Embed Size (px)
Citation preview

EE382A Lecture 6:
Register Renaming
Department of Electrical EngineeringStanford University
EE382A – Autumn 2009 John P ShenLecture 6- 1
Stanford University
http://eeclass.stanford.edu/ee382a

Announcements
• Project proposal due on Wed 10/142 3 pages submitted through email– 2-3 pages submitted through email
– List the group members– Describe the topic including why it is important and your thesis
Describe the methodology you will use (experiments tools machines)– Describe the methodology you will use (experiments, tools, machines)– Statement of expected results– Few key references to related work
• Still missing some photos
EE382A – Autumn 2009 John P ShenLecture 6- 2

Lecture 6 Outline
1. Branch Prediction (epilog)a. 2-level Predictorsb. AMD Opteron Examplec. Confidence Predictionc. Confidence Predictiond. Trace Cache
2. Register Data Flowa. False Register Dependencesb. Register Renaming Technique
R i t R i I l t tic. Register Renaming Implementation
EE382A – Autumn 2009 John P ShenLecture 6- 3

Dynamic Branch Prediction Using History
nPC to Icache
t t
prediction FA-mux
Decode Buffer
FetchnPC(seq.) = PC+4
PCBranchPredictor(using a BTB)
specu. target
specu. cond.
Dispatch Buffer
Decode
Dispatch
BTBupdate(target addr.and history)nPC=BP(PC)
Reservation
Dispatch
StationsIssueIssue
Execute
Branch
EE382A – Autumn 2009 John P ShenLecture 6- 4
Finish Completion Buffer

2-Level Adaptive Prediction [Yeh & Patt]
Nomenclature: {G,P}A{g,p,s}{ , } {g,p, }
Pattern History Table (PHT)PC00...0000...0100...10
Branch History Shift
(shift left when update)Register (BHSR)
1 0 1 1 1 PHTBits
old1 1 1 0 0
11...1011...11 Prediction
index
FSMLogic
new
1 1 1 1 0
To achieve 97% average prediction accuracy: G (1) BHR: 18 bits; g (1) PHT: 218 x 2 bits total = 524 kbitsP (512 4) BHR 12 bit (1) PHT 212 2 bit t t l 33 kbit
Branch ResultLogic
EE382A – Autumn 2009 John P ShenLecture 6- 5
P (512x4) BHR: 12 bits; g (1) PHT: 212 x 2 bits total = 33 kbitsP (512x4) BHR: 6 bits; s (512) PHT: 26 x 2 bits total = 78 kbits
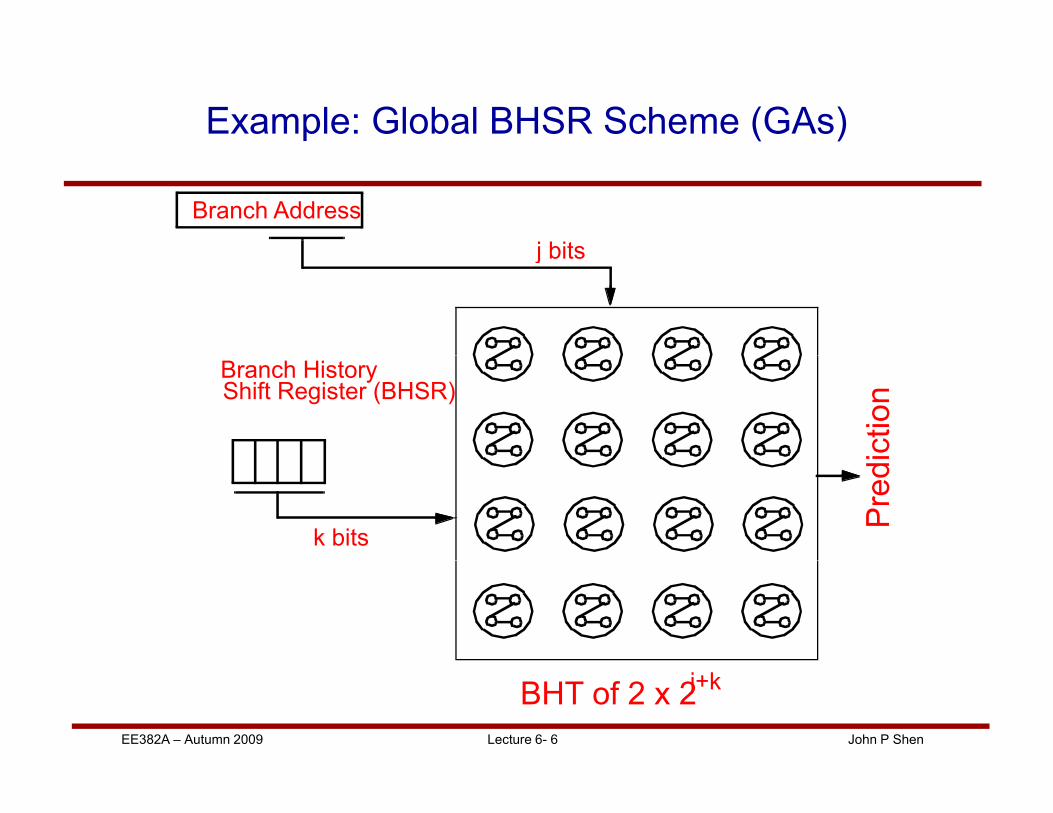
Example: Global BHSR Scheme (GAs)
Branch Address
j bitsj bits
ictio
n
Branch HistoryShift Register (BHSR)
Pre
di
k bits
EE382A – Autumn 2009 John P ShenLecture 6- 6
BHT of 2 x 2 j+k

Example: Per-Branch BHSR Scheme (PAs)
Branch Address
j bits Standard BHT
Branch HistoryShift R i t (BHSR)
j bitsi bits
Standard BHT
ctio
n
yShift Register (BHSR)k x 2 i
Pre
di
k bit
EE382A – Autumn 2009 John P ShenLecture 6- 7
BHT of 2 x 2 j+kk bits

Gshare Branch Prediction [McFarling]
Branch Address
j bits
xor
tionBranch History
Shift Register (BHSR)
Pre
dict
k bits
EE382A – Autumn 2009 John P ShenLecture 6- 8
BHT of 2 x 2 max(j,k)

Fetch & Predict Example:AMD OpteronAMD Opteron
EE382A – Autumn 2009 John P ShenLecture 6- 9

Why is Prediction Important in Opteron?
EE382A – Autumn 2009 John P ShenLecture 6- 10

Fetch & Predict Example:AMD OpteronAMD Opteron
EE382A – Autumn 2009 John P ShenLecture 6- 11

Other Branch Prediction Related Issues
• Multi-cycle BTBKeep fetching sequentially repair later (bubbles for taken branches)– Keep fetching sequentially, repair later (bubbles for taken branches)
– Need pipelined access though
• BTB & predictor in series– Get fast target/direction prediction from BTB only– After decoding, use predictor to verify BTB
• Causes a pipeline mini-flush if BTB was wrongp p g
– This approach allows for a much larger/slower predictor
• BTB and predictor integration C BTB ith th l l t f di t– Can merge BTB with the local part of a predictor
– Can merge both with I-cache entries
• Predictor/BTB/RAS updates
EE382A – Autumn 2009 John P ShenLecture 6- 12
– Can you see any issue?

Prediction ConfidenceA Very Useful Tool for SpeculationA Very Useful Tool for Speculation
• Estimate if your prediction is likely to be correct
A li ti• Applications– Avoid fetching down unlikely path
• Save time & power by waiting
– Start executing down both paths (selective eager execution)– Switch to another thread (for multithreaded processors)
• ImplementationImplementation– Naïve: don’t use NT or TN states in 2-bit counters– Better: array of CIR (correct/incorrect registers)
• Shift in if last prediction was correct/incorrect• Shift in if last prediction was correct/incorrect• Count the number of 0s to determine confidence
– Many other implementations are possibleUsing counters etc
EE382A – Autumn 2009 John P ShenLecture 6- 13
• Using counters etc

Branch Confidence Prediction
EE382A – Autumn 2009 John P ShenLecture 6- 14

Dynamic History Length
• Four types of history– Local (bimodal) history (Smith predictor)– Local (bimodal) history (Smith predictor)
• Table of counters summarizes local history• Simple, but only effective for biased branches
Local outcome history– Local outcome history• Shift register of individual branch outcomes• Separate counter for each outcome history
Gl b l t hi t– Global outcome history• Shift register of recent branch outcomes• Separate counter for each outcome history
– Path history• Shift register of recent (partial) block addresses• Can differentiate similar global outcome histories
EE382A – Autumn 2009 John P ShenLecture 6- 15
• Can combine or “alloy” histories in many ways

Understanding Advanced Predictors
• History lengthSh t hi t l t i i t– Short history—lower training cost
– Long history—captures macro-level behavior– Variable history length predictors
• Really long history (long loops)– Loop count predictors– Fourier transform into frequency domainFourier transform into frequency domain
• Limited capacity & interference– Constructive vs. destructive
Bi d k d YAGS– Bi-mode, gskewed, agree, YAGS– Read sec. 9.3.2 carefully
EE382A – Autumn 2009 John P ShenLecture 6- 16

High-Bandwidth Fetch: Trace Cache
E F G
Instruction Cache
Trace Cache
A B
E F GH I J
A B C D E F G H I JA BC
D
A B C D E F G H I J
(a) (b)
• Fold out taken branches by tracing instructions as they commit into a fill buffer
• Eric Rotenberg, S. Bennett, and James E. Smith. Trace Cache: A Low Latency Approach to High Bandwidth Instruction Fetching. MICRO,
EE382A – Autumn 2009 John P ShenLecture 6- 17
Latency Approach to High Bandwidth Instruction Fetching. MICRO, December 1996.

Intel Pentium 4 Trace Cache
Instruction TLBand Prefetcher
Front-End BTB Level-TwoUnified Data and
Instruct ion Decode
Instruction Cache
Trace CacheTrace Cache BTB
Instruction Fetch Queue
To renamer, execute, etc.
• No first-level instruction cache: trace cache only• Trace cache BTB identifies next trace• Miss leads to fetch from level two cache
Trace cache instructions are decoded (uops)
EE382A – Autumn 2009 John P ShenLecture 6- 18
• Trace cache instructions are decoded (uops)

Modern Superscalar, Out-of-order Processor
• Pipelining reduces cycle time
S l i IPCI-cache
FETCHBranchPredictor Instruction
InstructionFlow
• Superscalar increases IPC (instruction per cycle)
• Both schemes need to find lots of DECODE
Buffer
Integer Floating-point Media Memory
ILP in the program– Must simultaneously increase
number of instructions considered
Reorder
MemoryData
EXECUTE Flow
number of instructions considered, number of instructions executed, and allow for out-of-order execution
COMMITD-cacheStore
Queue
BufferRegisterData
(ROB)
Flow
EE382A – Autumn 2009 John P ShenLecture 6- 19

What Limits ILP
INSTRUCTION PROCESSING CONSTRAINTS
R C t ti C d D dResource Contention Code Dependences
Control Dependences Data Dependences
(Structural Dependences)
Control Dependences Data Dependences
T D d St C fli t(RAW) True Dependences
Anti-Dependences Output Dependences
Storage Conflicts(RAW)
(WAR) (WAW)
EE382A – Autumn 2009 John P ShenLecture 6- 20
Anti-Dependences Output Dependences(WAR) (WAW)

Register Renaming & Dynamic SchedulingDynamic Scheduling
• Register Renaming: address limitations of the scoreboard– Scoreboard limitation
• Up to one pending instruction per destination register
– Eliminate WAR and WAW dependences without stalling
• Dynamic schedulingy g– Track & resolve true-data dependences (RAW)– Scheduling hardware:
• Instruction window, reservation stations, common data bus, …
– Original proposal: Tomasulo’s algorithm [Tomasulo, 1967]
EE382A – Autumn 2009 John P ShenLecture 6- 21

Register Data Flow
Each ALU Instruction: INSTRUCTION EXECUTION MODEL
Ri Fn (Rj, Rk)R0R1
FU1
FU2•• •
Dest.Reg.
Funct.Unit
SourceRegisters Rm FUn
Interconnect• •
•
Registers Functional“Register Transfer” RegistersUnitsRegister Transfer
“Read”“Write”
“Execute”
Need Availability of Fn (Structural Dependences)Need Availability of Rj, Rk (True Data Dependences)Need Availability of Ri (Anti-and output Dependences)
EE382A – Autumn 2009 John P ShenLecture 6- 22
y ( p p )

Causes of (Register) Storage Conflict
REGISTER RECYCLING
MAXIMIZE USE OF REGISTERS
MULTIPLE ASSIGNMENTS OF VALUES TO REGISTERS
OUT OF ORDER ISSUING AND COMPLETION
LOSE IMPLIED PRECEDENCE OF SEQUENTIAL CODELOSE IMPLIED PRECEDENCE OF SEQUENTIAL CODE
LOSE 1-1 CORRESPONDENCE BETWEEN VALUES AND REGITERS
Ri•
••• DEF•••
USERi•••
WAW
USERi•
•••
WAR
EE382A – Autumn 2009 John P ShenLecture 6- 23
Ri DEF•••

The Reason for WAW and WAR:Register RecyclingRegister Recycling
COMPILER REGISTER ALLOCATIONSingle Assignment Symbolic RegCODE GENERATION Single Assignment, Symbolic Reg.
Map Symbolic Reg. to Physical Reg. Maximize Reuse of Reg.
CODE GENERATION
REG. ALLOCATION
9 $34: mul $14 $7, 4010 addu $15, $4, $1411 l $24 $9 4
INSTRUCTION LOOPS
a e euse o eg
For (k=1;k<= 10; k++)11 mul $24, $9, 412 addu $25, $15, $2413 lw $11, 0($25)14 mul $12, $9, 4015 addu $13, $5, $12
For (k=1;k<= 10; k++)t += a [i] [k] * b [k] [j] ;
$ , $ , $16 mul $14, $8, 417 addu $15, $13, $1418 lw $24, 0($15)19 mul $25, $11, $2420 dd $10 $10 $25
Reuse Same Set of Reg. in each IterationOverlapped Execution of
EE382A – Autumn 2009 John P ShenLecture 6- 24
20 addu $10, $10, $2521 addu $9, $9, 122 ble $9, 10, $34
different Iterations

Resolving False Dependences
Must Prevent (2) from completing•• before (1) is dispatched
(2) R3 ← R5 + 1
•(1) R4 ← R3 + 1
before (1) is dispatched
Must Prevent (2) from completing before (1) completes
(1) R3 ← R3 + R5
← R3•••
(2) R3 ← R5 + 1
•••
Stalling: delay dispatching (or write back) of the later instructionCopy Operands: Copy not-yet-used operand to prevent being overwritten
(WAR)
EE382A – Autumn 2009 John P ShenLecture 6- 25
( )Register Renaming: use a different register (WAW & WAR)

Register Renaming: The Idea
• Anti and output dependences are false dependencesr3 ← r1 op r2r3 ← r1 op r2r5 ← r3 op r4r3 ← r6 op r7
• The dependence is on name/location rather than data
• Given unlimited number of registers, anti and output dependences can always be eliminated
Renamedr1 ← r2 / r3
Originalr1 ← r2 / r3 r1 ← r2 / r3
r4 ← r1 * r5r8 ← r3 + r6
r1 ← r2 / r3r4 ← r1 * r5r1 ← r3 + r6
EE382A – Autumn 2009 John P ShenLecture 6- 26
r9 ← r8 - r4r3 ← r1 - r4

Register Renaming Technique
Register Renaming Resolves:
Design of Redundant Registers: Anti-Dependences Output Dependences
Design of Redundant Registers:
Number:OneMultipleA i i Multiple
Allocation:Fixed for Each RegisterPooled for all Regsiters
Architected PhysicalRegisters Registers
R1 P1 Pooled for all Regsiters Location:
Attached to Register File(Centralized)
R1R2•••
P1P2••• (Centralized)
Attached to functional units (Distributed)
•Rn
Pn
••
EE382A – Autumn 2009 John P ShenLecture 6- 27
•Pn + k

Register Renaming Implementation
• Renaming: Map a small set of architecture registers to a large set of physical registers– Map a small set of architecture registers to a large set of physical registers
– New mapping for an architectural register when it is assigned a new value
• Renaming buffer organization (how are registers stored)– Unified RF, split RF, renaming in the ROB– RF = register fileRF register file
• Number of renaming registers
• Number of read/write ports
• Register mapping (how do I find the register I am looking for)– Allocation, de-allocation, and tracking
EE382A – Autumn 2009 John P ShenLecture 6- 28

Renaming Buffer Options
• Unified/merged register file MIPS R10K Alpha 21264• Unified/merged register file – MIPS R10K, Alpha 21264– Registers change role architecture to renamed
• Rename register file (RRF) – PA 8500, PPC 620Holds new values until they are committed to ARF– Holds new values until they are committed to ARF
– Extra data transfer… • Renaming in the ROB – Pentium III• Note: can have a single scheme or separate for integer/FP
EE382A – Autumn 2009 John P ShenLecture 6- 29
• Note: can have a single scheme or separate for integer/FP

Unified Register File:Physical Register FSMPhysical Register FSM
EE382A – Autumn 2009 John P ShenLecture 6- 30

Number of Rename Registers
• Naïve: as many as the number of pending instructionsWaiting to be scheduled + executing + waiting to commit– Waiting to be scheduled + executing + waiting to commit
• Simplification– Do not need renaming for stores, branches, …
• Usual approach:– # scheduler entries ≤ # RRF entries ≤ # ROB entries
• Examples:– PPC 620: scheduler 15, RRF 16 (RRF), ROB 16– MIPS R12000: scheduler 48, RRF 64 (merged), ROB 48– Pentium III: scheduler 20, RRF 40 (in ROB), ROB 40
EE382A – Autumn 2009 John P ShenLecture 6- 31

Register File Ports
• Read: if operands read as instructions enter schedulerMax # ports = 2 * # instructions dispatched– Max # ports = 2 # instructions dispatched
• Read: if operands read as instruction leave scheduler– Max #ports = 2* # instructions issued
C b id th th # f i t ti di t h d• Can be wider than the # of instructions dispatched…
• Write: # of FUs or # of instructions committing– Depends on unified vs separate rename registers
• Notes:– Can implement less ports and have structural hazardsCa p e e t ess po ts a d a e st uctu a a a ds
• Need control logic for port assignment & hazard handling– When using separate RRF and ARF, need ports for the final transfer– Alternatives to increasing ports: duplicated RF or banked RF
EE382A – Autumn 2009 John P ShenLecture 6- 32
g p p• What are the issues?

Register Mapping(From Architectural to Physical Address)(From Architectural to Physical Address)
• Option 1: use a map table (ARF # → physical location)– Map holds the state of the register too… – Simple, but need two steps for reading (ok if operands read late)
• Option 2: associative search in RRF, ROB, … – Each physical register remembers its status (ok if operand read early)
EE382A – Autumn 2009 John P ShenLecture 6- 33
y g ( y)– More complicated but one step read

Integrating Map Tables with the ARF
EE382A – Autumn 2009 John P ShenLecture 6- 34

Renaming Operation: Allocation Lookup De-allocationAllocation, Lookup, De allocation
• At dispatch: for each instruction handled in parallelCheck the physical location & availability of source operands– Check the physical location & availability of source operands
– Map destination register to new physical register• Stall if no register available
N t t h h t t t bl– Note: must have enough ports to any map tables
• At complete: update physical location
• At commit/retire: for each instruction handled in parallelAt commit/retire: for each instruction handled in parallel– Copy from RRF/ROB to ARF & deallocate RRF entry OR– Upgrade physical location and deallocate register with old value
• It is now safe to do that• It is now safe to do that
• Question: can we allocate later or deallocate earlier?
EE382A – Autumn 2009 John P ShenLecture 6- 35

Renaming Operation
EE382A – Autumn 2009 John P ShenLecture 6- 36

Renaming Difficulties: Wide Instruction IssueWide Instruction Issue
• Need many ports in RFs and mapping tables
• Instruction dependencies during dispatching/issuing/committing– Must handle dependencies across instructions– E.g. add R1←R2+R3; sub R6←R1+R5
– Implementation: use comparators, multiplexors, countersImplementation: use comparators, multiplexors, counters• Comparators: discover RAW dependencies• Multiplexors: generate right physical address (old or new allocation)• Counters: determine number of physical registers allocatedp y g
EE382A – Autumn 2009 John P ShenLecture 6- 37

Renaming Difficulties: Mispredictions & ExceptionsMispredictions & Exceptions
• If exception/misprediction occurs, register mapping must be precise
• Separate RRF: consider all RRF entries free
• ROB renaming: consider all ROB entries freeg
• Unified RF: restore precise mapping – Single map: traverse ROB to undo mapping (history file approach)
ROB t b ld i• ROB must remember old mapping…
– Two maps: architectural and future register map • On exception, copy architectural map into future map…
Ch k i ti k l h k i t f t h d d– Checkpointing: keep regular check points of map, restore when needed• When do we make a checkpoint? On every instruction? On every branch?• What are the trade-offs?
W ’ll i it thi h l t
EE382A – Autumn 2009 John P ShenLecture 6- 38
• We’ll revisit this approach later on…

Dynamic Scheduling Based on Reservation Stations
Dispatch Buffer Reg. Write Back
der
Dispatch Reg. File Ren. Reg.AllocateReorderBuffer
inor
d
ReservationStations
Branch
Bufferentries
Integer Integer Float.- Load/f-ord
er
g gPoint Store
out-o
f-
Compl. Buffer(Reorder Buff.)rd
er
EE382A – Autumn 2009 John P ShenLecture 6- 39
Complete
inor

Embedded “Data Flow” Engine
Dispatch Buffer- Read register or
Reservation
Dispatch Read register or
- Assign register tag- Advance instructions to reservation stations
Stations
Branch
- Monitor reg. tag- Receive data being forwarded- Issue when all
operands ready“DynamicExecution”
operands ready
Completion Buffer
EE382A – Autumn 2009 John P ShenLecture 6- 40
Complete





























