Embed Size (px)
Citation preview

Efficient Re-ranking in Vocabulary Tree basedImage Retrieval
Xiaoyu Wang2, Ming Yang1, Kai Yu1
1NEC Laboratories America, Inc. 2Dept. of ECE, Univ. of MissouriCupertino, CA 95014 Columbia, MO 65211
{myang,kyu}@sv.nec-labs.com [email protected]
Abstract—Image retrieval using a large vocabulary tree oflocal invariant features can efficiently handle databases withmillions of images. However, a costly re-ranking step is generallyrequired to re-order the top candidate images to enforce spatialconsistency among local features. In this paper, we proposean efficient re-ranking approach which takes advantage of thevocabulary tree quantization to conduct fast feature matching.The proposed re-ranking algorithm involves no operations inthe high-dimensional feature space and does not assume a globaltransform between a pair of images, thus, it not only dramaticallyreduces the computational complexity but also improves theretrieval precision, which is validated using 1.26 millionimagesin the public ImageNet dataset and theSan Francisco Landmarkdataset including 1.7 million images.
I. I NTRODUCTION
Large-scale image retrieval from millions of images hasbeen an active research topic for decades [3], [8], whichattracts increasing interests due to its applications in web andmobile image search [6], [7], [11], [16], [12], [1], [14]. Interms of the methodologies and features, recent large-scaleimage retrieval algorithms may be categorized into two lines:1) compact hashing of global features; and 2) efficient indexingof local features by a vocabulary tree. Global features suchas GIST features [9] or color histograms delineate the holisticcontents of images, which can be compactly indexed by binarycodes [11] or hashing functions [15]. Thus, the retrieval isvery efficient on both computation and memory usage thoughit is unable to attend to the details of images. In the otherline of research, images are represented by a bag of localinvariant features [5] which are quantized into visual wordsby a huge vocabulary tree [6]. This vocabulary tree basedretrieval is very capable of finding near-duplicate images,i.e.,images of the same objects or scenes undergoing differentcapturing conditions, at the cost of memory usage for theinverted indexes of a large number of visual words.
In the vocabulary tree based image retrieval, since imagesare essentially represented by a bag of orderless visual words,the geometric relations of the local features or their spatiallayout are largely ignored. Therefore, a post re-ranking pro-cedure [7], [4] is often employed to re-order the retrievedcandidate images by verifying the geometrical consistencya-gainst the query image in order to further improve the retrievalprecision. Usually, in the geometrical re-ranking, the localfeature descriptors of two images are first matched reliablyusing the method in [5], then a RANSAC procedure [7]
is employed to fit a global affine transform. The candidateimages are re-ranked according to the number of inliers inthe RANSAC or fitting errors. This conventional re-rankingapproach confronts by two issues. First, this procedure isgenerally computational intensive because it operates on thehigh dimensional descriptors. The running time could be evenlonger than the retrieval. Second, the assumption of a globalaffine transform between two image may not hold,e.g., forimages of a 3D object from different view angles.
In viewing of these issues, we develop an efficient re-ranking method for vocabulary tree based retrieval that takesadvantage of the tree quantization to select a small set ofmatched local features and verify the consistency of theirindividual spatial local neighborhoods. The matched localfeatures with a more consistent neighborhood shall contributemore to the matching score to re-rank the candidate images.In this procedure, we do not resort to the high dimensional de-scriptors, thus it is very efficient. In addition, we do not assumea global transform between a candidate image to the query, soit is potentially more general than the RANSAC based method.The proposed re-ranking method is particularly beneficial toa recent large-scale image retrieval algorithm [14] where thespatial neighbors of the local features in the query has beenpre-calculated in spatial contextual weighting. We validate theeffectiveness of this re-ranking on theUKbench dataset [6]using 1.26 million images in theImageNet Challenge [2] asthe distractors and the landmark retrieval problem on theSanFrancisco Landmark dataset [1] including 1.7 million images.All the images in the experiments are publicly available.
After briefly reviewing some related work in Sec. II, weintroduce the vocabulary tree based image retrieval [6] andthe variant using spatial contextual weighting [14] in Sec.III.Following the same notations, we present the proposed effi-cient re-ranking method in Sec. IV, with experiments on twolarge datasets in Sec. V and the concluding remarks in Sec. VI.
II. RELATED WORK
In recent years, large-scale near-duplicate image retrievalbased on local invariant features [5] has been significantlyimproved by large hierarchical vocabulary trees [6], wherelocal features are encoded into a bag-of-words (BoW) his-togram [10] with millions of visual words. Therefore, thishistogram is so sparse that inverted indexes are well suitedtoimplement the indexing and searching efficiently. Moreover,

the tree structure substantially reduces the computation toquantize a feature descriptor into one of millions of words,e.g., for a tree with 7 layers and branch factor 10, only7× 10inner products of 128-D SIFT descriptors are needed, insteadof 107 for a flat structure. Visual words are weighted by theTF-IDF (term frequency-inverse document frequency) [10],[6], where the IDF reflects their discriminative abilities indatabase images and the TF indicates their importance in aquery image.
To take into account the spatial layout of local features, [7]proposed a post spatial verification stage to re-rank the top-1000 candidates by a variant of RANSAC algorithm assuminga global transform with 3-5 degree of freedom between thequery and candidate images. The spatial verification stagesubstantially improves the mean average precision (mAP) ofthe retrieval, however, the induced computational costs couldbe far more expensive than the the retrieval procedure itself.This geometric re-ranking procedure has been widely adoptedin many following up work.
The most related work to ours is [12] where the matchingfeature pairs between a query and candidate image are iden-tified using the descriptor quantization path in the vocabularytree. Then the geometric similarity scores of those matchingfeature pairs,i.e., the maximal number of features with similarlocation, orientation and scale ratio differences, are used to re-rank the candidates. This method essentially combines 3 one-order Hough transforms, which also assumes a single globaltransform between the query and candidate. We employ asimilar way to identify the subset of matched local features.The major differences are that we do not rely on the globaltransform assumption and we augment the matching scores ofthose features with consistent local spatial neighbors.
III. V OCABULARY TREE BASED IMAGE RETRIEVAL
In the section, we present the framework of the vocabularytree based image retrieval [6] shown in Fig. 1 and introducea recent work [14] which proposed to employ two types ofimage-dependent contextual information in weighting the localfeatures besides the TF-IDF weighting scheme.
SIFT featuresf = {x,u, s, θ} are first extracted fromboth query and database images, which include the descriptorx ∈ R
D, location u, characteristic scales in log domain,and orientationθ. Then, a vocabulary treeT is offline trainedby hierarchical K-means clustering of local descriptors with abranch factorK and depthL. Each nodevℓ,hℓ (v for short) inthe tree represents a visual word, whereℓ indicates its layerandhℓ is the node index at that layer.
A query imageq is represented by a bagIq of local descrip-tors{xi}i∈Iq , wherexi ∈ R
D andD = 128 for SIFT features.Eachxi is mapped to a path of visual words from the root toa leaf ofT , resulting in the quantizationT (xi) = {vℓ,hℓ
i }Li
ℓ=1.Thus, a query image is eventually represented by the set ofnode paths obtained from its descriptors,i.e., {T (xi)}i∈Iq . Thedatabase images are denoted by{dm}Mm=1. Using the same hi-erarchical quantization procedure, the local descriptorsym
j indm are mapped to the collection of node paths{T (ym
j )}j∈Idm .
The similarity scoresim(q, dm) between the queryq and adatabase imagedm is given by the average matching scoreamong all pairs of descriptors passing the same node paths.
sim(q, dm).=
1
|Iq||Idm |
∑
i∈Iq,j∈Id
w(vi)1(vi = vj). (1)
In particular, the matching score of two features quantizedtoone nodev is specified as the IDF term of this node [6]:
w(v) = idf(v) = log
(
M
Mv
)
, (2)
whereM is the total number of database images andMv isthe number of images containing at least one descriptor thatquantizes to the nodev.
…...
Re-order retrieved images
Local feature detection
Quantize features though the vocabulary tree
Feature Extraction
Image Retrieval
Re-Ranking
Query image
Stop Level
….
List
List
List
List
List
List
List
List
List
List
List
List
List List
List
….
List
List
Inverted indexes
Virtual inverted indexs
Fig. 1. The framework of vocabulary tree based image retrieval.
To enhance the discriminability of single local features,Wang et. al. [14] proposed adescriptor contextual weighting(DCW) and aspatial contextual weighting (SCW) of localfeatures to improve the IDF weighting scheme. The SCWcalculates spatial contextual statistics for each local feature,including the density of its adjacent features and their scalesand orientations, where the computation to determine thespatial neighborhoods is reusable in the proposed re-rankingmethod. Please refer to [14] for the details.
IV. PROPOSED EFFICIENT RE-RANKING
Given the top candidate images, we develop an efficientre-ranking method to re-order them according to the localgeometrical consistency of{xi} and {ym
j }. First we obtaina small subset of “matched” local descriptorsw.r.t. the vocab-ulary tree quantization, namely, we call the descriptors intwoimages as “matched” if they are quantized to a unique treenode at the deep levels of the tree. Afterwards, we constructtwo sub-graphs of these matched features based on their spatialneighborhood relations. The IDF weights of matched featuresin the intersection of two sub graphs are weighted by the ratio

of common neighbor features and added to the overall imagesimilarity score again to re-order the top candidates.
Specifically, for the queryq and a candidatedm, we calcu-late the intersection of all node paths{vi}i∈Iq and{vm
j }j∈Imd
,and only select those nodes (with depthl > L − 3) whosenqI(v
l,hl) = 1 and ndI(v
l,hl) = 1, denoted by{vl′,h′}. HerenqI and nd
I indicate the number of local features quantizedto a particular tree node. As the vocabulary tree is quitedeep, the subsets of descriptors{x′
i} and{y′j} that correspond
to {vl′,h′} are regarded roughly matched and only around10% − 20% of the initial feature sets. Then we build twographs from matched{x′
i} and {y′j} wherex′
i links to x′′i
which is in its spatial neighborhoodC(x′i). Here, letC(f)
denote the neighborhood of one feature given by the disc(u, R). Empirically we set the radiusR = 12× 2s (maximum150 pixels). Finally, we calculate the intersection of these 2graphs and add the weightedidf(vl′,h′) to the matching scoresim(q, dm) to re-order the top returned images. The finalsimilarity score of two images is defined as
sim(q, dm).= sim(q, dm) +
∑
{x′
i}
α(x′i)idf(v
l′,h′), (3)
whereα(x′i) =
|{x′′
i |x′′
i ∈C(x′
i) andy′′
i ∈C(y′
i)}||C(x′
i)| and x′′
i matchesto y′′
i , the ratio of common neighbors ofx′i in the query and
its matched featurey′i in the database image.
Query image q Database image d
: {x’i} : {y’i}: xi not in {x’i} : yi not in {y’i}
Fig. 2. Illustration of the proposed re-ranking process.
Figure 2 shows an illustrative example. The green circlesindicate the matched SIFT features by the tree quantizationand they have the one-on-one correspondences inq and d.According to their spatial neighborhoods drawn as orangedash circles, the features with larger common neighborhoodcontribute more to the final re-ranking similarity score. Whenthe global transform assumption does not hold, the number ofinliers in the RANSAC could be small and unable to reliablyre-rank the candidates. In such cases, this re-ranking methodallows local deformation and promotes those candidates withlarge consistent local image regions. Furthermore, the com-putation of the tree based quantization and finding out thespatial neighborhoods of local features are shared with theretrieval using spatial contextual weighting, thus, the inducedcomputation overhead is quite limited.
V. EXPERIMENTS
We re-rank the retrieval results of [14] to validate theproposed method using 3 public datasets,Ukbench, ImageNet,andSFLandmark. In all the experiments, we extract up to 2500SIFT features for each image using the VLFeat library [13].The system was implemented in C++ and all timings of theaverage retrieval timetr, including the re-ranking but not thefeature extraction, are based on asingle core of an 8-core Xeon2.44GHz blade server with 32G RAM. Next we introduce eachdataset and the evaluation criteria, then present the large-scaleretrieval performance.
A. The datasets
We conduct two large-scale image retrieval experimentswhere one experiment focuses on finding the same object inthe UKbench dataset with 1.26M images in theImageNet asthe distractors, and the other searches for the same landmarkor building in theSan Francisco Landmark dataset including1.7M images. To our best knowledge, these are among thelargest public datasets available for image retrieval.
UKbench was collected by [6], and includes 2550 differentobjects or scenes. Each one has 4 images taken from differentviewpoints. All the 10200 images are both indexed as databaseimages and used as queries. The retrieval performance ismeasured by4× recall at the top-4 candidate images, referredas N-S score [6] (maximum is 4), and the mean averageprecision (mAP).
ImageNet is an image database crawled from internet ac-cording to the WordNet hierarchy [2]. TheImageNet LargeScale Visual Recognition Challenge 2010 (ILSVRC2010)clearly specifies 1.26M images of 1000 categories as thetraining set (denoted byImageNet-T) and 50K images as thevalidation set (denoted byImageNet-V).
SFLandmark (the San Francisco Landmark dataset [1])contains 150K panoramic images collected in San Franciscowhich were converted to 1.06 million perspective centralimages (PCIs) and 638 thousand perspective frontal images(PFIs). The query images are 803 pictures captured by mobilephones. All the images are associated with one or severalbuilding IDs and true or approximate GPS locations. Weevaluate the recall rate of the top-1 candidate image in termsof building IDs, denoted byτ1.
B. Large-scale retrieval performance
In all the experiments, we employ a vocabulary tree withdepth L = 7 and branch factorK = 10. For the experi-ments on theUKbench dataset, the tree is trained using 8million randomly selected SIFT features from theImageNet-Vdataset which has no overlap withUKbench and ImageNet-T. Following the practice in [1], the vocabulary trees for theSFLandmark dataset are trained for PCIs and PFIs separately.
We compare the retrieval performance among thebaselinemethod in [6], the contextual weighting (CW) algorithm [14],our re-ranking method over the CW algorithm (denoted byCW+TreeRank), and the conventional re-ranking method usingthe RANSAC [7] (denoted byCW+RANSAC) in which the
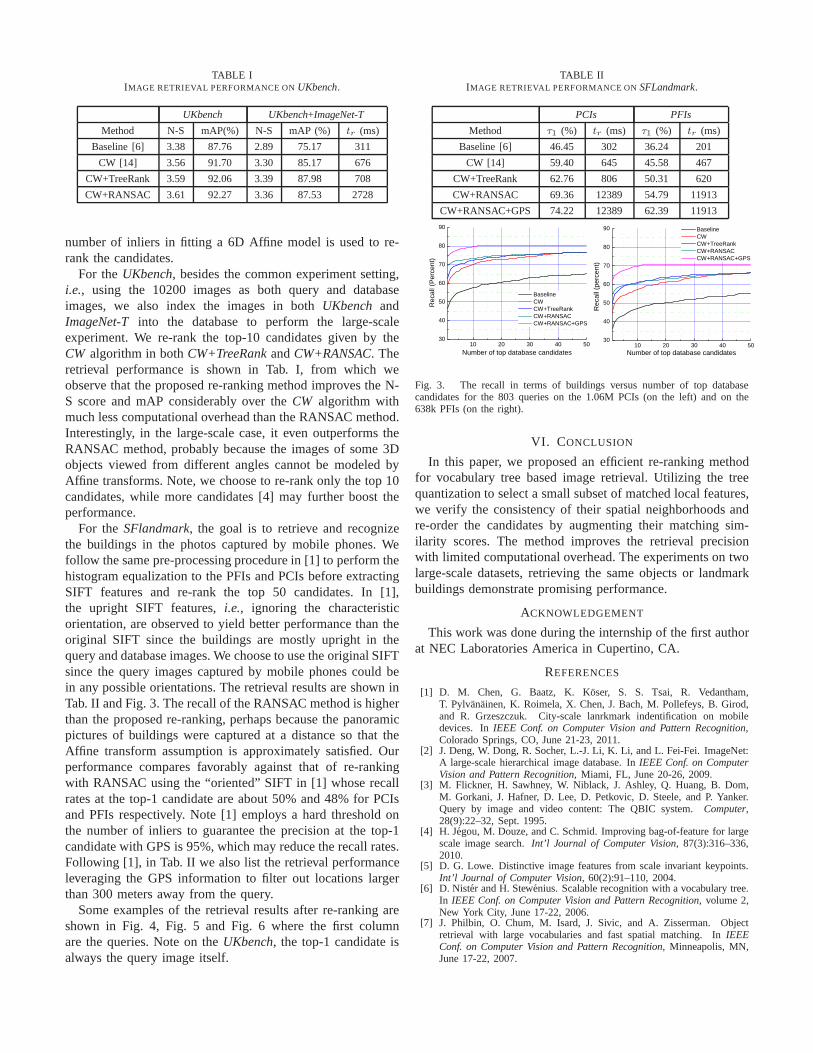
TABLE IIMAGE RETRIEVAL PERFORMANCE ONUKbench.
UKbench UKbench+ImageNet-T
Method N-S mAP(%) N-S mAP (%) tr (ms)
Baseline [6] 3.38 87.76 2.89 75.17 311
CW [14] 3.56 91.70 3.30 85.17 676
CW+TreeRank 3.59 92.06 3.39 87.98 708
CW+RANSAC 3.61 92.27 3.36 87.53 2728
number of inliers in fitting a 6D Affine model is used to re-rank the candidates.
For theUKbench, besides the common experiment setting,i.e., using the 10200 images as both query and databaseimages, we also index the images in bothUKbench andImageNet-T into the database to perform the large-scaleexperiment. We re-rank the top-10 candidates given by theCW algorithm in bothCW+TreeRank andCW+RANSAC. Theretrieval performance is shown in Tab. I, from which weobserve that the proposed re-ranking method improves the N-S score and mAP considerably over theCW algorithm withmuch less computational overhead than the RANSAC method.Interestingly, in the large-scale case, it even outperforms theRANSAC method, probably because the images of some 3Dobjects viewed from different angles cannot be modeled byAffine transforms. Note, we choose to re-rank only the top 10candidates, while more candidates [4] may further boost theperformance.
For theSFlandmark, the goal is to retrieve and recognizethe buildings in the photos captured by mobile phones. Wefollow the same pre-processing procedure in [1] to perform thehistogram equalization to the PFIs and PCIs before extractingSIFT features and re-rank the top 50 candidates. In [1],the upright SIFT features,i.e., ignoring the characteristicorientation, are observed to yield better performance thantheoriginal SIFT since the buildings are mostly upright in thequery and database images. We choose to use the original SIFTsince the query images captured by mobile phones could bein any possible orientations. The retrieval results are shown inTab. II and Fig. 3. The recall of the RANSAC method is higherthan the proposed re-ranking, perhaps because the panoramicpictures of buildings were captured at a distance so that theAffine transform assumption is approximately satisfied. Ourperformance compares favorably against that of re-rankingwith RANSAC using the “oriented” SIFT in [1] whose recallrates at the top-1 candidate are about 50% and 48% for PCIsand PFIs respectively. Note [1] employs a hard threshold onthe number of inliers to guarantee the precision at the top-1candidate with GPS is 95%, which may reduce the recall rates.Following [1], in Tab. II we also list the retrieval performanceleveraging the GPS information to filter out locations largerthan 300 meters away from the query.
Some examples of the retrieval results after re-ranking areshown in Fig. 4, Fig. 5 and Fig. 6 where the first columnare the queries. Note on theUKbench, the top-1 candidate isalways the query image itself.
TABLE IIIMAGE RETRIEVAL PERFORMANCE ONSFLandmark.
PCIs PFIs
Method τ1 (%) tr (ms) τ1 (%) tr (ms)
Baseline [6] 46.45 302 36.24 201
CW [14] 59.40 645 45.58 467
CW+TreeRank 62.76 806 50.31 620
CW+RANSAC 69.36 12389 54.79 11913
CW+RANSAC+GPS 74.22 12389 62.39 11913
10 20 30 40 5030
40
50
60
70
80
90
Rec
all (
Per
cent
)
Number of top database candidates
Baseline CW CW+TreeRank CW+RANSAC CW+RANSAC+GPS
10 20 30 40 5030
40
50
60
70
80
90
Rec
all (
perc
ent)
Number of top database candidates
Baseline CW CW+TreeRank CW+RANSAC CW+RANSAC+GPS
Fig. 3. The recall in terms of buildings versus number of top databasecandidates for the 803 queries on the 1.06M PCIs (on the left)and on the638k PFIs (on the right).
VI. CONCLUSION
In this paper, we proposed an efficient re-ranking methodfor vocabulary tree based image retrieval. Utilizing the treequantization to select a small subset of matched local features,we verify the consistency of their spatial neighborhoods andre-order the candidates by augmenting their matching sim-ilarity scores. The method improves the retrieval precisionwith limited computational overhead. The experiments on twolarge-scale datasets, retrieving the same objects or landmarkbuildings demonstrate promising performance.
ACKNOWLEDGEMENT
This work was done during the internship of the first authorat NEC Laboratories America in Cupertino, CA.
REFERENCES
[1] D. M. Chen, G. Baatz, K. Koser, S. S. Tsai, R. Vedantham,T. Pylvanainen, K. Roimela, X. Chen, J. Bach, M. Pollefeys, B. Girod,and R. Grzeszczuk. City-scale lanrkmark indentification onmobiledevices. InIEEE Conf. on Computer Vision and Pattern Recognition,Colorado Springs, CO, June 21-23, 2011.
[2] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet:A large-scale hierarchical image database. InIEEE Conf. on ComputerVision and Pattern Recognition, Miami, FL, June 20-26, 2009.
[3] M. Flickner, H. Sawhney, W. Niblack, J. Ashley, Q. Huang,B. Dom,M. Gorkani, J. Hafner, D. Lee, D. Petkovic, D. Steele, and P. Yanker.Query by image and video content: The QBIC system.Computer,28(9):22–32, Sept. 1995.
[4] H. Jegou, M. Douze, and C. Schmid. Improving bag-of-feature for largescale image search.Int’l Journal of Computer Vision, 87(3):316–336,2010.
[5] D. G. Lowe. Distinctive image features from scale invariant keypoints.Int’l Journal of Computer Vision, 60(2):91–110, 2004.
[6] D. Nister and H. Stewenius. Scalable recognition witha vocabulary tree.In IEEE Conf. on Computer Vision and Pattern Recognition, volume 2,New York City, June 17-22, 2006.
[7] J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisserman.Objectretrieval with large vocabularies and fast spatial matching. In IEEEConf. on Computer Vision and Pattern Recognition, Minneapolis, MN,June 17-22, 2007.

Fig. 4. Sample retrieval results inUKbench and ImageNet-T. The query image is shown in the first column followed by top-5candidates after re-ranking.
Fig. 5. Sample retrieval results on PCIs inSFLandmark. The query image is shown in the first column followed by top-5candidates after re-ranking.
Fig. 6. Sample retrieval results on PFIs inSFLandmark. The query image is shown in the first column followed by top-5candidates after re-ranking.
[8] Y. Rui, T. S. Huang, M. Ortega, and S. Mehrotra. Relevancefeedback:A power tool for interactive content-based image retrieval. IEEE Trans.Circuits Syst. Video Technol., 8(5):644–655, Sept. 1998.
[9] C. Siagian and L. Itti. Rapid biologically-inspired scene classificationusing features shared with visual attention.IEEE Trans. Pattern Anal.Machine Intell., 29(2):300–312, Feb. 2007.
[10] J. Sivic and A. Zisserman. Video google: A text retrieval approach toobject matching in videos. InIEEE Int’l Conf. on Computer Vision,volume 2, Nice, France, Oct. 13-16, 2003.
[11] A. Torralba, R. Fergus, and Y. Weiss. Small codes and large imagedatabases for recognition. InIEEE Conf. on Computer Vision andPattern Recognition, Anchorage, AK, June 23-28, 2008.
[12] S. S. Tsai, D. Chen, C. Takacs, V. Chandrasekhar, Ramakrishna, Vedan-tham, R. Grzeszczuk, and B. Girod. Fast geometric re-ranking for image-based retrieval. InIEEE Int’l Conf. on Image Processing, Hong Kong,
Sept. 26-29, 2010.[13] A. Vedaldi and B. Fulkerson. VLFeat: An open and portable library of
computer vision algorithms. http://www.vlfeat.org/, 2008.[14] X. Wang, M. Yang, T. Cour, S. Zhu, K. Yu, and T. X. Han. Contextual
weighting for vocabulary tree based image retrieval. InIEEE Int’l Conf.on Computer Vision, Barcelona, Spain, Nov. 6-13, 2011.
[15] Y. Weiss, A. Torralba, and R. Fergus. Spectral hashing.In NeuralInformation Processing Systems (NIPS), Vancouver, Canada, Dec. 9-11,2008.
[16] W. Zhou, Y. Lu, H. Li, Y. Song, and Q. Tian. Spatial codingfor largescale partial-duplicate web image search. InACM Multimedia, Florence,Italy, Oct. 25-29, 2010.
















![Image Retrieval for Image-Based Localization Revisited · 2015. 4. 9. · retrieval systems [7,25,30] and image retrieval approaches for image-based localization. The former aim at](https://img.dokumen.tips/doc/110x75/601719b1ed8cce647e7cea7c/image-retrieval-for-image-based-localization-revisited-2015-4-9-retrieval-systems.jpg)












