Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DO RIO GRANDE DO SULINSTITUTO DE INFORMÁTICA
PROGRAMA DE PÓS-GRADUAÇÃO EM COMPUTAÇÃO
Estudo e Implementação daProgramação Genética para
Síntese de Fala
por
EVANDRO FRANZEN
Dissertação submetida à avaliação, como requisitoparcial para a obtenção do grau de Mestre em Ciência da
Computação
Prof. Dr. Dante Augusto Couto BaroneOrientador
Porto Alegre, novembro de 2002.

2
CIP – CATALOGAÇÃO DA PUBLICAÇÃO
Franzen, EvandroEstudo e Implementação da Programação Genética para
Síntese de Fala / por Evandro Franzen. – Porto Alegre: PPGC daUFRGS, 2002.
113f.:il.Dissertação (mestrado) – Universidade Federal do Rio
Grande do Sul. Programa de Pós-Graduação em Computação, PortoAlegre, BR-RS, 2002. Orientador: Barone, Dante Augusto Couto.
1.Programação genética. 2. Síntese de fala. 3. ComputaçãoEvolucionária. I. Barone, Dante Augusto Couto. II. Título.
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SULReitora: Profª. Wrana PanizziPró-Reitor de Ensino: Prof. José Carlos Ferraz HennemannPró-Reitor Adjunto de Pós-Graduação: Prof. Jaime Evaldo FensterseiferDiretor do Instituto de Informática: Prof. Philippe Olivier Alexandre NavauxCoordenador do PPGC: Prof. Carlos Alberto HeuserBibliotecária – Chefe do Instituto de Informática: Beatriz Regina Bastos Haro

3
Agradecimentos
A meus pais pela dedicação, apoio e acompanhamento durante todos os anos deminha vida e por terem me proporcionado exemplos de comportamento e caráter.
A minha esposa pelos momentos de convívio, carinho e amor e pelo apoio duranteas atividades profissionais e acadêmicas.
Ao Dr. Dante Barone pela orientação e por todo o conhecimento que tiveoportunidade receber e compartilhar durante o convívio no período de desenvolvimentodo mestrado.
A todos os colegas de aula, de trabalhos, professores e demais pessoas com asquais tive oportunidade de conviver durante o mestrado.
Às demais pessoas que me proporcionaram momentos de apoio, lazer e reflexãotão importantes para o bom andamento das atividades e para superação das dificuldadesdo dia a dia.
A Deus, por tudo.

4
SumárioLista de abreviaturas ................................................................................ 05
Lista de figuras .......................................................................................... 06
Lista de tabelas .......................................................................................... 08
Resumo ....................................................................................................... 09
Abstract ...................................................................................................... 10
1 Introdução ............................................................................................ 12
2 Lingüística computacional: Síntese de fala....................................... 152.1 Lingüística computacional ................................................................................. 152.2 Aspectos básicos de um sistema de texto para fala .......................................... 152.3 Fonética, fonologia e os sons da fala................................................................. 172.3.1 Transcrição fonética .............................................................................................. 182.3.2 Classificação das vogais........................................................................................ 192.3.3 Classificação das consoantes ................................................................................ 212.4 Técnicas para síntese .......................................................................................... 222.4.1 Concatenação ........................................................................................................ 222.4.2 Síntese por sílaba .................................................................................................. 232.4.3 Síntese por fonemas .............................................................................................. 232.4.4 Síntese por Difone................................................................................................. 232.4.5 Síntese por Demi-sílaba ........................................................................................ 232.4.6 Formantes.............................................................................................................. 232.4.7 Fonte-Filtro ........................................................................................................... 242.5 Conversão letra para fonema em Língua Portuguesa ..................................... 242.6 Histórico e sistemas para síntese de fala ........................................................... 272.6.1 Sintetizadores atuais.............................................................................................. 282.6.2 Projeto Spoltech .................................................................................................... 29
3 Programação genética ......................................................................... 313.1 Princípios da evolução natural........................................................................... 313.2 Computação evolucionária................................................................................. 323.2.1 Algoritmos Genéticos ........................................................................................... 323.3 Programação Genética para descoberta de programas .................................. 333.3.1 Descoberta de programas ...................................................................................... 343.3.2 Atributos de um sistema para descoberta automática de programas..................... 343.4 Elementos principais da Programação Genética ............................................. 363.4.1 Estruturas que sofrem adaptação........................................................................... 373.4.2 Fitness ................................................................................................................... 393.4.3 Operadores genéticos ............................................................................................ 393.4.4 Critérios e parâmetros de controle ........................................................................ 41

5
3.4.5 Escolha da linguagem de programação................................................................. 423.5 Definição automática de funções ....................................................................... 433.5.1 Resolução hierárquica de problemas..................................................................... 433.6 O problema da definição automática de função............................................... 443.6.1 Criação de uma população inicial ......................................................................... 463.6.2 Preservação de estruturas em cruzamentos ........................................................... 46
4 Abordagem do sistema: Arquitetura proposta................................. 48
5 Modelagem do problema de conversão letra-fonema, usandoprogramação genética ............................................................................... 545.1 Definição de casos e avaliação de fitness ........................................................... 545.2 Estratégias para descoberta automática de programas para conversão letra-fonema ........................................................................................................................... 55
6 Resultados............................................................................................. 596.1 Caso 1 - Relação um para um e letras "t" e "d" antes de "i" ........................ 616.1.1 Resultados utilizando somente funções básicas.................................................... 616.1.2 Inserção de funções de domínio............................................................................ 646.2 Caso 2 - Nasalização de vogais ........................................................................... 676.3 Caso3 - Combinação "rr" .................................................................................. 726.4 Caso 4 - Regras envolvendo as letras "c", "s" e "z" ....................................... 756.4.1 Caso 4 - Funções sem argumentos ........................................................................ 786.5 Resultados utilizando definição automática de funções (ADF) ...................... 826.5.1 Caso 1 utilizando ADF.......................................................................................... 836.5.2 Caso 4 utilizando ADF.......................................................................................... 856.6 Tempos de processamento.................................................................................. 90
7 Conclusões ............................................................................................ 92Anexo 1 Representação de fonemas no "IPA - International Phonetic
Alphabet" e no sistema Festival .............................................. 95Anexo 2 Regras para conversão letra para fonema no sistema Festival
..................................................................................................... 96
Anexo 3 Código das funções de domínio utilizadas no problema......103
Anexo 4 Funções de definição de casos e avaliação de fitness ...........108
Bibliografia ..............................................................................................110

6
Lista de Abreviaturas
ADF Automatic Defined Functions
AG Algoritmos Genéticos
CE Computação Evolutiva
DAF Definição Automática de Funções
DSP Digital Signal Processing
HMM Hidden Markov Models
IA Inteligência Artificial
IPA International Phonetic Alphabet
LTS Letter To Sound
NLP Natural Language Processing
PE Programação Evolucionária
PG Programação Genética
PLN Processamento de Linguagem Natural
RNA Rede Neural Artificial
RPB Result Program Branch
TTS Text To Speech
VA Vida Artificial

7
Lista de Figuras
FIGURA 2.1 - Diagrama funcional de um sistema de texto para fala.................................15
FIGURA 2.2 - Diagrama representando o fluxo do processo de leitura em humanos ........15
FIGURA 2.3 - Aparelho fonador humano...........................................................................16
FIGURA 2.4 - Diagrama funcional do módulo de processamento de linguagem natural...17
FIGURA 2.5 - Evolução histórica da síntese de fala...........................................................27
FIGURA 3.1 - Indivíduos de uma população e a sua correspondente roleta de seleção.....31
FIGURA 3.2 - Operação de crossover em AG....................................................................32
FIGURA 3.3 - Reformulação de problemas como uma descoberta de programas .............33
FIGURA 3.4 - Fluxograma da PG.......................................................................................35
FIGURA 3.5 - Estrutura hierárquica correspondente a uma expressao-S em LISP............37
FIGURA 3.6 - Pais escolhidos para cruzamento e seus respectivos pontos de corte..........39
FIGURA 3.7 - Filhos gerados após a operação de cruzamento...........................................39
FIGURA 3.8 - Passos para resolução hierárquica de funções.............................................42
FIGURA 3.9 - Exemplo de um programa geral com um ramo de produção de resultadoe um ramo de definição de função ...............................................................44
FIGURA 4.1 - Arquitetura do sistema.................................................................................48
FIGURA 4.2 – Composição do módulo para definições do problema................................49
FIGURA 4.3 - Interface para definição de parâmetros gerais.............................................50
FIGURA 4.4 - Interface para definições relativos ao domínio do problema. .....................50
FIGURA 4.5 - Interface de saída para acompanhamento do problema...............................51
FIGURA 4.6 - Interface para validação de respostas produzidas na execução...................52
FIGURA 6.1 - Evolução de fitness para o caso 1, usando somente funções básicas. .........61
FIGURA 6.2 – Complexidade estrutural para o caso 1, usando somente funções básicas .63
FIGURA 6.3 - Gráfico de fitness para o caso 1 usando funções de domínio......................64
FIGURA 6.4 - Evolução da complexidade estrutural para o caso 1 usando funções dedomínio .......................................................................................................66
FIGURA 6.5 - Evolução do fitness para o caso 2 ...............................................................68
FIGURA 6.6 - Gráfico da complexidade estrutural para o caso 2 ......................................70
FIGURA 6.7 - Gráfico da evolução do fitness para o caso 3 ..............................................72
FIGURA 6.8 - Gráfico da complexidade estrutural para o caso 3 ......................................73

8
FIGURA 6.9 - Gráfico da evolução do fitness para o caso 4 ..............................................75
FIGURA 6.10 - Gráfico da complexidade estrutural para o caso 4 ....................................77
FIGURA 6.11 - Gráfico da evolução do fitness para o caso 4 usando funções dedomínio sem argumentos .......................................................................79
FIGURA 6.12 - Gráfico da complexidade estrutural para o caso 4 usando funções dedomínio sem argumentos .......................................................................80
FIGURA 6.13 Gráfico da evolução do fitness para o caso 1, usando ADF. .......................83
FIGURA 6.14 – Evolução da complexidade estrutural para o caso 1, usando ADF...........84
FIGURA 6.15 - Gráfico da evolução do fitness para o caso 4, usando ADF......................86
FIGURA 6.16 - Complexidade estrutural para o caso 4, usando ADF ..............................88

9
Lista de Tabelas
TABELA 2.1 Resumo da classificação das vogais .............................................................19
TABELA 2.2 - Resumo da classificação das consoantes....................................................21
TABELA 6.1 – Parâmetros utilizados em todas as execuções............................................59
TABELA 6.2 - Parâmetros para o caso 1, usando somente funções básicas ......................60
TABELA 6.3 – Validação para o caso 1, usando somente funções básicas........................63
TABELA 6.4 - Definições para o caso 1 com funções de domínio ....................................64
TABELA 6.5 – Validação para o caso 1, usando funções de domínio ...............................66
TABELA 6.6 - Definições para o caso 2.............................................................................67
TABELA 6.7 – Validação da melhor solução para o caso 2...............................................71
TABELA 6.8 - Definições para o caso 3.............................................................................71
TABELA 6.9 - Resultados da validação da melhor solução para o caso 3 .........................74
TABELA 6.10 - Definições para o caso 4...........................................................................74
TABELA 6.11 - Resultados da validação da melhor solução para o caso 4 .......................77
TABELA 6.12 - Definições para o caso 4 usando funções de domínio sem argumentos...78
TABELA 6.13 - Resultados da validação da melhor solução para o caso 4 .......................81
TABELA 6.14 - Definições para o caso 1, utilizando ADF................................................82
TABELA 6.15 - Resultados da validação para o caso 1, usando ADF. ..............................84
TABELA 6.16 – Definições para o caso 4, usando ADF....................................................85
TABELA 6.17 – Validação para o caso 4, usando ADF.....................................................89
TABELA 6.18 - Tempos aproximados das execuções.......................................................89

10
ResumoEste trabalho descreve a aplicação da Programação Genética, uma técnica de
Computação Evolucionária, ao problema da Síntese de Fala automática.
A Programação Genética utiliza as técnicas da evolução humana para descobrirprogramas bem adaptados a um problema específico. Estes programas, compostos deinstruções, variáveis, constantes e outros elementos que compõe uma linguagem deprogramação, são evoluídos ao longo de um conjunto de gerações.
A Síntese de Fala, consiste na geração automática das formas de ondas sonoras apartir de um texto escrito. Uma das atividades mais importantes, é realizada através daconversão de palavras e letras para os sons da fala elementares (fonemas). Muitossistemas de síntese são implementados através de regras fixas, escritas porprogramadores humanos.
Um dos mais conhecidos sistemas de síntese é o FESTIVAL, desenvolvido pelaUniversidade de Edimburgh, usando a linguagem de programação funcional LISP e umnúmero fixo de regras.
Neste trabalho, nós exploramos a possibilidade da aplicação do paradigma daProgramação Genética, para evoluir automaticamente regras que serão adotadas paraimplementação do idioma Português na ferramenta FESTIVAL, desenvolvido noprojeto SPOLTECH (CNPq – NSF cooperação entre UFRGS e Universidade doColorado).
A modelagem do problema, consiste na definição das regras de pronúncia doPortuguês Brasileiro, que a implementação do sistema FESTIVAL pronunciaerradamente, já que o mesmo foi implementado primariamente para o idioma Inglês. Apartir destas regras, o sistema de Programação Genética, desenvolvido neste trabalho,evolui programas que constituem boas soluções para a conversão de letras parafonemas.
A descrição dos resultados obtidos, cobre detalhes sobre a evolução das soluções,complexidade e regras implementadas, representadas pelas soluções mais bemadaptadas; mostrando que a Programação Genética, apesar de ser complexa, é bastantepromissora.
Palavras-chave: Programação Genética, Síntese de Fala, Computação Evolucionária.

11
TITLE: “STUDY AND IMPLEMENTATION OF GENETIC PROGRAMMING TOSPEECH SYNTHESIS”
AbstractThis work describes the application of Genetic Programming, an Evolutionary
Computation technique, to Automatic Speech Synthesis.
Genetic Programming uses some human evolution techniques in order to findfitted programs to a specific problem under solution. These programs, made of byinstructions, variables, constants and other programming language elements, evolvethrough a set of generations.
Speech synthesis consists of the automatic generation of sound waveforms, from awritten text. One of the major tasks involved is made through the conversion of wordsand letters to units corresponding to elementary speech sounds (phonemes) throughfixed rules written by programmers.
One of the most know synthesis system is FESTIVAL developed at the Universityof Edimburgh, using LISP functional language, and a fixed number of rules.
In this work, we have explored the possibility of application of the GeneticProgramming paradigm to evolve automatically rules that will be added to Festival toolimplementation for Portuguese in the context of the SPOLTECH project (CNPq – NSFcooperation between UFRGS and University of Colorado).
The problem modelling consists of defining Brazilian Portuguese pronunciationrules that FESTIVAL implementation word “pronounce” wrongly, since as it wasprimarily implemented to English. From these rules, the Genetic Programming systemdevelopped in this work evolve programs which are good solutions to BrazilianPortuguese letter phoneme conversion.
The description of the obtained results covers details about evolution of solutions,complexity and implemented rules represented by the best fitted solutions; showing thatthe application of the Genetic Programming, besides being complex, is quite promising.
Keywords: Genetic Programming, Speech Synthesis, Evolutionary Computing.

12
1 IntroduçãoApesar da evolução constante de hardware e software, grande parte das aplicações
computacionais ainda é baseada em algoritmos e rotinas adaptadas para um problemaespecífico. Além disso a imensa maioria destas ainda exige que o processo de interaçãoentre humanos e sistemas ocorra através da linguagem escrita e em alguns casos atravésde instruções pré-definidas.
Assim, um dos grandes objetivos em anos recentes, tem sido a criação de sistemascomputacionais que apresentem aspectos da inteligência humana, que possibilitem umainteração com alto grau de facilidade ou que tenham por exemplo a capacidade deresolução de problemas sem que sejam explicitamente programados para determinadaatividade.
Para que tais objetivos sejam atingidos, algumas questões fundamentais devem seravaliadas: Como poderão computadores resolver problemas, sem que sejamprogramados? Como os computadores podem encontrar o procedimento correto pararesolução de um problema, sem que sejam dadas a eles todas instruções necessárias paraisto? E ainda, como poderão computadores aprender a resolver por si própriosproblemas cada vez mais complexos?
O aprendizado humano pode ser caracterizado como um processo adaptativo, noqual as atividades evoluem para permitir uma melhor compreensão e resolução deproblemas. A Inteligência Artificial (IA) emprega diferentes técnicas e paradigmas natentativa de simular o processo de aprendizado humano em computadores. Acomputação evolucionária é um ramo da IA no qual são definidas técnicas baseadas nosprincípios da evolução humana. De acordo com Turing [KOZ 2000] a inteligência demáquina pode ser obtida através de uma abordagem biológica e pode haver uma relaçãodireta com técnicas de busca.
Dentro da Computação Evolutiva diferentes técnicas tem sido propostas, entreelas podemos citar Vida Artificial, Programação Evolucionária e Algoritmos Genéticos,além da Programação Genética que é objeto de estudo neste trabalho. Estas técnicasapresentam diversas características comuns como a utilização e avaliação de umconjunto de soluções e operações de reprodução, cruzamento, seleção ou mutação;entretanto diferem na implementação destas características e essencialmente na formade representação das soluções [FOG 2000].
A Programação Genética é uma técnica que tem como objetivo fazer evoluir umconjunto de programas de computador que são soluções candidatas a resolver umdeterminado problema. Através da evolução destas soluções é possível encontrar umconjunto de instruções que resolve o problema proposto [KOZ 92].
Processos de síntese e reconhecimento de voz, tradicionalmente são complexos eapresentam uma grande variabilidade, o que justifica a utilização e avaliação de diversastécnicas de IA para sua resolução. Como exemplo podemos citar as Redes NeuraisArtificiais (RNAs) que são utilizadas com alto grau de sucesso em diversos sistemas desíntese e reconhecimento de voz [LAW 2000].
A síntese de voz normalmente é composta de um conjunto de etapas queenvolvem desde a identificação do texto a ser sintetizado até a geração das ondas dafala. Uma etapa intermediária é a conversão do texto para unidades lingüísticas

13
equivalentes aos sons da linguagem; o problema é que esta relação não é direta e variade um idioma para outro, exigindo assim que sejam implementadas regras para que osistema de síntese possa efetuar essa etapa do processo.
Diversas aplicações tem utilizado a programação genética como forma de obtersoluções para atividades complexas. Em [KOZ 92] são descritas aplicações da técnica àproblemas de controle, planejamento de atividades, regressão simbólica ou descobertade funções.
O objetivo deste trabalho é descrever a aplicação da programação genética aproblemas de conversão de texto para fonema em processos de síntese de voz. Estaaplicação tem como meta principal descobrir programas que implementem as regraspara conversão citadas acima, a partir de exemplos. O aprendizado e descoberta deregras através de técnicas evolutivas, em especial a Programação Genética, é um tópicopouco explorado em trabalhos científicos desenvolvidos no PPGC(UFRGS).
Além da originalidade da aplicação da PG à processos desta natureza, oaprendizado de regras, poderá contribuir para a construção de sistemas adaptáveis adiferentes idiomas, ou variações regionais de um mesmo idioma. Poucos sistemas hojeem dia permitem a utilização em diferentes contextos, sem que para tal uso sejanecessário um trabalho extenso de implementação manual.
O trabalho desenvolvido está relacionado com o projeto Spoltech (CNPq-NSF) etem como meta identificar potenciais utilizações da Programação Genética ao sistemapara síntese implementado neste projeto. Uma descrição mais detalhada das atividades eresultados do Spoltech pode ser visualizada no capítulo 2.
O sistema será criado como uma ferramenta para aplicação da técnica a diversosproblemas, não se restringindo apenas ao descrito neste trabalho, permitindo destamaneira a reutilização futura. A arquitetura do sistema para que tal objetivo sejaatingido apresenta uma separação entre o núcleo e módulos de entrada, saída evalidação. Para aplicações a outros problemas é necessário implementar funçõesrelativas ao novo problema, as quais se encontram no módulo de entrada. Entretanto ofoco deste trabalho é a execução da técnica visando a descoberta de programas queimplementem regras para conversão de texto para fonema em língua portuguesa.
A dissertação está dividida em cinco capítulos. O capítulo 2 descreve os principaisconceitos relacionados ao processo de síntese de voz, em especial a síntese texto parafala. São descritas as etapas do processo com ênfase na conversão de texto para fonemae nas particularidades deste processo na língua portuguesa. Serão descritas tambémregras implementadas de forma manual para avaliação dos resultados obtidos naexecução da aplicação desenvolvida no trabalho.
O capítulo 3 apresenta uma descrição detalhada da programação genética e todosos mecanismos envolvidos em sua aplicação. É estabelecida ainda uma relação datécnica com outras semelhantes, além da descrição de resultados obtidos na suaaplicação a outros problemas.
No capítulo 4 são apresentadas as características do sistema implementado,incluindo a arquitetura básica e seus principais componentes. A partir de umaabordagem modular é possível aplicar a técnica a diferentes problemas sem que paratanto sejam necessárias modificações no núcleo do sistema. Diferentes aplicaçõespodem exigir a criação e uso de novas funções de domínio, uso de diferentes conjuntos

14
de terminais, casos de fitness, variações que em sua maior parte podem ser realizadassem um grande esforço de programação.
O capítulo 5 descreve o trabalho de modelagem da conversão de texto parafonema para sua resolução através da programação genética. Diversas questões sãoavaliadas e definidas, dentre estas estão a estrutura das soluções, forma de avaliaçãodos indivíduos, estrutura dos casos de fitness e dos conjuntos de funções e terminais.Embora a programação genética permita um alto grau de liberdade nas soluçõesproduzidas, deve haver um mínimo de restrição à sua estrutura, caso contrário a buscaseria inviabilizada devido a falta de convergência ou consumo exagerado de recursoscomputacionais.
Os resultados obtidos nas diversas execuções são descritos no capítulo 6. Paramelhor compreensão, as regras selecionadas são agrupadas em quatro casos e para cadaum deles são demonstradas e avaliadas as melhores soluções obtidas, gráficoscomparativos de fitness médio da população, do melhor e pior indivíduo e dacomplexidade estrutural média da população e do melhor indivíduo. Através destasinformações será possível efetivamente verificar a aplicabilidade da técnica aoproblema.
No capítulo 7 serão emitidas considerações e conclusões finais sobrecontribuições do trabalho desenvolvido e sugestões de alternativas futuras para oprosseguimento dos estudos.
O anexo 1 descreve os símbolos usados para representação dos fonemas nosistema Festival e no IPA (International Phonetic Alphabet). O anexo 2 tem por objetivodescrever as regras implementadas no sistema Festival, nas atividades do ProjetoSpoltech. Estas regras permitem uma comparação com os resultados implementadospelas soluções citadas no capítulo 7. Os anexos 3 e 4 descrevem os códigos relativos àimplementação de funções de domínio e de avaliação de fitness.

15
2 Lingüística computacional: Síntese de fala
2.1 Lingüística computacionalA transmissão de informação através de uma linguagem natural como Inglês,
Português ou Alemão é um procedimento bem estruturado. Emissores e receptoresdevem compreender e conhecer os elementos que compõe o processo, do contrário oentendimento falha ou ocorre de forma incompleta [HAU 99].
A lingüística computacional à subárea da computação que envolve o estudo defenômenos de percepção, cognição e investiga a produção e compreensão de linguagemfalada em sistemas computacionais, envolvendo hardware e software. Nos dias atuais, acomunicação entre humanos e máquinas está altamente limitada a formas restritas, queenvolvem linguagens de programação, comandos estruturados e dispositivostradicionais como teclado, mouse e monitor de vídeo [HAU 99].
Diversas aplicações práticas estão diretamente ligadas à lingüísticacomputacional, entre as quais podemos citar recuperação de informações em bases dedados, produção automática de texto e diálogo automatizado. Estas aplicaçõesnormalmente envolvem tarefas de decomposição de sinais em componentes,classificação de componentes e composição através de regras ou conhecimento.
A produção de fala de forma automática em sistemas computacionais é compostade duas atividades definidas como reconhecimento e síntese de fala. A atividade dereconhecimento de fala consiste em captar, reconhecer e interpretar sinais sonoros; emoutras palavras, converter um sinal acústico, capturado por microfone ou telefone paraum conjunto de palavras [LEM 2000]. A síntese de fala, por sua vez consiste na geraçãoautomática das formas de onda da voz, normalmente a partir de um texto escrito ouarmazenado[LEM 2000]. Cada um destes processos é realizado a partir de um conjuntode atividades complexas do ponto de vista computacional e que requerem portanto oestudo e aplicação de técnicas avançadas para sua realização.
2.2 Aspectos básicos de um sistema de texto para fala
Um sistema de texto para fala (Text To Speech - TTS) tem como meta principalreceber um texto de entrada, que pode ter sido inserido diretamente por um operador,obtido através de um scanner ou mesmo produzido de forma artificial por algumsoftware e efetuar a síntese do texto [DUT 96]. Existem diferenças fundamentais entresistemas para síntese de texto para fala e outras máquinas falantes como gravadores ouequipamentos que produzem sons a partir da concatenação de palavras ou sentençasisoladas com vocabulários limitados. Neste modelo de síntese, torna-se impossívelarmazenar todas palavras de uma determinada linguagem, portanto a tarefa central é aprodução de fala através da automática fonetização de sentenças através da pronúncia[DUT 96].

16
FIGURA 2.1 - Diagrama funcional de um sistema de texto para fala.
A fig. 2.1 mostra um diagrama funcional de um sintetizador de texto para fala,composto de dois grupos de atividades distintos. O módulo de processamento delinguagem natural (Natural Language Processing - NLP) deve ser capaz de produzir arepresentação fonética do texto, que inclui os sons da fala respectivos ao texto e tambéma entonação e ritmo necessários. O módulo de processamento de sinais digitaistransforma a informação simbólica recebida em sinais de onda sonora que compõe afala [DUT 96]. Estas duas fases são tradicionalmente chamadas de síntese de alto ebaixo nível, respectivamente. Entre estas tarefas é possível distinguir claramentecaracterísticas segmentais e suprasegmentais, envolvidas. Qualidade segmentalpressupõe a capacidade do módulo de linguagem natural de produzir sons da fala dealta qualidade, e suprasegmental refere-se à habilidade do módulo requerida paraexplorar a riqueza dos contornos prosódicos da fala. A naturalidade e inteligibilidade doresultado final está diretamente relacionada a ambos.
Para uma melhor compreensão das atividades a serem implementadas em umsistema para síntese de voz torna-se necessária antes de mais nada uma análise doprocesso da fala em seres humanos e da estrutura do aparelho fonador, responsável pelaprodução de fala [CHB 94].
Todos os seres humanos possuem mesmo que inconscientemente conhecimentoacerca das regras para leitura e formação da fala em sua língua nativa; tais regras sãotransmitidas de forma simplificada nos primeiros anos escolares. O processo de leituraem humanos passa pela visão de unidades escritas, por uma atividade mental que traduzestas unidades em sons a serem produzidos pelo aparelho fonador em uma etapa final,como podemos verificar na fig. 2.2 [DUT 96]. Em uma comparação direta com asetapas de um sistema de texto para fala poderíamos considerar o cérebro comoresponsável pelo processamento de linguagem natural e o aparelho fonador comounidade de processamento de sinais.
FIGURA 2.2 - Diagrama representando o fluxo do processo de leitura emhumanos.
SINTETIZADOR DE TEXTO PARA FALA
PROCESSAMENTODE LINGUAGEM
NATURAL
PROCESSAMENTODE SINAISDIGITAIS
TRANSCRIÇÃO FONÉTICA
FONES, PROSÓDIA
TEXTO FALA

17
A compreensão do aparelho fonador é importante para entender os parâmetrosenvolvidos na produção da voz e por este motivo é ainda um tópico de diversaspesquisas na área de fonética [KLA 90]. As principais partes do aparelho fonadorhumano indicadas na fig. 2.3 são [CHB 94]:
FIGURA 2.3 – Aparelho fonador humano
− pulmões, brônquios e traquéia são responsáveis pela corrente de ar, matéria-prima da fonação;
− na laringe encontram-se as cordas vocais, que produzem a energia sonorautilizada na fala
− cavidades supralaríngeas (faringe, boca e fossas nasais), funcionam comouma caixa de ressonância. A cavidade bucal pode variar profundamente emforma e volume, graças a movimentos de órgãos ativos, sobretudo da língua.Através da movimentação do palato mole (vélum), a cavidade nasal pode seracoplada à cavidade bucal. Estas cavidades são também conhecidas comotrato vocálico.
2.3 Fonética, fonologia e os sons da falaAnalisando de forma mais detalhada a funcionalidade do módulo de
processamento de linguagem natural descrito na fig. 2.4, podemos concluir que omesmo deve ser capaz de converter um texto em uma seqüência de fonemas,acompanhados da prosódia [DUT 96]. Esta transcrição obviamente não está explícita notexto a ser sintetizado e deve ser conseguida a partir de duas operações básicas, comomostra a fig. 2.4.

18
FIGURA 2.4 Diagrama funcional do módulo de processamento de linguagemnatural
De acordo com [BIS 99] a fonética visa o estudo dos sons da fala do ponto devista articulatório, verificando como os sons são articulados ou produzidos peloaparelho fonador e do ponto de vista acústico, analisando a realização das propriedadesfísicas da produção e propagação dos sons. A fonologia por sua vez, dedica-se àcompreensão dos sistemas de sons, sua descrição, estrutura e funcionamento, analisandoa forma das sílabas, morfemas, palavras e frases, como se organizam e como seestabelece a relação "mente e língua". Estes sons são conhecidos como fonemas.
Os sons são gerados pela passagem do ar fornecido pelos pulmões através do tratovocálico, o que ocorre de três formas distintas originando sons sonoros ou vocálicos,fricativos e plosivos: i) Sons sonoros são produzidos pela elevação da pressão do ar nospulmões, forçando sua passagem através do orifício das cordas vocais e causando assimsua vibração; ii) Sons fricativos são gerados pela formação de uma constrição em algumponto do trato vocálico, normalmente nos lábios, forçando a passagem do ar atravésdesta constrição com velocidade suficiente para produzir turbulência , criando assimuma fonte de "ruído branco"; iii) Sons plosivos resultam da constrição completa do tratovocálico em alguma parte, com acumulação, seguida de liberação abrupta de pressão. Oponto completo de fechamento pode ser efetuado em várias zonas de articulação e aexcitação pode ou não causar vibração nas cordas vocais [CHB 94]. Uma descriçãomais detalhada de sons e pontos de articulação pode ser encontrada em [SIL 99].
À medida que os sons gerados por uma das formas citadas propagam-se pelo tratovocálico, os mesmos apresentam alteração em seu espectro de freqüências, comressonância em algumas delas. Estas freqüências são denominadas formantes do som,sendo o número de formantes variável de acordo com o som [CAM 80]. Juntamentecom a freqüência fundamental, as formantes constituem os principais parâmetrosacústicos da voz; tipicamente para uma voz masculina, a freqüência fundamental variaentre 60 e 240 Hz, enquanto as três formantes variam em torno de 500 Hz, 1500 Hz e2500 Hz. Para a voz feminina, a freqüência fundamental tem valores entre 100 e 400Hz, enquanto as formantes estão aproximadamente 10% acima das masculinas [KLA90].
2.3.1 Transcrição fonética
Na maioria das linguagens, um texto escrito não corresponde a sua pronúncia;assim para descrever a pronúncia correta, um conjunto de representações simbólicas sefaz necessário. Cada idioma possui um alfabeto fonético diferente e um conjunto depossíveis fonemas e suas combinações. Um conjunto de fonemas pode ser definido
MÓDULO DE PROCESSAMENTO DE LINGUAGEM NATURAL
ANALISADOR MORFO-SINTÁTICO
Módulo de letraspara sons
Gerador daprosódia
Fonemas
Fonemas + prosódia

19
como um número mínimo de símbolos necessários para descrever qualquer possívelpalavra em uma linguagem [LEM 2000].
Fonemas são unidades mentais abstratas das quais o som é a realização física; suapronúncia depende dos efeitos contextuais e das características do locutor e suasemoções[LEM 2000]. Durante a fala contínua, os movimentos articulatórios dependemdos fonemas anteriores e posteriores. Os articuladores estão em diferentes posiçõesdependendo do movimento anterior e da preparação para o seguinte, o que causavariações em como um fonema individual é pronunciado. Estas variações são chamadasalofones, constituindo um subconjunto dos fonemas e seu efeito é conhecido comocoarticulação. Um exemplo clássico na maioria dos dialetos do idioma portuguêsbrasileiro ocorre com os fonemas [t] e [d] que apresentam variação diante do [i], sendopossível perceber esta variação comparando-se palavras como "dia" e "dado". Cabesalientar entretanto que em regiões como por exemplo no nordeste do Brasil, apronúncia é a mesma em ambas as situações.
O módulo para conversão de letra para fonema em sistemas de síntese temportanto, a responsabilidade de determinar automaticamente a transcrição fonética dotexto, que envolve primariamente a determinação de quais fonemas correspondem àsletras. Pode-se imaginar a princípio que um simples processo de busca em dicionárioseria suficiente, entretanto a partir de uma examinação detalhada percebe-se quediversas palavras podem ocorrer em diversos contextos, muitas das quais não constamem dicionários de pronúncia [DUT 96]. Além disso, a notação fonética nem sempre éperfeita, isto porque o sinal da fala é sempre contínuo e a notação fonética é semprediscreta.
Diversas convenções tem sido propostas com objetivo de permitir a transcriçãofonética de sons em qualquer idioma. Uma das mais difundidas é o " InternationalPhonetic Alphabet - IPA" proposto pela Sociedade Internacional de Fonética. O IPAentretanto emprega caracteres pouco comuns em máquinas de escrever e computadores,o que dificulta sua utilização em sistemas de texto para fala. O anexo 1 descreve ossímbolos do IPA para a língua portuguesa.
O alfabeto fonético é usualmente dividido em duas categorias principais, vogais econsoantes. Vogais são sempre sons vozeados, pois são produzidos com as cordasvocais em vibração, enquanto que consoantes podem ser vozeadas ou não vozeadas.Vogais tem uma amplitude consideravelmente mais alta do que consoantes e tambémsão mais estáveis e fáceis de analisar e descrever acusticamente [LEM 2000]. De acordocom [CAL 90] a língua portuguesa tem 26 fonemas segmentais. O acento é consideradocomo um fonema suprasegmental, como uma qualidade que se superpõe a certossegmentos.
2.3.2 Classificação das vogais
Vogais normalmente são classificadas segundo quatro critérios: quanto à região dearticulação, quanto ao timbre, quanto ao papel das cavidades bucal e nasal e quanto àintensidade. Os três primeiros critérios são fundamentalmente de base articulatória e oúltimo de base acústica[CHB 94].
a) Classificação quanto à região de articulação
Diz respeito ao ponto ou parte em que se dá o contato ou aproximação dos órgãosque cooperam para a produção dos fonemas. No caso das vogais, estes são a língua e

20
pálato. A vogal média [a] é produzida, mantendo-se a língua baixa, quase em posição dedescanso e a boca entreaberta.
Para passar da vogal [a] para as anteriores [e], [é], [i] levanta-se gradualmente aparte anterior da língua em direção ao pálato duro, ao mesmo tempo que diminui-se aabertura da boca. Para emitir as vogais posteriores [o],[ó],[u] eleva-se a parte posteriorda língua em direção ao véu palatino, arredondando progressivamente os lábios.
b) Classificação quanto ao timbre
Leva em consideração o maior ou menor grau de abertura dos lábios. Para vogal[a], a abertura é máxima e para vogais [e] e [i] o grau de abertura é mínimo.
c) Classificação quanto ao papel das cavidades bucal e nasal
É considerada aqui a posição da úvula durante a passagem de ar pelo tratovocálico. Quando a corrente sonora é impedida de ressoar na cavidade nasal devido àposição levantada da úvula, ocorre a produção das vogais orais([a],[e],[é],[i],[o],[ó],[u]).
Estando as fossas nasais acopladas à cavidade bucal, através do abaixamento daúvula, parte da corrente sonora ressoa na cavidade nasal, produzindo as vogais nasais([ã],[ẽ],[ĩ],[õ],[ũ]).
d) Classificação quanto à intensidade
Diz respeito, à qualidade física da vogal, que depende da força expiatória e daamplitude da vibração das cordas vocais. Vogais que encontram-se nas sílabaspronunciadas com maior intensidade chamam-se tônicas e caracterizam-se no idiomaPortuguês por um reforço da energia expiratória. Vogais que se encontram em sílabasnão acentuadas denominam-se átonas.
TABELA 2.1 – Resumo da classificação das vogais [CHB 94]
Região de articulaçãoIntensidade Papel dascavidades
bucal e nasal
TimbreAnterioresou palatais
Médias oucentrais
Posterioresou velares
Fechadas [i] [u]Semi-fechadas [e] [o]
Semi-abertas [é] [ó]
Orais
Abertas [a]
Fechadas [ĩ] [ũ]
Tônicas
Nasais
Semi-fechadas [ẽ] [ã] [õ]
Fechadas [i] [u]
Semi-fechadas [e] [o]
Átonas Orais
Abertas [a]

21
2.3.3 Classificação das consoantes
As consoantes da Língua Portuguesa tradicionalmente são classificadas em funçãode quatro critérios de base articulatória, ou seja, quanto ao modo de articulação, aoponto de articulação, a função das cordas vocais e quanto ao papel das cavidades bucal enasal. Vai-se analisar agora, em detalhes estas diferentes classes.
a) Classificação quanto ao modo de articulação
Diz respeito à maneira pela qual os fonemas consonantais são articulados. Vindoda laringe, a corrente de ar chega à boca, onde encontra obstáculos totais ou parciais daparte dos órgão bucais. Se o fechamento dos lábios ou a interrupção da corrente do ar étotal, são produzidas as consoantes oclusivas ([p],[t],[k],[b],[d],[g]).
Se o fechamento for parcial são produzidas as consoantes constritivas, que podemser: fricativas, vibrantes ou laterais. As fricativas ocorrem quando o trato vocálico éexcitado por um fluxo de ar turbulento, passando a corrente expiratória pela constrição([f],[s],[x],[v],[z],[j]). Vibrantes caracterizam-se pelo movimento vibratório rápido dalíngua [r], ou da úvula [R], que corresponde ao som de "rr". As laterais, são produzidaspela passagem da corrente expiratória pelos dois lados da cavidade bucal, em virtude deum obstáculo formado no centro desta, pelo contato da língua com os alvéolos dosdentes [l], ou com o pálato [L].
b) Classificação quanto ao ponto de articulação
Faz referência ao local onde os órgãos fonadores entram em contato para aemissão do som, podendo ser bilabiais ([p],[b],[m]), labidentais ([f], [v]), lingüodentais([t],[d],[s],[z]), alveolares ([l],[r],[n]) ou velares ([k],[g])).
c) Classificação quanto a função das cordas vocais
Quanto às vibrações das cordas vocais, produzem-se consoantes sonoras, quandoocorre vibração ou consoantes surdas caso contrário.
d) Classificação quanto ao papel das cavidades bucal e nasal
Havendo uma saída do ar exclusivamente pela boca, as consoantes são ditas oraise havendo uma penetração de ar nas fossas nasais, pelo abaixamento da úvula, asconsoantes são nasais ([m],[n],[ñ]).
A tab. 2.2 resume a classificação das consoantes.

22
TABELA 2.2 - Resumo da classificação das consoantes
Função dascavidades bucal e
nasal
Orais Nasais
ConstritivasModo dearticulação
Oclusivas
Fricativas Vibrantes Laterais
Oclusivas
Função das cordasvocais
Surdas Sonoras Surdas Sonoras Surdas Sonoras Sonoras
Bilabiais [p] [b] [m]
Labio-dentais
[f] [v]
Lingüo-dentais
[t] [d] [s] [z]
Alveolares [l] [r] [n]
Palatais [x] [j] [L] [ñ]
Pontode
arti-cula-ção
Velares [k] [g] [R]
2.4 Técnicas para sínteseAs técnicas para síntese de fala, podem ser classificadas como acústica ou
articulatória. Na síntese acústica, também chamada de funcional o processo concentra-se em aspectos do som produzido e na sua reprodução; normalmente através deamostras pré-gravadas [CAR 98]. Além das técnicas de síntese acústica, outra formapossível de produzir fala é a modelagem direta do sistema humano de produção de fala.Este método, chamado de síntese articulatória, envolve modelagem de articulaçõeshumanas, incluindo também cordas vocais. O estudo, portanto, concentra-se na causa dafala, no estudo da anatomia e fisiologia do aparelho fonador humano. Entretanto,embora este método permita uma alta qualidade no resultado final, possui uma grandecomplexidade potencial para sua implementação [LEM 2000].
As principais técnicas utilizadas nos sistemas atuais são a síntese porconcatenação, por formantes, predição linear e fonte-filtro e serão descritas a seguir.
2.4.1 Concatenação
Sintetizadores concatenadores executam o processamento dos sinais da fala apartir de um banco de dados de falas naturais [CAR 98]. As principais característicasfonológicas da linguagem devem estar armazenadas no banco de dados em questão. Aatividade básica envolvida no processo, consiste em concatenar segmentos e suavizar astransições entre eles. O segmento a ser usado varia e pode ser escolhido entre palavras,sílabas, fonemas, difones e demi-sílabas.
Para que a concatenação possa ser realizada, é necessário anteriormente umprocessamento do texto de entrada para identificação dos segmentos que o compõe

23
(sílabas, fonemas). A decisão de utilizar um ou outro segmento passa por uma análiseque leve em consideração as seguintes características: i) Tamanho do vocabulário; ii)relação entre qualidade do resultado final; iii) capacidade de armazenamento e; iv)tempo necessário para recuperação dos segmentos a partir do banco de dados. Cada umdos segmentos citados possui semelhanças e diferenças e apresenta algumas vantagens edesvantagens quando do seu uso [CAR 98].
2.4.2 Síntese por sílaba
Assim como na utilização de palavras, o número de sílabas existentes nalinguagem é um problema considerável na maioria dos idiomas. Entretanto, devido aopequeno número de interrupções e da diminuição sensível do problema decoarticulação, verificado na síntese por fonemas em geral, o resultado final é de boaqualidade e nitidez [CAR 98].
2.4.3 Síntese por fonemas
Os fonemas são a menor unidade da fala e correspondem efetivamente aos sonsproduzidos. A utilização destes como segmento para síntese foi a primeira alternativapara contornar o problema do grande número de palavras e sílabas. Entretanto, mesmoque a unidade de concatenação escolhida não seja o fonema em si, a conversão de textopara sons da fala, em nível de fonema, é necessária. [CAR 98].
2.4.4 Síntese por Difone
O difone representa a transição entre segmentos adjacentes[KLA 90]. A utilizaçãode fonemas, causa problemas de clareza na transição entre um fonema e outro. Oemprego de difones, tem por objetivo minimizar este problema, que ocorreprincipalmente devido ao fenômeno da coarticulação. A coarticulação não é consideradaum som e sim a adaptação da posição dos órgãos vocais, com objetivo de pronunciar ofonema seguinte, a partir da posição em que se encontram, em razão do fonemapronunciado.
A gravação dos difones engloba os segmentos da consoante com a vogal seguinte,bem como a mesma vogal com a consoante seguinte. Tais gravações, trazem embutidasa coarticulação necessária para maior clareza no resultado final.
2.4.5 Síntese por Demi-sílaba
A demi-sílaba é sutilmente diferente do difone. Enquanto em um difone, aseparação é realizada no meio da vogal, na demi-sílaba ela é feita tão logo ocorra atransição da consoante para a vogal; ou seja, um pouco antes do corte difônico.
C V C C V C
Difone Demi-sílaba
2.4.6 Formantes
As formantes são zonas onde se verificam marcas frequenciais de maiorintensidade, podendo ser consideradas como identidades do fonema e da fala. Sãodivididas em 3 bandas diferentes (200-1000, 500-2500, 1500-3500 Hz). Em cada umadas bandas o ponto de maior freqüência é denominado formante, não sendo portanto

24
necessário o armazenamento de toda a onda sonora representando o fonema; apenas asformantes que permitem caracterizá-lo. A quantidade de espaço necessária para oarmazenamento neste caso é infinitamente inferior às alternativas anteriores.
2.4.7 Fonte-Filtro
Esta técnica baseia-se na premissa de que a região vocal pode ser modelada comoum filtro linear que varia no tempo[CAR 98]. O filtro é excitado por uma fonte que gerapulsos de onda, modelando assim o som e produzindo o fonema específico. Em umaanalogia com o aparelho vocal humano, podemos comparar a fonte ao pulmão e o filtroàs cordas vocais, lábios e cavidades orais e nasais.
2.5 Conversão letra para fonema em Língua PortuguesaApós a conceituação de fonemas e da classificação de acordo com aspectos
relacionados à produção física dos sons, torna-se necessário abordar o problema sob oponto de vista do processo de conversão, e de que maneira ele pode ser realizadocomputacionalmente. Tradicionalmente, existem duas estratégias possíveis pararealização desta atividade, os quais são, processos baseados em dicionário ou baseadosem regras.
A estratégia baseada em dicionário consiste no armazenamento de um máximoconhecimento fonológico em um léxico. Para não implicar em tamanhos queinviabilizem o processo, entradas são geralmente restritas à morfemas, derivações destesou ainda regras que definem como componentes morfêmicas são modificadas, quandocombinadas em palavras [DUT 96].
Outra estratégia adotada é baseada em conjuntos de regras para conversão deletras para sons (LTS – Letter To Sound), também chamadas de letra-fonema ougrafema-fonema. Nesta estratégia apenas palavras pronunciadas de forma diferente dasregras em determinados contextos, devem ser armazenadas em um dicionário deexceções. Esta abordagem permite a expressão de diferentes regras de acordo comvariações regionais, extremamente comuns na Língua Portuguesa. O conjunto de regrasa serem mantidas é sensivelmente menor do que o dicionário léxico e ainda torna-sepossível representar um número quase infinito de palavras e combinações derivadasdestas regras, o que torna esta abordagem mais adaptada do que a conversão baseada emdicionário [DUT 96].
A conversão de letras para fonemas na maioria dos casos ocorre em nível depalavras; sendo assim, inicialmente um pré-processamento no texto de entrada deve serrealizado, visando traduzir ou eliminar elementos como abreviações, acrônimos, datas,números ou outros elementos semelhantes. A partir desta etapa, o texto será separadoem palavras e cada uma delas passará pelo processo de conversão de letras parafonemas. Embora em alguns contextos possa haver uma influência da palavra anteriorsobre o início da próxima, a escolha de palavras como unidades de conversão é a maisnatural e simples do ponto de vista de sistemas de texto para fala automáticos [DUT 96].
Na maioria dos idiomas, assim como na língua portuguesa, não há umacorrespondência exata entre número de letras e de fonemas. As regras para conversãotipicamente envolvem avaliação de fonemas anteriores e posteriores. Particularmente naLíngua portuguesa, os seguintes casos podem ser citados como exemplos [CHB 94]:

25
− Uma mesma letra simbolizando mais de um fonema (exame, xale, próximo).
− Um mesmo fonema representado por mais de uma letra (casa, cozinha,exame).
− Letras que por vezes não representam fonemas, funcionado como notaçõesléxicas (campo, regue).
− Casos em que letras não representam fonemas e tampouco notações léxicas(hotel, discípulo).
Vários autores tem proposto ao longo do tempo, conjuntos de regras para guiar aconversão; entretanto é impossível cobrir todos os aspectos e contextos verificados nalinguagem. De acordo com [SIL 93] as regras para conversão podem ser reunidas emdois grandes grupos: símbolos gráficos com representação única e com representaçãomúltipla. Este último grupo pode ser dividido em diversos subgrupos:, envolvendoelementos gráficos (letras) que podem representar mais de um elemento fônico(fonema) ou fonemas passíveis de representação por mais de uma letra. A grandemaioria das regras concentram-se no segundo grupo; uma vez que existindo umarepresentação biunívoca entre letra e fonema, basta produzir como resultado a próprialetra. Os diferentes subconjuntos de regras estão descritos abaixo[SIL 93]:
Grupo 1 - Relações biunívocas entre letra e fone. A combinação “nh” tem umarepresentação única, por este motivo encontra-se também neste grupo.
p → [p]b → [b]f → [f]v → [v]nh → [ñ]
Grupo 2 - Representações múltiplas
O subgrupo 1 descreve símbolos gráficos com valor fonológico múltiplo simples.Este grupo pode ser considerado como uma variação do anterior, onde algumas letraspossuem além da representação direta do fonema básico, uma pequena variação emcontextos ou até mesmo em regiões específicas.
[a] [t] [d]a t d [ã] [ts] [dz]
O subgrupo 2 descreve representações múltiplas de letras e fonemas. A maioriadas letras neste grupo pode representar mais de um fonema. Alguns fonemas como [u],são representados por mais de uma letra e letras como “m” ou “n” podem simbolizar umfonema ou ainda influenciar a representação da letra anterior, como no caso danasalização.

26
[n] i [i]
[V~ n] [i~] [e] n[V~ ņ] [y] e [e/][m] [e~]
m [õ]
[V~m] o [o/]
l [w] [ũ] [o] [l]
[λ] [φ] u [u]
lh
Subgrupo 3 - Representações da letra "r". A letra em questão pode ser consideradaum caso especial, pois a ocorrência da mesma em seqüência exige a produção de umfonema diferente. Os fonemas neste subgrupo não possuem uma representação por maisde uma letra.
rr [h]
[φ]r [r]
Subgrupo 4 - Representações das letras "g" e "j". Nesta situação, observa-seclaramente uma influência das letras seguintes na produção do fonema correto. A letra“u” em certos contextos é representada em outros não. A letra “j” possui umarepresentação única, porém o fonema produzido por ela possui representação tambémpela letra “g”.
[gu]gu [gw]
g [g]
j [z^]
Subgrupo 5 - Representações múltiplas de "q", "c", "s", "z". O nível decomplexidade neste caso é grande, existem fonemas simbolizados por mais de uma letra

27
e a combinação de uma mesma letra simbolizando diferentes fonemas. A letra “x” poderepresentar diferentes fonemas, de acordo com o contexto que é utilizada.
[ku]
[kw]qu [k]c ç
ss
sc [s]
xc sçs [z] x
z [ks] [ch] [š]
A partir dos contextos e grupos descritos acima, analisando-se exemplos depalavras onde sejam verificadas as diferentes situações, é possível deduzir as regras paraconversão de letras para fonemas. A descoberta das regras neste trabalho deveráportanto, envolver um número mínimo de situações de cada um dos grupos descritos.
2.6 Histórico e sistemas para síntese de falaDiversos esforços tem sido realizados ao longo dos anos para criar sistemas para
produção de fala. Inicialmente foram criados dispositivos mecânicos semelhantes ainstrumentos musicais, cujo objetivo era a produção de sons de vogais. Estes primeirosdispositivos foram desenvolvidos por Kratzenstein em 1779. Este trabalho foi estendidoe culminou 20 anos após com a criação da máquina de fala de Kempelen em Viena, queainda constituía-se de um dispositivo mecânico, baseado na produção de sons a partir dapressão do ar acionado manualmente por operadores humanos.
A partir de 1922 foram descritos e produzidos os primeiros sintetizadoreselétricos, sendo que o primeiro a ser considerado um sintetizador de fala foi o VODER(Voice Operating Demonstrator) introduzido por Homer Dudley e desenvolvido peloslaboratórios da empresa Bell. Após a demonstração do VODER o trabalho científico emsíntese de voz passou a receber uma maior atenção e um incremento no interesse, pois apartir daí foi demonstrado que fala inteligível poderia ser produzida artificialmente[LEM 2000].
O primeiro sintetizador por formantes foi o PAT (Parametric Artificial Talker)introduzido em 1953 por Walter Lawrence, o qual consistia de componentes pararessonância conectados em paralelo. Um dispositivo de vidro em movimento convertiasinais desenhados em funções para controle de três freqüências formantes: i) Amplitudede vozeamento; ii) freqüência fundamental e; iii) amplitude de ruído [LEM 2000].

28
O primeiro sintetizador articulatório, o DAVO (Dynamic Analog of the Vocaltract), foi introduzido em 1958 por George Rosen no M.I.T. e era controlado por fitascom sinais de controle criados e gravados manualmente. Entre 1970 e 1980 umaconsiderável quantidade de sistemas comerciais de texto para fala tornou-se disponível,sendo que o primeiro circuito integrado para síntese de fala pode ser considerado oVotrax, que possuía um chip que implementava sintetizadores em cascata[LEM 2000].
FIGURA 2.5 Evolução histórica da síntese de fala.
A fig. 2.5 ilustra a evolução dos sistemas para síntese. Tecnologias modernas parasíntese de fala envolvem métodos e algoritmos sofisticados e complexos. Alguns destesmétodos são os Modelos Ocultos de Markov(Hidden Markov Models - HMM),utilizados desde 1970 e as Redes Neurais Artificiais, cuja utilização é mais recente. Amaioria das técnicas atuais emprega princípios de inteligência artificial e aprendizado demáquina, principalmente na fase de processamento de linguagem natural.
Diversas aplicações comerciais atuais possuem um grande potencial para uso dasíntese de texto para fala. Dentre estas aplicações podemos citar serviços detelecomunicações, envolvendo respostas e atendimento telefônico automático, ensino delínguas apoiado por sistemas computacionais envolvendo diálogo, interfaces parausuários que possuem deficiências motoras ou visuais, multimídia e todas as formas depesquisas e sistemas envolvendo comunicação entre humanos e máquinas [LEM 2000].
2.6.1 Sintetizadores atuais
Neste item serão descritos de forma sucinta alguns sintetizadores utilizados emlarga escala.
a) DosvoxÉ um dos mais conhecidos sintetizadores de fala em Língua Portuguesa [DOS 98].
Baseia-se na concatenação de fonemas e possui dois componentes: Subsistema deconversão e subsistema de conversão e amplificação.
O subsistema de conversão recebe uma palavra e através de um conjunto deregras, representadas por uma máquina de estados finitos, retorna os respectivosfonemas que compõe a mesma. O subsistema de conversão e amplificação emite os sonsseqüencialmente dos fonemas obtidos pelo primeiro subsistema, em um dispositivo desaída [DOS 98].
b) MbrolaO sintetizador de fala Mbrola [MBR 2000] foi elaborado com o objetivo de servir
para síntese em qualquer idioma. A ferramenta baseia-se em um banco de dadosfonético específico para cada idioma.
Modelo articulatório 1950Kratzenstein 1779
Von Kempelen 1791
1800 1900
VODER 1939 Síntese por formantes 1953
Síntese articulatória 1958Síntese por regras 1959Síntese concatenativa 1958
Modelos sinosoidal 1984Redes neurais 1985PSOLA 1985
Klattalk 1981Mtalk 1979Votrax 1979
2000

29
Não existe neste sistema a necessidade de tradução da escrita para fonemas, parte-se diretamente destes. O funcionamento básico consiste na concatenação de difones e nadescrição de cada um destes quanto à prosódia.
2.6.2 Projeto Spoltech
Spoltech é um projeto de pesquisa em lingüistica computacional que tem porobjetivo criar, desenvolver e prover tecnologias de síntese e reconhecimento de fala emlíngua portuguesa. O projeto é de cooperação internacional, através do CNPq (Brasil) eNSF(Estados Unidos), sendo composto por pesquisadores, estudantes do Instituto deInformática e Instituto de Letras da Universidade Federal do Rio Grande do Sul, doDepartamento de Informática da Universidade de Caxias do Sul, CSLR/CU (Universityof Colorado, Boulder) e do CSLU/OGI (Oregon Graduate Institute). A coordenação doprojeto, recai sobre o Prof. Dr. Dante A. C. Barone, orientador do presente trabalho[SPO 2001].
Para síntese de texto para fala é utilizado o sistema Festival, que consiste de umframework para construção de sistemas para síntese, desenvolvido pela University ofEdimburgh(Escócia). A ferramenta Festival oferece a possibilidade da adição rápida eeficiente de novos módulos; sendo assim, não é necessário desenvolver a arquiteturacompleta do sistema de síntese e sim os módulos específicos para síntese no idioma emquestão ou ainda módulos relativos a outras técnicas de síntese que estejam sendopesquisadas.
O processo emprega a síntese acústica por concatenação, onde a unidadeempregada no processo é o difone. Duas diferentes bases de difones foram criadas,sendo a segunda mais completa. A lista de difones é uma combinação de todos osfonemas observados no idioma. Portanto para possibilitar a definição da base de difonese construir o processo de síntese foram inicialmente definidos os fonemas do idiomaportuguês brasileiro [SPO 2001]. O Anexo 1 mostra a tabela de fonemas empregada naferramenta Festival e sua representação equivalente no "IPA". Esta mesma notação foiutilizada na aplicação descrita neste trabalho.
O processo de conversão de letra para fonema é implementado através de umconjunto de regras descritas em um módulo LTS, conhecido como módulo de letras parasons. Abaixo podemos visualizar dois exemplos de regras criadas no ambiente dosistema Festival. A primeira define que ocorrendo a letra “m” após “o”, em final depalavra, simbolizado por #, será produzido o fonema [o~]. A segunda estabelece aprodução do fonema [s] sempre que ocorrer a letra “c” antes de “e” ou “i”.
( [ o m ] # = o~ ) ( [ c ] EI = s )
As regras implementadas efetuam corretamente a conversão na maioria dos casos;entretanto alguns problemas ocorrem:
− Palavras com letras “e” e “o”. Em diversas situações, as palavrasrepresentam diferentes fonemas sem que haja possibilidade de definir regrasaplicáveis a todas as situações. Para melhor conversão nestes casos foirealizada uma análise através de um dicionário de pronúncia comaproximadamente 20.000 palavras. A partir do levantamento das principaisocorrências verificadas, foram criadas regras para os casos mais comuns.

30
− Palavras homógrafas. Todas as palavras deste gênero constituem umasituação extremamente difícil de resolver por não haverem regras gerais quefuncionem para qualquer contexto.
− Ocorrências da letra x. Nas regras implementadas não é possível detalhartodos os casos em que a letra aparece, por serem muitos.
A partir da descrição das atividades necessárias para síntese de fala, é possívelperceber as dificuldades envolvidas para a realização completa deste processo. Aatividade de conversão de letra para fonema é de vital importância e apresenta variaçõesde acordo com contexto, idioma e região. Tais variações justificam a aplicação detécnicas avançadas com objetivo de diminuir a necessidade de alterações e adaptaçõesmanuais em sistemas computacionais para síntese de fala.

31
3 Programação genética
3.1 Princípios da evolução naturalA teoria da evolução humana foi proposta por Darwin em 1859 e é aceita até hoje
como a teoria biológica mais importante para explicação da origem e perpetuação davida. De acordo com Dobzanhansky [DOB 77], "Nada na biologia faz sentido, exceto aluz da evolução", tal afirmativa serve de exemplo da importância que a maioria dospesquisadores atribui a teoria.
De acordo com Darwin [FOG 2000], a história da vasta maioria das espécies étotalmente contada por alguns poucos processos estatísticos que agem sobre populaçõese espécies. Estes processos são a reprodução, mutação, competição e seleção. Areprodução é o mais conhecido e óbvio processo para perpetuação da vida e paraevolução; a mutação é garantida em um sistema que continuamente reproduz ele mesmoem um universo positivamente entrópico. A competição e seleção são conseqüênciasinescapáveis da expansão de populações que ocupam uma arena finita, uma vez que asespécies e indivíduos competem por recursos. A evolução portanto, é o resultado destafundamental interação entre estes processos que atuam sobre populações, geração apósgeração [FOG 2000].
Algumas questões podem ser formuladas em relação a como tais processos agemsobre uma evolução: O que está sendo otimizado pela evolução? Quão extensiva é estaotimização? Quais são os benefícios de otimização resultantes: para indivíduos ou paraas espécies como um todo? Quais os benefícios da seleção sexual? Os mecanismosevolucionários criam um emaranhado de efeitos que não podemos distinguir ouparticionar facilmente, mas que governa todo o processo evolucionário e pode serexpresso por um pequeno conjunto de regras [FOG 2000].
Organismos vivos podem ser vistos com uma dualidade de genótipo (acodificação genética básica) e seu fenótipo (a maneira que ele responde, suas atividades,psicologia e morfologia). De acordo com a teoria da evolução, a seleção natural é aforça evolucionária que prevalece na formação das características fenotípicas de umindivíduo na maior parte das situações encontradas na natureza. A variação destefenótipo é um resultado de larga atuação dos processo de mutação e recombinação. Ainteração entre espécies e seu ambiente (incluindo outros organismos) determina osucesso ou falha, que pode significar a morte de espécies[FOG 2000].
A seleção pode ser vista como guia para manutenção ou incremento da habilidadede sobreviver e reproduzir em um ambiente específico. Em um processo de evoluçãonatural entretanto, há enormes dificuldades de medir diretamente esta habilidade. Areprodução sexual por sua vez, oferece uma maneira significativa para geração dediversidade genética e como conseqüência, diversidade fenotípica; há um incrementona taxa de exploração do espaço de estados genotípicos/fenotípicos possíveis[FOG 2000].
Uma das tendências da evolução, é a geração de organismos com maiorcomplexidade, onde indivíduos tendem a apresentar uma maior capacidade de interaçãocom o ambiente e maior facilidade de resolver problemas. Este incremento decomplexidade, é necessário para aumentar a qualidade na atividade de antecipação aeventos ambientais [FOG 2000].

32
3.2 Computação evolucionáriaA idéia de simular inteligência e aprendizado em computadores utilizando
princípios evolutivos pode ser observada em um conjunto de técnicas propostas. Alémda Programação Genética, podemos citar ainda a Programação Evolucionária, VidaArtificial, Estratégias Evolucionárias e Algoritmos Genéticos. Estas técnicas envolvema evolução de programas, simples padrões numéricos, máquinas de estados ouindivíduos formados por strings de bits [FOG 2000].
3.2.1 Algoritmos Genéticos
Algoritmos Genéticos (AG) foram propostos inicialmente por John Holland [HOL75] e desde então vem sendo aplicados com sucesso em uma grande quantidade deproblemas, principalmente na área de otimização [DAV 91], [MIT 92].
Essencialmente a técnica engloba uma população de indivíduos codificados comocromossomos, tipicamente usando uma representação binária, cada indivíduo dapopulação representa uma solução para o problema em questão. A utilização derepresentações em níveis de abstração mais altos tem sido investigada. Como estasrepresentações são mais fenotípicas, facilitariam sua utilização em determinadosambientes, onde essa transformação "fenótipo - genótipo" é muito complexa [MIT 92].
Para medir a adaptação destes indivíduos ao ambiente (problema a ser resolvido) édefinida uma função de fitness, que é aplicada a cada solução candidata. Um critério deseleção vai fazer com que, depois de muitas gerações, o conjunto inicial de indivíduosgere indivíduos mais aptos. A maioria dos métodos de seleção são projetados paraescolher preferencialmente indivíduos com maiores notas de aptidão, embora nãoexclusivamente, a fim de manter a diversidade da população. Um método de seleçãomuito utilizado é o método da roleta, onde indivíduos de uma geração são escolhidospara fazer parte da próxima geração, através de um sorteio de roleta [MIT 92].
Neste método, cada indivíduo da população é representado na roletaproporcionalmente ao seu índice de aptidão. Assim, aos indivíduos com alta aptidão édada uma porção maior da roleta, enquanto aos de aptidão mais baixa é dada umaporção relativamente menor da roleta. Finalmente, a roleta é girada um determinadonúmero de vezes, dependendo do tamanho da população, e são escolhidos, comoindivíduos que participarão da próxima geração, aqueles sorteados na roleta [MIT 92].
FIGURA 3.1 - Indivíduos de uma população e a sua correspondente roleta deseleção
Um conjunto de operações é necessário para que, dada uma população, se consigagerar populações sucessivas que espera-se melhorem sua aptidão com o tempo. Estes

33
operadores são: cruzamento (fig.3.2) e mutação. Eles são utilizados para assegurar que anova geração seja totalmente nova, mas possua, de alguma forma, características deseus pais, ou seja, a população se diversifica e mantém características de adaptaçãoadquiridas pelas gerações anteriores. Para prevenir que os melhores indivíduos nãodesapareçam da população pela manipulação dos operadores genéticos, eles podem serautomaticamente colocados na próxima geração, através da reprodução elitista, queconsiste em manter o melhor indivíduo de uma geração para outra [MIT 92].
FIGURA 3.2 - Operação de crossover em AG
Um Algoritmo Genético opera sobre um conjunto de soluções, e desta maneirapode explorar diferentes regiões do espaço de busca, ao contrário de técnicastradicionais como Subida de Montanha (Hill Climbing) e Recozimento Simulado(Simullated Annealling) [MIT 92].
O Algoritmo Genético tradicional é representado pelos seguintes passos:
{ t = 0;
inicia_população (P, t)
avaliação (P, t);
repita até (t = d)
{ t = t +1;
seleção_dos_pais (P,t);
recombinação (P, t);
mutação (P, t);
avaliação (P, t);
sobrevivem (P, t) } }
onde:
t - tempo atual;
d - tempo determinado para finalizar o algoritmo;
P - população
Neste caso, t pode ser definido como a geração atual e d como o número degerações que serão processadas. Pode-se usar outros parâmetros para encerrar oprocessamento, sem se ater exclusivamente a um número fixo de gerações. O processode avaliação, é baseado em uma medição do fitness, que corresponde ao grau deadaptação de cada indivíduo[MIT 92].
3.3 Programação Genética para descoberta de programasA programação genética tem sido considerada por diversos autores como uma
extensão ou variação dos algoritmos genéticos devido à semelhança entre as duasabordagens. A principal diferença entre ambas está localizada na forma derepresentação das soluções. Enquanto os Algoritmos Genéticos utilizam uma
Ponto de crossoverPai 1: 1 1 0 1 0 1 1 1 1 0 1 Filho 1: 1 0 1 0 0 1 1 1 1 0 1Pai 2: 1 0 1 0 0 0 0 0 1 0 0 Filho 2: 1 1 0 1 0 0 0 0 1 0 0

34
representação abstrata e altamente estruturada, a Programação Genética apresenta comosolução programas de computador em uma linguagem de programação específica. Oobjetivo central portanto na Programação Genética é descobrir uma seqüência deinstruções que possa resolver o problema proposto.
3.3.1 Descoberta de programas
Muitos problemas semelhantes em aprendizado de máquina, inteligência artificiale processamento simbólico podem ser vistos como uma busca ou descoberta de umprograma de computador que produza determinadas saídas a partir de um conjuntoespecífico de entradas [BRA 92].
A partir da hipótese de que um programa correto possa ser induzido a partir de umconjunto de casos de testes, podemos considerar esta atividade como uma tarefa deindução, que por sua vez está sujeita a todos os méritos e armadilhas do raciocínioindutivo. Um dos principais problemas, é que uma hipótese indutiva está ligadadiretamente a capacidade que casos de teste tem de representar o problema inteiro. Amaioria dos problemas possui um conjunto grande de hipóteses possíveis [O'RE 95].
FIGURA 3.3 - Reformulação de problemas como uma descoberta de programas
O que torna a descoberta de programas especial e diferente de outras tarefasindutivas é que as soluções são expressas na forma de programas, que são soluçõesutilizáveis para especificação de uma atividade para uma classe geral de problemas, pelapossibilidade de parametrização através do uso de variáveis. Assim, um mesmoprograma é aplicável a uma classe geral e não a um único problema, bastando que sealtere o conjunto de parâmetros de entrada, para que se obtenha outra saída [O'RE 95].
Vários são os domínios onde a descoberta automática de programas pode seraplicada, dentre estes podemos citar: Estratégias de controle, planejamento, indução deseqüência, regressão simbólica, estratégias de jogos, descobertas empíricas, previsões eprogramação automática [O'RE 95].
3.3.2 Atributos de um sistema para descoberta automática de programas
De acordo com [KOZ 2000], um sistema para criação automática de programasdeveria ser capaz de criar entidades que possuem a maioria ou preferencialmente todasas capacidades descritas nos atributos abaixo:
Controle Planejamento Indução desequência
Descobertaempírica
Estratégiasde jogos
Formulação do problema de descoberta de programas
Algoritmo paradescoberta de
programas
Solução

35
1. Iniciar com o que necessita ser feito: Instrução de alto nível especificandorequerimentos para o problema
2. Dizer-nos como fazê-lo: Produzir um conjunto de instruções na forma de umaseqüência de passos que resolvem satisfatoriamente o problema
3. Produzir um programa de computador:
4. Determinar automaticamente o tamanho do programa: Determinar de formaautomática o número de passos que devem ser executados sem que devam serpré-especificados pelo usuário.
5. Reuso de código: Possuir a habilidade de automaticamente organizar gruposusáveis de código que podem ser reutilizados.
6. Reuso parametrizado: Criar unidades de código que possam ser reusadas comdiferentes instanciações dos valores (parâmetros formais).
7. Armazenamento interno: Utilizar armazenamento interno, através de variáveis,vetores, matrizes, pilhas e outras estruturas de dados.
8. Iterações, laços e recursões:
9. Organização própria de hierarquias: Habilidade de organizar automaticamentegrupos de passos em uma hierarquia
10. Determinar de forma automática a arquitetura do programa:
11. Usar ampla faixa de elementos de programação: Implementar elementosanálogos aos usados por programadores humanos, e que incluem macros,bibliotecas, tipos, ponteiros, operações condicionais, funções lógicas, funçõesinteiras, múltiplas entradas e saídas e outros.
12. Operar em uma forma bem definida: Distinguir de forma correta entre o que osistema precisa prover e o que ele produz.
13. Ser independente de problema: Independente, no sentido de que o usuário nãonecessita modificar os passos do sistema para cada novo problema.
14. Ampla aplicabilidade: Produzir soluções satisfatórias para uma amplavariedade de problemas em vários campos diferentes.
15. Escalabilidade: Permite aplicação em versões mais complexas para um mesmoproblema.
16. Ser competitivo com resultados produzidos por humanos: Produzir resultadosque sejam competitivos com aqueles produzidos por programadores,engenheiros e matemáticos.

36
3.4 Elementos principais da Programação Genética
O paradigma da Programação Genética segue a tendência da manipulação darepresentação do problema em Algoritmos Genéticos, pelo aumento da complexidadedas estruturas que sofrem adaptação. O paradigma é recente e foi proposto por John R.Koza [KOZ 92]. As operações são realizadas diretamente em programas de computadorhierarquicamente estruturados, que podem variar em forma e tamanho. A tarefa pode serresumida na busca pelo programa de computador mais adaptado, no espaço de todos ospossíveis programas.
FIGURA 3.4 - Fluxograma da PG.
Não
Sim
Gen:= 0
Criar randômicamente apopulação inicial
Critério de términosatisfeito
Determineresultado
FimAvaliar fitness de cadaindivíduo da população
i:=0
Gen:= Gen + 1Sim
i > M?
Selecionar probabilisticamente aoperação genética
Não
Selecionar um indivíduobaseado no fitness
Selecionar dois indivíduosbaseado no fitness
Executar reprodução i:= i + 1
Executar cruzamento
Insirir dois novos filhos na novapopulação
Copiar para a nova população
i:= i + 1
Pr Pc

37
A fig. 3.4 ilustra os passos empregados na técnica. Na simbologia empregada, M éo tamanho da população, i o número de indivíduos a população e Pr e Pc significamprobabilidades de operações de reprodução e cruzamento respectivamente. Estasprobabilidades serão detalhadas posteriormente.
O processo inicia com a geração de uma população inicial de programasrandomicamente criados, compostos de funções e terminais apropriados ao domínio doproblema. Cada programa é uma solução em potencial e é avaliado em termos de suaadaptação ao ambiente. O princípio da reprodução e sobrevivência do melhor é entãousado para criação de uma nova geração de programas a partir da atual. Programasencontrados nas gerações iniciais tendem a ser menos adaptados do que aquelesencontrados nas gerações seguintes [KOZ 92].
O estado deste processo consiste somente na atual população de indivíduos. Aúnica informação disponível para evolução dos programas é a medida do ajuste de cadaindivíduo. Não existem outras informações como por exemplo a estrutura interna, errosde representação ou efeitos que o programa possa ter tido sobre o ambiente.Tipicamente a solução para o problema é um indivíduo com melhor ajuste existente aofinal da execução do algoritmo [KOZ 92]. A medida do ajuste de cada indivíduo, assimcomo nos Algoritmos Genéticos é chamada de fitness.
A variabilidade dinâmica dos programas de computador ao longo da busca dasolução também se constitui em uma característica importante do paradigma, pois éextremamente difícil restringir o tamanho e a forma das soluções. Tais restriçõespoderiam diminuir a probabilidade de achar melhores soluções [KOZ 92].
Outra característica importante é que na programação genética o pré-processamento de entradas ou pós-processamento de saídas não é necessário ou exerceuma menor influência, uma vez que entradas, resultados intermediários e saídas sãoexpressados diretamente em termos de instruções ou valores relativos ao domínio doproblema [KOZ 92].
3.4.1 Estruturas que sofrem adaptação
Em qualquer sistema adaptativo, existem estruturas que são submetidas a umprocesso evolutivo, para que passem a funcionar melhor em seu ambiente. Emalgoritmos adaptativos genéticos, cada estrutura é um ponto individual em umapopulação de soluções, constituindo-se assim em um ponto individual no espaço debusca do problema, ocorrendo uma busca paralela. O paradigma da ProgramaçãoGenética, utiliza programas hierarquicamente estruturados que variam em tamanho eforma e são modificados durante o processo [KOZ 92].
O conjunto de possíveis estruturas na programação genética é formado peloconjunto de possíveis composições a partir de um conjunto de funções disponíveis Nfunc,F={f1, f2, f3...fNfunc}, exemplificadas a seguir e de um conjunto de terminais disponíveisNterm T={t1, t2, t3...tNterm}. Cada função fi requer um número z(fi) de argumentos z(f1),z(f2).... Ao definir o conjunto de funções possíveis, é necessário definir também ummapa de argumentos, que indica o número de argumentos necessários para cada umadas funções usadas para compor a estrutura [KOZ 92].
Como exemplos de funções podemos citar:
− operações aritméticas (+, -);

38
− funções matemáticas (Sin, Cos, Exp);
− operações booleanas (AND, OR, NOT);
− operadores lógicos (IF-THEN-ELSE);
− operadores de iteração (DO-UNTIL).
− funções do domínio da aplicação, desenvolvidas para o problema.
O conceito de terminal está relacionado à representação de programas sob a formade árvores. Um terminal não possui filhos, isto significa que não opera sobre nenhumargumento em caso de funções ou não constitui uma operação, como no caso deconstantes e variáveis. Terminais podem ser átomos constantes como letras, números ouvariáveis, que podem representar dados de entrada, sensores, variáveis de estado dosistema ou ainda funções sem argumentos [KOZ 92].
FIGURA 3.5 - Estrutura hierárquica correspondente a uma expressao-S em LISP.
Consideremos a fig. 3.5, que exemplifica um programa composto a partir de umconjunto de funções F={AND, OR, NOT} e do conjunto de terminais T={D0,D1}. Omapa de argumentos das função é Z={2, 2, 1}. A figura mostra a estrutura de umprograma (OR (AND (NOT D0) (NOT D1))(AND D0 D1)), que foi gerado em umapopulação inicial, para resolução do problema de função de paridade para doisargumentos. Os pontos externos da árvore são terminais, sobre os quais atuam asfunções que se encontram nos ramos internos da árvore [KOZ 92].
Para um funcionamento correto, dois requerimentos devem ser satisfeitos naescolha do conjunto de funções e terminais aplicáveis ao problema em questão: clausurae suficiência.
A propriedade de clausura, diz respeito ao fato de todos os indivíduos em umapopulação serem compostos de funções e terminais que executem corretamente, semerros. Qualquer combinação entre terminais e funções, deve resultar em um programaválido. Um caso clássico de falta de clausura, pode ser considerado a combinação deuma função de divisão com a constante zero. Existe a possibilidade de que estaconstante seja escolhida como segundo argumento da função em alguma solução. Talcombinação resulta em um erro de divisão por zero. Uma alternativa neste caso é aadoção de uma função de divisão protegida. Caso não seja possível satisfazer apropriedade, alguma alternativa deve existir, como alguma penalidade para o fitness ousimplesmente o descarte dos indivíduos cujo resultado não pode ser avaliado [KOZ 92].
OR
AND AND
NOT NOT D0 D1
D0 D1

39
Para satisfazer a propriedade de suficiência, o conjunto de funções e terminaisescolhido deve ser grande e poderoso o suficiente para resolver o problema. Algumacombinação possível de funções e terminais, deve constituir-se em uma solução correta.Em muitos domínios a escolha do conjunto de funções e terminais pode ser uma tarefadifícil, dependente de processo criterioso de análise e modelagem.
3.4.2 Fitness
Cada indivíduo tem associado a si uma medida numérica, que é o resultado dainteração dele com o ambiente; é em resumo uma medida do grau de adaptação desteindivíduo. Esta medida é que dirige diretamente o processo evolucionário, fazendo comque, quanto mais adaptado for um indivíduo maior a sua chance de permanecer ou tersuas características propagadas para as próximas gerações. A definição do fitness estáligada ao domínio do problema a ser resolvido [KOZ 92].
Podemos considerar quatro tipos básicos de fitness na programação genética:Fitness Básico, Fitness Padronizado, fitness de ajuste e fitness normalizado ouproporcional [KOZ 92].
O fitness básico é definido diretamente em função do domínio do problema, e namaioria das aplicações de acordo com um conjunto de casos de teste. Casos de teste sãofreqüentemente uma amostra do espaço de busca. No exemplo da função de paridade, ofitness básico poderia ser definido como o número de casos de fitness onde o valorretornado pelo programa é igual ao valor correto esperado [KOZ 98].
O fitness padronizado é relacionado com o fitness básico, e modifica este deforma que um valor mais baixo seja sempre melhor. Como exemplo para a função deparidade o fitness padronizado poderia ser definido como a soma a partir de N casos deteste da distância Hamming (erro) entre o valor retornado pelo programa e o valorcorreto esperado. O fitness padronizado é normalmente àquele que guia o processo deevolução. Indivíduos com menores valores estão mais próximos a resposta exata [KOZ98].
O fitness de ajuste é usado somente em casos em que uma resposta exata é exigidapara um problema, e o fitness proporcional é usado normalmente para definição daprobabilidade de um indivíduo ser selecionado para a próxima geração ou para algumaoperação genética [KOZ 98].
A avaliação do fitness é a atividade mais fundamental para uma boa evolução.Uma má função de avaliação, implica em processos sem boas soluções ou comconvergências prematuras para respostas pouco adaptadas. A avaliação ocorre em umaamostra que represente o problema; esta amostra é composta de casos de fitness. Cadacaso ou subconjunto de casos pode representar uma ou mais particularidades doproblema. O grau de adaptação final de um indivíduo é calculado sobre todos os casos,o que torna a escolha dos mesmos, uma tarefa fundamental na modelagem do problema.Uma análise profunda do processo de avaliação de fitness pode ser encontrado em[BAN 98].
3.4.3 Operadores genéticos
Existem duas operações primárias para modificação de estruturas: Reprodução deum único indivíduo e cruzamento (crossover), que se constitui em uma recombinação

40
sexuada de dois indivíduos [KOZ 92]. Outra operação utilizada em menor escala é amutação.
A reprodução é executada em dois passos: seleção de um indivíduo e cópia destepara a nova geração. Cada pai gera apenas um filho; o mecanismo da reproduçãoassexuada é a própria representação da teoria da evolução, da sobrevivência do maisadaptado. Indivíduos com alto grau de adaptação em geral são selecionados mais deuma vez para se reproduzirem.
A operação de cruzamento ocorre da seguinte forma: são escolhidos doisindivíduos para uma operação sexuada; em cada um dos pais é escolhido de formarandômica um ponto de cruzamento; a subárvore existente a partir do ponto escolhidono primeiro pai é inserida no ponto de cruzamento do segundo pai e vice-versa. As fig.3.6 e 3.7 ilustram esta operação.
FIGURA 3.6 - Pais escolhidos para cruzamento e seus respectivos pontos decorte.
FIGURA 3.7 - Filhos gerados após a operação de cruzamento
A operação de cruzamento cria variações na população pela produção de filhoscompostos de partes de cada um dos pais. A propriedade de clausura é mantida a partirdo momento que somente funções e terminais disponíveis nos conjuntos possíveiscontinuam sendo usadas. Se um ramo raiz é escolhido, um indivíduo inteiro é inseridocomo subárvore de outro e caso dois ramos raiz sejam escolhidos, serão gerados doisfilhos iguais a seus pais.
Operações de cruzamento, modificam a forma e tamanho dos programas, pois aocontrário do algoritmo genético convencional, onde um ponto de cruzamento é igual emdois pais, o que garante a manutenção do tamanho da string, na programação genética oponto selecionado é em geral diferente para cada um dos pais.
A mutação tradicional consiste em selecionar um indivíduo e um ponto aleatório esubstituir a subárvore a partir deste ponto por outra criada randomicamente. Se uma
OR
OR AND
NOT NOT D0
D0 D1
OR
ANDNOT
D0 D1D1 NOT
D1
NOT
D1
OR
OR
NOT NOT
D0 D1
OR
AND
D0 D1
AND
D0 NOT
D1

41
operação de cruzamento ocorrer em pontos onde existam terminais, o efeito é o mesmode uma mutação de um ponto.
3.4.4 Critérios e parâmetros de controle
A execução da técnica é dependente de um conjunto de parâmetros cujos valoressão normalmente escolhidos no início do processo. A escolha de diferentes valores paracada um dos parâmetros afeta diretamente a evolução e os recursos consumidos pelosistema [KOZ 92].
Um dos critérios importantes em uma técnica adaptativa é como saber e obter aofinal da execução o resultado do processamento. Na programação genética, o resultadofinal do processo é um único indivíduo mais adaptado ao ambiente, ou seja o vencedorao final é considerado a melhor solução possível para o problema. Em muitos casos senão houver uma estratégia elitista, não é possível garantir que o melhor indivíduo estarápresente na geração final. Uma estratégia elitista privilegia a perpetuação do melhorindivíduo nas próximas gerações, altas taxas de reprodução na maioria dos casos,garantem esta característica [KOZ 92].
Os parâmetros mais utilizados para controlar o processo são: tamanho dapopulação (M) e o número de gerações (N). O tamanho da população influenciadiretamente no rendimento e no esforço computacional necessário para produzirresultados, e o número de gerações serve como um critério de término, caso nenhumoutro critério seja estabelecido. Maiores populações também podem significar um maiorespaço de busca e portanto maior probabilidade de encontrar boas soluções [KOZ 92].
O percentual de execução de cruzamento (Pc), percentual de reprodução baseadaem fitness (Pr) e percentual de mutação (Pm) afetam a composição da próxima geração.Maiores taxas de cruzamento e mutação definem estratégias menos elitistas, e maiorvariabilidade das soluções da próxima geração. O percentual de cruzamento pode serdividido ainda em percentual de cruzamento, em pontos de função e em qualquer ponto.Estes últimos implicam em mudanças mais ou menos radicais no tamanho das soluções.A definição a priori de pontos de corte e taxas de cruzamento, reprodução e mutação éuma tarefa complexa. Na maior parte dos casos, execuções iniciais poderão indicarquais as melhores combinações para um problema específico [KOZ 92].
Outros parâmetros que influenciam a variação do tamanho das soluções são aprofundidade máxima tolerada na geração inicial e nas gerações seguintes. Limitar aprofundidade significa que a árvore representativa de um programa não poderá ter emsua ramificação mais profunda uma quantidade superior a um determinado número denodos fixado como limite. Árvores com maior profundidade significam soluções comum maior número de pontos. Em muitas aplicações um aumento do número de pontos éimportante para a solução do problema, porém um acréscimo desmedido pode consumirde forma ilimitada os recursos e prejudicar a convergência [KOZ 92].
A criação da geração inicial está relacionada à escolha de uma dentre trêsalternativas possíveis: Crescente, Subida Parcial ou Completa. A estratégia Crescente,produz indivíduos com tamanhos irregulares. A Completa, cria soluções nas quais nomínimo um dos nodos atinge a profundidade máxima. Na Subida Parcial, são criadosindivíduos com profundidades distribuídas entre tamanhos mínimos e máximos. Comoexemplo podemos supor que a profundidade máxima é 6, neste caso ocorre umadistribuição igual de indivíduos com profundidades 2, 3, 4, 5 e 6. Esta última alternativa

42
permite uma boa variabilidade na população sem soluções de tamanhos exagerados e éportanto a escolha mais comum [KOZ 92].
Outra escolha a ser realizada no início do processo diz respeito ao métodoutilizado para selecionar indivíduos para operações genéticas. Existem diversasvariações possíveis, entretanto as três alternativas tradicionais da técnica são: Seleçãoproporcional ao fitness, torneio e proporcional ao fitness com seleção excedente. Aprimeira é a alternativa empregada na maioria das execuções deste trabalho e éequivalente à “roleta”, comum nos Algoritmos Genéticos; soluções são escolhidasusando como critério o grau de adaptação, quanto mais adaptada maior a probabilidadede perpetuar seu material genético para as próximas gerações. A seleção por torneioenvolve a escolha de um determinado número de indivíduos (tamanho do torneio) deforma aleatória, dentre estes os melhores são submetidos à operação específica. Aseleção excedente é tipicamente usada com grandes populações e permite gerar atravésdas operações genéticas uma população maior do que o tamanho original, a seguir onúmero de indivíduos é reduzido novamente ao tamanho da população pelo descarte dosindivíduos menos adaptados.
3.4.5 Escolha da linguagem de programação
Após definir os principais conceitos relativos ao paradigma da ProgramaçãoGenética, e de utilizar como base para exemplo representações usando a linguagemLISP (LISt Processing), torna-se necessário definir de forma mais prática o motivo daescolha de LISP para implementação da maioria dos exemplos encontrados emtrabalhos sobre o assunto, e também se é possível a utilização de outras linguagens naimplementação da técnica.
Qualquer programa de computador escrito em alguma linguagem (C, PASCAL...)pode ser visto como uma seqüência de aplicações de funções ou operações, a umaseqüência de argumentos ou valores. Compiladores usam este fato internamente pararepresentar programas como uma árvore, posteriormente convertendo-a em código deassembly elementar. O paradigma é mais facilmente compreensível, se pensarmos emuma linguagem de programação que transparentemente trata um programa decomputador como seqüências de aplicações de funções a argumentos.
Além disso, uma linguagem de programação que permite que qualquer estruturaseja direta e imediatamente avaliada como um programa, é extremamente benéfica, poisdurante todo o processo programas são criados, modificados em sua forma e tamanho esão executados para avaliação do fitness. Esta funcionalidade, é diretamente obtida emLISP usando a função EVAL. Expressões LISP são escritas e avaliadas de uma formapré-fixada (* 2 3), ao contrário de outras linguagens de programação tradicionais queutilizam a forma (3 * 2). Esta abordagem facilita a manipulação hierárquica deprogramas.
Embora a maior parte dos exemplos e discussões existentes baseiam-se nalinguagem LISP, muitos autores tem utilizado C ou mesmo código de máquina emaplicações mais complexas ou direcionadas a um domínio específico. Um exemplo podeser encontrado em [BANZ 95], onde em uma aplicação para controle em tempo real demovimento de um robô Kephera programas foram representados na forma de código demáquina binário, devido a necessidade de maior velocidade. Em [FRA 94] é possívelencontrar uma implementação completa da técnica utilizando linguagem C.

43
3.5 Definição automática de funçõesA partir da exposição dos conceitos gerais da programação genética nas seções
anteriores, a partir desta será introduzido um conceito que estende a capacidade daprogramação genética, a descoberta automática de funções, que é fortemente baseadaem conceitos de resolução hierárquica de problemas.
A descoberta automática de funções (ADF - Automatic Defined Functions) foiintroduzida por John R. Koza em [KOZ 98] e tem por objetivo permitir ao paradigma daprogramação genética resolver problemas cada vez mais complexos através dadescoberta de sub-rotinas ou funções que podem ser reutilizadas. Estas sub-rotinaspermitem explorar regularidades existentes em problemas de diversas formas.
3.5.1 Resolução hierárquica de problemas
A resolução de problemas de forma hierárquica em um modelo top-down pode serdecomposta de três etapas distintas: i) Identificação de como um problema geral podeser decomposto em subproblemas; ii) resolução de cada um dos subproblemaspropostos; iii) resolução do problema geral através da integração das soluções de cadaum dos subproblemas agora disponíveis [KOZ 98].
FIGURA 3.8 - Passos para resolução hierárquica de funções
Tradicionalmente, a decomposição hierárquica pode ser uma forma de reduzir oesforço computacional necessário para resolver o problema. Podemos ainda citar outrasvantagens que podem emergir a partir de uma boa decomposição hierárquica de umproblema: Aplicação recursiva, reuso idêntico, reuso parametrizado, generalização eabstração.
A aplicação recursiva ou reuso idêntico pode ocorrer no momento em que épossível utilizar parte da decomposição de um subproblema novamente nadecomposição de outro subproblema. Neste caso, a solução invoca o mesmo passo quecompõe parte da solução de algum subproblema anterior que trabalhe nas mesmasvariáveis ou dados e execute as mesmas instruções; a vantagem é que não é necessárioreescrever este subproblema ou procedimento.
Em um reuso parametrizado ou na generalização de uma solução, também éreutilizada uma etapa que compõe um subproblema, porém ao ser utilizado um mesmoprocedimento para resolver o problema atual, serão usados diferentes dados de entradapara este procedimento. Em um exemplo, poderíamos considerar um problema da
Problemaoriginal 1
Subproblema1.1
Subproblema1.2
Solução p/ osubproblema
1.1
Solução p/ osubproblema
1.2
Solução p/ oproblemaoriginal 1
DecompõeResolversubproblemas
Resolverproblema original

44
derivada de uma soma g(x) = x3 + x4, que pode gerar a decomposição em doissubproblemas (3x2) e (4x3). Podemos desenvolver um procedimento geral pararesolução de xm e invocar este mecanismo em diferentes momentos com valoresdiferentes para m. O mecanismo, explora similaridades entre subproblemas, porém énecessário primeiro identificar estas similaridades para resolução por um mecanismogeral. Programadores humanos, utilizam extensivamente rotinas genéricas pararesolução de classes iguais de problemas [KOZ 98].
A abstração, diz respeito a capacidade de identificar determinadas instruções ouvariáveis que são irrelevantes para solução do problema, em determinado momento.Como exemplo, podemos considerar uma rotina que receba um conjunto de parâmetrose eventualmente desconsidere um ou mais destes parâmetros no momento da resoluçãodo problema. Em uma chamada a rotinas genéricas, somente são enviadas as variáveisnecessárias para resolução do subproblema, e não todas as variáveis que definem oestado do problema.
De acordo com as descrições acima, podemos resumir em cinco, os benefícios quereduzem o esforço computacional necessário a partir da decomposição hierárquica deproblemas [KOZ 98]:
1. Eficiência associada ao processo de decomposição hierárquica;
2. Eficiência obtida pela aplicação recursiva do processo de decomposição;
3. Reuso idêntico de soluções de problemas já resolvidos;
4. Reuso parametrizado, que reutiliza as mesmas soluções para subproblemasdiferentes;
5. Abstração, onde variáveis irrelevantes ampliam a capacidade e aplicabilidadede soluções para subproblemas.
3.6 O problema da definição automática de funçãoTendo em mente os benefícios da resolução hierárquica de problemas, algumas
questões práticas são levantadas: Como é possível implementar o processo de formaautomática e independente do domínio? Como fazer uma decomposição de umproblema em subproblemas? Como identificar quais são os subproblemas e comoresolvê-los? Após terem sido resolvidos os subproblemas, como montar a solução parao problema geral a partir destas soluções? [KOZ 98]
Para resolver as questões acima, a primeira idéia fundamental é a de introduzirsub-rotinas no processo de descoberta de programas; desta forma a estrutura de umasolução passará a ser composta de um programa principal e uma ou mais sub-rotinas.Anteriormente, ao definir os conceitos relativos a programação genética, uma dasdefinições necessárias referia-se ao conjunto de funções utilizadas. As funções nestecaso eram em sua maioria funções disponíveis na linguagem, e funções do domínio daaplicação criadas antes do processo por algum programador humano.
O grande objetivo da definição automática de funções é evoluir simultaneamentefunções ou sub-rotinas e um programa principal durante o mesmo processo deexecução. As funções são automaticamente definidas, porque assim como programaschamadores, serão criadas aleatoriamente a partir do conjunto básico de funções e

45
terminais disponíveis e serão submetidas ao mesmo processo de evolução natural, daíorigina-se o conceito de ADF. Durante o processo evolutivo, são criados programascontendo um ou mais ramos de definição de função e um programa principal, chamadode ramo de produção de resultados. O número de vezes que o ramo de produção deresultados chama algum dos ramos de definição de função para cada indivíduo emparticular não é predeterminado e é resultante do efeito evolucionário [ROS 96].
A evolução concorrente de unidades funcionais e programas chamadores capacitaa programação genética a realizar inteiramente o processo de resolução hierárquica defunções descrito anteriormente [KOZ 98].
FIGURA 3.9- Exemplo de um programa geral com um ramo de produção deresultado e um ramo de definição de função
O programa geral mostrado pela fig.3.9 tem oito diferentes pontos. Os primeirosseis são chamados invariantes, operações de cruzamento ou mutação não são realizadassobre eles, os mesmos permanecem fixos na estrutura de qualquer indivíduo. Pontosinvariantes aparecem acima da linha horizontal pontilhada. Os dois últimos representamconjuntos de instruções variantes e constituem o corpo das funções que emergem apartir do processo evolucionário [KOZ 98].
Definição dos pontos invariantes:
− (1) A raiz do programa constitui-se da função conectiva progn, que indica aexecução seqüencial dos ramos abaixo.
− (2) A instrução defun é a instrução LISP para iniciar a definição de umafunção.
− (3) O nome ADF0 é um nome genérico atribuído a função que será definidadinamicamente. Neste caso é possível usar outro nome genérico semmodificar a estrutura.
− (4) Lista de argumentos que serão recebidos pela função.
− (5) A função values do ramo de definição de função identificando o valorretornado pelo ramo de definição de função.
− (6) A função values do ramo de produção de resultados, identificando ovalor retornado pelo ramo de produção de resultado.
progn
defun values
ADF0 Listaargumentos
values
Corpo ramo deprodução de resultadosCorpo da
função ADF0
1
2
34 5
6
7 8

46
− Os pontos (7) e (8) são o conjunto de instruções criadas aleatoriamente eque são submetidas a evolução durante a execução.
Estes dois últimos tipos de ponto constituem-se efetivamente no resultado daextensão proposta . Cada indivíduo da população tem seu próprio ramo de definição defunções e de produção de resultados. De acordo com [KOZ 98], funções definidasautomaticamente, podem:
− Executar cálculos similares aos quais programadores humanos fariam;
− Executar cálculos diferentemente aos criados por programadores humanos;
− Redundantemente definir uma função que é equivalente a uma funçãoprimitiva disponível no conjunto de funções para o problema;
− Ignorar algumas das variáveis no processo;
− Ser totalmente ignorados pelos ramos de produção de resultados;
− Definir um valor constante, independente de todas as variáveis;
− Retornar valores idênticos às variáveis, desta forma definindoredundantemente um terminal do problema;
− Chamar redundantemente outra função definida.
3.6.1 Criação de uma população inicial
A população inicial de indivíduos, randomicamente gerada precisa ser criada comcada indivíduo tendo a estrutura definida na fig. 3.9, podendo apenas existir mais de umramo de definição de função. Um ramo de definição de função é criado a partir doconjunto de funções Fadf e do conjunto de terminais Tadf, disponíveis para resolução dafunção. O ramo de produção de resultados é uma composição randômica de funções apartir do conjunto de funções Frpb e do conjunto de terminais Trpb, disponíveis parasolução geral do problema [KOZ 98].
É possível definir diferentes conjuntos de funções e terminais para cada um dos ramos,o que ocorre pelo fato do ramo de produção de resultados ter disponível além dasfunções tradicionais, a função geral ADF0 para uso [KOZ 98].
3.6.2 Preservação de estruturas em cruzamentos
A operação de cruzamento conforme detalhada nas características gerais daprogramação genética consiste em selecionar dois pais e escolher de forma randômicaum ponto em cada um dos pais para corte. Parte do primeiro pai é inserido no segundo evice-versa, desta forma dois novos filhos são criados. Com o uso da definiçãoautomática de funções é necessário que em operações de cruzamento a estruturasintática da construção dos filhos seja mantida, para tanto alguns pontos não podem serescolhidos para cruzamento [KOZ 98].
Como podemos verificar na fig. 3.9, os pontos numerados de 1 a 6 são pontosinvariantes e nunca podem ser escolhidos como ponto de corte em operações decruzamento; tal preservação garante que todos os indivíduos da população terão sempreum ramo de produção de resultados, e no mínimo um ramo de definição de função.Caso existam mais ramos de definição de função, haverá um número maior de pontosinvariantes [KOZ 98].

47
A idéia básica do cruzamento com preservação da estrutura, é baseada nadefinição de um tipo para cada ponto em um indivíduo. Todas os pontos que compõeum ramo de definição de função possuem o número 7 em nosso exemplo e os pontos doramo de produção de resultados tem atribuídos a si o número 8. Em uma operação decruzamento, um ponto qualquer destes dois ramos é escolhido de forma aleatória. Apartir desta escolha, o ponto a ser escolhido no segundo pai deve ser qualquer ponto quetenha o mesmo tipo daquele escolhido no primeiro pai, o que garante a produção defilhos com estrutura sintática válida [KOZ 98].

48
4 Abordagem do sistema: Arquitetura propostaPara permitir a validação do paradigma da Programação Genética ao problema,
foi necessário desenvolver um sistema baseado nos princípios básicos desta técnica. Aproposta do trabalho não é desenvolver um aplicativo para realizar a síntese de formacompleta e sim criar um sistema para aplicação da técnica ao problema descrito e emtrabalhos futuros a outros.
O desenvolvimento utilizou a linguagem LISP (Allegro CL 3.0.2) . O ambiente dedesenvolvimento possui diversos componentes para desenvolvimento de interfacesgráficas, além de ser uma linguagem orientada a objetos baseada na linguagemCommon Lisp [SLA 98]. Outra escolha possível seria a utilização do próprio sistemaFestival e a linguagem Scheme, que constitui um dialeto da linguagem LISP e estápresente neste ambiente.
A justificativa para não utilização da ferramenta Festival baseiam-se em algumascaracterísticas da linguagem Scheme:
− Falta de recursos para programação orientada a objeto. O núcleo daimplementação da técnica utiliza classes e objetos e a sua implementação noreferido ambiente demandaria em profundas mudanças na implementaçãooriginal.
− Poucos recursos para criação de interfaces. Para uma boa avaliação dosresultados e da evolução e ainda para que a definição dos parâmetros decada execução fosse flexível, o uso de recursos gráficos é desejável.
− Algumas funções originais da linguagem não estão presentes neste dialeto,ou apresentam uma sintaxe diferente.
Embora a aplicação da técnica tenha sido realizada em um sistema independenteda ferramenta utilizada no projeto Spoltech, trabalhos futuros poderão permitir autilização da técnica ou dos resultados no processo de síntese realizado no Festival. Oaproveitamento destes resultados ou a adaptação do sistema desenvolvido no trabalhopara o sistema Festival, dependerá de uma análise sobre qual a melhor alternativa oucomo regras criadas como programas podem ser empregadas para conversão. Conformecitado anteriormente no item 2.6.2, as regras possuem formato diferente dos resultadosque serão descritos posteriormente neste trabalho. Estas análises e adaptações não sãoobjeto de estudo neste trabalho, a aplicação tem como objetivo investigar apossibilidade da utilização da técnica no processo de síntese.
Após a escolha da linguagem, o passo seguinte, foi definir as características dosistema a ser implementado. Os requisitos básicos, concentravam-se nasfuncionalidades tradicionais da programação genética, na criação da população inicial ede todo o processo evolutivo. Outro requisito da implementação é que houvesse um altograu de modularidade, para que fosse possível utilizá-la em trabalhos futuros, onde atécnica poderia ser aplicada a outros problemas.
Baseada nestes requisitos, foi proposta uma arquitetura na qual as funcionalidadesda Programação Genética são implementadas em um núcleo principal, separado dasinterfaces de entrada e saída, que compõe os demais módulos.

49
FIGURA 4.1 - Arquitetura do sistema
O núcleo da aplicação é baseado na implementação desenvolvida por Koza [KOZ98], que foi utilizada para validação da técnica com problemas clássicos como induçãode funções matemáticas, descoberta de funções booleanas entre outros. O móduloresponsável pela execução e controle, recebe um conjunto de parâmetros, incluindonome das funções de domínio. As funções definidas como responsáveis pela formaçãodos parâmetros básicos, conjunto de terminais, funções e de fitness são executadasretornando ao módulo de controle, todas as características do problema. Seguindo oprincípio da modularidade, todas as funcionalidades relativas ao problema, estãoisoladas do núcleo principal. Após a composição de todas as características doproblema, o processo evolutivo é iniciado, e somente é abortado pelo módulo decontrole quando a condição de término do problema é satisfeita.
O núcleo do sistema, possui ainda os módulos de geração da população inicial,operações genéticas e avaliação de indivíduos, que são executados pelo módulo decontrole e recebem os argumentos necessários para correta execução O módulo deavaliação, recebe como argumento o nome da função para cálculo de fitness de umindivíduo e executa a mesma para cada indivíduo da população. Após a formação eavaliação de uma geração inteira, são chamadas as funções dos componentes do móduloresponsável pela geração das informações para avaliação e acompanhamento doprocesso.
Os indivíduos são armazenados em uma matriz composta de objetos da classeindividual, que possui a seguinte estrutura:
(defstruct individual program (standardized-fitness 0) (adjusted-fitness 0) (normalized-fitness 0) (hits 0) (complex-estrut 0))
Cada indivíduo possui 5 propriedades que armazenam além do código doprograma, os vários fitness e a complexidade estrutural do mesmo. Quando um novo
INTERFACE SAÍDAINTERFACEENTRADA
NÚCLEO APLICAÇÃO
COMPONENTESDIÁLOGO
FUNÇÕESDOMÍNIO
MÓDULO PARADEFINIÇÕES DO
PROBLEMA
COMPONENTESSAÍDA
MÓDULOGERADOR DE
DADOS DESAÍDA
ARQUIVOSEXTERNOS
Geração da populaçãoinicial
Avaliação indivíduos
Operações genéticas
Controle e determinaçãode resultados
PARAMETROS
VALIDAÇÃO

50
indivíduo é criado, a classe é instanciada, as propriedades recebem os valorescomputados na avaliação e program recebe o conjunto de instruções.
Para a execução utilizando definição automática de funções, é definida outraestrutura adicional como segue:
(defstruct (adf-program (:print-function (lambda (instance stream depth) (declare (ignore depth)) (format stream "(progn (defun ADF0 (ARG0 ARG1 ARG2)~ ~% (values ~S))~ ~% (defun ADF1 (ARG0 ARG1 ARG2)~ ~% (values ~S))~ ~% (values ~S))" (adf-program-adf0 instance) (adf-program-adf1 instance) (adf-program-rpb instance)) ))) adf0 adf1 rpb)
A estrutura acima, inclui uma função para retornar o indivíduo criado de acordocom a estrutura padrão, que inclui neste exemplo, duas funções automaticamentedefinidas. A utilização de mais funções implicaria na modificação da classe da qual seoriginam os indivíduos.
A atividade de desenvolvimento mais complexa, concentrou-se na implementaçãodos módulos relativos ao problema e na programação de interfaces de entrada e saída. Épreciso salientar que módulos de interface são independentes do problema, conformedescrito nos requisitos do sistema.
Módulos relativos ao problema são responsáveis pela implementação de funçõesde domínio incluídas no conjunto de funções disponíveis para a execução, definição doconjunto de funções e terminais e finalmente pela definição e avaliação dos casos defitness. A fig. 4.2 ilustra a estrutura do módulo que recebe dos componentes da interfaceas características do problema e as disponibiliza para o núcleo da aplicação.
Figura 4.2 – Composição do módulo para definições do problema
Os parâmetros e especificações para cada execução são incluídos utilizando-seuma interface gráfica dividida em duas partes: Parâmetros gerais e especificação doproblema. Na primeira, são incluídos os parâmetros básicos: número de gerações,
MÓDULO PARA DEFINIÇÕES DO PROBLEMA
PARAMETROSGERAIS
CONJUNTODE FUNÇÕES
CONJUNTO DETERMINAIS
CASOS DEFITNESS
AVALIAÇÃODE FITNESS
CRITÉRIO DETÉRMINO

51
tamanho da população, profundidades máximas dos indivíduos, percentuais dasoperações de reprodução, cruzamento e mutação, tamanho do torneio e número de casosde fitness. O método para geração da população inicial, bem como o método de seleçãosão escolhidos a partir das alternativas descritas anteriormente, para cada um destesparâmetros. A interface foi desenvolvida com o intuito de escolher rapidamente entre asalternativas, reduzindo assim também a possibilidade de que seja informada uma opçãoincorreta. A fig. 4.3 mostra a interface e os parâmetros para uma execução.
FIGURA 4.3 - Interface para definição de parâmetros gerais
A interface para definições relativas ao domínio do problema inclui controles paradeterminação do conjunto de terminais, funções, número de argumentos das funções edos casos de fitness que incluem palavras e respectivos fonemas que constituem aresposta correta para cada caso. O número de funções automáticas indica se a estratégiade definição automática de funções será ou não utilizada na execução. Se o número defunções automáticas é igual a zero, a execução não emprega a estratégia, caso contráriosão indicadas quantas funções automáticas as soluções irão implementar e ainda oconjunto de terminais e funções para cada um dos ramos de definição de função.
FIGURA 4.4 - Interface para definições relativos ao domínio do problema.

52
A avaliação e acompanhamento dos resultados, ocorre através de uma interface desaída composta por arquivos externos em formato texto e componentes gráficos em tela,atualizados durante a execução. O módulo gerador de dados de saída, descrito naarquitetura é responsável por enviar informações, tanto para a interface de saída quantopara arquivos externos.
Informações enviadas à arquivos externos possuem naturalmente um nível dedetalhe maior por terem estes a finalidade de permitir a documentação dos resultados aposteriori, ao passo que a interface gráfica é usada para o acompanhamento do processoa cada geração, através de informações como geração atual, melhor fitness da geração,fitness, complexidade média da população e dados sobre o melhor indivíduo até ageração atual. Um acompanhamento do processo permite verificar se a evolução estárealmente tornando as soluções mais adaptadas, ou se está ocorrendo a convergênciapara um mínimo local; fenômeno comum em algoritmos baseados em abordagemheurística. A fig. 4.5 ilustra o acompanhamento de uma execução através da interface.
FIGURA 4.5 - Interface de saída para acompanhamento do problema.
Por fim, a arquitetura apresenta um módulo de validação de soluções produzidasdurante uma execução. O módulo de validação não possui uma interação direta com oprocesso evolutivo, mas é de vital importância ao final de uma execução para verificaros resultados para cada caso, bem como se a solução produzida tem um bomdesempenho em outras palavras, além daquelas utilizadas como casos de fitness.
A interface de validação inclui controles para informação de palavras usadas navalidação juntamente com seus respectivos fonemas, do indivíduo a ser validado emostra resultados produzidos por este indivíduo, que incluem o fitness e a respostadeste para cada palavra da lista de casos de validação.

53
FIGURA 4.6 - Interface para validação de respostas produzidas na execução
Após uma execução, é possível obter diretamente o melhor indivíduo através dobotão copiar. Para validação, usa-se outros casos de fitness que apresentem as mesmasregras que eram objeto da execução. O resultado da validação indica o fitness doindivíduo e as respostas produzidas. Esta interface serve também para verificar emsoluções com pouca adaptação, quais as regras não descobertas e também problemas deconvergência que venham a ocorrer em algumas execuções.
Após a descrição do sistema a ser utilizado para as execuções da técnica e parasua aplicação ao problema de conversão de letra para fonema, é necessária umadescrição detalhada da modelagem que tornará possível encontrar soluções. Todos osparâmetros e funções necessárias, ilustrados nas interfaces mostradas acima, sãoescolhidas a partir da análise descrita no próximo capitulo.

54
5 Modelagem do problema de conversão letra-fonema,usando programação genética
De acordo com a descrição dos contextos e regras que afetam o processo deconversão de letras para sons, é possível concluir que elas poderiam ser representadasatravés de programas de computador. Se fossem implementados por programadoreshumanos, é provável que este programas teriam a forma:
SE (letra atual é x) então o fonema é y SENÃO (subregra).
Sendo assim, o objetivo do trabalho de modelagem é fornecer a ProgramaçãoGenética condições de compor soluções iguais ou semelhantes através de um processoevolutivo. De acordo com [KOZ 92] a preparação para execução da programaçãogenética envolve cinco passos básicos:
− Determinação do conjunto de terminais− Determinação do conjunto de funções− Determinação da medição e casos de fitness− Determinação dos parâmetros e variáveis de controle da execução, e− Determinação do método para designação do resultado.
As duas últimas etapas podem variar de uma execução para outra sem qualquerdependência de uma estratégia específica para resolução do problema; entretanto adefinição de funções, terminais e fitness está diretamente relacionada à uma forma deresolução proposta. Problemas mais simples do que o descrito neste trabalho, podemnão necessitar de uma definição de estratégia ou podem possuir uma forma única enatural para obtenção de resultados. A estratégia, engloba a definição da estrutura dassoluções e dos resultados. Problemas semelhantes foram descritos em [BAN 98] e[AND 94].
Um exemplo clássico de uma estrutura pré-definida para a solução, é o problemade regressão simbólica múltipla [KOZ 92]. Neste problema, uma solução deve retornardois valores e não somente um. Para obter soluções corretas, uma função LIST2 foiutilizada como raiz; todas as soluções possuem esta como a função que é responsávelpor retornar os valores, o que garante a produção de uma resposta múltipla. Uma dassoluções descritas no exemplo foi:
( LIST2 (- (* X3 X1) (* X4 X2)) (+ (* X3 X2) (* X1 X4)))
A opção pela estrutura das soluções, é dependente da estrutura das respostas aoscasos de fitness. Caso a resposta exija a produção de mais de um valor, existem duasalternativas possíveis: i) A produção de uma resposta com todos os valores ou; ii) aavaliação sucessiva do indivíduo e a composição da resposta final com as diversasrespostas unitárias produzidas pela solução. Entretanto, antes de efetuar uma escolha énecessário descrever o processo de definição de casos e avaliação de fitness.
5.1 Definição de casos e avaliação de fitnessA atividade de conversão letra-fonema abordada no trabalho, pode ser resumida
como uma aplicação de regras sobre palavras ou letras, para descoberta de fonemas

55
correspondentes. Sendo assim, o passo inicial para determinação de uma ou maisestratégias para busca de soluções através da programação genética, é definir se casosde fitness consistirão em um conjunto de letras ou palavras. A utilização de letrasisoladas fica completamente descartada a partir da constatação de que duas letras podemsignificar um único fonema, ou ainda que uma determinada letra produz diferentesfonemas, de acordo com a anterior ou posterior a ela.
A definição dos casos de fitness, portanto recaiu sobre palavras. Considerou-separa efeito de medição de fitness uma palavra como um caso de fitness. A pontuaçãofinal do indivíduo, é medida a partir de todas as palavras que constituem o conjunto decasos. É importante salientar que o conjunto de palavras deve representar de formasignificativa as regras a serem implementadas pelas soluções. Através desta afirmação,podemos concluir que se determinada letra estiver envolvida em diferentes regras, masse apenas a ocorrência de uma ou outra destas regras estiver representada no conjuntode casos de fitness, as soluções somente poderão implementar aquelas que estiveremrepresentadas pelos casos fornecidos na execução em questão.
O conjunto de casos de fitness é definido na interface de entrada da aplicaçãocomo uma lista de palavras, cada uma delas composta por uma lista de letras ((p a t o) (ti p o)...). As respostas corretas para cada caso, são igualmente especificadas como listasde fonemas ((p a t o) (ts i p o)...). A definição de casos e respostas respectivas emforma de lista foi escolhida pela facilidade encontrada na linguagem LISP para oprocessamento de listas; entretanto outras estruturas de dados podem ser utilizadas, nãocomprometendo o processo de busca de soluções.
Avaliando-se a resposta produzida por cada indivíduo, o sistema calcula o fitnessbásico utilizando as seguintes regras:
− Caso o fonema produzido seja igual ao fonema esperado na posiçãoespecífica, são computados três pontos.
− Caso o fonema produzido seja diferente na posição, mas seja um fonemaesperado em qualquer outra posição da resposta, é computado um ponto.
O fitness padronizado deve sempre indicar melhores soluções tendo menoresvalores, tendendo a zero. Neste problema, é calculado subtraindo-se o fitness básicoobtido do maior valor possível para o mesmo. Assim, melhores soluções sempre terãovalores menores.
5.2 Estratégias para descoberta automática de programas para conversão letra-fonema
Após uma descrição detalhada da estrutura de casos de fitness e suas respostascorretas, torna-se possível analisar alternativas para a estrutura dos indivíduos. Para quehaja uma avaliação correta e padronizada do fitness, é importante a definição de umformato básico das respostas produzidas. Como exemplo, podemos citar outrasaplicações como no caso da obtenção de uma equação matemática para resolverdeterminado problema. Se a resposta esperada for um número e a medição de fitnessconstituir em avaliar a diferença entre o número produzido e o esperado, é vital que assoluções candidatas produzam como resultado um valor numérico, do contrário aavaliação de fitness torna-se uma atividade complexa e sujeita a erros.

56
Na modelagem proposta, tanto as palavras, quanto seus respectivos fonemas queconstituem a resposta correta para cada caso, são informados como listas. Sendo assim,a resposta avaliada na função que mede o fitness de um indivíduo deverá naturalmentevir em forma de uma lista de elementos. Surgem duas abordagens distintas: deixar acargo da solução produzir a lista completa dos fonemas ou deixar a cargo das soluções aprodução de cada fonema individualmente. Nesta última, a função de avaliação defitness executa uma solução diversas vezes de acordo com o número de letras de cadacaso de fitness. Dentro de cada abordagem existem ainda diferentes alternativas, sendoalgumas delas descritas a seguir.
Seguindo a primeira abordagem, o programa será executado uma única vez paracada palavra e deverá produzir a lista completa de fonemas correspondentes. Aobtenção de respostas em forma de lista pode ocorrer de duas maneiras: i) inserindo-sefunções que retornam valores em forma de lista como por exemplo LIST, CONS, ou;ii) inserindo-se uma função de domínio do problema, que tem por objetivo alterar umavariável de estado, que representa a resposta para o problema. Na primeira alternativa, aresposta produzida pelo programa é avaliada, enquanto que na segunda uma variávelglobal, modificada apenas pela função responsável pela composição da lista de fonemasserá avaliada.
A simples inserção de funções que retornam uma lista no conjunto de funções,não permite afirmar que a resposta virá na forma de uma lista; não há garantia de queestas funções serão usadas, tampouco que serão escolhidas como função inicial. Umaforma de contornar este problema é a utilização de uma estrutura rígida, onde umafunção semelhante a LIST2, citada no exemplo da regressão simbólica, consistiriasempre na função raiz de qualquer solução. Porém o número de elementos da lista, variade acordo com o número de fonemas que compõe uma palavra; como o conjunto decasos de fitness pode ser composto de palavras de diversos tamanhos, a fixação donúmero de argumentos de funções que irão produzir a resposta é um obstáculoconsiderável. Restringir o tamanho dos casos é indesejável do ponto de vista daexploração das variações existentes no idioma; além disso, não há uma correspondênciaexata no número de letras e fonemas.
A segunda alternativa é a utilização de uma função para modificação de umavariável de estado que represente a resposta para cada caso. A função implementada(FRESULT) tem por objetivo receber um parâmetro que é o fonema a acrescentar naresposta e modificar uma variável que representa o estado da resposta (*lvresult*). Afunção, deve fazer parte do conjunto de funções, com um argumento. Sempre que forexecutada em uma solução, será inserido ao final da lista o argumento recebido, casoeste não possua valor nulo. O código da função está descrito abaixo.
(defun FRESULT (pfone)(setf lvtemp '())(if (not (eq pfone nil)) (setf lvtemp (cons pfone lvtemp))) (setf vcontdo (- (length *lvresult*) 1)) (loop until (< vcontdo 0) do (setf lvtemp (cons (nth vcontdo *lvresult*) lvtemp)) (setf vcontdo (- vcontdo 1))) (setf *lvresult* lvtemp)(values pfone))

57
Além da função que modifica a resposta, uma função de repetição e funções deincremento de posição devem fazer parte do conjunto de funções ou terminais. Como apalavra é composta por diversas letras, as regras devem ser aplicadas seqüencialmente acada uma delas; portanto, fica a cargo do processo evolutivo descobrir como controlar aseqüência de aplicação, além de compor as respectivas regras. Para atingir este objetivoé criada uma função de repetição que executa diversas vezes um determinado conjuntode instruções recebidas como argumentos, de acordo com o tamanho da palavra que éobjeto de avaliação. Uma função de repetição específica para o domínio do problemafaz-se necessária, na medida que usando funções de repetição tradicionais, facilmenteverifica-se a ocorrência de um laço infinito ou ainda a incidência de indivíduos cujaavaliação de fitness torna-se extremamente lenta e complexa. As funções de incremento,aumentam o valor de uma variável de estado (*vposletra*) que define a posição atual,influenciando funções que retornam a letra na posição atual, bem como as letras nasposições anteriores e posteriores. Um exemplo de uma possível solução que apresentaesta estrutura, está descrito abaixo.
(DOLFON (IF (IF (FRESULT (CPOSAT)) (IF (IF T15 T13)(INCPOS) (CPOSAT)) (FRESULT T16)) T4 T6))
Na segunda abordagem avaliada, as soluções não produzem uma lista em umaexecução única para cada palavra, mas são executadas várias vezes de acordo com onúmero de letras. Nesta abordagem, existem duas alternativas possíveis, uma quemantém a função que modifica a variável de estado, representando a resposta e outra,que utiliza o retorno do programa avaliado e insere-o na lista. A função de repetição emqualquer uma das alternativas é retirada do conjunto de funções.
Na primeira alternativa, a função FRESULT é mantida no conjunto de funções, epode até mesmo ser chamada diversas vezes por cada solução. É comum nesta situação,a produção de respostas com um número de elementos superior ao esperado. Estaabordagem permite por exemplo que na execução de uma solução candidata, a mesmainsira mais de um valor na resposta. Abaixo, segue um exemplo desta estrutura.
(IF (IF (FRESULT (CPOSAT)) (IF T11 T11 T15)) T6 T8)
A última estratégia das três possíveis é semelhante à anterior, porém a funçãoFRESULT é retirada do conjunto de funções e é usada na avaliação de fitness. Nestasituação, o programa também é avaliado diversas vezes e a resposta do programa éinserida pela função de avaliação de fitness na resposta. A partir da não utilização deuma função específica para composição da lista de fonemas, a responsabilidade dassoluções fica sendo somente a de elaborar a regra e retornar o fonema específico paracada letra. A função de avaliação de fitness tem a responsabilidade de compor aresposta final, usando os valores retornados a cada execução de uma solução. Nestaabordagem é possível garantir que somente um único valor de resposta será produzidopelo indivíduo.
Diversas execuções iniciais permitiram verificar vantagens e desvantagens decada alternativa. Todas elas foram capazes de encontrar boas soluções; entretanto autilização de funções de repetição, apresentou um maior tempo de processamento. Outraconstatação básica foi a dependência da função de produção de resultados nas primeirasduas estratégias. A não utilização ou utilização em excesso desta instrução causadiversos problemas como produção de respostas nulas ou com tamanho superior aoesperado. A última alternativa mostrou um maior equilíbrio no consumo de recursos e

58
na evolução e ainda maior clareza nas soluções finais e por todos estes motivos foiescolhida; entretanto, é necessário salientar que qualquer uma das alternativas anterioresseria uma escolha válida.
Além da definição de uma estrutura de solução, outra definição importante é aforma como as soluções receberão as entradas do problema, que são constituídas pelasletras que formam palavras.
Se a entrada para o problema fosse a lista inteira, soluções deveriam possuir ahabilidade de extrair sucessivamente cada letra e aplicar as regras. Entretanto, aatividade de extrair a partir de uma lista um elemento envolve funções da linguagemcomo FIRST, SECOND, ou ainda uma função para obter um elemento em uma posiçãoespecífica como por exemplo NTH. Esta necessidade de extração sucessiva deve serrealizada seqüencialmente, caso a estrutura dos indivíduos siga a abordagem na qual éusada uma função de repetição como parte do conjunto de funções.
Após algumas simulações e avaliações iniciais foi possível verificar a dificuldadede encontrar soluções capazes de extrair elementos de lista, usando somente as funçõesbásicas da linguagem. O uso de funções tradicionais como FIRST, SECOND torna-seinviável, uma vez que extraem sempre um elemento em posição específica. Uma funçãocomo NTH para ser utilizada corretamente deve utilizar como um de seus parâmetros aposição da letra na lista, posição esta que deve ser incrementada seqüencialmente.Embora esta alternativa seja viável, o objetivo do processo não é descobrir programascapazes de extrair elementos de listas e sim soluções que implementem regras sobreestes elementos. Além disso, uma estratégia que exige das soluções a extração deelementos de lista a partir de funções primitivas se mostra extremamente custosa emtermos de desempenho e recursos do sistema.
Para obter melhor rendimento do sistema e maior facilidade para obterseqüencialmente cada elemento (letra) da lista (palavra), foram implementadas funçõesde domínio do problema que tem por objetivo retornar a posição atual (CPOSAT),anterior(CPOSAN1), posterior(CPOSPO1), levando em consideração uma variável quedefine a posição atual na lista. Além destas funções, foram criadas ainda funções paraincremento da posição atual da lista em uma (INCPOS) e duas (INCPOS2) unidades.Estas funções são importantes, uma vez que o sistema deverá aplicar as regrassucessivamente sobre cada uma das letras ou poderá de acordo com a solução criadaoptar pela não aplicação a uma determinada letra. Cabe portanto às soluções descobrir aforma e seqüência correta de uso destas funções. Diversos outros problemas descritosem [KOZ 92],[KOZ 98] utilizam funções de domínio, o que caracteriza a inserção deconhecimento prévio no processo de busca de soluções.
As funções para incremento de posição fazem parte do conjunto de terminaisapenas na abordagem que deixa a cargo da solução a repetição e incremento da posiçãoatual. Nas abordagens em que a função de avaliação de fitness executa diversas vezescada indivíduo, o incremento é feito antes de cada avaliação.
As entradas poderiam também ocorrer sob a forma de variáveis. Na avaliação, aprópria função de avaliação extrairia a letra atual, as letras anteriores e posteriores eatribuiria à variáveis globais a cada avaliação. As soluções processariam variáveis e nãoas funções de entrada citadas acima. Entretanto esta implementação não é viável,principalmente quando a repetição fica a cargo das soluções. Por este motivo, a escolharecaiu sobre funções de entrada, que funcionam para todas as estratégias descritasanteriormente.

59
6 ResultadosO conjunto de regras para conversão letra para fonema em língua portuguesa é
extremamente amplo. Míriam Barbosa da Silva em [SIL 93] descreve um conjunto demais de oitenta regras que cobrem os diversos contextos em que letras são empregadas.O item 2.5 descreveu anteriormente os diversos subgrupos que concentram estas regras.
A aplicação da técnica ao problema, envolveu a seleção de subconjuntos dessasregras. A aplicação utilizando como base o conjunto completo das regras poderia exigirum excesso de funções, terminais e casos de fitness. Além disso, as soluções tambémtenderiam a apresentar uma complexidade muito grande, dificultando uma análise maisdetalhada, necessária para compreensão do trabalho realizado. A descoberta de umasolução única para todas as regras, além de complexa poderia exigir um tempoinaceitável para ser encontrada.
Os diferentes casos aos quais a técnica foi aplicada foram elaborados pararefletirem os diferentes contextos como fonemas simbolizados por mais de uma letra,letras simbolizando diferentes fonemas, letras que não representam fonema algum eainda influências das letras anteriores e posteriores na produção do fonema relativo àletra na posição atual. Os casos foram definidos também com o objetivo de comparar osresultados em situações de maior e menor complexidade, uma vez que a capacidade deencontrar soluções para problemas de complexidade crescente é uma característicadesejável em qualquer técnica que simule um processo de aprendizado em máquinas.
A documentação dos resultados obtidos é descrita através dos seguintes aspectos:
− Citação e exemplificação das regras a serem descobertas;
− Definições para a execução, envolvendo conjunto de terminais, funções,casos de fitness e demais parâmetros de controle;
− Evolução do melhor, pior e fitness médio da população;
− Regras implementadas pelas soluções encontradas;
− Evolução da complexidade estrutural da população e melhor solução;
− Validação da solução;
Para cada subconjunto, foram realizadas diversas execuções para obtenção deresultados com bom grau de representatividade. Devido à natureza probabilística doprocesso, as diferentes execuções apresentaram um grau de variabilidade, tanto emvalores de fitness quanto na combinação de funções e terminais. Visando a uma análisemais detalhada, para cada caso será descrita uma execução que ilustra bons resultados.É preciso salientar entretanto, que bons resultados não foram obtidos somente naexecução descrita, em diversas outras foram obtidos resultados igualmente aceitáveis,com indivíduos com diferentes estruturas e graus de adaptação.
Alguns dos parâmetros de controle foram mantidos sem modificação em todas asexecuções. A manutenção destes parâmetros permite uma comparação isenta entre asdiversas alternativas e casos documentados. O tamanho da população e o número degerações foram os parâmetros que sofreram variações em determinadas execuções eserão descritos nas definições de cada caso, os demais parâmetros empregados, estãoresumidos na tab. 6.1.

60
TABELA 6.1 – Parâmetros utilizados em todas as execuções
Parâmetro Valor/Opção utilizada
Probabilidade de cruzamento em qualquer ponto 0.40
Probabilidade de cruzamento em ponto de função 0.45
Probabilidade de Reprodução 0.10
Probabilidade de Mutação 0.05
Profundidade máxima na geração inicial 6
Profundidade máxima para operações genéticas 10
Método para geração da população inicial Subida Parcial
Método de seleção de indivíduos Proporcional ao Fitness
Critério para término do processo Atingir o número máximo degerações ou descoberta de umasolução 100% correta
A definição destes parâmetros foi realizada após execuções iniciais e apósrevisões de problemas citados por outros autores [KOZ 92], [KOZ 98]. Após estaanálise foi possível levantar algumas questões importantes sobre estes parâmetros: i) Aprobabilidade de cruzamento em pontos de função acarreta em uma maior alteração nosindivíduos, enquanto cruzamentos em qualquer ponto torna-se as modificações maisaleatórias; ii) probabilidades de reprodução muito altas fazem com que o processoencontre rapidamente soluções com um bom grau de adaptação, mas apresentam umproblema da convergência prematura, ou seja, após encontrar uma solução bem adaptaesta não mais evolui; iii) as profundidades devem ser limitadas até um nível aceitável,caso contrário os indivíduos tem sua complexidade aumentada indefinidamente.
Nos problemas abordados em [KOZ 92], profundidades máximas na geraçãoinicial e após operações genéticas, obtinha-se que os valores empregados eramrespectivamente 6 e 17 nós. Os valores definidos neste trabalho, mantém o tamanhopara a geração inicial, porém utilizam profundidade de apenas 10 nós para geraçõessubseqüentes. Analisando as regras a serem implementadas nos subconjuntos que serãodescritos posteriormente, será possível perceber que em nenhuma das situações sãonecessários valores superiores; entretanto pode ser necessário um aumento destesparâmetros caso o conjunto de regras seja mais complexo.
A evolução das soluções é demonstrada através de um gráfico, englobando omelhor fitness da geração, o melhor fitness da execução, o pior fitness e ainda a médiada população.
O código da melhor solução para cada caso será descrito na íntegra com objetivode possibilitar uma avaliação detalhada da estratégia e forma como as regras são

61
implementadas. O conjunto completo de instruções entretanto, é de difícilentendimento, sendo assim as regras serão descritas também em uma linguagem natural.
Outro fator importante para avaliação dos resultados é o número de pontos(funções e terminais) das soluções. Este o qual é chamado de complexidade estrutural.A evolução desta medida será descrita também por um gráfico, mostrandocomplexidade do melhor e pior indivíduo, bem como a média da população.
A validação é realizada para comprovar que a solução produz efetivamente asrespostas corretas ou não, conforme as regras implementadas. Para evitar qualquertendência associada ao processo de treinamento, a validação será realizada com palavrasnão utilizadas no treinamento.
A seguir são detalhadas as execuções para cada subconjunto.
6.1 Caso 1 - Relação um para um e letras "t" e "d" antes de "i"O primeiro subconjunto de regras ao qual a técnica será aplicada engloba as regras
mais simples para conversão:
− relação direta entre letra e fonema, onde determinadas letras representamsempre o mesmo fonema independente do contexto. Estas letras no caso são“p”, “b” e “v”.
− letras “t” e “d” quando ocorrem antes de “i”, representam diferentesfonemas. A notação para estes fonemas será ts e dz, nos demais casos ofonema é utilizado o símbolo correspondente à própria letra. Esta variação écomum em determinadas regiões do Brasil, como por exemplo nas regiõesSul e Sudeste.
6.1.1 Resultados utilizando somente funções básicas
A execução descrita inicialmente emprega apenas funções básicas da linguagem,nenhuma função de domínio é utilizada. O objetivo é avaliar a capacidade de soluçãousando exclusivamente funções tradicionais da linguagem. Os parâmetros para estaexecução estão descritos na tab. 6.2.
TABELA 6.2 - Parâmetros para o caso 1, usando somente funções básicasParâmetro Definição para o problemaConjunto de funções (EQ IF IF AND OR)Número de argumentosdas funções
(2 2 3 2 2)
Conjunto de terminais ((CPOSAT) (CPOSPO1) t d i ts dz)Casos de fitness ((p a) (b e) (v i) (t i) (d i) (t a t o) (d a d o) (d i d i) (d i t i))Resposta esperada ((p a) (b e) (v i) (ts i) (dz i) (t a t o) (d a d o) (dz i dz i) (dz i
ts i))Número de gerações G = 50Tamanho da população M = 500
Os casos de fitness devem constituir-se em uma amostra representativa das regrasa serem implementadas pela solução. Com relação às regras em questão, é necessárioque as combinações das letras “t” ou “d” antes de “i” apareçam com razoável

62
freqüência, uma vez que todas as combinações restantes caracterizam a regra geral.Tanto a sílaba (v i) quanto (b e) representam a regra geral, mesmo que usem letrasdiferentes. A regra geral para este caso representa um ponto de convergência prematura.
O conjunto de funções possui uma função para comparação de igualdade (EQ), afunção IF que pode ser empregada com dois ou três argumentos e por este motivoaparece duas vezes no conjunto. As funções AND e OR são necessárias paracomparações mais complexas que envolvam duas condições.
O conjunto de terminais é composto apenas por uma função que retorna a letra naposição atual e por outra que retorna a letra na próxima posição. Esta definição garanteo conceito de suficiência, pois é possível implementar uma solução correta apenas comestas duas entradas, sem necessidade das letras nas demais posições. Segue-se noexemplo o princípio de que funções sem argumentos fazem parte do conjunto determinais.
O fitness básico máximo para um indivíduo é de 78 e é computado através dasoma da multiplicação de todos os fonemas esperados por 3. O fitness padronizado écalculado subtraindo-se o fitness do indivíduo deste valor máximo. O gráfico daevolução do fitness demonstra a evolução do fitness durante o processo, no gráfico sãodemonstrados o melhor fitness da geração, da execução, a média de fitness dapopulação e o fitness do pior indivíduo. A fig. 6.1 permite visualizar a evolução dassoluções para esta execução.
Evolução do fitness
0
10
20
30
40
50
60
70
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48
Gerações
Fitn
ess
Média fitness populaçãoMelhor fitness da geraçãoMelhor fitness da execuçãoPior fitness da geração
FIGURA 6.1 - Evolução de fitness para o caso 1, usando somente funções básicas
Os valores de fitness do melhor indivíduo da geração e da execução permanecemo mesmo durante todo o processo (fig.6.1). Neste exemplo o fitness do melhorindivíduo encontrado na geração 35 foi 6 e permaneceu durante o restante das gerações.A média do fitness da população cai de forma constante e a partir da obtenção damelhor resposta permanece estável, sofrendo apenas pequenas variações. Melhorias nomelhor fitness ocorrem de forma brusca; uma combinação correta de instruções implica

63
em respostas corretas para diversos fonemas. Este comportamento é uma característicaintrínseca do problema, uma vez que uma mesma regra é aplicável a vários casos.
Após a realização de três diferentes execuções, em nenhuma delas foi encontradauma resposta 100% correta para o problema, a melhor solução tem um percentualaproximado de 93% de acerto. O código do melhor indivíduo da execução documentadapara o caso, foi:
(IF (OR (AND (EQ T5 T4) (IF (OR (AND (EQ T5 T4)(CPOSPO1)) (CPOSAT)) (IF (CPOSAT) T7 (IF (AND(CPOSAT) (AND T6 (CPOSAT))) T5 T5)) (OR (CPOSAT)(EQ (IF T3 T5) (IF T6 (EQ T5 T4) T7))))) (EQ (IF (CPOSAT)T5) (IF T6 (OR (IF (EQ (IF (CPOSPO1) (CPOSAT) (OR(CPOSAT) T5)) (IF T4 T4 (CPOSAT))) (CPOSPO1) T7) T3)T7))) (AND (AND T6 (CPOSAT)) T7) (OR (OR (OR(CPOSAT) (CPOSAT)) (EQ (CPOSPO1) (OR T7 (IF T6(OR T3 (OR (CPOSAT) (OR (CPOSAT) T7))) (CPOSAT)))))(OR (IF (EQ T5 T4) (CPOSAT) T7) T3)))
Abaixo, um resumo das regras implementadas pelo indivíduo:
Se letra na posição atual é igual a “d” (T4) e a letra napróxima posição é igual a “i” (t5)
Retorna dzSenão
Retorna a letra na posição atual
O código envolve diversos pontos e combinações que não influenciam naprodução da resposta. Diversas comparações como por exemplo (EQ T5 T4) produzemsempre valores nulos ou em outras situações como em (IF T4 T4 (CPOSAT)) produzemsempre o mesmo valor, o que neste caso corresponde à posição atual.
O pior fitness da geração permanece o pior valor possível durante todo o processo.Indivíduos representando a pior solução, na maioria dos casos possuem códigos queproduzem valores nulos independentemente de valores de entradas.
Para o melhor indivíduo acima a complexidade estrutural é de 92 pontos. A fig.6.2 mostra a evolução da complexidade estrutural ao longo das gerações.

64
Evolução da com plexidade estrutural
0
20
40
60
80
100
120
140
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48
Gerações
Núm
ero
de p
onto
s(co
mpl
exid
ade)
Média complexidade estruturalComplexidade estrutural do m elhorComplexidade estrutural do pior
FIGURA 6.2 – Complexidade estrutural para o caso 1, usando somente funções básicas
Existe uma variação da complexidade tanto para o pior quanto para o melhorindivíduo. A complexidade do melhor indivíduo entretanto tende a aumentar ao longodas gerações; é comum observar que indivíduos que se constituem em boas soluçõesapresentam número cada vez maior de pontos. A média da população apresenta umcrescimento constante e na maior parte do tempo estável; com isto, é possível concluirque a melhoria do fitness neste caso, é acompanhada por um aumento na complexidadeestrutural.
A validação foi realizada utilizando-se 10 casos com um fitness total de 126. Aadaptação apresentado nestes casos foi de aproximadamente 98%, com um fitness de 3.A tab. 6.3 resume os resultados da validação.
TABELA 6.3 – Validação para o caso 1, usando somente funções básicas.
Palavras usadas Resultados esperados Resultados produzidos
((p a t o) (b e b a) (v i v e)(t i p o) (d i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
((p a t o) (b e b a) (v i v e)(ts i p o) (dz i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
((p a t o) (b e b a) (v i v e)(t i p o) (dz i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
6.1.2 Inserção de funções de domínio
Nesta execução, o subconjunto de regras a serem descobertas permanece o mesmodescrito no item 6.1.1, mas são inseridas funções que implementam detalhes da regra,que chamamos de funções de domínio. Um dos objetivos do trabalho é comparar ainfluência das funções de domínio no processo. As definições necessárias para aexecução estão resumidas abaixo (tab. 6.4).
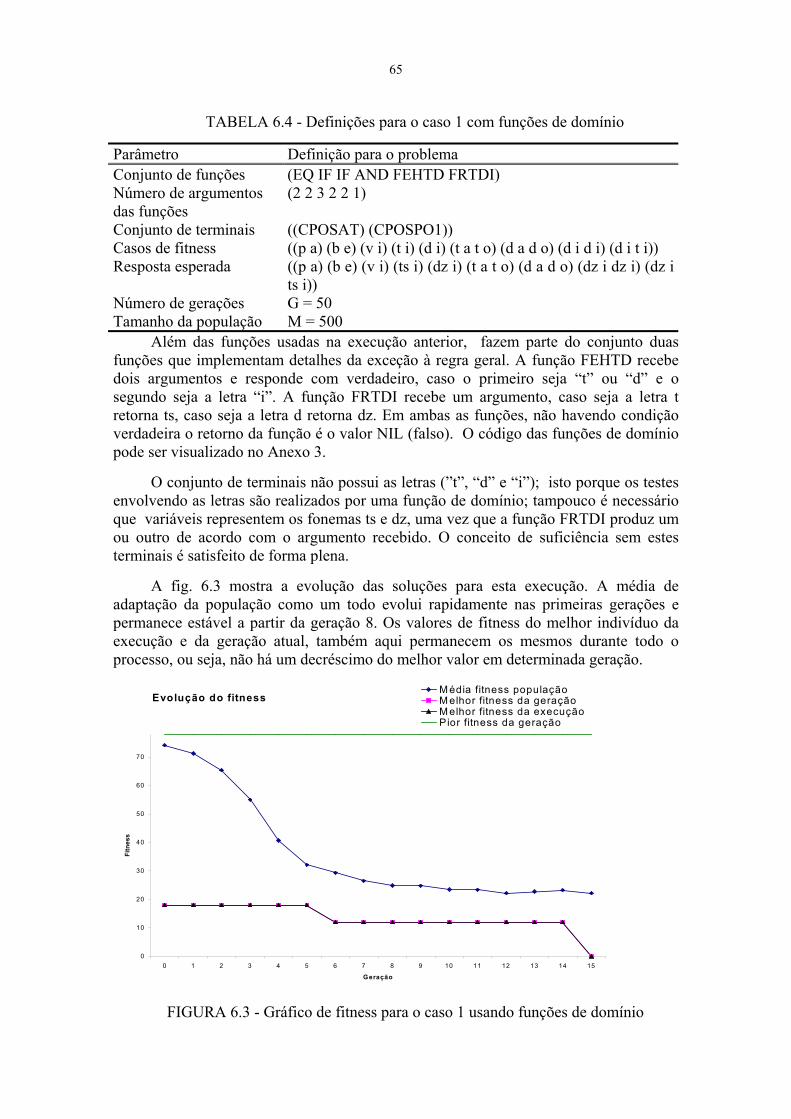
65
TABELA 6.4 - Definições para o caso 1 com funções de domínio
Parâmetro Definição para o problemaConjunto de funções (EQ IF IF AND FEHTD FRTDI)Número de argumentosdas funções
(2 2 3 2 2 1)
Conjunto de terminais ((CPOSAT) (CPOSPO1))Casos de fitness ((p a) (b e) (v i) (t i) (d i) (t a t o) (d a d o) (d i d i) (d i t i))Resposta esperada ((p a) (b e) (v i) (ts i) (dz i) (t a t o) (d a d o) (dz i dz i) (dz i
ts i))Número de gerações G = 50Tamanho da população M = 500
Além das funções usadas na execução anterior, fazem parte do conjunto duasfunções que implementam detalhes da exceção à regra geral. A função FEHTD recebedois argumentos e responde com verdadeiro, caso o primeiro seja “t” ou “d” e osegundo seja a letra “i”. A função FRTDI recebe um argumento, caso seja a letra tretorna ts, caso seja a letra d retorna dz. Em ambas as funções, não havendo condiçãoverdadeira o retorno da função é o valor NIL (falso). O código das funções de domíniopode ser visualizado no Anexo 3.
O conjunto de terminais não possui as letras (”t”, “d” e “i”); isto porque os testesenvolvendo as letras são realizados por uma função de domínio; tampouco é necessárioque variáveis representem os fonemas ts e dz, uma vez que a função FRTDI produz umou outro de acordo com o argumento recebido. O conceito de suficiência sem estesterminais é satisfeito de forma plena.
A fig. 6.3 mostra a evolução das soluções para esta execução. A média deadaptação da população como um todo evolui rapidamente nas primeiras gerações epermanece estável a partir da geração 8. Os valores de fitness do melhor indivíduo daexecução e da geração atual, também aqui permanecem os mesmos durante todo oprocesso, ou seja, não há um decréscimo do melhor valor em determinada geração.
Evolução do fitness
0
10
20
30
40
50
60
70
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Geração
Fitn
ess
M édia fitness populaçãoM elhor fitness da geraçãoM elhor fitness da execuçãoPior fitness da geração
FIGURA 6.3 - Gráfico de fitness para o caso 1 usando funções de domínio

66
Ao contrário da execução descrita na alternativa anterior, nesta foi possívelencontrar indivíduos que resolvessem completamente o problema. Um indivíduo commaior grau de adaptação possível é encontrado já na geração 15, satisfazendo destaforma o critério de término, que determina que ao ser encontrada uma solução 100%correta, a execução é encerrada. O código da solução 100% correta encontrada foi:
(IF (CPOSAT) (IF (FEHTD (CPOSAT) (CPOSPO1)) (FRTDI(IF (FRTDI (CPOSAT)) (CPOSAT) (CPOSAT))) (CPOSAT))(CPOSAT))
Nesta solução é possível perceber claramente as seguintes regras:
Se a letra na posição atual não é um valor nuloSe a letra na posição atual é igual a “t” e a letra napróxima é igual “i”
Retorna ts ou dz, de acordo com a letra na posiçãoatual (Aplica função FRTDI sobre letra na posiçãoatual)
SenãoRetorna a letra na posição atual
SenãoRetorna a letra na posição atual
Embora o indivíduo apresente ainda instruções que não contribuem para produçãode respostas corretas, é possível verificar que as soluções encontradas nesta execuçãotendem a se aproximar mais de implementações desenvolvidas por programadoreshumanos. Devido ao fato de funções como FRTDI e FEHTD implementarem parte daregra, o trabalho do processo evolutivo é facilitado e consequentemente, a melhorsolução é encontrada rapidamente.
É importante salientar que a maioria das soluções ainda implementa a regra geral,ou seja produz sempre a letra na posição atual, o que significa uma tendência ao mínimolocal, uma convergência prematura de boa parte dos indivíduos.
A complexidade estrutural do melhor indivíduo encontrado é de 14 pontos. A fig.6.4 descreve a evolução da complexidade estrutural na execução.

67
FIGURA 6.4 - Evolução da complexidade estrutural para o caso 1 usando funçõesde domínio
A variação da complexidade de melhores e piores indivíduos também ocorre nestasituação; porém os valores apresentados são muito inferiores àqueles verificados sem asfunções de domínio. Até a geração 15, na qual o processo foi finalizado, acomplexidade média dos indivíduos era de aproximadamente 23 pontos, enquanto naexecução documentada anteriormente era de 68 pontos. A diferença de pontos entre osmelhores indivíduos é 78 e mesmo levando-se em consideração que o melhor indivíduohavia sido obtido anteriormente na geração 35 é extremamente significativa.
Validando-se a solução com outras palavras obtêm-se sempre respostas corretaspara as regras envolvidas no treinamento. A tab. 6.5 ilustra o processo de validação.
TABELA 6.5 – Validação para o caso 1, usando funções de domínio
Palavras usadas Resultados esperados Resultados produzidos
((p a t o) (b e b a) (v i v e)(t i p o) (d i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
((p a t o) (b e b a) (v i v e)(ts i p o) (dz i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
((p a t o) (b e b a) (v i v e)(ts i p o) (dz i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
6.2 Caso 2 - Nasalização de vogaisNeste caso, o conjunto de regras a se obter envolve três situações básicas:
− relação direta entre letra e fone;
− ocorrência especial das letras "t" e "d" antes de "i" conforme o caso anteriore;
− nasalização de uma vogal quando da ocorrência de "m" ou "n" após umavogal em fim de palavra ou antes de uma consoante. Neste caso, as letrascitadas não simbolizam um fonema específico e funcionam como elemento
E volução do fitness
-2
8
18
28
38
48
58
68
78
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
G eração
Fitn
ess
M édia fitness populaçãoM elhor fitness da geraçãoM elhor fitness da execuçãoP ior fitness da geração

68
de nasalização da letra anterior. As notações (ax~, e~, i~, o~, u~) são usadaspara representação destes fonemas.
Analisando as regras acima, é possível observar que na maior parte dos casos, asletras citadas continuam tendo como representação fonêmica a própria letra. Asvariações ocorrem em contextos específicos, envolvendo segmentos anteriores eposteriores. As soluções deverão ser capazes de concluir que em determinado contextonenhum fonema deve ser gerado, ou outra representação que não a própria letra deve serretornada. A tab. 6.6 resume as definições para o caso.
TABELA 6.6 - Definições para o caso 2
Parâmetro Definição para o problemaConjunto de funções (EQ IF IF AND AND NOT FEHVOGAL FNASAL
FEHMN FEHTD FRTDI)Número de argumentosdas funções
(2 2 3 2 3 1 1 1 1 2 1)
Conjunto de terminais ((CPOSAT) (CPOSPO1) (CPOSAN1) (CPOSAN2)(CPOSPO2) NIL)
Casos de fitness ((a n t a n t) (e n t e n t) (i n t i n t i) (o n t o n t) (u n t u n t)(a n d a n d) (e n d e n d) (i n d i n d) (o n d o n d) (u n d un d) (a m p a m p) (e m p e m p) (i m p i m p) (o m p o mp) (u m p u m p) (a m b a m b) (e m b e m b) (i m b i m b)(o m b o m b) (u m b u m b) (a m a) (a n a))
Resposta esperada ((ax~ t ax~ t) (e~ t e~ t) (i~ ts i~ ts i) (o~ t o~ t) (u~ t u~ t)(ax~ d ax~ d) (e~ d e~ d) (i~ dz i~ d) (o~ d o~ d) (u~ d u~d) (ax~ p ax~ p) (e~ p e~ p) (i~ p i~ p) (o~ p o~ p) (u~ pu~ p) (ax~ b ax~ b) (e~ b e~ b) (i~ b i~ b) (o~ b o~ b) (u~b u~ b) (a m a) (a n a))
Número de gerações G = 200Tamanho da população M = 1,000
A complexidade das regras neste exemplo é maior do que a apresentada no caso 1.A regra para nasalização das vogais, possui uma implementação extensa, pois para cadauma das vogais, o fonema correspondente à nasalização é diferente. Execuções iniciaisque utilizaram apenas funções básicas demonstraram uma imensa dificuldade em gerarsoluções bem adaptadas. Outra constatação importante é que sem funções de domínio, oconjunto de terminais seria maior pois deveria possuir todos os fonemas representandoas nasalizações e todas as vogais a serem usadas nas comparações.
Partindo destas conclusões, foram acrescidas funções criadas a partir de umaanálise das regras a serem implementadas. Podemos classificar as funções em doisgrupos, as que devem ser utilizadas como condição e as que retornam valores paracomposição da resposta. No primeiro grupo estão FEHVOGAL, que recebe umargumento e retorna um valor lógico, indicando se o mesmo é ou não vogal e FEHMNcuja tarefa é retornar verdadeiro se o argumento recebido é uma das letras “m” ou “n”,além da função FEHTD utilizada no caso 1. No segundo grupo estão FNASAL queretorna o fonema correspondente à nasalização quando o argumento recebido for umavogal e FRTDI, descrita em execuções anteriores.

69
O conjunto de terminais é formado pelas letras nas duas posições anteriores(CPOSAN1 e CPOSAN2) e nas duas posteriores (CPOSPO1 e CPOSPO2), além daletra na posição atual (CPOSAT).
O fitness básico máximo que uma solução pode atingir é de 261 pontos, seguindoo princípio de cálculo da multiplicação de cada fonema esperado por 3. O fitnesspadronizado do melhor indivíduo, encontrado na geração 165, foi 16 (fig.6.5).
E vo lu ç ã o d o fitn e s s
0
5 0
1 0 0
1 5 0
2 0 0
2 5 0
0 7 14 21 28 35 42 49 56 63 70 77 84 91 98 105
112
119
126
133
140
147
154
161
168
175
182
189
196
G e ra ç ã o
Fitn
ess
M é d ia f itn e s s p o p u la çã oM e lh o r f itn e s s d a g e ra çã oM e lh o r f itn e s s d a e x e cu ç ã oP io r f itn e ss d a g e ra ç ã o
FIGURA 6.5 - Evolução do fitness para o caso 2
O código do melhor indivíduo foi:
(IF (IF (AND (CPOSPO1) (IF (IF (IF (CPOSPO2)(CPOSAN1) (AND (CPOSPO1) (IF (CPOSAT) (CPOSAT)(CPOSAT)) T6)) (FEHVOGAL (CPOSAN2)) (CPOSAN1))(IF (FEHVOGAL (CPOSAN1)) (CPOSAN1) (CPOSAN2))(IF (CPOSPO2) (CPOSAN1) (CPOSAN1))) T6) (IF(CPOSPO2) (FEHVOGAL (CPOSAN2)) (CPOSAN1))(CPOSAT)) (IF (AND (FEHVOGAL (CPOSAN2))(FEHVOGAL (CPOSAN2)) (CPOSAN1)) (CPOSAT) (IF(AND (FEHVOGAL (CPOSAT)) (IF (CPOSPO2)(CPOSAN1) (CPOSAN1)) (AND (CPOSPO1) (CPOSAT)T6)) (CPOSAN2) (IF (FEHVOGAL (CPOSPO1)) (CPOSAT)(FNASAL (CPOSAT))))) (IF (AND (IF (CPOSAN2)(CPOSAN1) (IF (CPOSAT) (FEHVOGAL (IF (CPOSPO2)(CPOSAN1) (FNASAL (AND (CPOSAT) (IF (CPOSPO2)(CPOSAN1) (CPOSAN1)) (CPOSAN1))))) (CPOSAN1))) (IF(AND (FEHVOGAL (CPOSAT)) (CPOSAT) (CPOSAN1))(AND (FEHMN (CPOSPO1)) (CPOSAN1) (CPOSAN1))(CPOSAN1)) (CPOSAT)) (CPOSAN2) (CPOSAN1)))
O indivíduo descrito acima obtém um bom fitness e constitui-se portanto, em umasolução aceitável para o problema. As regras implementadas são:

70
Se a letra na posição anterior não é nula e a letra nasegunda posição anterior é vogal
Retorna a letra na posição atualSenão
Se constante nula (não executa condição verdadeira)Senão
Se letra na posição posterior é vogalRetorna a letra na posição atual
SenãoRetorna nasalização da letra na posição atual
A primeira questão a ser ressaltada é que a maior parte das instruções observadasnão realizam nenhuma atividade, essencialmente porque retornam valores sempreverdadeiros ou nulos, independente dos parâmetros de entrada. Este é o caso dosseguintes conjuntos de instruções:
(IF (AND (CPOSPO1) (IF (IF (IF (CPOSPO2) (CPOSAN1)(AND (CPOSPO1) (IF (CPOSAT) (CPOSAT) (CPOSAT))T6)) (FEHVOGAL (CPOSAN2)) (CPOSAN1)) (IF(FEHVOGAL (CPOSAN1)) (CPOSAN1) (CPOSAN2)) (IF(CPOSPO2) (CPOSAN1) (CPOSAN1))) T6)
(AND (FEHVOGAL (CPOSAT)) (IF (CPOSPO2)(CPOSAN1) (CPOSAN1)) (AND (CPOSPO1) (CPOSAT)T6))
Nestes dois exemplos, o retorno será sempre nulo porque é executada uma funçãoAND sobre três parâmetros, sendo que o último (T6) é um terminal que tem valor nulofixo. A primeira das duas partes descritas é a condição do segundo IF da soluçãocompleta. Isto faz com que a primeira parte referente a condição verdadeira nunca sejaexecutada. A função portanto retornará sempre a letra na posição atual (CPOSAT).
O código que efetivamente produz as respostas é:
(IF (AND (FEHVOGAL (CPOSAN2)) (FEHVOGAL(CPOSAN2)) (CPOSAN1)) (CPOSAT) (IF (AND(FEHVOGAL (CPOSAT)) (IF (CPOSPO2) (CPOSAN1)(CPOSAN1)) (AND (CPOSPO1) (CPOSAT) T6))(CPOSAN2) (IF (FEHVOGAL (CPOSPO1)) (CPOSAT)(FNASAL (CPOSAT)))))
Nos casos que a posição atual é uma consoante, a sua nasalização é um valor nulo.Valores nulos não são inseridos na resposta final pela função de avaliação do fitness.
O melhor indivíduo da geração em determinadas momentos apresenta fitness piordo que o melhor da execução. Embora tal fato represente um decréscimo de adaptaçãoda melhor solução, esta variação pode levar a combinações diferentes, que em geraçõesseguintes poderão resultar em soluções melhores.
Observando a fig. 6.5, é possível constatar que o pior fitness permanece no limitemais baixo possível durante muitas gerações, passando a variar de forma maisacentuada quando melhores respostas passam a ser obtidas. Durante a maior parte daevolução entretanto, existe algum indivíduo que não produz nenhum fonema correto.

71
Um exemplo é o indivíduo abaixo, encontrado na geração 180, que produz sempre umvalor nulo.
(AND (CPOSPO1) (FEHVOGAL (CPOSAN2)) T6)
É possível perceber que a complexidade média aumenta progressivamenteenquanto complexidades do melhor e do pior indivíduos oscilam. Valores relativos aopior indivíduo, tendem a variar mais fortemente no início e diminuir a partir de geraçõesseguintes. O melhor indivíduo, embora apresente variações no número de pontos tende apossuir também uma complexidade crescente assim como a média da população(fig.6.6). A complexidade dos indivíduos neste subconjunto tende a crescer mais do queno caso anterior.
FIGURA 6.6 - Gráfico da complexidade estrutural para o caso 2
A complexidade estrutural do melhor indivíduo foi de 97 pontos. O número depontos dos indivíduos neste caso apresenta valores superiores àqueles verificados nocaso anterior. O aumento da complexidade das regras normalmente implica em soluçõesmaiores, uma vez que a técnica tende a buscar melhores soluções através decombinações exaustivas.
Embora bem adaptada aos casos de fitness usados para o treinamento, a soluçãoencontrada apresenta alguns problemas quando validada com outras palavras. Percebe-se na tabela abaixo que nas 30 palavras utilizadas na validação, a solução apresentou namaioria delas a produção de nasalização de vogais em final de palavra ou mesmo antesde consoantes diferentes de “m” ou “n” (tab.6.7).
A regra implementada não avalia se a letra após uma vogal é efetivamente “m” ou“n” e falha exatamente nesta situação. O fitness obtido na validação é de 127, dividindo-se este valor pelo total possível, que é 462, obtém-se uma corretude aproximada de73%.
E volução da com plexidade estru tura l
0
20
40
60
80
100
120
140
160
180
200
0 7 14 21 28 35 42 49 56 63 70 77 84 91 98 105
112
119
126
133
140
147
154
161
168
175
182
189
196
G eração
Núm
ero
de p
onto
s(C
ompl
exid
ade)
M édia com plex idade estrutura lC om plex idade es trutura l do m elhorC om plex idade es trutura ldo p io r

72
TABELA 6.7 – Validação da melhor solução para o caso 2.
Palavras usadas Resultados esperados Fonemas produzidos((a p e n a d o) (t e n t a)(m a n a d a) (a n t e n ad o) (a m i d o) (d i n do) (t i n t a) (m i n a da) (a d m i t e) (b a n do) (a b a t i d o) (p o n to) (b o n d e) (t a m p a)(t o m a) (d o m a d a)(m u n d o) (t e m p o)(p i m e n t a) (t e m i do) (p a t i n a) (a d i d o)(t u m b a) (d i n a) (b e tu m e) (a m a d a) (t em a) (a b a d i a) (d a n ad o) (t o b a t a))
((a p e n a d o) (t e~ t a)(m a n a d a) (ax~ t e na d o) (a m i d o) (dz i~d o) (ts i~ t a) (m i n ad a) (a d m i t e) (b ax~d o) (a b a ts i d o) (po~ t o) (b o~ d e) (t ax~p a) (t o m a) (d o m a da) (m u~ d o) (t e~ p o)(p i m e~ t a) (t e m i do) (p a ts i n a) (a dz i do) (t u~ b a) (dz i n a)(b e t u m e) (a m a d a)(t e m a) (a b a dz i a)(d a n a d o) (t o b a ta))
((ax~ p e n a d o) (t e~ t ax~)(m ax~ n a d a) (ax~ t e~ n a do) (ax~ m i d o) (d i~ d o~)(t i~ t ax~) (m i~ n a d a)(ax~ m i~ t e) (b ax~ d o~)(ax~ b a t i d o) (p o~ t o~) (bo~ d e~) (t ax~ p ax~) (t o~ ma) (d o~ m a d a) (m u~ d o~)(t e~ p o~) (p i~ m e t ax~) (te~ m i d o) (p ax~ t i n a) (ax~d i d o) (t u~ b ax~) (d i~ n a)(b e~ t u m e) (ax~ m a d a) (te~ m a) (ax~ b a d i ax~) (dax~ n a d o) (t o~ b a t a))
6.3 Caso3 - Combinação "rr"Neste caso, o conjunto de regras a se obter envolve os seguintes contextos:
− relações direta entre letra e fone;− ocorrência especial das letras "t" e "d" antes de "i" conforme o caso inicial
e;− casos da letra "r". Quando ocorrer duas vezes seguida a letra "r" representa o
fonema x, nas demais situações a representação é a própria letra.O conjunto das regras neste caso tem uma complexidade menor do que no caso
anterior, porém representa uma situação diferenciada na qual uma mesma letra poderepresentar mais de um fonema quando ocorrer duas vezes em seqüência. De formaanáloga ao caso anterior a segunda ocorrência da letra não deverá representar fonemaalgum. As definições para este caso são resumidas na tab. 6.8.
TABELA 6.8 - Definições para o caso 3
Parâmetro Definição para o problemaConjunto de funções (EQ IF IF AND AND NOT FEHTD FRTDI)Número de argumentosdas funções
(2 2 3 2 3 1 2 1)
Conjunto de Terminais ((CPOSAT) (CPOSPO1) (CPOSAN1) (CPOSAN2)(CPOSPO2) r x NIL)
Casos de fitness ((a r r a) (e r r e) (i r r i) (o r r o) (a r t i) (o r d i) (o r p o) (u rb a) (o r a r) (t o r r e) (t u r r a))
Resposta esperada ((a x a) (e x e) (i x i) (o x o) (a r ts i) (o r dz i) (o r p o) (u r ba) (o r a r) (t o x e) (t u x a))
Número de gerações G = 100Tamanho da população M = 1,000

73
As únicas funções de domínio utilizadas foram as mesmas empregadas no caso 1.Por se tratar de um conjunto de regras mais simples, funções de domínio foramutilizadas em menor escala, será possível avaliar novamente a capacidade do sistema emderivar regras a partir de terminais e funções básicas da linguagem.
O conjunto de terminais, é composto por funções representando as letras nasposições anteriores e posteriores, pela constante NIL, pela letra "r" e pelo fonema x.
O fitness básico máximo que uma solução pode atingir é de 120 pontos. O fitnesspadronizado do melhor indivíduo, encontrado na geração 81, foi 6. A fig. 6.7 demonstraa evolução das soluções ao longo do processo.
FIGURA 6.7 - Gráfico da evolução do fitness para o caso 3
Nesta execução, o fitness da melhor solução é encontrado na geração 81 e não émais obtido nas gerações seguintes. Para este subconjunto de regras, foram realizadasalém desta, outras duas execuções, nelas o melhor fitness permanece até o final ou poralgumas gerações. O código da solução mais adaptada foi:
(IF (IF (FEHTD (CPOSAT) (IF (IF (CPOSAT) (CPOSAT))(IF (IF (CPOSPO1) T8 (CPOSAN1)) T7 (CPOSAT)))) (AND(IF (EQ (CPOSAT) (IF (CPOSPO1) (CPOSAT) (CPOSAT)))(FEHTD (CPOSAT) (CPOSAT))) (FEHTD (CPOSAT) (IF(CPOSAT) (IF (IF (FEHTD (CPOSAT) (CPOSAT)) (FEHTD(CPOSAT) (CPOSPO1)) (CPOSAT)) (NOT T7) (AND(CPOSAT) (CPOSAN1) (CPOSAT)))))) (CPOSAT)) (IF(NOT (EQ (CPOSAT) (CPOSPO1))) (IF (EQ (CPOSAN1)(CPOSAT)) (IF (CPOSPO1) T7 (CPOSAT)) (CPOSAT))))
Evolução do fitness
0
20
40
60
80
100
120
0 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76 80 84 88 92 96
Geração
Fitn
ess
Média fitness populaçãoMelhor fitness da geraçãoMelhor fitness da execuçãoPior fitness da geração

74
A maior parte do código, a exemplo das soluções anteriores é desnecessária. Umexemplo é a condição do IF inicial que resultará sempre em um valor verdadeiro. Segueabaixo o resumo das regras descobertas na solução.
Se a letra na posição atual é igual a letra na posiçãoposterior
Retorna valor nuloSenão
Se a letra na posição anterior é igual a letra na posiçãoatual e a letra na posição posterior não é um valor nulo
Retorna o fonema x (T7)Senão
Retorna a letra na posição atualA solução implementa apenas regra correspondente a ocorrência de "rr" e a regra
geral. O caso das letras "t" e "d" não é resolvido corretamente. Outras soluçõesencontradas durante a execução implementam estas últimas regras, mas falham naocorrência “rr”. Um exemplo é a solução abaixo, encontrada na geração 79. Nesteindivíduo a combinação de "rr" leva a produção do fonema r, incorretamente.
(IF (IF (FEHTD (CPOSPO1) (CPOSPO1)) (AND (IF T8(CPOSAN1) (IF (IF (IF (CPOSAT) (IF (EQ (CPOSAT)(CPOSAT)) (FRTDI (CPOSAT)) (CPOSAT))) (CPOSAT)(FRTDI (CPOSAT))) (EQ (CPOSAT) (CPOSPO1))(CPOSAT))) (IF (IF (CPOSPO1) (CPOSAN1) (CPOSAT))(CPOSAT) (IF (CPOSAT) (IF (IF (CPOSAT) (FEHTD(CPOSAT) (EQ (CPOSAN1) (CPOSAT))) (CPOSAT))(CPOSAT))))) (CPOSAT)) (IF (NOT (EQ (CPOSAT)(CPOSPO1))) (IF (FEHTD (CPOSAT) (CPOSPO1)) (FRTDI(CPOSAT)) (CPOSAT))))
A complexidade estrutural do melhor indivíduo descrito foi de 60 pontos, porém évariável durante a maior parte do processo. A média da complexidade estrutural dapopulação tende a manter-se em valores próximos a complexidade do melhor indivíduoa partir da metade do total de gerações.
FIGURA 6.8 - Gráfico da complexidade estrutural para o caso 3
Evolução da complexidade estrutural
0
20
40
60
80
100
120
0 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99
Geração
Núm
ero
de p
onto
s(co
mpl
exid
ade)
Média complexidade estruturalComplexidade estrutural do melhor da geraçãoComplexidade estrutural do pior da geração

75
Os resultados do processo de validação mostrados abaixo confirmam a análise docódigo do melhor indivíduo. O fitness obtido na validação é 12, representando umacerto aproximado de 91%, relativo ao total do fitness da validação que é 144 (tab.6.9).
TABELA 6.9 - Resultados da validação da melhor solução para o caso 3
Palavras Respostas esperadas Fonemas produzidos((t a r r o) (b r i t a) (a r ri b a) (o t o r r i n o)(p i r o u) (p a r a r)(a t i r a) (a d i r) (t i r a)(d i t o))
((t a x o) (b r i t a) (a x i ba) (o t o x i n o) (p i r o u)(p a r a r) (a ts i r a)(a dz i r) (ts i r a) (dz i t o))
((t a x o) (b r i t a) (a x i b a)(o t o x i n o) (p i r o u)(p a r a r) (a t i r a) (a d i r)(t i r a) (d i t o))
6.4 Caso 4 - Regras envolvendo as letras "c", "s" e "z"O último subconjunto de regras possui a maior complexidade a ser enfrentada pela
técnica. As regras a serem implementadas são as seguintes:− relação direta entre letra e fone, ocorrência especial das letras "t" e "d" antes
de "i”;− a letra "c" quando utilizada antes das letras "e" ou "i" é representada pelo
fonema s, nos demais casos pelo fonema k. Não há a representação do casode "ch", portanto a regra foi ignorada neste subconjunto.
− a letra "s" representa o fonema z em duas situações, quando ocorrer entreduas vogais ou ainda quando utilizada antes de consoantes vozeadas ("d","b", "m", "g", "n").
− o emprego de "ss" resulta na produção de apenas um fonema s.− a letra "z" tem como conseqüência o fonema s quando ocorre após vogal em
fim de palavra, antes de consoante. Sempre que vier seguida de uma vogal ofonema correspondente é a própria letra.
Neste subconjunto são apresentados diversos contextos verificados na línguaportuguesa como: i) a produção de diferentes fonemas pela mesma letra; ii)um mesmofonema sendo representado por letras diferentes e; iii) uma situação na qual o final depalavra influencia a letra anterior. As definições para o caso estão na tab. 6.10.
TABELA 6.10 - Definições para o caso 4Parâmetro Definição para o problemaConjunto de funções (EQ IF IF FEHSCVO FEHTD FRTDI FEHSS
FEHVSV FEHVZNIL FEHCEI)Número de argumentos dasfunções
(2 2 3 2 2 1 2 3 3 2)
Conjunto de terminais ((CPOSAT) (CPOSPO1) (CPOSAN1) c s z k NIL)Casos de fitness ((c a s a) (c e s s a) (a c i) (a c e) (a s s o) (e c o) (a s a)
(o s s o) (e s d) (a s b) (t i s m o) (t i s s o) (d i s s o) (d ic a) (z e r o) (c e r z o) (a z) (o z) (c e c i) (c i c e) (o s a)(i s o) (e s a) (a s m) (o s n) (i s b) (i z) (u z) (d i) (t i))
Resposta esperada ((k a z a) (s e s a) (a s i) (a s e) (a s o) (e k o) (a z a) (o so) (e z d) (a z b) (ts i z m o) (ts i s o) (dz i s o) (dz i k a)(z e r o) (s e r z o) (a s) (o s) (s e s i) (s i s e) (o z a) (i zo) (e z a) (a z m) (o z n) (i z b) (i s) (u s) (dz i) (ts i))
Número de gerações G = 100Tamanho da população M = 1,000

76
O conjunto de funções apresenta novas funções de domínio. A complexidade e oconjunto de regras envolvidas requer determinados detalhes que são implementados porestas funções. Cada função de domínio é orientada a uma regra específica; porém caberáao processo descobrir como empregá-la corretamente e quais os argumentossignificativos.
A função FEHSCVO recebe dois argumentos e retorna verdadeiro caso o primeiroargumento for a letra "s" e o segundo for uma consoante vozeada ("d", "b", "m", "g","n"). A função FEHSS retorna verdadeiro somente se ambos os argumentos recebidosforem a letra "s". FEHVSV recebe três argumentos e verifica se a primeira e terceiraletras são vogais e a segunda é a letra "s", retornando verdadeiro em caso positivo. Afunção FEHVZNIL recebe igualmente três argumentos e testa se a primeira letra évogal, a segunda a letra "z" e a terceira possui valor nulo. Por fim a função FEHCEIrecebe dois argumentos e testa se o primeiro é a letra "c" e o segundo é "i" ou "e". Emtodas as funções, o valor retornado caso os testes não sejam verdadeiros é a constanteNIL.
O conjunto de terminais é composto pelas letras na posição atual, posterior eanterior. Não é exigido em nenhuma das regras a avaliação de uma letra na segundaposição anterior ou posterior; portanto a suficiência é mantida mesmo retirando-se estasentradas. Os demais componentes são as letras e fonemas envolvidos nas regras.
O fitness básico máximo que uma solução pode atingir é de 288 pontos. O fitnesspadronizado que orienta o processo é calculado subtraindo-se o fitness individual dasolução de 288. A definição dos casos de fitness neste conjunto é especialmentedelicada. Como o conjunto de regras a implementar é mais amplo, deve-se ter umcuidado extremo para que todas as regras possuam uma amostragem satisfatória semque o conjunto de casos torne-se excessivamente extenso.
O fitness padronizado do melhor indivíduo, encontrado na geração 60, foi 30. Afig. 6.9 demonstra a evolução das soluções para o caso.
FIGURA 6.9 - Gráfico da evolução do fitness para o caso 4
Evolução do Fitness
0
50
100
150
200
250
0 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99
Gerações
Fitn
ess
Média fitness populaçãoMelhor fitness da geraçãoMelhor fitness da execuçãoPior fitness da geração

77
É importante observar que algumas das funções de domínio foram ignoradas pelamelhor solução, entretanto em algumas soluções bem adaptadas tanto nesta quanto emoutras execuções elas foram utilizadas. O código da melhor solução é:
(IF (IF (EQ (IF T4 (CPOSAT) T5) T4) T6) (IF (FEHCEI(CPOSAT) (CPOSPO1)) T5 (IF (IF T4 (IF (IF T4 (CPOSAT)(IF T6 T5)) (IF (IF (EQ (CPOSPO1) T5) (IF (EQ(CPOSPO1) T5) T6)) (CPOSAT) (IF T4 (FEHTD (CPOSAT)(CPOSPO1)) T7)) T7) (CPOSAN1)) (CPOSAT) T7)) (IF T4(IF (IF (EQ (IF (IF (EQ (CPOSPO1) T5) T6) (FEHVZNIL T5T5 T8) (IF T4 (CPOSAT) T4)) T5) T6) (IF (EQ (IF (IF (EQ(CPOSAN1) T5) T6) T4 (IF T4 (CPOSAT) T7)) T5) T6) (IF(CPOSAT) (CPOSAT) T7)) (FEHVZNIL (CPOSPO1) T4(CPOSPO1))))
Este código resulta no seguinte conjunto de regras:
Se a letra na posição atual é igual a “c”Se a letra na posição atual é igual a “c” e a letra napróxima posição é igual a “i” ou a letra na próximaposição é igual a “e”
Retorna sSenão
Retorna kSenão
Se a letra na posição atual é igual a “s” e as letras naposição anterior e na posição posterior forem diferentesde “s”
Retorna zSenão
Se a letra na posição atual é igual a “s” e a letra naposição posterior é igual a “s”
Retorna sSenão
Se a letra na posição posterior não é igual “s” ea posição anterior é igual a “s”
Retorna valor nuloSenão
Retorna a letra na posição atual
A complexidade estrutural do melhor indivíduo, mostrada na fig. 6.10, foi de 89pontos. A complexidade estrutural apresentada neste caso é em média maior do que noscasos anteriores. O indivíduo mais bem adaptado apresentou um número de pontosmenor do que na solução verificada no caso 2; neste caso entretanto, foi obtido umindivíduo com adaptação maior. A tendência verificada é de um aumento constante,pois o sistema possui como resultado uma solução ainda distante da ideal e vaiaumentando a complexidade dos indivíduos na tentativa de obter melhores valores defitness.

78
Evolução da com plexidade estrutural
0
50
100
150
200
250
3000 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99
G erações
Núm
ero
de p
onto
s (c
ompl
exid
ade)
Média com plexidade estrutura lCom plexidade estrutura l do m elhor da geraçãoCom plexidade estrutura l do p ior da geração
FIGURA 6.10 - Gráfico da complexidade estrutural para o caso 4
A validação do indivíduo apresenta um acerto aproximado de 90%, com umfitness padronizado igual a 18. O total do fitness para estas palavras é 189.
TABELA 6.11 - Resultados da validação da melhor solução para o caso 4
Palavras Respostas esperadas Fonemas produzidos((c a c a) (c e c e) (c i c i)(c o c a) (a s s a) (i s s o)(e s s a) (a s a) (o s a)(u s e) ( a s b) (e s d)(i s m) (t i t i) (d i d i) (z iz a) (z e z o) (a z) (u z))
((k a k a) (s e s e) (s i s i)(k o k a) (a s a) (i s o)(e s a) (a z a) (o z a) (u ze) (a z b) (e z d) (i z m)(ts i ts i) (dz i dz i) (z i za) (z e z o) (a s) (u s))
((k a k a) (s e s e) (s i s i)(k o k a) (a s a) (i s o) (e s a)(a z a) (o z a) (u z e) (a z b)(e z d) (i z m) (t i t i) (d i d i)(z i z a) (z e z o) (a z) (u z))
6.4.1 Caso 4 - Funções sem argumentos
Até o presente momento todas as execuções utilizaram funções de domínio queoperavam sobre argumentos recebidos. Os argumentos corretos deveriam serselecionados pelo processo evolutivo; o recebimento de argumentos incorretos tornavaas funções sem efeito ou produzia resultados insatisfatórios. A descoberta deargumentos corretos não é um processo trivial uma vez que existem inúmerascombinações possíveis.

79
TABELA 6.12-Definições para o caso 4 usando funções de domínio semargumentos
Parâmetro Definição para o problemaConjunto de funções (EQ IF IF FEHSS)Número de argumentosdas funções
(2 2 3 2)
Conjunto de terminais ((CPOSAT) (CPOSPO1) (CPOSAN1) (FEHCEI)(FEHSCVO) (FEHTD) (FRTDI) (FEHVSV)(FEHVZNIL) c s z k NIL)
Casos de fitness ((c a s a) (c e s s a) (a c i) (a c e) (a s s o) (e c o) (a s a) (o ss o) (e s d) (a s b) (t- i s m o) (t- i s s o) (d i s s o) (d i c a)(z e r o) (c e r z o) (a z) (o z) (c e c i) (c i c e) (o s a) (i s o)(e s a) (a s m) (o s n) (i s b) (i z) (u z) (d i) (t- i))
Resposta esperada ((k a z a) (s e s a) (a s i) (a s e) (a s o) (e k o) (a z a) (o s o)(e z d) (a z b) (ts i z m o) (ts i s o) (dz i s o) (dz i k a) (z e ro) (s e r z o) (a s) (o s) (s e s i) (s i s e) (o z a) (i z o) (e z a)(a z m) (o z n) (i z b) (i s) (u s) (dz i) (ts i))
Número de gerações G = 100Tamanho da população M = 1,000
Nesta execução serão descritos resultados com as mesmas funções de domínioempregadas na execução anterior para o caso, porém estas funções farão parte doconjunto de terminais por não operarem sobre argumentos recebidos. Cada uma dasfunções irá operar diretamente sobre posição atual, anterior ou posterior (tab.6.12).Naturalmente a expectativa é que a produção de boas soluções seja bem mais simplesdevido ao fato de que as funções de domínio implementam partes das regras sem adependência de entradas escolhidas no processo evolutivo. O Anexo 2 descreve ocódigo das funções de domínio com e sem argumentos.
O tamanho do conjunto de funções é sensivelmente menor do que na execuçãoanterior ao passo que o conjunto de terminais é maior. A função FEHSS foi mantida noconjunto de funções porque como testa se ambos os parâmetros são a letra "s"; o testepode ocorrer na letra atual e na próxima ou ainda na anterior e na atual, o que torna apassagem de parâmetros corretos uma tarefa um pouco mais simples. A função foimantida também para não haver uma redução extrema do conjunto de funções. Asfunções AND e OR foram retiradas do conjunto porque todos os testes com condiçõescombinadas necessárias para a produção de soluções corretas são implementados pelasfunções de domínio.
Igualmente à execução anterior, o fitness básico máximo é de 288 pontos. Todosos parâmetros restantes foram mantidos para permitir uma comparação na evolução dasrespostas produzidas a partir da alteração das funções de domínio.
O fitness padronizado do melhor indivíduo, encontrado na geração 35, foi 9. Afig. 6.11 demonstra a evolução das soluções.

80
FIGURA 6.11 - Gráfico da evolução do fitness para o caso 4 usando funções dedomínio sem argumentos
A hipótese de uma evolução mais rápida se confirma plenamente. Já na geração35 foi encontrado um indivíduo com um grau de adaptação muito superior ao melhorencontrado na execução com funções que requerem argumentos. Embora tenha sidodescoberta uma solução com alto grau de adaptação, no restante do processo apopulação apenas converge para o mínimo local representado por esta solução semencontrar um valor ótimo para o fitness. Na maior parte das execuções realizadas comeste conjunto de parâmetros, ocorre a convergência da média da população para ofitness da melhor solução. O pior indivíduo entretanto permanece nos piores valores defitness possíveis, sempre existindo respostas que produzem valores nulos ou qualqueroutro que não faça parte do conjunto de fonemas. O código da melhor solução obtidafoi:
(IF (FEHSS (IF T13 (CPOSAT) (IF (IF (IF (IF (CPOSPO1)(CPOSAT) (IF (FEHCEI) T11 (CPOSAT))) T12 (IF T11 (IF(IF (FEHVZNIL) (CPOSAT) (FEHTD)) T11 (CPOSAT))(FEHCEI))) (FEHVSV) (CPOSAT)) (IF (IF (FEHVZNIL) T11(FEHSS (FRTDI) T13)) T11 (CPOSAT)))) (IF T14 (IF(FEHCEI) T11 T11) (CPOSAN1))) (FEHVZNIL) (IF(FEHCEI) T11 (IF (IF (FEHSCVO) T14 (IF (IF (IF (IF(FEHVZNIL) (FEHVZNIL) (FEHVZNIL)) T14 T14)(FEHVSV) (EQ (FEHVSV) (FEHSCVO))) (IF (FEHCEI) T11(CPOSAT)))) (IF (FEHVZNIL) (IF T11 (IF (IF (IF (FEHCEI)(FEHVZNIL)) (IF T12 T13 T10)) T11 T11) (CPOSAN1)) (IF(IF (FEHVZNIL) (IF (FEHVZNIL) (FEHVSV) (CPOSAT)) (IF(FEHVZNIL) (CPOSAT) (FEHTD))) (IF T11 (FRTDI) T11)(IF (FEHVSV) T12 (IF T11 (IF (FEHCEI) T11 (CPOSAT))(FEHCEI))))) (IF T11 T12 (CPOSAT)))))
Evolução do Fitness
0
50
100
150
200
250
0 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99
Geração
Fitn
ess
Média fitness populaçãoMelhor fitness da geraçãoMelhor fitness da execuçãoPior fitness da geração

81
As regras implementadas são:
Se a letra na posição atual é igual a “s” e a letra na próxima posição é “s”Retorna valor nulo
SenãoSe a posição atual for igual a “c” e a letra na próxima posição for igual a“e” ou a próxima letra for igual a “i”
Retorna sSenão
Se (a letra na posição atual é igual a “s” e a letra na próxima posiçãofor igual a constante vozeada) ou (a letra na posição atual é “s” e aanterior e a posterior são vogais)
Retorna zSenão
Se a letra na posição atual for a letra “z” e a letra na posiçãoanterior é vogal e a próxima é nula
Retorna sSenão
Se (a letra na posição atual é “t” ou “d”) e a letra napróxima posição é “i”
Retorna ts ou dz de acordo com a letra naposição atual
SenãoRetorna a letra na posição atual
É possível perceber que a solução possui uma maior eficiência e melhor aplicaçãodas funções e terminais. Existem poucas combinações de instruções sem efeito, fatoverificado na maior parte das execuções anteriores.
FIGURA 6.12 - Gráfico da complexidade estrutural para o caso 4 usando funçõesde domínio sem argumentos
Evolução da complexidade estrutural
0
20
40
60
80
100
120
140
160
0 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99
Geração
Com
plex
idad
e (N
úmer
o de
pon
tos)
Média complexidade estrutural
Complexidade estrutural do melhor da geração
Complexidade estrutural do pior da geração

82
A única regra não implementada de forma completa é a regra da letra "c". Quandoa letra ocorrer antes de "e" ou "i", será produzido o fonema s, porém nos demais casosserá produzida como resposta a própria letra, quando a resposta certa seria o fonema k.
A complexidade estrutural do melhor indivíduo descrito foi de 114 pontos, maiordo que o melhor indivíduo apresentado na execução anterior. É necessário salientar queembora a evolução apresente rapidamente complexidades altas, existe uma tendência deestabilização ao longo da evolução. A complexidade do melhor indivíduo e da média dapopulação tendem a manter-se entre 100 e 120 pontos, já a partir da geração 35(fig.6.12). A utilização de funções sem argumentos tem uma influência direta nacomplexidade, uma vez que a utilização de funções como argumentos de outras funçõesé um fator que normalmente produz uma maior variabilidade no tamanho. Tanto nageração da população inicial quanto nas operações de cruzamento, a tendência é aprodução de árvores com menor profundidade.
TABELA 6.13 - Resultados da validação da melhor solução para o caso 4
Palavras Resultados esperados Fonemas produzidos((c a c a) (c e c e) (c i c i)(c o c a) (a s s a) (i s s o)(e s s a) (a s a) (o s a)(u s e) ( a s b) (e s d) (i sm) (t- i t- i) (d i d i) (z i za) (z e z o) (a z) (u z))
((k a k a) (s e s e) (s i s i)(k o k a) (a s a) (i s o) (e sa) (a z a) (o z a) (u z e)(a z b) (e z d) (i z m) (t i ti) (d i d i) (z i z a) (z e zo) (a s) (u s))
((c a c a) (s e s e) (s i s i)(c o c a) (a s a) (i s o) (e s a)(a z a) (o z a) (u z e) (a z b)(e z d) (i z m) (ts i ts i) (dz idz i) (z i z a) (z e z o) (a s)(u s))
A validação do indivíduo apresenta um acerto aproximado de 94%. O fitnessobtido nesta atividade foi de 12, sendo o fitness total de 189.
6.5 Resultados utilizando definição automática de funções (ADF)Conforme descrito anteriormente, a definição automática de funções permite
estender a Programação Genética, evoluindo além de programas principais, funções quepoderão servir a estes programas. Com o objetivo de estabelecer uma comparação dosresultados obtidos com as execuções anteriores, serão descritas duas execuções, umapara o caso 1, de menor complexidade e outra para o caso 4, de maior complexidade. Apartir destes dois subconjuntos será possível avaliar o potencial da extensão da técnicaaplicada ao problema. Em ambos os casos serão adotadas duas funçõesautomaticamente definidas, que poderão possuir diferentes conjuntos de terminais efunções. Cada uma destas funções chamadas respectivamente de ADF0 e ADF1receberá três argumentos.

83
6.5.1 Caso 1 utilizando ADF
TABELA 6.14 - Definições para o caso 1, utilizando ADF:
Parâmetro Definição para o problemaConjunto de funções para o ramode produção de resultados
(EQ IF IF AND OR ADF0 ADF1)
Número de argumentos das funçõesdo ramo de produção de resultados
(2 2 3 2 2 3 3)
Conjunto de funções para asfunções ADF0 e ADF1
(EQ IF IF AND OR)
Número de argumentos das funçõesdo conjunto de funções disponíveispara ADF0 e ADF1
(2 2 3 2 2)
Conjunto de terminais ((CPOSAT) (CPOSPO1) t d i ts dz)Casos de fitness ((p a) (b e) (v i) (t i) (d i) (t a t o) (d a d o) (d i d i)
(d i t i))Resposta esperada ((p a) (b e) (v i) (ts i) (dz i) (t a t o) (d a d o) (dz i
dz i) (dz i ts i))Número de gerações G = 100Tamanho da população M = 1,000
Conforme descrito anteriormente, o caso 1 envolve relação direta entre letra efonema e o caso das letras “t” e “d” antes de “i”. Parte das especificações para aplicaçãoda programação genética usando definição automática de funções são iguais àsdefinidas na aplicação sem ADF. O conjunto de funções e terminais é o mesmo tantopara o ramo de produção de resultados quanto para cada uma das funçõesautomaticamente definidas, exceção feita ao conjunto de funções do ramo de produçãode resultados que além das funções anteriormente disponíveis possui tambémdisponíveis as funções ADF0 e ADF1, que possuem cada uma 3 argumentos.
Não foram utilizadas funções de domínio, tal estratégia visa estabelecercomparações entre a inserção de funções diretamente nas definições para o problema oua evolução de funções juntamente com um programa principal. A fig. 6.13 demonstra aevolução desta execução, que apresentou resultados semelhantes aos obtidos sem ADF.
O melhor indivíduo foi obtido na geração 89 e apresentou um fitness igual a 5. Ocódigo da melhor solução foi:
(progn (defun ADF0 (ARG0 ARG1 ARG2)(values (IF T3_ADF0 (IF ARG2 ARG1 T5_ADF0))))(defun ADF1 (ARG0 ARG1 ARG2)(values (IF (IF (IF ARG0 (IF (EQ ARG0 (OR T4_ADF1T4_ADF1)) T5_ADF1 (CPOSAT))) (EQ (CPOSPO1) (IF(EQ ARG0 (OR (AND ARG2 ARG1) T4_ADF1)) T5_ADF1(IF (EQ ARG0 (OR T4_ADF1 T4_ADF1)) T5_ADF1(CPOSAT))))) (OR T7_ADF1 (OR T7_ADF1 T5_ADF1))(CPOSAT))))(values (ADF1 (CPOSAT) T3 (CPOSPO1))))

84
As regras para conversão estão em sua totalidade implementadas na funçãoADF1. A lógica da solução envolve diversos testes aninhados, porém pode ser resumidade forma relativamente simples:
Se o primeiro argumento(ARG0) é nuloRetorna a letra na posição atual
SenãoSe (o primeiro argumento é igual a “d” e a letra napróxima posição é igual a “i”) ou (a letra na posiçãoatual é igual a letra na próxima posição)
Retorna dzSenão
Retorna a letra na posição atual
A regra relativa às letras “t” e “d” é implementada apenas parcialmente. O fonemadz é produzido de forma incorreta, caso a mesma letra ocorra de forma seguida; talocorrência não é verificada nos casos de treinamento, sendo assim esta implementaçãoincorreta não diminui o valor do fitness no processo evolutivo. A chamada ocorre com oprimeiro argumento sendo a letra da posição atual, o segundo o a letra “t” e o terceiro, aletra da próxima posição.
Evolução do fitness
0
10
20
30
40
50
60
70
80
0 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99
Gerações
Fitn
ess
Média fitness populaçãoMelhor fitness da geraçãoMelhor fitness da execuçãoPior fitness da geração
FIGURA 6.13 Gráfico da evolução do fitness para o caso 1, usando ADF.
A complexidade estrutural apresentou valores inferiores aos verificados naexecução do caso 1 sem funções de domínio e sem definição automática de funções. Omelhor indivíduo obtido nesta execução apresentou complexidade de 46 pontos, inferiorao melhor indivíduo na referida execução, que apresentou 92 pontos. A média dacomplexidade dos indivíduos nesta execução atinge valores levemente superiores a 100pontos; mas a partir da geração 50 aproximadamente, os valores passam a diminuir,estabilizando em valores próximos ao número de pontos do melhor indivíduo. A fig.6.14 mostra a evolução da complexidade estrutural.

85
Evolução da complexidade estrutural
0
50
100
150
200
250
300
3500 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99
Gerações
Núm
ero
de p
onto
s (c
ompl
exid
ade)
Média complexidade estruturalComplexidade estrutural do melhor da geraçãoComplexidade estrutural do pior da geração
FIGURA 6.14 – Evolução da complexidade estrutural para o caso 1, usando ADF.
A validação para a solução, está descrita abaixo. O fitness padronizado da melhorsolução foi 3, de um fitness básico total igual a 126. O percentual de acerto é superior a97%, semelhante ao verificado na validação da solução do caso 1 sem ADF (tab.6.15).
TABELA 6.15 - Resultados da validação para o caso 1, usando ADF.
Palavras usadas Resultados esperados Resultados produzidos
((p a t o) (b e b a) (v i v e)(t i p o) (d i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
((p a t o) (b e b a) (v i v e)(ts i p o) (dz i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
((p a t o) (b e b a) (v i v e)(t i p o) (dz i t o) (d e d o)(t u d o) (b a t a t a) (v i d a)(f a d a))
6.5.2 Caso 4 utilizando ADF
O caso 4 apresenta uma maior complexidade do que o caso 1, através dosresultados obtidos neste subconjunto foi possível avaliar mais detalhadamente osbenefícios da definição automática de funções. As definições para a execução estão natab. 6.16.

86
TABELA 6.16 – Definições para o caso 4, usando ADF
Parâmetro Definição para o problemaConjunto de funções para o ramode produção de resultados
(EQ IF IF AND FEHVOGAL NOT FEHSCVOADF0 ADF1)
Número de argumentos das funçõesdo ramo de produção de resultados
(2 2 3 2 1 1 2 3 3)
Conjunto de funções para asfunções ADF0 e ADF1
(EQ IF IF AND FEHVOGAL NOT FEHSCVO)
Número de argumentos das funçõesdo conjunto de funções disponíveispara ADF0 e ADF1
(2 2 3 2 1 1 2)
Conjunto de terminais ((CPOSAT) (CPOSPO2) (CPOSPO1)(CPOSAN1) (CPOSAN2) c s z k NIL t d ts dz)
Casos de fitness ((c a s a) (c e s s a) (a c i) (a c e) (a s s o) (e c o) (as a) (o s s o) (e s d) (a s b) (t i s m o) (t i s s o) (d is s o) (d i c a) (z e r o) (c e r z o) (a z) (o z) (c e ci) (c i c e) (o s a) (i s o) (e s a) (a s m) (o s n) (i sb) (i z) (u z) (d i) (t- i))
Resposta esperada ((k a z a) (s e s a) (a s i) (a s e) (a s o) (e k o) (a za) (o s o) (e z d) (a z b) (ts i z m o) (ts i s o) (dz i so) (dz i k a) (z e r o) (s e r z o) (a s) (o s) (s e s i)(s i s e) (o z a) (i z o) (e z a) (a z m) (o z n) (i z b)(i s) (u s) (dz i) (ts i))
Número de gerações G = 100Tamanho da população M = 1,000
Para esta execução, o conjunto de terminais é o mesmo para o ramo de produçãode resultados e para as funções automaticamente definidas. O conjunto de funçõesdifere apenas para o ramo de produção de resultados, no qual encontram-se também asfunções ADF0 e ADF1. As únicas funções de domínio utilizadas são FEHVOGAL,mantida devido ao alto grau de detalhe na implementação necessária para verificar seuma determinada letra é vogal e FEHSCVO pela complexidade da regra que exige umteste de ocorrência da letra "s" antes de uma consoante vozeada. Sem funções dedomínio, a complexidade para implementação das regras tende a ser maior, o quepermitirá novamente comparar a alternativa ADF com o uso das funções de domínio.
A variação do fitness demonstrada na fig. 6.15 caracteriza uma evolução maisgradativa e continuada do que as execuções anteriormente descritas. O melhor fitness dageração e execução permanecem o mesmo, todo o tempo e o fitness médio apresenta umdecréscimo constante. As variações diminuem sensivelmente a partir da geração 80. Amelhor solução alcançou um fitness de 31 e foi obtida na geração 85. Soluções comfitness de 32 pontos já são encontradas a partir da geração 52 e são praticamenteequivalentes à mais adaptada.

87
FIGURA 6.15 - Gráfico da evolução do fitness para o caso 4, usando ADF.
O código do melhor indivíduo foi:
(progn(defun ADF0 (ARG0 ARG1 ARG2)(values (IF (FEHVOGAL (CPOSAN1)) (IF (EQ ARG1(CPOSAT)) (EQ T7_ADF0 T10_ADF0) (IF (IF (CPOSPO1)(EQ T6_ADF0 (CPOSAT)) T7_ADF0) T7_ADF0 ARG2)) (IF(FEHVOGAL (IF (EQ ARG1 T9_ADF0) (EQ T6_ADF0T10_ADF0) T7_ADF0)) (IF (EQ ARG1 (EQ ARG1 (EQARG1 (FEHVOGAL T14_ADF0)))) (EQ T6_ADF0 (EQARG1 (EQ T6_ADF0 T7_ADF0))) ARG2) (IF (EQ T6_ADF0(CPOSAT)) (IF (EQ T7_ADF0 (EQ T6_ADF0 ARG1)) (EQT6_ADF0 T10_ADF0) T7_ADF0) (IF (EQ T11_ADF0(CPOSAT)) T14_ADF0 (CPOSAT)))))))(defun ADF1 (ARG0 ARG1 ARG2)(values (IF (CPOSAT) T10_ADF1 T6_ADF1)))(values (ADF0 T8 (CPOSPO1) (ADF0 T8 (CPOSPO2)T8))))
O fitness representa um acerto de aproximadamente 90%. As regras sãoimplementadas totalmente pela função ADF0 e podem ser resumidas nas seguintesatividades:
Evolução do Fitness
0
30
60
90
120
150
180
210
240
2700 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 98
Geração
Fitn
ess
Média fitness populaçãoMelhor fitness da geraçãoMelhor fitness da execuçãoPior fitness da geração

88
Se a letra na posição anterior é vogalSe a letra na posição atual é igual ao segundoargumento(ARG1)
Retorna um valor nuloSenão
Se a letra na posição posterior é nula ou a letra naposição atual é “c”
Retorna sSenão
Retorna o terceiro argumentoSenão
Se a letra na posição atual é igual a “c”Retorna s
SenãoSe a letra na posição atual é igual a “t”
Retorna dzSenão
Retorna a letra na posição atual
O ramo de produção de resultados faz duas chamadas à função ADF0, (ADF0 T8(CPOSPO1) e (ADF0 T8 (CPOSPO2) T8). A chamada interna retorna um valor queconstitui-se no terceiro parâmetro da chamada que vai efetivamente produzir o resultadoe como o segundo argumento passado nesta última referência é a posição posterior aregra de "ss" funciona corretamente. Outra questão importante é que o segundoargumento será "z" nas situações em que ocorre uma letra "s" antes de consoantevozeada e após vogal, sendo assim o retorno da função será exatamente este argumento.
Para melhor compreensão da aplicação das regras, três exemplos de chamadas doramo de produção de resultados, estão descritos abaixo. O resultado da primeiraaplicação de ADF0 é o terceiro argumento da segunda chamada.
(casa) = adf0 z s z = s => adf0 z a s = s adf0 z a z = a => adf0 z s a = a adf0 z nil z = z => adf0 z a z = z adf0 z nil z = a => adf0 z nil a = a
(osso) = adf0 z s z = o => adf0 z s z = o adf0 z o z = z => adf0 z s z = nil adf0 z nil z = s => adf0 z o s = s adf0 z nil z = o => adf0 z nil z = o
(asm) = adf0 z m z = a => adf0 z s a = a adf0 z nil z = z => adf0 z m z = z adf0 z nil z = m => adf0 z nil z = m
A função automaticamente definida ADF1 retorna sempre a constante nula, umavez que a letra na posição atual jamais será um valor nulo. O valor retornado é sempreT10_ADF1 que representa a constante NIL. Esta função é ignorada pelo ramo deprodução de resultados e não tem qualquer influência no resultado final. Argumentos e

89
terminais também são ignorados tanto pelas funções quanto pelo ramo de produção deresultados.
A solução encontrada é equivalente à descrita na primeira execução para o caso 4sem uso de ADF. Naquela execução, o melhor fitness encontrado foi de 30 pontos e osresultados obtidos foram semelhantes. A regra que converte a letra "c" para k ou stambém não foi implementada de forma completa. A principal diferença entre assoluções está na transferência da solução para uma função definida automaticamente ena complexidade estrutural apresentada por ambas. A fig. 6.16 descreve a evoluçãodesta complexidade durante o processo:
FIGURA 6.16 - Complexidade estrutural para o caso 4, usando ADF
A melhor resposta nesta execução possui 72 pontos, considerando-se somente ospontos funcionais como citado anteriormente. A diferença entre as melhores soluçõescom e sem ADF, foi de 17 pontos. Observando-se a média da complexidade estrutural épossível perceber que a diferença é ainda mais acentuada. Na execução sem a utilizaçãoda definição automática de funções, a complexidade média atingiu em seu ponto maisalto, valores próximos a 300 pontos, enquanto a fig.6.16 mostra que o número médio depontos atingiu valores máximos próximos a 100.
A validação do melhor indivíduo obteve um fitness de 24; uma vez que o maiorvalor possível é 189, o percentual de acerto do indivíduo é aproximadamente 88%, umpouco inferior ao obtido no treinamento.
Complexidade estrutural
0
20
40
60
80
100
120
0 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76 80 84 88 92 96
Geração
Núm
ero
de p
onto
s (c
ompl
exid
ade)
Média complexidade estruturalComplexidade estrutural do melhor da geraçãoComplexidade estrutural do pior

90
TABELA 6.17 – Validação para o caso 4, usando ADF
Casos de validação Respostas esperadas Respostas produzidas
((c a c a) (c e c e) (c i c i)(c o c a) (a s s a) (i s s o)(e s s a) (a s a) (o s a) (us e) ( a s b) (e s d) (i s m)(t i t i) (d i d i) (z i z a)(z e z o) (a z) (u z))
((k a k a) (s e s e) (s i s i)(k o k a) (a s a) (i s o) (e s a)(a z a) (o z a) (u z e) (a z b)(e z d) (i z m) (ts i ts i) (dz idz i) (z i z a) (z e z o) (a s)(u s))
((s a s a) (s e s e) (s i s i)(s o s a) (a s a) (i s o) (e sa) (a z a) (o z a) (u z e)(a z b) (e z d) (i z m) (t i zi) (d i z i) (z i z a) (z e zo) (a s) (u s))
6.6 Tempos de processamentoComo informação final sobre as diversas execuções e para possibilitar
comparações, a tab. 6.18 apresenta um resumo dos tempos aproximados de cada umadas execuções realizadas. Os tempos são expressos em minutos e convertido em horas epermitem avaliar o efeito dos parâmetros, da composição dos indivíduos e dascaracterísticas da modelagem do problema no desempenho da técnica.
TABELA 6.18 - Tempos aproximados das execuções
Execução Minutos Horas
Caso 1 - Relação um para um e letras "t" e "d" antes de "i".Resultados utilizando somente funções básicas
71 1,18
Caso 1 - Relação um para um e letras "t" e "d" antes de "i".Inserção de funções de domínio
31 0,52
Caso 2 - Nasalização de vogais. 1610 26,83
Caso3 - Combinação "rr". 192 3,20
Caso 4 - Regras envolvendo as letras "c", "s" e "z".Funções de domínio com argumentos.
960 16,00
Caso 4 - Regras envolvendo as letras "c", "s" e "z".Funções de domínio sem argumentos.
906 15,10
Caso 1 utilizando ADF 252 4,20
Caso 4 utilizando ADF 1435 23,92
Os parâmetros que influenciam diretamente o tempo de processamento são otamanho da população, o número de gerações e a complexidade estrutural. É possívelperceber que o caso 2, que possui 200 gerações e uma alta complexidade estrutural é oque demandou o maior tempo para execução. O caso 4 é o que possui a maiorcomplexidade estrutural e mesmo com a metade das gerações do caso 2, levou mais dametade do tempo deste último, o que confere a ele o maior tempo por geração.

91
A escolha dos casos de fitness é fundamental para descoberta de boas soluções eafeta de forma significativa o desempenho. Um grande conjunto de casos de fitness ouum maior número de fonemas esperados naturalmente implica em um tempo maior paraavaliação de cada indivíduo. Como o processo de avaliação é a atividade maisdemorada, estas características tem certamente uma influência decisiva na velocidade daexecução. Isto pode ser constatado também nos casos 2 e 4, que possuem maioresvalores para o fitness básico, fato decorrente de um maior número de letras e fonemas.
Outra constatação importante é que a manipulação de indivíduos com funçõesautomaticamente definidas é mais lenta se comparada à de indivíduos sem estaestrutura. A complexidade estrutural média para o caso 4 com ADF, por exemplo, éinferior ao mesmo caso sem ADF, porém o tempo de processamento foi maior. Pelo fatode gerar complexidades menores a estratégia com definição automática de funçõestende a apresentar melhor desempenho ao longo de um número maior de gerações.
O equipamento utilizado foi uma máquina Pentium 333 Mhz, 128 MB RAM. Épreciso salientar que os tempos apresentados dependem diretamente dos recursos doequipamento utilizado e da própria otimização do sistema. No desenvolvimento daaplicação de programação genética para este trabalho não houve uma avaliação dosmódulos e rotinas com objetivo de melhorar o desempenho; para aplicações maiscomplexas ou devido à necessidade de integração com outros sistemas, um trabalho deotimização é importante. A própria natureza aleatória do processo leva a diferentestempos em diferentes execuções, mesmo utilizando-se parâmetros iguais aos descritos.

92
7 ConclusõesEste trabalho apresentou a técnica de programação genética como uma forma de
descoberta automática de programas e expôs ainda os resultados de sua aplicação nadescoberta de regras para conversão de letra para fonema. O estudo baseou-se nascaracterísticas elementares descritas por John R. Koza [KOZ 92], [KOZ 98].
Conforme já observado por outros autores, no paradigma da ProgramaçãoGenética, a transformação entre o genótipo, que constitui codificação da solução e ofenótipo, que representa o comportamento do mesmo é uma atividade relativamenteóbvia. É possível constatar a partir dos resultados que o comportamento é observáveldiretamente diretamente nas instruções que compõe o indivíduo, não sendo necessárioportanto uma transformação complexa da saída para sua interpretação. Tal característicapode facilitar em futuras aplicações a extração do conhecimento produzido no processo.
Através do estudo, implementação e dos resultados obtidos nas diversasexecuções, foi possível constatar que a programação genética pode ser boa alternativapara o descobrimento de regras. Embora utilizando estratégias diferentes das quecertamente seriam usadas por um programador humano, a técnica foi capaz de produzira partir de instruções e terminais, soluções que resolvem senão de forma completa, demaneira aceitável a conversão de letra-fonema.
Os experimentos realizados demonstram que é possível construir sistemascapacitados a descobrir regras através de um aprendizado supervisionado, permitindoassim, a criação de sistemas desenvolvidos que tenham capacidade de adaptação adiferentes idiomas e suas variações regionais. A estratégia escolhida na atividade demodelagem permite o descobrimento de regras que funcionam corretamente paradiferentes contextos e entradas. O processo de modelagem descrito demonstra tambémque é possível utilizar outras abordagens para representação das soluções e que deacordo com objetivos e com necessidades de integração a outros sistemas podem seralternativas interessantes.
Conforme descrito no item 3.3.1, a indução de programas apresenta comoproblema clássico a formulação dos casos usados no treinamento. Algumas soluçõesencontradas apresentam regras que podem não funcionar em qualquer contexto, mas quesão verificáveis nos exemplos de palavras ou sílabas usados para o treinamento; talobservação enfatiza a importância e dependência da técnica de uma correta seleção doscasos de fitness. Esta escolha pode parecer em um primeiro momento óbvia, entretantoquanto maior o conjunto de regras a serem descobertas, maior a dificuldade envolvidanesta atividade. Um exemplo clássico desta dificuldade pode ser observado no caso 2,nas regras para nasalização de vogais. A partir dos casos usados para o aprendizado, anasalização acabou ocorrendo em situações incorretas, devido ao grande número decasos de nasalização usados no treinamento. Entretanto, um conjunto de casos de fitnessmais amplo como as palavras utilizadas na validação, tende a apresentar soluções quenão implementam a regra de nasalização.
Embora cada um dos subconjuntos descritos tenha obtido no mínimo uma soluçãoaceitável, não é possível afirmar que todas as execuções chegarão a uma boa solução.Uma das características dos resultados descritos é que eles representam amostras dosmelhores resultados para cada caso, sendo assim, a execução da técnica com os mesmosparâmetros e definições, não garante a obtenção de resultados iguais aos documentadosno trabalho.

93
Uma das dificuldades verificadas na análise dos resultados é a descrição dasatividades implementadas por cada solução. A dificuldade decorre diretamente doaumento da complexidade, do grande número de instruções que compõe estesindivíduos. Outro problema está relacionado com a própria linguagem LISP, utilizadaneste trabalho, que na maioria dos casos apresenta um código difícil de ser entendido epor conseqüência de difícil manutenção.
O tamanho e excesso de material genético inútil presente nas boas soluções é umproblema observado na grande maioria das soluções produzidas, e ocorreprincipalmente pelo alto grau de destruição de bons blocos de instruções, decorrente dasoperações de cruzamento e mutação. Variações nestas operações podem permitir umamaior preservação de bons blocos e consequentemente um tamanho médio menor dassoluções. Entretanto, é importante salientar que altas taxas de destruição tambémcolaboram para uma maior diversidade do material genético, fato que pode levar aconstrução de melhores blocos do que aqueles verificados nas gerações iniciais. Apartir destas constatações fica evidente a dificuldade para solucionar o problema e anecessidade de um aprofundamento desta análise em trabalhos futuros.
Os resultados descritos apresentam algumas variações que merecem análisedetalhada. A utilização de funções de domínio tem uma influência direta para geraçãode melhores soluções, o que é compreensível porque parte do trabalho esperado naexecução da técnica é feito manualmente e inserido como uma função pronta. Funçõesde domínio sem argumentos aumentam ainda mais a capacidade de solucionar oproblema, entretanto pode ser inviável em diferentes estratégias de solução ou ainda emdiferentes problemas. Funções sem argumentos podem ser consideradas como umexcesso de influência de programadores humanos, sendo que esta alternativa podedirecionar em demasia o processo.
A avaliação de fitness é uma das atividades mais importantes em qualquer técnicaevolutiva. A medição do grau de adaptação neste trabalho é simples e constitui nacomparação direta do resultado esperado, com aquele produzido por cada indivíduo.Diversos indivíduos possuem conjuntos de instruções bons, que entretanto não sãoexecutados ou estão mal situados na árvore representativa do indivíduo, o que faz comque a resposta final seja diferente daquela esperada. Sugere-se para futuros trabalhos, abusca de funções de avaliação que possam aproveitar estes blocos, pois a partir deoperações de cruzamento e mutação que envolvam estas soluções, possivelmente serãogeradas combinações com alto grau de adaptação.
A extensão da técnica, que permite evoluir funções, além de um ramo principal semostrou uma boa alternativa, tendo sido possível verificar a produção de resultadosiguais ou melhores e principalmente com diminuição do número de pontos das soluções.Esta diminuição produz soluções mais eficientes e diminui sensivelmente o consumo derecursos computacionais. O problema ao qual foi aplicada a técnica não apresenta umaregularidade ou aplicação sucessiva dos mesmos conjuntos de regras. Devido a isto areutilização foi pouco explorada. A utilização de diferentes estratégias, como porexemplo o uso de repetição na solução poderia levar a uma maior exploração dareutilização das funções automaticamente definidas.
Variações em conjuntos de funções e terminais, funções de domínios, funçõesautomaticamente definidas são demonstrações claras das alternativas possíveis a seremexploradas para busca de melhores soluções. A riqueza da representação da

94
programação genética proporciona estas e outras alternativas, que também merecem umaprofundamento em trabalhos futuros.
Os recursos computacionais e o tempo necessário para obtenção de soluçõestambém é um fator importante. A execução descrita nesta dissertação foi realizada emum conjunto reduzido de recursos computacionais e apesar disso boas soluções foramproduzidas. Respostas melhores podem ser obtidas usando-se sistemas computacionaisde alto desempenho. Os tempos de processamento descritos, embora aceitáveis, tendema crescer muito com o aumento do número de casos de fitness e da complexidade doproblema, que requer maiores conjuntos de funções e terminais.
Cabe enfatizar a importância do sistema desenvolvido de forma a facilitarvariações nos conjuntos de parâmetros do processo. Através deste sistema foi possívelvariar facilmente os diversos parâmetros e características do problema. Trabalhosfuturos poderão envolver a aplicação da Programação Genética a outras áreas doconhecimento humano, utilizando o sistema desenvolvido.
Finalizando, é possível concluir que a técnica tem um bom potencial paradescoberta de soluções para o domínio apresentado e ainda outros problemasrelacionados à síntese de voz. A facilidade oferecida pela representação da técnica, queutiliza instruções comuns em uma linguagem de programação, oferece umaflexibilidade e facilidade para abordagem de diferentes problemas.

95
Anexo 1 Representação de fonemas no "IPA -International Phonetic Alphabet" e no sistema Festival
Símbolos IPA SímbolosFestival(Spoltech)
Exemplos
A a Pá, gatoE e Medo, sedaε E Mel, péI i Vir, bicoO o Soma, morroכ > Avó, colau u Tu, bambuã,ẽ(nasalização vogais) ax~, e~, i~, o~, u~ Cama, tenda, monte.m m Maton n Nada, canoη n~ Ninho, vinhob b Bate, boip p Pai, patod d Dar, andart t Tu, tacog g Gola, gatok k Casa, querof f Faca, afiarv v Uva, vovôs s Saber, possoz z Bazar, casa∫ S Mecha, xarope3 Z Já, gelaλ L Filho, calhal l Lata, veludol w Fuzil, altor r Cara, maraR x Carroça, carrot, ts Tia, atirad, dz Dia, adiar

96
Anexo 2 Regras para conversão letra para fonema nosistema FestivalLetter to sound rules for Brazilian Portuguese;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(lts.ruleset; Name of rule set
port_br; Sets used in the rules
( (ALPHA a e i o u á é í ó ú â ê ô ü ã õ à b c ç d f g j k l m n p q rs t v w x y z) (PRE_RL b c d f g p t v k) (STV á é í ó ú â ê ô) (TV ã õ) (TREMA ü) (LNS l n s ) (AV a e i o u á é í ó ú â ê ô ü ã õ à) (AV_EI a o u á ó ú â ô ü ã õ à) (EI e i é í ê) (V a e i o u ) (AO a o) (AEOU a e o u á é ó ú) (AOU a o u)
(A a á â ã à) (E e é ê) (I i í) (O o ó ô õ) (U u ú)
(BDGLMN b d g l m n ) (MN m n ) (RL r l) (C_MN b c ç d f g h j k l p q r s t v w x y z #) (C b c ç d f g h j k l m n p q r s t v w x y z) (C_H b c ç d f g j k l m n p q r s t v w x y z) (C_QG b c ç d f h j k l m n p r s t v w x y z) ;; consoantes com exceção de Q e G (C_RL b c ç d f g h j k m n p q s t v w x y z) ;; consoantes com exceção do r e l (CVEL g k) ;; consoantes velares(incompleto) (QG q g) (CO l m n r z u) (TILDE "~"))
( ( [ a i ] x = a j ) ( [ a i ] s # = a j ) ( [ a m ] # = ax~ ) ( [ a n ] # = ax~ ) ( [ á m ] # = ax~1 ) ( [ á n ] # = ax~1 ) ( [ â m ] # = ax~1 ) ( [ â n ] # = ax~1 ) ( [ a ] C_MN = a ) ( [ a ] AV = a ) ( [ a ] MN C = ax~)

97
( [ a ] = a )
( [ á ] C_MN = a1 ) ( [ á ] MN C = ax~1 ) ( [ á ] AV = a1 ) ( [ á ] = a1 )
( [ â ] C_MN = a1 ) ( [ â ] MN C = ax~1 ) ( [ ã ] = ax~ )
( [ e i ] a = e j ) ( [ e i ] x = e j ) ( [ e i ] s # = e j ) ( [ e i ] # = e j ) ( [ e i ] j = e j ) ( [ e i ] r V = e j ) ( [ e i ] MN = e j ) ( [ e u ] = e w ) ( STV C + [ e o ] # = j u2 ) ( [ é u ] = E1 w ) ( [ é i ] AV = E j ) ( [ é i ] C_MN = E1 j ) ( [ e n ] # = e~ ) ( [ e m ] # = e~ ) ( [ é n ] # = e~1 ) ( [ é m ] # = e~1 ) ( [ ê n ] # = e~1 ) ( [ ê m ] # = e~1 ) ( C [ e ] # = i2 ) ( C [ e ] s # = i2 )
( [ e ] I = e ) ( [ e ] I s = e ) ( [ e ] MN C = e~ ) ( [ e ] C_MN = e ) ( [ e ] AV = e ) ( V [ e ] # = j ) ( STV C [ e ] # = j ) ( V [ e ] s # = j ) ( STV C [ e ] s # = j ) ( [ e ] # = i2 ) ( [ e ] = e )
( [ é ] u = E1 ) ( [ é ] i = E1 ) ( [ é ] C_MN = E1 ) ( [ é ] V = E1 ) ( [ é ] MN C = e~1 ) ( [ é ] = E1 )
( [ ê ] C_MN = e1 ) ( [ ê ] MN C = e~1 ) ( [ ê ] = e1 )
( [ e ] C a = e~ ) ( # [ e ] s = e ) ( # [ e ] x = e )
( # C [ e ] m = e~ ) ( # C [ e ] n = e~ )

98
( # [ e ] m = e~ ) ( # [ e ] n = e~ )
( STV C * [ i o ] # = j u ) ( [ i o ] # = i w ) ( STV C * [ i a ] # = j a ) ( STV C * [ i l ] # = j u )
( [ i l ] # = i w ) ( [ i u ] # = i w ) ( [ i m ] # = i~ ) ( [ i n ] # = i~ ) ( [ í m ] # = i~1 ) ( [ í n ] # = i~1 ) ( [ i ] r # = i ) ( STV C [ i ] V = j ) ( [ i ] MN C = i~ ) ( QG u [ i ] = i ) ( V [ i ] = j ( [ i ] = i ) ( [ í ] C_MN = i1 ) ( [ í ] MN C = i~1 ) ( [ í ] V = i1 ) ( [ í ] = i1 )
( C [ o ] # = u2 ) ( C [ o ] s # = u2 )
( [ o u ] = o w ) ( [ o l ] # = > w ) ( [ o i ] = o j ) ( [ ó i ] = >1 j ) ( [ o n ] C_H = o~ ) ( [ o m ] # = o~ ) ( [ o n ] # = o~ ) ( [ ó m ] # = >1 ) ( [ ó n ] # = >1 ) ( [ ô m ] # = o~1 ) ( [ ô n ] # = o~1 )
( CVEL [ o ] a = w ) ( CVEL [ o ] e = w ) ( STV C [ o ] V # = w ) ( V [ o ] s # = w ) ( STV C [ o ] V s # = w ) ( [ o ] C_MN = o ) ( [ o ] MN C = o~ ) ( [ o ] AV = o ) ( AV [ o ] # = w ) ( [ o ] # = u ) ( [ o ] = o )
( [ ó ] C_MN = >1 ) ( [ ó ] MN C = >1 ) ( [ ó ] V = >1 ) ( [ ó ] = >1 )
( [ ô ] C_MN = o1 ) ( [ ô ] MN C = o~1 ) ( [ ô ] V = o1 ) ( [ ô ] = o1 )

99
( [ õ ] = o~ )
( [ u o ] = w > ) ( [ u e ] C_MN # = w e ) ( STV C + [ u e ] # = w i ) ( [ u é ] # = w E ) ( [ u m ] # = u~ ) ( [ u n ] # = u~ ) ( [ ú m ] # = u~1 ) ( [ ú n ] # = u~1 )
( # [ u ] V r = u ) ( # [ u ] V m = u ) ( # [ u ] V s = u )
( C_QG [ u ] AV r = u ) ( C_QG [ u ] AV m = u ) ( C_QG [ u ] AV s = u ) ( QG [ u ] AO = w ) ( QG [ u ] EI = )
( V [ u ] CO = u ) ( AV [ u ] = w ) ( STV C + [ u ] AV = w )
( [ u ] C_MN = u ) ( [ u ] MN C = u~ ) ( [ u ] AV = u ) ( [ u ] = u )
( QG [ ü ] EI = w ) ( [ ú ] C_MN = u1 ) ( [ ú ] MN C = u~1 ) ( [ ú ] AV = u1 ) ( [ ú ] = u1 )
( [ b ] AV = b ) ( [ b ] RL AV = b ) ( [ b ] C = b ) ( [ b ] = b i )
( [ c h ] AV = S )
( [ c ] C_RL = k i ) ( [ c ] EI = s ) ( [ c ] AV_EI = k ) ( [ c ] RL AV = k ) ( [ c ] = s i )
( [ ç ] AV = s ) ( [ ç ] = s i )
( [ d ] I = dZ ) ( [ d ] AV = d ) ( [ d ] RL AV = d ) ( [ d ] = dZ )
( [ f ] AV = f ) ( [ f ] RL AV = f ) ( [ f ] = f i )

100
( [ g ú ] EI = g u1 ) ( [ g ü ] EI = g w ) ( [ g u ] EI = g ) ( [ g u ] AV_EI = g w ) ( [ g ] RL AV = g ) ( [ g ] EI = Z ) ( [ g ] AV_EI = g) ( [ g ] = g i )
( [ j ] AV = Z ) ( [ j ] = Z i )
( [ k ] AV = k ) ( [ k ] RL AV = k ) ( [ k ] = k i )
( [ l h ] V = L ) ( STV [ l i ] V = L ) ( STV [ l e ] V = L ) ( U [ l ] # = ) ( U [ l ] C = ) ( AV [ l ] # = w ) ( AV [ l ] C = w ) ( [ l ] AV = l ) ( [ l ] = l u~ )
( [ m ] AV = m ) ( AV [ m ] C = ) ( AV [ m ] # = ) ( [ m ] = m ax~ )
( [ n h ] AV = n~ )
( [ n ] AV = n ) ( AV [ n ] C_H = ) ( AV [ n ] # = ) ( [ n ] = n ax~ )
( [ p ] AV = p ) ( [ p ] RL AV = p ) ( [ p ] = p e ) ( [ q u ] EI = k ) ( [ q u ] AV_EI = k w ) ( [ q ü ] = k w ) ( [ q ú ] = k u1 ) ( [ q ] = k w )
( AV [ r r ] AV = x ) ( AV [ r ] AV = r ) ( AV [ r ] C = r ) ( PRE_RL [ r ] AV = r ) ( # [ r ] AV = x ) ( AV [ r ] # = r ) ( [ r ] = r i )
( [ s s ] AV = s ) ( [ s ç ] AV = s ) ( [ s c ] EI = s ) ( # [ s ] AV = s ) ( C [ s ] AV = s )

101
( AV [ s ] C = s ) ( AV [ s ] AV = z ) ( AV [ s ] # = s ) ( C [ s ] # = s ) ( [ s ] = i s )
( [ t e ] # = tS i2 ) ( [ t ] I = tS ) ( [ t ] AV = t ) ( [ t ] RL AV = t ) ( [ t ] = t )
( [ v ] AV = v ) ( [ v ] RL AV = v ) ( [ v ] = v i ) ( AV [ x c ] EI = s ) ( AV [ x s ] AV = s ) ( # EI [ x ] AV = z ) ( C [ x ] AV = S ) ( # [ x ] AV = S ) ( AV [ x ] C AV_EI = s ) ( AV [ x ] C RL AV = s ) ( AV [ x ] C = s ) ( AV [ x ] # = k s ) ( AV [ x ] AV = S )
( [ w ] AV = v ) ( [ w ] RL AV = v ) ( [ w ] = v i )
( [ y ] = i )
( [ z ] AV = z ) ( AV [ z ] C = s ) ( AV [ z ] # = s ) ( [ z ] = z i )
( ALPHA [ h ] ALPHA = ) ( # [ h ] = ) ( [ h ] # = )
(define (port_br_lts word features) "(port_br_lts WORD FEATURES)(let (phones dword) ;; (if (lts.in.alphabet word 'port_downcase) (set! word (port_cleanword word)) (if (string-equal word "")
nil;; else(begin (set! dword (port_downcase word)) (print dword) ;; (set! dword (port_downcase "equis"))) (set! phones (lts.apply dword 'port_br)) (print phones) (list word
nil(port.syllabify.phstress phones))))))

102
(define (port_cleanword word);(set! LETTERS (a e i o u á é í ó ú â ê ô ü ã õ à b c ç d f g j k l mn p q r s t v w x y z A E I O U Á É Í Ó Ú Â Ê Ô Ü Ã Õ À B C Ç D F G JK L M N P Q R S T V W X Y Z)) (if word
(if (string-matches word "[a-zA-ZáéíóúâêôüãõàçÁÉÍÓÚÂÊÔÜÃÕÀÇ]*") word ;; else (begin (set! letter (substring word 0 1)) (set! word (substring word 1 (string-length word))) (if (string-matches letter "[a-zA-ZáéíóúâêôüãõàçÁÉÍÓÚÂÊÔÜÃÕÀÇ]")
;(member (car word) LETTERS) (set! result (string-append letter (port_cleanword word))) (set! result (port_cleanword word)))
result)) nil))
(define (port_downcase word) "(port_downcase WORD)Downs case word by letter to sound rules becuase or accented formthis can't use the builtin downcase function." (lts.apply word 'port_downcase)) (provide 'port_br_lts)

103
Anexo 3 Código das funções de domínio utilizadas noproblema;; Implementação das funções externas necessárias para o problema;; Estas funções são usadas na resolução como conjunto de funções
; Modifica a lista que contém o resultado (*lvresult*); Usada em testes com estratégias iniciais(defun fresult (pfone) (setf lvtemp '()) (if (not (eq pfone nil)) (setf lvtemp (cons pfone lvtemp))) (setf vcontdo (- (length *lvresult*) 1)) (loop until (< vcontdo 0) do (setf lvtemp (cons (nth vcontdo *lvresult*) lvtemp)) (setf vcontdo (- vcontdo 1))) (setf *lvresult* lvtemp) (values pfone))
; Função que testa se o parâmetro ppos for maior que zero e menor ouigual ao tamanho da lista; retorna o caractere da posição atual(defun cposat () (let (vcpos) (setf vcpos NIL) (if (numberp *vposletra*)
(setf vcpos (if (and (> *vposletra* 0) (<= *vposletra* (length *lvcasofit*))) (nth (- *vposletra* 1) *lvcasofit*) NIL))) (values vcpos)))
; Função que testa se o parâmetro ppos for maior que um e menor ouigual ao tamanho da lista, retorna o caractere da posiçãoimediatamente anterior(defun cposan1 () (let (vcpos) (setf vcpos NIL) ; Teste se é número para evitar erro de tipo (if (numberp *vposletra*) (setf vcpos (if (and (> *vposletra* 1) (<= *vposletra* (length *lvcasofit*)) ) (nth (- *vposletra* 2) *lvcasofit*) NIL))) (values vcpos)))
; Função que testa se o parâmetro ppos for maior que dois e menor ouigual ao tamanho da lista, retorna o caractere duas posições atrás daatual(defun cposan2 () (let (vcpos) (setf vcpos NIL)(if (numberp *vposletra*) (setf vcpos (if (and (> *vposletra* 2) (<= *vposletra* (length *lvcasofit*)) ) (nth (- *vposletra* 3) *lvcasofit*) NIL))) (values vcpos)))

104
; Função que testa se o parâmetro ppos for maior que zero e menor queo tamanho da lista, retorna o caractere da posição imediatamenteposterior(defun cpospo1 () (let (vcpos) (setf vcpos NIL) ; Teste se eh número para evitar erro de tipo (if (numberp *vposletra*) (setf vcpos (if (and (> *vposletra* 0) (< *vposletra* (length *lvcasofit*)) ) (nth *vposletra* *lvcasofit*) NIL))) (values vcpos)))
; Função que testa se o parâmetro ppos for maior que zero e no minimodois a menos que o tamanho da lista; retorna a o caractere duas posições a frente da atual(defun cpospo2 () (let (vcpos) (setf vcpos NIL) ; Teste se eh número para evitar erro de tipo (if (numberp *vposletra*) (setf vcpos (if (and (> *vposletra* 0) (< *vposletra* (- (length *lvcasofit*)1))) (nth (+ *vposletra* 1) *lvcasofit*) NIL))) (values vcpos)))
; Macro que implementa uma repetição controlada; Executa o segundo argumento até que o predicado avaliado no primeiroseja satisfeito; Tem um dispositivo de proteção para que nunca ocorra loop infinito.; Usada em algumas estratégias
(defmacro dolfon (corpo) (let (vcontdo) (setf vcontdo 1) (loop until (> vcontdo (length *lvcasofit*)) do (eval corpo) (setf vcontdo (+ vcontdo 1)) )))
; Função de incremento protegido; Usada na avaliação de fitness para incremento da posição atual(defun incpos () (setf *vposletra* (+ *vposletra* 1)) (values *vposletra*))
;; Função de incremento protegido, que aumenta(defun incpos2 () (setf *vposletra* (+ *vposletra* 2)) (values *vposletra*))
;Verifica se a letra recebida como parametro eh uma vogal(defun fehvogal (pletra) (values (if (or (eq pletra 'a) (eq pletra 'e) (eq pletra 'i) (eq pletra 'o) (eq pletra 'u))

105
t nil)))
;Retorna a nasalizacao da vogal recebida como parametro;Caso nao seja vogal, retorna valor nulo
(defun fnasal (pvogal) (values (if (eq pvogal 'a) 'ax~ (if (eq pvogal 'e) 'e~ (if (eq pvogal 'i) 'i~ (if (eq pvogal 'o) 'o~ (if (eq pvogal 'u) 'u~ nil))))) ) )
;Verifica se a letra recebida como parametro eh letra m ou n(defun fehmn (pletra) (values (if (or (eq pletra 'm) (eq pletra 'n)) t nil)) )
; Verifica se o primeiro argumento é a letra t ou d; Verifica também se o segundo argumento é a letra i(defun fehtd (pletra pletra2) (values (if (or (eq pletra 't-) (eq pletra 'd)) (if (eq pletra2 'i) t nil) nil)) )
; Retorna fonemas das letras t e d quando elas forem antes de i(defun frtdi (pletra) (values (if (eq pletra 't) 'ts (if (eq pletra 'd) 'dz)) ))
;Verifica se o primeiro argumento é a letra c; Verifica também se o segundo argumento é e ou i(defun fehcei (pletra pletra2) (values (if (and (eq pletra 'c) (or (eq pletra2 'e) (eq pletra2 'i))) t nil)) )
; Verifica se o primeiro argumento é a letra s; Verifica se o segundo argumento é uma das letras (d,b,m,n ou g)(defun fehscvo (pletra pletra2) (values (if (and (eq pletra 's) (or (eq pletra2 'd) (eq pletra2 'b) (eq pletra2 'm) (eq pletra2 'n) (eq pletra2 'g))) t nil)) )

106
; Verifica se ambos os argumentos são s(defun fehss (pletra pletra2) (values (if (and (eq pletra 's) (eq pletra2 's)) t nil) ) )
; Verifica se o primeiro argumento é vogal; Verifica também se o segundo s; Por fim teste se o terceiro é vogal(defun fehvsv (pletra pletra2 pletra3) (values (if (and (fehvogal pletra) (eq pletra2 's) (fehvogal pletra3)) t nil)))
; Verifica se o primeiro argumento é vogal; Verifica se o segundo é z; Por fim se o terceiro tem valor nulo(defun fehvznil (pletra pletra2 pletra3) (values (if (and (fehvogal pletra) (eq pletra2 'z) (eq pletra3 nil)) t nil)));; A partir daqui algumas funções estão redefinidas;; As funções não possuem argumentos, a aplicação é diretamente sobrecaracteres em posições específicas.
; Função fehtd aplicada sobre a posição atual e a próxima(defun fehtd () (values (if (or (eq (cposat) 't) (eq (cposat) 'd)) (if (eq (cpospo1) 'i) t nil) nil)) )
; Função frtdi aplicada diretamente a posição atual(defun frtdi () (values (if (eq (cposat) 't) 'ts (if (eq (cposat) 'd) 'dz)) ))
; Função fechcei aplicada diretamente a posição atual e posterior(defun fehcei () (values (if (and (eq (cposat) 'c) (or (eq (cpospo1) 'e) (eq (cpospo1) 'i))) t nil)) )
; Função fehscvo aplicada diretamente a posição atual e próxima(defun fehscvo () (values (if (and (eq (cposat) 's)

107
(or (eq (cpospo1) 'd) (eq (cpospo1) 'b) (eq (cpospo1) 'm) (eq (cpospo1) 'n) (eq (cpospo1) 'g))) t nil)) )
; Verifica se a posicao anterior eh vogal, a atual s e a proxima vogal(defun fehvsv () (values (if (and (fehvogal (cposan1)) (eq (cposat) 's) (fehvogal (cpospo1))) t nil)))
; Verifica se a primeira eh vogal, a segunda z e a terceira nula; Implementação sem parâmetros(defun fehvznil () (values (if (and (fehvogal (cposan1)) (eq (cposat) 'z) (eq (cpospo1) nil)) t nil)))

108
Anexo 4 Funções de definição de casos e avaliação defitness; lvresult eh a lista de fonemas que um programa produz como resultado(defvar *lvresult*); lvcasofit eh a sequencia de letras que constitui um caso de fitness.(defvar *lvcasofit*); Variável que totaliza o fitness basico para calculo depois dofitness padronizado(defvar *vtotfitbas*); Variável que é usada para controlar a posição atual(defvar *vposletra*)
; Estrutura de cada caso de fitness. Tipo do vetor de casos(defstruct casos-fitness-letra-fonema palavra resfonemas )
; Definição dos casos de fitness, gera como resultado um vetorretornado ao programa da PG; Os casos compõe-se de um conjunto de letras e conjunto de fonemascorrespondente(defun define-casos-fitness-letra-fonema ()
(let (pcasosfit vcasosfit presultcasos vresultcasos caso-fitnesscasos-fitness indice numero-casos caso-atual vcontfon pfitmin) ; Obtém os casos dos componentes da interface (setf pcasosfit (widget :txtcasosfit :principal)) (setf vcasosfit (dialog-item-value pcasosfit)) (setf presultcasos (widget :txtresultcasos :principal)) (setf vresultcasos (dialog-item-value presultcasos)) (setf *vtotfitbas* 0) (setf casos-fitness (make-array *number-of-fitness-cases*)) (setf numero-casos (- (length vcasosfit) 1)) (setf indice 0) (loop until (> indice numero-casos) do (progn (setf caso-fitness (make-casos-fitness-letra-fonema)) (setf (casos-fitness-letra-fonema-palavra caso-fitness) (nth indice vcasosfit)) (setf (casos-fitness-letra-fonema-resfonemas caso-fitness) (nth indice vresultcasos)) (setf (aref casos-fitness indice) caso-fitness) (setf caso-atual (nth indice vresultcasos)) (setf vcontfon 1) (loop until (> vcontfon (length caso-atual)) do (progn (setf *vtotfitbas* (+ *vtotfitbas* 3)) (incf vcontfon))) (incf indice))) (setf pfitmin (widget :txtfitnessmin :principal)) (set-dialog-item-value pfitmin *vtotfitbas*) (print *vtotfitbas*) (values casos-fitness)))
; Avaliação dos casos de fitness, processo que retorna o fitnesspadronizado e hits. Recebe como argumento o programa a ser avaliado e

109
os casos de fitness. O numero de hits é uma contagem para cada palavracompleta acertada
(defun avaliacao-fitness-letra-fonema (programa conjunto-casos-fitness) (let (vtotfitbasind vhitsind vfitpadind vindice caso-fitnessvresprog vfonpos vfonposr vindfones vfitbascaso as-letras os-fonemastamresach tamresre vindaval vteste) (setf vtotfitbasind 0) (setf vhitsind 0) (dotimes (vindice *number-of-fitness-cases*) (setf caso-fitness (aref conjunto-casos-fitness vindice)) (setf as-letras (casos-fitness-letra-fonema-palavra caso-fitness)) (setf os-fonemas (casos-fitness-letra-fonema-resfonemas caso-fitness)) (setf *lvcasofit* as-letras) (setf *lvresult* '()) (setf *vposletra* 1) (dotimes (vindaval (length *lvcasofit*)) (fresult (eval programa)) (incf *vposletra* 1)) (setf vfitbascaso 0)
(setf tamresach (length *lvresult*)) (setf tamresre (length os-fonemas)) (if (< tamresach tamresre) (setf vtamrep tamresach) (setf vtamrep tamresre)) (if (and (> (length *lvresult*) 0) (not (eq *lvresult* nil))) ; Repete e pega cada fonema do resultado (dotimes (vindfones vtamrep) (setf vfonpos (nth vindfones *lvresult*)) (setf vfonposr (nth vindfones os-fonemas)) (if (eq vfonpos vfonposr) (progn (setf vtotfitbasind (+ vtotfitbasind 3)) (setf vfitbascaso (+ vfitbascaso 3))) (if (not (eq (member vfonpos os-fonemas) nil)) (progn (setf vtotfitbasind (+ vtotfitbasind 1)) (setf vfitbascaso (+ vfitbascaso 1))))) )(if (= (* (length os-fonemas) 3) vfitbascaso) (incf vhitsind)))) (setf vfitpadind (- *vtotfitbas* vtotfitbasind)) (if (< vfitpadind 0) (setf vfitpadind 0)); Retorna os valores (values vfitpadind vhitsind)))

110
Bibliografia[ALB 2000] ALBUQUERQUE, Paul; CHOPARD, Bastien; MAZZA, Christian;
TOMASSINI, Marco. On Impact of the Representation of FitnessLandscapes. In: EUROPEAN WORKSHOP ON GENETICPROGRAMMING, EUROGAP, 2000. Genetic Programming:European Conference: proceedings. Berlim: Springer 2000. P.1-15.(Lecture Notes in Computer Science, v.1802).
[AND 94] ANDRE, David. Learning and upgrading Rules for na OCR Systemusing Genetic Programming. In:IEEE WORLD CONGRESS ONCOMPUTACIONAL INTELIGENCE, WCCI, 1994, Orlando.Proceedings... Rscata-way: IEEE, 1994. Disponível em:<http://www.geneticprogramming.com>. Acesso em: 01 nov. 2000.
[BAN 95] BANZHAF, Wolfgang; NORDIN, Peter. Real time Control of aKephera Robot using Genetic Programming. Dortmund,Germany:[s.n.], 1995. Disponível em:<http://www.geneticprogramming.com>. Acesso em: 04 dez. 2000.
[BAN 98] BANZHAF, Wolfgang; NORDIN, Peter; KELLER Robert;FRANCONE, F.D. Genetic Programming An Introduction. Onthe Automatic Evolution of Computer Programs and ItsApplications. San Francisco:Morgan Kaufmann, 1998. 470 p.
[BAN 98a] BANZHAF, Wolfgang; NORDIN, Peter; CONRAD, Markus.Speech Sound Discrimination With Genetic Programming.1998. Disponível em: <http://www.geneticprogramming.com>.Acesso em: 04 dez. 2000.
[BAR 2000] BARONE, Dante; SCHRAMM, Maurício; FREITAS, Luis FelipeR. A Brazilian portuguese language corpus development. In:INTERNATIONAL CONFERENCE ON SPOKEN LANGUAGEPROCESSING 6., 2000, Beijing. Proceedings... [S.l.:s.n.], 2000. v.2, p. 579-582.
[BIS 99] BISOL, Leda. Introdução a estudos de fonologia do portuguêsbrasileiro. 2.ed. Porto Alegre. EDIPUCRS, 1999. 254 p.
[BRA 92] BRANKO SOUCEK; IRIS GROUP. Dynamic, Genetic andChaotic Programming. New York: John Wiley & Sons, 1992.
[CAL 90] CALLOU D.; LEITE Y. Iniciação à Fonética e à Fonologia. Riode Janeiro: J. Zahar, 1990.
[CAM 80] CAMPOS G.L. Síntese de Voz para o Idioma Português. 1980.Tese (Doutorado) - Escola Politécnica, Universidade de São Paulo,São Paulo.
[CAR 98] CARDON, André. Um Sistema de Síntese de Fala Através daConcatenação de Sílabas. 1998. Dissertação (Mestrado em

111
Ciência da Computação) – Instituto de Informática, UFRGS, PortoAlegre.
[CHB 94] CHBANE, Dimas T. Desenvolvimento de sistema paraConversão de textos em fonemas no idioma português. 1994.Dissertação (Mestrado em Engenharia) - Escola Politécnica,Universidade de São Paulo, São Paulo.
[COR 2000] CORDENONSI, André. Um Ambiente de Evolução deComportamentos para Sistemas Multiagentes Reativos. 2000.Dissertação (Mestrado em Ciência da Computação) – Instituto deInformática, UFRGS, Porto Alegre.
[DAV 91] DAVIS, Lawrence D. Genetic Algorithms Handbook. New York:Van Nostrand Reinhold, 1991. 383 p.il.
[DOB 77] DOBZHANSKY, T.; AYALA, F.J.; STEBBINS, G.L.;VALENTINE, J.W. Evolution. San Francisco:W.H.Freeman,1977.
[DOS 98] DOSVOX. Síntese de fala no sistema dosvox. 1998. Disponívelem: <http://caec.nce.ufrj.br/~dosvox/textos.html> Acesso em: 10maio 2002.
[DUT 96] DUTOIT Thierry. An Introduction to Text-To-SpeechSynthesis. Dordrecht: Kluwer Academic, 1996. 280 p.
[FOG 2000] FOGEL, David B. Toward a New Philosophy of MachineIntelligence. New York: IEEE Press, 2000. 270 p.
[FRA 94] FRASER, Adam P. Genetic Programming in C++. [S.l.]:University Of Salford: Cybernetics Research Institute, 1994.(Technical Report, 040)
[HAU 99] HAUSSER, Roland. Fundations of Computacional Linguistics.Man-Machine Comunication in Natural Language. Berlin:Springer-Verlag, 1999. 534 p.
[HOL 75] HOLLAND, John H. Adaptation in Natural and ArtificialSystems. Ann Arbor: University of Michigan Press, 1975.
[KLA 90] KLATT D.H.; KLATT L.C. Analysis, Synthesis and Perception ofVoice Quality Variations Among Female and Male Talkers.Journal of Acoustical Society of America. [S.l.], v.87, n.2,p.820-56, Feb. 1990.
[KOZ 90a] KOZA, John R. A Genetic Approach to Econometric Modeling.1990. Disponível em: <http://www.geneticprogramming.com>.Acesso em: 04 dez. 2000.
[KOZ 90b] KOZA, John R.; HALL, Margaret J. Genetic evolution and co-evolution of Computer Programs. 1990. Disponível em:<http://www.geneticprogramming.com>. Acesso em: 04 dez. 2000.

112
[KOZ 92] KOZA, John R. Genetic Programming: On the Programming ofComputers by Means of Natural Selection. Cambridge: The MITPress, 1992. 819 p.
[KOZ 98] KOZA, John R. Genetic Programming II: Automatic Discoveryof Reusable Programs. Cambridge: The MIT Press, 1998. 746 p.
[KOZ 2000] KOZA, John R.; KEANE, Martin A.; BENNETT F. H.; ANDRE,Davis. Genetic Programming: Turing's Third Way to AchieveMachine Intelligence. Disponível em:<http://www.geneticprogramming.com> Acesso em: 04 dez. 2000.
[LEM 2000] LEMMETTY, Sami. Review of speech synthesis technology.Disponível em:<http://www.acoustics.hut.fi/~slemmett/dippa/chap1.htm>. Acessoem 20 dez. 2000.
[LAW 2000] LAWRENCE, Steve. Natural Language Gramatical Inference withRecurrent Neural Networks. IEEE Transactions on Knowledgeand Data Engineering, New York, v.12, n.1, p.126-140, 2000.
[MIT 92] MITCHELL, Melanie. An Introduction to Genetic Algorithms.Cambridge: The MIT Press, 1992. 205 p.
[MBR 2000] MBROLA. Frequently Asked Questions with answers. 2000.Disponível em: <http://tcts.fpms.ac.be/synthesis/>. Acesso em 10maio 2002.
[O'MA 90] O'MALLEY, M.H.; Text-To-Speech Conversion Technology.Computer, Los Alamitos, v.23, n.8, p.17-23, Aug. 1990.
[O’NE 2000] O’NEIL, Michael; RYAN, Conor. Crossover in GramaticalEvolution: A Smooth Operator?. In: EUROPEAN WORKSHOPON GENETIC PROGRAMMING, EUROGAP, 2000. GeneticProgramming: European Conference: proceedings. Berlin:Springer, 2000. p.149-162. (Lecture Notes in Computer Science,v.1802).
[O'RE 95] O'REILLY, Una-May et al. An Analysis of Genetic Pro-gramming. Ottawa: Ottawa-Carleton Institute for ComputerScience, Carleton University, 1995.
[PET 2000] PETRY, Adriano. Bhattacharyya distance applied to speakeridentification. In: INTERNATIONAL CONFERENCE ONSIGNAL PROCESSING APPLICATIONS AND TECHNOLOGY,2000 , Dallas. Conference proceedings. [S.l. : DSP World], 2000.
[ROS 96] ROSCA, Justinian P.; BALLARD, Dana H. Evolution-basedDiscovery of Hierarchical Behaviors. In: INTERNATIONALCONFERENCE ON ARTIFICIAL INTELLIGENCE, 1996,Cambridge. Proceedings...[S.l.]: The MIT Press, 1996.

113
[ROS 96a] ROSCA, Justinian P. Generality versus Size in GeneticProgramming. In: GENETIC PROGRAMMING CONFERENCE,GP, 1996. Genetic Programming Conference: proceedings.Cambridge: The MIT Press. 1996.
[SIL 93] SILVA, Miriam B. Ensaios. Leitura, Ortografia e Fonologia.São Paulo: Ática, 1993. 110 p.
[SIL 99] SILVA, T.C. Fonética e Fonologia do Português, roteiro deestudos e guia de exercícios. São Paulo: Contexto, 1999. 254 p.
[SLA 98] SLADE, Stephen. Object-Oriented Common Lisp. Upper SaddleRiver: Prentice Hall PTR, 1998. 774 p.
[SPO 01] SPOLTECH. Advancing Human Language Technology in Braziland the United States Through Collaborative Research onPortuguese Spoken Language Systems. In: PROTEM-CC, 4., 2001,Rio de Janeiro. Projects Evaluation Workshop: internationalcooperation: procedings. Brasília: CNPw, 2001. p. 118-142.
[WES 2001] WESTERDALE, Thomas. Local Reinforcement andRecombination in Classifier Systems. Evolutionary Computing,Cambridge, v.3, n.9, p.259-281. 2001.





























