Embed Size (px)
Citation preview

Dendrograms &Dendrograms &PFGE analysisPFGE analysis
Paul VauterinApplied Maths BVBA

Outline of this talk:
Bottom line:
- be careful in interpreting dendrograms!
- Consider alternatives to UPGMA (i. e. single & complete linkage)
• Simple explanation of mainstream hierarchical clustering (UPGMA)
• Interesting alternatives to UPGMA
• How to interpret a dendrogram?
• Problem of degenerate (equivalent) solutions

Relevance of cluster analysisRelevance of cluster analysis
Cluster Analysis is the mathematical study of methodsfor recognizing natural groups within a set of entities
• Used as a data exploration/mining tool in virtually every field(psychology, economy, finance, astronomy, ...)
• Simply a tool that groups together related entities,based on the observed similarities between them
• Applicable to virtually any type of data.Only a similarity matrix is needed
• Applicable to large data sets (>10 000 entities)
• Easy to interpret (simple & intuitive mathematical principle)weak points easier to anticipate
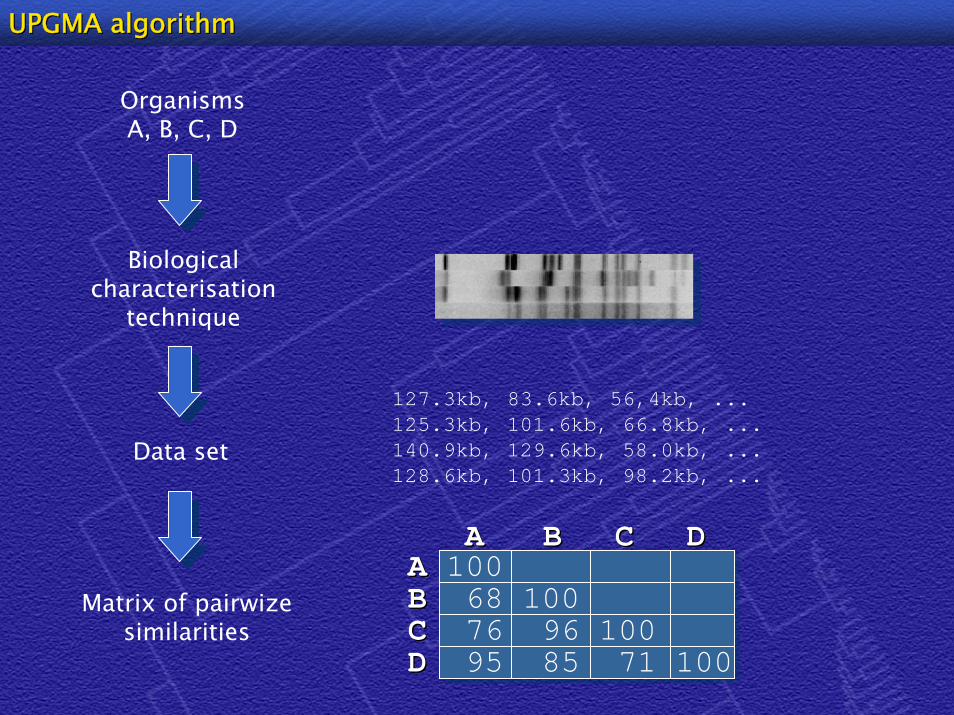
Matrix of pairwizesimilarities
UPGMA algorithmUPGMA algorithm
AA 100BB 68 100CC 76 96 100DD 95 85 71 100
AA BB CC DD
OrganismsA, B, C, D
Biologicalcharacterisation
technique
Data set
127.3kb, 83.6kb, 56,4kb, ...125.3kb, 101.6kb, 66.8kb, ...140.9kb, 129.6kb, 58.0kb, ...128.6kb, 101.3kb, 98.2kb, ...

AA 100BB 68 100CC 76 96 100DD 95 85 71 100
AA BB CC DD
UPGMA algorithmUPGMA algorithm
1. Find & merge two best matching
B + CB + C
2. Update the similarities (averaging)
3. Find & merge two best matching
A + DA + D
4. Update the similarities
BBCCAADD
96
75 95
1009080
5. Final merge
BC + ADBC + AD
BBCCAA 72 100DD 78 95 100
96
1009080
DD
BBCCAA
1009080

UPGMA algorithmUPGMA algorithm
Crucial step: determine similarities between two groups
UPGMA: average of all similarities

UPGMA algorithmUPGMA algorithm
Crucial step: determine similarities between two groups
Single linkage: highest similarity
(“best case” scenario)

UPGMA algorithmUPGMA algorithm
Crucial step: determine similarities between two groups
Complete linkage: lowest similarity
(“worst case” scenario)
... Other alternative schemes have been developed ...

How to interpret a dendrogram?How to interpret a dendrogram?
What does this tell you?AABBCC
UPGMA tree:
A & B are more close to each other than to C?
Not necesarily true!
Fundamental problem: potential alternative solutions
• Equally valid• “Hidden”• Might give another view
= not restricted to UPGMA or PFGE, but a major problem formost methods that summarise the original data

Degenerate dendrogram solutionsDegenerate dendrogram solutions
A simple example: PFGE, 3 organisms (A, B, C)
Similarities:
A B CA 100B 50 100C 50 0 100
UPGMA rule:Join highest similarities
First A+B
AA
BBCC
First A+C
AA
CCBB
Happens very often with discrete data with few degrees of freedom(bands on PFGE, but also MLST, MLVA, Spa typing, ...)
How to solve this?How to solve this?Detect and visualise in a special wayDetect and visualise in a special way
AACCBB
+ =
Bands
ABC

Degenerate dendrogram solutionsDegenerate dendrogram solutions

Degenerate dendrogram solutionsDegenerate dendrogram solutions
PFGE + band matching: even worse!
A B CA 100B 100 100C 0 100 100
““A=BA=B”” and and ““B=CB=C”” ““A=CA=C””
ABC
Compromises the concept of a “cluster of identical fingerprints”
“Relaxed view”: each member is identical toat least one other in the cluster
“Strict view”: each member is identical toall other members of the cluster
ALLWAYS human inspection needed anyway!
Complete linkageComplete linkageComplete linkage
Single linkageSingle linkageSingle linkage

““Case StudyCase Study””
0123456 # of different bands
• PFGE fingerprints
• (Dis)similarity:# of different bands
• Complete linkageclustering
Result=groups with members that haveno more than n bands differentwith any other member
= Good starting point forpattern naming

0123456 # of different bands
““Case StudyCase Study””
= Good starting point forfinding clusters of relatedpatterns
• PFGE fingerprints
• (Dis)similarity:# of different bands
• Single linkageclustering
Result=groups with members that haveno more than n bands differentwith some other members

How to interpret a dendrogram?How to interpret a dendrogram?
What does this tell you?AABBCC
Dendrogram: ... Suppose unique solution
... Still not necessarily anything!
A cluster algorithm will always produce a tree Garbage InGarbage Out ...
Need for methods to address the reliability of a dendrogram
Phylogenetics: standard tool = Felsenstein’s boostrap
Not (well) suited to most typing data sets
PFGE MLST VNTR

How to interpret a dendrogram?How to interpret a dendrogram?
Back to less sophisticated methods
E. g. error flags on cluster levels
Principle: each branch is an averagerepresentative of a variety of similarities
-> show standard deviation
• Visual inspection
• Cross-validation
• Large data sets are your friends!

Recipe 1: finding Recipe 1: finding ‘‘seedseed’’ groups for pattern naminggroups for pattern naming
Make sure you havea temporary fieldMake sure you haveMake sure you havea temporary fielda temporary field
Install the plugin“Dendrogram tools”Install the pluginInstall the plugin““Dendrogram toolsDendrogram tools””

Recipe 1: finding Recipe 1: finding ‘‘seedseed’’ groups for pattern naminggroups for pattern naming
Select “Complete Linkage”and “Different bands”Select Select ““Complete LinkageComplete Linkage””and and ““Different bandsDifferent bands””

Recipe 1: finding Recipe 1: finding ‘‘seedseed’’ groups for pattern naminggroups for pattern naming
Use “Fill field with cluster number”Use Use ““Fill field with Fill field with cluster numbercluster number””

Recipe 1: finding Recipe 1: finding ‘‘seedseed’’ groups for pattern naminggroups for pattern naming
Use 100% similarity Use 100% similarity Use 100% similarity
Specify minimum group sizeSpecify minimum Specify minimum group sizegroup size
Chose destination fieldChose destination fieldChose destination fieldWill overwrite any content!Will overwrite any content!

Recipe 1: finding Recipe 1: finding ‘‘seedseed’’ groups for pattern naminggroups for pattern naming
ResultsResultsResults
Resulting groups are guaranteed to consist of all identical fingerprints and have at least 5 members
Resulting groups are Resulting groups are guaranteed to consist of guaranteed to consist of all identical fingerprints all identical fingerprints and have at least 5 and have at least 5 membersmembers
Warning: numbering is notWarning: numbering is not““persistentpersistent””: other data set : other data set might give different valuesmight give different values

Recipe 2: find largest clusters in data setRecipe 2: find largest clusters in data set
Select “Single Linkage”and “Different bands”Select Select ““Single LinkageSingle Linkage””and and ““Different bandsDifferent bands””
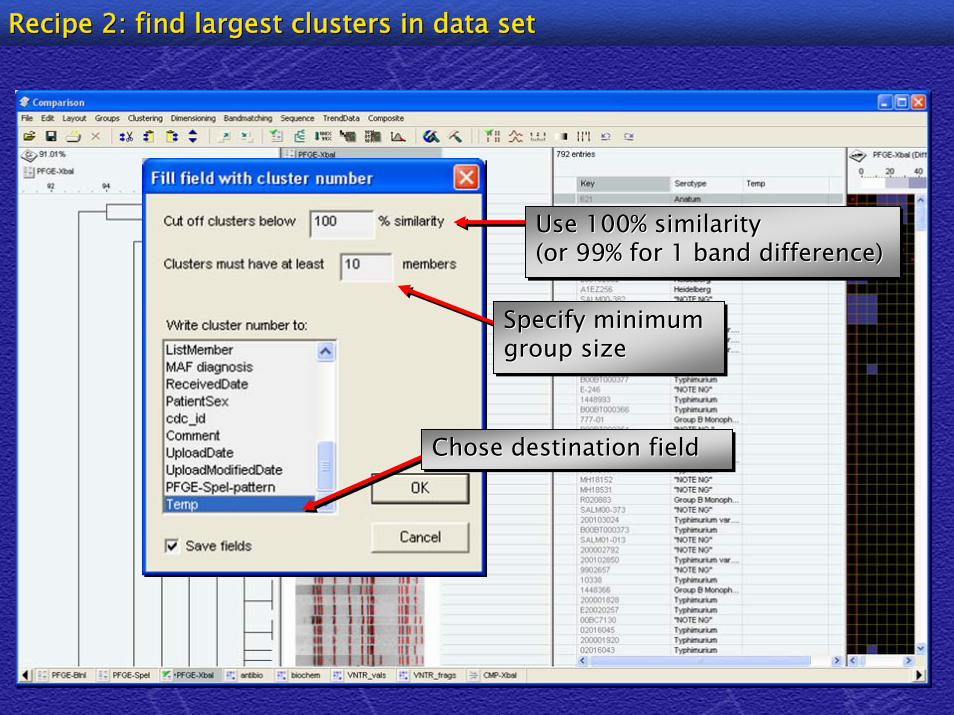
Recipe 2: find largest clusters in data setRecipe 2: find largest clusters in data set
Use 100% similarity(or 99% for 1 band difference) Use 100% similarityUse 100% similarity(or 99% for 1 band difference) (or 99% for 1 band difference)
Specify minimum group sizeSpecify minimum Specify minimum group sizegroup size
Chose destination fieldChose destination fieldChose destination field

Recipe 2: find largest clusters in data setRecipe 2: find largest clusters in data set
Use “Chart & Statistics” toolUse Use ““Chart & StatisticsChart & Statistics”” tooltool
Add “Temp” fieldAdd Add ““TempTemp”” fieldfield

Recipe 2: find largest clusters in data setRecipe 2: find largest clusters in data set
Use “sort by frequency”Use Use ““sort by frequencysort by frequency””

Recipe 2: find largest clusters in data setRecipe 2: find largest clusters in data set
Fingerprints not associated with any (large) clusterFingerprints not associated Fingerprints not associated with any (large) clusterwith any (large) cluster
Clusters ranked by sizeuse CTRL+click to select entriesClusters ranked by sizeClusters ranked by sizeuse CTRL+click to select entriesuse CTRL+click to select entries

Recipe 2: find largest clusters in data setRecipe 2: find largest clusters in data set

Recipe 2: find largest clusters in data setRecipe 2: find largest clusters in data set





























