Embed Size (px)
Citation preview

Evaluating the Significance of
Max-gap Clusters
Rose Hoberman
David Sankoff
Dannie Durand
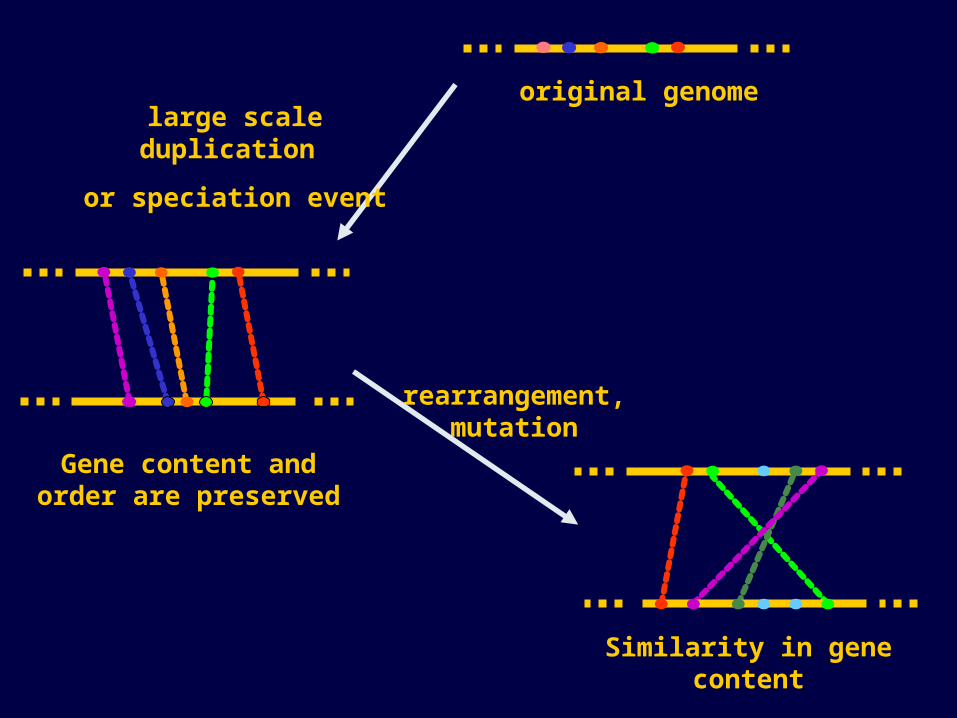
Gene content and order are preserved
rearrangement, mutation
Similarity in gene content
large scale duplication
or speciation event
original genome

TBOX
Cryb, Lhx, Nos, Tbx, Tcf, Prkar
MHC Abc, C3/4/5, Col, Hsp, Notch, Pbx, Psmb, Rxr, Ten
HOX Achr, Ccnd, Cdc, Cdk, Dlx, En, Evx, Gli, Hh, Hox, If, Inhb, Nhr, Npy/Ppy, Wnt
FGR Adr, Ank, Egr, Fgfr, Pa, Vmat, Lpl
MATN
Eya, Hck, Matn, Myb, Myc, Sdc, Src
… …
Local Spatial Evidence of Duplication
Ruvinsky and Silver, Gene, 97
Chromosome5
Chromosome11
60
65
70
Crybb1/2/3Cryba4
Nos1 50
40
45Tcf1
Tbx3/5
Cryba1, Nos2
Tbx2/4
Tcf2
Lhx1
Lhx5
5575

Gene Clustering for Functional Inference in Bacterial Genomes
The Use of Gene Clusters to Infer Functional Coupling, Overbeek et al., PNAS 96: 2896-2901, 1999.

Clusters are Commonly Used in Genomic Analyses
Genomic Analyses
Blanc et al 2003, recent polyploidy in Arabidopsis
Venter et al 2001, sequence of the human genome
Overbeek et al 1999, inferring functional coupling of genes in bacteria
Vandepoele et al 2002, duplications in Arabidopsis through comparison with rice
Vision et al 2000, duplications in Eukaryotes
Lawrence and Roth 1996, identification of horizontal transfers
Tamames 2001, evolution of gene order conservaiton in prokaryotes
Wolfe and Shields 1997, ancient yeast duplication
McLysaght02, genomic duplication during early chordate evolution
Coghlan and Wolfe 2002, comparing rates of rearrangements
Seoighe and Wolfe 1998, genome rearrangements after duplication in yeast
Chen et al 2004, operon prediction in newly sequenced bacteria
Blanchette et al 1999, breakpoints as phylogenetic features...

Clusters are Commonly Used in Genomic Analyses
Genomic Analyses
Blanc et al 2003, recent polyploidy in ArabidopsisVenter et al 2001, sequence of the human genome
Overbeek et al 1999, inferring functional coupling of genes in bacteria
Vandepoele et al 2002, duplications in Arabidopsis through comparison with rice
Vision et al 2000, duplications in Eukaryotes
Lawrence and Roth 1996, identification of horizontal transfers
Tamames 2001, evolution of gene order conservaiton in prokaryotes
Wolfe and Shields 1997, ancient yeast duplication
McLysaght02, genomic duplication during early chordate evolution
Coghlan and Wolfe 2002, comparing rates of rearrangements
Seoighe and Wolfe 1998, genome rearrangements after duplication in yeast
Chen et al 2004, operon prediction in newly sequenced bacteria
Blanchette et al 1999, breakpoints as phylogenetic features...
Need to assess cluster significance

Given: a genome: G = 1, …, n unique genes
a set of m special genes
Can we find a significant cluster of (a subset of) the
m homologs?

Can we find a significant cluster of the red genes?
How do we formally define a cluster?
Given: a genome: G = 1, …, n unique genes
a set of m special genes

Possible Cluster Parameters– size: number of red genes in the cluster
• Example: cluster size ≥ 3
size = 3 genes

Possible Cluster Parameters– size: number of red genes in the cluster
• Example: cluster size ≥ 3
– length: number of genes between first and last red gene
• Example: cluster length ≤ 6
length = 6

Possible Cluster Parameters– size: number of red genes in the cluster
• Example: cluster size ≥ 3
– length: number of genes between first and last red gene
• Example: cluster length ≤ 6
length = 6

Possible Cluster Parameters– size: number of red genes in the cluster
• Example: cluster size ≥ 3
– length: number of genes between first and last red genes
• Example: cluster length ≤ 6
– density: proportion of red genes (size/length)• Example: density ≥ 0.5
density = 6/11

Possible Cluster Parameters– size: number of red genes in the cluster
• Example: cluster size ≥ 3
– length: number of genes between first and last red genes
• Example: cluster length ≤ 6
– density: proportion of red genes (size/length)• Example: density ≥ 0.5
density = 6/11

Possible Cluster Parameters– size: number of red genes in the cluster
• Example: cluster size ≥ 3
– length: number of genes between first and last red genes
• Example: cluster length ≤ 6
– density: proportion of red genes (size/length)– compactness: maximum gap between adjacent red
genes
gap ≤ 4 genes

Max-Gap Cluster
• Commonly used in genomic analyses
• Expandable, ensures minimum local and global density
• Efficient algorithm to find them (Bergeron, Corteel, Raffinot 2002)
gap g

Max-Gap Clusters are Commonly Used in Genomic Analyses
Genomic Analyses
Blanc et al 2003, recent polyploidy in ArabidopsisVenter et al 2001, sequence of the human genome
Overbeek et al 1999, inferring functional coupling of genes in bacteria
Vandepoele et al 2002, duplications in Arabidopsis through comparison with rice
Vision et al 2000, duplications in Eukaryotes
Lawrence and Roth 1996, identification of horizontal transfers
Tamames 2001, evolution of gene order conservation in prokaryotes
Wolfe and Shields 1997, ancient yeast duplication
McLysaght02, genomic duplication during early chordate evolution
Coghlan and Wolfe 2002, comparing rates of rearrangements
Seoighe and Wolfe 1998, genome rearrangements after duplication in yeast
Chen et al 2004, operon prediction in newly sequenced bacteria
Blanchette et al 1999, breakpoints as phylogenetic features...

Statistical models
Statistical Models
Calabrese03
Danchin03
Durand03
Ehrlich97
Trachtulec01
HumanGenomeScience

A gap between statistical tests and cluster definitions used in practice
Genomic AnalysesBlanc et al 2003 Venter et al 2001
Overbeek et al 1999
Vandepoele et al 2002
Vision et al 2000
Lawrence and Roth 1996
Tamames 2001
Wolfe and Shields 1997 McLysaght02
Coghlan and Wolfe 2002
Seoighe and Wolfe 1998
Chen et al 2004
Blanchette et al 1999...
Statistical Models
Calabrese03
Danchin03
Durand03b
Ehrlich97
Trachtulec01
HumanGenomeScience•no analytical statistical
model for max-gap clusters•statistical significance
assessed through Monte Carlo randomization

A gap between statistical tests and cluster definitions used in practice
Genomic AnalysesBlanc et al 2003 Venter et al 2001
Overbeek et al 1999
Vandepoele et al 2002
Vision et al 2000
Lawrence and Roth 1996
Tamames 2001
Wolfe and Shields 1997 McLysaght02
Coghlan and Wolfe 2002
Seoighe and Wolfe 1998
Chen et al 2004
Blanchette et al 1999...
Statistical Models
Calabrese03
Danchin03
Durand03b
Ehrlich97
Trachtulec01
HumanGenomeScience

This Talk
• Analytical statistical tests– reference region model with m genes of interest– complete and incomplete clusters
• Relationship between cluster parameters and significance
• Future extension to whole-genome comparison

Outline
• Introduction
• Complete Clusters
• Incomplete Clusters
• Genome Comparison
• Open problems
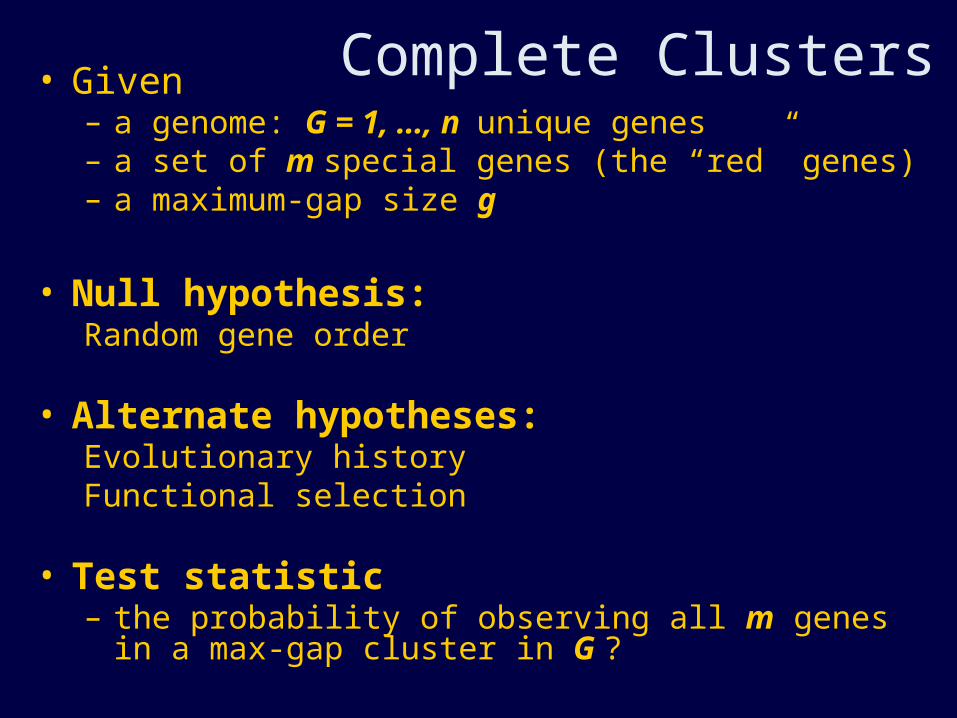
Complete Clusters• Given– a genome: G = 1, …, n unique genes – a set of m special genes (the “red” genes)– a maximum-gap size g
• Null hypothesis: Random gene order
• Alternate hypotheses:Evolutionary historyFunctional selection
• Test statistic– the probability of observing all m genes in a max-gap
cluster in G ?

Probability of a Complete Cluster
Count how many of the permutations of m red genes and n-m blue genes contain a max-gap cluster
1. At how many positions in the genome can we locate a cluster (e.g. place the leftmost red gene)?
2. Given the location of the first red gene, how many ways are there to place the remaining m-1 red genes so that they form a max-gap cluster?

w = (m-1)g + m
ways to choose
m-1 gapsways to place the
first gene and still
have w-1 slots left
edge
effects

w-1
For clusters at the end of the genome:– Length of the cluster is constrained– Sum of the gaps is constrained:
Counting clusters at the end of the genome
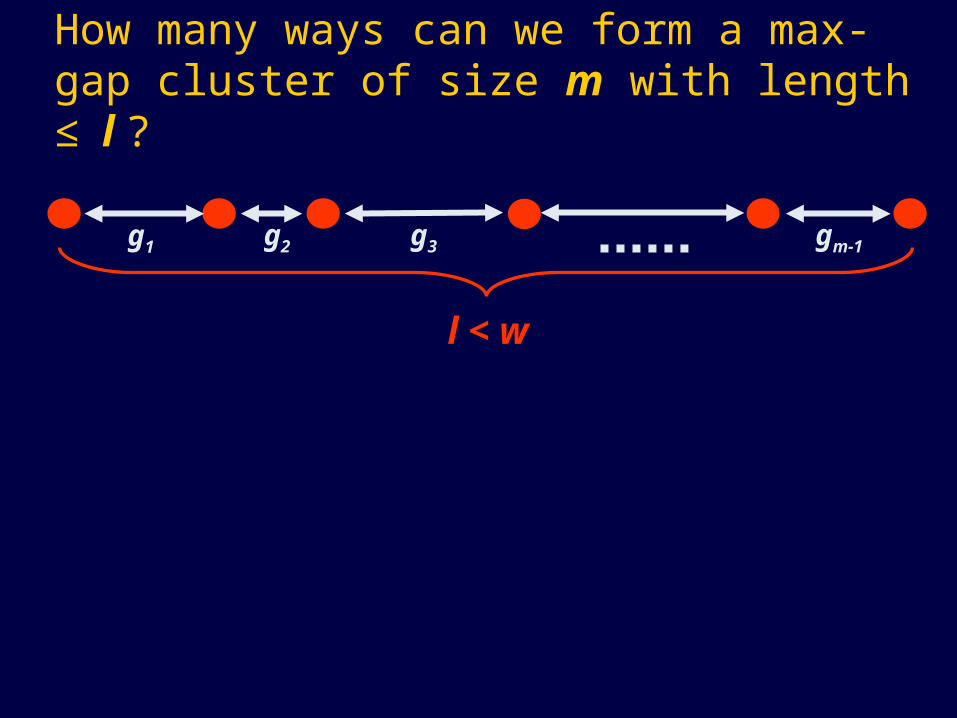
How many ways can we form a max-gap cluster of size m with length ≤ l ?
g1 g2 g3 gm-1
l < w
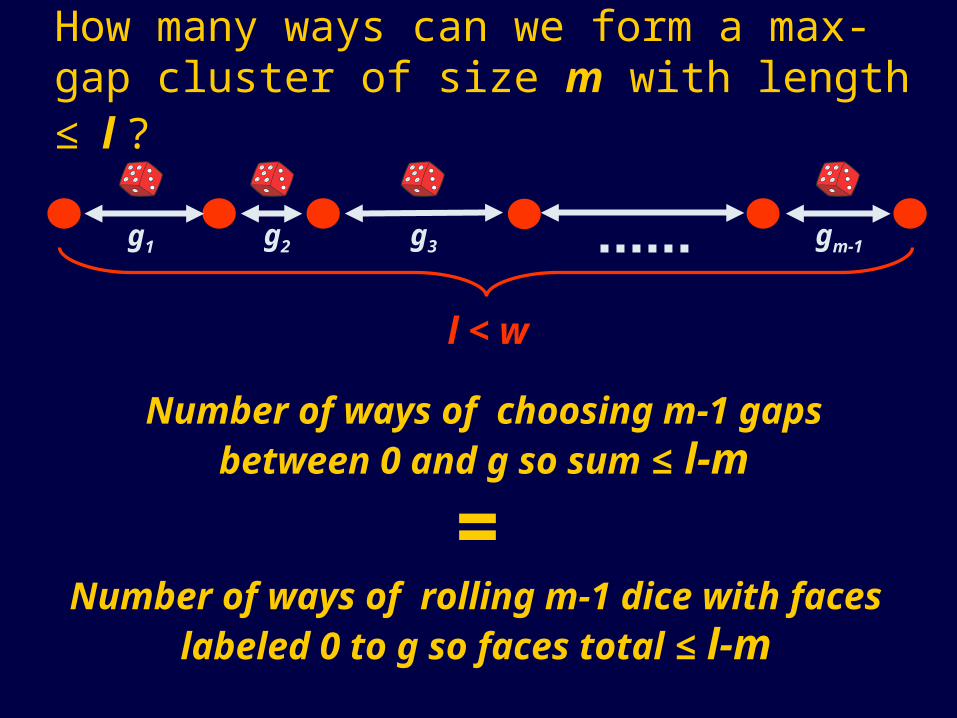
g1 g2 g3 gm-1
l < w
=
Number of ways of choosing m-1 gapsbetween 0 and g so sum ≤ l-m
Number of ways of rolling m-1 dice with faces labeled 0 to g so faces total ≤ l-m
How many ways can we form a max-gap cluster of size m with length ≤ l ?

g1 g2 g3 gm-1
=
Number of ways of choosing m-1 gapsbetween 0 and g so sum ≤ l-m
Number of ways of rolling m-1 dice with faces labeled 0 to g so faces total ≤ l-m
How many ways can we form a max-gap cluster of size m with length ≤ l ?

Accounting for edge effects is the least efficient part of calculation– Eliminate for faster approximation when w << n
Now we can calculate probabilities
for various parameter values
Final Probability
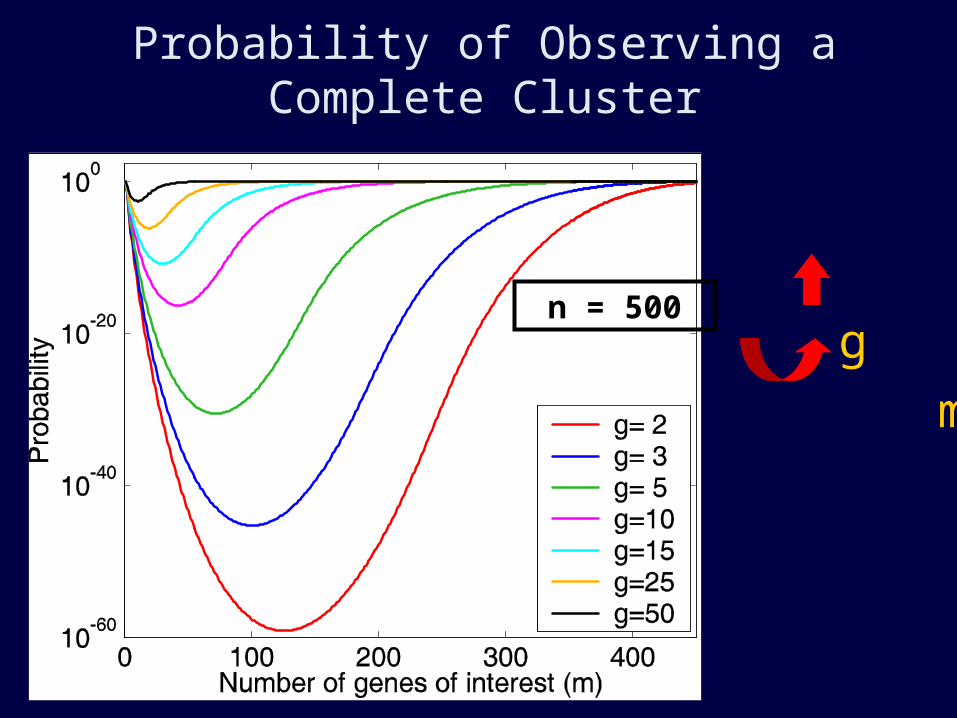
Probability of Observing a Complete Cluster
g
m n = 500
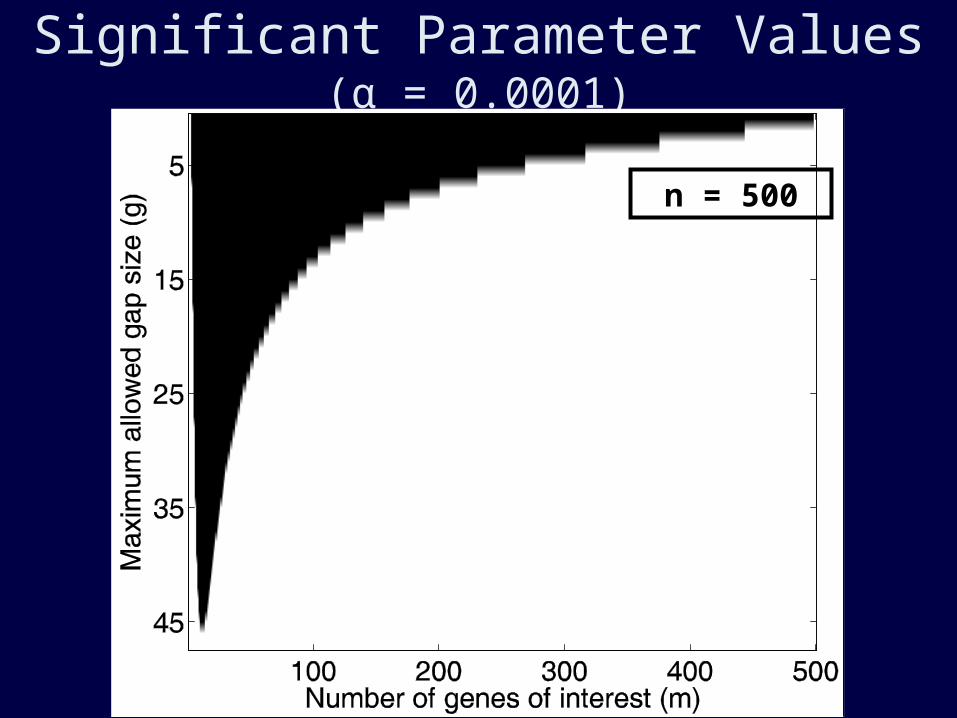
Significant Parameter Values (α = 0.0001)
n = 500

Significant Parameter Values (α = 0.0001)
n = 500

Outline
• Motivation
• Complete Clusters
• Incomplete Clusters
• Genome Comparison
• Open problems

Incomplete clusters
• Is it significant to find a max-gap cluster of size h < m?
• Test statistic: probability of finding at least one cluster
Given: m genes of interest
h=3
m=5, g=1

Enumerating clusters by starting position will lead to overcounting of permutations that include more than one cluster
Probability of incomplete gene clusters
m = 6, h = 3, g = 1

Alternative Approach
• Enumerate all permutations that do not contain any clusters of size h or larger
• Dynamic programming – Iteratively place “red” or “blue” genes making sure
not to create any cluster of size h or larger by judicious placement of “blue genes”
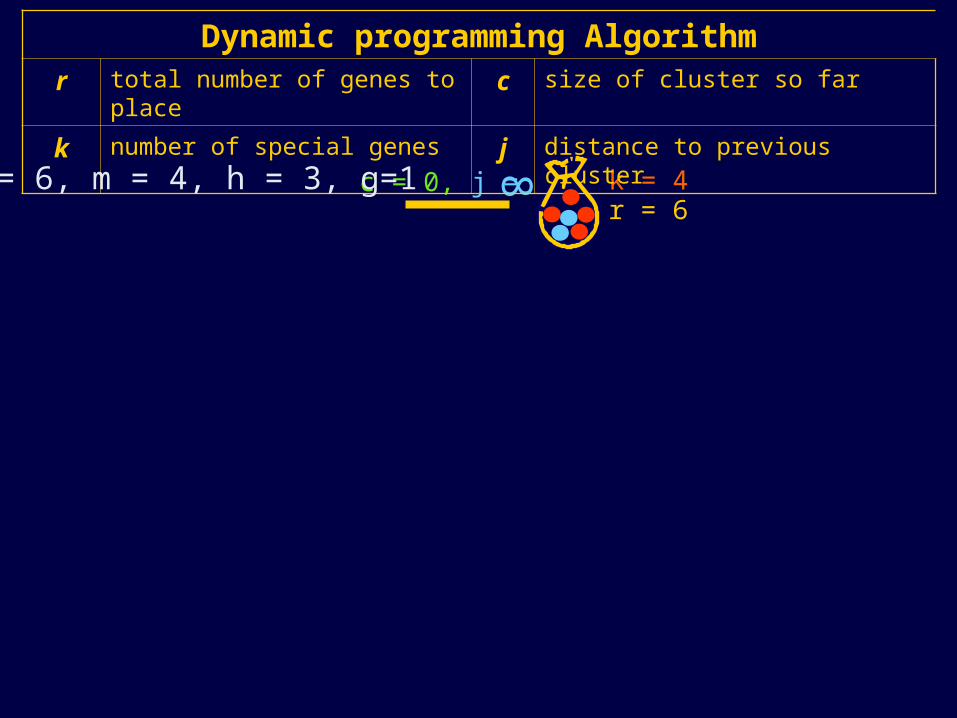
k = 4c = 0, j =
8
r = 6
Dynamic programming Algorithmr total number of genes to place c size of cluster so far
k number of special genes j distance to previous cluster
n = 6, m = 4, h = 3, g=1
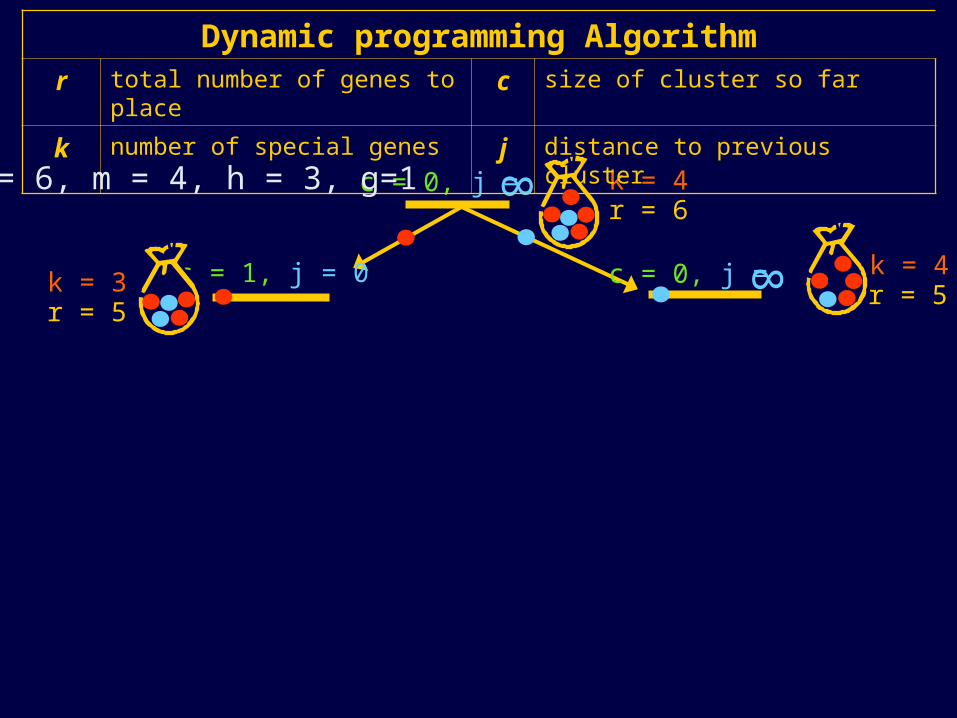
k = 4c = 0, j =
8
r = 6
c = 1, j = 0 c = 0, j =
8 k = 4r = 5k = 3
r = 5
Dynamic programming Algorithmr total number of genes to place c size of cluster so far
k number of special genes j distance to previous cluster
n = 6, m = 4, h = 3, g=1

k = 2r = 4
k = 4c = 0, j =
8
r = 6
c = 1, j = 0 c = 0, j =
8 k = 4r = 5k = 3
r = 5
c = 1, j = 1 k = 3r = 4
c = 1, j = 0
Dynamic programming Algorithmr total number of genes to place c size of cluster so far
k number of special genes j distance to previous cluster
n = 6, m = 4, h = 3, g=1
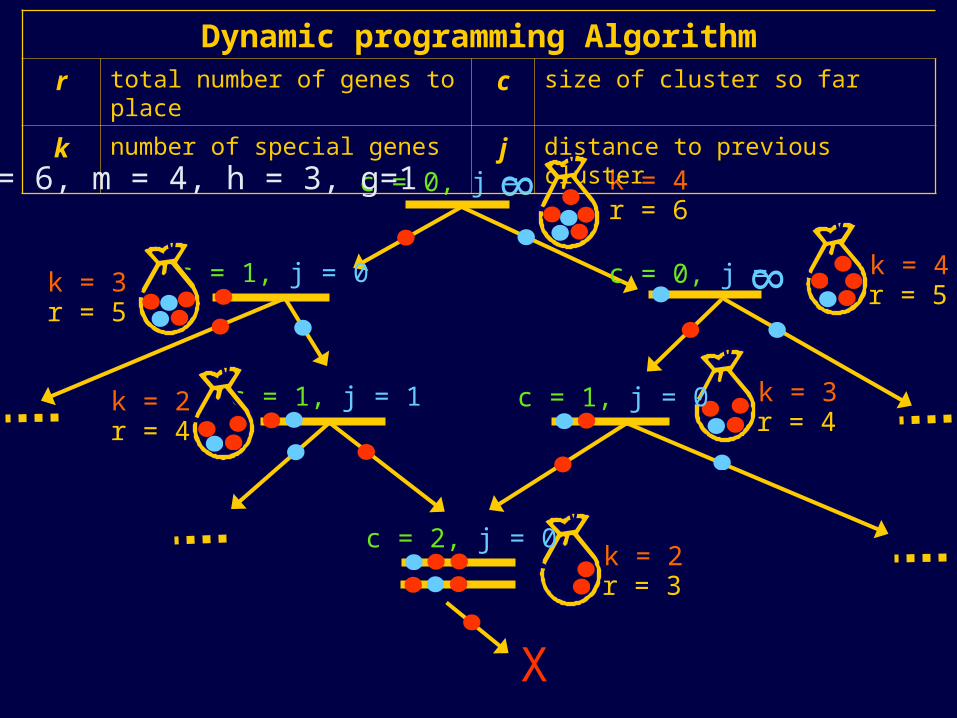
k = 2r = 4
k = 4c = 0, j =
8
r = 6
c = 1, j = 0 c = 0, j =
8 k = 4r = 5k = 3
r = 5
c = 1, j = 1 k = 3r = 4
c = 1, j = 0
k = 2r = 3
c = 2, j = 0
Dynamic programming Algorithmr total number of genes to place c size of cluster so far
k number of special genes j distance to previous cluster
X
n = 6, m = 4, h = 3, g=1

Incomplete cluster significance
h g
m ( )
significant region of parameter space shown in paper
n = 1000
m = 50
n = 500

Outline
• Motivation
• Complete Clusters
• Incomplete Clusters
• Extensions
• Genome Comparison

Possible Extensions
• Tandem duplications
• Gene families
• Extensions for prokaryotic genomes– Gene orientation– Circular genomes– Physical distance between genes
• Whole genome comparison

Whole genome comparison
Assuming identical gene content …
What is the probability that at least k genes form a max-gap cluster
in both genomes?
g 30
g 30

The probability of finding a max-gap cluster of size at least k is always one
An Odd Property
Example: g =1

The probability of finding a max-gap cluster of size at least k is always one
Example: g =1
An Odd Property
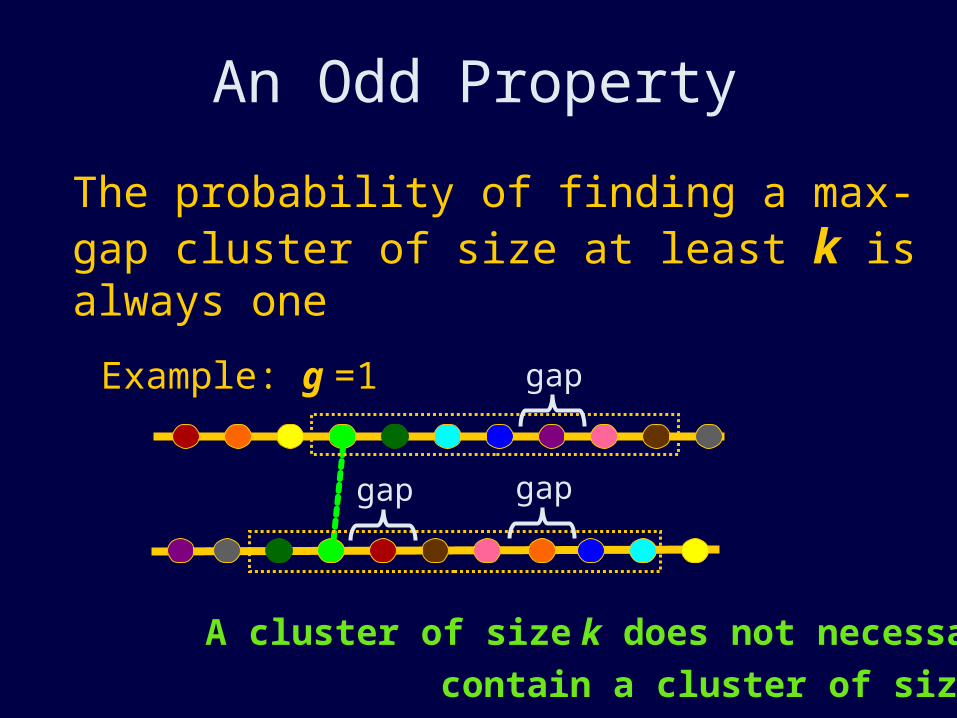
The probability of finding a max-gap cluster of size at least k is always one
Example: g =1
gap gap
An Odd Property
A cluster of size k does not necessarily
contain a cluster of size k-1!
gap

The probability of finding a max-gap cluster of size at least k is always one There will always be a cluster of size n
Example: g =1
An Odd Property

Conclusions
Presented statistical tests for max-gap clusters– Evaluate the significance of clusters of a pre-
specified set of genes– Choose parameters effectively– Understand trends

Thank You





























