Embed Size (px)
Citation preview

Exam 2 CS x260 Name: _________________KEY__46 points__________________ I will not use a source other than my brain on this exam (not neighbors, not notes, not books, etc): ____________________________________________ (please sign)
1. Consider the data set V1 V2 V3 V4 C(lass) 1 -1 -1 1 -1 1 1 1 -1 -1 1 -1 -1 -1 -1 1 1 1 1 -1 -1 -1 1 1 1 -1 1 -1 1 1 -1 1 -1 -1 1 -1 -1 1 -1 1 a) (2 pts) Which variable, Vi, would be selected by a decision tree learner of the type described in the text/lecture as the root of the decision tree? Explain. V1 Explanation: values of V1 perfectly discriminate class, or V1 optimizes DT split measure, least entropy, or P(C= -1|V1=1) = 1.0 and P(C=1|V1= -1) = 1.0 (1 point for V1 with no, or inadequate, explanation) b) (2 pts) Give the value of P(C=1|V2=1) as computed from the data table above (i.e., as a fraction or a floating point
number; do not use pseudo-counts): Pseudo-counts were discussed in textbook, and in the second machine learning lecture P(C=1 | V2 = 1) = [C=1, V2=1]/[V2=1] = 2/4 = 0.5 (2+1)/(4+2) = 3/6 (you would get the same answer in this case with pseudo-counts) c) (2 pts) Give the value of P(C=1|V2=1, V3=1) as computed from the table above (as a fraction or a floating point number; do not use pseudo-counts): P(C=1 | V2=1, V3=1) = [C=1,V2=1,V3=1]/[V2=1,V3=1] = 0/2 = 0.0 (0+1)/(2+2) = ¼ = 0.25 (you would get a different answer in this case with pseudo-counts)
5 minutes
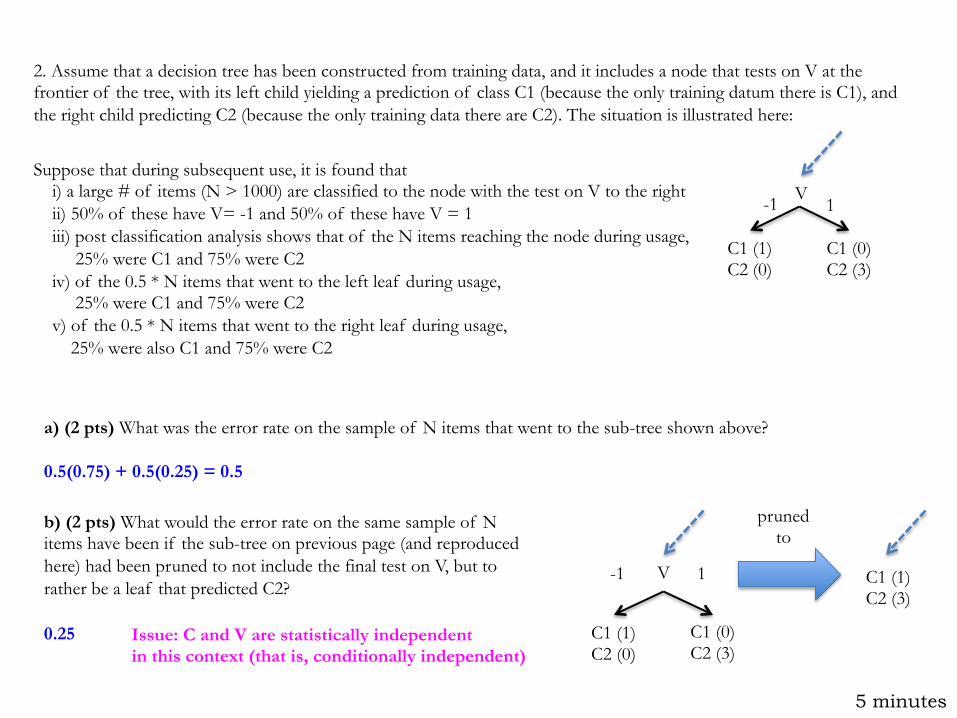
2. Assume that a decision tree has been constructed from training data, and it includes a node that tests on V at the frontier of the tree, with its left child yielding a prediction of class C1 (because the only training datum there is C1), and the right child predicting C2 (because the only training data there are C2). The situation is illustrated here:
V
C1 (1) C2 (0)
C1 (0) C2 (3)
-1 1
Suppose that during subsequent use, it is found that i) a large # of items (N > 1000) are classified to the node with the test on V to the right ii) 50% of these have V= -1 and 50% of these have V = 1 iii) post classification analysis shows that of the N items reaching the node during usage, 25% were C1 and 75% were C2 iv) of the 0.5 * N items that went to the left leaf during usage, 25% were C1 and 75% were C2 v) of the 0.5 * N items that went to the right leaf during usage, 25% were also C1 and 75% were C2
a) (2 pts) What was the error rate on the sample of N items that went to the sub-tree shown above? 0.5(0.75) + 0.5(0.25) = 0.5
b) (2 pts) What would the error rate on the same sample of N items have been if the sub-tree on previous page (and reproduced here) had been pruned to not include the final test on V, but to rather be a leaf that predicted C2? 0.25
V
C1 (1) C2 (0)
C1 (0) C2 (3)
-1 1 C1 (1) C2 (3)
pruned to
Issue: C and V are statistically independent in this context (that is, conditionally independent)
5 minutes
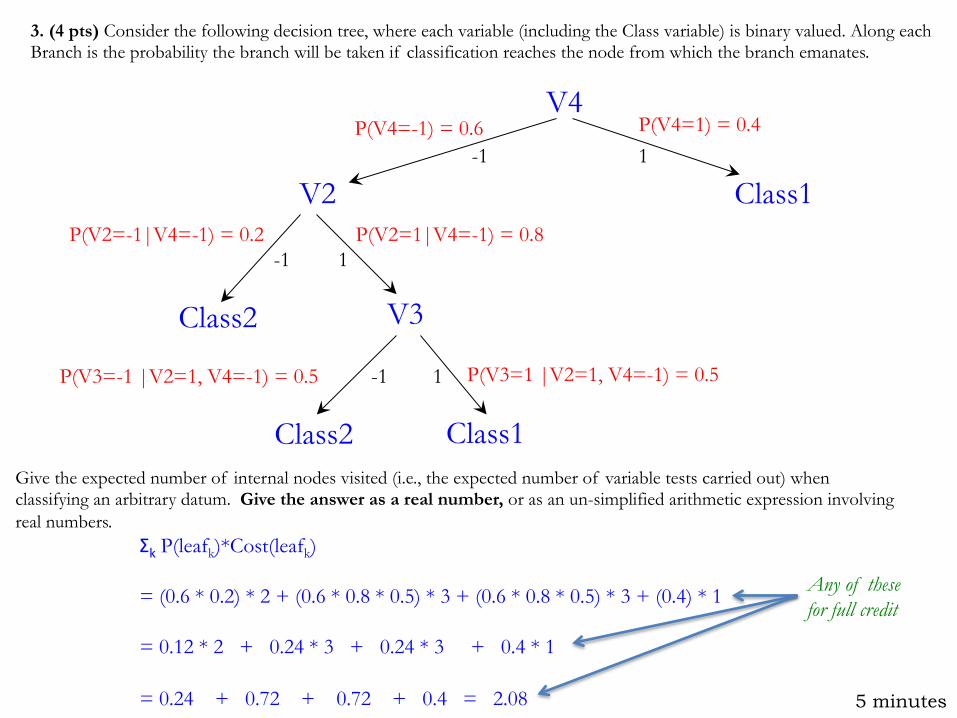
3. (4 pts) Consider the following decision tree, where each variable (including the Class variable) is binary valued. Along each Branch is the probability the branch will be taken if classification reaches the node from which the branch emanates.
V4
Class1 V2
V3
Class1 Class2
Class2
-1 1
-1 1
-1 1
P(V4=-1) = 0.6 P(V4=1) = 0.4
P(V2=-1|V4=-1) = 0.2 P(V2=1|V4=-1) = 0.8
P(V3=-1 |V2=1, V4=-1) = 0.5 P(V3=1 |V2=1, V4=-1) = 0.5
Give the expected number of internal nodes visited (i.e., the expected number of variable tests carried out) when classifying an arbitrary datum. Give the answer as a real number, or as an un-simplified arithmetic expression involving real numbers.
5 minutes
ΣkP(leafk)*Cost(leafk) = (0.6 * 0.2) * 2 + (0.6 * 0.8 * 0.5) * 3 + (0.6 * 0.8 * 0.5) * 3 + (0.4) * 1 = 0.12 * 2 + 0.24 * 3 + 0.24 * 3 + 0.4 * 1 = 0.24 + 0.72 + 0.72 + 0.4 = 2.08
Any of these for full credit
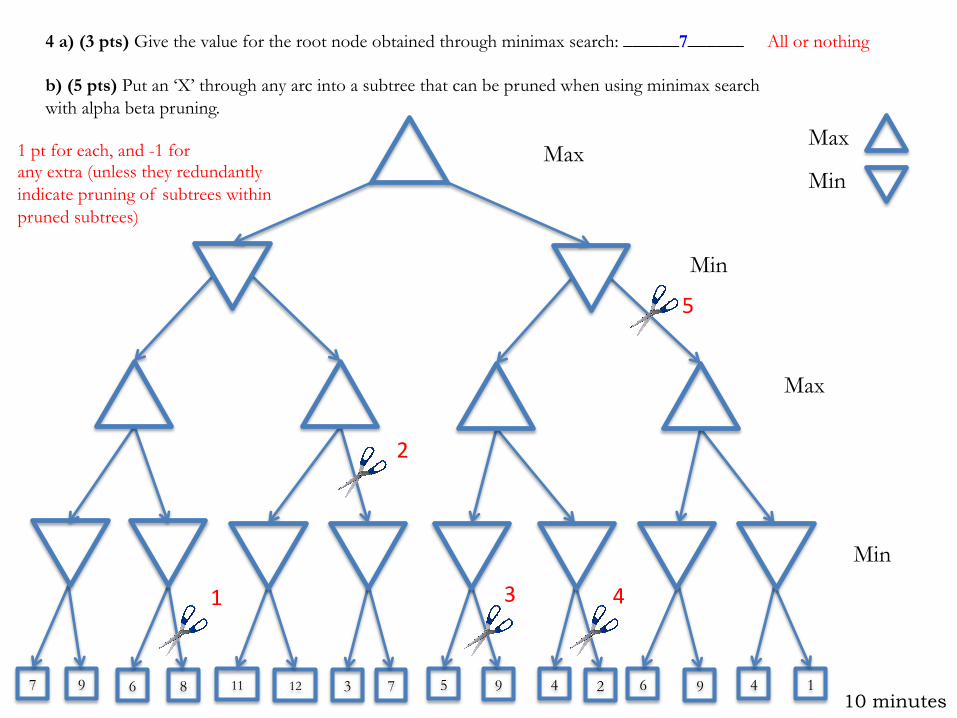
4 a) (3 pts) Give the value for the root node obtained through minimax search: ______7______ b) (5 pts) Put an ‘X’ through any arc into a subtree that can be pruned when using minimax search with alpha beta pruning.
9 6 8 12 7 4 9 5 7 3 2 6 9 4 1 11
Max
Min
10 minutes
Max
Max
Min
Min
All or nothing
1 pt for each, and -1 for any extra (unless they redundantly indicate pruning of subtrees within pruned subtrees)
1
2
3 4
5

5. Consider the following belief network: A B
C D E
G
a) (2 pts) Express P(a, ~b, ~c, d, e, f, ~g) only in terms of probabilities found in the probability tables of the network. P(a) P(~b) P(~c|a) P(d|a,~b) P(e|~b) P(f|~c) P(~g|d, e) = P(a)(1-P(b))(1-P(c|a))P(d|a,~b)P(e|~b)P(f|~c)(1-P(g|d,e)) this is ok too (if they missed my note)
F
Each variable is a binary-valued variable (e.g., A has values a and ~a, B has values b and ~b, etc). Probability tables are stored at each node. For purposes of expressing your answers, you can assume that P(~x|…) is explicitly stored, as well as P(x|…) (i.e., you don’t have to compute P(~x|…) as 1 - P(x|…). For each of the following, involve the minimal number of variables necessary.
b) (2 pts) Express P(~e |b, ~c) only in terms of probabilities found in the probability tables of the network. P(~e|b,~c) = P(~e|b) = 1-P(e|b) ok too 5 minutes

A B
C D E
GF
c) (2 pts) Express P(f | ~a) only in terms of probabilities found in the probability tables of the network. P(f|~a) = P(f, ~a)/P(~a) = [P(f, c, ~a) + P(f, ~c, ~a)]/P(~a) = [P(f | c,~a)P(c | ~a)P(~a) + P(f | ~c, ~a)P(~c | ~a)P(~a)]/P(~a) = [P(f|c)P(c|~a)P(~a) + P(f|~c)P(~c|~a)P(~a)]/P(~a) = P(f|c)P(c|~a) + P(f|~c)P(~c|~a) = P(f|c)P(c|~a) + P(f|~c)(1-P(c|~a)) ok too
d) (2 pts) Express P(b, ~d, e) only in terms of probabilities found in the probability tables of the network. P(b, ~d, e) = P(~d|a, b)P(e|b)P(a, b) + P(~d|~a, b)P(e|b)P(~a, b) = P(~d|a, b)P(e|b)P(a)P(b) + P(~d|~a, b)P(e|b)P(~a)P(b) e) (2 pts) Express P(b|e) only in terms of probabilities found in the probability tables of the network. P(b, e)/P(e) = P(e|b)P(b) / [P(e|b)P(b) + P(e|~b)P(~b)]
5. continued
5 minutes

6. From Poole and Mackworth
Answer the following questions about how knowledge of the values of some variables would affect the probability of another variable.
a) (2 pts) Can knowledge of the value of Projector_plugged_in affect your belief in the value of Sam_reading_book? Explain
5 minutes
No, in general, flow doesn’t occur through a V structure (Projector_Plugged_in is independent of Power_in_building, and no influence on the latter’s descendants either, unless the descendent is also a descendent of Projector_plugged_in. For more, see next page and discussion surrounding the sentence of Example 8.15 of section 8.3.2 of text “Note that the probability of tampering is not affected by observing smoke…”.
Short valid explanations for (a) • no flow through V structure • Whether the projector plugged in doesn’t influence power, lights, and reading (not the real reason, but intuition about why network is a reasonable model of reality, and 6.2 doesn’t do a good job of interpretation, perhaps deliberately, so that we can’t rely on it) • P(F=x) = Σ(E,D,C) P(F=x|E)P(E|D,C)P(D)P(C) ‘A’ not a factor (see coding in figure)
B
C
E
D
F
A
1 pt for ‘No’; 1 point for explanation

A
B
C
D
E
F
CanknowledgeofthevalueofProjector_plugged_inaffectyourbeliefinthevalueofSam_reading_book?Explain
A
F For fixed values of A and F, does P(F|A) = P(F)? Yes, so answer to 6a is NO (if A is all you are told) P(F|A) = P(F,A)/P(A) = [ P(F,e,d,c,b,A) + P(F,e,d,c,~b,A) + P(F,e,d,~c,b,A) + P(F,e,d,~c,~b,A) + P(F,e,~d,c,b,A) + P(F,e,~d,c,~b,A) + P(F,e,~d,~c,b,A) + P(F,e,~d,~c,~b,A) + P(F,~e,d,c,b,A) + P(F,~e,d,c,~b,A) + P(F,~e,d,~c,b,A) + P(F,~e,d,~c,~b,A) + P(F,~e,~d,c,b,A) + P(F,~e,~d,c,~b,A) + P(F,~e,~d,~c,b,A) + P(F,~e,~d,~c,~b,A) ] / P(A)
P(F|A) = P(F,A)/P(A) = [ P(F,e,d,c) P(b|c,A) P(A) + P(F,e,d,c) P(~b|c,A) P(A) + P(F,e,d,~c) P(b|~c,A) P(A) + P(F,e,d,~c) P(~b|~c,A) P(A) + P(F,e,~d,c) P(b|c,A) P(A) + P(F,e,~d,c) P(~b|c,A) P(A) + P(F,e,~d,~c) P(b|~c,A) P(A) + P(F,e,~d,~c) P(~b|~c,A) P(A) + P(F,~e,d,c) P(b|c,A) P(A) + P(F,~e,d,c) P(~b|c,A) P(A) + P(F,~e,d,~c) P(b|~c,A) P(A) + P(F,~e,d,~c) P(~b|~c,A) P(A) + P(F,~e,~d,c) P(b|c,A) P(A) + P(F,~e,~d,c) P(~b|c,A) P(A) + P(F,~e,~d,~c) P(b|~c,A) P(A) + P(F,~e,~d,~c) P(~b|~c,A) P(A) ] / P(A)
= P(F,e,d,c) (since P(b|c,A)+P(~b|c,A) = 1
= P(F,e,d,~c)
= P(F,e,~d,c)
= P(F,e,~d,~c)
= P(F,~e,d,c)
= P(F,~e,d,~c)
= P(F,~e,~d,c)
= P(F,~e,~d,~c)
= P(F) by marginalization
A longer answer for (a), though I would never expect you to write this down (though I might expect you use sigma notation as on last page).

6. From Poole and Mackworth
Answer the following questions about how knowledge of the values of some variables would affect the probability of another variable.
b) (2 pts) Can knowledge of the value of Screen_lit_up affect your belief in the value of Sam_reading_book? Explain
c) (2 pts) If Lamp_works was observed, then belief in some variables might be changed. List those affected variables.
5 minutes
Yes, Power_In_building is statistically dependent on Screen_lit_up (and any descendent), and Sam_reading book is statistically dependent on Power_in_building (and any ancestor). More abstractly, evidential reasoning followed by causal reasoning. For more, see discussion surrounding the sentence of Example 8.15 of section 8.3.2 of text “As expected, the probability of both tampering and fire are increased by the report. Because fire is increased, so is smoke” In the case of the exam problem, Screen lit up increases belief that Power in Building (evidential reasoning), which in turn increases belief that Sam (can be) reading a book (causal reasoning). Short acceptable answers in bold face green above or P(F|G) ≠ P(F) in general
ProjectorLampOn, ScreenLitUp, RaySays
C
F
G
1 pt for ‘yes’ and 1 pt for explanation
-0.5 pt for each missing and each
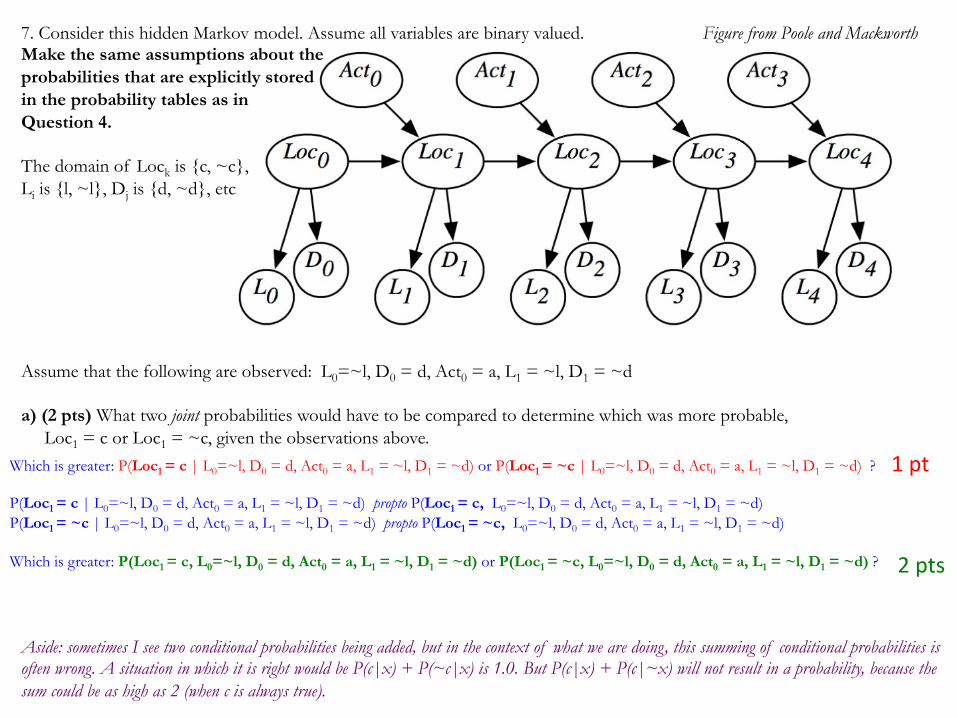
7. Consider this hidden Markov model. Assume all variables are binary valued. Make the same assumptions about the probabilities that are explicitly stored in the probability tables as in Question 4. The domain of Lock is {c, ~c}, Li is {l, ~l}, Dj is {d, ~d}, etc
Assume that the following are observed: L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d a) (2 pts) What two joint probabilities would have to be compared to determine which was more probable, Loc1 = c or Loc1 = ~c, given the observations above.
Figure from Poole and Mackworth
Which is greater: P(Loc1 = c | L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) or P(Loc1 = ~c | L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) ? P(Loc1 = c | L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) propto P(Loc1 = c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) P(Loc1 = ~c | L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) propto P(Loc1 = ~c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) Which is greater: P(Loc1 = c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) or P(Loc1 = ~c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) ?
1pt
2pts
Aside: sometimes I see two conditional probabilities being added, but in the context of what we are doing, this summing of conditional probabilities is often wrong. A situation in which it is right would be P(c|x) + P(~c|x) is 1.0. But P(c|x) + P(c|~x) will not result in a probability, because the sum could be as high as 2 (when c is always true).
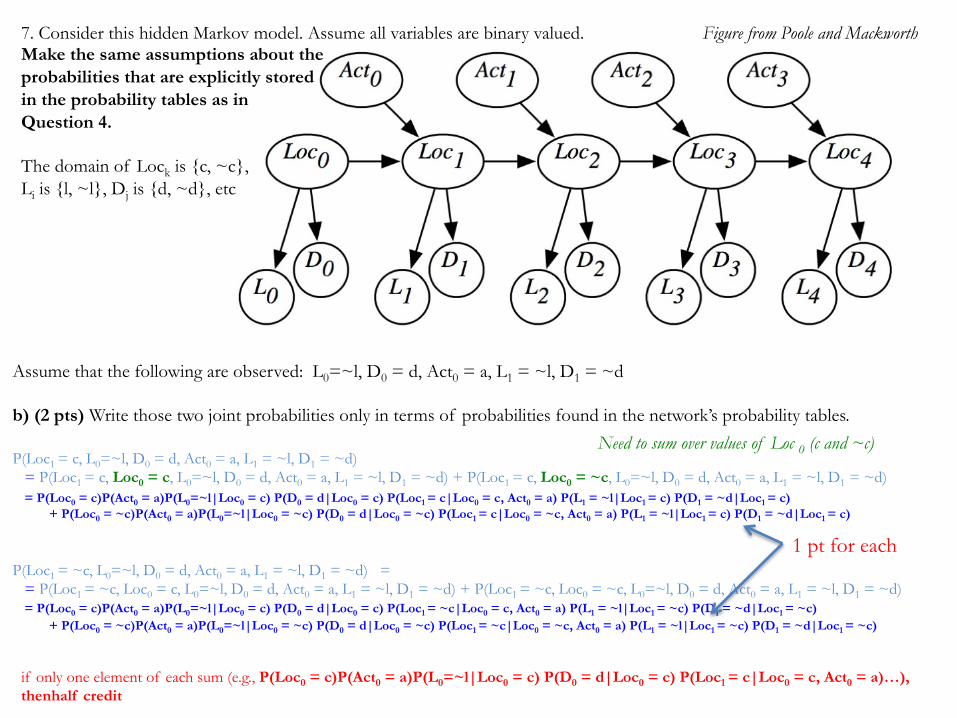
7. Consider this hidden Markov model. Assume all variables are binary valued. Make the same assumptions about the probabilities that are explicitly stored in the probability tables as in Question 4. The domain of Lock is {c, ~c}, Li is {l, ~l}, Dj is {d, ~d}, etc
Assume that the following are observed: L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d b) (2 pts) Write those two joint probabilities only in terms of probabilities found in the network’s probability tables. P(Loc1 = c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) = P(Loc1 = c, Loc0 = c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) + P(Loc1 = c, Loc0 = ~c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) = P(Loc0 = c)P(Act0 = a)P(L0=~l|Loc0 = c) P(D0 = d|Loc0 = c) P(Loc1 = c|Loc0 = c, Act0 = a) P(L1 = ~l|Loc1 = c) P(D1 = ~d|Loc1 = c) + P(Loc0 = ~c)P(Act0 = a)P(L0=~l|Loc0 = ~c) P(D0 = d|Loc0 = ~c) P(Loc1 = c|Loc0 = ~c, Act0 = a) P(L1 = ~l|Loc1 = c) P(D1 = ~d|Loc1 = c) P(Loc1 = ~c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) = = P(Loc1 = ~c, Loc0 = c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) + P(Loc1 = ~c, Loc0 = ~c, L0=~l, D0 = d, Act0 = a, L1 = ~l, D1 = ~d) = P(Loc0 = c)P(Act0 = a)P(L0=~l|Loc0 = c) P(D0 = d|Loc0 = c) P(Loc1 = ~c|Loc0 = c, Act0 = a) P(L1 = ~l|Loc1 = ~c) P(D1 = ~d|Loc1 = ~c) + P(Loc0 = ~c)P(Act0 = a)P(L0=~l|Loc0 = ~c) P(D0 = d|Loc0 = ~c) P(Loc1 = ~c|Loc0 = ~c, Act0 = a) P(L1 = ~l|Loc1 = ~c) P(D1 = ~d|Loc1 = ~c)
Figure from Poole and Mackworth
1 pt for each
if only one element of each sum (e.g., P(Loc0 = c)P(Act0 = a)P(L0=~l|Loc0 = c) P(D0 = d|Loc0 = c) P(Loc1 = c|Loc0 = c, Act0 = a)…), thenhalf credit
Need to sum over values of Loc 0 (c and ~c)
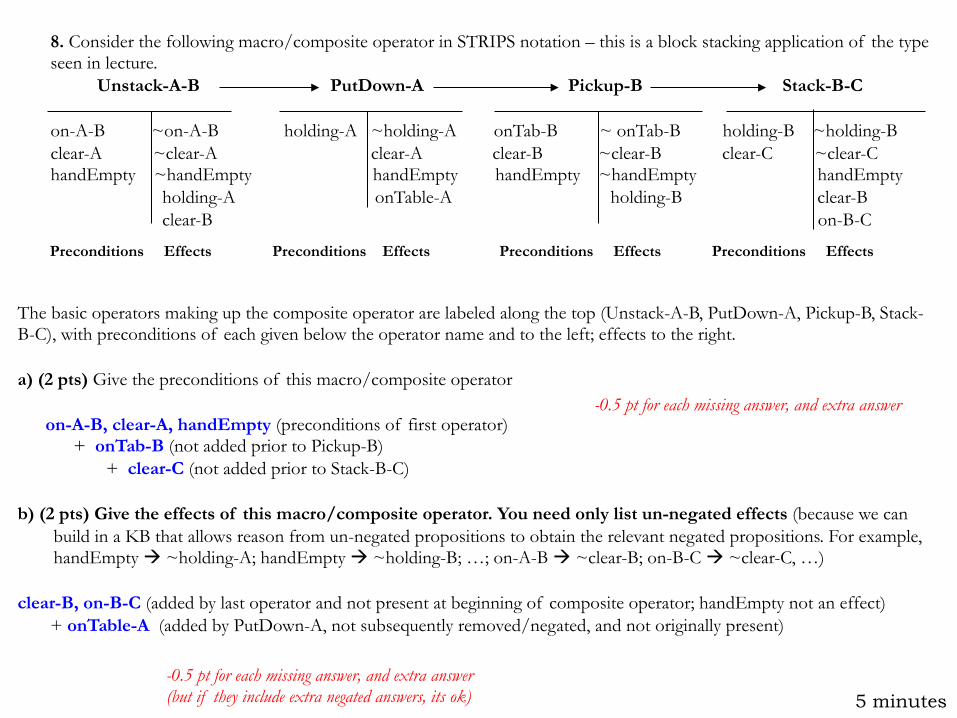
8. Consider the following macro/composite operator in STRIPS notation – this is a block stacking application of the type seen in lecture. Unstack-A-B PutDown-A Pickup-B Stack-B-C on-A-B ~on-A-B holding-A ~holding-A onTab-B ~ onTab-B holding-B ~holding-B clear-A ~clear-A clear-A clear-B ~clear-B clear-C ~clear-C handEmpty ~handEmpty handEmpty handEmpty ~handEmpty handEmpty holding-A onTable-A holding-B clear-B clear-B on-B-C
Preconditions Effects Preconditions Effects Preconditions Effects Preconditions Effects
The basic operators making up the composite operator are labeled along the top (Unstack-A-B, PutDown-A, Pickup-B, Stack-B-C), with preconditions of each given below the operator name and to the left; effects to the right. a) (2 pts) Give the preconditions of this macro/composite operator
on-A-B, clear-A, handEmpty (preconditions of first operator) + onTab-B (not added prior to Pickup-B) + clear-C (not added prior to Stack-B-C) b) (2 pts) Give the effects of this macro/composite operator. You need only list un-negated effects (because we can
build in a KB that allows reason from un-negated propositions to obtain the relevant negated propositions. For example, handEmpty à ~holding-A; handEmpty à ~holding-B; …; on-A-B à ~clear-B; on-B-C à ~clear-C, …)
clear-B, on-B-C (added by last operator and not present at beginning of composite operator; handEmpty not an effect) + onTable-A (added by PutDown-A, not subsequently removed/negated, and not originally present)
-0.5 pt for each missing answer, and extra answer (but if they include extra negated answers, its ok)
-0.5 pt for each missing answer, and extra answer
5 minutes











![CS 1110 Final ExamSolutionsMay 15th, 2014...CS 1110 Final ExamSolutionsMay 15th, 2014 The Important First Question: 1.[2 points] When allowed to begin, write your last name, rst name,](https://img.dokumen.tips/doc/110x75/5f4432752f5b752243691999/cs-1110-final-examsolutionsmay-15th-2014-cs-1110-final-examsolutionsmay-15th.jpg)

















