Embed Size (px)
Citation preview



Ensemble of Multi Features for Facial Expression
Recognition using Deep Learning Techniques
A Thesis submitted to Gujarat Technological University
for the Award of
Doctor of Philosophy
in
Computer/IT Engineering
By
Thacker Chintan Bhupeshbhai
Enrollment No. 159997107003
Under the supervision of
Dr. Ramji M. Makwana
GUJARAT TECHNOLOGICAL UNIVERSITY,
AHMEDABAD
May -2021

Ensemble of Multi Features for Facial Expression
Recognition using Deep Learning Techniques
A Thesis submitted to Gujarat Technological University
for the Award of
Doctor of Philosophy
in
Computer/IT Engineering
By
Thacker Chintan Bhupeshbhai
Enrollment No. 159997107003
Under the supervision of
Dr. Ramji M. Makwana
GUJARAT TECHNOLOGICAL UNIVERSITY,
AHMEDABAD
May -2021

© THACKER CHINTAN BHUPESHBHAI

iv
DECLARATION
I declare that the thesis entitled “Ensemble of Multi Features for Facial Expression
Recognition using Deep Learning Techniques” submitted by me for the degree of
Doctor of Philosophy is the record of research work carried out by me during the period
from October 2016 to May 2021 under the supervision of Dr. Ramji M. Makwana and
this has not formed the basis for the award of any degree, diploma, associateship,
fellowship, titles in this or any other University or other institution of higher learning.
I further declare that the material obtained from other sources has been duly acknowledged
in the thesis. I shall be solely responsible for any plagiarism or other irregularities, if
noticed in the thesis.
Signature of Research Scholar: Date: 20/05/2021
Name of Research Scholar: Thacker Chintan Bhupeshbhai
Place: Bhuj

v
CERTIFICATE
I certify that the work incorporated in the thesis “Ensemble of Multi Features for Facial
Expression Recognition using Deep Learning Techniques” submitted by Mr. Thacker
Chintan Bhupeshbhai was carried out by the candidate under my supervision/guidance.
To the best of my knowledge: (i) the candidate has not submitted the same research work
to any other institution for any degree/diploma, Associateship, Fellowship or other similar
titles (ii) the thesis submitted is a record of original research work done by the Research
Scholar during the period of study under my supervision, and (iii) the thesis represents
independent research work on the part of the Research Scholar.
Signature of Supervisor: ................................................... Date: 20/05/2021
Name of Supervisor: Dr. Ramji M. Makwana
Place: Rajkot

vi
Course-work Completion Certificate
This is to certify that Mr. Thacker Chintan Bhupeshbhai Enrollment no.159997107003
is a PhD scholar enrolled for PhD program in the branch Computer/IT Engineering of
Gujarat Technological University, Ahmedabad.
(Please tick the relevant option(s))
He/She has been exempted from the course-work (successfully completed
during M.Phil. Course)
He/She has been exempted from Research Methodology Course only
(successfully completed during M.Phil. Course)
He/She has successfully completed the PhD course work for the partial
requirement for the award of PhD Degree. His/ Her performance in the
course work is as follows-
Grade Obtained in Research
Methodology (PH001)
Grade Obtained in Self Study Course
(Core Subject) (PH002)
BB AB
Supervisor’s Sign
(Dr. Ramji M. Makwana)

vii
Originality Report Certificate
It is certified that PhD Thesis titled “Ensemble of Multi Features for Facial Expression
Recognition using Deep Learning Techniques” by Thacker Chintan Bhupeshbhai has
been examined by us.
We undertake the following:
a. Thesis has significant new work/knowledge as compared already published or are
under consideration to be published elsewhere. No sentence, equation, diagram,
table, paragraph, or section has been copied verbatim from previous work unless it
is placed under quotation marks and duly referenced.
b. The work presented is original and own work of the author (i.e. There is no
plagiarism). No ideas, processes, results or words of others have been presented as
Author own book.
c. There is no fabrication of data or results which have been complied/analysed.
d. There is no falsification by manipulating research materials, equipment or
processes, or changing or omitting data or results such that the research is not
accurately represented in the research record.
e. The thesis has been checked using “URKUND Plagiarism Checker” (copy of
originality report attached) and found within limits as per GTU Plagiarism Policy
and instructions issued from time to time (i.e., permitted similarity index <=10 %).
Signature of Research Scholar: Date: 20/05/2021
Name of Research Scholar: Thacker Chintan Bhupeshbhai
Place: Bhuj
Signature of Supervisor: ......................................................... Date: 20/05/2021
Name of Supervisor: Dr. Ramji M. Makwana
Place: Rajkot

viii
Copy Originality Report

ix

x
PhD Thesis Non-Exclusive License to
GUJARAT TECHNOLOGICAL UNIVERSITY
In consideration of being PhD Research Scholar at GTU and in the interests of the
facilitation of research at GTU and elsewhere I, “Thacker Chintan Bhupeshbhai” having
Enrollment No. 159997107003 hereby grant a non-exclusive, royalty free and perpetual
license to GTU on the following terms:
a) GTU is permitted to archive, reproduce and distribute my thesis, in whole or in a
part, and/or my abstract, in whole or in part (referred to collectively as the “Work”)
anywhere in the world, for non-commercial purposes, in all forms of media;
b) GTU is permitted to authorize, sub-lease, sub-contract or procure any of the acts
mentioned in the paragraph (a);
c) GTU is authorized to submit the Work at any National/International Library, under
the authority of their “Thesis Non- Exclusive License”;
d) The Universal Copyright Notice (©) shall appear on all copies made under the
authority of this license;
e) I undertake to submit my thesis, through my University, to any Library and
Archives. Any abstract submitted with the thesis will be considered to form part of
the thesis.
f) I represent that my thesis is my original work, does not infringe any rights of others,
including privacy rights, and that I have the right to make the grant conferred by this
non-exclusive license.
g) If third part copyrighted material was included in my thesis for which, under the
terms of the Copyright Act, written permission from the copyright owners is
required, I have obtained such permission from the copyright owners to do the acts
mentioned in paragraph (a) above for the full term of copyright protection.
h) I retain copyright ownership and moral rights in my thesis, and may deal with the
copyright in my thesis, in any way consistent with rights granted by me to my
University in this non-exclusive license.

xi
i) I further promise to inform any person to whom I mat hereafter assign or license my
copyright in my thesis of the rights granted by me to my University in this non-
exclusive license.
j) I am aware of and agree to accept the conditions and regulations of PhD including
all policy matters related to authorship and plagiarism.
Signature of the Research Scholar:
Name of Research Scholar: Thacker Chintan Bhupeshbhai
Date: 20/05/2021 Place: Bhuj
Signature of Supervisor: ...............................................................................
Name of Supervisor: Dr. Ramji M. Makwana
Date: 20/05/2021 Place: Rajkot.
Seal: M.D. Aiivine PXL Pvt. Ltd.

xii
Thesis Approval Form
The viva-voce of the PhD Thesis submitted by Mr. Thacker Chintan Bhupeshbhai
(Enrollment No. 159997107003) entitled Ensemble of Multi Features for Facial
Expression Recognition using Deep Learning Techniques was conducted on 20/05/2021
on Thursday at Gujarat Technological University.
(Please tick any one of the following options)
The performance of the candidate was satisfactory. We recommend that he be
awarded the PhD degree.
Any further modifications in research work recommended by the panel after 3
months from the date of first viva- voce upon request of the Supervisor or
request of Independent Research Scholar after which viva – voce can be re-
conducted by the same panel again.
The performance of the candidate was unsatisfactory. We recommend that he
should not be awarded the PhD degree.
(Dr. Ramji M. Makwana)
Name and signature of Supervisor with Seal
(Dr. Binod Kumar)
External Examiner-1 (Name and Signature)
(Dr. Sharnil Pandya)
External Examiner-2 (Name and Signature)
(Dr. Subodh Srivastava)
External Examiner-3 (Name and Signature)
(Briefly specify the modifications suggested by the panel)
(The panel must give justifications for rejecting the research work)

xiii
Abstract
As we move towards a digital world, Human-Computer Interaction becomes very important.
Facial Expressions are the key features of non-verbal communication and they play an
essential role in human-computer interaction. Facial Expressions play a crucial role in social
interactions and commonly used in the behavioural interpretation of emotions. It becomes easy
to understand anyone’s emotional state and intentions based on the shown facial expression.
Over the last few years, facial expression recognition has attracted researchers in psychology,
computer science, security and medicine-related fields. These fields have an extensive range of
applications like in surveillance cameras to identify suspicious person, patient’s painful
situation at hospital, online meeting or in E-learning system, music player play songs based on
person’s mood, driver’s tiredness from his expression while driving, robotics, behavioural
science, etc. based on facial expressions. Although human beings can identify the facial
expressions correctly and effortlessly, still reliable automatic facial expression recognition by
machines is a challenge.
Facial expression recognition system consists of different stages like Face Detection, Feature
Extraction and Emotion Classification. There are seven universally defined facial expressions:
Angry, Disgust, Fear, Happy, Neutral, Sad and Surprise. Facial expression recognition using
the Convolutional Neural Network has been actively researched in the last decade due to its
high number of applications in the human-computer interaction domain. As Convolutional
Neural Networks have an exceptional capability to learn, they outperform well on features
using its different pre-trained architectures. Existing state-of-the-art models have achieved
good recognition accuracy on laboratory trained facial expression datasets; however, they
struggle to achieve good accuracy for the real-time facial expression datasets trained in an
uncontrolled environment. Images captured in an uncontrolled setting or taken from the
internet contains many challenges like lower resolutions, occlusion, variations in lighting
conditions, and head pose variations.

xiv
The work introduced in this research focuses on recognizing facial expressions from the
images using deep learning techniques to improve its recognition accuracy. This research work
deals with investigating of methods using deep learning techniques to deal with the issue of
recognition accuracy of lower resolution images for facial expression recognition. The key
factor of this research is to improve the recognition accuracy of the real-time facial expression
dataset which contains real-world images with challenges and the laboratory trained dataset
images that are trained in a controlled environment for the cross-database evaluation study.
The feature extraction process becomes more difficult in real-world images than the images
trained in a controlled environment. In this research work, three models are proposed: Multi-
Layer Feature-Fusion based Classification (MLFFC) model, Multi-Model Feature-Fusion
based Classification (MMFFC) model and Novel facial expression recognition model based on
Normalized CNN. MLFFC and MMFFC model use the fusion concept of layers in different
aspects. The idea of fusion utilizes a combination of knowledge obtained from two different
domains for enhancing the feature extraction for the given images. In MLFFC model, the
concept of inter-layer feature fusion on InceptionV3 CNN architecture is applied. From the
literature survey, it is discovered that the majority of the work focuses on the feature maps
obtained at the last layer of the CNN model and gives little consideration to the advantages of
the extra layers of the model which has added some significant features. MLFFC proposed
model is tested on two publicly available datasets: laboratory trained CK+ dataset and real-
time facial expression dataset FER2013. The proposed model performs well and provides
better recognition accuracy on both kinds of facial expression datasets, unlike the models
which work exceptionally well on laboratory-trained facial expression dataset but fail to do so
when it comes to real-time facial expression dataset.
In MMFFC model, the concept of an ensemble of two CNN architectures is applied by
concatenating two feature vectors generated at final layers of VGG16 and ResNet50 CNN
architectures. Existing research approaches with the help of a single CNN model used to
extract facial expression recognition features. An Ensemble of CNN concept found from the
literature survey to improve the recognition accuracy. In this concept concatenation of features
from various networks helps to overcome the limitations of a single network and produce
superior performance. The MMFFC model is tested on two publicly available datasets:
laboratory-trained KDEF dataset and real-time facial expression dataset FER2013. The
proposed model performs well and provides better recognition accuracy on real-time facial
expression dataset as well as on laboratory-trained facial expression dataset. Results are
compared with other state-of-the-art methods.

xv
In the third model, a novel concept is proposed known as EfficientNet: Rethinking scaling
model for CNN is implemented. There are different EfficientNet models B0 to B7 based on the
Compound Scaling method to scale up CNN in a more structured way. Unlike the conventional
approaches that arbitrarily scale the network dimensions such as width, depth and resolution,
this approach uniformly scales the network dimension with a fixed set of scaling coefficients.
This is the important characteristic of this novel EfficientNet approach which works well on
higher resolution images. From a literature study, it is found that no work has been carried out
for facial expression recognition using this concept until date. Different optimizers applied to
EfficientNetB7 architecture to determine which optimizer performs well on this architecture
for facial expression recognition. Also, different optimizers applied to ResNet152 architecture
for the cross-evaluation study. Experimental results show that the RMSprop optimizer
performs well on EfficientNetB7 architecture and SGD optimizer performs well on ResNet152
architecture for facial expression recognition. The vanishing gradient descent issue is also
identified in the experimental results due to variance generated in the computational process.
Due to this issue, weirdness is caused by the model’s accuracy and loss graph instead of the
smooth curve. This issue is resolved by applying the proposed internal batch normalization
approach which retrains the model again by considering only batch normalization layers that
regularize the model and reduce layer inputs’ variances.
The experimental results demonstrate that all the proposed models achieve identical outcomes
for recognition accuracy compared the existing state-of-the-art methods.

xvi
Acknowledgment
Every achievement is a result of committed activities that too when headed and guided by
worthy and knowledgeable persons. It is with a sense of pride and pleasure that I humbly
look back to acknowledge those who have been a source of encouragement in my entire
endeavour.
First and foremost, I would like to express my sincere gratitude to my Ph.D. research
supervisor, Dr. Ramji M. Makwana for introducing me to this exciting research area
field and for his continuous support, guidance, inspiration and encouragement throughout
my Ph.D. research. His passion, his robust view of research and his quest to provide high-
quality work have made a deep impression on me. During our interactions, I have learned
extensively from him, including how to do positive thinking, how to look a problem from a
new perspective and how to approach the problem through systematic thinking. I am very
much obliged to him for his profound approach, motivation, and spending valuable time to
mould this work and bring a hidden aspect of research in a light.
I extend the special words of thanks to my Doctoral Progress Committee (DPC) members,
Dr. Narendra C. Chauhan and Dr. Apurva M. Shah for their excellent guidance,
valuable comments, useful suggestions and encouragement to visualize the problem from
the different perspective. Their humble approach and the way of appreciation for good
work have always created an amenable environment and boost-up my confidence to push
the limit. I owe a lot of gratitude to them for always being there for me and I feel
privileged to be associated with people like them during my life. Also, I would like to
thank my foreign supervisor Dr. Shishir Shah for their valuable guidance and support to
improve my research work.
I would also like to express my appreciation towards my parent institute, HJD Institute of
Technical Education and Research-Kutch, Dr. Jagdish Halai, Hon. Chairman sir and Dr.
Rasila Hirani, Institute Coordinator of this institute for providing all kinds of technical and
nontechnical support for my research work. It is a pleasure to thank my colleagues and
non-teaching staff of computer engineering department, who have directly or indirectly

xvii
helped me during my research work. My special regards to my dear friend Dr. Safvan
Vahora for his valuable suggestions and guidance.
I feel a deep sense of gratitude for my grandparents, mother, father, brother, who were part
of my vision. Their unfailing love and support have always been my strength. Their
patience and sacrifice will remain my inspiration for my entire life. Finally, my sincere
heartiest special thanks to my wife Bhoomi for her eternal support and understanding of
my goals and aspirations. Her support has always been my strength. Her patience and
sacrifice will remain my inspiration throughout my life. Without her support, I would not
have been able to complete much of what I have done. I am short of words to express my
loving gratitude to my loving son, Aadit, for his innocent smiles which inspired me during
the entire work.
Above all, I am very much thankful to the Almighty God for giving me this beautiful life
and standing by me at each stage of my life to complete this research.
Chintan B. Thacker

xviii
Table of Contents
Abstract ........................................................................................................................ xiii
Acknowledgment .......................................................................................................... xvi
Table of Contents ....................................................................................................... xviii
List of Abbreviations .................................................................................................... xxi
List of Figures ............................................................................................................ xxvii
List of Tables ............................................................................................................ xxxiii
1 Introduction .............................................................................................................. 1
1.1 Overview ............................................................................................................. 1
1.2 Research Motivation ............................................................................................ 3
1.3 Research Challenges ............................................................................................ 5
1.4 Problem Statement ............................................................................................... 7
1.5 Research Objectives and Scope ............................................................................ 8
1.5.1 Research Objectives ...................................................................................... 8
1.5.2 Scope of Research Work ............................................................................... 8
1.6 Organization of the Thesis ................................................................................... 9
2 Theoretical Background ......................................................................................... 11
2.1 Facial Expression Recognition System ............................................................... 11
2.1.1 Pre-processing for Face Detection ............................................................... 12
2.1.2 Feature Extraction ....................................................................................... 14
2.1.3 Facial Expression Classification .................................................................. 20
2.2 Deep Learning for Facial Expression Recognition.............................................. 25
2.2.1 Evolution of AI: Machine Learning and Deep Learning .............................. 25
2.2.2 Deep Neural Networks ................................................................................ 29
2.2.2.1 Convolutional Neural Networks .................................................................. 29
2.2.2.2 Deep Auto Encoder ..................................................................................... 31
2.2.2.3 Restricted Boltzmann Machine ................................................................... 32
2.2.2.4 Deep Belief Network .................................................................................. 32
2.2.2.5 Recurrent Neural Network .......................................................................... 33
2.2.2.6 Long Short-Term Memory .......................................................................... 35

xix
2.3 Convolutional Neural Network .......................................................................... 37
2.3.1 Convolutional Layer ................................................................................... 38
2.3.2 Pooling Layer ............................................................................................. 42
2.3.3 Fully Connected Layer ................................................................................ 43
2.3.4 Transfer Learning ....................................................................................... 44
2.4 Fusion Approach in Convolutional Neural Network ........................................... 46
2.4.1 Multi-Feature Fusion based approach .......................................................... 46
2.4.2 Ensemble of Multi-CNN Feature Fusion based approach ............................ 48
3 Literature Review ................................................................................................... 50
3.1 Overview ........................................................................................................... 50
3.2 Conventional FER Approaches .......................................................................... 51
3.3 Deep-Learning based FER Approaches .............................................................. 56
3.4 Multi-Feature Fusion based FER Approaches .................................................... 62
3.4.1 Multi-Feature fusion in a single model ........................................................ 62
3.4.2 Multi-Feature fusion using multi-model ...................................................... 65
3.5 Summary and Discussion ................................................................................... 68
4 Proposed Multi-Layer Feature-Fusion based Classification Model .................... 69
4.1 Introduction ....................................................................................................... 69
4.2 Inception-V3 CNN Architecture ........................................................................ 70
4.3 Proposed MLFFC ............................................................................................. 74
4.4 Dataset Details ................................................................................................... 77
4.4.1 CK+ Dataset ............................................................................................... 77
4.4.2 FER2013 Dataset ........................................................................................ 77
4.5 Experiment and Results ..................................................................................... 78
4.5.1 Experimental Setup and Implementation Details ......................................... 78
4.5.2 Experimental Results on Inception Module C layers ................................... 79
4.5.3 Experimental Results on CK+ Dataset ........................................................ 80
4.5.4 Experimental Results on FER2013 Dataset ................................................. 84
4.6 Discussion and Summary ................................................................................... 88
5 Proposed Multi-Model Feature-Fusion based Classification Model .................... 89
5.1 Introduction ....................................................................................................... 89
5.2 VGG-16 CNN Architecture ............................................................................... 90
5.3 ResNet-50 CNN Architecture ............................................................................ 91

xx
5.4 Proposed MMFFC model................................................................................... 94
5.5 Dataset Details ................................................................................................... 97
5.5.1 FER2013 Dataset ........................................................................................ 97
5.5.2 KDEF Dataset ............................................................................................. 98
5.6 Experiments and Results .................................................................................... 98
5.6.1 Experimental Setup and Implementation Details ......................................... 99
5.6.2 Experimental Results of Ensemble approach using different CNN
architectures ................................................................................................ 99
5.6.3 Experimental Results on FER2013 Dataset ............................................... 100
5.6.4 Experimental Results on KDEF Dataset .................................................... 105
5.7 Discussion and Summary ................................................................................. 109
6 Novel FER Model based on Normalized CNN..................................................... 110
6.1 Introduction ..................................................................................................... 110
6.2 EfficientNet Architecture and Working Methodology ...................................... 112
6.3 Proposed novel FER Model: EfficientNet-B7 .................................................. 117
6.4 Dataset Details ................................................................................................. 120
6.4.1 KDEF Dataset ........................................................................................... 120
6.4.2 FER2013 Dataset ...................................................................................... 121
6.5 Experiments and Results .................................................................................. 121
6.5.1 Experimental Results on proposed EfficientNet-B7 model ........................ 122
6.5.2 Internal Batch Normalization (IBN) & Experimental Results .................... 126
6.6 Discussion and Summary ................................................................................. 130
7 Conclusion and Further Enhancements .............................................................. 132
7.1 Conclusion....................................................................................................... 132
7.2 Future Enhancements ....................................................................................... 135
List of References ......................................................................................................... 137
List of Publications ...................................................................................................... 149

xxi
List of Abbreviations
1-D 1-Dimensional
2-D 2-Dimensional
3-D 3-Dimensional
AI Artificial Intelligence
AFER Automatic Facial Expression Recognition
Adam Adaptive Moment Estimation Optimizer
ANN Artificial Neural Network
AF Average Filter
AMF Adaptive Median Filter
AAM Active Appearance Model
AUs Action Units
AFEW Acted Facial Expression in Wild dataset
AUC Area Under the Curve
AutoML Automated Machine Learning
BF Bilateral Filter
BU-3DFE Binghamton University 3D Facial Expression dataset
BiLSTM Bidirectional Long Short-Term Memory

xxii
BDBN Boosted Deep Belief Network
BP4D Binghamton-Pittsburgh 4D Spontaneous expression dataset
CNN Convolutional Neural Network
CV Computer Vision
CK+ The Extended Cohn-Kanade dataset
Conv Convolutional
C-LSTM Convolutional Long Short-Term Memory
DCT Discrete Cosine Transform
1D DCT 1-Dimensional Discrete Cosine Transform
2D DCT 2-Dimensional Discrete Cosine Transform
DNN Deep Neural Network
DL Deep Learning
DAE Deep Auto Encoder
DBN Deep Belief Network
DWT Discrete Wavelet Transform
3DCNN 3-Dimensional Convolutional Neural Network
DISFA The Denver Intensity of Spontaneous Facial Action dataset
DSN Deep Spatial Network
DTN Deep Temporal Network

xxiii
DLBP Directional Local Binary Pattern
DTAN Deep Temporal Appearance Network
DTGN Deep Temporal Geometry Network
DTAGN Deep Temporal Geometry Appearance Network
DSAE Deep Sparse Auto Encoder
EmotiW Emotion Recognition in the Wild
ECNN Ensemble of Convolutional Neural Network
FER Facial Expression Recognition
FER2013 The Facial Expression Recognition 2013 dataset
FC Fully Connected
FACS Facial Action Coding System
FED-RO Facial Expression Dataset in the presence of Real Occlusion
FERA Facial Expression Recognition and Analysis dataset
FV Feature Vector
FLOPS Floating-Point Operations Per Second
GPU Graphics Processing Unit
GK Gaussian Kernel
GRU Gated Recurrent Units
GF Gaussian Filter

xxiv
HCI Human-Computer Interaction
HMM Hidden Markov Model
HOG Histogram of Oriented Gradients
ICA Independent Component Analysis
ICML International Conference on Machine Learning
IDE Integrated Developer Environment
IACNN Identity Aware Convolutional Neural Network
ILSVR ImageNet Large Scale Visual Recognition
IBN International Batch Normalization
JAFFE The Japanese Female Facial Expression dataset
KDEF The Karolinska Directed Emotional Faces dataset
KNN K-Nearest Neighbour
LBP Local Binary Pattern
LSTM Long Short-Term Memory
T-LSTM Temporal Long Short-Term Memory
MLFFC Multi-Layer Feature-Fusion based Classification
MMFFC Multi-Model Feature-Fusion based Classification
ML Machine Learning
MLP Multi-Layer Perceptron

xxv
MF Median Filter
MFFNN Multilayer Feed Forward Neural Network
MRE-CNN Multi-Region Ensemble Convolutional Neural Network
MLCNN Multi-level Convolutional Neural Network
MNF Multi-Network Fusion
MBConv Mobile Inverted Bottleneck Convolution
NIR Near-Infrared
NN Neural Network
NWPU-
RESISC
The Northwestern Polytechnical University Remote Sensing
Image Scene Classification dataset
OpenCV Open-Source Computer Vision
PCA Principal Component Analysis
POOL Pooling
RMSprop Root Mean Square Propagation optimizer
RNN Recurrent Neural Network
RBM Restricted Boltzmann Machine
ROI Region of Interest
ReLU Rectified Linear Unit
RBF Radial Basis Function
RAF-DB Real world Affective Faces Database

xxvi
RaFD Radboud Faces Database
ROC Receiver Operating Characteristic curve
SGD Stochastic Gradient Descent optimizer
SVM Support Vector Machine
SVD Singular Value Decomposition
SIFT Scale Invariant Feature Transform
SURF Speeded-Up Robust Features
STTM Spatio-Temporal Texture Map
SBP Sparse Batch Normalization
SFEW Static Facial Expressions in the Wild database
SDCNN Single Deep Convolutional Neural Network
SBN-CNN Sparse Batch Normalization Convolutional Neural Network
STC-NLSTM Spatio-Temporal Convolutional Features with Nested Long
Short-Term Memory
VIS Visible Light Spectrum
VGD Vanishing Gradient Descent

xxvii
List of Figures
FIGURE 1.1 Example of Facial Expression Recognition based on Human-Computer
Interaction [15]…………………………………………………………….1
FIGURE 1.2 Different Facial Expressions of one person from the JAFFE dataset[4]……2
FIGURE 1.3 Use of Facial Expression Recognition System to identify suspicious person
or criminal at the airport, railway station or any crowded place[16]……...3
FIGURE 1.4 Use of Facial Expression Recognition System to identify students'
engagement level in online classes[17]……………………………………4
FIGURE 1.5 Use of Facial Expression Recognition System to play songs based on a
person's mood[18]…………………………………………………………4
FIGURE 1.6 Example of high similarity between facial expressions in two different
classes[6,7]………………………………………………………………...6
FIGURE 1.7 Example of facial expression images taken in an uncontrolled environment
of FER2013 dataset which contains challenges like vaying illumination,
head pose variation, lower resolution and occlusion[9]…………………...6
FIGURE 1.8 Examples of laboratory trained facial expression dataset (a) CK+ (b) JAFFE
[6,14]………………………………………………………………………7
FIGURE 2.1 Conventional Facial Expression Recognition System[37]…………………11
FIGURE 2.2 Example of Image Rotation during the pre-processing phase[21]…………12
FIGURE 2.3 Example of Image Cropping during the pre-processing phase[21]………...12
FIGURE 2.4 Example of Illustration of the Intensity Normalization during the pre-
processing phase[21]……………………………………………………..13
FIGURE 2.5 Example of Face detection carried out on a sample image using OpenCV-
Python……………………………………………………………………14
FIGURE 2.6 Geometric and Appearance-based Feature Extraction[26]…………………14
FIGURE 2.7 Classification of different Feature Extraction Methods[28]………………..15
FIGURE 2.8 Feature Extraction using LBP Histogram Method[29]……………………..16

xxviii
FIGURE 2.9 Two sample facial expressions on the left-hand side and its optical method
result available on the right-hand side[30]……………………………….18
FIGURE 2.10 Feature-Point Tracking method using feature points displacements[29]…19
FIGURE 2.11 Feature extraction process in a Convolutional Neural Network generating
feature maps[31]………………………………………………………….19
FIGURE 2.12 Example of Seven basic Facial Expressions from CK+ dataset[32]……...20
FIGURE 2.13 Example of Support vector and hyperplane in the SVM method[36]…….23
FIGURE 2.14 Evolution of Artificial Intelligence (AI)[38]……………………………...25
FIGURE 2.15 Working methodology difference between Machine Learning and Deep
Learning[39]……………………………………………………………...27
FIGURE 2.16 Basic structure of Neural Networks with Input, Hidden and Output
layers[39]…………………………………………………………………28
FIGURE 2.17 Basic CNN Architecture[41]……………………………………………...30
FIGURE 2.18 Basic Structure of Deep Autoencoders (DAE)[44]……………………….31
FIGURE 2.19 Basic Structure of Restricted Boltzmann Machine (RBM)[45]…………..32
FIGURE 2.20 Basic Structure of Deep Belief Network (DBN) [46]…………………….33
FIGURE 2.21 The Schematic diagram of RNN Node[43]……………………………….34
FIGURE 2.22 Basic Structure of Recurrent Neural Network (RNN)[43]………………..35
FIGURE 2.23 The Schematic diagram of LSTM block with memory cell and gates[45]..36
FIGURE 2.24 General CNN Structure in facial expression recognition system[47]……..37
FIGURE 2.25 Convolutional Operation with Image matrix multiplies kernel or filter
matrix[49]………………………………………………………………...38
FIGURE 2.26 Example of dot product in Convolutional operation with image and
filter[48]…………………………………………………………………..39
FIGURE 2.27 Convolutional operation with Stride size of 2[48]………………………...40
FIGURE 2.28 Rectified Linear Unit (ReLU) Activation function[49]…………………...41
FIGURE 2.29 Rectified Linear Unit (ReLU) operation[48]……………………………...41
FIGURE 2.30 Example of Max pooling and Average pooling operations[48]………..…42

xxix
FIGURE 2.31 Example of Flattening operation converting into a single vector[47]…….43
FIGURE 2.32 Representation of features at different stages in the network[48]………...44
FIGURE 2.33 Conceptual diagram of transfer learning where learning of a new task relies
on the previously learned task[53]……………………………………….45
FIGURE 2.34 General framework of Multi-Feature-Fusion model[54]………………….47
FIGURE 2.35 Framework of Inter-layer Feature-Fusion process[54]…………………....47
FIGURE 2.36 Framework of Ensemble Multi-CNN feature-fusion-based approach[56]..48
FIGURE 4.1 Two 3x3 convolutions replacing one 5x5 convolution[130]……………….70
FIGURE 4.2 Basic Inception Module (naïve version)[132]……………………………...71
FIGURE 4.3 Inception Module with Dimension Reductions[132]……………………….71
FIGURE 4.4 The schematic diagram of Inception-V3 architecture[131]………………...72
FIGURE 4.5 Factorization process of Module A in Inception-V3 architecture[130]…….73
FIGURE 4.6 Factorization process of Module B in Inception-V3 architecture[130]…….73
FIGURE 4.7 Factorization process of Module C in Inception-V3 architecture[130]…….73
FIGURE 4.8 General framwork of Multi-Feature-Fusion model[54]…………………….74
FIGURE 4.9 Framework of Inter-layer Feature-fusion process[54]……………………...74
FIGURE 4.10 Proposed Multi-Layer Feature-Fusion based Classification (MLFFC)
model……………………………………………………………………..75
FIGURE 4.11 Example of images in the CK+ dataset with different emotions[126]……77
FIGURE 4.12 Example of images in the FER2013 dataset with different emotions[135].78
FIGURE 4.13 Confusion matrix using the proposed MLFFCmodel on the CK+ dataset..81
FIGURE 4.14 Classification report for the proposed MLFFC model on theCK+ dataset..82
FIGURE 4.15 ROC-AUC curve on the CK+ dataset for (a) without feature-fusion and (b)
with feature-fusion……………………………………………………….82
FIGURE 4.16 Accuracy graph of the proposed MLFFC model for the CK+ dataset for
batch size 8………………………………………………………..……...83

xxx
FIGURE 4.17 Accuracy graph of the proposed MLFFC model for the CK+ dataset for
batch size 16………………………………………………..…………….83
FIGURE 4.18 Confusion matrix using the proposed MLFFC model on the FER2013
dataset…………………………………………………………………….85
FIGURE 4.19 Classification report for the proposed MLFFC model on the FER2013
dataset…………………………………………………………………….86
FIGURE 4.20 ROC-AUC curve on the FER2013 dataset for (a) without feature-fusion and
(b) with feature-fusion ...…………...…………………………………….86
FIGURE 4.21 Accuracy graph of the proposed MLFFC model for the FER2013 dataset
with batch size 8………………………………………………………….87
FIGURE 4.22 Accuracy graph of the proposed MLFFC model for the FER2013 dataset
with batch size 16………………………………………………………...87
FIGURE 5.1 Sample architecture of Ensemble of Multi-CNN[55]………………………89
FIGURE 5.2 VGG-16 architecture diagram with its layers' details[55]………………….90
FIGURE 5.3 VGG-16 architecture diagram[146]………………………………………...91
FIGURE 5.4 Residual Learning: a building block concept[149]…………………………92
FIGURE 5.5 ResNet architecture diagram comparison to plain network[150]…………..93
FIGURE 5.6 Diagram shwoing conversion of residual block[150]………………………93
FIGURE 5.7 Sample framework of Ensemble of Multi-CNN feature-fusion[126]………94
FIGURE 5.8 Proposed Multi-Model Feature-Fusion based Classification (MMFFC)
model……………………………………………………………………..95
FIGURE 5.9 Example of images in the FER2013 dataset with different emotions[135]...97
FIGURE 5.10 Sample images in the KDEF dataset with different emotions[152]………98
FIGURE 5.11 Confusion matrix using the proposed MMFFC model on the FER2013
dataset…………………………………………………………………...102
FIGURE 5.12 Classification report for the proposed MMFFC model on the FER2013
dataset…………………………………………………………………...103
FIGURE 5.13 ROC-AUC curve on the FER2013 dataset for (a) without multi-model
fusion and (b) with multi-model fusion ………………………………...103

xxxi
FIGURE 5.14 Accuracy graph of the proposed MMFFC model for the FER2013 dataset
for batch size 16………………………………………………………...104
FIGURE 5.15 Accuracy graph of the proposed MMFFC model for the FER2013 dataset
for batch size 32………………………………………………………...104
FIGURE 5.16 Accuracy graph of the proposed MMFFC model for the FER2013 dataset
for batch size 64………………………………………………………...104
FIGURE 5.17 Confusion matrix using the proposed MMFFC model on the KDEF
dataset…………………………………………………………………...106
FIGURE 5.18 Classification report for the proposed MMFFC model on the KDEF
dataset…………………………………………………………………...107
FIGURE 5.19 ROC-AUC curve on the KDEF dataset for (a) without multi-model fusion
and (b) with multi-model fusion ………………………………………..107
FIGURE 5.20 Accuracy graph of the proposed MMFFC model for the KDEF dataset for
batch size 16.……………………………………………………………108
FIGURE 5.21 Accuracy graph of the proposed MMFFC model for the KDEF dataset for
batch size 32.……………………………………………………………108
FIGURE 6.1 ImageNet performance evaluation with other ConvNets[159]……………111
FIGURE 6.2 Model Scaling Approach[159]…………………………………………….112
FIGURE 6.3 Scaling up a Baseline model with different network width (w), depth (d), and
resolution (r) [159]……………………………………………………...113
FIGURE 6.4 A basic block representation of the EfficientNet-B0[161]………………..114
FIGURE 6.5 A basic representation of Depthwise and Pointwise Convolutions in (a) and
(b)[161]………………………………………………………………….115
FIGURE 6.6 Proposed Novel FER model with EfficientNet-B7 and ResNet152
architecture……………………………………………………………...117
FIGURE 6.7 Sample images in the KDEF dataset with different emotions[152]………120
FIGURE 6.8 Example of images in the FER2013 dataset with different emotions[135].121
FIGURE 6.9 Confusion matrix using the proposed novel EfficientNet-B7 model on the
KDEF dataset…………………………………………………………...123
FIGURE 6.10 Classification report for the proposed novel EfficientNet-B7 model on the
KDEF dataset…………………………………………………………...124

xxxii
FIGURE 6.11 Comparative analysis of recognition accuracy on the proposed
EfficientNet-B7 model and ResNet152 architecture by applying different
optimizers……………………………………………………………….124
FIGURE 6.12 Vanishing Gradient Descent problem due to Variance in model loss and
accuracy graph of the proposed EfficientNet-B7 model………………..126
FIGURE 6.13 Sample figure of batch normalization process with N as batch axis, C as the
channel axis and (H,W) as the spatial axes[163]………………………..127
FIGURE 6.14 Resultant smooth curve achieved by applying an Internal Batch
Normalization concept and reducing variance effect…………………...130

xxxiii
List of Tables
TABLE 2.1 Descriptions of seven facial expressions[34]………………………………...21
TABLE 3.1 Performance summary of facial expression recognition using deep-learning-
based approaches…………………………………………………………60
TABLE 3.2 Performance summary of Multi-Layer Feature-Fusion methods using deep
learning techniques……………………………………………………….64
TABLE 3.3 Performance summary of Multi-Layer Feature-Fusion methods using
Ensemble of CNN models using deep learning techniques……………...67
TABLE 4.1 Comparison accuracy on different layers on the proposed MLFFC
architecture……………………………………………………………….79
TABLE 4.2 Results on the CK+ dataset by using and not using feature-fusion approach on
the proposed MLFFC model……………………………………………..80
TABLE 4.3 Comparative analysis of the proposed MLFFC model with state-of-the-art
methods on the CK+ dataset……………………………………………...81
TABLE 4.4 Results on the FER2013 dataset by using and not using feature-fusion
approach on the proposed MLFFC model………………………………..84
TABLE 4.5 Comparative analysis of the proposed MLFFC model with state-of-the-art
methods on the FER2013 dataset………………………………………...85
TABLE 4.6 Comparative analysis of the Error-Rate on both the datasets using the
proposed MLFFC model………………………………………................88
TABLE 5.1 Comparison accuracy on two different CNN architectures using an ensemble
approach………………………………………………………………….99
TABLE 5.2 FER2013 dataset performance for VGG16, ResNet50 and proposed MMFFC
model using ensemble approach………………………………………...101
TABLE 5.3 Comparative analysis of proposed MMFFC model with state-of-the-art
methods on the FER2013 dataset……………………………………….102
TABLE 5.4 KDEF dataset performance for VGG16, ResNet50 and proposed MMFFC
model using an Ensemble approach…………………….………………105
TABLE 5.5 Comparative analysis of the proposed MMFFC model with state-of-the-art
methods on the KDEF dataset…………………………………………..106

xxxiv
TABLE 5.6 Comparative analysis of the Error-Rate on both the datasets using the
proposed MMFFC model…………………………………….................108
TABLE 6.1 EfficientNet-B0 Baseline Network[161]…………………………………...115
TABLE 6.2 Comparative analysis of the proposed EfficientNet-B7 model with
Optimizers………………………………………………………………122
TABLE 6.3 Comparative analysis on ResNet152 CNN architecture with different
Optimizers………………………………………………………………123
TABLE 6.4 Comparative result analysis of the proposed EfficientNet-B7 model with
different optimizers on the FER2013 dataset…………………………...125

1
CHAPTER 1
Introduction
1.1 Overview
Human-computer Interaction (HCI) is playing an essential role in everyone’s day to day
life activities. In this 21st century, we live in a digital world where most of our activities
are accomplished by computer-driven systems. With the rise of Artificial Intelligence (AI)
with its subareas Machine Learning and Deep Learning, the ability to combine intelligent
models with computer vision systems has become a popular way to handle more complex
application areas. One area that has been getting a rising amount of attention is the art of
detecting the emotional state of humans, depending on their faces because of its many
potential applications in today’s world. This task is known as Emotion detection of Facial
Expression Recognition (FER). A system that could automatically recognize human
emotions from their facial expressions could play an essential role in a wide range of
applications such as video games, to identify suspicious person, patient’s painful situation
at hospital, online meeting, E-learning system, music player play songs based on person’s
mood, driver’s tiredness from expressions while driving, robotics, behavioural science,
etc. [1].
FIGURE 1.1 Example of Facial Expression Recognition based on Human-Computer Interaction [15]

2
The human face plays a vital role in interpersonal communication, so understanding
someone’s emotional state through facial expressions becomes easy. Facial Expression
Recognition is the process of identifying a person’s mental state. These expressions are the
limits of a machine to feel emotions, which help to feel a certain kind of situation or action
[2]. Emotions can be described in several ways, but six basic universal expressions
proposed by Ekman et al. [3] are Anger, Disgust, Fear, Happy, Sad and Surprise. Sample
image of these expressions is shown below in figure 1.2. After some time, a neutral
expression is also added in this emotion category and now many facial expression datasets
contain seven facial expressions like Anger, Disgust, Fear, Happy, Neutral, Sad, and
Surprise.
FIGURE 1.2 Different Facial Expressions of one person from the JAFFE dataset [4,14]
In recent years, deep learning strategies have achieved great success as well as achieved
better accuracy than traditional methods due to the inexpensive computational power. One
example called the Convolutional Neural Network (CNN) has obtained excellent state-of-
the-art results in the field of computer vision (e.g., image classification, face recognition,
object detection). Different CNN models have been successfully applied to FER and have
shown better results than conventional methods for their efficiency in feature learning and
representations. A well-designed CNN trained on millions of images can set the parameters

3
of a series of filters, which capture both low-level generic features and high-level semantic
features. In addition, the current Graphics Processing Units (GPUs) accelerate the training
process of deep neural networks to address processing time issues in training and testing
phases. Although human beings can identify facial expressions correctly and effortlessly,
still reliable automatic facial expression recognition by machine is a challenge. Research is
going on to develop more reliable and robust deep learning models for facial expression
recognition. Many researchers are trying to improve the recognition accuracy and improve
the limitations of existing deep learning models [5].
1.2 Research Motivation
Facial Expressions are responses to a person’s internal emotional states, intentions or
social communications and make the other people understand. Facial variation analysis has
gained much attention from the scientific and industrial communities over recent decades
due to its potential value across information security and access control applications,
surveillance and image understanding. Ability to create and understand computers to
distinguish facial expressions and use that information in Human-Computer Interface to
take intelligent decisions by machine has generated considerable research interest in the
research community. If computers can analyze and understand different facial expressions
of a person based on their mood then automatic intelligent decisions can be taken which
will be further helpful in many applications like emergency cases at the hospital, a
student’s engaged time and feedback during online class, identify suspicious persons at
airport or railway stations, etc. [10] Above listed applications are illustrated in figure 1.3,
figure 1.4 and figure 1.5
FIGURE 1.3 Use of Facial Expression Recognition system to identify the suspicious person or criminal at
the airport, railway station or any crowded place [16]

4
FIGURE 1.4 Use of Facial Expression Recognition system to identify students’ engagement level in online
classes [17]
FIGURE 1.5 Use of Facial Expression Recognition system to play songs based on a person’s mood [18]
Automatic human facial expression recognition has been receiving increasing attention from
researchers in the deep learning area, and several solutions have been proposed. Most of the
existing work focused on a single CNN architecture for facial expression database. Rather than
expanding layers in CNN and making it more complex Deep CNN, researchers are dealing
with the concept of fusion of different internal layers and fusion of different models to improve
the recognition accuracy on facial expression database which contains real-world images. Deep
learning techniques are used to automatically extract useful features with the fusion-based
approach, are new active research directions compared with traditional methods for facial
expression recognition [11,12].

5
Deep Learning techniques have been shown to perform well in solving various computer
vision problems, which have not been possible using traditional machine learning techniques.
The application of deep learning techniques has surpassed the accuracy of classical methods in
several computer vision tasks. The advances in faster Graphics Processing Units (GPUs) and
models trained using deep learning in the ImageNet Challenge attract many researchers to
improve existing models’ recognition accuracy by tackling many research challenges.
Therefore, a reasonable approach would be to use a deep learning model to train the automatic
facial expression recognition (AFER) system and improve this task’s accuracy [13]. Motivated
by the above factors and the power of deep learning techniques, this research is carried out
with deep learning techniques to address the challenge of improving recognition accuracy
of lower resolution images for facial expression recognition and enhancing the
performance using a feature-fusion approach.
1.3 Research Challenges
Recognition of expressions done by machine is still considered a challenge in the facial
expression recognition process. Humans can easily analyze and identify the expressions
but for the machines, to identify the expressions more accurately is necessary to further
make intelligent decisions. Many researchers are working to improve the recognition
accuracy of facial expression recognition systems by handling some challenges. Under a
controlled environment, the FER system is working well and no longer a substantial
problem. However, it is still a challenge for machines to make accurate decisions in real-
life scenarios [11].
Instead of being realistic, many datasets on facial expressions appear to have their
expressions acted out. This is a drawback since the real emotion is not fully conveyed, and
thus, when a system is used in the real world, it may fail to properly recognize the realistic
expressions. Facial expression datasets are available in two categories: laboratory trained
facial expression dataset and real-world facial expression datasets. In real-world facial
expression datasets, images are captured in an uncontrolled environment, so it contains
many challenges like illumination variation, occlusions, head pose variations and lower
resolution images. While in the case of laboratory trained facial expression datasets,
images are captured under a controlled environment, so it contains fewer challenges than
the real-world facial expression datasets [13].

6
As facial expressions vary from person to person due to different ages, cultures, and
genders, recognizing emotion from the face is very challenging and another issue in the
facial expression recognition system. Variation of image size, the orientation of face,
glasses or mask on the faces, lightning conditions are the factors that increase the
complexity of the recognition task. Another research challenge is related to the high
similarity between two specific classes of facial expressions, e.g., disgust with anger and
sadness with fear, which leads to misclassification [8,11]. This problem is shown in figure
1.6. Challenges like non-frontal faces, lower resolutions, varying lighting conditions, and
occlusions in the images of facial expression datasets are shown in figure 1.7. Laboratory
trained facial expression dataset where images are taken in a controlled environment is
shown in figure 1.8
(a) Disgust (b) Angry (c) Sadness (d) Fear
FIGURE 1.6 Example of high similarity between facial expressions in two different classes [6,7]
FIGURE 1.7 Example of facial expression images taken in an uncontrolled environment of FER2013 dataset
which contains challenges like varying illumination, head pose variation, lower resolution and occlusion [9]

7
FIGURE 1.8 Examples of laboratory trained facial expression datasets (a) CK+ (b) JAFFE [6,14]
Also, a large amount of training data is required to carry out the feature extraction process
efficiently. A significant challenge that deep FER systems facing is a lack of sufficient
training data in terms of quality and quantity. To overcome the above challenges, robust
and reliable feature extraction techniques are required. Despite CNN’s better performance
on FER systems, still robust FER based on CNN remains a challenging unsolved problem
[12].
1.4 Problem Statement
The key problem to be addressed in this study is to recognize facial expressions more
precisely from the lower resolution images. Facial expression datasets classified into two
categories. First, laboratory trained datasets where images are captured in a controlled
environment. Second, real-world datasets where images are captured under the
uncontrolled open environment. The recognition task becomes more challenging for real-
world datasets due to various challenges like varying illumination, occlusion, head pose
variations, and lower resolution images. Many researchers are trying to improve the
recognition accuracy by tackling these challenges of facial expression datasets using deep
learning techniques. Further, it will enhance the facial expression recognition system’s
performance and make it more accurate to use in different applications. Based on the above
analysis, the problem definition is:
“To develop deep learning models for facial expression recognition using deep
learning techniques to extract unique and distinct features from images for achieving
better recognition accuracy compared to the existing state-of-the-art research work.”

8
1.5 Research Objectives and Scope
The objectives and scope of our research work are as follows:
1.5.1 Research Objectives
• To study and investigate various deep learning methods and models for facial
expression recognition
• To study and investigate existing feature fusion-based techniques used in
convolutional neural networks for improving recognition accuracy of a facial
expression recognition system
• To design and develop effective proposed models for efficient facial expression
recognition using deep learning techniques
• To evaluate and validate the performance of proposed models on laboratory trained
and standard facial expression datasets which contains real-world images
1.5.2 Scope of Research Work
• The proposed research work evaluated on the facial expression datasets contain
images captured in an uncontrolled environment. It includes challenges like
illumination variation, head pose variation, and lower resolution images. Also
evaluated for laboratory trained facial expression dataset contains images captured
in a controlled environment for the cross-database evaluation study.
• In the proposed research work, all the seven facial expressions are considered,
which includes: Happy, Angry, Sad, Neutral, Surprise, Disgust, and Fear. Only
Frontal faces without occlusion have been considered from the facial expression
database for evaluation.

9
• Ensemble of models with feature-fusion deep learning methods applied to carry out
accurate result in terms of classification of the expressions, which will further
enhance recognition accuracy. The most recent EfficientNet architecture applied to
the facial expression dataset improves its recognition accuracy by solving vanishing
gradient descent issue.
1.6 Organization of the Thesis
The contents of the thesis are organized as follows.
Chapter 2 presents an overview of Facial Expression Recognition System, Convolutional
Neural Network (CNN), and about Deep Learning.
Chapter 3 presents a comprehensive literature survey for facial expression recognition
using deep learning techniques with their pros and cons. This chapter also reviews and
analyses multi feature-fusion based deep learning approaches. In addition to this,
information related to facial expression datasets used for this research is described. This
survey helps to identify Research Gap and challenges to do this research. Three types of
algorithms are proposed in the thesis, and each one is explained briefly in chapters 4, 5,
and 6.
Chapter 4 describes the proposed Multi-Layer feature-fusion based Classification
(MLFFC) model using InceptionV3 CNN architecture. Inter-Layer feature fusion
technique has been applied in this model which integrates feature maps from different
layers instead of the last layer consideration. The proposed model is tested on different
internal layers of module C in InceptionV3 architecture as it contains higher feature
representations. It is found that concatenation of the internal layer with the final feature
vector layer improves the recognition accuracy. The standard CK+ and FER2013 datasets
are used to evaluate the proposed model.
Chapter 5 describes the proposed Multi-Model Feature-Fusion based Classification
(MMFFC) model, which uses an Ensemble of CNN model approach. In this model, the
concatenation of features of different layers from various networks helps to overcome the

10
limitation of a single network and produces robust and superior performance. Different
combinations of CNN have been tested for this approach, and finally, an ensemble of
VGG16 and ResNet50 architectures are selected and applied in this proposed model. The
standard KDEF and FER2013 datasets are used to evaluate the proposed model.
Chapter 6 describes the novel concept of EfficientNet architecture. Facial expression
recognition system investigated and implemented using EfficientNetB7 architecture. The
Novel concept of EfficientNet is introduced in 2019 is using the Compound Scaling
method to scale up CNN in a more structured way. From the literature review, it is found
that no work has been carried out for facial expression recognition using this architecture
until date. Different optimizers SGD, RMSProp, and Adam are applied to determine which
optimizer gives better performance in terms of recognition accuracy. Moreover, the
Vanishing Gradient Descent issue is resolved by applying the proposed internal batch
normalization method. This concept works well with higher resolution images, so the
standard KDEF dataset is used to evaluate this model. Also, FER2013 dataset is applied to
a cross-database study.
Chapter 7 contains the conclusion in which the contributions made in this thesis are
summarized, and the scope of further enhancement is outlined.

11
CHAPTER 2
Theoretical Background
2.1 Facial Expression Recognition System
Identifying an individual’s emotion depending on that person’s features is known as a
facial expression recognition system. Using a deep learning approach, the common
approach to facial expression recognition contains three steps: Face Detection, Feature
Extraction and Classification. Figure 2.1 shows the structure of a deep learning-based
facial expression recognition system. [19]
FIGURE 2.1 Conventional Facial Expression Recognition System [37]

12
2.1.1 Pre-processing for Face Detection
The first step in the facial expression recognition system structure is face detection which
is a pre-processing part. In this phase, the main task is to obtain pure facial images with
normalized intensity, uniform size and shape. Pre-process the input image helps to remove
noise - unwanted information and compensate illumination variations if required. For
converting an image into a normalized image for feature extraction task involves steps like
Face Alignment, Data Augmentation and Face Normalization. These steps include
processes like detecting feature points, rotating to line up, locating and cropping the face
region using a rectangle according to the model. [20] Example of Image Rotation, Image
Cropping and Image Intensity Normalization processes are shown in figure 2.2, 2.3 and
2.4, respectively.
FIGURE 2.2 Example of Image Rotation during the pre-processing phase [21]
FIGURE 2.3 Example of Image Cropping during the pre-processing phase [21]

13
FIGURE 2.4 Example of Illustration of the Intensity Normalization during the pre-processing phase [21]
Face detection is one of the most studied topics in computer vision area, not only because
of the challenging nature of face as an object but also due to the many applications that
require the application of face detection as a first step. During the past 15 years,
tremendous progress has been made due to data availability in an unconstrained
environment (so-called ‘in-the-wild’) through the Internet to develop robust facial
expression recognition algorithms using deep learning techniques [22].
Face detection refers to detecting the face region in a frame from images. Viola and Jones
[23] was the first algorithm that made face detection practically feasible in real-world
applications. Instead of working with image intensities, Papageorgiou et al. [24] developed
a framework based on Haar wavelet representation in 1998. Later in 2001, Viola and Jones
further developed this idea by proposing the Haar-like features that represent the changes
of texture or edges of particular facial regions and can be operated much faster than pixels
in the system. Also, OpenCV (Open-Source Computer Vision) library used in processing
the images. It comes with a programming interface to Python. OpenCV-Python used in
many algorithms to detect frontal faces using HaarCascade classifier function from
images. It will detect faces from the images by putting a rectangular box on frontal faces
in the image [25]. As an exercise, a sample image of mine with my friends implemented
using HaarCascade using OpenCV-Python and detected several frontal faces as shown in
figure 2.5

14
FIGURE 2.5 Example of Face Detection carried out on a sample image using OpenCV-Python
2.1.2 Feature Extraction
Feature Extraction usually occurs immediately after face detection. It can be considered
one of the essential stages of facial expression recognition, as their effectiveness depends
on the quality of the extracted features. The changes in the facial expression can be either
based on minor deformations in wrinkles/bulges or based on significant deformations in
eyes, eyebrow, mouth, nose, etc. The feature extraction process is classified as Appearance
based features (non-geometric/non-structural features) and Geometric/Structural based
features as shown in figure 2.6 [26]
FIGURE 2.6 Geometric and Appearance-based Feature Extraction [26]

15
Geometric based features represent the contour and position of face parts like forehead,
eye, nose, lips and chin. These features are extracted from a feature vector which is known
as face geometry. Geometric feature extraction encodes these features using point, stretch,
angle and other geometric relationships among the component. In Appearance-based
feature extraction method, single image filter or a filter bank is applied either on the
complete image or on the part of the image to extract changes in appearance [27].
Feature extraction can be performed using various mathematical models, image processing
techniques and computational intelligence tools such as neural networks of fuzzy logic.
Feature extraction methods are classified into four categories, namely: feature-based,
appearance-based, template-based and part-based approaches, as shown in figure 2.7 [28].
FIGURE 2.7 Classification of different Feature Extraction Methods [28]
Feature extraction may directly influence algorithms’ performance, which is usually the
bottleneck of the facial expression recognition system. Widely used feature extraction
methods in FER systems mainly include Gabor Filter, Local Binary Pattern (LBP), Optical
Flow method, Haar-like feature extraction, Feature point tracking etc.
A. Gabor Filter:
Gabor filters are the set of wavelets. Each wavelet occupies energy at a particular
frequency and particular orientation, expanding a signal using these set of wavelet gives
the localized frequency descriptor and capture feature of the signal. One of Gabor filter
specializations is that the scale of frequency or illumination and orientations property can

16
be tuned, so in many applications where the object of interest may appear at different scale
and pose, Gabor filter using multi-scale and multi-orientation is the most suitable for
feature extraction. Gabor kernel represented as a product of 2D Gaussian Kernel (GK) and
Sinusoidal kernel by equation (2.1) [27]
Where (x,y) is the position in the digital image and , are the standard deviations in x
and y direction respectively, is the project angle and is the opposite of project
frequency. Variables and can be found using the following equation (2.2)
B. Local Binary Pattern (LBP):
The LBP calculates the brightness relationship between each pixel contained in the image
and its local neighbourhood. Binary sequences are then coded to create a local binary
pattern. Finally, it uses a multi-region histogram as a feature description of the image as
shown in figure 2.8 [29]
FIGURE 2.8 Feature Extraction using LBP Histogram Method [29]
LBP operator is used here to take various sizes of pixel location, size of the pixel section is
not limited here, this is formulated as per the below equation (2.3)

17
………. (2.3)
Compared with Gabor wavelet, the LBP operator requires less storage space and higher
computational efficiency. However, the LBP operator is ineffective on the images with
noise.
C. Principal Component Analysis (PCA):
PCA is a transform that chooses a new coordinate system for the dataset such that the
greatest variance by any projection of the dataset comes to reside on the first axis, the
second greatest variance lies on the second axis, and so on. The goal of PCA is to reduce
the dimensionality of the data while retaining as much as the information present in the
original dataset. PCA has the ability to compress the data to lower dimensions by keeping
the most informative dimensions and rejecting the noisy and unnecessary dimensions so
that the data can be fed to machine learning algorithms. As per its name, principal
components are the direction along which most variance in data or the directions where the
data is most spread out, unlike other transform methods. [27,28] PCA will construct a set
of dominant features as per equation (2.4), the condition will contain true for newly
composed dominant feature ( ) is the linear combination of the primary criteria ( )
The dominant feature set is a set of mutually perpendicular axes where the condition will
be given as follows:
D. Discrete Cosine Transform (DCT):
The discrete cosine transform (DCT) is used to transform and compress the train or test
image in the frequency domain without losing the key features in the image or using the
key features. DCT represents the whole image as coefficients of various frequencies of
cosine. In DCT, low-frequency components of an image are extracted as it represents the
higher magnitude and rests high-frequency components are rejected. Low-frequency area
is in the low upper corner of the DCT matrix, and high-frequency coefficients increase
crossways into the lowermost right corner. Numerous techniques can extract low-
frequency areas, but the zigzag selection technique gives efficient selection [27].

18
The 1-Dimensional (1D) DCT is defined as per below equation (2.5):
2-Dimensional (2D) DCT is defined as per below equation (2.6):
E. Optical Flow Method:
Optical flow is the pattern of apparent motion caused by the relative motion. The optical
flow method’s basic principle is that each pixel in an image is assigned to a velocity
vector. These velocity vectors form a motion field for an image. In a motion moment, the
image point corresponds to the actual object point. In the field of FER, the optical method
is widely used to extract facial expression features from dynamic image sequences since it
highlights facial deformation and reflects the motion trend of image sequences as shown in
figure 2.9 [30]
FIGURE 2.9 Two sample facial expressions on the left-hand side and its optical method result available on
the right-hand side [30]

19
F. Feature Point Tracking:
The primary purpose of feature point tracking method is to synthesise the input emotional
expressions according to the displacement of the feature points, as shown in figure 2.10.
The feature point tracking methods often select some feature points with large changes in
the corner eye and mouth corner. Then, following these points will be able to get facial
feature displacement or deformation information [29,30].
FIGURE 2.10 Feature-Point Tracking method used with feature points displacement [29]
G. Feature Extraction in CNN:
In the case of Convolutional Neural Network (CNN), the feature extraction process
includes several convolutional layers followed by max-pooling and an activation function
as per its architecture, as shown in below figure 2.11. All these layers generate feature
maps in the feature extraction process [31].
FIGURE 2.11 Feature extraction process in a Convolutional Neural Network generating feature maps [31]

20
2.1.3 Facial Expression Classification
The last step of the facial expression recognition system is the classification that can be
realized either by attempting recognition or by interpretation. FER deals with the
classification of the face and its features into abstract classes that are entirely based on
visual information. Facial expression classification aims to design an appropriate
classification mechanism to identify facial expression. Earlier facial expressions were
categorized into six basic emotions: Disgust, Anger, Fear, Surprise, Happy and Sad. But
after some time, many of the recent research work includes Neutral expression in this list.
Hence facial expressions are categorized into seven basic emotions: Disgust, Anger, Fear,
Neutral, Surprise, Happy and Sad. Example of seven basic emotions is shown in figure
2.12 [33].
FIGURE 2.12 Example of Seven basic Facial Expressions from CK+ dataset [32]
To identify the above listed facial expressions, a process must be able to recognize facial
feature movements. According to these different emotions will be classified into seven
categories as mentioned in below table 2.1

21
TABLE 2.1 Descriptions of seven facial expressions [34]
Emotion Class Description of Facial Expressions
Happy Eyebrows are relaxed. The Mouth is open, and Mouth corners are
upturned.
Sad Eyes are slightly closed. Eyebrows are bent upward, and Mouth is
relaxed.
Fear Eyebrows are raised and pulled together. Eyes are open and
tensed.
Anger Eyebrows are pulled downward and together. Eyes are wide open,
and lips are tightly closed.
Surprise Eyebrows are raised. Eyes are wide open, and Mouth is open.
Disgust Eyebrows and eyelids are relaxed. The Upper lip is raised and
curled, often asymmetrically.
Neutral Eyebrows, Eyes and Mouth, are relaxed.
Some of the most relevant classification methods are Support Vector Machine (SVM),
AdaBoost Method, K-Nearest-Neighbor (KNN), Hidden Markov Model (HMM),
Bayesian Classification etc. explained below [30]
A. Hidden Markov Model (HMM):
Hidden Markov Model (HMM) is a Markov process containing hidden, unknown
parameters and can effectively describe the statistical model of the random signal
information. HMM consists of two interrelated processes. One is the underlying and
unobservable Markov chain with a certain number of states. The other is a set of
probability density distribution corresponding to each state [30]. The following triplet can
define an HMM:
Where A is the state transition probability matrix, B is the observation probability
distribution, and π is the initial state distribution. In a discrete density HMM, B represents
a matrix of probability entries. In a continuous density HMM, B is denoted by the
parameters of the probability distribution function of observations such as the Gaussian
distribution function or a mixture of Gaussians. HMM-based face recognition methods

22
have the following advantages: they allow expression changes and large head rotation, do
not need to retrain all the samples after adding new samples, but part of parameters are
given by experience [35].
B. Bayesian Network:
A Bayesian network is a probabilistic graphical model based on the Bayesian formula and
presents random variables via directed acyclic graphs. Bayesian network based on the
probabilistic reasoning is developed to solve the uncertainty and incompleteness problem.
A Bayesian classifier represents the dependencies among feature data and sample labels by
using a directed acyclic graph. Generally, Bayesian Network classifiers can be learned
using a fixed structure – the naïve-Bayes classifier [30].
Given a Bayesian Network classifier with a parameter set Ɵ, the optimizing classification
rule based on the maximum likelihood idea to classify an observed feature vector
with n dimension, to one of | C | class labels, c {1,2, …., |C|}, is denoted by [30]:
The Bayesian network can improve the classification accuracy. Still, it requires many
parameters that human experiences give part of them, and the estimated result deviates
from the actual result if the number of training samples is small [35].
C. K-Nearest Neighbor (KNN):
KNN is a type of instance-based learning classification algorithm. The KNN method
principle is that in the feature space one sample has k-closest samples, and its label is
assigned to the class most common among its KNNs by using a majority vote of its
neighbours. Without prior knowledge, the KNN classification algorithm frequently
employs the Euclidean distance as the distance metric [30]. Given two vectors
and their Euclidean distance is given as:

23
D. Support Vector Machine (SVM):
Support Vector machine method is based on the structural risk minimization principle for
classification method. It constructs a hyperplane or set of hyperplanes in a high or infinite-
dimensional space. Training data points are marked as belonging to one of the categories
with the most considerable distance to other categories [35]. The principle of SVM is to
transform the input vectors to a higher dimensional space by a non-linear transform. Then
an optimal hyperplane which separates the data can be found [30].
SVM algorithm helps to find the best line or decision boundary; this best boundary or
region is called a Hyperplane. SVM algorithm finds the closest point of the lines from
both the classes. These points are called support vectors. The distance between the vectors
and the hyperplane is called as margin, and the goal of SVM is to maximize the margin.
The hyperplane with maximum margin is known as Optimal hyperplane as shown in
below figure 2.13 [36]
FIGURE 2.13 Example of Support vector and hyperplane in the SVM method [36]

24
There are four types of kernel functions for the SVM model, such as the linear kernel, the
polynomial kernel, the radial basis function kernel and the sigmoid kernel mentioned
below: [30]
The linear kernel function is given as:
The polynomial kernel function is given as:
The radial basis kernel function is given as:
The sigmoid kernel function is given as:
E. Adaboost Algorithm Method:
The core idea of Adaboost is combining weak classifiers together to a more robust final
classifier by changing the distribution of data. One of the researchers has proposed a
classification method based on the Adaboost algorithm, where Haar features were used to
construct a weak classifier space and got a facial expression classifier using continuous
Adaboost algorithm for learning. This method concludes that this algorithm is faster
compared to the support vector machine. However, research also shows that this
classification method is not suitable for small samples [35].
F. Classification using Artificial Neural Network:
Artificial Neural Network (ANN) system is an algebra arithmetic system about
information processing simulated human brain neural system. It is a flexible mathematical
structure which can distinguish complex nonlinear relationships between input data and
output data. A neuron in an artificial neural network is defined as a set of input values and
associated weights. A training function adds the weights and associates the results to output. In
general, three layers are configured for neural network structure for organizing neurons that
are input layer, hidden layer and output layer. The input layer comprises the value of records
that are to be given as inputs to the next layer of neurons. The hidden layer is the next layer.
One Neural network may consist of several hidden layers. Then the number of hidden layers
can vary based on the application. The output layer is the final layer, where each node is

25
available for each class. Artificial Neural network has the advantage of the high-speed ability
due to its parallel processing mechanism; its distributed storage leads to the ability to recover
feature extraction and have a self-learning function, while it’s high parallelism non-linear
characteristic limit development to some degree [35,30].
2.2 Deep Learning for Facial Expression Recognition
2.2.1 Evolution of AI: Machine Learning and Deep Learning
Artificial Intelligence (AI) is the just as the word implies, the intelligence is artificial,
programmed by humans to perform human activities. This artificial intelligence is
incorporated into computer systems to create AI systems that ultimately function as units
of “thinking machine”. Humans design AI systems to make decisions from historical or
real-time data or both. AI systems have the ability to learn and adapt as they compile
information and make decisions. AI systems often incorporate machine learning, deep
learning and data analytics with artificial intelligence that enable intelligent decision
making. This intelligence is not human intelligence. It’s the machine’s best approximation
to human intelligence [38].
FIGURE 2.14 Evolution of Artificial Intelligence (AI) [38]

26
As shown in figure 2.14, Machine learning is a subset of AI, which implies for the fact
that we can build intelligent machines that can learn based on a provided dataset on its
own. Further, you will notice that Deep learning is a subset of Machine Learning where
similar machine learning algorithms are used to train Deep Neural Networks to achieve
better accuracy in those cases where former was not performing up to the mark.
Machine Learning:
It is an application of artificial intelligence that provides the AI system with the ability to
learn from the environment and applies that learning to make better decisions. In order to
do this effectively, there are three categories of machine learning algorithms that make this
possible known as Supervised Machine Learning, Unsupervised Machine Learning, and
Reinforcement Learning explained here [39]. A variety of algorithms that machine
learning uses to iteratively learn, describe and improve data to predict better outcomes.
These algorithms use statistical techniques to spot patterns and then perform actions on
these patterns.
Supervised Machine Learning: “Supervised” means that a teacher helps the program
throughout the training process: there is a training set with labelled data. For example, you
want to teach the computer to put red, blue and green socks into different baskets. First,
you show to the system each of the objects and tells what is what. Then, run the program
on a validation set that checks whether the learned function was correct or not. This type
of learning is commonly used for classification and regression. This method’s algorithms
are Naïve Bayes, Support Vector Machine, Decision Tree, K-Nearest Neighbours, Logistic
Regression, Linear and Polynomial regression etc.
Unsupervised Machine Learning: In unsupervised learning, you do not provide any
features to the program to search for patterns independently. Imagine you have a big
laundry basket that the computer has to separate into different categories: socks, t-shirts,
jeans etc. This is called Clustering, and unsupervised learning is often used to divide data
into groups by similarity. Unsupervised learning is also suitable for insightful data
analytics. For example, it can be used to find fraudulent transactions, forecast sales and
discounts or analyze customer’s preferences based on their search history. The
programmer does not know what they are trying to find, but there are indeed some
patterns, and the system can detect them. This method’s algorithms are K-means

27
clustering, DBSCAN, Mean-Shift, Principal Component Analysis (PCA), Singular Value
Decomposition (SVD) etc.
Reinforcement Learning: This is very similar to how humans learn: through trial.
Humans don’t need constant supervision to learn effectively, like in supervised learning.
By only receiving positive or negative reinforcement signals in response to our actions,
still, learn effectively. For example, a child learns not to touch a hot pan after feeling pain.
One of the essential parts of reinforcement learning is that it allows you to step away from
training on static datasets. Instead, the computer can learn in a dynamic, noisy
environment such as the real world. Algorithms used for these methods are for self-driving
cars, games, robots, resource management etc.
Deep Learning:
Deep learning is a subset of Machine learning. Deep Learning models can make their own
predictions entirely independent of humans. Machine learning models of the past still need
human intervention in many cases to arrive at the optimal outcome. Deep learning models
used for artificial neural networks. The design of this network is inspired by the biological
neural network of the human brain. It analyses the data with a logical structure similar to
how a human would conclude, as shown in below figure 2.15.
FIGURE 2.15 Working Methodology difference between Machine Learning and Deep Learning [39]

28
Deep learning is the next generation of machine learning algorithms that use multiple
layers to extract higher-level features from raw input. For instance, in image recognition
applications, instead of just recognizing matrix pixels, deep learning algorithms will
recognize edges at a certain level, nose at another level, and face at yet another level. With
the ability to understand data from the lower level all the way up the chain, a deep learning
algorithm can improve its performance over time and arrive at decisions at any given
moment in time.
Deep learning algorithms use complex multi-layered neural networks, where the level of
abstraction increases gradually by non-linear transformations of input data. In a neural
network, the information is transferred from one layer to another over connecting
channels, and they are known as weighted channels because each of them has a value
attached to it. All neurons have a unique number called bias. This bias added to the
weighted sum of inputs reaching the neuron is then applied to the activation function. The
result of the function determines if the neuron gets activated. Every activated neuron
passes on information to the following layers. This continues up to the second last layer.
The output layer in an artificial neural network is the final layer that produces outputs for
the program.
Most deep learning methods use neural network architectures, so deep learning models are
often referred to as Deep Neural Networks. The term “deep” usually refers to the number
of hidden layers in the neural network, as shown in figure 2.16. Traditional neural
networks only contain 2-3 hidden layers, while deep networks can have as many as 150.
Deep learning models are trained by using large sets of labelled data and neural network
architectures that learn features directly from the data without the need for manual feature
extraction.
FIGURE 2.16 Basic Structure of Neural Networks with Input, Hidden and Output layers [39]

29
2.2.2 Deep Neural Networks:
A Deep Neural Network (DNN) is an artificial neural network (ANN) with multiple
hidden layers of units between the input and output layers. Similar to shallow ANNs,
DNNs can model complex non-linear relationships. DNNs are typically designed as Feed
Forward Networks. Data flows from the input layer to the output layer without going
backwards. The links between the layers are one way which is in the forward direction,
and they never touch a node again. Different architectures have been developed to solve
problems in various domains or use-cases. E.g., CNN is used most of the time in computer
vision and image recognition, and RNN is commonly used in time series
problems/forecasting. More recently, CNNs have been applied to acoustic modelling for
Automatic Speech recognition, where they have shown success over previous models [40].
Different architectures are designed and developed as a part of deep neural networks
shown in figure 2.17. From which, below are the most common architectures of deep
neural networks:
1. Convolutional Neural Network (CNN)
2. Deep Auto Encoder (DAE)
3. Restricted Boltzmann Machine (RBM)
4. Deep Belief Network (DBN)
5. Recurrent Neural Network (RNN)
6. Long Short-Term Memory (LSTM)
2.2.2.1 Convolutional Neural Networks (CNN):
Convolutional Neural Networks (CNN) have broad applications in video and image
recognition, natural language processing, speech recognition, and computer vision
including Facial Expression Recognition. From several studies, it is found that CNN is
robust to face location changes and scale variations and behaves better than the multi-layer
perceptron (MLP) in the case of previously unseen face pose variations. CNN have several
advantages over DNN including the very similarity of the human visual processing
system, which is well adapted to the structure of 2D and 3D image processing, and the
effective learning and extraction of 2D features [41].

30
FIGURE 2.17 Basic CNN Architecture [41]
As shown in figure 2.17, CNN has three types of different layers: convolutional layers,
pooling layers, and fully connected layers. The convolutional layer has a collection of
learnable filters to convolve through the whole input image and produce various specific
types of activation feature maps. The convolution operation is associated with three main
advantages: local connectivity which learns correlations among neighbouring pixels;
weight sharing in the same feature map which significantly reduces the number of the
parameters to be learned; and shift-invariance to the location of the object. The pooling
layer follows the convolutional layer and is used to reduce the spatial size of the feature
maps and the network’s computational cost. Average pooling and max pooling are the two
most commonly used nonlinear down-sampling strategies for translation invariance. The
fully connected layer is usually included at the end of the network to ensure that all
neurons in the layer are fully connected to activations in the previous layer and to enable
2D feature maps to be converted to 1D feature maps for further feature representation and
classification [11].
A significant advantage of CNN over conventional approaches is its ability to concurrently
extract features, reduce data dimensionality, and capability to classify in one network
structure. Additionally, the CNN technique requires only minimal image processing due to
CNN’s robust ability to minimize noise during image acquisition [41].

31
2.2.2.2 Deep Autoencoder (DAE):
Autoencoders are neural networks that are used to reduce the dimensionality of datasets.
They are implemented in an unsupervised fashion to generate only a representation of the
dataset within their hidden layer neurons, also called the latent vector. Taking the same set
of values for both input and output of the network, an autoencoder learns to reduce a
dataset into a representation state and learns how to reconstruct the data sample to its
original form from the learned representations [43].
FIGURE 2.18 Basic Structure of Deep Autoencoders (DAE) [44]
Deep Autoencoder (DAE) was introduced to learn efficient coding for dimensionality
reduction. Figure 2.18 represents the structure of DAE which is composed of Encoder,
Decoder and Bottleneck layer. It reconstructs the original input image from the noisy
image conversion. It extracts only the features of an image and produces the output by
eliminating any disturbance or unnecessary noise in the system. The code layer, also
known as the “bottleneck” of the network presents the compressed image inputted into the
decoder. The decoder layer translates the encoder image (noisy image) back to its original

32
dimension (denoised image). Deep sparse autoencoder extracts low dimensional features
that efficiently represent human activity or movement, from data of human action or
motion with high dimensional [41].
2.2.2.3 Restricted Boltzmann Machine (RBM):
Restricted Boltzmann Machine is an artificial neural network where the unsupervised
learning algorithm can apply to build non-linear generative models from unlabelled data.
The goal is to train the network to increase the probability of vector in the visible units to
probabilistically reconstruct the input. It learns the probability distribution over its inputs.
As shown in figure 2.19, RBM is made of a two-layered network called the visible and
hidden layers. Each unit in the visible layer is connected to all units in the hidden layer,
and there are no connections between the units in the same layer [45].
FIGURE 2.19 Basic Structure of Restricted Boltzmann Machine (RBM) [45]
2.2.2.4 Deep Belief Network (DBN):
The DBN is a typical network architecture but includes a novel training algorithm. The
DBN is a multilayer network (typically deep, including many hidden layers) in which each
pair of connected layers is a restricted Boltzmann machine (RBM). In this way, a DBN is
represented as a stack of RBMs. In the DBN, the input layer represents the raw sensory
inputs, and each hidden layer learns abstract representations of this input. The output layer,

33
which is treated somewhat differently than the other layers, implements the network
classification. Training occurs in two steps: unsupervised pretraining and supervised fine-
tuning.
FIGURE 2.20 Basic Structure of Deep Belief Network (DBN) [46]
In unsupervised pretraining, each RBM is trained to reconstruct its input. The next RBM is
trained similarly, but the first hidden layer is treated as the input (or visible) layer, and the
RBM is trained by using the outputs of the first hidden layer as the inputs. This process
continues until each layer is pre-trained. When the pretraining is complete, fine-tuning
begins. In this phase, the output nodes are applied labels to give them meaning [46].
2.2.2.5 Recurrent Neural Network (RNN):
RNNs are a type of artificial neural network that includes a recurrent layer. The difference
of a recurrent layer from a regular fully-connected hidden layer s that neurons within a
recurrent layer could be connected to each other. In other words, the output of a neuron is
conveyed both to the neuron(s) within the next layer and to the next neuron within the
same layer. Using this mechanism, RNNs can carry information learned within a neuron to

34
the next neuron in the same layer. The traditional neural networks and CNN models
cannot remember any information from the past, as they do not contain any memory cell.
The RNN architecture has an internal memory such as the hidden state to store the
sequential input’s temporal dynamics, as shown in figure 2.22. The RNN model can
predict the class label based on the sequence of the previous context information. The
RNN maps the input data to a hidden state and hidden state data to the output, as shown in
figure 2.21 for sequence learning in the temporal domain [43]. These mappings are
mathematically expressed as:
Where is the input at time t, is the hidden state at time t, is the hidden state at
time t-1, is a non-linear function such as sigmoid, rectified linear unit or a hyperbolic
tangent and is the output at time t. is the weight matrix from the input to hidden
state, is the weight matrix from hidden to hidden and at last and are bias units
of hidden state and output state respectively.
FIGURE 2.21 The Schematic diagram of RNN Node [43]

35
FIGURE 2.22 Basic Structure of Recurrent Neural Network (RNN) [43]
2.2.2.6 Long Short-Term Memory (LSTM):
LSTM is an implementation of the Recurrent Neural Network. Unlike the earlier described
feed-forward network architectures, LSTM can retain the knowledge of previous states
and can be trained for work that requires memory or state awareness. LSTM partly
addresses a major limitation of RNN, i.e., the problem of vanishing gradients by letting
gradients to pass unaltered. As shown in figure 2.23, LSTM consists of blocks of memory
cell state through which signal flows while being regulated by input, forget and output
gates. These gates control what is stored, read and written on the cell [45].
In figure 2.23, C, , h represents a cell, input and output values. Subscript t denotes time
stamp value, i.e., t-1 is from previous LSTM block, and t indicates current block values.
The symbol is the sigmoid function and is the hyperbolic tangent function.
Operator + is the elementwise summation and x is the element-wise multiplication. The
computations of the gates are described in the below equations [45]:

36
where f, i, o are the forget, input and output gate vectors respectively. W, w, b and
represents weights of input, weights of recurrent output, bias and element-wise
multiplication respectively. There is a similar variation of the LSTM known as gated
recurrent units (GRU). GRUs are smaller in size than LSTM as they don’t include the
output gate, and perform better than LSTM on only some simpler datasets.
LSTM recurrent neural networks can keep track of long-term dependencies. So, they are
great for learning from sequence input data and building models that rely on context and
earlier states. The cell block of LSTM retains pertinent information of previous states. The
input, forget and output gates dictate new data going into the cell, what remains in the cell
and the cell values used to calculate the output of the LSTM block respectively [45].
FIGURE 2.23 The Schematic diagram of LSTM block with memory cell and gates [45]

37
2.3 Convolutional Neural Network (CNN):
Convolutional Neural Network (CNN) is one of the variants of neural networks used
heavily in the field of Computer Vision. It derives its name from the type of hidden layers
it consists of. In neural networks, Convolutional neural network (ConvNets or CNNs) is
one of the main categories to do image recognition, image classifications, object
detections, face recognitions etc. are some of the areas where CNNs are widely used.
Convolutional neural network (CNN) is a supervised learning method that can perform the
feature extraction and classification process simultaneously and can automatically
discover the multiple levels of representations in data, which has been widely used in the
field of computer vision [47]. The general structure of the basic CNN model is shown in
below figure 2.24
FIGURE 2.24 General CNN structure in facial expression recognition system [47]
The reason for the increasing popularity of CNNs may arise from its ability to learn and
extract features directly from raw input data (even distorted images) that conventional
machine learning and computer vision techniques require for manually extracted features.
CNNs combine the three steps of facial expression recognition (feature learning, feature
selection and feature classification) into one step and require minimal pre-processing.
Also, with the advantage of the graphical processing unit (GPU) technology, tasks that
require intensive computation can achieve promising results at low power consumption.
The CNNs gain the advantage by automatically learning features representation without
depending on human-crafted features using end-to-end system starting from raw pixels to
classifier outputs. Researchers focus on improving the performance of CNNs architecture
and methods such as layer design, activation function, regularization and exploring the
performance in different fields [11].

38
As shown in figure 2.24, CNN consists of an input and output layer and multiple hidden
layers. The hidden layers of a CNN typically consist of Convolutional layers, Pooling
layers, Fully connected layers and normalization layers.
2.3.1 Convolutional Layer:
The convolutional layer is the core building block of a CNN. Convolution is the first layer
to extract features from an input image that convolves the pixels of an input image with
the locally connected small area called the neuron’s respective field. In the CNN
terminology, this respective field is also called ‘kernel’ or ‘filter’ working as a feature
detector. The resulting dot product is the so-called ‘feature-map’ obtained by sliding these
filters over images. Every neuron shares a fixed set of weights with the respective fields in
a locally connected layer, which is called the weight-sharing scheme. A mathematical
operation that takes two inputs: image matrix and a filter or kernel, as shown in figure
2.25. [48]
FIGURE 2.25 Convolutional operation with Image matrix multiplies kernel or filter matrix [49]
This layer aims to figure out features in the image, for instance, the vertical/horizontal
edges, gradients, etc. In order to have multiple features examined, there will be various
different filters. Together, they will form the output of the neurons that are connected to
local regions in the input. In other words, the output after this layer is the features

39
extracted from the input of regions in the images. To get the result, dot-product is
performed between the Conv-Layer and the input layer, as shown in figure 2.26.
FIGURE 2.26 Example of Dot product in Convolutional operation with image and filter [48]
Mathematically, a convolution of two functions f and g is defined as:
which is nothing but dot product of the input function and a kernel function. Convolution
of an image with different filters can perform operations such as edge detection, blur and
sharpen by applying filters. The Conv-Layer will move step by step from left to right, top
to bottom on the input. At each stage, it will move by a number of Strides that was
specified.
Strides:
Stride is the number of pixels shifts over the input matrix. When the stride is 1 then it
moves the filters to 1 pixel at a time. When the stride is 2 then it moves the filters to 2
pixels at a time and so on. Below figure 2.27 shows convolution would work with a stride
of 2.

40
FIGURE 2.27 Convolution operation with Stride size of 2 [48]
Padding:
Sometimes filter does not fit perfectly fit the input image. Two options are available in this
case: One option is padding the picture with Zeros (Zero-Padding), and the other option is
Drop the part of the image where the filter did not fit it. Zero-Padding will pad the input
volume with zeros around the border. The nice feature of zero-padding is that it allows us
to control the size of the output. If the output size is the same as the input, we call this
padding same. If they are not the same, we call the padding valid. Then, the size of the
output layer will be calculated according to the below formula [49]:
where N is the input layer’s size, F is the size of the Conv-Layer, P is the number of zero-
padding is used, and S is the number of Strides. After performing Convolution, it will
activate the output according to the activation function. ReLU (Rectified Linear Unit) is
widely used at this step. This step can be combined with the Conv-Layer and form a single
step Convolution+ReLU
Non-Linearity (ReLU):
ReLU stands for Rectified Linear Unit for a non-linear operation. The output formula is
f(x) = max(0,x) as shown in figure 2.28.

41
FIGURE 2.28 Rectified Linear Unit (ReLU) Activation function [49]
ReLU’s purpose is to introduce non-linearity in ConvNet. Since the real-world data would
want ConvNet to learn would be non-negative linear values, as shown in figure 2.29.
There are other non-linear functions such as tanh or sigmoid that can also be used instead
of ReLU. Most of the researchers use ReLU since performance-wise ReLU is better than
the other two.
FIGURE 2.29 Rectified Linear Unit (ReLU) Operation [48]

42
2.3.2 Pooling Layer:
Sometimes when the images are too large, it is required to reduce the number of trainable
parameters. It is then desired to periodically introduce pooling layers between subsequent
convolution layers. Pooling is done for the sole purpose of reducing the spatial size of the
image. Pooling is done independently on each depth dimension; therefore, the depth of the
image remains unchanged. Spatial pooling is also called subsampling or down-sampling,
which reduces the size of each map but retains important information. Spatial pooling can
be of different types: Max Pooling, Average Pooling, Sum Pooling.
Max pooling takes the largest element from the rectified feature map. Finding and taking
the average value of the given elements is known as Average pooling. Sum of all elements
in the feature map call as Sum pooling. Example of Max pooling and Average pooling is
shown in below figure 2.30 [49]
FIGURE 2.30 Example of Max Pooling and Average Pooling operations [48]

43
The pooling operation has two advantages: the first being helping prevent the model from
over-fitting by providing as it makes an abstraction of the input volume. And the second, it
reduces the input volume hence reducing the number of learnable parameters and saving
computation resources.
2.3.3 Fully Connected Layer:
Fully connected layers are an essential component of CNN, which have been proven very
successful in recognizing and classifying images. The CNN process begins with
convolution and pooling, breaking down the image into features, and analyzing them
independently. The result of this process feeds into a fully connected neural network
structure that drives the final classification decision. The input to the fully connected layer
is the output from the final pooling or convolution layer, “Flattens” them and turns them
into a single vector that can be an input for the next stage. Below figure 2.31 shows
Flattening operation, which converts into a single feature vector [49].
FIGURE 2.31 Example of Flattening operation which will convert into a single vector [47]
After passing through the fully connected layers, the final layer uses the SoftMax
activation function to get probabilities of the input being in a particular class which is
known as Classification which classifies the outputs into the required label.

44
Convolution Neural Network made up of CONV, POOL and FC layers. These layers are
often stacked together follow the pattern:
INPUT [CONV RELU CONV RELU POOL] * 3 [FC + RELU]
* 2 FC
Here a pooling layer after two Conv-Layers which is a good idea for more extensive and
deeper networks. The idea of a more extensive and deeper network is that it will try to
extract small features related to the picture in the early layer. Later, when going more in-
depth, these features will gradually create bigger ones and have more meanings as shown
in below figure 2.32
FIGURE 2.32 Representation of features at different stages in the network [48]
2.3.4 Transfer Learning:
Transfer learning is a machine learning technique whereby a model is trained and
developed for one task and is then re-used on a second related task. In some cases where
the problem domain is similar, and the training dataset is too small, transfer learning can
be used instead of constructing a new model. Using transfer learning, one can use a pre-
defined model that is already trained on a dataset, and instead of retrieving the original
model. Transfer learning is usually applied when a new dataset is smaller than the original
dataset used to train the pre-trained model [50].
A good way to define transfer learning is to look at the student-teacher relationship. The
teacher offers a course after gathering details knowledge regarding that subject. Details
will be conveyed through a series of lectures over time. This can be considered that the
teacher (expert) is transferring information (knowledge) to the students (learner). The
same thing happens when it comes to deep learning, a network is trained with a significant

45
amount of data, and during the training, the model learns the weights and bias. These
weights can be transferred to other networks for testing or retraining a similar new model.
The network can start with pre-trained weights instead of training from scratch [42].
The basic premise of transfer learning is simple: take a model trained on a large dataset
and transfer knowledge to a smaller dataset. For object recognition or image recognition
with a CNN, freeze the early convolutional layers of the network and only train the last
few layers which make a prediction. The idea is the convolutional layers extract general,
low-level features that are applicable across images – such as edges, patterns, gradients –
and the later layers identify specific features within an image such as eyes or wheels [51].
The conceptual diagram for transfer learning method is shown in figure 2.33
FIGURE 2.33 Conceptual diagram of Transfer Learning where learning of a new task relies on the
previously learned task [53]

46
Regarding the initial training, transfer learning allows us to start with the learned features
on the ImageNet dataset and adjust these features and perhaps the model’s structure to suit
the new dataset instead of beginning the learning process on the data from scratch with
random weight initialization. TensorFlow is used to facilitate the transfer learning of the
new CNN pre-trained model [52].
Following is the general outline for transfer learning for object/image recognition [51]:
1. Load in a pre-trained CNN model trained on a large dataset
2. Freeze parameters (weights) in the model’s lower convolutional layers
3. Add custom classifier with several layers of trainable parameters to model
4. Train classifier layers on training data available for the task
5. Fine-tune hyperparameters and unfreeze more layers needed
2.4 Fusion Approach in Convolutional Neural Network:
CNN consists of the convolution layer, pooling layer and full-connection layer. The
number of different layers varies in amount. Each layer deals with the previous layer’s
output and then delivers the result to the next layer in order. In other words, the features
extracted by different layers become closer to the semantic information from the shallow
layer to deep layer. CNN provides an effective way between raw data and abstract
representation and is widely used for different given problems by combining many
operations, including deeper layers. From the literature review, two essential fusion
approaches were found for our proposed models: Multi-Feature fusion-based approach,
Ensemble (fusion) of multi-CNN feature fusion-based approach.
2.4.1 Multi-Feature Fusion-based Approach:
Most works deliver the feature maps of the last layer into the classifier, and few pay
attentions to feature information contained in additional layers. In fact, the feature
information hidden in different layers has the potential for feature discrimination capacity.
Therefore, many researchers tried to implement a fusion-based approach for feature
extraction from different CNN layers, which contains various properties. This approach
integrates feature maps from different layers in CNN instead of the last layer only. Results
show performance improvement in recognition accuracy of the model with this fusion of

47
features approach. But this approach usually uses the features with the same size, which
limit the effect of feature fusion. A framework of the multi-layers feature-fusion is shown
in figure 2.34 [54]
FIGURE 2.34 General Framework of Multi Feature-Fusion model [54]
As shown in figure 2.34, multi-layer feature fusion method simplifies the general structure
of CNN where features are extracted from different intermediate layers to achieve fusion
of these features at the fusion module. Further, it will be provided to fully connected layer
and classifier respectively to complete the recognition task. Instead of generating a feature
map at the final layer in CNN, here features from different intermediate layers are
extracted and finally concatenated as a fusion approach in fusion module to generate the
final feature map. This process is also known as Inter-Layer Feature Fusion approach, as
shown in figure 2.35. This approach gives the advantage to extract and merge different
features taken from different layers before providing to the final layer, which will help to
improve the recognition accuracy of a model for the given problem [54].
FIGURE 2.35 Framework of Inter-Layer Feature-Fusion process [54]

48
In a concatenation of features process as a part of a fusion approach, the concatenation
process usually designates a consolidated dimension to implement fusion. The principle of
the concatenation process is shown in the below formula: [54]
Where Xk is a set of output feature maps of one layer and k refers to the index of the layer.
From the above formula, each X has unique features and Zconcat can be regarded as a
fusion set with all the features. This denotes Zconcat increases the feature diversity, and
then, classifier gets more features instead of only the feature map of the last layer.
Therefore, the essence of the concatenation process is enriching feature diversity to make
classifier obtain better recognition ability.
2.4.2 Ensemble of Multi-CNN Feature Fusion-based Approach:
Convolution Neural Networks (CNN) are becoming increasingly popular in large-scale
image recognition and classification process. Existing CNN models use the single model
to extract the features but recognition accuracy is not adequate for real-time applications.
Therefore, many researchers have tried to implement ensemble of CNN models’ concept
for feature fusion in facial expression recognition to improve the recognition accuracy. In
the Ensemble of CNN concept, concatenation of layers from different CNN architecture is
carried out and finally generated a feature vector. Concatenating features from various
layers of various networks helps to overcome the limitations of a single network and
produced robust and superior performance. A Framework of Ensemble of Multi-CNN
feature fusion-based approach is shown in figure 2.36 [56]
FIGURE 2.36 Framework of Ensemble of Multi-CNN feature fusion-based approach [56]

49
In this concept, there are two possibilities of the feature-fusion process: One is to do
concatenate of two final feature vectors generated from two different CNN architectures
by providing the same input images to both the architectures. Another is to extract features
from different CNN architectures and concatenate them as a feature fusion-based
approach. After doing feature-fusion by any of the above methods, further, it will be
provided to fully connected layer and classification respectively to complete the
recognition process. This approach improves classification performance but complexity is
the major issue for implementing this approach [55].

50
CHAPTER 3
Literature Review
3.1 Overview
This research concerns about the recognition system by identifying facial expressions from
images by applying ensemble and fusion of features using deep learning techniques. Over
the last years, various methods have been proposed for facial expression recognition in
images. In this chapter, the literature review carried out for various conventional
approaches and deep learning-based approaches for facial expression recognition. Also,
the literature review is carried out for multi-feature fusion using two different methods
which are used in our research work: Multi-Feature Fusion based approach in a single
model and Multi-Feature Fusion by an ensemble of different models. A notable
characteristic of the conventional FER approach is that it is highly dependent on mutual
feature engineering. The researchers need to pre-process the image and select the
appropriate feature extraction and classification method for the target dataset. The
conventional FER procedure can be divided into three major steps: image pre-processing,
feature extraction and feature classification. Deep Learning has demonstrated outstanding
performance in many machine learning tasks including identification, classification and
target detection. In terms of FER, deep learning-based approaches highly reduce the
reliance on image pre-processing and feature extraction. They are more robust to the
environments with different elements, e.g., illumination and occlusion, which means that
they can significantly outperform than the conventional approaches. Also, it has the
potential capability to handle a high volume of data. Although deep-learning-based FER
generally produces better FER accuracy than conventional FER, it also requires a large
amount of processing capacity, such as a graphic processing unit (GPU). Also, a new
approach known as Multi-feature fusion is an effective way of facial expression
representation. The different features in many algorithms are combined to describe facial
expressions. CNN learns features through layer-by-layer propagation, which may lose
some important feature information at intermediate layers. Feature fusion from different
layers of a single CNN model or from different layers of other CNN models helps to
achieve better classification process, which helps to improve the recognition accuracy of

51
the facial expression recognition system. Detailed survey for multi-feature fusion approach
with comparative analysis and state-of-the-art methods presented in this chapter.
This literature survey divided into the following parts:
• Conventional FER approaches
• Deep Learning-based FER approaches
• Multi-Feature fusion-based approaches in a single model (Inter-Layer Feature
Fusion)
• Multi-Feature fusion-based approaches in an ensemble of multi models (Multi-
model feature fusion)
3.2 Conventional FER Approaches
Various types of conventional approaches have been studied for the facial expression
recognition system. These approaches’ commonality is detecting the face region and
extracting geometric features, or appearance features, or a hybrid of geometric and
appearance features on the target face. The conventional FER procedure can be divided
into three significant steps: Image pre-processing, Feature extraction and expression
classification [57].
Image Pre-processing:
This step is used to eliminate irrelevant information from the images and enhance the
detection ability of relevant information. Image pre-processing can directly affect the
extraction of features and the performance of expression classification. Some pictures may
have complex backgrounds, e.g., light intensity, occlusion, size, composed of colour or
gray-scaled images. These objective interference factors need to be pre-processed before
recognition [29]. Different processes of image pre-processing are described as: Noise
reduction is the first step of pre-processing. Average Filter (AF), Gaussian Filter (GF),
Median Filter (MF), Adaptive Median Filter (AMF) and Bilateral Filter (BF) are
frequently used image processing filters. Face detection is an essential pre-step in FER
systems to localize and extract the face region. The Normalization of the scale and gray-
scale is to normalise the size and colour of input images, which is to reduce calculation
complexity under the premise of ensuring the key features of the face [29].

52
In 1998, Papageorgiou et al. [58] developed a framework based on Haar wavelet
representation and later on in 2001, Viola and Jones further developed this idea by
proposing the Haar-like features that represent the changes of texture or edges of particular
facial regions and can be operated much faster than pixels in systems. They used Haar-like
features which compute the differences between the sums of pixels within those
rectangular areas. An algorithm known as a cascade of classifier used these features to
speed up the computation [59]. Weilong Chen et al. [60] proposed an illumination
normalization approach under changing lighting conditions for the facial recognition
system. They have used a Discrete Cosine Transform (DCT) method which helps to
recognize faces under changing illumination condition but failed to the shadowing and
specularity problems. Owusu et al. [61] used the Bessel down-sampling approach for face
image size reduction, but it protects the aspects and the perceptual worth of the original
image. Biswas et al. [62] used the Gaussian filter approach for resizing the input images,
which provides the smoothness to the images.
Normalization is the pre-processing method for reduction of illumination and variations of
the facial images. Idrissi et al. [63] used this normalization approach with the median filter
to achieve an improved face image. They have used this to extract eye positions which
makes it more robust for the FER systems and providing more clarity to the input images.
Zhang et al. [64] and Happy et al. [65] presented localization pre-processing method using
the Viola-Jones algorithm to detect facial images from the input image. Adaboost learning
algorithm and Haar-like features are used to detect the size and areas of the face images.
The localization is mainly used for spotting the size and locations of the face from the
image. Face alignment pre-processing method can be performed using the SIFT (Scale
Invariant Feature Transform) algorithm. ROI (Region of Interest) segmentation is an
essential pre-processing method that includes three functions: regulating the face
dimensions by dividing the colour components and face image, eye, or forehead and
mouth regions segmentation. Above SIFT and ROI methods used by Dahmane et al. [66]
and Hernandez et al. [67] respectively, in the facial expression recognition system. Demir
et al. [68] and Cossetin et al. [69] used the Histogram equalization method to conquer the
illumination variations, which useful for enhancing the contrast of the face images and to
improve the intensities.

53
Feature Extraction:
The feature extraction process is the next stage of the FER system. Feature extraction is
finding and depicting positive features of concern within an image for further processing.
It is a significant stage where feature extraction data depiction can be used to input the
classification. Common approaches used in the feature extraction process are geometric
features, appearance features and a hybrid of geometry and appearance features.
Ghimire and Lee [70] used two types of geometric features based on the position and
angle of 52 facial landmark points. First, the angle and Euclidian distance between each
pair of landmarks within a frame are calculated. Second, the distance and angles are
subtracted from the corresponding distance and angles in the first frame of the video
sequence. Two classifiers AdaBoost and SVM were applied to this approach. Junkai Chen
et al. [71] proposed feature extraction technique which works on the entire face. Facial
muscle movements were labelled by Histogram of Oriented Gradients (HOG), and
Support Vector Machine (SVM) is used as a classifier. Experiments were conducted on
JAFFE and CK+ datasets. Happy et al. [72] utilized a Local Binary Pattern (LBP)
histogram of different block sizes from a global face region as the feature vectors. They
classified various facial expressions using a Principal Component Analysis (PCA).
Although this method is implemented in real-time, the recognition accuracy tends to be
degraded because it cannot reflect local variations of the facial components to the feature
vector. Ghimire et al. [73] extracted region-specific appearance-based features by dividing
the entire face region into domain-specific local regions. Important local regions are
determined using an incremental search approach which reduces the feature dimensions
and improves the recognition accuracy. Aruna Bhadu et al. [74] used Discrete Cosine
Transform and Wavelet Transform, two different feature extraction techniques. Hybrid
features are extracted with DCT and DWT methods with AdaBoost as a classifier.
Experiments performed on the JAFFE dataset show that hybrid features give better results
than individual feature extraction techniques.
Bao et al. [75] proposed feature extraction method based on the Bezier curve on JAFFE
dataset with SVM as a classifier. Bezier control points are used to identify key parts of the
face like eyes, eyebrows and mouth. Elena Lozano et al. [76] proposed a method based on
geometric-features using the Active Shape Model approach. Active Shape model approach
is used to track the fiducial points, and then threshold segmentation is applied to determine

54
the mouth’s position. SVM classifier is applied to classify expressions into seven
categories. Huang et al. [77] proposed facial expression recognition method using
Speeded-Up Robust Features (SURF) method. The Probability density function is used as
initial classification, and Weighted majority voting classifier is used to get the output of
recognition. This proposed method has experimented on JAFFE dataset. Kamarol et al.
[78] proposed a method which uses appearance-based feature extraction using Spatio-
Temporal Texture Map (STTM) to extract features. This method is used due to its ability
to capture spatial and temporal changes of facial expressions. 3D Harris corner function is
used to extract spatiotemporal information from faces and classify the expressions with
SVM classifier. Toan et al. [79] proposed a hybrid approach in which geometric feature-
based method combined with PCA method and geometric feature-based method combined
with Independent Component Analysis (ICA) method. Features are extracted from
different regions of the face like eyes, mouth and nose. The integrated features are applied
to the neural network for classification. Experiments were performed on Caltech dataset
and achieved 90% accuracy. Bermani et al. [80] proposed a hybrid approach where
geometric-based features and appearance-based features were combined for feature
extraction. Radial Basis Function (RBF) neural network used as a classifier.
Some researchers have tried to recognize facial emotions using infrared images instead of
Visible Light Spectrum (VIS) image because visible light (VIS) image is variable
according to illumination status. Zhao et al. [81] used Near-Infrared (NIR) video
sequences and LBP-TOP (Local binary patterns from three orthogonal planes) feature
descriptors. This study uses component-based facial features to combine geometric and
appearance information of the face. For FER, an SVM and sparse representation classifiers
are used. Shen et al. [82] used infrared thermal videos by extracting horizontal and vertical
temperature difference from different facial sub-regions. For FER, the Adaboost algorithm
with the weak classifiers of k-Nearest Neighbor is used. Szwoch and Pieniazek [83]
recognized facial expression and emotion-based only on the Microsoft Kinect sensor’s
depth channel without using the camera. This study used local movements within the face
area to feature and recognize facial expressions using relations between particular
emotions. Sujono and Gunawan [84] used a Kinect motion sensor to detect face region
based on depth information and active appearance model (AAM) to track the detected
face. To the role of AAM is to adjust the shape and texture model in a new face, when
there is a variation of shape and texture compared to the training result. The change of key

55
features in AAM and fuzzy logic based on prior knowledge derived from Facial Action
Coding System (FACS) are used to recognize facial emotion. Wei et al. [85] proposed
FER using colour and depth information by Kinect sensor together. This study extracts
facial feature points vector by face tracking algorithm using captured sensor data and
recognizes six facial emotions by random forest algorithm.
Facial Expression Classification:
Facial expression classification is the final step in the facial expression recognition system
in which classifiers categorizes the expressions into seven categories: Happy, Sad, Fear,
Surprise, Disgust, Angry and Neutral. Recent research work has added Neutral expression
into the classification category. Many previous approaches worked on basic six
expressions: Happy, Sad, Fear, Angry, Disgust and Surprise. Commonly and widely used
classifiers in conventional methods include KNN (K-Nearest Neighbour), SVM (Support
Vector Machine), Naïve Bayes Classifier, AdaBoost Classifier, HMM (Hidden Markov
Model), Decision Tree and NN (Neural Network).
Many researchers [86-88] have used KNN classifier because it is simple and easy to
imply. An important characteristic of KNN classifier is that it is sensitive to the local
structure of the data. The result optimization has been done by varying size of
neighbourhood, i.e., value of k. None of the literature has shown any determined technique
to decide the value of k. Hence, it is concluded that the value of k is solely dependent on
the application and more precisely, on the kind of input features given to classify the
samples.
SVM classifier can find an excellent compromising solution on complex models by
providing limited sample data to obtain generalization ability. It is also possible to map
linearly indivisible data to higher dimensions by kernel functions to convert the data into
linear separable. By using kernel function, the system can effectively process high-
dimensional data. Liyuan Chen et al. [89] presented work for person relevant and person
irrelevant expression recognition. SVM with both linear function and Radial Basis
function (RBF) is used for classification purpose. Recognition of approx. 80% is achieved
for a few of the cases. Many researchers [90-93] have used SVM classifier in their
proposed approach for classification purpose.

56
AdaBoost [94-97] and Naïve Bayes [98-100] classifiers used by many researchers in the
facial expression recognition system. AdaBoost is sensitive to noisy and anomaly data. In
some problems, it can be less susceptible to the overfitting problem than other learning
algorithms. AdaBoost with a decision tree is often referred to as the best out-of-the-box
classifier. In other cases, Naïve Bayes classifier is highly scalable, requiring linear
parameters for the number of variables in learning problems. One advantage is that only a
small amount of training data is required to estimate the parameters required for
classification.
Many algorithms in facial expression recognition system have been using a neural network
as a classifier due to the high tolerance to noisy data and their ability to classify patterns
on which they have not been trained. Multilayer Feed Forward Neural Network (MFFNN)
using backpropagation algorithm for classification [61]. Bayesian neural network classifier
is the classification method which also includes input, hidden and output layers. The
classical backpropagation algorithm is used with Bayesian classifier and its accuracy
[101]. Some researchers [102-104] have used a probabilistic neural network as a classifier
in facial expression recognition.
The conventional approaches for facial expression recognition are less dependent on data
and hardware compared to deep learning-based approaches. However, feature extraction
and classification have to be designed manually and separately, which means two phases
cannot be optimised simultaneously. Advantage of the conventional approach is it requires
relatively lower computing power and memory than deep learning-based methods.
Therefore, these approaches are still being studied for use in real-time embedded systems
because of their low computational complexity.
3.3 Deep Learning-based FER Approaches
Despite the notable success of traditional facial recognition methods through the extracted
of handcrafted features, over the past decade researchers have directed to the deep learning
approach due to its high automatic recognition capacity. These deep learning-based
algorithms have been used for feature extraction, classification and recognition tasks. In
terms of FER, deep learning-based approaches are more robust to the environments with
different elements, e.g., illumination and occlusion, which means that they can

57
significantly outperform the conventional methods. Also, it has the potential capability to
handle a high volume of data. In recent decades, there has been a breakthrough in deep-
learning algorithms applied to the field of computer vision, including a convolutional
neural network (CNN) and recurrent neural network (RNN). The main advantage of CNN
is to completely remove or highly reduce the dependence on physics-based models or
other pre-processing techniques by enabling “end-to-end” learning directly from input
images. For the reasons, CNN has achieved state-of-the-art results in various fields
including object recognition, scene understanding, face detection and facial expression
recognition.
Mollahosseini et al. [105] propose deep CNN for FER across several available databases.
After extracting the facial landmarks from the data, the images reduced to 48x 48 pixels.
Then, they applied the augmentation data technique. The architecture consists of two
convolution-pooling layers, then add two inception styles modules, which contain
convolutional layers size 1x1, 3x3 and 5x5. They present the ability to use the network-in-
network technique, which allows increasing local performance due to the convolution
layers applied locally. This technique also makes it possible to reduce the over-fitting
problem.
Lopes et al. [106] Studied the impact of data pre-processing before the training the
network to have a better emotion classification. Data augmentation, rotation correction,
cropping, down-sampling with 32x32 pixels and intensity normalisation are the steps that
were applied before CNN consisting of two convolution-pooling layers ending with two
fully connected with 256 and 7 neurons. The best weight gained at the training stage is
used at the test stage. This experience was evaluated in three accessible databases: CK+,
JAFFE, BU-3DFE. Researchers show that combining all of these pre-processing steps is
more effective than applying them separately.
Mohammadpour et al. [107] proposed a novel CNN for detecting AUs of the face. The
network uses two convolution layers, each followed by a max-pooling and ending with
two fully connected layers that indicate the numbers of AUs activated. Cai et al. [108]
propose a novel architecture CNN with Sparse Batch normalization SBP. This network’s
property uses two convolution layers successive at the beginning, followed by max-
pooling then SBP, and to reduce the over-fitting problem, the dropout applied in the

58
middle of three fully connected. Li et al. [109] present a new method of CNN. Firstly, the
data introduced into VGGNet network, then they apply CNN’s technique with attention
mechanism of CNN. This architecture trained and tested in three large databases FED-RO,
RAF-DB and AffectNet. Detection of the essential parts of the face was proposed by
Yolcu et al. [110]. They used three CNN with same architecture each one detects a part of
the face such as eyebrow, eye and mouth. Before introducing the images into CNN, they
go through the crop stage and detect key-point facial. The iconic face obtained combined
with the raw image was introduced into the second type of CNN to detect facial
expression. Researchers show that this method offers better accuracy than the use of raw
images or iconize face alone.
Agrawal et al. [111] make a study of the influence variation of the CNN parameters on the
recognition rate using FER2013 database. First, all the images are all defined at 64x64
pixels. They make a variation in size and number of filters also the type of optimizer
chosen (Adam, SGD, AdaDelta) on a simple CNN, which contain two successive
convolution layers. The second layer plays the role the max-pooling, then a SoftMax
function for classification. According to these studies, researchers create two novel models
of CNN achieve average 65.23% and 65.77% of accuracy; the particularity of these
models is that they do not contain fully connected layers dropout. The same filter size
remains in the network. Deepak jain et al. [112] propose a novel deep CNN that includes
two residual blocks; each contains four convolution layers. These model trains on JAFFE
and CK+ databases after a pre-processing step, which allows cropping and normalizing the
intensity of the images.
Kim et al. [113] study variation facial expression during the emotional state; they propose
a Spatio-temporal architect with a combination between CNN and LSTM. At the first
time, CNN learns the spatial features of the facial expression in all the emotional state
frames followed by an LSTM applied to preserve the whole sequence of these spatial
features. Also, Yu et al. [114] Present a novel architecture called Spatio-Temporal
Convolutional with Nested LSTM (STC-NLSTM), this architecture based on three deep
learning sub-network such as 3DCNN for spatiotemporal extraction features followed by
temporal T-LSTM to preserve the temporal dynamic, then the convolutional C-LSTM for
modelled the multi-level features. Deep convolutional BiLSTM architecture was proposed
by Liang et al. [115], they create two DCNN, one of which is designated for spatial

59
features and the other for extracting temporal features in facial expression sequences, these
features fused at a level on a vector with 256 dimensions, and for the classification into
one of the six basic emotions, researchers used BiLTSM network. The pre-processing
stage used the Multitask cascade convolutional network to detect the face, then applied the
data augmentation techniques to broadening the database.
Liu et al. [116] proposed a novel Boosted Deep Belief Network (BDBN) for facial
expression recognition using three training stages iteratively in a unified loopy framework.
Their experiments have selected the first frame (with neutral expression), and the last three
frames from each image sequence to obtain more samples from the CK+ database.
Extensive experiments with CK+ and the JAFFE databases proved that their framework
achieved dramatic improvements over current state-of-the-art algorithms which have been
benchmarked on these two databases.
Burkert et al. [117] proposed a CNN architecture that does not depend on the handcrafted
features. Four parts compose this architecture, and the images are first pre-processed
automatically through a convolutional layer. The images are then down-sampled by the
pooling layer in the second part. The next block, called the FeatEx, serves as the
fundamental structure in this architecture inspired by GoogleNet. Finally, after two
concatenated FeatEx blocks, the extracted features are fed into a fully connected layer to
perform the classification. Different layers’ deep features are visualized to show its
validity, and evaluations are conducted with two standards datasets, namely, MMI and
CK+. Their experiment on the CK+ dataset evaluated seven classes and achieved a
recognition rate of 99.6%.
Inspired by the architecture of the AlexNet and GoogleNet, Mollahosseini et al. [118]
proposed their own CNN architecture in 2016, which consisted of two conventional CNN
modules (one of which contained a convolutional layer followed by a max-pooling layer),
four Inception modules and two fully connected layers, having only 25M operations
(compared to 100M in AlexNet). Face registration was performed to improve the
performance of FER by using the bidirectional warping of the active appearance model
(AAM) and a supervised method called IntraFace that adopted the SIFT features to extract
49 facial landmarks. Both subject-independent and cross-database experiments were
carried out on seven public standards datasets (MultiPIE, MMI, CK+, DISFA, FERA,

60
SFEW, and FER-2013), and six specific classes (angry, disgust, fear, happiness, sadness,
surprise, excluding the neutral and contempt classes) were evaluated on the CK+ dataset.
State-of-the-art performance analysis for facial expression recognition using deep-
learning-based approach is shown in below table 3.1
Table 3.1 Performance summary of facial expression recognition using deep-learning-based approaches
Author
Name
Year Methods/Algorithms Details Dataset Accuracy
(%)
Agrawal et al.
[111]
2020 Two proposed CNN models to
evaluate for different kernel sizes
and number of filters to overcome
the limitations of FER2013
dataset
FER2013 65.23% &
65.77%
Dandan Liang
et al. [115]
2020 BiLSTM network for fusion
approach of spatial features and
temporal dynamics using a deep
spatial network (DSN) and deep
temporal network (DTN)
CK+, Oulu-
CASIA &
MMI
99.4%,
91.07% &
80.71%
Gozde Yolcu
et al. [110]
2019 4-stage CNN structure: first CNN
for eyebrow segmentation,
second CNN for eye
segmentation, third CNN for
mouth segmentation and fourth
CNN for expression recognition
Radboud
Face
Database
(RaFD)
94.44%
Deepak
Kumar Jain et
al. [112]
2019 Single Deep Convolutional
Neural Network (SDCNN)
contains convolutional layers and
deep residual blocks
JAFFE &
CK+
95.23% &
93.24%
Jun Cai et al.
[108]
2018 Sparse Batch Normalization CNN
(SBN-CNN) model using a
convolutional network and Batch
Normalization to reduce the risk
of over-fitting
JAFFE &
CK+
95.24% &
96.87%

61
Yong Li et al.
[109]
2018 Convolutional Neural Network
with Attention mechanism
(ACNN) that focus on un-
occluded face regions and
perceive occlusion regions with
patch-based ACNN & global-
local-based ACNN versions
RAF-DB &
AffectNet
85.07% &
58.78%
Zhenbo Yu
et al. [114]
2018 Spatio-Temporal Convolutional
features with Nested LSTM
(STC-NLSTM) model which is
using 3DCNN method to extract
Spatio-temporal convolutional
features and dynamics of
expressions modelled by Nested
LSTM
CK+, Oulu-
CASIA,
MMI &
BP4D
99.4%,
93.45%,
84.53 &
58%
Andre Lopes
et al. [112]
2017 Facial expression recognition
system with CNN and different
pre-processing operations on
images to decrease variations
between images and reduces the
need for a large amount of data
CK+,
JAFFE &
BU-3DEF
96.76%,
86.74% &
83.50%
Mostafa et al.
[107]
2017 Proposed CNN architecture to
detect AUs
CK+ 97.01%
Dae Hoe Kim
et al. [113]
2017 Fusion of CNN and LSTM
architectures are used for spatial
feature representation and
temporal feature representation
respectively
MMI &
CASME II
69.94% &
58.54%
Ali
Mollahosseini
et al. [105]
2016 Deep Neural Network (DNN)
architecture consists of
convolutional, max-pooling and
four Inception layers
CK+,
FER2013
& MMI
93.2%,
66.4% &
77.9%

62
Peter Burkert
et al. [117]
2015 Deep Convolutional Neural
Network (DCNN) architecture
with FeatEx – Parallel Feature
Extraction blocks for reach
feature representation
MMI &
CK+
98.36% &
99.5%
Ping Liu et al.
[116]
2014 Boosted Deep Belief Network
(BDBN) characterize expression-
related facial shape changes, can
be learned and selected to form a
boosted strong classifier via a
joint fine-tune process in BDBN
framework
CK+ 93%
3.4 Multi-Feature Fusion based FER Approaches:
3.4.1. Multi-Feature Fusion in a single model (Inter-Layer Fusion):
Automatic human facial expression recognition has been receiving increasing attention
from researchers in a deep learning area, and several solutions have been proposed. Most
of the existing works have focused on the single model and methodology work using any
CNN architecture for facial expression database. Instead of increasing layers in CNN and
creating more complex Deep CNN, researchers are working on the concept of Fusion of
layers and models to improve the recognition accuracy of models and real-time facial
expression database which contains real-world images. Using deep learning techniques to
extract useful features from multi-model information automatically and their use in fusion
and classification are new research directions nowadays by dealing with different network
parameters to improve the system’s recognition accuracy. The following review examines
the state-of-the-art literature review for feature-fusion based approach from where we
found the concept of our research work.
Cehnhui Ma et al. [54] proposed multi-layers feature fusion based CNN fusion model
where intra-layer and inter-layer fusion mechanism are used on InceptionV3 and VGG16
CNN architectures for UCM and NWPU-RESISC database and achieved 98.4% and
95.32% accuracy respectively. The novelty lies in using this approach to enhance the

63
features by integrating information extracted from different layers of CNN to build more
discriminative feature representation for classification. According to data distribution and
selecting appropriate CNN models, choosing fusion methods is the conclusive research
point. This approach increases the computational burden, although multi-layer feature
fusion has achieved good results. Hai-Duong Nguyen et al. [119] presented a multi-level
convolutional neural network (MLCNN) approach that selects important mid-level and
high-level features their contribution. Feature maps generated at intermediate layers are
selected, and then fusion approach applied before applying to the classification layer. This
approach is evaluated on FER2013 dataset and achieved 73.03% recognition accuracy. A
drawback of the model is that it involves two stages for training. The plain model and the
MLCNN should be trained separately since the weights of the former are used.
Tianhao Tang et al. [120] presented a hybrid multimodal method that includes audio,
video frame, video sequence and face landmark movement. This method combines
acoustic features and facial features in both non-temporal and temporal mode. They have
applied this approach on Acted Facial Expression in Wild (AFEW) dataset and achieved
61.87% recognition accuracy in EmotiW challenge. Although researchers have achieved
better accuracy, but emotion recognition on video clips has not been solved entirely due to
lack of specific specimen samples in the dataset. VenkataRamiReddy et al. [121] presented
a multi-feature fusion-based approach extracted from different techniques. Researchers
have used Directional Local Binary Pattern (DLBP) and Discrete Cosine Transform
(DCT) methods to extract local and global features, respectively. Further, Weighted
summation and Principal Component Analysis (PCA) fusion methods can fuse the local
and global features extracted from facial images. Radial Bias Function (RBF) neural
network is used as a classifier for classification purpose. Cohan-Kanade (CK) database is
used to evaluate the proposed method and achieved 97% better recognition accuracy.
Kuang Liu et al. [122] proposed a model which consists of several different structured
subnets. Each subnet is a compact CNN model trained separately. Then the whole network
is structured by assembling these subnets together. The proposed network is evaluated on
FER2013 dataset and achieved 65.03% recognition accuracy. This proposed model’s main
advantage is to focus on different CNNs rather than one, which provides better
performance by combining all the results together, but will increase the complexity.
Yingruo et al. [123] proposed a novel Multi-Region Ensemble CNN (MRE-CNN)

64
framework for facial expression recognition which aims to enhance the learning power of
CNN models by capturing both the global and local features from multiple human face
sub-regions. Weighted prediction scores from each sub-network then aggregated to
produce the final prediction of high accuracy. The proposed method is evaluated on two
publicly available datasets AFEW and RAF-DB and achieved 76.73% & 47.43%
recognition accuracy, respectively.
Jung et al. [124] used two different types of CNN: the first extracts temporal appearances
feature from the image sequences known as deep temporal appearance network (DTAN),
whereas the second extract temporal geometry features from temporal facial landmark
points which are known as deep temporal geometry network (DTGN). These two models
are combined using a new integration method to boost the performance of facial
expression recognition which is known as a deep temporal appearance-geometry network
(DTAGN). This approach is applied to CK+ and Oulu-CASIA datasets and achieved
97.25% and 81.46% recognition accuracy, respectively. State-of-the-art performance
analysis based on recent research for a multi-feature fusion-based approach using deep
learning methods is shown in below table 3.2
Table 3.2 Performance summary of Multi-Layer Feature-Fusion Methods using Deep Learning techniques
Author
Name
Year Methods/Algorithms Details Dataset Accuracy
(%)
Chenhui Ma
et al. [54]
2019 Inter-Layer and Intra-Layer
Feature-Fusion using Inception-
V3 and VGG16 CNN architecture
UCM &
NWPU
97.7 % &
94.7%
Long D.
Nguyen et al.
[119]
2018 Multi-level Convolutional Neural
Network (MLCNN) approach by
an Ensemble of feature maps
from different layers
FER2013 73.03%
Tianaho Tang
et al. [120]
2018 Hybrid Multimodal (Audio +
Video feature data fusion)
AFEW 61.87%
Kuang Liu et
al. [122]
2018 Multi-Feature fusion with an
ensemble of CNN subnets
approach
FER2013 65.03%

65
Yingruo et al.
[123]
2018 Multi Region Ensemble CNN
(MRE-CNN) approach with
feature fusion
AFEW &
RAF-DB
47.43% &
76.7%
Jung et al.
[124]
2015 Multi-feature fusion of temporal
appearance features and temporal
geometry features
CK + 97.25%
VenkataRami
Reddy et al.
[121]
2014 Fusion of local and global
features with Directional Local
Binary Pattern (DLBP) and
Discrete Cosine Transform
(DCT) methods
CK 97%
3.4.2. Multi-Feature Fusion using multi-model (Multi-Model Fusion):
Long D. Nguyen et al. [125] and V. Vaidehi et al. [56] mentioned the use of an ensemble
of different CNN architectures for feature extraction. Then they concatenated output of
these architectures into a single image vector for the classification purpose instead of
getting one feature map by applying a single CNN architecture. Researchers conclude that
Concatenation of features from various networks helps to overcome the limitations of a
single network and produces robust and superior performance.
Long D. Nguyen et al. [125] proposed a novel deep neural network architecture based on
transfer learning for microscopic image classification where features are extracted from
three different pre-trained CNN architectures InceptionV3, ResNet50 and Inception-
ResNetV2. They created a fusion approach to multimodal with layers. They applied this
approach on 2D-Hela and PAP-Smear datasets and achieved 92.57% and 92.63%
accuracy, respectively. V. Vaidehi et al. [56] proposed Ensemble of Convolutional Neural
Networks (ECNN) based approach for facial expression recognition. The proposed model
addresses the challenges of facial expression, ageing, low resolution, and pose variations.
Features are extracted and concatenated from VGG16, Xception and Inception-V3 CNN
architectures before applying to classification. The proposed model was evaluated on
Web-Face and YouTube datasets and achieved 97.12% and 99% recognition accuracy,

66
respectively. A lot of Computation time is required to implement this approach which can
be resolved by using multiple GPUs.
Yingying Wang et al. [126] proposed an Auxillary model approach which combines
multiple face sub-regions and entire face image by a weighting factor which can capture
more vital information to improve recognition accuracy. Here four different CNN models
work parallel to find weights for Eyes, Mouth, Nose and whole facial image, and finally,
fusion will be applied of all these four models. This approach tested on JAFFE, CK+,
FER2013 and SFEW dataset and achieved 95.9%, 99.09%, 67.7%, 59.97% accuracy,
respectively. Hseng Li et al. [127] proposed an emotion recognition system for a
humanoid robot. They have mounted the camera on a robot’s head to detect live facial
expression recognition using CNN and LSTM approach. They have tested using JAFFE
and CK+ dataset and achieved 94.9% and 90.5% accuracy, respectively, which is
somewhat less compared to other state-of-the-art methods.
Alessandro Renda et al. [128] presented two direct ensemble strategies: Seed strategy and
Pre-processing strategy by combining the base classifiers’ outputs by using the most
common aggregation schemes: average and majority voting. The proposed approaches are
evaluated on two scenarios: CNN 10-S – training from scratch an Ad-hoc architecture and
VGG-16 – fine-tuning a pre-trained model. The proposed strategy is evaluated on
FER2013 dataset and achieved 70.5% recognition accuracy. Chao Li et al. [129] proposed
a multi-network fusion (MNF) model based on CNN to recognize facial expressions.
Researchers have trained two network structures in the experiment, one based on Tang’s
network structure, the other based on Caffe-ImageNet network structure and then used L2-
SVM for classification. The best network model parameters are extracted from the two
previous trained networks as the initialization parameters to MNF structure, and then MNF
structure is fine-tuned. The proposed model is evaluated on FER2013 and JAFFE datasets
and achieved 70.03% and 95.7% recognition accuracy, respectively. State-of-the-art
performance analysis based on recent research work for multi-feature fusion-based
approach in multi-model using deep learning methods are shown in below table 3.3

67
Table 3.3 Performance summary of Multi-Layer Feature-Fusion Methods using Ensemble of CNN models
using Deep Learning techniques
Author
Name
Year Methods/Algorithms Details Dataset Accuracy
(%)
V. Vaidehi et
al. [56]
2019 Ensemble of Convolutional
Neural Network (ECNN)
approach using VGG16, Xception
and Inception-V3 CNN
architectures
Web-Face
& YouTube
97.12 % &
99 %
Yingying
Wang et al.
[126]
2019 Auxiliary model approach which
combines multiple face sub-
regions and entire face image for
fusion approach using four
different CNN works in parallel
JAFFE,
CK+ &
FER2013
95.95%,
99.07% &
67.7%
Hseng Li et
al. [127]
2019 Hybrid Multimodal of CNN and
LSTM architecture for humanoid
robot mounted with camera
JAFFE &
CK+
94.9% &
90.5%
Long D.
Nguyen et al.
[125]
2018 Deep Neural Network (DNN)
architecture by feature-fusion
using InceptionV3, ResNet50 and
Inception-ResNetV2
2D-Hela &
PAP-Smear
92.57% &
92.63%
Yingru et al.
[123]
2018 Multi-Region Ensemble CNN
(MRE-CNN) approach with
feature fusion
AFEW &
RAF-DB
47.43% &
76.7%
Alessandro
Renda et al.
[128]
2018 Seed-strategy and Pre-processing
strategy using CNN-10S and
VGG16 Architecture for fine-
tuning and Ensemble approach
FER2013 70.53%
Chao Li et al.
[129]
2018 Multi-Network Fusion (MNF)
model based on the fusion
approach of Tang’s Network and
Caffe-ImageNet Network
FER2013
& JAFFE
70.03% &
95.7%

68
3.5 Summary and Discussion:
This chapter provides a review of literature on different facial expression recognition
methods and algorithms. Various methods and algorithms based on Conventional
approaches, Deep-Learning based techniques and Feature-Fusion based approaches are
discussed. Difference between conventional approaches and deep-learning-based
approaches with their advantages is explored. It concludes that researchers are working on
different deep-learning-based methods to improve facial expression recognition systems’
recognition accuracy. Nowadays, Feature-fusion based approach is used by many
researchers as it is an effective way of the facial expression representation and different
features in many algorithms or methods are combined to describe facial expressions.
Feature-fusion based approach is classified into two categories: Multi-Level feature fusion
in a single model and Multi-level feature fusion by different models. In the first concept,
in a single model feature-fusion can be applied at low-level or intermediate- level or at
high-level to achieve the best accuracy. It is also known as Inter-Layer or Intra-layer
multi-feature fusion-based approach. In the second concept of fusion-based approach,
ensemble of different models’ strategy can be applied to do multi-feature fusion. Features
generated at intermediate layers in different models can be combined together to get
advantages of other models into a single multimodal fusion-based approach. A State-of-
the-art literature review is explained in this chapter for both of these feature-fusion based
approaches.
From the above literature review, it is observed that many researchers are working to
improve the performance of existing CNN models on real-time facial expression datasets
which contains real-world images and also with laboratory trained images. Therefore, an
efficient model is required with deep-learning fusion techniques to extract essential
features from the images and classify emotions correctly. So, in our research work, we
have proposed three models: Multi-Layer Feature-Fusion based classification (MLFFC),
Multi-Modal Feature-Fusion based classification (MMFFC) and novel FER model based
on Normalized CNN approach.

69
CHAPTER 4
Proposed Multi-Layer Feature-Fusion based
classification (MLFFC) Model
4.1 Introduction
In this chapter, the proposed multi-layer feature-fusion based classification (MLFFC)
approach is presented to perform inter-layer fusion in InceptionV3 CNN architecture from
images for facial expression recognition. From the literature review, it is found that many
researchers are working to improve the recognition accuracy of facial expression datasets
which contains real-world images as well as laboratory-trained images. Novel approaches
are introduced by many researchers which include feature-fusion based approach. This
approach is classified into two categories: Feature-fusion based approach for a single
model and feature-fusion based approach for multi-modal. In a single model, feature-
fusion based can be applied at low-level or intermediate-level or at high-level to achieve
best recognition accuracy. It is also known as Inter-layer multi-features fusion-based
approach.
Many researchers have tried to implement a fusion-based approach for feature extraction
in facial expression recognition. From the literature survey, it is found that most of the
existing work focuses on the feature maps of the last convolutional layer in CNN and pay
little attention to the benefits of additional layers in the model. Feature information hidden
in the different layers has the potential for feature discrimination capacity [54].
InceptionV3 CNN architecture is talking about Factorization ideas, and the aim is to
reduce the number of parameters without decreasing the network efficiency [130]. So, in
this proposed MLFFC model, multi-feature fusion-based classification approach is applied
to InceptionV3 CNN architecture. The proposed model is evaluated on two facial
expression datasets containing real-world facial images and laboratory-trained facial
images to improve recognition accuracy. Facial expression dataset, which contains real-
world images contains more challenges like pose variations, illumination variation and
lower resolution images, making the feature extraction process more challenging.
Laboratory trained facial images are used for the cross-database evaluation study.

70
4.2 Inception-V3 CNN Architecture:
The inception deep convolutional architecture was introduced as GoogleNet in 2015
named as Inception-V1. Later the Inception architecture was refined in various ways, first
by introducing Batch Normalization which is known as Inception-V2. Later by additional
Factorization ideas which will be referred to as Inception-V3 architecture. Thus,
Inception-V3 is an extended version of GoogleNet. It contains the concept of Inception
module to reduce the number of connections/parameters. The Inception-V3 model is
trained on the ImageNet datasets, including the information that can identify 1000 classes
in ImageNet. The aim of factorizing convolutions is to reduce the number of parameters
without decreasing network efficiency [130].
Figure 4.1: Two 3x3 convolutions replacing one 5x5 convolution [130]
Factorization process shown in figure 4.1 to convert into smaller convolutions by taking
an example of two 3x3 convolutions replaces one 5x5 convolution. Using one layer of 5x5
filter, the number of parameters required is 5x5=25 while using two layers of 3x3 filters,
the number of necessary parameters is (3x3) + (3x3) = 18. It shows the number of
parameters reduced by 28% with this concept. The inception module uses the multiple
convolution and multi-level convolution to extract the features in different modules and
aggregate these extracted features at the end of the corresponding module, as shown in
figure 4.2. It is also known as “naïve” inception module. It performs convolution on input,

71
with three different sizes of filters (1x1, 3x3, 5x5). Additionally, max pooling is also
performed. The outputs are concatenated and sent to the next inception module [131].
Figure 4.2: Basic Inception module (naïve version) [132]
Moreover, the inception module reduces the dimensionality and uses the rectified linear
unit activation function to make it for dual purpose, as shown in figure 4.3. Deep neural
networks are computationally expensive. To make it cheaper, limit the number of input
channels by adding an extra 1x1 convolution before the 3x3 and 5x5 convolutions. Also,
1x1 convolution is added after the max-pooling layer [132].
Figure 4.3: Inception module with Dimension Reductions [132]
Using the above dimension reduced Inception module, Inception-V3 architecture was
built, shown in figure 4.4. The schematic diagram of Inception-V3 architecture includes

72
different 11 modules. In this architecture, the dropout layer with 70% ratio reduces the
network’s overfitting. Inception-V3 is a widely used image recognition model that has
been shown to attain greater than 78.1% accuracy on the ImageNet dataset. The model is
the culmination of many ideas developed by multiple researchers over the years. The
model itself comprises symmetric and asymmetric building blocks, including
convolutions, average pooling, max pooling, concatenation, dropouts, and fully connected
layers. Batch normalization is used extensively throughout the model and applied to
activation inputs. Loss is computed via SoftMax classifier.
Figure 4.4: The schematic diagram of Inception-V3 architecture [131]
As shown in figure 4.4, the architecture of Inception-V3 contains three kinds of Inception
modules named as Inception Module A, Inception Module B and Inception Module C.
With factorization, the number of parameters are reduced for the whole network, it is less
likely to be overfitting, and consequently, the network can go deeper. Factorization
process in these three modules is shown in figure 4.5, 4.6 and 4.7, respectively, where
Inception module C is proposed for promoting high dimensional feature representations.
The Auxiliary classifier used as a Regularizer in this architecture for batch normalization
purposes gives high-quality training. Efficient Grid Size Reduction is used to further
downsize feature maps, providing an efficient network [130].

73
Figure 4.5: Factorization process in Inception Module A in Inception-V3 architecture [130]
Figure 4.6: Factorization process in Inception Module B in Inception-V3 architecture [130]
Figure 4.7: Factorization process in Inception Module C in Inception-V3 architecture [130]

74
4.3 Proposed MLFFC:
Inspired from the concept of multi-feature fusion in Inception-V3 architecture represented
by Chenuhi Ma et al. [54], proposed Multi-Layer Feature-Fusion based Classification
approach is proposed here for the facial expression recognition system to improve
recognition accuracy. Chenhui Ma et al. [54] mentioned using multi-feature fusion in
Inception-V3 architecture by integrating feature maps from different layers instead of the
last layer of the network only, as shown in figure 4.7. Authors have also suggested Inter-
Layer feature-fusion based approach which gives the advantage to extract and merge
different features taken from different layers before providing to final layer as shown in
figure 4.8
FIGURE 4.8 General Framework of Multi Feature-Fusion model [54]
FIGURE 4.9 Framework of Inter-Layer Feature-Fusion process [54]

75
Proposed Multi-Layer feature-fusion based Classification approach is shown in figure
4.10. In this proposed model, we are working on the Inception Module C which gives
higher feature representations in Inception-V3 architecture and applies multi-feature
fusion by integrating feature maps from the layers of Inception Module C with its final
layer.
FIGURE 4.10 Proposed Multi-Layer Feature-Fusion based Classification (MLFFC) model
In this proposed MLFFC model, the multi-feature fusion technique is applied to the
module C layer of Inception-V3 architecture with its final layer. As module C represents
higher-level feature representations, the feature-fusion approach will give the advantage to
classify emotions efficiently. Module C of Inception-V3 architecture contains mixed 8,
mixed 9 and mixed 10 layers and then last convolutional layer will come where feature
vector will be generated. Features will be extracted from these layers and concatenated
with the final layer as an Inter-Layer feature-fusion process before it will further provide
to classifier process. To identify which layer’s fusion approach will give better result in
terms of recognition accuracy, evaluation process carried out for all these different
combinations and finally selected the layer for fusion approach which will provide better
recognition accuracy. This proposed MLFFC model aims to improve the recognition
accuracy of real-time facial expression datasets which contains real-world images with
lower-resolution images and challenges. Also, this proposed approach applied to

76
laboratory trained facial expression dataset for the cross-database evaluation study.
Proposed MLFFC algorithm is explained below.
4.3.1 Detailed Process (Algorithm) of Multi-Layer feature-fusion based
classification (MLFFC)
base_model = InceptionV3
Input: CK+ dataset (593 grey-scaled images) and FER2013 dataset (35887
grey-scaled images)
1. Initialize parameters nb_class, x, y, epoch, lr, bs, c, where
nb_class = number of facial expression classes
x = height of the image
y = width of the image
epoch = number of iterations
lr = learning rate
bs = batch size
c = classifier
2. for 1: epochs
train_data, val_data = train_test_split (dataset, 0.8)
bs = 8,16 and lr = 1e-1 to 1e-5
for 1: last_block_layer
if layer=8 // for Inception Module C
f1 = extract features from mixed8 layer of Inception module C
f2 = extract features from final layer of base_model
res_f = f1 f2 // feature-fusion approach
acc1 = predict result of res_f using classifier C
end if
if layer=9
f1 = extract features from mixed9 layer of Inception module C
f2 = extract features from final layer of base_model
res_f = f1 f2 // feature-fusion approach
acc2 = predict result of res_f using classifier C
end if
if layer=10
f1 = extract features from mixed9 layer of Inception module C
f2 = extract features from final layer of base_model
res_f = f1 f2 // feature-fusion approach
acc3 = predict result of res_f using classifier C
end if
end for
end for
3. Calculate maximum recognition accuracy
final_acc = max (acc1, acc2, acc3)
4. END

77
4.4 Dataset Details:
Proposed Multi-Layer Feature-Fusion based Classification (MLFFC) model is tested on
CK+ [134] and FER2013 [133] datasets by varying network parameters like batch size and
learning rate. Stochastic Gradient Descent (SGD) optimizer and SoftMax classifier used
for the evaluation purpose.
4.4.1 CK+ Dataset:
The Extended Cohn Kanade (CK+) database is the most extensively used laboratory-
controlled database for evaluating Facial Expression Recognition system. CK+ contains
593 images from 123 subjects. 123 university students range from 18 to 30 years old,
where 65% are female, 15% are African-American, and 3% are Asian or South American.
The emotions consist of anger, disgust, fear, happiness, sadness, surprise and neutral.
CK+ dataset contains 10,674 grey-scaled images with the resolution of 640x490 pixels.
Example of CK+ dataset image is shown in figure 4.11 [126]
FIGURE 4.11 Example of images in the CK+ dataset with different emotions [126]
4.4.2 FER2013 Dataset:
The FER2013 dataset was introduced during the International Conference on Machine
Learning (ICML) challenges in Representation learning. FER2013 is a large-scale, and
unconstrained database collected automatically by the Google image research API.

78
FER2013 dataset contains 35,887 real-world images taken in an uncontrolled
environment. So, it has many research challenges for researchers like head-pose variations,
illumination, lower resolution etc. Dataset images contain seven different facial
expressions: Anger, Disgust, Happy, Surprise, Fear, Sad and Neutral, with the resolution
of 48x48 pixels. Example of FER2013 dataset image is shown in figure 4.12 [11]
FIGURE 4.12 Example of images in the FER2013 dataset with different emotions [135]
4.5 Experiment and Results:
In this section, we have described the experimental setup, implementation details with
required library support, different parameters used in the proposed model, optimization of
these parameters, the benchmark datasets such as CK+ [134] and FER2013 [133] used to
assess the performance of the proposed model, the results of the proposed model on these
datasets and comparison of these results with state-of-the-art methods. Both the datasets
are divided into 80%-20% ration for training and validation process.
4.5.1 Experimental Setup and Implementation Details:
The proposed MLFFC model is implemented using Python, OpenCV and Deep Learning
API Keras with TensorFlow as a backend. The experiments are performed on NVIDIA
GeForce GTX 1050Ti 4GB Graphic Processing Unit (GPU) with i7 8th generation
windows processor system with 16GB RAM. Anaconda deep learning environment is
installed with Keras-TensorFlow libraries and PyCharm Community Edition as an IDE
tool is used for implementation with Python programming language.

79
In this implementation, we have used different evaluation parameters like maximum 100
epochs and batch size varying from 16, 32 and 64 for different learning rate values ranging
from 0.1 to 0.00001 for detailed analysis purposes. Stochastic Gradient Descent (SGD)
used as an Optimizer and SoftMax are used as a Classifier. These network parameters like
Epochs, Batch Size, Learning Rate, Optimizer and Classifier selection are essential to
carry out effective results in recognition accuracy.
4.5.2 Experimental Results on Inception Module C layers:
As discussed in Inception-V3 architecture, Inter-Layer Feature-Fusion approach applied
on the layers of Inception Module C. Layers of Inception Module C contains higher-level
feature representations. Combining layer of Inception Module C with final layer of
Inception-V3 architecture, Inter-Layer Feature-Fusion approach is applied. To decide
which layer of Inception Module C outperforms well in Inter-Layer Feature-Fusion
approach, experiments carried out by applying the proposed approach and measure the
recognition accuracy. Comparison of Accuracy on different layers in the proposed
architecture is evaluated on the CK+ dataset using network parameters Max Epochs = 100,
Batch Size =16 and Learning rate 0.001. Experiment results are shown in below table 4.1
Table 4.1: Comparison accuracy on different layers on the proposed MLFFC architecture
Inter-Layer Feature-Fusion on layers of
Inception Module C
Validation Accuracy (%)
Mixed 8 layer + final layer 94.17%
Mixed 9 layer + final layer 99.63%
Mixed 10 layer + final layer 97.16%
From the experimental results mentioned in table 4.1, concatenation of mixed 9 layer with
the final layer selected for further evaluation of proposed MLFFC model. Before applying
to the classifier, MLFFC model combines features of mixed 9 layer and final neural
network layer. Final feature vector will be generated by this fusion approach which further
provided to classifier for classification purpose. This proposed MLFFC model tested on
CK+ and FER2013 datasets with varying network parameters to improve the recognition

80
accuracy of the real-time dataset and the laboratory-trained dataset for cross-database
evaluation purpose.
4.5.3 Experimental Results on CK+ dataset:
Proposed MLFFC model is tested on CK+ dataset with varying network parameters values
such as Batch size 8, 16 and Learning rate: 0.1 to 0.00001. SGD used as an optimizer and
SoftMax as a classifier. Experiments were carried out in two different ways: Without
using the feature-fusion approach and using the feature-fusion approach to Inception-V3
architecture. Table 4.2 shows the CK+ dataset results giving better recognition accuracy
by using proposed MLFFC model for different batch-size and learning rate values. The
maximum accuracy of 99.69% obtained for batch size value 16 and learning rate value is
0.1 using the proposed MLFFC model. CK+ dataset contains 593 images, as explained in
section 4.4. So, only two batch size values 8 and 16 taken for the evaluation purpose with
different learning rate values.
Table 4.2: Results on the CK+ dataset by using and not using Feature-fusion approach on the proposed
MLFFC model
Implementation Result of MLFFC Model Accuracy (%) on CK+ dataset
Max. Epochs = 50 Learning rate
Batch Size 0.1 0.01 0.001 0.0001 0.00001
Results Without Feature-Fusion
8 99.07 99.02 99.38 99.07 99.38
16 99.17 98.91 99.02 99.17 98.91
Results With Feature-Fusion
8 99.63 99.43 99.58 99.38 99.63
16 99.69 99.27 99.63 99.27 99.17
Many researchers are trying to improve the recognition accuracy of real-time facial
expression dataset. Comparative analysis of the proposed MLFFC model with the state-of-
the-art methods for the CK+ dataset is shown in table 4.3. The confusion matrix is shown
in figure 4.13. Detailed Classification Report and the ROC-AUC for proposed MLFFC
model are shown in figure 4.14 and 4.15. ROC-AUC curve on the CK+ dataset without
and with feature-fusion approach is shown. Model’s performance is measured in both the
cases for different epochs vs. AUC values based on the classifier. Higher the AUC, better

81
the model is predicting the results. ROC-AUC analysis on CK+ dataset shows that the
average value of AUC is 92% without feature-fusion and 96% with feature-fusion
approach. AUC value is between 09.-1.0 which shows an excellent performance. Accuracy
chart of the proposed MLFFC model based on the CK+ dataset for batch size 8 and 16 is
shown in figure 4.16 and figure 4.17.
Table 4.3: Comparative analysis of a proposed MLFFC model with state-of-the-art methods on CK+ dataset
Method Name Accuracy
(%)
Multi Scale CNN (Discriminative Analysis + Auto Encoder) [136] 91.4%
3DCNN Model [137] 92.4%
Deep Neural Network Architecture [138] 93.2%
DSAE (Deep Sparse Auto Encoders) [139] 93.7%
IACNN (Identity Aware CNN) Model [140] 95.3%
Zero-Bias CNN Method [142] 98.3%
Siamese Model for expression recognition network [141] 98.5%
Concatenate of four CNN Models in parallel [126] 99.07%
Novel Texture Extraction Method [143] 99.36%
Proposed MLFFC Model 99.6%
FIGURE 4.13 Confusion matrix using the proposed MLFFC model on the CK+ dataset

82
FIGURE 4.14 Classification Report for the proposed MLFFC model on the CK+ dataset
(a) (b)
FIGURE 4.15 ROC-AUC curve on the CK+ dataset for (a) without feature-fusion (b) with feature-fusion

83
FIGURE 4.16 Accuracy graph of the proposed MLFFC model for the CK+ dataset for batch size 8
FIGURE 4.17 Accuracy graph of the proposed MLFFC model for the CK+ dataset for batch size 16

84
4.5.4 Experimental Results on FER2013 dataset:
Many researchers are trying to improve the recognition accuracy of real-time FER2013
dataset as it contains real-world images with many challenges for facial expression
recognition purpose. Our proposed MLFFC model is tested on FER2013 real-time dataset
with varying network parameters values such as Batch size 8, 16 and Learning rate: 0.1 to
0.00001. SGD used as an optimizer and SoftMax as a classifier. Experiments were carried
out in two different ways: Without using the feature-fusion approach and using the
feature-fusion approach to Inception-V3 architecture. Results are mentioned in table 4.4.
Table 4.4: Results on the FER2013 dataset by using and not using Feature-fusion approach on the proposed
MLFFC model
Implementation Result of MLFFC Model Accuracy (%) on FER2013 dataset
Max. Epochs = 50 Learning rate
Batch Size 0.1 0.01 0.001 0.0001 0.00001
Results Without Feature-Fusion
8 62.97 66.98 65.17 63.89 65.7
16 68.18 67.54 67.03 66.36 66.11
Results With Feature-Fusion
8 67.93 68.06 68.79 67.81 67.7
16 68.43 68.26 70.29 68.93 69.37
Table 4.4 shows the FER2013 dataset results with different batch-size and learning rate
values. Maximum accuracy 70.29% achieved for batch size value 16 and learning rate
value 0.001 using proposed MLFFC model. Many researchers worked and tried to
improve the recognition accuracy of FER2013 real-time facial expression dataset.
Comparative analysis of the proposed MLFFC model on the FER2013 dataset is shown in
table 4.5, where our proposed model has achieved third-highest recognition accuracy
compared with other methods. Confusion matrix is shown in figure 4.18. Detailed
Classification Report and the ROC-AUC curve for proposed MLFFC model are shown in
figure 4.19 and 4.20. ROC-AUC curve on the FER2013 dataset without and with feature-
fusion approach is shown. Model’s performance is measured in both the cases for different
epochs vs. AUC values based on the classifier. Higher the AUC, better the model is
predicting the results. ROC-AUC analysis on FER2013 dataset shows an excellent

85
prediction performance with feature-fusion approach. Evaluating on real-time facial
expression dataset with lower resolution images, some variance is generated during
evaluation of model and hence not smooth curve is generated in the AUC graph. Average
AUC value is between 0.9-0.97. Accuracy chart of proposed MLFFC model based on
FER2013 dataset for batch size 8 and 16 is shown in figure 4.21 and figure 4.22.
Comparative analysis of the Error-rate on both the datasets using proposed MLFFC
approach is shown in table 4.6
Table 4.5: Comparative analysis of the proposed MLFFC model with state-of-the-art methods on the
FER2013 dataset
Method Name Accuracy
(%)
An Ensemble of CNN – Subnets [122] 65.03%
Deep Neural Network [138] 66.4%
Multi-Task Network [144] 67.2%
Auxiliary Model [126] 67.7%
DCN+AMN (Alignment Mapping Network) [145] 71.8%
Ensemble of 3 MLCNN Model [56] 73.03%
Proposed MLFFC Model 70.29%
FIGURE 4.18 Confusion matrix using the proposed MLFFC model on the FER2013 dataset

86
FIGURE 4.19 Classification Report for the proposed MLFFC model on the FER2013 dataset
(a) (b)
FIGURE 4.20 ROC-AUC curve on the FER2013 dataset for (a) without feature-fusion (b) with feature-
fusion

87
FIGURE 4.21 Accuracy graph of the proposed MLFFC model for the FER2013 dataset with batch size 8
FIGURE 4.22 Accuracy graph of the proposed MLFFC model for FER2013 dataset with batch size 16

88
Table 4.6: Comparative analysis of the Error-Rate on both the datasets using the proposed MLFFC model
Databases
Without Fusion Method With Fusion Method
Recognition
Accuracy (%)
Error rate
(%)
Recognition
Accuracy (%)
Error rate
(%)
CK+ 99.17 0.83 99.69 0.31
FER2013 67.03 32.97 70.29 29.71
4.6 Discussion and Summary:
To improve the recognition accuracy of real-time facial expression dataset is a significant
challenge as it contains many challenges like head-pose variations, illumination, lower-
resolution images etc. In this chapter, we have proposed a Multi-Layer Feature-Fusion
based Classification (MLFFC) model, which works on Inter-Layer Feature-Fusion
approach. This proposed model aims to integrate feature maps from different layers
instead of the last layer only. In our proposed MLFFC model, inter-layer feature-fusion is
applied with an internal layer of Module C of Inception-V3 CNN architecture with its final
layer to improve the model’s recognition accuracy. The proposed model is evaluated on
FER2013 and CK+ datasets. Experimental results show that the proposed MLFFC model
has achieved better recognition accuracy on real-time facial expression dataset as well as
on laboratory-trained facial expression dataset. Experimental results validated on
FER2013 real-time facial expression dataset with the proposed model have achieved better
recognition accuracy (70.29%) compared to the state-of-the-art methods. For the cross-
database evaluation, experimental results validated on CK+ laboratory-trained facial
expression dataset with the proposed model have achieved the best recognition accuracy
(99.6%) compared to the state-of-the-art methods. Also, proposed MLFFC approach used
to reduce Error-rates in both the datasets. Without Feature-fusion approach, 0.83% and
32.97% error-rates are there for the CK+ and FER2013 dataset respectively. By using
proposed Feature-fusion approach, error-rate reduces from 0.83% to 0.31% for the CK+
dataset and from 32.97% to 29.71% for the FER2013 dataset. Inter-layer feature-fusion
approach using the proposed MLFFC model helps to overcome the challenges of real-time
facial expression dataset as well as a laboratory-trained facial expression dataset with
improved recognition accuracy in the experimental result.

89
CHAPTER 5
Proposed Multi-Model Feature-Fusion based
classification (MMFFC) Model
5.1 Introduction
In this chapter, the proposed multi-model feature-fusion based classification (MMFFC)
approach is presented to perform concatenation of features from different CNN
architectures for facial expression recognition. Many researchers have tried to implement
an ensemble of multi-CNN models for feature fusion in facial expression recognition.
From the literature survey, it is found that in existing research approaches single CNN
models are used to extract features for facial expression recognition. To improve
recognition accuracy, many researchers have proposed ensemble of CNN concept in which
they have concatenated layers from different CNN architectures and generated a final
feature vector. Long Nguyen et al. [55] and Vaidehi et al. [56] mentioned using an
ensemble of different CNN architectures for feature extraction and then concatenated the
output of these architectures into a single image vector for the classification purpose
instead of getting one feature map by applying single CNN architecture. Using this
approach, they conclude that concatenation of features from various networks helps to
overcome the limitation of a single network and produces robust and superior
performance. This will further help to improve the recognition accuracy of the model.
Sample architecture of the ensemble approach is shown in figure 5.1, where the same input
database images will be provided to different CNN architectures, and the final feature
vector will be generated by combining outputs from these architectures. Then it will be
provided to the classification stage for further process.
Figure 5.1: Sample architecture of Ensemble of multi-CNN [55]

90
In our proposed MMFFC model, we have analysed the performance of different CNN
architectures (InceptionV3, VGG16, VGG19 and ResNet50) for ensemble approach and
based on the better performance we have concatenated feature vectors generated at the last
layer of two CNN models VGG16 and ResNet50 by providing same input images to both
these architectures. Feature vector generates from each architecture VGG16 and ResNet50
then concatenated into a single final feature vector before applying to the classification
stage.
5.2 VGG-16 CNN Architecture:
VGG-16 is a Convolutional Neural Network (CNN) architecture used to win the ILSVR
(ImageNet) competition in 2014. This architecture was 1st runner up of the Visual
Recognition Challenge (ILSVR-2014) and was developed by Simonyan and Zisserman
from the University of Oxford. It is considered to be one of the excellent vision model
architecture till date. The unique thing about VGG-16 is that instead of having a large
number of hyper-parameters, they focused on having 16 CNV/FC layers including
convolutional layers of 3x3 filter with a stride 1 and always used same padding and max-
pool layer of 2x2 filter of stride 2. It follows this arrangement of convolution and max
pool layers consistently throughout the whole architecture. In the end, it has 2 FC (Fully
Connected layers) followed by a SoftMax for output. The 16 in VGG-16 refers to it has 16
layers that have weights. The VGG-16 architecture is shown in figure 5.3 and architecture
with its layers is shown in figure 5.2
Figure 5.2: VGG-16 Architecture diagram with its layer’s details [55]

91
Figure 5.3: VGG-16 Architecture diagram [146]
To conclude, VGG-16 consists of 16 weight layers containing 13 convolutional layers
with a filter size of 3x3 and three fully connected layers. The stride and padding of all
convolutional layers are fixed to 1 pixel. All convolutional layers are divided into five
groups, and a max-pooling layer follows each group. Max-pooling is carried out over a
2x2 window with stride 2. The number of filters of the convolutional layer group starts
from 64 in the first group and then increases by a factor of 2 after each max-pooling layer
until it reaches 512. All hidden layers are equipped with the rectification (ReLU) non-
linearity. The last layer of this model is the SoftMax layer which is used for classification.
The SoftMax layer can be replaced by a suitable classifier such as neural network, random
forest, support vector machine etc. The dropout layer is used to control the overfitting of
the network [147].
5.3 ResNet-50 CNN Architecture:
ResNet, short for Residual Network is a specific type of neural network introduced in
2015 by Xiangyu Zhang et al. [148]. The Residual network is a classical neural network
used as a backbone for many computer vision tasks. This model was the winner of the
ImageNet challenge in 2015. The fundamental breakthrough with ResNet was it allowed
us to train extremely deep neural networks with 150+ layers successfully. It is similar in

92
architecture to networks such as VGG-16 but with the additional identity mapping
capability. ResNet models fit a residual mapping to predict the delta needed to reach the
final prediction from one layer to the next rather than fitting the latent weights to predict
the final emotion at each layer. The identity mapping enables the model to bypass a typical
CNN weight layer if the current layer is not necessary. This further helps the model to
avoid overfitting to the training set. From an overall architecture and performance
perspective, ResNet allows for much deeper networks while training much faster than
other CNNs. The problem of training very deep networks has been alleviated with the
introduction of ResNet, and these ResNets are made up from Residual Blocks concept
which is shown in figure 5.4 [148,149]
Figure 5.4: Residual Learning: a building block concept [149]
Residual learning block, as shown in figure 5.4 using Skip Connection concept, which is
the core of residual blocks. Due to this skip connection, the output of the layer is not the
same now. Without using this skip connection, the input ‘x’ multiplied by the weights of
the layer followed by adding a bias term. This term goes through the activation function,
f() and we get the output as H(x). Without skip connection we get the output as H(x) = f(x)
while with the use of skip connection the output is changed to H(x) = f(x) + x. There
appears to be a slight problem with this approach when the input dimensions vary from
that of the output which can happen with convolutional and pooling layers. In this case,
when dimensions of f(x) are different from x, two approaches are there to solve this
problem: First, the skip connection is padded with extra zero entries to increase its
dimensions and second, the projection method is used to match the dimension which is

93
done by adding 1x1 convolutional layers to the input. The skip connections in ResNet
solve the problem of Vanishing gradient in deep neural networks by allowing this alternate
shortcut path for the gradient to flow through. ResNet architecture is shown in figure 5.5,
where a comparison is shown with the difference between plain and residual networks.
Figure 5.5: ResNet Architecture diagram comparison to plain network [150]
The diagram shown above visualizes ResNet34 architecture. For the ResNet50 model,
replace each two-layer residual block with a three-layer bottleneck block that uses 1x1
convolutions to reduce and subsequently restore the channel depth, allowing for a reduced
computational load calculating the 3x3 convolution as shown in figure 5.6.
Figure 5.6: Diagram shwoing conversion of residual block [150]

94
5.4 Proposed MMFFC Model:
Inspired from the concept of an ensemble of different CNN architectures explained by
Long Nguyen et al. [55] and Vaidehi et al. [56], we attempt to combine VGG16 and
ResNet50 CNN architectures by leveraging an ensemble approach in our proposed
MMFFC model. In proposed MMFFC model, we have analysed the performance of
different CNN architectures (InceptionV3, VGG16, VGG19 and ResNet50) for ensemble
approach and based on the better performance we have selected VGG16 and ResNet50 as
two different CNN architectures for Ensemble approach. In an ensemble approach,
concatenation of features generated from various networks helps to overcome the
limitations of a single network and produces robust and superior performance. We obtain a
feature vector generated from each individual architecture of VGG16 and ResNet50
architecture, then concatenated output of these into a single feature vector before applying
for the final emotion prediction classification. Here the size of the final feature vector
generated by this ensemble approach adds the size of a feature vector generated from each
network. Sample framework of ensemble of multi-CNN architecture for feature-fusion is
shown in figure 5.7 and proposed Multi-Modal Feature-Fusion based Classification
(MMFFC) model is shown in figure 5.8
Figure 5.7: Sample framework of Ensemble of Multi-CNN feature-fusion [126]

95
Figure 5.8: Proposed Multi-Modal Feature-Fusion based Classification (MMFFC) Model
As shown in figure 5.8, in our proposed MMFFC model VGG16 and ResNet50 considered
as CNN architecture 1 and CNN architecture 2, respectively for an ensemble approach.
Same input images provided to both the architectures. Both the architectures trained and
generated a feature vector at the end of the last layer before the classification stage.
Feature vector 1 (fv1) generated from CNN architecture 1 (VGG16) and feature vector 2
(fv2) generated from CNN architecture 2 (ResNet50) will be combined to create final
feature vector fv which is a combination of fv1 and fv2. Ensemble approach gives an
advantage over here by concatenating these architectures’ output into a single feature
vector for the classification purpose instead of getting one feature vector by applying
single CNN architecture. The proposed MMFFC model aims to improve the recognition
accuracy of real-time facial expression dataset, which contains real-world images with
challenges. Also, this proposed approach is applied to laboratory trained facial expression
dataset for the cross-database evaluation study. Proposed MMFFC algorithm is explained
below:

96
5.4.1 Detailed Process(Algorithm) of Multi-Model feature-fusion based
classification (MMFFC)
base_model1 = VGG16
base_model2 = ResNet50
Input: FER2013 dataset (35887 grey-scaled images) and KDEF dataset (4900
RGB images)
1. Initialize parameters nb_class, x, y, epoch, lr, bs, c, where
nb_class = number of facial expression classes
x = height of the image
y = width of the image
epoch = number of iterations
lr = learning rate
bs = batch size
c = classifier
2. for 1: epochs
train_data, val_data = train_test_split (dataset, 0.8)
bs = 16,32,64 and lr = 1e-1 to 1e-3 // for FER2013 dataset
for 1: last_block_layer // base_model1 VGG16
fv1 = generate feature vector for base_model1
acc1 = predict result of fv1 using classifier c
end for
for 1: last_block_layer // base_model2 ResNet50
fv2 = generate feature vector for base_model2
acc2 = predict result of fv2 using classifier c
end for
res_fr = fv1 fv2 // multi-model fusion approach
final_acc = predict result of res_fr using classifier C
end for
3. for 1: epochs
train_data, val_data = train_test_split (dataset, 0.8)
bs = 16,32 and lr = 1e-1 to 1e-5 // for KDEF dataset
for 1: last_block_layer // base_model1 VGG16
fv1 = generate feature vector for base_model1
acc1 = predict result of fv1 using classifier c
end for
for 1: last_block_layer // base_model2 ResNet50
fv2 = generate feature vector for base_model2
acc2 = predict result of fv2 using classifier c
end for
res_fr = fv1 fv2 // multi-model fusion approach
final_acc = predict result of res_fr using classifier C
end for
4. END

97
5.5 Dataset details:
Proposed Multi-Model Feature-Fusion based Classification (MMFFC) model is tested on
real-time facial expression dataset FER2013 [133] and laboratory trained facial expression
dataset KDEF [151] by varying network parameters like batch size and learning rate.
Stochastic Gradient Descent (SGD) optimizer and SoftMax classifier used for the
evaluation purpose.
5.5.1 FER2013 Dataset:
The FER2013 dataset was introduced during the International Conference on Machine
Learning (ICML) challenges in Representation learning. FER2013 is a large-scale, and
unconstrained database collected automatically by the Google image research API.
FER2013 dataset contains 35,887 real-world images taken in an uncontrolled
environment. So, it has many research challenges for researchers like head-pose variations,
illumination, lower resolution etc. Dataset images contain seven different facial
expressions: Anger, Disgust, Happy, Surprise, Fear, Sad and Neutral, with the resolution
of 48x48 pixels. Example of FER2013 dataset image is shown in figure 5.9 [11]
FIGURE 5.9 Example of images in the FER2013 dataset with different emotions [135]

98
5.5.2 KDEF Dataset:
The Karolinska Directed Emotional Faces (KDEF) dataset is created by Flykt & Ohman et
al. [151] from the department of clinical neuroscience, psychology section, Karolinska
Institute. KDEF is a set of totally 4900 pictures of human facial expressions. The
collection of pictures contains 70 individuals displaying seven different emotional
expressions. Each expression is viewed from 5 different angles. Dataset images have seven
different facial expressions: Anger, Disgust, Happy, Surprise, Fear, Sad and Neutral, with
the resolution of 224x224 pixels. Example of KDEF dataset image is shown in figure 5.10
[151,152]
FIGURE 5.10 Sample images in the KDEF dataset with different emotions [152]
5.6 Experiments and Results:
In this section, we have described the experimental setup, implementation details with
necessary library support, different parameters used in the proposed model, optimization
of these parameters, the benchmark datasets such as KDEF [151] and FER2013 [133] used
to assess the performance of the proposed model, the results of the proposed model on
these datasets and comparison of these results with state-of-the-art methods. Both the
datasets are divided into 80%-20% ration for training and validation process.

99
5.6.1 Experimental Setup and Implementation Details:
The proposed MMFFC model is implemented using Python and Deep Learning
environment using Keras API with TensorFlow as a backend. The experiments are
performed on NVIDIA GeForce GTX 1050Ti 4GB Graphic Processing Unit (GPU) with
i7 8th generation windows processor system with 16GB RAM. Anaconda deep learning
environment is installed with Keras-TensorFlow libraries. Google Colab and PyCharm
Community Edition used as an IDE tool for implementation purpose with Python
programming language.
In this implementation, we have used different evaluation parameters like maximum 100
epochs and batch size varying from 16, 32 and 64 for different learning rate values ranging
from 0.1 to 0.0001 for detailed analysis purposes. Stochastic Gradient Descent (SGD) used
as an Optimizer and SoftMax are used as a Classifier. These network parameters like
Epochs, Batch Size, Learning Rate, Optimizer and Classifier selection are essential in
order to carry out effective results in recognition accuracy.
5.6.2 Experimental results of Ensemble approach using different CNN
architectures:
As discussed in section 5.4, we have analysed the performance of different CNN
architectures (InceptionV3, VGG16, VGG19 and ResNet50) for an ensemble approach. To
decide which combination of two different CNN architectures from above gives better
performance in terms of recognition accuracy, experiments carried out by applying the
proposed approach and measure the recognition accuracy. Comparison of accuracy of a
different combination of two different CNN architectures evaluated on FER2013 dataset
by using network parameters as Max Epochs = 100, Batch size = 16 and learning rate
0.001. Experimental results are shown in Table 5.1
Table 5.1: Comparison accuracy on two different CNN architectures using an ensemble approach
An ensemble of two different CNN
architectures for proposed MMFFC model
Validation Accuracy (%)
InceptionV3 + VGG-16 50.24%
InceptionV3 + ResNet50 50.09%
VGG-16 + ResNet50 68.14%
VGG-19 + ResNet50 66.50%

100
From the experimental results mentioned in table 5.1, the combination of VGG-16 and
ResNet50 CNN architectures gives better recognition accuracy than the other
combinations of different CNN architectures. So, VGG-16 and ResNet50 two CNN
architectures selected for our proposed MMFFC model. Feature vectors generated at the
last layer of individual VGG-16 and ResNet50 architecture will be concatenated to create
a resultant feature vector as an ensemble approach. Resulting feature vector further
provided to classifier for classification purpose. This proposed MMFFC model tested on
KDEF and FER2013 datasets with varying network parameters to improve the recognition
accuracy of the real-time dataset and laboratory trained dataset for cross-database
evaluation purpose.
5.6.3 Experimental results on FER2013 dataset:
Proposed MMFFC model is tested on FER2013 real-time facial expression dataset with
varying network parameters values such as Batch size 16, 32 and 64 and Learning rate
varying from 0.1 to 0.001. Stochastic Gradient Descent (SGD) used as an optimizer and
SoftMax used as a classifier. Experiments are carried out for individual CNN architectures
VGG-16 and ResNet50 for the above network parameters. Then, experiments carried out
for the proposed MMFFC model (VGG-16 + ResNet50) using an ensemble approach.
Results are mentioned in table 5.2
Table 5.2 shows results in terms of recognition accuracy on the FER2013 dataset for
individual CNN architecture VGG-16 and ResNet50 and on the proposed MMFFC model
using the ensemble of VGG-16 & ResNet50 architectures. Maximum recognition accuracy
67.36% obtained for VGG-16 individual CNN architecture for batch size value 16 and
learning rate value 0.001. Similarly, maximum recognition accuracy 64.24% obtained
from ResNet50 individual CNN architecture for batch size value 32 and learning rate
value 0.001. In comparison with these two accuracy results, maximum accuracy of 68.14%
obtained using the proposed MMFFC approach for batch size value 64 and learning rate
value 0.01. As discussed in the literature review, many researchers worked and tried to
improve the recognition accuracy of FER2013 real-time facial expression dataset.

101
Table 5.2: FER2013 dataset performance for VGG16, ResNet50 and proposed MMFFC model using
ensemble approach
Implementation Result of MMFFC Model
Accuracy (%) on FER2013 Dataset
Max. Epochs = 50 Learning rate
Batch Size 0.1 0.01 0.001
Results of VGG16 Model
16 66.06 67.15 67.36
32 65.57 63.83 64.11
64 58.79 62.83 61.61
Results of ResNet50 Model
16 63.37 58.6 63.46
32 63.18 61.61 64.24
64 63.43 62.94 61.26
Results of Proposed MMFFC Model
16 66.93 65.63 67.61
32 68.08 65.97 67.33
64 67.95 68.14 66.99
Comparative state-of-the-art analysis of the proposed MMFFC model with other multi-
model methods on the FER2013 dataset is shown in table 5.3. Confusion matrix is shown
in figure 5.11. Detailed Classification Report and the ROC-AUC curve for proposed
MMFFC model are shown in figure 5.12 and 5.13. ROC-AUC curve on the FER2013
dataset without and with ensemble model approach is shown. Model’s performance is
measured in both the cases for different epochs vs. AUC values based on the classifier.
Higher the AUC, better the model is predicting the results. ROC-AUC analysis on
FER2013 dataset shows better prediction performance with an ensemble model approach.
To evaluate the model on real-time facial expression datasets contains lower resolution
images, some variance is generated during evaluation of model and hence not smooth

102
curve is generated in the AUC graph. Average AUC value generated here is between 0.8-
0.9. Also, Accuracy charts of proposed MMFFC model based on FER2013 dataset for
different batch sizes (16,32 and 64) are shown in figure 5.14, 5.15 and 5.16.
Table 5.3: Comparative analysis of the proposed MMFFC model with state-of-the-art methods on the
FER2013 dataset
Method Name Accuracy (%)
An Ensemble of CNN – Subnets [122] 65.03%
Deep Neural Network [138] 66.4%
Multi-Task Network [144] 67.2%
Auxiliary Model [126] 67.7%
DCN+AMN (Alignment Mapping Network) [145] 71.8%
Ensemble of 3 MLCNN Model [56] 73.03%
Proposed MMFFC Model 68.14%
FIGURE 5.11 Confusion matrix using the proposed MMFFC model on the FER2013 dataset

103
FIGURE 5.12 Classification Report for the proposed MMFFC model on the FER2013 dataset
(a) (b)
FIGURE 5.13 ROC-AUC curve on the FER2013 dataset for (a) without multi-model fusion (b) with multi-
model fusion

104
FIGURE 5.14 Accuracy graph of the proposed MMFFC model for the FER2013 dataset for batch size 16
FIGURE 5.15 Accuracy graph of the proposed MMFFC model for the FER2013 dataset for batch size 32
FIGURE 5.16 Accuracy graph of the proposed MMFFC model for the FER2013 dataset for batch size 64

105
5.6.4 Experimental results on KDEF dataset:
Proposed MMFFC model is also tested on laboratory trained KDEF dataset for cross-
database evaluation study with varying network parameters values such as Batch size 16
and 32, Learning rate varying from 0.1 to 0.0001. Stochastic Gradient Descent (SGD) used
as an optimizer and SoftMax used as a classifier. Experiments are carried out for the
proposed MMFFC model (VGG-16 + ResNet50) using an ensemble approach. Results are
mentioned in table 5.4. Results show that maximum recognition accuracy 92.04% on
KDEF dataset obtained for batch size value 16 and learning rate value 0.001.
Table 5.4: KDEF dataset performance for VGG16, ResNet50 and proposed MMFFC model using an
Ensemble approach
Implementation Result of MMFFC Model
Accuracy (%) on KDEF Dataset
Max. Epochs = 50 Learning rate
Batch Size 0.1 0.01 0.001
Results of VGG16 Model
16 90.61 90 89.79
32 88.36 87.77 89.59
Results of ResNet50 Model
16 88.97 83.87 90.81
32 85.1 81.63 87.55
Results of Proposed MMFFC Model
16 91.42 91.02 92.04
32 89.18 91.83 89.8
As discussed in the literature review, many researchers have also tried to improve the
recognition accuracy of laboratory trained facial expression dataset for the cross-dataset
evaluation purpose. Comparative state-of-the-art analysis of proposed MMFFC model on
KDEF dataset is shown in below table 5.5. Confusion matrix is shown in figure 5.17.
Detailed Classification Report and the ROC-AUC curve shown in figure 5.18 and 5.19.

106
ROC-AUC curve on the KDEF dataset without and with ensemble model approach is
shown. Model’s performance is measured in both the cases for different epochs vs. AUC
values based on the classifier. Higher the AUC, better the model is predicting the results.
ROC-AUC analysis on KDEF dataset shows better prediction performance with an
ensemble approach. Average AUC value generated here is between 0.8-0.9. Also,
Accuracy chart of proposed MMFFC model based on KDEF dataset for different batch
sizes 16 and 32 is shown in figure 5.20 and figure 5.21. Maximum recognition accuracy
92.04% achieved using proposed MMFFC model. Comparative analysis of the Error-rate
on both the datasets using the proposed MMFFC approach is shown in table 5.6
Table 5.5: Comparative analysis of proposed MMFFC model with state-of-the-art methods on KDEF dataset
Method Name Accuracy (%)
Histogram Oriented Gradients with SVM [153] 80.95%
Dynamic Bayesian Mixture Model [154] 85%
Gradient Laplacian RTNN Model [155] 88.16%
DCNN Model [156] 89.33%
Hybrid Approach for FER [157] 89.58%
Dense Facelivenet Model [158] 95.89%
Proposed MMFFC Model 92.04%
FIGURE 5.17 Confusion matrix using the proposed MMFFC model on the KDEF dataset

107
FIGURE 5.18 Classification Report for the proposed MMFFC model on the KDEF dataset
(a) (b)
FIGURE 5.19 ROC-AUC curve on the KDEF dataset for (a) without multi-model fusion (b) with multi-
model fusion

108
FIGURE 5.20 Accuracy graph of the proposed MMFFC model for the KDEF dataset for batch size 16
FIGURE 5.21 Accuracy graph of the proposed MMFFC model for the KDEF dataset for batch size 32
Table 5.6: Comparative analysis of the Error-Rate on both the datasets using the proposed MMFFC model
Method Databases
Error-Rate Analysis
Recognition
Accuracy (%)
Error rate
(%)
VGG16
FER2013
67.36 32.64
ResNet50 64.24 35.76
Ensemble
(VGG16+ ResNet50) 68.14 31.86
VGG16
KDEF
90.61 9.39
ResNet50 90.81 9.19
Ensemble
(VGG16+ ResNet50) 92.04 7.96

109
5.7 Discussion and Summary:
To improve the recognition accuracy of real-time facial expression dataset is a significant
challenge as it contains many challenges like head-pose variations, illumination, lower-
resolution images etc. In this chapter, we have proposed a Multi-Model Feature-Fusion
based Classification (MMFFC) model, which works on an ensemble of multi-CNN
approach. This proposed model aims to concatenate the output of different CNN
architectures for better feature extraction process instead of getting one feature map form
single CNN architecture. Our proposed MMFFC model, the ensemble of multi-CNN
approach for two CNN architectures VGG-16 and ResNet50 is carried out. The
concatenation of features from different networks helps to overcome the limitations of a
single network. It will further produce a robust and superior performance to improve
recognition accuracy. The only drawback is that complexity is increased due to the
concatenation of two different CNN architectures’ output instead of a single CNN
architecture. The proposed model is evaluated on FER2013 and KDEF datasets.
Experimental results show that the proposed MMFFC model has achieved better
recognition accuracy on real-time facial expression FER2013 dataset as well as on
laboratory-trained facial expression KDEF dataset. Experimental results validated on
FER2013 real-time facial expression dataset with the proposed model has achieved better
recognition accuracy (68.14%) compared to the state-of-the-art methods. For the cross-
database evaluation, experimental results validated on KDEF laboratory-trained facial
expression dataset with the proposed model has achieved the best recognition accuracy
(92.04%) in comparison with the state-of-the-art methods. Also, proposed MMFFC
approach used to reduce Error-rates in both the datasets. For the FER2013 dataset, Error-
rate reduces to 31.86% and 7.96% for the KDEF dataset using the proposed Ensemble
approach. An ensemble of a multi-CNN approach using the proposed MMFFC model
helps to overcome the challenges of real-time facial expression dataset as well as a
laboratory-trained facial expression dataset with improved recognition accuracy shown in
the experimental result. Based on experimental results, we conclude that the proposed
MMFFC model works much better and gives higher recognition accuracy with higher
resolution images than the lower resolution images in the facial expression datasets.

110
CHAPTER 6
Novel FER Model based on Normalized CNN
6.1 Introduction
In 2019, Mingxing et al. [159] have introduced “EfficientNet: Rethinking Scaling model
for CNN” concept in which EfficientNet B0 to B7 models are described. Advantage of this
concept is to improve recognition accuracy by reducing parameters and providing better
results comparing with existing architectures. EfficientNets are based on AutoML and
Compound Scaling approach. In particular, AutoML Mobile framework has been used to
develop a mobile-size baseline network, named as EfficientNet-B0; then Compound
Scaling method is used to scale up this baseline to obtain EfficientNet-B1 to B7 models.
Based on the literature survey and industry reference, it is found that no work has been
carried out for facial expression recognition using this latest model EfficientNet till date.
This EfficientNet approach is working well on high-resolution images, so we have studied
and implemented the proposed EfficientNetB7 model for facial expression recognition on
facial expression datasets which contains higher resolution images. EfficientNet using
compound scaling method to scale up CNN in a more structured way. It will uniformly
scale all the dimensions with a compound coefficient by principled scaling of depth, width
and resolution dimensions. Unlike conventional approaches that arbitrary scale network
dimensions such as width, depth and resolution. This approach uniformly scales each
dimension with a fixed set of scaling coefficients. Figure 6.1 summarizes the ImageNet
performance, where EfficientNets significantly outperform other ConvNets. In particular,
EfficientNetB7 surpasses the best existing accuracy but using 8.4x fewer parameters and
running 6.1x faster on inference. Besides ImageNet, EfficientNets also transfer well and
achieve state-of-the-art accuracy on widely used datasets, while reducing parameters by up
to 21x than existing ConvNets. [159]
In this chapter, EfficientNet architecture details are presented. Also, the proposed
EfficientNetB7 model is presented to perform a facial expression recognition task. For the
model performance comparison with EfficientNetB7, ResNet152 architecture is also
implemented for the facial expression recognition task. As per the literature review, no
work has been carried out for facial expression recognition with this novel EfficientNetB7

111
model till date. Different optimizers are applied to both the architectures and performance
analysis carried out in terms of recognition accuracy. Selection of the optimizer is essential
to decide the model’s better performance on facial expression dataset with higher
recognition accuracy. The different optimizers such as stochastic gradient descent (SGD),
RMSprop and Adam have experimented with the proposed EfficientNetB7 model and
ResNet152 architecture with network parameters such as epochs and learning rate. Also
Vanishing Gradient Descent (VGD) issue arise during evaluation of the proposed model to
measure accuracy and loss graph. This issue is further resolved by the proposed Internal
Batch Normalization (IBN) concept, which will help to reduce variance loss in the model
and achieve a smooth curve with optimized results.
Figure 6.1: ImageNet performance evaluation with other ConvNets [159]
As we can see in figure 6.1, EfficientNets significantly outperform other ConvNets. In
fact, EfficientNetB7 achieved new state-of-the-art accuracy compared with different
architectures being 8.4 times smaller and 6.1 times faster. The great thing about
EfficientNet is that not only do they have better accuracies compared to their counterparts,
they are also lightweight and thus, faster to run.

112
6.2 EfficientNet Architecture and Working methodology
Before the EfficientNets came along, the most common way to scale up ConvNets was
either by one of three dimensions – depth (number of layers), width (number of channels)
or image resolution (image size). EfficientNets, on the other hand, perform Compound
Scaling approach that scales all three dimensions while maintaining a balance between all
dimension of the network. The main difference between the scaling methods has also been
illustrated in below figure 6.2
Figure 6.2: Model Scaling Approach [159]
Above figure 6.2, (b) to (d) are conventional scaling that only increases one dimension of
network width, depth or resolution. (e) is the proposed compound scaling method that
uniformly scales all three dimensions with a fixed ratio. The idea of compound scaling
makes sense because if the input image is bigger (input resolution), then the network needs
more layers (depth) and more channels (width) to capture more fine-grained patterns on
the bigger image. This idea of Compound Scaling also works on existing MobileNet and
ResNet architectures.

113
Figure 6.3: Scaling up a Baseline Model with Different Network Width (w), Depth (d) and Resolution (r)
[159]
Authors of EfficientNet architecture ran many experiments scaling depth, width and image
resolution and made two main observations: First, scaling up any network width
dimension, depth or resolution improves accuracy, but the accuracy gain diminishes for
bigger models. Second, in order to pursue better accuracy and efficiency, it is critical to
balance all dimensions of network width, depth and resolution during ConvNet scaling.
Scaling Up a Baseline Model with Different Network Width (w), Depth (d) and
Resolution (r) Coefficients is shown in figure 6.3. Bigger networks with a larger width,
depth or resolution tend to achieve higher accuracy, but the accuracy gain quickly
saturates after reaching 80% as shown in above figure 6.3. It is demonstrating the
limitation of single dimension scaling. The individual scaling technique is called
Compound Scaling. [160]
Scaling network depth (number of layers), is the most common way used by many
ConvNets. With the advancements in deep learning, it has now been possible to train
deeper neural networks that generally have higher accuracy than their shallower
counterparts. The intuition is that deeper ConvNet can capture more prosperous and more
complex features. However, deeper networks are also the most challenging to train due to
the vanishing gradient problem. Figure 6.3 (middle) shows that accuracy saturates at
d=6.0, and no further improvement can be seen after. [160]

114
Scaling network width – that is, increasing the number of channels in Convolution layers –
is most commonly used for smaller sized models. Applications of wider networks seen in
MobileNets, MNasNet. While wider networks tend to capture more fine-grained features
and are easier to train, extremely wide but shallow networks tend to have difficulties in
capturing higher-level features. In figure 6.3 (left), accuracy quickly saturates when
networks become much wider with large w value. Also increasing image resolution to help
improve the accuracy of ConvNets. Figure 6.3 (right), accuracy increases with an increase
in input image size.
The authors used Neural Architecture Search approach similar to MNasNet, which is a
reinforcement learning-based approach where the authors developed a baseline neural
network architecture EfficientNet-B0. It optimizes both the accuracy and efficiency
measured on the floating-point operations per second (FLOPS) basis. Flops mean the
number of floating-point operations optimized and achieved a better result than other
models like Inception, ResNet etc. This developed architecture uses the Mobile Inverted
Bottleneck Convolution (MBConv). The researchers then scaled up this baseline network
to obtain a family of deep learning models, called EfficientNets. Its architecture is shown
in below figure 6.4
Figure 6.4: A basic block representation of the EfficientNet-B0 [161]
The EfficientNet-B0 architecture is summarized in table 6.1, where the MBConv layer is
nothing but an inverted bottleneck block with squeeze and excitation block along with
swish activation.

115
Table 6.1: EfficientNet-B0 Baseline Network [161]
In table 6.1, the architecture uses seven inverted residual blocks, but each is having
different settings. EfficientNet model architecture will have to scale in three stages:
Depthwise Convolution + Pointwise Convolution, Inverse Res and Linear bottleneck is
shown in figure 6.5 (a) and (b)
Figure 6.5: A basic representation of Depthwise and Pointwise Convolutions in (a) and (b) [161]

116
Depthwise Convolution and Pointwise Convolution divides the original convolution into
two stages to significantly reduce the calculation cost, with a minimum loss of accuracy.
This approach decreases trainable parameters by a large number. For Inverse Res, the
original ResNet blocks consist of a layer that squeezes the channels and then a layer that
extends the channels. In this way, it links skip connections to rich channel layers. In
MBConv, however, blocks consist of a layer that first extends channels and then
compresses them, so that layers with fewer channels are skip connected. Linear bottleneck
uses linear activation in each block’s last layer to prevent loss of information from ReLU
[161].
The main building block for EfficientNet is MBConv, an inverted bottleneck Conv, known
initially as MobileNetV2. Using shortcuts between bottlenecks by connecting a much
smaller number of channels (compared to expansion layers), it was combined with an in-
depth separable convolution, which reduced the calculation by almost k² compared to
traditional layers. Where k denotes the kernel size, it specifies the height and width of the
2-dimensional convolution window. Google Brain team suggested a newer activation that
tends to work better for deeper networks than ReLU, which is a Swish activation. Swish is
a multiplication of a linear and a sigmoid activation, Swish (x) = x * sigmoid (x)
To scale up EfficientNet architecture from EfficientNet-B0 to EfficientNet B1-B7, it is
necessary to use the following approach by taking network depth (d), width (w) and input
image resolution (r) as:

117
Intuitively, φ is a user-defined coefficient that determines how much additional resources
are available. The constants α, β, γ determine how to distribute these extra resources
across networks depth(d), width(w) and input resolution(r). Starting from the baseline
EfficientNet-B0, compound scaling method applied to scale it up with two steps:
STEP-1: First fix φ = 1, assuming twice more resources available, and do a small grid
search of α, β, γ. In particular, find the best values for EfficientNet-B0 are α = 1.2, β = 1.1,
γ = 1.15, under constraint of α * β2 * γ2 ≈ 2.
STEP-2: Then fix α, β, γ as constants and scale-up baseline network with different φ, to
obtain EfficientNet-B1 to B7.
6.3 Proposed novel FER model: EfficientNet-B7
Based on the literature survey and industry reference, it is found that no work has been
carried out for facial expression recognition using this latest concept of EfficientNet. So,
we have selected EfficientNet-B7 latest model as our proposed model for facial expression
recognition purpose. The proposed model approach is shown in figure 6.6
Figure 6.6: Proposed Novel FER model with EfficientNet-B7 and ResNet-152 architecture

118
In this proposed model, we have applied different optimizers (Adam, RMSprop and SGD)
on EfficientNet-B7 and ResNet152 pre-trained CNN architectures with varying network
parameters to decide which optimizers will provides better performance for the given FER
task. As no work is carried out for facial expression recognition on EfficientNet-B7 model,
it is essential to decide which optimizer gives better performance in terms of recognition
accuracy for facial expression recognition. ResNet152 architecture is used for the cross-
verification purpose with EfficientNet-B7 model. EfficientNet-B7 model is working well
on higher resolution images; performance evaluation is carried out KDEF dataset [151]
which contains higher resolution images and also on the FER2013 dataset [133] real-time
dataset which contains lower resolution images for cross-database evaluation. Proposed
algorithm is explained below in which different optimizers are applied to EfficientNet-B7
proposed model and ResNet152 model. Recognition accuracy will be generated for each
optimizer and stored. Maximum recognition accuracy using these three optimizers will be
considered as final recognition accuracy. This process is applied to both the models
EfficientNet-B7 and ResNet152.
6.3.1 Detailed Process (Algorithm) of proposed novel FER model
base_model1 = EfficientNet-B7
base_model2 = ResNet152
op1 = Adam optimizer
op2 = RMSprop optimizer
op3 = SGD optimizer
Input: KDEF dataset (4900 RGB images) and FER2013 dataset (35887 grey-
scaled images)
1. Initialize parameters nb_class, x, y, epoch, lr, bs, C, where
nb_class = number of facial expression classes
x = height of the image
y = width of the image
epoch = number of iterations
lr = learning rate
bs = batch size
C = classifier
2. for 1: epochs
train_data, val_data = train_test_split (dataset, 0.8)
for 1: last_block_layer
model = compile base_model1 with op1 optimizer
fv = generate feature vector for model
acc1 = predict result of fv using classifier C
end for

119
for 1: last_block_layer
model = compile base_model1 with op2 optimizer
fv = generate feature vector for model
acc2 = predict result of fv using classifier C
end for
for 1: last_block_layer
model = compile base_model1 with op3 optimizer
fv = generate feature vector for model
acc3 = predict result of fv using classifier C
end for
final_acc = max (acc1, acc2, acc3)
end for
3. for 1: epochs
train_data, val_data = train_test_split (dataset, 0.8)
for 1: last_block_layer
model = compile base_model2 with op1 optimizer
fv = generate feature vector for model
acc1 = predict result of fv using classifier C
end for
for 1: last_block_layer
model = compile base_model2 with op2 optimizer
fv = generate feature vector for model
acc2 = predict result of fv using classifier C
end for
for 1: last_block_layer
model = compile base_model2 with op3 optimizer
fv = generate feature vector for model
acc3 = predict result of fv using classifier C
end for
final_acc = max (acc1, acc2, acc3)
end for
4. END

120
6.4 Dataset details:
The proposed model is tested on KDEF dataset [151], which contains higher resolution
images and also on real-time facial expression dataset FER2013 [133], which includes
lower resolution images using network parameters like batch size and learning rate.
Different Optimizers (Adam, RMSprop and SGD) applied to check which optimizer
giving better performance in terms of recognition accuracy. SoftMax classifier used for the
classification purpose.
6.4.1 KDEF Dataset:
The Karolinska Directed Emotional Faces (KDEF) dataset is created by Flykt & Ohman et
al. [151] from the department of clinical neuroscience, psychology section, Karolinska
Institute. KDEF is a set of totally 4900 pictures of human facial expressions. The
collection of pictures contains 70 individuals displaying seven different emotional
expressions. Each expression is viewed from 5 different angles. Dataset images have seven
different facial expressions: Anger, Disgust, Happy, Surprise, Fear, Sad and Neutral, with
a resolution of 224x224 pixels. Example of KDEF dataset image is shown in figure 6.7
[151,152]
FIGURE 6.7 Sample images in the KDEF dataset with different emotions [152]

121
6.4.2 FER2013 Dataset:
The FER2013 dataset was introduced during the International Conference on Machine
Learning (ICML) challenges in Representation learning. FER2013 is a large-scale, and
unconstrained database collected automatically by the Google image research API.
FER2013 dataset contains 35,887 real-world images taken in an uncontrolled
environment. So, it has many research challenges for researchers like head-pose variations,
illumination, lower resolution etc. Dataset images contain seven different facial
expressions: Anger, Disgust, Happy, Surprise, Fear, Sad and Neutral, with a resolution of
48x48 pixels. Example of FER2013 dataset image is shown in figure 6.8 [11]
FIGURE 6.8 Example of images in the FER2013 dataset with different emotions [135]
6.5 Experiments and Results:
The proposed model is implemented using Python and Deep Learning environment using
Keras API with TensorFlow as a backend. The experiments are performed on NVIDIA
GeForce GTX 1050Ti 4GB Graphic Processing Unit (GPU) with i7 8th generation
windows processor system with 16GB RAM. Anaconda deep learning environment is
installed with Keras-TensorFlow libraries. Google Colab used as an IDE tool for
implementation purpose with Python programming language.

122
In this implementation, we have used different evaluation parameters like maximum 50
epochs for learning rate value 0.0001 on KDEF dataset, which contains higher resolution
images. Different Optimizers (Adam, RMSprop and SGD) applied for the given network
parameters value and recognition accuracy measured. The same process used on real-time
facial expression dataset FER2013 for the cross-database evaluation study. Based on
experimental results, the conclusion will be carried out that which optimizer for the given
network parameters was working well on EfficientNet-B7 and ResNet152 architectures to
improve recognition accuracy for facial expression recognition.
6.5.1 Experimental results on proposed EfficientNet-B7 model:
Proposed EfficientNet-B7 model is tested on KDEF dataset, which contains higher
resolution images by using network parameters as the maximum size of Epoch is 50, and
the learning rate value is 0.0001. Different optimizers are applied to this proposed model
EfficientNet-B7 by using these network parameters and measured recognition accuracy of
the model using KDEF dataset to decide which optimizer performs well for the facial
expression recognition task. Experimental results for different optimizers with its
recognition accuracy is shown in table 6.2
Table 6.2: Comparative analysis of the proposed EfficientNet-B7 model with different Optimizers
Optimizers Validation Accuracy (%)
Stochastic Gradient Descent (SGD) 62.41 %
RMSprop 91.78%
Adam 77.93%
Similarly, ResNet152 pre-trained CNN architecture is tested on KDEF dataset for cross
performance verification using the same above network parameters. Epochs size
maximum taken is 50, and the learning rate value is 0.0001. Different optimizers are
applied to this ResNet152 architecture using these network parameters and measured
recognition accuracy of the model using KDEF dataset to decided which optimizer is
performing well for facial expression recognition. Experimental results for different
optimizers with its recognition accuracy is shown in table 6.3

123
Table 6.3: Comparative analysis of the ResNet152 CNN architecture with different Optimizers
Optimizers Validation Accuracy (%)
Stochastic Gradient Descent (SGD) 88.77 %
RMSprop 70.40%
Adam 74.08%
From the experimental results mentioned in table 6.2 and table 6.3, proposed EfficientNet-
B7 novel model achieves highest 91.78% recognition accuracy with RMSprop optimizer
compared to the other optimizers. In comparison, ResNet152 architecture which is
implemented for cross-performance verification achieves 88.77% recognition accuracy
with SGD optimizer. It concludes that the proposed model gives better results with
RMSprop optimizer for facial expression recognition. Confusion matrix and Classification
Report generated for proposed EfficientNet-B7 model, which has achieved maximum
recognition accuracy with RMSprop optimizer is shown in figure 6.9 and 6.10,
respectively. Performance comparison evaluation of recognition accuracy using different
optimizers on proposed EfficientNet-B7 model with ResNet152 architecture is shown in
figure 6.11
FIGURE 6.9 Confusion Matrix using the proposed novel EfficientNet-B7 model on the KDEF dataset
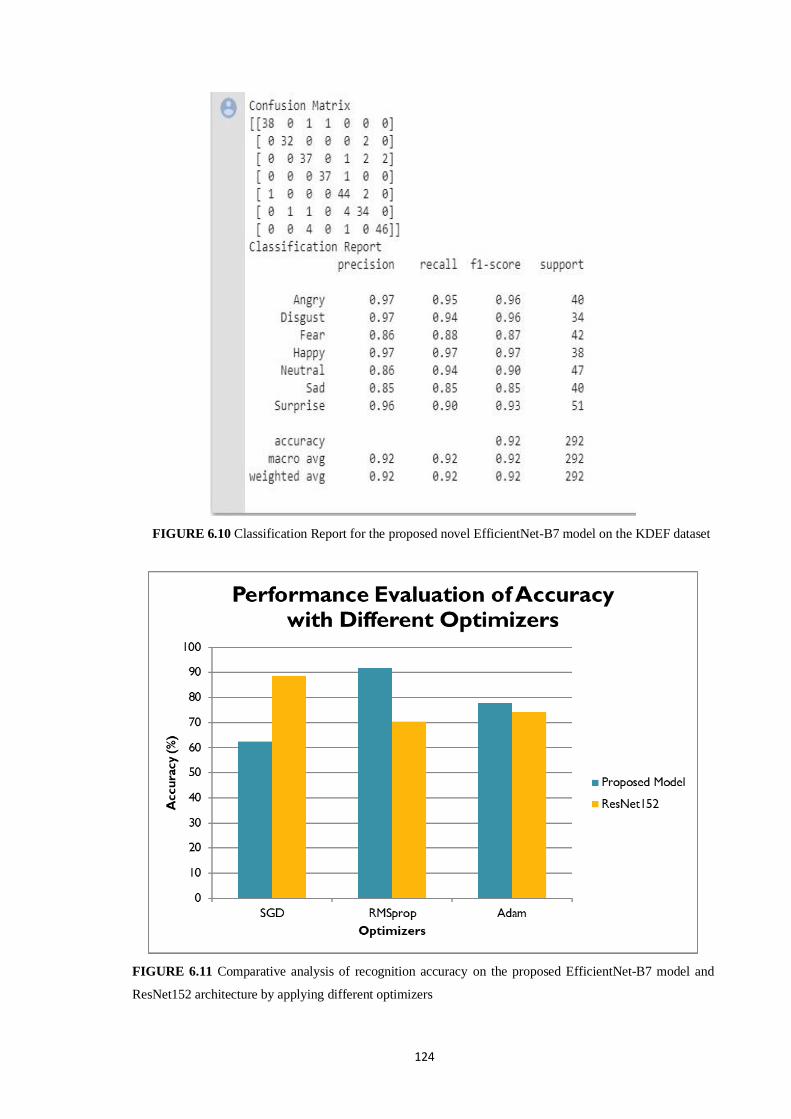
124
FIGURE 6.10 Classification Report for the proposed novel EfficientNet-B7 model on the KDEF dataset
FIGURE 6.11 Comparative analysis of recognition accuracy on the proposed EfficientNet-B7 model and
ResNet152 architecture by applying different optimizers

125
We have tested our proposed novel EfficientNet-B7 model on real-time facial expression
dataset FER2013 [135] which contains lower resolution images. From the literature
survey, we found that the proposed EfficientNet-B7 model gives better performance for
the database, which includes higher resolution images. To do the cross-database
evaluation, we have tested our proposed model on FER2013 dataset by keeping the same
network parameters value evaluated for KDEF dataset. Results mentioned in table 6.4
shows that the proposed model achieves maximum recognition accuracy 57.5% on
RMSprop optimizer, which is significantly less compared to the KDEF dataset
performance evaluation results. It proves that the proposed model does not perform well
on facial expression dataset, which contains lower resolution images. Experimental results
for different optimizers on proposed EfficientNet-B7 model with its recognition accuracy
for FER2013 facial expression dataset is shown in table 6.4
Table 6.4: Comparative result analysis of the proposed EfficientNet-B7 model with different optimizers on
the FER2013 dataset
Optimizers Validation Accuracy (%)
Stochastic Gradient Descent (SGD) 21.58 %
RMSprop 57.56%
Adam 51.23%
After achieving better recognition accuracy of 91.78% on proposed EfficientNet-B7 model
with RMSprop optimizer, Vanishing Gradient Descent problem was found in model
accuracy and loss graph as shown in figure 6.12. EfficientNet-B7 is a pre-trained CNN
architecture trained on ImageNet dataset values. When we apply KDEF facial expression
dataset, this model weight gives Variance with Zigzag pattern in the model loss graph. We
are not getting a smoother curve in model accuracy and model loss graph and making our
proposed model unstable due to this problem. To make our proposed model more stable
and reduce variance generated in model loss and accuracy graph, Internal Batch
Normalization (IBN) concept is applied.

126
FIGURE 6.12 Vanishing Gradient Descent problem due to Variance in model loss and accuracy graph of
the proposed EfficientNet-B7 model
6.5.2 Internal Batch Normalization (IBN) & Experimental results:
Internal working of Batch Normalization is explained below: [162]
• Batch Normalization aims to reduce internal covariate shift, and in doing so
aims to accelerate the training of deep neural nets.
• It accomplishes this via a normalization step that fixes the means and variance
of layer inputs.
• Batch Normalization also has a beneficial effect on the gradient flow through
the network, by reducing the dependence of gradients on the parameters’ scale or
initial values.

127
• This allows for the use of much higher learning rates without the risk of
divergence.
• Furthermore, Batch Normalization regularizes the model and reduces the need
for Dropout.
We apply a batch normalization as follows for a minibatch β where γ and β are learnable
parameters: [162]
FIGURE 6.13 Sample figure of Batch Normalization process with N as batch axis, C as the channel axis and
(H, W) as the spatial axes [163]

128
Transfer learning concept for EfficientNet:
• While EfficientNet reduces the number of parameters, training of convolutional
network is still a time-consuming task. To further reduce the training time, we can
utilize transfer learning techniques.
• Transfer learning means we use a pre-trained model and fine-tune the model on
new data
• In image classification we can think of dividing model into two parts
• One part of the model is responsible for extracting the key features from images,
like edges etc.
• Other part is using these features for the actual classification
• Usually, a CNN is built of stacked convolution blocks reducing the image size
while increasing the number of learnable features (filters). In the end, everything is
put together into a fully connected layer, which does the classification.
• The idea of transfer learning is to make the first part transferable, so that it can be
used for different tasks by replacing only the fully connected layer (often called
“top”)
Now we can train the last layer on our applied dataset while the feature extraction layers
are using weights from ImageNet. But unfortunately, we are getting vanishing gradient
issue due to variance generated in the model accuracy and loss graph. To resolve this
issue, we again re-train our model by applying the proposed Internal Batch Normalization
(IBN) concept, where keeping batch normalization layers active only. The process is
explained below:
By applying Internal Batch Normalization (IBN) concept, vanishing gradient issue is
resolved by reducing variance effect in our proposed model and making our model more

129
stable. Also making model accuracy and loss curve graph very smooth compared to the
existing one with the ROC-AUC curve, as shown in figure 6.14. In the figure, we can see
that better results are achieved for the ROC-AUC curve also.
Proposed Algorithm for EfficientNet-B7 model with Internal Batch Normalization
(IBN) approach:
6.5.3 Detailed Process (Algorithm) of proposed novel FER model using IBN
approach
base_model = EfficientNet-B7
opt = RMSprop optimizer
Input: KDEF dataset (4900 RGB images)
1. Initialize parameters nb_class, x, y, epoch, lr, bs, C, where
nb_class = number of facial expression classes
x = height of the image
y = width of the image
epoch = number of iterations
lr = learning rate
bs = batch size
C = classifier
2. for 1: epochs
train_data, val_data = train_test_split (dataset, 0.8)
for 1: last_block_layer
for layer in base_model.layers:
if isinstance (layer, batchnormalization):
layer.trainable = true
else
layer.trainable = false
end for
model = compile base_model with opt optimizer
fv = generate feature vector for model
result_acc = predict result of fv using classifier C
end for
end for
3. END

130
FIGURE 6.14 Resultant smooth curve achieved by applying an Internal Batch Normalization concept and
reducing variance effect
6.6 Discussion and Summary:
Mingxing et al. [159] have introduced “EfficientNet: Rethinking Scaling model for CNN”
concept in which EfficientNet B0 to B7 models are described in 2019. It is the best
classification model used in many recognition tasks. EfficientNet using Compound
Scaling method to scale up CNN in a more structured way to improve the recognition
accuracy by reducing parameters. Unlike conventional approaches that arbitrarily scale the
network dimensions such as width, depth and resolution, this approach uniformly scales
each dimension with a fixed set of scaling coefficients. From the literature survey and
industry reference, it is found that no work for facial expression recognition has been
carried out using this EfficientNet model till date. Also, this novel EfficientNet model
working well on higher resolution images.
In our proposed model, EfficientNet-B7 model is implemented using different optimizers
and network parameters on KDEF dataset, which contains higher resolution images.
Optimizers play an essential role in CNN models to improve the recognition accuracy to

131
decide which optimizer is performing well and give better recognition accuracy is an
important constraint. Different optimizers (RMSprop, Adam and SGD) applied on the
proposed novel EfficientNet-B7 model with varying parameters of a network used as
epochs and learning rate. Same network parameters values are applied on ResNet152
architecture for cross-performance architecture evaluation. The experimental results
concluded that the proposed EfficientNet-B7 model performs well using RMSprop
optimizer compared with other optimizers and achieved 91.78% recognition accuracy for
the facial expression recognition task. In another case, ResNet152 architecture performs
well using SGD optimizer compared with other optimizers and achieved 88.77%
recognition accuracy for the facial expression recognition task. Proposed EfficientNet-B7
model is also applied on real-time facial expression dataset FER2013 for cross-database
evaluation study, which contains lower resolution images. Experimental results show that
the proposed model has achieved maximum recognition accuracy of 57.56% using
RMSprop optimizer compared to other optimizers. So, it concludes that the proposed
model does not perform well on the datasets, which contains lower resolution images.
After achieving maximum 91.78% recognition accuracy on KDEF dataset using the
proposed novel EfficientNet-B7 model, Vanishing Gradient Descent issue is found in
model accuracy and loss graph due to the variance problem. This will make the model
unstable. So, to make the model more stable and to reduce Variance in the graph, Internal
Batch Normalization (IBN) concept proposed and applied which helps to remove Variance
in the graph and make model accuracy and loss graph smoother by making the model
more stable. Further, it will be helpful to improve recognition accuracy for the facial
expression recognition task.

132
CHAPTER 7
Conclusion and Further Enhancement
7.1 Conclusion
Various methods and algorithms have been investigated for improving the recognition
accuracy of facial expression recognition from images. Several methods have been
proposed to detect the facial expressions in the images. Most of the methods use the
laboratory-controlled facial expression datasets, which have controlled conditions. The
lighting is uniform, and the images have an entire frontal face. The laboratory-controlled
images have no occlusions in most of the cases. So, face detection and feature extraction
process get easier as a part of the facial expression recognition process. Therefore, facial
expression recognition on such datasets becomes a lot simpler than for real-time facial
expression datasets. For the latter type of datasets, the images are taken from the internet
and real-world images. Therefore, they have problems like a difference in lighting
conditions, varying head poses, resolutions of images, and various occlusions like
sunglasses, hairs etc. The thesis’s overall goal is to develop efficient models for facial
expression recognition using deep learning techniques to achieve better recognition
accuracy on lower-resolution images of real-time facial expression dataset for recognizing
seven basic facial expressions such as happy, disgust, surprise, anger, sad, fear and neutral.
In this research work, we have proposed three models for recognizing facial expressions
from images using deep learning techniques. To improve recognition accuracy of lower-
resolution images for real-time facial expression dataset and for the laboratory-trained
facial expression datasets, the specific contributions of this research work are summarised
as follows:
We have proposed Multi-Layer Feature-Fusion based Classification (MLFFC) model
which works on Inter-Layer Feature-Fusion approach. Objective of this proposed model is
to integrate feature maps from different layers of a network instead of the last layer of a
network. InceptionV3 CNN architecture has introduced Inception Module concept by
factorizing the convolution node and applying filter concatenation approach. InceptionV3
architecture provides better performance in terms of image recognition accuracy. In the
proposed MLFFC model, inter-layer feature-fusion is used with an internal layer of

133
Module C of InceptionV3 CNN architecture with its final layer to improve the model’s
recognition accuracy. The proposed model utilizes features from two different domains on
the facial expression recognition problem. Proposed MLFFC model is tested on real-time
facial expression dataset FER2013 which contains real-world images. It achieves better
recognition accuracy (70.29%) on this dataset in comparison with the state-of-the-art
methods. The quality of the features learned by the proposed model is further tested by
performing a cross-database study on the laboratory-controlled CK+ dataset. The proposed
model has achieved the best recognition accuracy (99.6%) on this laboratory-trained
dataset. Also, proposed MLFFC approach used to reduce Error-rates in both the datasets.
Without Feature-fusion approach, 0.83% and 32.97% error-rates are there for the CK+ and
FER2013 dataset respectively. By using proposed Feature-fusion approach, error-rate
reduces from 0.83% to 0.31% for the CK+ dataset and from 32.97% to 29.71% for the
FER2013 dataset. This shows that the proposed MLFFC model can work better on both
kinds of facial expression datasets – laboratory-controlled and real-time facial expression
datasets, unlike the models that work exceptionally well on laboratory-controlled facial
expression datasets but fail to do so when it comes to real-time facial expression datasets.
Another model we have proposed is the Multi-Modal Feature-fusion-based classification
(MMFFC) model which works on Ensemble of Multi-CNN approach concatenate the
output of different CNN architectures for better feature extraction process instead of
getting one feature map from a single CNN architecture. In proposed MMFFC model, an
ensemble of multi-CNN approach for two CNN architectures VGG-16 and ResNet50 is
carried out where the concatenation of features from final layers of both the architectures
is performed. This helps to overcome the limitation of a single network, and it will further
produce a robust and superior performance to improve recognition accuracy. Complexity
is increased here due to concatenating output of two different architectures instead of a
single architecture. For applying the ensemble approach, experiments performed on
different four architectures (InceptionV3, VGG16, VGG19 and ResNet50) by
concatenating feature vectors at output layers. Among these, VGG16 and ResNet50
architecture combinations provided better performance in terms of better recognition
accuracy; hence, we selected these two architectures in our proposed MMFFC model.
Further, the proposed model is tested on real-time facial expression dataset FER2013 and
achieved 68.14% better recognition accuracy than with other state-of-the-art methods. For
the cross-database evaluation, the proposed model is tested on laboratory-trained KDEF

134
facial expression dataset. It has also achieved better recognition accuracy of 92.04%
compared to other state-of-the-art methods. Also, proposed MMFFC approach used to
reduce Error-rates in both the datasets. For the FER2013 dataset, Error-rate reduces to
31.86% and 7.96% for the KDEF dataset using the proposed Ensemble approach. This
shows that the proposed MMFFC model can work better on both kinds of facial
expression datasets – laboratory-controlled and real-time facial expression datasets.
We have proposed the third model using the novel concept ‘EfficientNet: Rethinking
Scaling model for CNN’ introduced in 2019. This concept contains different EfficientNet-
B0 to B7 models based on Compound Scaling method to scale up CNN in a more
structured way. From the literature review and industry reference, it is found that no work
has been carried out for facial expression recognition using this novel EfficientNet
approach till date. It is the best image classification model to improve recognition
accuracy by reducing parameters. Unlike the conventional methods that arbitrarily scale
the network dimensions such as width, depth and resolution, this approach uniformly
scales each dimension with a fixed set of scaling coefficients. This is the important
characteristic of this novel EfficientNet approach which works well on higher resolution
images. As a network parameter, Optimizer plays a vital role in improving the recognition
accuracy of any model. In our proposed model, novel EfficientNet-B7 architecture is
implemented by applying different optimizers such as Adam, RMSprop and SGD to
decide which optimizer performs better to give better recognition accuracy for our
proposed model. This concept works well with higher resolution images, so we have tested
our proposed model on laboratory-trained KDEF facial expression dataset by applying
different optimizers and other network parameters. Experimental results show that
proposed EfficientNet-B7 model performs well using RMSprop optimizer compared with
other optimizers and achieved better recognition accuracy 91.78%. We tested the same
approach on ResNet152 CNN architecture for cross-performance evaluation and achieved
88.77% recognition accuracy using SGD optimizer. Proposed EfficientNet-B7 model is
also tested on real-time facial expression dataset FER2013 which contains lower
resolution images for cross-database evaluation purpose. Experimental results declared
that the proposed model had achieved maximum 57.56% recognition accuracy using
RMSprop optimizer compared with other optimizers which are significantly less than the
KDEF dataset, which contains higher resolution images. Hence it is concluded that our
novel proposed EfficientNet-B7 model works better on higher resolution images. After

135
achieving better accuracy 91.78% on our proposed EfficientNet-B7 model using KDEF
dataset, Vanishing Gradient Descent issue found in the result performance of model
accuracy and loss graph due to variance generated in network calculation process and
making model unstable. Internal Batch Normalization (IBN) proposed approach is applied
by re-training the model using transfer learning concept and keeping all the normalization
layers active only except other layers. This will help to reduce variance in the resulting
graph to resolve the issue of vanishing gradient issue.
In summary, the thesis contributes to the study, investigation and development of novel
proposed models for improving the performance of facial expression recognition task
using deep learning techniques on real-time facial expression datasets as well as on
laboratory-trained facial expression datasets.

136
7.2 Future Enhancements
Among all the works presented here in this thesis, there are areas to progress and improve
further. Putting aside what we have successfully achieved, several useful extensions that
can be addressed to further improvements as explained below:
• Without considering the influence of head pose variations, only frontal faces are
taken for training and implementation purpose. So, further faces from several
views can be considered from the images or videos which may help to improve the
recognition accuracy.
• Complex and hybrid methodologies of Convolutional Neural Network and
Recurrent Neural Network (CNN+RNN) can be used to boost the facial expression
recognition system’s performance.
• The deep learning techniques lack sufficient data to be the most effective it can.
Therefore, it may be useful to pre-train a deep CNN on many other databases
before applying a fine-tuning process.
• We have considered Appearance-based features for our research work. So, a hybrid
method can be developed in the future by combining geometric features and
appearance-based features to improve the performance of the facial expression
recognition system.

137
List of References
[1] Shao, J., & Qian, Y. (2019). Three convolutional neural network models for facial expression
recognition in the wild. Neurocomputing, 355, pp. 82-92
[2] Cao, T., & Li, M. (2019). Facial Expression Recognition Algorithm Based on the Combination
of CNN and K-Means. In Proceedings of the 2019 11th International Conference on Machine
Learning and Computing, pp. 400-404
[3] Ekman, P., & Keltner, D. (1997). Universal facial expressions of emotion. Segerstrale U, P.
Molnar P, eds. Nonverbal communication: Where nature meets culture, pp. 27-46
[4] Revina, I. M., & Emmanuel, W. S. (2018). A survey on human face expression recognition
techniques. Journal of King Saud University-Computer and Information Sciences.
[5] Yu Miao (2018). A Real Time Facial Expression Recognition System using Deep Learning.
Masters of Applied Science thesis. University of Ottawa.
[6] Patrick Lucey et al. “The extended cohn-kanade dataset (ck+): A complete dataset for action
unit and emotion-specified expression”. In: Proceedings of the 2010 IEEE Computer Society
Conference on Computer Vision and Pattern Recognition Workshops.2010, pp. 94–101
[7] Michael Lyons et al. “Coding Facial Expressions with Gabor Wavelets”. In: Proceedings of
the 3rd. International Conference on Face & Gesture Recognition. 1998, pp. 200–205.
[8] I. J. Goodfellow, D. Erhan, P. L. Carrier, A. Courville, M. Mirza, B. Hamner, W. Cukierski,
Y. Tang, D. Thaler, D.-H. Lee et al., “Challenges in representation learning: A report on three
machine learning contests,” in International Conference on Neural Information Processing.
Springer, 2013, pp. 117–124.
[9] Pramerdorfer, C., & Kampel, M. (2016). Facial expression recognition using convolutional
neural networks: state of the art. arXiv preprint arXiv:1612.02903.
[10] Mellouk, W., & Handouzi, W. (2020). Facial emotion recognition using deep learning: review
and insights. Procedia Computer Science, 175, pp. 689-694.
[11] Li, S., & Deng, W. (2020). Deep facial expression recognition: A survey. IEEE Transactions
on Affective Computing.
[12] Utami, P., Hartanto, R., & Soesanti, I. (2019). A Study on Facial Expression Recognition in
Assessing Teaching Skills: Datasets and Methods. Procedia Computer Science, pp. 544-552.
[13] Fathima, A., & Vaidehi, K. (2020). Review on facial expression recognition system using
machine learning techniques. In Advances in Decision Sciences, Image Processing, Security
and Computer Vision, pp. 608-618, Springer, Cham.
[14] Japanese Female Facial Expression Dataset: www.kasrl.org/jaffe.html
[15] Robust Facial expression recognition based on human computer interaction:
http://gsse.pafkiet.edu.pk/robust-fpga-based-face-recognition-system/

138
[16] Facial expression recognition market applications top 7 trends:
https://www.thalesgroup.com/en/markets/digital-security/government/biometrics/facial-
recognition
[17] Zeng, H., Shu, X., Wang, Y., Wang, Y., Zhang, L., Pong, T. C., & Qu, H. (2020).
EmotionCues: Emotion-Oriented Visual Summarization of Classroom Videos. IEEE
Transactions on Visualization and Computer Graphics.
[18] Musically Knowledge Company app recommends music based on your facial expressions:
https://musically.com/2020/07/24/mmp-app-recommends-music-based-on-your-facial-
expression/
[19] Jung, H., Lee, S., Park, S., Kim, B., Kim, J., Lee, I., & Ahn, C. (2015). Development of deep
learning-based facial expression recognition system. In 2015 21st Korea-Japan Joint
Workshop on Frontiers of Computer Vision, pp. 1-4, IEEE.
[20] Hemalatha, G., & Sumathi, C. P. (2014). A study of techniques for facial detection and
expression classification. International Journal of Computer Science and Engineering
Survey, 5(2), 27.
[21] Lopes, A. T., de Aguiar, E., De Souza, A. F., & Oliveira-Santos, T. (2017). Facial expression
recognition with convolutional neural networks: coping with few data and the training sample
order. Pattern Recognition, 61, pp. 610-628.
[22] Zafeiriou, S., Zhang, C., & Zhang, Z. (2015). A survey on face detection in the wild: past,
present and future. Computer Vision and Image Understanding, 138, pp. 1-24.
[23] Paul Viola et al. “Robust real-time face detection”. In: International journal of computer vision
57.2 (2004), pp. 137–154.
[24] Constantine P Papageorgiou et al. (1998) “A general framework for object detection”.In:
Proceedings of the sixth international conference on Computer vision , pp. 555–562.
[25] Sharma, M., Anuradha, J., KManne, H., & Kashyap, G. S. (2017). Facial detection using deep
learning. In School of Computing Science and Engineering. VIT University.
[26] Shepley, A. J. (2019). Deep Learning For Face Recognition: A Critical Analysis. arXiv
preprint arXiv:1907.12739.
[27] Sharma, A. K., Kumar, U., Gupta, S. K., Sharma, U., & LakshmiAgrwal, S. (2018). A survey
on feature extraction technique for facial expression recognition system. In 2018 4th
International Conference on Computing Communication and Automation (ICCCA), pp. 1-6,
IEEE.
[28] Pali, V., Goswami, S., & Bhaiya, L. P. (2014). An extensive survey on feature extraction
techniques for facial image processing. In 2014 International Conference on Computational
Intelligence and Communication Networks, pp. 142-148, IEEE.
[29] Huang, Y., Chen, F., Lv, S., & Wang, X. (2019). Facial expression recognition: A
survey. Symmetry, 11(10), 1189.

139
[30] Zhao, X., & Zhang, S. (2016). A review on facial expression recognition: feature extraction
and classification. IETE Technical Review, 33(5), pp. 505-517.
[31] Khoshdeli, M., Cong, R., & Parvin, B. (2017). Detection of nuclei in H&E stained sections
using convolutional neural networks. In 2017 IEEE EMBS International Conference on
Biomedical & Health Informatics (BHI), pp. 105-108, IEEE.
[32] Vedantham, R., & Reddy, E. S. (2020). A robust feature extraction with optimized DBN-SMO
for facial expression recognition. Multimedia Tools and Applications, pp. 1-26.
[33] Kumar, Y., & Sharma, S. (2017). A systematic survey of facial expression recognition
techniques. In 2017 international conference on computing methodologies and communication
(ICCMC), pp. 1074-1079, IEEE.
[34] Harshitha, S., Sangeetha, N., Shirly, A. P., & Abraham, C. D. (2019). Human facial expression
recognition using deep learning technique. In 2019 2nd International Conference on Signal
Processing and Communication (ICSPC), pp. 339-342, IEEE.
[35] Wu, T., Fu, S., & Yang, G. (2012). Survey of the facial expression recognition research.
In International Conference on Brain Inspired Cognitive Systems, pp. 392-402, Springer,
Berlin, Heidelberg.
[36] About Support Vector Machine Algorithm and its types details:
https://www.javatpoint.com/machine-learning-support-vector-machine-algorithm
[37] Shi, M., Xu, L., & Chen, X. (2020). A Novel Facial Expression Intelligent Recognition Method
Using Improved Convolutional Neural Network. IEEE Access, 8, pp. 57606-57614.
[38] Evolution of Artificial Intelligence, Machine Learning and Deep Learning details:
https://towardsdatascience.com/ai-machine-learning-deep-learning-explained-simply-
7b553da5b960
[39] Machine Learning Algorithm and its different types in detail : https://medium.com/ai-in-plain-
english/artificial-intelligence-vs-machine-learning-vs-deep-learning-whats-the-difference-
dccce18efe7f
[40] Benuwa, B. B., Zhan, Y. Z., Ghansah, B., Wornyo, D. K., & Banaseka Kataka, F. (2016). A
review of deep machine learning. In International Journal of Engineering Research in
Africa,Vol. 24, pp. 124-136, Trans Tech Publications Ltd.
[41] Abiodun, O. I., Jantan, A., Omolara, A. E., Dada, K. V., Umar, A. M., Linus, O. U., & Kiru,
M. U. (2019). Comprehensive review of artificial neural network applications to pattern
recognition. IEEE Access, 7, pp. 158820-158846.
[42] Alom, M. Z., Taha, T. M., Yakopcic, C., Westberg, S., Sidike, P., Nasrin, M. S., & Asari, V.
K. (2019). A state-of-the-art survey on deep learning theory and
architectures. Electronics, 8(3), 292.
[43] Sit, M., Demiray, B. Z., Xiang, Z., Ewing, G. J., Sermet, Y., & Demir, I. (2020). A
comprehensive review of deep learning applications in hydrology and water resources. Water
Science and Technology.

140
[44] Vachhani, B., Bhat, C., Das, B., & Kopparapu, S. K. (2017). Deep Autoencoder Based Speech
Features for Improved Dysarthric Speech Recognition. In Interspeech, pp. 1854-1858.
[45] Shrestha, A., & Mahmood, A. (2019). Review of deep learning algorithms and
architectures. IEEE Access, 7, pp. 53040-53065.
[46] Deep learning architectures: https://developer.ibm.com/articles/cc-machine-learning-deep-
learning-architectures/
[47] Wang, Y., Li, Y., Song, Y., & Rong, X. (2019). Facial Expression Recognition Based on
Random Forest and Convolutional Neural Network. Information, 10(12), 375.
[48] Understanding of Convolutional Neural Network CNN – Deep Learning:
https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-
deep-learning-99760835f148
[49] Ajit, A., Acharya, K., & Samanta, A. (2020). A Review of Convolutional Neural Networks.
In 2020 International Conference on Emerging Trends in Information Technology and
Engineering (ic-ETITE), pp. 1-5, IEEE.
[50] Julin, F. (2019). Vision based facial emotion detection using deep convolutional neural
networks.
[51] Transfer learning with Convolutional Neural Networks:
https://towardsdatascience.com/transfer-learning-with-convolutional-neural-networks-in-
pytorch-dd09190245ce
[52] Hussain, M., Bird, J. J., & Faria, D. R. (2018). A study on cnn transfer learning for image
classification. In UK Workshop on Computational Intelligence, pp. 191-202, Springer, Cham.
[53] Improve your model accuracy by Transfer Learning: https://medium.com/data-science-
101/transfer-learning-57ce3b98650
[54] Ma, C., Mu, X., & Sha, D. (2019). Multi-layers feature fusion of convolutional neural network
for scene classification of remote sensing. IEEE Access, 7, pp. 121685-121694.
[55] Nguyen, L. D., Lin, D., Lin, Z., & Cao, J. (2018). Deep CNNs for microscopic image
classification by exploiting transfer learning and feature concatenation. In 2018 IEEE
International Symposium on Circuits and Systems (ISCAS), pp. 1-5, IEEE.
[56] Mohanraj, V., Chakkaravarthy, S. S., & Vaidehi, V. (2019). Ensemble of convolutional neural
networks for face recognition. In Recent Developments in Machine Learning and Data
Analytics, pp. 467-477, Springer, Singapore.
[57] Ko, B. C. (2018). A brief review of facial emotion recognition based on visual
information. sensors, 18(2), 401.
[58] Papageorgiou, C. P., Oren, M., & Poggio, T. (1998). A general framework for object detection.
In Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), pp. 555-
562, IEEE.

141
[59] Viola, P., & Jones, M. J. (2004). Robust real-time face detection. International journal of
computer vision, 57(2), pp. 137-154.
[60] Weilong Chen, MengJooEr, Shiqian Wu (2006), "Illumination Compensation and
Normalization forRobust Face Recognition Using Discrete Cosine Transform in Logarithm
Domain", IEEE transactions on systems, man and cybernetics— part b: cybernetics, Vol. 36(2)
pp.458-466.
[61] Owusu, E., Zhan, Y., & Mao, Q. R. (2014). A neural-AdaBoost based facial expression
recognition system. Expert Systems with Applications, 41(7), pp. 3383-3390.
[62] Biswas, S., & Sil, J. (2015). An efficient expression recognition method using contourlet
transform. In Proceedings of the 2nd International Conference on Perception and Machine
Intelligence, pp. 167-174.
[63] Ji, Y., & Idrissi, K. (2012). Automatic facial expression recognition based on spatiotemporal
descriptors. Pattern Recognition Letters, 33(10), pp. 1373-1380.
[64] Zhang, L., Tjondronegoro, D., & Chandran, V. (2014). Random Gabor based templates for
facial expression recognition in images with facial occlusion. Neurocomputing, 145, pp. 451-
464.
[65] Happy, S. L., & Routray, A. (2014). Automatic facial expression recognition using features of
salient facial patches. IEEE transactions on Affective Computing, 6(1), pp. 1-12.
[66] Dahmane, M., & Meunier, J. (2014). Prototype-based modeling for facial expression
analysis. IEEE Transactions on Multimedia, 16(6), pp. 1574-1584.
[67] Hernandez-Matamoros, A., Bonarini, A., Escamilla-Hernandez, E., Nakano-Miyatake, M., &
Perez-Meana, H. (2015, September). A facial expression recognition with automatic
segmentation of face regions. In International Conference on Intelligent Software
Methodologies, Tools, and Techniques, pp. 529-540, Springer, Cham.
[68] Uçar, A., Demir, Y., & Güzeliş, C. (2016). A new facial expression recognition based on
curvelet transform and online sequential extreme learning machine initialized with spherical
clustering. Neural Computing and Applications, 27(1), pp. 131-142.
[69] Cossetin, M. J., Nievola, J. C., & Koerich, A. L. (2016). Facial expression recognition using a
pairwise feature selection and classification approach. In 2016 International Joint Conference
on Neural Networks (IJCNN), pp. 5149-5155, IEEE.
[70] Ghimire, D., & Lee, J. (2013). Geometric feature-based facial expression recognition in image
sequences using multi-class adaboost and support vector machines. Sensors, 13(6), pp. 7714-
7734.
[71] Chen, J., Chen, Z., Chi, Z., & Fu, H. (2014). Facial expression recognition based on facial
components detection and hog features. In International workshops on electrical and computer
engineering subfields, pp. 884-888.

142
[72] Happy, S. L., George, A., & Routray, A. (2012). A real time facial expression classification
system using local binary patterns. In 2012 4th International conference on intelligent human
computer interaction (IHCI) (pp. 1-5). IEEE.
[73] Ghimire, D., Jeong, S., Lee, J., & Park, S. H. (2017). Facial expression recognition based on
local region specific features and support vector machines. Multimedia Tools and
Applications, 76(6), pp. 7803-7821.
[74] Bhadu, A., Kumar, V., Shekhawat, H. S., & Tokas, R. (1956). An improved method of feature
extraction technique for facial expression recognition using Adaboost neural
network. International Journal of Electronics and Computer Science Engineering (IJECSE)
Volume, 1, pp. 1112-1118.
[75] Bao, H., & Ma, T. (2014). Feature extraction and facial expression recognition based on bezier
curve. In 2014 IEEE International Conference on Computer and Information Technology, pp.
884-887, IEEE.
[76] Lozano-Monasor, E., López, M. T., Fernández-Caballero, A., & Vigo-Bustos, F. (2014). Facial
expression recognition from webcam based on active shape models and support vector
machines. In International Workshop on Ambient Assisted Living, pp. 147-154, Springer,
Cham.
[77] Huang, H. F., & Tai, S. C. (2012). Facial expression recognition using new feature extraction
algorithm. ELCVIA Electronic Letters on Computer Vision and Image Analysis, 11(1), pp. 41-
54.
[78] Kamarol, S. K. A., Jaward, M. H., Parkkinen, J., & Parthiban, R. (2016). Spatiotemporal
feature extraction for facial expression recognition. IET Image Processing, 10(7), pp. 534-541.
[79] Do, T. T., & Le, T. H. (2008). Facial feature extraction using geometric feature and
independent component analysis. In Pacific Rim Knowledge Acquisition Workshop, pp. 231-
241, Springer, Berlin, Heidelberg.
[80] Bermani, A. K., Ghalwash, A. Z., & Youssif, A. A. (2012). Automatic facial expression
recognition based on hybrid approach. Editorial Preface.
[81] Zhao, G., Huang, X., Taini, M., Li, S. Z., & PietikäInen, M. (2011). Facial expression
recognition from near-infrared videos. Image and Vision Computing, 29(9), pp. 607-619.
[82] Shen, P., Wang, S., & Liu, Z. (2013). Facial expression recognition from infrared thermal
videos. In Intelligent Autonomous Systems 12, pp. 323-333, Springer, Berlin, Heidelberg.
[83] Szwoch, M., & Pieniążek, P. (2015). Facial emotion recognition using depth data. In 2015 8th
International Conference on Human System Interaction (HSI), pp. 271-277, IEEE.
[84] Gunawan, A. A. (2015). Face expression detection on Kinect using active appearance model
and fuzzy logic. Procedia Computer Science, 59, pp. 268-274.
[85] Wei, W., Jia, Q., & Chen, G. (2016). Real-time facial expression recognition for affective
computing based on Kinect. In 2016 IEEE 11th Conference on Industrial Electronics and
Applications (ICIEA), pp. 161-165, IEEE.

143
[86] Sohail, A. S. M., & Bhattacharya, P. (2007). Classification of facial expressions using k-nearest
neighbor classifier. In International Conference on Computer Vision/Computer Graphics
Collaboration Techniques and Applications, pp. 555-566, Springer, Berlin.
[87] Wang, X. H., Liu, A., & Zhang, S. Q. (2015). New facial expression recognition based on
FSVM and KNN. Optik, 126(21), pp. 3132-3134.
[88] Valstar, M., Patras, I., & Pantic, M. (2004). Facial action unit recognition using temporal
templates. In RO-MAN 2004. 13th IEEE International Workshop on Robot and Human
Interactive Communication (IEEE Catalog No. 04TH8759), pp. 253-258, IEEE.
[89] Chen, L., Zhou, C., & Shen, L. (2012). Facial expression recognition based on SVM in E-
learning. Ieri Procedia, 2, pp. 781-787.
[90] Michel, P., & El Kaliouby, R. (2003). Real time facial expression recognition in video using
support vector machines. In Proceedings of the 5th international conference on Multimodal
interfaces, pp. 258-264.
[91] Tsai, H. H., & Chang, Y. C. (2018). Facial expression recognition using a combination of
multiple facial features and support vector machine. Soft Computing, 22(13), pp. 4389-4405.
[92] Hsieh, C. C., Hsih, M. H., Jiang, M. K., Cheng, Y. M., & Liang, E. H. (2016). Effective
semantic features for facial expressions recognition using SVM. Multimedia Tools and
Applications, 75(11), pp. 6663-6682.
[93] Saeed, S., Baber, J., Bakhtyar, M., Ullah, I., Sheikh, N., Dad, I., & Sanjrani, A. A. (2018).
Empirical evaluation of SVM for facial expression recognition. Int. J. Adv. Comput. Sci.
Appl, 9(11), pp.670-673.
[94] Wang, Y., Ai, H., Wu, B., & Huang, C. (2004). Real time facial expression recognition with
adaboost. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR,
Vol. 3, pp. 926-929, IEEE.
[95] Liew, C. F., & Yairi, T. (2015). Facial expression recognition and analysis: a comparison study
of feature descriptors. IPSJ transactions on computer vision and applications, 7, pp. 104-120.
[96] Gudipati, V. K., Barman, O. R., Gaffoor, M., & Abuzneid, A. (2016). Efficient facial
expression recognition using adaboost and haar cascade classifiers. In 2016 Annual
Connecticut Conference on Industrial Electronics, Technology & Automation (CT-IETA), pp.
1-4, IEEE.
[97] Zhang, S., Hu, B., Li, T., & Zheng, X. (2018). A Study on Emotion Recognition Based on
Hierarchical Adaboost Multi-class Algorithm. In International Conference on Algorithms and
Architectures for Parallel Processing, pp. 105-113, Springer, Cham.
[98] Moghaddam, B., Jebara, T., & Pentland, A. (2000). Bayesian face recognition. Pattern
recognition, 33(11), pp. 1771-1782.
[99] Mao, Q., Rao, Q., Yu, Y., & Dong, M. (2016). Hierarchical Bayesian theme models for
multipose facial expression recognition. IEEE Transactions on Multimedia, 19(4), pp.861-873.

144
[100] Surace, L., Patacchiola, M., Battini Sönmez, E., Spataro, W., & Cangelos. (2017). Emotion
recognition in the wild using deep neural networks and Bayesian classifiers. In Proceedings of
the 19th ACM International Conference on Multimodal Interaction (pp. 593-597).
[101] Mahersia, H., & Hamrouni, K. (2015). Using multiple steerable filters and Bayesian
regularization for facial expression recognition. Engineering Applications of Artificial
Intelligence, 38, pp. 190-202.
[102] Kusy, M., & Zajdel, R. (2014). Application of reinforcement learning algorithms for the
adaptive computation of the smoothing parameter for probabilistic neural network. IEEE
transactions on neural networks and learning systems, 26(9), pp. 2163-2175.
[103] Neggaz, N., Besnassi, M., & Benyettou, A. (2010). Application of improved AAM and
probabilistic neural network to facial expression recognition. Journal of Applied
Sciences(Faisalabad), 10(15), pp. 1572-1579.
[104] Fazli, S., Afrouzian, R., & Seyedarabi, H. (2009). High-performance facial expression
recognition using Gabor filter and probabilistic neural network. In 2009 IEEE International
Conference on Intelligent Computing and Intelligent Systems, Vol. 4, pp. 93-96, IEEE.
[105] Mollahosseini, A., Chan, D., & Mahoor, M. H. (2016). Going deeper in facial expression
recognition using deep neural networks. In 2016 IEEE Winter conference on applications of
computer vision (WACV), pp. 1-10, IEEE.
[106] Lopes, A. T., de Aguiar, E., De Souza, A. F., & Oliveira-Santos, T. (2017). Facial
expression recognition with convolutional neural networks: coping with few data and the
training sample order. Pattern Recognition, 61, pp. 610-628.
[107] Mohammadpour, M., Khaliliardali, H., Hashemi, S. M. R., & AlyanNezhadi, M. M.
(2017). Facial emotion recognition using deep convolutional networks. In 2017 IEEE 4th
international conference on knowledge-based engineering and innovation (KBEI), pp. 0017-
0021, IEEE.
[108] Cai, J., Chang, O., Tang, X. L., Xue, C., & Wei, C. (2018). Facial expression recognition
method based on sparse batch normalization CNN. In 2018 37th Chinese Control Conference
(CCC), pp. 9608-9613, IEEE.
[109] Li, Y., Zeng, J., Shan, S., & Chen, X. (2018). Occlusion aware facial expression
recognition using cnn with attention mechanism. IEEE Transactions on Image
Processing, 28(5), pp. 2439-2450.
[110] Yolcu, G., Oztel, I., Kazan, S., Oz, C., Palaniappan, K., Lever, T. E., & Bunyak, F. (2019).
Facial expression recognition for monitoring neurological disorders based on convolutional
neural network. Multimedia Tools and Applications, 78(22), pp. 31581-31603.
[111] Agrawal, A., & Mittal, N. (2020). Using CNN for facial expression recognition: a study
of the effects of kernel size and number of filters on accuracy. The Visual Computer, 36(2),
pp. 405-412.

145
[112] Jain, D. K., Shamsolmoali, P., & Sehdev, P. (2019). Extended deep neural network for
facial emotion recognition. Pattern Recognition Letters, 120, pp. 69-74.
[113] Kim, D. H., Baddar, W. J., Jang, J., & Ro, Y. M. (2017). Multi-objective based spatio-
temporal feature representation learning robust to expression intensity variations for facial
expression recognition. IEEE Transactions on Affective Computing, 10(2), 223-236.
[114] Yu, Z., Liu, G., Liu, Q., & Deng, J. (2018). Spatio-temporal convolutional features with
nested LSTM for facial expression recognition. Neurocomputing, 317, pp. 50-57.
[115] Liang, D., Liang, H., Yu, Z., & Zhang, Y. (2020). Deep convolutional BiLSTM fusion
network for facial expression recognition. The Visual Computer, 36(3), pp. 499-508.
[116] Liu, P., Han, S., Meng, Z., & Tong, Y. (2014). Facial expression recognition via a boosted
deep belief network. In Proceedings of the IEEE conference on computer vision and pattern
recognition, pp. 1805-1812.
[117] Burkert, P., Trier, F., Afzal, M. Z., Dengel, A., & Liwicki, M. (2015). Dexpression: Deep
convolutional neural network for expression recognition. arXiv preprint arXiv:1509.05371.
[118] Mollahosseini, A., Chan, D., & Mahoor, M. H. (2016). Going deeper in facial expression
recognition using deep neural networks. In 2016 IEEE Winter conference on applications of
computer vision (WACV), pp. 1-10, IEEE.
[119] Nguyen, H. D., Yeom, S., Oh, I. S., Kim, K. M., & Kim, S. H. (2018). Facial expression
recognition using a multi-level convolutional neural network. In International Conference on
Pattern Recognition and Artificial Intelligence, pp. 217-221.
[120] Liu, C., Tang, T., Lv, K., & Wang, M. (2018). Multi-feature-based emotion recognition
for video clips. In Proceedings of the 20th ACM International Conference on Multimodal
Interaction, pp. 630-634.
[121] VenkataRamiReddy, C., Kishore, K. K., Bhattacharyya, D., & Kim, T. H. (2014). Multi-
feature fusion based facial expression classification using DLBP and DCT. International
Journal of Software Engineering and Its Applications, 8(9), pp. 55-68.
[122] Liu, K., Zhang, M., & Pan, Z. (2016). Facial expression recognition with CNN ensemble.
In 2016 international conference on cyberworlds (CW), pp. 163-166, IEEE.
[123] Fan, Y., Lam, J. C., & Li, V. O. (2018). Multi-region ensemble convolutional neural
network for facial expression recognition. In International Conference on Artificial Neural
Networks, pp. 84-94, Springer, Cham.
[124] Jung, H., Lee, S., Yim, J., Park, S., & Kim, J. (2015). Joint fine-tuning in deep neural
networks for facial expression recognition. In Proceedings of the IEEE international
conference on computer vision, pp. 2983-2991.
[125] Nguyen, L. D., Lin, D., Lin, Z., & Cao, J. (2018). Deep CNNs for microscopic image
classification by exploiting transfer learning and feature concatenation. In 2018 IEEE
International Symposium on Circuits and Systems (ISCAS), pp. 1-5, IEEE.

146
[126] Wang, Y., Li, Y., Song, Y., & Rong, X. (2019). Facial Expression Recognition Based on
Auxiliary Models. Algorithms, 12(11), 227.
[127] Li, T. H. S., Kuo, P. H., Tsai, T. N., & Luan, P. C. (2019). CNN and LSTM based facial
expression analysis model for a humanoid robot. IEEE Access, 7, pp. 93998-94011.
[128] Renda, A., Barsacchi, M., Bechini, A., & Marcelloni, F. (2018). Assessing Accuracy of
Ensemble Learning for Facial Expression Recognition with CNNs. In International Conference
on Machine Learning, Optimization, and Data Science, pp. 406-417, Springer, Cham.
[129] Li, C., Ma, N., & Deng, Y. (2018). Multi-network fusion based on cnn for facial expression
recognition. In 2018 International Conference on Computer Science, Electronics and
Communication Engineering (CSECE 2018). Atlantis Press.
[130] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the
inception architecture for computer vision. In Proceedings of the IEEE conference on computer
vision and pattern recognition, pp. 2818-2826.
[131] Review: Inception-V3 -1st Runner up in ILSVRC 2015: https://sh-
tsang.medium.com/review-inception-v3-1st-runner-up-image-classification-in-ilsvrc-2015-
17915421f77c
[132] A simple guide to the versions of the Inception Network:
https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-
7fc52b863202
[133] Kaggle dataset real time FER2013: https://www.kaggle.com/deadskull7/fer2013
[134] Facial Expression dataset CK+ : http://www.consortium.ri.cmu.edu/ckagree/
[135] Tran, E., Mayhew, M. B., Kim, H., Karande, P., & Kaplan, A. D. (2018). Facial expression
recognition using a large out-of-context dataset. In 2018 IEEE Winter Applications of
Computer Vision Workshops (WACVW), pp. 52-59, IEEE.
[136] Rifai, S., Bengio, Y., Courville, A., Vincent, P., & Mirza, M. (2012). Disentangling factors
of variation for facial expression recognition. In European Conference on Computer Vision,
pp. 808-822, Springer, Berlin, Heidelberg.
[137] Liu, M., Li, S., Shan, S., Wang, R., & Chen, X. (2014). Deeply learning deformable facial
action parts model for dynamic expression analysis. In Asian conference on computer vision,
pp. 143-157, Springer, Cham.
[138] Mollahosseini, A., Chan, D., & Mahoor, M. H. (2016). Going deeper in facial expression
recognition using deep neural networks. In 2016 IEEE Winter conference on applications of
computer vision (WACV), pp. 1-10, IEEE.
[139] Zeng, N., Zhang, H., Song, B., Liu, W., Li, Y., & Dobaie, A. M. (2018). Facial expression
recognition via learning deep sparse autoencoders. Neurocomputing, 273, pp. 643-649.
[140] Meng, Z., Liu, P., Cai, J., Han, S., & Tong, Y. (2017). Identity-aware convolutional neural
network for facial expression recognition. In 2017 12th IEEE International Conference on
Automatic Face & Gesture Recognition (FG 2017), pp. 558-565, IEEE.

147
[141] Zhang, Z., Luo, P., Loy, C. C., & Tang, X. (2018). From facial expression recognition to
interpersonal relation prediction. International Journal of Computer Vision, 126(5), pp. 550-
569.
[142] Khorrami, P., Paine, T., & Huang, T. (2015). Do deep neural networks learn facial action
units when doing expression recognition?. In Proceedings of the IEEE International
Conference on Computer Vision Workshops, pp. 19-27.
[143] Al-Sumaidaee, S. A., Abdullah, M. A., Al-Nima, R. R. O., Dlay, S. S., & Chambers, J. A.
(2017). Multi-gradient features and elongated quinary pattern encoding for image-based facial
expression recognition. Pattern Recognition, 71, pp. 249-263.
[144] Devries, T., Biswaranjan, K., & Taylor, G. W. (2014). Multi-task learning of facial
landmarks and expression. In 2014 Canadian Conference on Computer and Robot Vision, pp.
98-103, IEEE.
[145] Kim, B. K., Dong, S. Y., Roh, J., Kim, G., & Lee, S. Y. (2016). Fusing aligned and non-
aligned face information for automatic affect recognition in the wild: a deep learning approach.
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Workshops, pp. 48-57.
[146] Review: VGG-16 Architecture used in ILSVR 2014 Challenge:
https://towardsdatascience.com/step-by-step-vgg16-implementation-in-keras-for-beginners-
a833c686ae6c
[147] Gopalakrishnan, K., Khaitan, S. K., Choudhary, A., & Agrawal, A. (2017). Deep
convolutional neural networks with transfer learning for computer vision-based data-driven
pavement distress detection. Construction and Building Materials, 157, pp. 322-330.
[148] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition.
In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-
778.
[149] Introduction to ResNet Residual Network: https://www.mygreatlearning.com/blog/resnet/
[150] Architectures in convolutional neural networks: https://www.jeremyjordan.me/convnet-
architectures/
[151] The Karolinska Directed Emotional Faces dataset: https://kdef.se/home/aboutKDEF.html
[152] Vedantham, R., & Reddy, E. S. (2020). A robust feature extraction with optimized DBN-
SMO for facial expression recognition. Multimedia Tools and Applications, pp. 1-26.
[153] Eng, S. K., Ali, H., Cheah, A. Y., & Chong, Y. F. (2019). Facial expression recognition in
JAFFE and KDEF Datasets using histogram of oriented gradients and support vector machine.
In IOP Conference Series: Materials Science and Engineering, Vol. 705, No. 1, p. 012031, IOP
Publishing.
[154] Faria, D. R., Vieira, M., Faria, F. C., & Premebida, C. (2017). Affective facial expressions
recognition for human-robot interaction. In 2017 26th IEEE International Symposium on
Robot and Human Interactive Communication (RO-MAN), pp. 805-810, IEEE.

148
[155] Pandey, R. K., Karmakar, S., Ramakrishnan, A. G., & Saha, N. (2019). Improving facial
emotion recognition systems using gradient and laplacian images. arXiv preprint
arXiv:1902.05411.
[156] Fei, Z., Yang, E., Li, D. D. U., Butler, S., Ijomah, W., Li, X., & Zhou, H. (2020). Deep
convolution network based emotion analysis towards mental health
care. Neurocomputing, 388, pp. 212-227.
[157] Puthanidam, R. V., & Moh, T. S. (2018). A Hybrid approach for facial expression
recognition. In Proceedings of the 12th International Conference on Ubiquitous Information
Management and Communication, pp. 1-8.
[158] Hung, J. C., Lin, K. C., & Lai, N. X. (2019). Recognizing learning emotion based on
convolutional neural networks and transfer learning. Applied Soft Computing, 84, 105724.
[159] Tan, M., & Le, Q. V. (2019). Efficientnet: Rethinking model scaling for convolutional
neural networks. arXiv preprint arXiv:1905.11946.
[160] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks:
https://amaarora.github.io/2020/08/13/efficientnet.html
[161] Reviewing EfficientNet: Increasing the accuracy and robustness of CNNs:
https://heartbeat.fritz.ai/reviewing-efficientnet-increasing-the-accuracy-and-robustness-of-
cnns-6aaf411fc81d
[162] Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training
by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.
[163] Wu, Y., & He, K. (2018). Group normalization. In Proceedings of the European
conference on computer vision (ECCV) (pp. 3-19).

149
List of Publications
• Chintan Thacker, Dr. Ramji Makwana, “Human Behavior Analysis through Facial
Expression Recognition in images using Deep Learning”, International Journal of
Innovative Technology and Exploring Engineering, Vol. 9, Issue 2, 2019. ISSN:
2278-3075 (Scopus Indexed)
• Chintan Thacker, Dr. Ramji Makwana, “Ensemble of Multi Features Layers in CNN
for Facial Expression Recognition using Deep Learning”, International Journal of
Recent Technology and Engineering, Vol. 8, Issue 4, 2019. ISSN: 2278-3878
(Scopus Indexed)
• Chintan Thacker, Dr. Ramji Makwana, “A Review on Intelligent Video Surveillance
System for Human Behavior Analysis”, International Journal of Institute on
Emerging Research and Engineering Technology, 2018. ISSN: 2320-7590
• Chintan Thacker, Dr. Ramji Makwana, “Multimodal Ensemble fusion of CNN for
Facial Expression Recognition using Deep Learning Techniques”, The Imaging
Science Journal (Taylor & Francis Group, SCI-Scopus Indexed) (Under Review)




























