Embed Size (px)
Citation preview

Interpretable R-CNN
Tianfu Wu1,3, Xilai Li1, Xi Song, Wei Sun1, Liang Dong2 and Bo Li4
Department of ECE1 and CS2, and the Visual Narrative Cluster3, North Carolina State UniversityYunOS BU, Alibaba Group4
{tianfu wu, xli47, wsun12, ldong6}@ncsu.edu, {xsong.lhi, boli.lhi}@gmail.com
Abstract
This paper presents a method of learning qualitativelyinterpretable models in object detection using populartwo-stage region-based ConvNet detection systems (i.e.,R-CNN) [22, 61, 9, 26]. R-CNN consists of a regionproposal network and a RoI (Region-of-Interest) predic-tion network.By interpretable models, we focus on weakly-supervised extractive rationale generation, that is learningto unfold latent discriminative part configurations of ob-ject instances automatically and simultaneously in detec-tion without using any supervision for part configurations.We utilize a top-down hierarchical and compositional gram-mar model embedded in a directed acyclic AND-OR Graph(AOG) to explore and unfold the space of latent part con-figurations of RoIs. We propose an AOGParsing opera-tor to substitute the RoIPooling operator widely used in R-CNN, so the proposed method is applicable to many state-of-the-art ConvNet based detection systems. The AOGPars-ing operator aims to harness both the explainable rigor oftop-down hierarchical and compositional grammar modelsand the discriminative power of bottom-up deep neural net-works through end-to-end training. In detection, a bound-ing box is interpreted by the best parse tree derived fromthe AOG on-the-fly, which is treated as the extractive ratio-nale generated for interpreting detection. In learning, wepropose a folding-unfolding method to train the AOG andConvNet end-to-end. In experiments, we build on top of theR-FCN [9] and test the proposed method on the PASCALVOC 2007 and 2012 datasets with performance compara-ble to state-of-the-art methods.
1. Introduction
1.1. Motivation and Objective
Recently, dramatic success has been made through bigdata driven deep neural networks [45, 40] which advanceprediction accuracy significantly, and even outperform hu-mans in image classification tasks [27, 69]. In the lit-
An end user: Why do you predict that the two bounding boxes contain person and bicycle respectively?
Machine.: Not only are the detection scores highest among all categories I have seen in training across all candidate bounding boxes I have compared in inference, but also the parse trees are consistent with the unified model learned.
Configuration
Parse tree
Configuration
Parse tree
Figure 1. Top: Detection examples by the proposed method testedin the PASCAL VOC 2007 test dataset. In addition to predictedbounding boxes and detection scores, our method also outputs thelatent discriminative parse trees and part configurations as qual-itatively extractive rationale in detection, which are computed ina weakly-supervised way, that is only object bounding boxes areavailable in training. The parse trees are inferred on-the-fly in thespace of latent full structures represented by a top-down hierar-chical and compositional grammar model. Bottom: An imaginedconversation between the algorithm and an end user who was try-ing to understand the prediction results. See text for details. (Bestviewed in color and magnification)
erature of object detection, there has been a critical shiftfrom more explicit representation and models such as themixture of deformable part-based models (DPMs) [18]and its many variants, and hierarchical and compositionalAND-OR graphs (AOGs) models [66, 82, 73, 74], to lesstransparent but much more accurate ConvNet based ap-proaches [61, 9, 60, 50, 26, 10]. Meanwhile, it has beenshown that deep neural networks can be easily fooled byso-called adversarial attacks which utilize visually imper-ceptible, carefully-crafted perturbations to cause networksto misclassify inputs in arbitrarily chosen ways [57, 2], even
1
arX
iv:1
711.
0522
6v1
[cs
.CV
] 1
4 N
ov 2
017

……Terminal-node Feature Maps
AND-node
OR-node
Terminal-node
Image ConvNets
Region of Interest (RoI)
Interpret an RoI
Top-
down
Gra
mm
ar M
odelAND-OR Graph (AOG)
Parse Tree ConfigurationObject Detection
Figure 2. Illustration of the proposed end-to-end integration of a generic top-down grammar model represented by a directed acyclic AND-OR Graph (AOG) and bottom-up ConvNets. For clarity, we show an AOG constructed for a 3× 3 grid using the method proposed in [66]The AOG unfolds the space of all possible latent part configurations (with rectangular parts and binary split rule). We build on top ofthe R-FCN method [9]. Based on the AOG, we use Terminal-node sensitive maps and propose an AOGParsing operator to substitute theposition-sensitive RoIPooling operator in the R-FCN, which will infer the best parse tree for a RoI on-the-fly, as well as the best partconfiguration. We keep the bounding box regression branch unchanged, which is not shown in the figure for clarity. See text for details.(Best viewed in color and magnification)
with one-pixel attack [67]. And, it has also been shown thatdeep learning can easily fit random labels [80]. It is dif-ficult to analyze why state-of-the-art deep neural networkswork or fail due to the lack of theoretical underpinnings atpresent [1]. From cognitive science perspective, state-of-the-art deep neural networks might not learn and think likepeople who know and can explain “why” [43]. Neverthe-less, there are more and more applications in which predic-tion results of computer vision and machine learning mod-ules based on deep neural networks have been used in mak-ing decisions with potentially critical consequences (e.g.,security video surveillance and autonomous driving).
Prediction without interpretable justification will havelimited applicability eventually based on the intuitive factthat people could get frustrated if someone close to her/himdid something critical without convinced explanation, letalone machine systems. So, it becomes a crucial issue ofaddressing machine’s inability to explain its predicted de-cisions and actions (e.g., eXplainable AI or XAI proposed
in the DARPA grant solicitation [12]), that is to improveaccuracy and transparency jointly: Not only is an inter-pretable model capable of computing correct predictions ofa random example with very high probability, but also ra-tionalizing its predictions, preferably in a way explainableto end users. Generally speaking, learning interpretablemodels is to let machines make sense to humans, whichusually consists of many aspects. So there has not been auniversally accepted definition of the notion of model in-terpretability. Especially, it remains a long-standing openproblem to measure interpretability in a quantitative way.This paper focuses on learning qualitatively interpretablemodels in object detection. We aim to rationalize the pop-ular two-stage region-based ConvNet detection system, i.e.R-CNN [22, 61, 9] qualitatively with simple extension andwithout hurting the detection performance. Figure 1 showssome examples of the explanations computed by the pro-posed method with weakly-supervised training.

1.2. Method Overview
This paper presents a method of learning qualitativelyinterpretable models in object detection with end-to-end in-tegration of a generic top-down hierarchical and composi-tional grammar model and bottom-up ConvNets as shownin Figure 2. We adopt R-CNN [22, 61, 9] in detection,which consists of (i) A region proposal component for ob-jectness detection. Class-agnostic object bounding box pro-posals, i.e. RoIs (Region-of-Interest), are generated eitherby utilizing off-the-shelf objectness detectors such as the se-lective search [70] or by learning an integrated region pro-posal network (RPN) [61] end-to-end. (ii) A RoI predictioncomponent. It is used to classify and regress bounding boxproposals based on the RoIPooling operator. RoIPoolingcomputes equally-sized feature maps to accommodate dif-ferent shapes of the proposals. By interpretable models,we focus on weakly-supervised extractive rationale gener-ation in the RoI prediction component, that is learning tounfold latent discriminative part configurations of RoIs au-tomatically and simultaneously in detection without usingany supervision for part configurations. To that end, weutilize a generic top-down hierarchical and compositionalgrammar model embedded in a directed acyclic AND-ORGraph (AOG) [66, 74] to explore and unfold the space oflatent part configurations of RoIs (see an example in the topof Figure 2). There are three types of nodes in an AOG:an AND-node represents binary decomposition of a largepart into two smaller ones, an OR-node represents alterna-tive ways of decomposition, and a Terminal-node representsa part instance. The AOG is consistent with the general im-age grammar framework [21, 83, 17, 82]. We propose anAOGParsing operator to substitute the RoIPooling oper-ator in the R-CNN based detection systems. In detection,each bounding box is interpreted by the best parse tree de-rived from the AOG on-the-fly, which is the extractive ra-tionale generated for detection (see Figure 1).
In learning, we propose a folding-unfolding method totrain the AOG and ConvNet end-to-end. In the folding step,OR-nodes in the AOG are implemented by MEAN opera-tors (i.e., each OR-node computes the average sum of chil-dren nodes). In the unfolding step, they are implemented byMAX operators (i.e., each OR-node selects the best childnode). The folding step is to integrate out all latent partconfigurations. The unfolding step is to maximize out thelatent part configurations, explicitly inferring the best parsetree for each RoI per category, then classifying a RoI basedon the scores of the inferred parse trees. The folding stepis to ensure fair comparison between children nodes of anOR-node in the unfolding step since it is not reasonable tomake decision on selecting the best child with parametersin the AOG not trained sufficiently, especially at the begin-ning with randomly initialized parameters. The final parsetree is used as the extractive rationale for a detected object,
which is contrastive (competed with all possible part con-figurations in the AOG) and selective (only used all the partconfigurations derived from the AOG).
In experiments, we build on top of the R-FCN [9] withthe residual net [27] pretrained on the ImageNet [63] asbackbone. We test our method on the PASCAL VOC 2007and 2012 datasets with performance comparable to state-of-the-art methods. We also perform the ablation study ondifferent aspects of the proposal method.
2. Related WorkIn general, model interpretability is very difficult to char-
acterize. In the context of supervised learning, Lipton[49] investigated the motives for interpretability includingtrust [38, 62], causality [58], transferability [5] and informa-tiveness [38], and properties of interpretable models includ-ing transparency in terms of simulatability and decompos-ability and post-hoc interpretability in term of textual andvisual explanation. It remains open problems to formalizethese real-world objectives for generic purpose, which im-plies a crucial discrepancy between the widely used objec-tive functions in supervised or weakly-supervised learningand these real-world objectives.
In the literature of cognitive psychology, Lake et al [43]argued that one crucial aspect in building machines thatlearn and think like people is to build causal model ofthe world that support explanation and understanding (i.e.,learning as a form of model building), rather than merelysolving pattern recognition problems. Lombrozo and Vasi-lyeva [51] proposed that explanation and causation are in-timately related in the sense that explanations often appealto causes, and causal claims are often answers to implicit orexplicit questions about why or how something occurred.Wilkenfeld and Lombrozo [72] investigated the role of ex-planation in learning and reasoning. One of the challengesis how to build computational models of these cognitivetheories that could be used to model explanation effective-ness. From social science perspectives, Miller surveyedmore than 200 papers in social science venues related toexplainable AI and pointed out three major findings [56]:(i) Explanations are contrastive. People do not ask whyevent P happened, but rather why event P happened in-stead of some event Q. (ii) Explanations are selective. Peo-ple rarely, if ever, expect an explanation that consists of anactual and complete cause of an event. (iii) Explanations aresocial. They are a transfer of knowledge, presented as partof a conversation or interaction, and are thus presented rel-ative to the explainer’s beliefs about the explainee’s beliefs.The proposed integration of top-down grammar models canshape extractive rationale to be contrastive and selective asshown in Figure 2.
In building computer vision and machine learning sys-tems, accuracy, efficiency and transparency are usually the

three main “fighting” axes. In the early days of computervision, visual recognition was usually addressed by devel-oping sparse interpretable models such as template match-ing, syntactic pattern recognition [19] and visual Geons [4],but suffered from the well-known semantic gap in han-dling appearance and structural variations. More broadly,in the early days of AI, reasoning methods were usuallylogic and symbolic. These early rule-based systems cangenerate theorem proving types of interpretable justifica-tions [64, 68, 32, 41, 71], but were much less effective, tooexpensive to build and too brittle against the complexitiesof the real world. With recent advances in computer visionand machine learning problems using big data, high-endGPUs and deep neural networks, accuracy and efficiencyof visual recognition tasks and beyond have been improvedsignificantly, which has led to an explosion of applicationsin which people’s decision making is affected critically bymachine’s prediction results. Efforts in addressing modelinterpretability w.r.t. deep neural networks can be roughlycategorized into the following two lines of work.
Interpret post-hoc interpretability of deep neural net-works by associating explanatory semantic informationwith nodes in a deep neural network. There are a vari-ety of methods including identifying high-scoring imagepatches [23, 52] or over-segmented atomic regions [62]directly, visualizing the layers of convolutional networksusing deconvolutional networks to understand what con-tents are emphasized in the high-scoring input imagepatches [79], identifying items in a visual scene and recountmultimedia events [78, 20], generating synthesized imagesby maximizing the response of a given node in the net-work [14, 44, 65] or by developing a top-down generativeconvolutional networks [54, 76], and analyzing and visual-izing state activation in recurrent networks [29, 36, 46, 16]to link word vectors to semantic lexicons or word proper-ties. On the other hand, Hendricks et al [28] extended theapproaches used to generate image captions [37, 55] to traina second deep network to generate explanations without ex-plicitly identifying the semantic features of the original net-work. Most of these methods are not model-agnostic ex-cept for [62]. More recently, the latest network dissectionwork [3] reported empirically that interpretable units arefound in representations of the major deep learning archi-tectures [40, 6, 27] for vision, and interpretable units alsoemerge under different training conditions. On the otherhand, they also found that interpretability is neither an in-evitable result of discriminative power, nor is it a prerequi-site to discriminative power. Most of these methods are notmodel-agnostic except for [62, 39]. In [39], a classic tech-nique in statistics, influence function, is used to understandthe black-box prediction in terms of training sample, ratherthan extractive rationale justification.
Learn interpretable models directly. Following the
analysis-by-synthesis principle, generative image model-ing using deep neural networks has obtained significantprogress with very vivid and sharp images synthesized sincethe breakthrough work, generative adversarial network [24],was proposed [13, 25, 8, 76, 59]. Apart from deep neuralnetworks, Lake et al [42] proposed a probabilistic programinduction model for handwritten characters that learns in asimilar fashion to what people learn and works better thandeep learning algorithms. The model classifies, parses, andrecreates handwritten characters, and can generate new let-ters of the alphabet that look right as judged by Turing-liketests of the model’s output in comparison to what real hu-mans produce. There are a variety of interpretable modelsbased on image grammar [83, 17, 48, 82], which can offerintuitive and deep explanation, but often are suffered fromdifficulties in learning model structures and recently beingoutperformed in terms of accuracy by deep neural networkssignificantly.
Spatial attention-like mechanism has been widely stud-ied in deep neural network based systems, including, butnot limited to, the seminal spatial transform network [30]which warps the feature map via a global parametric trans-formation such as affine transformation, the exploration ofglobal average pooling and class specific activation mapsfor weakly-supervised discriminative localization [81], thedeformable convolution network [10] and active convolu-tion [31], and more explicit attention based work in imagecaption and visual question answering (VQA) such as theshow-attend-tell work [77] and the hierarchical co-attentionin VQA [53]. Attention based work unfold the localizationpower of filter kernels in deep neural networks. The pro-posed end-to-end integration of the top-down full structuregrammar and bottom-up deep neural networks attempts toharness the power from both methodologies in visual recog-nition, which can be treated as hierarchical and composi-tional structure based spatial attention mechanism.
Our Contributions. This paper makes three main con-tributions to the emerging field of learning interpretablemodels as follows.
• It presents a method of integrating a generic top-downgrammar model, embedded in an AOG, and bottom-upConvNets end-to-end to learn qualitatively interpretablemodels in object detection.
• It presents an AOGParsing operator which can be usedto substitute the RoIPooling operator widely used in R-CNN based detection systems.
• It shows detection performance comparable to state-of-the-art R-CNN systems, thus provides a promisingmethod of addressing accuracy and transparency jointlyin learning deep models for object detection.
Paper Organization. The remainder of this paper is or-ganized as follows. Section 3 presents details of the pro-

posed end-to-end integration of a top-down grammar modeland ConvNets. Section 4 shows experimental results andablation study of the proposed method. Section 5 concludesthis paper with some discussions.
3. Problem Formulation
In this section, we first briefly present backgrounds onthe R-CNN detection framework [61, 9] and the construc-tion of the top-down AOG [66, 74] to be self-contained.Then, we present the end-to-end integration of AOG andConvNets, as well as the AOGParsing operator and thefolding-unfolding learning method.
3.1. Backgrounds
Background on the R-CNN Framework. The R-CNN framework consists of three components: (i) A Con-vNet backbone such as the Residual Net [27] for featureextraction, parameterized by Θ0 and shared between theregion-proposal network (RPN) and the RoI prediction net-work. (ii) The RPN network for objectness detection (i.e.,category-agnostic detection through binary classificationbetween foreground objects and background) and boundingbox regression, parameterized by Θ1. Denote by B a RoI(i.e., a foreground bounding box proposal) computed by theRPN. (iii) The RoI prediction network for classifying a RoIB and refining it, parameterized by Θ2, which utilizes theRoIPooling operator and usually use one or two fully con-nected layer(s) as the head classifier and regressor. We buildon top of the R-FCN method [9] in our experiments. In R-FCN, position-sensitive score maps are used in RoIPooling,that is to treat cells in a RoI (e.g., 7×7 cells) as object partseach of which has its own score map. The final classifica-tion is based on the majority voting after RoIPooling. Theparameters Θ = (Θ0,Θ1,Θ2) can be trained end-to-end.More details are referred to [61, 9].
Background on the AOG. In the R-CNN framework,a RoI is interpreted as a predefined flat configuration. Tolearn interpretable models, we need to explore the spaceof latent part configurations defined in a RoI. To that end,a RoI is first divided into a grid of cells as done in theRoIPooling operator (e.g., 3 × 3 or 7 × 7). Denote bySx,y,w,h and tx,y,w,h a non-terminal symbol and a termi-nal symbol respectively, both representing the sub-grid withleft-top (x, y) and width and height (w, h) in the RoI. Weonly utilize binary decomposition, either Horizontal cut orV ertical cut, when interpreting a non-terminal symbol. We
have four rules as follows,
Sx,y,w,hTermination−−−−−−−−→ tx,y,w,h (1)
Sx,y,w,h(l;↔)V er.Cut−−−−−→ Sx,y,l,h · Sx+l,y,w−l,h (2)
Sx,y,w,h(l; l) Hor.Cut−−−−−→ Sx,y,w,l · Sx,y+l,w,h−l (3)Sx,y,w,h → tx,y,w,h| (4)
Sx,y,w,h(lmin;↔)| · · · |Sx,y,w,h(w − lmin;↔)|Sx,y,w,h(lmin; l)| · · · |Sx,y,w,h(h− lmin; l)
where lmin represents the minimum side length of a validsub-grid allowed in the decomposition (e.g., lmin = 1).When instantiated, the first rule will be represented byTerminal-nodes, both the second and the third by AND-nodes, and the fourth by OR-nodes.
The top-down AOG is constructed by applying the fourrules in a recursive way [66, 74]. Denote an AOG by G =(V,E) where V = VAnd ∪ VOr ∪ VT and VAnd, VOr andVT represent a set of AND-nodes, OR-nodes and Terminal-nodes respectively, and E a set of edges. We start with V =∅ and E = ∅, and a first-in-first-out queue Q = ∅. Wecreate the root OR-node for the entire RoI (e.g., a 3×3 gridS0,0,3,3) and push it in both Q and V . While the queue Qis not empty, we first pop a node out of it, then update theAOG: If it is an OR-node, we apply the fourth rule. Weupdate both Q and V with nodes created for all valid non-terminal symbols on the right hand side which are not in Vyet. We update E with edges from the OR-node to nodes onthe right hand side. If it is an AND-node, we apply eitherthe second or the third rule depending on the type of cutassociated with the AND-node (horizontal or vertical) andupdate Q,V and E accordingly.
The top-down AOG unfolds all possible latent configu-rations. We further introduce a super OR-node whose childnodes are those OR-nodes that occupy the entire grid morethan certain threshold (e.g., 0.5). The super OR-node isused in the unfolding step of learning the AOG model tohelp find better interpretation for noisy RoIs from the RPNnetwork. Figure 2 shows the AOG constructed for a 3 × 3grid. In [66], The two child nodes of an AND-node are al-lowed to overlap up to certain ratio, which we do not use inour experiments for simplicity.
A parse tree is an instantiation of the AOG, which fol-lows the breadth-first-search (BFS) order of nodes in theAOG, selects the best child node for each encountered OR-nodes, keeps both child nodes for each encountered AND-node, and terminates at each encountered Terminal-node. Aconfiguration is generated by collapsing all the Terminal-nodes of a parse tree onto the image domain.
3.2. The Integration of AOG and ConvNets.
We now present a simple end-to-end integration of thetop-down AOG and ConvNets, as illustrated in Figure 2.

We build on top of the R-FCN method [9]. We only changeits position-sensitive RoIPooling operator to the proposedAOGParsing operator.
Consider an AOG Gh,w,lminwith the grid size being
h×w and the minimum side length lmin allowed for nodes(e.g., G3,3,1 in Figure 2). Denote by F (v) ∈ F the Terminal-node sensitive score map for a Terminal-node v ∈ VT . AllF (v)’s have the same dimensions, C ×H ×W , where theheight H and the width W are the same as those of thelast layer in the ConvNet backbone, and the channel C thenumber of classes in detection (e.g., C = 21 in the PAS-CAL VOC benchmarks including 20 foreground categoriesand 1 background). F (v)’s are usually computed through1 × 1 convolution on top of the last layer in the ConvNetbackbone. Denote by fB(v) the C-d score vector of a Ter-minal node v placed in a RoI B, which is computed byaverage pooling in the corresponding sub-grid occupied byv (in the same way that the position-sensitive RoIPoolingof R-FCN computes the score vector of a RoI grid cell).Following the depth-first search (DFS) order, the score vec-tors of Terminal-nodes are then passing through the AOG inthe forward step w.r.t. the folding-unfolding stage in learn-ing. Following the breadth-first-search (BFS) order, the bestparse tree per category for a RoI is inferred in the backwardstep in the unfolding stage, as well as the part configuration.We elaborate the forward and backward computation in thenext section.
Remark: The number of channels C of Terminal-nodescore maps can take values other than the number of classes,and we add a fully connected layer on top of the AOG topredict the class scores. We keep it simple in this paper.
3.3. The Folding-Unfolding Learning
Since the Terminal-node sensitive maps are computedwith randomly initialized convolution kernels, it is not rea-sonable to select the best child for each OR-node at the be-ginning in the forward step, and all nodes not retrieved bythe parse trees will not get gradient update in the backwardstep. So, we resort to a folding-unfolding learning strat-egy. In the folding stage, OR-nodes are implemented byMEAN operators and AND-nodes by SUM operators, thusthe AOG is actually an AND Graph and all nodes will beupdated in the backward computation. The folding stageis usually trained for one or two epochs. In the unfoldingstage, OR-nodes are implemented by element-wise MAXoperators and AND-nodes still by SUM operators, leadingto the AOGParsing operator. For notational simplicity, wewrite G for an AOG Gw,h,lmin
. In both forward and back-ward computation, all RoIs are processed at once in imple-mentation and we present the algorithms using one RoI Bfor clarity.
Forward Computation. Denote by QDFS(G) the DFSqueue of nodes in an AOG G. Forward computation (see
Forward(G,F, B, isFolding);while QDFS(G) is not empty do
Pop a node v from the QDFS(G);if v is an OR-node then
if isFolding thenfB(v) = 1
|ch(v)|∑
u∈ch(v) fB(u)
ω0(v) = 1|ch(v)|
∑u∈ch(v) ω0(u)
elsefB(v) = maxu∈ch(v) fB(u) (element-wise)iB(v) = argmaxu∈ch(v) fB(u)(element-wise)
endelse if v is an AND-node then
fB(v) =∑
u∈ch(v) fB(u)
ω0(v) =∑
u∈ch(v) ω0(u)
else if v is a Terminal-node thenCompute fB(v) in F (v) ∈ F, and ω0(v) = 1
endendNormalize the score vector of the root OR-node O;if isFolding then
fB(O) = fB(O)/ω0
elseCompute ω1 using Algorithm 2;fB(O) = fB(O)/ω1 (element-wise)
endAlgorithm 1: Forward computation with AOG.
ComputeOmega1(G, iB);for c = 0, · · · , C − 1 do
Initialize qBFS = {O} (O is the root OR-node) ;Set ω1(c) = 0;while qBFS is not empty do
Pop a node v from the qBFS ;if v is an OR-node then
Push the best child node inqBFS = qBFS ∪ {iB(v, c)}
else if v is an AND-node thenPush the two child nodes inqBFS = qBFS ∪ ch(v)
else if v is a Terminal-node thenω1(c)+ = 1
endend
endAlgorithm 2: Computing the forward normalizationweight ω1 in the unfolding stage.
Algorithm 1) is to compute score vectors for all nodes fol-lowing QDFS(G) in both folding and unfolding stages. It

AOG772 AOG551 AOG331
Figure 3. Examples of latent part configurations unfolded byAOGs. (Best viewed in color and magnification)
also computes the assignment of the best child node of OR-nodes in unfolding stage, denoted by iB(v), v ∈ VOr. In theforward step, the score vector of the root OR-node needs tobe normalized for fair comparison, especially in the unfold-ing stage where different parse trees have different num-ber of Terminal-nodes. Denote by ω0(v) the normalizationweight in the folding stage which is a scalar shared by allcategories. Denote by and ω1 the normalization weight vec-tor in the unfolding stage which is a C-d vector since dif-ferent categories might infer different best parse trees in in-terpreting an RoI B.
Backward Computation. Similarly, by changing theDFS queue to the BFS queue, we can define backward com-putation using the AOG based on Algorithm 1 for the fold-ing stage, and on Algorithm 2 for the unfolding stage.
4. ExperimentsIn this section, we present experimental results on the
PASCAL VOC 2007 and 2012 benchmarks [15]. We alsogive the ablation study on different aspects of the proposedmethod. We build on top of the R-FCN method [9], which isa fully convolutional version of R-CNN framework amongthe state-of-the-art variants of R-CNN. We implement ourmethod using the latest MXNet 1 [7]. Our source code willbe released upon publication.
Setting and Implementation Details. We conduct ex-periments with different settings: (i) Three different AOGs,G3,3,1, G5,5,1 and G7,7,2 (G7,7,1 is too slow to train, thus notreported). Note that we do not change the bounding boxregression branch in the RoI prediction except for the RoI
1https://github.com/apache/incubator-mxnet
grid size which is changed to match the AOGs. (ii) De-formable vs non-deformable AOGs. We modified the lat-est R-FCN with deformable convolution [11] (i.e. RFCN-d) and we reused the code released on the Github 2. Fordeformable AOGs, we allow Terminal-nodes deformablein computing their score vector fB(v)’s similar to the de-formable RoIPooling used in [11]. (iii) Folding vs Folding-Unfolding training procedure. We follow the same hyper-parameter setting provided in the RFCN-d source code forfair comparison: the number of epochs is 7, the learningrate starts with 0.0005 and the scheduling step is at 4.83, thewarm-up step is used with a smaller learning rate 0.00005for 1000 min-batches, and online hard-negative mining isadopted in training.
Ablation Study. The proposed integration of AOG andConvNets is simple which substitutes the original RoIPool-ing operator with the AOGParsing operator. The RoIPool-ing is computed with a predefined and fixed flat configura-tion (e.g., 7× 7 grid). The AOGParsing is computed with ahierarchical and compositional AND-OR graph constructedon top of the same grid to explore much large number of la-tent configurations. Terminal-nodes use the same operatorsas the cells in the RoIPooling. AND-nodes and OR-nodesadopt very simple operators, SUM, MEAN or element-wiseMAX. So, we expect that the proposed integration will nothurt the accuracy performance of the baseline R-CNN sys-tem, but is capable of output extractive rationale justifica-tion using the parse trees inferred on-the-fly for each de-tected object. The RoIPooling operator is a special case ofthe AOGParsing operator.
We conduct the ablation study in the PASCAL VOC2007 benchmark. Table 1 and Table 2 show the breakdownperformance and comparisons. The results show that allof the variants are comparable in terms of accuracy perfor-mance, which matches with our expectation. In terms of theextractive rationale justification, We found that AOG772 isbetter since we can observe much more diversities of latentpart configurations unfolded. For AOG551 and AOG331,the flat configurations (5 × 5 and 3 × 3) dominate (i.e., thelearning converges to the RoIPooling case) although we stillobserve a lot diversities of parse trees. Fig. 3 shows somequalitative comparisons. Figure 4 shows the learned modeland more qualitative examples.
Results. We also test the integration on the PASCALVOC 2012 benchmark with results shown in Table. 3. Wereport comparisons with the RFCN-d [9, 11] only since itis one of the state-of-the-art methods. We did not con-duct experiments on other datasets such as the MicrosoftCOCO [47] due to the short of GPU computing resource.Based on the ablation study, we think the accuracy perfor-mance will be very similar to the RFCN-d method.
2https://github.com/msracver/Deformable-ConvNets
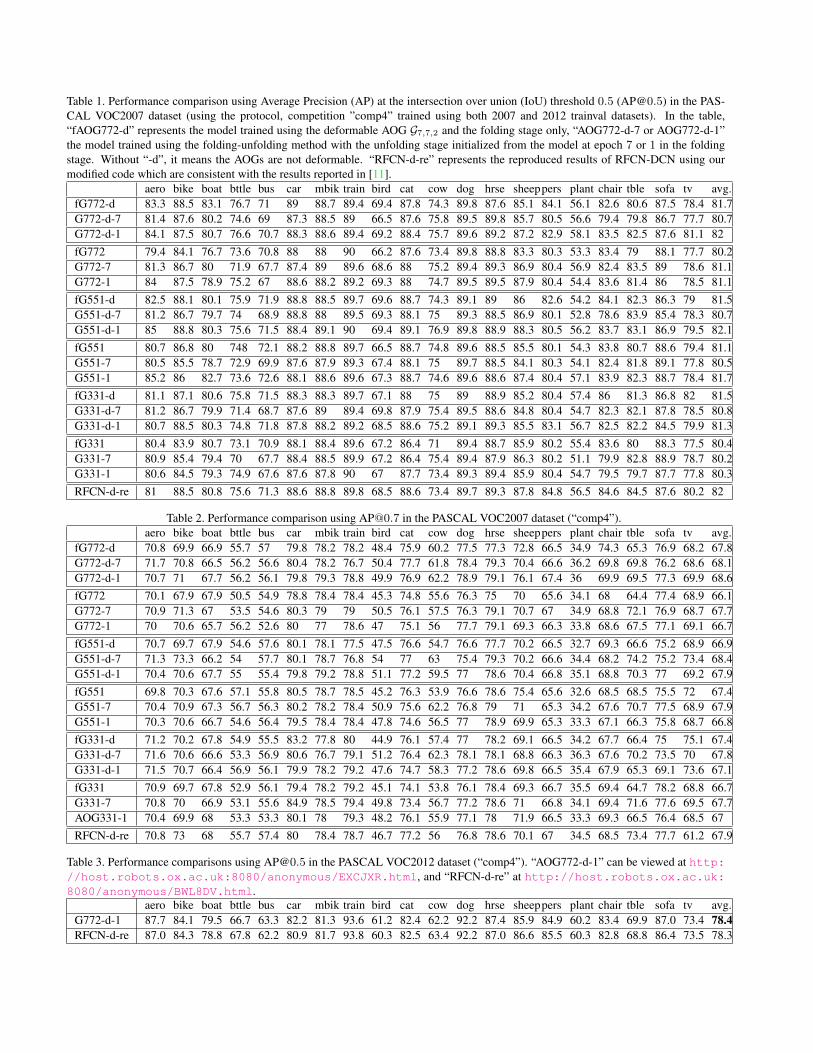
Table 1. Performance comparison using Average Precision (AP) at the intersection over union (IoU) threshold 0.5 ([email protected]) in the PAS-CAL VOC2007 dataset (using the protocol, competition ”comp4” trained using both 2007 and 2012 trainval datasets). In the table,“fAOG772-d” represents the model trained using the deformable AOG G7,7,2 and the folding stage only, “AOG772-d-7 or AOG772-d-1”the model trained using the folding-unfolding method with the unfolding stage initialized from the model at epoch 7 or 1 in the foldingstage. Without “-d”, it means the AOGs are not deformable. “RFCN-d-re” represents the reproduced results of RFCN-DCN using ourmodified code which are consistent with the results reported in [11].
aero bike boat bttle bus car mbik train bird cat cow dog hrse sheeppers plant chair tble sofa tv avg.fG772-d 83.3 88.5 83.1 76.7 71 89 88.7 89.4 69.4 87.8 74.3 89.8 87.6 85.1 84.1 56.1 82.6 80.6 87.5 78.4 81.7G772-d-7 81.4 87.6 80.2 74.6 69 87.3 88.5 89 66.5 87.6 75.8 89.5 89.8 85.7 80.5 56.6 79.4 79.8 86.7 77.7 80.7G772-d-1 84.1 87.5 80.7 76.6 70.7 88.3 88.6 89.4 69.2 88.4 75.7 89.6 89.2 87.2 82.9 58.1 83.5 82.5 87.6 81.1 82fG772 79.4 84.1 76.7 73.6 70.8 88 88 90 66.2 87.6 73.4 89.8 88.8 83.3 80.3 53.3 83.4 79 88.1 77.7 80.2G772-7 81.3 86.7 80 71.9 67.7 87.4 89 89.6 68.6 88 75.2 89.4 89.3 86.9 80.4 56.9 82.4 83.5 89 78.6 81.1G772-1 84 87.5 78.9 75.2 67 88.6 88.2 89.2 69.3 88 74.7 89.5 89.5 87.9 80.4 54.4 83.6 81.4 86 78.5 81.1fG551-d 82.5 88.1 80.1 75.9 71.9 88.8 88.5 89.7 69.6 88.7 74.3 89.1 89 86 82.6 54.2 84.1 82.3 86.3 79 81.5G551-d-7 81.2 86.7 79.7 74 68.9 88.8 88 89.5 69.3 88.1 75 89.3 88.5 86.9 80.1 52.8 78.6 83.9 85.4 78.3 80.7G551-d-1 85 88.8 80.3 75.6 71.5 88.4 89.1 90 69.4 89.1 76.9 89.8 88.9 88.3 80.5 56.2 83.7 83.1 86.9 79.5 82.1fG551 80.7 86.8 80 748 72.1 88.2 88.8 89.7 66.5 88.7 74.8 89.6 88.5 85.5 80.1 54.3 83.8 80.7 88.6 79.4 81.1G551-7 80.5 85.5 78.7 72.9 69.9 87.6 87.9 89.3 67.4 88.1 75 89.7 88.5 84.1 80.3 54.1 82.4 81.8 89.1 77.8 80.5G551-1 85.2 86 82.7 73.6 72.6 88.1 88.6 89.6 67.3 88.7 74.6 89.6 88.6 87.4 80.4 57.1 83.9 82.3 88.7 78.4 81.7fG331-d 81.1 87.1 80.6 75.8 71.5 88.3 88.3 89.7 67.1 88 75 89 88.9 85.2 80.4 57.4 86 81.3 86.8 82 81.5G331-d-7 81.2 86.7 79.9 71.4 68.7 87.6 89 89.4 69.8 87.9 75.4 89.5 88.6 84.8 80.4 54.7 82.3 82.1 87.8 78.5 80.8G331-d-1 80.7 88.5 80.3 74.8 71.8 87.8 88.2 89.2 68.5 88.6 75.2 89.1 89.3 85.5 83.1 56.7 82.5 82.2 84.5 79.9 81.3fG331 80.4 83.9 80.7 73.1 70.9 88.1 88.4 89.6 67.2 86.4 71 89.4 88.7 85.9 80.2 55.4 83.6 80 88.3 77.5 80.4G331-7 80.9 85.4 79.4 70 67.7 88.4 88.5 89.9 67.2 86.4 75.4 89.4 87.9 86.3 80.2 51.1 79.9 82.8 88.9 78.7 80.2G331-1 80.6 84.5 79.3 74.9 67.6 87.6 87.8 90 67 87.7 73.4 89.3 89.4 85.9 80.4 54.7 79.5 79.7 87.7 77.8 80.3RFCN-d-re 81 88.5 80.8 75.6 71.3 88.6 88.8 89.8 68.5 88.6 73.4 89.7 89.3 87.8 84.8 56.5 84.6 84.5 87.6 80.2 82
Table 2. Performance comparison using [email protected] in the PASCAL VOC2007 dataset (“comp4”).aero bike boat bttle bus car mbik train bird cat cow dog hrse sheeppers plant chair tble sofa tv avg.
fG772-d 70.8 69.9 66.9 55.7 57 79.8 78.2 78.2 48.4 75.9 60.2 77.5 77.3 72.8 66.5 34.9 74.3 65.3 76.9 68.2 67.8G772-d-7 71.7 70.8 66.5 56.2 56.6 80.4 78.2 76.7 50.4 77.7 61.8 78.4 79.3 70.4 66.6 36.2 69.8 69.8 76.2 68.6 68.1G772-d-1 70.7 71 67.7 56.2 56.1 79.8 79.3 78.8 49.9 76.9 62.2 78.9 79.1 76.1 67.4 36 69.9 69.5 77.3 69.9 68.6fG772 70.1 67.9 67.9 50.5 54.9 78.8 78.4 78.4 45.3 74.8 55.6 76.3 75 70 65.6 34.1 68 64.4 77.4 68.9 66.1G772-7 70.9 71.3 67 53.5 54.6 80.3 79 79 50.5 76.1 57.5 76.3 79.1 70.7 67 34.9 68.8 72.1 76.9 68.7 67.7G772-1 70 70.6 65.7 56.2 52.6 80 77 78.6 47 75.1 56 77.7 79.1 69.3 66.3 33.8 68.6 67.5 77.1 69.1 66.7fG551-d 70.7 69.7 67.9 54.6 57.6 80.1 78.1 77.5 47.5 76.6 54.7 76.6 77.7 70.2 66.5 32.7 69.3 66.6 75.2 68.9 66.9G551-d-7 71.3 73.3 66.2 54 57.7 80.1 78.7 76.8 54 77 63 75.4 79.3 70.2 66.6 34.4 68.2 74.2 75.2 73.4 68.4G551-d-1 70.4 70.6 67.7 55 55.4 79.8 79.2 78.8 51.1 77.2 59.5 77 78.6 70.4 66.8 35.1 68.8 70.3 77 69.2 67.9fG551 69.8 70.3 67.6 57.1 55.8 80.5 78.7 78.5 45.2 76.3 53.9 76.6 78.6 75.4 65.6 32.6 68.5 68.5 75.5 72 67.4G551-7 70.4 70.9 67.3 56.7 56.3 80.2 78.2 78.4 50.9 75.6 62.2 76.8 79 71 65.3 34.2 67.6 70.7 77.5 68.9 67.9G551-1 70.3 70.6 66.7 54.6 56.4 79.5 78.4 78.4 47.8 74.6 56.5 77 78.9 69.9 65.3 33.3 67.1 66.3 75.8 68.7 66.8fG331-d 71.2 70.2 67.8 54.9 55.5 83.2 77.8 80 44.9 76.1 57.4 77 78.2 69.1 66.5 34.2 67.7 66.4 75 75.1 67.4G331-d-7 71.6 70.6 66.6 53.3 56.9 80.6 76.7 79.1 51.2 76.4 62.3 78.1 78.1 68.8 66.3 36.3 67.6 70.2 73.5 70 67.8G331-d-1 71.5 70.7 66.4 56.9 56.1 79.9 78.2 79.2 47.6 74.7 58.3 77.2 78.6 69.8 66.5 35.4 67.9 65.3 69.1 73.6 67.1fG331 70.9 69.7 67.8 52.9 56.1 79.4 78.2 79.2 45.1 74.1 53.8 76.1 78.4 69.3 66.7 35.5 69.4 64.7 78.2 68.8 66.7G331-7 70.8 70 66.9 53.1 55.6 84.9 78.5 79.4 49.8 73.4 56.7 77.2 78.6 71 66.8 34.1 69.4 71.6 77.6 69.5 67.7AOG331-1 70.4 69.9 68 53.3 53.3 80.1 78 79.3 48.2 76.1 55.9 77.1 78 71.9 66.5 33.3 69.3 66.5 76.4 68.5 67RFCN-d-re 70.8 73 68 55.7 57.4 80 78.4 78.7 46.7 77.2 56 76.8 78.6 70.1 67 34.5 68.5 73.4 77.7 61.2 67.9
Table 3. Performance comparisons using [email protected] in the PASCAL VOC2012 dataset (“comp4”). “AOG772-d-1” can be viewed at http://host.robots.ox.ac.uk:8080/anonymous/EXCJXR.html, and “RFCN-d-re” at http://host.robots.ox.ac.uk:8080/anonymous/BWL8DV.html.
aero bike boat bttle bus car mbik train bird cat cow dog hrse sheeppers plant chair tble sofa tv avg.G772-d-1 87.7 84.1 79.5 66.7 63.3 82.2 81.3 93.6 61.2 82.4 62.2 92.2 87.4 85.9 84.9 60.2 83.4 69.9 87.0 73.4 78.4RFCN-d-re 87.0 84.3 78.8 67.8 62.2 80.9 81.7 93.8 60.3 82.5 63.4 92.2 87.0 86.6 85.5 60.3 82.8 68.8 86.4 73.5 78.3

AOG772-d-1
0.1204 0.00570.0957 0.15560.14030.0356 0.08190.3330
0.0012 0.00930.0164 0.04240.1109
0.00010.0152 0.0028 0.03120.0024 0.03410.0428
0.0005 0.01150.0024 0.00160.0018
0.00010.0030 0.00120.0008 0.00110.00210.0008 0.0494 0.01620.0013 0.01970.0099
0.0001 0.03540.0092 0.00270.0633
0.0103 0.0121 0.03230.0851 0.00300.0168
0.0001 0.01110.0089 0.09150.04980.0011 0.0171 0.01190.1022 0.0902
0.0002 0.0585 0.00470.0283 0.0364 0.01280.0023
0.00060.0247 0.00090.0374 0.1477
0.0004 0.0023 0.00180.0021 0.00770.0222 0.00010.0151 0.00090.0007 0.00220.0645
0.00060.0572 0.01880.0080 0.0100
0.00010.0483 0.00280.0506 0.0412 0.01770.1758
0.0005 0.0168 0.02880.0805 0.2308
0.2599
0.0014 0.06570.0443
0.5337
0.00640.0143 0.00120.0601
0.2276
0.0034 0.02470.1911
0.3055
0.0007 0.00680.0021 0.04310.0121 0.0010 0.00490.0014 0.00440.0014
0.00300.0965 0.0355
0.00030.0270 0.0031 0.02670.0349
0.0013 0.0103 0.0334
0.0005 0.0006 0.00030.0032 0.00060.0058 0.00080.0420
0.00100.0096 0.1073
0.0005 0.01030.0200 0.04460.0180
0.0029 0.0745 0.0203
0.1440
0.0007 0.02800.0138
0.0250
0.00360.0050 0.00040.0036
0.0593
0.0015 0.00270.0075
0.3542
0.0007 0.00180.0007 0.00380.0080
0.00260.0121
0.00030.0038 0.00090.0008
0.00120.0021
0.00030.0008 0.0014 0.00030.0005 0.0011
0.00090.0200
0.00030.0022 0.00060.0017
0.00180.03130.0015 0.1375
0.0006 0.0283 0.01160.0040
0.00040.0716
0.0015 0.00120.0007 0.00010.00290.0173
0.0013 0.0380
0.00060.0233 0.00320.0334
0.0027 0.0923
0.2973
0.0010 0.01430.0756
0.1241
0.00140.0105 0.00210.0071
0.0345
0.0010 0.05580.0674
0.3047
0.0015 0.0110 0.1142
0.00060.0153 0.0263 0.02330.0033
0.00060.2296 0.0143
0.0022 0.0007 0.00440.0854 0.00050.0009 0.00160.0021
0.00110.0243 0.0109
0.00100.0368 0.0072 0.00210.0116
0.0049 0.0268 0.3047
0.2670
0.0015 0.03800.0149
0.2790
0.00380.0138 0.00150.0937
0.2668
0.0022 0.02430.0867
0.3609
0.0001 0.0089 0.00170.0528 0.01370.0003 0.0011 0.00190.0085 0.00810.00120.1054 0.01390.0597 0.0178
0.24140.08560.5101 0.3103
0.0027 0.05090.0084
0.1079
0.0016 0.0023 0.00300.0487
0.1417
0.0010 0.02060.0239
0.1897 0.0707
0.0019 0.00970.0116
0.3051
0.00130.0010 0.00320.0030
0.1457
0.0013 0.01620.0406
0.0611
0.00210.0634 0.01200.00200.0079 0.07080.0010 0.02010.1055
0.04480.03030.0313 0.1458
0.0007 0.00960.0217
0.0212
0.0021 0.0038 0.0008 0.0052
0.0443
0.0008 0.01260.0041
0.3696
0.00100.00270.0010 0.00220.00210.0148 0.0027 0.07920.00080.01490.00390.0898
0.13780.14790.1577
0.00030.0273 0.01150.00090.0007 0.01190.00080.1092 0.0048
0.16000.12020.2386 0.24260.05180.1363 0.05200.09930.2563 0.02880.04850.0275
0.9682
0.0083 0.00270.0017 0.0041 0.00290.0011 0.00160.0036
0.00220.0023 0.00030.0009
Figure 4. Top: The learned AOG for the PASCAL VOC dataset (using 2007 and 2012 trainval) where class distributions are plotted for eachnode. Bottom: Examples of latent part configurations unfolded by AOGs using the learned model “AOG772-d-1”. We show one randomexample per category in VOC 2007 test dataset. (Best viewed in color and magnification)
Runtime. The runtime is mainly affected by the sizeof an AOG. Our current implementation of the AOG arenot optimized with some operators are written in Python in-stead of C/C++. “AOG772” roughly takes 0.78s per image,“AOG551” roughly takes 1.3s per image and “AOG331”roughly takes 0.25s per image. RFCN-d roughly takes0.36s per image.
Limitations and Discussions. The proposed method hastwo main limitations to be addressed in future work. First,although it can show qualitative extractive rationales in de-tection in a weakly-supervised way, it is difficult to measurethe model interpretability, especially in a quantitative way.We plan to conduct some pilot human study to measure howexplainable the parse trees could be based on crowd sourc-ing such as the Amazon Mechanic Turk. For quantitative in-terpretability, we will investigate rigorous definitions whichcan be formalized as a interpretability-sensitive loss termin end-to-end training. Second, Current implementation ofthe proposed method did not improve the accuracy perfor-
mance. We will explore new operators for AND-nodes andOR-nodes in the AOG to improve performance. We hopedetection performance will be further improved with theinterpretability-sensitive loss term integrated.
5. Conclusions and Discussions5.1. Conclusions
This paper presented a method of integrating a generictop-down grammar model with bottom-up ConvNets inan end-to-end way for learning qualitatively interpretablemodels in object detection using the R-CNN framework.It builds on top the R-FCN method and substitutes theRoIPooling operator with an AOGParsing operator to un-fold the space of latent part configurations. It proposed afolding-unfolding method in learning. In experiments, theproposed method is tested in the PASCAL VOC 2007 and2012 benchmarks with performance comparable to state-of-the-art R-CNN based detection methods. The proposed

method computes the optimal parse tree in the AOG as qual-itatively extractive rationale in “justifying” detection re-sults. It sheds light on learning quantitatively interpretablemodels in object detection.
5.2. Discussions: Quest for Learning InterpretableModels from Scratch
In our on-going work, we are studying approaches oflearning qualitatively and quantitatively interpretable mod-els built on top of the proposed method in this paper. Thekey idea is to define an objective function that accounts fortwo types of losses balanced by a trade-off parameter: Dis-criminative loss (how well does the model predict the ex-pected outputs?) and Interpretability loss (how well doesthe model explain its prediction?). Ideally, an interpretablemodel would be capable of automatically learning and cap-turing latent semantic structures which are not annotated inthe training data. We focus on capabilities of generatingextractive rationale without supervision that we think an in-terpretable model should have. We propose the followingthree desired characteristics.
Generalizability in the equivalent ensemble of a ran-dom sample x. The intuitive idea lies in two aspects: (i)For an input sample x, there are a set of transformations(such as geometric and appearance transformations includ-ing the adversarial attacks [2]) which can generate percep-tually equivalent new samples w.r.t. the label, i.e., so-calledJulesz ensemble [33, 34], denoted by J (x) (x is included).For example, many data augmentation tricks have been ex-ploited widely in training deep neural networks (such as thepopular horizontally flipping, random crops and color jitter-ing, etc) [40] and in training online object trackers [35]. (ii)If a pre-trained model f(·) was an underlying interpretableone, it is reasonable to expect that it can generalize well inJ (x), predicting the same label and comparable scores asthose of x to other new samples in J (x). To learn an inter-pretable model f(·) from scratch, the equivalent ensemblesof training samples should be taken into account.
Explainability and Sparsity in the space of latent partconfigurations of x. The intuitive idea is that an underlyinginterpretable model f(·) should focus much more on themost “meaningful” latent part configuration for a randomsample, which covers the most important underlying se-mantic regions including both intrinsic and contextual ones,not necessarily connected, of an image w.r.t. the label. Fur-thermore, the focused latent part configuration should bestable and consistent between x and other new samples inJ (x). If we could unfold the space of latent part configu-rations, which is usually huge, we can evaluate the explain-ability score in the spirit similar to the masking and scalingoperators used in [75] for evaluating information contribu-tions of bottom-up/top-down computing processes in a hi-erarchical model.
Stability of the focused latent part configurations acrossdifferent images within a category. The intuitive idea is thatthe number of distinct focused latent part configurations un-folded for different samples within a category should besmall, i.e., most of them shared among a subset of samples.
To formalize the three characteristics, one key is to ex-plore the space of latent part configurations and then ex-ploit it for rationale generation during learning interpretablemodels from scratch. To that end, the AOG used in this pa-per will be exploited.
References[1] S. Arora, A. Bhaskara, R. Ge, and T. Ma. Provable bounds
for learning some deep representations. In Proceedings ofthe 31th International Conference on Machine Learning,ICML 2014, Beijing, China, 21-26 June 2014, pages 584–592, 2014. 2
[2] A. Athalye and I. Sutskever. Synthesizing robust adversarialexamples. CoRR, abs/1707.07397, 2017. 1, 10
[3] D. Bau, B. Zhou, A. Khosla, A. Oliva, and A. Torralba. Net-work dissection: Quantifying interpretability of deep visualrepresentations. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, 2017. 4
[4] I. Biederman. Recognition-by-components: A theory of hu-man image understanding. Psychological Review, 94:115–147, 1987. 4
[5] R. Caruana, H. Kangarloo, J. D. Dionisio, U. Sinha, andD. Johnson. Case-based explanation of non-case-basedlearning methods. In Proceedings of the AMIA Symposium,American Medical Informatics Association, pages 212–215,1999. 3
[6] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman.Return of the devil in the details: Delving deep into convo-lutional nets. In British Machine Vision Conference, BMVC2014, Nottingham, UK, September 1-5, 2014, 2014. 4
[7] T. Chen, M. Li, Y. Li, M. Lin, N. Wang, M. Wang, T. Xiao,B. Xu, C. Zhang, and Z. Zhang. Mxnet: A flexible and effi-cient machine learning library for heterogeneous distributedsystems. CoRR, abs/1512.01274, 2015. 7
[8] X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever,and P. Abbeel. Infogan: Interpretable representation learn-ing by information maximizing generative adversarial nets.CoRR, abs/1606.03657, 2016. 4
[9] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: object detection viaregion-based fully convolutional networks. In NIPS, pages379–387, 2016. 1, 2, 3, 5, 6, 7
[10] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, andY. Wei. Deformable convolutional networks. CoRR,abs/1703.06211, 2017. 1, 4
[11] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, andY. Wei. Deformable convolutional networks. CoRR,abs/1703.06211, 2017. 7, 8
[12] DARPA. Explainable artificial intelligence(xai) program, http://www.darpa.mil/program/explainable-artificial-intelligence, full solicitation athttp://www.darpa.mil/attachments/ darpa-baa-16-53.pdf. 2

[13] E. L. Denton, S. Chintala, A. Szlam, and R. Fergus. Deepgenerative image models using a laplacian pyramid of adver-sarial networks. In Advances in Neural Information Process-ing Systems 28: Annual Conference on Neural InformationProcessing Systems 2015, December 7-12, 2015, Montreal,Quebec, Canada, pages 1486–1494, 2015. 4
[14] D. Erhan, Y. Bengio, A. Courville, and P. Vincent. Visu-alizing higher-layer features of a deep network. TechnicalReport 1341, University of Montreal, June 2009. Also pre-sented at the ICML 2009 Workshop on Learning Feature Hi-erarchies, Montreal, Canada. 4
[15] M. Everingham, S. M. Eslami, L. Gool, C. K. Williams,J. Winn, and A. Zisserman. The pascal visual objectclasses challenge: A retrospective. Int. J. Comput. Vision,111(1):98–136, Jan. 2015. 7
[16] M. Faruqui, J. Dodge, S. K. Jauhar, C. Dyer, E. H. Hovy,and N. A. Smith. Retrofitting word vectors to semantic lex-icons. In NAACL HLT 2015, The 2015 Conference of theNorth American Chapter of the Association for Computa-tional Linguistics: Human Language Technologies, Denver,Colorado, USA, May 31 - June 5, 2015, pages 1606–1615,2015. 4
[17] P. F. Felzenszwalb. Object detection grammars. In IEEEInternational Conference on Computer Vision Workshops,ICCV 2011 Workshops, Barcelona, Spain, November 6-13,2011, page 691, 2011. 3, 4
[18] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ra-manan. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell.,32(9):1627–1645, Sept. 2010. 1
[19] K. S. Fu and J. E. Albus, editors. Syntactic pattern recog-nition : applications. Communication and cybernetics.Springer-Verlag, Berlin, New York, 1977. 4
[20] C. Gan, N. Wang, Y. Yang, D. Yeung, and A. G. Hauptmann.Devnet: A deep event network for multimedia event detec-tion and evidence recounting. In IEEE Conference on Com-puter Vision and Pattern Recognition, CVPR 2015, Boston,MA, USA, June 7-12, 2015, pages 2568–2577, 2015. 4
[21] S. Geman, D. Potter, and Z. Y. Chi. Composition systems.Quarterly of Applied Mathematics, 60(4):707–736, 2002. 3
[22] R. Girshick. Fast R-CNN. In Proceedings of the Interna-tional Conference on Computer Vision (ICCV), 2015. 1, 2,3
[23] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea-ture hierarchies for accurate object detection and semanticsegmentation. In Proceedings of the 2014 IEEE Conferenceon Computer Vision and Pattern Recognition, CVPR ’14,pages 580–587, 2014. 4
[24] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu,D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio.Generative adversarial nets. In Advances in Neural Informa-tion Processing Systems 27: Annual Conference on NeuralInformation Processing Systems 2014, December 8-13 2014,Montreal, Quebec, Canada, pages 2672–2680, 2014. 4
[25] T. Han, Y. Lu, S. Zhu, and Y. N. Wu. Learning generativeconvnet with continuous latent factors by alternating back-propagation. CoRR, abs/1606.08571, 2016. 4
[26] K. He, G. Gkioxari, P. Dollr, and R. Girshick. Mask R-CNN.In Proceedings of the International Conference on ComputerVision (ICCV), 2017. 1
[27] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learningfor image recognition. In IEEE Conference on ComputerVision and Pattern Recognition (CVPR), 2016. 1, 3, 4, 5
[28] L. A. Hendricks, Z. Akata, M. Rohrbach, J. Donahue,B. Schiele, and T. Darrell. Generating visual explanations.In Computer Vision - ECCV 2016 - 14th European Confer-ence, Amsterdam, The Netherlands, October 11-14, 2016,Proceedings, Part IV, pages 3–19, 2016. 4
[29] M. Hermans and B. Schrauwen. Training and analysing deeprecurrent neural networks. In Advances in Neural Infor-mation Processing Systems 26: 27th Annual Conference onNeural Information Processing Systems 2013. Proceedingsof a meeting held December 5-8, 2013, Lake Tahoe, Nevada,United States., pages 190–198, 2013. 4
[30] M. Jaderberg, K. Simonyan, A. Zisserman, andK. Kavukcuoglu. Spatial transformer networks. InAdvances in Neural Information Processing Systems 28:Annual Conference on Neural Information ProcessingSystems 2015, December 7-12, 2015, Montreal, Quebec,Canada, pages 2017–2025, 2015. 4
[31] Y. Jeon and J. Kim. Active convolution: Learning theshape of convolution for image classification. CoRR,abs/1703.09076, 2017. 4
[32] W. L. Johnson. Agents that learn to explain themselves. InProceedings of the Twelfth National Conference on ArtificialIntelligence (Vol. 2), AAAI’94, pages 1257–1263, 1994. 4
[33] B. Julesz. Visual pattern discrimination. IRE Transactionsof Information Theory, 8(2):84–92, 1962. 10
[34] B. Julesz. Dialogues on Perception. MIT Press, 1995. 10[35] Z. Kalal, K. Mikolajczyk, and J. Matas. Tracking-
learning-detection. IEEE Trans. Pattern Anal. Mach. Intell.,34(7):1409–1422, July 2012. 10
[36] A. Karpathy, J. Johnson, and F. Li. Visualizing and under-standing recurrent networks. CoRR, abs/1506.02078, 2015.4
[37] A. Karpathy and F. Li. Deep visual-semantic alignments forgenerating image descriptions. In IEEE Conference on Com-puter Vision and Pattern Recognition, CVPR 2015, Boston,MA, USA, June 7-12, 2015, pages 3128–3137, 2015. 4
[38] B. Kim. Interactive and interpretable machine learningmodels for human machine collaboration. Phd dissertation,Massachusetts Institute of Technology, 2015. 3
[39] P. W. Koh and P. Liang. Understanding black-box predic-tions via influence functions. In International Conference onMachine Learning (ICML), 2017. 4
[40] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenetclassification with deep convolutional neural networks. InNeural Information Processing Systems (NIPS), pages 1106–1114, 2012. 1, 4, 10
[41] C. Lacave and F. J. Dıez. A review of explanation methodsfor bayesian networks. Knowl. Eng. Rev., 17(2):107–127,June 2002. 4
[42] B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum. Human-level concept learning through probabilistic program induc-tion. Science, 350(6266):1332–1338, 2015. 4

[43] B. M. Lake, T. D. Ullman, J. B. Tenenbaum, and S. J. Ger-shman. Building machines that learn and think like people.CoRR, abs/1604.00289, 2016. 2, 3
[44] Q. V. Le, M. Ranzato, R. Monga, M. Devin, G. Corrado,K. Chen, J. Dean, and A. Y. Ng. Building high-level fea-tures using large scale unsupervised learning. In Proceed-ings of the 29th International Conference on Machine Learn-ing, ICML 2012, Edinburgh, Scotland, UK, June 26 - July 1,2012, 2012. 4
[45] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceed-ings of the IEEE, 86(11):2278–2324, 1998. 1
[46] J. Li, X. Chen, E. H. Hovy, and D. Jurafsky. Visualizingand understanding neural models in NLP. In NAACL HLT2016, The 2016 Conference of the North American Chapterof the Association for Computational Linguistics: HumanLanguage Technologies, San Diego California, USA, June12-17, 2016, pages 681–691, 2016. 4
[47] T. Lin, M. Maire, S. J. Belongie, L. D. Bourdev, R. B.Girshick, J. Hays, P. Perona, D. Ramanan, P. Dollar, andC. L. Zitnick. Microsoft COCO: common objects in context.CoRR, abs/1405.0312, 2014. 7
[48] M. A. Lippow, L. P. Kaelbling, and T. Lozano-Perez. Learn-ing grammatical models for object recognition. In Logic andProbability for Scene Interpretation, 24.02. - 29.02.2008,2008. 4
[49] Z. C. Lipton. The mythos of model interpretability. CoRR,abs/1606.03490, 2016. 3
[50] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y.Fu, and A. C. Berg. SSD: Single shot multibox detector. InECCV, 2016. 1
[51] T. Lombrozo and N. Vasilyeva. Causal Explanation, chapterII-9, pages 416–419. Oxford University Press, 2016. 3
[52] J. Long, N. Zhang, and T. Darrell. Do convnets learn cor-respondence? In Advances in Neural Information Process-ing Systems 27: Annual Conference on Neural InformationProcessing Systems 2014, December 8-13 2014, Montreal,Quebec, Canada, pages 1601–1609, 2014. 4
[53] J. Lu, J. Yang, D. Batra, and D. Parikh. Hierarchicalquestion-image co-attention for visual question answering.In Advances in Neural Information Processing Systems 29:Annual Conference on Neural Information Processing Sys-tems 2016, December 5-10, 2016, Barcelona, Spain, pages289–297, 2016. 4
[54] Y. Lu, S. Zhu, and Y. N. Wu. Learning FRAME modelsusing CNN filters. In Proceedings of the Thirtieth AAAIConference on Artificial Intelligence, February 12-17, 2016,Phoenix, Arizona, USA., pages 1902–1910, 2016. 4
[55] J. Mao, W. Xu, Y. Yang, J. Wang, and A. L. Yuille. Deepcaptioning with multimodal recurrent neural networks (m-rnn). CoRR, abs/1412.6632, 2014. 4
[56] T. Miller. Explanation in artificial intelligence: Insights fromthe social sciences. CoRR, abs/1706.07269, 2017. 3
[57] A. M. Nguyen, J. Yosinski, and J. Clune. Deep neural net-works are easily fooled: High confidence predictions forunrecognizable images. In IEEE Conference on ComputerVision and Pattern Recognition, CVPR 2015, Boston, MA,USA, June 7-12, 2015, pages 427–436, 2015. 1
[58] J. Pearl. Causality: Models, Reasoning and Inference. Cam-bridge University Press, New York, NY, USA, 2nd edition,2009. 3
[59] A. Radford, L. Metz, and S. Chintala. Unsupervised repre-sentation learning with deep convolutional generative adver-sarial networks. CoRR, abs/1511.06434, 2015. 4
[60] J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi.You only look once: Unified, real-time object detection. InCVPR, pages 779–788, 2016. 1
[61] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: To-wards real-time object detection with region proposal net-works. In Neural Information Processing Systems (NIPS),2015. 1, 2, 3, 5
[62] M. T. Ribeiro, S. Singh, and C. Guestrin. ”why should I trustyou?”: Explaining the predictions of any classifier. CoRR,abs/1602.04938, 2016. 3, 4
[63] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh,S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein,A. C. Berg, and L. Fei-Fei. ImageNet Large Scale VisualRecognition Challenge. International Journal of ComputerVision (IJCV), 115(3):211–252, 2015. 3
[64] E. H. Shortliffe and B. G. Buchanan. A model of inexactreasoning in medicine. Mathematical biosciences, 23:351–379, 1975. 4
[65] K. Simonyan, A. Vedaldi, and A. Zisserman. Deep in-side convolutional networks: Visualising image classifica-tion models and saliency maps. CoRR, abs/1312.6034, 2013.4
[66] X. Song, T. Wu, Y. Jia, and S. Zhu. Discriminatively trainedand-or tree models for object detection. In Proceedingsof 2013 IEEE Conference on Computer Vision and PatternRecognition (CVPR), Portland, OR, USA., June 23-28, pages3278–3285, 2013. 1, 2, 3, 5
[67] J. Su, D. V. Vargas, and S. Kouichi. One pixel attack forfooling deep neural networks. CoRR, abs/1710.08864, 2017.1
[68] W. R. Swartout, C. Paris, and J. D. Moore. Explanations inknowledge systems: Design for explainable expert systems.IEEE Expert, 6(3):58–64, 1991. 4
[69] C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4,inception-resnet and the impact of residual connections onlearning. CoRR, abs/1602.07261, 2016. 1
[70] J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, andA. W. M. Smeulders. Selective search for object recognition.IJCV, 104(2):154–171, 2013. 3
[71] M. van Lent, W. Fisher, and M. Mancuso. An ExplainableArtificial Intelligence System for Small-unit Tactical Behav-ior. In National Conference on Artificial Intelligence, pages900–907, June 2004. 4
[72] D. A. Wilkenfeld and T. Lombrozo. Inference to the best ex-planation (ibe) versus explaining for the best inference (ebi).Science and Education, pages 1–19, 2015. 3
[73] T. Wu, B. Li, and S. Zhu. Learning and-or model to representcontext and occlusion for car detection and viewpoint esti-mation. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI),38(9):1829–1843, 2016. 1

[74] T. Wu, Y. Lu, and S. Zhu. Online object tracking, learningand parsing with and-or graphs. CoRR (Under minor revisionfor TPAMI), abs/1509.08067, 2015. 1, 3, 5
[75] T. Wu and S. C. Zhu. A numerical study of the bottom-up andtop-down inference processes in and-or graphs. InternationalJournal of Computer Vision (IJCV), 93(2):226–252, 2011.10
[76] J. Xie, Y. Lu, S. Zhu, and Y. N. Wu. A theory of generativeconvnet. In Proceedings of the 33nd International Confer-ence on Machine Learning, ICML 2016, New York City, NY,USA, June 19-24, 2016, pages 2635–2644, 2016. 4
[77] K. Xu, J. Ba, R. Kiros, K. Cho, A. C. Courville, R. Salakhut-dinov, R. S. Zemel, and Y. Bengio. Show, attend and tell:Neural image caption generation with visual attention. InProceedings of the 32nd International Conference on Ma-chine Learning, ICML 2015, Lille, France, 6-11 July 2015,pages 2048–2057, 2015. 4
[78] Q. Yu, J. Liu, H. Cheng, A. Divakaran, and H. S. Sawhney.Multimedia event recounting with concept based represen-tation. In Proceedings of the 20th ACM Multimedia Con-ference, MM ’12, Nara, Japan, October 29 - November 02,2012, pages 1073–1076, 2012. 4
[79] M. D. Zeiler and R. Fergus. Visualizing and understandingconvolutional networks. In Computer Vision - ECCV 2014 -13th European Conference, Zurich, Switzerland, September6-12, 2014, Proceedings, Part I, pages 818–833, 2014. 4
[80] C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals.Understanding deep learning requires rethinking generaliza-tion. 2016. 2
[81] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Tor-ralba. Learning deep features for discriminative localization.In 2016 IEEE Conference on Computer Vision and PatternRecognition, CVPR 2016, Las Vegas, NV, USA, June 27-30,2016, pages 2921–2929, 2016. 4
[82] L. Zhu, Y. Chen, Y. Lu, C. Lin, and A. L. Yuille. Max mar-gin AND/OR graph learning for parsing the human body.In 2008 IEEE Computer Society Conference on ComputerVision and Pattern Recognition (CVPR 2008), 24-26 June2008, Anchorage, Alaska, USA, 2008. 1, 3, 4
[83] S. C. Zhu and D. Mumford. A stochastic grammar of images.Foundations and Trends in Computer Graphics and Vision,2(4):259–362, 2006. 3, 4




![arXiv:1507.06550v1 [cs.CV] 23 Jul 2015katef/papers/IEF.pdfmodel fwith a ConvNet with parameters f (i.e. ConvNet weights). As the ConvNet takes I g(y t) as inputs, it has the ability](https://img.dokumen.tips/doc/110x75/5ffcc3c0280e273ad22bcce9/arxiv150706550v1-cscv-23-jul-2015-katefpapersiefpdf-model-fwith-a-convnet.jpg)
























