Embed Size (px)
Citation preview

Digital Text and
Data Processing
Week 7

□ POS: total counts: normalise by token count
□ Unicode support
□ Synchronic and diachronic variation (dialects and historical changes)
□ Not knowing beforehand what is possible / relevant
Challenges

□ Digital humanities methodology often demands experimentation
□ Method is mostly inductive approach (cf. deductive approach advocated by Stanley Fish)
□ When experiments are not motivated, there is a risk that the research simply exposes "a correlation between a formal feature the computer program just happened to uncover and a significance that has simply been declared, not argued for".
□ Also see Chris Anderson, The End of Theory

□ The DH methodology is partly inductive and partly deductive
□ Computational analyses often lead to unexpected results
□ Techniques can help scholars to generate hypotheses

□ Data acquisition
□ Clean up and enrichment (removal of stopwords, POS, lemmatisation)
□ Quantification
□ Data analysis
Phases

□ Page images and machine-readable text (removal of typography and of paratext)
□ Low quality of OCR, see, e.g. Laura Mandell, How to Read a Literary Visualisation
□ Motivation of the choice of a specific edition
Data acquisition


□ Text2Genome□ OSCAR□ NeuroElectro□ Peter Murray Rust’s
work on Chemical Compounds
TM on recent scientific articles

□ The right to read does not imply the right to mine
□ Study commissioned by EC led by by prof. Ian Hargreaves
Licences

Article 7.2 of Settlement:
□Creation of a “Research Corpus”;
□Solely for “non-consumptive” reading, or research “in which computational analysis is performed on one or more Books, but not research in which a researcher reads or displays substantial portions of a Book to understand the intellectual content presented within the Book”
Google Books Settlement


□ Lev Manovich, The Language of New Media
□ Textual narrative: linearity and reliance on typography
□ Database: random access, non-linear, no form
Database and Narrative


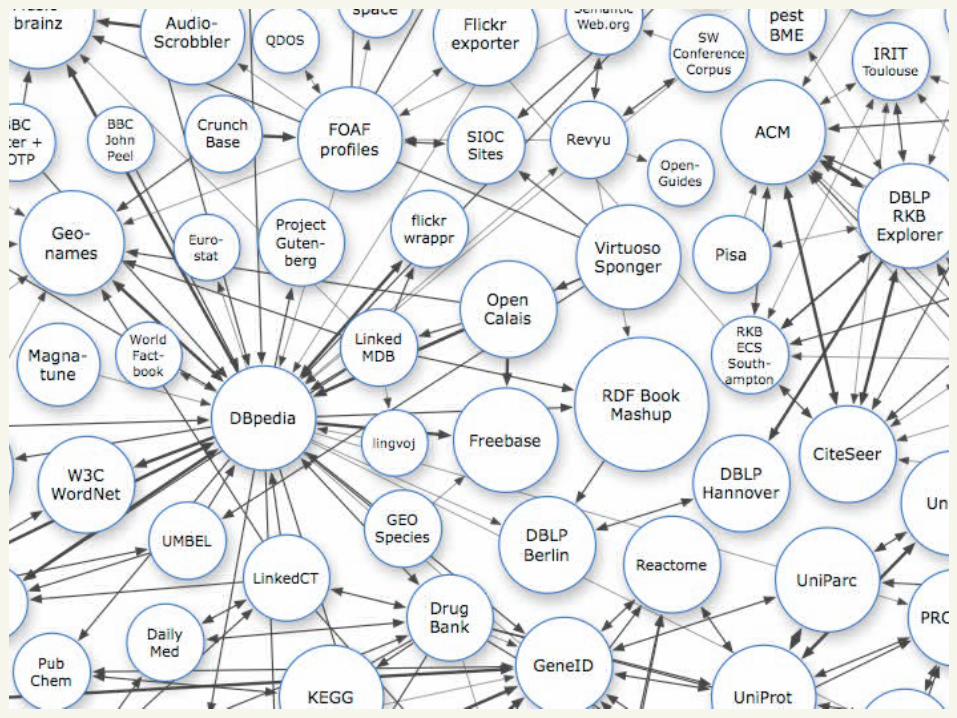
The Semantic web
□ Envisaged by Tim Berners-Lee as “a web of data that can be processed directly and indirectly by machines”
□ RDF-Triples
□Examples:
Subject: “Book-URI” Predicate: “hasISBN” Object: “978-0-252-07829-0”

dbPedia



Nano-Publications

Semantic Publishing

STCN SPARQL Endpoint















![A Diachronic-Synchronic Review of Gender in English1 · A diachronic-synchronic review of gender in English 47 “[...] a gr am mati cal cla ss ifi cat ion of nouns, pr onoun s, or](https://img.dokumen.tips/doc/110x75/5e7528c60ed4875d11738949/a-diachronic-synchronic-review-of-gender-in-english1-a-diachronic-synchronic-review.jpg)













