Embed Size (px)
Citation preview

© 2013 IBM Corporation
Do C and Java ProgramsScale Differently on Hardware Transactional Memory?
Rei Odaira (IBM Research - Tokyo)
Jose G. Castanos(IBM Research – T. J. Watson Research Center)
Takuya Nakaike (IBM Research - Tokyo)

© 2013 IBM Corporation2
IBM Research – Tokyo
Hardware Transactional Memory (HTM) Coming into the Market
Blue Gene/Q
2012
zEC12
2012
4th Generation
Core Processor
2013
Intel
POWER8

© 2013 IBM Corporation3
IBM Research – Tokyo
Many Programming Languages to Support TM
� Transactional langugage constructs
–Being discussed for C++
� TM intrinsic support
–GNU C/C++ compiler
– IBM XL C/C++ compiler
�Software TM (STM) support
–DSTM2 for Java
–TinySTM for C/C++
–Haskell, Closure, etc.

© 2013 IBM Corporation4
IBM Research – Tokyo
Our Goal
�Which programming language to choose?
�More specifically,
–Focus on C and Java.
–Do they scale differently on HTM?
– If yes, what are the reasons?

© 2013 IBM Corporation5
IBM Research – Tokyo
Our Methodology
�Measured C and Java STAMP benchmarks.
–Widely used TM benchmark suite.
�Experimented on IBM zEC12’s HTM.

© 2013 IBM Corporation6
IBM Research – Tokyo
Transactional Memory
�At programming time
–Enclose critical sections with transaction begin
and end directives.
lock();a->count++;unlock();
tbegin();a->count++;tend();

© 2013 IBM Corporation7
IBM Research – Tokyo
Transactional Memory
�At execution time
–A transaction observed
as one step by other
threads.
–Multiple transactions
executed in parallel as
long as no memory
conflict.
� Higher parallelism
than locks.
tbegin();a->count++;tend();
tbegin();b->count++;tend();
tbegin();a->count++;tend(); tbegin();
a->count++;tend();
Thread X Thread Y

© 2013 IBM Corporation8
IBM Research – Tokyo
HTM in IBM zEC12
� Instruction set
– TBEGIN: Begin a transaction
– TEND: End a transaction
– TABORT, NTSTG, etc.
� Micro-architecture
– Hold read set in L1 and L2 caches (~1MB)
– Hold write set in L1 cache and store buffer (8KB)
– Conflict detection using cache coherence protocol
– 256-byte cache line
� Roll back to immediately after TBEGIN when:
– Conflict, footprint overflow, etc.
TBEGINif (cc!=0)
goto abort handler......TEND

© 2013 IBM Corporation9
IBM Research – Tokyo
STAMP Benchmarks [Minh et al., 2008]
�Most widely used benchmark suite for TM
�Written in C
Refines a Delaunay meshyada
vacation-low
Emulates travel reservation systemvacation-high
Creates efficient graph representationssca2
Routes paths in mazelabyrinth
kmeans-low
Implements K-means clusteringkmeans-high
Detects network intrusionintruder
Performs gene sequencinggenome
Learns structure of a Bayesian networkbayes

© 2013 IBM Corporation10
IBM Research – Tokyo
Java STAMP Benchmarks
�Ported from C STAMP by UC Irvine.
–Dialect of Java language used.
Our contributions:
� Ported to standard Java language.
� Modified to use HTM intrinsics for Java.
� com.ibm.htm.HTM.begin(), HTM.end(), etc.
� Intrinsics converted to HTM instructions by our
just-in-time (JIT) compiler

© 2013 IBM Corporation11
IBM Research – Tokyo
Comparing C and Java STAMP Benchmarks
TM_BEGIN();status =
TMTABLE_INSERT(startHashToConstructEntryTables[j],(ulong_t)startHash,(void*)constructEntryPtr );
TM_END();
AtomicRegion.begin();try {check = startHashToConstructEntryTables[newj].table_insert(startHash, constructEntryPtr);
} finally {AtomicRegion.end();
}
C / sequencer_run() in genome
Java / Sequencer.run() in genome

© 2013 IBM Corporation12
IBM Research – Tokyo
Experimental Settings and Environment
� Default runtime options used for STAMP
– Large data set
� C
– 64 bits, -O3, IBM XL C/C++ compiler for z/OS
� Java
– 64-bit IBM J9/TR
– 4-GB Java heap with mark-and-sweep GC
– Iterated for 2 minutes and measured the second half.
� Environment
– z/OS 1.13 with UNIX System Services
– 16-core 5.5-GHz zEC12 with 6 GB memory

© 2013 IBM Corporation13
IBM Research – Tokyo
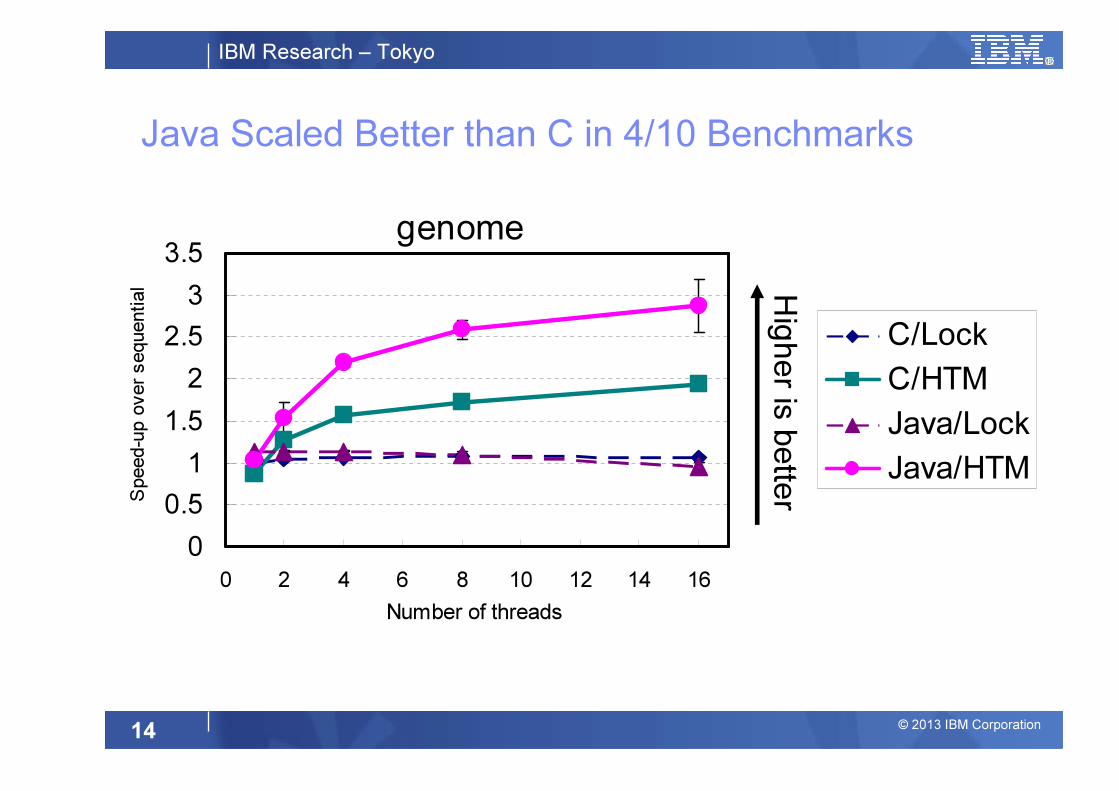
Overview of the Results
�Among 10 benchmarks in STAMP,
� Java scaled better than C in 4 benchmarks.
�C scaled better than Java in 2 benchmarks.
�C and Java scaled similarly in 4 benchmarks.
–Both scaled well in 1 benchmark.
–Both did not scale in 3 benchmarks.
© 2013 IBM Corporation14
IBM Research – Tokyo
yada
0
0.2
0.4
0.6
0.8
1
1.2
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/Lock
C/HTM
Java/Lock
Java/HTM
Java Scaled Better than C in 4/10 Benchmarks
genome
0
0.5
1
1.5
2
2.5
3
3.5
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential H
igh
er is
bette
r

© 2013 IBM Corporation15
IBM Research – Tokyo
yada
0
0.2
0.4
0.6
0.8
1
1.2
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/Lock
C/HTM
Java/Lock
Java/HTM
Java Scaled Better than C in 4/10 Benchmarks
intruder
0
0.5
1
1.5
2
2.5
3
3.5
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential H
igh
er is
bette
r

© 2013 IBM Corporation16
IBM Research – Tokyo
yada
0
0.2
0.4
0.6
0.8
1
1.2
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/Lock
C/HTM
Java/Lock
Java/HTM
Java Scaled Better than C in 4/10 Benchmarks
Hig
her is
bette
r
Similar in vacation-high
vacation-low
0
1
2
3
4
5
6
7
8
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential

© 2013 IBM Corporation17
IBM Research – Tokyo
yada
0
0.2
0.4
0.6
0.8
1
1.2
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/Lock
C/HTM
Java/Lock
Java/HTM
C Scaled Better than Java in 2/10 Benchmarks
Hig
her is
bette
r
Similar in kmeans-high
kmeans-low
0
2
4
6
8
10
12
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential

© 2013 IBM Corporation18
IBM Research – Tokyo
yada
0
0.2
0.4
0.6
0.8
1
1.2
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/Lock
C/HTM
Java/Lock
Java/HTM
C and Java Scaled Similarly in 4/10 Benchmarks
Hig
her is
bette
r
ssca2
0
1
2
3
4
5
6
7
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential

© 2013 IBM Corporation19
IBM Research – Tokyo
yada
0
0.2
0.4
0.6
0.8
1
1.2
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/Lock
C/HTM
Java/Lock
Java/HTM
C and Java Scaled Similarly in 4/10 Benchmarks
Hig
her is
bette
r
bayes
0
0.5
1
1.5
2
2.5
3
3.5
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
labyrinth
0
0.2
0.4
0.6
0.8
1
1.2
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential

© 2013 IBM Corporation20
IBM Research – Tokyo
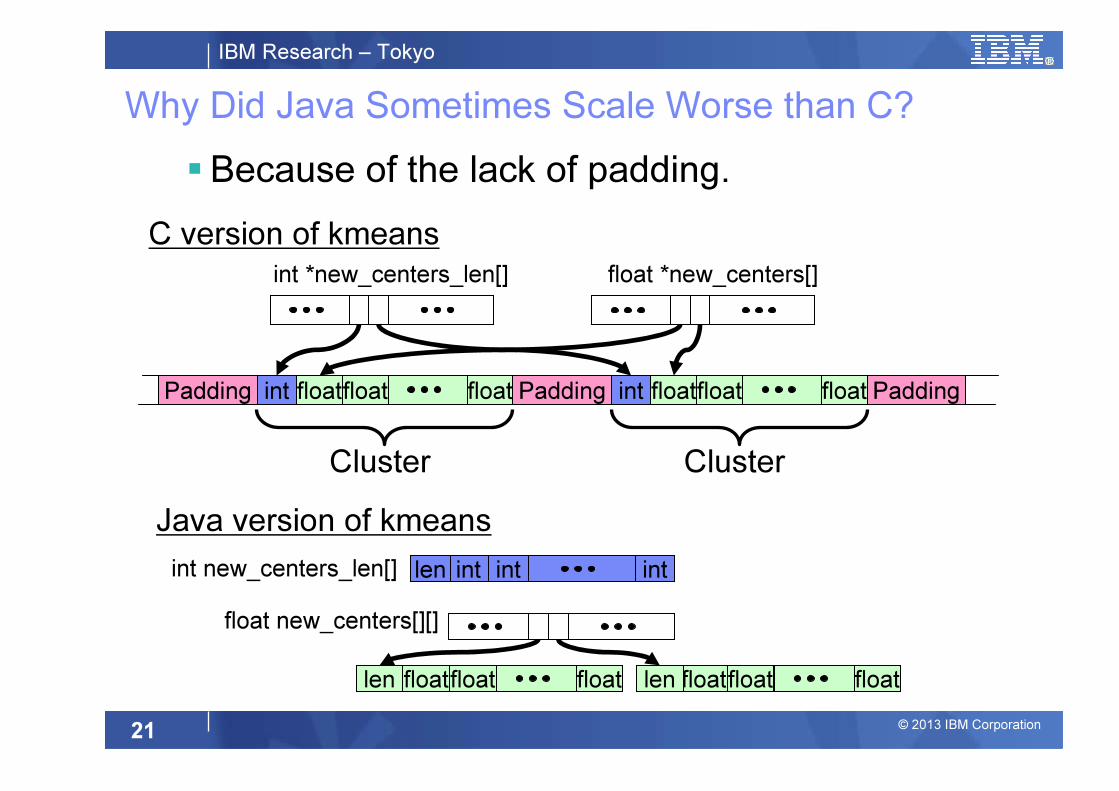
Why Did C Sometimes Scale Worse than Java?
�Because of the conflicts at malloc().
� Java
–Objects allocated from thread-local heaps.
�C
–Global data manipulated in z/OS malloc().
� Used a simple thread-local allocator attached
with STAMP. (free() not supported).
� Should use efficient malloc(), like TCMalloc.
© 2013 IBM Corporation21
IBM Research – Tokyo
Why Did Java Sometimes Scale Worse than C?
�Because of the lack of padding.
C version of kmeans
int floatfloat float Padding int floatfloat float PaddingPadding
int *new_centers_len[] float *new_centers[]
Cluster Cluster
Java version of kmeans
int int intint new_centers_len[]
float new_centers[][]
floatfloat floatfloatfloat float
len
len len
© 2013 IBM Corporation22
IBM Research – Tokyo
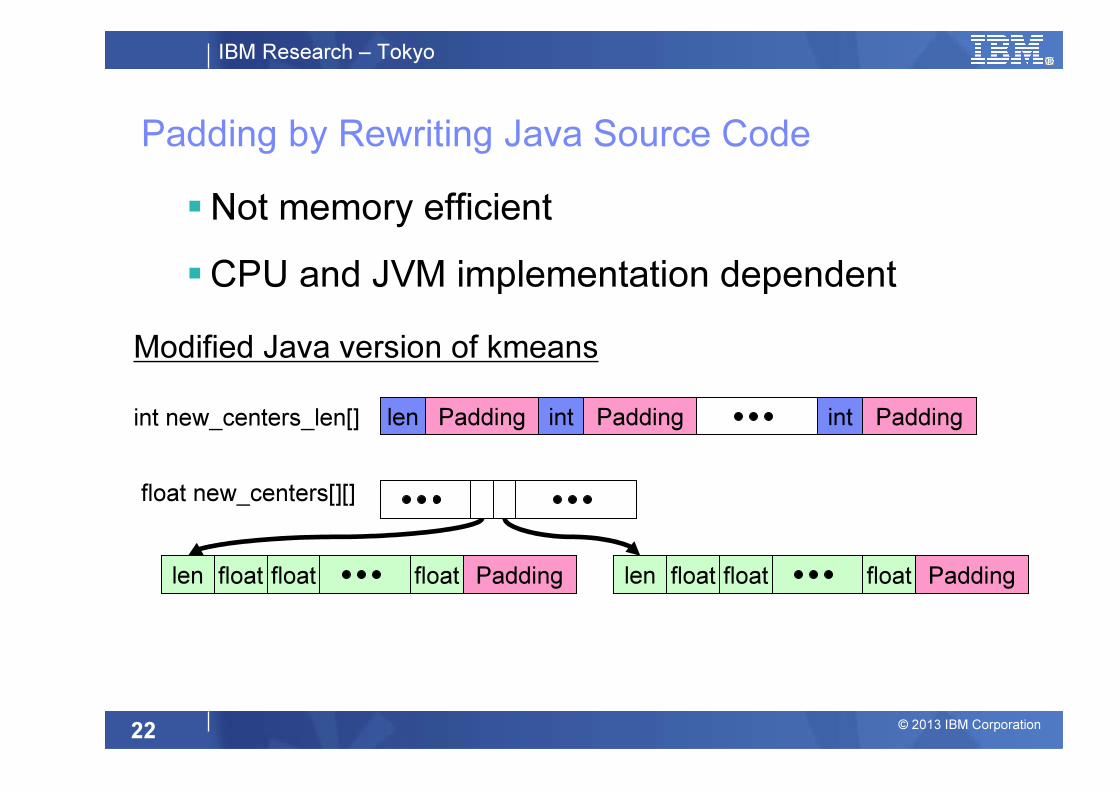
Padding by Rewriting Java Source Code
�Not memory efficient
�CPU and JVM implementation dependent
Modified Java version of kmeans
len int intint new_centers_len[]
float new_centers[][]
float float floatfloat float float
Padding Padding Padding
Padding Paddinglen len

© 2013 IBM Corporation23
IBM Research – Tokyo
Better Solutions
�Structs in Java
–Being proposed.
�Automatic mechanism in Java VM
–Collocate objects accessed in the same
transaction.
–Separate objects updated in different
transactions.

© 2013 IBM Corporation24
IBM Research – Tokyo
Why Did Java Sometimes Scale Worse than C?
� Java VM service invoked during transactions.
� In the vacation benchmark, profiling code executed in transactions.
–Profiling needed for JIT-compiler optimizations.
–Global data updated by the profiling code.
� Profiling disabled for certain methods.
�Abort-prone JVM services:
–JIT compiler, code patching, etc.
� HTM-aware JVM services needed.

© 2013 IBM Corporation25
IBM Research – Tokyo
genome
0
0.5
1
1.5
2
2.5
3
3.5
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/before
C/after
Java/before
Java/after
C vs. Java after Modifications
Hig
her is
bette
r
C: thread-local malloc()

© 2013 IBM Corporation26
IBM Research – Tokyo
intruder
0
0.5
1
1.5
2
2.5
3
3.5
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/before
C/after
Java/before
Java/after
C vs. Java after Modifications
Hig
her is
bette
r
C: thread-local malloc()

© 2013 IBM Corporation27
IBM Research – Tokyo
kmeans-low
0
2
4
6
8
10
12
14
16
0 2 4 6 8 10 12 14 16
Number of threads
Speed-u
p o
ver
sequential
C/before
C/after
Java/before
Java/after
C vs. Java after Modifications
Hig
her is
bette
r
C: thread-local malloc()
Java: padding

© 2013 IBM Corporation28
IBM Research – Tokyo
vacation-low
0
1
2
3
4
5
6
7
8
0 2 4 6 8 10 12 14 16
Number of threads
Sp
ee
d-u
p o
ve
r se
qu
en
tia
l
C/before
C/after
Java/before
Java/after
C vs. Java after Modifications This gap is
our future
work.
Hig
her is
bette
r
C: thread-local malloc()
Java: profiling disabled

© 2013 IBM Corporation29
IBM Research – Tokyo
Conclusion
�Do C and Java scale differently on HTM?
� Yes
�But after appropriate optimizations A
� Scale similarly
�HTM-aware system software really needed.
–Thread-local malloc()/free()
–Automatic collocation and padding in Java VM
–Transaction-aware Java VM services

© 2013 IBM Corporation
backup
© 2013 IBM Corporation31
IBM Research – Tokyo
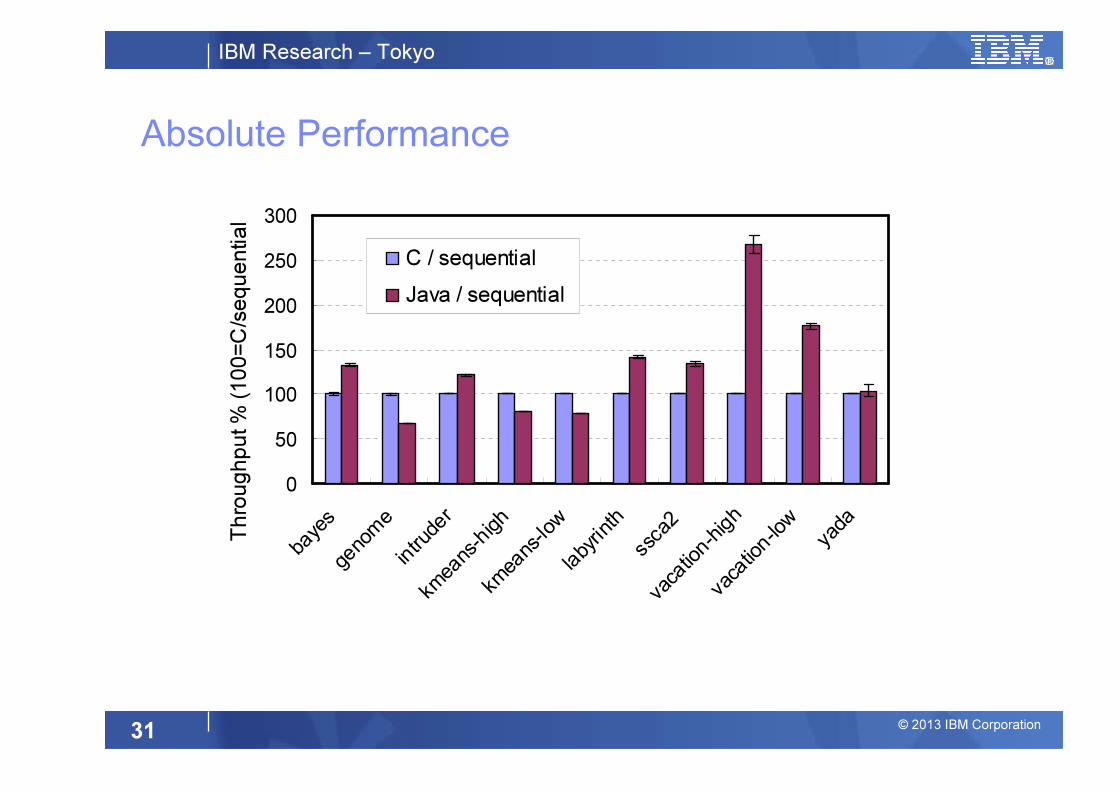
Absolute Performance
0
50
100
150
200
250
300
baye
sge
nom
ein
trude
rkm
eans
-hig
hkm
eans
-low
laby
rinth
ssca
2va
catio
n-hi
ghva
catio
n-lo
w
yadaT
hro
ug
hp
ut %
(10
0=
C/s
eq
ue
ntia
l)C / sequential
Java / sequential





























