Embed Size (px)
Citation preview

Empirical Investigations of WWW Surfing Paths
Jim PitkowUser Interface Research
Xerox Palo Alto Research Center

August 1999
Agenda
• A few characteristics of the Web and clicks• Aggregate click models
– user surfing behaviors– post-hoc hit prediction
• Individual click models– entropy– path prediction

August 1999
1
10
100
1000
10000
100000
1000000
10000000
Aug-92
Feb-93
Aug-93
Feb-94
Aug-94
Feb-95
Aug-95
Feb-96
Aug-96
Feb-97
Aug-97
Feb-98
Aug-98
Ser
ver
s
Source: World Wide Web Consortium, Mark Gray, Netcraft Server Survey
Web is big, Web is good
1 new server every 2 seconds7.5 new pages per second

August 1999
Users, sessions, and clicks
Current Internet Universe Estimate 97.1 million
Time spent/month 7:28:16
Number of unique sites visited/month 15
Page views/month 313
Number of sessions/month 16
Page views/session 19
Time spent/session 0:28:01
Time spent/site 0:31:27Duration of a page viewed 0:01:28
Source Nielsen//NetRatings February 1999

August 1999
Popularity of pages—Zipf
• Zipf Distribution:– frequency is
inversely proportionate to rank
• Zipf Law:– slope equals
minus one

August 1999
Enter Exit
Users enter a website at variouspages and begin surfing
Continuing surfers distribute themselves down various paths
Surfers arrive at pages having traveled different paths
After some number of page visits surfers leave the web site
(a)
(b)
(c)
(d)
p1
p3
p2

August 1999
Model of surfing
VL = VL-1 + L
• Where L is the number of clicks and is L varies as independent and identically distributed Gaussian random variables
• Surfing proceeds until the perceived cost is larger
than the discounted expected future value

August 1999
Random walk with a stopping threshold• Two parameter inverse Gaussian distribution
• mean (L) = and variance (L) = 3/
L
L
LLP
2
3
3 2exp
2)(

August 1999
Experimental design• Client data
– Georgia Tech (3 weeks August, 1994)
– Boston University (1995)• tens of thousands of requests
• Proxy data– AOL (5 days in December, 1997)
• tens of millions of requests
• Server data– Xerox WWW Site (week during May 1997)
August 1999
0
4,000
8,000
12,000
16,000
20,000
0 5 10 15 20 25 30 35 40 45 50
Clicks
Fre
qu
ency
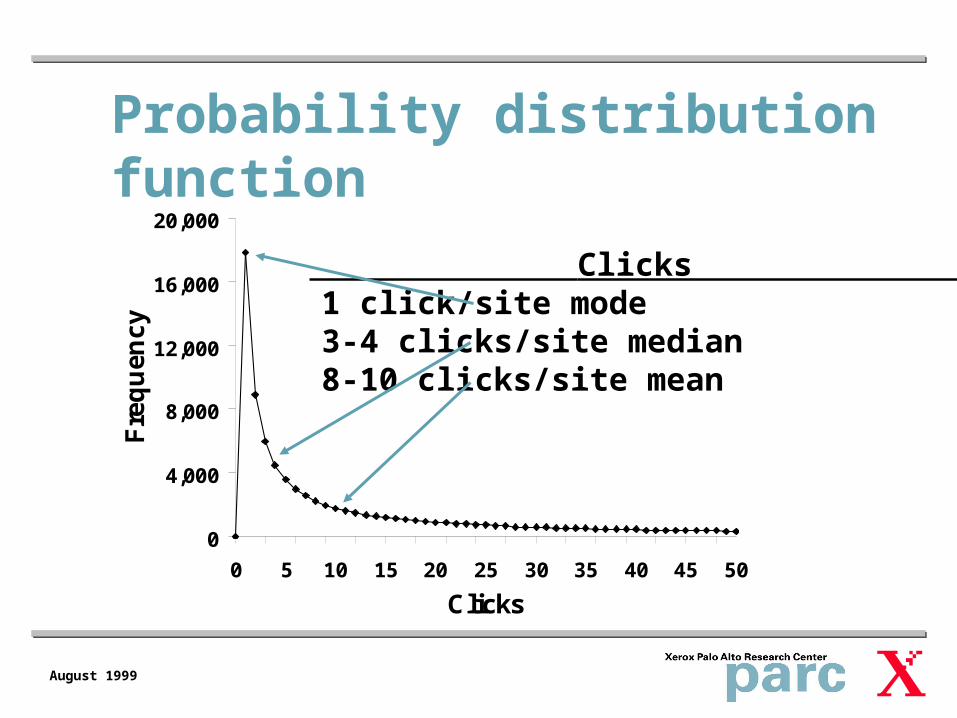
Probability distribution function
Clicks 1 click/site mode3-4 clicks/site median8-10 clicks/site mean

August 1999
0.00
0.25
0.50
0.75
1.00
0 25 50 75 100
Clicks
Pro
bab
ilit
y
Experimental
inverse Gaussian
Cumulative distribution function
*** Experimental
— inverse Gaussian
75% of the distribution accounted for in three clicks

August 1999
Two observations
• Inverse Gaussian distribution has very long tail– expect to see large deviations from average
• Due to asymmetric nature of the Inverse Gaussian distribution, typical behavior does not equal average behavior

August 1999
An interesting derivation
• Up to a constant given by the third term, the probability of finding a group surfing at a given level scales inversely in proportion to its depth
2og
2
)(og
2
3)(og
2
2
lL
LLlLPl
2/3)( LLP

August 1999
Number of surfers at each level
1
10
100
1000
1 10 100 1000
log(Clicks)
log
(Fre
qu
en
cy)
2/3)( LLP

August 1999
Implications of the Law of Surfing
• Implications on techniques designed to enhance performance– HTTP Keep-Alive, Pre-fetching of content
• Can adapt content based location on curve in a cost sensitive manner– different user modalities (browser, searcher, etc.)– expend different CPU resources for different users
• Web site visitation modeling

August 1999
Spreading Activation
Pump activation into source
Activation spreads through
the network
Activation settles into asymptotic pattern
August 1999
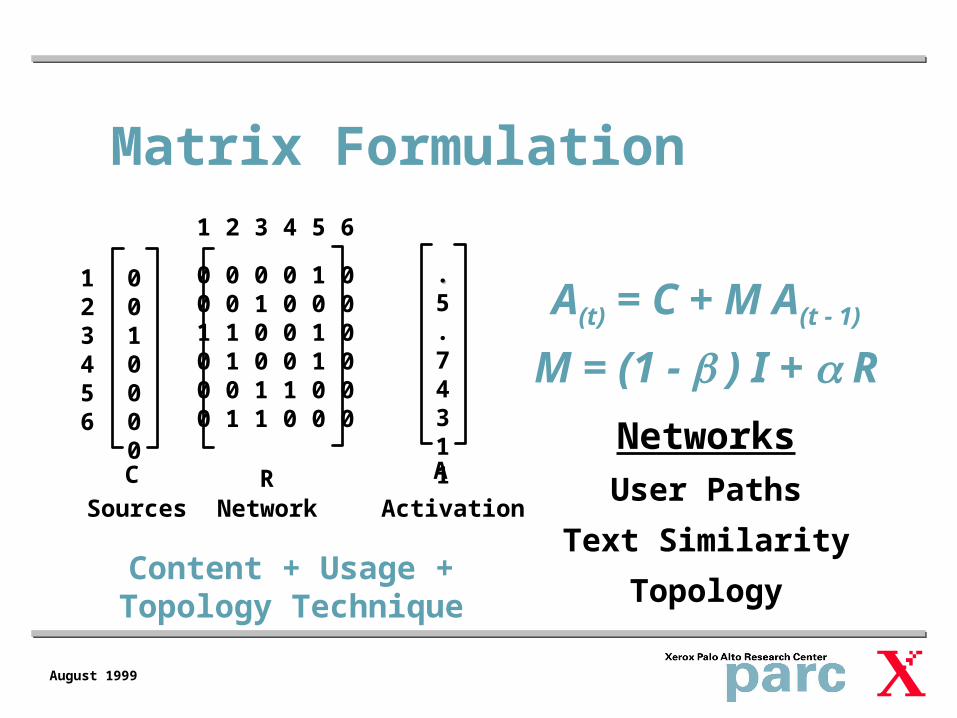
Matrix Formulation
0010000
123456
0 0 0 0 1 00 0 1 0 0 01 1 0 0 1 00 1 0 0 1 00 0 1 1 0 00 1 1 0 0 0
1 2 3 4 5 6
C R
..5
.74311
A
Sources Network Activation
Content + Usage + Topology Technique
A(t) = C + M A(t - 1)
M = (1 - ) I + R
NetworksUser Paths
Text Similarity
Topology

August 1999
Application to hit prediction
• Let fL be the fraction of users who, having surfed along L-1 links, continue to surf to depth L.
• Define the activation value Ni,L as the number of users who are at node i after surfing through L clicks
Lkk
kiLLi NSfN ,,1,
),,1(1
),,(1
LF
LFfL
August 1999
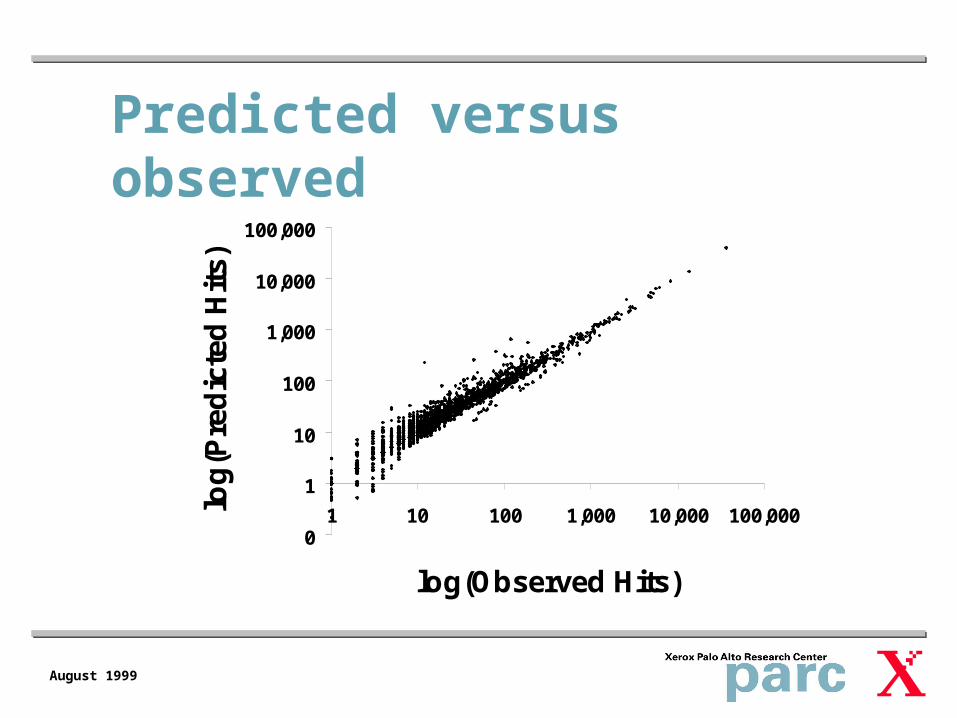
Predicted versus observed
0
1
10
100
1,000
10,000
100,000
1 10 100 1,000 10,000 100,000
log(Observed Hits)
log
(Pre
dic
ted
Hit
s)

August 1999
Proportion of surfers traversing link
Fre
quen
cy
Surfing probabilities
by outlinkdensity
No. Links, Li2 (df = 6)
0 < Li 3 25.21
3 < Li 6 26.44
6 < Li 9 172.99
9 < Li 12 59.70
12 < Li 3666.30

August 1999
Investigating user paths
• Each user path can be thought of as an ngram and represented as tuples of the form <X1, X2, … Xn> to indicate sequences of page clicks– Distribution of ngrams is the Law of Surfing
• Determine the conditional probability of seeing the next page given a matching prior ngram
),...,|Pr( 1 knnnn XXxX

August 1999
Uncertainty and entropy
• Conditional probabilities are also know as as kth-order Markov approximations/models
• Entropy is the expected (average) uncertainty of the random variable measured in bits– minimal number of bits to encode information– uncertainty in the sequence of letters in languages

August 1999
Mathematics of entropy
Xx
Xx
xpxp
xpxp
XpEXH
)(log)(
)(
1log)(
)(
1log)(
2
2
2

August 1999
Conditional entropy
nn Xx
knknnnnnknnn xXxXXHxpXXXH ),...,|()(),...|( 111
Xx Yy
yxpyxpYXH ),(log),(),( 2
),...,|()|()(),...,( 111211 nnn XXXHXXHXHXXH
Conditional probability
Chaining rule
Joint probabilities
August 1999
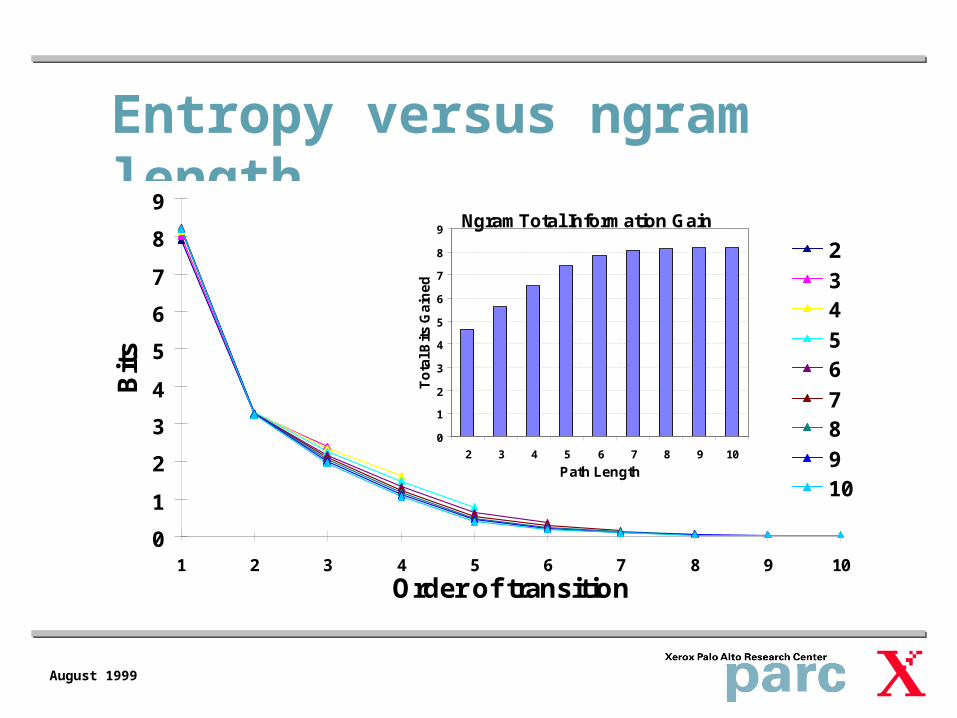
Entropy versus ngram length
0
1
2
3
4
5
6
7
8
9
1 2 3 4 5 6 7 8 9 10
Order of transition
Bit
s
2
34
56
78
910
NgramTotal Information Gain
0
1
2
3
4
5
6
7
8
9
2 3 4 5 6 7 8 9 10
Path Length
To
tal B
its
Ga
ine
d

August 1999
Path predictions
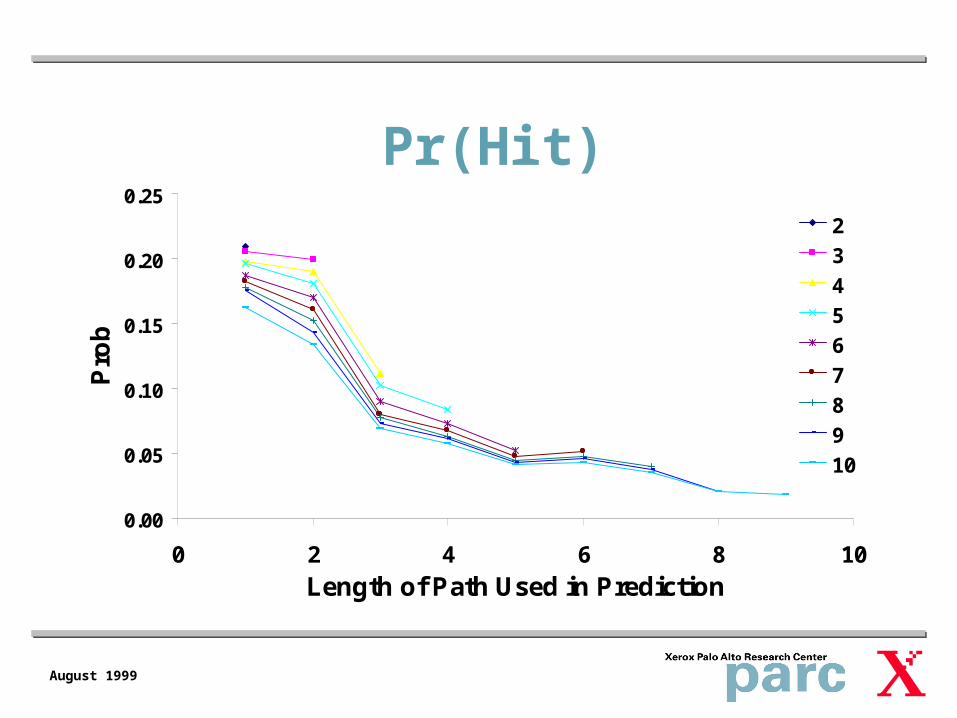
Pr(PPM) the probability that a penultimate path, <xn-1,…xn-k>, observed in the test data was matched by the same penultimate path in the training data
Pr(Hit|PPM) the probability that page xn is visited, given that <xn-1,…xn-k>, is the penultimate path and the highest probability conditional on that path is p(xn|xn-1,…xn-k )
Pr(Hit) = Pr(Hit|PPM)*Pr(PPM), the probability that the page visited in the test set is the one estimated from the training as the most likely to occur

August 1999
Pr(Path Match)
0.00
0.20
0.40
0.60
0.80
1.00
0 2 4 6 8 10
Length of Path Used in Prediction
Pro
b
2
3
4
5
6
7
8
9
10

August 1999
Pr(Hit|Path Match)
0.00
0.20
0.40
0.60
0.80
1.00
0 2 4 6 8 10
Length of Path Used in Prediction
Pro
b
2
3
4
5
6
7
8
9
10
August 1999
Pr(Hit)
0.00
0.05
0.10
0.15
0.20
0.25
0 2 4 6 8 10
Length of Path Used in Prediction
Pro
b
2
3
4
5
6
7
8
9
10

August 1999
Principles of path prediction
• Paths are not completely modeled by 1st order Markov approximations
• Path Specificity Principle: longer paths contain more predictive power than lower order paths
• Complexity Reduction: keep models as simple and as small as possible

August 1999
Agenda revisited
• A few characteristics of the Web and clicks• Aggregate click models
– user surfing behaviors– post-hoc hit prediction
• Individual click models– entropy– path prediction

August 1999
Areas of further investigation
• Advance the state of predictive modeling– Move from post-hoc to a-priori prediction of user
interactions on the Web– Test hypothetical models of Web site usage
• Validate existing and new models on more representative data sets
• Understand new and emerging applications– streaming video and audio, mobile, etc.

August 1999
More information
http://www.parc.xerox.com/istl/projects/uir/projects/Webology.html





























