Embed Size (px)
Citation preview

Deep LearningNeural Network with
Memory (1)Hung-yi Lee

Memory is important
47
47
11
1 2 3
Input:2 dimensions
Output:1 dimension
𝑥1 𝑥2 𝑥3
�̂� 1 �̂� 2 �̂� 3
1 4 4
1 7 7
1
+
Network needs memory to achieve this
11
23

Memory is important
x1 x2
y
c1
1010
Network with Memory 1-10
1 1 1 1
1
1
MemoryCell4
747
11
1 2 3
𝑥1 𝑥2 𝑥3
�̂� 1 �̂� 2 �̂� 3
0
4 7
1111
111
1
1
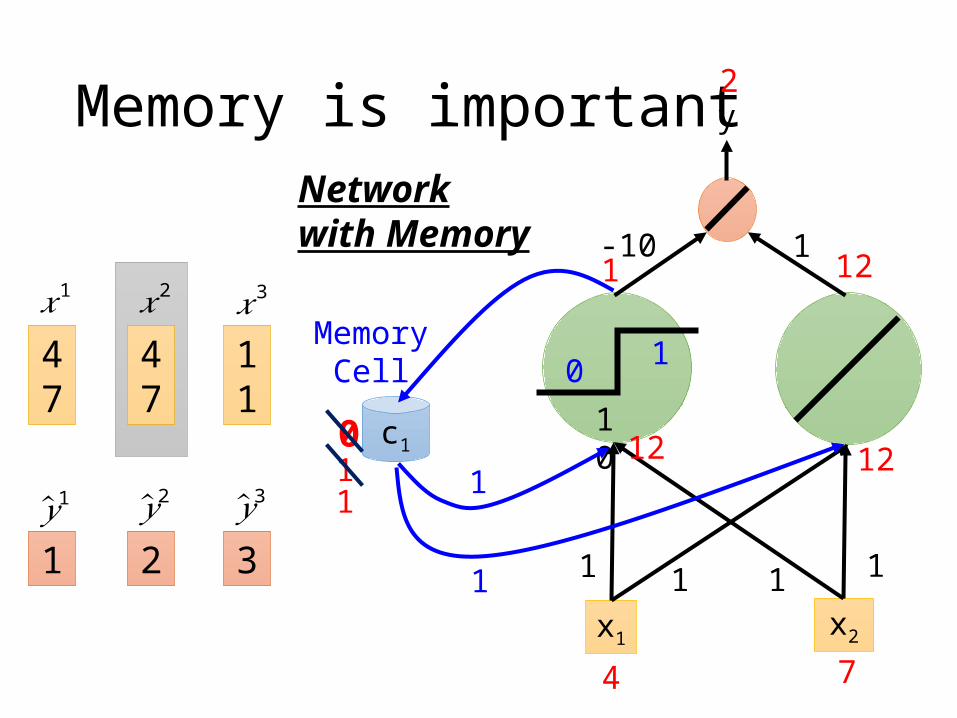
Memory is important
x1 x2
y
c1
1010
Network with Memory 1-10
1 1 1 1
1
1
MemoryCell4
747
11
1 2 3
𝑥1 𝑥2 𝑥3
�̂� 1 �̂� 2 �̂� 3
0
4 7
1212
121
2
11

Memory is important
x1 x2
y
c1
1010
Network with Memory 1-10
1 1 1 1
1
1
MemoryCell4
747
11
1 2 3
𝑥1 𝑥2 𝑥3
�̂� 1 �̂� 2 �̂� 3
0
1 1
33
30
3
110

Outline
Recurrent Neural
Network (RNN)
Long short-term memory
(LSTM)
Application on language modeling
Today we will simply assume we already know the parameters in the network.Training will be discussed in the next week.

Outline
Recurrent Neural
Network (RNN)
Long short-term memory
(LSTM)
Application on language modeling
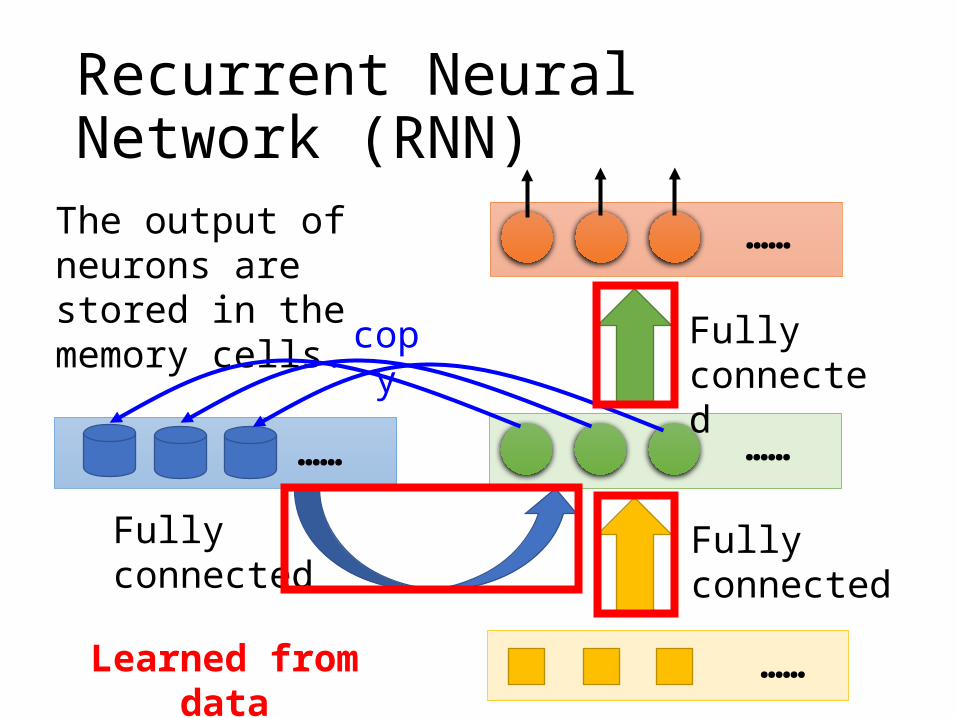
Recurrent Neural Network (RNN)
…………
……
……The output of neurons are stored in the memory cells.
Fully connected
Fully connected
Fully connected
copy
Learned from data

Recurrent Neural Network (RNN)
…………
……
……The output of neurons are stored in the memory cells.
copy
xWi
Wo
Wh
Wix+Whhh
a=σ(Wix+Whh)
Woa
y=Softmax(Woa)
a

Recurrent Neural Network (RNN)
…………
……
……The output of neurons are stored in the memory cells.
copy
x’
Wi
Wo
Wh
Wix’+Whah
a’=σ(Wix’+Wha)
Woa’
y’=Softmax(Woa’)
aa’

Recurrent Neural Network (RNN)
copy copy
x1 x2 x3
y1 y2 y3
Output yi depends on x1, x2, …… xi
(xi are vectors)Input data: ……
Wi
Wo
Wh Wh WhWi Wi
Wo Wo
0a1
a1 a2a2 a3
The same network is used again and again.

Outline
Recurrent Neural
Network (RNN)
Long short-term memory
(LSTM)
Application on language modeling
(simplified version)
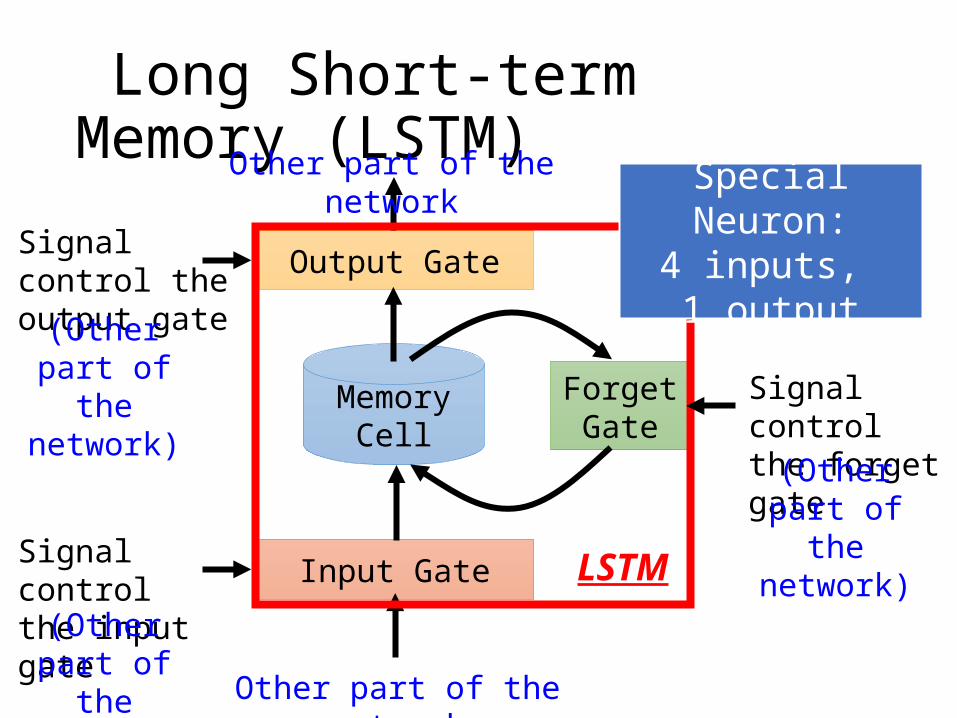
MemoryCell
Long Short-term Memory (LSTM)
Input Gate
Output Gate
Signal control the input gate
Signal control the output gate
Forget Gate
Signal control the forget gate
Other part of the network
Other part of the network
(Other part of the network)
(Other part of the network)
(Other part of the network)
LSTM
Special Neuron:4 inputs, 1 output

𝑧
𝑧𝑖
𝑧 𝑓
𝑧𝑜
𝑔 (𝑧 )
𝑓 (𝑧𝑖 )multiply
multiplyActivation function f is usually a sigmoid function
Between 0 and 1
Mimic open and close gate
c
𝑐 ′=𝑔 (𝑧 ) 𝑓 (𝑧 𝑖 )+𝑐𝑓 (𝑧 𝑓 )
h (𝑐′ )𝑓 (𝑧𝑜 )
𝑎¿h (𝑐′ ) 𝑓 (𝑧𝑜 )
𝑔 (𝑧 ) 𝑓 (𝑧 𝑖 )
𝑐 ′𝑓 (𝑧 𝑓 )
𝑐𝑓 (𝑧 𝑓 )
𝑐

x1 x2 Input
Original Network:Simply replace the neurons with LSTM
𝑎1 𝑎2
……
……
𝑧1 𝑧 2

x1 x2
+
+
+
+
+
+
+
+
Input
𝑎1 𝑎2
4 times of parameters

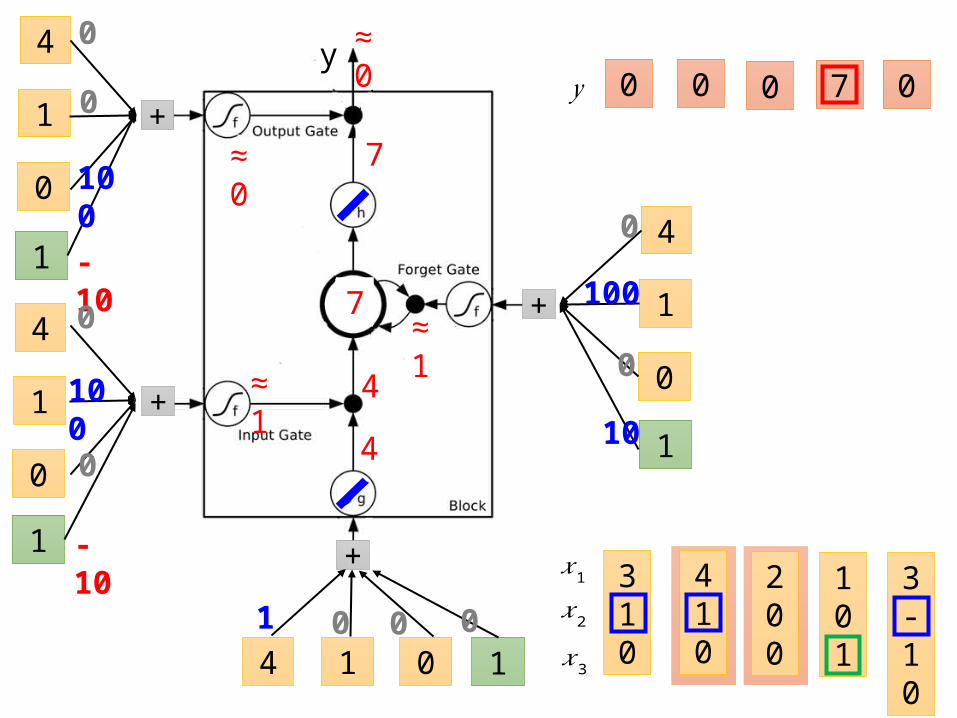
LSTM - Example
100
0
𝑥1
𝑥2
𝑥3
𝑦
310
0
200
0
410
0
200
0
101
7
3-10
0
610
0
101
6
When x2 = 1, add the numbers of x1 into the memory
When x3 = 1, output the number in the memory.
0 0 3 3 7 7 7 0 6
When x2 = -1, reset the memory
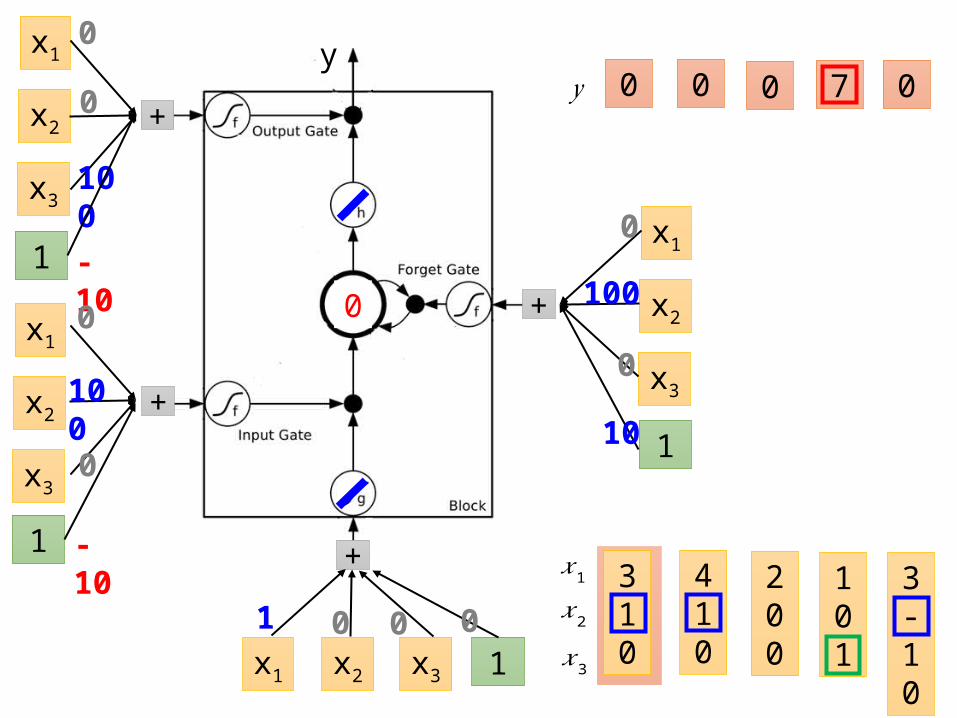
𝑥1
𝑥2
𝑥3
𝑦
310
0
410
0
200
0
101
7
3-10
0
+
+
+
+
x1 x2 x3
x1
x2
x3
x1
x2
x3
x1
x2
x3
y
1 0 0
1000
0
1
1
1
1
0
-10
0
0
100
-10
0
010
1000

𝑥1
𝑥2
𝑥3
𝑦
310
0
410
0
200
0
101
7
3-10
0
+
+
+
+
3 1 0
3
1
0
3
1
03
1
0
y
1 0 0
1000
0
1
1
1
1
0
-10
0
0
100
-10
0
010
100
3
≈1 3
≈103
3≈0
≈0
𝑥1
𝑥2
𝑥3
𝑦
310
0
410
0
200
0
101
7
3-10
0
+
+
+
+
4 1 0
4
1
0
4
1
04
1
0
y
1
1
1
1
4
≈1 4
≈137
7≈0
≈0
1 0 0
1000
0
0
-10
0
0
100
-10
0
010
100

𝑥1
𝑥2
𝑥3
𝑦
310
0
410
0
200
0
101
7
3-10
0
+
+
+
+
2 0 0
2
0
0
2
0
02
0
0
y
1
1
1
1
2
≈0 0
≈17
7≈0
≈0
1 0 0
1000
0
0
-10
0
0
100
-10
0
010
100

𝑥1
𝑥2
𝑥3
𝑦
310
0
410
0
200
0
101
7
3-10
0
+
+
+
+
1 0 1
1
0
1
1
0
11
0
1
y
1
1
1
1
1
≈0 0
≈17
7≈1
≈7
1 0 0
1000
0
0
-10
0
0
100
-10
0
010
100

𝑥1
𝑥2
𝑥3
𝑦
310
0
410
0
200
0
101
7
3-10
0
+
+
+
+
3 -1 0
3
-1
0
3
-1
03
-1
0
y
1
1
1
1
3
≈0 0
≈07
0≈0
≈0
0
1 0 0
1000
0
0
-10
0
0
100
-10
0
010
100

Outline
Recurrent Neural
Network (RNN)
Long short-term memory
(LSTM)
Application on language modeling

Language model (LM)
• Language model: Estimated the probability of word sequence • Word sequence: w1, w2, w3, …., wn
• P(w1, w2, w3, …., wn)
• Useful in speech recognition• Different word sequence can have the same
pronunciation
recognize speechor
wreck a nice beach
If P(recognize speech)>P(wreck a nice beach)
Output = “recognize speech”

Language model
• How to estimate P(w1, w2, w3, …., wn)• Collect a large amount of text data as training data• However, the word sequence w1, w2, …., wn may not
appear in the training data• N-gram language model: P(w1, w2, w3, …., wn) = P(w1|
START)P(w2|w1) …... P(wn|wn-1)• Estimate P(beach|nice) from training data
𝑃 (beach |nice )=𝐶 (𝑛𝑖𝑐𝑒 h𝑏𝑒𝑎𝑐 )𝐶 (𝑛𝑖𝑐𝑒 )
Count of “nice” in the training data
Count of “nice beach” in the training data
P(“wreck a nice beach”)=P(wreck|START)P(a|wreck)P(nice|a)P(beach|nice)

Language model - Smoothing• Training data:• The dog ran ……• The cat jumped ……
P( jumped | dog ) = 0P( ran | cat ) = 0
The probability is not accurate.
The phenomenon happens because we cannot collect all the possible text in the world as training data.
Give some small probability
This is called language model smoothing.
0.0001
0.0001

Neural-network based LM
Neural Network
P(b|a): not from count, but the NN that can predict the next word.
P(“wreck a nice beach”)=P(wreck|START)P(a|wreck)P(nice|a)P(beach|nice)
1-of-N encoding of “START”
P(next word is “wreck”)
Neural Network
1-of-N encoding of “wreck”
P(next word is “a”)
Neural Network
1-of-N encoding of “a”
P(next word is “nice”)
Neural Network
1-of-N encoding of “nice”
P(next word is “beach”)

Neural-network based LM
……
……
……
Fully connected
Fully connected
The hidden layer of the related words are close.
If P(jump|dog) is large, then P(jump|cat) increase accordingly.
h1
h2
dog
cat
rabbit
(even there is not “… cat jump …” in the data)
Smoothing is automatically done.
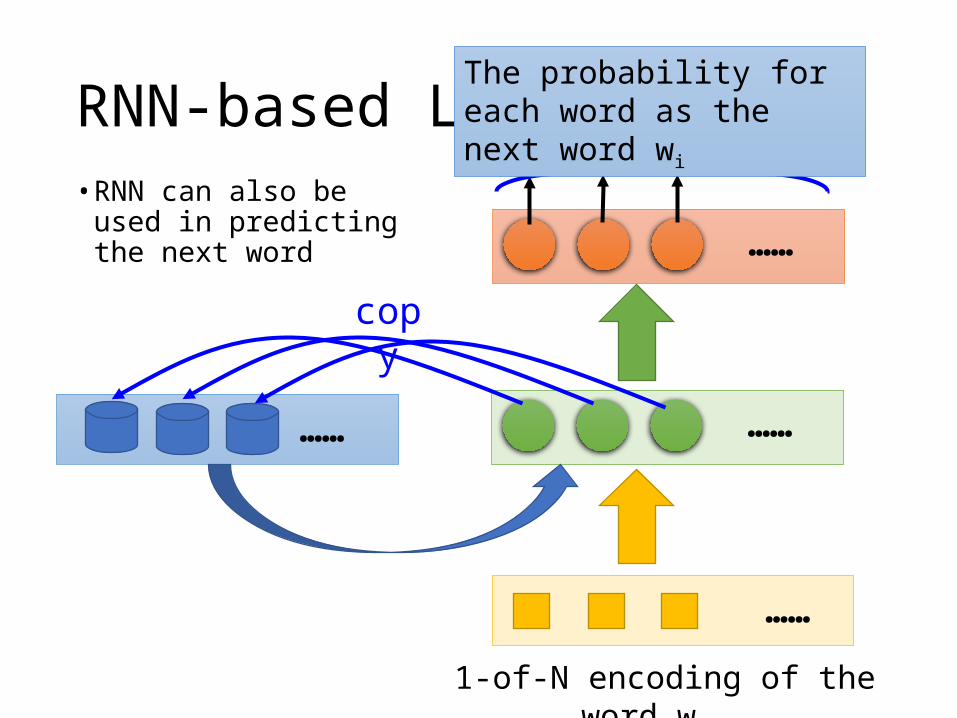
RNN-based LM• RNN can also be used
in predicting the next word
…………
……
……
copy
1-of-N encoding of the word wi-1
The probability for each word as the next word wi
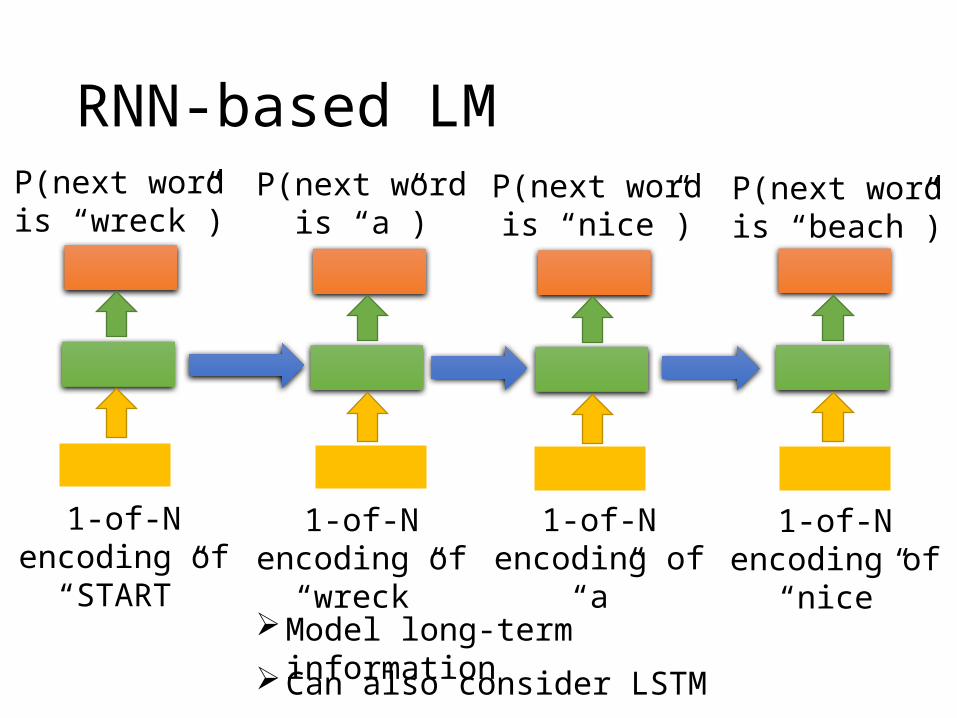
RNN-based LM
1-of-N encoding of “START”
1-of-N encoding of “wreck”
1-of-N encoding of “a”
1-of-N encoding of “nice”
Model long-term information
Can also consider LSTM
P(next word is “wreck”)
P(next word is “a”)
P(next word is “nice”)
P(next word is “beach”)

Another Applications
• Composer• http://people.idsia.ch/~juergen/blues/
• Sentence generation• http://www.cs.toronto.edu/~ilya/rnn.html

Summary – Network with Memory
Recurrent Neural
Network (RNN)
Long short-term memory
(LSTM)
Application on language modeling


Appendix

Long term memory
x1 x2 x3
y1 y2 y3
x4
y4
……

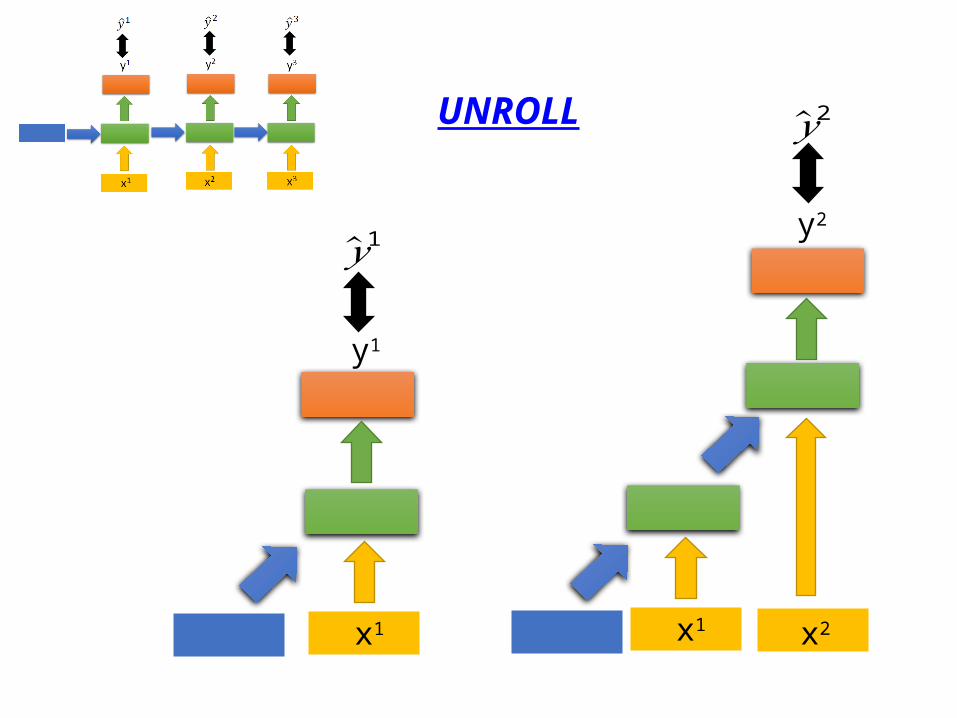
RNN - Training
copy copy
x1 x2 x3
y1 y2 y3
Training data: ……
……
Training the parameters to let close to
�̂� 1�̂� 2 �̂� 3
x1 x2
y1
y2
�̂� 1
�̂� 2
x1
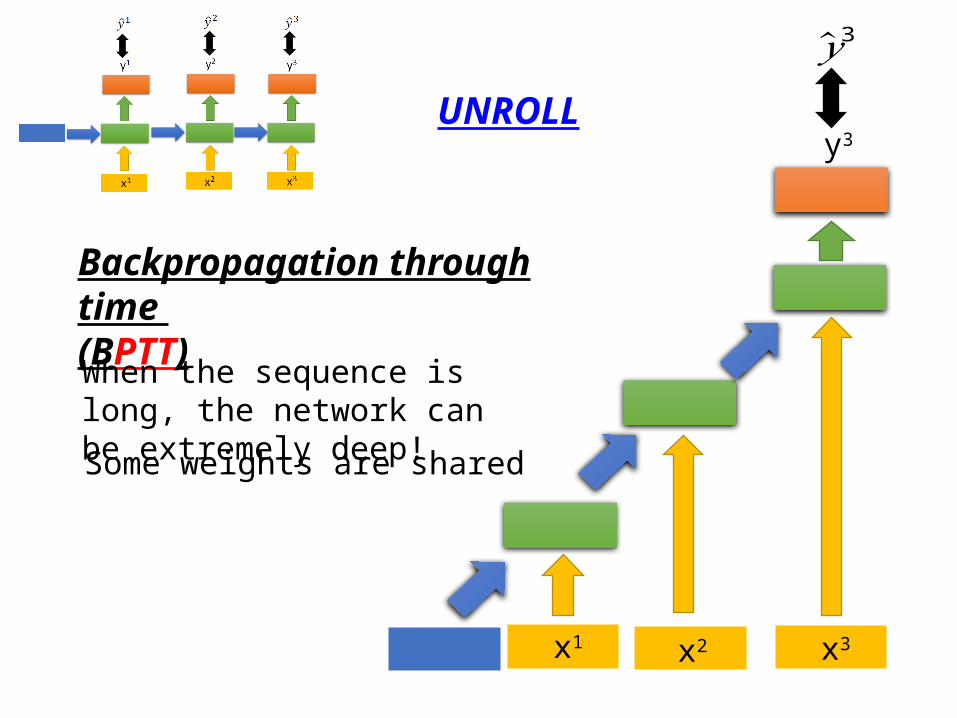
UNROLL
x3
y3
�̂� 3
x2x1
Backpropagation through time (BPTT)
When the sequence is long, the network can be extremely deep!
UNROLL
Some weights are shared

The task that needs memoryStructured Leargning v.s. RNN
TSI TSI TSI I I N N N
Speech RecognitionPOS Tagging
John saw the saw.
PN V D N
x1 x2 x3 x4
y1 y2 y3 y4
Structured learning can also deal with these problems
What are their difference?
x1 x2 x3 x4
y1 y2 y3 y4 ……
……

Outlook
• Speech recognition• http://www.cs.toronto.edu/~fritz/absps/RNN13.pdf
• Structured + Deep• http://research.microsoft.com/pubs/210167/rcrf_v9.pdf

Neural-network based LM
• Training• Training data: “Hello how are you …… ”
Neural Network
“Hello”
“how”
“are”
……
“how” have the largest probability
“are” have the largest probability
“you” have the largest probability
……
Input: Target:





























