Embed Size (px)
Citation preview

Karl%W.%Schulz%%
Director,%Scien4fic%Applica4ons%
Texas%Advanced%Compu4ng%Center%(TACC)%
%
MVAPICH User’s Group ! August 2013, Columbus, OH
Experiences*Using*MVAPICH*in*a*Produc8on*HPC*Environment*at*TACC*

Acknowledgements
• Sponsor: National Science Foundation – NSF%Grant%#OCIH1134872%Stampede%Award,%
“Enabling,%Enhancing,%and%Extending%Petascale%Compu4ng%for%Science%and%
Engineering” – NSF%Grant%#OCIH0926574%H%“TopologyHAware%%MPI%Collec4ves%and%Scheduling”%
• Professor D.K. Panda and his
team at OSU

Outline%
• Brief%clustering%history%at%TACC%– InfiniBand%evalua4on%– MVAPICH%usage%
– Op4miza4ons%
• Stampede%
– System%overview%
– MPI%for%heterogeneous%compu4ng%
– Other%new%goodies%%

Brief%Clustering%History%at%TACC%
• Like%many%sites,%TACC%was%deploying%small%clusters%in%
early%2000%4meframe%
• First%“large”%cluster%was%Lonestar2%in%2003%– 300%compute%nodes%originally%
– Myrinet%interconnect%
– debuted%at%#26%on%Top500%• In%2005,%we%built%another%small%research%cluster:%%
Wrangler!(128%compute%hosts)%
– 24%hosts%had%both%Myrinet%and%early%IB%
– single%%24Hport%Topspin%switch%%– used%to%evaluate%price/performance%of%%
commodity%Linux%Cluster%hardware%

Early%InfiniBand%Evalua4on%
• Try%to%think%back%to%the%2004/2005%4meframe……%
– only%296%systems%on%the%Top500%list%were%clusters%
– mul4ple%IB%vendors%and%stacks%
– “mul4Hcore”%meant%dualHsocket%
– we%evaluated%a%variety%of%stacks%across%the%two%interconnects%– our!first!exposure!to!MVAPICH!(0.9.2%via%Topspin%and%0.9.5%via%
Mellanox)%
20
5 Tables
MPI Distribution
Interconnect Support
Software Revision Distributor
MPICH (ch_p4) Ethernet 1.2.6 Argonne National Lab
MPICH-GM Myrinet 1.2.6..14 Myricom (MPICH based) MPICH-MX Myrinet 1.2.6..0.94 Myricom (MPICH based)
IB-TS Infiniband 3.0/1.2.6 Topspin (MVAPICH 0.9.2) IB-Gold Infiniband 1.8/1.2.6 Mellanox (MVAPICH 0.9.5)
LAM Infiniband Myrinet Ethernet
7.1.1 Indiana University
VMI/MPICH-VMI Myrinet Ethernet 2.0/1.2.5 NCSA (MPICH based)
Table 1: Summary of the various MPI implementations and interconnect options considered in the performance comparisons.
MPICH-GM 7.05 ȝs MPICH-MX 3.25 us LAM-GM 7.77 ȝs
Myrinet
VMI-GM 8.42 ȝs IB-Gold 4.68 ȝs
IB-Topspin 5.24 ȝs Infiniband LAM-IB 14.96 ȝs MPICH 35.06 ȝs
LAM-TCP 32.63 ȝs GigE VMI-TCP 34.29 ȝs
Table 2: Zero-Byte MPI Latency Comparisons.
Example(MPI(Latency(Measurements,(circa(2005(
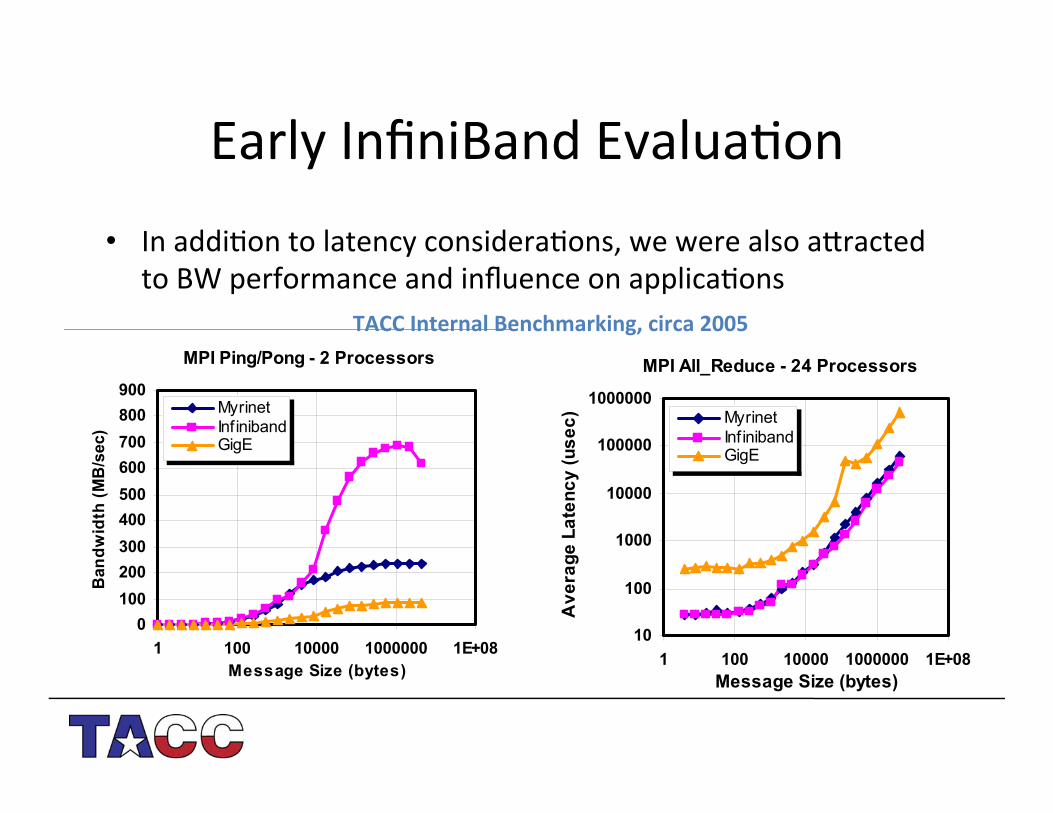
Early%InfiniBand%Evalua4on%
• In%addi4on%to%latency%considera4ons,%we%were%also%adracted%to%BW%performance%and%influence%on%applica4ons%6 Figures
MPI Ping/Pong - 2 Processors
0100
200300
400500
600700
800900
1 100 10000 1000000 1E+08Message Size (bytes)
Ban
dw
idth
(M
B/s
ec)
MyrinetInf inibandGigE
(a)
MPI Ping/Pong - 2 Processors
0
50
100
150
200
250
1 100 10000 1000000 1E+08Message Size (bytes)
Ban
dw
idth
(M
B/s
ec)
MPICH-GMMPICH-MXLAM-GMVMI-GM
(b)
MPI Ping/Pong - 2 Processors
0
100
200
300
400
500
600
700
800
1 100 10000 1000000 1E+08Message Size (bytes)
Ban
dw
idth
(M
B/s
ec)
IB-TSIB-GOLDLAM-IB
(c)
MPI Ping/Pong - 2 Processors
0102030405060708090
100
1 100 10000 1000000 1E+08Message Size (bytes)
Ban
dw
idth
(M
B/s
ec)
MPICHLAM-TCPVMI-TCP
(d)
Figure 1: MPI/Interconnect bandwidth comparisons for a Ping/Pong micro-benchmark using 2 processors: (a) Best case results for each of the three interconnects, (b) MPI Comparisons over Myrinet, (c) MPI Comparisons over Infiniband, (d) MPI Comparisons over Gigabit Ethernet.
21
MPI All_Reduce - 24 Processors
10
100
1000
10000
100000
1000000
1 100 10000 1000000 1E+08Message Size (bytes)
Ave
rage
Lat
ency
(use
c) MyrinetInf inibandGigE
(a)
MPI All_Reduce - 24 Processors
10
100
1000
10000
100000
1000000
1 100 10000 1000000 1E+08Message Size (bytes)
Ave
rage
Lat
ency
(use
c) MPICH-GMMPICH-MXLAM-GMVMI-GM
(b)
MPI All_Reduce - 24 Processors
10
100
1000
10000
100000
1000000
1 100 10000 1000000 1E+08Message Size (bytes)
Ave
rage
Lat
ency
(use
c) IB-TSIB-GOLDLAM-IB
(c)
MPI All_Reduce - 24 Processors
10
100
1000
10000
100000
1000000
1 100 10000 1000000 1E+08Message Size (bytes)
Ave
rage
Lat
ency
(use
c) MPICHLAM-TCPVMI-TCP
(d)
Figure 4: MPI/Interconnect latency comparisons for an All_Reduce micro-benchmark using 24 processors: (a) Best case results for each of the three interconnects, (b) MPI Comparisons over Myrinet, (c) MPI Comparisons over Infiniband, (d) MPI Comparisons over Gigabit Ethernet.
24
TACC(Internal(Benchmarking,(circa(2005(

Early%InfiniBand%Evalua4on%
TACC(Internal(Benchmarking,(circa(2005(
Application Scalability - WRF
0
24
68
1012
1416
18
0 10 20 30 40 5# of Processors
Spe
edU
p Fa
ctor
0
MyrinetInf inibandGigE
Figure 6: MPI/Interconnect comparisons from the Weather Research and Forecast Model (WRF).
Application Scalability - GAMESS
0
0.5
1
1.5
2
2.5
3
0 10 20 30 40 5# of Processors
Spe
edU
p Fa
ctor
0
MyrinetInf inibandGigE
Figure 7: MPI/Interconnect comparisons from the GAMESS application.
26
Application Scalability - HPL
0
5
10
15
20
25
30
35
0 10 20 30 40 5# of Processors
Spee
dUp
Fact
or
25
Figure 5: MPI/Interconnect comparisons from High Performance Linpack (HPL): (a) Best case results for each of the three interconnects, (b) MPI Comparisons over Myrinet, (c) MPI Comparisons over Infiniband, (d) MPI Comparisons over Gigabit Ethernet.
0
MyrinetInf inibandGigE
(a)
Myrinet MPI Comparisons - HPL
0
5
10
15
20
25
30
0 10 20 30 40 5# of Processors
Spe
edU
p Fa
ctor
0
MPICH-GMMPICH-MXLAM-GM
(b)
Infiniband MPI Comparisons - HPL
0
5
10
15
20
25
30
35
0 10 20 30 40 5# of Processors
Spee
dUp
Fact
or
0
IB-TSIB-GOLDLAM-IB
(c)
GigE MPI Comparisons - HPL
0
2
4
6
8
10
12
0 10 20 30 40 5# of Processors
Spee
dUp
Fact
or
0
MPICHLAM-TCPVMI-TCP
(d)

Brief%Clustering%History%at%TACC%
• Based%on%these%evalua4ons%and%others%within%the%community,%our%next%big%cluster%was%IB%based%
• Lonestar3%entered%produc4on%in%2006:%– OFED%1.0%was%released%in%June%%2006%(and%we%ran%it!)%
– First%produc4on%Lustre%file%system%%
%(also%using%IB)%
– MVAPICH%was%the%primary%MPI%stack%
– workhorse%system%for%local%and%%
na4onal%researchers,%expanded%in%2007%
%
� Debuted%at%#12%on%Top500%%

Brief%Clustering%History%at%TACC%
• These%clustering%successes%ul4mately%
led%to%our%next%big%deployment%in%
2008,%the%first%NSF%“Track%2”%system,%
Ranger:*– $30M%system%acquisi4on%
– 3,936%Sun%fourHsocket%blades%– 15,744%AMD%“Barcelona”%processors%
– All%IB%all%the%4me%(SDR)%H%no%ethernet%
• Full%nonHblocking%7Hstage%Clos%fabric%• ~4100%endpoint%hosts%• >1350%MT47396%switches%
• challenges!encountered!at!this!scale!led!to!more!interac;ons!and!collabora;ons!with!OSU!team!
� Debuted%at%#4%on%Top500%%%%

Ranger:%MVAPICH%Enhancements%%
• The%challenges%encountered%at%this%scale%led%to%more%
direct%interac4ons%with%the%OSU%team%
• Fortunately,%I%originally%met%Professor%Panda%at%IEEE%
Cluster%2007%
– original%discussion%focused%on%“mpirun_rsh”%for%which%enhancements%were%released%in%MVAPICH%1.0%
– subsequent%interac4ons%focused%on%ConnectX%collec4ve%performance,%job%startup%scalability,%SGE%integra4on,%
sharedHmemory%op4miza4ons,%etc.%
– DK%and%his%team%relentlessly%worked%to%improve%MPI%
performance%and%resolve%issues%at%scale;%helped%to%make%
Ranger%a%very%produc4ve%resource%with%MVAPICH%as%the%
default%stack%for%thousands%of%system%users%

Ranger:%MVAPICH%Enhancements%
0
200
400
600
800
1000
1200
1 10 100 1000 10000 100000 1000000 10000000
1E+08
Message Size (Bytes)
Ban
dwid
th (M
B/s
ec)
Ranger - OFED 1.2 - MVAPICH 0.9.9Lonestar - OFED 1.1 MVAPICH 0.9.8
Effec4ve%bandwidth%was%improved%
at%smaller%message%size%
Ranger(Deployment,(2008(

Ranger:%MVAPICH%Enhancements%
Ranger(Deployment,(2008(

MVAPICH%Improvements%
Ranger(Deployment,(2008(
10
100
1000
10000
100000
1000000
10000000
1 10 100 1000 10000 100000 1000000 10000000
Aver
age
Tim
e (u
sec)
.
Size (bytes)
Allgather, 256 Procs
MVAPICH MVAPICH-devel OpenMPI
1st!large!16Ccore!IB!system!available!for!MVAPICH!tuning!!

Ranger%MPI%Comparisons%
Ranger(Deployment,(2008(
1
10
100
1000
10000
100000
1 10 100 1000 10000 100000 1000000 10000000
Aver
age
Tim
e (u
sec)
Size (bytes)
Bcast, 512 Procs
MVAPICH OpenMPI
0
100
200
300
400
500
600
700
800
1 10 100 1000 10000 100000 1000000 10000000
MB
/sec
c
Size (bytes)
SendRecv, 512 Procs
MVAPICH OpenMPI OpenMPI --coll basic
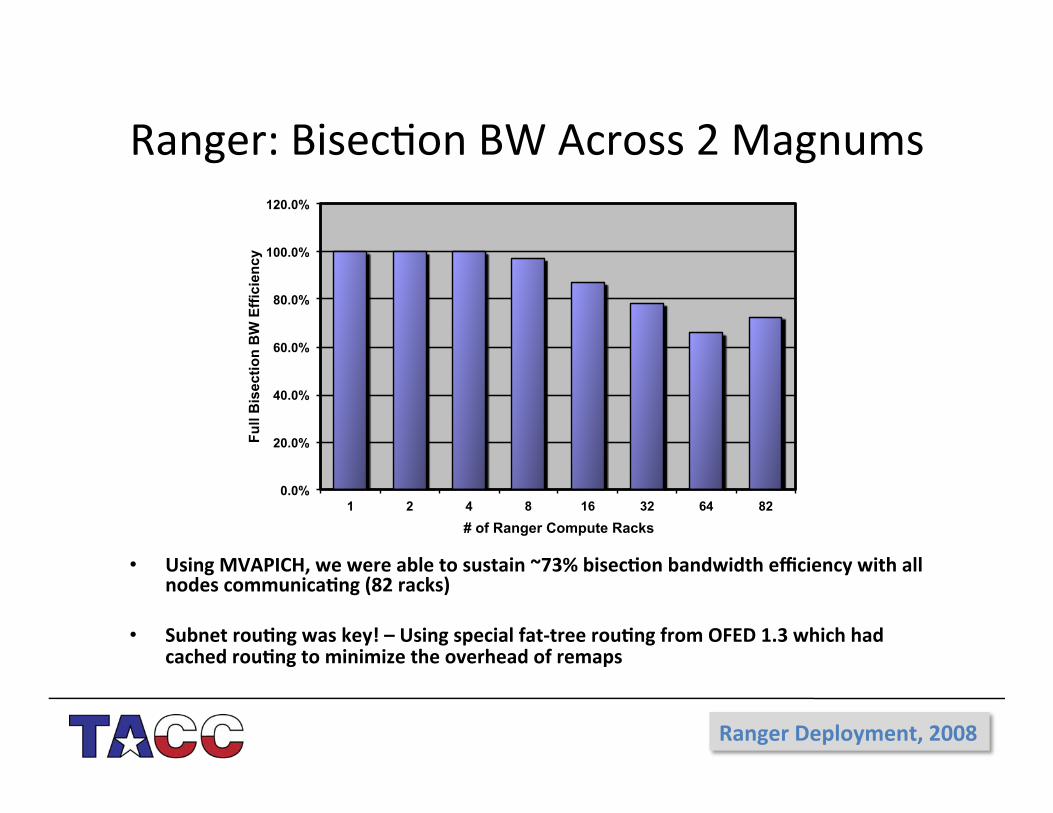
Ranger:%Bisec4on%BW%Across%2%Magnums%
• Using(MVAPICH,(we(were(able(to(sustain(~73%(bisecMon(bandwidth(efficiency(with(all(nodes(communicaMng((82(racks)(
• Subnet(rouMng(was(key!(–(Using(special(fatVtree(rouMng(from(OFED(1.3(which(had(cached(rouMng(to(minimize(the(overhead(of(remaps(
0.0%
20.0%
40.0%
60.0%
80.0%
100.0%
120.0%
1 2 4 8 16 32 64 82
Full
Bis
ectio
n B
W E
ffic
ienc
y
# of Ranger Compute Racks
Ranger(Deployment,(2008(

Clustering%History%at%TACC%
• Ranger’s%produc4on%lifespan%was%
extended%for%one%extra%year%%
– went%offline%in%January%2013%
– we%supported%both%MVAPICH%and%
MVAPICH2%on%this%resource%
• Our%next%deployment%was%Lonestar4%in%2011:%
– 22,656%Intel%Westmere%cores%
– QDR%InfiniBand%– joint%NSF%and%UT%resource%– first%TACC%deployment%with%MVAPICH2%
only%(v%1.6%at%the%4me)%
– only!real!deployment!issue!encountered!was!MPI!I/O!support!for!Lustre!
� Debuted%at%#28%on%Top500%%

Clustering%History%at%TACC*• Our%latest%largeHscale%
deployment%began%in%
2012:%Stampede!
• A%followHon%NSF%Track%2%deployment%targeted%to%
replace%Ranger!
• Includes%a%heterogeneous%compute%environment%
� %Currently%#6%on%Top500%%

Stampede%H%High%Level%Overview%
• Base%Cluster%(Dell/Intel/Mellanox):%
– Intel%Sandy%Bridge%processors%– Dell%dualHsocket%nodes%w/32GB%RAM%
(2GB/core)%
– 6,400%compute%nodes%
– 56%Gb/s%Mellanox%FDR%InfiniBand%
interconnect%
– More%than%100,000%cores,%2.2%PF%peak%
performance%
• CoHProcessors:%%
– Intel%Xeon%Phi%“MIC”%Many%Integrated%
Core%processors%
– Special%release%of%“Knight’s%Corner”%(61%cores)%
– All%MICs%were%installed%on%site%at%TACC%
– 7.3%PF%peak%performance%
• Entered*produc8on*opera8ons*on**January*7,*2013*

Stampede%Footprint%
Machine%Room%Expansion%
Added%6.5MW%of%addi4onal%power%
Ranger%Stampede%
8000%u2%
~10PF%
6.5%MW%
3000%u2%
0.6%PF%
3%MW%

Innova4ve%Component%
• One%of%the%goals%of%the%NSF%solicita4on%was%to%“introduce!a!major!new!innova;ve!capability!component!to!science!and!engineering!research!communi;es”!
• We%proposed%the%Intel%Xeon%Phi%coprocessor%(MIC%or%KNC)%
– one%first%genera4on%Phi%installed%per%host%during%ini4al%deployment%%
– in%addi4on,%480%of%of%these%6400%hosts%now%have%2%MICs/host%
– project%also%has%a%confirmed%injec4on%of%1600%future%genera4on%MICs%
in%2015%%
� Note:!base!cluster!formally!accepted!in!January,!2013.!The!Xeon!Phi!coCprocessor!component!just!recently!completed!acceptance.!
� MVAPICH!team!involved!in!both!facets!

Addi4onal%Integrated%Subsystems%
• Stampede%includes%16%1TB%Sandy%Bridge%shared%memory%nodes%with%
dual%GPUs%
• 128%of%the%compute%nodes%are%also%equipped%with%NVIDIA%Kepler%K20%
GPUs%for%visualiza4on%analysis%(and%also%include%MICs%for%performance%
bakeHoffs)%
• 16%login,%data%mover%and%management%servers%(batch,%subnet%
manager,%provisioning,%etc)%
%
• Souware%included%for%high%throughput%compu4ng,%
remote%visualiza4on%
• Storage%subsystem%(Lustre)%driven%by%Dell%H/W:%
– Aggregate%Bandwidth%greater%than%150GB/s%
– More%than%14PB%of%capacity%
%

c473%903(
c486%802(
c417%602(
c542%703(
c558%903(c547%103(
c564%401(
0"
1000"
2000"
3000"
4000"
5000"
6000"
7000"
"July" "August" "October" "November"
#"of"Com
pute"Nod
es"In
stalled"
Stampede"Ini4al"Provisioning"History"
System%Deployment%History%
Stability!tests!begin!(12/23/12)!
December% January%
Early!user!program!begins!(12/6/12)!
Ini;al!Produc;on!(1/7/13)!
HPL!!SB!+!2000!MICs!
(10/25/12)!
February% March%
Last!MIC!!Install!
(3/23/13)!
Full!System!HPL!May!2013!

Stampede InfiniBand Topology
Stampede%InfiniBand%(fatHtree)%
~75%Miles%of%InfiniBand%Cables%
8%Core%Switches%

MPI%Data%Movement%
H%Historical%Perspec4ve%Across%Plavorms%H%%Comparison%to%previous%genera4on%IB%fabrics%
0
1000
2000
3000
4000
5000
6000
7000
1 10 100
1000 10000
100000
1000000
10000000
100000000
MPI
Ban
dwid
th (M
B/s
ec)
Message Size (Bytes)
Stampede
Lonestar 4
Ranger
[FDR]!
[QDR]!
[SDR]!

What%is%this%MIC%thing?%
Basic%Design%Ideas:%
• Leverage%x86%architecture%(a%CPU%with%many%cores)%
• Use%x86%cores%that%are%simpler,%but%allow%for%more%%
compute%throughput%
• Leverage%exis4ng%x86%programming%models%
• Dedicate%much%of%the%silicon%to%floa4ng%point%ops.,%%
keep%some%cache(s)%
• Keep%cacheHcoherency%protocol%
• Increase%floa4ngHpoint%throughput%per%core%
• Implement%as%a%separate%device%
• Strip%expensive%features%(outHofHorder%execu4on,%
branch%predic4on,%etc.)%
• Widened%SIMD%registers%for%more%
%throughput%(512%bit)%
• Fast%(GDDR5)%memory%on%card%

Programming%Models%for%MIC%
• MIC%adopts%familiar%X86Hlike%instruc4on%set%(with%61%cores,244%
threads%in%our%case)%
%
• Supports%full%or%par4al%offloads%%(offload%everything%or%direc4veH
driven%offload)%
%
• Predominant%parallel%programming%model(s)%with%MPI:%– Fortran:%OpenMP,%MKL%
– C:%OpenMP/Pthreads,%MKL,%Cilk%
– C++:%OpenMP/Pthreads,%MKL,%Cilk,%TBB%
%
• Has%familiar%Linux%environment%%
– you%can%login%into%it%– you!can!run!“top”,!debuggers,!your!na;ve!binary,!etc%

Example%of%Na4ve%Execu4on%
• Interac4ve%programming%example%
– Request%interac4ve%job%(srun)%
– Compile%on%the%compute%node%
– Using%the%Intel%compiler%toolchain%
– Here,%we%are%building%a%simple%hello%world…%
• First,%compile%for%SNB%and%run%on%the%host%
– note%the%__MIC__%macro%can%be%used%to%isolate%
MIC%only%execu4on,%in%this%case%no%extra%output%is%
generated%on%the%host%
• Next,%build%again%and%add%“Hmmic”%to%ask%the%
compiler%to%crossCcompile!a%binary%for%na4ve%MIC%execu4on%%
– note%that%when%we%try%to%run%the%resul4ng%binary%
on%the%host,%it%throws%an%error%
– ssh%to%the%MIC%(mic0)%and%run%the%executable%out%
of%$HOME%directory%
– this%4me,%we%see%extra%output%from%within%the%
guarded__MIC__%macro%
login1$ srun –p devel --pty /bin/bash –l!c401-102$ cat hello.c!#include<stdio.h>!int main()!{! printf("Hook 'em Horns!\n");!!#ifdef __MIC__! printf(" --> Ditto from MIC\n");!#endif!}!!c401-102$ icc hello.c!c401-102$ ./a.out !Hook 'em Horns!!!c401-102$ icc –mmic hello.c!c401-102$ ./a.out!bash: ./a.out: cannot execute binary file!!c401-102$ ssh mic0 ./a.out!Hook 'em Horns!! --> Ditto from MIC!
Interactive Hello World

Example%of%Offload%Execu4on%
!dec$ offload target(mic:0) in(a, b, c) in(x) out(y)!!$omp parallel!!$omp single ! call system_clock(i1)!!$omp end single!!$omp do! do j=1, n! do i=1, n! y(i,j) = a * (x(i-1,j-1) + x(i-1,j+1) + x(i+1,j-1) + x(i+1,j+1)) + &! b * (x(i-0,j-1) + x(i-0,j+1) + x(i-1,j-0) + x(i+1,j+0)) + &! c * x(i,j)! enddo! do k=1, 10000! do i=1, n! y(i,j) = a * (x(i-1,j-1) + x(i-1,j+1) + x(i+1,j-1) + x(i+1,j+1)) + &! b * (x(i-0,j-1) + x(i-0,j+1) + x(i-1,j-0) + x(i+1,j+0)) + &! c * x(i,j) + y(i,j)! enddo! enddo! enddo!!$omp single ! call system_clock(i2)!!$omp end single!!$omp end parallel !!
Kernel!of!a!finiteCdifference!!stencil!code!(f90)!

Stampede%Data%Movement%
• One%of%the%adrac4ve%features%of%the%Xeon%Phi%environment%is%the%ability%to%
u4lize%MPI%directly%between%host%and%MIC%pairs%
– leverage%capability%of%exis4ng%code%bases%with%MPI+OpenMP%
– requires%extensions%to%MPI%stacks%in%order%to%facilitate%
– reacquaints%users%with%MPMD%model%as%we%need:%
• MPI%binary%for%Sandy%Bridge%
• MPI%binary%for%MIC%
– provides%many%degrees%of%tuning%freedom%for%load%balancing%%
• With%new%souware%developments,%we%can%support%symmetric%MPI%mode%runs%
• But,%let’s%first%compare%some%basic%performance…%
Intel® Xeon Phi™ Coprocessor-based Clusters Multiple Programming Models
offload
Offload
CPU Coprocessor
CPU Coprocessor
Native
CPU Coprocessor
CPU Coprocessor
Pthreads, OpenMP*, Intel® Cilk™ Plus, Intel® Threading Building Blocks used for parallelism within MPI processes
Data
Data
Data
Data
Data
Data
Symmetric
CPU Coprocessor
CPU Coprocessor
Data
Data
Data
Data
offload
New models
MPI Messages Offload data transfers
* Denotes trademarks of others
[from!Bill!Magro!!Intel!MPI!Library,!OpenFabrics!2013]!

Stampede%Data%Movement%
• Efficient%data%movement%
is%cri4cal%in%a%
heterogeneous%compute%
environment%(SB+MIC)%
• Let’s%look%at%current%
throughput%between%host%
CPU%and%MIC%using%
standard%“offload”%
seman4cs%
– bandwidth%measurements%are%likely%
what%you%would%expect%
– symmetric%data%
exchange%rates%
– capped%by%PCI%XFER%max%
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((offload)(
MIC(to(CPU((offload)(

Stampede%Host/MIC%MPI%Example%
login1$ srun –p devel -n 32 --pty /bin/bash –l!!$ export MV2_DIR=/home1/apps/intel13/ mvapich2-mic/76a7650/ !$ $MV2_DIR/intel64/bin/mpicc -O3 -o hello.host hello.c!$ $MV2_DIR/k1om/bin/mpicc -O3 -o hello.mic hello.c!!$ cat hosts!c557-503!c557-504!c557-503-mic0!c557-504-mic0!$ cat paramfile !MV2_IBA_HCA=mlx4_0!$ cat config!-n 2 : ./hello.host!-n 2 : ./hello.mic!!$ MV2_MIC_INSTALL_PATH=$MV2_DIR/k1om/ MV2_USER_CONFIG=./paramfile $MV2_DIR/intel64/bin/mpirun_rsh -hostfile hosts -config config!! Hello, world (4 procs total)! --> Process # 0 of 4 is alive. ->c557-503.stampede.tacc.utexas.edu! --> Process # 1 of 4 is alive. ->c557-504.stampede.tacc.utexas.edu! --> Process # 2 of 4 is alive. ->c557-503-mic0.stampede.tacc.utexas.edu! --> Process # 3 of 4 is alive. ->c557-504-mic0.stampede.tacc.utexas.ed!
Compila4on%
(2%binaries)%
Configura4on%
Files%
Execu4on%

Phi%Data%Movement%%
OSU!Bandwidth!Test%Intel%MPI%4.1.0.030%(Feb%2013)%
DAPL:%ofaVv2Vmlx4_0V1u((
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((offload)(MIC(to(CPU((offload)(
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((MPI)(MIC(to(CPU((MPI)(
asymmetry!undesired!for!;ghtly!coupled!scien;fic!applica;ons…!
Offload!Test!(Baseline)%

Phi%Data%Movement%(improvement)%
OSU!Bandwidth!Test%Intel%MPI%4.1.1.036%(June%2013)%
DAPL:%ofaVv2Vscif0((
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((offload)(MIC(to(CPU((offload)(
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((MPI)(MIC(to(CPU((MPI)(
Offload!Test!(Baseline)%

Phi%Data%Movement%(improvement)%
OSU!Bandwidth!Test%Intel%MPI%4.1.1.036%(June%2013)%
DAPL:%ofaVv2Vmlx4_0V1,ofaVv2VmcmV1((
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((offload)(MIC(to(CPU((offload)(
Offload!Test!(Baseline)%
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((MPI)(MIC(to(CPU((MPI)(
New!developments!to!improve!data!transfer!paths:!!• CCL!Direct!• CCLCproxy!(hybrid!provider)!

Phi%Data%Movement%(improvement)%
OSU!Bandwidth!Test%MVAPICH2%Dev%Version%(July%2013)%
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((offload)(MIC(to(CPU((offload)(
Offload!Test!(Baseline)%
New!developments!to!proxy!messages!through!HOST!
0%
1%
2%
3%
4%
5%
6%
7%
Band
width((G
B/sec)(
Data(Tranfer(Size(
CPU(to(MIC((MPI)(MIC(to(CPU((MPI)(

Addi4onal%MPI%Considera4ons%%

Job%Startup%Scalability%%
Improvements%(1%Way)%
• Less%than%20%seconds%to%
launch%MPI%
across%all%6K%
hosts%
0.1
1
10
100
1 4 16 64 256 1024 4096
Tim
e (s
ecs)
# of Hosts
1 MPI Task/Host
MVAPICH2/1.9b
Intel MPI/4.1.0.030

Job%Startup%Scalability%H%16%Way%
• Repeat%the%same%
process%with%16H
way%jobs%
• Majority%of%our%
users%use%1%MPI%
task/core%
• 2.5%minutes%to%
complete%at%32K%
(but%this%is%s4ll%
improving)%
0.1
1
10
100
1000
1 8 64 512 4096 32768
Tim
e (s
ecs)
# of Hosts
16 MPI Tasks/Host
MVAPICH/1.9b
Intel MPI/4.1.0.030

MPI%Latency%Improvements%
Host%%1%
Socket*1*XFER*
8(Host%%2%
8(
v 1.9b
v 4.1.0.030
0.6$
0.8$
1$
1.2$
1.4$
1.6$
1.8$
2$
MPI$Laten
cy$(u
secs)$
MVAPICH2$ Intel$MPI$
Host%%1%
Socket*0*XFER*
0(Host%%2%
0(
• Op4miza4ons%have%
provided%improvement%in%
newer%releases%
• Best%case%latency%at%the%moment%is%1.04%μsecs%
with%MVAPICH2%1.9%
%
• Note:%these%are%best%case%results%(core!8!to!core!8)%
OSU!Microbenchmarks!(v3.6)!
v 1.8
v 1.9b
v 1.9
v 4.1.0.016
v 4.1.0.030
v 4.1.1.036
0.6$
0.8$
1$
1.2$
1.4$
1.6$
1.8$
2$
MPI$Laten
cy$(u
secs)$
MVAPICH2$ Intel$MPI$

Performance%Characteris4cs:%%
MPI%Latencies%
• Minimum%value%approaching%
1%microsecond%latencies%
• Notes:%
– switch%hops%are%not%free%– maximum%distance%across%
Stampede%fabric%is%5%switch%
hops%
• These%latency%differences%
con4nue%to%mo4vate%our%%
topologyHaware%efforts%
#"switch"hops
Avg"Latency"(μsec)
1 1.073 1.765 2.54

Topology%Considera4ons%
• At%scale,%process%mapping%with%respect%to%topology%can%
have%significant%impact%on%applica4ons%
4x4x4(3D(Torus((Gordon,(SDSC)(FatVtree((Stampede,(TACC)(

Topology%Considera4ons%%
• Topology%query%service%(now%in%produc4on%%
on%Stampede)%H%NSF%STCI%with%OSU,%SDSC%
– caches%the%en4re%linear%forwarding%table%(LFT)%%for%each%IB%switch%H%via%OpenSM%plugin%or%
%ibnetdiscover%tools%– exposed%via%network%(socket)%interface%such%that%%
an%MPI%stack%(or%user%applica4on)%can%query%the%%
service%remotely%
– can%return%#%of%hops%between%each%host%or%%full%directed%route%between%any%two%hosts%
query c401-101:c405-101 c401-101 0x0002c90300776490 0x0002c903006f9010 0x0002c9030077c090 c405-101 %
%
0
100
200
300
400
500
600
700
64
128
256
512 1K
2K
4K
8K
Late
ncy
(us)
Number of Processes
Default Topo-Aware
Nearest%neighbor%applica4on%benchmark%
from%Stampede%[courtesy%H.%Subramoni,%SC%12]%
45%%

Stampede/MVAPICH2%Mul4cast%Features%
• Hardware%support%for%mul4Hcast%in%this%new%genera4on%of%IB%
– MVAPICH2%has%support%to%use%this%
– means%that%very%large%MPI_bcasts()%can%be%much%more%efficient%
– drama4c%improvement%with%increasing%node%count%
– factors%of%3H5X%reduc4on%at%16K%cores%
0"2"4"6"8"
10"12"14"16"18"20"
16" 64" 256" 1024" 4096" 16384"
Average'Time'(usecs)'
#'of'MPI'Tasks'
88Byte'MPI'Bcast'
Without"Mul3cast"
With"Mul3cast"
0"
5"
10"
15"
20"
25"
16" 64" 256" 1024" 4096" 16384"
Average'Time'(usecs)'
#'of'MPI'Tasks'
256:Byte'MPI'Bcast'
Without"Mul3cast"
With"Mul3cast"
Use%MV2_USE_MCAST=1%on%Stampede%to%enable%%

A%Community%Thank%You%
• DK%and%his%team%have%consistently%gone%well%above%and%beyond%
the%role%of%tradi4onal%academic%souware%providers%
• MVAPICH%has%evolved%into%produc4on%souware%that%is%
suppor4ng%science%in%virtually%all%disciplines%on%systems%around%
the%world%
• Performance%is%cri4cal%and%the%team%consistently%delivers%novel%
methods%to%improve%performance%on%fastHchanging%hardware%%
• The%openHsource%HPC%community%benefits%tremendously%from%
this%effort:%%
MPI_Send(&THANK_YOU,1000,MPI_INT,OSU,42,MPI_COMMUNITY);!