Embed Size (px)
Citation preview

Quantitative Structure-Activity RelationshipsQuantitative Structure-Property-RelationshipsQuantitative Structure Property Relationships
SAR/QSAR/QSPR modeling
Alexandre VarnekAlexandre VarnekFaculté de Chimie, ULP, Strasbourg, FRANCE

SAR/QSAR/QSPR models
• Development• Validation• Application• Application

Classification and Regression models
• Development• Validation• Application• Application

Development of the models• Selection and curation of experimental data• Preparation of training and test sets (optionaly)
S l ti f i iti l t f d i t d th i• Selection of an initial set of descriptors and their normalisation
• Variables selection (optionally)Variables selection (optionally)• Selection of a machine-learning method
Validation of models• Training/test set• Training/test set• Cross-validation
- internal,- external
Application of the Modelspp• Models Applicability Domain

Development the models
• Experimental Data: selection and cleaning• Descriptors• Descriptors • Mathematical techniques• Statistical criteria

Data selection: Congenericity problem g y p
• Congenericity principle is the assumption that « similarcompounds give similar responses ». This was the basic
i t f QSAR Thi t t llrequirement of QSAR. This concerns structurallyhomogeneous data sets.
• Nowdays, experimentalists mostly produce structurallydiverse (non-congeneric) data setsdiverse (non congeneric) data sets

Data cleaning:g
• Similar experimental conditions• Dublicates• Structures standardization• Removal of mixtures• …..

The importance of Chemical Data Curation
Dataset curation is crucial for any cheminformatics analysis (QSARmodeling, clustering, similarity search, etc.).
Currently, it is uncommon to describe procedures used for curationin research papers; procedures are implemented or employedin research papers; procedures are implemented or employeddifferently in different groups.
We wish to emphasize the need to create and popularizestandardized curation strategy, applicable for any ensemble ofcompoundscompounds.

What about these structures? (real examples)

Why duplicates are unsafe for QSAR ?Duplicates are identical compounds present in a given dataset.p p p g
CH3
HOCH3
OH
CH3
H3C
OH
3
CH3
OH
CH3H3C
CH3OH
CH3
OH
ID = 256 ID = 879 ID = 2346
Manual identification of duplicates is practically impossible especially when the dataset is large.
ID = 256 ID = 879 ID = 2346
Activity analysis of duplicates is also highly important to identify cases where one occurrence isidentified as ‘active’ and another one as ‘weak active’ or ‘inactive’.
CH3
HO
OH
CH3
OH
CH3
H3C
H3C
CH3OHACTIVE INACTIVE

Structural standardizationFor a given dataset chemical groups have to be written in a standardized way taking
Aromatic compounds
For a given dataset, chemical groups have to be written in a standardized way, takinginto account critical properties (like pH) of the modeled system.
OH OH
These two different representations of the same
Cl Cl
These two different representations of the samecompound will lead to different descriptors, especiallywith certain fingerprint or fragmental approaches.
Carboxylic acids, nitro groups etc.
CH3 CH3
NOO
N+OHOOHO OO O–O
N
X
N
XX X X
For a given dataset, these functional groups have to be written in a consistent way toavoid different descriptor values for the same chemical group.

Normalization of carboxylic, nitro groups, etc.

removal of inorganics
All inorganic compounds must be removed since our QSARmodeling strategy includes the calculation of moleculardescriptors for organic compounds only.p g p y
This is an obvious limitation of the approach. However the total fraction ofinorganics in most available datasets is relatively small.
To detect inorganics, several solutions aregavailable:
- Automatic identification using incombination Jchem (ChemAxon cxcalccombination Jchem (ChemAxon, cxcalcprogram) to output the empirical formulaof all compounds and simple scripts toremove compounds with no carbon;
- Manual inspection of compoundspossessing no carbon atom usingNotepad++ toolsNotepad++ tools.

removal of mixtures
Fragments can be removed according to the number of constitutive atoms or the molecular weight.

However, some cases are particularly difficult to treat.
removal of mixtures, p y
ID=172
Examples from DILI - BIOWISDOM dataset:
ID=172
CLEANED FORM BY CHEMAXONThe two eliminated compounds could be active !
ID=1700
INITIAL FORM .
MANUAL INSPECTION/VALIDATION IS STILL CRUCIAL
ID=1700
INITIAL FORMCLEANED FORM BY CHEMAXON Ok.

removal of salts
Options Remove Fragments, Neutralize and Transform of Chemaxon Standardizer. have to be used simultaneously for best results.y

Aromatization and 2D cleaningCh A St d di ff t t ti b iChemAxon Standardizer offers two ways to aromatize benzene rings,both of them based on Hűckel’s rules.
“General Style”General Style
CH3
NH
O
OH
NH
“Basic Style”
CH3 O
OH
NH
Most descriptor calculationk i th “b ipackages recognize the “basic
style” only.http://www.chemaxon.com/jchem/marvin/help/sci/aromatization-doc.html


Preparation of training and test sets
Building of structure -property models
Selection of the best models according to t ti ti l it i
Trai
statistical criteria Splitting of an initial data set into training
ining set
Initial
and test sets
data set
Test “Prediction” calculations using the best structure -
10 – 15 %
gproperty models

Recommendations to prepare a test setRecommendations to prepare a test set
• (i) experimental methods for determination of activities in the training and test sets should be similar;and test sets should be similar;
• (ii) the activity values should span several orders of magnitude, but ( ) y p gshould not exceed activity values in the training set by more than 10%;
(iii) th b l b t ti d i ti d h ld b• (iii) the balance between active and inactive compounds should be respected for uniform sampling of the data.
References: Oprea, T. I.; Waller, C. L.; Marshall, G. R. J. Med. Chem. 1994, 37, 2206-2215

Descriptors
• Variables selction• Normalization• Normalization
descriptorsle
cule
sm
ol
Pattern matrixPattern matrix

Selection of descriptors for QSAR model
QSAR models should be reduced to a set of descriptors which is QSAR models should be reduced to a set of descriptors which is as information rich but as small as possible.as information rich but as small as possible.
Objective selection (independent variable only) Objective selection (independent variable only) Statistical criteria of correlations Statistical criteria of correlations PairwisePairwise selection (Forward or Backward Stepwise selection) selection (Forward or Backward Stepwise selection) Principal Component AnalysisPrincipal Component Analysisp p yp p yPartial Least Square analysisPartial Least Square analysisGenetic AlgorithmGenetic Algorithm
……………….……………….
Subjective selection Subjective selection Descriptors selection based on mechanistic studiesDescriptors selection based on mechanistic studiesDescriptors selection based on mechanistic studiesDescriptors selection based on mechanistic studies

Preprocessing strategy for the derivation of modelsfor use in structure-activity relationships (QSARs)y p (Q )
1. identify a subset of columns (variables) with significantcorrelation to the response; 2 remove columns (variables) with zero (small) variance;2. remove columns (variables) with zero (small) variance; 3. remove columns (variables) with no unique information; 4. identify a subset of variables on which to construct a model; 5 address the problem of chance correlation5. address the problem of chance correlation.
D. C. Whitley, M. G. Ford, D. J. LivingstoneJ. Chem. Inf. Comput. Sci. 2000, 40, 1160-1168

Descriptors Normalisation
*(1/ )n
s
descriptors
2 * 2(1/ ) ( )n
1
(1/ )j iji
m n x
olec
ules
2 * 2
1
(1/ ) ( )j ij ji
s n x m
mo
Pattern matrix*
ij ij jx x m Normalisation 1 (Unit Variance scaling):
Pattern matrix
No malisation 2 (Mean Cent ing Scaling)
*ij jx m
x
ij ij j( g)
Normalisation 2 (Mean Centring Scaling):j j
ijj
xs

Data NormalisationData Normalisation
Initial Norm 1 Norm 2Initialdescriptors
Norm. 1 Norm. 2

Machine-Learning Methods

Fitting models’ parametersg p
Y = F(ai , Xi )
Xi - descriptors (independent variables)ai - fitted parameters
The goal is to minimize Residual Sum of Squared (RSS)
N
yyRSS 2)(
i
icalci yyRSS1
,exp, )(

Multiple Linear Regressionp g
Activity Descriptor Y
Y1 X1
Y
Y2 Y2… … XYn Xn
Yi = a0 + a1 Xi1

Multiple Linear Regression
y=ax+b
Residual Sum of
b
fSquared (RSS)
N
RSS 2)(
a
i
icalci yyRSS1
2, )(

Multiple Linear Regressionp g
Activity Descr 1 Descr 2 … DescrmActivity Descr 1 Descr 2 … Descrm
Y1 X11 X12 … X1m
Y2 X21 X22 … X2m
… … … … …
Yn Xn1 Xn2 … Xnm
Yi = a0 + a1 Xi1 + a2 Xi2 +…+ am Xim

kNN (k Nearest Neighbors)
Activity Y assessment calculating a weighted mean of theactivities Yi of its k nearest neighbors in the chemical space
Descriptor 2Descriptor 2
1TRAINING SET
crip
tor 1TRAINING SET
A.Tropsha, A.Golbraikh, 2003D
esc

Biological and Artificial Ne ronBiological and Artificial Neuron

Multilayer Neural Networky
Neurons in the input layer correspond to descriptors, neurons in the output layer to properties being predicted neurons in the hidden layer to nonlinearlayer – to properties being predicted, neurons in the hidden layer – to nonlinear latent variables

SVM: Support Vector Machine
1 b0, bxw
1, bxw
1, bxw
2w
Support Vector Classification (SVC)

SVM: MarginsgThe margin is the minimal distance of any training point todistance of any training point to the separating hyperplane
1Margin
w

Support Vector Regressionpp g
ε-Insensitive Loss Function
otherwise
if
0:Only the points outside the ε-
t b li d i li otherwisetube are penalized in a linear fashion

Kernel Trick
)(),(),( xxxxK In high-dimensional feature space
In low-dimensionalinput space
Any non-linear problem (classification, regression) in the original input space can be y p ( , g ) g p pconverted into linear by making non-linear mapping Φ into a feature space with higher dimension

QSAR/QSPR models
• Development• Validation• Application• Application

Preparation of training and test sets
Building of structure -property models
Selection of the best models according to t ti ti l it i
Trai
statistical criteria Splitting of an initial data set into training
ining set
Initial
and test sets
data set
Test “Prediction” calculations using the best structure -
10 – 15 %
gproperty models

Validation
5 Fold Cross Validation
Estimation of the models predictive performance
5‐ Fold Cross Validation
All compoundsof the dataset are predicted
Dataset Fold1 Fold2 Fold5Fold3 Fold4

Leave-One Out Cross-ValidationN‐ Fold Internal Cross Validation
• Cross-validation is performed AFTER variables selection on the entire dataset.
• On each fold, the “test” set contains only 1 molecule

Statistical parameters for Regression
42

Fitti lid tiFitting vs validation
LogKpred
Stabilities (logK) of Sr2+L complexes in water
LogKcalc
6
9
12
9
12
Fit 5-CV9
12 LOO
-3
0
3
6
R2 = 0.682RMSE = 1.620
3
6
R2 = 0.886RMSE = 0.97 0
3
6
R2= 0.826RMSE = 1.20
3 6 9 12 15
3
LogKexp
0 3 6 9 12 15 0 3 6 9 12 15
All molecules were used for the model preparation
Each molecule was predicted in external CV
Each molecule was “predicted” in internal CV

Regression Error Characteristic (REC)Regression Error Characteristic (REC)
REC curves are widely used to compare of the performance of different models. The gray line corresponds to average value model (AM). For a given model, the area between AM and corresponding calculated curve reflects its quality.

Statistical parameters for Classification
Confusion Matrix

Classification Evaluation
sensitivity = true positive rate (TPR) = hit rate = recallTPR = TP / P = TP / (TP + FN) ( )
false positive rate (FPR)FPR = FP / N = FP / (FP + TN)
specificity (SPC) = True Negative Rate SPC = TN / N = TN / (FP + TN) = 1 − FPR
positive predictive value (PPV) = precisionPPV = TP / (TP + FP)
ti di ti l (NPV)negative predictive value (NPV)NPV = TN / (TN + FN)
accuracy (ACC)y ( )ACC = (TP + TN) / (P + N)
balanced accuracy (BAC)BAC (sensitivity + sensitivity ) / 2 (TP / (TP + FN) + TN / (FP + TN)) /2BAC = (sensitivity + sensitivity ) / 2 = (TP / (TP + FN) + TN / (FP + TN)) /2

Receiver Operating Characteristic (ROC)
TPR
Plot of the sensitivity vs (1 − specificity) for a binary classifier system as its discrimination thresholdsystem as its discrimination threshold is varied.
The ROC can also be representedThe ROC can also be represented equivalently by plotting the fraction of true positives (TPR = true positive
) h f i f f l i irate) vs the fraction of false positives (FPR = false positive rate).
Ideally, Area Under Curve (AUC) => 1
FPR

ROC (Receiver Operating Characteristics)
100% TP FP0 1 2 3 a b c d
FN TN0 1 2 3
4 5 6 7 8 9
a b c d
e f g h i j
FN TN0 1 2 3
4 5 6 7 8 9 e f g h i j
Ideal model:TP%
02
58a c
gjAUC=0.84
Ideal model:AUC=1.00
1 2
346
7
8
9
b c
d
e fh
Useless model:AUC=0.50
0% 100%
7 9ei
0% 100%FP%

When a model is accepted ?
Regression Models Classification Models
3 classes
Determination coefficient R2 > R02 BA > 1/q for q classes
49
Here, R02 = 0.5

“Chance correlation” problem“Chance correlation” problem
2,000 1
1,500 0 751,500 0.75
1,000 0.5
198019751970year
1965

a model MUST be validated on new independentdata to avoid a chance correlationdata to avoid a chance correlation
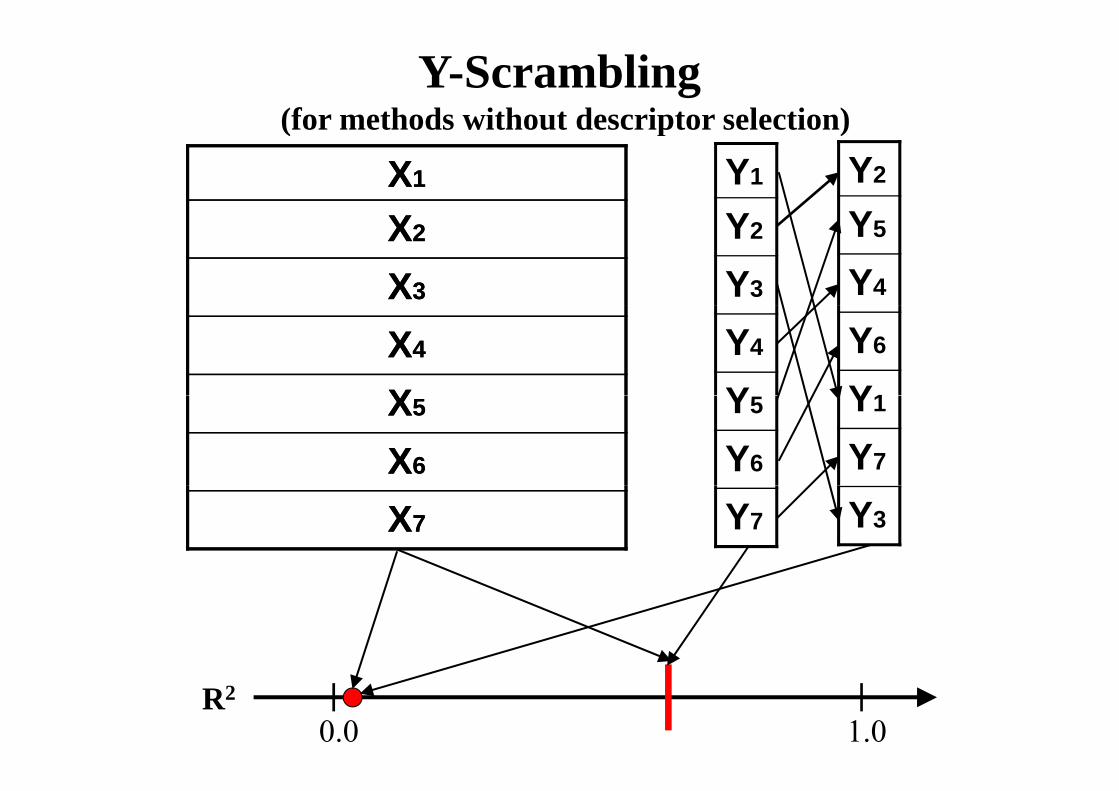
Y-Scrambling (for methods without descriptor selection)(for methods without descriptor selection)
Y2
YY1
YX1
XX1
X Y5
Y4
Y2
Y3
X2
X3
X2
X3
Y6
Y1
Y4
YX4
XX4
X Y1
Y7
Y5
Y6
X5
X6
X5
X6
Y3Y7X7X7
R2
0.0 1.0

Y-Scrambling (for methods without descriptor selection)(for methods without descriptor selection)
Y4
YY1
YX1
XX1
X Y1
Y5
Y2
Y3
X2
X3
X2
X3
Y2
Y6
Y4
YX4
XX4
X Y6
Y3
Y5
Y6
X5
X6
X5
X6
Y7Y7X7X7
R2
0.0 1.0

Y-Scrambling (for methods without descriptor selection)(for methods without descriptor selection)
Y7
YY1
YX1
XX1
X Y6
Y3
Y2
Y3
X2
X3
X2
X3
Y5
Y4
Y4
YX4
XX4
X Y4
Y1
Y5
Y6
X5
X6
X5
X6
Y2Y7X7X7
R2
0.0 1.0

QSAR/QSPR models
• Development• Validation• Application• Application

QSPR Models Test compound
Prediction Performance
Q p
R b t f QSPR d l A li bilit d i f d l
Is a test compound similarto the t i i t
- Descriptors type;- Descriptors selection;
Robustness of QSPR models Applicability domain of models
to the training setcompounds?
Descriptors selection;- Machine-learning methods;- Validation of models.

Applicability domain of QSAR models
Descriptor 2 The new compound will be predicted bythe model, only if :
Di ≤ <Dk> + Z × skwith Z, an empirical parameter (0.5 by default)
y
Descriptor 1TRAINING SET
= TEST COMPOUNDDescriptor 1
OUTSIDE THE DOMAININSIDE THE DOMAIN
Will be predictedWill not be predicted

Applicability Domain ApproachesApplicability domain of QSAR models
Fragment –based methods
C ( C)
Density based methods
Fragment Control (FC)
Model’s Fragment Control
(MFC)
1-SVM
(MFC)
Distance –based methods Range –based methods
zkNN Bounding Box (BB)

Ensemble modelingg

Hunting season …
Single hunter

Hunting season …
Many hunters

Ensemble modelling

Ensemple modelingp g
Y1 Y2 Y3
Consensus = n
Y1Consensus
iiYn 1

Screening and hits selection
Database
Screening and hits selection
O
VirtualSreeningN
OH
ClCOOH
Br gN
NOH
Hits
NOH
COOH
QSPR model
U l
ExperimentalT t
OBr
Uselesscompounds
Tests






![Emerging patterns mining and automated detection of contrasting ...infochim.u-strasbg.fr/CS3_2016/Conferences/Comm CS3 2016_Lepa… · Case study (I): Structural alerts [12] Bissell-Siders](https://img.dokumen.tips/doc/110x75/5f97ca090069562ede52ae75/emerging-patterns-mining-and-automated-detection-of-contrasting-infochimu-cs3.jpg)






















