Embed Size (px)
Citation preview

Econometrıa de series de tiempo aplicada amacroeconomıa y finanzas
Series de Tiempo Estacionarias (Univariadas)
Carlos Capistran Carmona
ITAM

Serie de tiempo
Una serie de tiempo es una sequencia de valores usualmenteregistrados en intervalos de tiempo equidistantes.
xt t = 1, 2, ..., T.
Ejemplos:I Numero de nacimientos por ano en Mexico.I Produccion semanal de autos en VW Mexico.I Precios diarios del cierre de alguna accion (e.g., TELMEX).I Produccion industrial mensual en Mexico.I Inflacion mensual en Mexico.
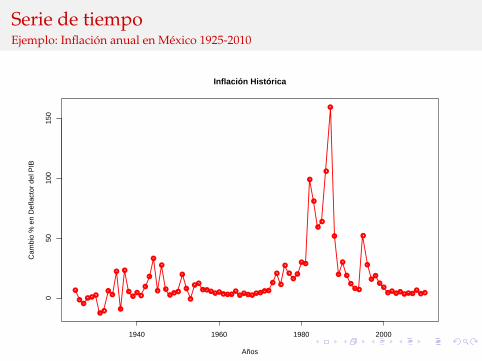
Serie de tiempoEjemplo: Inflacion anual en Mexico 1925-2010
●
●●
●●●
●●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●●
●
●
●
●●
●●●●●●●●●
●●●●●●●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●
●●●●●●●
●●●
Inflación Histórica
Años
Cam
bio
% e
n D
efla
ctor
del
PIB
1940 1960 1980 2000
050
100
150

Procesos estocasticos baseProceso iid (iid)
εt es un proceso independiente e identicamente distribuido (iid)si:
I εt, εs son independientes pero tienen la misma distribucion.
Ejemplo: xt = εt, εt ∼ N(0, 1), t = 1, ..., 100.
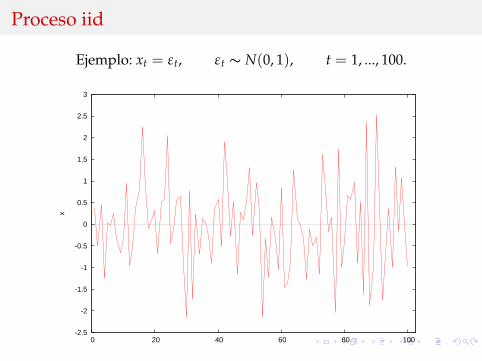
Proceso iid
Ejemplo: xt = εt, εt ∼ N(0, 1), t = 1, ..., 100.
-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5
3
0 20 40 60 80 100
x

Procesos estocasticos baseMartingala en diferencias (md)
La secuencia M es llamada una martingala si:
E[Mt | Mt−j, j = 1, 2, ..., t
]= Mt−1.
Una Martingala en diferencias se define como: xt = Mt −Mt−1.I Propiedades:
E[xt | Mt−j, j ≥ 1
]= 0,
cov (xt, xt−k) = E[xtxt−k | Mt−j, j ≥ 1
]= 0.
Notese que no es independiente, ya que para eso se necesita:
E[(g(ξt − E [g (ξt)]) h(ξt−j)
]= 0.

Procesos estocasticos baseRuido Blanco
εt es un proceso de ruido blanco si:I corr (εt, εs) = 0 ∀ t 6= sI E [εt] es constante para todo t (usualmente 0).
Un proceso de ruido blanco basicamente no tiene estructuratemporal (lineal).Las principales propiedades de una serie de ruido blanco conmedia cero son:
I No hay correlacion entre terminosI Valores pasados no ayudan a pronosticar valores futuros
Si se utiliza un criterio de mınimos cuadrados, se puede mostrarque el mejor pronostico de todos los valores futuros de un procesode ruido blanco es simplemente la media de la serie.Notese que:
ruido blanco ; Martingala en diferencias ; iid.
Estacionariedad y ergodicidad
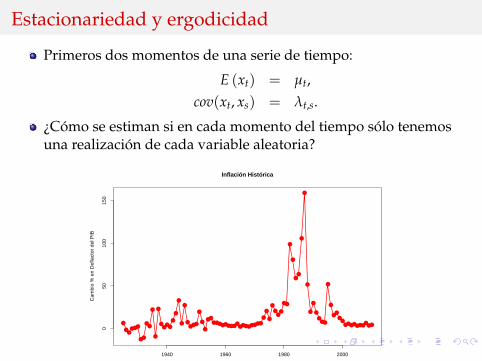
Primeros dos momentos de una serie de tiempo:
E (xt) = µt,cov(xt, xs) = λt,s.
¿Como se estiman si en cada momento del tiempo solo tenemosuna realizacion de cada variable aleatoria?
●
●●
●●●
●●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●●
●
●
●
●●
●●●●●●●●●
●●●●●●●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●
●●●●●●●
●●●
Inflación Histórica
Años
Cam
bio
% e
n D
efla
ctor
del
PIB
1940 1960 1980 2000
050
100
150

Estacionariedad y ergodicidadEstacionariedad
Se dice que un proceso estocastico xt es estacionario de segundoorden (o “estacionario en covarianzas”) si sus primeros dosmomentos no dependen del tiempo:
E [xt] = µ,Var [xt] = σ2,
Cov [xt, xt−τ] = λτ.
Notese que la covarianzas solo dependen de la distancia y no deltiempo.Se dice que un proceso estocastico xt es estacionario en sentidoestricto si la distribucion conjunta de (xt, ..., xt−k) es independientede t para todo k (extremadamente difıcil de probar).

Estacionariedad y ergodicidadErgodicidad
La ergodicidad requiere que valores del proceso suficientementeseparados en el tiempo casi no esten correlacionados.Una definicion, aunque no muy estricta, es: una serie de tiempoestacionaria es ergodica si cov [xt, xt−τ]→ 0 cuando τ → ∞.La ergodicidad permite que al promediar una serie en el tiempo,uno este continuamente anadiendo informacion nueva y relevanteal promedio.Desafortunadamente no es posible probar ergodicidad,simplemente se asume.

Estacionariedad y ergodicidad
Si una serie de tiempo cumple con los supuestos deestacionariedad y ergodicidad, entonces es posible formarbuenos estimadores de las cantidades de interes promediando atraves del tiempo.Un estimador consistente de la media es la media muestral:
µ =1T
T
∑t=1
xt.
Un estimador consistente de la autocovarianza es laautocovarianza muestral:
λτ =1T
T
∑t=1
(xt − µ) (xt−τ − µ) .
Un estimador consistente de la autocorrelacion es laautocorrelacion muestral:
ρτ =λτ
λ0.

Operadores y filtros
Operador rezago:Ljxt = xt−j.
Operador diferencia:
∆jxt =(
1− Lj)
xt = xt − xt−j.
Un filtro cambia las propiedades dinamicas de una serie detiempo.

Operadores y filtrosEjemplos
Ejemplos de filtros:
xt = yt + 3yt−1 + 2yt−2,= (1 + 3L + 2L2)yt.
xt = yt − yt−1,xt = (1− L)yt.
Un ejemplo de la aplicacion del operador rezago:
xt = axt−1 + εt,(1− aL)xt = εt,
xt =εt
(1− aL),
si |a| < 1 entonces :
xt =∞
∑j=0
ajLjεt =∞
∑j=0
ajεt−j.

Modelos Autorregresivos (AR)AR(p)
Autorregresivo de orden p, AR(p):
xt =p
∑j=1
φjxt−j + εt,
εt : ruido blanco, E [εt] = µ, var (εt) = σ2
tambien puede escribirse como:
φp (L) xt = εt,
donde φp (L) = 1−p
∑j=1
φjLj.

Modelos Autorregresivos (AR)Condicion de estacionariedad
La condicion para que un AR(p) sea estacionario es que las raıcesde la ecuacion caracterıstica
1− φ1z− φ2z2 − ... ı−φpzp = 0,
esten fuera del cırculo unitario (i.e. que el inverso de las raıcesesten dentro del cırculo unitario, que es lo que usa Eviews).Lo que esta condicion garantiza es que el proceso
φp (L) xt = εt,
pueda escribirse como
xt = φp (L)−1 εt,
con φp (L)−1 convergiendo a cero, lo que implica que lasautocorrelaciones decaeran conforme aumenta la longitud delrezago.

Modelos Autorregresivos (AR)AR(1)
Algunos aspectos importantes de un AR(1):
xt = φxt−1 + εt empieza en t = 0,
xt =t
∑j=0
φjεt−j + x0φt.
asumiendo que x0 = 0, entonces:
E(xt) = µt
∑j=0
φj =
{µ[
1−φt+1
1−φ
]si φ 6= 1
µ (t + 1) si φ = 1
var (xt) = E[(xt − E (xt))
2]
= E
( t
∑j=0
φj (εt−j − µ))2
= σ2
t
∑j=0
φ2j =
{σ2[
1−φ2(t+1)
1−φ2
]si φ 6= 1
σ2 (t + 1) si φ = 1

Modelos Autorregresivos (AR)AR(1)
Un modelo AR(1):
xt = φxt−1 + εt
es estacionario si |φ| < 1.¿Porque?En este caso, la media y la varianza estan dadas por:
E(xt) =µ
1− φ
var(xt) =σ2
1− φ2

Modelos Autorregresivos (AR)AR(1)
La autocovarianza entre xt y xt−1 esta dada por:
cov(xt, xt−1) = E [(xt − E [xt]) (xt−1 − E [xt−1])]= E [xtxt−1] = E [(φxt−1 + εt) xt−1]= φE
[x2
t−1]+ E [εtxt−1] = φE
[x2
t−1]
= φvar(xt−1).
El segundo termino desaparece porque xt = ∑tj=0 φjεt−1−j y por lo
tanto E[εt ∑t−1
j=0 φjεt−1−j
]= E
[∑t−1
j=0 φjεtεt−1−j
]= 0.
Por lo tanto la autocorrelacion esta dada por:
ρ1 = corr(xt, xt−1) =cov(xt, xt−1)
var(xt)=
φvar(xt−1)var(xt)
= φ,
si var(xt) = var(xt−1) que ocurre cuando |φ| < 1.En general, la funcion de autocorrelacion esta dada por:
ρk = corr(xt, xt−k) = φk.
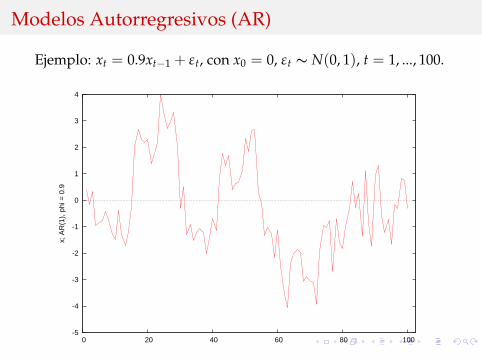
Modelos Autorregresivos (AR)
Ejemplo: xt = 0.9xt−1 + εt, con x0 = 0, εt ∼ N(0, 1), t = 1, ..., 100.
-5
-4
-3
-2
-1
0
1
2
3
4
0 20 40 60 80 100
x; A
R(1
), p
hi =
0.9
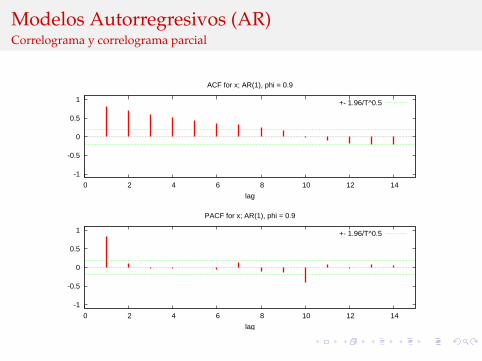
Modelos Autorregresivos (AR)Correlograma y correlograma parcial
-1
-0.5
0
0.5
1
0 2 4 6 8 10 12 14
lag
ACF for x; AR(1), phi = 0.9
+- 1.96/T^0.5
-1
-0.5
0
0.5
1
0 2 4 6 8 10 12 14
lag
PACF for x; AR(1), phi = 0.9
+- 1.96/T^0.5

Promedios Moviles (MA)MA(q)
Promedio movil de orden q, MA(q):
xt =q
∑j=0
θjεt−j θ0 = 1.
tambien puede escribirse como:
xt = θq(L)εt,
donde θq(L) = 1 +q
∑j=1
θjLj.

Promedios Moviles (MA)MA(1)
Algunos aspectos de un MA(1) :
xt = εt + θ1εt−1,
de donde se obtiene:
E [xt] = 0,
var(xt) = E[(xt − E [xt])
2]
= E[(xt)
2]
= E[(εt + θ1εt−1)
2]
= E[ε2
t + θ1εtεt−1 + θ21ε2
t−1]
=(1 + θ2
1)
σ2.

Promedios Moviles (MA)MA(1)
La autocovarianza de primer orden esta dada por:
cov(xt, xt−1) = E [(xt − E [xt]) (xt−1 − E [xt−1])]= E [xtxt−1] = E [(εt + θ1εt−1) (εt−1 + θ1εt−2)]= E
[εtεt−1 + θ1εtεt−2 + θ1ε2
t−1 + θ21εt−1εt−2
]= E
[θ1ε2
t−1]
= θ1σ2.
Por lo que la autocorrelacion de primer orden es:
corr(xt, xt−1) =cov(xt, xt−1)
var(xt)=
θ1σ2(1 + θ2
1
)σ2
=θ1(
1 + θ21
) .
notese que es posible estimar ρ1 = corr(xt, xt−1), pero entoncesobtendrıamos dos estimadores de θ1, uno siempre dentro de la region[−1, 1] , el otro siempre fuera de esa region.

Promedios Moviles (MA)MA(1)
La autocovarianza de segundo orden es:
cov(xt, xt−2) = E [xtxt−2]= E [(εt + θ1εt−1) (εt−2 + θ1εt−3)]= E
[εtεt−2 + θ1εtεt−3 + θ1εt−1εt−2 + θ2
1εt−1εt−3]
= 0.
de donde se observa que todas las autocovarianzas (y por lo tantoautocorrelaciones) mayores a q (el orden del MA) son cero.Los procesos MA siempre son estacionarios.
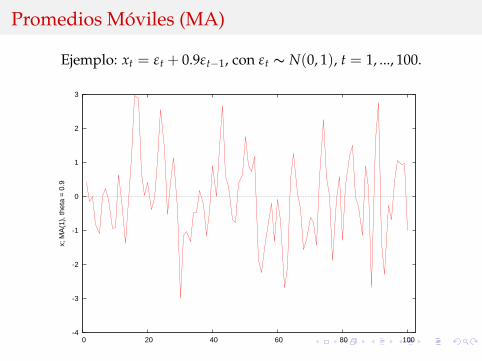
Promedios Moviles (MA)
Ejemplo: xt = εt + 0.9εt−1, con εt ∼ N(0, 1), t = 1, ..., 100.
-4
-3
-2
-1
0
1
2
3
0 20 40 60 80 100
x; M
A(1
), th
eta
= 0
.9
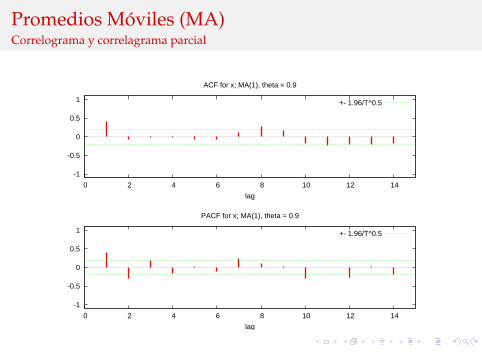
Promedios Moviles (MA)Correlograma y correlagrama parcial
-1
-0.5
0
0.5
1
0 2 4 6 8 10 12 14
lag
ACF for x; MA(1), theta = 0.9
+- 1.96/T^0.5
-1
-0.5
0
0.5
1
0 2 4 6 8 10 12 14
lag
PACF for x; MA(1), theta = 0.9
+- 1.96/T^0.5

Modelos Autorregresivos y de Promedios Moviles(ARMA)
Proceso autorregresivo y de promedios moviles de orden p,q,ARMA(p, q):
φp(L)xt = θq(L)εt.
Un ejemplo es el proceso ARMA(1, 1):
xt = φxt−1 + εt + θ1εt−1.

Modelos Autorregresivos y de Promedios Moviles(ARMA)
Los procesos mixtos pueden generarse agregando otros modelos.Por ejemplo:
xt ∼ AR(m), yt ∼ AR(n), xt ⊥ yt
φ1(L)xt = εt
φ2(L)yt = ηt
εt ⊥ ηt, con media cerozt = xt + yt
=εt
φ1(L)+
ηt
φ2(L)
=1
φ1(L)φ2(L)[φ2(L)εt + φ1(L)ηt]
φ1(L)φ2(L)zt = [φ2(L)εt + φ1(L)ηt]⇒ zt ∼ ARMA(m + n, r), r = max(m, n).

Metodologıa de Seleccion de Modelos Box-Jenkins
Los procesos ARMA tienen firmas (ACF y PACF) que permitenidentificarlos, sin embargo dichas firmas son demasiado parecidaso complejas, lo cual dificulta la seleccion de la especificacion.Box y Jenkins propusieron una tecnica estadıstica para la seleccionde un modelo ARMA que se ajuste a los datos, la cual consiste delas siguientes etapas
1 Identificacion2 Estimacion3 Diagnostico4 Pronostico

Metodologıa Box-Jenkins (Identificacion)Seleccion del orden de un ARMA(p,q)
Para seleccionar el orden del proceso, es decir, p y q, se utilizan losllamados criterios de informacion. Los dos mas populares son elAkaike (1974) y el Bayesiano de Schwarz (1978):
AIC = ln(
σ2p,q
)+
2(p + q)T
,
BIC = ln(
σ2p,q
)+
(p + q) ln(T)T
,
donde T es el tamano de la muestra. Se escogen los valores de p yq que minimizan el criterio de informacion seleccionado.En caso de que no sea posible discriminar entre modelos, esposible quedarnos con los modelos relevantes y tratar decombinarlos de alguna forma (modelado denso: “Thickmodeling”).

Metodologıa Box-Jenkins (Estimacion)Estimacion de un ARMA(p,q)
Bajo el supuesto de que se conoce el orden p y q del procesoARMA, es posible hacer uso distintos de metodos de estimacionde parametros los cuales son puestos en practica con la ayuda deprogramas computacionales.Si el orden del proceso ARMA no es conocido, este puede serestimado con la ayuda de los criterios de informacion. Para dichoproposito se estiman procesos ARMA de manera recursiva con unorden creciente tanto en p como en q ( p = 1, . . . , pmax yq = 1, . . . , qmax). Finalmente se elige la combinacion (p∗, q∗) queminimiza el criterio seleccionado.

Metodologıa Box-Jenkins (Estimacion)Estimacion de un AR(p)
Se mostrara la estimacion para el caso de un proceso AR(p), parael cual sus parametros pueden ser estimados mediante tresmetodos:
1 Maxima Verosimilitud2 Metodo de Momentos (Ecuaciones Yule-Walker)3 Mınimos Cuadrados

Metodologıa Box-Jenkins (Estimacion)Estimacion de un AR(p)
Maxima Verosimilitud
Si conocemos la distribucion del ruido blanco que genera elproceso AR(p), los parametros pueden ser estimados usando elmetodo de maxima verosimilitudTomando x1 como dada, la verosimilitud condicional para lasn− 1 observaciones restantes es
L∗ = p (x2, x3, . . . , xn|x1)= p (x2|x1) p (x3|x1, x2) (xn|x1, x2, . . . , xn−1)
Para obtener la verosimilitud no condicional habra que calcular
L = p (x1) L∗

Metodologıa Box-Jenkins (Estimacion)Estimacion de un AR(1)- Maxima Verosimilitud
Bajo el supuesto de un proceso AR(1) con ruido blanco gaussiano, i.e.
xt = φxt−1 + εt E[εt] = µ var[εt] = σ2
las distribuciones son:t = 1
x1 ∼ N(
µ
1− φ,
σ2
1− φ2
)t = 2
x2|x1 ∼ N(µ + φx1, σ2)
t > 1
xt|xt−1, . . . , x1 ∼ N(µ + φxt−1, σ2)

Metodologıa Box-Jenkins (Estimacion)Estimacion de un AR(1)- Maxima Verosimilitud
La funcion de Verosimilitud es
L =1√2π
(σ2
1− φ2
)− 12
exp
{−1− φ2
2σ2
(y1 −
µ
1− φ
)2}
T
∏t=2
1√2πσ2
exp
{(xt − φxt−1)
2
2σ2
}La log-verosimilitud es
l = −T2
ln(2π)− 12
ln(
σ2
1− φ2
)− 1− φ2
2σ2
(y1 −
µ
1− φ
)2
−n− 12
ln(σ2)− T
∑t=2
(xt − φxt−1)2
2σ2
la estimacion de los parametros se obtiene de maximizar ya seaanalıticamente o mediante una optimizacion numerica.

Metodologıa Box-Jenkins (Estimacion)Estimacion de un AR(p)
Metodo de Momentos - Ecuaciones Yule-Walker
Las ecuaciones Yule-Walker son extraıdas de la funcion deautocorrelacion de un proceso AR(p), la cual tiene la siguienteforma:
ρj ={
1, para j=0;φ1ρj−1 + φ2ρj−2 + . . . + φpρj−p, para j=1,2,. . . .
por lo tanto existen p parametros distintos y hay p ecuacionesYule-Walker. Se puede resolver este sistema reemplazando ρj(correlacion teorica) por ρj (correlacion muestral) y obtenerestimadores de los parametros φi para i = 1, 2, . . . , p.

Metodologıa Box-Jenkins (Estimacion)Estimacion de un AR(p)
Mınimos Cuadrados
Se ajusta por MCO la siguiente especificacion:
xt = φ1xt−1 + φ2xt−2 + · · ·+ φpxt−p + ut
si la ecuacion satisface las condiciones de estacionariedad MCOarroja estimadores consistentes. Ademas
√T(φi − φi
)i = 1, 2, . . . , p se distribuye asintoticamente normal.El estimador de MCO es equivalente al estimador de MV cuandoel vector de errores sigue una distribucion normal multivariada.

Metodologıa Box-Jenkins (Estimacion)Estimacion de un MA(q)
Se presenta la estimacion de un proceso MA(q) por el metodo deMaxima Verosimilitud, dicho metodo no es el unico disponiblepara estimarlo, pero cualquier metodo que pretenda hacerlo debeser capaz de estimar una funcion no lineal en los parametros (porejemplo, mınimos cuadrados no lineales).

Metodologıa Box-Jenkins (Estimacion)Estimacion de un MA(1)
Maxima Verosimilitud
Se calcula la funcion de verosimilitud, para el caso
xt = µ + εt + θεt−1 εt ∼i.i.d. N(0, σ2)
las probabilidades condicionales son:I t = 1 Bajo el supuesto ε0 = 0
x1|(ε0 = 0) ∼ N(µ, σ2)ε1 = x1 − µ
I t = 2
x2|(x1, ε0 = 0) ∼ N(µ− θε1, σ2)ε2 = x2 − µ− θε1

Metodologıa Box-Jenkins (Estimacion)Estimacion de un MA(1)
Las probabilidades condicionales son en general de la formap(yt|εt−1)
I t > 1
xt|(xt−1, . . . , x1, ε0 = 0) ∼ N(µ− θεt−1, σ2)εt = xt − µ− θεt−1
La funcion de verosimilitud es
L =T
∏t=1
p(yt|εt−1)
=T
∏t=1
1√2πσ2
exp{− ε2
t2σ2
}

Metodologıa Box-Jenkins (Estimacion)Estimacion de un MA(1)
La log-verosimilitud es
l = −T2
ln(2π)− T2
ln(σ2)− 12σ2
T
∑t=1
ε2t
el ultimo termino de la expresion es una funcion no lineal de losparametros por lo cual es necesario el uso de metodos iterativospara obtener los estimadores.La estimacion de un proceso ARMA(p, q) comparte el reto deestimacion presente en un proceso MA.

Metodologıa Box-Jenkins (Diagnostico)Pruebas de Diagnostico
La inferencia estadıstica que se hace a partir de MCO o MV puedeser aplicada en el contexto de la estimacion de un proceso ARMAsiempre y cuando se cumplan las condiciones de estacionariedad.Los residuales del modelo proveen informacion importante, siestos no aproximan un ruido blanco el modelo seleccionado no essatisfactorio y es necesario una nueva especificacion.

Metodologıa Box-Jenkins (Pronostico)Pronosticos por pasos
Denotemos por pt+h,t al pronostico realizado en t para el horizonteh.Se define el error de pronostico como et+h,t = xt+h − pt+h,t. Noteseque pt+h,t es conocido en el tiempo t, mientras que et+h,t y xt+h loson hasta el periodo t + h.El error cuadratico medio (ECM) de un pronostico es
ECM =H
∑h=1
e2t+h,t =
H
∑h=1
(xt+h − pt+h,t)2
el cual promedia el error de pronostico de manera simetrica.Se puede demostrar que el mınimo en el ECM se alcanza cuandoel pronostico de la variable pt+h,t es la esperanza condicional de lavariable xt+h, dada toda la informacion disponible en el tiempo t.

Metodologıa Box-Jenkins (Pronostico)Pronosticos por pasos para un AR(1)
Consideramos un proceso AR(1) de la forma
xt = φxt−1 + εt E[εt] = µ var[εt] = σ2
Para calcular el pronostico un paso hacia adelante del procesopartimos de saber que su verdadero valor es
xt+1 = φxt + εt+1
El pronostico, es la esperanza condicional de xt+1 dada lainformacion disponible en el tiempo t, cuando se minimiza elECM esto es
pt+1,t = E[xt+1|xt] = φxt + µ
el error asociado es
et+1,t = xt+1 − E[xt+1|xt]= xt+1 − φxt − µ
= εt+1 − µ

Metodologıa Box-Jenkins (Pronostico)Pronosticos por pasos para un AR(1)
El pronostico dos pasos hacia adelante es
pt+2,t = E[xt+2|xt] = φE[xt+1|xt] + µ = φ2xt + (1 + φ)µ
et+2,t = xt+2 − E[xt+2|xt]= φxt+1 + εt+2 − φE[xt+1|xt]− µ
= φet+1,t + εt+2 − µ
= εt+2 + φεt+1 − (1 + φ)µ
El pronostico h pasos hacia adelante es
pt+h,t = E[xt+h|xt] = φhxt + µ(
1 + φ + φ2 + · · ·+ φh−1)
et+h,t = εt+h + φεt+h−1 + φ2εt+h−2 + · · ·+ φh−1εt+1
−(
1 + φ + φ2 + · · ·+ φh−1)
µ

Metodologıa Box-Jenkins (Pronostico)Pronosticos por pasos para un AR(1)
Las propiedades del error de pronostico de horizonte h son
E[et+h,t] = 0
Var[et+h,t] =(
1 + φ2 + φ4 + · · ·+ φ2(h−1))
σ2
Conforme el horizonte de pronostico crece
pt+h,t −→µ
1− φcuando h −→ ∞
Var[et+h,t] −→σ2
1− φ2 cuando h −→ ∞
i.e. el valor pronosticado tiende a la media no condicional delproceso, y la varianza del error de pronostico se incrementa haciala varianza no condiconal del proceso.

Metodologıa Box-Jenkins (Pronostico)Pronosticos por pasos para un AR(1)
Al tener una distribucion para el error de pronostico es posibleconstruir intervalos de confianza (IC) para los pronosticos h pasoshacia adelante.Para el caso de un pronostico un paso hacia adelante
et+1,t ∼ N(0, (1 + φ)σ2)
por lo cual un IC al 95 % esta dado por
IC : µ + φxt ± 1,96[(1 + φ)σ2] 1
2

Metodologıa Box-Jenkins (Pronostico)Pronosticos por pasos para un MA(1)
Consideremos un proceso MA(1) de la forma
xt = µ + εt + θεt−1 E[εt] = 0 var[εt] = σ2
Para calcular el pronostico un paso hacia adelante del procesopartimos de saber que su verdadero valor es
xt+1 = µ + εt+1 + θεt
El pronostico, cuando se minimiza el ECM, es
pt+1,t = E[xt+1|xt] = µ + θεt
El valor de εt depende de los valores previos de ε, para laimplementacion es comun fijar ε0 = 0, esta aproximacion pierdeimportancia conforme el tamano de muestra crece.Calculamos el error asociado
et+1,t = xt+1 − E[xt+1|xt]= xt+1 − µ− θεt = εt+1

Metodologıa Box-Jenkins (Pronostico)Pronosticos por pasos para un MA(1)
El pronostico dos pasos hacia adelante es
pt+2,t = E[xt+2|xt] = µ
et+2,t = xt+2 − E[xt+2|xt] = xt+2 − µ = εt+2 + θεt+1
En un proceso MA(1) el pronostico por pasos tiene el siguienteesquema
pt+h,t = µ h ≥ 2var(et+h,t) = (1 + θ2)σ2 h ≥ 2
para dos periodos adelante, el pronostico de un MA(1) essimplemente la media no condicional de la serie, y la varianza delerror de pronostico es la varianza de la serie.

Teorema de Wold
xt univariada, estacionaria y con media cero. It consiste del pasadoy del presente de la serie: xt−j, j ≥ 0.(Representacion de Wold) Cualquier proceso estacionario {xt}puede representarse como:
xt = c(L)εt + vt =∞
∑j=0
cjεt−j + vt,
donde c0 = 1 y ∑∞j=0 c2
j < ∞. El termino εt es ruido blanco yrepresenta el error hecho al pronosticar xt basandose en unafuncion lineal de rezagos de xt :
εt = xt − P(xt | It−1).
vt un proceso linealmente determinıstico y no esta correlacionadocon εt−j ∀j, mientras que ∑∞
j=0 cjεt−j es llamado el componentelinealmente no determinıstico (i.e. estocastico).

Procesos Determinısticos
Son aquellos que pueden ser pronosticados perfectamente, dadoque conocemos la funcion que los genera.Por ejemplo, si la funcion generadora es:
yt = a + bt,
entonces, el valor de yt+1 puede ser pronosticado perfectamente,al igual que el de yt+k :
yt+1 = a + b(t + 1),yt+k = a + b(t + k).

Descomposicion Tradicional de una Serie de Tiempo
Una serie de tiempo puede pensarse como compuesta de distintoselementos, algunos de ellos determinısticos y otros estocasticos:
yt = tendencia + estacionalidad + resto,yt = t + s + ε,
los dos primeros han sido considerados tradicionalmente comodeterminısticos, asi que la parte estocastica es a lo que llamamosresto.La tendecia puede ser lineal, o puede ser ajustada por unpolinomio de mas alto grado. Tambien puede presentar cambiosestructurales o ser estocastica. En caso de presentar tendencia, lasseries son no estacionarias.

Estacionalidad
Existen varios metodos para tratar datos estacionales:En el caso en que sea verdaderamente repetitiva, podemos utilizar
un filtro de promedios moviles: y∗t =12∑
j=−12ajyt−j aj = a−j.
Incluir una variable dicotomica (dummy) para cada “estacion” (yno incluir una constante). Esto asume que la estacionalidad nocambia en la muestra.Usar datos “ajustados estacionalmente”. El factor estacional seestima tıpicamente usando un filtro de dos lados para los datos decada “estacion” en anos contiguos. De esta forma se puedenextraer una amplia gama de factores estacionales. Algunos filtrosson el X-12 ARIMA o el TRAMO-SEATS. Sin embargo, el ajusteestacional tambien altera las auto-correlaciones de las series.Aplicar una diferencia estacional. Si s es el numero de estaciones(4 para trimestres, 12 para meses), entonces: ∆syt = yt − yt−s. Laserie ∆syt esta libre de estacionalidad, sin embargo, esto tambienelimina la tendencia de largo plazo.

Bibliografıa
Box, George E.P., Gwilym M. Jenkins y Gregory C. Reinsel. 2008.Time Series Analysis Forecasting and Control. 4a ed. NewJersey:Wiley.
Brooks, Chris. 2008. Introductory Econometrics for Finance. 2a ed.Cambridge:Cambridge University Press.
Enders, Walter. 2010. Applied Econometric Time Series. 3a ed. NewJersey:Wiley.
Guerrero, Vıctor. 2003. Analisis Estadıstico de Series de TiempoEconomicas. 2a ed. Mexico:Thomson.
Granger, Clive W.J. y Paul Newbold. 1986. Forecasting EconomicTime Series. 2a ed. San Diego:Academic Press.
Hamilton, James D. 1994. Times Series Analysis. PrincetonUniversity Press.








![4a ed. (Señales aleatorias y ergodicidad) communication ......Introducción a la teoria y Sistemas de Comunicación [Lathi] Communication systems, an introduction to signals and noise](https://img.dokumen.tips/doc/110x75/6132024adfd10f4dd73a2b8b/4a-ed-seales-aleatorias-y-ergodicidad-communication-introduccin-a.jpg)




















