Embed Size (px)
Citation preview

Enhancing the Serviceability and the Availability of IMS-Based
Multimedia Services: Avoiding Core Service Failures
Mohamed BOUCADAIR
France Telecom R&D
Cardiff, 17/09/2008

Agenda
• Context
• Challenges
• Potentials of P2P and autonomic techniques
• Focus on Robustness and Availability
• Proposals to avoid core segment failures

Context• PSTN renewal is a fact
• IMS and TISPAN have been adopted as the main architectures for the deployment of conversational services
• These architectures are centralized and suffer from several hurdles related to robustness and availability
• Current deployments assume a vertical model: both service and transport layers are managed by the same administrative entity…
• In the meantime, autonomic solutions and P2P-based alternatives have been promoted
• These techniques present numerous potentials…that can be exploited by telcos

Potentials of P2P and Autonomic techniques: Examples
• Allow dynamic and autonomous behaviours instead of "static/frozen" one
• Implement scalable service offerings through “intelligent” load distribution
• Avoid DoS (Denial of Service) and SPAM attacks since the service logic is distributed among several nodes. The impact of a DoS attack may not be critical as for a centralised service platform
• Enable fast re-route, dynamic failure detection and failure repair
• Enhance service reliability
• Reduce CAPEX and OPEX
• Etc.

Challenges
• Enhance current IMS-based service offerings• Exploit autonomic techniques in operational
networks and propose viable scenarios of usage of these promising techniques
• Focus on Robustness and availability• This paper presents only a part of a toolkit
elaborated within the EURESCOM study: "P1755, P2PSIP Potentials in telecommunications"– The toolkit covers several areas such as access
failures, core failures, avalanche restart, flash crowds, etc.

Enhancing Robustness of IMS-based architectures
• The main objective is to propose a set of viable solutions aiming to enhance the robustness and the availability of current IMS-based architectures owing to the activation of autonomic techniques
• A Service Provider's standpoint is adopted for the deployment of autonomic techniques
• The adopted rationale argues in favor of introducing autonomic means into current operational service platforms in order to build survival and deterministic networks– autonomic means are not used as alternative solutions but as an
enhancement to the already deployed ones– For backward compatibility and for migration issues, it is recommended
to enforce the proposed solutions as backup ones in the earlier stages of deployment
– Once field proven, the proposed mechanisms could be enforced as primary procedures to deliver more sophisticated services

Macroscopic view of IMS-based architectures
• IMS-based architectures may be devided into three segments:
– Access segment• This segment encloses functions which are required for connecting customers’
equipment to the service• This segment may include for instance BGF or P-CSCF• Several of access functions are embedded in SBC (Session Border Controllers)
– Core segment• This segment is the place where the service logic and required functions such as
routing, billing, etc. are hosted• Within IMS architecture, this segment is responsible for interconnecting to internal or
external AS (Application Servers) • Examples of core IMS functional elements : I-CSCF, S-CSCF, HSS, etc.
– Border segment or Interconnection segment• This segment groups required functions to interconnect with external realms• These external realms may be VoIP ones, PSTN, PLMN or any other voice service
domain• Usually this segment is implemented by an SBC

Macroscopic View of an IMS-enabled Service Domain
Core PF
Service Provider
SBC1
SBC1_b
SBC2
SBC2_b SBC3
SBC3_b
SBC4
SBC4_b
Service POP1
Service POP2
Service POP3
Service POP4
Access POP: physical redundancy
is usually implemented

Macroscopic View of an IMS-enabled Service Domain
Core PF
Service Provider
SBC1
SBC1_b
SBC2
SBC2_b SBC3
SBC3_b
SBC4
SBC4_b
Service POP1
Service POP2
Service POP3
Service POP4
SBC is the first service contact point of each User
Equipment
UE1

Macroscopic View of an IMS-enabled Service Domain
Core PF
Service Provider
SBC1
SBC1_b
SBC2
SBC2_b SBC3
SBC3_b
SBC4
SBC4_b
Service POP1
Service POP2
Service POP3
Service POP4
The service topology is hidden. Only SBCs are
visible to external parties
UE1

SBC nodes
• SBC stands for Session Border Controller• SBC have been introduced to solve several
problems encountered in SIP deployments• Examples of functions supported by these nodes
are– Topology hiding– NAT Traversal– Solve protocol mismatch– Etc.
• SBC are considered as a single point of failure

Focus on core service failures
• Failure of core segment
– When access to core service nodes is broken
– Problems reltaed to:• Availbility of the core service nodes• Routing problems;• Etc.

Focus on core service failures: Scenario 1
Core PF
Service Provider
SBC1
SBC1_b
SBC2
SBC2_bSBC3
SBC3_b
SBC4
SBC4_b
Service POP1
Service POP2
Service POP3
Service POP4
Failure
One or many core service nodes are out of service: the service can not be delivered
to end users

Focus on core service failures: Scenario 1
Core PF
Service Provider
SBC1
SBC1_b
SBC2
SBC2_bSBC3
SBC3_b
SBC4
SBC4_b
Service POP1
Service POP2
Service POP3
Service POP4
Failure
UE1
UA1 is unable to register to the service or to invoke its
subscribed services

Focus on core service failures: Scenario 2
Core PF
Service Provider
SBC1
SBC1_b
SBC2
SBC2_bSBC3
SBC3_b
SBC4
SBC4_b
Service POP1
Service POP2
Service POP3
Service POP4
Failure
One or many access SBCs are unable to reach core
service nodes: the service can not be delivered to end
users

Focus on core service failures: Scenario 2
Core PF
Service Provider
SBC1
SBC1_b
SBC2
SBC2_bSBC3
SBC3_b
SBC4
SBC4_b
Service POP1
Service POP2
Service POP3
Service POP4
Failure
UE1
UA1 is unable to register to the service or to invoke its
subscribed services

Proposal to Enhance IMS architectures
• Unlike current IMS-based deployments, this solution aims to involve actively SBC nodes in the failure detection and reactivation processes
• Additional functions and interfaces are introduced for this purpose
• The characteristics of the proposed solution are as follows:– Assess the availability of core service through the invocation of
dedicated messages
– Detect an un-reachability problem between a given SBC and core service platform
– Adopt a collaborative mode in which SBCs will intervene in the routing resolution process

Proposal to Enhance IMS architectures
• Two scenarios may be envisaged:
– (1) Partial Failure • This means that at least one SBC can reach core service nodes• In this scenario, a new procedure is introduced and implemented by
SBCs• This procedure consists to select an SBC_PROXY which will relay
messages to core service platform. A multicast channel is used for this purpose
– (2) Full Failure• All SBCs fail to reach core service nodes• Once this occurs, all SBCs activate their autonomous mode and are
acting as a network of co-equal peers, intervening during the routing process
• Messages are not routed to core service nodes anymore, but are processed by SBCs themselves

Partial Failure
• If Multicast is enabled, a multicast group is configured and all SBCs and Interconnection nodes are member of this group. If not, P2PSIP like mechanisms are used to create an SBC overlay network
• Means to subscribe to this multicast group are activated in all SBCs (e.g. IGMP)
• Keep alive messages are issued regularly to assess to availability to reach core service nodes– How to implement this function is not detailed in this paper
• Once an unavailability is detected, a given SBC sends a dedicated request to select an SBC_PROXY which is able to reach core service nodes– The request is sent to the aforementioned multicast group– Responses are sent using unicast– If several offers are received, the local SBC makes its decision based
on some criteria such as CPU, IGP path, etc.– All subsequent communications will cross this SBC_PROXY

Example of a Call Flow during a partial failure
UE1 SBC1 SBC4SBC2 UE4
(1) Keep-alive
Core PF Is out of service
(2) SBC_PROXY_REQUEST()
(3a) SBC_PROXY_OFFER()(3b) SBC_PROXY_OFFER()
SBC2 is selectedas SBC_PROXY
(4a) INVITE(UE4)(4b) INVITE(UE4)
(4c) INVITE(UE4)(4d) INVITE(UE4)
(5a) OK(5b) OK
(5c) OK(5d) OK
(6a) ACK)(6b) ACK
(6c) ACK(6d) ACK)
RTP RTP RTP RTP
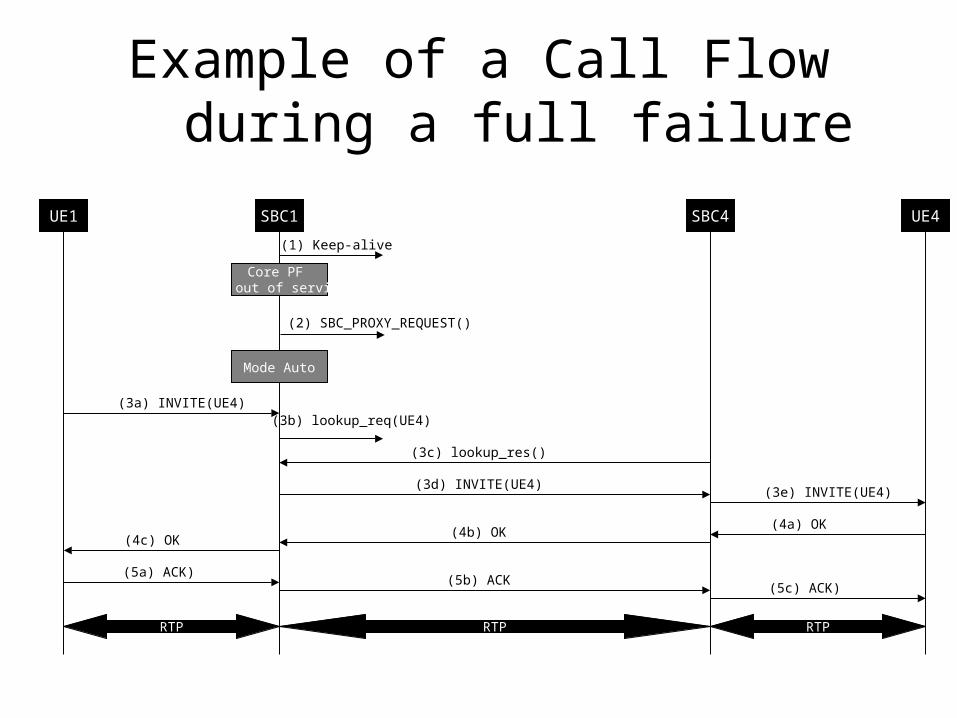
Example of a Call Flow during a full failure
UE1 SBC1 SBC4 UE4
(1) Keep-alive
Core PF Is out of service
(2) SBC_PROXY_REQUEST()
Mode Auto
(3a) INVITE(UE4)
(3d) INVITE(UE4)(3e) INVITE(UE4)
(4a) OK(4b) OK
(4c) OK
(5a) ACK)(5b) ACK
(5c) ACK)
RTP RTP RTP
(3b) lookup_req(UE4)
(3c) lookup_res()

Conclusions
• Owing to autonomic behaviors, the service is delivered to end users even in case of partial or full failures
• Customers are not aware about occurred failures
• Further effort should be undertaken to assess the validity of the proposed solution for the delivery of sophisticated services

Questions?





























