Embed Size (px)
Citation preview

Discourse Parsing in the Penn Discourse Treebank: Using Discourse Structures to Model Coherence and
Improve User Tasks
Ziheng Lin
Ph.D. Thesis Proposal
Advisors: Prof Min-Yen Kan and Prof Hwee Tou Ng

2
Introduction A text is usually understood by its discourse
structure Discourse parsing: a process of
Identifying discourse relations, and Constructing the internal discourse structure
A number of discourse frameworks has been proposed: Mann & Thompson (1988) Lascarides & Asher (1993) Webber (2004) …

3
Introduction The Penn Discourse Treebank (PDTB):
Is a large-scale discourse-level annotation Follows Webber’s framework
Understanding a text’s discourse structure is useful: Discourse structure and textual coherence have a strong
connection Discourse parsing is useful in modeling coherence
Discourse parsing also helps downstream NLP applications Contrast, Restatement summarization Cause QA

4
Introduction Research goals:
1. Design an end-to-end PDTB-styled discourse parser
2. Propose a coherence model based on discourse structures
3. Show discourse parsing improves downstream NLP application

5
Outline
1. Introduction2. Literature review
1. Discourse parsing2. Coherence modeling
3. Recognizing implicit discourse relations4. A PDTB-styled end-to-end discourse parser5. Modeling coherence using discourse relations6. Proposed work and timeline7. Conclusion

6
Discourse parsing Recognize the discourse relations between two
text spans, and Organize these relations into a discourse
structure Two main classes of relations in PDTB:
Explicit relations: explicit discourse connective such as however and because
Implicit relations: no discourse connective, harder to recognize parsing implicit relations is a hard task

7
Discourse parsing Marcu & Echihabi (2002):
Word pairs extracted from two text spans Collect implicit relations by removing connectives
Wellner et al. (2006): Connectives, distance between text spans, and event-based features Discourse Graphbank: explicit and implicit
Soricut & Marcu (2003): Probabilistic models on sentence-level segmentation and parsing RST Discourse Treebank (RST-DT)
duVerle & Prendinger (2009): SVM to identify discourse structure and label relation types RST-DT
Wellner & Pustejovsky (2007), Elwell & Baldridge (2008), Wellner (2009)

8
Coherence modeling Barzilay & Lapata (2008):
Local coherence Distribution of discourse entities exhibits certain
regularities on a sentence-to-sentence transition Model coherence using an entity grid
Barzilay & Lee (2004): Global coherence Newswire reports follow certain patterns of topic shift Used a domain-specific HMM model to capture topic
shift in a text

9
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations
1. Methodology2. Experiments
4. A PDTB-styled end-to-end discourse parser5. Modeling coherence using discourse relations6. Proposed work and timeline7. Conclusion

10
Methodology Supervised learning on a maximum entropy
classifier Four feature classes
Contextual features Constituent parse features Dependency parse features Lexical features

11
Methodology: Contextual features Dependencies between two adjacent discourse
relations r1 and r2 independent fully embedded argument shared argument properly contained argument pure crossing partially overlapping argument
Fully embedded argument and shared argument are the most common ones in the PDTB

12
Methodology:Contextual features For an implicit relation curr that we want to
classify, look at the surrounding two relations prev and next six binary features:

13
Methodology:Constituent parse features Collect all production rules
Three binary features to check whether a rule appears in Arg1, Arg2, and both
S NP VPNP PRPPRP “We”……

14
Methodology:Dependency parse features Encode additional information at the word level Collect all words with the dependency types from their
dependents:
Three binary features to check whether a rule appears in Arg1, Arg2, and both
“had” nsubj dobj“problems” det nn advmod“at” dep

15
Methodology:Lexical features Marcu & Echihabi (2002) show word pairs are
a good signal to classify discourse relationsArg1: John is good in math and sciences.Arg2: Paul fails almost every class he takes.
(good, fails) is a good indicator for a contrast relation
Stem and collect all word pairs from Arg1 and Arg2 as features

16
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations
1. Methodology2. Experiments
4. A PDTB-styled end-to-end discourse parser5. Modeling coherence using discourse relations6. Proposed work and timeline7. Conclusion

17
Experiments
w/ feature selection Employed MI to select the top 100 rules, and top 500 word pairs (as word
pairs are more sparse) Production rules, dependency rules, and word pairs all gave significant
improvement with p < 0.01 Applying all feature classes yields the highest accuracy of 40.2% Results show predictiveness of feature classes:
production rules > word pairs > dependency rules > context features
w/o feature selection w/ feature selection
count accuracy count accuracy
Production Rules 11,113 36.7% 100 38.4%
Dependency Rules 5,031 26.0% 100 32.4%
Word Pairs 105,783 30.3% 500 32.9%
Context Yes 28.5% Yes 28.5%
All 35.0% 40.2%
Baseline 26.1%

18
Experiments Question: can any of these feature classes be omitted to achieve the same
level of performance? Add in feature classes in the order of their predictiveness
production rules > word pairs > dependency rules > context features
The results confirm that each additional feature class contributes a marginal performance
improvement, and all feature classes are needed for the optimal performance
Production Rules
Dependency Rules
Word pairs Context Acc.
100 100 500 Yes 40.2%
100 100 500 39.0%
100 500 38.9%
100 38.4%

19
Conclusion Implemented an implicit discourse relation classifier Features include:
Modeling of the context of the relations Features extracted from constituent and dependency trees Word pairs
Achieved an accuracy of 40.2%, a 14.1% improvement over the baseline
With a component that handles implicit relations, continue to design a full parser

20
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations4. A PDTB-styled end-to-end discourse parser
1. System overview2. Components3. Experiments
5. Modeling coherence using discourse relations6. Proposed work and timeline7. Conclusion

21
System overview The parsing algo mimics the PDTB annotation
procedure Input – a free text T Output – discourse structure of T in the PDTB
style Three steps:
Step 1: label Explicit relation Step 2: label Non-Explicit relation (Implicit, AltLex,
EntRel and NoRel) Step 3: label attribution spans

22
System overview

23
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations4. A PDTB-styled end-to-end discourse parser
1. System overview2. Components3. Experiments
5. Modeling coherence using discourse relations6. Proposed work and timeline7. Conclusion

24
Components:Connective classifier Use syntactic features from Pitler & Nenkova
(2009) A connective’s context and POS give indication of
its discourse usage E.g., after is a discourse connective when it is followed
by a present particle, such as “after rising 3.9%” New contextual features for connective C:
C POS prev + C, prev POS, prev POS + C POS C + next, next POS, C POS + next POS The path from C to the root

25
Components:Argument labeler Label Arg1 and Arg2 spans in two steps:
Step 1: identify the locations of Arg1 and Arg2 Step 2: label their spans
Step 1 - argument position classifier: Arg2 is always associated with the connective Use contextual and lexical info to locate Arg1
Step 2 – argument extractor: Case 1 – Arg1 and Arg2 in the same sentence
Case 2 – Arg1 in some previous sentence: assume the immediately previous

26
Components: Explicit classifier Human agreement:
94% on Level-1 84% on Level-2
We train and test on Level-2 types Features:
Connective C C POS C + prev

27
Components: Non-Explicit classifier Non-Explicit: Implicit, AltLex, EntRel, NoRel Modify the implicit classifier to include the
AltLex, EntRel and NoRel AleLex is signaled by non-connective
expressions such as “That compared with”, which usually appear at the beginning of Arg2 Add another three features to check the beginning
three words of Arg2

28
Components: Attribution span labeler Label the attribution spans for Explicit, Implicit, and AltLex Consists of two steps:
Step 1: split the text into clauses Step 2: decide which clauses are attribution spans
Features from curr, prev and next clauses: Unigrams of curr Lowercased and lemmatized verbs in curr First term of curr, Last term of curr, Last term of prev, First term of next Last term of prev + first term of curr, Last term of curr + first term of next Position of curr in the sentence Production rules extracted from curr
curr nextprev

29
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations4. A PDTB-styled end-to-end discourse parser
1. System overview2. Components3. Experiments
5. Modeling coherence using discourse relations6. Proposed work and timeline7. Conclusion

30
Experiments Each component in the pipeline can be tested
with two dimensions: Whether there is error propagation from previous
component (EP vs no EP), and Whether gold standard parse trees and sentence
boundaries or automatic parsing and sentence splitting are used (GS vs Auto)
Three settings: GS + no EP: per component evaluation GS + EP Auto + EP: fully automated end-to-end evaluation

31
Experiments Connective classifier
Argument extractor

32
Experiments Explicit classifier
Non-explicit classifier

33
Experiments Attribution span labeler
Evaluate the whole pipeline: GS + EP gives F1 of 46.8% under partial match and 33% under exact
match Auto + EP gives F1 of 38.18% under partial match and 20.64% under
exact match

34
Conclusion Designed and implemented an end-to-end
PDTB-styled parser Incorporated the implicit classifier into the pipeline
Evaluated the system both component-wise as well as with error propagation
Reported overall system F1 for partial match of 46.8% with gold standard parses and 38.18% with full automation

35
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations4. A PDTB-styled end-to-end discourse parser5. Modeling coherence using discourse relations
1. A relation transition model2. A refined approach: discourse role matrix3. Conclusion
6. Proposed work and timeline7. Conclusion

36
A relation transition model Recall: Barzilay & Lapata (2008)'s coherence
representation models sentence-to-sentence transitions of entities
Well-written texts follow certain patterns of argumentative moves Reflected by relation transition patterns
A text T can be represented as a relation transition:

37
A relation transition model Method and preliminary results:
Extract the relation bigrams from the relation transition sequence
[Cause Cause], [Cause Contrast], [Contrast Restatement], [Restatement Expansion]
A training/test instance is a pair of relation sequences: Sgs = gold standard sequence Sp = permuted sequence
Task: rank the pair (Sgs, Sp) Ideally, Sgs should be ranked higher, ie, more coherent
Baseline: 50%

38
A relation transition model The rel transition sequence is sparse
Expect longer articles to give more predictable sequence
Perform experiments with diff sentence thresholds

39
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations4. A PDTB-styled end-to-end discourse parser5. Modeling coherence using discourse relations
1. A relation transition model2. A refined approach: discourse role matrix3. Conclusion
6. Proposed work and timeline7. Conclusion

40
A refined approach: discourse role matrix Instead of looking at the discourse roles of
sentences, we look at the discourse roles of terms
Use sub-sequences of discourse roles as features Comp.Arg2 Exp.Arg2, Comp.Arg1 nil, …

41
A refined approach: discourse role matrix Experiments:
Compared with Barzilay & Lapata (2008) ’s entity grid model

42
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations4. A PDTB-styled end-to-end discourse parser5. Modeling coherence using discourse relations6. Proposed work and timeline
1. Literature review on several NLP applications2. Proposed work3. Timeline
7. Conclusion

43
Literature review on several NLP applications
Text summarization: Discourse plays an important role in text
summarization Marcu (1997) showed that RST tree is a good
indicator of salience in text PDTB relations are helpful in summarization:
Generic summarization: utilize Instantiation and Restatement relations to recognize redundancy
Update summarization: use Contrast relations to locate updates

44
Literature review on several NLP applications
Argumentative zoning (AZ): Proposed by Teufel (1999) to automatically
construct the rhetorical moves of argumentation of academic writings
Label sentences with 7 tags: aim, textual, own, background, contrast, basis,
and other Has been shown that AZ can help in:
Summarization (Teufel & Moens, 2002) Citation indexing (Teufel et al., 2006)

45
Literature review on several NLP applications
Why-QA: Aims to answer generic question “Why X?” Verberne et al. (2007) showed that discourse
structure in RST framework is helpful in a why-QA system
Prasad and Joshi (2008) generate why-questions with the use of causal relations in the PDTB
We believe that the PDTB hierarchical relation typing will help in designing a why-QA system

46
Proposed work Work done:
A system to automatically recognize implicit relations Sec 3, EMNLP 2009
An end-to-end discourse parser Sec 4, a journal in preparation
Coherence model based on discourse structures Sec 5, ACL 2011
Next step, I propose to work on one of the NLP applications Aim: show that discourse parsing can improve the
performance of this NLP app

47
Timeline
2010 Sep – Dec Continue working on the coherence model Done
2010 Nov – Dec Write an ACL submission on the coherence model Done
2011 Jan – May Work on NLP application In progress
2011 May – Jul Thesis write-up
2011 Aug Thesis defense

48
Outline
1. Introduction2. Literature review3. Recognizing implicit discourse relations4. A PDTB-styled end-to-end discourse parser5. Modeling coherence using discourse relations6. Proposed work and timeline7. Conclusion

49
Conclusion Designed and implemented an implicit discourse
classifier in the PDTB Designed and implemented an end-to-end discourse
parser in the PDTB representation Proposed a coherence model based on discourse
relations Proposed work: apply discourse parsing in one
downstream NLP application Summarization, argumentative zoning, or why-QA
Parser Demo

50
Thank you!

51
Back up slides

52
The Penn Discourse Treebank A discourse level annotation over the WSJ corpus Adopts a binary predicate-argument view on discourse
relations Explicit relations: signaled by discourse connectives
Arg2: When he sent letters offering 1,250 retired major leaguers the chance of another season,
Arg1: 730 responded. Implicit relations:
Arg1: “I believe in the law of averages,”declared San Francisco batting coach Dusty Baker after game two.Arg2: [accordingly] “I’d rather see a so-so hitter who’s hot come
up for the other side than a good hitter who’s cold.”

53
The Penn Discourse Treebank AltLex relations:
Arg1: For the nine months ended July 29, SFE Technologies reported a net loss of $889,000 on sales of $23.4 million.
Arg2: AltLex [That compared with] an operating loss of $1.9 million on sales of $27.4 million in the year-earlier period.
EntRel:Arg1: Pierre Vinken, 61 years old, will join the board as a
nonexecutive director Nov. 29.Arg2: Mr. Vinken is chairman of Elsevier N.V., the Dutch
publishing group.

54
The Penn Discourse Treebank

55
Experiments Classifier: OpenNLP MaxEnt Training data: Sections 2 – 21 of the PDTB Test data: Section 23 of the PDTB Feature selection: Use Mutual Information(MI)
to select features for production rules, dependency rules, and word pairs separately
Majority baseline: 26.1%, where all instances are classified into Cause

56
Components:Argument labeler

57
A relation transition model
can be represented by:
or:

58
Experiments
The classifier labels no instances of Synchrony, Pragmatic Cause, Concession, and Alternative The percentages of these four types are too small: totally only 4.76% in
the training data As Cause is the most predominant type, it has high recall but low precision

59
Methodology:Constituent parse features Syntactic structure within one argument may constrain the relation type
and the syntactic structure of the other argument(a) Arg1: But the RTC also requires “working” capital to maintain the bad
assets of thrifts that are soldArg2: [subsequently] That debt would be paid off as the assets are sold
(b) Arg1: It would have been too late to think about on Friday.
Arg2: [so] We had to think about it ahead of time.

60
Components:Connective classifier PDTB defines 100 discourse connectives Features from Pitler and Nenkova (2009):
Connective: because Self category: IN Parent category: SBAR Left sibling category: none Right sibling category: S Right sibling contains a VP: yes Right sibling contains a trace: no trace

61
Experiments
Connective classifier: Adding the lexico-syntactic and path features
significantly (p < 0.001) improves accuracy and F1 for both GS and Auto
The connective with the highest number of incorrect labels is and and is always regarded as an ambiguous connective
62
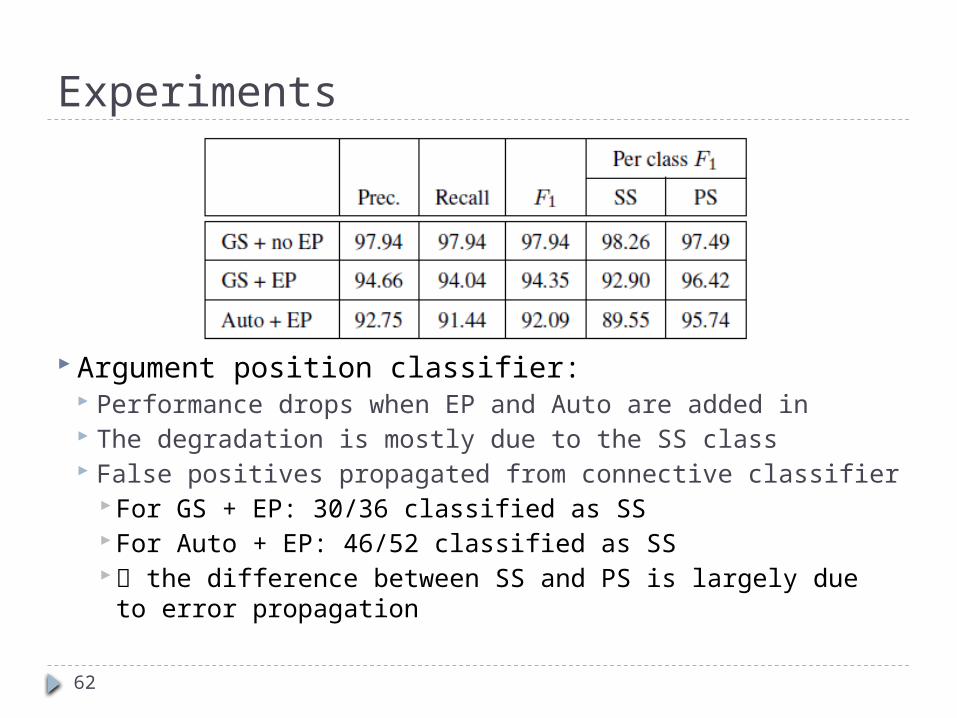
Experiments
Argument position classifier: Performance drops when EP and Auto are added in The degradation is mostly due to the SS class False positives propagated from connective classifier
For GS + EP: 30/36 classified as SS For Auto + EP: 46/52 classified as SS the difference between SS and PS is largely due to error
propagation

63
Experiments
Argument extractor - argument node identifier: F1 for Arg1, Arg2, and Rel (Arg1+Arg2) Arg1/Arg2 nodes for subordinating connectives are the easiest
ones to locate 97.93% F1 for Arg2, 86.98% F1 for Rel
Performance for discourse adverbials are the lowest Their Arg1 and Arg2 nodes are not strongly bound

64
Experiments
Argument extractor: Report both partial and exact match GS + no EP gives a satisfactory Rel F1 of 86.24% for partial match The performance for exact match is much lower than human
agreement (90.2%) Most misses are due to small portions of text being deleted from /
added to the spans by the annotators

65
Experiments
Explicit classifier: Human agreement = 84% A baseline that uses only connective as features
yields an F1 of 86% under GS + no EP Adding new features improves to 86.77%

66
Experiments
Non-explicit classifier: A majority baseline (all classified as EntRel) gives F1
in the low 20s GS + no EP shows a F1 of 39.63% Performance for GS + EP and Auto + EP are much
lower Still outperforms baseline by ~6%

67
Experiments
Attribution span labeler: GS + no EP achieves F1 of 79.68% and 65.95% for partial and
exact match With EP: degradation is mostly due to the drop in precision With Auto: degradation is mostly due to the drop in recall

68
Experiments Evaluate the whole pipeline:
Look at the Explicit and Non-Explicit relations that are correctly identified
Define a relation as correct if its relation type is classified correctly, and both Arg1 and Arg2 are labeled correctly (partial or exact)
GS + EP gives F1 of 46.8% under partial match and 33% under exact match
Auto + EP gives F1 of 38.18% under partial match and 20.64% under exact match
A large portion of misses come from the Non-Explicit relations

69
A lexical model Lapata (2003) proposed a sentence ordering model
Assume the coherence of adjacent sentences is based on lexical word pairs:
The coherence of the text is thus:
RST enforces two possible canonical orders of text spans: Satellite before nucleus (e.g., conditional) Nucleus before satellite (e.g., restatement)
A word pair-based model can be used to check whether these orderings are enforced

70
A lexical model Method and preliminary results:
Extract (wi-1,j, C, wi,k) as features:
Use mutual information to select top n features, n = 5000
Accuracy = 70%, baseline = 50%

71
Experiments
w/o feature selection Production rules and word pairs yield significantly better performance Contextual features perform slightly better than the baseline Dependency rules perform slightly lower than baseline, and applying all
feature classes does not yield the highest accuracy noise
w/o feature selection
count accuracy
Production Rules 11,113 36.7%
Dependency Rules 5,031 26.0%
Word Pairs 105,783 30.3%
Context Yes 28.5%
All 35.0%
Baseline 26.1%

72
Components: Argument labeler: Argument position classifier
Relative positions of Arg1: SS: in the same sentence as the connective (60.9%) PS: in some previous sentence of the connective (39.1%) FS: in some sentence following the sentence of the
connective (0%, only 8 instances, thus ignored) Classify the relative position of Arg1 as SS or PS Features:
Connective C, C POS Position of C in the sentence (start, middle, end) prev1, prev1 POS, prev1 + C, prev1 POS + C POS prev2, prev2 POS, prev2 + C, prev2 POS + C POS

73
Components: Argument labeler: Argument extractor When Arg1 is classified as in the same sentence (SS) as
Arg2, it can be one of: Arg1 before Arg2 Arg2 before Arg1 Arg1 embedded within Arg2 Arg2 embedded within Arg1
Arg1 and Arg2 nodes in the parse tree can be syntactically related in one of three ways:

74
Components: Argument labeler: Argument extractor Design an argument node identifier to
identify the Arg1 and Arg2 subtree nodes within the sentence parse tree
Features: Connective C C’s syntactic category (subordinate, coordinate, adverbial) Numbers of left and right siblings of C Path P of C to the node under consideration Path P and whether the size of C’s left sibling is greater
than one The relative position of the node to C

75
Components: Argument labeler: Argument extractor When Arg1 is classified as in some previous
sentence (PS), we use the majority classifier Label the immediately previous sentence as Arg1
(76.9%)

![The Leeds Arabic Discourse Treebank: Annotating Discourse ...[Ahmed was unable to attend the ceremony.] Arg1 He was tired. [In contrast] DC [he went to the hospital.] Arg2 However,](https://img.dokumen.tips/doc/110x75/601d46b56d1880699c7dd630/the-leeds-arabic-discourse-treebank-annotating-discourse-ahmed-was-unable.jpg)



























