Embed Size (px)
Citation preview

I. DNA as Genetic Material ● An early clue to the genetic role of DNA stems from the work of Frederick Griffith, who was studying two strains of Streptococcus penumoniae, designated as S (smooth) & R (rough). Figure 1: Griffith’s Experiment
● Griffith suspected that some component of the S strain was being passed along to the R strain, causing it to become pathogenic (disease-causing). He called this phenomenon Transformation.
\● He was never able to identify the transforming agent (DNA) responsible for the conversion of the R cells into lethal S cells. Today, we understand transformation to be a process by which a cell can absorbed free DNA from its surroundings & thus express a new trait. ● Oswald Avery attempted to identify the mysterious transforming agent that Griffith could not. He attempt to exposed living R cells to components of dead S cells. Whichever S cell component resulted in the transformation of the living R cells must be the transforming agent in Griffith’s original experiment …
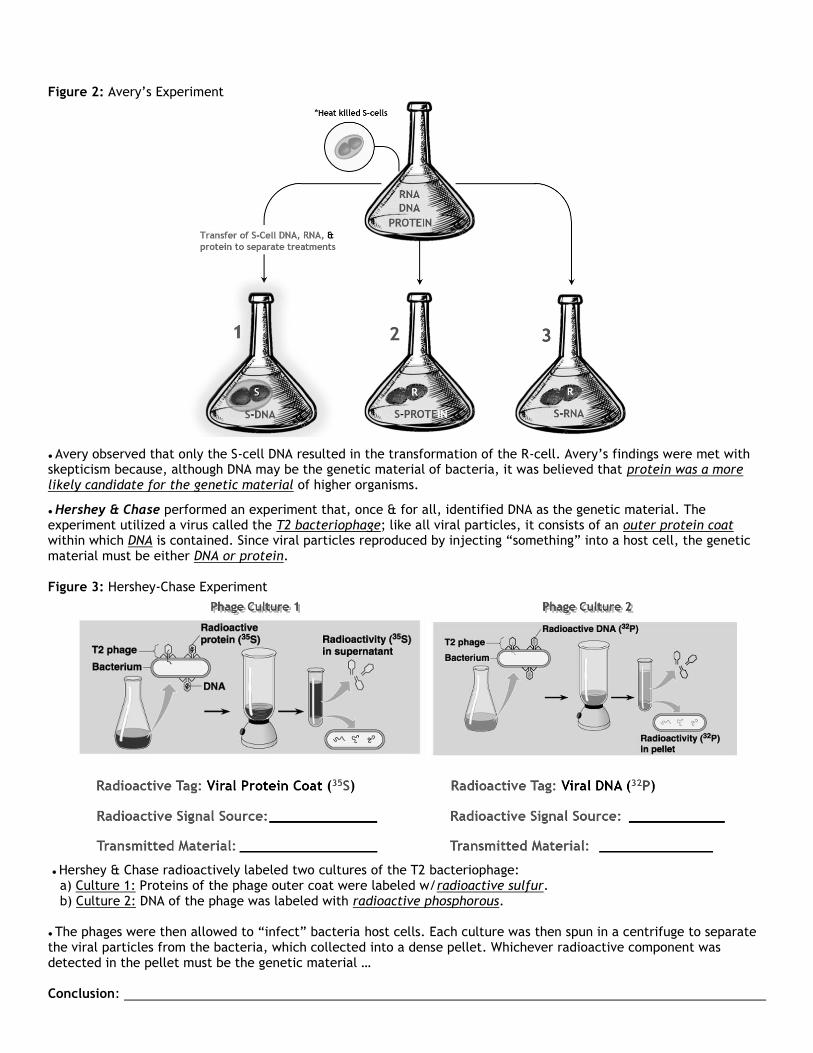
Figure 2: Avery’s Experiment
● Avery observed that only the S-cell DNA resulted in the transformation of the R-cell. Avery’s findings were met with skepticism because, although DNA may be the genetic material of bacteria, it was believed that protein was a more likely candidate for the genetic material of higher organisms.
● Hershey & Chase performed an experiment that, once & for all, identified DNA as the genetic material. The experiment utilized a virus called the T2 bacteriophage; like all viral particles, it consists of an outer protein coat within which DNA is contained. Since viral particles reproduced by injecting “something” into a host cell, the genetic material must be either DNA or protein. Figure 3: Hershey-Chase Experiment
● Hershey & Chase radioactively labeled two cultures of the T2 bacteriophage: a) Culture 1: Proteins of the phage outer coat were labeled w/radioactive sulfur. b) Culture 2: DNA of the phage was labeled with radioactive phosphorous. ● The phages were then allowed to “infect” bacteria host cells. Each culture was then spun in a centrifuge to separate the viral particles from the bacteria, which collected into a dense pellet. Whichever radioactive component was detected in the pellet must be the genetic material … Conclusion:

II. Basic DNA Chemistry Figure 4: Nucleotides
● Nucleotide:
a) A DNA nucleotide can bear 1 of 4 Nitrogenous Bases which are classified into 2 groups: ● Purines: adenine & guanine (one 5-sided + one 6-sided ring). ● Pyrimidines: cytosine & thymine (one 6-sided ring).
Figure 5: Nucleotide Chains
● Nucleotides are joined by enzymes known as Polymerases. DNA nucleotides are joined by DNA Polymerase. These enzymes join the 5’ phosphate of an incoming nucleotide with the 3’ hydroxyl group exposed at the end of a preexisting nucleotide chain. The covalent bond formed between them is called a Phosphodiester Bond. ● Nucleotide Chain:

III. Discovering DNA’s 3-D Structure Figure 6: X-Ray Diffraction
Method of X-Ray Diffraction X-Ray Photo of DNA: Photo 51
● This technique was used to take photographs of molecules like DNA. When exposed to X-rays, the atoms of the sample scatter the rays onto photographic film behind the sample. This causes the film to develop wherever the X-rays strike. ● In the early 1950’s the most detailed X-ray photograph of DNA was taken by Dr. Rosalind Franklin, an image now known as “photo 51”. It was this photograph that provided critical information regarding DNA’s structure to James Watson & Francis Crick. Watson & Crick built scale models of the DNA components & then fit them together according to X-ray diffraction data. After several trials, they worked out a model that fit the experimental data ...
Figure 7: DNA Double Helix Structure Antiparallel Arrangement of Nucleotide Chains Arrangement of Nucleotide Bases
● Each strand of the molecule is arranged in an Antiparallel manner. This means that is one strand begins with a 5’phosphate at one end & ends with a 3’ hydroxyl at the other, the neighboring strand runs in the reverse manner. ● The DNA molecule was found to have a constant diameter (.2nm). In order to maintain this diameter, the nitrogenous bases would have to be organized such that each purine from one strand of the molecule is paired with a pyrimidine from the other. But which purine base was paired with which pyrimidine base?

Figure 7.1: Evidence for DNA Base-Pairing
● Evidence for the specific manner in which bases were paired within the DNA molecule was provided by Dr. Erwin Chargaff. He observed that the percentage of adenine bases were nearly equal to thymine, whereas the percentage of cytosine bases were nearly equal to guanine. ● Watson & Crick interpreted these base ratios to suggest that adenine base pairs with thymine, & guanine base pairs with cytosine … Figure 7.2: DNA Base-Pairing
● These bases pair together because their structures are Complementary, meaning that they “fit together” to form a unified whole, or Base Pair. The structures of adenine & thymine allow them to form 2 hydrogen bonds to establish an AT base pair. Additionally, the structures of guanine & cytosine allow them to form 3 hydrogen bonds to establish a GC base pair. ● DNA Structure:

IV. DNA Replication Figure 8: Semiconservative Model of DNA Replication
● The semiconservative model suggests that when DNA replicates during the S-phase of the cell cycle, both strands of the molecule separate. Each strand can then serve as a template (guide) for the construction of a new complementary strand. The result is the formation of 2 genetically identical daughter DNA molecules. ● Semiconservative Replication: Stages of DNA Replication Figure 8.1: DNA Replication: Unzipping & Unwinding: Origins of Replication
● The Origins of Replication are specific regions along DNA where the molecule can begin to replicate. Multiple origins of replication exist to make the overall process proceed faster.

Figure 8.2: DNA Replication: Unzipping & Unwinding: Replication Fork
● Helicase: ● Topoisomerase: ● Single Stranded Binding Proteins: Figure 8.3: DNA Replication: Priming of DNA Templates
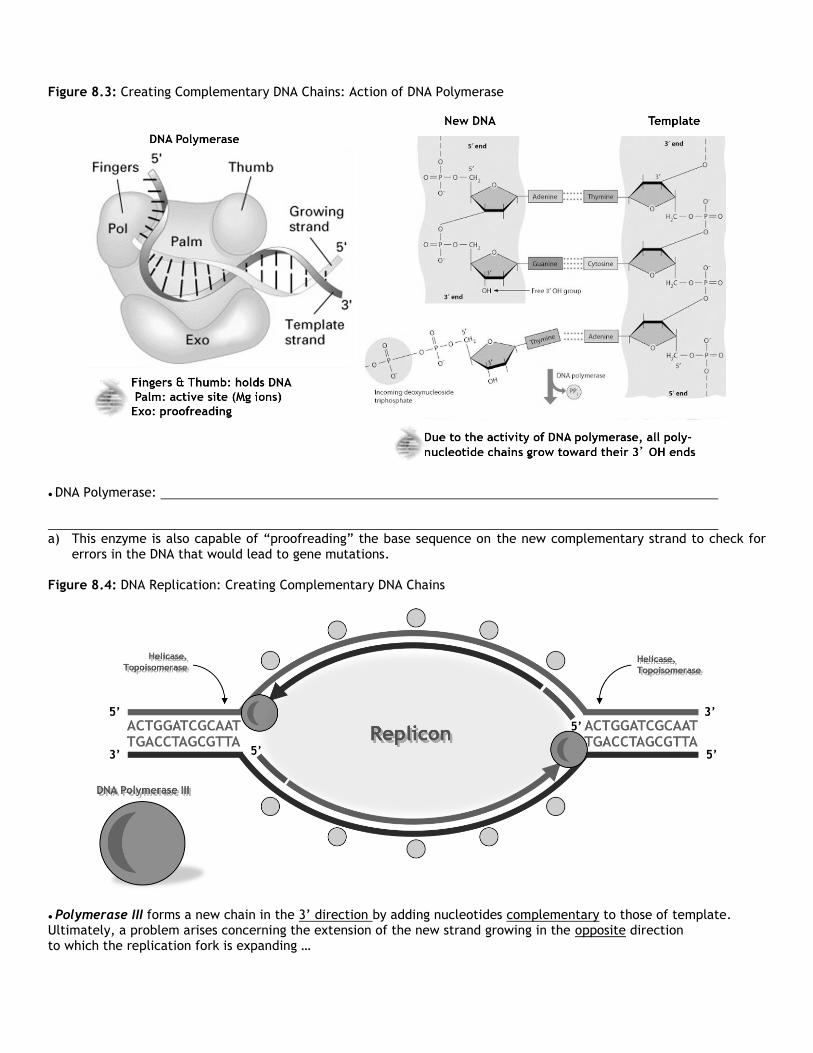
Figure 8.3: Creating Complementary DNA Chains: Action of DNA Polymerase
● DNA Polymerase: a) This enzyme is also capable of “proofreading” the base sequence on the new complementary strand to check for
errors in the DNA that would lead to gene mutations. Figure 8.4: DNA Replication: Creating Complementary DNA Chains
● Polymerase III forms a new chain in the 3’ direction by adding nucleotides complementary to those of template. Ultimately, a problem arises concerning the extension of the new strand growing in the opposite direction to which the replication fork is expanding …

● Helicase & Topoisomerase continue to “unzip” & “unwind” the helix to expand each replication fork. Consequently, a “gap” opens up behind the 5’ end of each RNA primer ...
● Primase reattaches to each template strand to deposit an additional RNA primer BEHIND the pre-existing ones near each replication fork ...
● DNA Polymerase III attaches to each new primer & creates new DNA in the gaps created by the expanding replication forks. Eventually, new gaps will open up behind the newly-formed strand as the replication forks continue to expand …

● Once again, primase deposits new primers at each replication fork & DNA polymerase III creates new DNA to fill the gaps.
● At this point, two distinct DNA strands begin to appear along each template strand …
● Leading Strand: ● Lagging Strand: a) Once the construction of the leading & lagging strands is complete, DNA polymerase I will remove the primers one
the lagging strand & replace the resulting gaps with DNA …

● The gaps created by the removal of RNA primers along the lagging strands are “filled-in” by DNA polymerase I …
● Despite the action of DNA polymerase I, a “gap” exists between the backbones of adjacent Okazaki fragments. The backbone of these fragments are joined by an enzyme called DNA Ligase …

● The action of ligase joins the sugar-phosphate backbone in between each Okazaki fragment along the lagging strands to form a continuous sugar-phosphate backbone…
● DNA Ligase:
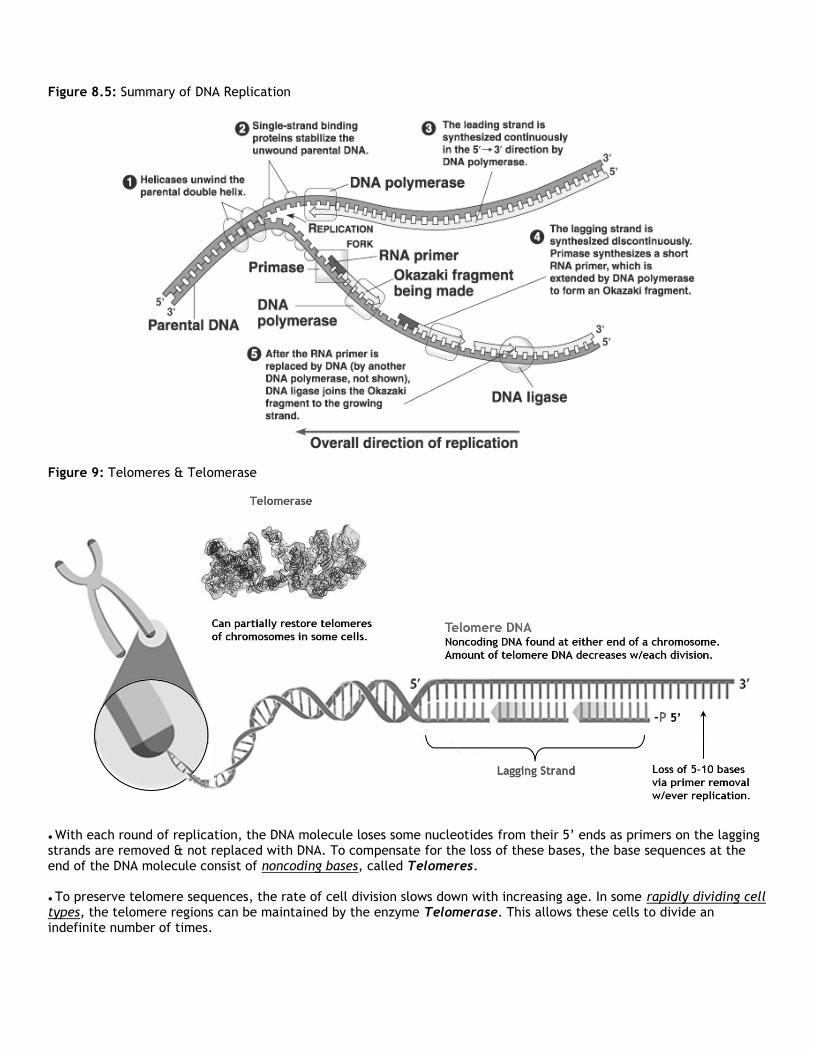
Figure 8.5: Summary of DNA Replication
Figure 9: Telomeres & Telomerase
● With each round of replication, the DNA molecule loses some nucleotides from their 5’ ends as primers on the lagging strands are removed & not replaced with DNA. To compensate for the loss of these bases, the base sequences at the end of the DNA molecule consist of noncoding bases, called Telomeres. ● To preserve telomere sequences, the rate of cell division slows down with increasing age. In some rapidly dividing cell types, the telomere regions can be maintained by the enzyme Telomerase. This allows these cells to divide an indefinite number of times.

V. Genetic Mutations Figure 10: Base Substitutions
● Base Substitution: Effects of Base Substitutions
Figure 11: Nonsense Mutations
● Nonsense Mutation: base substitution creating a stop codon w/in mRNA where none previously existed. Results in a shorter than normal polypeptide leading to an almost always nonfunctional protein.
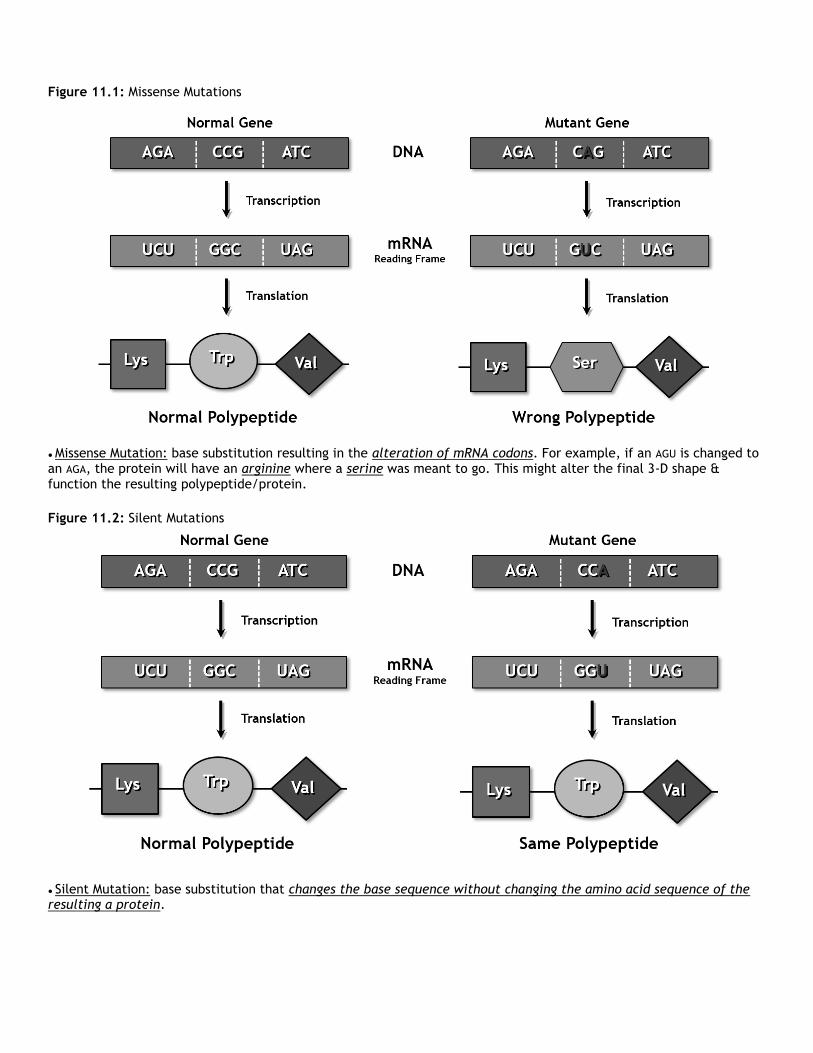
Figure 11.1: Missense Mutations
● Missense Mutation: base substitution resulting in the alteration of mRNA codons. For example, if an AGU is changed to an AGA, the protein will have an arginine where a serine was meant to go. This might alter the final 3-D shape & function the resulting polypeptide/protein.
Figure 11.2: Silent Mutations
● Silent Mutation: base substitution that changes the base sequence without changing the amino acid sequence of the resulting a protein.

Figure 12: Deletions, Insertions, & Frameshifts
● Deletion:
● Insertion:
● Frameshift:






























