Embed Size (px)
Citation preview

Renewable energies | Eco-friendly production | Innovative transport | Eco-efficient processes | Sustainable resources ©
2014 -
IF
P E
nerg
ies n
ouvelle
s
Direction Technologies, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014
Enhanced Oil Recovery simulation Performances on New Hybrid Architectures
A. Anciaux, J-M. Gratien, O. Ricois, T. Guignon,
P. Theveny, M. Hacene

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
ArcEOR reservoir simulator
New generation research reservoir simulator (RS)
based on Arcane/ArcGeoSim platform:
Parallel grid management
Physics
Numerical services: schemes, non linear solvers, linear solvers…
Focus on Enhanced Oil Recovery Processes:
Thermal simulation with steam
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 2

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Linear solver inside RS
At each time step : non linear system to solve
Newton
For each Newton iteration : solve Ax = b (BiCGStab + precond.).
Typical BO simulation: 80 % of time is spent in linear solver
A: unstructured sparse matrix
Non symetric
Block CSR Format (3x3: Black Oil 3 phases)
Adjacency graph close to reservoir grid connectivity.
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 3

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
GPU Linear solver inside RS
Are we able to accelerate solver with GPU ?
What we need on GPU?
sparse matrix vector product (SpMV)
preconditioner
Base vector linear algebra (CUBLAS)
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 4

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
SpMV on GPU
CSR Block matrices:
Non zero elements are small blocks (1x1,2x2,3x3,4x4…..)
SpMV exploits block structure to reduce indirection cost:
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 5

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
SpMV on GPU
Also we use texture cache for x :
1. Bind texture with x
2. Compute y=A.x
3. Synchronize
4. Unbind texture
Compare to Cusparse Ellpack (best perf. on our matrices)
Cusparse provides a Block CSR format (BSR):
Not as fast as point Cusparse Ellpack on our systems
Slower than CSR with 3x3, close to Ellpack for 4x4
Directly use original structure (no csr2ell)
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 6

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Single GPU SpMV performances
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 7
11830
30311 31790
26394 27866
29525
12630
37411
40023
33234
35036
37258
14259
42100
45162
37749
39689
42224
10317
22956
25121
22799 23150
11544
29016 29866
27383
29419 29455
12709
32800 33906
31115
33341 33294
21598 22359
9389 8234 8287
6811
11136 12664
8028 7229 7291 6673
3521 2796 2351 2355 2367 2189
Canta (3x3),n=24048
MSUR_9 (4x4),n=86240
IvaskBO (3x3),n=148716
GCSN1 (3x3),n=556594
GCS2K (3x3),n=1112946
spe10 (2x2),n=21888426
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
50000
matrices
MFL
OP
S
SpMV on Nvidia K20c/K40c/K40cBoost (NOECC) compared to Intel [email protected] Ghz
IFPEN spmv v2 IFPEN spmv v2 K40
IFPEN spmv v2 K40 Boost cusparse ELLPACK
cusparse ELLPACK K40 cusparse ELLPACK K40 Boost
CPU 8 cores CPU 4 cores
CPU
X1.7
x17
x4.2

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Polynomial
Neuman Polynomial:
P(x) = Ix+Nx+N2x+N3x+...Nd x with N= I - w.D-1 .A
Only requires SpMV and vector algebra
As preconditioner: y = P(x)
Highly parallel in every context (MPI, GPU, Pthread ….)
(very) low numerical efficiency
High FLOP Cost: degree ‘d’ means ‘d’ SpMV to apply
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 8
© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
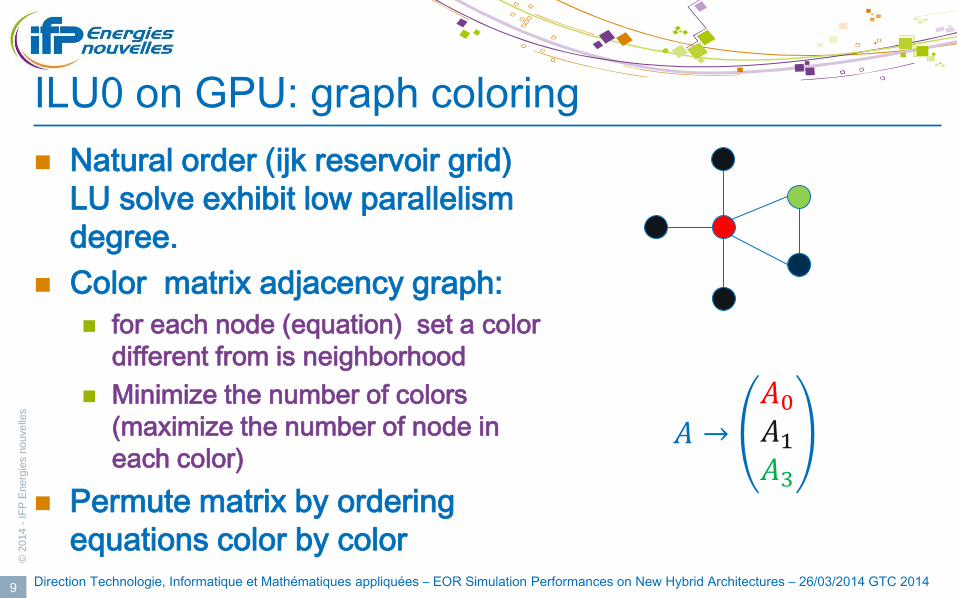
ILU0 on GPU: graph coloring
Natural order (ijk reservoir grid)
LU solve exhibit low parallelism
degree.
Color matrix adjacency graph:
for each node (equation) set a color
different from is neighborhood
Minimize the number of colors
(maximize the number of node in
each color)
Permute matrix by ordering
equations color by color Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 9
𝐴 →
𝐴0
𝐴1
𝐴3

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
ILU0 on GPU: Permuted solve
Li , Ui : sparse blocks
Solve L.x = y :
1. x1 = D1-1.y1
2. x2 = D2-1.y2 – L2.x1
3. …
Solve U.x = y :
1. x4 = D4-1.y4
2. x3 = D3-1.y2 – U3.x4
3. …
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 10
SpMV
Block tri. solve

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Color ILU0: performances and drawback
system ILU0 CPU Solve (1
core)
Color ILU0
GPU Solve
(1GPU)
GPU/CPU
acceleration
spe10 3.18e+08 1.99e+07 16
GCS2K 2.75e+08 1.67e+07 16.5
IvaskBO 6.30e+07 5.14e+06 12.2
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 11
K40c NOECC / E5-2680, average processor cycles / LU solve
2 colors with majority of
nodes:
GCS2K example:
Color Number of vertices
0 179635
1 179634
2 5754
3 5630
4 179
5 149
6 1
Coloring has negative impact
on Krylov solver convergence.

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
AMGP and CPR-AMG
Split linear system 𝐴𝑥 = 𝑟 :
𝐴 =𝐴1,1 𝐴1,2
𝐴2,1 𝐴2,2, 𝑥 =
𝑋1
𝑋2, 𝑟 =
𝑅1
𝑅2
𝐴1,1 is the presure block, 𝐴2,2 is the saturation block
AMGP: only solve 𝐴1,1 with AMG
𝐴1,1𝑋1 = 𝑅1
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 12

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
AMGP and CPR-AMG
CPR-AMG: solve 𝐴1,1 with AMG and the whole system with a
simple preconditioner (ILU0 or polynomial):
𝐴𝑥(1) = 𝑟 with ILU0 , 𝑥(1) =𝑋1
(1)
𝑋2(1)
𝐴1,1𝑋1(2)
= 𝑅1 − 𝐴1,1𝑋11
− 𝐴1,2𝑋21
with AMG
final preconditioner solution is: 𝑋1
(1)+ 𝑋1
(2)
𝑋2(1)
We use AmgX from Nvidia
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 13
SpMV

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Spe10 30 days simulation with GPU
total solver time inside 30 days simulation (1e-4):
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 14
Solver type Total num. of iterations total solver time (s)
ILU0 CPU 1 core 3498 820
Block Jacobi ILU0 CPU, 8 cores MPI 3812 270
Block Jacobi ILU0 CPU, 16 cores MPI 3756 145
CPR-AMG CPU (IFPSolver) 1 core 361 430
CPR-AMG CPU (IFPSolver), 8 cores MPI 497 143
CPR-AMG CPU (IFPSolver), 16 cores MPI 413 68
Color ILU0 GPU 1 core/1 gpu 10977 153
Poly GPU 1 core/1 gpu 8765 186
AMGP AmgX PMIS GPU, 1 core/1 gpu 989 62
CPR-AMG AmgX PMIS, Poly GPU, 1 core /1 gpu 538 55
K40c NOECC / E5-2680 2 sockets
© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
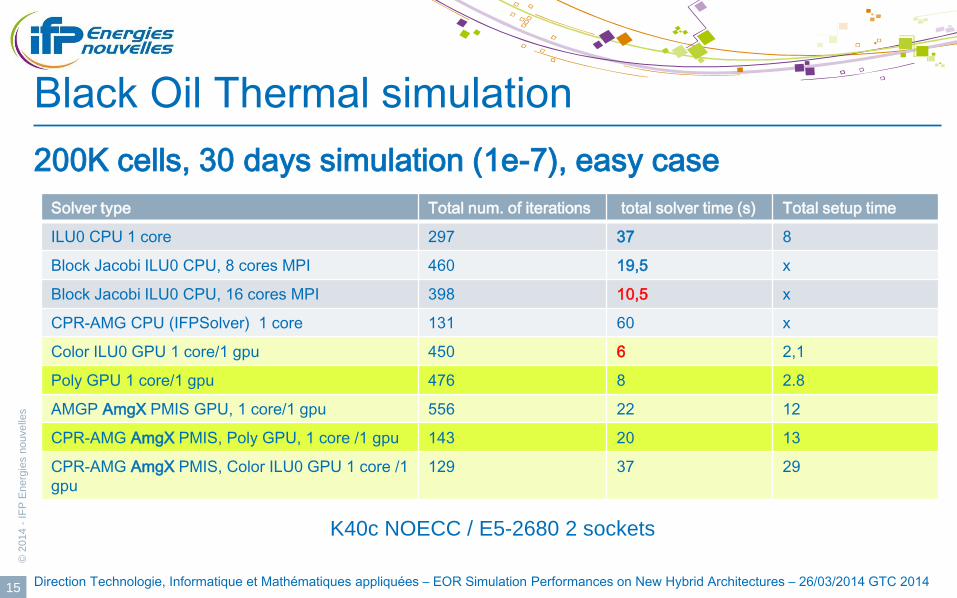
Black Oil Thermal simulation
200K cells, 30 days simulation (1e-7), easy case
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 15
Solver type Total num. of iterations total solver time (s) Total setup time
ILU0 CPU 1 core 297 37 8
Block Jacobi ILU0 CPU, 8 cores MPI 460 19,5 x
Block Jacobi ILU0 CPU, 16 cores MPI 398 10,5 x
CPR-AMG CPU (IFPSolver) 1 core 131 60 x
Color ILU0 GPU 1 core/1 gpu 450 6 2,1
Poly GPU 1 core/1 gpu 476 8 2.8
AMGP AmgX PMIS GPU, 1 core/1 gpu 556 22 12
CPR-AMG AmgX PMIS, Poly GPU, 1 core /1 gpu 143 20 13
CPR-AMG AmgX PMIS, Color ILU0 GPU 1 core /1
gpu
129 37 29
K40c NOECC / E5-2680 2 sockets

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
GPU with MPI
2 primary objectives:
How to make an hybrid GPU+MPI SpMV, does it works efficiently ?
How the full solver behaves (with polynomial) ? Does it scale ?
Test system: Bullx Blade
2xE5 [email protected] Ghz + 2xK20m /node (ECC ON)
5 nodes: 80 cores + 10 gpus
Infiniband backplane
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 16

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
GPU SpMV with MPI
Split local SpMV for process p :
y(p) = A(p)int . x
(p)
Get x(p) ext with halo/neigh.
exchange
y(p) ext = A(p)
ext . x(p)
ext
y(p) = y(p) + y(p) ext
Reorder local matrix to
minimize y(p) ext and x(p)
ext : External dependent equations at
end.
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 17
A(p)int A(p)
ext A(p)ext
x(p)
y(p)
x(p)ext x(p)
ext
p y(p)ext

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
GPU SpMV with MPI
GPU + MPI SpMV WorkFlow:
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 18
y(p) = A(p)int . x
(p) y(p) = y(p) + y(p) ext
GPU
CPU y(p)
ext = A(p)ext . x
(p) ext
x exchange
Not real scale time

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
GPU SpMV with MPI: good news
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 19
4,70E+10
9,24E+10
1,34E+11
1,78E+11
2,15E+11
8,51E+09 1,68E+10
2,51E+10 3,41E+10
4,32E+10
8 16 32 48 64 80
0,0E+00
5,0E+10
1,0E+11
1,5E+11
2,0E+11
2,5E+11
batch reserved cores
FLO
PS
SpMV MPI+GPU FiveSpot800-800-10_7 2x2 n=12800000, K20m ECC + [email protected], 80 cores
+ 10 gpus
MPI 1c1gpu/s CusparseEll
MPI 1c1gpu/s IFPENV2
MPI 8c/s async com
x5.5
x4.9
12.8M. Cells (2x2)
Close to x5 acc. 1c+1gpu/s
against full socket use
1 node with 2 gpus equiv. to
5 nodes full socket use!

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
GPU SpMV with MPI: bad news
500K Cells (3x3)
3.5 acc. 2c+1g/s against 16c
(full node)
At the and: CPU is faster
Thanks to L3 cache effect
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 20
3,89E+10
6,42E+10
8,15E+10
1,01E+11
1,10E+11
1,01E+10
2,27E+10
7,00E+10
1,17E+11
1,41E+11
8 16 32 48 64 80
0,0E+00
2,0E+10
4,0E+10
6,0E+10
8,0E+10
1,0E+11
1,2E+11
1,4E+11
1,6E+11
batch reserved cores
FLO
PS
SpMV MPI+GPU GCSN1 3x3 n=556594, K20m ECC + [email protected], 80 cores + 10
gpus
MPI 1c1gpu/s CusparseEll
MPI 1c1gpu/s IFPENV2
MPI 8c/s async com
x0.7
x3.5

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Stand alone MPI+GPU solver
Test with Polynomial (spe10 matrix)
Multi GPU intrinsic scalability?
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 21
1c/1g 2c/2g 4c/4g 6c/6g 8c/8g 10c/10g
Total solver
time (s)
20,7 11.5 5.8 5.1 3.7 3.2
It. 669 704 616 748 634 626
Acc. 1 1.8 3.5 4 5,6 6,5

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Conclusions and work in progress
Thanks to AmgX: good GPU CPR-AMG preconditioner
(1gpu)
But the « every day » preconditioner (Color ILU0) is not
enough good:
New coloring algorithm for decent numerical behavior?
MPI+GPU:
SpMV : ok with big systems (at least 200K equations per GPU)
CPR-AMG and Color ILU0: work in progress
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 22

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Thanks
Special thanks to Nvidia AmgX Team:
Marat Arsaev and Joe Eaton
François Courteille (Nvidia)
Work partialy supported by PETALH ANR project
Direction Technologie, Informatique et Mathématiques appliquées – EOR Simulation Performances on New Hybrid Architectures – 26/03/2014 GTC 2014 23

© 2
014 -
IF
P E
nerg
ies n
ouvelle
s
Renewable energies | Eco-friendly production | Innovative transport | Eco-efficient processes | Sustainable resources
www.ifpenergiesnouvelles.com

![OpenSPARSE: An Open Platform for Sparse Basic …2018/10/04 · New Efficient General Sparse Matrix Formats for Parallel SpMV Operations. Euro-Par ’17. • [SpMV] G. Flegar, E](https://img.dokumen.tips/doc/110x75/5f700a0acfa3a50ed5328929/opensparse-an-open-platform-for-sparse-basic-20181004-new-efficient-general.jpg)





![A reduced-precision streaming SpMV architecture for ... · A reduced-precision streaming SpMV architecture for Personalized PageRank on FPGA ... [11, 23] as real-world graphs present](https://img.dokumen.tips/doc/110x75/6049fa038fd34e46526c8245/a-reduced-precision-streaming-spmv-architecture-for-a-reduced-precision-streaming.jpg)





















