Embed Size (px)
Citation preview

1st International Workshop on Generalization in Information Retrieval (GLARE 2018) 22nd October 2018, Turin, Italy
Department of Information Engineering University of Padua, Italy
Nicola Ferro@frrncl
From Evaluating to Forecasting Performance: How to Turn IR, NLP, and RecSys into
Predictive Sciences

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
If We Were Civil Engineers…
!2
If Civil Engineering Were
Like IR…Fuhr, N. (2012). Salton Award Lecture: Information Retrieval As Engineering Science. SIGIR Forum, 46(2):19–28.

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
If We Were Civil Engineers…
!2
If Civil Engineering Were
Like IR…Fuhr, N. (2012). Salton Award Lecture: Information Retrieval As Engineering Science. SIGIR Forum, 46(2):19–28.

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
If We Were Civil Engineers…
!2
If Civil Engineering Were
Like IR…Fuhr, N. (2012). Salton Award Lecture: Information Retrieval As Engineering Science. SIGIR Forum, 46(2):19–28.

© Nicola FerroReperimento dell’Informazione, A.A 2016/2017 LM in Ingegneria Informatica
If We Were Mechanical Engineers…
!3

© Nicola FerroReperimento dell’Informazione, A.A 2016/2017 LM in Ingegneria Informatica
If We Were Mechanical Engineers…
!3

© Nicola FerroReperimento dell’Informazione, A.A 2016/2017 LM in Ingegneria Informatica
If We Were Mechanical Engineers…
!3
How much does each component contribute to the overall
performance of an IR system?
?

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Dagstuhl Perspectives Workshop (2017)
!4
Towards Cross-Domain Performance Modeling and Prediction: IR/RecSys/NLP
Ferro, N., Fuhr, N., Grefenstette, G., Konstan, J. A., Castells, P., Daly, E. M., Declerck, T., Ekstrand, M. D., Geyer, W., Gonzalo, J., Kuflik, T., Lind ́en, K., Magnini, B., Nie, J.-Y., Perego, R., Shapira, B., Soboroff, I., Tintarev, N., Verspoor, K., Willemsen, M. C., and Zobel, J. (2018). Manifesto from Dagstuhl Perspectives Workshop 17442 – From Evaluating to Forecasting Performance: How to Turn Information Retrieval, Natural Language Processing and Recommender Systems into Predictive Sciences. Dagstuhl Manifestos, Schloss Dagstuhl–Leibniz-Zentrum fu ̈r Informatik, Germany, 7(1).

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Strategic Workshop in Information Retrieval (SWIRL 2018)
!5
Allan, J., Arguello, J., Azzopardi, L., Bailey, P., Baldwin, T., Balog, K., Bast, H., Belkin, N., Berberich, K., von Billerbeck, B., Callan, J., Capra, R., Carman, M., Carterette, B., Clarke, C. L. A., Collins-Thompson, K., Craswell, N., Croft, W. B., Culpepper, J. S., Dalton, J., Demartini, G., Diaz, F., Dietz, L., Dumais, S., Eickhoff, C., Ferro, N., Fuhr, N., Geva, S., Hauff, C., Hawking, D., Joho, H., Jones, G. J. F., Kamps, J., Kando, N., Kelly, D., Kim, J., Kiseleva, J., Liu, Y., Lu, X., Mizzaro, S., Moffat, A., Nie, J.-Y., Olteanu, A., Ounis, I., Radlinski, F., de Rijke, M., Sanderson, M., Scholer, F., Sitbon, L., Smucker, M. D., Soboroff, I., Spina, D., Suel, T., Thom, J., Thomas, P., Trotman, A., Voorhees, E. M., de Vries, A. P., Yilmaz, E., and Zuccon, G. (2018). Research Frontiers in Information Retrieval – Report from the Third Strategic Workshop on Information Retrieval in Lorne (SWIRL 2018). SIGIR Forum, 52(1).
Performance Explanation and Prediction

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
The Challenge
It is impossible to make strong predictions on how an IR system (but also RecSys and NLP ones) will work until it is tested in an operational mode
There are new IR applications launched every day and they often require substantial investments
each new instantiation of these applications can only be evaluated retrospectively
There is a growing need to predict the expected performance of a method for an application before it is implemented and to have more sophisticated design techniques that allow us to ensure that IR systems meet expected performance in given operational conditions
!6

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Problem Areas Performance models: Instead of regarding only overall performance figures, we should develop rigorous and systematic evaluation protocols focused on explaining performance differences
Measures: We need a better understanding of the assumptions and user perceptions underlying different metrics, as a basis for judging about the differences between methods
Assumptions: The assumptions underlying our algorithms, evaluation methods, datasets, tasks, and measures should be identified and explicitly formulated. Furthermore, we need strategies for determining how much we are departing from them in new cases
Application features: The gap between test collections and real-world applications should be reduced. Most importantly, we need to determine the features of datasets, systems, contexts, tasks that affect the performance of a system
Performance prediction: We need to develop models of performance which describe how application features and assumptions affect the system performance in terms of the chosen measure, in order to leverage them for prediction of performance
!7

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Overall Framework for Performance Prediction
!8

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Overall Framework for Performance Prediction
!8
N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
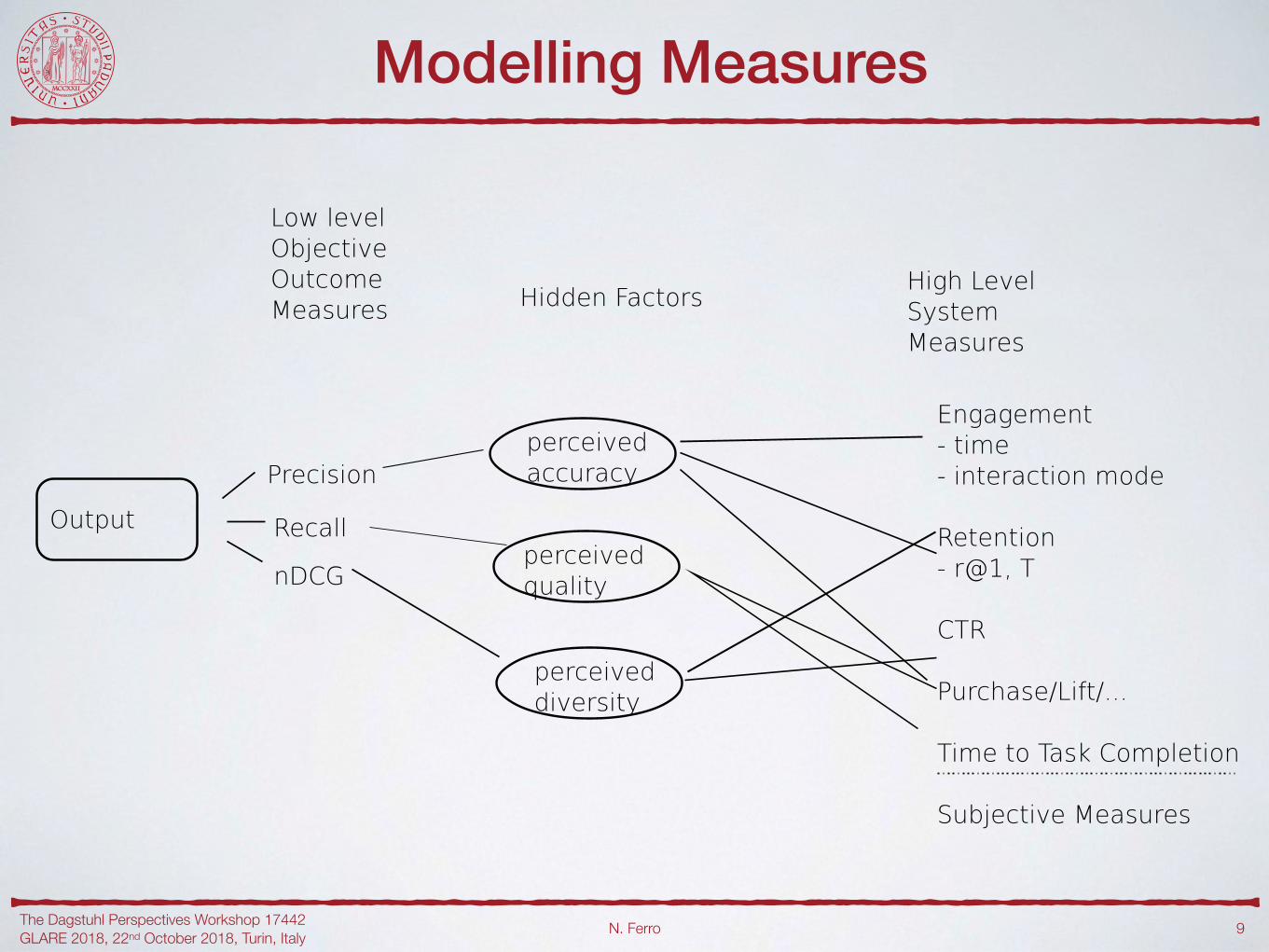
Modelling Measures
!9

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
But… Assumptions on Measurement Scales
!10
SCIENCE Vol. 103, No. 2684
that there will eventuate one or another of the scales Thus, the case that stands at the median (mid-point) listed in Table 1.l of a distribution maintains its position under all trans-
The decision to discard the scale names commonly formations whieh preserve order (isotonic group), but encountered in writings on measurement is based on an item located at the mean remains at the mean only the ambiguity of such terms as "intensive" and "ex- under transformations as restricted as those of the tensive." Both ordinal and interval scales have at linear group. The ratio expressed by the coefficient
TABLE 1
Scale Basic Empirical , Iflathematical Permissible Statistics Operations Group Structure (invariantive)
NOMINAL D~terminafion of Permutation group of cases eqi~alitq m' = f (sf Mode f (m) means any one-to-one
substitution . Contingency correlation
ORDINA~, Determination of Isotonic o r o w Median greater or less - m i = f ( a )
f ( o ) mean,s any monotonic Percentiles increasing function
Determination of General linear group Mean equality of intervals m' = a s + b Standard deviation or differences Hank-order correlation
Product-moment correlation
RATIO Determination of Simila~6ty group Coefficient of variation equality of ratios
times been called intensive, and both interval and ratio scales have sometimes been labeled extensive.
I t will be noted that the column listing the basic operations needed to create each type of scale is cumu- lative :to an operation listed opposite a particular scale must be added all those operations preceding it. Thus, an interval scale can be erected only provided we have an operation for determining equality of intervals, for determining greater or less, and for determining equal- ity (not greater and not less). To these operations must be added a method for ascertaining equality of ratios if a ratio scale is to be achieved.
In the column which records the group structure of each scale are listed the mathematical transformations which leave the scale-form invariant. Thus, any nu- meral, x, on a scale can be replaced by another numeral, x', where x' is the fanetion of x listed in this column. Each mathematical group in the column is contained in the group immediately above it.
The last column presents examples of the type of statistical operations appropriate to each scale. This column is cumulative in that all statistics listed are admissible for data scaled against a ratio scale. The criterion for the appropriateness of a statistic is ia-variatzce under the transformations in Column 3.
1 A classification essentially equivalent to tha t contained in this table was llrr.8 u t t 11 11cf11r1. lllr 1 1 1 lernational Congress for the Unity of S1.1t1111'. Sv [ , t~ f t~ l t~ l - The writer is1!I41. indebted to the 1.1tt. f'l.111. (; for a stimulating[). nir l , l~~~rFdiscussion which led to the completion of the table in essen-tially i ts present form.
5' = a o
of variation remains invariant only under the simi- larity transformation (multiplication by a constant). (The rank-order correlation coefficient is usually deemed appropriate to an ordinal scale, but actually this statistic assumes equal intervals between succes- sive ranks and therefore calls for an interval scale.)
Let us now consider each scale in turn.
The fiomifial scale represents the most unrestricted assignment of numerals. The numerals are used only as labels or type numbers, and words or letters mould serve as well. Two types of nominal assignments are some- times distinguished, as illustrated (a) by the 'num- bering' of football players for the identification of the individuals, and (b) by the 'numbering' of types or classes, where each member of a class is assigned the same numeral. Actually, the first is a special case of the second, for when we label our football players we are dealing with unit classes of one member each. Since the purpose is just as well served when'any two designating numerals are interchanged, this scale form remains invariant under the general substitution or permutation group (sometimes called the symmetric group of transformations). The only statistic rele- vant to nominal scales of Type A is the number of cases, e.g. the number of players assigned numerals. But once classes containing several individuals have
Stevens, S. S. (1946). On the Theory of Scales of Measurement. Science, New Series, 103(2684):677–680. Robertson, S. (2006). On GMAP: and Other Transformations. CIKM 2006, pages 78–83.
Ferrante, M., Ferro, N., and Pontarollo, S. (2018). A General Theory of IR Evaluation Measures. IEEE TKDE.

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Overall Framework for Performance Prediction
!11

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Topic and System Effects: Model
!12
Yij = µ·· + �i + �j� �� �JQ/2H
+ �ij����1``Q`
⌧2
⌧1
⌧n
↵1 ↵2
System
Y12
↵p...
...
Yij
...
......
...
...
...Topic
Y1pY11
Y21 Y22 Y2p
Yn1 Yn2 Ynp
µ1·
µ2·
µi·
µn·
µ·pµ·jµ·2µ·1 µ··Banks, D., Over, P., and Zhang, N.-F. (1999). Blind Men and Elephants: Six Approaches to TREC data. Information Retrieval, 1(1-2):7–34.Tague-Sutcliffe, J. M. and Blustein, J. (1994). A Statistical Analysis of the TREC-3 Data. TREC-3, pages 385–398.

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Breaking-down the System Effect: Model
is the stop list effect, is the stemmer effect, and is the IR Model effect
It requires a Grid-of-Points (GoP)
!13
Yijkl =µ···· + ⌧i + ↵j + �k + �l| {z }J�BM 1z2+ib
+
(↵�)jk + (↵�)jl + (��)kl + (↵��)jkl| {z }AMi2`�+iBQM 1z2+ib
+ "ijkl|{z}1``Q`
↵j �k �l
Ferro, N. and Silvello, G. (2016). A General Linear Mixed Models Approach to Study System Component Effects. SIGIR 2016, pages 25–34Ferro, N. and Silvello, G. (2018). Toward an Anatomy of IR System Component Performances. JASIST, 69(2):187–200.

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Topic and System Interaction Effect
To estimate the topic*system interaction effect, you need more replicates for each (topic, system) pair - which typically you do not have in a standard experimental setting
[Robertson and Kanoulas, 2012] used simulated data to generate the (topic, system) replicates and shown the importance of this interaction effect
[Voorhees et al., 2017] used random partitioning of the document corpus to generate the (topic, system) replicates and reported improvements in determining which systems are significantly different
[Ferro and Sanderson, 2017] studied the impact of document partitions
!14
Yij = µ+ ⌧i + ↵j + (⌧↵)ij + "ij
(⌧↵)ij
Robertson, S. E. and Kanoulas, E. (2012). On Per-topic Variance in IR Evaluation. SIGIR 2012, pages 891–900 Voorhees, E. M., Samarov, D., and Soboroff, I. (2017). Using Replicates in Information Retrieval Evaluation. ACM TOIS, 36(2):12:1–12:21. Ferro, N. and Sanderson, M. (2017). Sub-corpora Impact on System Effectiveness. SIGIR 2017, pages 901–904

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Overall Framework for Performance Prediction
!15

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Application Features
Task and data features affecting performance, such as language
dynamicity of data
task context
curation of data
data structure /connectedness
…
!16

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
From Another Perspective: Validity of Experiments
Internal validity: Claims are supported by the data→ Reproducibility, statistical analysis
External validity: extent to which results of a study can be generalized→ Prediction
!17
Fuhr, N. (2017). Some Common Mistakes In IR Evaluation, And How They Can Be Avoided. SIGIR Forum, 51(3):32–41.
N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
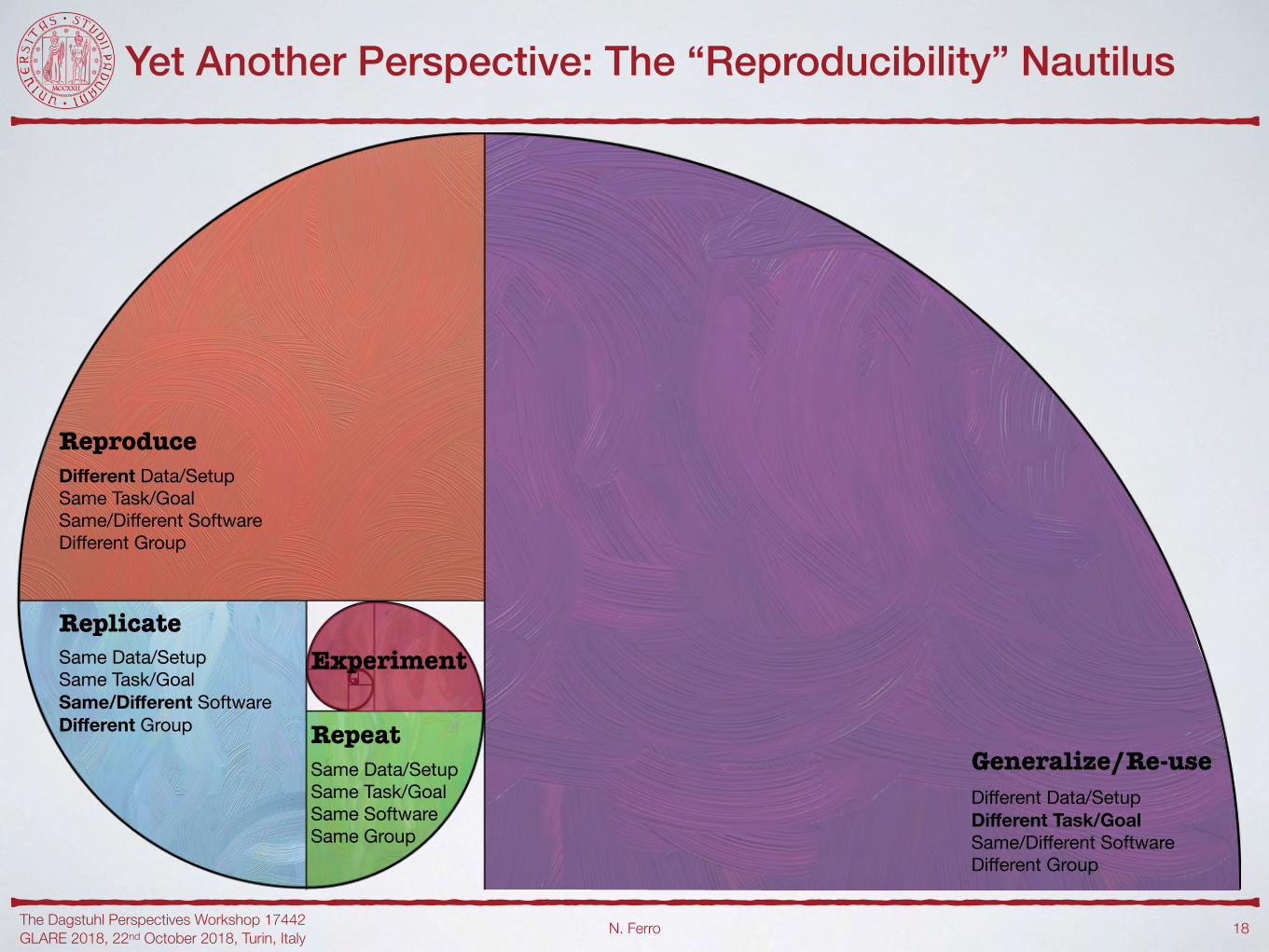
Same Data/SetupSame Task/GoalSame SoftwareSame Group
Repeat
ReplicateSame Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
ReproduceDifferent Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
Generalize/Re-useDifferent Data/SetupDifferent Task/GoalSame/Different SoftwareDifferent Group
Experiment
Yet Another Perspective: The “Reproducibility” Nautilus
!18
N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Same Data/SetupSame Task/GoalSame SoftwareSame Group
Repeat
ReplicateSame Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
ReproduceDifferent Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
Generalize/Re-useDifferent Data/SetupDifferent Task/GoalSame/Different SoftwareDifferent Group
Experiment
Yet Another Perspective: The “Reproducibility” Nautilus
!18
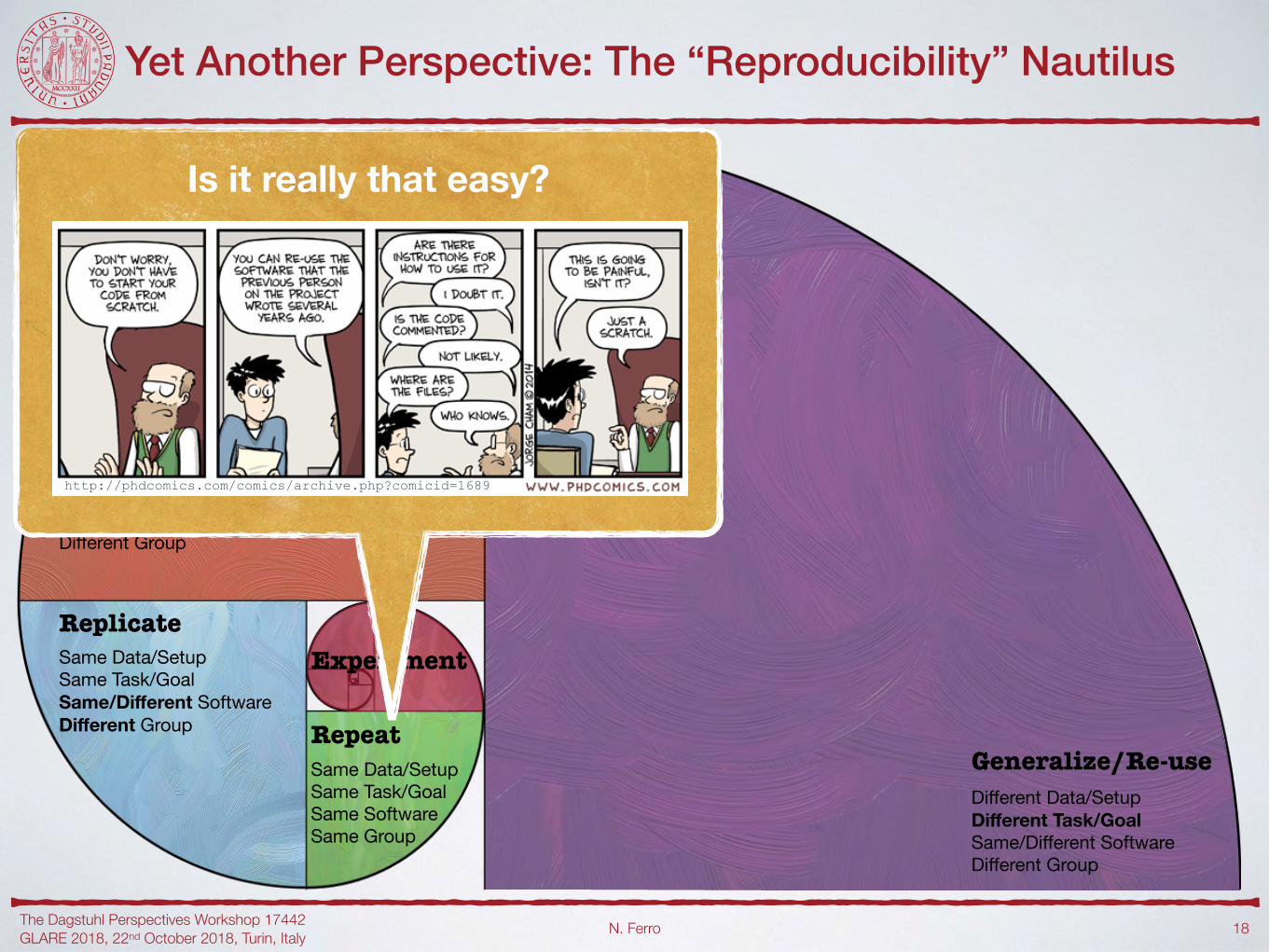
Is it really that easy?
http://phdcomics.com/comics/archive.php?comicid=1689

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Same Data/SetupSame Task/GoalSame SoftwareSame Group
Repeat
ReplicateSame Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
ReproduceDifferent Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
Generalize/Re-useDifferent Data/SetupDifferent Task/GoalSame/Different SoftwareDifferent Group
Experiment
Yet Another Perspective: The “Reproducibility” Nautilus
!18
Cranfield/Evaluation Campaigns …BUT…
✦ format babele, lack of data and metadata formats✦ shared data and code repositories, difficulties in
adoption (DIRECT, EvaluatIR, OpenRuns, TIRA, EaaS, EvAll,…)
✦ scripts are not workflows, actionable papers, ……BUT…
Are all of these core IR research? Cultural mismatch

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Same Data/SetupSame Task/GoalSame SoftwareSame Group
Repeat
ReplicateSame Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
ReproduceDifferent Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
Generalize/Re-useDifferent Data/SetupDifferent Task/GoalSame/Different SoftwareDifferent Group
Experiment
Yet Another Perspective: The “Reproducibility” Nautilus
!18
Somehow standard approach in IR evaluation …BUT…
✦ typically done with-in group, in a repeatability-like fashion
✦ how to quantify when “reproduced” - same ranked list, correlation among ranked lists, same effectiveness score, confidence bounds on effectiveness score, close distributions of effectiveness score, similar statistical significance (p-values, effect sizes, …), …
✦ what about the user-side 😱?…Initial investigation in CENTRE@CLEF/NTCIR/TREC…
http://www.centre-eval.org/
N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Same Data/SetupSame Task/GoalSame SoftwareSame Group
Repeat
ReplicateSame Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
ReproduceDifferent Data/SetupSame Task/GoalSame/Different SoftwareDifferent Group
Generalize/Re-useDifferent Data/SetupDifferent Task/GoalSame/Different SoftwareDifferent Group
Experiment
Yet Another Perspective: The “Reproducibility” Nautilus
!18
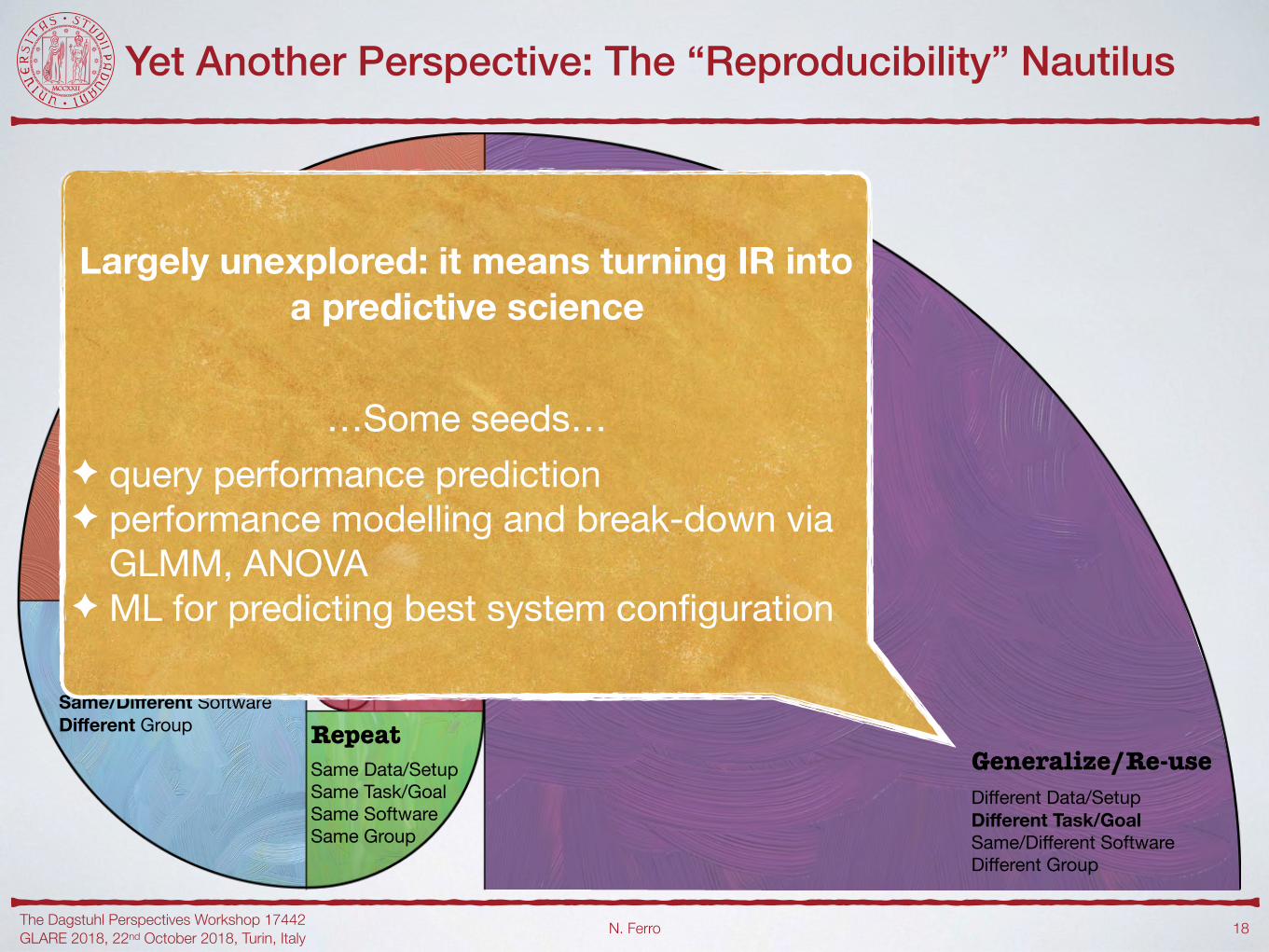
Largely unexplored: it means turning IR into a predictive science
…Some seeds…✦ query performance prediction✦ performance modelling and break-down via
GLMM, ANOVA✦ ML for predicting best system configuration

N. FerroThe Dagstuhl Perspectives Workshop 17442 GLARE 2018, 22nd October 2018, Turin, Italy
Conclusion & Outlook
Performance (quality) prediction important Scientifically: external validity
Practically: estimate effort vs. performance before building system
Research on performance prediction Better understanding of existing methods(rather than just developing new ones)
Manifesto describes framework for research
!19
Ferro, N., Fuhr, N., Grefenstette, G., Konstan, J. A., Castells, P., Daly, E. M., Declerck, T., Ekstrand, M. D., Geyer, W., Gonzalo, J., Kuflik, T., Lind ́en, K., Magnini, B., Nie, J.-Y., Perego, R., Shapira, B., Soboroff, I., Tintarev, N., Verspoor, K., Willemsen, M. C., and Zobel, J. (2018). Manifesto from Dagstuhl Perspectives Workshop 17442 – From Evaluating to Forecasting Performance: How to Turn Information Retrieval, Natural Language Processing and Recommender Systems into Predictive Sciences. Dagstuhl Manifestos, Schloss Dagstuhl–Leibniz-Zentrum fu ̈r Informatik, Germany, 7(1).






























