Embed Size (px)
Citation preview

Deep Learning Tools
Emanuele [email protected]
5th Feb 2018
Introduction to Neural Networks 2017/2018
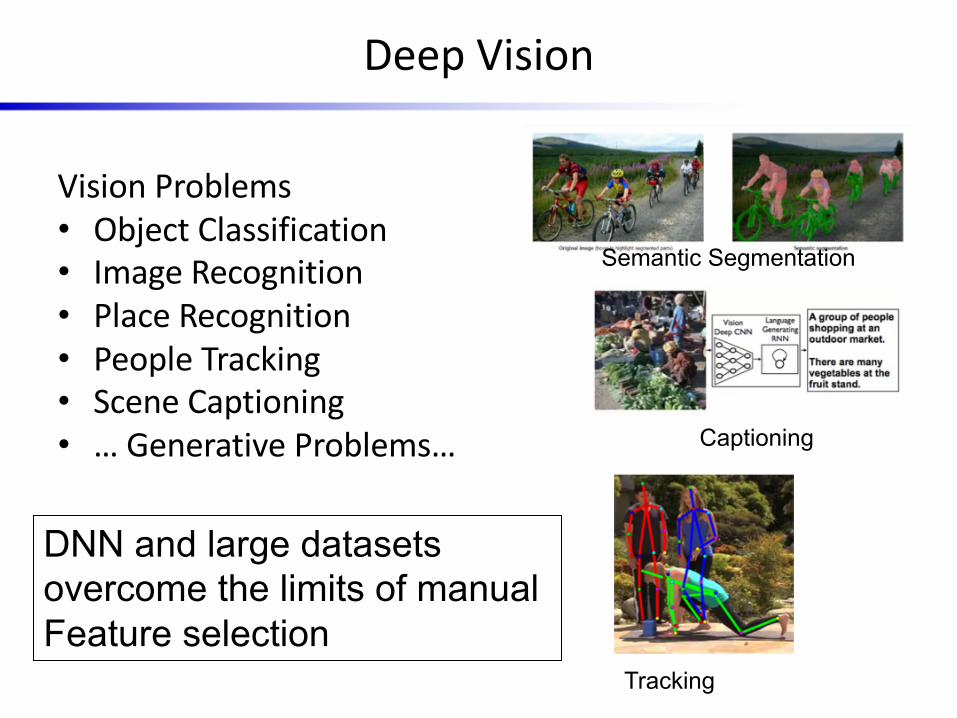
Deep Vision
Vision Problems• Object Classification• Image Recognition• Place Recognition• People Tracking• Scene Captioning• … Generative Problems…
Semantic Segmentation
Captioning
DNN and large datasets overcome the limits of manual Feature selection
Tracking

NVIDIA Autonomous Driving
https://www.youtube.com/watch?v=HJ58dbd5g8g

Segmentation
https://codeac29.github.io/projects/linknet/index.html

ImageNet
• Over 15M labeled high resolution images• Roughly 22K categories• Collected from web and labeled by Amazon
Mechanical Turk
http://image-net.org/

ILSVRC
ILSVRC yearly competition with 1.2M images, correct if an image is in the 5 top labels

ILSVRC 2016
I. Object localization for 1000 categories.II. Object detection for 200 fully labeled categories.III.Object detection from video for 30 fully labeled
categories.IV.Scene classification for 365 scene categories (Joint with
MIT Places team) on Places2 Database http://places2.csail.mit.edu.
V. Scene parsing for 150 stuff and discrete object categories (Joint with MIT Places team).

Concept Recaps
• Pooling• Training Instances (N)• Batch (B per iteration)• Mini-batch (if B<<N)• Epoch (every N/B iterations)– Batch Mode (N=B)– Mini-batch Mode (1 < B < N)– Stochastic (B=1)
• Stochastic Gradient Descent (SGD)• SGD with Momentum

Software Tools for Deep Learning
• Many software frameworks are available for Deep Learning practice and research
• Highly optimized and tuned due to the industrial interest in the topic
• Examples– TensorFlow: Google, C++ https://www.tensorflow.org/
– Theano: Univ, Python https://github.com/Theano/Theano
– Torch: C++, Lua, Python http://pytorch.org/
– Tiny-Dnn: C++ https://github.com/tiny-dnn
– Keras: Google, Python https://keras.io/
• Looking at the support of CPU and GPU optimizations
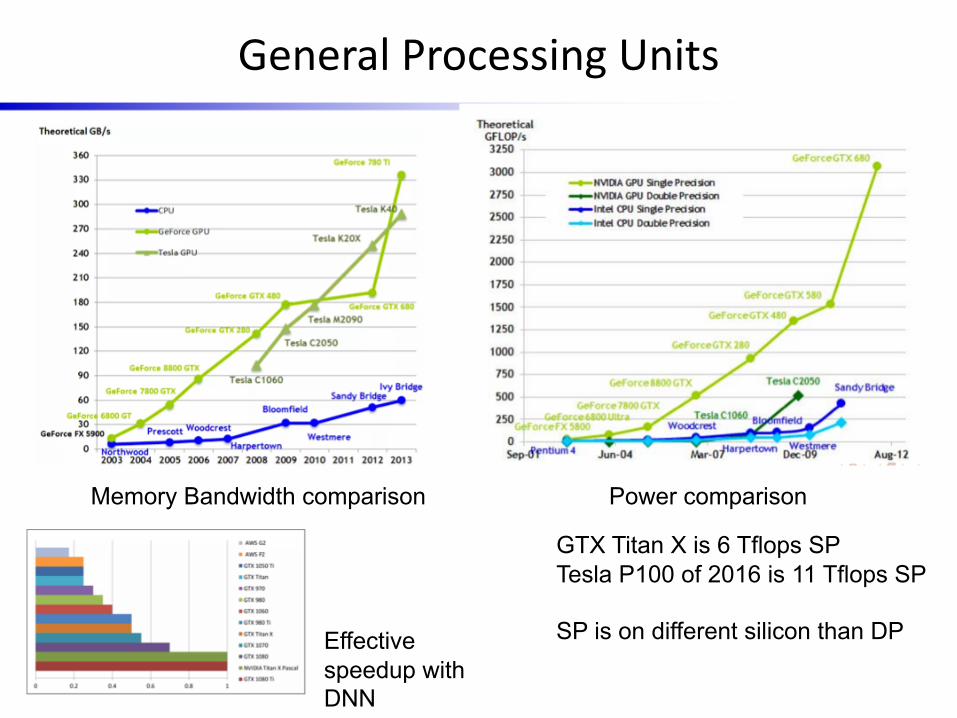
General Processing Units
Memory Bandwidth comparison Power comparison
GTX Titan X is 6 Tflops SPTesla P100 of 2016 is 11 Tflops SP
SP is on different silicon than DPEffective speedup with DNN
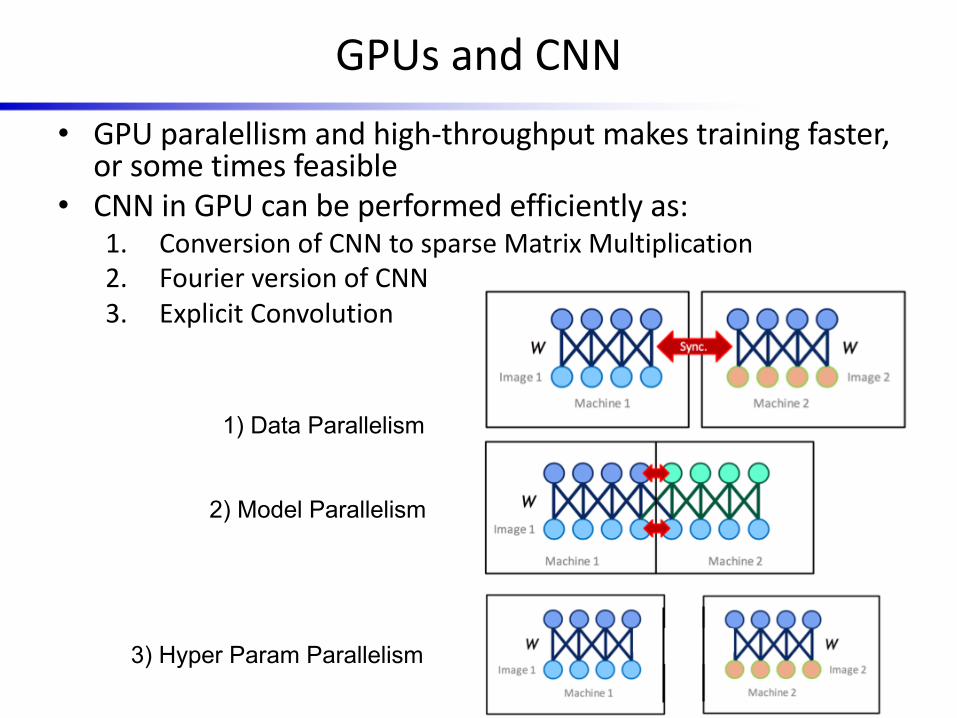
GPUs and CNN• GPU paralellism and high-throughput makes training faster,
or some times feasible• CNN in GPU can be performed efficiently as:
1. Conversion of CNN to sparse Matrix Multiplication2. Fourier version of CNN 3. Explicit Convolution
1) Data Parallelism
2) Model Parallelism
3) Hyper Param Parallelism

CPU SIMD
• GPUs are great but we can use effectively modern CPUs• Intel AVX2 provides 16 registers at 256bit
– 8/4 single/double respectively– Fused Multiply and Accumulate
• Analysis by Google– “Improving the speed of neural networks on CPUs”, Vanhoucke et al. (PDF)
• Use– Theano is based on dynamic C code generation and it uses CPU features– Tensorflow needs to be compiled from source

Common Concepts in DNN Software
• Most DNN SW are based on the concept of Computational Graph and Automatic Differentiation
• The objective is the efficient computation of the Gradient for the optimizer
• Three Gradient computation approaches:– Numeric– Symbolic– Automatic Differentiation

Automatic Differentiation
• General concept for solving
• If the top-most function is scalar, as loss functions then it can be realized by two passes over the computational graph– Bottom-up evaluation of C(x)– Top-down evaluation of the gradient pushing results toward
each Jacobian• This Backward AD is most suited for scalar emitting
functions

Backward Example
Berland

Applied Jacobian
• In reality we are not interested in the full Jacobian but the application of the Jacobian by a generic vector à smaller problem
• Moreover resulting graph is generally independent of the batch size
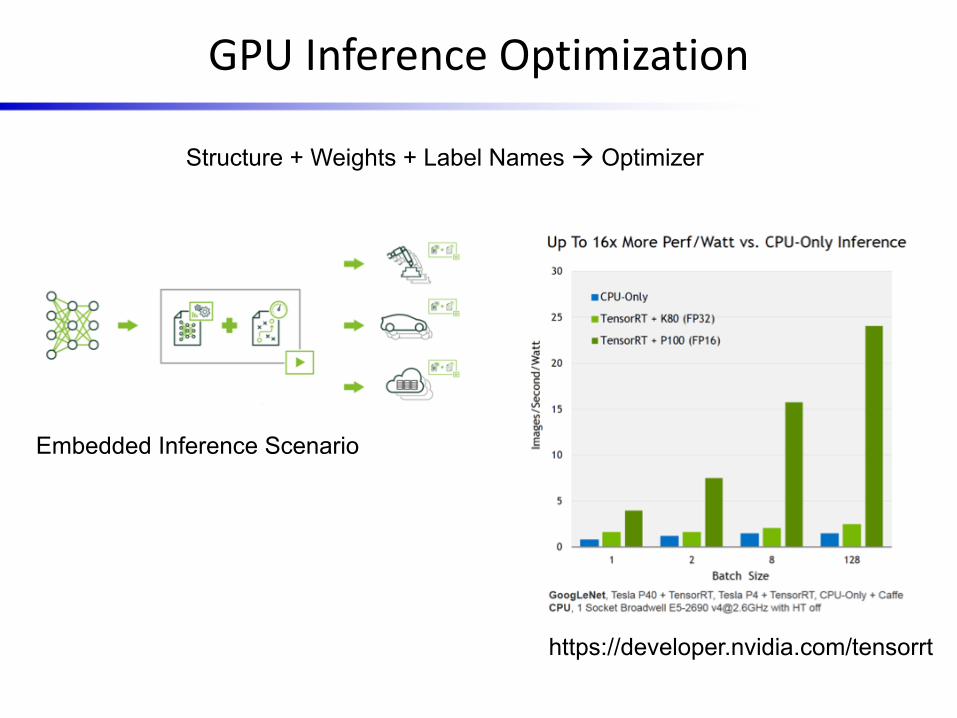
GPU Inference Optimization
https://developer.nvidia.com/tensorrt
Structure + Weights + Label Names à Optimizer
Embedded Inference Scenario

How Big are the Models?
https://culurciello.github.io/tech/2016/06/04/nets.html

How Big are the Models?
• VGGNet runner up of ILSVRC 2014 with 140M parameters (500MB model)
• GPU Limit is the amount of memory in GPU (4-12GB)
Smaller is better because1) Less distributed bandwidth2) Smaller embedding for Cars
and Smarphones(Cloud not always an option)
Deep Compression(lossless)
e.g. 240MB to 7MB for AlexNet

Model Pruning
• Deep Compression assumes to minimize the effect due to the pruning of the connections
AlexNet pruning

TensorFlow
• C++ framework by Google (PDF) with Python
API
• CPU (C++) and GPU (CUDA/OpenCL)
• Distributed using Hadoop FS
• Based on dataflow graph
• General Optimization framework, e.g. PDE,
SVM and more
• High-level API for DNN since TF 1.0
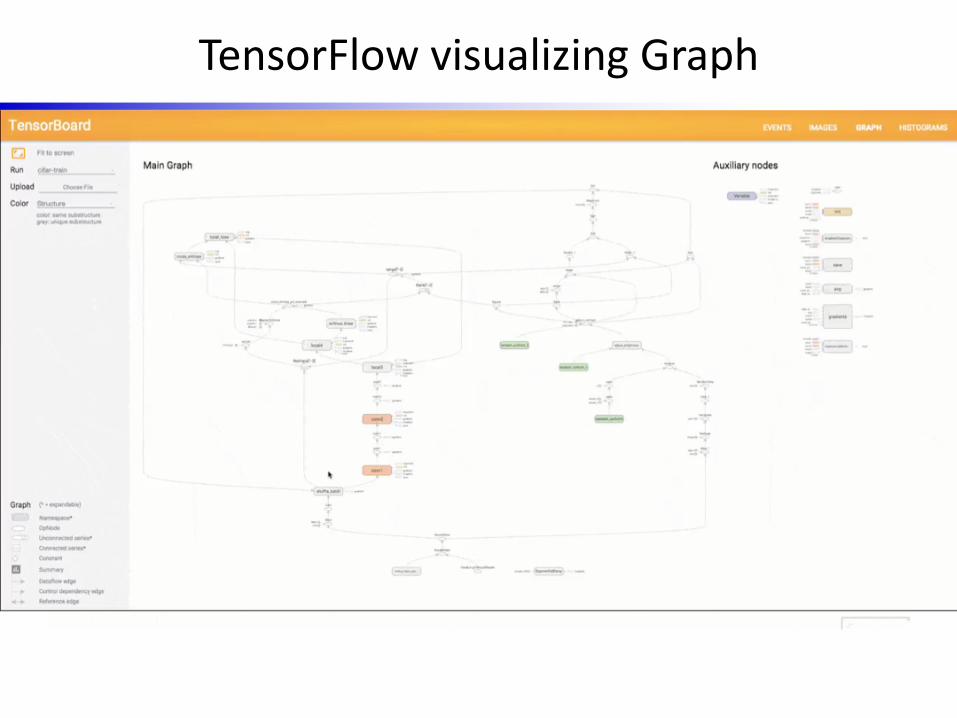
TensorFlow visualizing Graph
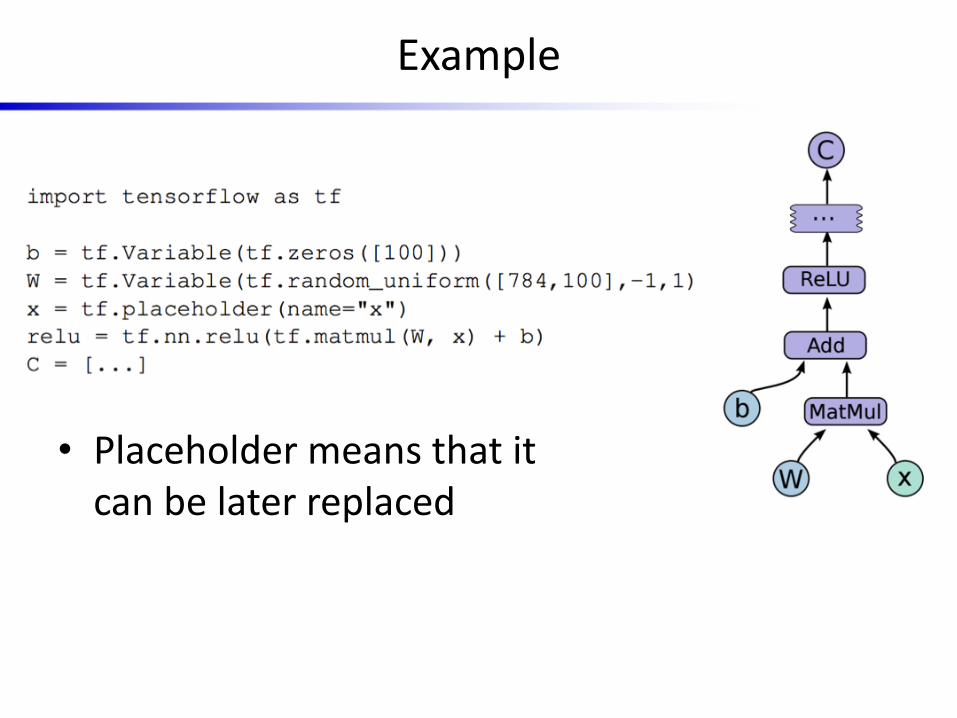
Example
• Placeholder means that it can be later replaced

TensorFlow is Generic
• Mandelbrotxs = tf.constant(Z.astype(np.complex64))zs = tf.Variable(xs)ns = tf.Variable(tf.zeros_like(xs, tf.float32))
zs_ = zs*zs + xs
step = tf.group(zs.assign(zs_),ns.assign_add(tf.cast(not_diverged,
tf.float32)))
https://www.tensorflow.org/tutorials/mandelbrot GitHub

TensorFlow for Regression
GitHub

Example Gradient
Equivalent to the AD concept
Function Gradient

Example
• Check Jupyter from – https://github.com/eruffaldi/handson-ml
• Taken from the book on SkLearn and Tensorflow

Theano
• Python framework initially developed by Canadian University (PDF) MILA– Development by MILA stopped since October 2017
• Highly integrated with the Python numpy tensor library• Backends
– CPU is based on Cached dynamic C code generation– GPU is based on CUDA
• General optimizer with some specializations for DNN– Can be used as a general-purpose tool– PyMC3 is a probabilistic programming framework based on Theano for gradients
computations• Graph Structure
– Bipartite DAG – Variable– Operations
• Approach:1. Construction of Computational Graph2. Graph Optimization3. Code Generation
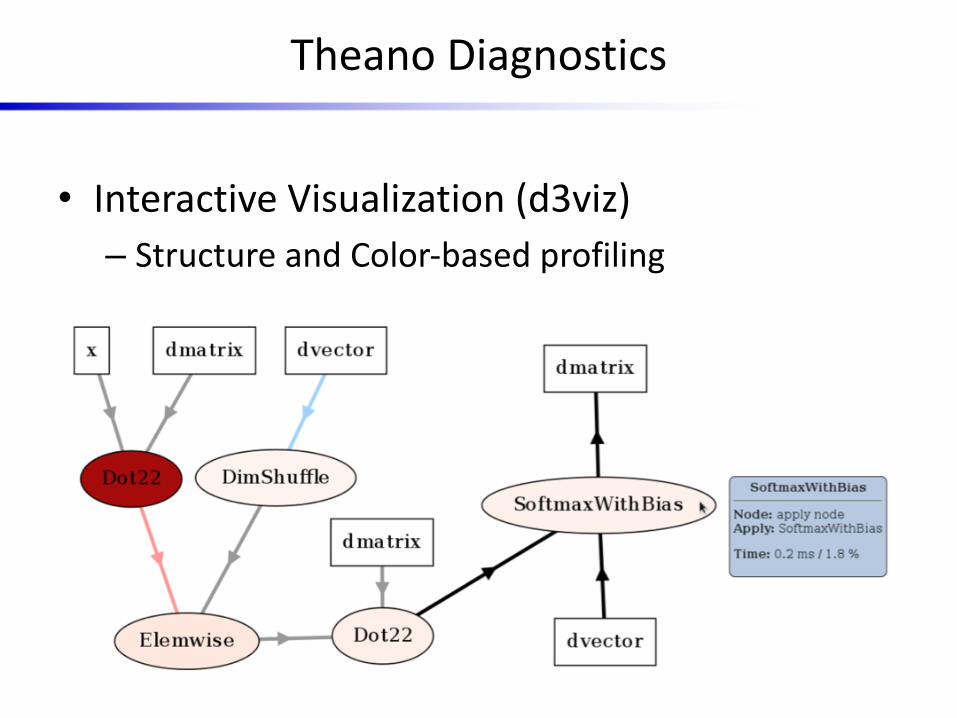
Theano Diagnostics
• Interactive Visualization (d3viz)– Structure and Color-based profiling
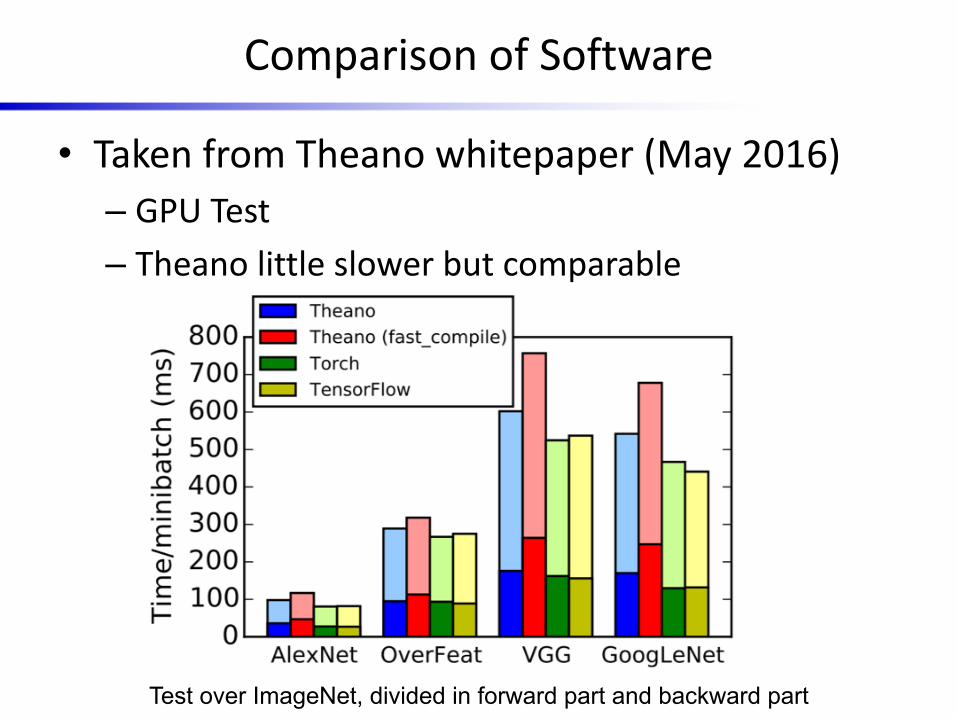
Comparison of Software
• Taken from Theano whitepaper (May 2016)– GPU Test– Theano little slower but comparable
Test over ImageNet, divided in forward part and backward part

Keras
• Keras is an example of high-level DNN library that supports both Tensorflow , Theano, CNTK
• Works at the level of Network Layers• A basic model is Sequential and can be built from layers
from keras.layers import Dense, Activation model.add(Dense(units=64, input_dim=100)) model.add(Activation('relu')) model.add(Dense(units=10)) model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])

Keras Train and Eval
• Given a model 4 operations– model.fit(x_train, y_train, epochs=5,
batch_size=32)– model.train_on_batch(x_batch, y_batch)– loss_and_metrics = model.evaluate(x_test, y_test,
batch_size=128)– classes = model.predict(x_test, batch_size=128)

VGG16 in Keras GitHub

MINST Dataset
• The MNIST dataset consists of handwritten digit images and it is divided in 60,000 examples for the training set and 10,000 examples for testing
(28x28 grayscale)
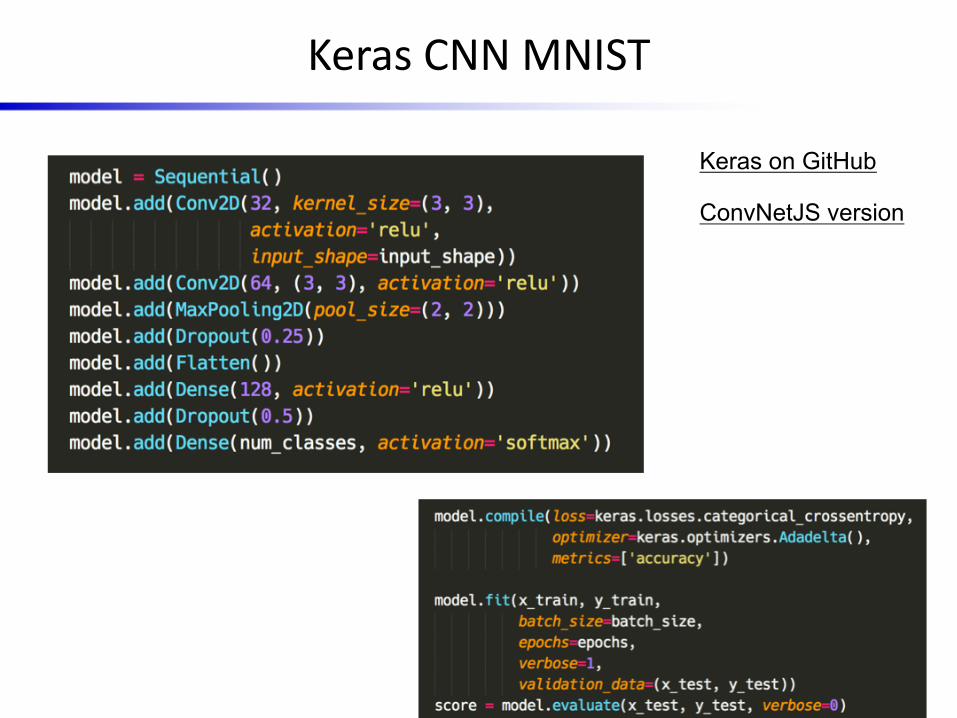
Keras CNN MNIST
Keras on GitHub
ConvNetJS version

DIGITS
• High-level tools by Nvidia based on Torch or Caffe that allows a Web-based training of NN models.
• Dataset Creation• Model Creation with existing Network or Custom one• Job-based• Visualization of Network and Inference

Interoperability
• Having at disposal several libraries how we can interoperate between then for reusing training for inference, or transfer learning?
• Fight against fragmentation
• For a while Caffe models have been used for exchange, ONNX or NNEF are proposed as interoperable solutions – Open Neural Network Exchange Format or Neuranl Network Exchange Format
• Tools around ONNX– Direct or indirect support for specific libraries– Runtime support by Nvidia TensorRT
ONNX

ONNX
• Which kind of format is ONNX?
– Based on Google Protobuf serialization
– Describes network layers eventually with trained parameters
– Node, Graph, Attribute, Operator, Value, Shape
– All operators here:
https://github.com/onnx/onnx/blob/master/docs/Operators.md
• Example with TF
– https://github.com/onnx/tutorials/blob/master/tutorials/OnnxT
ensorflowImport.ipynb
• Repository of Pre-trained Networks
– https://github.com/onnx/models
– E.g. ResNet-50 is 92MB

Preprocessing for Image Data
• For image data it is sufficient to normalize in the range [0,1] or [-1,1]• Most network support variable sized images by adjusting pooling size• In specific cases we can employ custom preprocessing• What does preprocessing?
– Reduces data variability– Helps NN if small dataset
• What about color representation (RGB vs YUV)?– Any trichromatic space will suffice– But we can take advantage from

Reducing Overfitting in Image Data
• When the number of parameters is large there is a tendency to overfitting
• Dataset Augmentation is a solution, and it is particularly effective in image Data– Use label invariant transformation
• If the network is not affine invariant then we can use rotation/translation of input images
• Also gamma/color transformations
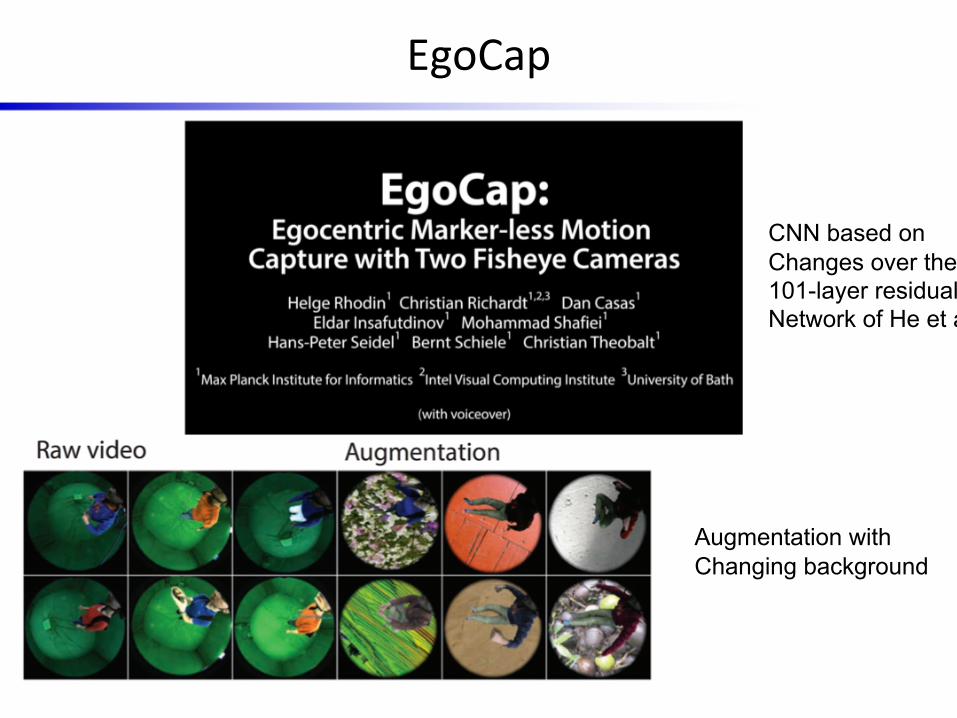
EgoCap
Augmentation withChanging background
CNN based onChanges over the101-layer residualNetwork of He et al

Augmentation in Keras

CIFAR10
• CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
• The test batch contains exactly 1000 randomly-selected images from each class.
http://www.cs.toronto.edu/~kriz/cifar.html

ConvNetJS
– CIFAR10 demo
Input
First Layer

CIFAR10 with Keras
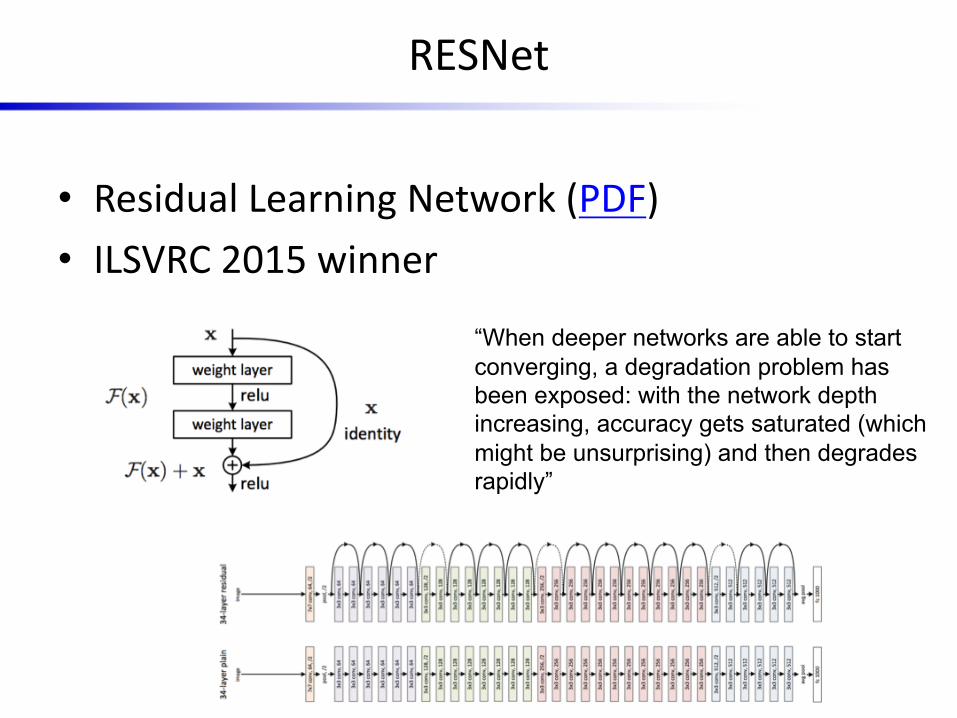
RESNet
• Residual Learning Network (PDF)• ILSVRC 2015 winner
“When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly”

Image Segmentation with Fully convolutional
1. Need of full output for segmentation2. Adaptation of classic to fully conv

CNN Over other Data Types
• Convolution is “natural” for images but what happens with other data?
Deep Learning, Goodfellow et al., MIT, 2017
Dimensions Single-Channel Multi-Channels
1D Audio Multi-track skeleton in time
2D Audio as FFT (rows are frequencies)
Color image RGB
3D CT Scan Video
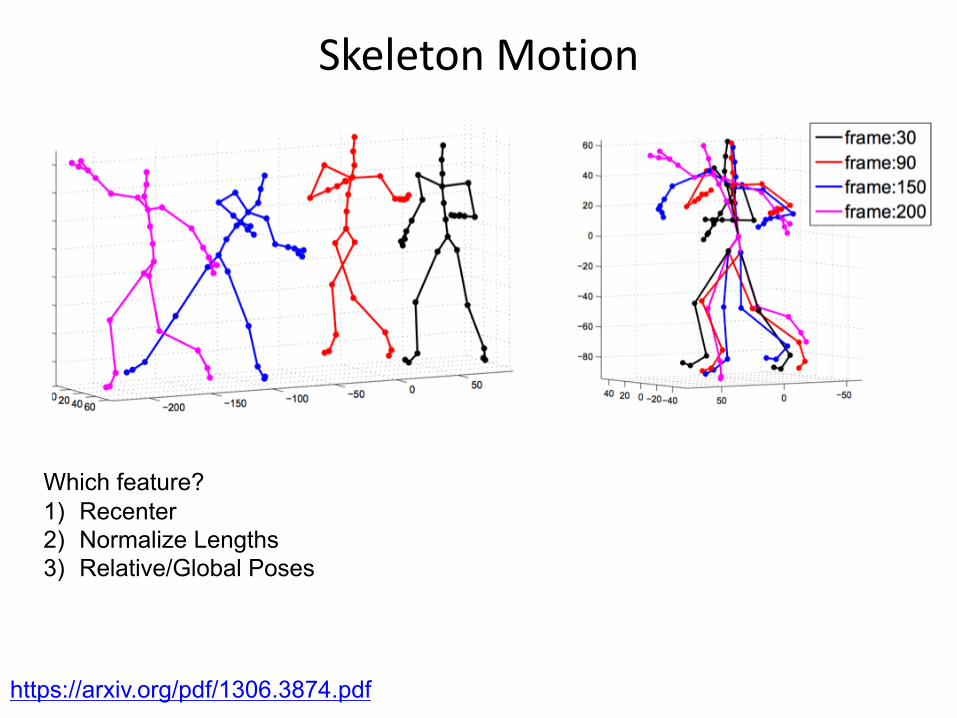
Skeleton Motion
Which feature?1) Recenter2) Normalize Lengths3) Relative/Global Poses
https://arxiv.org/pdf/1306.3874.pdf
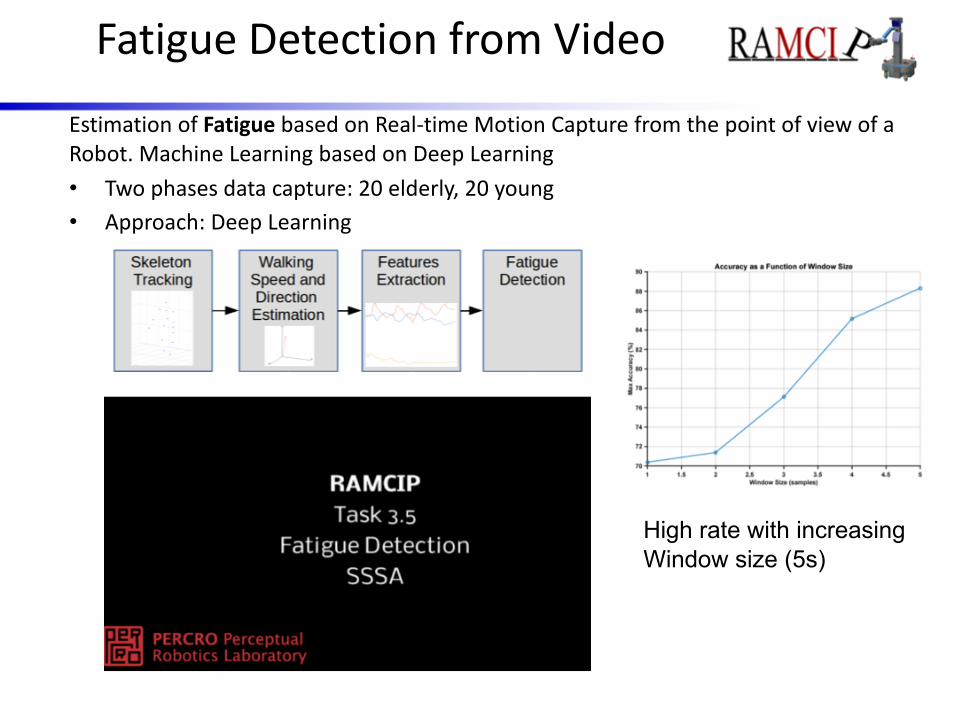
Fatigue Detection from VideoEstimation of Fatigue based on Real-time Motion Capture from the point of view of a Robot. Machine Learning based on Deep Learning• Two phases data capture: 20 elderly, 20 young• Approach: Deep Learning
High rate with increasingWindow size (5s)




























