Embed Size (px)
Citation preview

Emotional Speech
Guest Lecturer: Jackson Liscombe
CS 4706
Julia Hirschberg
4/20/05

4/20/05 CS 4706 2
Assumptions (1)
• Prosody is– pitch ≈ fundamental frequency (f0)– loudness ≈ energy (rms)– duration ≈ speaking rate, hesitation
• Prosody carries meaning– given/new– focus– discourse structure

4/20/05 CS 4706 3
Assumptions (2)
• Text to Speech Synthesis (TTS)– formant-based– concatenative / unit selection– Articulatory
• Machine learning techniques– predefined set of features– learn rules on a training corpus– apply rules to unseen data

4/20/05 CS 4706 4
Outline
• Why do we care about emotional speech?
• Emotional Speech Defined
• Perception Studies
• Production Studies
• Lauren Wilcox on voice quality

4/20/05 CS 4706 5
Emotion. What is it Good For?
• Spoken Dialogue Systems– customer-care centers– task planning– tutorial systems– automated agents
• Approaching Artificial Intelligence

4/20/05 CS 4706 6
Emotion. Why is it ‘hard’?
• Colloquial def. ≠ Technical def.
• Emotions are non-exclusive
• Human consensus low

4/20/05 CS 4706 7
Study I: Consensus
• Liscombe et al. 2003• User study to classify emotional speech tokens• Semantically neutral (dates and numbers)• 10 emotions:
– confident, encouraging, friendly, happy, interested
– angry, anxious, bored, frustrated, sad
• Example
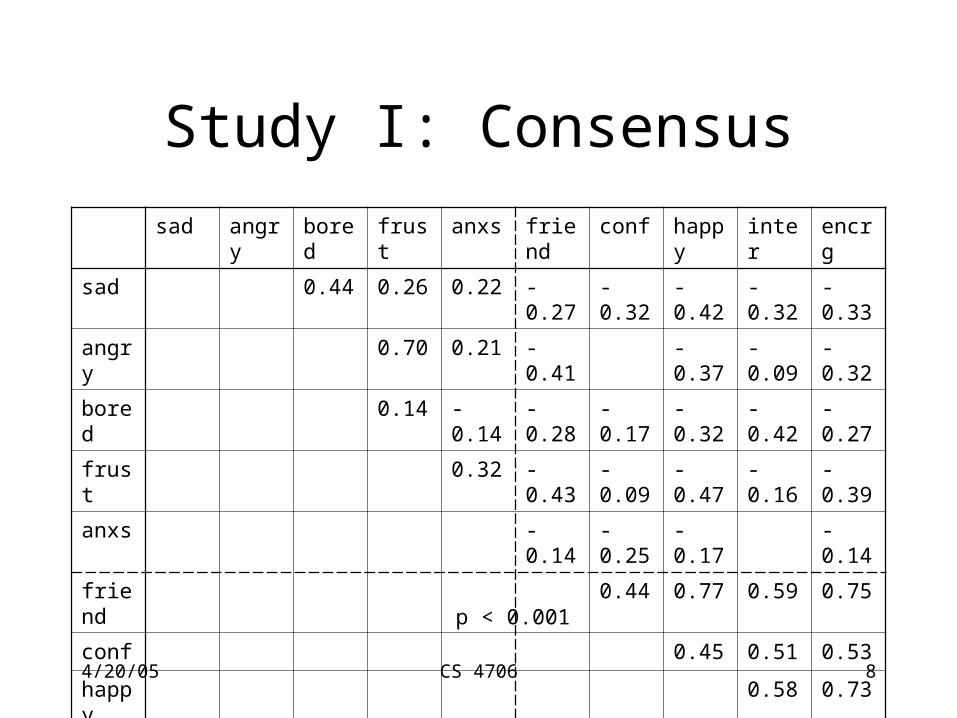
4/20/05 CS 4706 8
Study I: Consensus
sad angry bored frust anxs friend conf happy inter encrg
sad 0.44 0.26 0.22 -0.27 -0.32 -0.42 -0.32 -0.33
angry 0.70 0.21 -0.41 -0.37 -0.09 -0.32
bored 0.14 -0.14 -0.28 -0.17 -0.32 -0.42 -0.27
frust 0.32 -0.43 -0.09 -0.47 -0.16 -0.39
anxs -0.14 -0.25 -0.17 -0.14
friend 0.44 0.77 0.59 0.75
conf 0.45 0.51 0.53
happy 0.58 0.73
inter 0.62
p < 0.001

4/20/05 CS 4706 9
Study I: Consensus
• Emotions are heavily correlated
• Emotions are non-exclusive
• Are emotion labels appropriate?– activation– valency

4/20/05 CS 4706 10
Perception of Emotional Speech
• Machine learning to predict emotional states in human speech
• Common Features– prosody– lexical items– voice Quality

4/20/05 CS 4706 11
Acted Speech
• 1990s - present• Aubergé, Campbell, Cowie, Douglas-
Cowie, Hirscheberg, Liscombe, Mozziconacci, Oudeyer, Pereira, Roach, Scherer, Schröder, Tato, Yuan, Zetterholm, …

4/20/05 CS 4706 12
Study II: Acted Speech
• 4 actors
• 10 emotions
• Binary decision trees (RIPPER)
• Accuracy ranged from 70% - 80%
• Prosody indicative of anger, happy, sad
• Voice quality indicative of anxious, bored

4/20/05 CS 4706 13
Emotional Speech in Spoken Dialogue Systems
• Batliner, Huber, Fischer, Spilker, Nöth (2003)
– Verbmobil (Wizard of Oz scenarios)
• Ang, Dhillon, Krupski, Shriberg, Stolcke (2002)
– DARPA Communicator
• Lee, Narayanan (2004)– Speechworks call-center
• Prosodic, Lexical, and Discourse-level features

4/20/05 CS 4706 14
Study III: Call-center
• AT&T’s “How May I Help You” system
• Predict anger and frustration
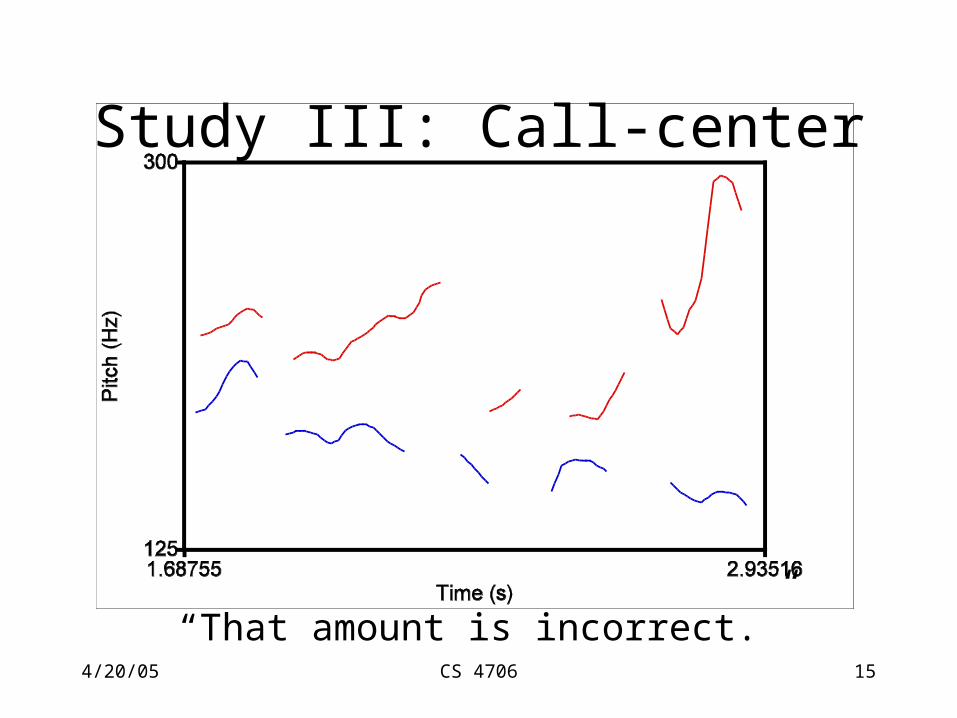
4/20/05 CS 4706 15
Study III: Call-center
“That amount is incorrect.”
4/20/05 CS 4706 16
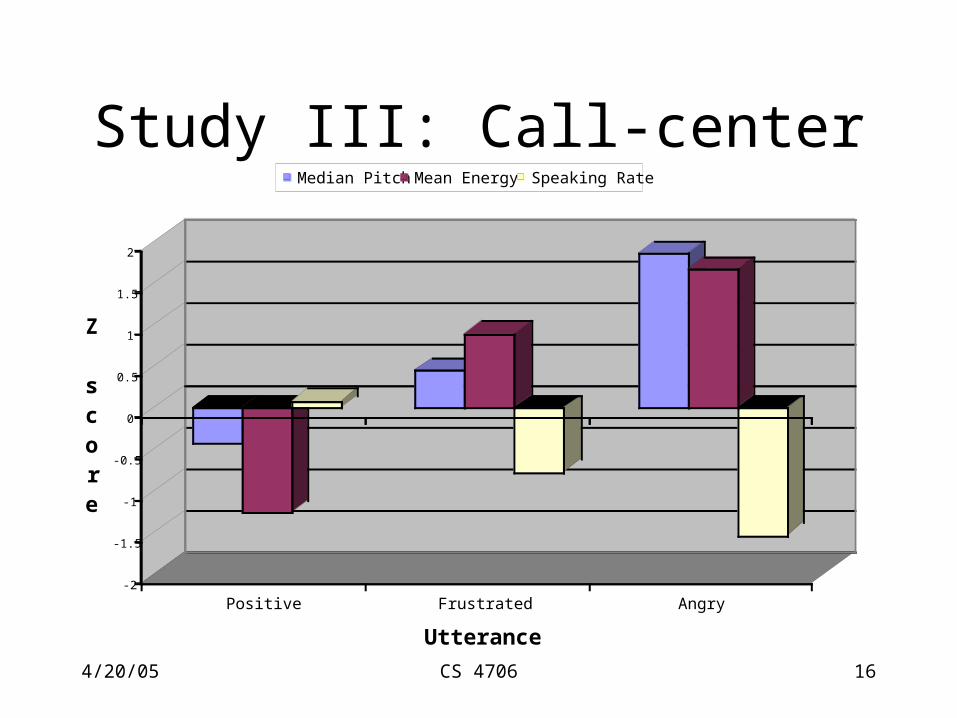
Study III: Call-center
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
Z score
Positive Frustrated Angry
Utterance
Median Pitch Mean Energy Speaking Rate
4/20/05 CS 4706 17
Study III: Call-center
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
Z score
Positive Positive Positive
Utterance
Median Pitch Mean Energy Speaking Rate

4/20/05 CS 4706 18
Study III: Call-center
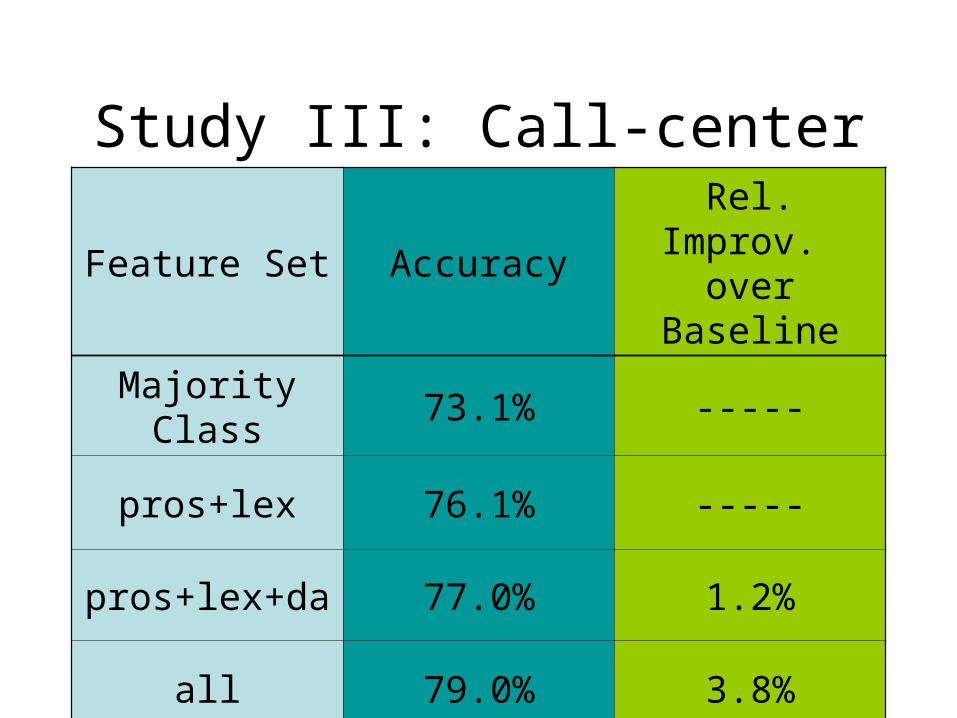
• Feature sets– Prosodic (f0, rms, speaking rate)– Discourse (turn number, dialog act)– Lexical (words)– Contextual (dialogue history)
4/20/05 CS 4706 19
Study III: Call-center
Feature Set AccuracyRel. Improv. over Baseline
Majority Class 73.1% -----
pros+lex 76.1% -----
pros+lex+da 77.0% 1.2%
all 79.0% 3.8%

4/20/05 CS 4706 20
Study IV: Tutorial
• Physics tutorial system
• Detect student uncertainty
• Examples

4/20/05 CS 4706 21
Production of Emotional Speech

4/20/05 CS 4706 22
TTS: Where are we now• Natural sounding speech for some utterances
– Where good match between input and database• Still…hard to vary prosodic features and retain
naturalness– Yes-no questions: Do you want to fly first
class?• Context-dependent variation still hard to infer
from text and hard to realize naturally:

4/20/05 CS 4706 23
– Appropriate contours from text– Emphasis, de-emphasis to convey focus,
given/new distinction: I own a cat. Or, rather, my cat owns me.
– Variation in pitch range, rate, pausal duration to convey topic structure
• Characteristics of ‘emotional speech’ little understood, so hard to convey: …a voice that sounds friendly, sympathetic, authoritative….
• How to mimic real voices?

4/20/05 CS 4706 24
Examples of Emotional Synthesis
http://emosamples.syntheticspeech.de/

The Role of Voice Quality in Communicating Emotion,
Mood, and AttitudeChrister Gobl, Ailbhe Ni Chasaide
Some slide content borrowed from an online voice quality tutorial by K. Marasek
Experimental Phonetics Groupat the
Institute of Natural Language Processing University of Stuttgart, Germany
L. Wilcox: Overview of Speech Communication paper for COMS4706

4/20/05 CS 4706 26
Voice Quality:• The characteristic auditory “coloring” of one’s voice
• Derived from a variety of laryngeal and supralaryngeal features
• Present throughout one’s speech.
• The natural and distinctive tone of speech sounds produced by a particular person yields a particular voice (Trask 1996).
• This paper focuses on harsh voice, tense voice, modal voice, breathy voice, whispery voice, creaky voice, and lax-creaky voice and the role of these voice qualities in affective expression.
• The larynx is used to transform an airstream into audible sounds. This process is central to perceived voice quality.
Most people in linguistics view voice qualities in terms of one quality in contrast with another.
Phonemic voice quality has a contrastive function in the phonological system of a language.

4/20/05 CS 4706 27
Experiment:
-Subjects are asked to listen to synthesized utterances.
-Utterances were synthesized with seven different voice qualities.
-Subjects were asked to identify pairs of opposing affective attributes

4/20/05 CS 4706 28
Motivation for experiment
• Many vocal expressions signal affect: pitch variables, speech rate, pausing structure, duration of accented/unaccented syllables, these are easier to measure that voice quality
• Voice quality is said to play a fundamental role in affective communication but few empirical studies seek to understand voice source correlates.
• Some natural voice qualities said to map to affect and therefore assist in characterizing emotion in speech (based on phonetic observations)

4/20/05 CS 4706 29
Motivation for Experiment-Different researchers have found varied mappings in their own empirical studies.
Further study could confirm some previous findings:
Lavar ‘80, Scherer ‘86, Laukkanen ‘96• Breathy: intimacy• Whispery: confidentiality, secrecy• Harsh voice: anger• Tense voice: anger, joy, fear• Lax voice: sadness
But not all agree:
• Murray, Arnott (’93)Breathy: anger, happinessModal to tense: sadness

4/20/05 CS 4706 30
Motivation for Experiment-Some findings conclude that glottal source contributes to the perception
of valence as well as vocal effort (Laukkanen ‘97).
-Synthesis might be an ideal tool for examining how individual features of a signal contribute to the perception of affect.
-Previous work has generated emotive synthetic speech through manipulation of voice quality parameters (Cahn, ’90, Murray, Arnott ’95) but the synthesizers used didn’t offer full control of these parameters (DECtalk)
-Voice quality might signal strong as well as milder emotional states and speaker attitude

4/20/05 CS 4706 31
Different speech source behaviors generate different voice qualities. Larynx adjusts in
different ways to create different phonatory gestures, features
Laver (’80) defines three which are considered in this paper:
Adductive tension(interarytenoid muscles adduct the
arytenoid muscles)
Medial compression(adductive force on vocal processes-
adjustment of ligamental glottis)
Longitudinal pressure (tension of vocal folds)Recall scary glottis animation
diagram online voice quality tutorial by
K. Marasek Experimental Phonetics Group at the Institute of Natural Language Processing ,
University of Stuttgart, Germany

4/20/05 CS 4706 32
Modal voice
neutral mode
muscular adjustments are moderate
vibration of the vocal folds is periodic with full closing of glottis, so no audible friction noises are produced when air flows through the glottis.
frequency of vibration and loudness are in the lowto mid range for conversational speech

4/20/05 CS 4706 33
Tense voice – voiced phonation• Very strong tension of the vocal
folds, very high tension in the vocal tract leads to harsh voice quality.
4/20/05 CS 4706 34
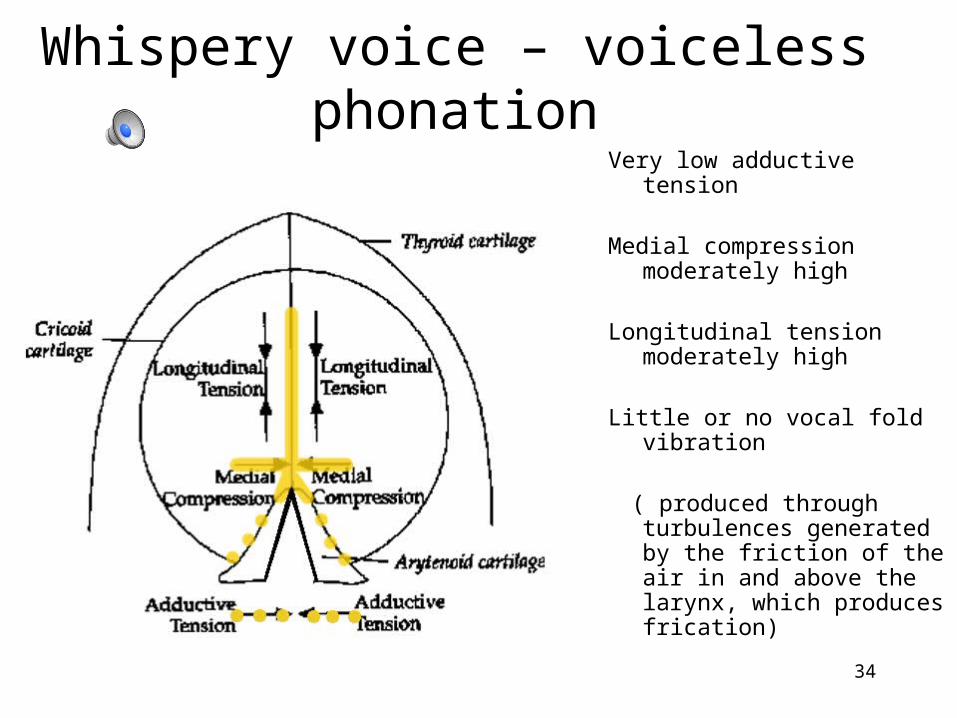
Whispery voice – voiceless phonation
Very low adductive tension
Medial compression moderately high
Longitudinal tension moderately high
Little or no vocal fold vibration
( produced through turbulences generated by the friction of the air in and above the larynx, which produces frication)

4/20/05 CS 4706 35
Creaky voice – voiced phonation
• vocal folds vibrate at a very low frequency – vibration is somewhat irregular, vibrating mass is “heavier” because of low tension (only the ligamental part of glottis vibrates)
• The vocal folds are strongly adducted
• longitudinal tension is weak
• Moderately high medial compression
• Vocal folds “thicken” and create an unusually thick and slack structure.

4/20/05 CS 4706 36
Lax - creaky
Despite definition of creaky voice quality, creaky voice is found to have high glottal tension at times, and low tension at others
Different creaky quality, lax-creaky was created in experiment as separate from creaky.
Lax-creaky = breathy voice settings + reduced aspiration noise and added “creakiness” for experiment.

4/20/05 CS 4706 37
Breathy voice – voiced phonation
• Tension is low
• minimal adductive tension,
• weak medial compression
• medium longitudinal tension of the vocal folds –folds do not come together completely leading to frication

4/20/05 CS 4706 38
Voice quality estimation is difficult
If estimated with respect to a controlled neutral quality, how is that controlled quality known to be truly neutral? One must match the natural laryngeal behavior to the neutral model of behavior.
How adequate are the models of vocal fold movements for the description of real phonation?
The established relationships between a produced acoustical signal and the voice source are complex and since we are only able to observe the behavior of voicing indirectly, prone to error. Otherwise need direct source signal: obtained by invasive techniques (ouch) and invasion might interfere with signal.

4/20/05 CS 4706 39
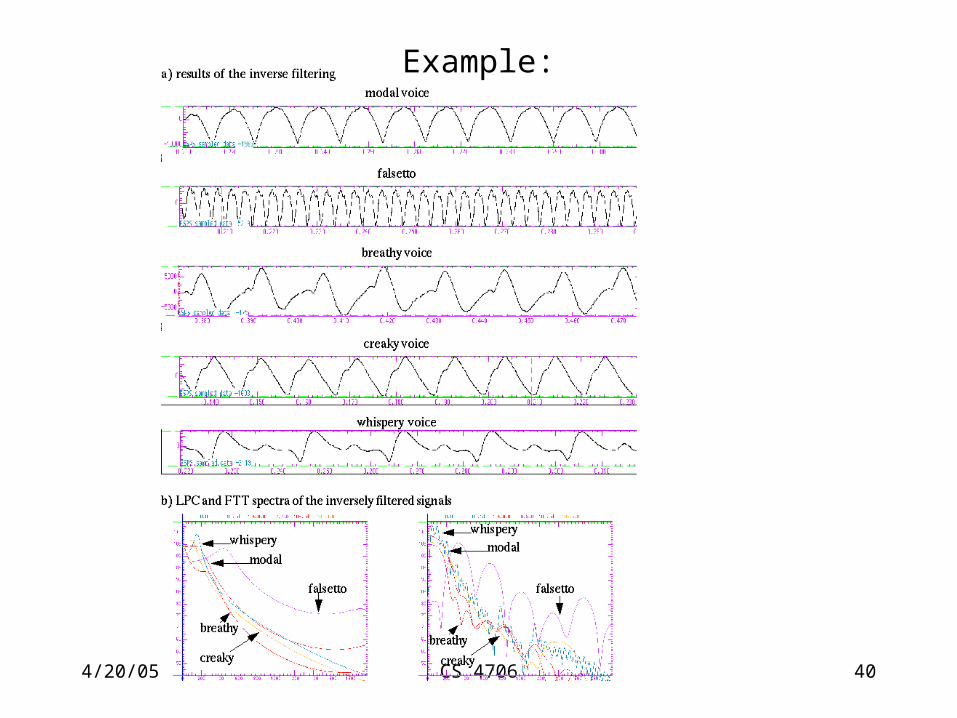
Voice quality estimationInverse filtering approach:
Speech production = source signal + vocal tract filter response
Inverse filtering cancels the effects of the vocal tracts, resulting signal is estimate of source – ill-posed problem
(popular approaches are automatic- based on linear predictive analysis – but do worse for non-modal (colorful) qualities
Still need to measure the inversely filtered signal
4/20/05 CS 4706 40
Example:

4/20/05 CS 4706 41
Experiment:
-Subjects are asked to listen to synthesized utterances.
-Utterances were synthesized with seven different voice qualities.
-Subjects were asked to identify pairs of opposing affective attributes

4/20/05 CS 4706 42
Experiment - details
Natural utterances recorded in anehoic chamber ("anechoic" = "without echo”) high quality recording of the Swedish utterance “ja adjo” (semantically neutral) statement heard by non-swedish speaking native speakers of Irish English. The recording was digitized at high sampling frequency and high resolution (16bit) and prepared for analysis

4/20/05 CS 4706 43
Experiment- details
Recorded utterance analyzed and parameterized. The popular LF (Liljencrants-Fant) model of differentiated glottal flow (Fant et al., 1995) was used to match the measured glottal waveform with a theoretical model of the voice source. Using LF: a waveform is described by a set of mathematical functions that model a given segment of the waveform. The following parameters were used in the experiment:
• EE - excitation strength
• RA – normalized value of TA - time constant of the exponential curve, describes the "rounding of the corner" of the waveform between t4 and t3 divided by t0 (amount of residual airflow after the main excitation prior to ax glottal closure.
• RG – measure of glottal frequency as determined by the opening branch of the glottal pulse (normalized to fundamental frequency)
• RK – measure of glottal pulse skew, defined by the relative durations of the opening and closing branches of the glottal pulse.

4/20/05 CS 4706 44
Experiment - detailsUtterance resynthesized with modal voice quality (moderate
tension) formant synth (KLSYN88a synth Sensimetrics corp- Boston) allowing control of source and filter parameters and different variations of each
Once synthesized with modal voice, the modal stimuli is reproduced six times, each time with a different non-modal voice quality (tense, breathy, whispery, creaky, harsh, lax-creaky) . This is done by adjusting parameters such as
- fundamental frequency- Open Quotient (OQ) (ratio of the time in which the vocal folds are
open and the whole pitch period duration)- Speed Quotient (also called skewness or rk)- (ratio of rise and fall time of the glottal flow -more, differently to create different voice qualities

4/20/05 CS 4706 45
Experiment - details
• Perception tests constructed with each of the stimuli and given to subjects:8 short subtests with 10 randomally chosen stimuli were given to subjects. Interval between sets: 7 secswithin each set of stimuli: 4 sec interval
• Subjects respond to the affective content of the stimuli on a scale of 1 to 7 (opposite terms on either side): responses elicited for one particular pair of opposite affective attributes (bored vs. interested, friendly vs. hostile, sad vs. happy, intimate vs. formal, timid vs. confident afraid vs. unafraid)
• 12 subjects partipicated: 6 male, 6 female
4/20/05 CS 4706 46
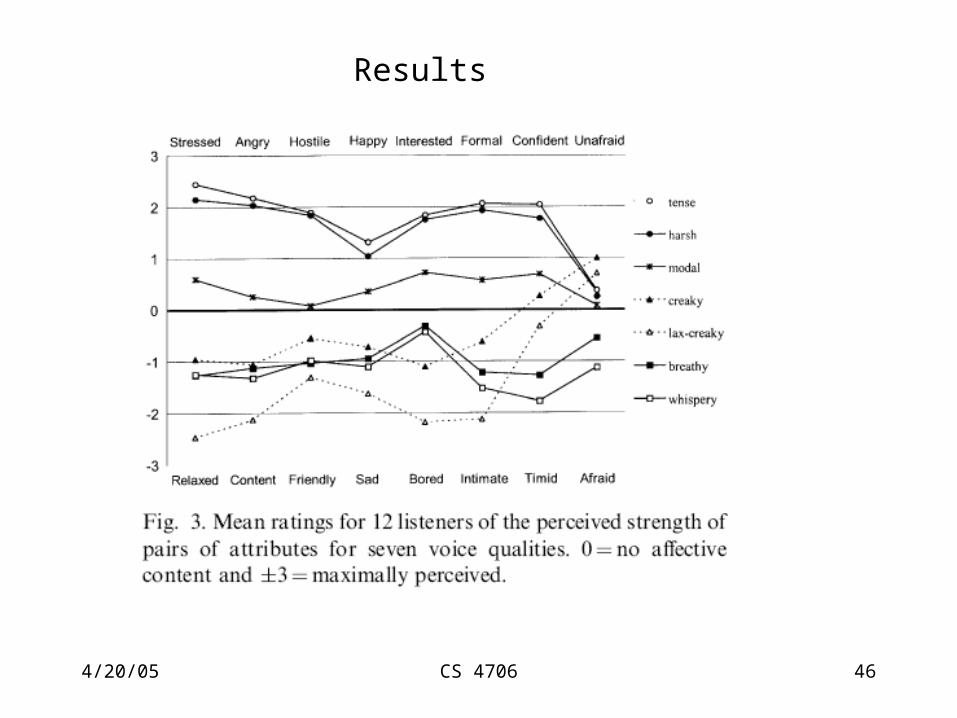
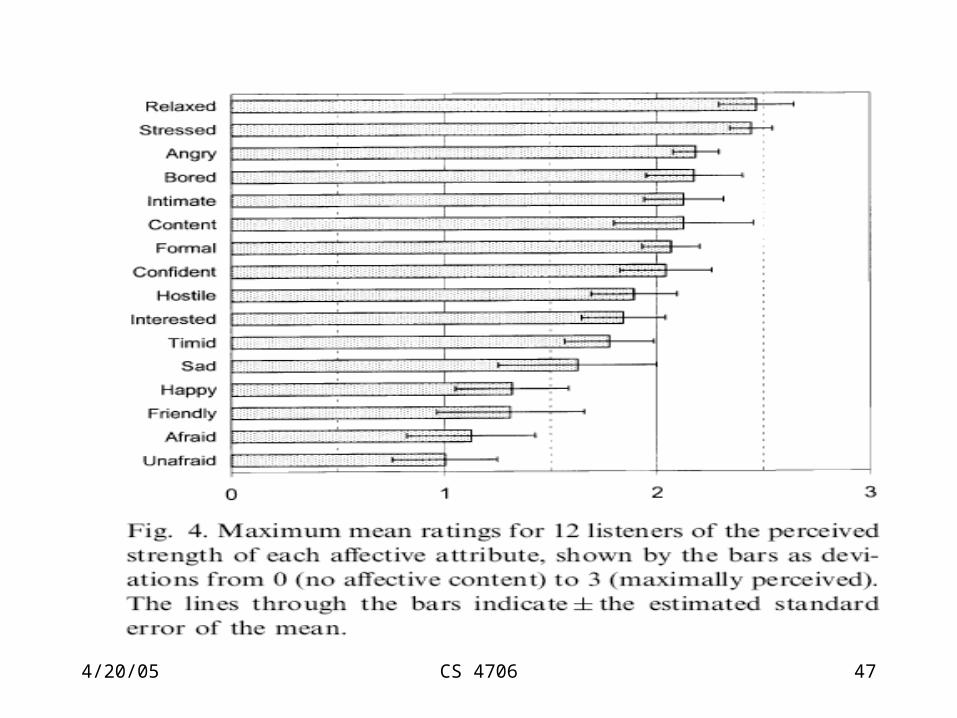
Results
4/20/05 CS 4706 47

4/20/05 CS 4706 48
ResultsVoice quality and subject variable were statistically highly significant
Differences between individual qualities were statistically significant
Most readily perceived:Relaxation and stress
Highly perceived:Anger, boredom, intimacy, content, formal(aside from anger- these could be categorized as states, moods,
attitudes, so consistent with experiment goal)
Least well perceived:Unafraid, afraid, friendly, happy, sad
Milder states better signaled than strong emotion

4/20/05 CS 4706 49
ResultsNotice modal stimuli is not perceived as totally neutral Similar response patterns occurred with breathy/whispery and tense/harshLax-creaky vs creaky does show significant differences
Results and their comparison to previous findings:Lax-creaky: lower arousal, activationWhispery: timid, afraid Tense: high arousal/activation (confident, interested, happy, angry)Breathy, whispery, creaky, and more so lax creaky: relaxed, content, intimate,
friendly, sad, bored)Lax-creaky, more so than whispery- effectively signaled intimacyAnd lax-creaky, more so than breathy, signaled sadness Linking of breathy voice to
anger and happiness were not supportedA shift from modal to tense elicited happy affect (rather than sad as proposed by
Murray/Arnott ’99)Anger is shown to link to tense voice and joy (Scherer ’86)As one moves from high to low activation stimuli set, cross-subject variability
increases

4/20/05 CS 4706 50
Some pros and cons of this study
+ Showed that voice quality alone can evoke differences in speaker affect
- But when comparing only synthesized voices, isn’t it a question of which is relatively more colorful?
+ voice qualities are multi-colored and each map to a variety of affective expression(expressions are in some cases related, in others unrelated)
+ traditional view that voice quality conveys valence of emotion but not activation is challenged (for affective states with negative valence, activation still differentiates them and is detected with voice quality alone)
- Hard to know to what degree naturally occurring phonomena matches model matches synthesis and which level to look at to improve or criticize when hearing final synthesis.
- Aside from a phonetic system, subjects might associate voice qualities depending on personal situations, events, etc (could whispery sound sinister?)
- When only deciding between 2 extremes, subjects might have difficulty trying “not” to listen for the purpose of choosing one or another (?)
- but same data reduction occurred, so beginning natural utterance not exact “copy”





























