Embed Size (px)
Citation preview

Big Graph Data Management
Antonio Maccioni
held-by
where
Rome
14 May 2015 Big Data Course
locatedIn
topi
c
whe
n
affil
iate
d
is-a

this talk is about
● Graph Databases: models, languages, use cases
● Graph Database Management Systems
● Graph Processing Systems (intro)
● Open Problems in Graph Data Management ● ...and research project around us

scenario
is going towards graph search capabilities (Tao, Unicorn, Open Graph protocol, etc.)
is working on PGX (Parallel Graph Analytics), has launched Green-Marl and has implemented an RDF layer on top of Oracle NoSQL
developing a layer, VERTEXICA, for graph mining on top of the analytical database
launched the language interface SQL-GR to run graph analysis on top of its analytical database
has been working on the “Knowledge Graph” for a while, has created Pregel and has launched Cayley
has just aquired Aurelius TitanDB
has open-sourced its graph database FlockDB
has working on Trinity, an in-memory graph database

“Over 25 percent of enterprises will use graph databases by 2017”
- Enterprise DBMS, Q1 2014. Forrester Research
scenario
“graph databases are catching on commercially” - Michael Stonebraker (2014 ACM Turing Award)

nosql scenarioSimple data models
“Graph Databases are an odd fish in the NoSQL pond”
- P.J. Sadalage, M. Fowler - NoSQL Distilled
Simple data models

But if we want to represent connections we may opt for a graph database management systems:
nosql scenarioSimple data models

a graph
1
63
4
52
[1]->2->4->5[2]->3[3]->5[4]->5->6[5]->6
from\to 1 2 3 4 5 6
1 0 1 0 1 1 0
2 0 0 1 0 0 0
3 0 0 0 0 1 0
4 0 0 0 0 1 1
5 0 0 0 0 0 1
6 0 0 0 0 0 0
Adjacency matrix Adjacency lists

admin
works
belongsbelongs
admin
friends
married
belongs
belongs
likes
worked
friendslikes
follows
graph + data = graph database

why graph databases?
● More natural modeling
● Manage connections explicitly
● Run algorithms of network science (e.g., PageRank)

use case 1: semantic web
● A Web-scale architecture● for metadata and data
management (together)● for interoperarbility of data and services
● Web of Data● Compatible with other Web
technologies● Based a set of W3C standards
(HTTP, IRI/URI,RDF, SPARQL, OWL)
● Web 3.0● make information understandable by machines
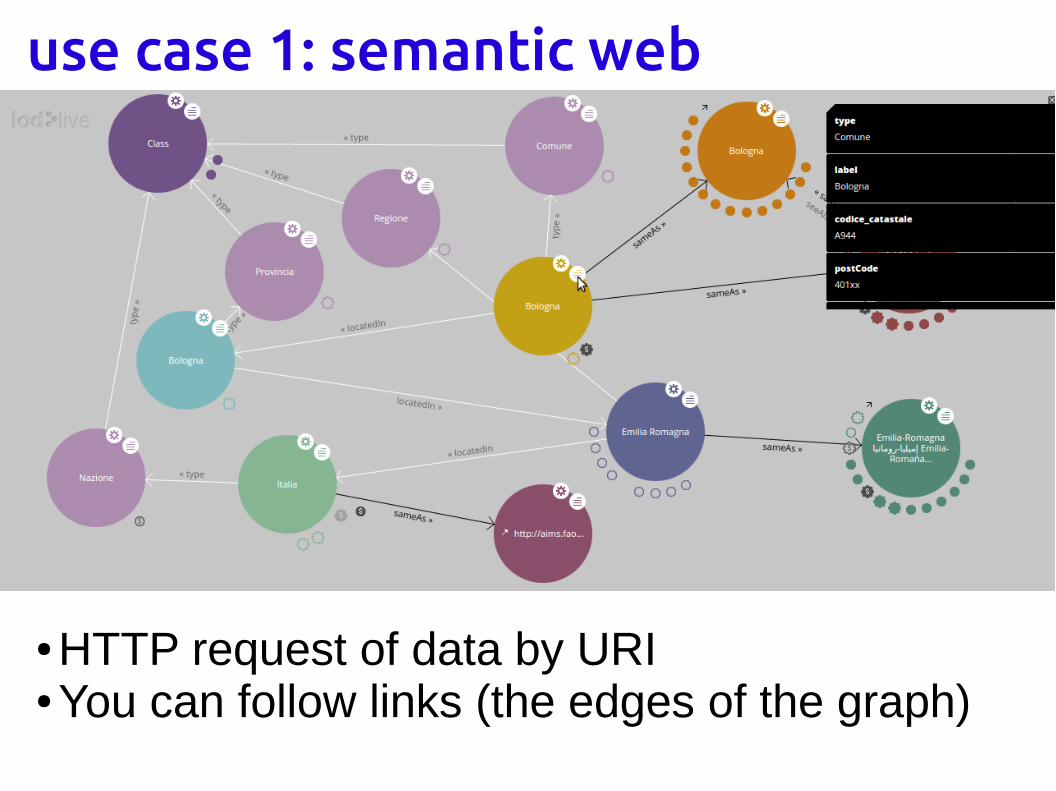
● HTTP request of data by URI● You can follow links (the edges of the graph)
use case 1: semantic web

Semantic Web + Open Data = Linked Open Data
use case 1: semantic web

use case 1: semantic web

sparql
Which are the names of the people married with people born in Honolulu?
SELECT ?name{ ?person1 married ?person2 . ?person2 born ?city . ?city name “Honolulu” . ?person1 name ?name1 .}
?person1 ?person2married
?cityHonolulu name
name
?name1
name

SELECT ?name{ ?person1 married ?person2 . ?person2 born ?city . ?city name “Honolulu” . ?person1 name ?name1 .}
sparql?person1 ?person2
married
?cityHonolulu name
name
?name1
Pattern matching style of querying
p2
n1
c2
p1
c1
name MichelleObama
marriedBarackObama
name
born
locatedIn
ChicagoHonolulu
USA
locatedIn
name
name
name
born
name

Pattern matching style of querying
SELECT ?name{ ?person1 married ?person2 . ?person2 born ?city . ?city name “Honolulu” . ?person1 name ?name1 .}
p2
n1
c2
p1
c1
name MichelleObama
marriedBarackObama
name
born
locatedIn
ChicagoHonolulu
USA
locatedIn
name
name
name
born
sparql?person1 ?person2
married
?cityHonolulu name
name
?name1
name

triple stores
s p op1 married p2
p1 name Michelle Obama
p2 born c2
c2 name Honolulu
us name USA
... ... ...
Indexes on: (s,p,o), (s,o,p), (p,s,o), (p,o,s), (o,s,p), (o,p,s)
G:
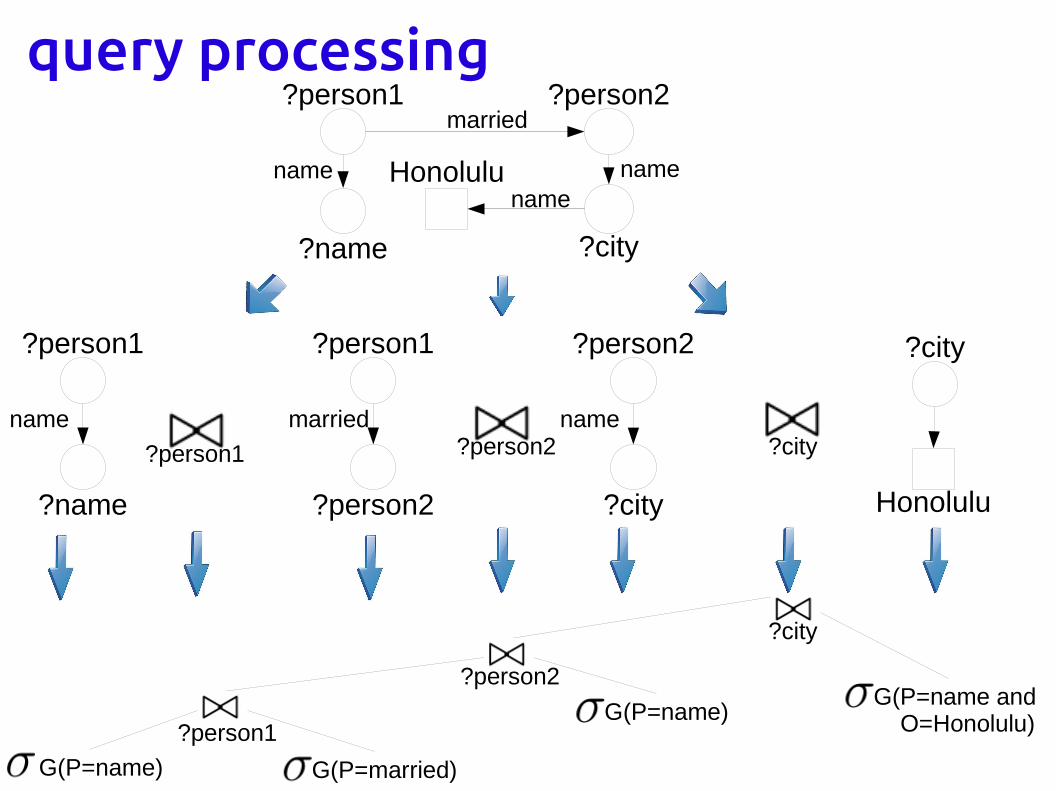
query processing
G(P=name and O=Honolulu)
G(P=married)G(P=name)
G(P=name)
?person1 ?person2married
?city
Honoluluname
name
?name
?person1
?person1
?person2
?person2 ?city
?city
?person1
?name
name
name
?person1
?person2
married
?person2
?city
name
?city
Honolulu

use case 2: social networks
admin
works
belongsbelongs
admin
friends
married
belongs
belongs
likes
worked
friendslikes
follows

Find common friends for every single profile visit
~ 1.2 billions tuples * average number of friends per person
FRIEND 1 FROM_DAY FRIEND 2
use case 2: social networks

Find common friends for every single profile visit
~ 1.2 billions tuples * average number of friends per person
FRIEND 1 FROM_DAY FRIEND 2
use case 2: social networks

graph database management systems
Three main properties:
1. Property Graph (as data model)2. Index-free Adjacency (as physical
level organization)3. Path-traversal (as query language)

It's a schema-less
data model
A property graph is a directed multigraph g = (N, E) where every node n N∈ and every edge e E∈ is associated with a set of pairs <key, value>, called properties.
property graph data model

We say that a (graph) database g satisfies the index-free adjacency if the existence of an edge between two nodes n
1 and n
2 in g can
be tested on those nodes and does not require to access an external, global, index.
index-free adjacency
GOAL: make the cost of a basic traversal independent of the size of the database, in case keeping O(1)

index-free adjacency
...trying to keep the cost of a basic traversal O(1)

index-free adjacency
...trying to keep the cost of a basic traversal O(1)

neo4j physical layer
I. Robinson, J. Webber, E. Eifrem – Graph Databases, 2013.
● Store files for different parts of the graph
● Node store
● Relationship store
● Property store● Each record contains 4 properties● The properties of an element may use more records● Property's values can be either stored in the property store or stored in a dynamic
string store

titan, infinitegraph, levelgraph
LevelGraph
Built above the extensible column storeApache Cassandra
Built above the Object Oriented Database Objectivity/DB
Built on node.js above the key-value store LevelDB but pluggable to different stores

Server Mode1. Go to http://www.neo4j.org/, download Neo4J Server and unzip it
2. Run the command ./bin/neo4j start (use bin\Neo4j.bat on Windows)
3. Find a graphical dashboard at http://localhost:7474/
4. You can also use it with REST API: http://localhost:7474/db/data/
building a neo4j graph db

Embedded mode
1. Import in your java project the library neo4j-kernel-*-*-*.jar and its classes:
2. Create the database:
3. Create nodes and edges:
4. Set the properties:
import org.neo4j.graphdb.*;import org.neo4j.graphdb.factory.GraphDatabaseFactory;
GraphDatabaseService gdb = new GraphDatabaseFactory().newEmbeddedDatabase("/home/...");
Node n1 = gdb.createNode();Node n2 = gdb.createNode();Relationship e12 = n1.createRelationshipTo(n2, EdgeType.TYPE);
n1.setProperty(“name”, “Rome”);n2.setProperty(“name”, “Italy”);e12.setProperty(“type”, “locatedIn”);
Enum implementing RelationshipType
building a neo4j graph db

BLUEPRINTS
GREMLIN
PIPES
Blueprints is a property graph model interface with provided implementations.
Gremlin is a domain specific language for traversing property graphs
FRAMESFrames exposes the elements of a Blueprints graph as Java objects: software is written in terms of domain objects and their relationships to each other.
REXTER
FURNACEFurnace is a property graph algorithms package
http://www.tinkerpop.com/tinkerpop stack

building a graph db with blueprintshttps://github.com/tinkerpop/blueprints/wiki
1. Import in your java project the libraries blueprints-core-*.*.*.jar and blueprints-neo4j-graph-*.*.*.jar with their classes:
2. Create the database:
3. Create nodes and edges:
4. Set the properties:
import com.tinkerpop.blueprints.*;import com.tinkerpop.blueprints.impls.neo4j.Neo4jGraph;
Graph gdb = new Neo4jGraph("/home/...");
Vertex n1 = gdb.addVertex(null);Vertex n2 = gdb.addVertex(null);Edge e12 = gdb.addEdge(null, n1, n2, “locatedIn”);
n1.setProperty(“name”, “Rome”);n2.setProperty(“name”, “Italy”);e12.setProperty(“type”, “locatedIn”);

querying a graph database
●Gremlin:● Imperative query language● Descendant of languages such as XPATH
●Cypher:● Declarative query language● Descendant of languages such as SQL
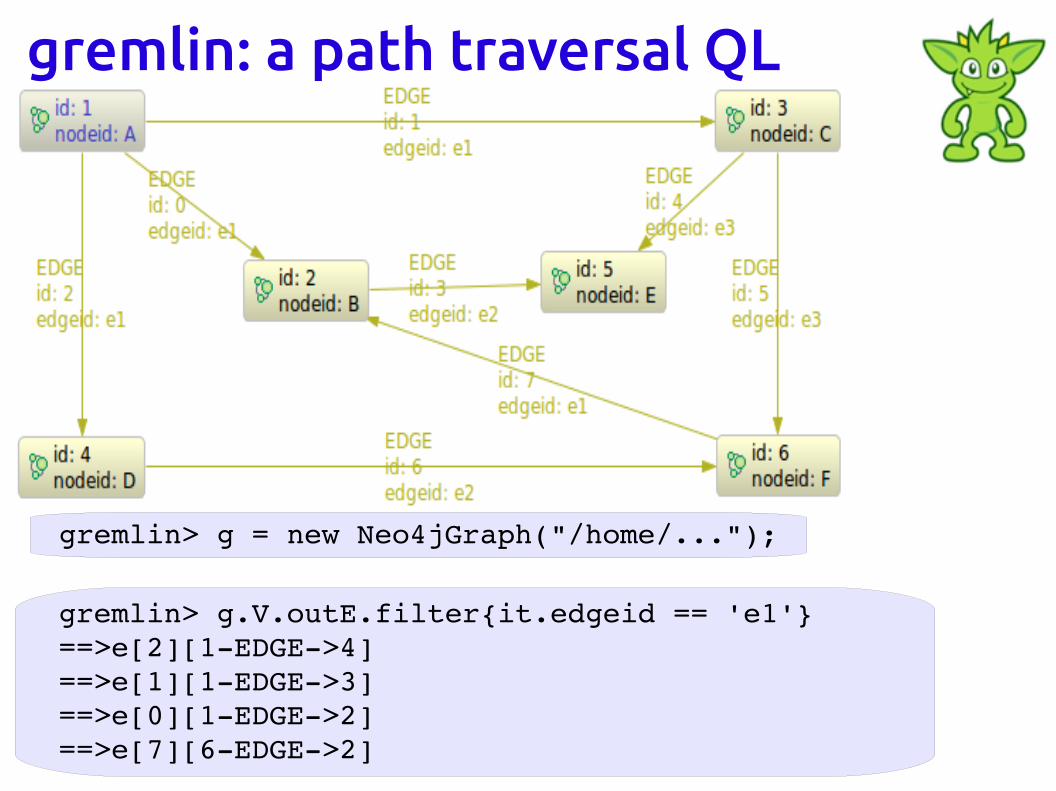
gremlin> g = new Neo4jGraph("/home/...");
gremlin> g.V.outE.filter{it.edgeid == 'e1'}==>e[2][1EDGE>4]==>e[1][1EDGE>3]==>e[0][1EDGE>2]==>e[7][6EDGE>2]
gremlin: a path traversal QL

gremlin> g.V.outE.filter{it.edgeid == 'e1'}.inV.outE.filter{it.edgeid == 'e2'}.inV.nodeid
==>F==>E==>E
gremlin: a path traversal QL

cypher: a pattern matching QL
START: starting point in the graph
MATCH: the pattern to match, bound to the starting point
WHERE: filtering criteria
RETURN: what to return

MATCH: the pattern to match, bound to the starting point
cypher: a pattern matching QL
node1edge1>node2edge2>node3node1[?]>node2[?]>node3
node1[*]>node3
Live hands-on a graph database about beers at http://console.neo4j.org/?id=beer
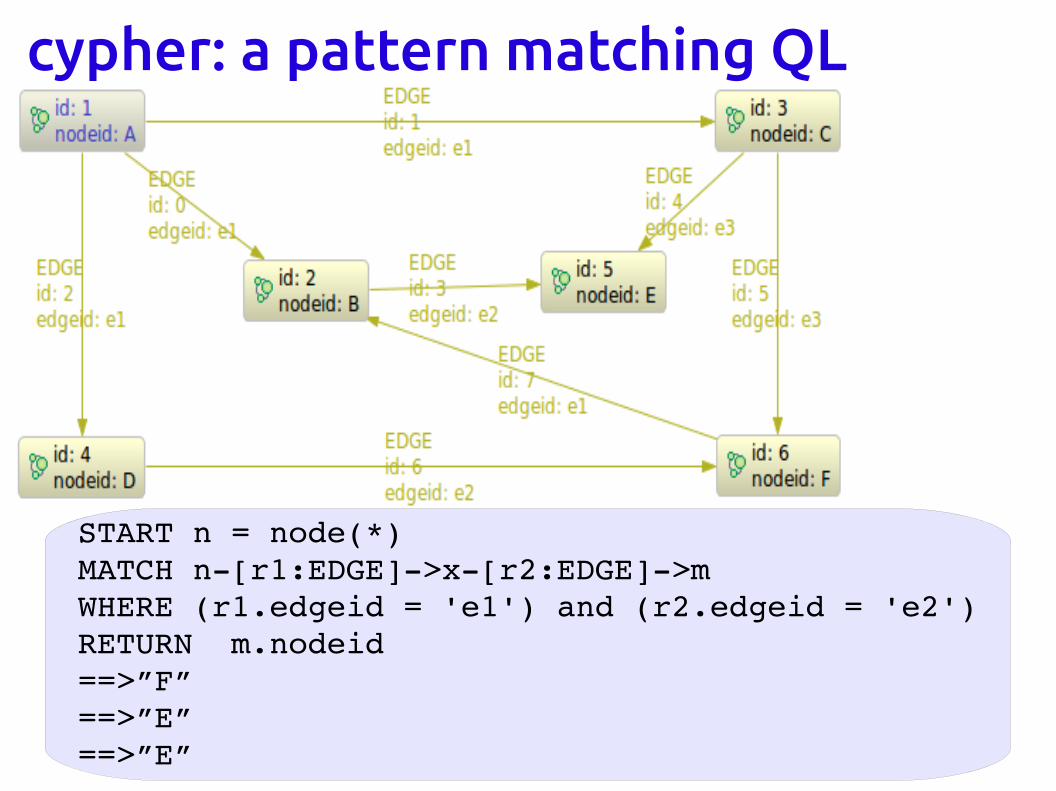
START n = node(*)MATCH n[r1:EDGE]>x[r2:EDGE]>mWHERE (r1.edgeid = 'e1') and (r2.edgeid = 'e2')RETURN m.nodeid==>”F”==>”E”==>”E”
cypher: a pattern matching QL

● Secondary Indexes: defined on properties
● Transactions: graph databases usually support ACID properties. In Neo4J all operations have to be performed in a transaction:
● Other programming language wrappers:
try ( Transaction tx = gdb.beginTx() ){ tx.success();}
other features

graph processing systems
Pregel/Giraph
● Frameworks to compute (distributed) graph analysis on large graphs:● have similar motivations of Hadoop, Spark, etc.● help programmers to focus on the algorithm rather
than on the implementation● support different types of graphs● provide a variety of algorithms already implemented
GraphLab/Dato Pegasus

google pregel/apache giraph● User specifies a vertex program
● Computation runs a sequence of supersteps
● In each superstep the program is executed over all the vertexes
● The program can use messages received in a previous superstep from the neighbors and can send messages to them for the next superstep
● A vertex can deactivate itself and the computation halts when all the vertexes are deactivated.

● How to model a graph database?
● How to migrate data and queries from existing databases?
● How to scale queries over large graphs?
research problems about graph DBs

Compact: Sparse: Dense: Reduces the number of data accesses
Can violate property graph constraints
Accesses and updates can be inefficient
Reduces number of joins
Needs human intervention for a semantic enrichment
modeling graph databases

Orienting the ER:
modeling graph databases
ENTITY 1
ENTITY 2
RELATIONSHIP
(0:1)
RELATIONSHIP : 0
(0:1)
ENTITY 1
ENTITY 2
ENTITY 1
ENTITY 2
RELATIONSHIP
(0:N)
RELATIONSHIP : 1
(0:1)
ENTITY 1
ENTITY 2
ENTITY 1
ENTITY 2
RELATIONSHIP
(0:N)
RELATIONSHIP : 2
(0:N)
ENTITY 1
ENTITY 2
R. De Virgilio, A. Maccioni, R. Torlone – Model-driven design of graph databases, ER International Conference on Conceptual Modeling, 2014.

Oriented-ER:
modeling graph databases
R. De Virgilio, A. Maccioni, R. Torlone – Model-driven design of graph databases, ER International Conference on Conceptual Modeling, 2014.

Partitioning:modeling graph databases
Rule 1: if a node n is disconnected then it forms a group by itself.
Rule 2: if a node n has w−(n)>1 and w+(n)>0 then n forms a group by itself.
Rule 3: if a node n has w−(n)<2 and w+(n)<2 then n is added to the group of a node m such that there exists the edge (m, n) in the O-ER diagram.
R. De Virgilio, A. Maccioni, R. Torlone – Model-driven design of graph databases, ER International Conference on Conceptual Modeling, 2014.

Partitioning:modeling graph databases
R. De Virgilio, A. Maccioni, R. Torlone – Model-driven design of graph databases, ER International Conference on Conceptual Modeling, 2014.

Graph Database Templatemodeling graph databases
R. De Virgilio, A. Maccioni, R. Torlone – Model-driven design of graph databases, ER International Conference on Conceptual Modeling, 2014.

SQLselect *from Twhere T.A1 = v1
R. De Virgilio, A. Maccioni, R. Torlone – R2G: a Tool for Migrating Relations to Graphs – EDBT International Conference on Extending Database Technology, 2014
R2G: from relations to graphs

R2G: unifiability of data values• Joinable tuples t1 R∈ 1 and t2 ∈ R2:
– there is a foreign key constraint between R1.A and R2.B and t1[A] = t2[B].
• Unifiability of data values t1[A] and t2[B]:– (i) t1=t2 and both A and B do not belong to a multi-attribute
key;– (ii) t1 and t2 are joinable and A belongs to a multi-attribute key;– (iii) t1 and t2 are joinable, A and B do not belong to a
multi-attribute key and there is no other tuple t3 that is joinable with t2.
R. De Virgilio, A. Maccioni, R. Torlone – R2G: a Tool for Migrating Relations to Graphs – EDBT International Conference on Extending Database Technology, 2014

R2G: schema graph
Full Schema Paths:
FR.fuser US.uid US.uname→ →FR.fuser FR.fblog BG.bid BG.bname→ → →FR.fuser FR.fblog BG.bid BG.admin US.uid US.uname→ → → → → ...
R. De Virgilio, A. Maccioni, R. Torlone – R2G: a Tool for Migrating Relations to Graphs – EDBT International Conference on Extending Database Technology, 2014

R2G: data migration
R. De Virgilio, A. Maccioni, R. Torlone – R2G: a Tool for Migrating Relations to Graphs – EDBT International Conference on Extending Database Technology, 2014

R2G: query migration
R. De Virgilio, A. Maccioni, R. Torlone – R2G: a Tool for Migrating Relations to Graphs – EDBT International Conference on Extending Database Technology, 2014

scalability over real-world graphs
Graph Databases are hard to scale
> 500 million users > 1.2 billion active users > 500 million users

power-law graphs
scale-free graphspreferential attachment
Graph Databases are hard to scale
10% of the users follow the same five users
real-world graphs

Replication Partitioning
Graph Databases are very hard to scale
10% of the users follow the same five users
real-world graphs

real-world graphs
A. Maccioni, D. J. Abadi – Scalable Pattern Matching over Compressed Graphs via Sparsification

follows
follows
follows
real-world graphs
A. Maccioni, D. J. Abadi – Scalable Pattern Matching over Compressed Graphs via Sparsification

real-world graphs
A. Maccioni, D. J. Abadi – Scalable Pattern Matching over Compressed Graphs via Sparsification

any redundancy?
A. Maccioni, D. J. Abadi – Scalable Pattern Matching over Compressed Graphs via Sparsification

high-degree node
low-degree nodecompressor node
SPARSIFICATION
sparsification
A. Maccioni, D. J. Abadi – Scalable Pattern Matching over Compressed Graphs via Sparsification

GREEDY SPARSIFICATION
2 B
1 C
A3 5
4
6
2B
1 C
A3
5
4
BC
AB
ABC
6
compression via sparsification
2B
1 C
A
3
5
4
ABC
6
SPACE-AWARE SPARSIFICATION
A. Maccioni, D. J. Abadi – Scalable Pattern Matching over Compressed Graphs via Sparsification

with Space-aware Compressed Graphs
graph pattern matchingwith Greedy Compressed Graphs
A. Maccioni, D. J. Abadi – Scalable Pattern Matching over Compressed Graphs via Sparsification

●How to shard/partition a graph database?
●How to visualize large graphs?● Specialized startups are addressing the problem
●Standardization of a query language
●Graph processing with GPUs● Medusa-gpu, MapGraph
●What is the best way to implements graph layer on top of SQL/NoSQL systems?● IBM, Oracle, Teradata, HP, ...
open problems

●Graphs are used in many fields● Social Networks, Bioinformatics, Semantic Web, Geo-informatics, ...
●Graphs are more complicated to manage than other types of data● and we need different considerations
●When we need to store a big graph● we have many options, each one with both advantages and disadvantages
●Scaling queries over graph databases is still an infant area of database industry and research
conclusion

thanks for the attention