Embed Size (px)
Citation preview

対話型映像認識理解における動的学習戦略に関する試み
”Mission incomplete, but not impossible”- @_akisato on Twitter
木村 昭悟, 南 泰浩, 坂野 鋭, 前田 英作, 杉山 弘晃
日本電信電話(株) コミュニケーション科学基礎研究所

今日お話しすること
December 9, 2010"Mission incomplete, but not impossible"2
昨年の研究構想的なposition talkに対する進捗報告
故に、既出の内容がたびたび登場する点をご容赦下さい。
Keywords Cognitive Developmental Approach :〔昨年の復習〕 自ら発達し成長する素養を計算機に与えたい
Video Language Processing :「自然言語処理」 に映像を理解するためのヒントが?
Video Morphological Analysis :「形態素解析」 が実現できること、これが全ての始まり
Dynamical Learning Strategy :これらの概念を順を追って自力で獲得しなければならない

昨年、私はこんな発表をさせていただきました。
December 9, 20103 "Mission incomplete, but not impossible"
木村 ほか “映像認識理解への認知発達的アプローチ”、電子情報通信学会技術報告、PRMU2009-144、栃木県日光市、2009年12月

昨年の発表でお話ししたこと
December 9, 2010"Mission incomplete, but not impossible"4
1. 人間が映像を理解できるのはなぜか?
2. 計算機が映像を理解できていないのはなぜか?
3. そもそも「映像を理解する」とはどういうことか?
4. 計算機は「映像を理解」できるようになるのか?
5. できるとするならば、どうすれば良いのか?
Keywords:【認知発達】 人間の発達過程に学ぶ【知識獲得】 知識は与えられるものではない【発達段階】 計算機だって成長できる【動的遷移】 成長すればできることが増えてくる

「映像を理解する」とはどういうことか?
人間とて認識理解能力が産まれつきあるわけではない。
成人であっても、知らないことは理解できない。
これを踏まえると、「映像を理解する」 とは
× 与えられた映像から最も尤もらしい意味を抽出
○ 与えられた映像と自身の持つ知識とから、その知識を組み合わせたりある種の変換をすることで、最も尤もらしい意味を抽出
高度な映像の認識や理解の実現には、人間と同様の【発達】と【知識獲得】の導入が不可欠!
December 9, 20105 "Mission incomplete, but not impossible"

何でも人間と同じようにすれば良いのか?
December 9, 2010"Mission incomplete, but not impossible"6
それはNoでしょう。
2度のニューロブームにおける失敗の教訓:神経細胞レベルの模擬と高次機能の模擬との間にギャップ
計算機の優れた特性の活用:人間をはるかに凌ぐ高速並列演算や大量・確実な記憶
発達過程の完全記述の非現実性:機能そのものの自然発生や発達を記述することはほぼ不可能
人間は人間、計算機は計算機:「身体性」なき計算機に、人間と同じようなことをさせることはできない。
認識・理解をより高度化する上で重要となる要素を抽出し、計算機が得意とする特性と融合させるアプローチがより現実的

発達と知識獲得を軸にした映像理解の枠組
December 9, 2010"Mission incomplete, but not impossible"7
大まかに初期・中期・後期の3つの発達段階を想定
各発達段階に対応する主要機能を想定
[ 初期段階 ]
Innate behavior(Bottom-up)
Fully supervised
[ 中期段階 ]
Knowledge-based(Top-down)
Reinforcement
[ 後期段階 ]
Innate/knowledgehybrid
Semi-supervised
• 感覚器相当の機能から重要信号要素を抽出
• その信号要素に対する知識を外部から順次蓄積
• 蓄えた知識がどの程度信頼できるか能動的に検証
• 自身の知識を統合して自律的に映像を解釈
• 真に必要なときのみ外部から知識を要求
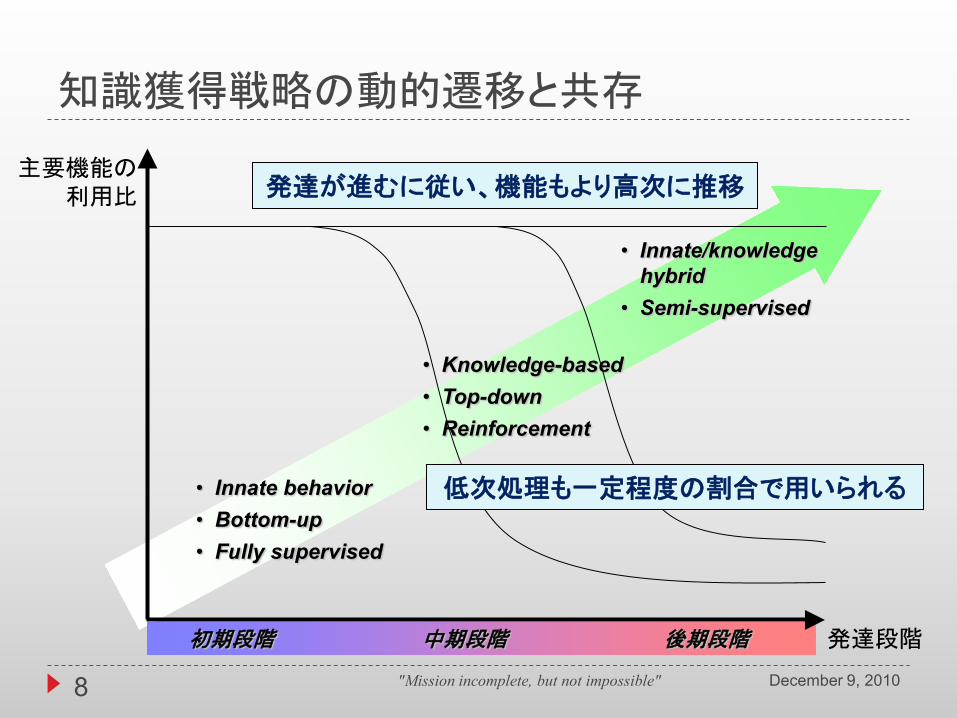
知識獲得戦略の動的遷移と共存
December 9, 2010"Mission incomplete, but not impossible"8
初期段階 中期段階 後期段階 発達段階
主要機能の利用比
• Innate behavior• Bottom-up• Fully supervised
• Knowledge-based• Top-down• Reinforcement
• Innate/knowledgehybrid
• Semi-supervised
発達が進むに従い、機能もより高次に推移
低次処理も一定程度の割合で用いられる

構想の実現に必要な機能は何か?
December 9, 2010"Mission incomplete, but not impossible"9
重要領域特定
知識獲得蓄積
[ 初期段階 ]Innate behavior
(Bottom-up)Fully supervised
[ 中期段階 ]Knowledge-based
(Top-down)Reinforcement
[ 後期段階 ]Innate/knowledge
hybridSemi-supervised
知識選別基準
獲得知識補正
知識構造構築
動的学習戦略

成果0: 構想実現のためのアプローチ
December 9, 201010 "Mission incomplete, but not impossible"
Kimura et al. "Medie Scene Learning: A framework for extracting meaningful parts from audio and video signals,“ NTT Technical Review, November 2010.

機能実現へ: 自然言語処理にヒント?
December 9, 2010"Mission incomplete, but not impossible"11
A woman is riding on a horse.
A/ woman/ is/ riding/ on/ a/ horse.
A/ woman/ is/ riding/ on/ a/ horse.n. v. mv. prep. a.a. n.
Semantic analysis
Parsing
Morphological analysis
Text
Text semantic description
Morphemedictionary
Knowledge dictionary
Parsing dictionary
Explicit/implicit information of the text can be
derived.

「映像言語処理」を考えてみよう
December 9, 2010"Mission incomplete, but not impossible"12
Person
Horse
Person
Horse
Riding
Meaning:A person is riding on a horse.
Video clip
Video morphological analysis
Video morphemedictionary
Video parsing
Video parsing dictionary
Video semantic analysis
Video semantic description
Video knowledge dictionary
Explicit/implicit information of
the video can be derived.

映像言語処理の実現には 何が必要か?
December 9, 2010"Mission incomplete, but not impossible"13
映像の「言語体系」を計算機自身が学び構築する
「形態素」「構文」「意味」の候補を探り当てる
「形態素」「構文」「意味」の候補に適切な知識を与える
保有知識の水準に合わせて学び方を動的に変化させる
「形態素解析」「構文解析」「意味解析」を、成熟度に合わせて順を追って構築
Video morphological analysis
Video morphemedictionary
Video parsing
Video parsing dictionary
Video semantic analysis
Video semantic description
Video knowledge dictionary
Explicit/implicit information of
the video can be derived.
Video clip
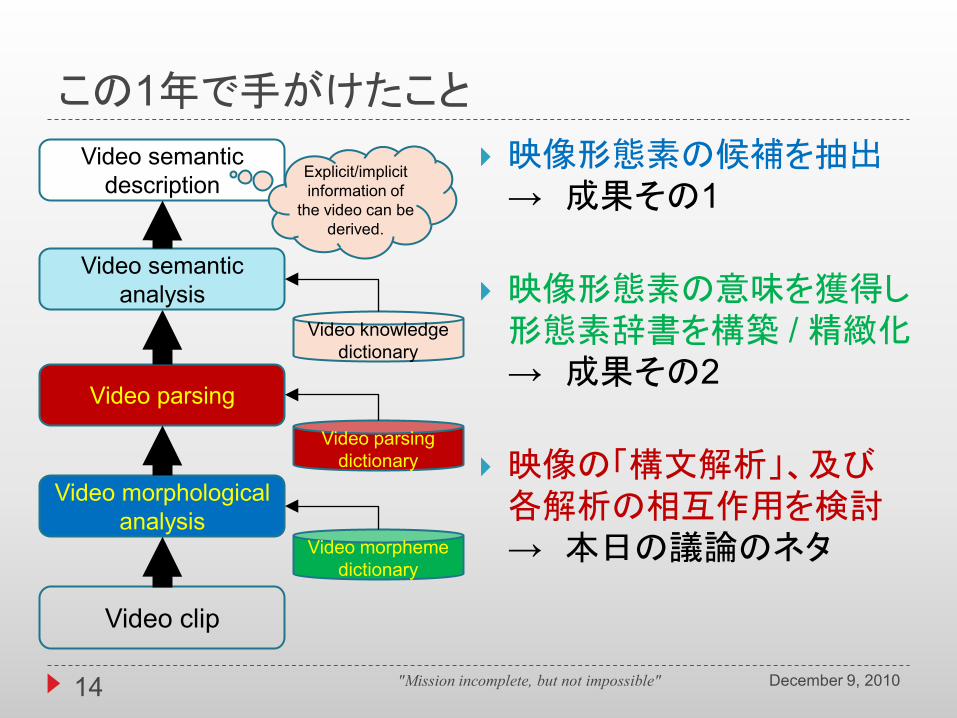
この1年で手がけたこと
December 9, 2010"Mission incomplete, but not impossible"14
映像形態素の候補を抽出→ 成果その1
映像形態素の意味を獲得し形態素辞書を構築 / 精緻化→ 成果その2
映像の「構文解析」、及び各解析の相互作用を検討→ 本日の議論のネタ
Video clip
Video morphological analysis
Video morphemedictionary
Video parsing
Video parsing dictionary
Video semantic analysis
Video semantic description
Video knowledge dictionary
Explicit/implicit information of
the video can be derived.

成果1: 映像形態素の候補を取り出す
December 9, 201015 "Mission incomplete, but not impossible"
1. 福地ほか “グラフコストの逐次更新を用いた映像顕著領域の自動抽出”、電子情報通信学会論文誌、Vol.J93-D, No.8, pp.1523-1532, 2010年8月
2. Akamine et al. "Fully automatic extraction of salient objects in near real-time,"the Computer Journal, doi: 10.1093/comjnl/bxq075, November 2010.

Saliency-based Graph Cuts (SGC)
December 9, 2010"Mission incomplete, but not impossible"16
映像顕著性に基づき注目領域を高速・高精度に推定
入力映像
視線位置推定•人間の視覚特性を模擬する統計モデルを独自に構築•そのモデルに基づいて、注目しやすい画像中の位置を自動的に推定
注目領域抽出•推定視線位置周辺の画像特徴、及び構成要素の空間的連続性を考慮して、主要構成要素を自動抽出

映像形態素候補の抽出と選択
December 9, 2010"Mission incomplete, but not impossible"17
1.目立つ領域は「形態素」である可能性が高いはず
2.その領域が「形態素」であるかどうか =取り出した領域に意味を持たせるかどうか は、教育者たる人間が判断する

成果2: 映像形態素の意味を獲得する
December 9, 201018 "Mission incomplete, but not impossible"
Sekhon et al. "Action planning for interactive visual scene understanding based on knowledge confidence defined on latent spaces,“ 電子情報通信学会技術報告、
PRMU2010-83、福岡県福岡市、2010年9月

皆さんならどんな「意味」を与えますか?
December 9, 2010"Mission incomplete, but not impossible"19
壁、窓、建物
広告、釧路
回文
ジョーク、つまらない
何が問題なのか? Semantic gap の存在
Semantics の個人間分散の大きさ
1. 対象とする人間を固定し、2. その人に適切な質問をすることで解決可能、なはず!

対話を通じた映像形態素の意味付け
December 9, 2010"Mission incomplete, but not impossible"20
対話を通した学習において、計算機が、特に、どのように質問をすれば良いか? を考える
質問の種類を選ぶ鍵 = 保有知識の確信度
確信度に応じて質問の対象をできるだけ絞り込む→ 有用な教師情報を多く回収 & ノイズラベルを抑制
ConfidenceLow High
What is this? Which is this? Is this … ? This is …

議論: 映像形態素解析のその先へ
December 9, 201021 "Mission incomplete, but not impossible"
木村 ほか “対話型映像認識理解における動的学習戦略に関する取り組み,“電子情報通信学会技術報告、PRMU2010-***、山口県山口市、2010年12月

構想の実現に必要な機能は何だったのか?
December 9, 2010"Mission incomplete, but not impossible"22
重要領域特定
知識獲得蓄積
[ 初期段階 ]Innate behavior
(Bottom-up)Fully supervised
[ 中期段階 ]Knowledge-based
(Top-down)Reinforcement
[ 後期段階 ]Innate/knowledge
hybridSemi-supervised
知識選別基準
獲得知識補正
知識構造構築
動的学習戦略
成果1
成果2
今後やるべきこと
成果0

今後やるべきことは何か?
December 9, 2010"Mission incomplete, but not impossible"23
知識構造構築= より上位の機能の実現
「映像構文」の探索/構築
知識の汎化を支える擬似的な推論機能の実現
動的学習戦略= 学習戦略の動的遷移
構文解析と形態素解析との相互作用
Video clip
Video morphological analysis
Video morphemedictionary
Video parsing
Video parsing dictionary
Video semantic analysis
Video semantic description
Video knowledge dictionary
Explicit/implicit information of
the video can be derived.

「映像構文」の探索と構築
December 9, 2010"Mission incomplete, but not impossible"24
構文解析 =
形態素の関係を記述する
その関係に意味を与える
映像の場合には…
UpperPerson
LowerHorse
Riding
共起
位置
Video clip
Video morphological analysis
Video morphemedictionary
Video parsing
Video parsing dictionary
Video semantic analysis
Video semantic description
Video knowledge dictionary
Explicit/implicit information of
the video can be derived.
形状

関連研究、はありますが… [Siddiquie+ CVPR2010]
December 9, 2010"Mission incomplete, but not impossible"25
複数物体の関係性を考慮した対話型active learning 物体領域と不確定領域との位置関係に基づく質問生成
関係性そのものの意味を問うことはできない
Q Q
AA
M
MQ
E
E E

構文解析と形態素解析との相互作用
December 9, 2010"Mission incomplete, but not impossible"26
形態素解析の不確定性
部分領域の情報だけでは実体を特定できない場合も
構文知識を援用すれば…UpperJockey?Policeman?
LowerHorse? Tiger? Unicorn?
Horse
Video clip
Video morphological analysis
Video morphemedictionary
Video parsing
Video parsing dictionary
Video semantic analysis
Video semantic description
Video knowledge dictionary
Explicit/implicit information of
the video can be derived.
Jockey

関連研究、はありますが… [Ladicky+ BMVC2010]
December 9, 2010"Mission incomplete, but not impossible"27
一般物体認識・物体領域・深度の同時推定
目指すべき実現形態の1つではある
膨大なクラスを扱える構造にはなっていない
Object class
Disparity
Segmentation

まとめ
December 9, 2010"Mission incomplete, but not impossible"28
計算機が映像を理解できるようになるためにはどうすれば? という根本的かつ難解な問いに対し
1年前に提案した枠組を実現するための具体的なアプローチを提案しました。 〔映像言語処理〕
このアプローチに基づいて、この1年で行った研究を整理して紹介しました。 〔映像形態素解析〕
より高次の処理を実現するための方向性について議論しました。 〔動的学習戦略〕
まだまだ課題は山積、でも光は見えつつあります。
“Mission incomplete, but not impossible.”

Thank you for your kind attentionAcknowledgment
We would like to thank all the collaborators and supporters for this research: Ken Fukuchi, Koji Miyazato, Shigeru Takagi (ONCT), Kazuma Akamine (Miyazaki Univ.) Gurbachan Singh Sekhon (UBC) Hirokazu Kameoka, Kunio Kashino, Junji Yamato, Takahito Kawanishi (NTT CS Labs) Koh Takeuchi, Tomohiko Suzuki (Waseda Univ.), Takuya Isomura (Univ. Tokyo) Hiroyuki Arai (NTT Cyber Space Labs)
This work is supported by Grant-in-Aid for Scientific Research on Innovative Areas “Founding a creative society via collaboration between humans and robots”.
December 9, 201029 "Mission incomplete, but not impossible"
Corresponding authorAkisato Kimura, Ph.D @ NTT CS Labs.





























