Embed Size (px)
Citation preview

FFTs, Portability, & Performance
Steven G. Johnson, MIT Dept. PhysicsMatteo Frigo, ITA Software (formerly MIT LCS)

A Need for Speed?
Scientists(along with gamers)
often pushperformance limits
low-level programming?
Codes havelong lifetimes,
and needflexibility & portability
high-level programming?
Perhaps there is a better way?

FFTW
• C library for real & complex FFTs (arbitrary size/dimensionality)
• Computational kernels (80% of code) automatically generated
• Self-optimizes for your hardware: portability + performance
(+ parallel versions for threads & MPI)
free software: http://www.fftw.org/

?The “Fastest Fourier Transform in the West”
no code is always fastest, but…
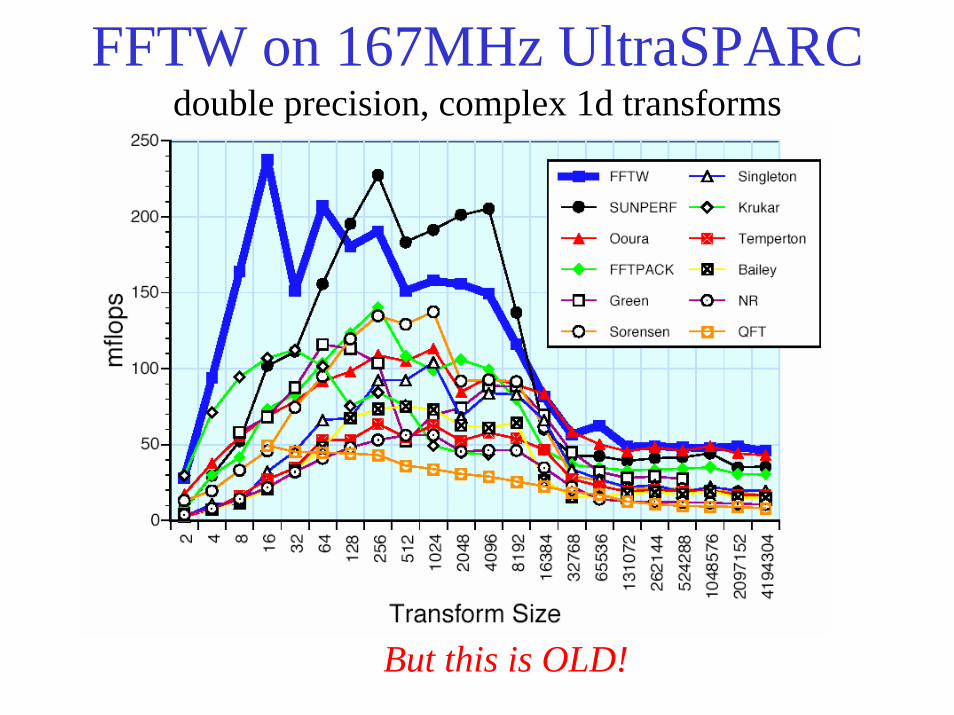
FFTW on 167MHz UltraSPARCdouble precision, complex 1d transforms
But this is OLD!

okay, I’ll present some new stuff…
FFTW 3.0(soon to be released)
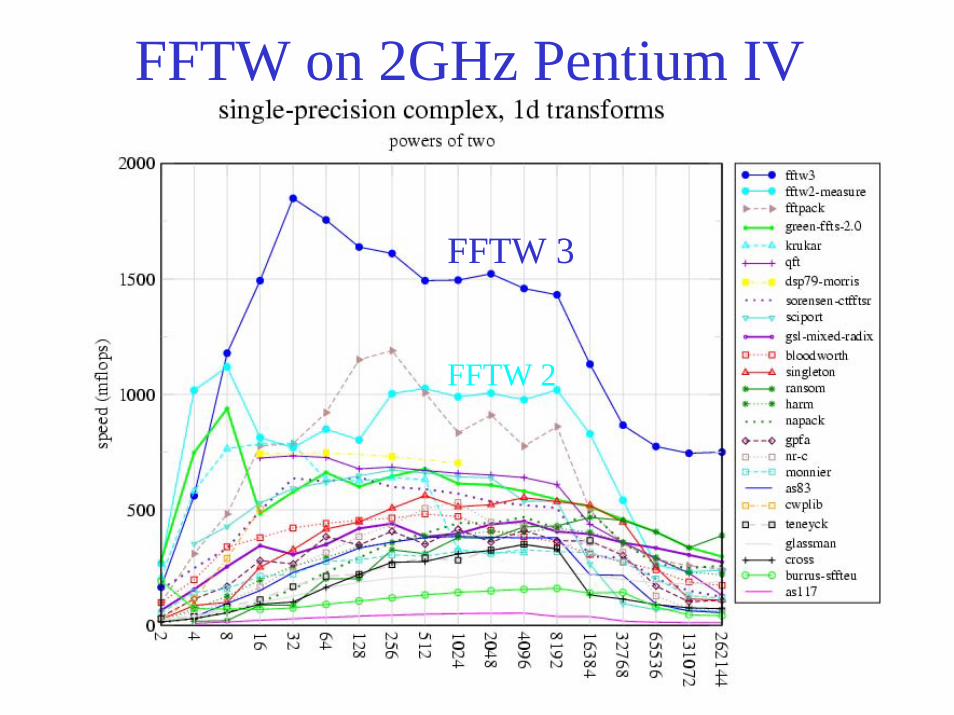
FFTW on 2GHz Pentium IV
FFTW 3
FFTW 2
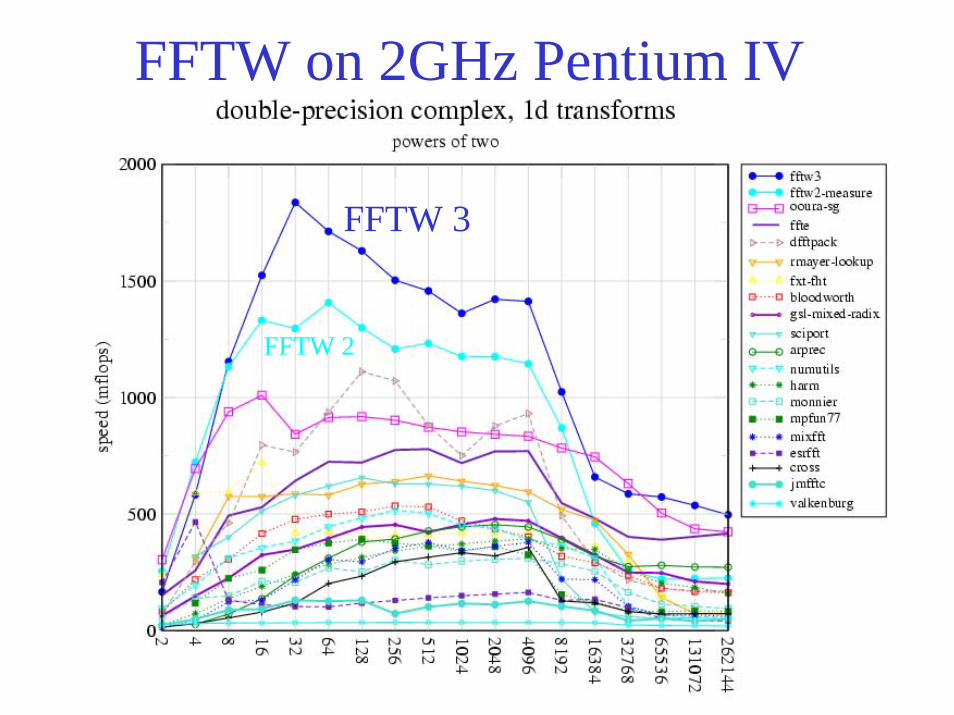
FFTW on 2GHz Pentium IV
FFTW 3
FFTW 2
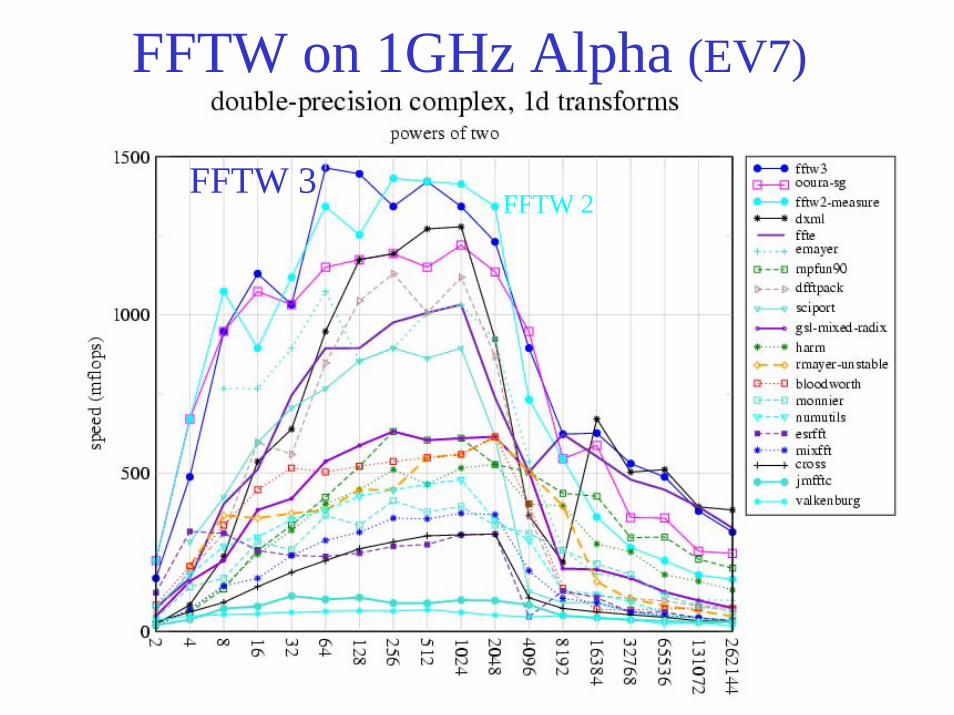
FFTW on 1GHz Alpha (EV7)
FFTW 3FFTW 2

Why is FFTW fast?
FFTW implements many FFT algorithms:A planner picks the best composition
by measuring the speed of different combinations.1
The resulting plan is executedwith explicit recursion:
enhances locality2
3 The base cases of the recursion are codelets:highly-optimized dense code that is
automatically generated by a special-purpose “compiler”

FFTW is easy to use{
complex x[n];plan p;
p = plan_dft_1d(n, x, x, FOR WARD, MEASURE);...
execute(p); /* repeat as needed */...destroy_plan(p);
}
Key fact: usually,many transforms of same size
are required.

Outline
FFT algorithm basics
Recursion and caches
The planner
The codelet generator

Outline
FFT algorithm basics
Recursion and caches
The planner
The codelet generator
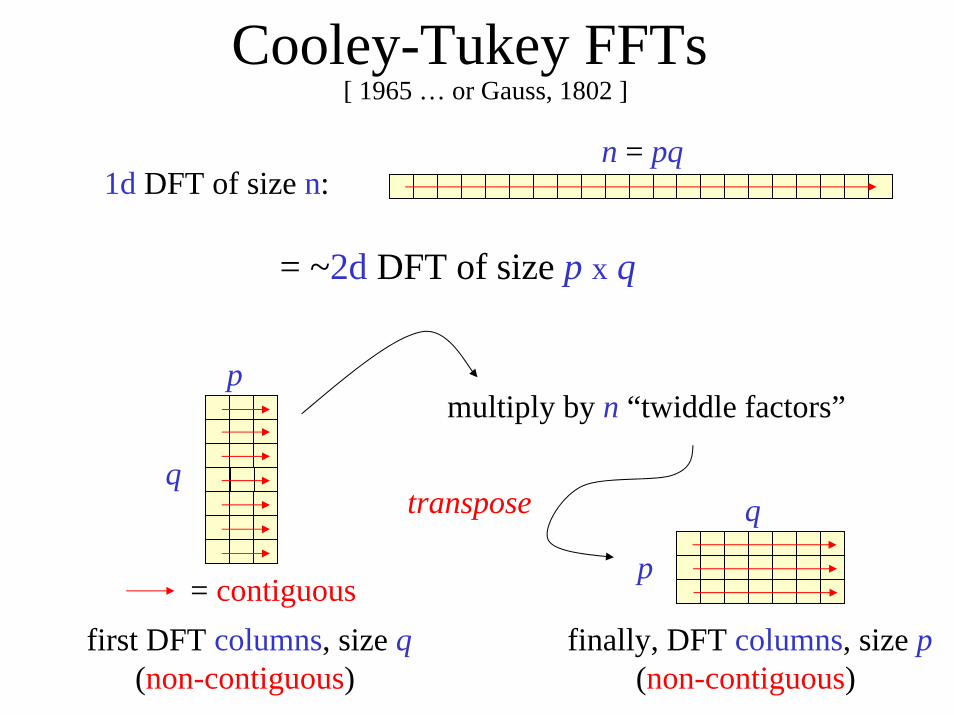
Cooley-Tukey FFTs[ 1965 … or Gauss, 1802 ]
n = pq1d DFT of size n:
= ~2d DFT of size p x q
multiply by n “twiddle factors”
q
p
transpose
p
q
= contiguousfirst DFT columns, size q
(non-contiguous) finally, DFT columns, size p
(non-contiguous)

Cooley-Tukey FFTs[ 1965 … or Gauss, 1802 ]
n = pq1d DFT of size n:
= ~2d DFT of size p x q
= Recursive DFTs of sizes p and q
O(n2) O(n log n)(divide-and-conquer algorithm)

Cooley-Tukey FFTs[ 1965 … or Gauss, 1802 ]
twiddlessize-q DFTssize-p DFTs

Outline
FFT algorithm basics
Recursion and caches
The planner
The codelet generator
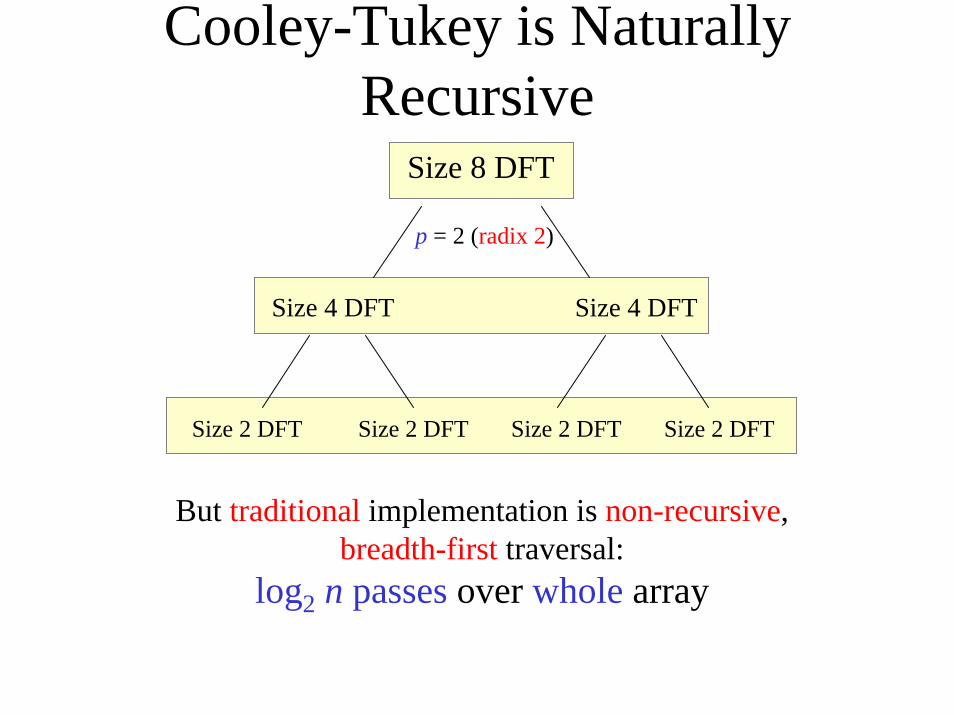
Cooley-Tukey is Naturally Recursive
But traditional implementation is non-recursive,breadth-first traversal:
log2 n passes over whole array
Size 8 DFT
Size 4 DFT Size 4 DFT
Size 2 DFT Size 2 DFT Size 2 DFT Size 2 DFT
p = 2 (radix 2)

Recursive Divide & Conquer is Good
Size 8 DFT
Size 4 DFT Size 4 DFT
Size 2 DFT Size 2 DFT Size 2 DFT Size 2 DFT
p = 2 (radix 2)
eventually small enough to fit in cache…no matter what size the cache is
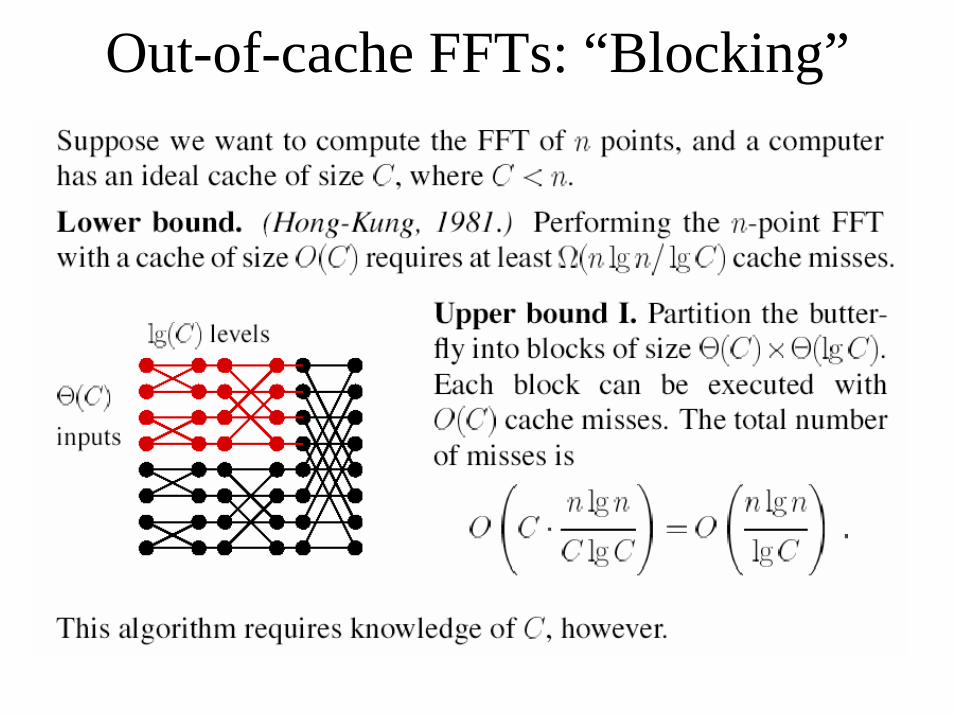
Out-of-cache FFTs: “Blocking”

Cache-oblivious Recursive FFT
[ Vitter & Shriver, 1994 ]

Cache Obliviousness• A cache-oblivious algorithm does not know the cache size
— it can be optimal for any machine& for all levels of cache simultaneously
• They exist for matrix multiplication, LU decomposition, sorting, transposition, binary search trees, etc. [Frigo et al. 1999]
— all via the recursive divide & conquer approach
FFTW uses a finite-radix (p) recursive cache-oblivious algorithm with suboptimal “cache complexity” O(n log[n/C]),
…but an optimal algorithm is used in the generator (cache == registers)

Outline
FFT algorithm basics
Recursion and caches
The planner
The codelet generator

The Planner
• There are many choices in implementing the C-T algorithm— which factor p? & memory access ordering…
Each algorithm step is represented by a solver.
• The planner tries the different solver combinations for a given n,
measures their speed, and picks the fastest.
— uses dynamic programming
— can use heuristics or saved plansif planning time is a concern

Vectors and Solversa problem is specified as a DFT(v,n):
multi-dimensional transform n of multi-dimensional vectors v
SOLVE[v,n] Directly solve size n with 1d vector (loop) v
by an efficient codelet (hard-coded FFT loop)
CT-FACTOR[p]DFT(v, n = pq) =
DFT(vxp, q)
+ v size-p DFTs with twiddles[loop v of hard-coded twiddle codelet p]
VECLOOP DFT(vxm, n) = loop m of DFT(v,n)
each solver knows what problems it can solveand tells the planner its recursive “child” problems

Dynamic Programmingthe assumption of “optimal substructure”
DFT(16) = fastest of: CT-FACTOR[2]: 2 DFT(8)CT-FACTOR[4]: 4 DFT(4)
DFT(8) = fastest of:CT-FACTOR[2]: 2 DFT(4)CT-FACTOR[4]: 4 DFT(2)SOLVE[1,8]
Try all applicable solvers:assume VECLOOP
strips off loops
If exactly the same problem appears twice,assume that we can re-use the plan.

More Solvers (out of ~16 total)
(a) DFT(vxm, n) = loop m of DFT(v,n)
(b) DFT(mxv, n) = loop m of DFT(v,n)ORVECLOOP
i.e. interchange loop orders!
INDIRECT DFT(v,n) = DFT(v,{}) + DFT(v,n)
zero-dimensional DFT = copy loop in-place

Actual Plan for size 219=524288(2GHz Pentium IV, double precision, out-of-place)
CT-FACTOR[4] (buffered variant)CT-FACTOR[32] (buffered variant)
VECLOOP(b) x32CT-FACTOR[64]
INDIRECT
VECLOOP(a) x4SOLVE[64, 64]
VECLOOP(b) x64VECLOOP(a) x4
COPY[64]
~2000 lineshard-coded C!INDIRECT
+VECLOOP(b)
(+ …)=
demolishes FFTW 2for large 1d sizes
Unpredictable: (automated) experimentation is the only solution.

Outline
FFT algorithm basics
Recursion and caches
The planner
The codelet generator

The Codelet Generatora domain-specific FFT “compiler”
• Generates fast hard-coded C for FFTs of arbitrary size
Necessary to give the planner a large space of codelets to
experiment with.
Exploits modern CPUdeep pipelines & large register sets.
Allows easy experimentation with different optimizations & algorithms.
…and you only have to get it right once.

The Codelet Generatorwritten in Objective Caml [Leroy, 1998], an ML dialect
Symbolic graph (dag)
Simplifications
Cache-oblivious scheduling(cache .EQ. registers)
Optimized C code (or other language)
n
powerful enoughto e.g. derive real-input FFTfrom complex FFT algorithmand even find new algorithms
Abstract FFT algorithmCooley-Tukey: n=pq,
Prime-Factor: gcd(p,q) = 1,Rader: n prime, …
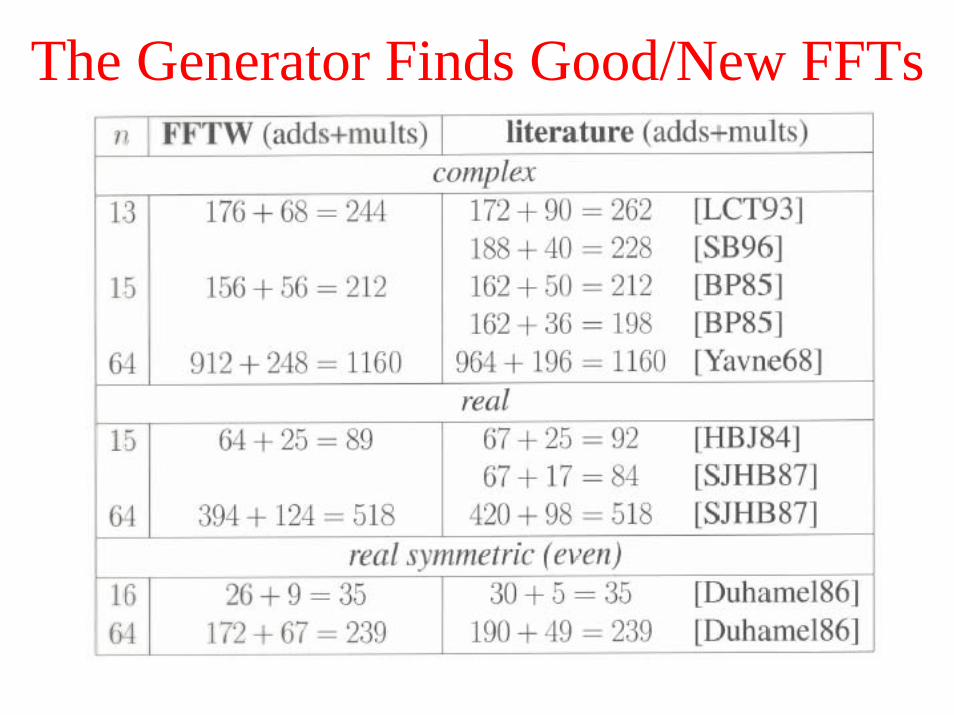
The Generator Finds Good/New FFTs

Symbolic Algorithms are EasyCooley-Tukey in OCaml

Simple Simplifications
Well-known optimizations:
Algebraic simplification, e.g. a + 0 = a
Constant folding
Common-subexpression elimination

Symbolic Pattern Matching in OCamlThe following actual code fragment issolely responsible for simplifying multiplications:
stimesM = function| (Uminus a, b) -> stimesM (a, b) >>= suminusM| (a, Uminus b) -> stimesM (a, b) >>= suminusM| (Num a, Num b) -> snumM (Number.mul a b)| (Num a, Times (Num b, c)) ->
snumM (Number.mul a b) >>= fun x -> stimesM (x, c)| (Num a, b) when Number.is_zero a -> snumM Number.zero| (Num a, b) when Number.is_one a -> makeNode b| (Num a, b) when Number.is_mone a -> suminusM b| (a, b) when is_known_constant b && not (is_known_constant a) ->
stimesM (b, a)| (a, b) -> makeNode (Times (a, b))
(Common-subexpression elimination is implicitvia “memoization” and monadic programming style.)

Simple Simplifications
Well-known optimizations:
Algebraic simplification, e.g. a + 0 = a
Constant folding
Common-subexpression elimination
FFT-specific optimizations:
_________________ negative constants…
Network transposition (transpose + simplify + transpose)

A Quiz: Is One Faster?Both compute the same thing, and
have the same number of arithmetic operations:
a = 0.5 * b;c = 0.5* d;e = 1.0 + a;f = 1.0 -c;
Faster because no separate load for -0.5
a = 0.5 * b;c = -0.5 * d;e = 1.0 + a;f = 1.0 + c;
10–15% speedup

Non-obvious transformations require experimentation

Quiz 2: Which is Faster?accessing strided array
inside codelet (amid dense numeric code)
array[stride * i] array[strides[i]]
strides[i] = stride * i
using precomputed stride array:
This is faster, of course!Except on brain-dead architectures…
…namely, Intel Pentia:integer multiplication
conflicts with floating-point
up to ~20% speedup

SIMD: The Revenge of the Crays= Single Instruction, Multiple Data
Available on most popular processors today:
Pentium III+ SSE: operate on 4 floatvaluesPowerPC G4 AltiVec: operate on 4 floatvalues
AMD Athlon 3dNow!: operate on 2 floatvalues
Pentium IV SSE2: operate on 2 double values
Modify only the generator to produce SIMD codelets[ initiated by S. Kral and F. Franchetti, Univ. Vienna ]
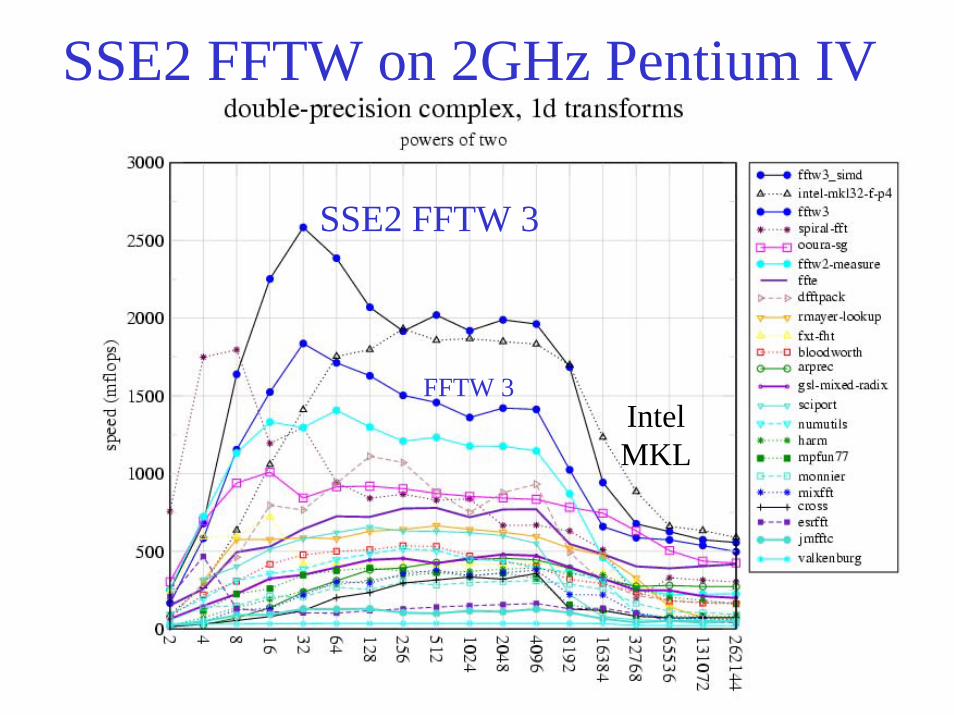
SSE2 FFTW on 2GHz Pentium IV
SSE2 FFTW 3
FFTW 3IntelMKL
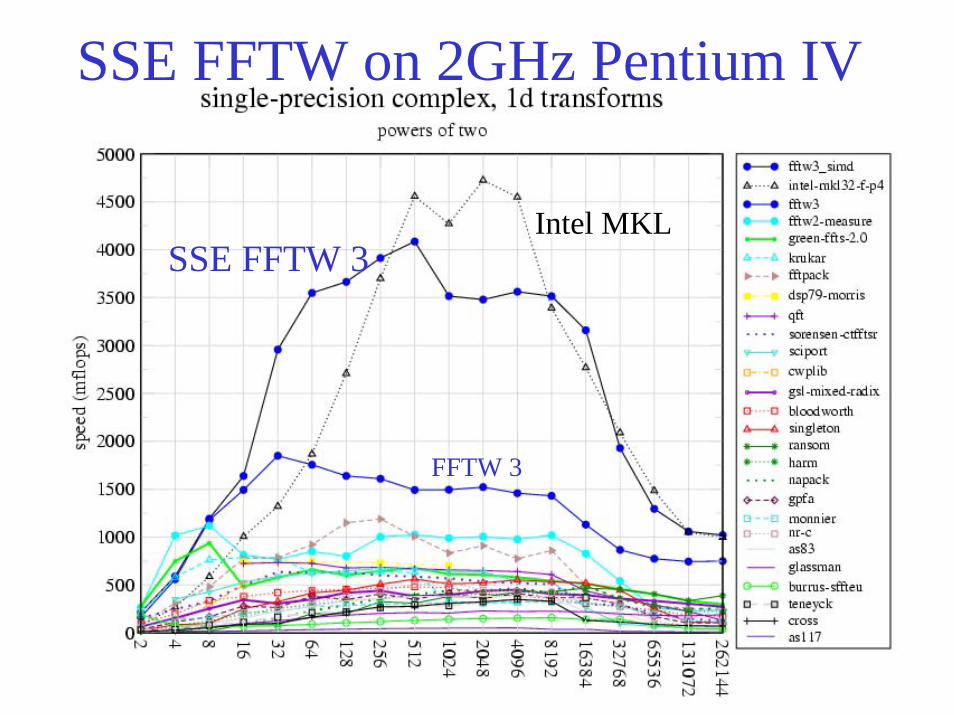
SSE FFTW on 2GHz Pentium IV
SSE FFTW 3
FFTW 3
Intel MKL

with a generator,it’s easy to include
less-popular cases…
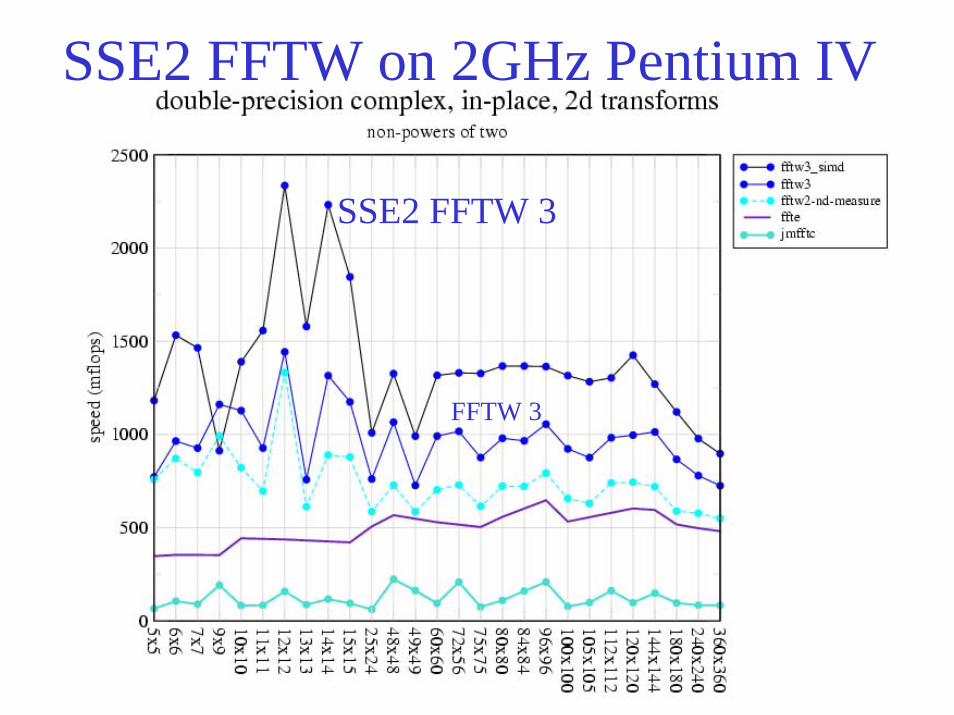
SSE2 FFTW on 2GHz Pentium IV
SSE2 FFTW 3
FFTW 3

We’ve Come a Long Way
1965 Cooley & Tukey, IBM 7094, 36-bit single precision:size 2048 DFT in 1.2 seconds
2003 FFTW3+SIMD, 2GHz Pentium-IV 64-bit double precision:size 2048 DFT in 50 microseconds (24,000x speedup)
(= 30% improvement per year)

We’ve Come a Long Way?In the name of performance,computers have become complex and
•
unpredictable.Optimization is hard:you cannot simply minimize the number of operations.
•
The solution is to avoid the details, not embrace them:(Recursive) composition of simple modules
+ feedback (self-optimization)High-level languages (not C) & code generationare a powerful tool for high performance.
•

FFTW Homework Problems?• Try an FFTPACK-style back-and-forth solver
• Implement Vector-Radix for multi-dimensional n
• Pruned FFTs: VECLOOP that skips zeros
• Better heuristic planner—some sort of optimization of per-solver “costs?”
• Modify generator for fixed-point arithmetic—e.g. faster integer MDCT for Ogg Vorbis audio
• Implement convolution solvers





























