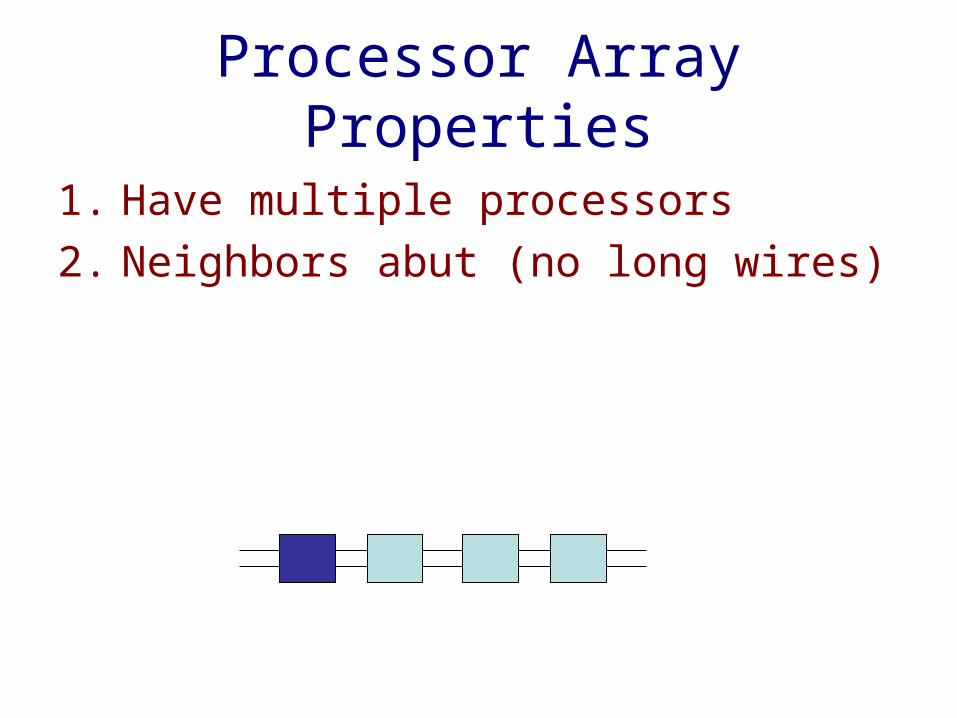
Processor Array Properties
1. Have multiple processors
2. Neighbors abut (no long wires)

Processor Array Properties
1. Have multiple processors
2. Neighbors abut
3. Only neighbors communicate directly

Processor Array Properties
1. Have multiple processors
2. Neighbors abut
3. Only neighbors communicate directly
4. Have a constant # of processor types

Processor Array Properties
1. Have multiple processors
2. Neighbors abut
3. Only neighbors communicate directly
4. Have a constant # of processor types
5. Scale: larger problems larger arrays
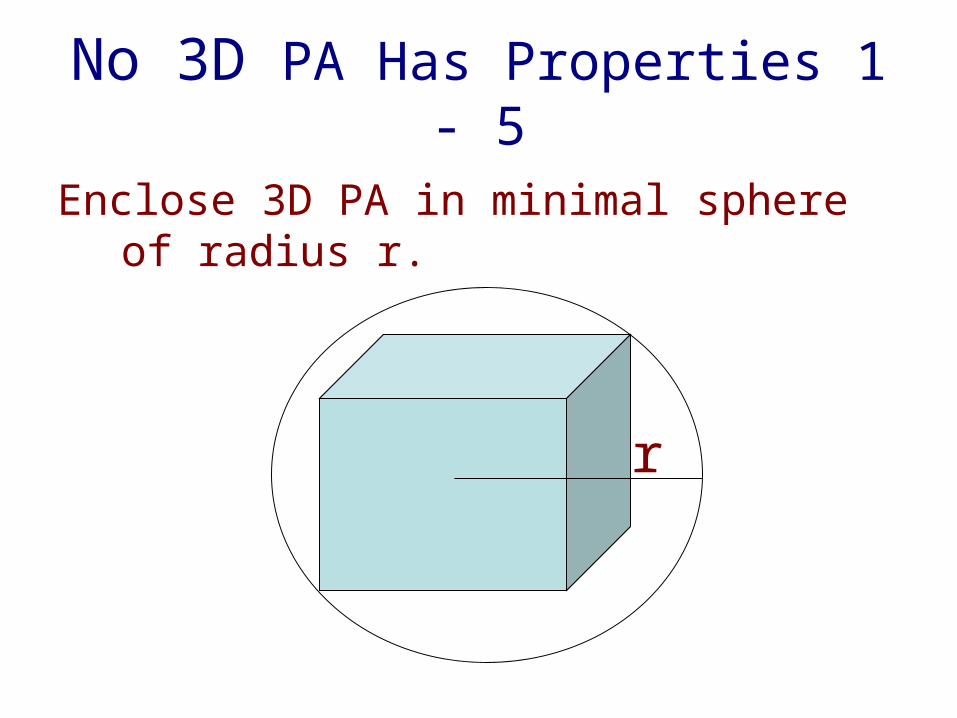
No 3D PA Has Properties 1 - 5
Enclose 3D PA in minimal sphere of radius r.
r

No 3D PA Has Properties 1 - 5
Scale PA in all 3 dimensions.
r

No 3D PA Has Properties 1 - 5
1. Power consumption = Θ( r3 ).
r

No 3D PA Has Properties 1 - 5
1. Power consumption = Θ( r3 ).
2. Heat dissipation via surface = Θ( r2 ).
r

VLSI Design Forces in 2006
“Nature, to be commanded, must be obeyed.”
– Sir Francis Bacon
• Power is scarce limit clock frequency
parallelism
• Power is scarce limit resistive delay
limit long communication

Trends in GPP in 2006
• Chip multiprocessors (CMP)
• Vector IRAM
• Cell
• TRIPS
• RAW

Trends in GPP in 2006
Chip Multiprocessors (CMP)– Parallel processors– Crossbar

Trends in GPP in 2006
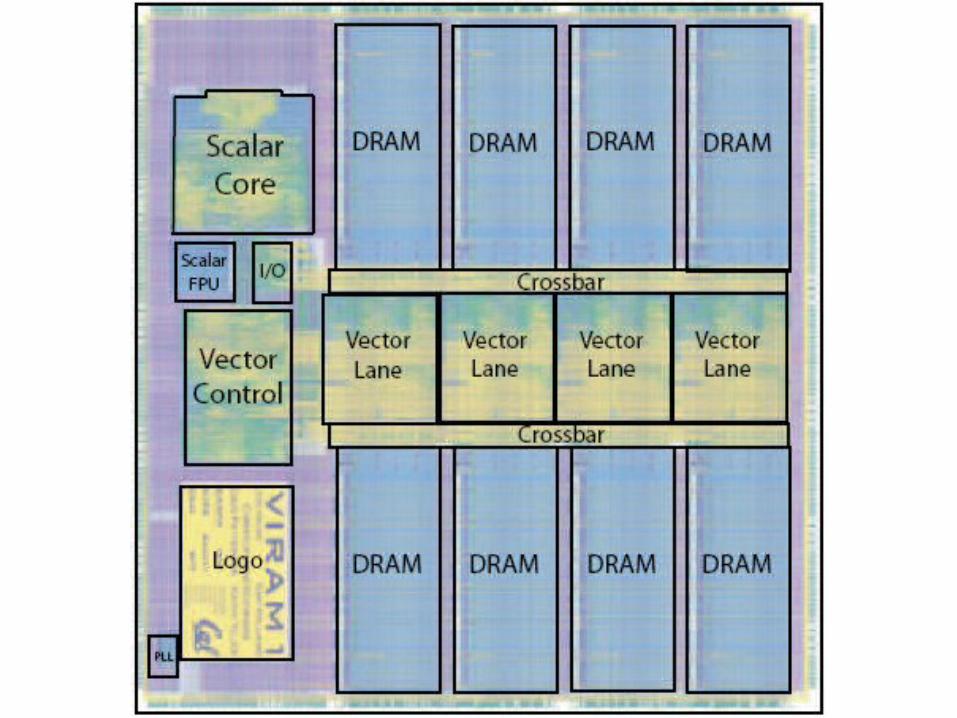
Vector IRAM – Vector Intelligent RAM
• For mobile multimedia devicesStream data processing
• Combine GPP and DSP– Parallel – linear array– Crossbar

Trends in GPP in 2006
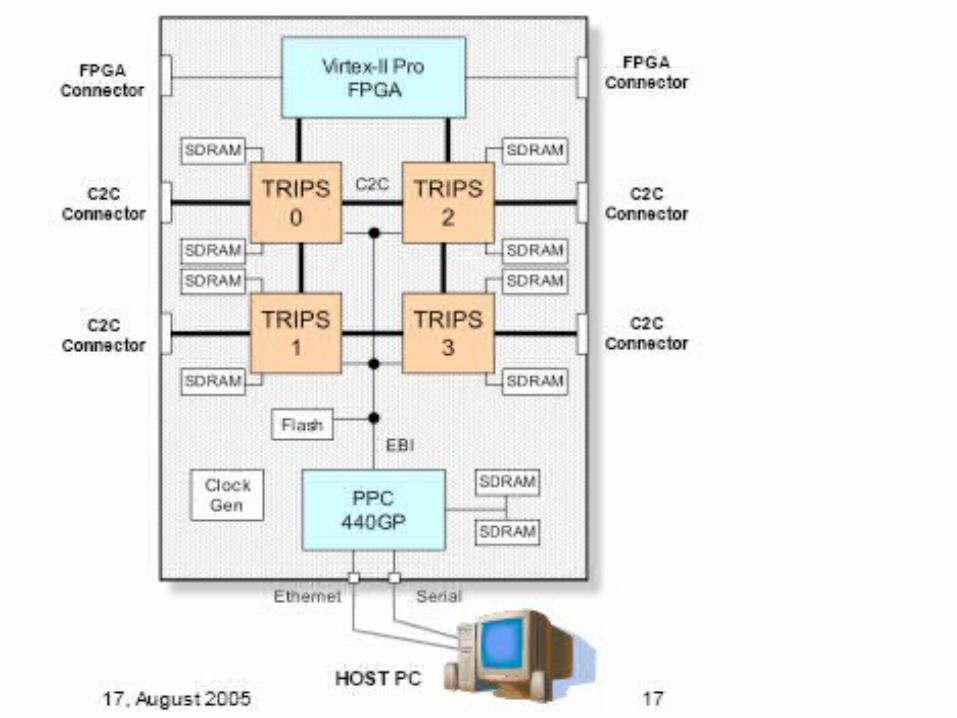
Cell processor“The Department of Energy said Wednesday that it had
awarded I.B.M. a contract to build a supercomputer capable of 1,000 trillion calculations a second, using an array of 16,000 Cell processor chips that I.B.M. designed for the coming PlayStation 3 video game machine.” Sept. 7, 2006. NY Times.
• Parallel processors – BIU – Bus interface unit– RMT – Replacement management table– SL1 – 1st-level cache– PPE – PowerPC Element– SPE – Synergistic Processor Element– Element interconnect bus


Trends in GPP in 2006
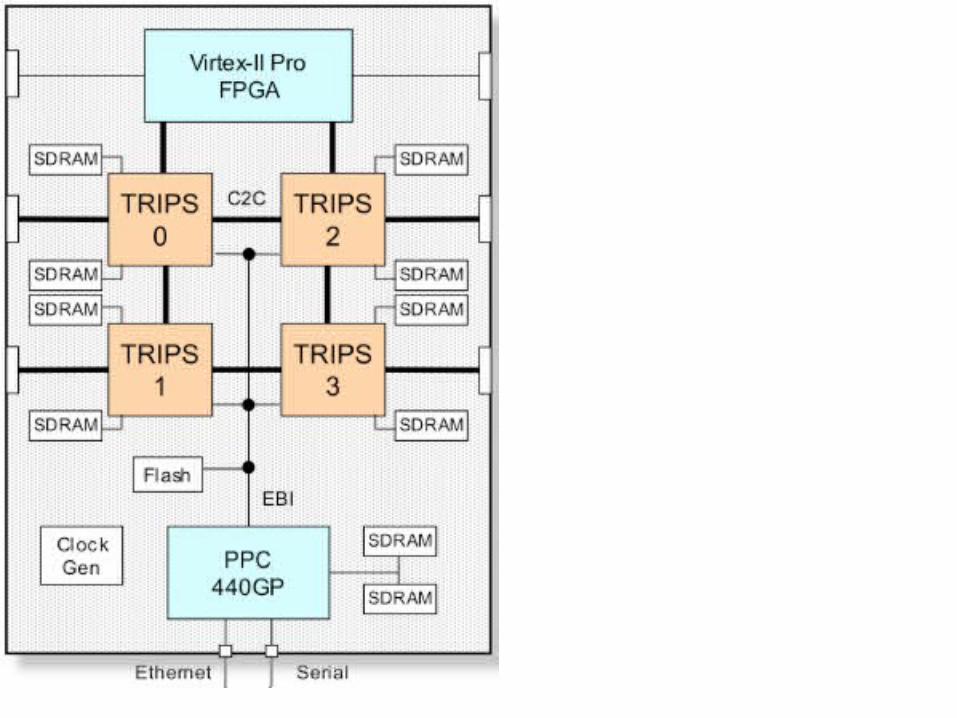
• TRIPSTera-op, Reliable, Intelligently adaptive
Processing System
The following slides are taken from a talk:
"The Design and Implementation of the TRIPS Prototype Chip," HotChips 17, Palo Alto, CA, August, 2005.
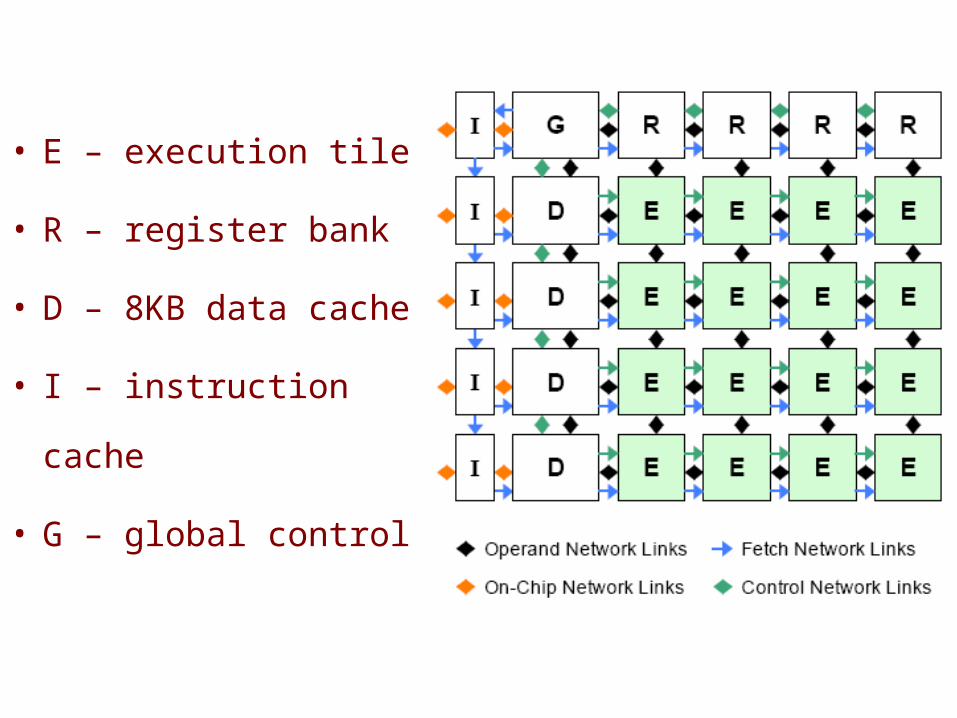
• E – execution tile
• R – register bank
• D – 8KB data cache
• I – instruction cache
• G – global control
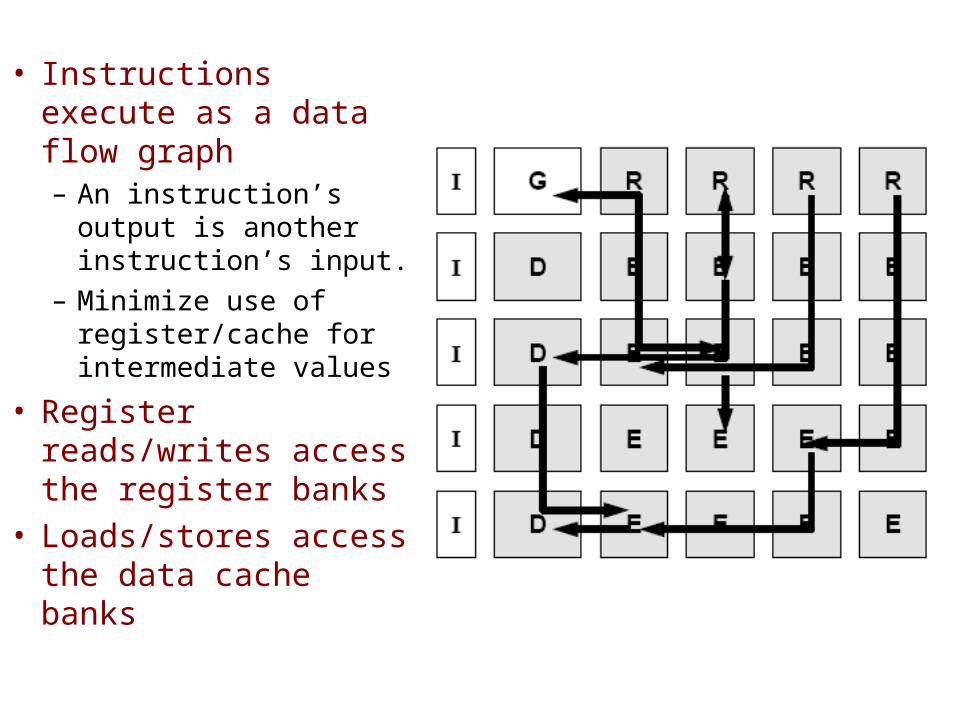
• Instructions execute as a data flow graph– An instruction’s output
is another instruction’s input.
– Minimize use of register/cache for intermediate values
• Register reads/writes access the register banks
• Loads/stores access the data cache banks



Trends in GPP in 2006
RAW (MIT)The following slides are taken from a RAW talk:
Evaluating The Raw Microprocessor: Scalability and Versatility Presented at the International Symposium on Computer Architecture, June 21, 2004.

ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
RF>>
+
Replace the crossbar with a point-to-point, pipelined, routed network.
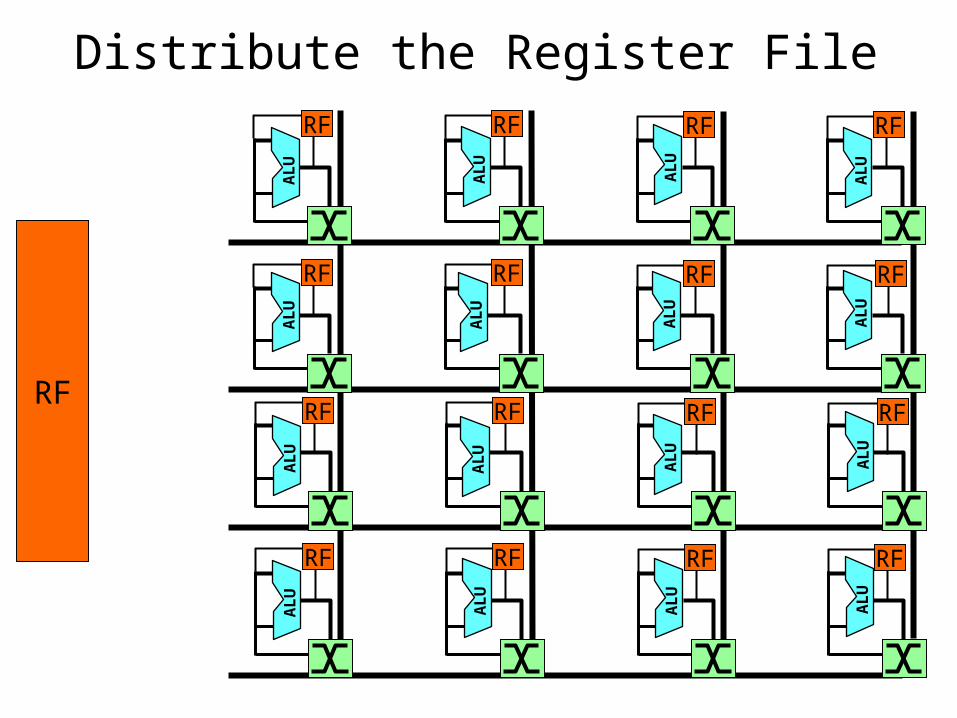
Distribute the Register File
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
RF
RFRF RFRF
RFRF RFRF
RFRF RFRF
RFRF RFRF
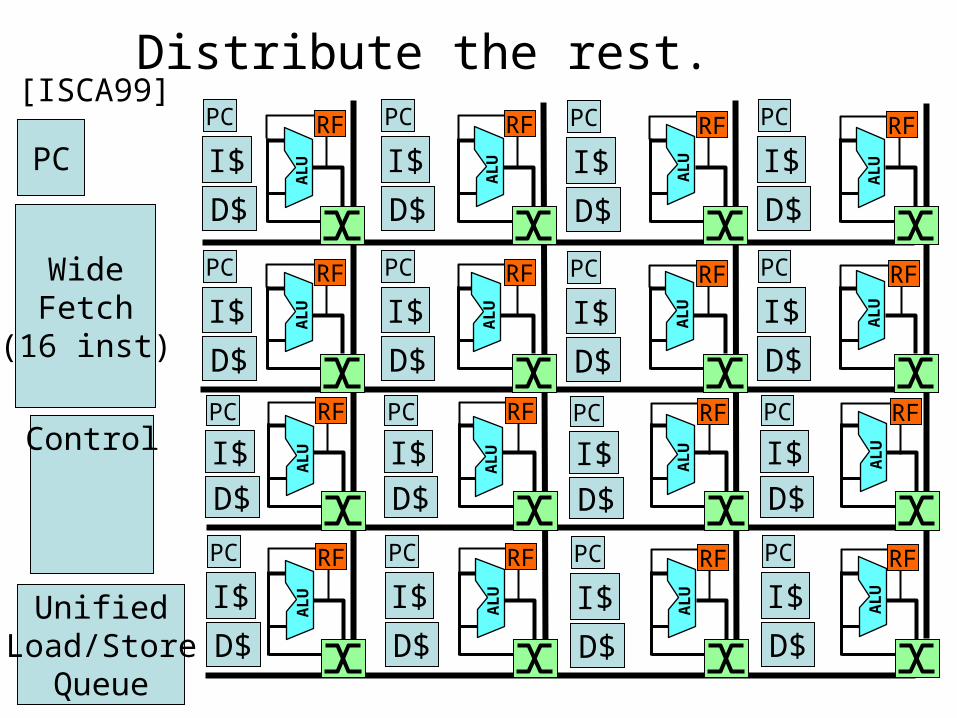
Distribute the rest.
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
RFRF RFRF
RFRF RFRF
RFRF RFRF
RFRF RFRF
Control
WideFetch
(16 inst)
UnifiedLoad/Store
Queue
PC I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$PC
D$I$
PC
D$I$
PC
D$I$
PC
D$
[ISCA99]
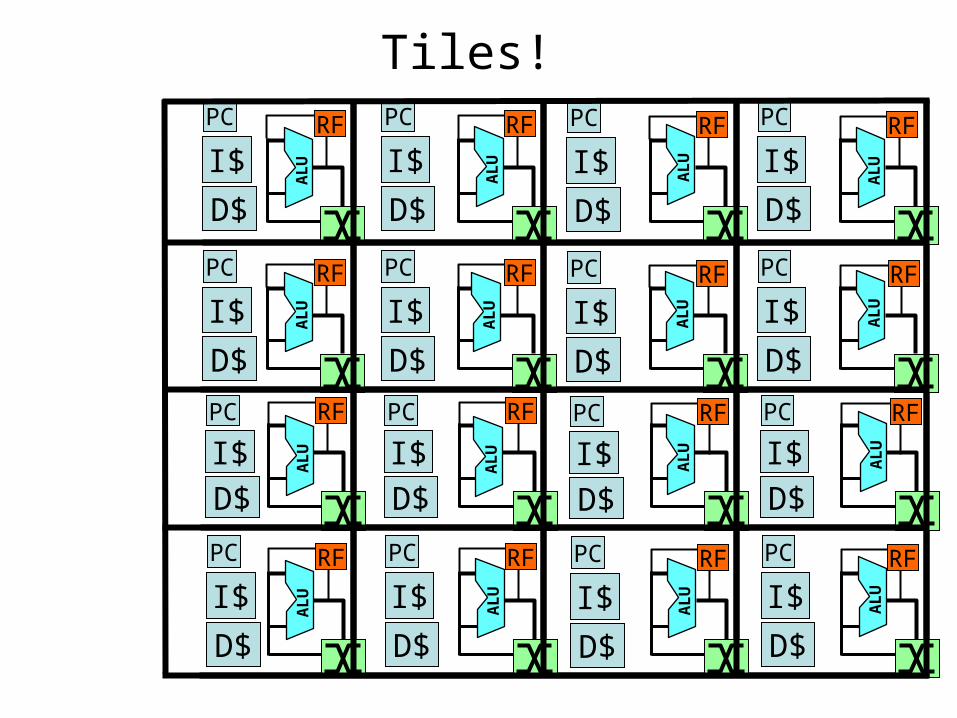
Tiles!
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
ALU
RFRF RFRF
RFRF RFRF
RFRF RFRF
RFRF RFRF
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$
PC
D$
I$PC
D$I$
PC
D$I$
PC
D$I$
PC
D$

Conclusions•VLSI Scalable microprocessors are possible.
Constant factors are beginning to give way to asymptotics: - 16 ALU Raw – Oct 2002 - 64 ALU Raw – Now - 1,024 ALU Raw - 2010 - 32,768 ALU Raw – If Moore’s Law makes it to 2 nm•There is an opportunity to make processors more
“versatile” i.e., steal applications from custom chips.
•Tiled Processor Architectures are a promising approach and merit further research.

GPP Predictions: In 10 Years
• Encapsulate registers/cache/processors into an array.
• Partition off-chip memory: Encapsulate memory & processor.
Safely increase parallel access (concurrent programming)
• For non-recursive applications GPP (mobile multimedia):
– no bus; quasi-nearest neighbor networks.
• For recursive applications GPP (gaming, control)
– replace bus w/ lean on-chip short-diameter communication network.
– 1 network-on-chip routes register/cache/instruction/control.
– Need >= 1K processors/chip to justify network-on-chip.

Predictions
• Increasing complexity of:– Applications– Technology
Increasing specialization of labor

Predictions
• Increasing complexity of:– Applications– Technology
Increasing specialization of labor
• Rate of change of increase in complexity is increasing over time Increasing adaptability is important!

Yet another taxonomy!
RECONFIGURABILITY
ARCHITECTURALSPECIFICITY
ASICPROTOTYPEASIC
GPP CCM
STATIC DYNAMIC
SPECIFIC
GENERAL

Yet another taxonomy!
ASICPROTOTYPEASIC
GPP CCM
STATIC DYNAMIC
SPECIFIC
GENERAL
ARCHITECTURALSPECIFICITY
RECONFIGURABILITY
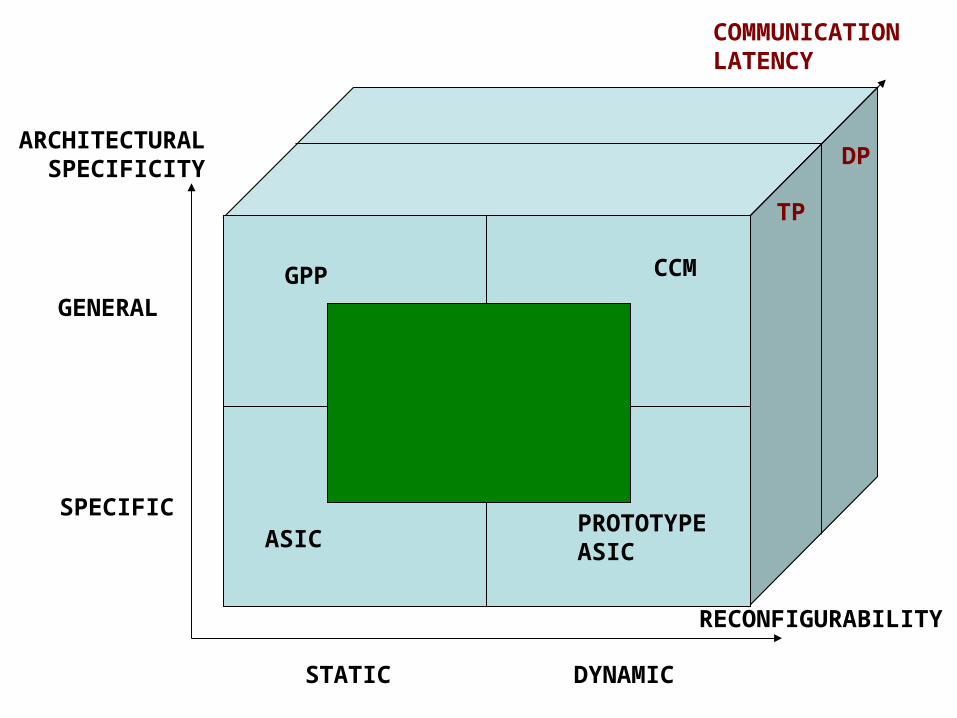
STATIC DYNAMIC
COMMUNICATIONLATENCY
TP
DP
ASICPROTOTYPEASIC
GPP CCM
ARCHITECTURALSPECIFICITY
SPECIFIC
GENERAL
RECONFIGURABILITY

DP Communication Topology
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
EDGE ISA(2D VLIW)
With CoresFFT, RISC
High Throughput (iterative)Communication topology

TP Communication Topology
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
FPGA FPGA
EDGE ISA(2D VLIW)
With CoresRAM, RISC
Low Latency (recursive)Communication topology

General PurposeLanguage
Domain SpecificLanguage
Computational Model
ComputeSubstrate
CommunicateSubstrate
ConfigurableHardware
StaticHardware
Fabrication Technology
DISCIPLINE PROCESS
CS, DE
CS, CE
CE, EE
EE
EE, ME
Circuit layout
Processor architecting
CompilingCS
CS, DE
Application programDE
CE, EE Processor layout
FPGA/Circuit design
Language design
Fabrication process
Compute model design

Conclusion
• Last 20 years witnessed dramatic advances

Conclusion
• Last 20 years witnessed dramatic advances
• Next 20 years will witness even more dramatic advances.

Spare slides follow
Recursive Computation via a Tree of Meshes Network?

Quasi-Scalable
Quasi-Scalable

Quasi-Scalable
RF D$ GLOBAL LOCAL
ADDRESS

Interleave Memory & Processor Tiles
• Slightly more chips
• Compiler localizes memory
accesses
• EDGE ISA deals with
variable access times
(TRIPS).

Cell architecture
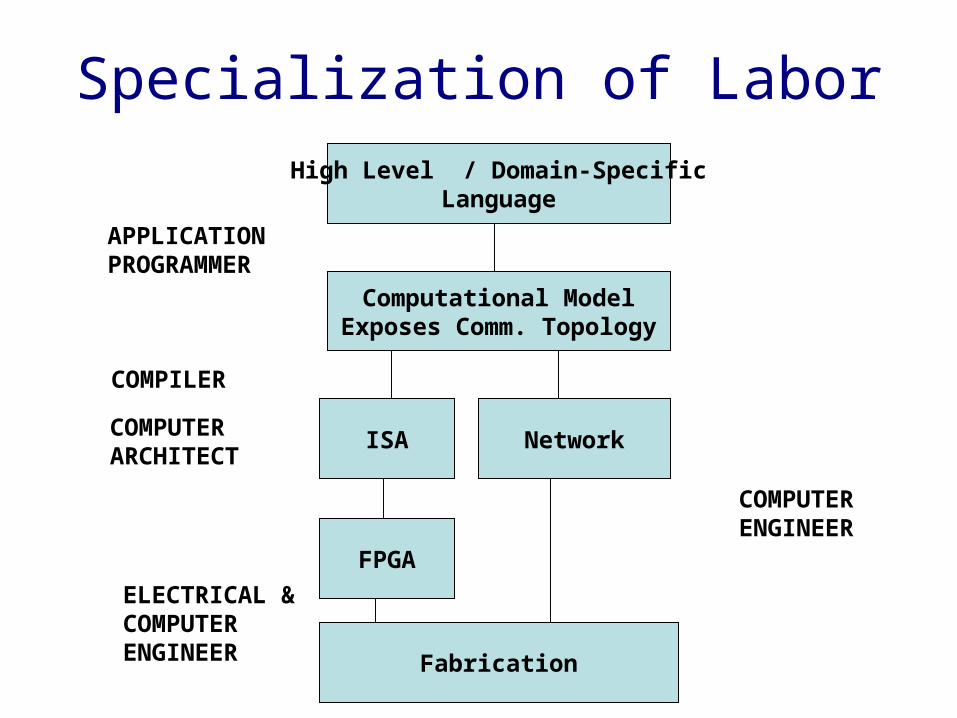
Specialization of LaborHigh Level / Domain-Specific
Language
Computational ModelExposes Comm. Topology
ISA Network
FPGA
Fabrication
APPLICATIONPROGRAMMER
COMPILER
COMPUTERARCHITECT
COMPUTERENGINEER
ELECTRICAL &COMPUTERENGINEER
![GPU$Programming$$ - Chalmers€¦ · [Programming Languages]: Processors—Code generation General Terms Languages, Performance Keywords Arrays,Dataparallelism,Dynamiccompilation,GPGPU,](https://img.dokumen.tips/doc/110x75/5fb6783b05a4886ecc597da4/gpuprogramming-programming-languages-processorsacode-generation-general.jpg)




























