Embed Size (px)
Citation preview
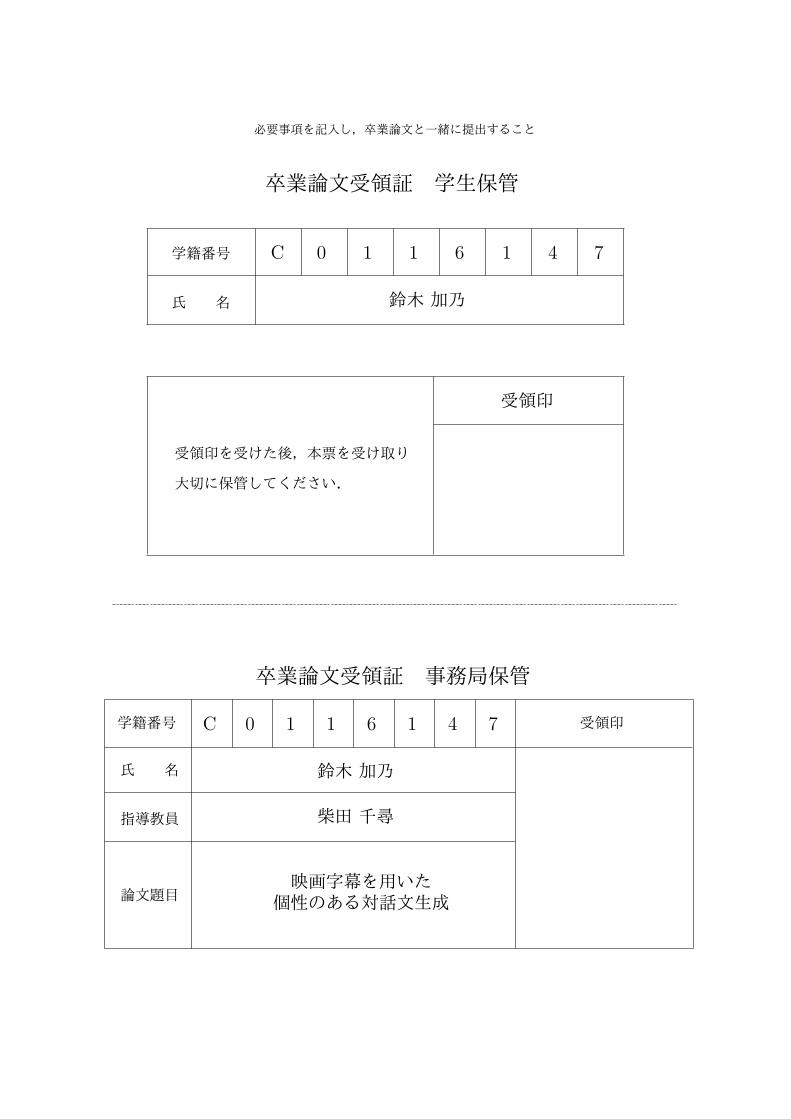
必要事項を記入し,卒業論文と一緒に提出すること
卒業論文受領証 学生保管
学籍番号
氏 名 鈴木 加乃
C 0 1 1 6 1 4 7
受領印を受けた後,本票を受け取り
大切に保管してください.
受領印
卒業論文受領証 事務局保管
学籍番号
氏 名
指導教員
論文題目
受領印C 0 1 1 6 1 4 7
鈴木 加乃
柴田 千尋
映画字幕を用いた個性のある対話文生成

2019年 度
映画字幕を用いた個性のある対話文生成
鈴木加乃
柴田研究室
┌ (┌^ o^)┐ キレイに切り取ってね ┌ (^ o^┐)┐
[ 卒 業 論 文 ]
映画字幕を用いた個性のある対話文生成
(指 導 教 員) 柴田 千尋
コンピュータサイエンス学部 柴田研究室
学籍番号 C0116147
鈴木 加乃
[ 2019年度 ]

東 京 工 科 大 学
卒 業 論 文
論 文 題 目
映画字幕を用いた個性のある対話文生成
指 導 教 員 柴田 千尋
提 出 日 2020年 01月 24日
提 出 者
学 部
学籍番号
氏 名
コンピュータサイエンス 学 部
C0116147
鈴木 加乃

2019年度 卒 業 論 文 概 要
論 文 題 目
映画字幕を用いた個性のある対話文生成
コンピュータサイエンス学部
C0116147学籍番号
氏
名鈴木 加乃
指導教員
柴田 千尋
【概 要】
近年,対話文生成は注目されており, 企業のホームページのお問い合わせフォームに
AIチャットボットを導入している企業が多いことから, AI技術を使って対話ができる技
術は増えてきているが, 個性のある対話文は少ないというのが現状である. そこで, より
個性のある対話文を作りたいと考えた。
本研究の分野である深層学習とは何層にもなるニューラルネットを関数近似に使う多
層ニューラルネットによる学習のことである.
近年の研究では, Sequence-to-Sequence(以下 Seq2Seq)モデルを用いた対話文生成が行
われた. これは系列変換モデルであり, 1 対 1 の対話文をデータセットとし学習を行う.
対話文生成以外にも機械翻訳でよく用いられている. また, 個性をつけるため転移学習を
用いて対話文を生成する研究が行われた. 転移学習とは事前学習で利用したデータセット
や学習結果を再利用し, より精度の高い特徴を捉えるために用いられる手法である.
本研究では, 提案手法として Attention 付き Seq2Seq モデルを用いた対話文生成と個
性のある対話文生成を行うための転移学習を組み合わせた手法を提案する. Attentionと
は Decode時に入力系列の情報を直接参照できるようにする仕組みをもつモデルである.
データセットには映画字幕を用い, 事前学習を行う. そして映画字幕を映画ジャンルごと
にクラスタリングを行い, 特定ジャンルのデータセットのみを取り出したものを用いて転
移学習を行うことで, 個性のある対話文を生成する.
提案手法で対話文生成を行なった結果, データセット内の発話文の方が文章や会話が成
り立っており, 個性のある応答文が多かった. しかし, データセットの前処理が不十分な
ため, 不適切な表現や意味の通らない固有名詞のある応答文も生成されてしまった. そし
て一番個性のある応答文が多いジャンルは「ファンタジー」であった.
改善案として, データセットの前処理を丁寧に行うことや形態素解析の方法を変えるこ
とで単語辞書や単語ベクトルの見直しをすること, より特徴的な (個性のある)映画字幕
をデータセットにすることなどが挙げられる.

目次
第 1章 序論 1
1.1 背景 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 本研究の目的 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
第 2章 理論 2
2.1 機械学習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.2 深層学習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.3 ニューラルネットワーク . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.3.1 活性化関数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.4 Recurrent Neural Network . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.5 Long Short-Term Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.6 Sequence-to-Sequence(Seq2Seq) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.7 Attention付き Seq2Seq . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.8 転移学習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
第 3章 関連研究 10
3.1 Seq2seqを用いた対話文生成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.2 転移学習による対話文への個性の付与 . . . . . . . . . . . . . . . . . . . . . . . . . . 10
第 4章 提案手法 12
4.1 Attention付き Seq2seqを用いた対話文生成 . . . . . . . . . . . . . . . . . . . . . . 12
4.2 個性のある対話文生成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
第 5章 実装 13
5.1 開発環境 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
5.2 データセット . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
5.2.1 映画字幕を用いたデータセット . . . . . . . . . . . . . . . . . . . . . . . . . 13
5.2.2 映画字幕のジャンル分け . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
5.3 対話文生成の実装 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
5.4 個性のある対話文の実装 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
第 6章 実験結果と評価 19
6.1 実験に用いたパラメータ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
6.2 評価項目 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
- i -

6.3 結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
6.4 考察 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
6.4.1 生成結果からの考察 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
6.4.2 評価結果からの考察 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
6.4.3 改善案 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
第 7章 結論 27
7.1 結論 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
7.2 今後の展望 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
謝辞 28
参考文献 29
付録 30
- ii -

図目次
1.1 対話文のモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 個性をつけた対話文のモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2.1 入力信号が 2つのパーセプトロン . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 ニューラルネットワークの構造 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.3 シグモイド関数のグラフ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.4 ステップ関数のグラフ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.5 L層の RNNの構造 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.6 LSTMモデルの構造 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.7 Seq2Seqモデルの構造 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.8 Attentionモデルの構造 (出典: [5]より抜粋) . . . . . . . . . . . . . . . . . . . . . . 8
2.9 Attention付き Seq2Seqモデルの構造 . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.10 マルチタスク学習を実現する手法 (出典: [7]より抜粋) . . . . . . . . . . . . . . . . . 9
4.1 提案手法の概要図 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6.1 事前学習による lossの推移 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
6.2 文章が成り立っている応答文の数 (評価結果) . . . . . . . . . . . . . . . . . . . . . . 22
6.3 会話が成り立っている応答文の数 (評価結果) . . . . . . . . . . . . . . . . . . . . . . 22
6.4 個性のある文章 (会話)である応答文の数 (評価結果) . . . . . . . . . . . . . . . . . . 23
- iii -

表目次
5.1 映画字幕 ジャンル別の映画数と会話数 . . . . . . . . . . . . . . . . . . . . . . . . . 14
6.1 生成した対話文 (個性をつける前) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
6.2 発話文「何してた?」の応答文 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
6.3 ジャンル「ファンタジー」らしい個性をつけた対話文のうち評価の高いもの . . . . . . 25
7.1 生成した対話文 (個性をつける前) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
7.2 生成した対話文 (ジャンル「アクション」らしい個性をつけたもの) . . . . . . . . . . 31
7.3 生成した対話文 (ジャンル「SF」らしい個性をつけたもの) . . . . . . . . . . . . . . . 32
7.4 生成した対話文 (ジャンル「ドラマ」らしい個性をつけたもの) . . . . . . . . . . . . . 33
7.5 生成した対話文 (ジャンル「コメディー」らしい個性をつけたもの) . . . . . . . . . . 34
7.6 生成した対話文 (ジャンル「スリラー」らしい個性をつけたもの) . . . . . . . . . . . 35
7.7 生成した対話文 (ジャンル「ロマンス」らしい個性をつけたもの) . . . . . . . . . . . 36
7.8 生成した対話文 (ジャンル「ホラー」らしい個性をつけたもの) . . . . . . . . . . . . . 37
7.9 生成した対話文 (ジャンル「アニメ」らしい個性をつけたもの) . . . . . . . . . . . . . 38
7.10 生成した対話文 (ジャンル「ファンタジー」らしい個性をつけたもの) . . . . . . . . . 39
7.11 生成した対話文 (ジャンル「アドベンチャー」らしい個性をつけたもの) . . . . . . . . 40
7.12 生成した対話文 (ジャンル「クライム」らしい個性をつけたもの) . . . . . . . . . . . 41
7.13 生成した対話文 (ジャンル「ドキュメンタリー」らしい個性をつけたもの) . . . . . . . 42
7.14 生成した対話文 (ジャンル「歴史」らしい個性をつけたもの) . . . . . . . . . . . . . . 43
7.15 生成した対話文 (ジャンル「音楽」らしい個性をつけたもの) . . . . . . . . . . . . . . 44
7.16 生成した対話文 (ジャンル「ミステリー」らしい個性をつけたもの) . . . . . . . . . . 45
7.17 生成した対話文 (ジャンル「ボリウッド」らしい個性をつけたもの) . . . . . . . . . . 46
- iv -

第 1章
序論
1.1 背景
近年,対話文生成は注目されており, 企業のホームページのお問い合わせフォームに AIチャットボッ
ト*1を導入している企業が多い.
AI技術を使って対話ができる技術は増えてきているが, 個性のある対話文は少ないというのが現状で
ある. そこで, より個性のある対話文を作りたいと考えた。例えば関西弁や敬語など個性豊かな対話文
が作れれば, AIチャットボットとのやりとりが面白くなりコミュニケーションも円滑になるのではない
かと考える.
1.2 本研究の目的
本研究の目的は, 手入力した発話文に対して応答文を自動生成するというものである. 図 1.1に示す
ような形で対話文生成を行う.
図 1.1 対話文のモデル
また, データセットをクラスタリングし, 分類されたデータセットから再度学習させることによって
対話文に個性をつけ, 個性豊かな応答文を生成することも目的である. イメージとしては図 1.2に示す
ように口調を変化させる.
図 1.2 個性をつけた対話文のモデル
*1 AI(人工知能)を活用した自動会話プログラムのこと
- 1 -

第 2章
理論
2.1 機械学習
機械学習とは,機械がデータを解析 (分離平面や回帰曲線,事後確率の計算)することでデータから知
識を引き出すことである [1]. 予測解析, 統計学習とも呼ばれており, Webサイトや顔認識など幅広く機
械学習モデルが使われている. 機械学習には教師あり学習と教師なし学習がある.
教師あり学習は訓練データが与えられていることが前提条件として,入力データと出力データのペア
群をアルゴリズムに与え学習させることで,適切な出力を生成する,
一方で教師なし学習は, 入力データのみアルゴリズムに与えることで最適な出力を生成する.
2.2 深層学習
深層学習とは機械学習という研究分野の中でも特に, 何層にもなるニューラルネットを関数近似に使
う, 多層ニューラルネットによる学習のことである [2]. 自然言語処理の分野においても深層学習を適用
したことで解析性能が向上している.
2.3 ニューラルネットワーク
ニューラルネットワークとは, 生物の神経回路を元にして作られた多層パーセプトロンである [3].
パーセプトロンとは複数の信号を入力として受け取り, ひとつの信号を出力するものである. ここで述
べる信号とは 0か 1の 2値であり, 信号が流れることによって情報が先へと伝達される. 以下の図 2.1
に 2つの信号を入力として伝達するパーセプトロンの図を示す.
x1, x2 は入力信号, y は出力信号, w1, w2 は重みである. 入力信号がニューロン (図 2.1の◯の部分)
に伝達されるとそれぞれの固有の重みが乗算される. 伝達された信号の総和が閾値 (式 (2.1)ではθで
示す)を超えた場合に 1が出力される. これらを以下の式 (2.1)に示す.
y =
{0 (w1x1 + w2x2 ≤ θ)1 (w1x1 + w2x2 > θ)
(2.1)
ニューラルネットワークには適切な重みパラメータをデータから自動で学習できる性質がある.
ニューラルネットワークの仕組みを図 2.2に示す.
- 2 -
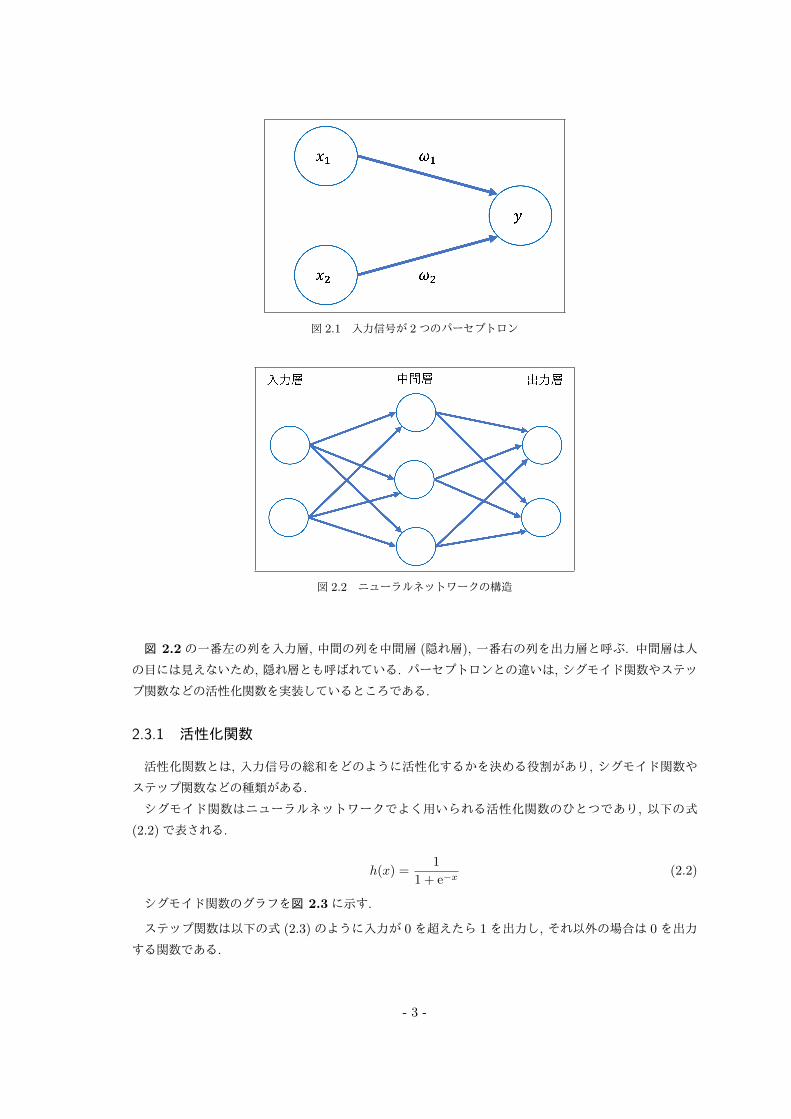
図 2.1 入力信号が 2つのパーセプトロン
図 2.2 ニューラルネットワークの構造
図 2.2の一番左の列を入力層, 中間の列を中間層 (隠れ層), 一番右の列を出力層と呼ぶ. 中間層は人
の目には見えないため, 隠れ層とも呼ばれている. パーセプトロンとの違いは, シグモイド関数やステッ
プ関数などの活性化関数を実装しているところである.
2.3.1 活性化関数
活性化関数とは, 入力信号の総和をどのように活性化するかを決める役割があり, シグモイド関数や
ステップ関数などの種類がある.
シグモイド関数はニューラルネットワークでよく用いられる活性化関数のひとつであり, 以下の式
(2.2)で表される.
h(x) =1
1 + e−x(2.2)
シグモイド関数のグラフを図 2.3に示す.
ステップ関数は以下の式 (2.3)のように入力が 0を超えたら 1を出力し, それ以外の場合は 0を出力
する関数である.
- 3 -

図 2.3 シグモイド関数のグラフ
h(x) =
{0 (x ≤ 0)1 (x > 0)
(2.3)
ステップ関数のグラフを図 2.4に示す.
図 2.4 ステップ関数のグラフ
2.4 Recurrent Neural Network
Recurrent Neural Network(以下 RNN)とは, 可変長の入力列を扱うことに優れたネットワークであ
り, 主に自然言語や時系列データなど連続性のあるデータに対して扱う再帰ニューラルネットワークで
ある [2]. 前の時刻の隠れ状態ベクトルと現時刻の入力ベクトルを使い, 隠れ状態ベクトルを更新すると
いう仕組みである.
RNNは長さ T の入力ベクトル列 X = (x1, x2, ..., xTX))が与えられた時の l 層目の隠れ状態ベクト
ルを以下の式 (2.4)のように再帰的に更新する.
- 4 -

h(1)t = a(1)
(W (1)
[h(l−1)t
h(1)t−1
]+ b(1)
)(2.4)
以下の図 2.5に L層の RNNの構造を示す.
図 2.5 L層の RNNの構造
また、RNNには誤差逆伝播法*1(時間方向誤差逆伝播*2とも呼ばれる)や双方向再帰ニューラルネッ
ト*3, ゲート付再帰ニューラルネット*4などがある.
2.5 Long Short-Term Memory
Long Short-Term Memory(以下 LSTM) とは, もっとも代表的なゲート付きニューラルネットのこ
とである [2]. RNNは時間方向に深いニューラルネットとなっているため, 時系列が離れているもの同
士に発生した誤差を伝搬させることが勾配消失の影響で困難であるという性質を持っている. すなわち
長期記憶*5を苦手とし, 短期記憶*6だけを学習してしまう傾向がある.
そこで, 時間方向の隠れ状態の計算に,ゲートと呼ばれる誤差が伝播しやすくなるショートカットを加
えた関数 h(1) = f (1)(h(l−1))を一般化したものを使って, 長期の情報を集約できるようにした RNNが
ゲート付き再帰ニューラルネットである.
LSTMでは入力 (input)ゲート i, 忘却 (forget)ゲート f , 出力 (output)ゲート oの 3つのゲートを
使用する. また, 長期の情報を保持するセル (cell)と呼ばれる別の隠れ状態ベクトル cを使用すること
*1 時刻 Tから時刻 1に遡って誤差を伝播する方法*2 back-propagation through time(BPTT)*3 bi-directional recurrent neural networks(双方向 RNN)*4 長期記憶と短期記憶のバランスを学習するニューラルネット*5 long-term memory*6 short-term memory
- 5 -
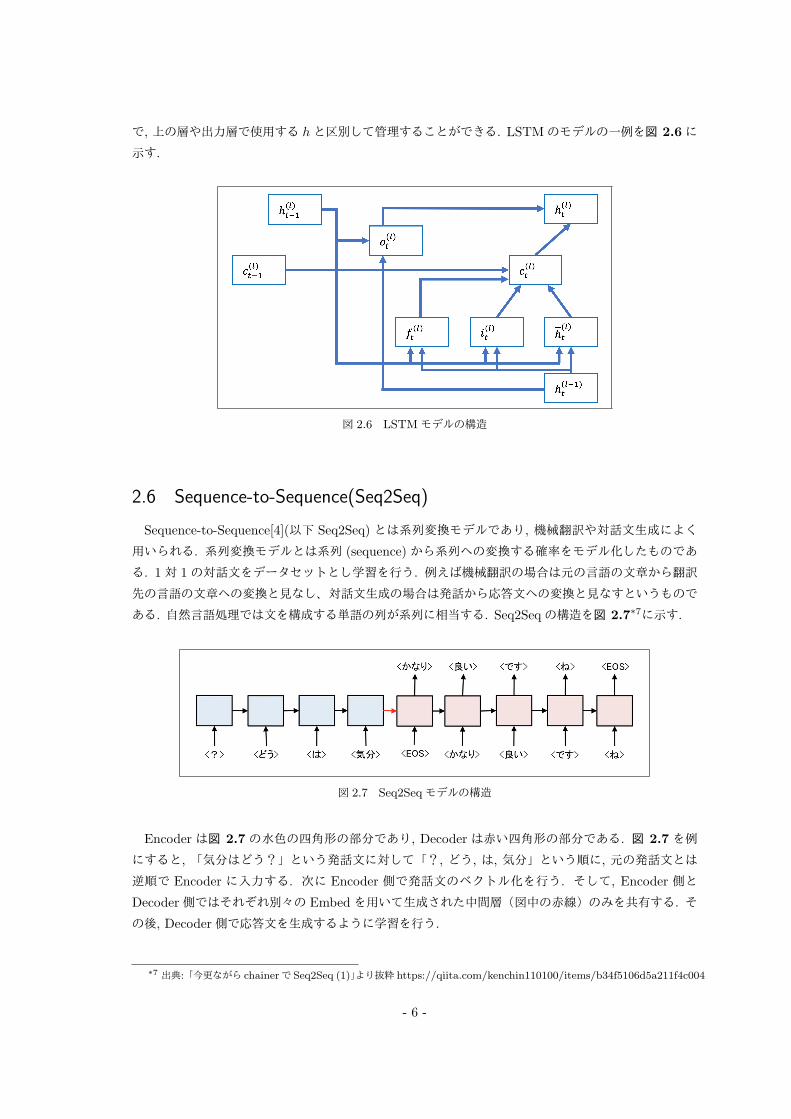
で, 上の層や出力層で使用する hと区別して管理することができる. LSTMのモデルの一例を図 2.6に
示す.
図 2.6 LSTMモデルの構造
2.6 Sequence-to-Sequence(Seq2Seq)
Sequence-to-Sequence[4](以下 Seq2Seq) とは系列変換モデルであり, 機械翻訳や対話文生成によく
用いられる. 系列変換モデルとは系列 (sequence) から系列への変換する確率をモデル化したものであ
る. 1対 1の対話文をデータセットとし学習を行う. 例えば機械翻訳の場合は元の言語の文章から翻訳
先の言語の文章への変換と見なし、対話文生成の場合は発話から応答文への変換と見なすというもので
ある. 自然言語処理では文を構成する単語の列が系列に相当する. Seq2Seqの構造を図 2.7*7に示す.
図 2.7 Seq2Seqモデルの構造
Encoder は図 2.7 の水色の四角形の部分であり, Decoder は赤い四角形の部分である. 図 2.7 を例
にすると, 「気分はどう?」という発話文に対して「?, どう, は, 気分」という順に, 元の発話文とは
逆順で Encoder に入力する. 次に Encoder 側で発話文のベクトル化を行う. そして, Encoder 側と
Decoder側ではそれぞれ別々の Embedを用いて生成された中間層(図中の赤線)のみを共有する. そ
の後, Decoder側で応答文を生成するように学習を行う.
*7 出典:「今更ながら chainerで Seq2Seq (1)」より抜粋 https://qiita.com/kenchin110100/items/b34f5106d5a211f4c004
- 6 -

また, Seq2Seqの入力系列を X, 出力系列を Y で表すと以下の式 (2.5)(2.6)となる. 入力系列中の i
番目の要素を xi とし,同様に出力系列中の j 番目の要素を yj とする. そして入力文長を I とし, 出力文
長を J とする.
X = (x1, ..., xi, ..., XI) = (xi)Ii=1 (2.5)
Y = (y1, ..., yj , ..., yJ) = (yj)Jj=1 (2.6)
そして, ある入力系列 X が与えられたときに, ある出力系列 Y へ変換する条件付き確率 P (Y |X)を
考える. これをモデル化したものが系列変換モデルであり, Seq2Seqでは長い時系列データにも対処す
るため LSTMが用いられている. 出力系列の各位置 j で yj が生成される条件付き確率の乗算で構成さ
れるモデルを式 (2.7)を以下に示す.
Pθ(Y |X) =
J+1∏j=1
Pθ(yj |Y<j , X) (2.7)
また, シーケンスの終わりを表現するために EOS(End Of Sequenceの略)という記号を使う.
2.7 Attention付き Seq2Seq
Attention付き Seq2Seqとは、Seq2Seqと Attentionがベースとなったモデルである.
Attention [5]とは, Decode時に入力系列の情報を直接参照できるようにする仕組みを持つモデルで
ある. Seq2Seqモデルでは入力系列の情報を Encoderで圧縮したベクトルでしか Decoderに伝えるこ
とができないため,入力系列が長いと入力系列の情報を Decoderにしっかりと伝えることが難しくなる.
それを克服するものが Attentionである. Attentionの構造を図 2.8に示す.
Attention は時刻 t における Decoder の隠れ層ベクトル ht と Encoder の各時刻の隠れ層ベクトル
hs のスコアを計算し時刻 t でどの入力単語に注目するかのスコア αt を決定する. このスコアを元に
Encoderの隠れ層ベクトルの加重平均 ct を求めそれを元に時刻 tの隠れ層ベクトル ht を計算する.
そして, 時刻 tの Decoderの隠れ層ベクトルと各入力に対する Encoderの隠れ層ベクトルのスコア
を計算し, Softmax*8を取ることで時刻 tの出力に影響を与える入力情報の割合を計算する. そして入力
側の隠れ層を足し合わせることで, Decoderの隠れ層と結合し変換を行い, 時刻 tの最終的な隠れ層ベ
クトルを得ている.
Attention付き Seq2Seqモデルの構造を図 2.9*9に示す.
図 2.9の「At」と記されている部分が Attentionモデルであり, Encoder側では、毎回出力される中
間ベクトルを Attention Modelの中に記憶させる. Encoderの中間ベクトルの加重平均を Decoderに
入力することで前後にある単語どこにでも注目できるように最適化していくのである.
*8 出力で得た数値の和が 1.0になるように整える関数*9 出典: 「今更ながら chainerで Seq2Seq(2)~Attention Model編~」より抜粋
https://qiita.com/kenchin110100/items/eb70d69d1d65fb451b67
- 7 -
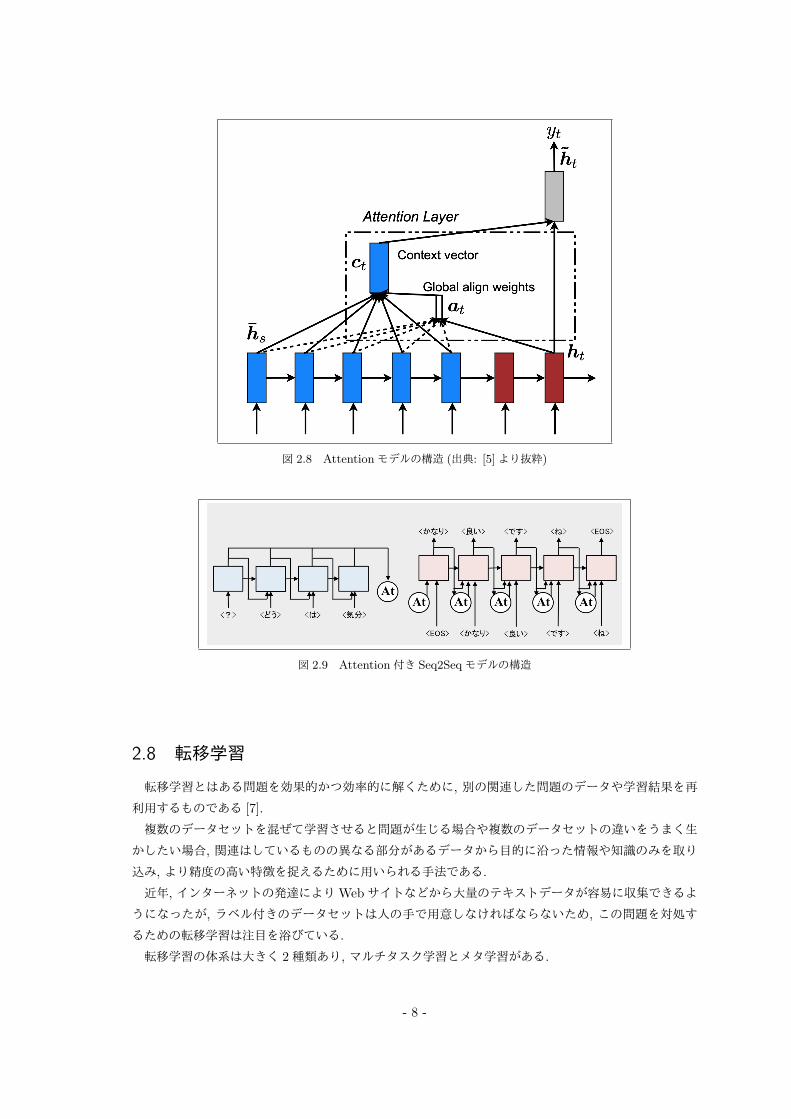
図 2.8 Attentionモデルの構造 (出典: [5]より抜粋)
図 2.9 Attention付き Seq2Seqモデルの構造
2.8 転移学習
転移学習とはある問題を効果的かつ効率的に解くために, 別の関連した問題のデータや学習結果を再
利用するものである [7].
複数のデータセットを混ぜて学習させると問題が生じる場合や複数のデータセットの違いをうまく生
かしたい場合, 関連はしているものの異なる部分があるデータから目的に沿った情報や知識のみを取り
込み, より精度の高い特徴を捉えるために用いられる手法である.
近年, インターネットの発達によりWebサイトなどから大量のテキストデータが容易に収集できるよ
うになったが, ラベル付きのデータセットは人の手で用意しなければならないため, この問題を対処す
るための転移学習は注目を浴びている.
転移学習の体系は大きく 2種類あり, マルチタスク学習とメタ学習がある.
- 8 -

マルチタスク学習とは元ドメイン*10と目標ドメイン*11が互いのドメインから知識を転移して, 両方
のドメインで遅く精度を向上させるというものである. これを実現する手法を図 2.10に示す.
図 2.10 マルチタスク学習を実現する手法 (出典: [7]より抜粋)
図 2.10の (a)のは各ドメインを目標ドメインとして個別に転移することを全ドメインについて行う
手法である. A, B, Cの 3つのドメインがある場合, 最初に Bと Cを元ドメインに設定し Aを目標ド
メインとして転移学習を行う. 同様に Aと Cから Bへ, Aと Bから Cへと転移学習を行っていく.
図 2.10の (b)のは全ドメインに共通する知識を求め, それらを全ドメインに転移学習を行う手法で
ある.A, B, Cに共通する知識を求め, それを用いて各ドメインでの学習結果を最適化していくのである.
図 2.10の黒く塗りつぶされた部分が転移学習される知識であり, 個別に転移学習する場合は (a)の
方が転移学習される知識量が多く, 共通部分を転移学習する場合は (b)の方が転移学習される知識量が
多い. また, 個別に転移学習する場合は全てのドメインについて転移学習を行う必要があるため, 実行コ
ストは大きい. しかし, 共通部分を転移学習する場合は, 共通する知識を各ドメインで共有できるためコ
ストが小さい.
一方, メタ学習とはデータセットの規模や分布, 仮設空間などの問題の特性に応じて, 適切な学習手法
を選択するためのメタ知識を獲得するというものである.
*10 転移学習する知識の送り手側*11 転移学習の受け手側
- 9 -

第 3章
関連研究
3.1 Seq2seqを用いた対話文生成
Oriol Vinyalsらは Seq2Seqモデル [4]モデルを用いた対話文生成の研究 [6]を行った. データセット
には IT Helpdesk Troubleshooting datasetというクローズドメインとmovie transcript datasetとい
うオープンドメインを用いて学習を行った. Seq2Seqモデルを使うことで与えられた発話から次の発話
を予測し, 応答文を生成するというモデルである.
作成したモデルと既存のモデル (CleverBot*1)にそれぞれ 200の質問 (発話文)を入力し, 応答文を生
成した結果を人の手で評価を行った. その結果, CleverBotは 200の質問のうち 60回答が好ましいと評
価されたのに対し, 作成したモデルは 200の質問のうち 97回答が好ましいと評価された. 既存のモデル
よりも有用性が証明された.
3.2 転移学習による対話文への個性の付与
対話生成のスタイル制御を行うために,赤間らが転移学習を用いた対話文生成の研究 [8]を行った. 一
貫したスタイルを付与するため特定のキャラクターの対話データを大量に用意して学習する手法は以前
から提案されていたが, 大量のキャラクター別の対話データを必要とせず,従来よりも低いコストで応
答にスタイルを付与するという目的により, その研究では Seq2Seqモデル [4]を用いた応答生成モデル
に転移学習を組み合わせる手法を提案している.
まず, キャラクターらしさなどを考慮せずに大規模な対話データセットを用意し事前学習を行う. そ
して事前学習した応答生成モデルをもとにして,特定のス タイルに制限した少規模な対話データを用い
た転移学習を行う.
データセットは事前学習用に Twitterから抽出された対話データと, スタイル付与用に TV番組字幕
データ (話者は黒柳徹子*2, おじゃる丸*3の 2種)から抽出した対話データを使用している. 事前学習用
のデータ数は 370万会話,スタイル付与用のデータ数は黒柳徹子が 12564会話, おじゃる丸が 1476会話
である.
応答文を生成した結果を人の手で評価した. 結果 57生成された対話文のうち、黒柳徹子スタイルで
は適切な応答文が 53(93.0%) でスタイル付与に成功した応答文が 47(82.5%) であった. 一方, おじゃ
*1 https://www.cleverbot.com/*2 テレビ朝日「徹子の部屋」の字幕データを使用*3 NHK「おじゃる丸」の字幕データを使用
- 10 -

る丸スタイルでは適切な応答文が 23(40.4%)でスタイル付与に成功した応答文が 50(87.7%)であった.
黒柳徹子スタイルでは既存のモデルより有用性があるという結果になったが, 低年齢層向けで使用単語
数の少ないおじゃる丸スタイルではスタイル付与は成功した一方, 適切な応答文が 50%を下回る結果と
なった.
転移学習を用いることで,大量のキャラクター別の対話データを必要とせず,従来よりも 低いコスト
で応答にスタイルを付与することができる.
- 11 -

第 4章
提案手法
本研究では「Attention付き Seq2Seqを用いた対話文生成」と「個性のある対話文生成」を組み合わ
せた対話文生成の手法を提案する. 発話文を人の手で入力し, それに対して個性のある応答文を生成す
る. 提案手法の概要図を図 4.1に示す.
図 4.1 提案手法の概要図
4.1 Attention付き Seq2seqを用いた対話文生成
本研究では対話文生成に Attention付き Seq2Seqを用いる. データセットには映画字幕から抽出した
対話文を使用し, 事前学習を行う. その後, 事前学習モデルを保存する.
4.2 個性のある対話文生成
本研究では個性のある対話文生成を行うため, 事前学習したモデルをロードし, ジャンル分けした映
画字幕のデータセットの中から特定ジャンルのデータセットのみを取り出したものを用いて転移学習を
行う. 転移学習を行うことで, 事前学習のモデルよりも個性のある応答文を生成する.
- 12 -

第 5章
実装
5.1 開発環境
開発環境は以下のものを利用した.
• macOS Mojave 10.14.6
• Python 3.7.3
• Chainer 6.4.0
• cupy-cuda100 6.4.0
• MeCab 0.996.2
• GeForce GTX 980 Ti
5.2 データセット
5.2.1 映画字幕を用いたデータセット
対話文生成のためのデータセットは, 映画字幕のデータを取り扱っている opensubtitles.org*1から
Webスクレイピングしたものから対話文を抽出して作成した. 抽出した映画数は 834本で, そこから抽
出した会話数は 851526会話である.
データセットの前処理は,スクレイピングしてきたものから日本語以外の映画字幕やデータが破綻
しているもの (文字が破綻しているものなど)を取り除き, 会話文かどうか判断するために字幕を表示す
る間隔が 5秒以内のものだけを対話文のセットとみなし、発話文-対話文のセットに成形した.
5.2.2 映画字幕のジャンル分け
個性のある対話文生成をするために,抽出した映画字幕のデータを手作業でジャンル分けした. ジャ
ンル分けを行うにあたり参考にしたWebサイトはWikipedea*2と Filmarks(フィルマークス)映画*3で
ある. データセットを以下のジャンル別に振り分けた.
*1 opensubtitles.org: https://www.opensubtitles.org/ja*2 Wikipedia: https://ja.wikipedia.org/wiki/*3 Filmarks映画: https://filmarks.com
- 13 -

• アクション• SF(サイエンスフィクション)
• ドラマ• コメディー• スリラー• ロマンス• ホラー• アニメ• ファンタジー• アドベンチャー• クライム• ドキュメンタリー• 歴史• 音楽• ミステリー• ボリウッド
ジャンル別の映画数と会話数を表 5.1に示す. 複数ジャンルに振り分けている映画もある.
表 5.1 映画字幕 ジャンル別の映画数と会話数
ジャンル 映画数 会話数
アクション 179 196370
SF(サイエンスフィクション) 114 120330
ドラマ 103 116434
コメディー 92 103132
スリラー 84 80012
ロマンス 70 79419
ホラー 97 71393
アニメ 65 65964
ファンタジー 57 53466
アドベンチャー 34 40390
クライム 19 22880
ドキュメンタリー 19 21409
歴史 17 19464
音楽 9 8244
ミステリー 7 8052
ボリウッド 4 6368
- 14 -

5.3 対話文生成の実装
本研究では深層学習のフレームワークに Chainer*4を使用した. 形態素解析はMeCab*5を使用し, 映
画字幕のデータセットに分かち書きを行い単語辞書を作成した. また, データセットを発話文-応答文の
ペアにすることで学習のネットワークに適用させた.
コードは Gin04ghによる Attention付き Seq2Seq[9]を改良し利用した. Attention付き Seq2Seqモ
デルのネットワークを Listing5.1に示す.
Listing 5.1 Attention付き Seq2Seqモデルのネットワーク
1 # -*- coding: utf-8 -*-
2 #Attention Sequence to Sequence クラス Model
3 class AttSeq2Seq(chainer.Chain):
4 def __init__(self, vocab_size, embed_size, hidden_size, batch_col_size):
5 """Attention + のインスタンス化 Seq2Seq
6
7 Args:
8 vocab_size: 語彙数のサイズ9 embed_size: 単語ベクトルのサイズ
10 hidden_size: 隠れ層のサイズ11 """
12 super(AttSeq2Seq, self).__init__(
13 f_encoder = LSTMEncoder(vocab_size, embed_size, hidden_size), # 順向きの Encoder
14 b_encoder = LSTMEncoder(vocab_size, embed_size, hidden_size), # 逆向きの Encoder
15 attention = Attention(hidden_size), # Attention Model
16 decoder = AttLSTMDecoder(vocab_size, embed_size, hidden_size) # Decoder
17 )
18 self.vocab_size = vocab_size
19 self.embed_size = embed_size
20 self.hidden_size = hidden_size
21 self.decode_max_size = batch_col_size # デコードはが出力されれば終了する、出力されない場合の最大出力語彙数 EOS
22 # 順向きのの中間ベクトル、逆向きのの中間ベクトルを保存するためのリストを初期化EncoderEncoder
23 self.fs = []
24 self.bs = []
25
26 def encode(self, words, batch_size):
27 """の計算 Encoder
28
29 Args:
30 words: 入力で使用する単語記録されたリスト31 batch_size: ミニバッチのサイズ
*4 https://chainer.org/*5 オープンソース形態素解析エンジン: https://taku910.github.io/mecab/
- 15 -

32 """
33 c = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype=’
float32’))
34 h = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype=’
float32’))
35 # 順向きのの計算 Encoder
36 for w in words:
37 c, h = self.f_encoder(w, c, h)
38 self.fs.append(h) # 計算された中間ベクトルを記録39 # 内部メモリ、中間ベクトルの初期化40 c = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype=’
float32’))
41 h = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype=’
float32’))
42 # 逆向きのの計算 Encoder
43 for w in reversed(words):
44 c, h = self.b_encoder(w, c, h)
45 self.bs.insert(0, h) # 計算された中間ベクトルを記録46 # 内部メモリ、中間ベクトルの初期化47 self.c = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype=’
float32’))
48 self.h = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype=’
float32’))
49
50 def decode(self, w):
51 """の計算 Decoder
52
53 Args:
54 w: で入力する単語 Decoder
55 Returns:予測単語56
57 """
58 att_f, att_b = self.attention(self.fs, self.bs, self.h)
59 t, self.c, self.h = self.decoder(w, self.c, self.h, att_f, att_b)
60 return t
61
62 def reset(self):インスタンス変数を初期化する63 """
64 """
65 # の中間ベクトルを記録するリストの初期化 Encoder
66 self.fs = []
67 self.bs = []
68 # 勾配の初期化69 self.zerograds()
70
71 def __call__(self, enc_words, dec_words=None, train=True):順伝播の計算を行う関数
- 16 -

72 """
73
74 Args:
75 enc_words: 発話文の単語を記録したリスト76 dec_words: 応答文の単語を記録したリスト77 train: 学習か予測か78 Returns:計算した損失の合計79 or 予測したデコード文字列80 """
81 enc_words = enc_words.T
82 if train:
83 dec_words = dec_words.T
84 batch_size = len(enc_words[0]) # バッチサイズを記録85 self.reset() # 内に保存されている勾配をリセット model
86 enc_words = [chainer.Variable(xp.array(row, dtype=’int32’)) for row in
enc_words] # 発話リスト内の単語を型に変更Variable
87 self.encode(enc_words, batch_size) # エンコードの計算88 t = chainer.Variable(xp.array([0 for _ in range(batch_size)], dtype=’int32
’)) # <eosをデコーダーに読み込ませる>
89 loss = chainer.Variable(xp.zeros((), dtype=’float32’)) # 損失の初期化90 ys = [] # デコーダーが生成する単語を記録するリスト91 # デコーダーの計算92 if train: # 学習の場合は損失を計算する93 for w in dec_words:
94 y = self.decode(t) # 単語ずつをデコードする 1
95 t = chainer.Variable(xp.array(w, dtype=’int32’)) # 正解単語を型に変換 Variable
96 loss += F.softmax_cross_entropy(y, t) # 正解単語と予測単語を照らし合わせて損失を計算
97 return loss
98 else: # 予測の場合はデコード文字列を生成する99 for i in range(self.decode_max_size):
100 y = self.decode(t)
101 y = xp.argmax(y.data) # 確率で出力されたままなので、確率が高い予測単語を取得する
102 ys.append(y)
103 t = chainer.Variable(xp.array([y], dtype=’int32’))
104 if y == 0: # を出力したならばデコードを終了する EOS
105 break
106 return ys
本研究の実装では対話文生成の方法として, 手入力した発話文に対して応答文の生成を自動で行い, 応
答文を 1文生成するというものである.
- 17 -

5.4 個性のある対話文の実装
本研究では個性のある対話文を生成するため, データセットである映画字幕をジャンル分けし, それ
ぞれのジャンルごとの映画字幕を用いて転移学習を行う. 転移学習に用いる学習のネットワークは事前
学習で用いたものと同じ, Attention付き Seq2Seqモデルを使用する.
また, 転移学習を行ったモデルを用いて個性のある対話文生成を行う. 手入力した発話文に対して個
性のある応答文の生成を自動で行い, 応答文を 1文生成する.
- 18 -

第 6章
実験結果と評価
6.1 実験に用いたパラメータ
応答文は 20単語以内になるように生成した. 以下のパラメータで対話文生成を行なった.
• 事前学習のエポック数: 100回
• 転移学習のエポック数: 20回
• 埋め込み層: 200層
• バッチサイズ: 256
• 隠れ層: 1000層
• optimizer: Adam
• データセットの単語登録数: 72711
• 事前学習データ数: 851500
6.2 評価項目
評価方法は, 研究室のメンバーおよび東京工科大学の学生 7人に生成した対話文を見てもらう. 個性
をつける前の対話文生成において, 生成された応答文の文章について 評価をつけてもらう. 評価項目は
以下の通りである.
• 応答文は文章として成立しているか (破綻はないか)
• 会話は成立しているか
さらに, 個性をつけた対話文生成において, 生成された応答文の文章についても評価をつけてもらう.
評価項目は以下の通りである。
• 応答文は文章として成立しているか (破綻はないか)
• 会話は成立しているか• 応答文に個性は出ているか
以上の項目について, ○か×の 2値評価を行う. 各ジャンルの対話文生成を 20個ずつ行なったため,
満点は各 20点である.
- 19 -

6.3 結果
事前学習時の total lossの推移を以下の図 6.1に示す.
図 6.1 事前学習による lossの推移
また, 以下の 20文を発話文とし、事前学習のモデルと転移学習のモデル (個性をつけるためのモデル)
を用いて対話文生成を行なった.
• データセット内から抜き出した発話文 (データセット内の発話文)
– おはよう
– こんにちは
– みんな!一緒にワインを飲むか?
– 何してた?
– 悲しんでる?
– お腹すいた?
– 朝ごはん何食べる?
– 何が望みだ?
– ここはどこだ?
– どこ行くの?
• データセットにはない発話文 (データセット外の発話文)
– あなたに興味はないわ
– パパ、おもちゃ買ってよ~
– これからお出かけですか?
– 話しかけてこないで
– 頂点に立つ覚悟はある?
– 卒業式まで…あと少しだね
– 数学の単位は取れそう?
- 20 -
– 魔法でなんとかしてくれよ!
– 今日はもう帰ってくれ
– さっきのテレビつまらないよね?
生成した対話文のうち, 個性をつける前の生成結果を表 6.1に示す.
表 6.1 生成した対話文 (個性をつける前)
発話文 応答文
おはよう どうも
こんにちは こんにちは
みんな!一緒にワインを飲むか? -探し出す-ネブラスカの誕生日?
何してた? 別に
悲しんでる? その話は?
お腹すいた? いいわ
朝ごはん何食べる? アソコでこんな楽しい機会になっちゃうから
何が望みだ? 私は人々の助けを借りてきました
ここはどこだ? ここは危険な場所だ
どこ行くの? ここで待ってろ
あなたに興味はないわ そうか
パパ、おもちゃ買ってよ~ エバ、ほんとに君のパパは...
これからお出かけですか? (雨宮)さあ奥様
話しかけてこないで 私は怖くない
頂点に立つ覚悟はある? いいぞ!(ハルオ)なに?
卒業式まで…あと少しだね “素敵な温室用”
数学の単位は取れそう? そうよね
魔法でなんとかしてくれよ! -これでウーズマが必要です-アメ邪魔されてませんよ
今日はもう帰ってくれ ああフアン会えて嬉しいよ
さっきのテレビつまらないよね? 私は休暇中ですから
また, 生成した対話文の評価について 7 人中 5 人以上が「○」と判断した数を項目ごとに集計した.
その結果を, 図 6.2~図 6.4に示す.
- 21 -
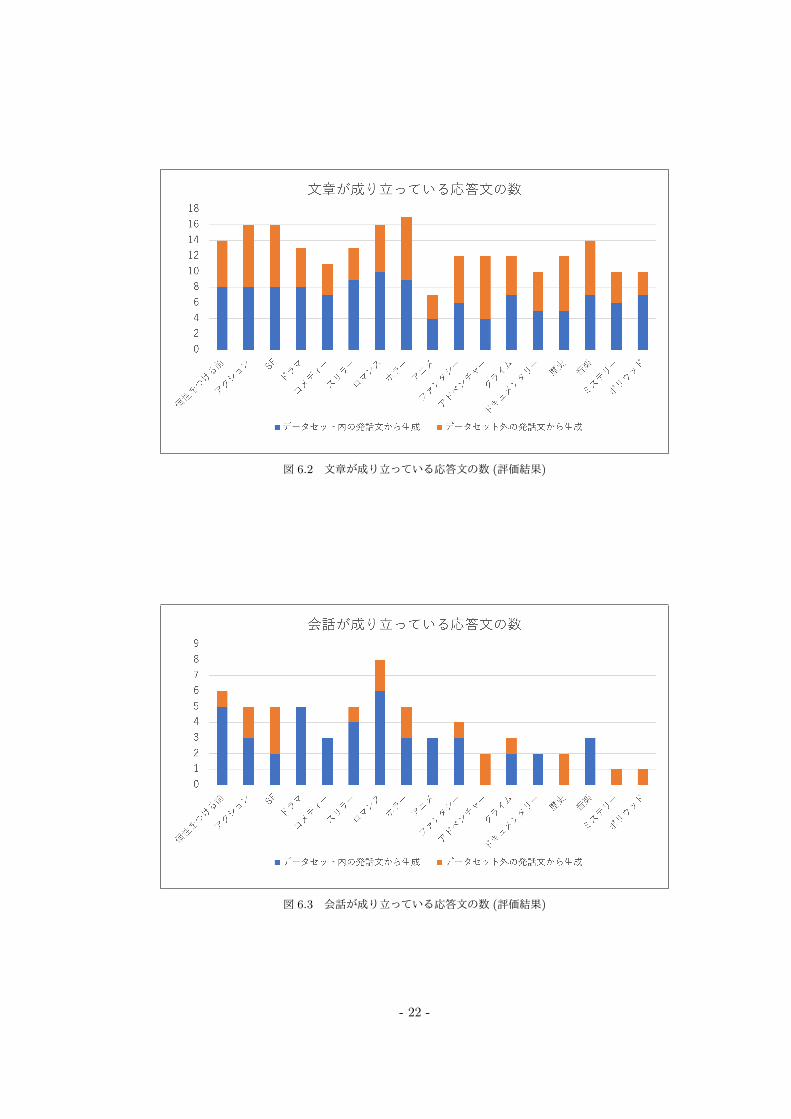
図 6.2 文章が成り立っている応答文の数 (評価結果)
図 6.3 会話が成り立っている応答文の数 (評価結果)
- 22 -
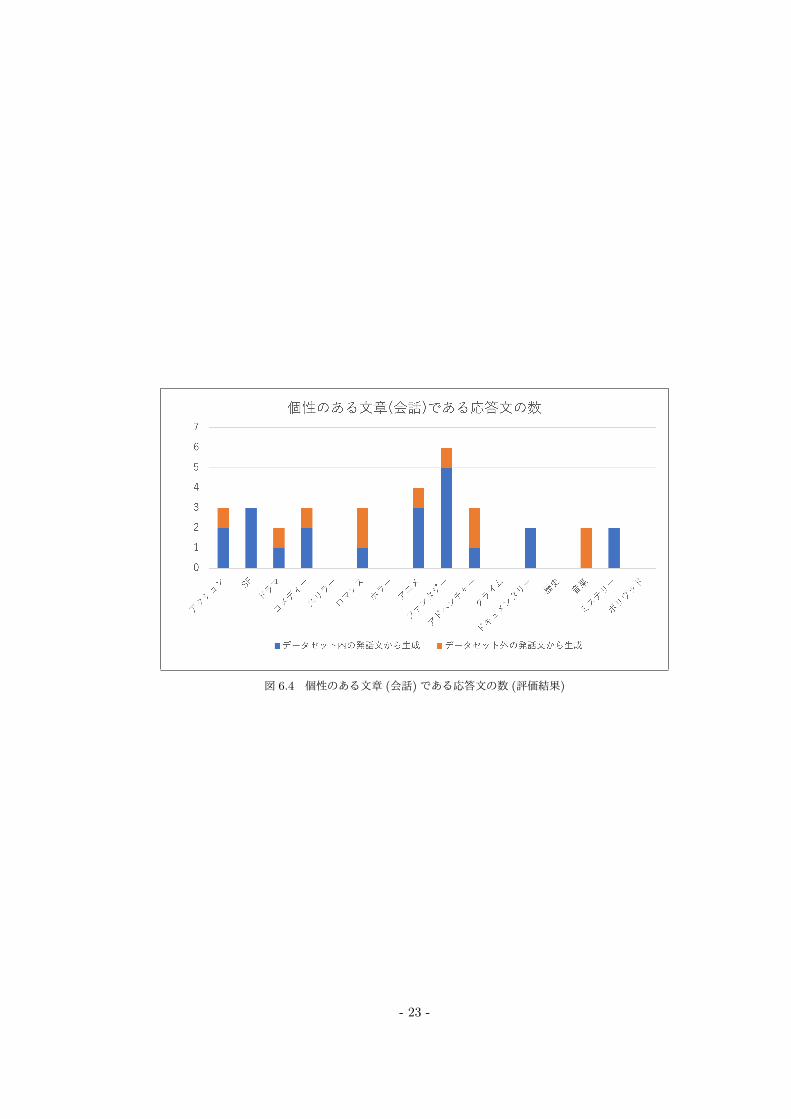
図 6.4 個性のある文章 (会話)である応答文の数 (評価結果)
- 23 -

6.4 考察
6.4.1 生成結果からの考察
全体的にデータセット外の発話文よりもデータセット内の発話文の方が会話の成り立っている対話
文が多かった. どちらの発話文に対しても言えることは,映画字幕ゆえデータセットに固有名詞が多く,
記号 (「」”‘-―など)やセリフを喋っている人を示す表記 (例: (遠藤))が含まれていたので, データ
セットにノイズがあり対話文生成が上手くいっていないケースが多くあった. また, データセットであ
る映画字幕に不適切な表現を含む内容もあったので, データセットとしてふさわしくないものが含まれ
ていた.
評価結果の中で, 個性のある文章 (会話)である応答文の数が一番多い発話文「何してた?」の応答文
を表 6.2に示す.
表 6.2 発話文「何してた?」の応答文
ジャンル 応答文
個性をつける前 別に
アクション 話を付けてきた
SF 答えろよ...
ドラマ ー何にしたんですか?
コメディー 何を?
スリラー 別に
ロマンス 違うか?
ホラー 何かの...
アニメ きれいな狩り
ファンタジー 何ををしている?
アドベンチャー ヘクターの写真を飾るか?
クライム 何をやったんだ?
ドキュメンタリー 最後のドキュメントは?
歴史 大したの食糧を...
音楽 ああ
ミステリー 誰が...
ボリウッド 何の勉強だ?
表 6.2を見てわかるようにジャンルごとの応答文が多種多様である. 特に個性のある応答文として評
価されたジャンルはアクション、SF、アニメ、ドキュメンタリーである. この 4つのジャンルに関して
は応答文の文章が成り立っており, アクションと SFについては会話も成り立っている.
また映画数の少ないジャンルについては, ジャンル「音楽」に挙げられるように「オペラ」「曲」「バ
ンド」などその映画ジャンル特有の単語が含まれているため個性のある文章を生成できたものがあるこ
とから, ジャンルごとの特有の単語があれば個性のある応答文と判断されやすいのではないかと考える.
- 24 -

しかし, データ数が少ないゆえに応答文が生成されないことや主語に記号 (「)が使われてしまうことが
ある. そもそもジャンル「ボリウッド」はジャンルとしての知名度が非常に低いため, 個性の有無を判
断しづらい.
一方, 映画数の多いジャンルについては, 全体的に文章の破綻しているものが少なく, しっかりとした
文章になっているものが多く生成できていると言える. また, 映画数の少ないジャンルよりも会話が成
り立っている対話文が多く, 転移学習の際はデータセットが多い方が上手く対話文生成を行えることが
分かった. ジャンル「ドラマ」の応答文には「...」を使うなどシリアスな雰囲気が出ている応答文もあっ
たが, ジャンルによっては個性のある応答文が少ないものがあり, データセット数が多いゆえに多様な
表現があることで個性が付きにくかったのではないかと考える.
そして評価結果の中で, 個性のある文章 (会話)である応答文の数が一番多いジャンル「ファンタジー」
の生成結果より, 評価の高いのものを表 6.3に示す.
表 6.3 ジャンル「ファンタジー」らしい個性をつけた対話文のうち評価の高いもの
発話文 応答文
おはよう おはよう?おはようですと?
こんにちは みなさん聞くのが怖いでしょ?
悲しんでる? もちろんダイアナもそうだ
ここはどこだ? ここは花果山だ
どこ行くの? 彼女が天の戦士と来ている
さっきのテレビつまらないよね? 本当の自分で殺されんの?
評価の高い応答文は全部で 6個あり, データセット内の発話文で評価の高い応答文は 5個あるのに対
しデータセット外の発話文で評価の高い応答文は 1個である. 生成結果に着目すると, 「天の戦士」と
いうファンタジーらしい単語が応答文に含まれている. また, 発話文「おはよう」に対して「おはよう?
おはようですと?」という独特な言い回しの応答文を生成することができた.
6.4.2 評価結果からの考察
文章が成り立っている応答文の数が一番多いジャンルは「ホラー」であり, 文章が成り立っていると
評価された応答文は 17個である. 次に評価の高いジャンルは「アクション」「ロマンス」「SF」であり,
文章が成り立っていると評価された応答文は 16個である. これらのジャンルは映画数が多いジャンル
である. すなわちデータセットの多いジャンルであり, データセットが多い方が文章が成り立っている
応答文を生成できると言える. 全ジャンルを合わせると, データセット内の発話文で文章が成り立って
いると評価された応答文は 118 個 (69.4%) であり, データセット外の発話文では 97 個 (57.1%), 合計
で 215個 (63.2%)である. データセット内の発話文の方が文章の成り立っている応答文を生成できるが
データセット外の発話文でも文章の成り立っている応答文を生成できると言える.
また会話が成り立っている応答文の数が一番多いジャンルは「ロマンス」であり, 会話が成り立って
いると評価された応答文は 8個である. 次に評価の高いものは個性をつける前の応答文であり, 会話が
成り立っていると評価された応答文は 6個である. その次に評価の高いジャンルは「ドラマ」「アクショ
ン」「SF」「スリラー」「ホラー」であり, 会話が成り立っていると評価された応答文は 5 個である. 映
- 25 -

画数 (データセット) の多いジャンルの方が会話が成り立っていると評価された応答文が多い. データ
セット内の発話文で会話が成り立っていると評価された応答文は 44個 (25.9%)であり, データセット
外の発話文では 19個 (11.2%), 合計で 63個 (18.5%)である. データセット内の発話文の方が会話が成
り立っている応答文が圧倒的に多いが, ジャンル「歴史」「ミステリー」「ボリウッド」「アドベンチャー」
に関してはデータセット外の発話文のみ会話が成り立っている応答文がある. 一方, データセット内の
発話文のみ会話が成り立っている応答文があるジャンルは「コメディー」「アニメ」「音楽」「ドキュメン
タリー」であり, ジャンルによって適切であるデータセットが違うと考える.
そして個性のある文章 (会話)である応答文の数が一番多いジャンルは「ファンタジー」であり, 個性
のある文章 (会話)であると評価された応答文は 6個である. データセット内の発話文で評価の高い応答
文は 5 個あるのに対しデータセット外の発話文で評価の高い応答文は 1 個しかない. 次に評価の高い
ジャンルは「アニメ」であり個性のある文章 (会話) であると評価された応答文は 4 個である. データ
セット内の発話文で会話が成り立っていると評価された応答文は 22個 (12.9%)であり, データセット
外の発話文では 11個 (6.5%), 合計で 33個 (9.7%)である. 個性のある文章 (会話)であると評価された
応答文が 0個のジャンルは 5個もあり, それは「歴史」「クライム」「スリラー」「ボリウッド」「ホラー」
である, 他の項目よりも評価が圧倒的に低い結果となった. データセット内の発話文のみ個性のある文
章 (会話)である応答文があるジャンルは「ミステリー」「SF」「ドキュメンタリー」である. データセッ
ト外の発話文のみ個性のある文章 (会話)である応答文があるジャンルは 1個もない. これらの評価結果
より, データセット内の発話文の方が個性のある応答文を生成できると考える.
6.4.3 改善案
本研究で対話文生成を行なった結果, 問題点や改善すべき点がある.
まず 1つ目の問題点は, データセットの前処理が不十分な点である. 映画字幕 (データセット)に不適
切な表現が含まれていることや文章内に必要のない記号 (「」”‘-―など), セリフを喋っている人を示す
表記 (例: (遠藤))が含まれていたので, データセットにノイズがあり, 対話文を生成する際に文章や
会話の成立した応答文を作れない場合があった. この問題を解決するため, データセットの前処理をさ
らに丁寧に行う必要があると考えられる.
2つ目の問題点は, データセットが映画字幕であるゆえにデータセット内に固有名詞が多く存在し, 各
固有名詞が単語辞書内に登録されてしまうことから, 対話文生成を行なった際, 適切でない固有名詞が
主語になってしまい (人名が主語に来るべきところに地名や謎の固有名詞が入るなど)文章や会話とし
て成り立たなくなってしまう問題があった. この問題を解決するため, 形態素解析に MeCab以外のも
のを用いることで, 固有名詞の単語辞書の登録方法を見直すなど固有名詞など頻度の少ない単語の単語
ベクトルを改善する必要があると考えられる.
3つ目の問題点は, 映画ジャンルのクラスタリング方法である. 本研究ではデータセットの映画字幕を
映画ジャンルごとにクラスタリングし, 全てのジャンルに対して対話文生成を行なった. 中には「ボリ
ウッド」など非常にマイナーなジャンルもあり, 個性のある文章 (会話)かどうか評価する際にどう判断
して良いのか分からないという声が評価者からあった. また, 個性がつきにくいジャンルがあり, その映
画の登場人物が特徴的な喋り方をしていないデータセットが多くなってしまったと考えられる. この問
題を解決するため, あまり知られていない映画ジャンルを個性をつけるためのデータセットとして使う
ことを避けることや, より特徴的な喋り方をする映画の映画字幕をデータセットとして集め, 個性的な
文章 (会話)を作れるようにする必要がある.
- 26 -

第 7章
結論
7.1 結論
本研究では映画字幕を用いて、Attention付き Seq2Seqを用いた対話文生成と個性のある対話文生成
を行うための転移学習を組み合わせた, 個性のある対話文生成の手法を提案した.
対話文を生成した結果, データセット内の発話文の方がデータセット外の発話文よりも文章や会話が
成り立っている応答文が多かった. また, データセットである映画字幕に不適切な表現や不要な記号が
含まれていたため, 文章が成り立っていない応答文も生成されてしまった. また, 一番個性のある文章
(会話)を生成できた発話文は「何してた?」であり, 多種多様な応答文を生成することができた.
そして, 生成した対話文の評価を行なった結果, 一番個性のある文章 (会話)が多いジャンルは「ファ
ンタジー」であり, 全体的にもデータセット内の発話文の方が個性のある文章 (会話)を生成できた. 一
方, データセット外の発話文は個性のある文章 (会話)であると評価された応答文が 1つもないジャンル
もあった. 非常にマイナーである映画ジャンル「ボリウッド」は個性のある文章 (会話)かどうか評価す
る際にどう判断して良いか分からないという声も評価者からあがった.
改善案としてはデータセットから不適切な表現や不要な記号を取り除くなど丁寧な前処理を行うこと
や形態素解析にMeCab以外のものを用いることで, 固有名詞など頻度の少ない単語に対する単語辞書
や単語ベクトルを改善すること, マイナーな映画ジャンルを個性をつけるためのデータセットとして使
うことを避けること, より特徴的な喋り方をする映画の映画字幕をデータセットとすることなどが挙げ
られる.
7.2 今後の展望
今後の展望としては, データセット内にある不適切な表現のものやノイズを除去するなどし, データ
セットの前処理を丁寧に行いたい. また, 形態素解析に MeCab以外の物を使うことで固有名詞の単語
ベクトルを改善したい. そして, データセットのクラスタリングの方法を変え感情分析を行うなどし, 個
性のある対話文生成のためのデータセットを作成したい. さらに, Attention付き Seq2Seq以外の手法
を用いて, より自然な対話文や個性のある対話文を生成したい.
- 27 -

謝辞
本研究を進めるにあたって, 様々なご指導をいただきました柴田先生に深く感謝いたします. そして,
研究を進めるにあたり多くの助言を下さった柴田研究室の皆さん, 対話文の評価をして下さった皆さん
に感謝いたします.
- 28 -

参考文献
[1] Andreas C. Muller, Sarah Guido 著 : “Pythonではじめる機械学習” (2017).
[2] 坪井祐太, 海野裕也, 鈴木潤 著 : “機械学習プロフェッショナルシリーズ 深層学習による自然言語
処理” (2017).
[3] 斎藤康毅 著 : “ゼロから作る DeepLearing -Python で学ぶディープラーニングの理論と実装”
(2016).
[4] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. : “Sequence to sequence learning with neural
networks.” (Advances in neural information processing systems. 2014.).
[5] Minh-Thang Luong, Hieu Pham, Christopher D. Manning : “Effective Approaches to
Attention-based Neural Machine Translation” (Proceedings of the 2015 Conference on Empir-
ical Methods in Natural Language Processing).
[6] Oriol Vinyals, Quoc V. Le : “A Neural Conversational Model” (ICML Deep Learning Work-
shop 2015).
[7] 神嶌 敏広 : “転移学習” (人工知能学会誌 (2010)).
[8] 赤間 怜奈 稲田 和明 小林 颯介 佐藤 祥多 乾 健太郎 : “転移学習を用いた対話応答のスタイル制
御” (言語処理学会 第 23回年次大会 発表論文集).
[9] Gin04gh : “datascience” https://github.com/Gin04gh/datascience/blob/master/
samples_deeplearning_python/attention_seq2seq.ipynb (2019/12/29).
- 29 -

付録
本研究で生成した対話文を表 7.1~表 7.17に示す.
表 7.1 生成した対話文 (個性をつける前)
発話文 応答文
おはよう どうも
こんにちは こんにちは
みんな!一緒にワインを飲むか? -探し出す-ネブラスカの誕生日?
何してた? 別に
悲しんでる? その話は?
お腹すいた? いいわ
朝ごはん何食べる? アソコでこんな楽しい機会になっちゃうから
何が望みだ? 私は人々の助けを借りてきました
ここはどこだ? ここは危険な場所だ
どこ行くの? ここで待ってろ
あなたに興味はないわ そうか
パパ、おもちゃ買ってよ~ エバ、ほんとに君のパパは...
これからお出かけですか? (雨宮)さあ奥様
話しかけてこないで 私は怖くない
頂点に立つ覚悟はある? いいぞ!(ハルオ)なに?
卒業式まで…あと少しだね “素敵な温室用”
数学の単位は取れそう? そうよね
魔法でなんとかしてくれよ! -これでウーズマが必要です-アメ邪魔されてませんよ
今日はもう帰ってくれ ああフアン会えて嬉しいよ
さっきのテレビつまらないよね? 私は休暇中ですから
- 30 -

表 7.2 生成した対話文 (ジャンル「アクション」らしい個性をつけたもの)
発話文 応答文
おはよう 今年の 7月 4日も、すばらしい週末にな
こんにちは やあ
みんな!一緒にワインを飲むか? -上空た名前は?-ああ
何してた? 話を付けてきた
悲しんでる? それは事態を恐れてる
お腹すいた? 君といられれば満足さ
朝ごはん何食べる? 何も無かった
何が望みだ? 俺に違いない
ここはどこだ? どこだ?
どこ行くの? 彼女が現れるの?
あなたに興味はないわ 少し歩き回って
パパ、おもちゃ買ってよ~ いいよ
これからお出かけですか? いつも、皆の話を聞いたか?
話しかけてこないで お願い
頂点に立つ覚悟はある? そうだ…その先が…
卒業式まで…あと少しだね <頭蓋ここをナニ>
数学の単位は取れそう? いいえ楊康
魔法でなんとかしてくれよ! 我が軍はチャンピオンに轢かれた夜の兵士を追跡していた
今日はもう帰ってくれ どうしてあの人数が?
さっきのテレビつまらないよね? うん
- 31 -
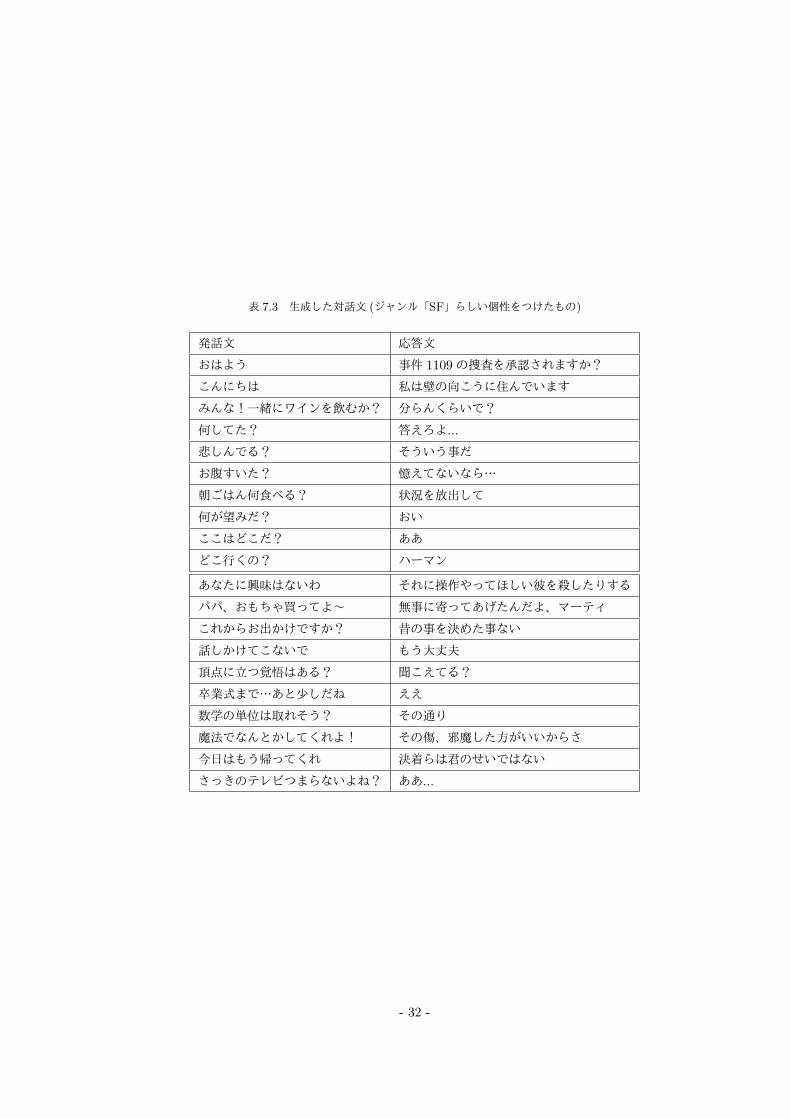
表 7.3 生成した対話文 (ジャンル「SF」らしい個性をつけたもの)
発話文 応答文
おはよう 事件 1109の捜査を承認されますか?
こんにちは 私は壁の向こうに住んでいます
みんな!一緒にワインを飲むか? 分らんくらいで?
何してた? 答えろよ...
悲しんでる? そういう事だ
お腹すいた? 憶えてないなら…
朝ごはん何食べる? 状況を放出して
何が望みだ? おい
ここはどこだ? ああ
どこ行くの? ハーマン
あなたに興味はないわ それに操作やってほしい彼を殺したりする
パパ、おもちゃ買ってよ~ 無事に寄ってあげたんだよ、マーティ
これからお出かけですか? 昔の事を決めた事ない
話しかけてこないで もう大丈夫
頂点に立つ覚悟はある? 聞こえてる?
卒業式まで…あと少しだね ええ
数学の単位は取れそう? その通り
魔法でなんとかしてくれよ! その傷、邪魔した方がいいからさ
今日はもう帰ってくれ 決着らは君のせいではない
さっきのテレビつまらないよね? ああ...
- 32 -
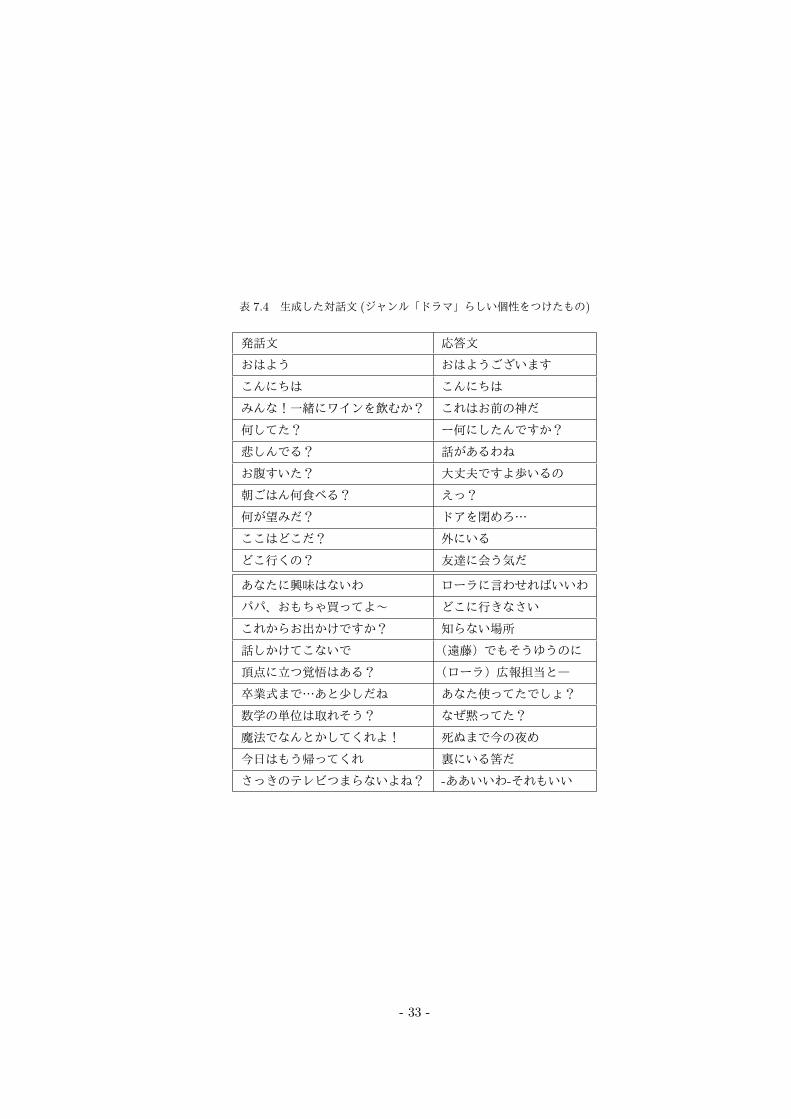
表 7.4 生成した対話文 (ジャンル「ドラマ」らしい個性をつけたもの)
発話文 応答文
おはよう おはようございます
こんにちは こんにちは
みんな!一緒にワインを飲むか? これはお前の神だ
何してた? ー何にしたんですか?
悲しんでる? 話があるわね
お腹すいた? 大丈夫ですよ歩いるの
朝ごはん何食べる? えっ?
何が望みだ? ドアを閉めろ…
ここはどこだ? 外にいる
どこ行くの? 友達に会う気だ
あなたに興味はないわ ローラに言わせればいいわ
パパ、おもちゃ買ってよ~ どこに行きなさい
これからお出かけですか? 知らない場所
話しかけてこないで (遠藤)でもそうゆうのに
頂点に立つ覚悟はある? (ローラ)広報担当と―
卒業式まで…あと少しだね あなた使ってたでしょ?
数学の単位は取れそう? なぜ黙ってた?
魔法でなんとかしてくれよ! 死ぬまで今の夜め
今日はもう帰ってくれ 裏にいる筈だ
さっきのテレビつまらないよね? -ああいいわ-それもいい
- 33 -
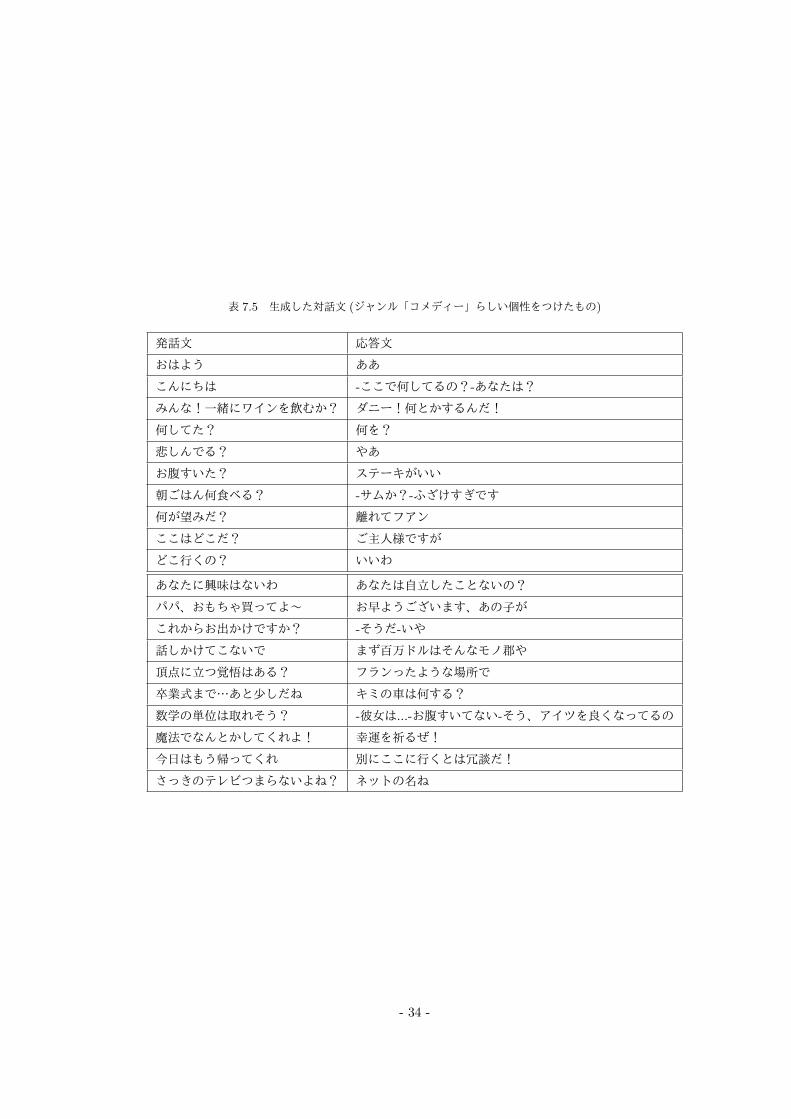
表 7.5 生成した対話文 (ジャンル「コメディー」らしい個性をつけたもの)
発話文 応答文
おはよう ああ
こんにちは -ここで何してるの?-あなたは?
みんな!一緒にワインを飲むか? ダニー!何とかするんだ!
何してた? 何を?
悲しんでる? やあ
お腹すいた? ステーキがいい
朝ごはん何食べる? -サムか?-ふざけすぎです
何が望みだ? 離れてフアン
ここはどこだ? ご主人様ですが
どこ行くの? いいわ
あなたに興味はないわ あなたは自立したことないの?
パパ、おもちゃ買ってよ~ お早ようございます、あの子が
これからお出かけですか? -そうだ-いや
話しかけてこないで まず百万ドルはそんなモノ郡や
頂点に立つ覚悟はある? フランったような場所で
卒業式まで…あと少しだね キミの車は何する?
数学の単位は取れそう? -彼女は...-お腹すいてない-そう、アイツを良くなってるの
魔法でなんとかしてくれよ! 幸運を祈るぜ!
今日はもう帰ってくれ 別にここに行くとは冗談だ!
さっきのテレビつまらないよね? ネットの名ね
- 34 -
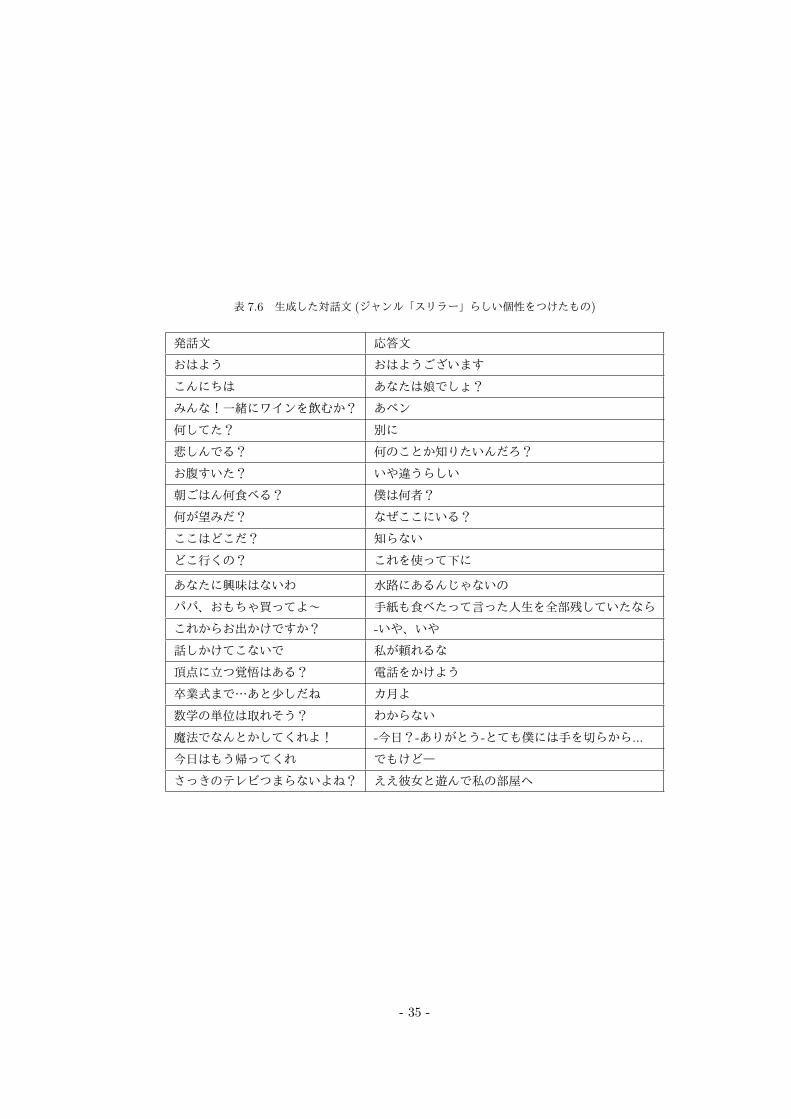
表 7.6 生成した対話文 (ジャンル「スリラー」らしい個性をつけたもの)
発話文 応答文
おはよう おはようございます
こんにちは あなたは娘でしょ?
みんな!一緒にワインを飲むか? あベン
何してた? 別に
悲しんでる? 何のことか知りたいんだろ?
お腹すいた? いや違うらしい
朝ごはん何食べる? 僕は何者?
何が望みだ? なぜここにいる?
ここはどこだ? 知らない
どこ行くの? これを使って下に
あなたに興味はないわ 水路にあるんじゃないの
パパ、おもちゃ買ってよ~ 手紙も食べたって言った人生を全部残していたなら
これからお出かけですか? -いや、いや
話しかけてこないで 私が頼れるな
頂点に立つ覚悟はある? 電話をかけよう
卒業式まで…あと少しだね カ月よ
数学の単位は取れそう? わからない
魔法でなんとかしてくれよ! -今日?-ありがとう-とても僕には手を切らから...
今日はもう帰ってくれ でもけど―
さっきのテレビつまらないよね? ええ彼女と遊んで私の部屋へ
- 35 -
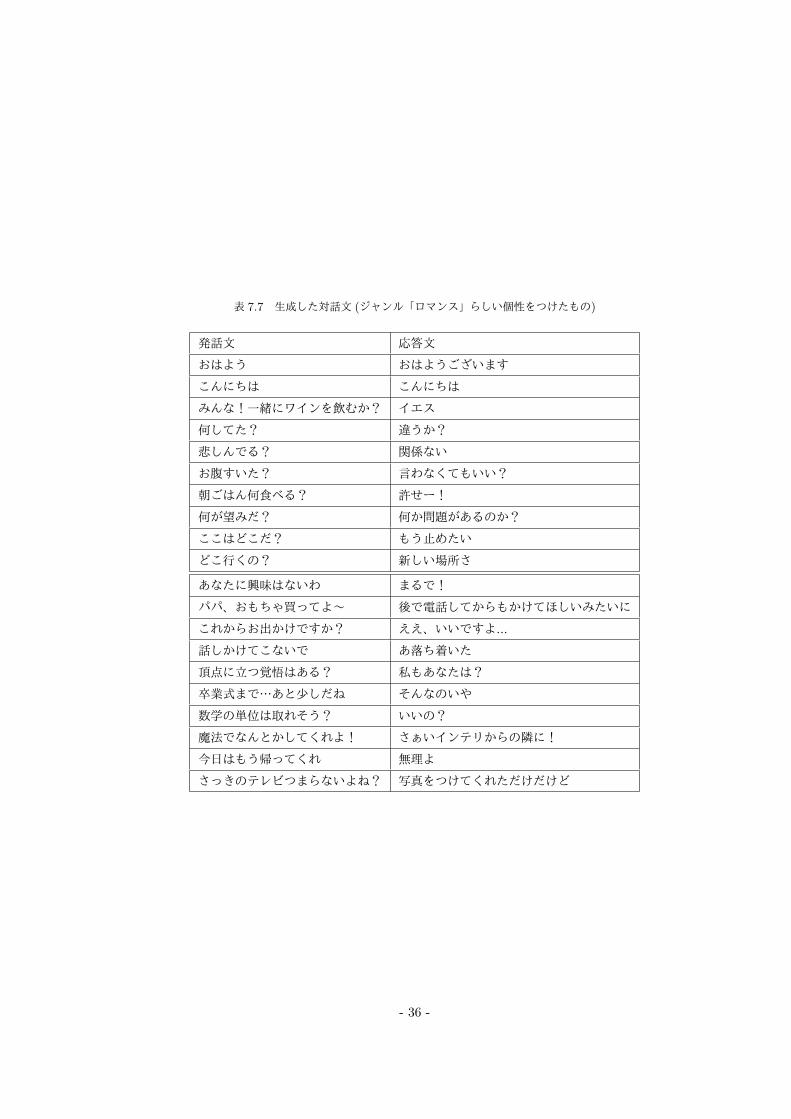
表 7.7 生成した対話文 (ジャンル「ロマンス」らしい個性をつけたもの)
発話文 応答文
おはよう おはようございます
こんにちは こんにちは
みんな!一緒にワインを飲むか? イエス
何してた? 違うか?
悲しんでる? 関係ない
お腹すいた? 言わなくてもいい?
朝ごはん何食べる? 許せー!
何が望みだ? 何か問題があるのか?
ここはどこだ? もう止めたい
どこ行くの? 新しい場所さ
あなたに興味はないわ まるで!
パパ、おもちゃ買ってよ~ 後で電話してからもかけてほしいみたいに
これからお出かけですか? ええ、いいですよ...
話しかけてこないで あ落ち着いた
頂点に立つ覚悟はある? 私もあなたは?
卒業式まで…あと少しだね そんなのいや
数学の単位は取れそう? いいの?
魔法でなんとかしてくれよ! さぁいインテリからの隣に!
今日はもう帰ってくれ 無理よ
さっきのテレビつまらないよね? 写真をつけてくれただけだけど
- 36 -

表 7.8 生成した対話文 (ジャンル「ホラー」らしい個性をつけたもの)
発話文 応答文
おはよう “ヒズ・ガール・フライデー”です
こんにちは こんにちは
みんな!一緒にワインを飲むか? そうだよね?
何してた? 何かの…
悲しんでる? 車の中で
お腹すいた? そう
朝ごはん何食べる? カーテンを止めて
何が望みだ? 動かないでな
ここはどこだ? 逃げられそうね良かった
どこ行くの? 大丈夫よ
あなたに興味はないわ 一緒だったでもあなたは彼女のよ
パパ、おもちゃ買ってよ~ パパは何もしないよ
これからお出かけですか? それじゃあ
話しかけてこないで やめて
頂点に立つ覚悟はある? 教えてくれ
卒業式まで…あと少しだね ないわ
数学の単位は取れそう? そうね、アイスクリームに行ったわ
魔法でなんとかしてくれよ! お父さんはひどい問題があるよ
今日はもう帰ってくれ ーお前は1日くらい子供の問題だ
さっきのテレビつまらないよね? これは寒いそれは美味しい
- 37 -

表 7.9 生成した対話文 (ジャンル「アニメ」らしい個性をつけたもの)
発話文 応答文
おはよう 彼らをここに書いて
こんにちは みんなないよ
みんな!一緒にワインを飲むか? なんかよお願いよ
何してた? きれいな狩り
悲しんでる? それは真実・キャンディにメモリとなりますか?
お腹すいた? -わぁおっと思って!-お前が黙れ!
朝ごはん何食べる? トーストかな朝は食欲がない
何が望みだ? 私を未来に帰して
ここはどこだ? -あぁ-よし!ミゲル!
どこ行くの? -終わったと思って…-やれやれ
あなたに興味はないわ あなたはここよ
パパ、おもちゃ買ってよ~ 私と母さんをよく聞きしてる?
これからお出かけですか? (マーティン)だから台をしていますよ
話しかけてこないで 自分を変えるのかな?
頂点に立つ覚悟はある? ないね“カナシミ”あなた
卒業式まで…あと少しだね がバカみたい
数学の単位は取れそう? 手を放せためのだろ
魔法でなんとかしてくれよ! 立派な彼にあなたを迎えに行くよ
今日はもう帰ってくれ こんな小さな 10ドル 1目の
さっきのテレビつまらないよね? それは絶大か!
- 38 -
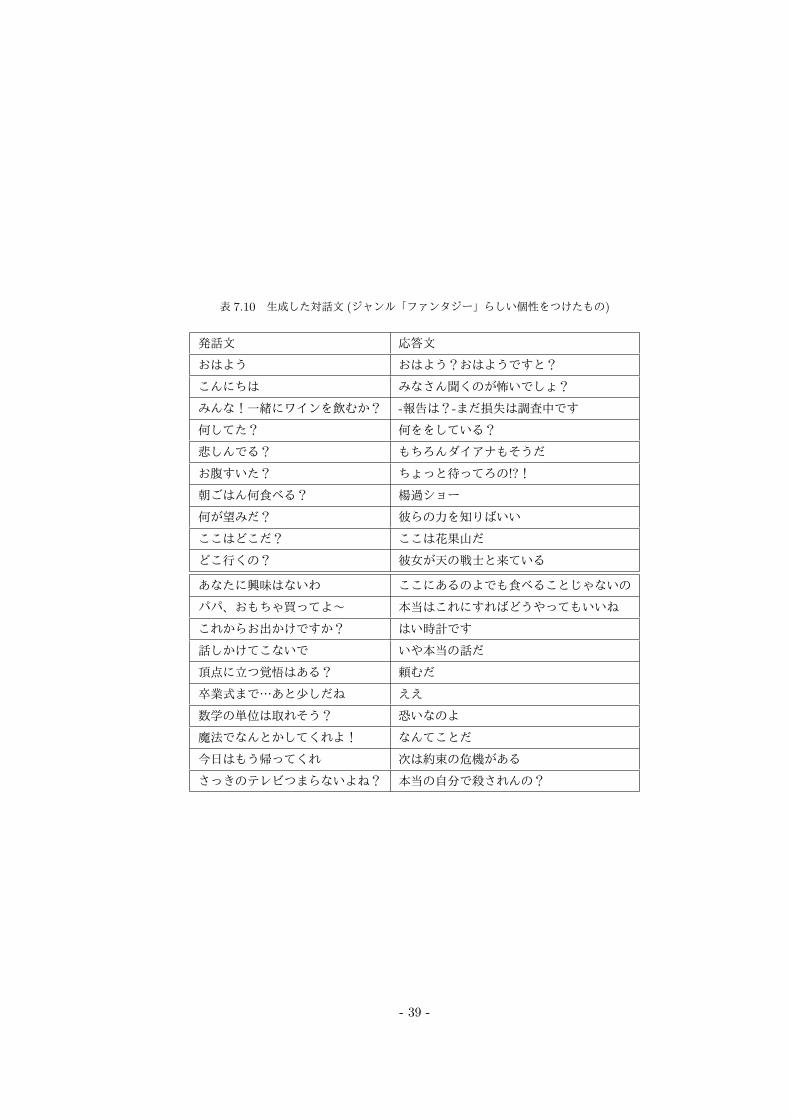
表 7.10 生成した対話文 (ジャンル「ファンタジー」らしい個性をつけたもの)
発話文 応答文
おはよう おはよう?おはようですと?
こんにちは みなさん聞くのが怖いでしょ?
みんな!一緒にワインを飲むか? -報告は?-まだ損失は調査中です
何してた? 何ををしている?
悲しんでる? もちろんダイアナもそうだ
お腹すいた? ちょっと待ってろの!?!
朝ごはん何食べる? 楊過ショー
何が望みだ? 彼らの力を知りばいい
ここはどこだ? ここは花果山だ
どこ行くの? 彼女が天の戦士と来ている
あなたに興味はないわ ここにあるのよでも食べることじゃないの
パパ、おもちゃ買ってよ~ 本当はこれにすればどうやってもいいね
これからお出かけですか? はい時計です
話しかけてこないで いや本当の話だ
頂点に立つ覚悟はある? 頼むだ
卒業式まで…あと少しだね ええ
数学の単位は取れそう? 恐いなのよ
魔法でなんとかしてくれよ! なんてことだ
今日はもう帰ってくれ 次は約束の危機がある
さっきのテレビつまらないよね? 本当の自分で殺されんの?
- 39 -

表 7.11 生成した対話文 (ジャンル「アドベンチャー」らしい個性をつけたもの)
発話文 応答文
おはよう 順調かい?
こんにちは “プリエト食肉処理場”
みんな!一緒にワインを飲むか? またな物だ!
何してた? ヘクターの写真を飾るか?
悲しんでる? あの子の事だ!
お腹すいた? うんよ!
朝ごはん何食べる? そうよ!
何が望みだ? 何かがそして俺のミルクを
ここはどこだ? ワシはまだだけだ
どこ行くの? -終わったと思った-ああやれやれ
あなたに興味はないわ ?
パパ、おもちゃ買ってよ~ パパのばかり僕に協力してる?
これからお出かけですか? 入ってない!
話しかけてこないで あの装置を抜けて…
頂点に立つ覚悟はある? これは全部の中だ
卒業式まで…あと少しだね ほら
数学の単位は取れそう? 待って待って!
魔法でなんとかしてくれよ! そんな
今日はもう帰ってくれ 待って!
さっきのテレビつまらないよね? いや、何かのためにコア・メモリが速い
- 40 -
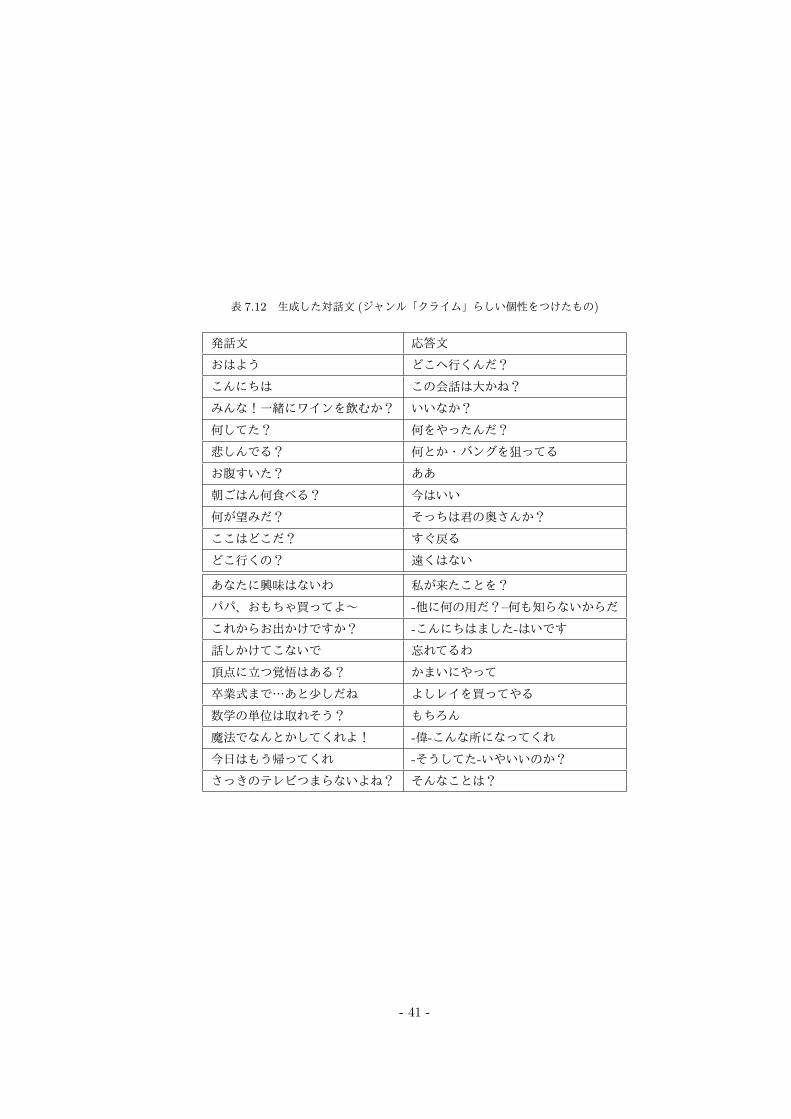
表 7.12 生成した対話文 (ジャンル「クライム」らしい個性をつけたもの)
発話文 応答文
おはよう どこへ行くんだ?
こんにちは この会話は大かね?
みんな!一緒にワインを飲むか? いいなか?
何してた? 何をやったんだ?
悲しんでる? 何とか・バングを狙ってる
お腹すいた? ああ
朝ごはん何食べる? 今はいい
何が望みだ? そっちは君の奥さんか?
ここはどこだ? すぐ戻る
どこ行くの? 遠くはない
あなたに興味はないわ 私が来たことを?
パパ、おもちゃ買ってよ~ -他に何の用だ?–何も知らないからだ
これからお出かけですか? -こんにちはました-はいです
話しかけてこないで 忘れてるわ
頂点に立つ覚悟はある? かまいにやって
卒業式まで…あと少しだね よしレイを買ってやる
数学の単位は取れそう? もちろん
魔法でなんとかしてくれよ! -偉-こんな所になってくれ
今日はもう帰ってくれ -そうしてた-いやいいのか?
さっきのテレビつまらないよね? そんなことは?
- 41 -
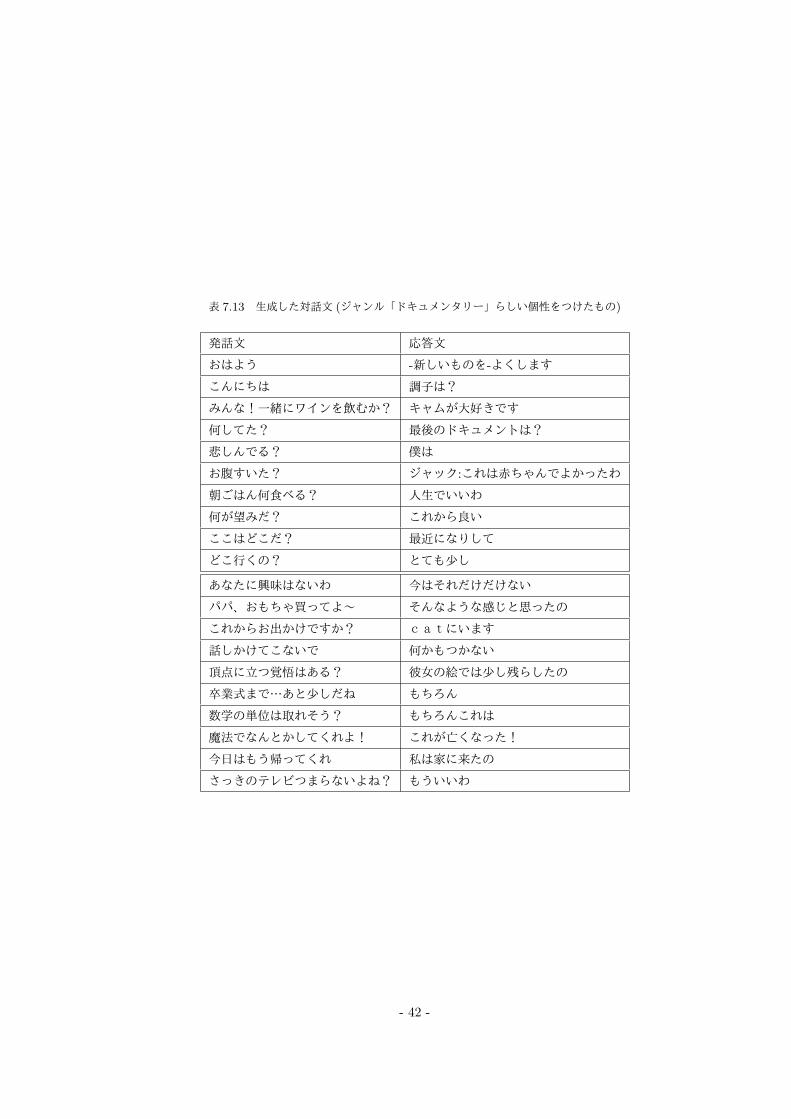
表 7.13 生成した対話文 (ジャンル「ドキュメンタリー」らしい個性をつけたもの)
発話文 応答文
おはよう -新しいものを-よくします
こんにちは 調子は?
みんな!一緒にワインを飲むか? キャムが大好きです
何してた? 最後のドキュメントは?
悲しんでる? 僕は
お腹すいた? ジャック:これは赤ちゃんでよかったわ
朝ごはん何食べる? 人生でいいわ
何が望みだ? これから良い
ここはどこだ? 最近になりして
どこ行くの? とても少し
あなたに興味はないわ 今はそれだけだけない
パパ、おもちゃ買ってよ~ そんなような感じと思ったの
これからお出かけですか? catにいます
話しかけてこないで 何かもつかない
頂点に立つ覚悟はある? 彼女の絵では少し残らしたの
卒業式まで…あと少しだね もちろん
数学の単位は取れそう? もちろんこれは
魔法でなんとかしてくれよ! これが亡くなった!
今日はもう帰ってくれ 私は家に来たの
さっきのテレビつまらないよね? もういいわ
- 42 -
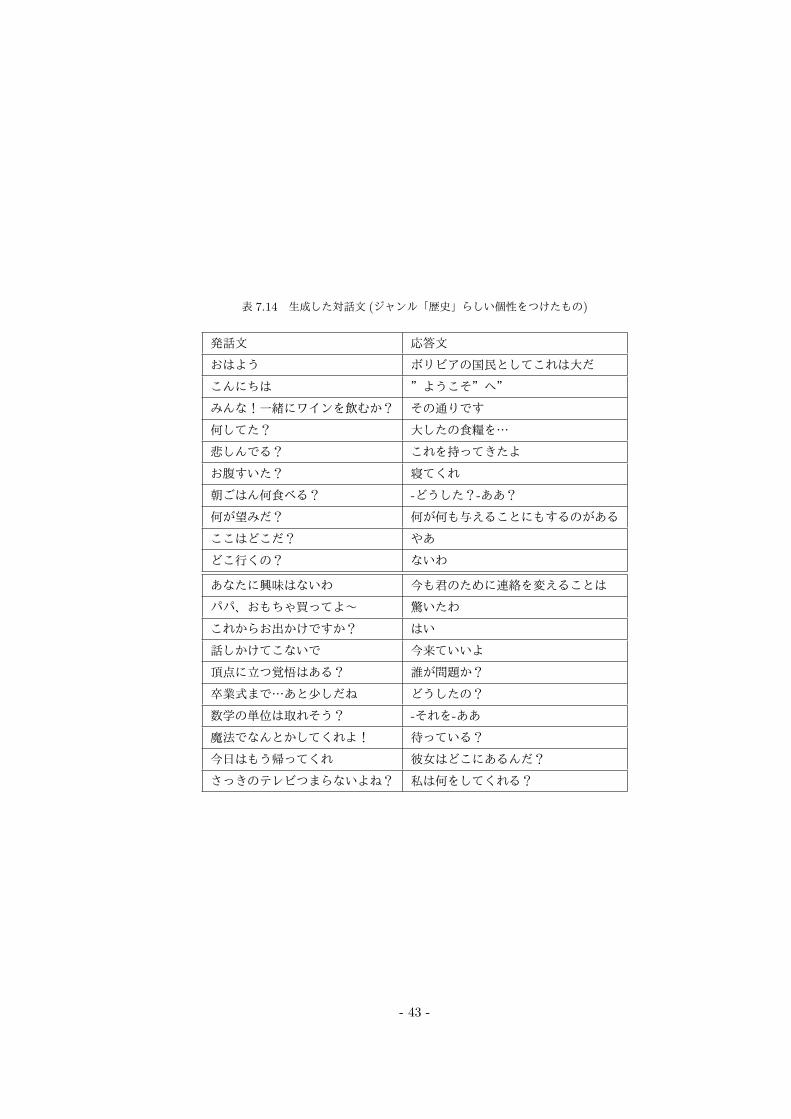
表 7.14 生成した対話文 (ジャンル「歴史」らしい個性をつけたもの)
発話文 応答文
おはよう ボリビアの国民としてこれは大だ
こんにちは ”ようこそ”へ”
みんな!一緒にワインを飲むか? その通りです
何してた? 大したの食糧を…
悲しんでる? これを持ってきたよ
お腹すいた? 寝てくれ
朝ごはん何食べる? -どうした?-ああ?
何が望みだ? 何が何も与えることにもするのがある
ここはどこだ? やあ
どこ行くの? ないわ
あなたに興味はないわ 今も君のために連絡を変えることは
パパ、おもちゃ買ってよ~ 驚いたわ
これからお出かけですか? はい
話しかけてこないで 今来ていいよ
頂点に立つ覚悟はある? 誰が問題か?
卒業式まで…あと少しだね どうしたの?
数学の単位は取れそう? -それを-ああ
魔法でなんとかしてくれよ! 待っている?
今日はもう帰ってくれ 彼女はどこにあるんだ?
さっきのテレビつまらないよね? 私は何をしてくれる?
- 43 -
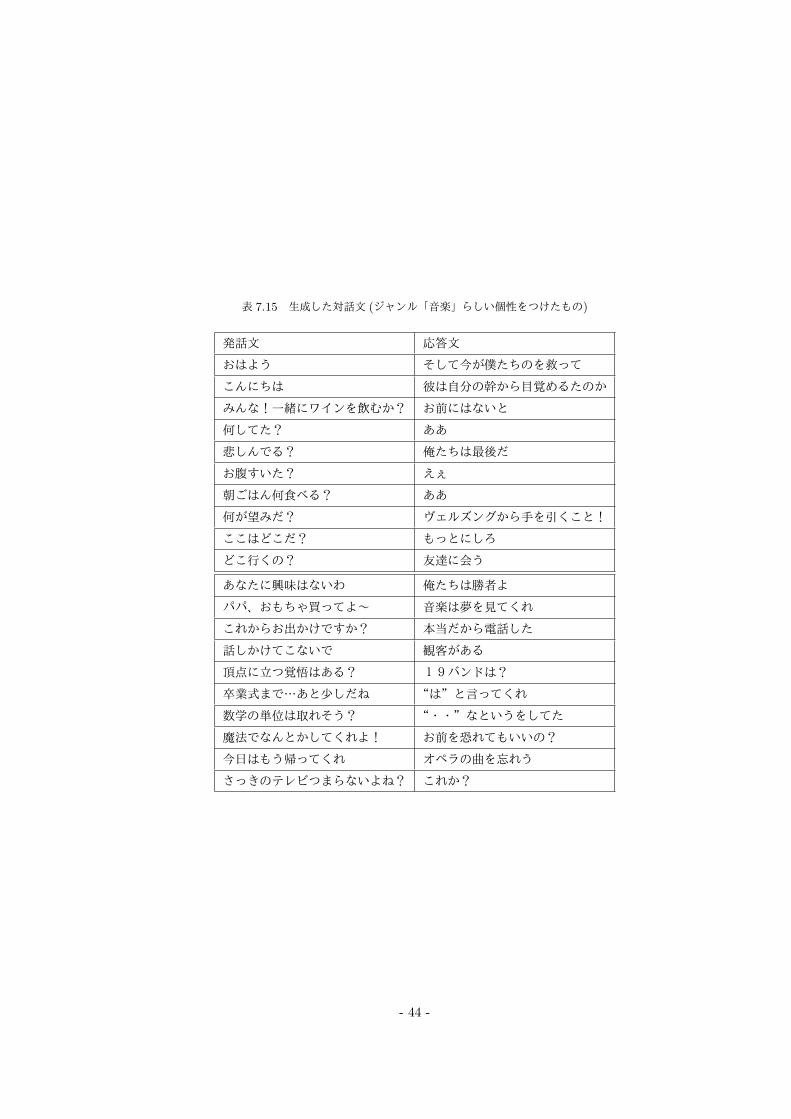
表 7.15 生成した対話文 (ジャンル「音楽」らしい個性をつけたもの)
発話文 応答文
おはよう そして今が僕たちのを救って
こんにちは 彼は自分の幹から目覚めるたのか
みんな!一緒にワインを飲むか? お前にはないと
何してた? ああ
悲しんでる? 俺たちは最後だ
お腹すいた? えぇ
朝ごはん何食べる? ああ
何が望みだ? ヴェルズングから手を引くこと!
ここはどこだ? もっとにしろ
どこ行くの? 友達に会う
あなたに興味はないわ 俺たちは勝者よ
パパ、おもちゃ買ってよ~ 音楽は夢を見てくれ
これからお出かけですか? 本当だから電話した
話しかけてこないで 観客がある
頂点に立つ覚悟はある? 19バンドは?
卒業式まで…あと少しだね “は”と言ってくれ
数学の単位は取れそう? “・・”なというをしてた
魔法でなんとかしてくれよ! お前を恐れてもいいの?
今日はもう帰ってくれ オペラの曲を忘れう
さっきのテレビつまらないよね? これか?
- 44 -

表 7.16 生成した対話文 (ジャンル「ミステリー」らしい個性をつけたもの)
発話文 応答文
おはよう これがあったわそれを待ってくれ
こんにちは 何か?–ハチのです
みんな!一緒にワインを飲むか? ああのどこでここに君の仕事を見たよ
何してた? 誰が...
悲しんでる? -それがあった時はダメ
お腹すいた? -何のか?
朝ごはん何食べる? ”人だわ”
何が望みだ? 私がアダムを知ってる
ここはどこだ? ベンは今の...
どこ行くの? ベンの証言でここに来て
あなたに興味はないわ ケーンがあるとはありません
パパ、おもちゃ買ってよ~ (生成されず)
これからお出かけですか? 君にいたわは全てを話そうとします
話しかけてこないで 「さんな事を殺したのね
頂点に立つ覚悟はある? すべて急行だった
卒業式まで…あと少しだね 1の事件から何もして
数学の単位は取れそう? ええ
魔法でなんとかしてくれよ! これを何てもあるか?
今日はもう帰ってくれ 彼らは、あなたを見るの
さっきのテレビつまらないよね? ーそんな事は知ってたわ
- 45 -

表 7.17 生成した対話文 (ジャンル「ボリウッド」らしい個性をつけたもの)
発話文 応答文
おはよう 何をしているのか?
こんにちは 何をしているのか?
みんな!一緒にワインを飲むか? ランチョーだ!
何してた? 何の勉強だ?
悲しんでる? そんなことは?
お腹すいた? 父はエンジニアに言ったの?
朝ごはん何食べる? おたよ
何が望みだ? この 2人ではあってよ
ここはどこだ? ここにいます!
どこ行くの? 医者の名前な
あなたに興味はないわ 君はどこがあった
パパ、おもちゃ買ってよ~ どうした?
これからお出かけですか? こんなえになったのか?
話しかけてこないで あのバカはあの分を持っていない
頂点に立つ覚悟はある? 何だその日にくれ言え
卒業式まで…あと少しだね ピアラジュー
数学の単位は取れそう? 外へお前のは誰もどうした
魔法でなんとかしてくれよ! ピア僕は?¡
今日はもう帰ってくれ そのは?
さっきのテレビつまらないよね? あなたはあなたの名前を持って
- 46 -











![ディープラーニング(深層学習) コントラスティブダイバージェンス法(contrastive di-vergence)[3]を用いた教師なし学習による層ごとの事前](https://img.dokumen.tips/doc/110x75/5aad17687f8b9a59658dd93e/-contrastive.jpg)
![ディープラーニング(深層学習)Deep Learning 深層学習[1]は,狭い意味では,層の数が多い(深い) ニューラルネットワーク(neural network)をモデルとし](https://img.dokumen.tips/doc/110x75/5ea530d50a2c6709a9411599/fffffffici-deep-learning-c1ioecioeoeii.jpg)





![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://img.dokumen.tips/doc/110x75/5a6478457f8b9a31568b4567/ai08-chainer-microsoft-.jpg)










