Embed Size (px)
DESCRIPTION
http://fvalente.zxq.net/paperpdf/feat_dis.pdf
Citation preview

Multistream Speaker Diarization of Meetings Recordings beyond MFCC
and TDOA Features
Deepu Vijayasenan, Fabio Valente and Herve Bourlard
Idiap Research Institute, CH-1920, Martigny, Switzerland{deepu.vijayasenan,fabio.valente,herve.bourlard}@idiap.ch
Abstract
Many state-of-the-art diarization systems for meeting recordings are based on the HMM/GMM frameworkand the combination of spectral (MFCC) and Time Delay of Arrivals (TDOA) features. This paper presentsan extensive study on how multistream diarization can be improved beyond these two sets of features. Whileseveral other features have been proven effective for speaker diarization, little efforts have been devotedto integrate them into the MFCC+TDOA state-of-the-art baseline and to the authors’ best knowledge,no positive results have been reported so far. The first contribution of this paper consists in analyzingthe reasons of this, investigating through a set of oracle experiments the robustness of the HMM/GMMdiarization when also other features (the Modulation Spectrum features and the Frequency Domain LinearPrediction features) are integrated. The second contribution of the paper consists in introducing a non-parametric multistream diarization method based on the Information Bottleneck (IB) approach. In contraryto the HMM/GMM which makes use of log-likelihood combination, it combines the feature streams in anormalized space of relevance variables. The previous analysis is repeated revealing that the proposedapproach is more robust and can actually benefit from other sources of information beyond the conventionalMFCC and TDOA features. Experiments based on the Rich Transcription data (heterogeneous meetingsdata recorded in several different rooms) show that it achieves a very competitive error of only 6.3% when fourfeature streams are used, compared to the 14.9% of the HMM/GMM system. Those results are analyzed interms of error sensitivity to the stream weightings. To the authors’ best knowledge this is the first successfulattempt to reduce the speaker error combining other features with the MFCC and the TDOA and the firststudy to show the shortcomings of the HMM/GMM in going beyond this baseline. As last contribution, thepaper also addresses issues related to the computational complexity of multistream approaches.
Key words: Speaker Diarization, Meeting recordings, Multi-stream modeling, NIST Rich Transcription,Information Bottleneck diarization.
1. Introduction
Speaker diarization aims at identifying “who spoke when” in a given audio recording and is a fundamentalstep for several applications including speaker based indexing and retrieval, structuring audio documentsand extracting statistics for speaker adaptation in speech recognition. This problem is often casted as anunsupervised learning task where both the number of speakers as well as speech segments correspondingto each speaker need to be identified. Diarization has been extensively applied to data like broadcastrecordings [1].
Recent applications include meeting recordings, i.e., spontaneous multi-party discussions. In contrary tobroadcast data, they are characterized by shorter speaker turns and spontaneous speaking style. Furthermoremeetings are recorded in non-intrusive way with a microphone array thus representing significantly morechallenging data compared to broadcast recordings. Those systems are periodically compared on datasetsacquired in different rooms with variable setups and recording devices. This benchmark is done during theNIST Rich Transcription campaigns [2] with the purpose of investigating their robustness to multiple setups.
Preprint submitted to Elsevier

Typical diarization systems are based on HMM/GMM systems and use Mel Frequency Cepstral Coeffi-cients (MFCC) as features [3, 4]. Each HMM state represents a speaker whose emission probabilities aremodeled using a GMM. The diarization follows multiple steps of agglomerative clustering and realignment.The system is initialized with an over determined number of speakers, and, at each iteration, the two mostsimilar clusters (according to some distance measure) are merged. After that, the time boundaries of seg-ments are realigned using a Viterbi algorithm. The process is iteratively repeated until a stopping criterionis met.
When the meetings are recorded with Multiple Distance Microphones (MDM), the redundancy of thesignal is often used as auxiliary information to the spectral features. MFCC features are combined withthe Time Delay of Arrivals (TDOA) of the signal at each microphone which carry the location informationof the speaker [5]. MFCC and TDOA features together produce state-of-the-art performances in speakerdiarization of meeting data. The combination typically happens at model level, i.e., a separate GMM isestimated for each feature stream and their log-likelihood are weighted to produce a single score [6]. Severalevaluation systems make use of those two feature streams [7, 6, 8, 9] proven to be very effective in reducingthe diarization error.
While TDOA features stay the most common source of extra information, other alternatives such asmodulation spectrogram features [10], prosodic features [11] and also visual features [12] have been exploredas complementary source of information. However, most of the systems in literature report combination ofonly two feature streams, i.e., MFCC plus TDOA, MFCC plus modulation spectrum or MFCC plus prosodicfeatures. Though those different streams were found to reduce the error, there was little attempt to integratethem into state-of-the-art diarization which make use of MFCC and TDOA. To the authors’ best knowledge,no positive results have been reported using HMM/GMM systems when integrating more than two features.
This work focuses on integrating additional complementary acoustic features in such a state-of-the-art diarization system. The first contribution of this paper consists in analyzing a conventional multi-stream diarization method based on GMM modeling. The analysis is done considering common MFCC andTDOA features at first. Later two other feature sets extracted from long signal time spans, namely theModulation Spectrum (MS) and the Frequency Domain Linear Prediction (FDLP) features, are included.The comparison is done using a set of oracle experiments. The oracle aims at finding the lowest possibleerror that can be achieved by the diarization systems when the best possible feature weighting is used.This enables us to study the combination regardless of any development data set. After that, weights areestimated on a development data set and the results are compared with those obtained from the oracleexperiments. The investigation reveals a number of novel facts, in particular provides evidence on whyno positive results have been reported in combining those features together with MFCC and TDOA inHMM/GMM diarization system.
The second contribution of the paper consists in introducing a novel multistream method. This is doneextending the Information Bottleneck (IB) system, a non-parametric diarization method proposed in [13] .In contrary to the HMM/GMM method, the IB combines the information in a space of relevance variables,i.e., variables that carry relevant information to the problem. Contrarily to the HMM/GMM, the quantitieshandled by the IB system are probabilities and not log-likelihoods. The rationale behind this consists in thefact that probability estimates could be more robust to different statistics. The previous analysis is repeatedrevealing that the proposed approach is more robust to weights variations and can actually benefit from theother sources of information beyond the conventional MFCC and TDOA features.
Increasing the number of feature streams has the direct effect of increasing the computational complexity.As last contribution, this work compares the two systems (HMM/GMM and IB) in terms of real-time factorsrevealing that the second is significantly faster than the first, achieving faster-than-real-time diarization evenwith four different feature streams.
The remainder of the paper is organized as follows: section 2 describes the baseline state-of-the-artHMM/GMM diarization system and section 3 describes its extension to handle multiple feature streams.Section 4 describes the Information Bottleneck diarization system and section 5 introduces its extension tohandle multiple feature streams. The experimental setup based on Rich Transcription data is presented insection 6 while experiments using oracle and estimated weighting are presented in sections 7 and 8. Thecomparison is done on the two conventional features (MFCC+TDOA) and on four features combination
2

(MFCC+TDOA+MS+FDLP). Sections 7 and 8 also investigate the differences between the two combina-tions schemes and show why the IB is more suitable to include several feature streams. Finally section 9addresses complexity issues. The paper is concluded in section 10 where results are summarized and thenovel findings are discussed.
2. HMM/GMM diarization
Let us consider a conventional diarization system based on the HMM/GMM framework described in[3, 4]. Each speaker is modeled by an HMM state with a minimum duration of 3 seconds. The emissionprobabilities are modeled using Gaussian Mixture Models (GMM). Let us designate the emission probabilitydistribution bck of cluster ck with:
bck(st) =∑
r
wrckN (st, µ
rck,Σr
ck) (1)
where st is the input feature, N (.) is the Gaussian pdf and wrck, µr
ck, Σr
ckare the weights, means and
covariance matrices (diagonal) corresponding to rth mixture Gaussian of cluster ck.The diarization follows an agglomerative clustering framework. The algorithm is initialized with an over
determined number of clusters estimated using either uniform linear segmentation or by speaker segmentationmethods. The clustering then merges the two most similar speakers iteratively until a stopping criterionis met. The distance measure to determine the most nearest clusters is based on a modified BayesianInformation Criterion (BIC) [14] which removes the need of tuning factor or heuristics needed by the originalBIC formulation [15]. The clustering stops when none of the BIC values are positive, i.e., none of the mergessatisfy the merge criterion. The modified BIC criterion for a pair of clusters ci and cj with respective GMMmodels bci(.) and bcj(.) is given by
∑
st∈ci∪cj
log bci+j(st)−
∑
st∈cj
log bcj(st)−∑
st∈ci
log bci(st) (2)
where bci+j(.) represent the GMM model estimated with data belonging to both the clusters ci and cj . The
number of Gaussian components in the model bci+jis the total number of Gaussian components in bci and
bcj together. A Viterbi realignment is performed after each merge to smooth the current speaker boundaries.The optimal path (c1, . . . , cT ) is estimated as:
copt = argminc
∑
t
[− log bct(st)− log(actct+1)] (3)
where ct is the speaker cluster at time t. The term acicj represents the transition probability from speakerstate ci to cj . The transition probabilities incorporate a minimum duration constraint (3 seconds) in orderto smooth the boundaries and avoid very fast speaker changes.
3. HMM/GMM multistream diarization
Whenever multiple feature streams are used, a separate model (GMM) is estimated for each stream. Alinear weighting of log likelihoods is then considered in the computation of the BIC distance measure andin the realignment (for details see [5, 6]).
Let {slt}, l = 1, . . . ,M be the input feature streams. A separate GMM emission distribution bjck(.) isestimated for each feature stream. A combined log likelihood logLck(st) is computed for each cluster ck as:
logLck(st) =
M∑
l=1
Pl log[
blck(slt)]
(4)
3

where, Pl corresponds to the weight of each feature stream (∑
l Pl = 1). This combined likelihood logLck(.)replaces the log likelihood terms log bck(.) in the estimation of BIC criterion (Equation 2) and during theViterbi realignment (Equation 3).
It can be noticed that the likelihood of a multidimensional Gaussian distribution with mean µ =[µ1, . . . , µd]
′, diagonal covariance matrix Σ = diag(σ21 , . . . , σ
2d) for an input feature vector s = [s1, . . . , sd]
′ isgiven by:
N (s, µ,Σ) = (2π)−d2
(
Πdq=1σ
2q
)−12 exp
(
−Σdq=1
(sq−µq)2
2σ2q
)
(5)
Where d denotes the feature dimension. If the feature vector has a large dimension, the number of terms(each term is positive) in the summation increases. This would decrease the likelihood (or equivalentlyincrease the negative log likelihood). Thus the range of log likelihoods in the summation in Equation 4varies according to the feature vector dimension.
The two most common features used in multistream diarization are spectral features (MFCC) togetherwith delay features (TDOA) [5, 6] (see section 6 for TDOA extraction). Such a system ranked first in severalNIST evaluations [2], [4] and provides state-of-the-art performances.
4. IB based Speaker Diarization
Let us now describe a non-parametric diarization system based on Information Bottleneck (IB) principleproposed in [13]. In contrary to the HMM/GMM system, the clustering happens in a space of relevancevariables. The algorithm is based on an IB clustering step followed by a Viterbi realignment that smoothsthe speaker boundaries.
The Information bottleneck (IB) clustering [16, 17] is a distributional clustering framework based oninformation theoretic principles. The clustering depends on a set of relevance variables that carries usefulinformation about the problem. Motivated by the success of GMMs in speaker recognition application, wechoose in [13] the components of a background GMM as relevance variables.
Consider a set of input speech segments X = {x1, . . . , xT } obtained from uniform linear segmentationto be clustered into a set of speaker clusters C = {c1, . . . , cK}. Let Y be the set of relevance variables thatcarries the information pertaining to the problem (components of the background GMM). According to IBprinciple, the clustering representation C is a compact representation of input elements X ( minimize themutual information I(X,C) between the segments and the clusters ) and preserves as much informationas possible about the relevance variables (maximize the mutual information I(Y,C) between the relevancevariables and the clusters). This corresponds to the maximization of:
F = I(Y,C)−1
βI(X,C) (6)
Where β (Notation consistent with [16] ) is a Lagrange multiplier. The objective function in Equation (6)is optimized with respect to the stochastic mapping p(C|X).
In this work, we use a greedy algorithm namely Agglomerative Information Bottleneck (aIB) to optimizethe IB criterion [18]. The algorithm is initialized with singleton clusters, i.e., each input point xi is consideredas a separate cluster. Each step of the algorithm merges two clusters such that the loss in the mutualinformation I(Y,C) (first term in Equation 6) is minimum. It can be proved that this loss of mutualinformation in combining two clusters c1 and c2 can be represented in terms of a Jensen-Shannon divergence:
∆F(c1, c2) = [p(c1) + p(c2)] · JS[p(y|c1), p(y|c2)] (7)
The Jensen-Shannon divergence JS[p(y|c1), p(y|c2)] is given by:
π1KL [p(y|c1)||q(y)] + π2KL [p(y|c2)||q(y)] (8)
where πj =p(cj)
p(c1)+p(c2), q(y) represents the distribution of relevance variables after the cluster merge and
KL denotes the Kullback-Leibler divergence between two distributions. This computation depends only4

on the distribution p(yj |xi) which can be estimated directly from Bayes’ rule. A similar function, i.e., aJensen-Shannon divergence, is obtained whenever the loss of mutual information I(X,C) (second term inEquation 6) is minimized after each merge (see [13] for details).
Consider now a background GMM trained on the entire recording given by, f(st) =∑
j wjN (st, µj , σj).The conditional probability of Gaussian component j (relevance variable) with respect to an input featurest is calculated using Bayes’ rule as:
p(yj |st) =wjN (st, µj ,Σj)
∑
r wrN (st, µr,Σr)(9)
This expression gives the frame level distribution of relevance variables. Each input segment xi consists ofa set of frames. The conditional distribution p(yj |xi) is obtained by averaging the frame level distributionsacross all frames. Once the conditional distributions p(yj |xi) are estimated, the system follows the agglom-erative clustering. The number of clusters is determined using a Normalized Mutual Information (NMI)criterion:
NMI =I(Y,C)
I(Y,X)(10)
Eq. 10 represents the fraction of original mutual information preserved in the clustering representation.This quantity monotonically decreases with the cluster merge and is thresholded to determine the numberof clusters. The value of threshold is obtained by tuning on a development data. After clustering, arealignment step, described in the the next section, is performed to smooth the speaker boundaries.
4.1. Realignment
The realignment incorporates a speaker duration constraint, and improves the performance of diarizationby smoothing the boundaries estimated by the aIB algorithm. Conventional systems perform realignmentbased on HMM/GMM modeling. On the other hand, whenever IB diarization is performed, the realignmentcan happen directly in the relevance variable space as follows. The output of IB clustering represents a hardpartition (p(ci|st) ∈ {0, 1}) of the feature stream (s1, . . . , sT ) (input variables for realignment) into clusters{c1, . . . , cK}. It can be shown that in this case of hard clustering, the optimization of the IB objectivefunction in Equation 6 can be re-written as minimization of E(KL(P (Y |X)||P (Y |C))) [19], where KL(., .)denotes the Kullback-Leibler divergence between distributions. This expression can be developed as:
E(KL(P (Y |S)||P (Y |C))) =∑
t
p(st)∑
i
p(ci|st)KL(p(Y |st)||p(Y |ci)) =∑
t
p(st)KL(p(Y |st)||p(Y |ct))
(11)
where, ct is such that p(ci|st) = 1. Assuming equal priors for the feature frames st, the IB optimizationbecomes (see [20] for the proof):
minE(KL(P (Y |S)||P (Y |C))) = min∑
t
KL(p(Y |st)||p(Y |ct)) (12)
The term p(Y |ct) denotes the distribution of relevance variables for each speaker. This can be seen as the“speaker model” estimated using p(Y |st). While the GMM realignment selects the speaker that maximizesthe log-likelihood sum, the proposed approach selects the speaker that minimize the KL divergence betweenp(Y |st) and p(Y |ct). The problem of minimizing the KL divergence between a feature stream representedas distributions and a set of learned models has been explored previously in the context of automatic speechrecognition [21]; The formula for estimated the ”speaker model” p(y|ci) is simply given by:
p(y|ci) =1
p(ci)
∑
st:st∈ci
p(y|st)p(st) (13)
In case of equal priors p(st), the estimation formula becomes the arithmetic mean of the distributions p(y|st).Thus the speaker model for a cluster ct is the average of distributions p(y|st) assigned to it.
5

The objective function in Equation(12) can be extended to include the minimum duration constraint asin case of HMM/GMM system. Thus the realignment finds the best path that optimizes the IB criterionwith a minimum duration constraint in the hard clustering assignment case. The optimal path is selectedas:
copt = argminc
∑
t
[KL(p(Y |st)||p(Y |ct))− log(actct+1)] (14)
It can be seen that this equation is similar to Equation 3. The negative log-likelihood (− log bct(st))is replaced by the KL divergence KL(p(Y |st)||p(Y |ct)) which serves as the distance measure between thespeaker model and the input features p(Y |st).
The entire speaker diarization algorithm is summarized below (details in [13]) :
1 Acoustic feature extraction from the beamformed audio.
2 Speech/non-speech segmentation and rejection of non-speech frames.
3 Uniform segmentation of speech in chunks of fixed size 2.5s i.e., set X .
4 Estimation of background Gaussian Mixture Model with shared diagonal covariance matrix i.e., set Y .
5 Estimation of conditional distribution p(y|x).
6 Agglomerative clustering until the stopping criterion is met.
7 KL realignment step to smoothen speaker boundaries.
When only MFCC features are used, this system provides comparable performances to HMM/GMM di-arization with a significant speed-up because of the non-parametric nature of the clustering (see [13], [20]for details).
5. IB Multistream diarization
This section introduces an extension of the IB system able to handle multiple streams of information.Let us consider the case in which multiple input features {slt}, l = 1, . . . ,M are available. The combinationcan be performed directly in the relevance variable space. The proposed model is extended using separatealigned background GMMs for each individual feature stream. Initially a background model is estimated forMFCC feature stream. The parameters of the other GMMs are estimated using the same mapping betweenfeature frame indices and GMM components. For example assume the parameters of the jth Gaussiancomponent of MFCC GMM are estimated from features {smfcc
t” }. Then the corresponding component ofother GMMs would be estimated from features {slt”} i.e., from same frame indices {t”}. Thus there is aone-to-one correspondence between the Gaussian components of the background GMMs.
Following the estimation of the background GMMs, the distribution p(y|slt) is estimated using Bayes’rule as in Equation 9 for each feature stream. The estimation of p(y|s1t , . . . , s
Mt ) is obtained as a weighed
average of individual distributions, i.e.,
p(y|s1t , . . . , sMt ) =
∑
l
p(y|slt)Pl (15)
where Pl represents the weight corresponding to feature slt such that∑
l Pl = 1. Note that all the values ofindividual distributions p(y|slt) in the linear combination are in the normalized range between 0 and 1 (seeEq. 9), and hence this approach does not suffer from changes in the feature dimensionality. The distributionsp(y|s1t , . . . , s
Mt ), are averaged across all frames in a speech segment to obtain the distribution corresponding
6

to the input speech segment p(y|x) and are used as the input to aIB clustering. The realignment also usesthe combined distribution p(y|s1t , . . . , s
Mt ). Note that, the rest of the clustering remains the same.
In contrary to the HMM/GMM system, the entire IB diarization, composed of clustering and realignment,is based on the relevance variable distributions p(y|slt) rather than GMM log-likelihoods.
6. Experimental Setup
The experimental setup for evaluation consists of 17 meetings recorded with Multiple Distance Micro-phones (MDM) across five different meeting rooms coming from the NIST Rich Transcription evaluationcampaigns [2]. The meetings’ names and the number of channels that composes the corresponding micro-phone array are listed in Table 1. The amount of data is double compared to the previous study [13].
The pre-processing and feature extraction are composed of the following parts. A beamforming [22] isperformed to estimate a single audio stream from the multiple microphones audio. The beamforming isperformed with the BeamformIt toolkit [23] which first selects a reference channel based on average crosscorrelation with other channels. Time Delay of Arrival features (TDOA) of all other channels are thencomputed with respect to this reference channel using GCC-PHAT. Hence, TDOA feature dimension is oneless than number of microphones and is variable across meetings. Short temporal windows of 30ms with10ms overlap are then considered from the beamformed output and 19 MFCC coefficients are estimatedfrom those.
Two other sets of features based on long temporal context are explored in this work: the ModulationSpectrum and Frequency Domain Linear Prediction features. The rationale behind investigating thosefeatures is that they could capture the long term dependencies, which the short term spectral features arenot capable of. Furthermore they have shown to provide complementary information and robustness inother meeting-related tasks like speech recognition [24], [25].
• Modulation Spectrogram Features – The modulation spectrum (MS) represents the slowly varyingcomponents of the spectrum and is extracted as described in [26]. Those features have been proven morerobust to noise and reverberation compared to the MFCC in speech recognition tasks. Furthermorethey have been shown to provide also speaker related information in [27].
• FDLP features – Frequency Domain Linear Prediction (FDLP) provides a smoothed approximationto the temporal envelope of a signal [28], [25]. FDLP is performed over sub-bands of audio signal overa large time window (typically one second), that yields a parametric model of the temporal envelope.Short term spectral integration is performed over smoothed envelope and short term spectral energiesare converted to 19 dimensional short term cepstrum like features. A gain normalization step isapplied to the linear prediction. Those features have been shown to increase robustness in case ofspeech recorded in reverberant conditions [25],[24].
The performance of the algorithms are evaluated using Diarization Error (DER), official metric in theNIST evaluations [2]. DER consists of speech/non-speech error and speaker error. We use the samespeech/non-speech segmentation with a speech/non-speech error of 5.2% across all the experiments. Henceonly speaker error is reported in this paper.
The comparison will cover conventional MFCC+TDOA features (referred in the following as two streamscombination) and MFCC + TDOA + MS + FDLP features (referred in the following as four streamscombination). Since the sum of weights is unity, the problem of weight selection has one degree of freedomfor two feature streams (MFCC+TDOA), while in case of four feature streams (MFCC+TDOA+MS+FDLP)the problem has three degrees of freedom.
To study the performances of the diarization systems on the evaluation data, independently of any weightestimation scheme or development data, we propose two different types of oracle experiments referred asmeeting-wise oracle and global oracle. The meeting-wise oracle is the best possible weighting that yields theminimum speaker error for each meeting. It provides the best meeting-wise performance using the featurecombination scheme. This is obtained by varying the individual feature weights Pl between zero and one
7

Table 1: List of meetings used for evaluation in the paper with associated number of microphones. Those have been used forpurposes of NIST evaluations [2]
sl.no. meeting id #microphones1 CMU 20050912-0900 22 CMU 20050914-0900 23 CMU 20061115-1030 34 CMU 20061115-1530 35 EDI 20050216-1051 166 EDI 20050218-0900 167 EDI 20061113-1500 168 EDI 20061114-1500 169 NIST 20051024-0930 710 NIST 20051102-1323 711 NIST 20051104-1515 712 NIST 20060216-1347 713 TNO 20041103-1130 1014 VT 20050408-1500 415 VT 20050425-1000 716 VT 20050623-1400 417 VT 20051027-1400 4
such that∑
l Pl = 1 for each meeting m and selecting the set of weight values that minimize the speakererror. This results in a set of weights {Pm
l } for each meeting recording.The global oracle is the best possible set of weights across all meetings that corresponds to the least
diarization error in the dataset. In other words, the same set of weights is applied to all the meetings. Thisis obtained by varying the individual features weights Pl between zero and one such that
∑
l Pl = 1. Theset of values {Pl} that minimizes the speaker error for the entire data set is selected.
The oracle experiments on the evaluation dataset permit the study of the two systems under the idealweighting that minimizes the speaker error. The comparison between meeting-wise and global oracles couldprovide insights about the robustness of the diarization respect to the feature weighting. These studies arepresented in Section 7.
The actual combination weights are estimated by minimizing the error on a separate development dataset. The development dataset used for parameter tuning consists of ten meetings recorded across 5 differentmeeting rooms and is the same as described in [13]. It contains data recorded in multiple meeting roomswith varying number of microphones representative of the test data set. In Section 8, results using estimatedweights are presented and compared to those obtained using oracle weights.
7. Oracle Experiments
Table 2 presents the results of oracle experiments on two as well as four feature streams for theHMM/GMM system. The meeting-wise oracle weights are depicted in Figure 1. The global oracle weightsare given by (Pmfcc, Ptdoa) = (0.96, 0.04) in case of two stream combination and (Pmfcc, Ptdoa, Pms, Pfdlp) =(0.88, 0.01, 0.01, 0.10) in case of four streams.
Table 2 shows that the use of four streams can improve the diarization error from 5.1% to 2.1% in case ofmeeting-wise oracle weights and from 9.2% to 6.7% in case of global oracle weights. This corresponds to animprovement of 60% relative in the first case and 30% relative in the second. Furthermore, when the oracleweights are chosen globally, i.e., same weights are used across all the meetings, the performance degradesby more than 4% absolute in both two and four feature stream cases.
8

0 2 4 6 8 10 12 14 16 18
10−4
10−3
10−2
10−1
100
101
−−meeting id→
−−
Ptd
oa→
mtgwise oracle HMM/GMMmtgwise oracle IB
10−2
10−1
10−3
10−2
10−1
10−3
10−2
10−1
−−Ptdoa
→−−Pms
→
−−
Pfd
lp→
mtgwise oracle HMM/GMM
mtgwise oracle IB
(a) (b)
Figure 1: Feature weights that corresponds to lowest speaker error for each meeting (meeting-wise oracle) (a) 2 stream combi-nation and (b) Four feature combination; The plots report both cases of HMM/GMM and IB.
Table 2: Speaker error for HMM/GMM system in case of two (MFCC+TDOA) and four (MFCC+TDOA+MS+FDLP) featurestreams computed using meeting-wise and global oracle weights.
meeting-wise oracle global oracle2 features 5.1 9.24 features 2.1 6.7
Let us now consider the Information Bottleneck (IB) system described in section 4. As before, weconsider the meeting-wise and global oracle performances reported in Table 3. Results show that the useof four streams can improve the diarization error from 5.8% to 2.8% in case of meeting-wise oracle weightsand from 7.9% to 4.6% in case of global oracle weights. This corresponds to a improvement of 50% relativein the first case and 40% relative in the second. The meeting-wise oracle weights are depicted in Figure 1.The global oracle weights are given by (Pmfcc, Ptdoa) = (0.85, 0.15) in case of two stream combination and(Pmfcc, Ptdoa, Pms, Pfdlp) = (0.45, 0.15, 0.15, 0.25) in case of four streams. When the oracle weights arechosen globally, i.e., with same weights for all the meetings, the performances degrade by 2% in both twoand four feature stream case.
Table 3: Speaker error for IB system in case of two (MFCC+TDOA) and four (MFCC+TDOA+MS+FDLP) stream combina-tions computed using meeting-wise and global oracle weights
meeting-wise oracle global oracle2 features 5.8 7.94 features 2.8 4.6
Comparing the IB system with the HMM/GMM (Tables 2 and 3), it is possible to notice that:
• The meeting-wise oracle results are similar for the two systems, the HMM/GMM slightly outperformingthe IB.
• When the meeting-wise oracle weights are replaced with global oracle weights the HMM/GMM systemdegrades by 4% absolute while the IB system degrades only by 2%. This is verified both in case oftwo and four stream systems.
9

0 2 4 6 8 10 12 14 16 180
5
10
15
20
25
30
35
40
45
50
−− meeting id →
−−
spk
r er
r →
HMM/GMM System − 2 features
meeting wise oracleglobal oracle
0 2 4 6 8 10 12 14 16 180
5
10
15
20
25
30
35
40
45
50
−− meeting id →
−−
spk
r er
r →
IB System − 2 features
meeting wise oracleglobal oracle
(a) (b)
Figure 2: Comparison of meeting-wise oracle (feature weights that minimize speaker error for each meeting) performance withthe global oracle performance (same feature weights across all meetings that minimize the overall speaker error) in case of twostream combination (a) HMM/GMM system (b) IB system
0 2 4 6 8 10 12 14 16 180
5
10
15
20
25
30
−− meeting id →
−−
spk
r er
r →
HMM/GMM System − 4 features
meeting wise oracleglobal oracle
0 2 4 6 8 10 12 14 16 180
5
10
15
20
25
30
−− meeting id →
−−
spk
r er
r →
IB System − 4 features
meeting wise oracleglobal oracle
(a) (b)
Figure 3: Comparison of meeting-wise oracle (feature weights that minimize speaker error for each meeting) performance withthe global oracle performance (same feature weights across all meetings that minimize the overall speaker error) for four featurestream combination (a) HMM/GMM system (b) IB system
Figure 1 plots the set of meeting-wise oracle weights for IB and HMM/GMM systems in case of (a)two and (b) four feature streams. The best per-meeting weights span a larger dynamic range in case ofHMM/GMM system. On the other hand, most of the weights are in similar range in case of the IB system.Furthermore Figure 2 plots the speaker error for the 17 meetings when weights are chosen by meeting-wiseoracle and by global oracle in case of two streams for (a) the HMM/GMM and (b) IB systems. Similar graphsare plotted in case of four feature streams in Figure 3. It can be noticed that, in case of HMM/GMM, the useof a global weights instead of meeting-wise weights degrades the performance considerably (meeting ids 5, 6,7, 8, 13 - EDI and TNO - see Table 1). The reason of this effect can be found in the combination scheme thatthe two systems implement. In case of HMM/GMM, the combination happens at log-likelihood level (seeEquation 4) where an independent GMM is estimated for each feature stream. Figure 4 plots the average log-likelihoods computed using GMMs estimated from the four different streams (MFCC, TDOA, MS, FDLP).While features with constant dimensionality (MFCC, MS, FDLP) produce constant log-likelihood ranges
10

0 2 4 6 8 10 12 14 16 1810
0
101
102
103
−− meeting id →
−−
neg
log
likel
ihoo
d →
2 2
2 2
1515 15 15
7
7
7 7
9
4
7
3
2
mfcctdoamsfdlp
Figure 4: Negative log-likelihoods for different feature streams across all meetings. The numbers adjacent to the delay featuresdenotes the feature dimension. It can be seen that the likelihood range of delay features varies across different meetings.Meetings with higher delay feature dimension (meetings 5-8) have highest value for negative log likelihoods
across meetings, TDOA features, whose dimensionality depends on the number of microphones, produceconsiderably varying log-likelihood ranges. This would cause the meeting-wise oracle weights to changesignificantly in case of HMM/GMM (see Figure 1) and the performance of global-oracle (same weightingfixed for all meetings) degrades a lot for certain recordings (e.g. EDI and TNO where arrays are composedof 16 and 10 microphones - see Figure 2,3 and Table 1). This is verified both in case of two and four featurestreams.
In case of IB diarization, individual background GMMs are estimated as described in Section 5. Theindividual relevance variable distributions p(y|slt) are then computed. The feature combination happens inthe space of relevance variables. Since individual distributions are normalized, problems associated withdiverse statistics of features are avoided. This explains that meeting-wise oracle weights have similar ranges(see Figure 1) and that the performance of global-oracle degrades comparatively less w.r.t. the HMM/GMMsystem (see Figure 2,3). This is verified both in case of two and four feature streams.
Let us further study the sensitivity of the speaker error as a function of the individual weights. Thesensitivity is defined as the standard deviation of speaker error when each pair of weights are simultaneouslyperturbed from their oracle value by ±0.05 (so that the sum is unity) for 2 feature streams. If the errorchanges considerably, the standard deviation will be high. The same definition then is extended for the 4feature streams. Figure 5 illustrates the speaker error sensitivity for the two systems at meeting level. Itcan be observed that the standard deviation in case of HMM/GMM system is higher as compared to the IBsystem for several recordings, i.e., the speaker error varies more in case of HMM/GMM system when thefeature weights are perturbed from their oracle values. The log-likelihood combination is more sensitive incase of certain meetings (5,6,7,13) with larger number of microphones. In other words, besides degrading theperformances, those meetings appear more sensitive to weights variations, i.e., changing slightly the weightsfrom their oracle values produces large changes in the final error.
The oracle experiments furthermore reveal another issue with four streams optimization (MFCC,TDOA, MS and FDLP) where the problem has three degrees of freedom. Since, the four weights(Pmfcc, Ptdoa, Pms, Pfdlp) lie in a three dimensional subspace (
∑
l Pl = 1), the speaker error can be vi-sualized by fixing one of the weights and plotting as a function of the other two. For instance, Figure 6illustrates the speaker error on the evaluation data set in the neighborhood of global minimum for the IBsystem 6(a) and for the HMM/GMM system 6(b). It can be seen that the speaker error function of theweights has multiple local minima, i.e., several different weightings produce similar low speaker error.
11

0 2 4 6 8 10 12 14 16 180
5
10
15
20
25
−− meeting id →
−−
std
dev
. →
HMM/GMM
IB
Figure 5: Comparison of the speaker error sensitivity w.r.t. feature stream weights in the neighborhood of the global oracle.The HMM/GMM system is more sensitive than the IB system especially on recordings with a larger number of microphones.
00.1
0.20.3
0.4
0
0.1
0.2
0.3
0.46
7
8
9
10
11
12
13
−− Pms
→−− Pfdlp
→
−−
spk
r er
r →
00.05
0.10.15
0.2
00.05
0.10.15
0.27
8
9
10
11
12
13
14
15
16
−− Pms
→−− Pfdlp
→
−−
spk
r er
r →
(a) (b)
Figure 6: Speaker error as a function of feature stream weights in the neighborhood of global minimum. The plots areobtained fixing Ptoda at the global minimum value and plotting the remaining two dimensions for (a) the IB system and (b)the HMM/GMM systems
8. Estimated combination weights
This section investigates the case in which the combination weights are estimated from the developmentdata set described in section 6. Typically this is obtained by varying feature weights Pl between 0 and 1such that
∑
l Pl = 1 and selecting the weights as those that minimize the diarization error on the separate
development data set.In case of two feature streams (MFCC and TDOA), the problem has just one degree of freedom and the
speaker error is a smooth function which presents a well defined minimum (e.g., see [6] Figure 8, and [29]Figure 1). The estimated weights are (Pmfcc, Ptdoa) = (0.9, 0.1) for the HMM/GMM and (Pmfcc, Ptdoa) =(0.7, 0.3) for the IB system.
In case of four feature streams (MFCC, TDOA, MS and FDLP), the problem has three degrees offreedom. Similarly to what noticed before, the speaker error on the development data set contains againmultiple local minima. This does not allow for any straightforward choice. In order to overcome this issue,a simple smoothing procedure which averages in neighboring points the errors on the development data
12

set is proposed. The error smoothing is used in order to move the weights towards low error regions of thehyper-plane rather than low error points, thus avoiding local minima. The speaker errors with such obtainedweights are reported in Table 4.
Table 4: Comparison of speaker error : selecting the feature stream weights based on minimum value of smoothed speakererror obtained on development data set.
HMM/GMM IB2 features 12.4 11.64 features 14.9 6.3
Table 5: Comparison of speaker error : selecting the feature stream weights based on minimum value of speaker error obtainedon development data set (without any smoothing).
HMM/GMM IB2 features 12.4 11.64 features 16.5 8.9
Results show that:
• The IB outperforms the HMM/GMM system, the difference being only 0.8% in case of two featuresand 8.6% in case of four features.
• Both systems have obviously inferior performance than the respective oracles, the difference beinglarger in case of HMM/GMM.
• IB can benefit from the use of four different feature streams reducing the error from 11.6% to 6.3%while in case of HMM/GMM the performance degrades by 2%, i.e., from 12.4% to 14.9%.
Figure 7 plots the individual meetings speaker error in case of global oracle and estimated weights forthe four streams HMM/GMM and the IB system. Again it can be noticed that the most of the HMM/GMMdegradation with respect to the global oracle comes from meetings with large number of microphones (EDIand TNO see Table 1) which presents higher speaker error sensitivity (see Figure 5).
In order to investigate the effect of the smoothing on the development speaker error, Table 5 reportsthe results obtained without such a smoothing. It can be noticed that the smoothing does not alter resultsin case of two feature streams, in fact the error function on the development data has a single minimumwhich is not altered by the smoothing. Furthermore the smoothing improves the results both in case ofHMM/GMM and IB.
9. Computational Complexity
This section analyzes the complexity of the HMM/GMM and IB diarization systems. Both systemsfollow an agglomerative clustering framework. This requires calculation of a distance measure betweenevery pair of clusters. In case of HMM/GMM system, this distance measure is given by the modifiedBIC criterion. Computing BIC involves the estimation of a Gaussian Mixture Model (GMM) using theExpectation Maximization algorithm. In case of multiple feature streams, a new GMM model needs tobe estimated for each feature stream per each BIC computation (see Equation 4), thus increasing thecomputational complexity.
In contrast to this, the IB system estimates a background GMM only once and then the combinationhappens in the space of relevance variable distributions (Equation 15). The distance measure in this spaceis based on a Jensen-Shannon divergence (Equation 7) that can be computed in close form. This calculationdoes not depend on the number of feature streams, since the dimension of relevance variables depends only
13

0 2 4 6 8 10 12 14 16 180
10
20
30
40
50
60
−− meeting id →
−−
spk
r er
r →
HMM/GMM System − 4 features
global oracleestimated wts
0 2 4 6 8 10 12 14 16 180
5
10
15
20
25
30
35
40
45
50
−− meeting id →
−−
spk
r er
r →
IB System − 4 features
global oracleestimated wts
(a) (b)
Figure 7: Comparison of the global oracle performance (same feature weights across all meetings that minimize the overallspeaker error) and estimated weights performance in case of four feature stream combination for the (a) HMM/GMM system(b) IB system.
Table 6: Algorithm time used by different steps - relevance distribution estimation, agglomerative clustering, KL realignment- in terms of real time factors for the IB system
estimate IB KLp(y|x) clustering realign
2 feat 0.24 0.08 0.094 feat 0.52 0.09 0.11
on the number of components of the background GMM models. Thus, once the combined distribution p(y|x)is estimated, computational complexities of clustering and realignment steps stay the same.
The algorithm complexities are bench-marked on a normal desktop Machine (AMD AthlonTM
64x2 Dualcore processor 2.6 GHz, 2GB RAM). The run-time of algorithms are averaged across different meetings andmultiple iterations. Table 6 reports the real time factors of various steps for IB diarization algorithm. Themajority of the algorithm time ( roughly 60% in case of two features and 70% in case of four features) isspent in estimating the relevance variable distributions. The clustering and realignment complexities stayalmost constant with the addition of new features.
Table 7 illustrates the comparison with HMM/GMM system. The proposed IB system is running in realtime and is 8 times faster than HMM/GMM system in the two streams case and around 14 times fasterin the four streams case. Addition of two feature streams slows down the HMM/GMM system by a factorof 3, while this is only 1.7 in case of IB system. Thus the IB system is computationally more efficient ascompared to the HMM/GMM.
10. Summary and Conclusions
Speaker diarization based on multiple feature streams has been an active research field over last years.Motivated by the success of the MFCC and TDOA combination, other feature streams extracted on longer
Table 7: Comparison of real time factors between IB and HMM/GMM system
HMM/GMM IB2 feats 3.8 0.414 feats 11.3 0.72
14
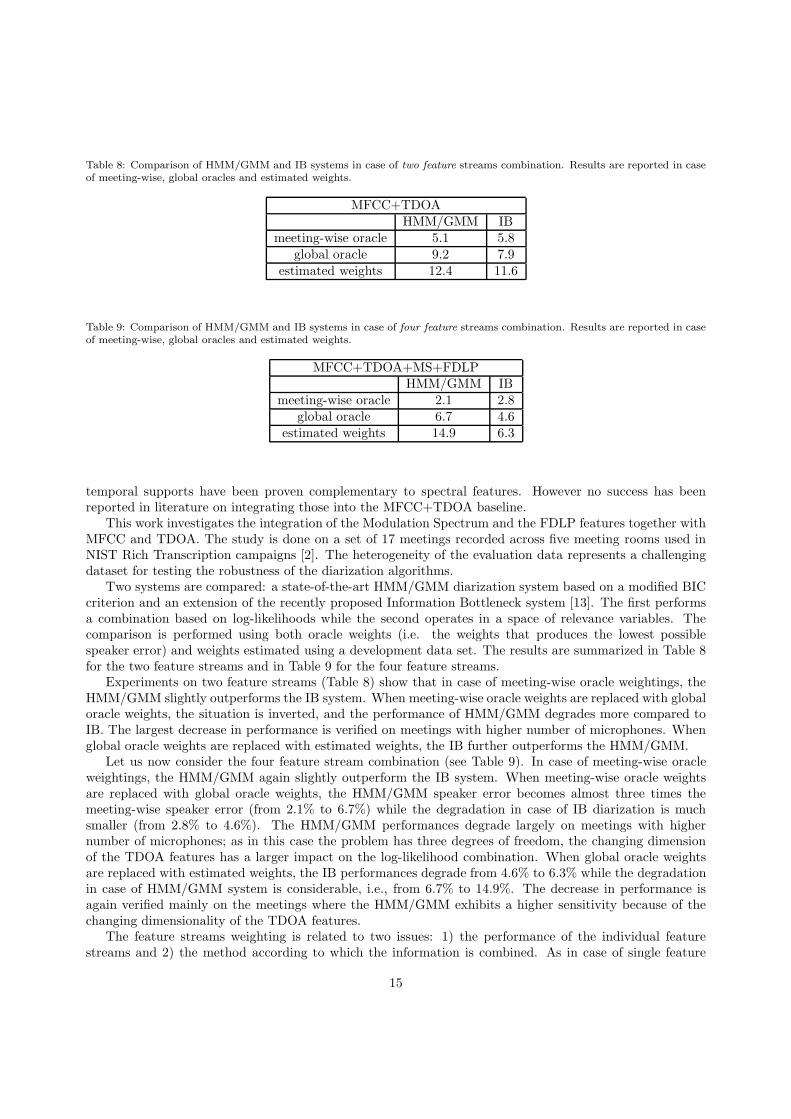
Table 8: Comparison of HMM/GMM and IB systems in case of two feature streams combination. Results are reported in caseof meeting-wise, global oracles and estimated weights.
MFCC+TDOAHMM/GMM IB
meeting-wise oracle 5.1 5.8global oracle 9.2 7.9
estimated weights 12.4 11.6
Table 9: Comparison of HMM/GMM and IB systems in case of four feature streams combination. Results are reported in caseof meeting-wise, global oracles and estimated weights.
MFCC+TDOA+MS+FDLPHMM/GMM IB
meeting-wise oracle 2.1 2.8global oracle 6.7 4.6
estimated weights 14.9 6.3
temporal supports have been proven complementary to spectral features. However no success has beenreported in literature on integrating those into the MFCC+TDOA baseline.
This work investigates the integration of the Modulation Spectrum and the FDLP features together withMFCC and TDOA. The study is done on a set of 17 meetings recorded across five meeting rooms used inNIST Rich Transcription campaigns [2]. The heterogeneity of the evaluation data represents a challengingdataset for testing the robustness of the diarization algorithms.
Two systems are compared: a state-of-the-art HMM/GMM diarization system based on a modified BICcriterion and an extension of the recently proposed Information Bottleneck system [13]. The first performsa combination based on log-likelihoods while the second operates in a space of relevance variables. Thecomparison is performed using both oracle weights (i.e. the weights that produces the lowest possiblespeaker error) and weights estimated using a development data set. The results are summarized in Table 8for the two feature streams and in Table 9 for the four feature streams.
Experiments on two feature streams (Table 8) show that in case of meeting-wise oracle weightings, theHMM/GMM slightly outperforms the IB system. When meeting-wise oracle weights are replaced with globaloracle weights, the situation is inverted, and the performance of HMM/GMM degrades more compared toIB. The largest decrease in performance is verified on meetings with higher number of microphones. Whenglobal oracle weights are replaced with estimated weights, the IB further outperforms the HMM/GMM.
Let us now consider the four feature stream combination (see Table 9). In case of meeting-wise oracleweightings, the HMM/GMM again slightly outperform the IB system. When meeting-wise oracle weightsare replaced with global oracle weights, the HMM/GMM speaker error becomes almost three times themeeting-wise speaker error (from 2.1% to 6.7%) while the degradation in case of IB diarization is muchsmaller (from 2.8% to 4.6%). The HMM/GMM performances degrade largely on meetings with highernumber of microphones; as in this case the problem has three degrees of freedom, the changing dimensionof the TDOA features has a larger impact on the log-likelihood combination. When global oracle weightsare replaced with estimated weights, the IB performances degrade from 4.6% to 6.3% while the degradationin case of HMM/GMM system is considerable, i.e., from 6.7% to 14.9%. The decrease in performance isagain verified mainly on the meetings where the HMM/GMM exhibits a higher sensitivity because of thechanging dimensionality of the TDOA features.
The feature streams weighting is related to two issues: 1) the performance of the individual featurestreams and 2) the method according to which the information is combined. As in case of single feature
15

stream, the HMM/GMM and the IB performances are similar, the first point does not explain the verydifferent weighting that the system provides and suggests that they treat the information in the same way.On the other hand, HMM/GMM and IB perform the combination in very different ways: the first using GMMlog-likelihoods, the second using relevance variable distributions. Log-likelihoods will depend on the featuredimensionality (changing in case of TDOA) and also on the feature variance (often very different betweenstreams). The optimal weighting in case of log-likelihoods will try to bring their values to comparable rangesso that no stream completely overcome the other, which explains why in case of HMM/GMM, the optimalweights are often below 0.1 (see also Figure 4 for the log-likelihoods ranges). On the other hand, relevancevariable probabilities are in the range 0 to 1, thus the optimal TDOA weighting does not have to makeany scaling to make them comparable and will only depend on their performance/complementarity. Thisis also supported by the fact that, despite of different weights, the ranking of the feature is the same forboth systems. In summary, as the log-likelihood is proportional to the dimension of the TDOA features(dependent on the number of microphones in the array), the optimal meeting-wise weights have very differentvalues (see Figure 1). This explains the performance degradations whenever they are replaced with weightsfixed across all the meetings. Furthermore this also explains the sensitivity issues, i.e. why, in those cases,a small perturbation from the oracle values can produce a large difference in performance. The IB systemperforms the combination using the probabilities of relevance variables, i.e., normalized quantities, thus isless affected from the dimensionality of the TDOA features. This lead to a smaller drop in performanceswhen moving from oracle weights to development data.
Comparing Table 9 and Table 8, it can be noticed that the HMM/GMM can benefit from the use fourfeature streams only whenever oracle weightings is used; changing oracle weights with actually estimatedweights degrades the results. On the other hand, the IB approach is able to benefit from other sources ofinformation even when weights are estimated on development data set and exhibit a smaller sensitivity tochanges in those weighting.
To the authors’ best knowledge, this is the first successful attempt to further reduce the speaker errorincorporating other features along with the MFCC and TDOA. The speaker error obtained with estimatedweights by the IB system (6.3%) is a very competitive result compared to what reported in literature on thesame task. The paper also explains through a set of oracle experiments the shortcomings of GMM modelingfor diarization in case of four feature streams.
Furthermore, the computational requirements of HMM/GMM and IB systems are compared in terms ofreal time factors for the two stream as well as four stream feature combination. The experimental outcomesreport that the IB system is significantly faster than the HMM/GMM system and is able to achieve realtime diarization even with four input feature streams.
Thus the IB system provides a robust method to integrate multiple features beyond MFCC and TDOAfor speaker diarization producing a very low speaker error with limited increase in computation complexity.This makes the system appealing for processing large amounts of meeting recordings.
Acknowledgements
The authors would like to thank colleagues involved in the AMI and IM2 projects, Dr. John Dines(IDIAP) and Samuel Thomas (Johns Hopkins University) for their help with this work as well as theanonymous reviewers for their comments. This work was funded by the Swiss Science Foundation throughIM2 grant, by the EU through SSPnet grant and by the Hasler foundation through the SESAME grant.
References
[1] S. Tranter and D. Reynolds, “An overview of automatic speaker diarisation systems,” IEEE Transactions on Audio,Speech and Language Processing, vol. 14, pp. 1557–1565, September 2006.
[2] “http://www.nist.gov/speech/tests/rt/rt2006/spring/,” .[3] Jitendra Ajmera, Robust Audio Segmentation, Ph.D. thesis, Ecole Polytechnique Federale de Lausanne (EPFL), 2004.[4] Xavier Anguera, Robust Speaker Diarization for Meetings, Ph.D. thesis, Universitat Politecnica de Catalunya, 2006.[5] J.M. Pardo, X. Anguera, and C. Wooters, “Speaker diarization for multi-microphone meetings: Mixing acoustic features
and inter-channel time differences,” in International Conference on Speech and Language Processing, 2006.
16

[6] J.M. Pardo, X. Anguera, and C. Wooters, “Speaker Diarization For Multiple-Distant-Microphone Meetings Using SeveralSources of Information,” IEEE Transactions on Computers, vol. 56, no. 9, pp. 1212–1224, 2007.
[7] X. Anguera, C. Wooters, B. Peskin, and M. Aguilo, “Robust speaker segmentation for meetings: The ICSI-SRI spring2005 diarization system,” Lecture Notes in Computer Science, vol. 3869, pp. 402, 2006.
[8] C. Wooters and M. Huijbregts, “The ICSI RT07s speaker diarization system,” Lecture Notes in Computer Science, vol.4625, pp. 509–519, 2008.
[9] D.A. van Leeuwen and M. Konecny, “Progress in the AMIDA speaker diarization system for meeting data,” MultimodalTechnologies for Perception of Humans: International Evaluation Workshops Clear 2007 and Rt 2007, Baltimore, MD,USA, May 8-11, 2007, Revised Selected Papers, p. 475, 2008.
[10] O. Vinyals and al., “Modulation spectrogram features for speaker diarization,” in Proceedings of Interspeech, 2008.[11] G. Friedland and al., “Prosodic and other Long-Term Features for Speaker Diarization,” IEEE Transactions on Audio,
Speech, and Language Processing, vol. 17, no. 5, pp. 985–993, 2009.[12] A.K. Noulas and B. Krose, “On-line multi-modal speaker diarization.,” Proceedings of ICMI, pp. 350–357, 2007.[13] D. Vijayasenan and al., “An information theoretic approach to speaker diarization of meeting data,” IEEE Transactions
on Audio, Speech and Language Processing, vol. 17, no. 7, pp. 1382 – 1393, 2009.[14] J. Ajmera, I. McCowan, and H. Bourlard, “Robust speaker change detection,” Signal Processing Letters, IEEE, vol. 11,
no. 8, pp. 649–651, 2004.[15] S.S. Chen and P.S. Gopalakrishnan, “Speaker, environment and channel change detection and clustering via the bayesian
information criterion,” in Proceedings of DARPA speech recognition workshop, 1998, pp. 127–138.[16] Naftali Tishby, F.C. Pereira, and W. Bialek, “The information bottleneck method,” in NEC Research Institute TR, 1998.[17] Noam Slonim, The Information Bottleneck: Theory and Applications, Ph.D. thesis, The Hebrew University of Jerusalem,
2002.[18] Noam Slonim, N. Friedman, and Naftali Tishby, “Agglomerative information bottleneck,” in Proceedings of Advances in
Neural Information Processing Systems. MIT Press, 1999, pp. 617–623.[19] P. Harremoes and N. Tishby, “The Information bottleneck revisited or how to choose a good distortion measure,” in
IEEE International Symposium on Information Theory, 2007. ISIT 2007, 2007, pp. 566–570.[20] D. Vijayasenan and al., “KL realignment for speaker diarization with multiple feature streams,” in 10th Annual Conference
of the International Speech Communication Association, 2009.[21] Guillermo Aradilla, Acoustic Models for Posterior Features in Speech Recognition, Ph.D. thesis, Ecole Polytechnique
Federale de Lausanne, Lausanne , Switzerland, 2008.[22] X. Anguera, C. Wooters, and J. H. Hernando, “Speaker diarization for multi-party meetings using acoustic fusion,” in
Proceedings of Automatic Speech Recognition and Understanding, 2006, pp. 426–431.[23] X. Anguera, “Beamformit, the fast and robust acoustic beamformer,” in
http://www.icsi.berkeley.edu/xanguera/BeamformIt, 2006.[24] S. Ganapathy and al., “Front-end for far-field speech recognition based on frequency domain linear prediction,” in
Proceedings of INTERSPEECH, Brisbane, Australia, 2008.[25] S. Thomas and al., “Recognition of Reverberant Speech Using Frequency Domain Linear Prediction,” IEEE Signal
Processing Letters, vol. 15, pp. 681–684, 2008.[26] B Kingsbury, N Morgan, and S Greenberg, “Robust speech recognition using the modulation spectrogram,” Speech
Communication, vol. 25, pp. 117132, 1998.[27] T Kinnunen and al., “Dimension reduction of the modulation spectrogram for speaker verification,” in Proc. Odyssey:
The Speaker and Language Recognition Workshop, Stellenbosch, South Africa, 2008.[28] M. Athineos and al., “Frequency-domain linear prediction for temporal features,” in Proceedings of IEEE Workshop on
Automatic Speech Recognition and Understanding, ASRU ’03., 2003.[29] D. Vijayasenan and al., “Integration of TDOA Features in Information Bottleneck Framework for Fast Speaker Diariza-
tion,” in Interspeech 2008, 2008.
17





























