Embed Size (px)
Citation preview

A importância do ecossistema Java em aplicações baseadas em Big Data

2
Quem sou eu?Vinícius Aires BarrosCiência da Computação 2016 - UFTMestrando em Ciência da Computação - ICMC USPLaboratório de Sistemas Distribuídos e Programação Concorrente - LaSDPCÁreas de Interesse: IoT, Distributed Systems, Big Data (...)Github: @v4ires Website: http://viniciusaires.me

1. O que é Big Data?
2. Importância do Java
3. Ferramentas
a. Apache Hadoop
b. Apache Spark
3
Agenda

Big Data4

“
5
Big Data é definido como um conjunto de dados estruturados ou não estruturados que não puderam
ser percebidos, adquiridos, gerenciados e processados pelos
modelos tradicionais de hardware e software.

6
Contexto● Big Data (5V’s)
○ Volume○ Variedade○ Velocidade○ Veracidade○ Valor
● Internet das Coisas (IoT)● Grandes Volumes de
Dados● Programação Distribuída
e Paralela● Dados Estruturados, Não
Estruturados e Semiestruturados
● Bancos de Dados SQL e NoSQL
● MapReduce● Apache Hadoop

7
Exemplos:
● Redes Sociais● Veículos não tripulados● Dispositivos móveis
Contexto:
● Rede mundial de dispositivos● Análise de Dados● Aprendizagem de Máquina
Social, Media & Mobile

Importância do Java e JVM no Ecossistema de Big Data
8
❏ Hadoop❏ Spark❏ Drill❏ Storm❏ Kafka❏ Akka❏ ...
9
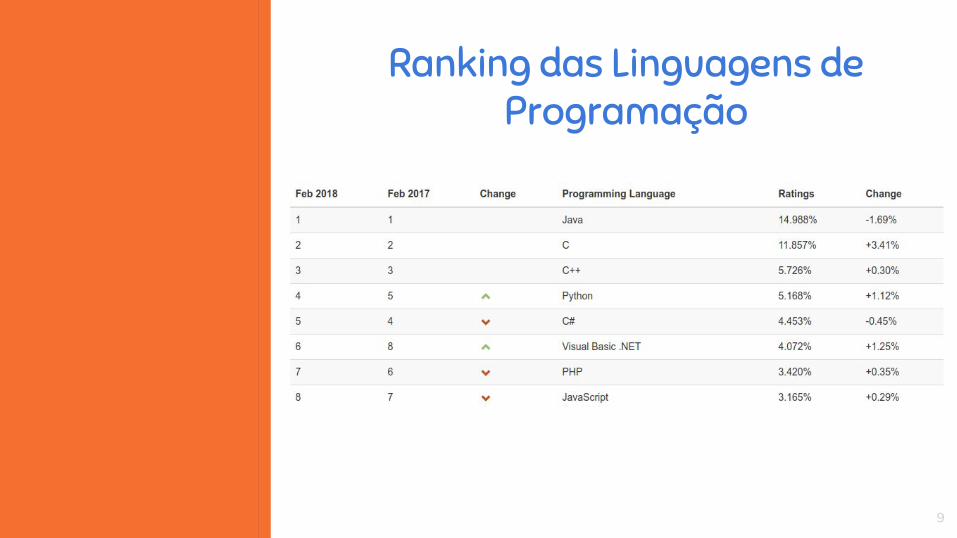
Ranking das Linguagens de Programação
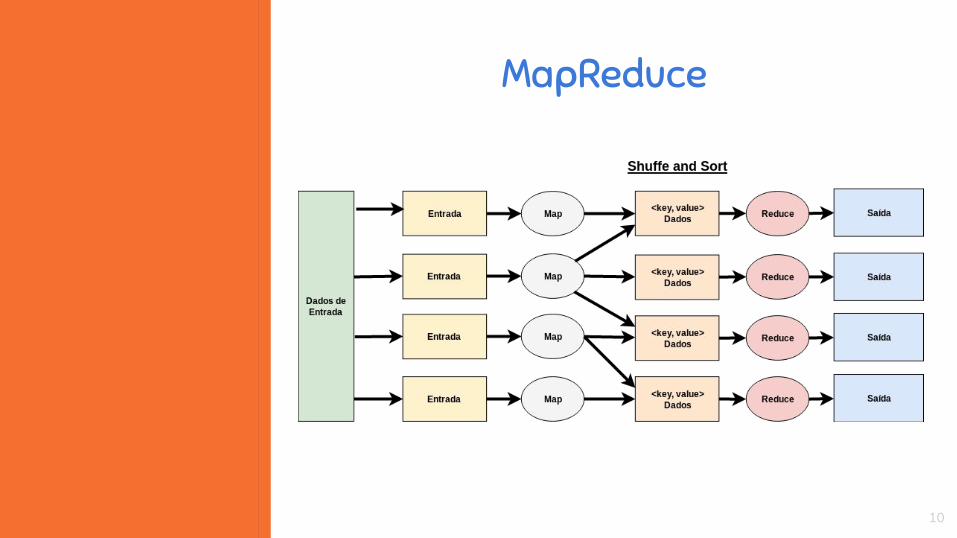
MapReduce
10

11
O que é Hadoop?

“
12
O Apache Hadoop é um software de código aberto mantido pela Apache
Foundation que tem como propósito fornecer uma implementação livre
do modelo de programação MapReduce.
“
13
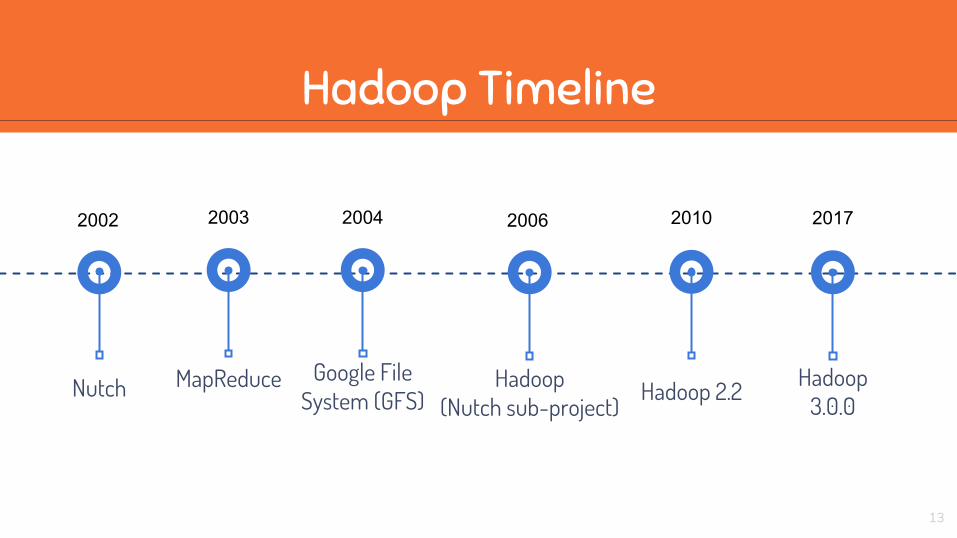
Nutch Hadoop (Nutch sub-project)
Hadoop 3.0.0
2002
MapReduce
2003
Google File System (GFS)
2004 2006 2017
Hadoop 2.2
2010
Hadoop Timeline

14
Características
❏ Implementação em Java❏ Arquitetura Mestre Escravo (Master/Slave)❏ Modelo de Programação MapReduce❏ Hadoop Distributed File System (HDFS)❏ Memória Secundária (Disco)❏ Processamento Distribuído❏ Escalável❏ Tolerante a Falhas

15
O que não é?
❏ Linguagem de Programação❏ Biblioteca de Aprendizagem de Máquina❏ Processamento em Tempo Real❏ Solução Definitiva❏ Hadoop ≠ Spark

16
Quem utiliza?
17
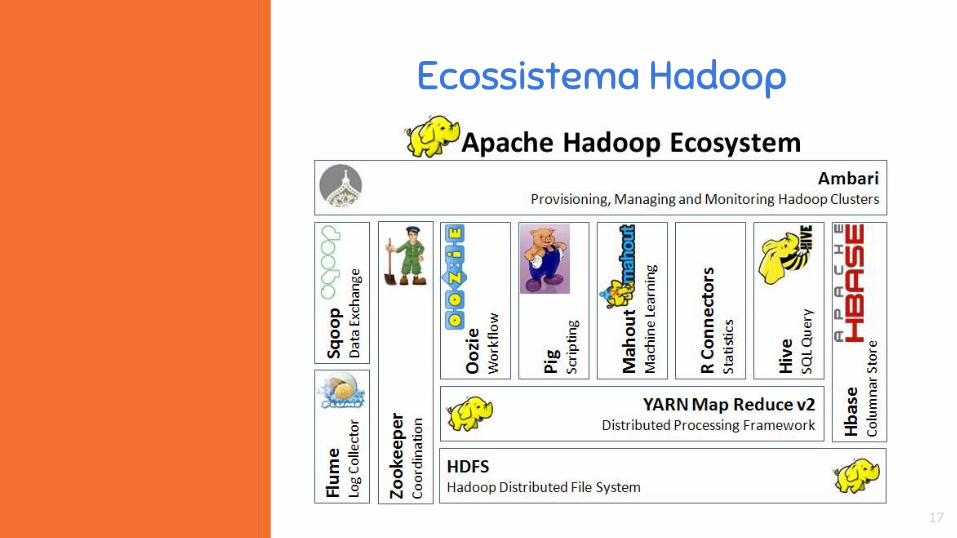
Ecossistema Hadoop

18
Literatura Básica
19
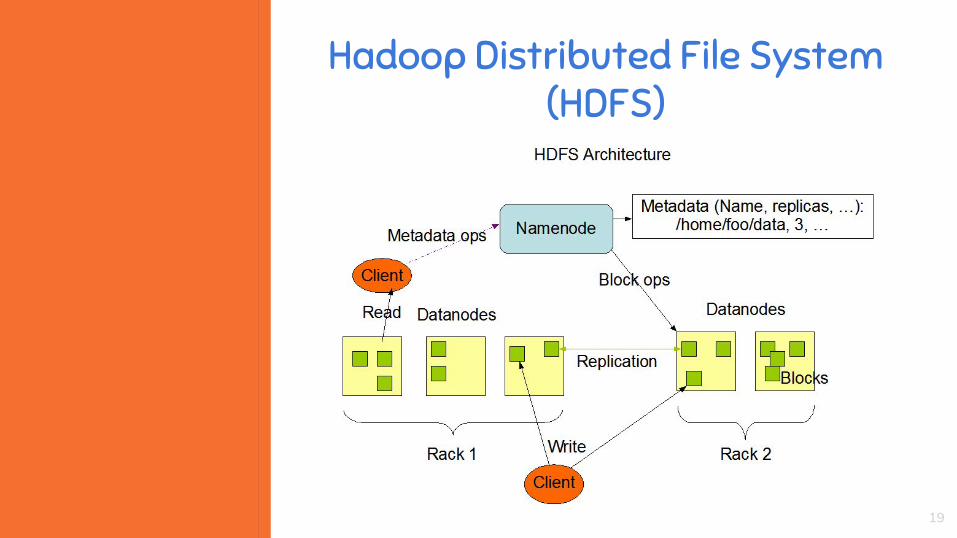
Hadoop Distributed File System (HDFS)

20
Configuração Hadoop
Single Node Multi Node
Documentação Oficial: http://hadoop.apache.org/
CMD’s Básicos

21
Hadoop Streaming
● Suporte a outras Linguagens de Programação;
● Ex: Python, Ruby, JavaScript, C#, outras;● Qualquer Linguagem de Programação com
stdin e stdout.

22
O que é Spark?

“
23
O Apache Spark é um software de código aberto mantido pela Apache
Foundation que tem como propósito fornecer uma implementação livre r
melhorada do modelo de programação MapReduce.
“
24
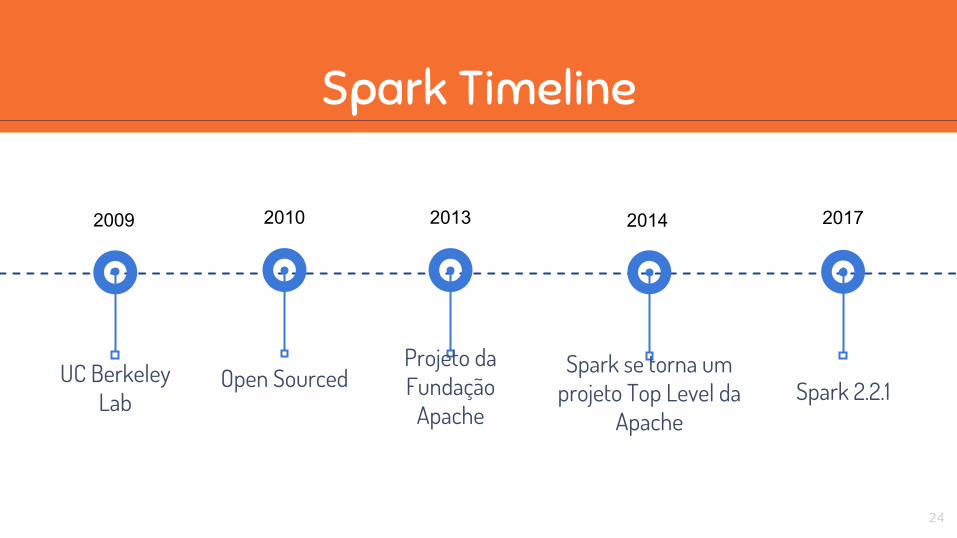
UC Berkeley Lab
Spark se torna um projeto Top Level da
Apache
2009
Open Sourced
2010
Projeto da Fundação
Apache
2013 2014
Spark 2.2.1
2017
Spark Timeline

25
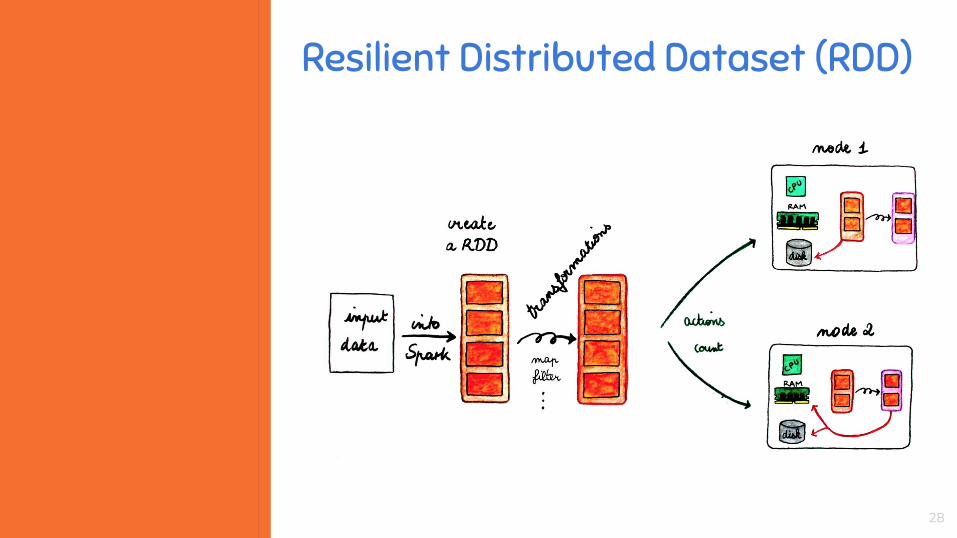
Características❏ Implementação em Scala❏ Arquitetura Mestre Escravo (Master/Slave)❏ Modelo de Programação MapReduce❏ Resilient Distributed Dataset (RDD)❏ Memória Principal (RAM)❏ Processamento Distribuído❏ Processamento em Tempo Real❏ Escalável❏ Tolerante a Falhas❏ Integração com Hadoop e HDFS

26
O que não é?
❏ Linguagem de Programação❏ Solução Definitiva❏ Substituto do Hadoop
27
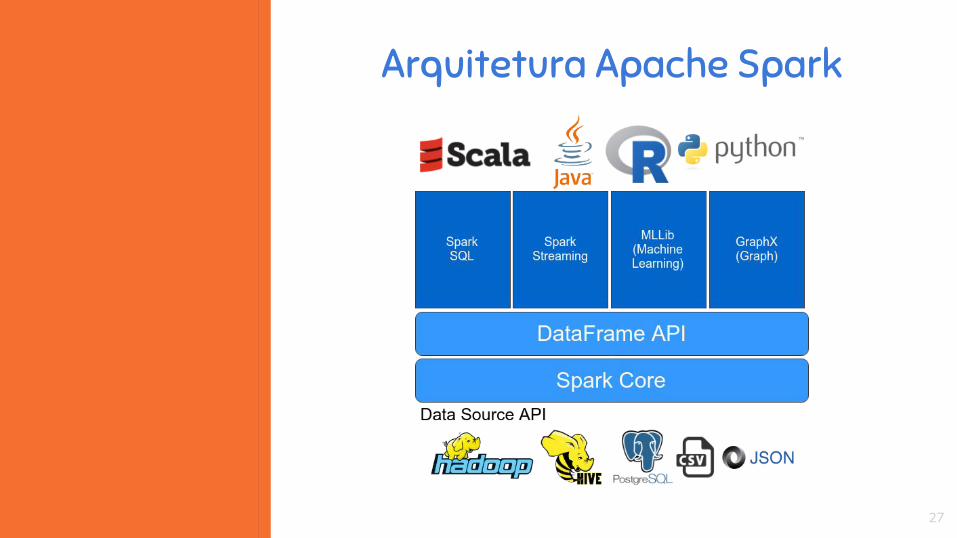
Arquitetura Apache Spark
28
Resilient Distributed Dataset (RDD)
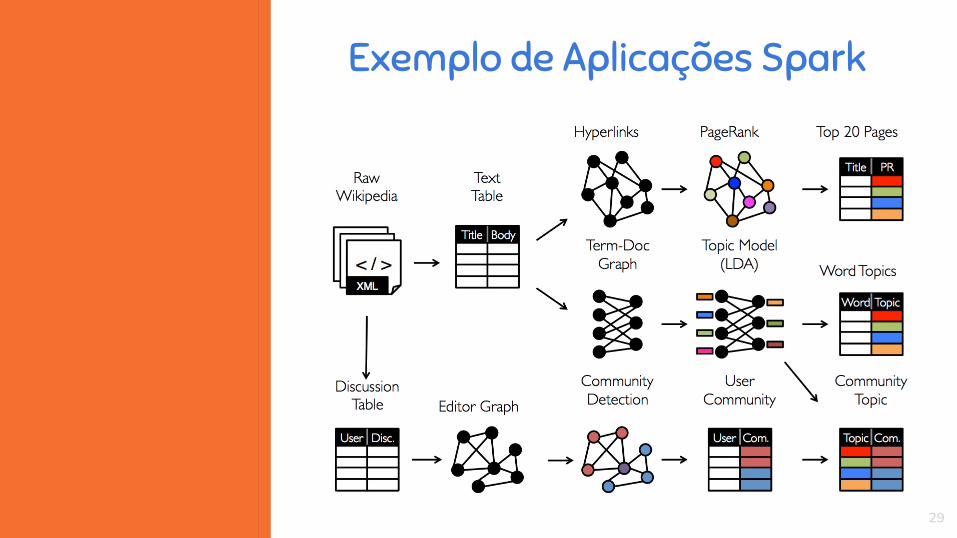
29
Exemplo de Aplicações Spark

30
Literatura Básica

31
Quem utiliza?

32
Configuração Spark
Documentação Oficial

33






























