Embed Size (px)
Citation preview

1
Die binäre Logistische Regression �ein vielseitiges und robustes
Analyseinstrumentsozialwissenschaftlicher Forschung
Eine Einführung für Anwender
- Marcel Erlinghagen -
Gelsenkirchen, Oktober 2003
Gliederung1 Was heißt �Regression�?
2 Das Regressionsprinzip am Beispiel der �linearen Einfachregression�
3 Warum logistische Regression?
4 Datenvoraussetzungen und Datenvorbereitung für die logistische Regression
5 Interpretation der Regressionsergebnisse
6 Die Regressionsanalyse als iteratives Verfahren
7 �Odd Ratios� � eine weitere Darstellungsform der Schätzergebnisse
8 Ausblick

2
1Was heißt �Regression�?
Ziel von Wissenschaft:Klärung von Zusammenhängen zwischen unterschiedlichen Sachverhalten

3
Es gibt zwei Arten von Zusammenhängen:a) exakte Zusammenhänge (bspw. �Naturgesetze�)
mathematisch darstellbar als Funktionsgleichung; bspw.: y = f(x)
b) zufallsabhängige (�stochastische�) Zusammenhänge mathematisch darstellbar als Regressionsgleichung; bspw.: y = bx + a
�Regression� (engl. regression = Zurückentwicklung, Rückbildung) � Inwiefern lässt sich die Ausprägung einer abhängigen Variable auf die Ausprägung einer unabhängigen Variable zurückführen (�regressieren�)?
2Das Regressionsprinzip am
Beispiel der�linearen Einfachregression�

4
Beispiel 1Wie hängt das Einkommen einer Personen mit der Dauer des Schulbesuches zusammen?
1. Schritt: Modellbildung
�Das Einkommen einer Person steigt proportional zur Schulbesuchsdauer� (linearer Zusammenhang)
oder auch
geschätzte Einkommenshöhe = unbekannter Faktor multipliziert mit der Schulbesuchsdauer zuzüglich einerunbekannten Störgröße
oder auch
y = bx + a
2. Schritt: Beobachtungsdaten gewinnen
Person Schuljahre EinkommenHerr Müller 8 1400Frau Meier 10 2100Herr Schulz 13 2100Herr Schmidt 9 1800Frau Mustermann 10 1900Herr Kleinknecht 15 2000Frau Dorfner 13 2200Herr Beier 8 1600Herr Dudenhofen 10 1600

5
3. Schritt: Regressionsparameter schätzenUnter der Modellvoraussetzung y = bx + a� Wie groß ist a und b?
�Es gilt eine Gleichung zu finden, mit deren Hilfe die Werte der abhängigen Variablen [...] aufgrund der Werte der explikativenVariablen [...] so geschätzt werden können, dass die Schätzfehler minimal sind� (Kromrey 2000: 474).
0
500
1000
1500
2000
2500
3000
0 5 10 15 20Schuljahre
Eink
omm
en
Die Regressionsparameter a (Störfaktor; Achsenab-schnitt) und b (Regressionskoeffizient; Steigung) werden aus den Beobachtungswerten mittels der �Methode der kleinsten Quadrate� (Ordinary-Least-Square- oder OLS-Regression) geschätzt.
In unserem Beispiel ergibt sich dabei:
y = 82,639x + 974,07
0
500
1000
1500
2000
2500
3000
0 5 10 15 20Schuljahre
Eink
omm
en
y = 82,639x + 974,07R2 = 0,5443

6
3Warum logistische Regression?
Beispiel 2Wie hängt die Besetzung einer betrieblichen Führungsposition mit der Dauer des Schulbesuches einer Person zusammen?
1. Schritt: Modellbildung
�Die Wahrscheinlichkeit, dass eine Person eine betriebliche Führungsposition inne hat, steigt mit der Dauer des Schulbesuchs.� (linearer Zusammenhang ????)
7
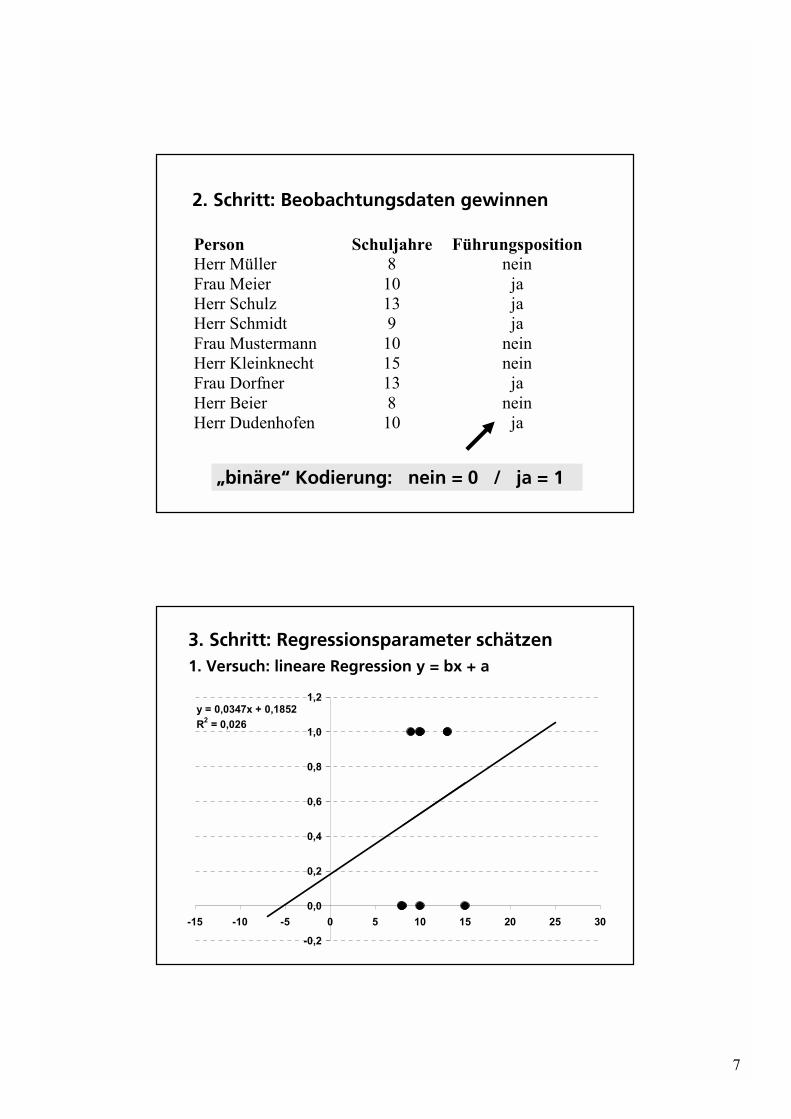
2. Schritt: Beobachtungsdaten gewinnen
Person Schuljahre FührungspositionHerr Müller 8 neinFrau Meier 10 jaHerr Schulz 13 jaHerr Schmidt 9 jaFrau Mustermann 10 neinHerr Kleinknecht 15 neinFrau Dorfner 13 jaHerr Beier 8 neinHerr Dudenhofen 10 ja
�binäre� Kodierung: nein = 0 / ja = 1
3. Schritt: Regressionsparameter schätzen1. Versuch: lineare Regression y = bx + a
y = 0,0347x + 0,1852R2 = 0,026
-0,2
0,0
0,2
0,4
0,6
0,8
1,0
1,2
-15 -10 -5 0 5 10 15 20 25 30

8
Zur Analyse kategorialer Daten (hier: Führungsposi-tion ja/nein) ist die lineare Regression nicht brauch-bar
� Binäre Logistische Regression
Lineare Reg.gleichung: y = bx + a
logistische Reg.gleichung: x
x
ee
10
10
11 ββ
ββ
π+
+
+
=
Vorteile:
� Schätzwerte können nie > 1 oder < 0 werden
� Die Regressionsgleichung simmuliert eine allmähliche Annäherung an die Extremwerte 0 und 1 (kein linearer Zusammenhang) (�Maximum-Likelihood-Schätzung�)
Besonders wichtig!
Bei der linearen Regression wird der Einfluss der erklärenden Variablen auf die abhängige Variable direkt geschätzt.
Bei der logistischen Regression wird der Einfluss der erklärenden Variablen auf die Wahrscheinlichkeit geschätzt, dass die abhängige Variable den Wert �1� annimmt.
9
-0,2
0,0
0,2
0,4
0,6
0,8
1,0
1,2
-15 -10 -5 0 5 10 15 20 25 30
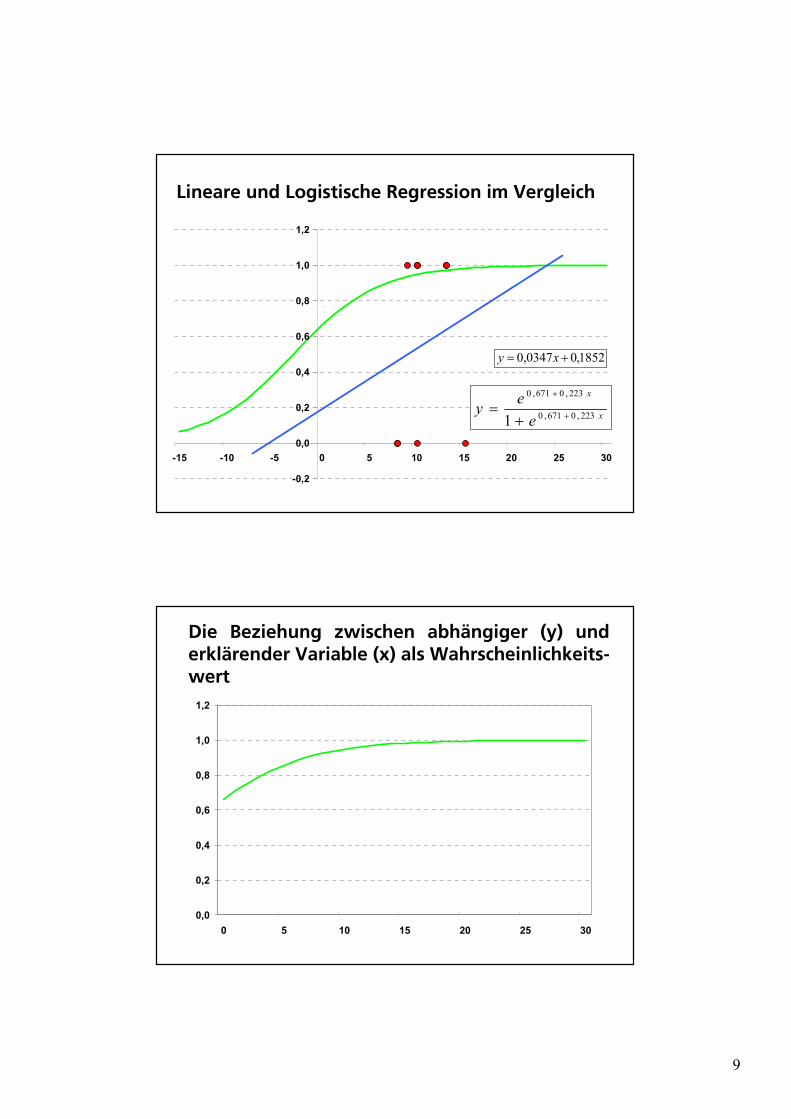
Lineare und Logistische Regression im Vergleich
x
x
eey 223,0671,0
223,0671,0
1 +
+
+
=
1852,00347,0 += xy
Die Beziehung zwischen abhängiger (y) und erklärender Variable (x) als Wahrscheinlichkeits-wert
0,0
0,2
0,4
0,6
0,8
1,0
1,2
0 5 10 15 20 25 30

10
Die Logitische Regression wird in der Praxis nicht in �Zwei-Variablen-Fällen� wie dem Beispiel angewendet. Der Vorteil des Verfahrens besteht vielmehr darin, dass die Einflüsse mehrerer erklärender Variablen auf eine abhängige Variable gleichzeitig untersucht werden können. Das Verfahren bietet die Möglichkeit, die jeweils nicht interessierenden Variablen zu kontrollieren.
4Datenvoraussetzungen und Datenvorbereitung für die
logistische Regression

11
DatenvoraussetzungenDie abhängige Variable muss als dichotome Dummy-Variable zerlegbar sein � typische ja/nein Fragestellung (Kodierung 0/1)
Die unabhängigen (erklärenden) Variablen können jedwedes Messniveau besitzen. Sowohl metrische als auch nominal skalierte Daten können einfließen
Die Abhängige Variable
Beispielfragestellung:�Welche Faktoren beeinflussen die Wahrscheinlichkeit, zwischen 1992 und 1996 ehrenamtlich aktiv zu werden?� (Quelle der Beispieldaten: SOEP)
Kodierung der abhängigen Variable EHRE:
0 = nicht ehrenamtlich aktiv geworden
1 = ehrenamtlich aktiv geworden
ACHTUNG: Es dürfen nur solche Fälle (Personen) in die Untersuchung aufgenommen werden, die prinzipiell �im Risiko sind� ehrenamtlich aktiv zu werden. Das heißt, dass Personen, die bereits zum Beginn des Untersuchungszeitraums ehrenamtlich aktiv sind, aus der Untersuchung ausgeschlossen werden müssen. �

12
Die erklärenden VariablenWelche erklärenden Variablen in die Untersuchung einbezogen werden, hängt vom Modell (oder von unserer Theorie) ab. Hier: Wir nehmen an, dass folgende Variablen die Ehrenamts-Aufnahme-Wahrscheinlichkeit beeinflussen:
�Geschlecht
�Erwerbsstatus
�Alter
�Haushaltskontext
�Qualifikation
Vorbereitung der Ursprungsdaten für die Regressionsschätzungmetrische Variablen müssen nicht verändert werden
dichotome Variablen (bspw. Geschlecht) müssen nicht verändert werden (wenn Kodierung 0/1)
kategoriale Variablen mit mehr als 2 Ausprägungen müssen in dichotome Dummy-Variablen zerlegt werden

13
Beispiel für die VariablenzerlegungHöchster Schulabschluss (SCHULE) mit den Ursprungswerten 1 = Hauptschule, 2 = Realschule und 3 = Gymnasium wird zerlegt in 3 Einzelvariablen
SCHULE1 (Hauptschule ja/nein):1 wenn Hauptschulabschluss; alle anderen 0
SCHULE2 (Realschule ja/nein):1 wenn Realschulabschluss; alle anderen 0
SCHULE3 (Abitur ja/nein):1 wenn Abitur; alle anderen 0
ACHTUNG: Missing-Werte müssen in einer eigenen Dummy-Variable in die Schätzung einbezogen werden, also wenn SCHULE=missing, dann SCHULMIS=1 wenn kein Schulabschluss bekannt; alle anderen 0 !!! �
Dummy Kodie-rung
Dummy Kodie-rung
Geschlecht ErwerbsstatusMann* 0 voll erwerbstätig* R_ES1 0/1Frau R_SEX 1 unregelm./teilzeit erwerbst. R_ES2 0/1Alter arbeitslos R_ES3 0/116-25 Jahre R_AGE1 0/1 Rentner R_ES4 0/126-40 Jahre R_AGE2 0/1 sonst. Nicht-Erwerbstätige R_ES5 0/141-60 Jahre* R_AGE3 0/1 Schulabschlussälter als 60 Jahre R_AGE4 0/1 missing R_SCH1 0/1Haushalt kein Abschluss R_SCH2 0/1alleinstehend R_HH1 0/1 Hauptschulabschluss R_SCH3 0/1Paar ohne Kind* R_HH2 0/1 Realschulabschluss* R_SCH4 0/1alleinerziehend R_HH3 0/1 (Fach-)Hochschulreife R_SCH5 0/1Paar + 1 Kind R_HH4 0/1 Abschluss verbessert R_SCH5 0/1Paar + 2 Kinder R_HH5 0/1Paar + 3 o. mehr Kinder R_HH6 0/1sonstige R_HH7 0/1
* Referenzgruppe
Variablenzerlegung im Beispieldatensatz

14
ACHTUNG 1: Referenzkategorie auswählen
Nicht alle erklärenden Variablen werden in die Rechnung einbezogen. Um die späteren Schätzergebnisse interpretieren zu können, muss in jedem Variablenblock eine Referenzkategorie ausgewählt werden. Alle Ergebnisse sind nur im Hinblick auf diese Referenzkategorie zu interpretieren
Auswahlkriterien:
� die bestbesetzte Kategorie
� Interpretatorische Gründe
�
ACHTUNG 2: �Strukturelle Nullen� vermeiden
Es sind sogenannte �Strukturelle Nullen� zu vermeiden. �Strukturelle Nullen� entstehen dann, wenn einzelne Kategorien der erklärenden Variablen sich logisch ausschließen.
Bsp.: Kategorie Alter mit einer Ausprägung �jünger als 16 Jahre� und Kategorie Berufsabschluss mit einer Ausprägung �Hochschulabschluss�.
Solche Effekte sind nicht immer zu vermeiden, sollten aber auf jeden Fall bewußt sein und bei der Interpretation berücksichtigt werden.
Außerdem empfiehlt sich ein Kreuztabellentest zwischen jeder einzelnen kategorialen erklärenden Variable und der abhängigen Variable.
�

15
ChecklisteNur Fälle einbeziehen, die �im Risiko� sind
abhängige Variable als dichotome Dummy-Variable
Je nach Meßniveau und Modellannahmen sind die erklärenden Variablen aufzubereiten
Nicht zuviele erklärende Variablen einführen. Faustregel: Pro 100 Analysefälle eine erklärende Variable. In unserem Beispielfall: ca. 6000 Personen im Analysedatensatz, d.h. es sollten nicht mehr als maximal 60 erklärende Variablen einbezogen werden (wir haben 23 ausgewählt)
Sensible Auswahl der Referenzkategorie
�Strukturelle Nullen� vermeiden
��
�
�
�
�
5Interpretation der
Regressionsergebnisse

16
Signifikanz***: p <= 0,01
**: 0,01 < p <= 0,05*: 0,05 < p <= 0,1
Koeffizient Signifikanz
GeschlechtMänner RG �Frauen -0,278*** 0,000Erwerbsstatusregelm. Vollzeit RG �unregelm./Teilzeit 0,189 0,132arbeitslos -0,199 0,218Rentner -0,051 0,713sonst. nicht-erwerbstätige 0,358*** 0,003Alter16-25 Jahre -0,006 0,96826-40 Jahre 0,033 0,69741-60 Jahre RG �älter als 60 Jahre -0,374*** 0,008HaushaltstypEin-Personen-Haushalt -0,314** 0,011Paar ohne Kinder RG �Alleinerziehend -0,214 0,225Paar mit einem Kind -0,026 0,801Paar mit zwei Kindern 0,284*** 0,006Paar mit drei Kindern + 0,379*** 0,010sonst. Haushalte -0,273 0,139Schulabschlussmissing 0,317 0,338kein Abschluss -0,588** 0,016Hauptschulabschluss -0,116 0,161Realschulabschluss RG �(Fach-)Hochschulreife 0,057 0,589Abschluss verbessert 0,357 0,142Konstante -1,291*** 0,000n 6012Pseudo R2 0,043RG = Referenzgruppe
HaushaltstypEin-Personen-Haushalt -0,314**Paar ohne Kinder RGAlleinerziehend -0,214Paar mit einem Kind -0,026Paar mit zwei Kindern 0,284***Paar mit drei Kindern + 0,379***sonst. Haushalte -0,273Schulabschlussmissing 0,317kein Abschluss -0,588**Hauptschulabschluss -0,116Realschulabschluss RG(Fach-)Hochschulreife 0,057Abschluss verbessert 0,357
Abhängige Variable: Ehrenamt aufgenommen

17
ChecklisteWichtig sind insbesondere zwei Werte: Die Koeffizienten (SPSS: �Regressionskoeffizient B�) und das Signivikanzniveau (SPSS: �Sig.�).
Negative (positive) Koeffizienten bedeuten einen negativen (positiven) Zusammenhang � Bei kategorialen Dummies: Wenn Ausprägung zutrifft, reduziert (erhöht) sich die Wahrscheinlichkeit, dass die abhäbngige Variable den Wert 1 annimmt. Bei metrischen Variablen: Wenn sich die unabhängige Variable um eine Einheit erhöht, dann erhöht (verringert) sich die Wahrscheinlichkeit, dass die abhängige Variable den Wert 1 annimmt.
�
�
Checkliste (Fortsetzung)Koeffizienten sind nur in der Richtung des Zusammenhangs zu interpretieren (�eine Variabel erhöht/vermindert die Wahrscheinlichkeit, dass ...�)
Koeffizienten sind nur in Bezug auf die jeweilige Referenzgruppe zu interpretieren.
Es können nur statistisch signifikante Ergebnisse interpretiert werden.
Ab welchem Signifikanzniveau Zusammenhänge als bestätigt gelten, ist Definitionssache (allerdings �Signifikanzgrenze� > 0,1 in der Forschungsliteratur unüblich).
�
�
�
�

18
6Die Regressionsanalyse als
iteratives Verfahren
Es empfiehlt sich, nicht nur ein einziges Modell zu schätzen, sondern iterativ vorzugehen, in dem man nach und nach einzelne �Variablenblöcke� in die Schätzungen einbezieht.
Dabei ist darauf zu achten:
a) Wie verändern sich die Koeffizienten (Vorzeichenwechsel)?
b) Wie verändert sich die Signifikanz?
1. Empfehlung

19
Schätzung1
Schätzung2
Schätzung3
Schätzung4
GeschlechtMänner RG RG RG RGFrauen -0,292*** -0,320*** -0,285*** -0,278***Erwerbsstatusregelm. Vollzeit RG RG RG RGunregelm./Teilzeit 0,220* 0,262** 0,203 0,189arbeitslos -0,202 -0,193 -0,208 -0,199Rentner -0,497*** -0,057 -0,067 -0,051sonst. Nicht-erwerbstät. 0,454*** 0,459*** 0,400*** 0,358***Alter16-25 Jahre 0,067 0,074 -0,00626-40 Jahre 0,114 0,054 0,03341-60 Jahre RG RG RGälter als 60 Jahre -0,507*** -0,384*** -0,374***HaushaltstypEin-Personen-Haushalt -0,302** -0,314**Paar ohne Kinder RG RGAlleinerziehend -0,224 -0,214Paar mit einem Kind -0,020 -0,026Paar mit zwei Kindern 0,308*** 0,284***Paar mit drei Kindern + 0,383*** 0,379***sonst. Haushalte -0,273 -0,273Schulabschlussmissing 0,317kein Abschluss -0,588**Hauptschulabschluss -0,116Realschulabschluss RG(Fach-)Hochschulreife 0,057Abschluss verbessert 0,357Konstante -1,293*** -1,322*** -1,358*** -1,291***n 6012 6012 6012 6012Pseudo R2 0,024 0,029 0,039 0,043RG = Referenzgruppe
2. Empfehlung
Es empfiehlt sich, nach der Schätzung eines Gesamtmodells u.U. weitere differenziertere Schätzungen vorzunehmen. Beispielsweise bietet es sich in unserem Beispiel an, alle Modelle jeweils nochmals getrennt für Männer und Frauen zu berechnen.
Begründung: Durch die gemeinsame Schätzung können gegenläufige Einflüsse sich gegenseitig aufheben und daher nicht erkannt werden.
ACHTUNG: Auf Fallzahlen achten !

20
Männer Frauen
Erwerbsstatusregelm. Vollzeit RG RGunregelm./Teilzeit 0,481 0,192arbeitslos -0,174 -0,210Rentner -0,219 0,076sonst. nicht-erwerbstätige 0,214 0,443***Alter16-25 Jahre 0,017 -0,05326-40 Jahre 0,016 0,01041-60 Jahre RG RGälter als 60 Jahre -0,330 -0,345*HaushaltstypEin-Personen-Haushalt -0,183 -0,447***Paar ohne Kinder RG RGAlleinerziehend -0,211 -0,181Paar mit einem Kind -0,079 0,029Paar mit zwei Kindern 0,217 0,334**Paar mit drei Kindern + 0,318 0,432**sonst. Haushalte -0,112 -0,463*Schulabschlussmissing 0,776* -0,273kein Abschluss -0,342 -0,858**Hauptschulabschluss -0,044 -0,203*Realschulabschluss RG RG(Fach-)Hochschulreife -0,156 0,321**Abschluss verbessert 0,356 0,440Konstante -1,258*** -1,603***n 2586 3426Pseudo R2 0,026 0,057RG = Referenzgruppe
7�Odd Ratios��
eine weitere Darstellungsformen der Schätzergebnisse

21
ProblemDurch die Schätzung der Koeffizienten können wir zwar die Signifikanz und die Richtung des Zusammenhangs zwischen abhängiger und unabhängiger Variable bestimmen, aber es sind keine Aussagen über die Stärke des Zusammenhangs möglich!
Alternative: Berechnung von �Odd Ratios�
A B C D E F Gsonstige
Todesursache Hirntumor nWahrscheinlichkeit d. Todes durch HT (in %)
Gegenwahrschein-lichkeit sonst. Tod (in %)
Odds (Tod durch HT/sonst. Gründe)
1 Männer 60000 100 60100 0,166389 99,833611 0,0016672 Frauen (RG) 35000 24 35024 0,068524 99,931476 0,0006863
4Prozentsatzdifferenz Männer-Frauen 0,097865
56 Differenz der beiden Odds 0,00098178 Odd Ratio Mann/Frau (RG) 2,4305569
10 "Wahrscheinlichkeits-Ratio" 2,42817511
12Diff. Zw. Odd & Wahrscheinlichkeits-Ratio 0,002380
Beispiel (a) zur Berechnung und Interpretation von �Odd Ratios�
Die Wahrscheinlichkeit von Männern, an einem Gehirntumor zu sterben, ist rund 2,4mal so groß wie die Wahrscheinlichkeit von Frauen, an einem Gehirntumor zu sterben
Exkurs: Was sind �Odd Ratios� und wie werden sie interpretiert?
22
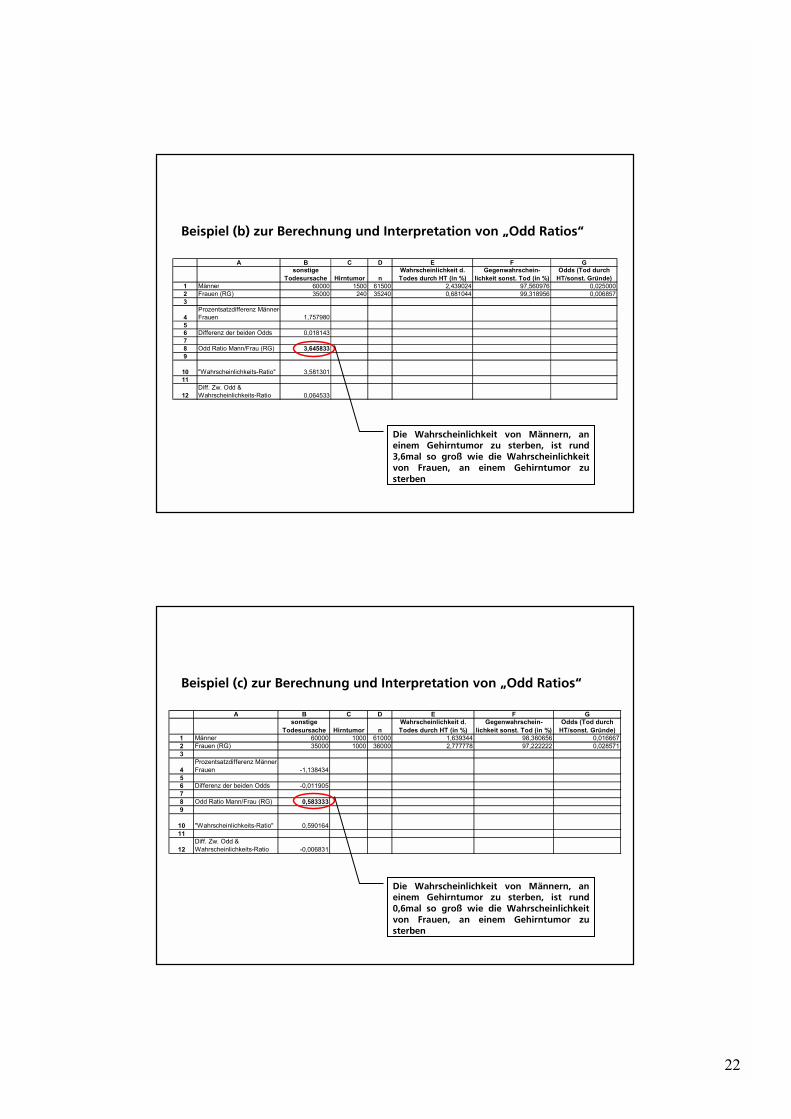
Beispiel (b) zur Berechnung und Interpretation von �Odd Ratios�
A B C D E F Gsonstige
Todesursache Hirntumor nWahrscheinlichkeit d. Todes durch HT (in %)
Gegenwahrschein-lichkeit sonst. Tod (in %)
Odds (Tod durch HT/sonst. Gründe)
1 Männer 60000 1500 61500 2,439024 97,560976 0,0250002 Frauen (RG) 35000 240 35240 0,681044 99,318956 0,0068573
4Prozentsatzdifferenz Männer-Frauen 1,757980
56 Differenz der beiden Odds 0,01814378 Odd Ratio Mann/Frau (RG) 3,6458339
10 "Wahrscheinlichkeits-Ratio" 3,58130111
12Diff. Zw. Odd & Wahrscheinlichkeits-Ratio 0,064533
Die Wahrscheinlichkeit von Männern, an einem Gehirntumor zu sterben, ist rund 3,6mal so groß wie die Wahrscheinlichkeit von Frauen, an einem Gehirntumor zu sterben
Beispiel (c) zur Berechnung und Interpretation von �Odd Ratios�
A B C D E F Gsonstige
Todesursache Hirntumor nWahrscheinlichkeit d. Todes durch HT (in %)
Gegenwahrschein-lichkeit sonst. Tod (in %)
Odds (Tod durch HT/sonst. Gründe)
1 Männer 60000 1000 61000 1,639344 98,360656 0,0166672 Frauen (RG) 35000 1000 36000 2,777778 97,222222 0,0285713
4Prozentsatzdifferenz Männer-Frauen -1,138434
56 Differenz der beiden Odds -0,01190578 Odd Ratio Mann/Frau (RG) 0,5833339
10 "Wahrscheinlichkeits-Ratio" 0,59016411
12Diff. Zw. Odd & Wahrscheinlichkeits-Ratio -0,006831
Die Wahrscheinlichkeit von Männern, an einem Gehirntumor zu sterben, ist rund 0,6mal so groß wie die Wahrscheinlichkeit von Frauen, an einem Gehirntumor zu sterben

23
Wie sind Odd Ratios im Regressionsmodell zu interpretieren?
� Die Werte von Odd Ratios (OR) liegen theoretisch zwischen 0 und unendlich.
� OR < 1 bedeutet für die Analysegruppe eine geringere Wahrscheinlichkeit, dass die abhängige Variable �1� ergibt, als die Referenzgruppe.
� OR > 1 bedeutet für die Analysegruppe eine höhere Wahrscheinlichkeit, dass die abhängige Variable �1� ergibt, als die Referenzgruppe.
Was ist bei der Interpretation von Odd Ratios im Regressionsmodell zu beachten?
a) Der �einfache� Fall: OR > 1
ORs mit einem Wert > 1 sind relativ einfach zu interpretieren.
Bsp.: Frau: Referenzgruppe / Mann: OR= 1,432***
Abhängige Variable: Ehrenamtsaufnahme
�Männer haben (unter Kontrolle aller anderen Variablen im Modell) gegenüber Frauen eine um 43,2 % erhöhte Wahrscheinlichkeit, ein Ehrenamt aufzunehmen.�

24
b) Der �knifflige� Fall: OR < 1
ORs mit einem Wert < 1 sind schwieriger zu interpretieren.
Bsp.: Frau: Referenzgruppe / Mann: OR= 0,650***
Abhängige Variable: Ehrenamtsaufnahme
�Männer haben (unter Kontrolle aller anderen Variablen im Modell) gegenüber Frauen eine 0,650mal so große Wahrscheinlichkeit, ein Ehrenamt aufzunehmen.�
ACHTUNG: Das heißt NICHT, dass Männer eine um 35 % verringerte Wahrscheinlichkeit der Ehrenamtsaufnahme gegenüber Frauen aufweisen (also nicht 1 - 0,650 = 0,350) !!!
�
Interpretationsbeispiele bei OR < 1
OR 1-OR (Falsch!) %0,95 5,00 5,260,90 10,00 11,110,85 15,00 17,650,80 20,00 25,000,75 25,00 33,330,70 30,00 42,860,65 35,00 53,850,60 40,00 66,670,55 45,00 81,820,50 50,00 100,000,45 55,00 122,220,40 60,00 150,000,35 65,00 185,710,30 70,00 233,33
P = (1 / 0,95)-1= 0,0526
P = (1 / 0,70)-1= 0,4286
P = (1 / 0,50)-1= 1
! VORSICHT !
??? A hat eine um 100 % verringerte Wahrscheinlichkeit als B ???

25
Bei OR Werten <= 0,5 bietet sich eine umgekehrte Interpretation an.
Interpretationsbeispiele
OR 1-OR (Falsch!) %0,95 5,00 5,260,90 10,00 11,110,85 15,00 17,650,80 20,00 25,000,75 25,00 33,330,70 30,00 42,860,65 35,00 53,850,60 40,00 66,670,55 45,00 81,820,50 50,00 100,000,45 55,00 122,220,40 60,00 150,000,35 65,00 185,710,30 70,00 233,33
Die Referenzgruppe hat eine doppelt so hohe Wahrscheinlichkeit wie die Analysegruppe
Die Referenzgruppe hat eine um 122 % erhöhte Wahrscheinlichkeit gegenüber der Analysegruppe
Der �noch kniffligere� Fall: OR <= 0,5
8Ausblick

26
3. Sitzung (Praxis)Donnerstag, 27.11.2003, 9.30-12.00 Uhr� Kurze Wiederholung der wichtigen methodischen Punkte� Gemeinsame Begutachtung der �Übungs-Rohdaten� und Plan zur Aufbereitung der Daten
für die logistische Regression4. Sitzung (Praxis)Donnerstag, 11.12.2003, 9.30-12.00 Uhr� Einführung in STATA� Aufbereitung der Daten in STATA5. Sitzung (Praxis)Donnerstag, 29.01.2004, 9.30-12.00 Uhr� Anwendung der eigentlichen Logistischen Regression in STATA� Diskussion und Interpretation der Schätzergebnisse6. Sitzung (Praxis) (optional)Donnerstag, 26.02.2004, 9.30-12.00 Uhr� Bei Bedarf: Gemeinsamer Einstieg in eine neue Analyse mit anderer Fragestellung und
anderen Daten7. Sitzung (Theorie)Donnerstag, 25.03.2004, 9.30-12.00 Uhr� Ausblick: Weitere multivariate Analyseverfahren (bspw. multiple Logistische Regression,
Übergangsratenmodelle etc.); Gemeinsamkeiten und Unterschiede zur Binären Logistischen Regression
Die weiteren Sitzungen
�Generally, descriptive studies are thus much morerelevant for sociology as an explanatory enterprise thancurrent journals and university curricula would have usbelief.�
(Wippler/Lindenberg 1987: 159)
Trotz der Vorzüge und Möglichkeiten multivariaterAnalyseinstrumente insbesondere für die sozialwissenschaftliche Forschung sollten scheinbar �einfache� deskriptive Verfahren nicht vernachlässigt und deren Nutzen nicht unterschätzt werden:
Schlussbemerkung





























