Embed Size (px)
Citation preview

ENGS 116 Lecture 13 1
Caches and Virtual Memory
Vincent H. Berk
October 31st, 2008
Reading for Today: Sections C.1 – C.3 (Jouppi article)
Reading for Monday: Sections C.4 – C.7
Reading for Wednesday: Sections 5.1 – 5.3

ENGS 116 Lecture 12 2
Improving Cache Performance
• Average memory-access time (AMAT) = Hit time + Miss rate Miss penalty (ns or clocks)
• Improve performance by:
1. Reducing the miss rate
2. Reducing the miss penalty
3. Reducing the time to hit in the cache

ENGS 116 Lecture 12 3
Reducing Miss Rate
• Larger Blocks• Larger Cache• Higher Associativity

ENGS 116 Lecture 12 4
Classifying Misses: 3 Cs
• Compulsory: The first access to a block is not in the cache, so the block must be brought into the cache. Also called cold start misses or first reference misses. (Misses even in an infinite cache)
• Capacity: If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being discarded and later retrieved. (Misses in fully associative, size X cache)
• Conflict: If block-placement strategy is set associative or direct mapped, conflict misses (in addition to compulsory & capacity misses) will occur because a block can be discarded and later retrieved if too many blocks map to its set. Also called collision misses or interference misses. (Misses in N-way set associative, size X cache)

ENGS 116 Lecture 12 5
3Cs Absolute Miss Rate (SPEC92)
Conflict
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 4 8
16 32 64
128
1-way
2-way
4-way
8-way
Capacity
Compulsory Compulsory vanishingly small

ENGS 116 Lecture 12 6
2:1 Cache Rule
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1 2 4 8 16 32 64 128
1-way
2-way
4-way
8-wayCapacity
Compulsory
Conflict
miss rate 1-way associative cache size X = miss rate 2-way associative cache size X/2

ENGS 116 Lecture 12 7
3Cs Relative Miss Rate
Cache Size (KB)
Mis
s R
ate
per
Typ
e
0%
20%
40%
60%
80%
100%1 2 4 8
16 32 64
128
1-way
2-way4-way
8-way
Capacity
Compulsory
Conflict
Flaws: for fixed block sizeGood: insight

ENGS 116 Lecture 12 8
How Can We Reduce Misses?
• 3 Cs: Compulsory, Capacity, Conflict
• In all cases, assume total cache size not changed
• What happens if we:
1) Change Block Size: Which of 3Cs is obviously affected?
2) Change Associativity: Which of 3Cs is obviously affected?
3) Change Compiler: Which of 3Cs is obviously affected?

ENGS 116 Lecture 12 9
Block Size (bytes)
Miss Rate
0%
5%
10%
15%
20%
25%
16
32
64
12
8
25
6
1K
4K
16K
64K
256K
1. Reduce Misses via Larger Block Size

ENGS 116 Lecture 12 10
2. Reduce Misses: Larger Cache Size
• Obvious improvement
but:
• Longer hit time
• Higher cost
• Each cache size favors a block-size, based on memory bandwidth
AMAT = Hit time + Miss rate Miss penalty (ns or clocks)

ENGS 116 Lecture 12 11
3. Reduce Misses via Higher Associativity
• 2:1 Cache Rule:
– Miss Rate DM cache size N ≈ Miss Rate 2-way SA cache size N/2
• Beware: Execution time is final measure!
– Will clock cycle time increase?
• 8-Way is almost fully associative

ENGS 116 Lecture 12 12
Example: Avg. Memory Access Time vs. Miss Rate• Example: assume CCT = 1.10 for 2-way, 1.12 for 4-way,
1.14 for 8-way vs. CCT direct mapped
Cache Size Associativity
(KB) 1-way 2-way 4-way 8-way
1 2.33 2.15 2.07 2.01
2 1.98 1.86 1.76 1.68
4 1.72 1.67 1.61 1.53
8 1.46 1.48 1.47 1.43
16 1.29 1.32 1.32 1.32
32 1.20 1.24 1.25 1.27
64 1.14 1.20 1.21 1.23
128 1.10 1.17 1.18 1.20
(Red means A.M.A.T. not improved by more associativity)

ENGS 116 Lecture 12 13
Reducing Miss Penalty
• Multilevel caches• Read priority over write
AMAT = Hit time + Miss rate Miss penalty (ns or clocks)

ENGS 116 Lecture 12 14
1. Reduce Miss Penalty: L2 Caches
• L2 EquationsAMAT = Hit TimeL1 + Miss RateL1 Miss PenaltyL1
Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 Miss PenaltyL2
AMAT = Hit TimeL1 + Miss RateL1 (Hit TimeL2 + Miss RateL2 Miss PenaltyL2)
• Definitions:– Local miss rate — misses in this cache divided by the total
number of memory accesses to this cache (Miss rateL2)– Global miss rate — misses in the cache divided by the total
number of memory accesses generated by the CPU (Miss RateL1 Miss RateL2)
– Global miss rate is what matters —indicates what fraction of memory accesses from CPU go all the way to main memory

ENGS 116 Lecture 12 15
Comparing Local and Global Miss Rates
• 32 KByte 1st level cache;Increasing 2nd level cache
• Global miss rate close to single level cache rate provided L2 >> L1
• Don’t use local miss rate
• L2 not tied to CPU clock cycle!
• Cost & A.M.A.T.
• Generally fast hit times and fewer misses
• Since hits are few, target miss reduction

ENGS 116 Lecture 12 16
Relative CPU Time
Block Size
11.11.21.31.41.51.61.71.81.9
2
16 32 64 128 256 512
1.361.28 1.27
1.34
1.54
1.95
L2 cache block size & A.M.A.T.
• 32KB L1, 8-byte path to memory

ENGS 116 Lecture 12 17
2. Reduce Miss Penalty: Read Priority over Write on Miss
• Write through with write buffers offer RAW conflicts with main memory reads on cache misses
• If simply wait for write buffer to empty, might increase read miss penalty (old MIPS 1000 by 50%)
• Check write buffer contents before read; if no conflicts, let the memory access continue
• Write Back?
– Read miss replacing dirty block
– Normal: Write dirty block to memory, and then do the read
– Instead copy the dirty block to a write buffer, then do the read, and then do the write
– CPU stalls less frequently since restarts as soon as read finished

ENGS 116 Lecture 12 18
Reducing Hit Time
• Avoiding Address Translation in index
AMAT = Hit time + Miss rate Miss penalty (ns or clocks)

ENGS 116 Lecture 13 19
1. Fast Hits by Avoiding Address Translation
• Send virtual address to cache? Called Virtually Addressed Cache or Virtual Cache vs. Physical Cache
– Every time process is switched logically must flush the cache; otherwise get false hits
>> Cost is time to flush + “compulsory” misses from empty cache
– Must handle aliases (sometimes called synonyms): Two different virtual addresses map to same physical address
• Solution to aliases
– HW guarantees each block a unique physical address OR page coloring used to ensure virtual and physical addresses match in last x bits
• Solution to cache flush
– Add process identifier tag that identifies process as well as address within process: cannot get a hit if wrong process

ENGS 116 Lecture 13 20
Virtually Addressed Caches
CPU
TB
$
MEM
VA
PA
PA
ConventionalOrganization
CPU
$
TB
MEM
VA
VA
PA
Virtually Addressed CacheTranslate only on miss
Synonym Problem
CPU
$ TB
MEM
VA
PATags
PA
Overlap $ accesswith VA translation:requires $ index toremain invariantacross translation
VATags
L2 $

ENGS 116 Lecture 13 21
• If index is physical part of address, can start tag access in parallel with translation so that can compare to physical tag
• Limits cache to page size: what if want bigger caches and uses same trick?
– Higher associativity moves barrier to right
– Page coloring (software OS requires that all Aliases share lower address bits, leads to set-associative pages!)
2. Fast Cache Hits by Avoiding Translation: Index with Physical Portion of Address
0Page Address Page Offset
Address Tag Index Block Offset
31 1112

ENGS 116 Lecture 14 22
Virtual Memory
• Virtual Address (232, 264) to Physical Address mapping (228)
• Virtual memory in terms of cache:
– Cache block?
– Cache miss?
• How is virtual memory different from caches?
– What controls replacement
– Size (transfer unit, mapping mechanisms)
– Lower-level use

ENGS 116 Lecture 14 23
Figure 5.36 The logical program in its contiguous virtual address space is shown on the left; it consists of four pages A, B, C, and D.
C
A
B
0
4K
8K
12K
16K
20K
24K
28K
Physical address:
A
C
B
D
0
4K
8K
12K
Virtual address:
Physical main memory
Virtual memory
D Disk
ENGS 116 Lecture 14 24
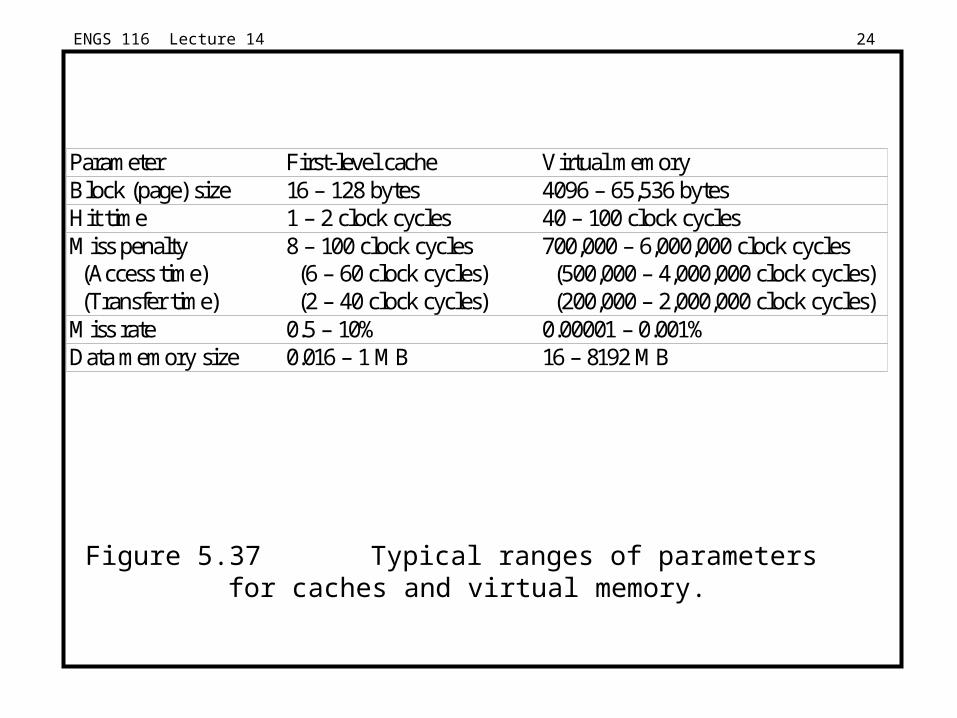
Figure 5.37 Typical ranges of parameters for caches and virtual memory.
Parameter First-level cache Virtual memoryBlock (page) size 16 – 128 bytes 4096 – 65,536 bytesHit time 1 – 2 clock cycles 40 – 100 clock cyclesMiss penalty (Access time) (Transfer time)
8 – 100 clock cycles (6 – 60 clock cycles) (2 – 40 clock cycles)
700,000 – 6,000,000 clock cycles (500,000 – 4,000,000 clock cycles) (200,000 – 2,000,000 clock cycles)
Miss rate 0.5 – 10% 0.00001 – 0.001%Data memory size 0.016 – 1 MB 16 – 8192 MB

ENGS 116 Lecture 14 25
Virtual Memory
• 4 Questions for Virtual Memory (VM)?
– Q1: Where can a block be placed in the upper level?
fully associative, set associative, or direct mapped?
– Q2: How is a block found if it is in the upper level?
– Q3: Which block should be replaced on a miss?
random or LRU?
– Q4: What happens on a write?
write back or write through?
• Other issues: size; pages or segments or hybrid

ENGS 116 Lecture 14 26
Figure 5.40 The mapping of a virtual address to a physical address via a page table.
Page offsetVirtual page number
Virtual address
Page table
Physical address
Main memory

ENGS 116 Lecture 14 27
Fast Translation: Translation Buffer (TLB)• Cache of translated addresses
• Data portion usually includes physical page frame number, protection field, valid bit, use bit, and dirty bit
• Alpha 21064 data TLB: 32-entry fully associative
43
21
Page-frame address <30>
Page offset <13>
<30> Tag
<21> Physical page #
(low-order 13 bits of address)
34-bit physical address
(high-order 21 bits of address)
32:1 MUX
V R W<1> <2><2>
<13>
<21>

ENGS 116 Lecture 14 28
Selecting a Page Size• Reasons for larger page size
– Page table size is inversely proportional to the page size;
therefore memory saved
– Fast cache hit time easy when cache ≤ page size (VA caches);
bigger page makes it feasible as cache grows in size
– Transferring larger pages to or from secondary storage,
possibly over a network, is more efficient
– Number of TLB entries is restricted by clock cycle time, so a larger
page size maps more memory, thereby reducing TLB misses
• Reasons for a smaller page size– Fragmentation: don’t waste storage; data must be contiguous within page
– Quicker process start for small processes
• Hybrid solution: multiple page sizes– Alpha: 8 KB, 16 KB, 32 KB, 64 KB pages (43, 47, 51, 55 virtual addr bits)

ENGS 116 Lecture 14 29
Alpha VM Mapping
• “64-bit” address divided into 3 segments
– seg0 (bit 63 = 0) user code/heap
– seg1 (bit 63 = 1, 62 = 1) user stack
– kseg (bit 63 = 1, 62 = 0)
kernel segment for OS
• Three level page table, each one page
– Alpha only 43 bits of VA
– (future min page size up to 64 KB 55 bits of VA)
• PTE bits; valid, kernel & user, read & write enable (no reference, use, or dirty bit)
– What do you do?
Page table entry
Page table entry
Page table entry
Page Table Base Register
+
+
+
Physical address
page offsetphysical page-frame number
Main memory
Virtual address
page offsetlevel3seg0/seg1 selector
level1 level2
21
10 10 10 13
000 … 0 or 111 … 1
8 bytes32 bit address32 bit fields
L2 page table
L3 page table
L1 page table
. . .
. . .
. . .
. . .. . . . . .

Memory Hierarchy
<28>

ENGS 116 Lecture 14 31
Protection
• Avoid separate processes to access each others memory– Causes Segmentation Fault: sigSEGV– Useful for Multitasking systems– Operating system issue
• Each Process has its own state– Page tables– Heap, Text, Stack pages– Registers, PC
• To prevent processes from modifying their own page tables:– Rings of protection, Kernel vs. User
• To prevent processes from modifying other process memory:– Page tables point to distinct physical pages

ENGS 116 Lecture 14 32
Protection 2
• Each page needs:
– PID bit
– Read/Write/Execute bit
• Each process needs
– Stack frame page(s)
– Text or code pages
– Data or heap pages
– State table keeping:» PC and other CPU status registers
» State of all registers

ENGS 116 Lecture 14 33
Alpha 21064• Separate Instruction & Data
TLB & Caches
• TLBs fully associative
• TLB updates in SW(“Private Arch Lib”)
• Caches 8KB direct mapped, write through
• Critical 8 bytes first
• Prefetch instr. stream buffer
• 2 MB L2 cache, direct mapped, WB (off-chip)
• 256 bit path to main memory, 4 x 64-bit modules
• Victim buffer: to give read priority over write
• 4-entry write buffer between D$ & L2$
StreamBuffer
WriteBuffer
Victim Buffer
Instr Data





























