Embed Size (px)
Citation preview

Overview
• What is deployment all about anyway?
• Who is doing it?
• Planning and metrics
• Issue 1: Communications
• Issue 2: Fabric management
• Where are we now?
Where are we now?
Are the developers bailing out? Who is flying the plane?
We have paying passengers – do we know where we are going? … oh, and can we keep it working,
navigate, land and offer a real service?
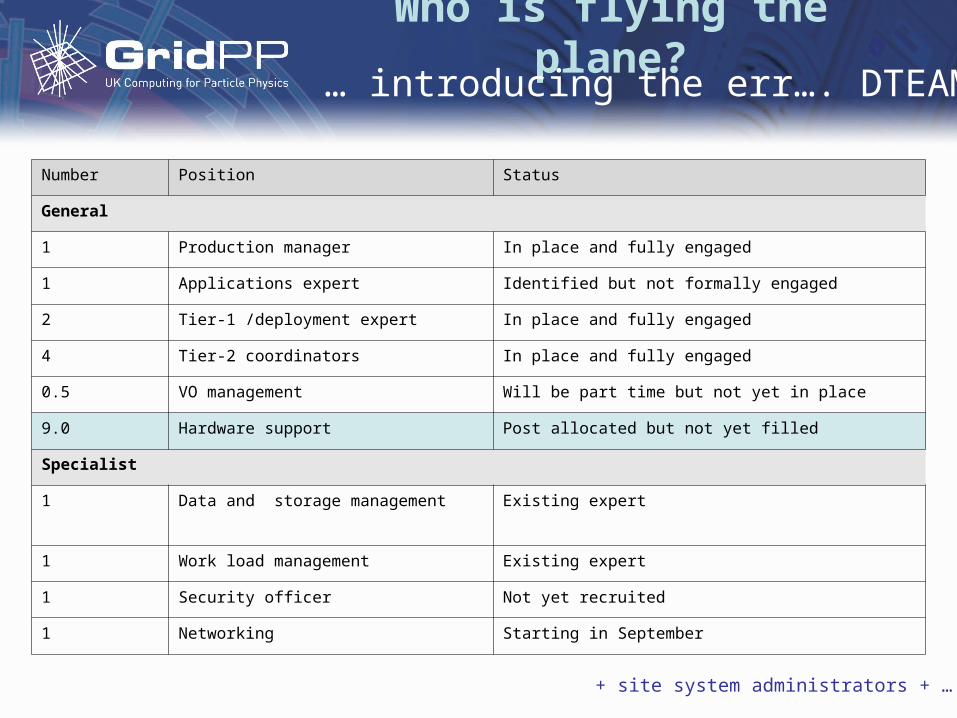
Who is flying the plane?
Number Position Status
General
1 Production manager In place and fully engaged
1 Applications expert Identified but not formally engaged
2 Tier-1 /deployment expert In place and fully engaged
4 Tier-2 coordinators In place and fully engaged
0.5 VO management Will be part time but not yet in place
9.0 Hardware support Post allocated but not yet filled
Specialist
1 Data and storage management Existing expert
1 Work load management Existing expert
1 Security officer Not yet recruited
1 Networking Starting in September
… introducing the err…. DTEAM
+ site system administrators + …

Deployment Board
• Replaces GridPP1 Technical Board• Mandate
– Determine and oversee execution of tech plan– Report to PMB– Ensure GridPP-wide issues discussed/solved– Provide forum for tech info exchange– Oversee deployment and use of GridPP h/w– Tier1 – Tier2 coordination/liaison– Ensure integration of external tech developments

DB members
• Production Manager• Tier1/A Manager• 4 T2 Technical Coordinators• HEP SYSMAN chair• CERN T0/Deployment• Applications Area Coordinator• Middleware Area Coordinator• Technical experts (invited by DB chair)• UK NGS• EGEE/Ireland• DB chair ~18 people

DB relations
PMB
DB UB
T1AB T2B M/S/N APPS
LCG
/EG
EE
/CE
RN
T0
UK
NG
S
GridPP DTEAM

What must deployment address?
Core infrastructure services
•Resource brokers•Informational services•Data management services•Virtual Organisation management•Replica Location Service• BDII
Grid monitoring•Monitor operational performance•Monitor operational state•Problem resolution + operations support tools
Middleware deployment•Required local validation of common middleware•Feedback issues to LCG/EGEE•Continuous upgrade•Mechanism(s)
Resource induction•New site joining procedures•Provide support for middleware installation•Advise on operational procedures
Resource support•Respond to and coordinate resolution of fabric problems•Engage wider community to resolve new problems
User support•Provide a support service for users (filter and distribute)•Monitor effectiveness of support•Provide training and induction courses•Documentation (and quality)

Areas (2)
Communication•Representation within experiments•Procedures and mechanisms within community
Applications•Ensuring local VOs receive support and guidance•Participate in testing and validation exercises
Components•Workload management•Data management•Storage management• Information services
Network services•Network performance monitoring
•Demand (aggregate traffic) vs supply (performance)
•Resource allocation/reservation
Inter-grid collaboration•Participate in discussions to work closer with other Grids•Ensure interoperability of infrastructure and services
Service-level agreements•Monitor Tier-2 compliance with MoUs•Access policies
Security•Certification authority•Implement and monitor policy•Incident response•Policy management
Operations planning•Understand usage patterns•Capacity planning•Monitoring problems log

Navigation
• No clear plans within LCG for overall deployment – improving • Some confusion about EGEE connections• GridPP2 project plan is not complete and we have dependencies• Currently developing in a “best guess” environment• It is not always clear exactly where decisions get made
What does the planning environment look like so far?There are already pressing issues to be addressed:
•What is the UK stance regarding fabric management tools (LCFGng is being phased out)• How are we going to measure deployment and operations success – metrics•What is the communications plan given that LCG-ROLLOUT has become a gossip column – support, news, problem reporting

Are we communicating…?
AreasGrid news – no well defined broadcast route – e.g. middleware updatesSite News – operational incidents on Grid, site updatesSupport – user, deploymentProblems – As found by daily tests or discovered by users
Issues• LCG-ROLLOUT is overloaded!• Lack of visibility about what is happening at sites – upgrade, site
problem • Problems may generate many queries• No tracking for support or logging of queries• … and therefore poor ability to search for other experiences
Options
1) Set up a new news area based on RSS (new entries are placed in categories that people can register to receive updates from) – just use of GOC pages?
2) Establish support desk for GridPP – but there are concerns about expertise
3) DTEAM area & better documentation

An example
[LCG-Problems] mail list has 2 members!

Are we going up or down?
Metric Data available? Notes Current (12th Sept) Target… by date
Number of sites in production
YesSites available to run jobs of supported Vos
14 17 Dec-04
Number of registered users
YesNumber of users registered on GridPP website?
90 100 Dec-04
Number of active grid users
PartlyPool accounts and multiple DN mapping cause problem
Number of supported VOs
Yes Active or supported? Sites vary. 10 Sep-05
Percentage of available resources utilised
PartlyAverage over what period? Fluctuates so we need a time period sample.
14.6% CPU (vs 14.9% for LCG)
Peak number of concurrent jobs
Possible Issue of grid vs non-grid jobs. 2130 2500 Dec-04
Average number of concurrent jobs
1642 1800 Dec-04
Percentage of jobs submitted via grid (vs local submission)
No
Would require the establishment of a local site VO otherwise there is no way to track locally submitted jobs
Unknown
Number of jobs not terminated by themselves or the batch system
PossibleNot currently monitored. Numbers provided are based on LHCb analysis for the whole of LCG.
61%
Accumulated site downtime per week (scheduled or not scheduled)
Yes
What do we actually want to measure - e.g. accumulated sites down for more than 12hrs in month?
2
Total CPUs available
YesMeaning of "available". CPU weightings may not be accurate at the present time.
2110 2300 Dec-04
Metrics
Work in progress!

Metrics (2)
Metric Data available? Notes Current (12th Sept) Target… by date
CPUs upSome measure of how fast systems are being installed and made available
83%
Storage available Yes Does not account for muliple Ses 939 TBTotal jobs submitted
Yes Done already. Could monitor. 46580 (LHCb)
Accumulated wait time for accessing files on SE
No
This is possible only at the application level - experiments might monitor it. I/O rates to files are only likely to be a problem for the Tier-1 and tape access.
CPU hours per VO
Yes 46580 (LHCb)
Storage used YesPublished in MDS. Also viewable in gstat. Only the default SE is published.
7.8 TB N/a
Data transferred over WAN?
Possible
Possible for specific protocols such as gFTP (via file transfer record). Experiments know the amounts of data transferred.
14.5TB (LHCb) N/a
UK's relative contribution to experiment's monitored running
NoEvolve to fraction of year's CPU power delivered (for all VOs) by UK
20% for Atlas 25.6% for LHCb
Based on CPUs releative
to LCG?
Data transfer rates per day
No
Traffic depends on jobs/applications running. Overall site traffic can be currently be monitored but not grid only traffic.
Network bandwidth utilisation
No
Needs to be available - MRTG gives an indication. WP7 within EDG looked at network monitoring - are the tools being used? Need to monitor - capacity, availability and utilisation (max bandwidth, max throughput, aggregate bandwidth, roundtrip/delay times)
UK GOC (identified) "events" per week
No
GOC role not adequately defined (runs a collection of functional jobs against common failure points). No historical information provided. Fault logging at present is not always useful - define a "fault". Failures identified can have several underlying cau
No No
Work in progress!

• Migration to SL3 is starting.• Next public release of LCG supports SL3 WNs,
certification complete.– Service nodes remain at RH7.3 for now.– LCFGng is not an option SL3 nodes.– LCG supports one install method for SL3.
• Manual install techique (Actually not very manual)• Can be built into any framework already in use
– Kickstart and scripts, Cfengine, NPACI Rocks, Quattor, stateless linux or even LCFG
• This release expected this month.
Maintenance

Quattor
• Community effort for quattor installaion of LCG2 nearing completion. 98% done.
• Quattor has similar architecture and concept to LCFG. LCFG effort not wasted.
• Advantages– CERN and the RAL Tier1/A will use quattor for LCG. - Support
and self help for others available .– LCG M/W will not be tied to or released with quattor.
• Disadvantages– A lot to learn before any pay back.

Steve’s 5 questions
Once SL3 port is available is RH 7.3 still wanted anywhere?
Is an OS other than SL3 needed for GridPP sites and users?
Does any site have a conflict with proposed deployment of LCG into SL3?
Is there a site to work with RAL learning Quattor?
Should the UK use or at least favour one fabric management solution?
Yes – probably Quattor
Maybe on very few shared sites
Need to ask experiments – perhaps if CERN upgrades soon
No – most want to move off of RH 7.3
Manchester?

Summary
• Smooth running. Easy and seamless deployments. Service quality
• The DTEAM!
• The plans (& metrics) are being developed – many dependencies
• LCFG will be phased out. Quattor on SLC3 is coming.
• LCG2 deployed. 1500+ CPUs
• LCG-ROLLOUT needs to migrate to news & helpdesk services






























