Embed Size (px)
Citation preview

HAL Id: tel-00159149https://tel.archives-ouvertes.fr/tel-00159149
Submitted on 2 Jul 2007
HAL is a multi-disciplinary open accessarchive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come fromteaching and research institutions in France orabroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, estdestinée au dépôt et à la diffusion de documentsscientifiques de niveau recherche, publiés ou non,émanant des établissements d’enseignement et derecherche français ou étrangers, des laboratoirespublics ou privés.
Décodage des codes algébriques et cryptographieDaniel Augot
To cite this version:Daniel Augot. Décodage des codes algébriques et cryptographie. Génie logiciel [cs.SE]. UniversitéPierre et Marie Curie - Paris VI, 2007. �tel-00159149�

Departement de formation doctorale en informatique Ecole doctorale de Paris VIUFR Informatique
Decodage des codes algebriques etcryptographie
Memoire d’habilitation a diriger des recherches
presentee et soutenue publiquement le 7 juin 2007
pour l’obtention du
Diplome d’habilitation a diriger des recherches de l’universitePierre et Marie Curie – Paris VI
(specialite informatique)
par
Daniel Augot
Composition du jury
Rapporteurs : Patrick FitzpatrickDaniel LazardAmin Shokrollahi
Examinateurs : Philippe FlajoletFrancois MorainNicolas SendrierAnnick Valibouze

Mis en page avec la classe thloria.

Table des matières
1 Introduction générale 51.1 Travaux en codage . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2 Travaux en cryptographie . . . . . . . . . . . . . . . . . . . . . . 6
I Codage 9
2 Introduction au codage algébrique 112.1 Problématique du codage et théorème de Shannon . . . . . . . . 112.2 La distance de Hamming . . . . . . . . . . . . . . . . . . . . . . 122.3 Obstacles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.4 Les codes cycliques . . . . . . . . . . . . . . . . . . . . . . . . . 142.5 Le décodage en liste et l'algorithme de Sudan . . . . . . . . . . 152.6 Les codes de Reed-Solomon . . . . . . . . . . . . . . . . . . . . . 152.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 Décodage des codes cycliques généraux 193.1 Dé�nition des codes cycliques avec la transformée de Fourier . . 193.2 Erreur et syndromes . . . . . . . . . . . . . . . . . . . . . . . . . 203.3 Polynôme localisateur et identités de Newton . . . . . . . . . . . 203.4 Un exemple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.5 Historique des travaux utilisant les bases de Gröbner . . . . . . 223.6 Contributions théoriques . . . . . . . . . . . . . . . . . . . . . . 223.7 Contributions pratiques . . . . . . . . . . . . . . . . . . . . . . . 243.8 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4 Décodage des codes d'évaluation avec l'algorithme de Sudan 27
4.1 Trois exemples de codes d'évaluation . . . . . . . . . . . . . . . 284.2 Problème du décodage des codes d'évaluation et approximation
par des polynômes . . . . . . . . . . . . . . . . . . . . . . . . . . 294.3 Le schéma de principe des algorithmes de Sudan et Guruswami 304.4 Généralisations . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
1

2 Table des matières
4.5 Implémentation . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.6 Décodage local des codes de Reed-Muller d'ordre 1 . . . . . . . 334.7 Application en cryptanalyse . . . . . . . . . . . . . . . . . . . . 344.8 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
II Cryptographie 37
5 Utilisation de problèmes de codage en cryptographie 395.1 Chi�rement fondé sur le décodage des codes de Reed-Solomon . 405.2 Fonction de hachage fondée sur le décodage par syndrome . . . 415.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
6 Cryptographie fondée sur le protocole de Di�e-Hellman 476.1 Protection des droits d'auteurs . . . . . . . . . . . . . . . . . . . 486.2 Réseaux sans �l . . . . . . . . . . . . . . . . . . . . . . . . . . . 496.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
III Conclusion et perspectives 53
7 Conclusion et perspectives de recherches 557.1 Décodage des codes de Reed-Solomon avec l'algorithme de Gu-
ruswami-Sudan . . . . . . . . . . . . . . . . . . . . . . . . . . . 557.2 Généralisation en codes géométriques . . . . . . . . . . . . . . . 567.3 Cryptographie basée sur les codes de Reed-Solomon . . . . . . . 56
IV Présentations détaillées 59
8 Décodage avec les bases de Gröbner 618.1 Le problème du décodage . . . . . . . . . . . . . . . . . . . . . . 618.2 Les équations de Newton . . . . . . . . . . . . . . . . . . . . . . 628.3 Algorithmes algébriques . . . . . . . . . . . . . . . . . . . . . . . 658.4 Les travaux sur le décodage avec les bases de Gröbner . . . . . . 668.5 Élimination et spécialisation . . . . . . . . . . . . . . . . . . . . 668.6 La variété associée à l'idéal des équations de Newton . . . . . . 678.7 Propriétés algébriques . . . . . . . . . . . . . . . . . . . . . . . . 728.8 Utilisation des équations de Newton en décodage . . . . . . . . 788.9 Décodage en ligne . . . . . . . . . . . . . . . . . . . . . . . . . . 788.10 Décodage formel . . . . . . . . . . . . . . . . . . . . . . . . . . . 808.11 En pratique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81

3
9 Décodage par interpolation 839.1 Introduction aux algorithmes de décodage par interpolation . . 839.2 Algorithmes de Sudan et Guruswami-Sudan : interpolation e�cace 869.3 Algorithme de Sudan : recherche de racines . . . . . . . . . . . . 879.4 Généralisation aux codes géométriques . . . . . . . . . . . . . . 889.5 Généralisations multivariées . . . . . . . . . . . . . . . . . . . . 909.6 Généralisation aux codes produits de codes de Reed-Solomon . . 919.7 Généralisation aux codes de Reed et Muller . . . . . . . . . . . 939.8 Spéci�cité des corps �nis . . . . . . . . . . . . . . . . . . . . . . 95
V Annexes 97
A Informations annexes 99A.1 Étudiants encadrés . . . . . . . . . . . . . . . . . . . . . . . . . 99A.2 Enseignement . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101A.3 Publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101A.4 Contrats de recherche . . . . . . . . . . . . . . . . . . . . . . . . 105
Bibliographie 107

4 Table des matières
RemerciementsJe tiens tout d'abord à remercier mes trois rapporteurs. D'abord les étrangers.
Merci à Patrick Fitzpatrick, qui connait bien mon travail, d'avoir bien voulu êtrerapporteur et d'avoir fait le déplacement depuis Cork, en Irlande.
Merci aussi à Amin Shokrollahi, pour l'intérêt qu'il porte à mon travail. Je tiensaussi à le remercier de m'avoir associé au jury de son étudiant Andrew Brown.
En�n, merci à Daniel Lazard, pour l'exigence qu'il a montré vis-à-vis de cedocument. Cet e�ort qu'il m'a demandé a été bien nécessaire.
Merci à Annick Valibouze d'avoir bien voulu m'éclairer sur quelques proprié-tés des fonctions symétriques élémentaires. Sa patiente relecture du document aégalement permis de l'améliorer.
Je suis très reconnaissant à François Morain, pour l'accueil qu'il me fait à l'écolepolytechnique.
Dois-je remercier Nicolas Sendrier, collègue de tous les jours, prêt à résoudrequasi instantanément tous les problèmes ?
Je suis aussi très honoré de la présence de Philippe Flajolet, plus qu'éminent,qui déjà avait montré de l'intérêt à ma thèse, et qui est encore présent maintenant.
Maintenant il me reste à remercier tous les collègues. Il y a tant de monde. . . Ily a d'abord Pascale Charpin qui toujours m'a aidé et soutenu, dans des momentsdi�ciles, et encore Nicolas Sendrier, mais aussi Anne Canteaut, qui les ont compris.
Quant au projet Codes, serais-je capable de remercier tous ces gens qui m'onttant apporté ? Je vais surtout énumérer les thésards que j'ai co-dirigé, avec d'autresdirecteurs eux habilités alors que je ne l'étais pas : Lancelot Pecquet, Cédric Ta-vernier, Magali Bardet et Raghav Bhaskar. Je suis content et �er de leur succèsrespectifs, dans di�érents domaines, dans di�érents lieux.
En�n, salut à tous les étudiants, présents ou passés, du projet, pour l'ambiancesympathique qu'ils contribuent à instaurer dans cette équipe si chaleureuse. Je suisvraiment heureux de partager la vie quotidienne avec tous.

Chapitre 1
Introduction générale
La théorie des codes correcteurs est une discipline de l'artefact, qui cherche àconstruire des objets mathématiques particuliers, utilisables dans les schémas decommunication, principalement pour protéger les messages contre le bruit. Un codedé�nit une manière d'ajouter de la redondance à une suite de symboles, et le toutest transmis sur le canal de transmission. On espère que cette redondance permettrade reconstruire le message, même si des perturbations se sont produites.
La construction historique des codes correcteurs est algébrique : les grandesfamilles des codes cycliques, codes de Reed-Solomon, codes BCH, codes de Reed-Muller, reposent sur les polynômes univariés ou multivariés sur les corps �nis. Lespropriétés bien connues de ces objets mathématiques permettent de donner les pro-priétés des codes ainsi construits.
À ces objets mathématiques que sont les codes sont associés des algorithmes dedécodage, qui permettent d'éliminer le bruit qui a perturbé la transmission. Il y ades algorithmes de décodage génériques, qui décodent tout code, et des algorithmesdédiés à chaque famille de code construite. Les algorithmes génériques sont peue�caces, alors que pour un code donné, on peut tirer parti de sa structure pourconstruire l'algorithme de décodage. Il n'est en général pas facile de construireun algorithme de décodage e�cace associé à un code donné. Étant donné la fortestructure mathématique des codes que je considère, les algorithmes historiques dedécodage utilisent, souvent sans le savoir, les méthodes de calcul formel : algorithmed'Euclide, algorithme de Berlekamp-Massey etc.
Mes travaux de recherche se situent donc à l'intersection de la discipline descodes correcteurs d'erreurs et du calcul formel, avec une intention d'applications desalgorithmes du calcul formel au codage. Ma thèse portait sur la famille des codescycliques : j'ai mis une mise en équation algébrique du problème de déterminer ladistance minimale des codes cycliques [Aug93]. En collaboration avec Paul Camion,j'y ai aussi donné un algorithme de construction de base normale dans un corps�ni, reposant sur le calcul de vecteurs cycliques et de la forme de Frobenius d'unematrice. Mais je n'ai pas développé par la suite cet axe de recherche précis (algèbrelinéaire sur les corps �nis).
1.1 Travaux en codageAprès ma thèse, je me suis intéressé au problème du décodage des codes cy-
cliques, que j'ai essayé de mettre en équations. J'ai utilisé principalement une miseen équation induite par les identités de Newton. Le problème est l'étude de la variétéassociée à cette mise en équation : il n'est pas évident que les solutions obtenues parrésolution du système correspondent aux solutions du problème de décodage asso-
5

6 Chapitre 1. Introduction générale
cié. La ligne de mire de ces travaux est le décodage d'un sous ensemble des codescycliques, les codes à résidus quadratiques, qui sont de bons codes, mais qu'on nesait pas décoder de manière e�cace. Ces mises en équations sont ensuite résoluesavec les logiciels de calcul de base de Gröbner de Jean-Charles Faugère, qui, àl'époque de ma thèse, étaient déjà les plus performants. Ces problèmes de décodagedes codes cycliques ont formé une partie de la thèse de Magali Bardet en 2004, quej'ai co-encadrée [Bar04], avec Jean-Charles Faugère.
Une autre famille de codes, plus restreinte encore que celle des codes cycliques,mais très importante, est celle des codes de Reed-Solomon. Ces codes sont optimauxrelativement à certaines bornes, et présentent la propriété de bien se décoder. Ilssont ainsi largement employés, dans de nombreuses situations.
En 1996, une percée remarquable a été obtenue par Madhu Sudan. En relâchantquelque peu la problématique de la correction d'erreurs, il a obtenu, pour les codesde Reed-Solomon, un algorithme de correction capable de supprimer beaucoup plusde bruit que les algorithmes classiques. Ce résultat a valu a Sudan le prix Nevan-linna 2002 (et aussi pour d'autres travaux, en théorie de la complexité notamment).Cet algorithme, conceptuellement très simple, est très algébrique. Il n'a pas étécomplètement décrit par Sudan. En e�et, il procède en deux étapes : une étaped'interpolation bivariée, et une étape de factorisation bivariée. Sudan s'est contentéde signaler que ces deux étapes peuvent se faire de manière � polynomiale �. Laporte était ouverte à la recherche de bons algorithmes pour résoudre ces deux pro-blèmes, et aussi à la généralisation de cet algorithme à d'autres codes que les simplescodes de Reed-Solomon.
Au premier rang des codes candidats à être décodés par des variantes de l'algo-rithme de Sudan �gurent les codes géométriques. J'ai co-encadré la thèse de LancelotPecquet sur ces sujets : formulation de l'algorithme de Sudan pour les codes géomé-triques, et optimisation des méthodes de calcul formel pour l'algorithme de Sudan,pour les codes de Reed-Solomon et pour les codes géométriques [Pec01].
L'algorithme de Sudan a ouvert la brèche du décodage d'un grand nombre d'er-reurs. Dans ce domaine, j'ai aussi co-encadré, avec Pascale Charpin, la thèse de Cé-dric Tavernier sur le décodage des codes de Reed-Muller. Ces codes, moins � bons �que les codes BCH ou les codes de Reed-Solomon, sont toutefois des objets trèsnaturels, qui trouvent de nombreuses applications en cryptographie. Les codes deReed-Muller sont construits en utilisant des polynômes multivariés de petit degré surle corps F2 : le problème de décodage de ces codes est un problème d'approximationde points par un polynôme de bas degré. Cédric Tavernier a trouvé et implémenté unbon algorithme pour trouver les meilleures approximations d'un ensemble de points,et a ensuite appliqué son algorithme pour trouver les meilleures approximations decertaines sorties de l'algorithme de chi�rement DES [Tav04].
Ces approximations peuvent être utilisées pour monter une attaque particulière,la cryptanalyse linéaire de Matsui [Mat94b]. Ce n'est pas mon sujet de mener cettecryptanalyse complètement, et l'algorithme de Cédric Tavernier permet de faireautomatiquement le travail préalable de trouver les approximations, travail que lecryptanalyste devait auparavant faire à la main.
1.2 Travaux en cryptographieEn ce domaine de la cryptographie, j'ai aussi travaillé sur l'exploitation des ré-
sultats négatifs en codage. Pour beaucoup de codes, le problème décisionnel associéau décodage est NP-complet, et surtout il est e�ectivement réputé di�cile dansla communauté. De nombreux cryptosystèmes à clé publique ont été construitssur cet aspect négatif de la théorie des codes, dont le système fondateur de McE-liece [McE78]. Avec Matthieu Finiasz, j'ai proposé un nouvel algorithme de chif-

1.2. Travaux en cryptographie 7frement à clé publique (hélas � cassé �), et surtout une fonction de hachage avecréduction de sécurité. Ces travaux ont fait l'objet d'une partie de la thèse de Mat-thieu Finiasz [Fin04].
Toujours en cryptographie, j'ai mené une activité beaucoup plus proches desapplications, sur des fondements très di�érents. Dans ces travaux-là, je n'ai plusutilisé la théorie des codes correcteurs d'erreurs, et j'ai utilisé à chaque fois le pro-tocole fondateur de la cryptographie à clé publique : celui de Di�e-Hellman [DH76]ou ses variantes. Ce protocole permet à deux utilisateurs de se mettre d'accord surune clé secrète en échangeant uniquement des données publiques au su et au vu del'attaquant. Cette clé secrète peut ensuite être utilisée pour sécuriser des échangesultérieurs, en utilisant la cryptographie à clé secrète.
Presque tout de suite après ma thèse, avec Caroline Fontaine, j'ai travaillé auproblème de la protection des droits d'auteurs dans un projet d'intégration et dedi�usion des ressources patrimoniales européennes. Nous avons proposé un systèmeparticulier de gestion des clés, et nous sommes allés jusqu'à la réalisation d'unprototype, qui a fait l'objet d'une démonstration devant des représentants de laCommission Européenne. Ces travaux constituent la moitié de la thèse de CarolineFontaine [Fon98].
En�n, dans le cadre d'une collaboration avec les projets Arles (architectures lo-gicielles et systèmes distribués) et Hipercom (réseaux sans �l) de l'INRIA, j'ai euaussi à m'intéresser à quelques aspects de la sécurisation des réseaux sans �l. Unedes solutions envisagées a été de mettre en place dans le réseau une clé secrète, enutilisant une version à n utilisateurs du protocole de Di�e-Hellman. Une telle géné-ralisation n'existe pas de manière directe ou canonique. Avec Raghav Bhaskar, nousavons conçu une variante du protocole de Di�e-Hellman, qui présente des caracté-ristiques intéressantes : il n'y a pas besoin d'une forte structuration des participants ;une défaillance d'un des participants n'empêche pas les autres membres d'obtenir laclé secrète. Ces caractéristiques rendent ce protocole très adapté aux réseaux avecperte de message, et nous pensons pousser assez loin la mise en ÷uvre pratique dece protocole. Ces travaux étaient le c÷ur de la thèse de Raghav Bhaskar [Bha06],que j'ai co-encadrée avec Valérie Issarny.
Structure du document Ce document présente mes travaux de recherche depuisla soutenance de ma thèse, en prétendant à l'exhaustivité. Il y a cependant certainsde mes travaux que j'ai choisi d'exposer avec un certain niveau de détails, et d'autresde manière plus succincte. C'est pour cela que le document est structuré en deuxprincipaux volets : un volet de survol de mes travaux, en codage et en cryptographie ;un volet de présentation précise de mes travaux en codage.
Le premier volet est en deux parties : codage, cryptographie. En codage, j'aiestimé nécessaire de faire une présentation générale du domaine, pour amener lesproblématiques qui m'ont principalement intéressé : le décodage des codes cycliques,et le décodage des codes d'évaluation. En cryptographie, les problématiques dontje parle sont plus simples à aborder : je présente dans un premier chapitre mesconstructions de systèmes à clé publique reposant sur la théorie des codes correcteursd'erreurs, et dans un deuxième chapitre mes travaux applicatifs reposant sur leprotocole de Di�e-Hellman (protection des droits d'auteurs, réseaux sans �l).
Le deuxième volet ne parle que du codage et détaille les constructions des codesconsidérés, leurs dé�nitions et les algorithmes de décodage. La partie sur le déco-dage des codes cycliques avec les bases de Gröbner contient un certain nombre derésultats nouveaux sur la mise en équation que j'ai étudiée, résultats non publiés. Laprésentation est assez abrupte, et essentiellement technique, avec toutes les preuves.La partie sur le décodage à la Sudan détaille des généralisations multivariées de Su-dan, en mettant l'accent sur les di�cultés rencontrées, qui sont celles, générales, du

8 Chapitre 1. Introduction générale
passage des polynômes univariés aux polynômes multivariés.En�n, une partie � administrative �, récapitule les étudiants que j'ai co-encadrés,
mes activités d'enseignement, donne la liste classée de mes publications, et la listedes contrats de recherche dans lesquels j'ai été impliqué.

Première partie
Codage
9


Chapitre 2
Introduction au codage
algébrique
Dans ce chapitre, je présente à grands traits la problématique du décodage, etles notions de la théorie des codes correcteurs, de manière à introduire le sujet demes travaux. En e�et la problématique du codage et du décodage n'est pas connueen général par les non-spécialistes, aussi m'a-t'il semblé nécessaire de bien faire cesrappels. Il faut de plus introduire une certaine � botanique �, un peu déroutante,de codes correcteurs d'erreurs (codes cycliques, BCH, à résidus quadratiques etc),parmi les plus classiques.
Il faut comprendre qu'en grande partie, la théorie des codes correcteurs produitdes artefacts : on construit des objets très particuliers. Ces objets sont certains codeset leurs algorithmes de décodage, pour traiter un problème, celui de la transmission�able des données.
Mes travaux en codage sont situés dans le domaine des algorithmes de décodagedes codes ayant une dé�nition fortement algébrique. La dé�nition de ces codes re-pose sur les propriétés des polynômes univariés ou multivariés sur un corps �ni. Lesalgorithmes pour les décoder utilisent les outils du calcul formel. Notamment, j'uti-lise les bases de Gröbner pour décoder tous les codes cycliques. Les méthodes issuesdu calcul formel sont aussi employées pour améliorer l'algorithme de Guruswami-Sudan, pour décoder les codes de Reed-Solomon.
2.1 Problématique du codage et théorème de Shan-non
Le problème à l'origine de l'émergence de la théorie des codes correcteurs est celuide la transmission �able d'information sur des canaux de communication soumisà des perturbations. Dans un tel canal, le signal reçu après propagation dans lecanal bruité peut être di�érent que celui émis. Le problème dépend du canal decommunication, et de la manière dont celui-ci a�ecte les signaux émis. Un desmodèles les plus étudiés est celui du canal binaire symétrique : chaque bit 0 ou 1émis par la source peut être transformé en son complémentaire avec une probabilitép < 1/2.
L'idée naturelle pour améliorer la transmission est d'ajouter de la redondanceau message émis. À la réception, on espère ensuite d'être capable d'utiliser cetteredondance pour retrouver le message émis.
Le système le plus simple est de répéter chaque bit émis, par exemple 2t + 1fois. Ainsi, pour t = 1, on transmet 000 pour 0, et 111 pour 1. La règle de décodage
11

12 Chapitre 2. Introduction au codage algébrique
est celle du décodage majoritaire : on décode en 0 si le mot reçu a une majorité de0 et en 1 sinon. Le calcul des probabilités permet de montrer que le taux d'erreuraprès correction tend vers zéro quand t croît. Le défaut de cette méthode est quele nombre de bits transmis par bit utile est grand quand t croît : on consommebeaucoup trop de bande passante pour transmettre un bit.
De manière plus générale, on considère les symboles à émettre dans un corps �niFq. On va les regrouper par paquets de k symboles, avant de les encoder en motsde longueur n, avec n > k. En termes mathématiques, on a une fonction de codage,linéaire, injective :
φ : Fkq → Fn
q
m 7→ φ(m) = c
et on dit que m est le message, et c est le mot de code associé. Le code C est l'imagede φ : C = φ(Fk
q ). On dit que C est un code de longueur n et de dimension k. Letaux de transmission (ou rendement) du code est le rapport k/n, noté R. C'est unequantité qu'on cherche à optimiser.
On émet le mot de code c. Le canal transforme le mot émis c ∈ C ⊂ Fnq en un
mot bruité c′ ∈ Fnq , qui n'est plus nécessairement dans le codes C. Du coté de la
réception, on essaye de retrouver c à partir de c′. Un algorithme de décodage associéà C est un algorithme D :
D : Fnq → C ∪ {ε}c′ 7→ D(c′)
tel que D(c′) = c, si c′ n'est pas trop di�érent de c, ou D(c′) = ε, si l'algorithmeéchoue (s'il y a trop d'erreurs, par exemple).
Le théorème de codage de canal, démontré par Shannon en 1948, justi�e cetteapproche, qui consiste à ajouter de la redondance. Pour chaque canal, il existe untaux limite R0, tel que, pour tout taux de transmission R < R0, il existe un codeC de taux transmission R, et un algorithme de décodage associé, tel que le tauxd'erreur après décodage tend vers zéro, quand la longueur de C croît.
Ce théorème célèbre a une preuve probabiliste, et il est non constructif. Il nedit pas quels codes choisir, et ni comment construire les algorithmes de décodageassociés. On peut dire que l'objectif majeur du codage est la construction e�ectivede codes et de leurs algorithmes associés, permettant de réaliser les promesses duthéorème de Shannon.
2.2 La distance de HammingDans le cas des canaux dits q-aires symétriques, cette problématique se traduit
en termes de mathématiques discrètes, comme l'a montré Hamming en 1950.L'espace de Hamming est Fn
q muni de la distance de Hamming :d(x, y) = {i ∈ {1, . . . , n}| xi 6= yi} ,
et on dé�nit aussi le poids d'un mot x ∈ Fnq
w(x) = {i ∈ {1, . . . , n}| xi 6= 0} = d(x, 0).
Pour un code C ⊂ Fnq de dimension k, on dé�nit la distance minimale de C, d(C) :
d(C) = minx,y∈C,x 6=y
d(x, y).
On parle de code [n, k, d]q qui est la notation consacrée.

2.2. La distance de Hamming 13
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
������������������������������������
������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � �
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���� �������� ���
!�!"
#�#$
%�%&
'�'(
)�)* +�+,
-�-. /�/0
Fig. 2.1 � Pour un code de distance minimale d, les sphères centrées sur les motsdu code de rayon t = b(d− 1)/2c sont disjointes.
Pour les canaux en question, on connaît l'algorithme de décodage qui minimisela probabilité d'erreur. C'est celui qui retourne le mot de code le plus proche du motreçu, pour la distance de Hamming. C'est le décodage à maximum de vraisemblance.On montre que la probabilité d'erreur après décodage à maximum de vraisemblanceest d'autant plus faible que la distance minimale est grande. Mais on ne connaîtaucun code pour lequel il existe un algorithme de décodage à maximum de vraisem-blance vraiment meilleur que la recherche exhaustive sur tous les mots du code. Ledécodage à maximum de vraisemblance est donc un objectif trop ambitieux, et onse contente de corriger un nombre limité d'erreurs.
On note traditionnellement t = b(d− 1)/2c, qui est la capacité de correction deC. Si moins de t erreurs se sont produites, alors il y a unicité du mot de code leplus proche (voir la �gure 2.1). On dit que le code C est t-correcteur.
Dans ce modèle là, les problèmes principaux de la théorie deviennent :1. la construction : trouver des � bons � codes, ayant une bonne dimension k et
une bonne distance minimale d. Ces deux objectifs sont antagonistes.

14 Chapitre 2. Introduction au codage algébrique
2. le décodage : trouver les algorithmes de décodage associés.
2.3 ObstaclesEn ce qui concerne le problème de la construction de bons codes, un code linéaire
de longueur n et de dimension k pris au hasard aura une bonne distance minimale,avec une très forte probabilité. Mais nous avons un résultat de complexité dû àVardy [Var97], qui montre que le problème décisionnel associé au calcul de la dis-tance minimale est un problème NP-complet. La théorie de la complexité donneseulement une indication sur le pire cas, pour des algorithmes déterministes. Maisla pratique montre aussi que déterminer la distance minimale d'un code est di�cilepour les instances aléatoires. Par la pratique, je pense aux algorithmes déterministesaussi bien qu'aux algorithmes probabilistes.
En ce qui concerne le décodage, on a aussi que le problème décisionnel associé audécodage est lui aussi NP-complet [BMvT78]. Comme précédemment, la pratiquemontre que les instances aléatoires sont tout aussi di�ciles. Ce résultat a été renforcépar Bruck et Naor, qui montrent que le problème du décodage, même en autorisantun temps de précalcul aussi long que l'on désire, reste un problème di�cile [BN90].Cette dernière considération a beaucoup de sens et est bien réelle, car dans unschéma de communication, le code est �xé, et on décode répétitivement des motsbruités : on peut donc s'autoriser un précalcul énorme. On aurait donc pu espérergagner beaucoup en faisant un précalcul sur le code, mais ce n'est pas le cas.
Donc, pour résumer, en reprenant dans l'ordre les points 1 et 2 du paragrapheprécédent :
1. construction : il est di�cile de connaître la distance minimale d'un code donnéd, donc sa capacité de correction t (sauf cas exceptionnel) ;
2. décodage : il est di�cile de décoder un code donné (sauf cas exceptionnel).On cherche à construire des codes dont on puisse prouver quelque chose sur ladistance minimale, et pour lesquels on puisse construire des algorithmes de décodageassociés e�caces. Ce seront des codes très particuliers : on va du cas général descodes linéaires vers des codes particuliers, voire exceptionnels. Plusieurs voies sontpossibles pour obtenir ces constructions, la mienne est dans la tradition du codagealgébrique, qui utilise des outils issus de l'algèbre pour élaborer ces constructions. Jevais parler principalement des codes cycliques, des codes BCH, des codes à résidusquadratiques, des codes de Reed-Solomon, et des codes géométriques, voir �gure 2.2.
2.4 Les codes cycliquesLes codes cycliques sont une famille très restreinte de codes, au premier rang
desquels on trouve les codes BCH (Bose-Chauduri-Hocquenghem).Les codes BCH C'est une construction qui, étant donnée une distance minimaled0 et une longueur n, donne un code de longueur n et distance minimale d, d ≥ d0.De plus, pour t0 = b(d0 − 1)/2c, les codes obtenus ont un algorithme de décodageassocié corrigeant t0 erreurs, de faible complexité.
Toutefois, il se peut que la distance minimale d d'un code BCH soit plus grandeque d0, et que sa capacité de correction t = b(d − 1)/2c soit supérieure à t0. Leproblème de la détermination de la vraie distance minimale des codes BCH se pose.Ensuite se pose aussi le problème de la correction d'erreurs jusqu'à la vraie capacitéde correction.

2.4. Les codes cycliques 15
Codes géométriques
Codes BCH Codes de Reed−Solomon
Codes à résidus quadratiques
Codes cycliques Codes linéaires
Tjhai et al
Fig. 2.2 � Inclusion des principales familles de codes algébriques. Les surfaces nerendent pas compte des réelles proportions respectives de ces familles de codes. Parexemple, la famille des codes cycliques est très petite par rapport à celle des codeslinéaires.

16 Chapitre 2. Introduction au codage algébrique
Dans ma thèse [Aug93], j'ai montré comment il est possible de déterminer ladistance minimale d d'un code BCH en faisant des calculs de bases de Gröbner.Ensuite, j'ai réalisé que des approches à base de base de Gröbner peuvent êtreutilisées pour le problème du décodage jusqu'à la vraie capacité de correction t. Cettedernière veine a été développée avec Jean-Charles Faugère, en encadrant MagaliBardet pour une partie de sa thèse [Bar04].
Ces résultats permettent en réalité de calculer la distance minimale de tout codecyclique [Aug93, ACS90, Aug96a, Aug94], et de décoder tout code cyclique jusqu'àsa vraie capacité de correction [Aug98]. Dans la classe des codes cycliques, on peutdonc chercher de meilleurs codes que les codes BCH, car les codes BCH ont le défautde ne pas avoir une très bonne dimension, quand la distance minimale est grande.Les codes à résidus quadratiques Parmi les codes cycliques, les codes à résidusquadratiques ont une bonne distance minimale, pour un bon taux de transmission1/2. Mais ce sont des codes pour lesquels aucun algorithme e�cace de décodagen'existe. Voir �gure 2.2 pour les classes principales de codes. Le problème de déco-der les codes à résidus quadratiques est si di�cile à aborder que di�érents auteurstraitent au cas par cas le problème du décodage de ces codes. Pour chaque instancede petite longueur (n = 23, 31, 41, 47 etc) de ces codes, ces auteurs vont conce-voir un algorithme de décodage associé. Ces algorithmes sont en fait des formules,précalculées, que l'on évalue pour chaque mot à décoder. Le résultat de cette évalua-tion donne le mot de code le plus proche. Les résultats que j'ai obtenus avec MagaliBardet et Jean-Charles Faugère [Bar04, ABF02, ABF03, ABF05] montrent que cesformules peuvent être obtenues automatiquement, par la théorie de l'élimination etles bases de Gröbner. Si d'autres travaux ont déjà proposé d'utiliser les bases deGröbner pour décoder les codes cycliques, notre mise en équation sapparaît commeplus facile à résoudre en pratique.
Plutôt que de chercher des formules, on peut aussi résoudre le système d'équa-tions en ligne, pour chaque mot reçu : il apparaît en réalité que les formules de-viennent vite gigantesques (pour les codes à résidus quadratiques), alors que le calculde la base de Gröbner, une fois les paramètres instanciés, se déroule rapidement.
2.5 Le décodage en liste et l'algorithme de SudanOn peut relâcher l'hypothèse que l'algorithme de décodage retourne un seul mot
de code, et chercher à décoder τ > t erreurs. Dans le cas le pire, il y a plusieurssolutions au problème de corriger τ erreurs (voir �gure 2.3). On exige que l'algo-rithme de décodage retourne tous les mots de codes à distance τ du mot reçu. Onappelle cela le décodage en liste.
Le notion du décodage en liste a été introduite par Elias et Wozencraft à la �ndes années 1950 [Eli57, Woz58]. Ils l'ont introduite de manière théorique, en étudiantles béné�ces du décodage en liste pour la qualité de la transmission, sans donnerd'algorithmes le réalisant. Cette situation a perduré juqu'au milieu des années 1990.Les premiers algorithmes de décodage en liste sont dûs à Sudan et à Guruswami, àla �n des années 1990.
On peut se demander quel mot choisir lorsque l'algorithme de décodage en listeretourne plusieurs solutions. C'est en fait une situation du cas le pire. Lorsque lerayon de décodage τ n'est pas trop grand, alors il y a dans le cas moyen un seulmot à distance τ du mot reçu, voir �gure 2.3. On peut aussi lever l'ambiguïté ense reposant sur une éventuelle redondance naturelle des mots émis (par exemple, ilsappartiennent au français), ou ne retenir que le mot de code le plus vraisemblabledans la liste renvoyée par l'algorithme.
La problématique centrale du décodage en liste est de savoir dans quelle mesureτ peut augmenter. Quand τ devient trop grand, le nombre de mots de codes dans

2.5. Le décodage en liste et l'algorithme de Sudan 17
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
������������������������������������
������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � �
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���������������������������������������������������������������������������������
���� �������� ���
!�!"
#�#$
%�%& '�'( )�)*
+�+,-�-./�/0
Fig. 2.3 � Décodage en liste : le point A est à égale distance de deux mots de code.Le point B a un seul mot de code à distance τ > t. Le point A correspond au casle pire, le point B au cas moyen.

18 Chapitre 2. Introduction au codage algébrique
une boule de rayon τ devient exponentiel en la longueur n. Il ne peut donc pas yavoir d'algorithme e�cace pour corriger beaucoup d'erreurs, et la sortie d'un telalgorithme ne serait pas utilisable, à cause de la taille de la liste. Pour avoir desalgorithmes raisonnables de décodage en liste, on doit donc faire croître τ sous lacontrainte que la taille de liste retournée reste petite.
Comme précédemment pour le décodage classique, on ne connait pas d'algo-rithme de décodage en liste des codes quelconques. Les algorithmes de Sudan etGuruswami sont les premiers exemples d'algorithmes de décodage en liste, maisseulement pour la classe très restreinte des codes de Reed-Solomon, voir �gure 2.2.
2.6 Les codes de Reed-SolomonUne classe tout-à-fait exceptionnelle de codes est la famille des codes de Reed-
Solomon, qui est un cas particuler des codes BCH. Ce sont des codes dé�nis surun gros alphabet Fq, non binaire, et qui sont de longueur n ≤ q. Ils sont donc delongueur bornée à taille d'alphabet q �xée. Ce sont des codes optimaux, ils véri�entl'égalité d = n− k + 1, où k est la dimension et d la distance minimale (la borne deSingleton a�rme que la distance minimale de tout code [n, k, d]q véri�e d ≤ n−k+1).On peut donc corriger jusqu'à
t = b(n− k)/2c
erreurs. Avec un décodage unique, c'est le meilleur taux de correction qu'on puisseobtenir. Ces codes sont très employés en pratique, avec un spectre large d'applica-tions : stockage (CD, DVD), transmissions (ADSL, TNT), etc.
Le problème du décodage des codes de Reed-Solomon se reformule simplementde la manière suivante.
Étant donnés n points (xi, yi) ∈ F2q, et un degré k < n, trouver les
polynômes f(X) de degré au plus k, tel que f(xi) = yi pour le plusd'indices i possible.
Ce problème est quelquefois appelé le problème de la reconstruction de polynômes.En utilisant cette formulation du problème, Sudan et Guruswami [Sud97, GS99] ontconçu un algorithme permettant de décoder jusqu'à
τ = bn−√
knc
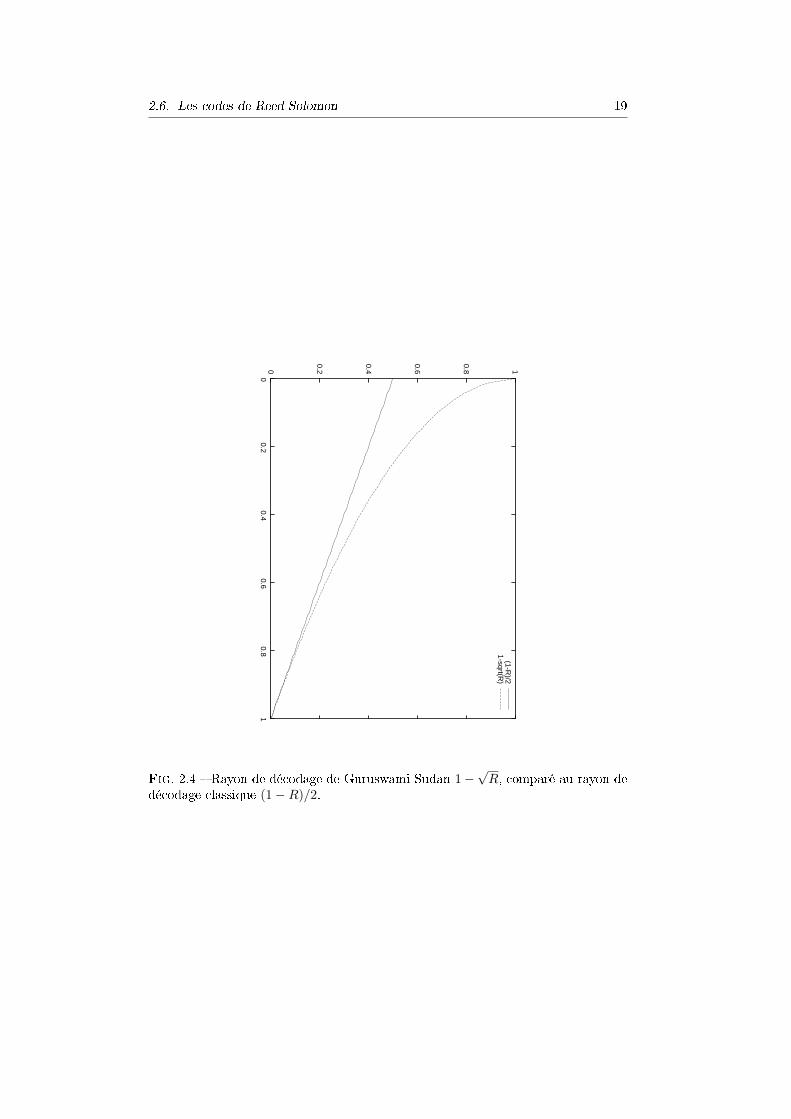
erreurs. Si l'on rapporte le rayon de décodage à la longueur en formant la quantitéτ/n, et qu'on l'étudie par rapport au taux de transmission R = k/n, on obient
τ
n≤ 1−
√R,
alors que le rayon classique estt
n≤ 1−R
2.
Ces deux rayons de décodage sont comparés dans la �gure 2.4.Cet algorithme est fondamental pour les raisons suivantes :� il décode beaucoup plus d'erreurs que le décodage unique ;� il permet de corriger des taux d'erreurs proche de 1, alors que les algorithmesclassiques ne permettent de décoder que jusqu'à un taux d'erreurs de 1/2 ;
� le rayon obtenu, 1−√
R, semble être optimal. On sait qu'il l'est pour les codesgénéraux, on ne sait pas s'il l'est pour les codes de Reed-Solomon.
2.6. Les codes de Reed-Solomon 19
0
0.2
0.4
0.6
0.8 1
0 0.2
0.4 0.6
0.8 1
(1-R)/2
1-sqrt(R)
Fig. 2.4 � Rayon de décodage de Guruswami-Sudan 1−√
R, comparé au rayon dedécodage classique (1−R)/2.

20 Chapitre 2. Introduction au codage algébrique
Il est aussi fondamental car il s'est révélé contenir des principes généraux, permet-tant de décoder d'autres sortes de codes, et sur des canaux de transmissions plusgénéraux que le canal q-aire symétrique. Madhu Sudan a obtenu le prix Nevan-linna 2002, pour l'ensemble de ses travaux, dont le décodage en liste des codes deReed-Solomon.
Lancelot Pecquet, sous ma direction, a contribué à la généralisation de cet algo-rithme à la classe des codes géométriques [Pec01]. Cette classe de codes est impor-tante pour la principale raison suivante. Alors que les codes de Reed-Solomon sontde longueur bornée, à alphabet Fq �xé, la longueur des codes géométriques peutcroître, tout en restant de � bons � codes.
Du point de vue de son implantation, l'algorithme de Guruswami-Sudan est trèsproche du calcul formel. Il utilise comme ingrédients de base
1. une interpolation bivariée : il faut trouver un polynôme Q(X, Y ) passant parles points (xi, yi), avec une certaine multiplicité ;
2. une recherche de racine : il faut trouver tous les polynômes f(X) tel queQ(X, f(X)) = 0.
Guruswami et Sudan ont simplement considéré que ces étapes pouvaient se faire entemps polynomial, ce qui n'est pas su�sant, et cet algorithme est souvent considérécomme trop � lourd �pour être utilisé.
J'ai contribué avec Lancelot Pecquet à améliorer la deuxième étape de cet al-gorithme, dans le cas de codes de Reed-Solomon, et dans le cas des codes géomé-triques [AP98b, AP00a]. On peut considérer maintenant que cette dernière étapepeut-être e�cacement réalisée avec une bonne complexité, et le point d'obstructionest le premier point, l'interpolation.
J'ai aussi étudié la généralisation de l'algorithme de Guruswami-Sudan auxcodes de Reed-Muller, qui sont une généralisation multivariée des codes de Reed-Solomon [AEKM+06]. J'obtiens un meilleur rayon de décodage que Pellikaan et Wu,qui ont aussi abordé ce problème [PW04a, PW04b].
2.7 ConclusionOn peut décoder tout code cyclique jusqu'à sa vraie capacité de correction, en
utilisant une mise en équation du problème du décodage. Il faut écrire la mise enéquation pour chaque code considéré, et cela s'oppose aux algorithmes génériques,par exemple pour le décodage des codes BCH. Avec Magali Bardet et Jean-CharlesFaugère, nous avons étudié une nouvelle mise en équation, plus e�cace que cellesprécédemment considérées. Nous pouvons soit obtenir des formules en fonction desparamètres avec un précalcul de base de Gröbner, soit e�ectuer le calcul de la basede Gröbner en ligne, pour chaque mot reçu : cette dernière approche est la pluse�cace. Nous avons étudié aussi le problème de décoder au delà de la capacitéclassique de correction. Mais nous n'avons gagné que quelques unités par rapportau rayon classique de décodage.
Le décodage en liste des codes de Reed-Solomon permet décoder bien au delà durayon de décodage classique. C'est la percée fondamentale de Sudan et Guruswami.Avec Lancelot Pecquet, j'ai étudié le volet implémentation de cet algorithme, etla généralisation de cet algorithme aux codes géométriques, et aux codes de Reed-Muller.

Chapitre 3
Décodage des codes cycliques
généraux
Dans ce chapitre, je rappelle le principe du décodage de tout code cyclique avecdes bases de Gröbner, jusqu'à la vraie capacité de correction. Cette idée a déjà étéconsidérée par di�érents auteurs. Ce décodage repose sur la notion de syndrome,et de décodage par syndrome, qui est assez technique à introduire pour les codescycliques. Il y a plusieurs mises en équations du problème, et celle que j'ai étudiéerepose sur les identités de Newton.
Il y a de plus deux manières de décoder avec les bases de Gröbner. Soit faire unprécalcul de base de Gröbner, pour obtenir des formules pour le décodage, soit faireun calcul de base de Gröbner pour chaque mot reçu. Nous verrons que la deuxièmesolution est la plus e�cace, et permet de décoder les codes BCH en grande longueur,et les codes à résidus quadratiques en longueur moyenne.
3.1 Dé�nition des codes cycliques avec la transfor-mée de Fourier
Les codes cycliques binaires sont des codes de longueur n, dé�nis sur F2, avecn impair. À tout mot c = (c0, . . . , cn−1) de longueur n, on lui associe le polynômec(X) = c0 + c1 + · · ·+ cn−1X
n−1.Soit α une racine primitive n-ième de l'unité, dans une extension de degré
m de F2 : α ∈ F2m . La transformée de Fourier discrète de c est le vecteur S =(S0, . . . , Sn−1), avec
Si = c(αi), i ∈ {0, . . . , n− 1}.
On peut passer de mot S au mot c, par une opération similaire.Pour dé�nir un code cyclique C, il faut se donner un ensemble de dé�nition
Q ⊂ {0, . . . , n − 1}. Le code cyclique d'ensemble de dé�nition Q = {i1, . . . , il} estl'ensemble des mots c dont leur transformée de Fourier S = (S0, . . . , Sn−1) véri�e :Si1 = · · · = Sil
= 0.
Les codes BCH au sens strict de distance construite δ sont des codes cycliquestels que l'ensemble de dé�nition contient l'intervalle {1, . . . , δ − 1}. Leur distanceminimale est alors supérieure ou égale à δ. On a de plus un algorithme e�cacequi décode jusqu'à b(δ − 1)/2c erreurs. En réalité leur distance minimale peut êtresupérieure à δ, et on ne sait pas comment étendre les algorithmes existant pourdécoder plus d'erreurs.
21

22 Chapitre 3. Décodage des codes cycliques généraux
Une autre classe de code cyclique est la classe de codes à résidus quadratiques,dont l'ensemble de dé�nition Q est l'ensemble des résidus quadratiques modulo n.On peut montrer que la distance minimale de ces codes est supérieure à b√nc.Les tables montrent que pour les petites longueurs, la distance minimale d de cescodes est bien meilleure que la borne b√nc. Ce sont des codes pour lesquels onne connaît pas d'algorithme e�cace pour les décoder jusqu'à b(√n− 1)/2c, encoremoins jusqu'à b(d − 1)/2c. Berlekamp les a quali�és de � bons codes di�ciles àdécoder � [Ber68].
3.2 Erreur et syndromesSoit C un code cyclique de longueur n et d'ensemble de dé�nition Q ⊂ {1, . . . , n−
1}. Décoder un mot y ∈ Fn2 donné revient à trouver le mot c ∈ C le plus proche
de y. On écrit y = c + e, où e et c sont inconnus, et où e est l'erreur. Si on trouvel'erreur e, alors on retrouve le mot de code, en faisant c = y − e.
Soit S la transformée de Fourier, connue, de y, alorsSi = y(αi) = c(αi) + e(αi), i ∈ {0, . . . , n− 1}.
Or, pour i ∈ Q, on a c(αi) = 0, et doncSi = e(αi), i ∈ Q. (3.1)
Donc si Q = {i1, . . . , il}, les coe�cients Si1 , . . . , Silde la transformée de Fourier de e
sont connus. On les appelle les syndromes de e. Si on connaissait tous les coe�cientsde la transformée de Fourier de e, alors e serait déterminé, et on pourrait retrouverle mot de code c. Le problème est qu'on ne connaît que les syndromes.
Rappelons que si d est la distance minimale du code C, alors t = b(d − 1)/2cest sa capacité de correction. On cherche donc l'erreur e de poids au plus t dont lescoe�cients Si1 , . . . , Sil
de sa transformée de Fourier sont connus.
3.3 Polynôme localisateur et identités de NewtonSi l'erreur e est de poids w, soient j1, . . . , jw les indices des composantes non
nulles de e, qui sont forcément égales à 1, car nous sommes dans le cas binaire (motsdé�nis dur F2). On encode ces positions j1, . . . , jw dans le polynôme localisateur σ(Z)comme suit :
σ(Z) =w∏
i=1
(1− αjiZ) =w∑
i=0
σiZi, (3.2)
où les σi sont les fonctions symétriques élémentaires de αj1 , . . . , αjw , que l'on noteZ1, . . . , Zw : ce sont les localisateurs de l'erreur. Le problème de décodage est alorséquivalent à celui de trouver σ(Z). À partir de σ(Z), on trouve ses racines, puis lesindices j1, . . . jw, donc e. On considère le problème résolu quand on a trouvé σ(Z).
Soient tous les coe�cients S0, . . . , Sn−1 de la transformée de Fourier de e, alorson a les identités de Newton entre les coe�cients Si et les coe�cients σi :
Si +
i−1∑j=1
σjSi−j + iσi = 0, i ≤ w,
Si +w∑
j=1
σjSi−j = 0, i > w.
(3.3)

3.4. Un exemple 23On note IN l'idéal engendré par ces identités. C'est à dire que je considère lesmembres gauches des égalités précédentes comme des polynômes dans l'anneau
F2[σw, . . . , σ1, Sn−1, . . . , S0],
et IN est l'idéal engendré par tous ces polynômes. De manière générale, j'ommettraile membre droit � =0 � des équations, pour que ne considérer que les parties gauchesqui sont des polynômes.
Nous considérons ce système comme un système linéaire en les σi, dont lescoe�cients sont les Si. Plusieurs problèmes se posent, quand on utilise ces équationspour décoder un code cyclique d'ensemble de dé�nition Q :
1. contrairement au cas de la caractéristique nulle, le système n'est pas triangu-laire en les σi : quand i est pair, le terme iσi disparaît ;
2. on ne connait pas à priori le poids w = 1 de l'erreur e : on ne sait donc pascomment écrire les équations ;
3. une partie seulement des Si sont connus : les Si pour i ∈ Q ; les autres Si,i 6∈ Q sont inconnus.
Il faut donc éliminer du système les Si, i 6∈ Q, et résoudre en les σi.
3.4 Un exempleJe redonne le décodage fait dans [RYT90], qui peut être exposé rapidement.
Il s'agit du code à résidus quadratiques de longueur 31, binaire. Son ensemble dedé�nition est l'ensemble des carrés non nuls modulo 31 :
Q = {1, 2, 4, 5, 7, 8, 9, 10, 14, 16, 18, 19, 20, 25, 28}
C'est un code [n = 31, k = 16, d = 7]2 qui est donc théoriquement capable decorriger t = b(d − 1)/2c = 3 erreurs. Soit y = c + e le mot reçu, c le mot de code,que l'on cherche, et e l'erreur. On connaît les syndromes de l'erreur, Si, i ∈ Q, eton cherche les fonctions symétriques σ1, σ2, σ3 en fonction des syndromes (Si)i∈Q.Les identités de Newton contiennent, entre autres, les équations :
S1 + σ1 = 0S3 + S2σ1 + S1σ2 + 3σ3 = 0
S5 + S4σ1 + S3σ2 + S2σ3 = 0S6 + S5σ1 + S4σ2 + S3σ3 = 0S7 + S6σ1 + S5σ2 + S4σ3 = 0S9 + S8σ1 + S7σ2 + S6σ3 = 0S10 + S9σ1 + S8σ2 + S7σ3 = 0
Dans ces équations les syndromes S3 et S6 ne sont pas connus, car 3 et 6 ne sont pasdans l'ensemble de dé�nition de C. Il faut donc déterminer σ1, σ2, σ3 en fonction deS1, S2, S4, S5, S7, S8, S9, S10, en éliminant S3 et S6.Les auteurs [RYT90] établissent, à la main, les points suivants :
1. si S51 = S5 et S7
1 = S7, alors σ2 = σ3 = 0 et l'erreur est de poids 1, et sonpolynôme localisateur n'a qu'un terme σ1 = S1.
2. si S51 6= S5 et si
S151 + S8
1S7 + S51S2
5 + S31S5S7 + S1S
27 + S3
5 = 0, (3.4)alors σ3 = 0, l'erreur est de poids 2 et
σ2 =S7 + S5S
21
S51 + S5
. (3.5)

24 Chapitre 3. Décodage des codes cycliques généraux
3. sinon l'erreur est de poids 3, et
σ2 =S7
((S7 + S5S
21)S7 + (S5 + S5
1)S9
)S2
1(S7 + S71)(S2
5 + S1S9 + S101 )
+S2
5 + S1S9
S1(S7 + S71)
, (3.6)et
σ3 =S2
5 + S1S9 + σ2S81
S7. (3.7)
Ces formules sont assez fastidieuses à obtenir, sujettes à erreur. Elles sont aussidépendantes du code : ainsi les auteurs Chen, Reed, Truong et d'autres [RYT90,RYTH90, RTCY92, CRT94, LWCL95, HRTC01, CTR+03, TCCL05], construisent àchaque fois des nouvelles formules pour les codes à résidus quadratiques de longueurs31, 23, 41, 73, 47, 71, 79, 97, et en�n 103 et 113.
Il semble naturel d'utiliser les outils du calcul formel pour automatiser l'obten-tion des formules. Les questions sont alors : peut-on obtenir des formules de degré1 en les σi en éliminant les Si qui ne sont pas des syndromes ? En�n, le problèmede l'e�cacité se pose : il faudrait pouvoir déterminer la taille des formules.
3.5 Historique des travaux utilisant les bases deGröbner
Il y a eu un certain nombre de travaux où les bases de Gröbner sont utiliséespour décoder les codes cycliques. On peut les classer suivant deux axes : choix dela mise en équation, décodage en un coup ou décodage en ligne.Une autre mise en équation Il y a plusieurs manières de mettre en équationle problème du décodage des codes cycliques. Chacune de ces mises en équationsrelie algébriquement les σi aux syndromes Si. La mise en équation historique, avecl'utilisation des bases de Gröbner remonte à Cooper [CI90, CI91b, CI91a], pourdécoder les codes BCH jusqu'à leur vraie capacité de correction. La mise en équationde Cooper utilise directement la dé�nition de la transformée de Fourier, plutôt queles identités de Newton. Elle a l'inconvénient d'avoir un degré élevé, et un grandnombre de solutions parasites. Cette mise en équation a été étudiée par Loustaunauet von York [LY97], et Caboara et Mora [CM02], pour les codes cycliques généraux,et ils ont donné des preuves correctes des a�rmations de Cooper.Décodage en un coup et décodage en ligne L principe que j'ai présenté surl'exemple précédent est quali�é de décodage en un coup (one-step decoding) : onfait un précalcul pour déterminer symboliquement les σi en fonction des syndromes.On utilise ces formules en ligne, en substituant les valeurs des syndromes des motsreçus. Ce décodage a été considéré pour les codes cycliques quelconques par Chen,Helleseth, Reed et Truong [CRHT94b].
Chen, Helleseth, Reed, Truong [CRHT94d, CRHT94a] ont aussi utilisé la mise enéquation de Cooper, avec les syndromes instanciés. Pour chaque mot reçu, on écritle système avec les syndromes instanciés S∗i ∈ F2m , plutôt qu'avec les indéterminéesSi. On fait le calcul de base de Gröbner en ligne, pour chaque mot reçu. Ils montrentque l'on peut ainsi obtenir directement les coe�cients du polynôme localisateur.
3.6 Contributions théoriques
Équations de corps Pour un code de longueur n, les localisateurs Zi, qui sontdes racines n-ièmes de l'unité, véri�ent les équations � de corps � Xn+1i −Xi = 0,
donc X2m
i −Xi = 0, où F2m est le corps de décomposition de Xn− 1. Les fonctions

3.6. Contributions théoriques 25symétriques élémentaires et les coe�cients de la transformée de Fourier, qui sont desfonctions algébriques des localisateurs, véri�ent donc aussi σ2m
i −σi = 0, S2m
i −Si =0.
Tous les auteurs précédents ont toujours considéré des idéaux contenant ceséquations de corps (c'est-à-dire leur termes gauche), pour chacune des variables.Premièrement cela permet de ne considérer que les solutions dans F2m plutôt quedans la clôture algébrique de F2. Deuxièmement, avec ces équations de corps, lesidéaux sont radicaux et de dimension zéro, et il est plus facile de démontrer qu'onva bien obtenir des formules de degré un pour les σi.L'inconvénient est que les polynômes σ2m
i − σi, S2m
i − Si peuvent être de degréélevé, même en longueur n petite. Par exemple, pour le code à résidus quadratiquesde longueur 41, le corps de décomposition sur F2 de X41 − 1 est F220 , ce qui obligeà rajouter les polynômes σ220
i − σi à l'idéal. De tels degrés ne sont pas utilisablesen pratique. Il est donc tentant d'enlever les équations de corps. C'est ce que nousavons étudié, dans le cas du décodage en ligne, et dans le cas du décodage en uncoup. Les di�cultés rencontrées sont que les idéaux ne sont plus de dimension zéro,et que nous n'avons pas pu prouver la radicalité des ces idéaux.
Nous avons obtenu les résultats suivants.1. Nous avons prouvé que cette approche est correcte dans le cas du décodage
en ligne. Soit S∗i1 , . . . , S∗illes syndromes du mot reçu y. Alors l'idéal IN des
identités de Newton, avec instanciation des syndromes Si 7→ S∗i , i ∈ Q,engendrent un idéal dans F2m [(Si)i 6∈Q, σ1, . . . , σw]. Nous avons montré quequand on élimine les � syndromes inconnus � Si, i 6∈ Q, l'idéal d'élimina-tion IN ∩ F2m [σ1, . . . , σw] contient les polynômes σi − σ∗i , où les σ∗i sont lescoe�cients du polynôme localisateur de l'erreur.
2. Dans le cas du décodage en un coup, lorsque les syndromes sont � formels �,l'idéal IN des relations de Newton est dans l'anneau de polynômes
F2[(Si)i∈Q, (Si)i 6∈Q, σ1, . . . , σw].
Quand on élimine les (Si)i 6∈Q, l'idéal IN ∩F2[(Si)i∈Q, σ1, . . . , σw] contient desrelations de degré 1 en les σi, dont les coe�cients sont des polynômes en lesSi, i ∈ Q. Toutefois, on ne sait pas dire si les initiaux s'annulent quand onles spécialise en les syndromes, ce qui pose des problèmes de division pourtrouver les σi, quand on spécialise.
3. Dans le contexte du décodage en un coup, j'ai construit une mise en équation,telle que le calcul de la base de Gröbner donne des formules du type σj −Fj((Si)i∈Q) = 0, voir appendice 8. Il n'y a ainsi plus de problèmes de divisionpar zéro à la spécialisation.
Mise en équation avec les formules deWaring L'inconvénient de l'idéal IN desidentités de Newton, pour le décodage, est qu'il contient des indéterminées Si, i 6∈ Q,qu'il faut éliminer. On peut écrire une autre mise en équation, où n'interviennentque les syndromes Si, i ∈ Q.
En utilisant la partie triangulaire des identités de Newton, puis les identitéssuivantes, on voit qu'il existe des relations directes générales qui lient les Si aux σi,de la forme :
Si = Wi(σ1, . . . , σw), i ∈ {0, . . . , n− 1}.
Ce sont les formules de Waring dont on connait une expression explicite [LN96].Dans le contexte du décodage, on ne connait que les Si, i ∈ Q, et on considèrel'idéal
IW : {Si −Wi(σ1, . . . , σw), i ∈ Q} .

26 Chapitre 3. Décodage des codes cycliques généraux
En calculant une base de Gröbner de IW pour l'ordre lexicographique σw > . . . , σ1 >(Si)i∈Q, on obtient des formules de degré 1 pour les σi, en fonction des Si, i ∈ Q. Onpeut aussi calculer la base de Gröbner avec les syndromes instanciés, au décodageen ligne, pour chaque mot reçu. Avec Magali Bardet et Jean-Charles Faugère, nousavons considéré cette mise en équation [Bar04].
Par rapport à l'idéal des identités de Newton, cette mise en équation présentel'intérêt que les Si, i 6∈ Q sont déjà éliminés. En revanche, les polynômes Wi sontde degré d'autant plus élevé en σ1, . . . , σw que l'indice i augmente. Dans le cas descodes à résidus quadratiques, les indices i ∈ Q, sont éparpillés dans tout {1, . . . , n}.Il y aura donc de grands indices i ∈ Q, donc des équations de haut degré, ce quipose un problème d'e�cacité.
3.7 Contributions pratiques
Décodage en un coup Pour le décodage en un coup, les articles d'origine netraitent que des exemples de petites longueur, par exemple n = 16 dans Caboara etMora, voire 23 dans Loustaunau et von York [CM02, LY97]. La principale raison estl'emploi des équations de corps, et peut-être aussi la mauvaise e�cacité des logicielsutilisés.
En utilisant son logiciel Fgb et les idéaux sans les équations de corps, Jean-Charles Faugère et moi avons pu pousser un peu les calculs. Nous avons calculé parexemple, la base de Gröbner pour le code à résidus quadratiques de longueur 41, voir�gure 3.1. On voit que les calculs deviennent très vite impraticables. Il sembleraitque sommes nous confrontés au théorème de Bruck et Naor [BN90], qui indique quele décodage d'un code linéaire général est di�cile, même avec précalcul.Décodage en ligne Le principe du décodage en ligne est d'instancier les syndromesdu mot reçu, en faisant Si 7→ S∗i , dans le système des identités de Newton, puis decalculer la base de Gröbner de cet idéal. En pratique, c'est beaucoup plus e�caceque de calculer la base de Gröbner symbolique, puis de substituer ensuite : c'estla comparaison entre une formule explicite et un algorithme. L'algorithme est plusrapide que l'évaluation de la formule. Même plus, la formule est impossible à obtenir.
En ce qui concerne les codes BCH, Magali Bardet a ainsi pu décoder 15 erreurspar rapport au code BCH de paramètres [n = 127, k = 43, d = 31], obtenu avec unedistance construite de δ = 29. Avec les algorithmes classiques, on décode seulementbδ−1c/2 = 14 erreurs. De même, en longueur 511, elle a pu décoder plusieurs codesBCH jusqu'à leur vraie distance minimale.
Magali Bardet a aussi pu décoder des codes à résidus quadratiques de moyennelongueur, voir �gure 3.2.Décodage au delà de la capacité de correction de correction du code Nousavons prouvé que l'idéal IN des identités de Newton, relativement au décodageen ligne, est une bonne mise en équation. La propriété fondamentale pour établirl'existence de polynômes de degré 1 en les σi dans IN est que la variété associée àl'idéal IN est de cardinal 1. En termes de codage, cela signi�e qu'il y a unicité dumot de code à distance w. Cette unicité se produit pour un nombre d'erreurs w ≤ toù t est la capacité de correction du code.
L'unicité du mot de code le plus proche peut aussi se produire pour un nombred'erreurs τ > t, pour certains mots reçus y. Dans ce cas, la variété associée à IN ,spécialisée sur les syndromes de y est de dimension 0. On aura bien des formulesde degré 1 en les σi. Magali Bardet a ainsi décodé des codes BCH de longueur 511,pour un nombre d'erreurs supérieur de quelques unités à la capacité de correctionde ces codes. Pour tous les essais e�ectués (10 000 décodages à la distance 52 pourle code BCH 47-correcteur), il y avait une unique solution.

3.7. Contributions pratiques 27
σ4S23 + . . . ,σ4S9 + . . . ,σ4S5 + . . . ,σ4S1 + . . . ,σ3 + σ2S1 + . . . ,σ2(S23S
29S1 + · · ·+ S2
5S321 + S5S
371 + S1) + . . . ,
σ2(S23S5S131 + S23S
591 + · · ·+ S3
5S261 + S2
5S311 + S5S
361 + S41
1 ) + . . . ,σ2(S23S5 + · · ·+ S9S
601 + S9S
191 ) + . . . ,
σ2(S39 + S9S
25S8
1 + S9S591 + S9S
181 + S2
5S581 + S27
1 ) + . . . ,σ2(S3
9S381 + · · ·+ S9S
151 + S3
5S501 ) + . . . ,
σ2(S23S9S321 + · · ·+ S2
5S541 + S5S
591 ) + . . . ,
σ2(S39S33
1 + · · ·+ S9S511 + S3
5S451 + S5S
551 + S60
1 ) + . . . ,σ2(S23S5S
311 + S23S
361 + S2
9S25S31
1 + S29 + S9S
25S40
1 + S9S501 + S9S
91 + S5S
541 ) + . . . ,
σ2(S49S20
1 + · · ·+ S25S5
1 + S5S511 + S5S
101 ) + . . . ,
σ2(S23S321 + S2
9S371 + · · ·+ S9S
51 + S2
5S451 + S5S
501 + S55
1 ) + . . . ,σ2(S4
9S5S101 + · · ·+ S9S
25S32
1 + S9S5S371 + S2
5 + S511 + S10
1 ) + . . . ,σ2(S23S
39 + S23S9S
181 + · · ·+ S9S
25S31
1 + S9S5S361 + S9S
411 + S9 + S2
5S401 + S5S
451 ) + . . . ,
σ2(S23S9S5S131 + · · ·+ S9S
411 + S9 + S3
5S351 + S5S
451 + S9
1) + . . . ,σ2(S23S
29S5 + · · ·+ S3
5S311 + S2
5S361 + S5S
411 + S5 + S46
1 ) + . . . ,σ2(S23S
29S5
1 + · · ·+ S9S371 + S5 + S46
1 + S51) + . . . ,
σ2(S23S9S5S81 + · · ·+ S3
5S301 + S45
1 + S41) + . . . ,
σ2(S23S5S91 + · · ·+ S9S5S
231 + S9S
281 + S2
5S271 + S37
1 ) + . . . ,σ2(S23S9S1 + S23S
25 + S3
9S61 + S9S
25S14
1 + S9S241 + S33
1 ) + . . . ,σ2(S23S
101 + · · ·+ S5S
281 ) + . . . ,
σ2(S29S2
1 + S9S111 + S4
5 + S25S10
1 + S5S151 + S20
1 ) + . . . ,+350 polynômes en S23, S9, S5, S1.
Fig. 3.1 � Base d'élimination de 〈IN 〉∩F2[σ4, . . . , σ1, (Si)i∈Q] pour le code à résidusquadratiques [41,22,9], calculée et formatée par Magali Bardet.
longueur n nombre d'erreurs degré de l'extension nombre d'opérations71 5 F235 211,1
73 6 F29 215,3
89 8 F211 226,2
113 7 F228 220
Fig. 3.2 � Nombre d'opérations arithmétiques pour décoder des codes à résidusquadratiques binaires.

28 Chapitre 3. Décodage des codes cycliques généraux
Codes � faciles � et codes � di�ciles � Alors que la méthode (identités deNewton puis élimination des Si, i 6∈ Q), est la même dans les deux cas, la di�érenceentre les ensembles de dé�nition des codes BCH et des codes à résidus quadratiquessu�t à faire changer grandement les temps de calcul de base de Gröbner.
Les codes BCH, qui ont une très grande régularité de leur ensemble de dé�nition,se décodent avec beaucoup moins d'opérations que les codes à résidus quadratiques,dont l'ensemble des zéros est dispersé. Ainsi, le décodage des BCH en longueur 511ne pose pas de problème, alors que les calculs deviennent di�ciles pour les codes àrésidus quadratiques en longueur 113.
Jean-Charles Faugère a aussi considéré l'idée de la trace du précalcul : il exécuteun décodage pour une erreur donnée, et il garde une trace de ce calcul, pour l'al-gorithme F4 [Fau99]. Cette trace évite de refaire toutes les opérations de mise enplace de la matrice principale intervenant dans F4, on réutilise celle obtenue par leprécalcul, en changeant ses coe�cients. Cette méthode permet de gagner un ordrede grandeur (1000) par rapport au calcul direct de la base de Gröbner.
3.8 ConclusionLes travaux précédents aux nôtres ont mis l'accent sur le décodage en un coup,
en espérant éviter un calcul de base de Gröbner pour chaque mot reçu. Nous avonsvu au contraire que le décodage en ligne est plus e�cace, grâce à de nouvelles misesen équations, sans les équations de corps. Toutefois, nous ne sommes pas encoreen mesure de donner la complexité exacte de ces calculs, et il semble que le coûtdépende grandement du code utilisé.
La question que j'avais posée à Magali Bardet pour sa thèse était de savoir siles codes cycliques pouvait se décoder en temps polynomial, à l'opposé des codeslinéaires généraux. Une voie pour prouver ce résultat était d'utiliser le décodage enun coup, et d'estimer la taille des formules. Cette question était trop ambitieuse :il semble di�cile, de prédire la taille d'une base de Gröbner de manière réaliste. Lapratique indique aussi que les formules seront grandes (explosion du décodage enun coup pour les codes à résidus quadratiques), et le théorème de Bruck et Naor,sur la di�culté du décodage des codes linéaires généraux avec précalcul, s'appliquepeut-être aussi pour la classe des codes cycliques.

Chapitre 4
Décodage des codes
d'évaluation avec l'algorithme
de Sudan
Une famille de codes présentant des exemples importants pour la théorie et lapratique est la famille des codes obtenus par évaluation. Soit X un ensemble. Cetteconstruction générale consiste à évaluer un certain ensemble L de fonctions
f : X → Fq,
sur des points distincts P1, . . . , Pn ∈ X. On obtient une fonction d'évaluation :ev : L → Fn
q
f 7→ (f(P1), . . . , f(Pn)),
et le code d'évaluation obtenu est C = ev(L), l'image par ev de L.Au premier plan des codes d'évaluation, on trouve les codes de Reed-Solomon,
qui sont parmi les codes les plus utilisés, et qui de plus sont optimaux par rapportà la borne de Singleton sur la distance minimale d'un code. Ils sont obtenus enprenant comme espace L une famille de polynômes univariés sur Fq. Les codes deReed-Solomon se généralisent avec les codes géométriques, qui utilisent la théoriedes courbes algébriques sur un corps �ni.
La deuxième famille est celle de codes de Reed-Muller, où les points P1, . . . , Pnsont dans l'espace a�ne Fmq , et l'espace L des polynômes à évaluer est l'espace
des polynômes à m variables sur Fq de degré inférieur à r. On s'intéresse toutparticulièrement au cas r = 1 : l'espace L est l'ensemble des applications a�nes surFq, et on obtient le code de Reed-Muller d'ordre 1.
J'ai encadré deux thèses sur le décodage de ces deux familles :� Lancelot Pecquet [Pec01] a travaillé sur les codes de Reed-Solomon et surles codes géométriques, qui se décodent avec l'algorithme de Guruswami-Sudan [GS99].
� Cédric Tavernier [Tav04] a étudié le décodage des codes de Reed-Muller d'or-dre 1, en se basant sur l'algorithme de Goldreich, Rubinfeld et Sudan [GRS95].
Les deux algorithmes sont des algorithmes de décodage en liste : on décode plusd'erreurs que la capacité de correction classique, dans les deux cas (Reed-Solomon etReed-Muller), mais on perd l'unicité de la solution. En revanche, on gagne beaucoupen capacité de correction, comme nous le verrons.
29

30 Chapitre 4. Décodage des codes d'évaluation avec l'algorithme de Sudan
4.1 Trois exemples de codes d'évaluation
Les codes de Reed-Solomon Ces codes se contruisent de la manière suivante.On se donne x1, . . . , xn ∈ Fq, tous distincts (et donc n ≤ q). Soit ev la fonctiond'évaluation
ev : Fq[X] → Fnq
f 7→ (f(x1), . . . , f(xn)).
Soit Lk l'espace des polynômes de degré inférieur à k, k < n :Lk = {f(X) ∈ Fq[X]; deg f(X) < k}
Le code de Reed-Solomon de dimension k est :RSk = {ev f(X); f(X) ∈ Lk} .
C'est un code [n, k, n− k + 1]q. Bien qu'optimaux en termes de distance minimale,le défaut de ces codes est que leur longueur est bornée par q. En pratique et pour�xer les idées, un des codes de Reed-Solomon le plus utilisé est le code [n = 255, k =239, d = 17]256.Les codes géométriques Ils servent à remédier au principal problème des codesde Reed-Solomon, qui est d'avoir une longueur bornée par la taille de l'alphabet Fq.La construction historique est due à Goppa [Gop77, Gop81].
Soit X une courbe lisse projective dé�nie sur Fq, soient P1, . . . , Pn, n pointsFq-rationnels de X , et un espace L(D) associé à un diviseur D sur la courbe. Onsuppose qu'aucune fonction de L(D) n'a de pôle en un des Pi. Alors on dé�nit lafonction d'évaluation :
ev : L(D) → Fnq
f 7→ (f(P1), . . . , f(Pn)).
Pour raccourcir la notation, on note P le diviseur P1+· · ·+Pn. Le code géométriqueΓ(P,D) est
Γ(P,D) = ev L(D).
Si g est le genre de la courbe, et deg D le degré du diviseur D, la dimension k deΓ(P,D) est supérieure ou égale à deg D− g + 1 (Théorème de Riemman-Roch), etsa distance minimale supérieure ou égale à n− deg D. On obtient des codes longsen prenant des courbes ayant un grand nombre de points sur Fq.En pratique, il est di�cile de construire des bases des espaces L(D) pour des di-viseurs D quelconques sur des courbes quelconques. La classe de codes géométriquesla plus en vue pour les applications est celle des codes hermitiens. Ils existent quandq = r2, et ils sont dé�nis en utilisant la courbe hermitienne, dont l'équation planea�ne est :
yr + y = xr+1.
Pour cette courbe, on peut expliciter complétement la construction de Goppa, et lescodes hermitiens sont très bien connus [Sti93]. La courbe hermitienne a r3 pointsa�nes Fq-rationnels, et une place à l'in�ni P∞. Son genre est r(r−1)/2. En prenantD = kP∞, on sait décrire explicitement une base de chaque espace L(kP∞), pourk variable [Sti93]. Muni de cette base, on sait construire la fonction d'évaluationcorrespondante. Les codes hermitiens sont si bien connus qu'ils sont exposés demanière élémentaire (sans la théorie des courbes algébriques) dans [JH04].
Pour les comparer aux codes de Reed-Solomon, considérons le cas où l'alphabetFq est de taille 16 = 42. Le nombre de points a�nes est 43 = 64, le genre est

4.2. Problème du décodage des codes d'évaluation et approximation par des polynômes31(4 · 3)/2 = 6. Pour les valeurs intéressantes de k, en considérant l'espace L(kP∞),on obtient une famille de codes du type
[n = 64,≥ k − 6,≥ 64− k + 1]16.
Les codes de Reed-Solomon bâtis sur le même alphabet auront des paramètres dutype
[n = 16, k, 16− k + 1]16,
le code hermitien est donc sensiblement plus long, avec une petite perte sur ladimension.Les codes de Reed-Muller Ils peuvent être vus comme une généralisation mul-tivariées des codes de Reed-Solomon. Au contraire des codes de Reed-Solomon, cesont des codes très longs pour un petit alphabet, par exemple pour l'alphabet binaireF2. On se donne n points distincts P1, . . . , Pn ∈ Fm
q , et l'espace de polynômes :Lr = {f ∈ Fq[X1, . . . , Xm], deg f ≤ r}.
La fonction d'évaluation correspondante est :ev : Lr → Fn
q
f 7→ (f(P1), . . . , f(Pn)).
Dans le cas binaire, en prenant n = 2m, et {P1, . . . , Pn} tous les éléments de Fm2 , on
obtient un code de longueur 2m, de dimension ∑ri=0
(mi
), et de distance minimale2m−r. Le cas le plus simple est le code de Reed-Muller à m variables d'ordre 1,obtenu pour r = 1. C'est un code [n = 2m, k = m + 1, d = 2m−1]2. Ces codes nesont pas très bons en termes de codage (trop petite dimension), mais ils sont trèsimportants en cryptographie, et ont été utilisés historiquement (photographies deMars par la sonde Mariner 9, en 1971).
4.2 Problème du décodage des codes d'évaluationet approximation par des polynômes
Dans le cas des codes d'évaluation considérés dans ce chapître, il y a un lientrès fort entre décodage et approximation. Je présente ce lien pour le cas simple descodes de Reed-Solomon.
Soit RSk le code de Reed-Solomon de dimension k, construit avec n élémentsdistincts x1, . . . , xn ∈ Fq. Soit y = (y1, . . . , yn) ∈ Fn
q le mot reçu. Décoder τ erreurs,c'est trouver le mot de code c ∈ RSk, tel que
d(c, y) ≤ τ,
où d est la distance de Hamming. Soit f(X) le polynôme tel que c = ev f(X). Alorsle problème de décoder y devient celui de trouver les polynômes f(X), deg f(X) < k,tels que :
|{i, f(xi) = yi}| ≥ n− τ.
Si on cherche le polynôme d'interpolation de Lagrange p(X) tel que p(xi) = yi,i ∈ {1, . . . , n}, alors le degré de p(X) est typiquement n − 1. Dans le contexte quinous intéresse, on cherche un polynôme f(X) de petit degré (borné par k), et ontolère que la courbe Y − f(X) ne passe pas par tous les points (xi, yi).On peut aussi voir le problème comme le problème d'approximation suivant.
Soit n points (xi, yi) ∈ F2q, vus comme une fonction xi 7→ yi, trouverles polynômes de bas degré approchant au mieux cette fonction, pour la
métrique de Hamming.

32 Chapitre 4. Décodage des codes d'évaluation avec l'algorithme de Sudan
Cette problématique se généralise au cas des codes de Reed-Muller. Les polynômesunivariés sont remplacés par des polynômes à plusieurs variables de petit degré.Étant donnés n points P1, . . . , Pn ∈ Fm
q , et n valeurs y1, . . . , yn ∈ Fq, on cherchele polynôme à m variables de degré au plus r qui interpole au mieux les points(Pi, yi) ∈ Fm+1
q , pour la distance de Hamming.
4.3 Le schéma de principe des algorithmes de Su-dan et Guruswami
Pour présenter mes contributions, je dois donner le principe des algorithmesde décodage en liste des codes d'évaluation, sur le cas simple des codes de Reed-Solomon. Ces algorithmes forment toute une famille, qui va du cas le plus simple(algorithme de Sudan), au plus élaboré (algorithme de Kötter et Vardy), en passantpar l'algorithme de Guruswami-Sudan, qui est une étape intermédiaire essentielleentre ces deux extrêmes.
J'ai besoin de rappeler la dé�nition du (u, v)-degré pondéré d'un polynôme biva-rié. C'est le maximum des (u, v)-degrés pondérés de ses monômes, où le (u, v)-degrépondéré du monôme XiY j est ui+ vj. Je note wdegu,vQ(X, Y ) le (u, v)-degré pon-déré du polynôme Q(X, Y ).L'algorithme de Sudan Pour décoder y = (y1, . . . , yn) ∈ Fn
q dans le code deReed-Solomon, de dimension k, dé�ni sur le support x1, . . . , xn, je rappelle qu'ilfaut trouver f(X) de degré inférieur à k, tel que d(ev f(X), y)) ≤ τ .
L'idée fondatrice de Sudan est de construire un polynôme d'interpolation, Q(X, Y ) ∈Fq[X, Y ], tel que :
1. Q(X, Y ) 6= 0 (non trivialité) ;2. Q(xi, yi) = 0 pour i de 1 à n (interpolation) ;3. wdeg1,k−1Q(X, Y ) < n− τ (majoration du degré pondéré).
Alors, on montre que si f(X) est solution du problème de décodage, on aQ(X, f(X)) = 0, ou encore Y − f(X)|Q(X, Y ).
Ainsi l'algorithme de Susan comporte deux étapes :Interpolation : trouver Q(X, Y ) tels que les conditions 1. 2. et 3. sont sa-
tisfaites ;Recherche de racines : trouver les facteurs Y − f(X) de Q(X, Y ).
Ces deux étapes n'ont pas été précisées plus profondément par Sudan, qui s'estcontenté de remarquer qu'elles pouvaient se faire en temps polynomial en la longueurn du code.
Pour analyser le nombre d'erreurs que peut corriger cet algorithme, il resteà déterminer à quelles conditions le polynôme d'interpolation Q(X, Y ) existe.
Les conditions d'interpolation dé�nissent un système d'équations linéaires surles coe�cients de Q(X, Y ). Pour qu'il existe une solution non nulle, il su�t d'avoirplus d'inconnues que d'équations. Le nombre d'équations est le nombre de conditionsd'interpolation qui est n, et le nombre de termes NQ de Q est donné par la condition3 ci-dessus, de majoration du degré pondéré. Les calculs donnent :
τ ≤ n−√
2(k − 1)n. (4.1)Ce rayon de décodage est supérieur au rayon classique t = bn−k
2 c, quand k/n ≤0, 172.

4.4. Généralisations 33L'algorithme de Guruswami-Sudan L'amélioration de Guruswami-Sudan per-met d'obtenir un rayon de décodage toujours supérieur au rayon classique bn−k
2 c,pour tout taux de transmission R = k/n ∈ [0, 1]. On se donne deux paramètresauxiliaires d (un degré) et s (un ordre de multiplicité), et on cherche un polynômeQ(X, Y ) d'interpolation, tel que :
1. Q(X, Y ) 6= 0 (non trivialité) ;2. Q(xi, yi) = 0, avec multiplicité s, pour i de 1 à n (interpolation) ;3. wdeg1,k−1Q(X, Y ) < d (majoration du degré pondéré).
Alors, en faisant la même analyse que précédemment, et en optimisant le degréd, on trouve
τ ≤ n−
√(k − 1)n
(1 +
1s
), (4.2)
qui tend versn−
√(k − 1)n
quand s croît. En prenant le rayon relatif τn des sphères de décodage, et le taux de
transmission R ≈ kn , la formule (4.1) donne
τ
n≤ 1−
√2R, (4.3)
alors que la formule (4.2) donneτ
n≤ 1−
√R. (4.4)
La rayon classique de décodage unique est donné part
n≤ 1−R
2. (4.5)
Ces trois rayons de décodage sont tracés sur la �gure 4.1. On voit que l'algorithmede Guruswami-Sudan est toujours supérieur, en termes de capacité de correction,à l'algorithme classique.
4.4 GénéralisationsCes algorithmes se généralisent aux codes géométriques et aux codes de Reed-
Muller. Mais aussi ils se généralisent à d'autres canaux de transmission que lecanal q-aire symétrique, seul considéré jusqu'ici. Ce sont des canaux où le dispositifde réception des messages donne une information de qualité sur chaque symbolepossible. Le problème de décoder en utilisant cette information de qualité s'appellele décodage souple des codes de Reed-Solomon.Généralisation à d'autres codes Ce principe de décodage se généralise bien auxcodes géométriques. Cette généralisation a d'abord été faite par Shokrollahi et Was-serman [SW99], pour l'algorithme de Sudan, sans multiplicités. Ensuite Guruswami-Sudan ont, dans une seule publication [GS99], introduit la notion de multiplicités,à la fois pour les codes de Reed-Solomon et pour la classe des codes géométriquesdits à un point. Ce sont des codes où l'espace L(D) des fonctions à évaluer est dela forme L(kP ) : ce sont les fonctions qui n'ont pas de pôles en dehors du point P ,et elles ont un pôle au plus d'ordre k au point P . Les fonctions dans L(kP ) sont

34 Chapitre 4. Décodage des codes d'évaluation avec l'algorithme de Sudan
0
0.2
0.4
0.6
0.8 1
0 0.2
0.4 0.6
0.8 1
(1-x)/21-sqrt(2*x)
1-sqrt(x)
Fig. 4.1 � Comparaison des rayons de décodage de l'algorithme classique, de Sudanet de Guruswami-Sudan.

4.5. Implémentation 35assez faciles à manier : l'ordre de leur pôle en P joue le rôle du degré des polynômesunivariés, et elles ont au plus k zéros sur la courbe.
Sous ma direction, Lancelot Pecquet a dans sa thèse [Pec01] formulé l'algorithmepour les codes géométriques où l'espace L(D) est associé à un diviseur D de formegénérale. Ces codes ont quelquefois de meilleurs paramètres que les codes à unpoint [Mat01].
J'ai aussi étudié la généralisation de cet algorithme au codes de Reed-Muller. Ladi�culté est de passer des polynômes univariés aux polynômes multivariés. Bien quela généralisation de l'algorithme soit claire, l'optimisation des paramètres auxiliairess (la multiplicité) et d (le degré) n'est pas immédiate. Ce problème a déjà été traitépar Pellikaan et Wu [PW04a, PW04b], avec di�érentes analyses, notamment avec lathéorie des bases de Gröbner. Je donne une nouvelle analyse, reposant sur le lemmede Schwartz-Zippel [Sch80, Zip79], qui borne le nombre de zéros d'un polynômemultivarié sur un corps �ni. L'analyse que j'ai faite conduit à un meilleur rayon dedécodage [AEKM+06].Généralisation à d'autres canaux Dans certains schémas de communication,le dispositif récepteur donne pour chaque symbôle une liste des symboles les plusplausibles, en attribuant à chacun une information de �abilité, qui est une proba-bilité. Un décodeur souple est un décodeur qui prend en compte cette information,et retourne le mot de code le plus probable.
Kötter et Vardy [VK00, KV03] ont montré comment transformer cette informa-tion de �abilité en information algébrique, pour décoder les codes de Reed-Solomon,et les codes géométriques. L'algorithme obtenu est de complexité polynomiale enla longueur : c'est le premier décodeur souple des codes de Reed-Solomon de com-plexité non exponentielle.
Plus précisément, pour chaque position xi le récepteur propose une liste de sym-boles yi1, . . . , yil ∈ Fq les plus probables, avec des coe�cient de �abilité µi1, . . . , µil.Alors on peut associer à ces coe�cients de �abilités des multiplicités si1, . . . , sil.Cette association doit se faire de manière cohérente par rapport au problème dudécodage. Une fois ces multiplicités sij trouvées, le problème d'interpolation estalors de trouver Q(X, Y ) tel que :
1. Q(X, Y ) 6= 0 (non trivialité) ;2. Q(xi, yij) = 0, avec multiplicité sij , pour i de 1 à n, pour j de 1 à l
(interpolation) ;3. wdeg1,k−1Q(X, Y ) < d (majoration du degré pondéré).
Si les multiplicités sont bien choisies, alors parmi les polynômes f(X) tels queQ(X, f(X)) = 0, on trouvera les f(X) tels que ev f(X) = c, pour les mots de codec les plus vraisemblables.
Lancelot Pecquet a proposé dans sa thèse une méthode di�érente de celle deKötter et Vardy pour assigner des multiplicités en fonction des informations de �a-bilité. La di�culté est de déterminer une association cohérente de multiplicités auxinformations de qualité. En fait, il est même surprenant qu'une information de na-ture probabiliste (la qualité des symboles reçus) puisse être traduite en informationalgébrique (multiplicités d'interpolation).
4.5 ImplémentationCes algorithmes comportent tous les deux étapes suivantes dont la formulation
précise peut éventuellement varier suivant les codes et les canaux :

36 Chapitre 4. Décodage des codes d'évaluation avec l'algorithme de Sudan
interpolation : on cherche un polynôme en une variable, à coe�cients desfonctions ou des polynômes, qui passe par un ensemble de points, aveccertaines multiplicités.
recherche de racines : On cherche les racines (qui sont des polynômes oudes fonctions) de ce polynôme.
Avec Lancelot Pecquet nous avons contribué à la recherche de racines, maisseulement dans le cas de l'algorithme de Sudan simple, sans multiplicités [AP98a,AP00b], dans le cas des codes de Reed-Solomon, et dans le cas des codes géomé-triques. Lancelot Pecquet a ensuite traité le cas avec multiplicités dans sa thèse.
Notre contribution est une adaptation de la méthode de Newton pour appro-cher les racines d'une équation. Classiquement, pour trouver les solutions f(X) deQ(X, f(X)) = 0, on cherche d'abord les racines f0 de Q(0, Y ). Ces racines serventensuite de point de départ pour construire le développement de f(X), en utilisationdes itérations de Newton.
Mais dans le contexte très précis de l'algorithme de Sudan, nous avons montrécomment obtenir les points de départ f0 sans utiliser la factorisation univarié deQ(X, 0). On évite donc la recherche de racines d'un polynôme univarié sur un corps�ni. Cela rend la recherche de racines pour Sudan complétement déterministe, etainsi l'algorithme de Sudan est déterministe dans sa globalité. C'est aussi l'algo-rithme le plus e�cace en pratique, grâce à la rapidité de convergence de la méthodede Newton : il su�t de log2 k itérations pour trouver une racine de degré k deQ(X, Y ).
En revanche, en présence de multiplicités, la contribution de Lancelot Pecquet,ainsi que toutes celles publiées, nécessite une recherche de racines d'un polynômeunivarié sur un corps �ni.
En pratique, j'ai implémenté l'algorithme de Sudan en C pour les codes de Reed-Solomon, et en Aldor (anciennement Axiom) pour les codes géométriques les plussimples, les codes hermitiens [Sti93]. L'étape la plus coûteuse en temps est l'étaped'interpolation, alors que le problème et l'algorithme associés sont conceptuellementplus simples que pour l'étape de recherche de racines. La plupart des auteurs consi-dèrent que c'est cette étape qui est la plus coûteuse, et de nombreuses approchesont été proposées. Voir appendice 9.
4.6 Décodage local des codes de Reed-Muller d'or-dre 1
Nous allons décrire une problématique très proche du décodage, mais qui seformule en termes � fonctionnels �. Ce problème a été le problème central de lathèse de Cédric Tavernier, sous ma direction [Tav04].
On suppose qu'on a accès à une fonction g � boîte noire �g : Fm
2 7→ F2.
Le modèle de représentation de g est le suivant : on lui soumet x ∈ Fm2 , et on reçoit
en réponse g(x). On cherche la fonction a�ne f : Fm2 → F2 qui coïncide au mieux
avec g, c'est-à -dire telle que la probabilitéPr
x∈Fm2
(f(x) = g(x))
est maximale.

4.7. Application en cryptanalyse 37Si on écrit tout le vecteur des valeurs de g, avec la fonction d'évaluation des
codes de Reed-Muller :g(x)x∈F2m = ev g,
alors c'est exactement le problème de décodage ev g dans le code de Reed-Mullerd'ordre 1. En e�et f doit être telle que d(ev f, ev g) est minimale, et ev f est dansle code de Reed-Muller, d'ordre 1.
Mais il faut penser à des applications où le nombre m de variables est grand, parexemple, m = 64. En prenant la fonction d'évaluation dé�nie pour les Reed-Muller,on obtient un vecteur de longueur n = 264 qui est impossible à manipuler.
Un décodeur local est un algorithme qui fait un certain nombre de requêtesx 7→ g(x), et qui doit retourner la liste des fonctions f les plus proches. Comme ledécodeur local ne dispose pas de la totalité du vecteur des valeurs ev g, il y a uneprobabilité d'échec. Cette probabilité d'échec est la somme de la probabilité de nepas retourner une des fonctions les plus proches, et de la probabilité de retournerune fonction trop éloignée (probabilité de non détection plus probabilité de faussealarme).
Le décodeur local doit être de faible complexité, faire un petit nombre de requêtesx 7→ g(x), et avoir une faible probabilité d'échec.
Cédric Tavernier, se reposant sur les travaux de Goldreich, Rubinfeld et Su-dan [GRS95], a construit un algorithme de grande e�cacité pour résoudre ce pro-blème. Le nombre de requêtes à l'oracle est O(u/ε2), la probabilité d'échec estde l'ordre de 2−u, où u est un paramètre intervenant de manière linéaire dans lacomplexité qui est
O(um
ε2),
où ε est tel quePr
x∈Fm2
(f(x) = g(x)) =12− ε.
La limite du taux d'erreur admissible est 1/2, et ici ε est un paramètre d'entrée del'algorithme.
4.7 Application en cryptanalyse
Approximation par des polynômes univariés Thomas Jakobsen [Jak98] amontré comment utiliser l'algorithme de Sudan simple pour trouver des approxima-tions univariées simples de l'algorithme de chi�rement de Knudsen et Nyberg [NK93,NK95].
Le principe est le suivant : on considère l'algorithme de chi�rement comme uneboîte noire g, dont les entrées sont les messages clairs (ou une partie des messagesclairs), et les sorties les messages chi�rés (ou une partie des messages chi�rés). Onconsidère un certain nombre n de messages clairs comme des éléments x1, . . . , xndans un corps �ni F2m , et on écrit le vecteur
g(x1), . . . , g(xn).
On cherche le polynôme de petit degré qui approche au mieux ces valeurs, pour ladistance de Hamming. Jakobsen a montré comment utiliser l'algorithme de Sudanpour trouver ces approximations.
De telles approximations sont ensuite utilisées pour faire une cryptanalyse, c'est-à -dire pour trouver une faiblesse dans l'algorithme de chi�rement, permettant deretrouver la clé au bout du compte. Je ne décrirai pas en détails la cryptanalyse, etje me contente d'étudier l'étape de recherche d'approximations de bas degré. Cette

38 Chapitre 4. Décodage des codes d'évaluation avec l'algorithme de Sudan
méthode, mise au point par Jakobsen, a bien fonctionné pour le système de Knudsenet Nyberg, car celui-ci est spéci�é en termes d'opérations simples sur les corps �nis,légèrement perturbées pour briser la régularité.
J'ai essayé d'utiliser mon implémentation en C de l'algorithme de Sudan pourcryptanalyser un système de chi�rement à clé secrète, dans le cas d'une expertised'algorithme de chi�rement développé en interne à Canal+.
Je n'ai pas trouvé de bonnes approximations pour l'algorithme de Canal+. Pourl'expliquer, il faut voir que la méthode de Jakobsen est adaptée pour des systèmesde chi�rement qui s'expriment naturellement en termes de corps �nis, et d'opéra-tions polynomiales univariés sur ces corps �nis, comme le système de chi�rement deKnudsen et Nyberg.
En revanche, ce n'était pas le cas de l'algorithme de Canal+ que j'ai analysé, quiest décrit en termes d'opérations bit à bit, qui ne trouvent pas d'expression simpleen termes de corps �ni. C'est le cas en général de la plupart des algorithmes dechi�rement disponibles.
Il faut donc se tourner vers des fonctions qui � collent mieux au problème � :les polynômes multivariés sur F2, de bas degré. Ces polynômes s'évaluent sur F2, cequi correspond mieux aux manipulations bit à bit.Approximation par des polynômes multivariés Cédric Tavernier a utilisél'algorithme de sa thèse pour trouver automatiquent des approximations linéairesdes fonctions de sortie de l'algorithme de chi�rement DES. De telles approxima-tions sont ensuite utilisées pour mener une cryptanalyse linéaire, comme l'a faitMatsui [Mat94b, Mat94a]. Je ne m'étendrai pas sur la totalité de la cryptanalyselinéaire, mais uniquement sur l'étape préalable de recherche d'approximations.
On considère les entrées de l'algorithme de chi�rement DES (clé et messagesclairs) comme vecteurs de m bits, et on considère un bit de sortie du DES. Onobtient ainsi une fonction g : Fm
2 → F2 qui est représentée par un algorithme : onlui soumet x et on obtient g(x).
Cédric Tavernier a retrouvé automatiquement avec son algorithme l'approxima-tion linéaire du DES trouvée � à la main � par Matsui. Cédric Tavernier a aussitrouvé des meilleures approximations que celle de Matsui, pour des versions réduitesdu DES.
Il a de plus trouvé de nombreuses approximations, de l'ordre d'une centaine,pour certaines versions réduites. Le fait d'avoir plusieurs approximations plutôtqu'une conduit à une amélioration de la cryptanalyse totale.
4.8 ConclusionLes codes dé�nis par interpolation permettent de corriger beaucoup d'erreurs
quand on utilise le décodage en liste, dont la meilleure réalisation est due à Su-dan et Guruswami. Cette percée est aussi fondamentale car elle se généralise bienà d'autres codes, dont la classe importante des codes géométriques. De plus c'est lepremier exemple de décodage en liste e�cace, dont on ne connait pas de réalisationpour d'autres classes de codes.
Elle se généralise aussi bien à d'autres types de canaux de communications,comme l'ont montré Kötter et Vardy. Ceux-ci ont ainsi réalisé une percée en intro-duisant le premier algorithme de décodage souple des codes de Reed-Solomon.
Ces algorithmes à haut pouvoir de correction peuvent aussi être utilisés encryptanalyse. La méthode est d'approcher les fonctions de sorties des algorithmes dechi�rement par des fonctions plus simples : les polynômes univariés ou multivariésde bas degré. C'est grâce à leur fort pouvoir de correction que ces algorithmestrouvent des approximations des fonctions de chi�rement. En e�et, les fonctionsde chi�rement sont en particulier conçues pour être loin des polynômes (univariés

4.8. Conclusion 39ou multivariés), et les algorithmes de décodage classiques ne peuvent pas décoderautant d'erreurs.
Le principal problème qui reste à régler est celui de fournir une implémentatione�cace des algorithmes de Sudan et Guruswami. Ceux-ci ne sont en e�et pas assezrapides pour être utilisés en pratique, bien qu'une implémentation matérielle aitdéjà été proposée [AKS04].

40 Chapitre 4. Décodage des codes d'évaluation avec l'algorithme de Sudan

Deuxième partie
Cryptographie
41


Chapitre 5
Utilisation de problèmes de
codage en cryptographie
En cryptographie à clé publique, on utilise des problèmes algorithmiques di�-ciles, pour construire des primitives cryptographiques, comme le chi�rement ou lehachage. Les problèmes mathématiques les plus utilisés en standard sont fondés surdes problèmes de la théorie des nombres (logarithme discret pour Di�e-Hellman,factorisation pour RSA [DH76, RSA78]).
Il est souhaitable de bâtir des primitives cryptographiques sur d'autres problé-matiques que celles-ci, pour di�érentes raisons. Premièrement, suivant la problé-matique utilisée, les cryptosystèmes peuvent avoir des caractéristiques di�érenteset intéressantes (longueur de la clé, taille des messages, rapidité de chi�rement,de déchi�rement). Deuxièmement, on peut s'inquièter de faire reposer la sécuritédes systèmes cryptographiques sur un socle si étroit : tout progrès algorithmiquedans ces domaines met en danger le système. Il y a aussi le spectre de l'ordinateurquantique : si celui-ci voit le jour, alors la plupart des primitives cryptographiquess'e�ondrent.
Un certain nombre de systèmes reposent sur des problèmes di�ciles de la théoriedes codes, à commencer par le système de McEliece [McE78], qui est presque aussiancien que RSA. Ce système est fondé sur la di�culté de décoder un code linéairebinaire quelconque. À ce jour, aucun algorithme e�cace ne permet de résoudre ceproblème, que ce soit en classique ou en quantique. Le cryptosystème de McElieceprésente des caractéristiques di�érentes des autres systèmes, avec des avantages(rapidité, caractère exponentiel des attaques) et des inconvénients (principalementla taille de la clé publique).
J'ai proposé, avec Matthieu Finiasz [AF03], un système de chi�rement qui reposesur la di�culté du décodage des codes de Reed-Solomon, qui présente l'avantaged'avoir des clés bien plus courtes que McEliece. Sa sécurité est hélas mal fondée, etil a été � cassé �.
Ensuite, avec Matthieu Finiasz et Nicolas Sendrier, j'ai proposé une fonctionde hachage basée sur le décodage de codes aléatoires [AFS03, AFS05a, AFS05b,AFS05c]. À l'opposé du système précédent, notre proposition a une sécurité bienétablie. Curieusement, aucune proposition de fonction de hachage reposant sur lescodes n'a précédé la notre, alors que la primitive du hachage est une des plus simplesà obtenir.
Dans les deux cas, en plus de propositions théoriques, nous avons proposé desjeux de paramètres concrets. Pour cela, il faut bien analyser les meilleurs algo-rithmes pour résoudre les problèmes, ce que nous avons fait avec Nicolas Sendrieret Matthieu Finiasz, dans les deux cas.
43

44 Chapitre 5. Utilisation de problèmes de codage en cryptographie
5.1 Chi�rement fondé sur le décodage des codes deReed-Solomon
La di�culté du problème Nous avons vu que le problème du décodage descodes linéaires binaires généraux est un problème di�cile, tant du point théoriqueque pratique [BMvT78]. Il est naturel de se poser la question pour la classe beaucoupplus restreinte des codes de Reed-Solomon. Guruswami et Vardy ont exactementmontré que ce problème est di�cile [GV05]. La formulation du problème pour lescodes de Reed-Solomon se précise comme suit.
Étant donnés x1, . . . , xn ∈ Fq, y = (y1, . . . , yn) ∈ Fq, k, τ ∈ N, trouverf ∈ Fq[X], deg f ≤ k, telle que
|{i ∈ {1, . . . , n} | f(xi) 6= yi}| ≤ τ.
Guruswami et Sudan ont montré que le problème décisionnel associé est NP-complet. Cela peut paraître surprenant, car les algorithmes de décodage par inter-polation que nous avons étudiés permettent de décoder jusqu'à n−
√kn erreurs. En
fait, le problème devient di�cile lorsque l'on essaye de décoder un grand nombred'erreurs, signi�cativement au delà de ce rayon de décodage de Guruswami et Su-dan, voir la �gure 5.1.0.0.0.
Avec Matthieu Finiasz, nous avons étudié ce problème [AF03] du point de vuepratique, et, empiriquement, les meilleurs algorithmes sont bien exponentiels en lalongueur du code.
Citons aussi les travaux de Kiayias et Yung, qui ont étudié le problème du déco-dage des codes de Reed-Solomon, aussi en vue de l'utiliser en cryptographie [KY02b,KY02a]. Sous des hypothèses calculatoires faibles, ils montrent, entre autres, qu'ilest di�cile de distinguer une instance ayant une solution d'une instance aléatoire.Dans notre contexte, cela signi�e que la donnée de c + E ne révéle aucune informa-tion sur c et E.Le cryptosystème Augot-Finiasz Avec Matthieu Finiasz [AF03], nous avonsproposé un système de chi�rement à clé publique, fondé sur la di�culté du décodagedes codes de Reed-Solomon.
Le principe est très similaire au cryptosystème de McEliece, que je rappelle. Onconsidère un code C, pour lequel un algorithme de décodage secret existe. Pourchi�rer un message clair considéré comme un mot c ∈ C, on se contente de lui ra-jouter une erreur aléatoire e, et on transmet y = c+e. À la réception, le destinataireconnaît l'algorithme de décodage secret associé au code C, et peut recouvrir c et eà partir de y.
Le système original de McEliece utilise des codes de Goppa classiques, dont lastructure est cachée par une permutation secrète des positions. Nous avons proposéd'utiliser des codes basés sur les codes de Reed-Solomon, en cachant leur algorithmede décodage.
On considère C un code qui est la somme directe d'un code de Reed-Solomonet de la droite engendrée par un mot : C = RSk ⊕E, où E est une erreur de poidsélévée, et RSk le code de Reed-Solomon de dimension k. Il est facile de construire unalgorithme de décodage de C, lorsque l'erreur E est connue. On peut alors construireun cryptosystème similaire à celui de McEliece.
Pour spéci�er le code C sans révéler E, il su�t de donner P = c+E, où c ∈ RSkest pris au hasard. En e�et le code RSk est considéré comme une donnée constanteà tous les utilisateurs. Retrouver c et E à partir de P est exactement le problèmedu décodage des codes de Reed-Solomon, qui est di�cile.

5.1. Chi�rement fondé sur le décodage des codes de Reed-Solomon 45
0
0.2
0.4
0.6
0.8 1
0 0.2
0.4 0.6
0.8 1
1-sqrt(x)
Fig. 5.1 � Tracé de la courbe τ = 1−√
R. Au delà de cette courbe (surface colorée),le problème de décoder τ erreurs dans un code de Reed-Solomon de taux de trans-mission R = k
n est di�cile. En dessous, il devient facile, en utilisant l'algorithme deGuruswami-Sudan.

46 Chapitre 5. Utilisation de problèmes de codage en cryptographie
De plus la donnée de P est assez courte : il su�t de donner un mot de longueurn, à comparer au cryptosystème de McEliece basé sur les codes de Goppa, où il fautdonner une matrice k × n, qui est la matrice génératrice du code masqué.
En pratique, nous avons proposé un système de chi�rement à clé publique, dontla clé publique est de 3072 bits, à comparer aux ≈ 500000 bits obtenus pour lecryptosystème classique de McEliece.
Attaques et réparations Notre cryptosystème a subi une attaque sur le mes-sage : il existe un algorithme, qui est capable de retrouver le message clair à partirdu message chi�ré. Cette attaque est due à Coron [Cor03a, Cor04], et ne permetpas de retrouver c et E à partir de c+E. Mais elle montre que le code C = RSk ⊕Eest décodable en temps polynomial, même sans connaître E.
Avec Pierre Loidreau [AFL03], nous avons proposé une réparation, assez tech-nique, qui utilise des propriétés de l'opérateur trace : Tr : F2m → F2. Cette techniquepermettait de faire échouer l'algorithme de Coron. Mais Coron a pu adapter sonalgorithme à ce nouveau contexte, pour cryptanalyser le nouveau système de chif-frement [Cor03b]. Kiayias et Yung ont aussi essayé de réparer notre système, sanssuccés [KY04].
En conclusion, notre système ne posséde pas de réduction de sécurité. C'est-à-dire que nous n'avons pas pu montrer qu'il est équivalent de retrouver le messageclair à partir du message chi�ré et de résoudre le problème du décodage du code deReed-Solomon associé. Et d'ailleurs cette équivalence est fausse, comme l'algorithmede Coron le montre.
Le problème de décodage des codes de Reed-Solomon, dans sa version di�cile(quand le taux d'erreur est élevé), est cependant une primitive intéressante pourbâtir des cryptosystèmes. Mais ceux-ci semblent di�ciles à obtenir : Kiayias et Yungont proposé quelques maigres primitives fondées sur ce problème [KY01b, KY01a,KY02b, KY02a, KY05]. Entre autres ils ont proposé un mécanisme de chi�rementà clé secrète (certes peu rapide), et ils ont le mérite d'avoir bâti une réduction desécurité, garantissant la sécurité de leur système.
Comme mentionné plus haut, un des sous-produits de notre proposition de cryp-tosystème est l'étude des meilleurs algorithmes pour décoder les codes de Reed-Solomon quand le taux d'erreur est élevé. C'est important car cela permettra éven-tuellement d'échelonner d'autres cryptosystèmes fondés sur le décodage des codesde Reed-Solomon. Par exemple, Kiayias et Yung, bien que faisant des systèmes avecune réduction de sécurité théorique, ne font pas cette étude algorithmique, et neproposent donc pas des paramètres concrets.
5.2 Fonction de hachage fondée sur le décodage parsyndrome
Notion de fonction de hachage Une fonction de hachage cryptographique estune fonction h : {0, 1}∗ → {0, 1}r, prenant en entrée un mot binaire de longueurquelconque, retournant un mot de taille �xe, de r bits, et telle que
1. étant donné y, il est di�cile de trouver x tel que h(x) = y (pre-image resis-tance) ;
2. étant donné y et x tel que h(x) = y, il est di�cile de trouver x′ tel queh(x′) = y (second pre-image resistance) ;
3. il est di�cile de trouver un couple (x, x′) tel que h(x) = h(x′) (collisionresistance).

5.2. Fonction de hachage fondée sur le décodage par syndrome 47
��
@@
��
@@
��
@@
��
@@- - - -- - - - - -
? ? ? ? ?
��@@f f f . . . f g
x1 x2 x3 xl padding
IV
x1 x2 x3 xl
y
Fig. 5.2 � Schéma itératif de Merkle et Damgård, où f est la fonction de compres-sion.
Une telle primitive, qui semble très simple, est pourtant fort utile en cryptogra-phie, et est constamment et fréquemment utilisée (certi�cats numériques, intégritédes documents numériques etc).
Nous nous contenterons de dé�nir la notion de di�culté à l'aide de la notionheuristique de facteur de travail (WF , work factor), qui est le nombre d'opérationsélémentaires nécessaires à atteindre l'un des buts ci-dessus. On estime actuellementqu'un facteur de travail de 280 garantit une grande sécurité.
Les fonctions de hachage les plus populaires sont celles basées sur MD4, qui estun schéma général d'algorithme : MD4, MD5, SHA et ses variantes, RIPEMD etc. Ils'agit d'algorithmes dédiés, très proches des algorithmes de la cryptographie à clésecrète. Ces fonctions ont été récemment attaquées [WLF+05, WY05, BCJ+05]après l'annonce [WFLY04]. Il y a depuis une forte demande de nouvelles fonctionsde hachage cryptographiques, et une nouvelle proposition serait très pertinente,pour palier aux faiblesses de sécurité des fonctions connues.
Le principe de Markle et Damgård Nous allons proposer une constructionde fonction de hachage, suivant le schéma classique de Merkle et Damgård [Mer90,Dr90], qui repose sur la notion de fonction de compression. Une fonction de com-pression est une fonction f : Fl
2 → Fr2, avec l > r
On découpe alors le message x ∈ {0, 1}∗ en blocs de r bits x1 . . . xn. On itèreensuite l'opération
zi+1 ← f(zi||xi),
où zi est l'état courant, initialisé à un vecteur constant z1, et où xn, le dernier bloc,a été au préalable augmenté (paddé).En�n, une dernière transformation g est éventuellement appliquée au dernier
état zn obtenu, pour obtenir le haché �nal g(zn). Cette construction est �gurée surle schéma 5.2.
Il est prouvé [Mer90, Dr90] que la sécurité de la fonction globale h n'est pasmoindre que celle de la fonction itérée f . Le concepteur de la fonction de hachageh peut alors se concentrer sur les fonctions auxiliaires f et g.
C'est ce que nous ferons, mais nous avons d'abord besoin de donner la notionde décodage par syndrome.
Décodage par syndrome Un code linéaire binaire C de longueur n étant un F2sous espace vectoriel de Fn2 , il peut être spéci�é par sa matrice de parité H, qui est
telle quec ∈ C ⇐⇒ Hct = 0.

48 Chapitre 5. Utilisation de problèmes de codage en cryptographie
Dans le contexte du décodage, soit y ∈ Fn2 le mot reçu, et c mot de code à distance
w de y. On écrit c = y − e, où e est l'erreur, et on aHct = 0 =⇒ Hyt = Het.
On connait donc la quantité S = Het qu'on appelle le syndrome de e. Pour décoder,il su�t de trouver e de poids inférieur à w tel que Het = S. C'est le problème dudécodage par syndrome, qui est prouvé et réputé di�cle [BMvT78, BN90], mêmeavec précalcul.
De même, lorsque S = 0, trouver e 6= 0, de poids inférieur à w, tel que Het = 0est aussi un problème di�cile : c'est la recherche de mots de poids faible dans uncode [Var97].Notre fonction de compression Pour construire notre fonction de compression,nous proposons premièrement de choisir strictement aléatoirement une matrice deparité H r × n binaire, et nous considérons le code C associé.
Ensuite, notons Wn,w l'ensemble des mots binaires de longueur n et de poids w.Nous proposons de prendre comme fonction de compression la fonction
f : Wn,w → Fr2
e 7→ Het.
qui est à la fois di�cile à inverser (décodage par syndrome), et pour laquelle il estdi�cile de trouver e1, e2 ∈Wn,w tels que
f e1 = f e2,
ce qui correspond à la recherche de mots de faible poids : si f e1 = f e2, où e1 et e2sont de poids inférieur à w, alors f(e1 − e2) = 0, c'est-à-dire que le mot e1 − e2 estdans le code, et a un poinds inférieur à 2w.
Cette fonction de compression ne se prête pas facilement à une réalisation pra-tique : il faut en e�et trouver un moyen de coder les éléments de Wn,w. Première-ment, le cardinal de Wn,w est (n
w
), qui n'est pas une puissance de 2. Ensuite, lesalgorithmes réalisant un codage des entiers de {0, . . . ,
(nw
)−1} vers Wn,w requièrent
une arithmétique de grands entiers (manipulation de coe�cients binomiaux) et sontcoûteux [Cov73].
Nous proposons de considérer l'ensemble Rn,w des mots réguliers de longueur net de poids w. Cet ensemble est dé�ni quand n est un multiple de w : on découpel'intervalle {0, . . . , n−1} en w intervalles de longueur n
w . Un mot régulier de longueurn et de poids w est un mot ayant exactement un 1 dans chacun de ces intervalles,voir Figure 5.3. Le cardinal de Rn,w est alors ( n
w )w.Pour construire notre fonction de hachage, nous avons le choix de n et de w, que
nous prenons tel que wn soit une puissance de 2, par exemple 2l0 . Alors le cardinal
de Rn,w est 2wl0 , soit 2l avec l = wl0.Il est alors facile de construire un codage φ : {0, 1}l → Rn,w, de plus très e�cace.Nous proposons donc comme fonction de compression la fonction f suivante :
f : {0, 1}l → Fr2
x 7→ H(φ(x))t.
Rappelons que notre fonction est une fonction de compression : on doit choisir lesparamètres tels que l > r.Sécurité théorique On peut se demander si le problème d'inverser, c'est-à-dire detrouver un mot régulier admettant un syndrome donné, n'est pas devenu facile, encomparaison du problème standard de décodage par syndrome. La même question

5.2. Fonction de hachage fondée sur le décodage par syndrome 49
n
n
w
Fig. 5.3 � Un mot de poids régulier : chaque trait vertical plein indique un � 1 �,les autres positions étant nulles.

50 Chapitre 5. Utilisation de problèmes de codage en cryptographie
se pose pour le problème des collisions. Matthieu Finiasz a montré dans sa thèse queles problèmes décisionnels associés à ces deux problèmes sont NP-complets [Fin04].
Nous pensons de plus que le problème est di�cile pour des instances aléatoires,et non pas seulement dans le cas le pire, comme dans le cas du décodage classique.C'est pourquoi nous préconisons de choisir la matrice H aléatoirement, et de lagarder en table, plutôt que d'utiliser la matrice de parité d'un code particulier, quipourrait avoir trop de structure.
À l'opposé des fonctions de hachage usuelles, notre construction présente uneréduction de sécurité : inverser la fonction de hachage revient exactement à décoder.Il y a peu de propositions de fonctions à sécurité : la notre et celle de Lenstra et al.qui repose sur la théorie des nombres [CLS06].Sécurité en pratique En pratique, nous avons étudié les algorithmes de déco-dage basés sur la méthode de la recherche d'ensembles d'informations dont il existebeaucoup de variantes [Bar98]. Ces méthodes sont génériques, mais elles sont fa-ciles à adapter aux cas des mots réguliers. La complexité de ces algorithmes estexponentielle en r, la taille du haché. Il est alors possible de concevoir un jeu deparamètres tel que le coût de cet algorithme soit de l'ordre de 280, comme je l'aifait avec Matthieu Finiasz [AFS03].
Notre fonction de compression prête cependant le �anc à une autre attaque, quiest celle du paradoxe des anniversaires généralisé de Wagner [Wag02]. La complexitéde cette méthode est aussi exponentielle, mais avec un exposant plus petit.
Cette remarque sur notre première proposition de paramètres a été faite par Co-ron et Joux [CJ04], ce qui permet de casser notre premier jeu de paramètres. Tou-tefois la complexité reste exponentielle, et le schéma de principe reste bon. Il su�tsimplement de réajuster les paramètres, comme nous l'avons fait dans [AFS05a,AFS05b, AFS05c].E�cacité Notre fonction de compression nécessite très peu de calculs : il su�t defaire un produit matrice-vecteur, à coe�cients dans le corps F2. La seule opérationarithmétique mise en ÷uvre est le xor binaire, très peu coûteux. Le tableau 5.1présente des jeux de paramètres pour lesquels la sécurité est établie. On voit qu'ily a compromis entre la taille de la matrice H et le nombre de xor à e�ectuer parbit du message.
En pratique, nous avons constaté que le facteur limitant la rapidité de la fonctionde hachage est la latence des accès mémoire : la matrice H étant assez grosse, ellene contient pas dans la mémoire cache des processeurs, et les accès à la mémoiredeviennent prépondérants devant les opérations dans le processeur.
5.3 ConclusionNous avons proposé deux nouvelles constructions de primitives cryptographiques
fondées sur les codes. La première construction, un algorithme de chi�rement, pré-sente l'avantage de présenter des clés plus courtes, mais ne posséde pas de réductionde sécurité : elle a été cassée, sans aucune réparation en vue. On voit cependant quele problème du décodage des Reed-Solomon est potentiellement intéressant pour lacryptographie (Kiayias et Yun [KY01b, KY01a, KY02b, KY02a, KY05]), mais laréalisation de primitives cryptographiques e�caces et pertinentes est un objectiffuyant.
La deuxième construction, plus basique, d'une fonction de hachage, présente uneréduction de sécurité. Mais il a été assez di�cile de concevoir un jeu de paramètresgarantissant une bonne sécurité.
Cette fonction de hachage complète la famille des cryptosystèmes fondés sur lescodes : le chi�rement était couvert par McEliece [McE78], la signature par Courtois,

5.3. Conclusion 51log2
(nw
)w n NXOR matrix size
16 41 2686976 64.0 ∼ 1 Gbit15 44 1441792 67.7 550 Mbits14 47 770048 72.9 293 Mbits13 51 417792 77.6 159 Mbits12 55 225280 84.6 86 Mbits11 60 122880 92.3 47 Mbits10 67 68608 99.3 26 Mbits9 75 38400 109.1 15 Mbits8 85 21760 121.4 8.3 Mbits7 98 12544 137.1 4.8 Mbits6 116 7424 156.8 2.8 Mbits5 142 4544 183.2 1.7 Mbits4 185 2960 217.6 1.1 Mbits
Tab. 5.1 � Choix de paramètres pour r = 400 et a = 4. NXOR est le nombre dexor bit à bit à e�ectuer, par bit de message (tableau compilé par M. Finiasz).
Finiasz et Sendrier [CFS01], et le hachage par notre proposition. Cependant ellesou�re, comme les autres systèmes fondés sur les codes, du défaut de devoir stockerune matrice de grande taille.

52 Chapitre 5. Utilisation de problèmes de codage en cryptographie

Chapitre 6
Cryptographie fondée sur le
protocole de Di�e-Hellman
L'archétype même du protocole d'échange de clé est le protocole de Di�e-Hellman [DH76]. Étant donné un générateur g d'un groupe cyclique, deux utili-sateurs Alice et Bob peuvent convenir d'une clé secrète comme suit :
1. Alice envoie sur un canal public gxa à Bob ;2. Bob envoie sur un canal public gxb à Alice ;3. Alice peut calculer (gxb)xa , Bob peut calculer (gxa)xb ;4. ces deux données sont égales, elles peuvent servir de clé partagée dans une
application ultérieure.Dans ce chapitre, je décris deux travaux que j'ai e�ectués en vue d'applica-
tions directes, et ces deux travaux reposent tous les deux sur le protocole de Di�e-Hellman. Le premier travail étudiait certains problèmes relatifs aux droits d'auteurs,le deuxième traitait de problèmes de distibution de clé dans des réseaux sans �l.Protection des droits d'auteurs Avec Caroline Fontaine, dans le cadre du pro-jet européen Aquarelle (1996-2000), j'ai utilisé le protocole de Di�e-Hellman pourmettre en ÷uvre une autorité de certi�cation dans un schéma de protection dedroits d'auteurs, dans le projet européen Aquarelle pour la di�usion du patrimoineculturel européen.
La technique utilisée pour protéger les droits d'auteurs était celle du marquaged'image : on incruste une information invisible dans l'image, de sorte à identi�erle propriétaire de l'image. Notre contribution a été de dé�nir comment gérer lesclés dans un système complet de marquage d'images, en faisant abstraction del'algorithme de marquage lui-même [Aug96b, AF97, AF98, ADF98, ABD+99].Réseaux sans �l Dans un autre contexte d'application, les réseaux Ad Hoc, j'aiencadré la thèse de Raghav Bhaskar, qui a travaillé sur la généralisation du protocolede Di�e-Hellman à un nombre quelconque de participants. Il n'y a pas de généralisa-tion immédiate, ni canonique, du protocole de Di�e-Hellman, et de nombreuses pro-positions ont été avancées, dont notamment le protocole CLIQUE [AST00, STW00,STW96], les protocoles à base d'arbre [KPT00] et le protocole BM [BD95]. Nousavons contribué au domaine en proposant un nouveau protocole, qui présente la ca-ractéristique intéressante de résister au pertes de message. Nous avons à la fois uneproposition cryptographique avec une preuve de sécurité [ABIS05, ABIS07], maisaussi avec nos collègues de HiperCom, nous spéci�ons complètement ce protocoledans les réseaux avec perte de message [BMA+06].
53

54 Chapitre 6. Cryptographie fondée sur le protocole de Di�e-Hellman
6.1 Protection des droits d'auteurs
6.1.1 Le projet européen AquarelleDans le cadre du projet européen Aquarelle (1996-2000), j'ai eu à m'occuper,
avec Caroline Fontaine, des problèmes liés à la protection d'images di�usées surInternet. Ce projet européen, très important en nombre de participants, visait àuni�er et à intégrer les ressources patrimoniales européennes, des grands muséesnationaux ou d'instituts privés. Le but de cette uni�cation était de présenter unaccès cohérent au patrimoine culturel européen, en utilisant le Web, alors naissant.
Les partenaires culturels s'étaient inquiétés du problème de la protection desdroits d'auteurs relatifs aux images di�usées par le système. La solution envisagéeétait d'utiliser la technique du marquage d'images (watermarking). Cela consisteà rajouter une sorte de �ligrane, invisible à l'÷il nu, mais qui peut être détectéesuivant un procédé donné. Ce �ligrane contient de l'information au sujet de l'ayant-droit sur l'image.
6.1.2 Problèmes de clés relatifs au marquage d'imagesTrès vite, il est apparu que la notion de marquage n'était pas claire. Principale-
ment le problème se pose de savoir comment l'opération de marquage est paramétréepar des clés. En e�et, si on a une opération de marquage �xe, sans clé, notée f :
f(I,M) 7→ I∗
où M est un message à camou�er, I l'image, et I∗ l'image marquée, alors l'attaquant,qui connaît f ,1 peut déterminer comment le marquage a été fait, et enlever lamarque.
Il faut donc supposer que l'opération de marquage est paramétrée par une cléK :
fK(I,M) 7→ I∗,
de sorte que l'attaquant, pour retirer la marque, doit essayer toutes les clés K.Le problème se situe au niveau de la preuve de l'existence de la marque : pour
cela il faut détenir la clé K. Se pose alors la problématique suivante :� soit le propriétaire de l'image, disposant de la clé K, e�ectue la véri�cationlui même, mais il ne peut pas convaincre autrui ;
� soit il donne la clé K pour permettre à autrui de véri�er l'existence de lamarque. Dans ce cas, il compromet la sécurité de la marque, puisqu'il a révéléla clé K de marquage.
Nous avions décidé de faire e�ectuer la véri�cation de la marque par un tiersde con�ance. C'est quelqu'un qui est considéré comme �able à la fois par les ayant-droits et par les personnes désirant avoir une preuve de l'existence de la marque.
6.1.3 Séparation du marquage et de la véri�cationIl reste alors le problème de savoir qui e�ectue l'opération de marquage. Si
le marquage est à la charge du tiers de con�ance, alors se pose le problème delui transférer les images non marquées de manière sécurisée. De plus, si le tiersde con�ance gère de nombreux ayants-droit, il peut succomber sous une chargede calcul trop lourde (les algorithmes de marquage dont nous disposions en 1996prenaient de l'ordre d'une minute pour marquer une seule image).
1Je rappelle les principe de Kerckho� en cryptographie, qui stipule que le secret doit résider
dans les clés et non pas dans les méthodes ou les algorithmes, qui �nissent en général par être
éventés.

6.2. Réseaux sans �l 55Nous avons décidé de répartir le travail comme suit : à charge de l'ayant droit
de marquer les images, à charge du tiers de con�ance de véri�er le marquage. Ainsile coût du marquage n'était pas reporté sur les tiers de con�ance.
Les clés de marquage doivent alors être partagées entre l'ayant-droit et le tiers decon�ance. Nous avons proposé d'employer le protocole de Di�e-Hellman pour éta-blir la clé entre l'ayant-droit et le tiers de con�ance [Aug96b, AF97, AF98, ADF98,ABD+99].
Dans le cadre du projet Aquarelle, nous avons réalisé un prototype (DHWM :Di�e-Hellman Watermarking) de l'échange de clés entre les deux parties, suivies dela phase de marquage, et de la phase de véri�cation. Pour la partie marquage etvéri�cation du marquage proprement dite, nous avons travaillé sur deux algorithmesproposés par l'Université Catholique de Louvain (Benoit Macq, Jean-François De-laigle). En�n, pour la partie réseau, nous avons utilisé le protocole HTTP (version 1.0à l'époque). La principale di�culté était lors de l'étape de véri�cation de la marque :le chargement d'une image par le serveur implémentant le tiers de con�ance néces-site un processus de upload qui était très mal documenté.
Ce prototype a fait l'objet d'une démonstration devant des représentants de laComission Européenne.
Ces travaux sont anciens, et je n'ai pas poursuivi dans cette direction par la suite.Par souci de complétude, je signale que les domaines de la cryptographie et du mar-quage ont évolué pour se rencontrer, pour dé�nir la sécurité du marquage [Fur05,CDF06], et pour aussi introduire le � marquage à clé publique � [UUC+05]. Doncla séparation que nous avions faite entre cryptographie et marquage n'est plus d'ac-tualité.
6.2 Réseaux sans �l
6.2.1 La variante de Hughes du protocole de Di�e-HellmanLes protocoles de mise en accord de clé semblent intéressants pour instiller de
la sécurité dans des petits réseaux sans �l. En e�et sur de tels canaux de communi-cation, il est facile d'écouter les messages transmis, et d'injecter des messages frau-duleux. Une solution intéressante est d'utiliser la cryptographie symétrique, pourchi�rer les messages a�n d'obtenir de la con�dentialité, et aussi pour authenti�erles messages. Les méthodes pour atteindre ces objectifs nécessitent l'existence d'uneclé partagée par tous les membres du réseaux. Il reste alors le problème de mettretous les membres du réseau d'accord sur une clé secrète.
Le protocole de Di�e-Hellman permet à deux utilisateurs de se mettre d'accordsur un clé partagée, en échangeant seulement des données publiques. Il n'est pasévident de généraliser ce protocole à m utilisateurs. Avec Raghav Bhaskar, nousavons proposé un protocole d'échange de clé basé sur la variante dite de Hughesdu protocole de Di�e-Hellman [Hug94]. Cette variante, présentée informellement àCRYPTO'94, est peu connue. Elle est présentée dans le livre de Schneier, deuxièmeédition [Sch95]. Je la rappelle ici :
1. Alice envoie sur un canal public gxa à Bob ;2. Bob envoie sur un canal public gxaxb à Alice ;3. Alice peut calculer (gxaxb)x−1
a = gxb ;4. Alice et Bob partagent donc gxb .On voit que le secret gxb est �xé par Bob, et ne dépend pas de la contribution
d'Alice gxa . C'est ce que nous utiliserons.

56 Chapitre 6. Cryptographie fondée sur le protocole de Di�e-Hellman
6.2.2 Pour un nombre quelconque d'utilisateursPour généraliser à m+1 utilisateurs M0, . . . ,Mm, on va d'abord supposer qu'ils
sont d'accord sur un chef M0. Le protocole se déroule comme suit :1. chaque membre Mi, i ∈ {1, . . . ,m}, envoie au chef M0 gxi , qu'on appelera sa
contribution ;2. le chef M0 répond gxix0 à chaque membre Mi, ∈ {1, . . . ,m} ;3. chaque membre Mi peut calculer (gxix0)x−1
i = gx0 : tous les membres par-tagent donc gx0 .
Pour rendre la clé réellement dépendante des contributions de chaque membre,on décide que la clé partagée sera
gx0∏
i∈{1,...,m}
gxix0 .
6.2.3 Preuve de sécuritéUne preuve de sécurité, d'un tel protocole, est une réduction d'un problème
décisionnel réputé di�cile à celui d'une attaque sur la clé partagée. Ainsi on déduiraqu'un attaquant e�cace ne peut pas exister, car on pourrait l'utiliser pour résoudrele problème di�cile.
Très précisément, il faut dé�nir le modèle de sécurité qui dé�nit le cadre danslequel la réduction va se faire [BCP02, KY03] :
1. modélisation précise des participants, d'exécutions concurrentes du protocole ;2. modélisation de la notion de session, et des changements dynamiques de la
composition du groupe ;3. modélisation de l'attaquant : les moyens mis à sa disposition, et ses objectifs.
Raghav Bhaskar, dans sa thèse, a prouvé la sécurité de ce protocole contre un ad-versaire passif (qui se contente d'écouter les communications). Pour un adversaireactif, il su�t de faire une transformation générique due à Katz et Yung, qui consisteà authenti�er tous les messages échangés avec des signatures électroniques [KY03].Toutefois, pour des raisons d'e�cacité, Raghav Bhaskar a construit une versiondirectement authenti�ée du protocole, qui nécessite moins d'échanges que la trans-formation générique de Katz et Yung. Les deux versions du protocole admettentune preuve de sécurité dans le cas de l'adversaire actif [ABIS07].6.2.4 Résistance aux pertes de messages
Nous comparons notre protocole aux protocoles existants dans les tables 6.1 et6.2. La table 6.1 rassemble les protocoles ayant un nombre non constant d'étapes,alors que la table 6.2 présente les protocoles ayant un nombre constant d'étapes.Notre protocole se compare favorablement aux protocoles existants.
Mais surtout, notre protocole résiste aux pertes de messages comme suit :� si un membre Mi échoue à faire parvenir sa contribution à M0, celui-ci ne levoit pas, mais le protocole fonctionne correctement pour le reste du groupe ;� si un membre ne reçoit pas la réponse du chef, il échoue à calculer la clé, maisle reste du groupe calcule correctement la clé.
Ces propriétés rendent notre protocole bien adapté aux réseaux sans �l, où lespertes de message sont fréquentes.
De plus notre protocole présente l'intêrêt qu'il su�t de se mettre d'accord surun chef, les autres membres n'ayant pas besoin de structurer. L'inconvénient est quele chef a une charge de calcul plus lourde que les autres participants : le protocoleest déséquilibré, et nous l'appelons AGDH (Asymetric Group Di�e-Hellman).

6.2. Réseaux sans �l 57Expo par membre Messages Broadcasts Étapes
ITW [ITW82] m m(m− 1) 0 m− 1GDH.1 [STW96] i + 1 2(m− 1) 0 2(m− 1)GDH.2 [BCP02] i + 1 m− 1 1 mGDH.3 [STW96] 3 2m− 3 2 m + 1Perrig [Per99] log2 m + 1 m m− 2 log2 mDutta [DB05] log3 m m m log3 m
Tab. 6.1 � Récapitulatif des protocoles à grand nombre d'étapess pour m membres.Expo par membre Messages Étapes Structure
Octopus [BW98] 4 3m− 4 4 HypercubeBDB [BD95, KY03] 3 2m 2 CercleCatalano [BC04] m + 1 m(m− 1) 2 AucuneKLL [KLL04] 3 2m 2 Cercle
NKYW [NLKW04] 2‡ m 2 chefSTR [KPT04] (m− i)∗ m 2 arbre
Le notre (AGDH) 2∗∗ m 2 chef† : m exponentiations pour la station de base.‡ : m + 1 exponentiations et (m− 1) inverse pour le n÷ud parent.∗ : jusqu'à 2m exponentiations pour le n÷ud � sponsor �.∗∗ : m exponentiations pour le chef.Tab. 6.2 � Présentation des protocoles ayant un nombre constant d'étapes, pour mmembres.
6.2.5 De la cryptographie aux réseauxCes bonnes propriétés du protocole ont intéressé nos collégues de l'INRIA tra-
vaillant dans le domaine des réseaux sans �l. Avec Raghav Bhaksar, Cédric Adjih, etPaul Mühlethaler du projet HiperCom, j'ai travaillé à la spéci�cation du protocolepour les réseaux sans �l [BMA+06]. La principale di�culté est de s'assurer que tousles membres ont bien la même vision du groupe, et qu'ils sont d'accord sur le chef.
Pour cela, le chef du groupe émet périodiquement des messages IGROUP, dans le-quel il inclut sa réponse cryptographique telle que précédemment, et la compositiondu groupe, telle qu'il la conçoit. De son coté, chaque membre Mi envoie un messageIREPLY, où il met sa contribution cryptographique. On maintient, au niveau de tousles participants, les deux propriétés suivantes :
� chaque membre sait l'existence d'un chef et la composition du groupe à laréception des messages IGROUP ;
� le chef connait les membres qui sont présents dans le groupe à la réceptiondes messages IREPLY qu'il reçoit.
Il y a un problème de démarrage du processus. Nous le réglons avec un mécanismed'auto-élection du chef : quand un membre ne reçoit pas de messages IGROUP, ildécide de s'auto-élire chef. Cela se produit en cas de défection du chef, ou en casde scission du réseau. Ce mécanisme d'auto-élection peut présenter des con�its,quand plusieurs membres s'élisent chef simultanément. Une règle simple permet derésoudre ces con�its : est chef celui qui a l'identi�ant le plus faible (adresse MAC,adresse IP, etc).
Les travaux sont en cours pour spéci�er complètement ce protocole : la des-cription simple en quelques lignes, vue ci-dessus, donne lieu à plusieurs pages depseudocode pour décrire tous les états de tous les membres, avec leurs transitions.

58 Chapitre 6. Cryptographie fondée sur le protocole de Di�e-Hellman
Sécurité dans le monde réel Une question di�cile est de savoir si le protocole,ainsi adapté et spéci�é pour les réseaux avec perte de messages, est toujours sûrau sens formel (c'est-à-dire qu'il admet une preuve de sécurité). En e�et, dansnotre adaptation, il y a beaucoup de répétitions des messages IGROUP du chef, pourcon�rmer sa vision du groupe, et aussi des messages IREPLY des membres pourcon�rmer leur présence. De plus la notion de session devient assez di�use quand lesnotions temporelles paraîssent.
En résumé, les notions très formelles des modèles cryptographiques standardsdeviennent �oues dans notre adaptation aux réseaux sans �l. La problématique derecherche qui se pose est de prouver la sécurité du protocole adapté. Cela passed'abord par dé�nir un modèle de sécurité, qui doit nécessairement dévier de ceuxproposés en standard dans la littérature [BR94, BCPQ01, KY03].
6.3 ConclusionLe protocole de Di�e-Hellman, considéré comme fondateur en 1976 de la crypto-
graphie à clé publique, se révèle être très intéressant pour les applications. En ce quime concerne, je suis passé d'une utilisation heuristique de ce protocole (marquaged'image), à une utilisation plus rigoureuse (réseaux sans �ls). Dans le premier cas, jen'avais pas établi de preuve de sécurité du protocole mis en place pour le marquaged'images, alors que dans le deuxième cas, avec Raghav Bhaskar, nous avons fourniun preuve de sécurité du protocole cryptographique.
Pour ce dernier cas, nous avons tenté d'adapter le protocole au cas des réseauxavec perte de message. Cela est assez di�cile de bien spéci�er le protocole réel, etdu point de vue théorique, le modèle de sécurité cryptographique ne re�ète plusl'application réelle. Développer un modèle de sécurité est la première étape avantde fournir la preuve de sécurité. Mais cela est di�cile, et notamment, c'est la notionmême de session qui pose problème, comme souligné dans [BM06].

Troisième partie
Conclusion et perspectives
59


Chapitre 7
Conclusion et perspectives de
recherches
En guise de conclusion, je vais présenter des axes de recherche, dans la continuitédu codage algébrique. Le codage algébrique est le mieux incarné par les codes deReed-Solomon, et les codes géométriques, qui sont de très bons codes, massivementutilisés en pratique. Alors que ces codes étaient jusque maintenant décodés sur labase de la � décision dure � les travaux de Kötter et Vardy [VK00, KV03] ont ou-vert la porte au décodage � à décision souple � des codes de Reed-Solomon, surla base de l'algorithme de Guruswami-Sudan et de l'introduction de multiplicitésvariables dans l'interpolation bivariée. Toutefois de nombreux problèmes se posentpour traduire cette approche dans les applications, le principal étant celui de l'im-plémentation. Les deux étapes des algorithmes à base d'interpolation (interpolationbivariée et recherche de racines) sont encore trop coûteuses pour atteindre les débitsde transmission exigés actuellement, sur du matériel raisonnable.
Mes propositions de travaux futurs sont : le décodage en liste des codes deReed-Solomon et des codes géométriques ; la construction des codes géométriques etl'étude des algorithmes classiques (non basés sur l'interpolation) pour les décoder ;en�n l'étude des aspects négatifs du problème du décodage pour construire descryptosystèmes fondés sur les codes d'évaluation.
7.1 Décodage des codes de Reed-Solomon avec l'al-gorithme de Guruswami-Sudan
Je propose d'abord de développer des méthodes pour l'implantation e�cace del'algorithme de Guruswami-Sudan. En e�et les auteurs se sont contentés de décrireleurs algorithmes comme étant de complexité polynomiale, en utilisant comme boîtesnoires deux briques provenant du calcul formel : la résolution exacte de systèmesd'équations linéaires et la factorisation de polynômes à plusieurs variables sur lescorps �nis. Si des algorithmes ont été proposés pour résoudre ces problèmes, iln'est pas clair quel est le plus susceptible d'être appliqué en pratique. Il faut doncles implémenter pour mieux saisir leur e�cacité. J'ai déjà une implémentation enlangage de bas niveau, C, dans le cas où les multiplicités sont égales à 1, mais le casdes multiplicités supérieures semble plus di�cile à implanter de manière e�cace. Jecompte développer les algorithmes utilisant des bases de Gröbner qui interviennenten tant qu'objets dans l'étape d'algèbre linéaire et il semble que des techniques dechangement de bases [FGLM93] peuvent être employées pour obtenir le polynômeminimal d'interpolation [LO06] ; quant à l'étape de factorisation, je compte la rendre
61

62 Chapitre 7. Conclusion et perspectives de recherches
�factorisation-free�, ce qui a déjà été possible dans le cas de l'algorithme de Sudansimple, avec multiplicité égale à un.
7.2 Généralisation en codes géométriques
L'axe majeur de mes futurs travaux sera la construction des codes géomé-triques et le développement de leurs algorithmes de décodage. Comme déjà dit, lescodes géométriques permettent de remédier à un défaut majeur des codes de Reed-Solomon : la taille de l'alphabet d'un code de Reed-Solomon doit être supérieureà la longueur du code, ce qui empêche d'utiliser des codes de Reed-Solomon trèslongs. Les codes géométriques présentent l'avantage, à alphabet �xé, de permettrede construire des codes aussi longs que l'on désire. Réciproquement, à longueurdonnée, on peut se permettre d'avoir un alphabet plus petit, donc plus maniable.L'utilisation de cette dernière propriété a été étudiée dans pour accélérer le décodagedans [BS04], et aussi dans le contexte du codage pour les disques durs dans [MM05].
Il faut étudier l'algorithme de Guruswami-Sudan pour les codes géométriques.En e�et, la généralisation des codes de Reed-Solomon aux codes géométriques étantnaturelle, la généralisation aux codes géométriques se fait correctement [GS99].
Comme pour les codes de Reed-Solomon, il faut faire baisser la complexité desalgorithmes. Le travail d'implantation reste à faire, et de grandes connaissances descourbes algébriques sont nécessaires, pour manier e�cacement les outils à mettre en÷uvre. Toutefois, toute amélioration obtenue dans le cas des Reed-Solomon s'éten-dra peu ou prou aux cas des courbes géométriques, à condition de généraliser avecles bons objets. Donc les bonnes idées obtenues pour le cas des Reed-Solomon de-vraient se prolonger naturellement au cas des codes géométriques.
Une nouvelle question se pose, qui n'existe pas dans le cas des codes de Reed-Solomon (car ceux-ci sont uniquement déterminés, alors que la classe des codes géo-métriques est très variée) : peut-on construire (et décoder) des codes géométriquesqui sont bons pour le décodage en liste ? En e�et, Guruswami à montré [Gur04] quedes codes bons pour le critère classique de la distance minimale peuvent prétendre àêtre bons pour le décodage en liste, mais que l'on peut obtenir des résultats encoremeilleurs en essayant de chercher directement des codes bons pour le décodage enliste.
En�n, ces algorithmes de décodage, bien que très prometteurs en termes decapacité de correction, ne sont pas aussi bien �nalisés que les algorithmes à base decalcul de syndrome, comme survolés dans [HP95]. Ces derniers algorithmes sont biencompris, et des implantations matérielles ont déjà été soit proposées, soit réalisées àtitre de prototype [AKS04]. Je pense qu'on peut encore améliorer ces algorithmes, enutilisant l'arithmétique rapide des polynômes. La transformée de Fourier discrèteest en e�et très rapide en caractéristique 2, même en très petite longueur : parexemple on a 1014 multiplications pour la longueur 511 [Fed06].
7.3 Cryptographie basée sur les codes de Reed-So-lomon
Comme déjà mentionné, la di�culté du décodage a été établie pour la classerestreinte des codes de Reed-Solomon [GV05], qui sont, avec les codes géométriques,le point central de mon programme de recherche. C'est une aubaine, car cela permetd'avoir des instances di�ciles d'un problème en cherchant dans une classe plusrestreinte. Cela signi�e, par exemple, que les instances di�ciles sont plus courtes àspéci�er, ce qui pourrait se traduire, en cryptographie, par des clés publiques plus

7.3. Cryptographie basée sur les codes de Reed-Solomon 63courtes. Je cherche donc à construire des cryptosystèmes basés sur le problème dudécodage des codes de Reed-Solomon.
Le système de chi�rement que j'ai proposé a été cassé, car il était mal fondé :il existait une attaque autre que l'attaque frontale du problème du décodage sous-jacent. Je propose de construire des systèmes cryptographiques bien fondés sur ladi�culté du décodage des codes de Reed-Solomon. Pour cela je commencerai avecles travaux de Kiayias et Yung [KY05], qui sont capables d'utiliser la primitive dudécodage des codes de Reed-Solomon dans diverses constructions cryptographiques.Ils ont déjà fait le travail de prouver les bonnes propriétés cryptographiques du pro-blème du décodage des codes de Reed-Solomon, et sont capables de bâtir des primi-tives cryptographiques avec les bonnes réductions de sécurité. Toutefois les primi-tives obtenues sont quelque peu ésotériques, et je me concentrerai sur la constructionde primitives plus classiques.
Il semble intéressant de se poser ici aussi la question de la généralisation auxcodes géométriques. La question théorique qui se pose ici, est d'établir la di�cultédu décodage pour des codes géométriques à alphabet �xé. Un résultat partiel est dûà Cheng [Che05], qui ne s'applique qu'aux codes géométriques dé�nis sur les courbeselliptiques, dont l'alphabet croît exponentiellement en la longueur du code. Or lescodes géométriques sont intéressants en ce qu'on peut faire croître la longueur enconservant une taille �xe pour l'alphabet. En conséquence, si des cryptosystèmespeuvent être construits sur le problème du décodage des codes géométriques, ilsdevraient avoir des clés plus courtes que ceux construits avec les codes de Reed-Solomon, car utiliseraient un alphabet plus petit.

64 Chapitre 7. Conclusion et perspectives de recherches

Quatrième partie
Présentations détaillées
65


Chapitre 8
Décodage des codes cycliques
avec les bases de Gröbner
Ce chapitre est consacré à mes travaux sur le décodage des codes cycliques géné-raux, jusqu'à et au delà de la capacité de correction t = bd−1
2 c, en utilisant la théoriede l'élimination et les bases de Gröbner. Le problème est, à partir des syndromesde l'erreur, de retrouver l'erreur, ou plus précisément le polynôme localisateur del'erreur. Nous verrons qu'il y a deux approches :
� décodage avec syndromes spécialisés ;� décodage avec syndromes symboliques ;
et nous dirons laquelle de ces méthodes est préférable en pratique.Ces travaux sont une prolongation des travaux de ma thèse. En e�et, alors que
dans ma thèse, je me contentais de déterminer, avec des systèmes d'équations al-gébriques, les mots de poids minimal des codes cycliques, je me suis rendu compteensuite que les mêmes méthodes peuvent être utilisées en décodage. Les techniquesemployées pour faire les calculs reposant fortement sur la théorie des bases de Gröb-ner, cela a conduit assez naturellement à une codirection de thèse avec Jean-CharlesFaugère. L'étudiante était Magali Bardet, et nous avons obtenu de nouveaux résul-tats, notamment grâce à la mise en équations donnée par les identités de Newton.
Dans ce chapitre, je présente les propriétés mathématiques de l'idéal engendrépar les équations de Newton, en caractéristique �nie.
8.1 Le problème du décodage des codes cycliques
Soit Fq le corps à q éléments, et n un entier premier à q. Dans le cas de cer-tains énoncés généraux, nous noterons F le corps de base, non nécessairement �ni.Les énoncés les plus signi�catifs en terme de codage seront obtenus sur F2 quenous noterons bien F2. Un code cyclique C de longueur n sur Fq est un idéal deFq[X]/(Xn − 1). L'anneau Fq[X]/(Xn − 1) étant principal, tout code cyclique Cadmet un polynôme générateur g(X), qui divise Xn − 1. En se donnant une ra-cine primitive n-ième de l'unité α sur Fq, avec α ∈ Fqm , on dé�nit l'ensemble dedé�nition Q du code C :
Q = {i ∈ {0, . . . , n− 1}; g(αi) = 0}. (8.1)On a donc
c ∈ C ⇐⇒ c(αi) = 0, ∀i ∈ Q. (8.2)67

68 Chapitre 8. Décodage avec les bases de Gröbner
Soit y le mot reçu, que l'on écrit y = c + e où c étant le mot de code émis et où eest l'erreur. Alors en calculant y(αi), pour i ∈ Q, on obtient
y(αi) = c(αi) + e(αi) = e(αi); i ∈ Q. (8.3)Ainsi, le décodeur connaît les e(αi) pour i ∈ Q, que l'on appelle les syndromes del'erreur. On les note S∗i , i ∈ Q. On note bien que les S∗i sont dans l'extension Fqm deFq, celle où réside la racine n-ième de l'unité. De plus, comme e(X) est à coe�cientsdans Fq, on a e(αi)q = e(αiq mod n), soit
S∗iq = S∗iq mod n, i ∈ Q. (8.4)
Nous dirons qu'une famille de S∗i , i ∈ {0, . . . , n − 1}, véri�ant les équations (8.4)est admissible pour le problème du décodage. Nous sommes en mesure de formulerle problème du décodage d'un code cyclique.Problème : Décodage par syndrome d'un code cyclique
Instance : � q une puissance d'un nombre premier, une représentation du corps�ni Fq ;� n premier à q, une représentation de Fqm , le corps de décomposition deXn − 1 ;
� Q = {i1, . . . , il}, dé�nissant un code cyclique,� t ∈ N,� des syndromes admissibles S∗i1 ,. . ., S∗il
.Question : Existe-t-il e(X) ∈ Fq[X], deg e(X) < n, et w(e) ≤ t tels que
e(αi) = S∗i , i ∈ {i1, . . . , il}.
C'est le strict pendant du problème du décodage par syndrome, adapté au casparticulier des codes cycliques, et que nous donnons ci-dessous :Problème : Décodage par Syndrome (d'un code quelconque).Instance : Une matrice r × n binaire H, un mot S de F r
2 et un entier w > 0.Question : Existe-t-il un mot x dans Fn
2 de poids ≤ w tel que HxT = S ?Le problème Décodage par Syndrome est NP-complet [BMvT78]. Le cas descodes cycliques n'est pas connu. Guruswami et Sudan on récemment démontré quele décodage des codes de Reed-Solomon est aussi NP-complet [GV05]. Or les codesde Reed-Solomon peuvent être vus comme des codes cycliques pour lesquels n|q−1,c'est-à-dire des codes dé�nis sur Fq de longueur n telle que le corps de décompositionde Xn−1 est Fq. Cela pourrait indiquer que le décodage de certains codes cycliquesest un problème di�cile. Mais les codes de Reed-Solomon intervenant dans la preuvesont tels que la taille de l'alphabet est très grande par rapport à la longueur. Celane dit donc rien d'intéressant relativement au problème du décodage des codescycliques binaires, par exemple.
8.2 Les équations de NewtonIl y a à distinguer le cas binaire q = 2, et le cas dit q-aire. La di�érence avec
le cas q-aire, en ce domaine est fondamentale : les syndromes, qui sont dans le casq-aire certains coe�cients de la transformée de Fourier, deviennent les fonctionspuissances des localisateurs de l'erreur, que nous dé�nissons comme suit. Dans lecas binaire, si par exemple e = (e0, . . . , en−1) est l'erreur, alors les localisateurs dee sont les Z∗
i = αji , où j1, . . . , jw sont les indices des positions non nulles de e, et

8.2. Les équations de Newton 69où w est le poids de l'erreur. Par exemple, si e = (0, 1, 0, 0, 1), le poids de e est 2,et les localisateurs sont Z∗
1 = α1 et Z∗2 = α4. Nous avons alors
S∗j =w∑
i=1
ei · (αj)i=∑
i|ei 6=0
(αi)j =w∑
i=1
(Z∗i )j , j ∈ {1, . . . , n}. (8.5)
Dans le cas q-aire, nous notons Y ∗i , i ∈ {1, . . . , w} les valeurs de e sur ses positions
non nulles. Par exemple, soit le mot e = (0, β, 0, 0, β + 1), dé�ni sur F4, avec β2 =β + 1, nous lui associons ses localisateurs comme précédemment, mais nous luiassocions aussi Y ∗
1 = β, et Y ∗2 = β + 1.
Nous notons F la transformée de Fourier :F : Fq
n → Fqn
e 7→ S∗ = (S∗0 , . . . , S∗n−1)(8.6)
où nous notons encore S∗j = e(αj). On a alors
S∗j =w∑
i=1
ei · (αj)i=∑
i|ei 6=0
ei(αi)j =w∑
i=1
Y ∗i (Z∗
i )j , j ∈ {1, . . . , n}.
Dé�nissons les fonctions symétriques des localisateurs de e :σ∗i =
∑1≤j1<...,ji≤w
X∗j1 · · ·X
∗jw
, i ∈ {1, . . . , w}, (8.7)
et le polynôme localisateur
σ∗(Z) = 1 +w∑
i=1
σ∗i Zi =w∏
i=1
(1− Z∗i Z). (8.8)
Les algorithmes de décodage des codes cycliques se focalisent sur le problème detrouver le polynôme localisateur de l'erreur, en fonction des syndromes de l'erreur.Il reste alors le problème de trouver les racines du polynôme localisateur, maison considère que c'est un problème facile à résoudre en pratique, par la méthodedite de Chien [Chi64], qui est une recherche exhaustive e�cace. Donc nous nousconcentrerons sur le problème de trouver les σi. Le lien entre les syndromes (qui sontles fonctions puissances ou les coe�cients de la transformée de Fourier) est donnépar les relations de Newton. Dans la notation qui suit, nous enlevons l'astérisque∗ pour indiquer que l'on considère les systèmes polynomiaux d'indéterminées σi etSi.Proposition 1. Soit e ∈ Fq[X]/(Xn − 1) un mot de poids w, alors sa transforméede Fourier S∗n et les fonctions symétriques élémentaires associées σ∗w véri�ent lapartie circulaire des identités de Newton IC,n,w
IC,n,w =
Sw+i mod n +w∑
j=1
σjSw+i−j mod n, i ∈ {1, . . . , n}
; (8.9)
Si, de plus, e est à coe�cients 0 ou 1 (c'est le cas lorsque e ∈ F2[X]/(Xn− 1)), sesfonctions puissances et symétriques élémentaires véri�ent la partie triangulaire desidentités de Newton :
IT,w = {Si +i−1∑j=1
Si−jσj + iσi i ∈ {1, . . . , w}}. (8.10)

70 Chapitre 8. Décodage avec les bases de Gröbner
Nous numérotons les équations de Newton précisément comme suit :
eqi :
Si +
i−1∑j=1
σjSi−j + iσi, i ≤ w,
Si +w∑
j=1
σjSi−j , i ≥ w.
(8.11)
On peut aussi écrire la partie circulaire des identités de Newton sous la formepolynomiale suivante :
S(Z)σv(Z) = 0 mod Zn − 1, avec S(Z) =n∑
i=1
SiZn−i et σv(Z) = 1 +
v∑i=1
σiZi.
(8.12)Notons une troisième écriture de la partie circulante des équations de Newton, sousforme matricielle. Soit la matrice CS :
CS =
S0 S1 . . . Sn−2 Sn−1
S1 S2 . . . Sn−1 S0... ...Sn−1 S0 . . . Sn−3 Sn−2
. (8.13)
Alors IC,n,w s'écrit :
CS
σw
σw−1...σ1
10...0
= 0. (8.14)
En�n, dans le cas où le mot e est à coe�cients dans {0, 1}, en utilisant la partietriangulaire des équations de Newton, puis la partie circulante, nous pouvons ré-cursivement exprimer chaque Si en fonction des σi. Par exemple, pour w = 2, leséquations de Newton sont de la forme :
S1 + σ1 = 0S2 + σ1S1 + 2σ2 = 0
S3 + σ1S2 + σ2S1 = 0S4 + σ1S3 + σ2S2 = 0
...On obtient :
S1 = σ1
S2 = σ21 + 2σ2
S3 = σ31 + 3σ2σ1
S4 = σ41 + 4σ2σ
21 + 2σ2
2...

8.3. Algorithmes algébriques 71De manière générale, il existe un polynôme Wi = Ww,i(σ1, . . . , σw) tel que
Si = Ww,i(σ1, . . . , σw). (8.15)On a même une formule pour les polynômes Ww,i :
Ww,i(σ1, . . . , σw) =∑
(−1)i2+i4+i6+··· (i1 + i2 + · · ·+ iw − 1)!i1! · · · iw!
i σi11 · · ·σiw
w ,
(8.16)où la somme est prise sur les w-uplets tel que i1 + 2i2 + · · ·+ wiw = i. Ces formulessont appelées les formules de Waring [LN96].
Pour le lecteur non habitué aux corps �nis, nous remarquons que la partie tri-angulaire des équations de Newton ne permet pas d'exprimer facilement les σi enfonction des Si, car des termes iσi peuvent s'annuler lorsque la caractéristique p di-vise i. Ce problème ne se pose pas en caractéristique 0, où on peut toujours exprimerfacilement les fonctions symétriques élémentaires en terme des fonctions puissances.
Les identités de Newton font intervenir les σi, que nous cherchons, les syndromesSi, i ∈ Q, que nous connaissons, mais aussi les Si, i 6∈ Q, que nous ne connaissonspas dans le contexte du décodage. On peut aussi voir le système des équationscomme un système linéaire en les σi, à coe�cients les syndromes connus, mais aussiles syndromes inconnus. Nous allons étudier les propriétés de l'idéal des équationsde Newton, quand on élimine les syndromes inconnus, dans le but de trouver les σien fonction des syndromes Si, i ∈ Q.
J'ai présenté, page 21, un exemple introductif, dû à [RYT90], qui illustre biencette démarche.
8.3 Algorithmes algébriques de décodage des codescycliques
Il est remarquable que, à la vue seule de l'ensemble de dé�nition Q d'un codecyclique C, on soit souvent capable de borner inférieurement la distance minimalede C. On dispose ainsi de la célèbre borne BCH, mais aussi des bornes de Hartman-Tzeng [HT72], de la borne de Roos [Roo83]. Plus remarquable encore est le fait qu'àchacune de ces bornes soit associé un algorithme de décodage jusqu'à t = bd′−1
2 c,où d′ est la borne inférieure que l'on a obtenue sur la distance minimale du codeconsidéré. Dans le cas des codes BCH, on utilise alors l'algorithme de Berlekamp-Massey ou l'algorithme d'Euclide, et on a des généralisations correspondant auxbornes de Hartman-Tzeng et de Roos [FT91]. Ces algorithmes ont la propriétéd'être génériques, en un certain sens : bien que ne s'appliquant pas à tout codecyclique, ils sont capables de décoder tous les codes dont l'ensemble de dé�nitionpermet d'établir la borne BCH, la borne de Hartman-Tzeng ou la borne de Roos.
Toutefois, lorsque l'ensemble de dé�nition du code cyclique C est quelconque, onn'a pas d'algorithme pour décoder C, même si l'on est capable de borner inférieure-ment la distance minimale avec des algorithmes génériques [MS88]. Ainsi, il n'existepas d'algorithme algébrique général pour décoder tout code cyclique. Un des casles plus importants est celui des codes à résidus quadratiques qui sont des codesspéci�ques pour lesquels on n'a pas d'algorithme de décodage général bien que l'onsoit capable de borner a priori la distance minimale, avec la fameuse square-rootbound [PHB98]. Tout au plus dispose-t-on d'algorithmes de décodage pour chaquecas particulier : nous citerons les références [RYT90, RYTH90, RTCY92, CRT94,LWCL95, HRTC01, CTR+03, TCCL05] qui montrent bien qu'un nouvel algorithmede décodage est à concevoir pour chaque longueur de code à résidus quadratiquesconsidéré, à savoir les longueurs 31, 23, 41, 73, 47, 71, 79, 97, et en�n 103 et 113.

72 Chapitre 8. Décodage avec les bases de Gröbner
Dans le cas des codes à résidus quadratiques non binaires, les algorithmes sont en-core dédiés [Hum92, HH93, HH95, HH98]. D'autres codes, dit de Zettelberg, sontencore considérés dans [DN93, DN92], avec des algorithmes encore Ad Hoc.
Quand la longueur des codes à résidus quadratiques croît, la taille des formulescroît, et souvent les auteurs échouent à obtenir des relations de degré 1. Par exemple,pour le code à résidus quadratiques de longueur 41, de capacité de correction 4, lesauteurs [RTCY92] obtiennent une relation de degré 4 pour σ2, en fonction dessyndromes connus. Il faut alors factoriser cette relation, à chaque décodage, pourtrouver 4 valeurs possibles pour σ2, que l'on teste ensuite.
Dans certains cas, la réalisation matérielle (hardware) est envisagée [DN94].Nous faisons notre étude en deux étapes : nous étudions la variété associée à
l'idéal engendré par les équations de Newton, et ensuite nous étudions l'idéal dé�nipar les équations. Nous pensons que cet idéal est radical, mais nous n'avons pule prouver. Nous introduisons un idéal qui le contient, et qui a la propriété d'êtreradical. En�n nous montrons que ce nouvel idéal contient bien des formules de degré1 qui peuvent être utilisées pour le décodage.
8.4 Les travaux sur le décodage avec les bases deGröbner
L'idée de décoder les codes cycliques avec les bases de Gröbner a été introduitepar Chen, Reed, Helleseth et Truong [CRHT94d, CRHT94c]. Ils n'utilisent pas lesrelations de Newton, mais directement l'expression des syndromes en termes deslocalisateurs donnée par
S∗j =w∑
i=1
ei · (αj)i=∑
i|ei 6=0
(αi)j =w∑
i=1
(Zi)j , j ∈ Q; (8.17)
où les S∗j , j ∈ Q sont les syndromes (connus) du mot reçu, et les Zi, i ∈ {1, . . . , v}sont les localisateurs (inconnus) que l'on cherche à déterminer. Ils considèrent undécodage avec syndromes spécialisés : c'est-à-dire que pour chaque mot reçu on cal-cule une base de Gröbner. Ils ont montré que, pour l'ordre lexicographique, une basede Gröbner de l'idéal engendré par ces relations contient le polynôme localisateurde l'erreur. Ce système a ensuite été étudié par Loustaunau et von York [LY97],avec des syndromes non spécialisés, pour obtenir des polynômes tels que, lorsqueles coe�cients sont spécialisés, on obtienne le polynôme localisateur.
Ces systèmes ont été considérés pour le problème de déterminer la distanceminimale d'un code cyclique [MS03, Sal02, Sal03]. Caboara et Mora [CM02] a�nentl'étude de la base de Gröbner du système (8.17), avec des syndromes symboliques,pour améliorer l'analyse de Loustaunau et von York.
À notre connaissance, nos travaux sont les seuls étudiant le système des équationsde Newton.
8.5 Élimination et spécialisationPour tenter d'avoir une notation claire, nous mettrons systématiquement une
astérisque lorsque nous parlerons d'une valeur donnée S∗i ∈ Fqm , par exemple unsyndrome donné d'une erreur donnée ; par opposition au symbole Si qui servirad'indéterminée dans des systèmes d'équations. De même, nous di�érencierons σ∗i ∈Fqm de l'indéterminée σi, et Z∗
i ∈ Fqm de l'indéterminée Zi. Nous dirons aussi queS∗i (resp. σ∗i , Z∗
i ) est une spécialisation de Si (resp. σi, Zi). Nous notons de plusSn (respectivement σv) le vecteur (S0, . . . , Sn−1) (respectivement (σ1, . . . , σv).)

8.6. La variété associée à l'idéal des équations de Newton 73En�n, pour des énoncés généraux, nous utiliserons les indéterminées x1, . . . , xn.
Théorème 1. Soit un idéal I ∈ F[x1, . . . , xn], et Ik = I ∩ F[xk+1, . . . , xn] le k-ième idéal d'élimination. Soit G une base de Gröbner de I pour un ordre éliminantx1, . . . , xk, alors
G ∩ F[x1, . . . , xn]
est une base de Gröbner de Ik.
Théorème 2. Soit un idéal I ∈ F[x1, . . . , xn], et V la variété associée, i.e. l'en-semble des zéros communs des polynômes de I. Soit Vk = Prk(V ), la projection deV sur les n − k dernières coordonnées, et Ik = I ∩ F[xk+1, . . . , xn] le k-ième idéald'élimination. Alors
V (Ik) = Vk, (8.18)où Vk est la fermeture de Vk.
Corollaire 1. Soit un idéal I ∈ F[x1, . . . , xn], Ik le k-ième idéal d'élimination, Vk
la projection de V (I) sur les n− k dernières coordonnées. Si V (Ik) ou Vk est �nie,alors
V (Ik) = Vk.
Autrement dit, toute solution partielle (x∗k+1, . . . , x∗n) ∈ V (I∩F[xk−1, . . . , xn]) s'étend
en au moins une solution (x1, . . . , xn) ∈ V (I).
Soit f ∈ F[y, x], où x = (x1, . . . , xn). Nous notons LT (f) le terme de tête d'unpolynôme f , LT (I) l'ensemble des termes de tête d'un idéal I, et LTy(f) le termede tête de f vu comme un polynôme de Fq[y][x].Théorème 3 (Théorème de spécialisation, cas zéro-dimensionnel [Gia89]).Soit I ⊂ F[y, x] un idéal de dimension zéro, et ϕx∗ une spécialisation x 7→ x∗ detoutes les variables sauf une :
ϕx∗ : F[y, x]→ F[y]. (8.19)Alors il existe un polynôme g ∈ I, tel que ϕx∗(g) engendre ϕx∗(I), et degy g =degy ϕx∗(g).
Proposition 2 ([FGT01]). Soit F[y, x] = F[y, x1, . . . , xn], et soit G une base deGröbner d'un idéal I ⊂ F[y, x], et soit ϕx∗ une spécialisation x 7→ x∗ de toutes lesvariables sauf y. Pour g ∈ I, notons δ(g) = degy g − degy ϕx∗(g), la chute de degréde g, et δ(I) = ming∈I δ(g).
Soit g0 ∈ G de degré minimal en y tel que ϕx∗(g0) 6= 0. Alors ϕx∗(g0) engendreϕx∗(I), et δ(I) = δ(g0). De plus, s'il existe h ∈ I tel que ϕx∗(LTy(h)) 6= 0, alorsdegy g0 = degy ϕx∗(g0), et LT (ϕx∗(I)) = ϕx∗(LTx(I)).
8.6 La variété associée à l'idéal des équations deNewton
La transformée de Fourier véri�e la propriété suivante, relative au poids, suivantce au'énonce le théorème suivant, souvent référencé comme le théorème de Blahut.Nous le donnons dans le contexte de la clôture algébrique de Fq.Théorème 4. Soit S∗(Z) =
∑ni=1 S∗i Zn−i la transformée de Fourier de c ∈ Fn
q .Alors le poids de c est égal au rang de la matrice circulante suivante CS∗ :
CS∗ =
S∗0 S∗1 . . . S∗n−2 S∗n−1
S∗1 S∗2 . . . S∗n−1 S∗0...
...S∗n−1 S∗0 . . . S∗n−3 S∗n−2
. (8.20)

74 Chapitre 8. Décodage avec les bases de Gröbner
Démonstration. Ce théorème est bien connu, dans le cas où c ∈ Fq. Je redonne unepreuve fonctionnant dans le cas de la clôture algébrique. Écrivons c = (c0, . . . , cn−1).On a S∗i
S∗i+1...S∗i+n−1
= F
c0
αic1...α(n−1)icn−1
,
avec
F =
1 1 . . . 11 α1 . . . αn−1
... ... . . . ...1 αn−1 . . . α(n−1)(n−1)
.
Alors :
CS∗ = F
c0 c0 . . . c0
c1 αc1 . . . αn−1c1... ... . . . ...cn−1 αn−1cn−1 . . . α(n−1)(n−1)cn−1
= F
c0 0 . . .0 c1 0 . . .... . . .0 . . . 0 cn−1
F.
Maintenant F est une matrice de Vandermonde inversible, et le rang de la matriceintérieure est égal au poids de c.
Le théorème suivant est une sorte de réciproque des relations de Newton, et faitle lien entre le poids des solutions du système et le poids v pour lequel est écritle système. De plus, il décrit la très forte structure des solutions du système deséquations de Newton.Théorème 5. Soit S∗ ∈ Fn
q et e la transformée de Fourier inverse de S∗.1. La partie circulante du système spécialisé des équations de Newton IC,n,v(S 7→
S∗) a une solutionρ∗ = (ρ∗1, . . . , ρ
∗v) ∈ Fv
2,
si et seulement si le poids w de e est inférieur ou égal à v.2. Soit ρ∗ une solution comme précédemment, si on note
σ∗(Z) =w∏
j=1
(1− Z∗j Z) = 1 +
w∑i=1
σ∗i Zi,
le polynôme localisateur de e, les Z∗j étant les localisateurs de e, et si on construit
ρ∗(Z) = 1 +v∑
i=1
ρ∗i Zi,
à partir de ρ∗, alors ρ∗(Z) est multiple de σ∗(Z).3. Dans le cas où q est une puissance de 2, si S∗ et ρ∗ sont de plus solutions de
la partie triangulaire IT,v(S 7→ S∗), alors e est un mot à coe�cients 0 ou 1, et ilexiste G(Z) ∈ F2[Z], et un entier l ≥ 0, tels que ρ∗(Z) est de la forme
ρ∗(Z) = σ∗(Z)G(Z)2Zl. (8.21)

8.6. La variété associée à l'idéal des équations de Newton 75Démonstration. 1. Prouvons que d'abord s'il existe une solution ρ∗ à IC,n,v(S 7→S∗), alors le poids w de e véri�e w ≤ v. Soit CS∗ la matrice construite à partir de latransformée de Fourier de e comme dans (8.20). À partir de l'expression matriciellede la partie circulante des équations de Newton, on véri�e que la solution (ρ∗1, . . . , ρ
∗v)
conduit à une expression de la (v + 1)-ième colonne de la matrice en termes des vpremières colonnes. De même, la (v + 2)-ième colonne s'exprime linéairement entermes des v colonnes précédentes. La même propriété est véri�ée pour la (v + i)-ième colonne de la matrice, pour i ∈ {1, . . . , n− v}. Ainsi les v premières colonnesengendrent l'espace de toutes les colonnes. La rang de la matrice est donc inférieurou égal à v, et le poids de e est donc inférieur à v d'après le théorème 4.
Réciproquement, si le poids de e est w, avec w ≤ v, alors les fonctions symé-triques élémentaires σ∗1 , . . . , σ∗w des localisateurs de e sont solutions de la partiecirculante des équations de Newton pour le poids w, et on véri�e, à partir de (8.14)que
(σ∗1 , . . . , σ∗w, σ∗w+1 = 0 . . . , σ∗v = 0)
est solution de IC,n,v(S 7→ S∗).2. Soit F ⊂ Fv
q l'ensemble des solutions ρ∗vde IC,n,v(S 7→ S∗). Alors comme le
rang de CS∗ est w, la forme matricielle des équations de Newton (8.14) permet dedire que F est un espace a�ne de dimension v − w. Soit F ′ l'espace
F ′ =
{ρ∗ = (ρ∗1, . . . , ρ
∗v) ∈ Fv
q | σ∗(Z) divise ρ∗(Z) = 1 +v∑
i=1
ρ∗i Zi
},
alors F ′ est aussi un espace a�ne et dim F ′ = v − w. Soit ρ∗ ∈ F ′ et ρ∗(Z) lepolynôme construit à partir de ρ∗, comme σ∗(Z)|ρ∗(Z) et S∗(Z)σ∗(Z) = 0 modZn − 1, on a
S∗(Z)ρ∗(Z) = 0 mod Zn − 1,
c'est-à-dire (ρ∗1, . . . , ρ∗v) ∈ F . Donc F ′ ⊂ F . Comme F ′ et F ont même dimension,
ils sont égaux.3. Soit σ∗(Z) le polynôme localisateur de e, et ρ∗(Z) comme dans l'énoncé du
théorème, alors le point 2. du théorème donne σ∗(Z)|ρ∗(Z). Soit donc Z∗1 , . . . , Z∗
wles localisateurs de e, et Z∗w+1 . . . , Z∗
v les racines de ρ∗(Z) qui ne sont pas racinesde σ∗(Z). Comme S∗ et ρ∗ sont racines des équations de Newton triangulaires, ilsvéri�ent les formules de Waring
S∗i = Wv,i(ρ∗1, . . . , ρ∗v), i ∈ {1, . . . , n} (8.22)
et comme les ρ∗i sont les fonctions symétriques élémentaires de Z∗1 , . . . , Z∗
v , celadonne :S∗i =
v∑j=0
Z∗j
i, i ∈ {1, . . . , n}. (8.23)
D'autre part, S∗ est la transformée de Fourier de e. Soit Y ∗j , j ∈ {1, . . . , w} le
coe�cient de e en la position Z∗j , avec Y ∗
j 6= 0. Le calcul de la transformée deFourier donne
S∗i =w∑
j=1
Y ∗j Z∗
ji, i ∈ {1, . . . , n}. (8.24)

76 Chapitre 8. Décodage avec les bases de Gröbner
En égalisant les termes de droite de (8.23) et (8.24), on obtient la relation matricielle
Z∗1 . . . Z∗
w Zw+1 . . . Z∗v
Z∗12 . . . Z∗
w2 Zw+1
2 . . . Z∗v2
... ...Z∗
1n . . . Z∗
wn Z∗
w+1n . . . Z∗
vn
Y ∗1 + 1...
Y ∗w + 11...1
= 0. (8.25)
En considérant la matrice constituée des v premières lignes de la matrice de droite,nous avons une matrice de Vandermonde, de déterminant(
v∏i=1
Z∗i
) ∏1≤j1<j2≤v
(Z∗j2 − Z∗
j1)
,
qui doit être nul. Cela peut se produire de trois manières, compte tenu du fait queles premiers Z∗
j , j ∈ {1, . . . , w}, sont distincts et non nuls :1. soit l'un des Z∗
j est nul, pour w + 1 ≤ j ≤ v ;2. soit Z∗
j1= Z∗
j2, pour w + 1 ≤ j1, j2 ≤ v ;
3. soit Z∗j1
= Z∗j2, avec 1 ≤ j1 ≤ w et w + 1 ≤ j2 ≤ v.
Dans le cas 1, on peut réécrire (8.25), en enlevant la j-ième colonne de la matrice.On constate que Z∗
j = 0 donne un facteur Z de ρ∗(Z).Dans le cas 2, l'e�et de la caractéristique 2 est d'annuler les termes Z∗
j1et Z∗
j2dans l'équation (8.25), que l'on peut réécrire en enlevant la j1-ième et la j2-ièmecolonne. On constate que Z∗
j1= Z∗
j2contribue à l'apparition d'un facteur carré dans
ρ∗(Z).Dans le cas 3, les colonnes j1 et j2 vont s'additionner, et on obtient une relation
Z∗
1 . . . Z∗w Zw+1 . . . Z∗
v
Z∗12 . . . Z∗
w2 Zw+1
2 . . . Z∗v2
... ...Z∗
1n . . . Z∗
wn Z∗
w+1n . . . Z∗
vn
Y ∗1 + 1...Y ∗
j1...Y ∗
w + 11...1
= 0. (8.26)
où la colonne j2 a disparu de la matrice de gauche, et où le vecteur de droite a unterme en 1 de moins.
Dans les trois cas 1, 2, et 3, on a diminué la taille de la matrice de gauche, enéliminant des colonnes faisant intervenir des Z∗
j , avec w + 1 ≤ j ≤ v. En répétantle processus, on obtient une relation :
Z∗1 . . . Z∗
w
Z∗12 . . . Z∗
w2
... ...Z∗
1n . . . Z∗
wn
Y ∗
1 + ε1...Y ∗
w + εw
= 0, (8.27)
qui ne contient plus les Z∗j , w+1 ≤ j ≤ v, et où εi = 0 ou 1 (e�et de la caractéristique
2). Le déterminant de la sous-matrice issue de w premières lignes est égal à(w∏
i=1
Z∗i
) ∏1≤j1<j2≤w
(Z∗j2 − Z∗
j1)
,

8.6. La variété associée à l'idéal des équations de Newton 77qui est non nul car les Z∗
j , j ∈ {1, . . . , w} sont distincts et non nuls. On a donc Y ∗1 + ε1...
Y ∗w + εw
= 0,
ce qui entraîne Y ∗i = εi, i ∈ {1, . . . , w}, ce qui n'est possible que si εi = 1 et Yi = 1,
i ∈ {1, . . . , w}, car les Yi sont non nuls : e est donc bien un mot binaire. Dans leprocessus qui a conduit à la forme (8.27), avec εi = 1, i ∈ {1, . . . , w}, on note qu'àchaque étape on a eu
� soit l'existence d'un indice j, j ∈ {(w+1), . . . , v}, tel que Z∗j = 0 qui contribue
au facteur Zl annoncé dans l'équation 8.21 de l'énoncé du théorème ;� soit deux indices j1, j2 ∈ {(w + 1), . . . , v} tel que Z∗
j1= Z∗
j2, ce qui contribue
au facteur G(Z)2 de l'équation 8.21 de l'énoncé du théorème ;� soit j1 ∈ {1, . . . , w} et j2 ∈ {(w + 1), . . . , v} tels que Z∗
j1= Z∗
j2, ce qui change
la valeur de εj1 en εj1 + 1. Pour j1 donné, comme εj1 �nit par être égal à 1 aubout du processus, le cas où il existe j2 tel que Z∗
j2= Z∗
j1n'a pu se produire
qu'un nombre pair de fois, ce qui contribue au facteur G(Z)2 de l'équation 8.21de l'énoncé du théorème.
Corollaire 2. Soit I = IC,n,v∩Fq[S] l'idéal d'élimination des fonctions symétriques.Alors V (I) est l'ensemble des transformées de Fourier des mots de poids inférieurou égal à v. On a de plus dim V (I) = v.
Soit J = (IC,n,v + It,v) ∩ Fq[S]. Alors V (J) est l'ensemble des fonctions sy-métriques élémentaires des mots à coe�cients 0 ou 1 de poids au plus v. De plusdim V (J) = 0.
Démonstration. Dans le premier cas, on a V (I) = Pr(V ) où Pr(V ) est la projection,sur l'espace des transformées de Fourier, de la variété V = V (IC,n,v). Or Pr(V ) estl'ensemble des transformées de Fourier des mots de poids inférieur ou égal à v. Nousmontrons que c'est un fermé. En e�et, d'après le théorème 4, le mot e est de poidsinférieur ou égal à v si et seulement si la matrice
CS∗ =
S∗0 S∗1 . . . S∗n−2 S∗n−1
S∗1 S∗2 . . . S∗n−1 S∗0... ...S∗n−1 S∗0 . . . S∗n−3 S∗n−2
. (8.28)
est de rang inférieur à v. Cela se produit quand tous les mineurs d'ordre v + 1 sontnuls, ce qui constitue bien un ensemble d'équations algébriques sur les Si. DoncV (I) = Pr(V ) = Pr(V ).
La variété V = V (IC,n,v ∩ F2[S]) est l'ensemble des transformée de Fourier desmots de Fn
q de poids inférieur à w. Soit W = F−1(V ), l'image inverse de V parla transformée de Fourier. Alors W est une variété de même dimension que V , carV est algébrique et F est linéaire inversible . Soit S = {i1, . . . , iw} ⊂ {1, . . . , n},de cardinal w, avec w ≤ v. Alors l'ensemble des mots e ∈ Fn
q de support S estl'ensemble
WS ={
e ∈ Fn
q ; ej = 0, j 6∈ S}
, (8.29)qui est une variété de dimension w (c'est un sous-espace vectoriel de dimension w).Nous avons en�n
W =⋃
S,|S|≤v
WS , (8.30)

78 Chapitre 8. Décodage avec les bases de Gröbner
qui est une variété de dimension v, en tant qu'union de variétés de dimension infé-rieure ou égale à v, dont au moins une est de dimension v.
Dans le deuxième cas, l'ensemble des mots binaires de poids inférieur à v est �ni.Donc les fonctions puissance associées sont en nombre �ni. Le corollaire 1 s'appliquedirectement.
8.7 Propriétés algébriques de l'idéal des équationsde Newton
Dans cette partie, nous allons étudier la radicalité de l'idéal des équation deNewton. Dans un premier temps, nous considérons l'idéal des équations de Newton(triangulaires et circulantes) auquel on adjoint les équations de corps. Nous noteronsdonc I0
N,n,v le système :
I0N,n,v =
Si +∑i−1
j=1 σjSi−j + iσi, i ∈ {1, . . . , v}Sv+i +
∑vj=1 σjSv+i−j , i ∈ {1, . . . , n}
Sn+i + Si, i ∈ {1, . . . , v}σqm
j − σj , j ∈ {1, . . . , v}Sqm
j − Sj , j ∈ {1, . . . , n}
⊂ F2[S, σv]. (8.31)
où Fqm est le corps de décomposition de Xn − 1 sur Fq.Nous utiliserons la proposition suivante.Proposition 3. Soit I un idéal de F[x1, . . . , xn], de dimension zéro. Si pour chaquechaque indéterminée xi, i ∈ {1, . . . , n}, I contient un polynôme de F[xi] sans fac-teurs multiples, alors I est radical.
Démonstration. C'est une conséquence directe de la proposition 2.7 du chapitre 2de [CLO05].Corollaire 3. L'idéal I0
N,n,v est radical et de dimension 0.
Une de nos contributions est de montrer que l'on manipuler des idéaux sansintroduire les équations de corps, tout en gardant les bonnes propriétés de radicalité.En e�et les équations de corps sont du type Sqm
i − Si, où Fqm est le corps dedécomposition de Xn − 1 sur Fq, et qm peut être élevé, même pour des codes delongueur modeste. Par exemple, pour le code à résidus quadratiques de longueur 41,le cors de décomposition de X41 − 1 est F220 . L'idéal I0
N,n,v contient les équationsS220
i − Si. Nous notons IN,n,v l'idéal sans les équations de corps :
IN,n,v =
Si +
∑i−1j=1 σjSi−j + iσi, i ∈ {1, . . . , v}
Sv+i +∑v
j=1 σjSv+i−j , i ∈ {1, . . . , n}Sn+i + Si, i ∈ {1, . . . , v}
⊂ F2[S, σv]. (8.32)
Nous allons étudier les idéaux auxiliaires suivant :Dé�nition 1. Soit A = Fq[Z1, . . . , Zv, σ1, . . . , σv, A1, . . . , An, . . . An+v], nous dé�-nissons les idéaux suivants de A : l'idéal des fonctions symétriques :
Iσ,v =
⟨σi −
∑1≤j1<···<ji≤v
Zj1 . . . Zji ; i ∈ {1, . . . , v}
⟩; (8.33)
l'idéal des fonctions puissances :
IS,n,v =⟨
Si −∑v
j=1 Zij , i ∈ {1, . . . , n + v};
Si+n − Si, i ∈ {1, . . . , v}
⟩. (8.34)

8.7. Propriétés algébriques 79Il faut bien noter la présence des relations Si+n − Si qui re�ètent que les Z∗
i ,i ∈ {1, . . . , v}, sont des racines n-ièmes de l'unité.
Nous aurons besoin du théorème suivant.Théorème 6 (Machi-Valibouze [Val95]). Soit f(Z) = Zv +
∑vi=1 σiZ
v−i ∈F[σv][Z]. Soient les polynômes fi, i ∈ {1, . . . , v}, construits de proche en prochecomme suit (modules de Cauchy) :
f1(Z1) = f(Z1), (8.35)fi+1(Z1, . . . , Zi+1) =
fi(Z1, . . . , Zi−1, Zi)− fi(Z1, . . . , Zi−1, Zi+1)Zi − Zi+1
. (8.36)Alors pour i ∈ {1, . . . , v}, fi ∈ F[σv][Z1, . . . , Zi]. De plus, en considérant l'ordrelexicographique Zv > Zv−1 > · · · > Z1 > σv > · · · > σ1, fi a un terme de tête enZi uniquement, et Gσ,v = {f1, . . . , fv} est une base de Gröbner de Iσ,v.
Proposition 4. (IS,n,v + Iσ,v) ∩ Fq[Sn, σv] = IN,n,v.
Démonstration. Nous pouvons déduire les relations de Newton (triangulaires etcirculantes) à partir de la dé�nition des fonctions puissances et des fonctions symé-triques élémentaires. Nous avons donc
IN ⊂ (IS + Iσ) ∩ Fq[σ1, . . . , σv, S1, . . . , Sn, . . . , Sn+v]. (8.37)Pour prouver l'inclusion inverse, nous procédons en deux temps : nous prouvonsd'abord que IS + Iσ = IN + Iσ, et ensuite que
(IN + Iσ) ∩ F[σ1, . . . , σv, S1, . . . , Sn+v] = IN . (8.38)Les formules de Waring sont déduites des identités de Newton :
Si −Wv,i(σ1, . . . , σv) = 0 mod IN , i ∈ {1, . . . , n + v}. (8.39)Notons si, i ∈ {1, . . . , v}, les polynômes si =
∑1≤j1<···<ji≤v Zj1 . . . Zji
, alors σi −si ∈ Iσ, etSi −Wv,i(s1, . . . , sv) ∈ IN + Iσ.En�n, notons pi, i ∈ {1, . . . , n + v}, le polynôme ∑v
j=1 Zij , alors, d'après les
formules de Waring : pi = Wv,i(s1, . . . , sv), ce qui entraîneSi − pi ∈ IN + Iσ, i ∈ {1, . . . , n + v},
i.e. IS ⊂ IN + Iσ. Donc IS + Iσ ⊂ IN + Iσ et l'égalité IS + Iσ = IN + Iσ s'ensuit.Nous prouvons maintenant (8.38). Soit GN une base de Gröbner de IN , pour unordre quelconque, et soit Gσ la base de Gröbner de Iσ décrite dans le théorème 6.Alors
GN ∪Gσ
est une base de Gröbner de IN + Iσ. En e�et, d'après le théorème 6, Gσ ne contientaucun polynôme dont le terme de tête contient une des indéterminées σj . Donc lestermes de tête des polynômes de GN et Gσ sont étrangers, GN ∪ Gσ est bien unebase de Gröbner. Le théorème d'élimination des bases de Gröbner entraîne que
(GN ∪Gσ) ∩ F2[σ1, . . . , σn, A1, . . . , An+v] (8.40)est une base de Gröbner de (IN + Iσ) ∩ F2[σ1, . . . , σv, S1, . . . , Sn+v]. Comme
Gσ ∩ F2[σ1, . . . , σv] = {0},
GN est une base de Gröbner de (IN + Iσ) ∩ F2[σ1, . . . , σv, S1, . . . , Sn+v].

80 Chapitre 8. Décodage avec les bases de Gröbner
En pratique on a toujours observé que l'idéal IN,n,v est radical, et c'est celui-làque nous avons utilisé pour les expérimentations. Nous allons construire un idéalplus gros que IN,n,v, mais qui présente plus de propriétés algébriques, et pour lequelnous aurons beaucoup de propriétés intéressantes. Nous avons besoin de la notiond'idéal saturé, pour éliminer de IN,n,v les composantes correspondant au mots depoids strictement inférieurs à v.Dé�nition 2. Soit I ⊂ F[x1, . . . , xn] un idéal, et soit f ∈ F[x1, . . . , xn] �xé. Lasaturé de I par rapport à f est l'idéal
I : f∞ = {g ∈ F[x1, . . . , xn] : fmg ∈ I pour un m > 0} (8.41)Proposition 5. Soit I = 〈f1, . . . , fs〉 ⊂ F[x1, . . . , xn] un idéal et soit un polynômef ∈ F[x1, . . . , xn] �xé. Soit y une nouvelle indéterminée et soit
I = 〈f1, . . . , fs, 1− fy〉 ⊂ F[x1, . . . , xn, y],
alors I : f∞ = I ∩ F[x1, . . . , xn].
Lemme 1. Soit I ∈ F[x1, . . . , xn] un idéal et f ∈ F[x1, . . . , xn] �xé, tels que dim(I :f∞) = 0. Alors, pour tout x ∈ V (I : f∞), f(x) 6= 0. En particulier (I : f∞)+ 〈f〉 =〈1〉.
Démonstration. Soit I = I + 〈1− fy〉, tel que I : f∞ = I ∩ F[x1, . . . , xn]. AlorsPr(V (I)) = V (I : f∞), (8.42)
où Pr est la projection (y, x1, . . . , xn) 7→ (x1, . . . , xn). Comme V (I : f∞) est �ni,on a que Pr(V (I)) est �ni aussi. Donc Pr(V (I)) est donc égal à sa fermeture. On adonc
V (I : f∞) = Pr(V (I)). (8.43)Comme tout élément (y, x1, . . . , xn) de I véri�e f(x1, . . . , xn) 6= 0, cette propriétéest conservée par projection.Proposition 6. Soit n, v > 0, et soit Z les indéterminées Z1, . . . , Zv. Considéronsle polynôme
∆(Z1, . . . , Zv) = Z1 · · ·Zv
∏1≤i<j≤v
(Zi − Zj) . (8.44)
Alors l'idéal saturé IS,n,v : ∆∞ contient les polynômes
Zni − 1, i ∈ {1, . . . , v},
et les polynômesSqm
i − Si, i ∈ {1, . . . , n}
où Fqm est le corps de décomposition de Xn − 1 sur Fq. En particulier, c'est unidéal radical de dimension 0.
Démonstration. D'après les relations Si+n − Si, i ∈ {1, . . . , v}, nous avons0 = Sn+i − Si mod IS,n,v (8.45)
=v∑
j=1
Zn+ij −
v∑j=1
Zij mod IS,n,v (8.46)
=v∑
j=1
Zij
(Zn
j − 1)
mod IS,n,v. (8.47)

8.7. Propriétés algébriques 81Les équations (8.47) peuvent s'écrire matriciellement comme suit :
M
Zn1 − 1...
Znv − 1
=
0...0
mod IS,n,v, (8.48)
où M la matrice carrée v × v (Mi,j) =(Zi
j
). Le déterminant de cette matrice est∆. En considérant l'idéal suivant :
IS,n,v = IS,n,v + 〈1− y∆〉,
on a que ∆ est inversible modulo IS,n,v, ce qui entraîne que la matrice M estinversible modulo IS,n,v. Nous avons donc Zn
1 − 1...Zn
w − 1
= 0 mod IS,n,v. (8.49)
Donc, pour i ∈ {1, . . . , v}, Zni − 1 ∈ IS,n,v ∩ F[Sn, Zv] = IS,n,v : ∆∞. Si Fqm est le
corps de décomposition de Xn−1, alors Xn−1|Xqm−X : cela entraîne Zqm
i −Zi ∈IS,n,v : ∆∞, pour i ∈ {1, . . . , v}, qui entraîne à son tour Sqm
j − Sj ∈ IS,n,v : ∆∞,pour j ∈ {1, . . . , n + v}, par linéarité de x 7→ xqm sur Fq.Corollaire 4. On a dim IS,n,v : ∆∞ = 0. Pour tout (Z∗, S∗) ∈ V (IS,n,v : ∆∞),∆(Z∗) 6= 0. En particulier (IS,n,v : ∆∞) + 〈∆〉 = 〈1〉.
Ce corollaire découle directement du lemme suivant.Lemme 2. Soit I ∈ F[x1, . . . , xn] un idéal et f ∈ F[x1, . . . , xn] �xé, tels que dim(I :f∞) = 0. Alors, pour tout x ∈ V (I : f∞), f(x) 6= 0. En particulier (I : f∞)+ 〈f〉 =〈1〉.
Démonstration. Soit I = I + 〈1− fy〉, tel que I : f∞ = I ∩ F[x1, . . . , xn]. AlorsPr(V (I)) = V (I : f∞), (8.50)
où Pr est la projection (y, x1, . . . , xn) 7→ (x1, . . . , xn). Comme V (I : f∞) est �ni,on a que Pr(V (I)) est �ni aussi. Donc Pr(V (I)) est donc égal à sa fermeture. On adonc
V (I : f∞) = Pr(V (I)). (8.51)Comme tout élément (y, x1, . . . , xn) de I véri�e f(x1, . . . , xn) 6= 0, cette propriétéest conservée par projection.Corollaire 5. L'idéal
〈Iσ,v + (IS,n,v : ∆∞)〉 ∩ Fq[S, σv] (8.52)contient les équations de corps
Sqm
i − Si, i ∈ {1, . . . , n + v}, et σqm
i − σi, i ∈ {1, . . . , v}. (8.53)C'est donc un idéal radical de dimension zéro.
Nous noterons I∞N,n,v l'idéal 〈Iσ,v + (IS,n,v : ∆∞)〉 ∩ Fq[S, σv]. On a IN,n,v ⊂I∞N,n,v.

82 Chapitre 8. Décodage avec les bases de Gröbner
Proposition 7. Dans le cas de la caractéristique 2, soit Tn,v l'ensemble des (S∗, σ∗v)où S∗ est la transformée de Fourier d'un mot binaire e de poids exactement v, etσ∗v est l'ensemble des fonctions symétriques élémentaires de e. Alors
V (I∞N ) = Tv et I∞N = I(Tv). (8.54)Démonstration. Nous avons V (I∞N ) ⊂ V (IN ), donc V (I∞N ) ne contient que des motsde poids inférieur à v, par le théorème 5. Or tout mot de poids exactement v conduità une solution (σ∗v, S∗n) de I∞N . Donc Tn,v ⊂ V (IN,n,v). Soit maintenant (S∗, ρ∗
v) ∈
V (I∞N,n,v), alors S∗n est la transformée de Fourier d'un mot e de poids strictementinférieur à v. Soit σ∗(Z) le polynôme localisateur de e. Alors le théorème 5 nous ditque ρ∗(Z) = 1 +
∑vi=1 ρ∗i Z
i est de la formeρ∗(Z) = σ∗(Z)G(Z)2Zl. (8.55)
avec : ou bien l ≥ 1 ou bien deg G(Z) ≥ 1, car deg σ∗(Z) ≤ v − 1. Alors, par lecorollaire 1, (S∗n, ρ∗) s'étend en
(Z∗v, ρ∗
v, S∗) ∈ V ((IS + Iσ) : ∆∞), (8.56)
où Z∗ = (Z∗1 , . . . , Z∗
v ) est tel que, par dé�nition de l'idéal Iσ,v :
ρ∗(Z) =v∏
i=1
(1− Z∗i Z). (8.57)
La forme de ρ∗(Z) donnée par (8.55) entraîne que soit l'un des Z∗j est nul, soit
deux d'entre eux sont égaux. Dans les deux cas, ∆(Z∗1 , . . . , Z∗
v ) = 0, ce qui estcontradiction avec le corollaire 4. Donc V (I∞N ) = Tv, et on en déduit I∞N = I(Tv),car I∞N est radical.
La proposition précédente permet de ne pas considérer les solutions de poidsstrictement inférieur à v dans la variété associée à IN . Ces solutions sont appeléesspurious solutions dans [Sal02], qui ne traite toutefois que le cas du calcul de ladistance minimale.Corollaire 6. Soit S∗ la transformée de Fourier d'un mot e. Alors, si e est de poidsexactement v,
I∞N (S 7→ S∗) = 〈σv − σ∗v , . . . , σ1 − σ∗1〉 , (8.58)où σ∗1 , . . . σ∗v sont les fonctions symétriques élémentaires des localisateurs de e. Si eest de poids di�érent de v, alors
I∞N (S 7→ S∗) = 〈1〉 . (8.59)Démonstration. Soit e un mot de poids exactement v de transformée de Fourier S∗n.Le théorème 5 entraîne que les solutions ρ∗1, . . . , ρ
∗v de IN (S 7→ S∗) sont telles que
le polynôme ρ∗(Z) = 1 +∑
ρ∗i Zi est multiple du polynôme localisateur σ∗(Z) =
1+∑w
i=1 σ∗i Zi, où w est le poids de e. Comme e est de poids exactement v, ρ∗(Z) =σ∗(Z), et donc
V (IN (S 7→ S∗)) = {(σ∗v , . . . , σ∗1)} . (8.60)D'autre part on a aussi V (I∞N (S 7→ S∗)) 3 (σ∗v , . . . , σ∗1). Donc
V (I∞N (S 7→ S∗)) = V (IN (S 7→ S∗)) = {(σ∗v , . . . , σ∗1)} . (8.61)Comme les deux idéaux à gauche et à droite de (8.61) sont radicaux, on a bien
I∞N (S 7→ S∗) = 〈σv − σ∗v , . . . , σ1 − σ∗1〉 . (8.62)

8.7. Propriétés algébriques 83Si e est de poids di�érent de v, nous montrons que V (I∞N (S 7→ S∗) = ∅, le résultaten découlant par le Nullstellenstaz faible. Supposons d'abord que le poids de e estsupérieur strictement à v. Alors s'il existe ρ∗ tel que ρ∗ ∈ V (I∞N (S 7→ S∗)), alors lespoids de e est inférieur ou égal à v, par le théorème 5, ce qui est une contradiction.
Supposons pour �nir que le poids de e est strictement inférieur à v. Soit ρ∗ ∈V (I∞N (S 7→ S∗)), alors le théorème 5 entraîne que
ρ∗(Z) = σ∗(Z)G(Z)2Zl, (8.63)où ρ∗(Z) = 1+
∑ρ∗i Z
i, et où σ∗(Z) est le polynôme localisateur de e. Le corollaire 1nous permet d'étendre (ρ∗, S∗) en (Z∗, ρ∗, S∗), tel que
(Z∗, ρ∗, S∗) ∈ V (Iσ + (IS : ∆∞)). (8.64)Mais le forme de ρ∗(Z) entraîne que soit l'un des Z∗
i est nul, soit deux d'entreeux sont égaux. Dans les deux cas, ∆(Z∗) = 0, ce qui est impossible d'après lecorollaire 4.Théorème 7. Pour chaque j ∈ {1, . . . , v}, pour chaque S∗, qui est la transforméede Fourier d'un mot de poids exactement v, I∞N contient un polynôme de la formeqj(S)σj + rj(S), tel que qj(S∗) 6= 0.
Démonstration. Soit j ∈ {1, . . . , v}, et considérons l'idéal d'éliminationIj = I∞N ∩ F2[σj , S]. (8.65)
Soit S∗ la transformée de Fourier d'un mot de poids exactement v. L'idéal Ij est unidéal de dimension zéro. Le théorème 3, de spécialisation dans le cas zéro dimen-sionnel, s'applique. Il existe donc gj ∈ Ij tel que
gj(S 7→ S∗) (8.66)engendre Ij(S 7→ S∗), et tel que degσj
gj(S 7→ S∗) = degσjgj . Nous savons, par lethéorème 6 que
I∞N (S 7→ S∗) = 〈σv − σ∗v , . . . , σ1 − σ∗1〉 . (8.67)Donc
Ij(S 7→ S∗) =⟨σj − σ∗j
⟩. (8.68)
On en déduit que gj est de degré 1 en σj . Donc gj = qjS)σj + rj(S), avec de plusqj(S∗) 6= 0.Théorème 8. Pour chaque i ∈ {1, . . . , v}, l'idéal I∞N,v contient un polynôme σi +ri(S).
Démonstration. Soit i ∈ {1, . . . , v}. Pour chaque transformée de Fourier S∗ d'unmot de poids v, il existe dans I∞N,v un polynôme g = q(S)σi +r(S), tel que q(S) 6= 0.Soit g1, . . . , gl tous ces polynômes, de la forme q1(S)σi + r1(S), . . . , ql(S)σi + rl(S).Soit I = I∞N,v ∩ Fq[S]. Alors V (I) est l'ensemble des transformées de Fourier desmots de poids exactement v, et pour chaque S∗ ∈ V (I), il existe un qj(S) tel queqj(S∗) 6= 0. On a donc
V (〈q1, . . . , ql〉+ I) = ∅, (8.69)donc, d'après le Nullstellenstaz faible
〈q1, . . . , ql〉+ I = Fq[S]. (8.70)Il existe donc t1, . . . , tl ∈ Fq[S], et t ∈ I, tels que
t1q1 + . . . tlql + t = 1. (8.71)

84 Chapitre 8. Décodage avec les bases de Gröbner
En faisant la combinaison linéaire t1g1 + . . . tlgl, on at1g1 + . . . tlgl = (t1q1 + . . . tlql)σi + (t1r1 + . . . tlrl)
= (1− t)σi + (t1r1 + . . . tlrl)= σi + r(S) mod I
(8.72)
Comme g1, . . . , gl ∈ I∞N,n, et I ⊂ I∞N,v, on a σi + r(S) ∈ I∞N,v.Ainsi, nous avons des formules donnant, pour les mots de poids v donné, les
fonctions symétriques élémentaires en fonctions de tous les coe�cients de la trans-formée. Mais dans le contexte du décodage, on est intéressé par des formules pourles σi en fonction seulement des syndromes SQ connus.
8.8 Utilisation des équations de Newton en déco-dage
Après avoir étudié les propriétés du système des équations de Newton en consi-dérant le vecteur entier S∗ de la transformée de Fourier, nous étudions le systèmedes équations de Newton lorsque l'on connait qu'une partie de la transformée deFourier. Dans le contexte du décodage, le code C est donné son ensemble de dé-�nition Q, de complémentaire N , et un mot c est dans le code C si et seulementsi
c(αi) = 0, i ∈ Q. (8.73)Le motif d'erreur e est donc connu par les e(αi), i ∈ Q. Le problème naturel quise pose alors est le suivant : peut-on éliminer, dans les équations de Newton, lessyndromes inconnus Sj , j ∈ N , et obtenir des formules de degré un en les σi, où lesσi sont les fonctions symétriques élémentaires des localisateurs. Il y a deux manièresde traiter ce problème :
1. soit le décodage formel : on élimine par un précalcul les syndromes incon-nus dans le système IN (ou I∞N ), pour obtenir des formules de de la formeqj(SQ)σj + rj(SQ). Au moment du décodage, on substitue les syndromes S∗Qpour obtenir les valeurs des σi.
2. soit le décodage en ligne : au moment du décodage, on e�ectue la substitutionsS 7→ S∗ dans le système IN (ou I∞N ), et on élimine les syndromes inconnusSN , pour obtenir les valeurs des σi, par des relations de degré 1.
Dans les deux cas, il faut prouver qu'on obtient des formules de degré 1 en lescoe�cients σi du polynôme localisateur.
Nous étudions d'abord le résultat pour le point 2, où l'on substitue d'abord,pour éliminer ensuite. Ensuite nous étudions le point 1. Des di�cultés techniquesse présentent : nous aimerions pouvoir utiliser l'idéal des relations de Newton IN,n,vplutôt que I∞N,n,v, car il peut être coûteux de calculer une base de Gröbner de cedernier. Mais nous avons seulement prouvé la radicalité de I∞N,n,v, bien que nousconjecturons que IN,n,v soit aussi radical, donc nous établirons le résultat pour ledécodage formel en utilisant I∞N,n,v, alors que pour le décodage en ligne nous pouvonsutiliser IN,n,v.
8.9 Décodage en ligneThéorème 9. Soit S∗Q l'ensemble des syndromes d'une erreur e de poids w, telleque e est le seul mot de poids inférieur à v admettant S∗Q comme syndromes (c'estle cas si v ≤ t). Soit I l'idéal
IN,v(SQ 7→ S∗Q) + 〈σw+1, . . . , σv〉 , (8.74)

8.9. Décodage en ligne 85alors,
I =⟨σ1 − σ∗1 , . . . , σw − σ∗w, σw+1, . . . , σv, Sj − S∗j , j ∈ N
⟩ (8.75)Démonstration. La preuve est en deux étapes : on montre d'abord l'égalité desvariétés associées ; puis que l'idéal du membre de gauche de 8.75 est radical.
Soit donc (ρ∗, S∗N ) solution de I(SQ 7→ S∗Q, σw+1, . . . , σv). Alors par le théo-rème 5, le poids de la transformée de Fourier inverse e′ de (S∗N , S∗Q) est inférieur àv. Étant donnée l'hypothèse que e est le seul mot de poids inférieur à v admettantS∗Q comme syndromes, on a e = e′, et S∗N = SN (e). D'autre part, le théorème 5,entraîne que ρ∗(Z) est multiple du polynôme localisateur σ∗(Z) de e. Comme lestermes ρ∗w+1, . . . , ρ
∗v sont nuls, on a ρ∗(Z) = σ∗(Z). Les variétés associées sont bien
égales.Pour la radicalité, on construit l'idéal
J = IS,w(SQ 7→ S∗Q) + Iσ,w + 〈σw+1, . . . , σv〉 ∈ F1[Zw, σvSN ], (8.76)qui est tel que
J ∩ F2[σv, S] = IN,v(SQ 7→ S∗Q) + 〈σw+1, . . . , σv〉 . (8.77)Alors J est de dimension zéro, et les seules racines Z∗
w = (Z∗1 , . . . , Z∗
w) telles que(Z∗
w, σ∗w, σ∗w+1 = 0, . . . , σ∗v = 0S∗N ) ∈ V (J) sont, à permutation prés, les racinesdu polynôme localisateur σ∗(Z). Elles véri�ent donc ∆w(Zw) 6= 0. En utilisant leséquations Si+n − Si = 0, on construit le système
M
Zn1 − 1...
Znw − 1
=
0...0
mod J, (8.78)
où M est la matrice carrée v × v (Mi,j) =(Zi
j
), de déterminant ∆w(Zw). Alors∆w(Zw) est inversible modulo J , et donc Zn
i − 1 ∈ J , i ∈ {1, . . . , w}. L'idéal Jcontient donc les équations de corps, il est radical.Théorème 10. Soit S∗Q les syndromes d'une erreur e de poids w, telle que e estle seul mot de poids inférieur à v admettant S∗Q comme syndromes (c'est le cas siv ≤ t). Alors, si w = v
I∞N (SQ 7→ S∗Q) =⟨σ1 − σ∗1 , . . . , σv − σ∗v , Sj − S∗j , j ∈ N
⟩ (8.79)et si w 6= v alors
I∞N (SQ 7→ S∗Q) = 〈1〉 . (8.80)Démonstration. Supposons que w = v, alors, soit (σ∗v, S∗n) ∈ V (I∞N (SQ 7→ S∗Q)).Alors le poids de la transformée inverse e′ de (S∗Q, S∗N ) est égal à v (proposition 7).Comme e est l'unique mot de poids v admettant S∗Q comme syndromes, on a e = e′.Cela prouve l'égalité des variétés. L'égalité des idéaux s'ensuit car I∞N,v est radical.
Dans le décodage en ligne (calcul avec les syndromes spécialisés), on peut utili-ser l'idéal IN,v(SQ 7→ S∗Q), en annulant progressivement σ1, . . . , σv, puis σ2, . . . , σv,jusqu'à obtenir une base de Gröbner di�érente de 1, auquel cas on a dans la basede Gröbner les polynômes σj − σ∗j , ce qui donne les coe�cients du polynôme loca-lisateur.
Une autre solution est d'utiliser l'idéal I∞N (SQ 7→ S∗Q), en augmentant le poidsjusqu'à l'obtention d'une base de Gröbner di�érente de 〈1〉. Alors on aura bienobtenu, dans la base de Gröbner, les polynômes σi−σ∗i , donnant les coe�cients dupolynôme localisateur.

86 Chapitre 8. Décodage avec les bases de Gröbner
8.10 Décodage formelNous nous intéressons à l'idéal IN ∩ F2[σv, SQ], c'est-à-dire à l'idéal obtenu en
éliminant les syndromes inconnus. L'objectif est de trouver des formules de degréun pour les σi. Nous avons le théorème suivant, similaire au théorème 7, mais avecla propriété que seuls les syndromes SQ apparaissent dans les formules pour les σi.Proposition 8. Soit C un code cyclique et v inférieur à la capacité de correctiont de C. Alors, pour tout j ∈ {1, . . . , v}, et pour chaque S∗Q, qui est la transforméede Fourier d'un mot de poids exactement v, il existe pj = qj(S)σj + rj(SQ) ∈I∞N,v ∩ F2[σv, SQ], tel que qj(S∗Q) 6= 0,
Démonstration. On a d'abord queV (I∞N,v ∩ F2[SQ]) (8.81)
est l'ensemble des syndromes des mots de poids exactement v (théorème de ferme-ture dans le cas d'un idéal de dimension zéro). Notons TQ,v cet ensemble. AlorsI(TQ,v) = I∞N,v ∩ F2[SQ]), car l'idéal I∞N,v ∩ F2[SQ] est radical. Soit l'idéal d'élimi-nation
I∞j = I∞N,v ∩ F2[σj , SQ], (8.82)soit Gj une base de Gröbner réduite pour un ordre éliminant σj , et �nalement gjde degré minimal en σj que l'on écrit
gj = pj(Sq)σlj + . . . (8.83)
Supposons l > 1. Soit S∗Q un syndrome de poids exactement v, alors, d'après lethéorème 10
I∞j (SQ 7→ S∗Q)) =⟨σj − σ∗j
⟩. (8.84)
Le théorème 2 entraîne donc pj(S∗Q) = 0 (chute de degré). Cela est vrai pour toutsyndrome S ∈ TQ,v de mot de poids v, on a donc pj ∈ I(TQ,v) = I∞j ∩ F2[SQ], cequi est une contradiction car Gj est une base de Gröbner réduite. Donc
gj = qj(S)σj + rj(S). (8.85)On a de plus, qj(S∗Q) 6= 0, car gj(SQ 7→ S∗Q) est une base de Gröbner de Ij(SQ 7→S∗Q), laquelle est égale à σj − σ∗j , où σ∗j est le j-ième coe�cient du polynôme loca-lisateur de e.
De même que précédemment, nous avons en réalité le résultat plus fort suivant :Corollaire 7. Si v est plus petit que la capacité de correction du code C, d'ensemblede dé�nition Q, alors, pour chaque i ∈ {1, . . . , v}, l'idéal I∞N,v ∩ Fq[σv, SQ] contientun polynôme σi + ri(SQ).
Démonstration. Soit i ∈ {1, . . . , v}, pour chaque transformée de Fourier S∗ d'unmot de poids v, il existe g = q(Sq)σi + r(SQ) ∈ I∞N,v ∩F2[σv, SQ] tel que q(SQ) 6= 0.Soit, pour tous les mots de poids v, g1, . . . , gl, tous ces polynômes, de la formeq1(SQ)σi + r1(SQ), . . . ql(SQ)σi + r(SQ). Soit I = I∞N,v ∩ F1[SQ]. Alors V (I) estl'ensemble des syndromes de mots de poids exactement v, et pour chaque S∗Q ∈ V (I),il existe un qj(SQ) tel que qj(S∗Q) 6= 0. On a donc
V (〈q1, . . . , ql〉+ I) = ∅, (8.86)et donc
〈q1, . . . , ql〉+ I = Fq[SQ] (8.87)

8.11. En pratique 87Il existe donc t1, . . . , tl ∈ Fq[SQ], et t ∈ I, tels que
t1q1 + · · ·+ tlql + t = 1. (8.88)En faisant la combinaison linéaire t1g1 + · · ·+ tlgl, on a
t1g1 + . . . tlgl = (t1q1 + . . . tlql)σi + (t1r1 + . . . tlrl)= (1− t)σi + (t1r1 + . . . tlrl)= σi + r(SQ) mod I
(8.89)
Comme g1, . . . , gl ∈ I∞n,v ∩ Fq[σv, SQ], et que I ⊂ Fq[σv, SQ], on a σi + r(SQ) ∈Fq[σv, SQ].
8.11 En pratiqueMagali Bardet a montré dans sa thèse que le décodage formel, c'est-à-dire l'ob-
tention de formules dans lesquelles on substitue les syndromes, devient vite impra-ticable. La �gure 3.1 donne un exemple, en petite longueur i.e. 41, où on voit déjàque les formules deviennent vite trop importantes pour être utilisées.
Magali Bardet a proposé de faire un calcul de base de Gröbner pour chaque motà décoder, en spécialisant les syndromes (décodage en ligne). Ces calculs peuventêtre grandement accélérés, en utilisant la technique de la trace du pré-calcul. Cettetechnique consiste à tirer, dans une étape de précalcul, un syndrome S∗Q au hasard,et à calculer la base de Gröbner de IN,v(SQ 7→ S∗Q). Pendant cette étape, on garde enmémoire tous les calculs fructueux : en e�et un algorithme de base de Gröbner e�ec-tue essentiellement des réductions de polynômes par rapport à d'autres polynômes,et la plupart de ces réductions sont nulles, donc ne contribuent pas au résultat �nal(algorithmes de Buchberger, algorithme F4). Une fois qu'on a gardé toutes les opé-rations qui ne donnent pas de réduction à zéro, on réapplique l'algorithme de basede Gröbner, en n'e�ectuant que les calculs mémorisés.
Cette méthode est conjecturelle : elle repose que sur l'hypothèse que tous lessyndromes (au moins ceux de même poids) vont se comporter génériquement de lamême manière, par rapport aux étapes du calcul de la base de Gröbner. En pratique,cela a bien été véri�é pour tous les décodages e�ectués.
Le nombre d'opérations arithmétique sur le corps de décomposition de Xn − 1,où n est la longueur du code, est assez faible, voir la �gure 3.2, page 25.

88 Chapitre 8. Décodage avec les bases de Gröbner

Chapitre 9
Décodage par interpolation
Ce chapitre est consacré à mes travaux sur les algorithmes de Sudan, Shokrollahi-Wasserman et Guruswami-Sudan, pour le décodage des codes d'évaluation, tels queles codes de Reed-Solomon et les codes géométriques. Ces algorithmes reposent sur lenotion de décodage en liste : on augmente le rayon de décodage, mais la conséquenceest que l'on perd l'unicité du mot de code le plus proche, obtenue lorsqu'on décodejusqu'à bd−1
2 c erreurs. Ces algorithmes reposent tous sur le même schéma généralsuivant : soit (xi, yi), i ∈ {1, . . . , n}, la donnée du problème, et on cherche f(X)telle que f(xi) = yi pour le grand nombre d'indices possible. On construit unpolynôme Q(X, Y ), tel que Q(xi, yi) = 0, avec des conditions sur le degré pondéréde Q(X, Y ) telles que si f(X) est solution du problème, alors Q(X, f(X)) = 0.Il ne reste plus qu'à factoriser Q(X, Y ) pour récupérer les facteurs Y − f(X). Lesproblèmes liés au calcul du polynôme Q(X, Y ), ainsi qu'à sa factorisation ont été misde cotés par Sudan et Guruswami, et des nombreuses propositions ont été faites pourrésoudre ces problèmes e�cacement. Nous avons contribué, avec Lancelot Pecquet,à ce domaine, en proposant une méthode rapide de recherche de racines f(X) d'unpolynôme Q(X, Y ), dans le cas simple de l'algorithme de Sudan.
La deuxième contribution (non publiée) est l'étude de généralisations multi-variées de l'algorithme de Guruswami-Sudan, lorsqu'on traite des codes de Reed-Muller et des codes produits de codes Reed-Solomon. Pellikaan et Wu ont traité leproblème [PW04b] du décodage des codes de Reed et Muller, avec une analyse repo-sant sur la théorie des bases de Gröbner. Nous proposons une analyse plus simple,reposant sur un lemme de Schwarz-Zippel généralisé, qui donne un meilleur rayonde décodage.
9.1 Introduction aux algorithmes de décodage parinterpolation
9.1.1 Le problèmeOn considère le code de Reed-Solomon, dé�ni comme code d'évaluation, comme
suit : soit X = {x1, . . . , xn}, un ensemble de n points distincts dans le corps �ni Fq,soitLk = {f ∈ Fq[X]; deg f < k} . (9.1)
Le code de Reed-Solomon Ck, de paramètres [n, k, n− k + 1] est l'ensembleCk = {(f(x1), . . . , f(xn)), f ∈ Lk} . (9.2)
Le problème du décodage en liste des codes de Reed-Solomon est le suivant :89

90 Chapitre 9. Décodage par interpolation
Problème Décodage en liste des codes de Reed-Solomon
Instance � q une puissance d'un nombre premier� n, k ∈ N, 1 ≤ k < n, t, 1 ≤ t < n� X = {x1, . . . , xn} ⊂ Fq, les xi étant distincts : c'est le support du code deReed-Solomon Ck.� y = (y1, . . . , yn) ∈ Fn
q .Réponse La liste de tous les mots de code à distance au plus t de y.Dé�nition 3. Soit f ∈ Fq[X], x1, . . . , xn n éléments distincts de Fq, et y =(y1, . . . , yn) ∈ Fn
q . La distance de Hamming de f à y, notée d(f, y) est
|{i ∈ {1, . . . , n}; f(xi) 6= yi}| (9.3)Avec cette notation, on peut écrire le problèmeRéponse La liste de tous les polynômes f ∈ Fq[X], de degré inférieur à k tels que
d(f, y) ≤ t.Notons qu'une manière équivalente de dé�nir la réponse est la suivante :Réponse la liste de tous les polynômes de degré inférieur à k tels que f(xi) = yipour au moins µ = n− t valeurs de l'indice i.Ainsi on peut voir ce problème comme un problème d'approximation pour la dis-tance de Hamming. L'interpolation de Lagrange nous permet d'interpoler sur toutesles valeurs, mais nous perdons la contrainte sur le degré : si on veut des solutionsavec un degré inférieur à k, il faut admettre de n'interpoler que sur un nombremoindre de points. On peut parler d'interpolation partielle.9.1.2 La di�culté du problème
Goldreich, Rubinfeld et Sudan ont montré [GRS00] que le problème, où les xine sont pas distincts, apparemment proche est NP-dur. Précisément, le problèmeest le suivant.Problème reconstruction de polynômes.Instance � q une puissance d'un nombre premier
� k, t, µ ∈ N,� n points (xi, yi) ∈ F2
q, i ∈ {1, . . . , n}. Il n'est pas requis que les xi soientdistincts.Question Existe-t'il un polynôme de degré au plus k tel que f(xi) = yi pour aumoins µ valeurs de i.
En réalité il est explicitement utilisé dans la preuve [GRS00] que les xi nesont pas distincts : une instance quelconque du problème du problème Subsetsum [GJ79] est réduite à une instance de reconstruction de polynômes, où il ya des couples (xi, yi), (xj , yj), avec des égalités xi = xj . Mais en ce qui concerne levrai problème de décodage, c'est-à-dire quand les xi sont distincts, Guruswami etVardy [GV05] ont montré que le problème du décodage des codes de Reed-Solomonest aussi NP-dur. Hélas les codes pour lesquels ils montrent que le problème dudécodage est di�cile sont des codes sur un alphabet Fq avec q exponentiel en lalongueur, ce qui limite nettement la portée du résultat en pratique.9.1.3 L'algorithme de Berlekamp-Welch
Toutefois dans le cas où n − µ = t < n−k2 , le problème est résoluble en temps
polynomial, grâce notamment à l'algorithme de Berlekamp-Welch [WB86]. Nous lerappelons brièvement, car il est le premier algorithme de décodage par interpolation,et permet de bien introduire l'algorithme de Guruswami-Sudan.Algorithme de Berlekamp-Welch

9.1. Introduction aux algorithmes de décodage par interpolation 91Constantes q une puissance d'un nombre premier ;Données (x1, . . . , xn) ∈ Fn
q , k ∈ N, le support du code de Reed-Solomon ; y =(y1, . . . , yn) le mot reçu.
Résultat L'unique polynôme f de degré inférieur à k tel que d(f, y) ≤ t = n−k2 .
Étape d'interpolation trouver U(X) et V (X) tel queU(xi)yi + V (xi) = 0, i ∈ {1, . . . , n}, (9.4)
et tel quedeg U(X) ≤ t et deg V (X) < k + t. (9.5)
Étape de recherche de racines retourner f = V (X)U(X) .
On montre que si Q(X, Y ) = U(X)Y + V (X) véri�e (9.4) et (9.5), alors lafraction −V (X)
U(X) ne dépend pas de Q. En particulier on retrouvera bien la solutionf au problème de décodage, car elle permet de construire les polynômes
U(X) = E(X) et V (X) = f(X)E(X) (9.6)où E(X) =
∏(X −xij
) est le polynôme localisateur des erreurs, c'est-à-dire tel queE(xi) = 0 quand f(xi) 6= yi.9.1.4 L'algorithme de Guruswami-Sudan
La percée fondamentale dans le domaine du décodage des codes de Reed-So-lomon est due à Sudan [Sud97], pour être ensuite améliorée par Guruswami etSudan [GS99]. Nous rappelons brièvement l'algorithme de Guruswami-Sudan, ce-lui de Sudan en étant un cas particulier. L'idée est d'améliorer l'algorithme deBerlekamp-Welch, en introduisant un polynôme Q(X, Y ), non plus de degré 1, maisde degré supérieur à 1. Dans cet algorithmes intervient la notion de multiplicité,que dé�nissons comme suit.Dé�nition 4. Soit f = f(X1, . . . , Xm) = f0 + f1 + · · ·+ fd, où fi est homogène dedegré i. La multiplicité de f en (0, . . . , 0) est le plus petit indice i tel que fi 6= 0. Soitp = (p1, . . . , pm) ∈ Fm
q , la multiplicité de f en p, notée mult(f ; p), est la multiplicitéen 0 de f(X1 + p1, . . . , Xm + pm).
Nous avons aussi besoin de la notion de degré pondéré.Dé�nition 5. Le degré pondéré par u1, . . . , um du monôme aXi1
1 · · ·Ximm est u1i1 +
· · ·umim. Soit f = f(X1, . . . , Xm) ∈ Fq[X1, . . . , Xm], le degré pondéré de f , notéwdegu1,...,um
f est le maximum des degrés pondérés des monômes de f .
Nous pouvons donner le principe de l'algorithme de Guruswami-Sudan :Algorithme de Guruswami-SudanConstantes q une puissance d'un nombre premier ; (x1, . . . , xn) ∈ Fn
q le supportdu code de Reed-Solomon , k, µ ∈ N ;
Données y = (y1, . . . , yn) le mot reçu.Résultat tous les polynômes f de degré inférieur à k tel que f(xi) = yi pour aumoins µ valeurs de i.Paramètres auxiliaires d et s à déterminer dans l'analyse de l'algorithme.Étape d'interpolation trouver un polynôme Q(X, Y ) ∈ Fq[X, Y ] tel que
1. Q(X, Y ) 6= 0,2. wdeg1,k−1Q(X, Y ) ≤ d,

92 Chapitre 9. Décodage par interpolation
3. mult(Q; (xi, yi)) = s, i ∈ {1, . . . , n}.Factorisation Constituer la liste L des f = f(X) tels que Q(X, f) = 0.véri�cation retourner les f ∈ L tels que deg f < k, et d(f, y) < t.
Pour analyser l'algorithme, on procède en deux étape : premièrement, on consta-te que Qf = Q(X, f) est de degré au plus d (grâce à la condition de degré pondéré) ;ensuite si f(xi) = yi pour µ valeurs de i, alors le polynôme Qf a au moins sµ zéros,comptés avec multiplicité. Donc si
sµ > d, (9.7)Q(X, f) est identiquement nul. Deuxièmement, il faut être assuré qu'un polynômeQ(X, Y ) existe quelque soit le mot y à décoder. On remarque que résoudre l'étaped'interpolation revient à résoudre un système d'équations linéaires, dont les incon-nues sont les coe�cients de Q(X, Y ). On écrit donc la condition
NQ > Neq (9.8)où NQ est le nombre de termes de Q, et Neq le nombre d'équations linéaires imposéespar les conditions mult(Q; (xi, yi)) = s, i ∈ {1, . . . , n}. Cela donne
d(d + 2)2(k − 1)
> n
(s + 1
2
). (9.9)
En éliminant d dans (9.9) et dans (9.7), on obtientThéorème 11. L'algorithme de Guruswami-Sudan, avec le choix s pour la multi-plicité, décode jusqu'à t erreurs, avec
t = n− µ ≤ n
(1−
√k − 1
n(1 +
1s)
). (9.10)
L'algorithme de Sudan d'origine, revient à faire s = 1 (ne pas considérer demultiplicités). Dans ce cas, la capacité de correction est t = n(1 −
√2k−1
n ). Àl'opposé, quand s croît, on obtient une capacité de correction de n(1 −
√R), où
R = k−1n est sensiblement le taux de transmission du code. On exprime aussi ce
taux de correction sous la forme n −√
n(n− d), où d est la distance minimale ducode.
Du point de vue de la complexité de cet algorithme, les auteurs citent les papiersprincipaux sur la factorisation multivariée [Len85, Kal85, Gri86], en a�rmant quecelle-ci peut se faire en temps polynomial déterministe en q et le degré du polynôme,ou en temps polynomial probabiliste en log q et le degré du polynôme. Nous verronsdans la suite quelques travaux, en codage, pour traiter e�cacement le problème del'interpolation, et aussi le problème de la factorisation.
9.2 Algorithmes de Sudan et Guruswami-Sudan :interpolation e�cace
Rappelons le problème à résoudre pour e�ectuer la première étape, où on cherchele polynôme Q(X, Y ).Données {x1, . . . , xm} ⊂ Fq, y = (y1, . . . , yn) ∈ Fn
q , d un degré, et s un ordre demultiplicité.
Question Trouver un polynôme Q(X, Y ) ∈ Fq[X, Y ] tel que

9.3. Algorithme de Sudan : recherche de racines 931. Q(X, Y ) 6= 0,2. wdeg1,k−1Q(X, Y ) ≤ d,3. mult(Q; (xi, yi)) = s, i ∈ {1, . . . , n}.
Le problème est un système à n(s+12
)= O(ns2) équations (pour chaque point le
nombre d'équations correspond au nombre de monômes de degré inférieur ou égalà s− 1). L'approche utilisant l'algorithme de Gauss donne donc O(n3s6).
Nous citerons les principaux travaux dans ce domaine. Il y a deux approches :la première est l'approche par matrices structurées [OS99, OS03a], qui a donné lieuà un brevet [OS03b]. Cette approche consiste à dire que le système d'équationsà résoudre est dé�ni par une matrice fortement structurée, que l'on peut stockerde manière compacte. Les auteurs parlent de � structure de déplacement �, et ob-tiennent une complexité de O(ln2s4), où l est la taille de la liste des solutions. Notonsque cette approche s'applique aussi aux codes géométriques hermitiens, avec unecomplexité de O(lq7) = O(ln7/3).
Une autre approche est de construire, par un processus itératif, une famille de po-lynômes Qi(X, Y ), où i = 1, . . . , l et l une borne sur la taille de la liste, qui se calculeexplicitement. Ces polynômes véri�ent les conditions d'interpolation jusqu'à un cer-tain point (xi, yi), et on les met à jour pour passer au point suivant xi+1, yi+1). C'estun algorithme très similaire à l'algorithme de Berlekamp-Massey [Ber68, Mas69].Cette approche a été suggérée par [NH00]. On peut faire remonter ces techniquesà l'algorithme � FIA �(Fundamental Iterative Algorithm) de Feng et Tzeng [FT91],qui est un algorithme qui donne la plus courte combinaison linéaire des premièrescolonnes d'une matrice, algorithme étudié dans la thèse de Kötter [K�96], dans lecontexte du décodage des codes géométriques.
On constate aussi qu'on peut construire une base de Gröbner de l'idéal des po-lynômes qui satisfont les contraintes d'interpolation [MTV04], et retenir dans cettebase un polynôme Q(X, Y ) minimal. O'Kee�e et Fitzpatrick [OF02] étudient le pro-blème de l'interpolation en utilisant les bases de Gröbner, dans un contexte pluslarge, avec application au décodage et (oralement) ils prétendent avoir une com-plexité de O(n2s4). Lee et O'Sullivan [LO06], et Aleknovich [Ale02, Ale05] utilisentl'approche par bases de Gröbner, en pouvant écrire directement une base Gröbner del'idéal pour un ordre donné, que l'on transforme en une base de Gröbner pour l'ordredésiré. En�n Sakata a proposé une version de son algorithme BMS (Berlekamp-Massey-Sakata) [Sak90], pour trouver un polynôme d'interpolation [SNF00, Sak01].Il l'applique aussi aux codes géométriques hermitiens, pour obtenir une complexitéde O(s6n5/2k−1/2).
9.3 Algorithme de Sudan : recherche de racinesRappelons le problème.
Données X = {x1, . . . , xn} n points distincts dans Fq, y = (y1, . . . , yn) le motreçu, Q(X, Y ) un polynôme dans Fq[X][Y ], tel que Q(xi, yi) = 0, avec lamultiplicité s.
Question trouver tous les polynômes f ∈ Fq[X], deg f ≤ k, tels que Q(X, f) = 0.Nous avons contribué dans le cadre de l'algorithme de Sudan simple (s = 1) à
l'étape de recherche de racines. Notons qu'à l'étape d'interpolation, on peut choisirQ = Q(X, Y ) de degré minimal. Soit alors Q′(X, Y ) la dérivée de Q par rapport àY . On la propriété suivante :Proposition 9. Soit X = {x1, . . . , xn} ⊂ Fq, et y = (y1, . . . , yn) ∈ Fn
q à décoder.Soit Q(X, Y ), de degré minimal en Y , véri�ant Q(xi, yi) = 0, pour i ∈ {1, . . . , n}.Alors

94 Chapitre 9. Décodage par interpolation
1. pour toute solution f(X) du problème de décodage, telle que Q(X, f) = 0, ilexiste une position i ∈ {1, . . . , n} telle que f(xi) = yi, et Q′(xi, yi) 6= 0.
2. soit de plus f1 et f2 tels que Q(X, f1) = Q(X, f2) = 0, si de plus il existe i telque Q′(xi, yi) 6= 0 et f1(xi) = f2(xi), alors f1 = f2.
Ainsi, quand Q′(xi, yi) 6= 0, on peut appliquer la méthode de Newton au poly-nôme Q(X, Y ) ∈ Fq[X][Y ], en itérant
f ← f − Q(X, f)Q′(X, f)
mod (X − xi)k, (9.11)
où f est initialisée par f ← yi. En e�et, les solutions cherchées véri�ent f(xi) = yien au moins un indice i tel que Q′(xi, yi) 6= 0 : on peut donc prendre ce pointcomme initialisation de la méthode de Newton. On peut l'arrêter au bout de dlog keitérations, car nous ne sommes intéressés que par les solutions de degré au plus k,et la méthode de Newton est à convergence doublement quadratique. L'algorithmeque nous proposons est donc :Recherche de racines dans le cas de l'algorithme de SudanDonnées X = {x1, . . . , xn} ⊂ Fq, y = (y1, . . . , yn) ∈ Fn
q , Q(X, Y ) de degré mini-mal véri�ant les conditions de l'étape d'interpolation.
Initialiser I = {i ∈ {1, . . . , n};Q′(xi, yi) 6= 0}, L = ∅Boucle pour i ∈ I
1. faire les dlog2 ke itérations de Newton (9.11), en initialisant f par f ← yi,2. L← L ∪ {f},3. enlever de I les indices j tels que f(xj) = yj .
Véri�cation retourner les f ∈ L tels que d(f, y) < t.Les autres travaux traitant ce problème de recherche de racines sont ceux de Rothet Ruckenstein [RR00] (qui s'appliquent au cas où s = 1) et ceux de Gao et Shokrol-lahi [GS00] qui s'appliquent à l'algorithme de Guruswami-Sudan, avec s > 1. Dansces travaux, à une étape donnée de l'algorithme, le polynôme Q(X, Y ) est spécialiséen Y , ce qui donne un polynôme univarié que l'on factorise par des méthodes clas-siques. Le résultat de cette factorisation donne des points de départ pour calculerle développement des solutions. Dans le cas de [RR00], on voit apparaître une mé-thode d'éclatement des points, alors que dans le cas [GS00], on utilise la méthodedu polygone de Newton. Il est à noter que notre proposition évite cette étape de fac-torisation, car les points de départ de la méthode de Newton sont déjà disponibles,ce sont les yi, tels que Q′(xi, yi) 6= 0. Une autre approche est proposée par Nielsenet Høholdt, où le problème est ramené à celui d'une factorisation dans un grandcorps �ni [NH00, HN99]. Ils traitent à la fois des codes de Reed-Solomon et descodes géométriques. Notre contribution s'applique aux codes de Reed-Solomon etaux codes géométriques, évite la factorisation univariée, ce qui a l'intérêt de rendrele décodage déterministe. En revanche, notre méthode ne permet de traiter le casoù s > 1, car il n'y a plus de point où Q′(xi, yi) 6= 0 (la multiplicité est supérieureà 1).
9.4 Généralisation aux codes géométriquesUne généralisation majeure des codes de Reed-Solomon est celle des codes géo-
métriques, due à Goppa [Gop77]. Soit X une courbe projective, absolument irré-ductible, non singulière dé�nie sur Fq. Soient X = {P1, . . . , Pn}, n points distincts

9.4. Généralisation aux codes géométriques 95Fq-rationnels, et G un diviseur Fq-rationnel de X , tel qu'aucun de Pi ne soit dansle support de G. Soit L(G) l'espace de fonctions sur la courbe :
L(G) = {f ∈ Fq(X ); (f) + G ≥ 0} . (9.12)Le code géométrique C(X, G), correspondant aux points de X et à l'espace L(G),est
C(X, G) = {(f(P1), . . . , f(Pn)); f ∈ L(G)} . (9.13)Si deg G < n, alors c'est un code [n, k, d], avec k ≥ deg G + 1− g, et d ≥ n− deg G,où g est le genre X . Si de plus 2g − 2 < deg G < n, alors la dimension du code estexactement k = deg G+1−g. Cette généralisation présente de grandes potentialités :alors que dans le cas des codes de Reed-Solomon la longueur n est bornée par la tailleq de l'alphabet Fq, dans le cas des codes géométriques, à q �xé, on peut construiredes courbes avec un nombre de points arbitrairement grand. De plus, il existe, dansla classe des codes de Goppa, des codes de paramètres asymptotiquement meilleursque les codes aléatoires [TVZ82]. En�n, en longueur petite, on peut construire detrès bons codes [Bro98].
Nous pouvons reprendre point par point tout ce qui a été dit précédemmentsur les codes de Reed-Solomon, et cela se généralise bien au codes géométriques.Cheng [Che05] a montré que le problème du décodage des codes géométriques estdi�cile, pour la classe des codes géométriques dé�nis sur les courbes elliptiques, maisen utilisant, comme dans le cas des codes de Reed-Solomon, des tailles d'alphabetexponentielles en la la longueur du code.
L'algorithme de Sudan et l'algorithme de Guruswami-Sudan se généralisent bien,dans leur principe, aux codes géométriques. Cela a été dans le cas s = 1 (algorithmede Sudan) par Shokrollahi et Wasserman [SW99]. Guruswami et Sudan, en intro-duisant les multiplicités s > 1, ont aussi généralisé aux codes géométriques dits � àun point � : ce sont les codes pour lesquels le diviseur G est de la forme αP∞, oùP∞ est un point particulier de la courbe, et où α est un entier. Il est frappant quela capacité de correction est encore n−
√n(n− d′) où d′ est la distance construite
du code géométrique.Dans sa thèse Lancelot Pecquet montre comment utiliser l'algorithme de Guru-
swami-Sudan dans le cas où le diviseur G n'est pas un diviseur à un point. Celanous semble intéressant car il arrive que l'on puisse obtenir de meilleurs paramètresen considérant des codes à diviseur général, comme par exemple ceux obtenus avecla contruction de Xing [Xin01, Xin05]. Il obtient encore une capacité de correctionde n−
√n(n− d′).
Schématiquement, les algorithmes comportent toujours les deux grandes étapesd'interpolation et de recherche de racines. Plus précisément, la structure est :constantes X une courbe dé�nie sur Fq, P1, . . . , Pn n points Fq-rationnels de X ,
D un diviseur dont le support ne contient aucun des Pi.données y = (y1, . . . , yn) le mot reçu.résultat tous les f ∈ L(D) tels que d(f, y) ≤ t.étape d'interpolation trouver un polynôme Q(Y ) in Fq(X )[Y ] tel que
1. Q(X) 6= 0 ;2. les coe�cients Qi de Q(Y ) sont dans des espaces L(Di) convenables ;3. la � multiplicité �de Q(Y ) en (Pi, yi) est supérieure ou égale à s.
étape de recherche de racines trouver les f ∈ Fq(X ) tels que Q(f) = 0, avecf ∈ L(D), et d(f, y) ≤ t.
En ce qui concerne l'étape d'interpolation, Høholdt et Nielsen [HN99] étendentleur algorithme aux codes hermitiens, c'est-à-dire aux codes géométriques dé�nis

96 Chapitre 9. Décodage par interpolation
que la courbe d'équation Xq+1 + Y q+1 + Zq+1 = 0 sur Fq2 . Sakata [SNF00, Sak01]a aussi traité le cas des codes hermitiens avec son algorithme BMS.
Avec Lancelot Pecquet, nous avons montré que la méthode de Newton, quenous utilisons avec des points de départ déjà connus, se généralise au cas des codesgéométriques. Elle présente encore l'avantage d'éviter une factorisation univariée.sou�re du même défaut, qui est de ne s'appliquer qu'au cas où s, l'ordre de mul-tiplicité est égal à 1. D'autre part, Wu et Siegel [WS01] ont généralisé la méthodede factroisation de Roth et Ruckenstein aux codes géométriques, et dans le cadregénéral de l'algorithme de Guruswami-Sudan (s ≥ 1). L'algorithme de Gao et Sho-krollahi [GS00] s'applique aussi au cas des codes géométriques, et avec s ≥ 1.
9.5 Généralisations multivariées
Il peut être fructueux de considérer des généralisations multivariées d'algo-rithmes � univariés �. On peut voir les algorithmes de Sudan et de Guruswami-Sudan comme des algorithmes univariés qui utilisent, à un moment donné de lapreuve de leur correction, la propriété qu'un polynôme qui a plus de zéros, comp-tés avec multiplicités, que son degré, est identiquement nul. Dans le cas univarié,étant donné un ensemble S = {x1, . . . , xn} de n points distincts dans Fq, nousconsidérions la fonction d'évaluation
ev : Fq[X] → (Fq)n
f(X) 7→(f(xi)(xi∈X)
) (9.14)
nous considérons L = {f ∈ Fq[X],deg f < k} et le code de Reed-Solomon dedimension k est l'ensemble
{ev f ; f ∈ L} (9.15)Dans le cas multivarié, nous construisons Sm = {x1, . . . , xn}m, et la fonction d'éva-luation
evm :Fq[X1, . . . , Xm] → (Fq)
nm
f(X1, . . . , Xm) 7→ (f(xi1 , . . . , xim))(xi1 ...,xim )∈Sm
(9.16)
et nous considérons deux possibilités pour l'espace L des polynômes à évaluer.1. L = {f = f(X1, . . . , Xm), deg f ≤ r}, où deg est le degré total. Ce code cor-
respond au code de Reed-Muller d'ordre r à m variables. Nous nous intéressonsau cas q > r, pour lequel la dimension est (m+r
r
).2. L = {f(X1, . . . , Xm), degXi
f(X1, . . . , Xm) < k, i ∈ {1, . . . ,m}}, ce qui don-nera le code ⊗mC1 qui est le code produit m fois du code de Reed-SolomonC1 de dimension k. La dimension du code est km.
En�n, du point de vue multivarié, citons les travaux de Parvaresh et Vardy [PV05b,PV05a], qui permettent de décoder simultanément plusieurs mots de code, en faisantl'hypothèse que les erreurs sur chaque mot sont localisées sur les mêmes positions.Cela revient à traiter un problème multivarié, mais di�érent du notre, où la fonctiond'évaluation est la suivante :
evm :Fq[X]× · · · × Fq[X] → (Fn
q )m
(f1(X), . . . , fm(X)) 7→ (ev f1(X), . . . , ev fm(X)),
ce qui revient à considérer simultanément m mots du code Ck. De manière simi-laire à l'algorithme de Sudan, ils construisent un polynôme Q(X1, . . . , XM , Y ), avec

9.6. Généralisation aux codes produits de codes de Reed-Solomon 97des conditions d'interpolation qui conviennent. Si les erreurs, sur les mots reçus,occurrent sur les même positions, ils peuvent corriger un nombre d'erreurs de
t ≤ n
(1− m+1
√(k − 1
n
)m
(1 +1s) · · · (1 +
m
s)
)
dont la limite, quand s croît, estn(1−R
mm+1
),
ce qui est un résultat très favorable, supérieur au rayon 1 − R1/2 obtenu parGuruswami-Sudan.
9.6 Généralisation aux codes produits de codes deReed-Solomon
9.6.1 L'algorithmeNous donnons d'abord l'algorithme qui en fait est un � principe algorithmique �,
qui consiste, comme l'algorithme original, en deux étapes : une étape d'interpolation,et une étape de factorisation.Décodage pour le degré partielDonnées (x1, . . . , xn) ∈ Fn
q , y = (yi1,...,im)(i1,...,im) ∈ Fnm
q , k, µ ∈ N.Paramètres auxiliaires k′ et s à déterminer dans l'analyse de l'algorithme.Étape d'interpolation trouver un polynôme Q(X1, . . . , Xm, Y ) tel que
1. Q(X1, . . . , Xm, Y ) 6= 0,2. Si l'on écrit,
Q =∑
i1,...,im,j
qi1,...,im,jXi11 . . . Xim
m Y l (9.17)
alors Q n'a pas de terme qi1,...,im,j si au moins un indice il véri�entil + kj > k′.
3. mult(Q(xi1 , . . . , xim), yi1,...,im
) = s, pour tout (i1, . . . , im) ∈ {1, . . . , n}m.Factorisation trouver les f = f(X1, . . . , Xm) tel que Q(X1, . . . , Xm, f).Véri�cation retourner les f tels que deg f ≤ r, et d(f, y) < t.
Lorsque l'on substitue la solution f(X1, . . . , Xm) dans Q(X1, . . . , Xm, Y ), onobtient, par construction, un polynôme Qf = Q(X1 . . . , Xm, f) de degré en chacunede ses variables borné par k′. Mais nous n'avons pas de théorème semblable au casunivarié, qui permettrait de dire qu'un polynôme qui a plus de racines que son degréest identiquement nul. En revanche, nous pouvons prendre avantage de la structurede Xm, pour avoir tout de même un lemme bornant le nombre de zéros d'un telpolynôme.
9.6.2 Un lemme sur le nombre de zérosProposition 10. Soit Q = Q(x1, . . . , xm) de degré au plus k′ en chaque variable,soit X = {x1, . . . , xm} un ensemble de n points distincts de Fq. La somme desmultiplicités de Q sur l'ensemble Xm est au plus
mk′nm−1 (9.18)

98 Chapitre 9. Décodage par interpolation
Démonstration. Par récurrence. Le résultat est vrai pour m = 1. Supposons vrai lerésultat pour m− 1. Soit J l'ensemble d'indices suivant :
J = {j ∈ {1, . . . , n}, Q(X1, . . . , Xm−1, xj) = 0}, (9.19)de telle sorte que l'on peut écrire, pour j ∈ J :
Q(X1, . . . , Xm) = (Xm − xj)tj Qj(X1, . . . , Xm), (9.20)avec tj > 0. On a donc
Q(X1, . . . , Xm) = Q(X1, . . . , Xm)∏j∈J
(Xm − xj)tj , (9.21)
et on note que degXmQ(X1, . . . , Xm) = k′ −
∑j∈J tj . Soit S la somme des multi-
plicités de Q(X1, . . . , Xm) sur Xn. AlorsS =
∑(i1,...,im)
mult(Q(X1, . . . , Xm), (xi1 , . . . , xim))
=∑
im∈J′
∑(i1,...,im−1)
mult(Q(X1, . . . , Xm), (xi1 , . . . , xim))
+∑
im∈J
∑(i1,...,im−1)
mult(Q(X1, . . . , Xm), (xi1 , . . . , xim))
= S′ + S′′.
(9.22)
On calcule S′ :S′ =
∑im∈J′
∑(i1,...,im−1)
mult(Q(X1, . . . , Xm), (xi1 , . . . , xim)),
=∑
im∈J′
∑(i1,...,im−1)
mult(Q(X1, . . . , Xm), (xi1 , . . . , xim)).
≤∑
im∈J′
∑(i1,...,im−1)
mult(Q(X1, . . . , Xm−1, xim), (xi1 , . . . , xim−1)).
L'hypothèse de récurrence nous permet de dire queS′ ≤
∑im∈J′
(m− 1)k′nm−2 = |J ′|(m− 1)k′nm−2.
(9.23)De même
S′′ =∑
im∈J
∑(i1,...,im−1)
mult(Q(X1, . . . , Xm), (xi1 , . . . , xim))
=∑
im∈J
∑(i1,...,im−1)
(tj + mult(Qj(X1, . . . , Xm), (xi1,...,im))
)≤ nm−1
∑i∈J
tj + |J |(m− 1)k′nm−2
(9.24)
DoncS = S′ + S′′
≤ nm−1∑j∈J
tj + (|J |+ |J ′|)(m− 1)k′nm−2
≤ nm−1k′ + (m− 1)k′nm−1
= mk′nm−1
(9.25)

9.7. Généralisation aux codes de Reed et Muller 99
9.6.3 Analyse de l'algorithmeArmé de ce lemme, nous pouvons analyser l'algorithme. On en déduit :
Proposition 11. Soit Q(X1, . . . , Xm, Y ) comme dans l'algorithme 9.6.1. Soit f =f(X1, . . . , Xm) tel que degXi
f ≤ k pour chaque indéterminée Xi, et tel que
f(xi1 , . . . , xim) = yi1,...,im (9.26)pour au moins µ indices (i1, . . . , im). Alors si µ est tel que
sµ > mk′nm−1, (9.27)on a Q(X1, . . . , Xm, f) = 0.
En�n, pour justi�er complètement l'algorithme, il faut s'assurer que le polynômeQ, avec les contraintes sur les degrés partiels, existe pour tout entrée (y1, . . . , yn).Pour cela, nous écrivons encore la condition
NQ > Neq, (9.28)où NQ est le nombre de termes de Q et Neq le nombre d'équations. Le nombred'équations est
Neq = nm
(m + 1 + s− 1
s− 1
)= nm
(m + s
m + 1
)= nm · s . . . (s + m)
(m + 1)!. (9.29)
Le nombre de termes estk′m+1
(m + 1)k
L'équation (9.28) donne
k′ > n m+1
√k
n· s . . . (s + m)
(m + 1)!. (9.30)
Pour �nir, en combinant (9.30) et (9.27), on obtient :Proposition 12. L'algorithme précédent décode jusqu'à t erreurs, avec
t = nm − µ ≤ nm
(1− m+1
√mm+1
m!· r
n· (1 +
1s· · · (1 +
m
s)
)(9.31)
dont la limite est, quand s croît :
nm
(1− m+1
√mm+1
m!· r
n
). (9.32)
9.7 Généralisation aux codes de Reed et MullerNous pouvons construire l'algorithme suivant, qui est une généralisation très
directe de l'algorithme de Guruswami-Sudan.Décodage pour le degré totaldonnées (x1, . . . , xn) ∈ Fn
q , y = (yi1,...,im)(i1,...,im) ∈ Fnm
q , r, µ ∈ N.paramètres auxiliaires d et s à déterminer dans l'analyse de l'algorithme.

100 Chapitre 9. Décodage par interpolation
étape d'interpolation trouver un polynôme Q(X1, . . . , Xm, Y ) tel que1. Q(X1, . . . , Xm, Y ) 6= 0,2. wdeg1,...,1,rQ(X1, . . . , Xm, Y ) ≤ d,3. multQ(xi1 , . . . , xim
, yi1,...,im) = s, pour tout (i1, . . . , im) ∈ {1, . . . , n}m.
étape de recherche de racines retourner les facteurs (Y − f) de Q, tels quedeg f ≤ r et f(xi1 , . . . , xim) = yi1,...,im pour au moins µ indices (i1, . . . , im).
On voit tout de suite que le polynôme Qf = Q(X1, . . . , Xm, f) est de degré totalborné par d, et que son nombre de racines, comptés avec multiplicités est au moinssm. Encore une fois nous sommes confrontés au problème de borner le nombre dezéros, parmi Xm, d'un tel polynôme Qf . Wu et Pellikaan [PW04b, PW04a] utilisentle théorie de l'escalier (footprint) d'un l'idéal. Il considère l'idéal
I(q, m) = 〈Xqi −Xi; i ∈ {1, . . . ,m}〉
des polynômes qui s'annulent sur Fmq , puis l'idéal I(q, m)s des polynômes qui s'an-
nulent avec la multiplicité s. Soit IQf= I(q, m)s +f , alors Wu et Pellikaan bornent
inférieurement par une certaine quantité binf le nombre de points sous l'idéal IQf,
en utilisant que la somme des multiplicités de Qf est supérieure ou égale à sµ. D'unautre coté, il borne supérieurement par bsup le nombre de points sous l'idéal IQf
, enutilisant que le degré de Qf est borné par d. En écrivent la condition binf > bsup, ilsen déduisent que Qf doit être identiquement nul. Au �nal, ils obtiennent un rayonde décodage
t < qm
(1− m+1
√r
q(1 +
1s) · · · (1 +
m
s))m
−→s→+∞ nm
(1− m+1
√r
q
)m
De notre part, nous utiliserons une généralisation du lemme de Schwarz-Zi-ppel [Sch80, Zip79] permet de borner le nombre de zéros, sur Fm
q d'un polynômemultivarié à m variables de degré inférieur à d par dqm−1 (c'est-à-dire que la pro-portion des zéros parmi tous les éléments de Fm
q est dq ). Nous avons besoin du même
genre de lemme, mais en comptant les zéros avec multiplicité.Lemme 3 (Schwarz-Zippel avec multiplicités). Soit Q = Q(X1, . . . , Xm) ∈Fq[X1, . . . , Xm] de degré total au plus d. Soient X = {x1, . . . , xn} un ensemble de néléments distincts de Fq. Alors la somme des multiplicités de Q, prise sur l'ensembleXn, est bornée par dnm−1.
La preuve suit les mêmes lignes que la preuve du lemme 10. Nous avons donc :Proposition 13. Soit Q(X1, . . . , Xm, Y ) comme dans l'algorithme 9.7. Soit f =f(X1, . . . , Xm) tel que deg f ≤ r, et tel que
f(xi1 , . . . , xim) = yi1,...,im
(9.33)pour au moins µ indices (i1, . . . , im). Alors si
sµ > dnm−1, (9.34)on a Q(X1, . . . , Xm, f) = 0.
Pour �nir d'étudier la capacité de correction de l'algorithme, nous devons déter-miner quand est-ce que le polynôme Q de l'étape d'interpolation existe pour touteentrée de l'algorithme. Pour être sûr que Q existe quelque soit le mot reçu y, nousdevons imposer encore
NQ > Neq (9.35)

9.8. Spéci�cité des corps �nis 101où NQ est le nombre de termes de Q, et Neq. le nombre d'équations données parle point 3. de l'algorithme. Le nombre d'équations est le même que dans le casdes codes produits. Et on calcule que le nombre de termes NQ d'un polynôme Qvéri�ant la condition 2 d'interpolation est au moins.
dm+1
r(m + 1)!. (9.36)
L'équation 9.35 donne la condition su�sante :dm+1
r(m + 1)!> nm · s . . . (s + m)
(m + 1)!. (9.37)
En combinant (9.34)et (9.37), après calcul, on obtient :Proposition 14. L'algorithme précédent décode jusqu'à t erreurs, avec
t ≤ nm(1− m+1
√r
n(1 +
1s) · · · (1 +
m
s)) −→
s→+∞ nm
(1− m+1
√r
n
). (9.38)
Ce qui est meilleur que le rayon de décodage obtenue par Pellikaan et Wu avecl'analyse utilisant les bases de Gröbner.
En résumé, les deux algorithmes de décodage, des codes produits de codes deReed-Solomon, et de codes de Reed-Muller, voient leur performance se dégraderquand le nombre m de variables augmentent (à cause du facteur m+1
√). C'est àl'opposé de l'algorithme de Parvaresh et Vardy, qui voit ses performances s'améliorerquand le nombre de variables augmente.
9.8 Spéci�cité des corps �nisRemarquons que ces algorithmes n'utilisent en aucun cas le fait que les codes
sont dé�nis sur Fq. En réalité, on pourrait dé�nir des codes théoriques sur n'importequel corps, et ces algorithmes fonctionnerait parfaitement. En revanche, lorsquel'alphabet est Fq, les codes de Reed-Muller prennent une structure particulière,suivant un résultat dû à Kasami, Lin et Peterson [KLP68]. Soit RMq(r, m) le codede Reed-Muller construit sur Xm = Fm
q . Un mot de RMq(u, m) est donc du typec = (f(xi1 , . . . , xim
))(i1,...,im)∈{1,...,q}m (9.39)où {x1 = 0, . . . , xq} est une énumération de Fq. Soit RMq(u, m)∗ le code raccourciobtenu en enlevant de chaque mot de RMq(r, m) la composante correspondant àl'évaluation en (x1 = 0, . . . xm = 0), on obtient un code de longueur qm − 1.Proposition 15. Soit d−1 la distance minimale de RMq(r, m)∗. Le code RMq(r, m)est le code
C0 ∩ Fqm−1q , (9.40)
où C0 est le code BCH primitif au sens strict de distance construite d − 1 (qui estun cas particulier de code de Reed-Solomon).
Ainsi Pellikaan et Wu [PW04b], en utilisant alors l'algorithme de Guruswami-Sudan � univarié �, obtiennent une capacité de correction de
n = n−√
(n− d)n =(1−
√r/q) (9.41)
Une autre construction utilise le fait que l'ensemble Am(Fq) des points P ∈Fm
q constitue une courbe algébrique, lisse sur sa partie a�ne Am, ayant un seul

102 Chapitre 9. Décodage par interpolation
point à l'in�ni P∞ correspondant à une seule place Q∞, et de genre g = 12 ((q2 −
1)(q +1)m−1− qm+1 +1). Les équations dé�nissant cette courbe sont explicitementconnues [PSvW91], et les bases des espace L(lQ∞) sont aussi explicitement connues.De cette manière, ils interprètent le code de Reed-Muller comme un code géomé-trique à un point sur cette courbe. En utilisant encore l'algorithme de Guruswami-Sudan, cette fois pour les codes géométriques, Pellikaan et Wu obtiennent une ca-pacité de correction de
n
(1−
√r(q + 1)m−1
n
)(9.42)
qui est sensiblement égale à celle obtenue en (9.41) quand q est grand (n = qm).En ce qui concerne les codes produits de codes de Reed-Solomon, l'astuce de
Parvaresh, El-Khamy, McEliece et Vardy [PEKMV] est de considérer le code produit⊗2C1 comme un sous-code du code de Reed et Muller de paramètre r = 2k (en e�etun polynôme de degré k en chacune de ses deux variables est de degré total au plus2k). En utilisant le résultat de Wu et Pellikaan, ils obtiennent ainsi une capacité decorrection de
t < n
(1−
√r
q
). (9.43)

Cinquième partie
Annexes
103


Annexe A
Informations annexes
A.1 Étudiants encadrés
A.1.1 Thèse de Lancelot Pecquet : décodage en liste descodes géométriques
Thèse soutenue le 18 décembre 2001, à l'Université Paris VI.Lancelot Pecquet a travaillé sur les algorithmes de Sudan [Sud97], Shokrollahi-
Wasserman [SW99] et Guruswami-Sudan [GS99], de décodage des codes de Reed-Solomon et des codes géométriques. Il a proposé une version de l'algorithme deGuruswami-Sudan pour les codes géométriques dits � à plusieurs points �, c'est àdire lorsque l'espace des fonctions à évaluer n'est pas un espace de Riemman-Rochde la forme L(kP ) , mais un espace de Riemann-Roch L(D), avec D quelconque. Ila implémenté en Magma ces algorithmes.
Il a aussi proposé une méthode de décodage � souple �, suivant le principe deKötter et Vardy [KV03]. Le problème est le suivant : dans la chaîne de transmission,le dispositif physique est capable, pour chaque symbole reçu, de donner une infor-mation de qualité (soft information), plutôt que de choisir un symbole dans Fq, leplus probable. Il est alors utile, pour améliorer le décodage, de prendre en comptecette information, pour trouver le mot de code le plus vraisemblable.
Les algorithmes de décodage par interpolation construisent un polynôme d'in-terpolation, dont les facteurs contiennent les solutions du problème de décodage.L'idée est de traduire les informations de qualité en conditions algébriques d'interpo-lation : les multiplicités. Ce principe a aussi été généralisé aux codes géométriques,et Lancelot Pecquet a proposé une règle di�érente que celle de Kötter et Vardy pourtransformer les informations de qualité en multiplicités.
A.1.2 Thèse de Cédric Tavernier : testeurs, problèmes dereconstruction univariés et multivariés, et applicationà la cryptanalyse du DES
Thèse soutenue le 14 janvier 2005, à l'École Polytechnique.La problématique est la suivante : on a accès à une fonction f : Fn
2 → F2, avec ngrand (par exemple, n = 64 ou n = 128), grâce à un oracle qui, lorsqu'on lui soumetx ∈ Fn
2 , retourne f(x). Soit l la fonction F2-linéaire, inconnue, la plus proche def au sens de la distance de Hamming. C'est-à-dire que l est la fonction F2-linéairetelle que la distance
d = |{x ∈ Fn2 ; f(x) 6= l(x)}|
est minimale. On se pose les questions suivantes :105

106 Annexe A. Informations annexes
� est-ce que d est plut petit qu'un seuil donné ?� quelle est la fonction F2-linéaire la plus proche (au sens de la distance deHamming) de f ?
On ne peut pas voir accès à la totalité du vecteur des valeurs (f(x);x ∈ Fn2 ), car
n est trop grand. On considère donc des algorithmes qui font un petit nombre derequêtes f(x) pour un certain nombre de valeurs x, si possible polynomial en n.
On aura une réponse probabiliste aux deux questions ci-dessus. Le premier pro-blème a été étudié initialement dans [GLR+91] et on appelle un testeur un pro-gramme qui teste si d est est en dessous d'un certain seuil. Le deuxième problème,qui s'apparente à de la correction d'erreurs, a connu une solution en temps poly-nomial avec l'algorithme de Goldreich-Rubinfeld-Sudan [GRS95, GRS00]. On parlede décodage local : on ne connait qu'une partie, in�me, des valeurs de f(x), et onveut retrouver la fonction l la plus proche de f .
Cédric Tavernier a montré que répondre au premier problème ne coûte pas moinscher que de déterminer la fonction linéaire la plus proche. Il a donné une complexitéprécise pour l'algorithme de Goldreich-Rubinfeld-Sudan, et a ensuite amélioré cettecomplexité, ainsi que le nombre d'appel à la fonction f .
Ces algorithmes peuvent être employés pour étudier certaines combinaisons li-néaires des bits de sortie d'une fonction de chi�rement f : Fn
2 × Fk2 → Fn
2 , où nest la taille en bits des messages, k la taille en bits des clés. Cédric Tavernier aappliqué son algorithme au schéma du DES, et il a retrouvé automatiquement lesmeilleures approximations linéaires de certaines sur de l'algorithme de chi�rementDES, données par Matsui [Mat94b], ainsi que de nombreuses autres.
A.1.3 Thèse de Magali Bardet : étude des systèmes algé-briques surdéterminés. Applications aux codes correc-teurs et à la cryptographie
Thèse soutenue le 8 décembre 2004, à l'université Paris VI. Co-direction avecJean-Charles Faugère.
Magali Bardet a étudié des outils issus des méthodes de base de Gröbner pourtraiter de certains problèmes en cryptographie et en théorie des codes. La partiecodage est décrite, de manière détaillée dans le chapitre 8 du présent document.Essentiellement, le problème du décodage est mis en équations, et les propriétés dusystème d'équations, relativement au problème de décodage posé, sont étudiées. Ellea montré que les résolutions de ces systèmes, avec des algorithmes de calcul de basesde Gröbner, comme ceux que Jean-Charles Faugère a développés [Fau99, Fau02],est e�cace. On obtient en e�et un coût, en nombre d'opérations arithmétique dansun corps �ni, comparable au coût du décodage d'un code BCH de même capacité decorrection, mais en ayant la possibilité de corriger des codes cycliques quelconques.
L'autre partie de la thèse traite de l'étude de la complexité algorithmique de larésolution, avec des algorithmes de calcul de base de Gröbner, de systèmes d'équa-tions surdéterminés généraux. Cela a de nombreuses applications en cryptographie,comme par exemple la cryptanalyse de HFE [FJ03].
A.1.4 Thèse de Raghav Bhaskar : protocoles cryptographi-ques pour les réseaux Ad Hoc
Thèse soutenue le 26 juin 2006. Co-direction avec Valérie Issarny.Le sujet de départ était la sécurisation du système de �chiers distribué AdHocFS,
développé dans le projet Arles de l'INRIA Rocquencourt. Alors qu'il semblait claird'utiliser du chi�rement pour sécuriser les �chiers, le problème de la gestion de la clérestait posé. Il a semblé immédiatement intéressant d'élaborer une solution à base

A.2. Enseignement 107de protocoles de mise en accord de clé, qui sont une généralisation à n utilisateurs duprotocole de Di�e-Hellman [DH76], dé�ni pour deux utilisateurs. Il n'y a pas de tellegénéralisation directe du protocole à n utilisateurs, et de nombreuses propositionsont été faites, avec de plus ou moins bonnes performances (en terme de la quantitédes calculs à e�ectuer et de la quantité de message échangées) . Nous avons produitune contribution dans ce domaine, qui est meilleure à de nombreux points de vue quel'existant. Raghav Bhaskar a aussi prouvé la sécurité du protocole dans le modèle desécurité de Bresson, Chevassut, Pointcheval [BCP02]. Une telle preuve de sécuritéest essentiellement une preuve par l'absurde, où il est montré qu'un attaquant contrele protocole peut être utilisé pour résoudre le problème algorithmique dit de Di�e-Hellman décisionnel. À partir du moment où il est admis que ce problème estdi�cile, on en déduit qu'il n'y a pas d'attaquant e�cace contre le protocole.
En�n, nous avons étudié la mise en ÷uvre de ce protocole, à travers une col-laboration avec le projet Hipercom de Rocquencourt(Paul Mühlethaler et CédricAdjih) [BMA+06]. En e�et, dans le monde cryptographique, les messages arriventtoujours à bon port, ce qui n'est pas le cas notamment dans les réseaux Ad Hoc, oùle phénomène de perte de paquets est important. Il fallait donc adapter le protocoleau contexte pratique des réseaux Ad Hoc, en utilisant des mécanismes réseaux. Dupoint de vue de l'application à de tels réseaux, notre protocole présente la qualitéd'être très robuste : la défaillance d'un des participants au protocole, n'empêchepas les autres participants restants de mener le protocole à bien.
A.2 Enseignement1. Cours de codes correcteurs d'erreurs dans le DEA Algorithmique, Paris VI,
2001-2004, 20 heures partagées avec Jean-Pierre Tillich.2. Mastère MPRI (Mastère Parisien de Recherche en Informatique), 2004-2006,
où j'enseigne toujours (51 heures, partagées avec Jean-Charles Faugère etJean-Pierre Tillich). Ce dernier cours permet de développer les liens entrealgorithmes de calcul formel et codage.
3. TD de Caml en license d'informatique à Paris VI (Thèrese Hardin enseignant)en 2000-2001. Ce module a ensuite été arrêté. Je me suis investi dans ce coursà cause de l'intérêt que j'avais pour le projet Focal.
4. TD de java à l'École polytechnique en 2001.5. Cours de cryptologie dans le DEA Informatique Fondamentale et Applications
de l'université de Marne-la-Vallée 2003-2005. Devenu le Mastère InformatiqueRecherche où j'enseigne toujours.
A.3 Publications
Articles longs dans des revues avec comité de lecture1. Daniel Augot, Pascale Charpin, and Nicolas Sendrier. Sur une classe de po-
lynômes scindés de l'algèbre F2m [Z]. Comptes Rendus de l'Académie desSciences, 312 :649�751, 1991.
2. Daniel Augot, Pascale Charpin, and Nicolas Sendrier. Studying the locatorpolynomial of minimum weight codewords of BCH codes. IEEE Transactionson Information Theory, 38(3) :960�973, 1992.
3. Daniel Augot and Paul Camion. Forme de Frobenius et vecteurs cycliques.Comptes rendus de l'Académie des Sciences, 318 :183�188, 1993.

108 Annexe A. Informations annexes
4. Daniel Augot and Nicolas Sendrier. Idempotents and the BCH bound. IEEETransactions on Information Theory, 40(1) :204�207, January 1994.
5. Daniel Augot. Description of minimum weight codewords of cyclic codes byalgebraic systems. Finite Fields Appl., 2(2) :138�152, 1996.
6. Daniel Augot and Françoise Lévy dit Véhel. Bounds on the minimum distanceof the duals of BCH code. IEEE Transactions on Information Theory, 1996.
7. Daniel Augot and Paul Camion. On the computation of minimal polyno-mials, cyclic vectors and Frobenius forms. Linear Algebra and its Applications,260 :61�94, 1997.
8. Daniel Augot, Jean-Marc Boucqueau, Jean-François Delaigle, Caroline Fon-taine, and Eddy Goray. Secure delivery of images over open networks. Pro-ceedings of the IEEE, 87(7) :2605�2614, November 1999.
9. Daniel Augot and Lancelot Pecquet. A Hensel lifting to replace factoriza-tion in list-decoding of Algebraic-Geometric and Reed-Solomon codes. IEEETransactions on Information Theory, 46(7) :2605�2614, November 2000.
10. Daniel Augot, Raghav Bhaskar, Valerie Issarny, and Daniele Sacchetti. Athree round authenticated group key agreement protocol for adhoc networks.Pervasive and Mobile Computing, 3(1) :36�52, 2007.
Articles longs dans des conférences internationales avec comité de lec-ture
1. Daniel Augot, Pascale Charpin, and Nicolas Sendrier. Weights of some binarycyclic codes throughout the Newton's identities. In Gérard Cohen and PascaleCharpin, editors, Eurocode 90. Springer-Verlag, 1990.
2. Daniel Augot. A deterministic algorithm for computing a normal basis in a�nite �eld. In Eurocodes 94, Abbaye de la Bussière, France, 1994.
3. Daniel Augot, Jean-Francois Delaigle, and Caroline Fontaine :. A scheme formanaging watermarking keys in the Aquarelle multimedia distributed system.In Jean-Jacques Quisquater, Yves Deswarte, Catherine Meadows, and DieterGollmann, editors, ESORICS, number 1485 in Lecture Notes in ComputerScience. Springer-Verlag, 1998.
4. Daniel Augot and Caroline Fontaine. Key issues for watermarking digitalimages. In SPIE, EUROPTO - Conference on Electronic Imaging : Processing,Printing, and Publishing in Color, EUROPTO, pages 176�185, Zürich, Suisse,1998.
5. Daniel Augot and Matthieu Finiasz. A public key encryption scheme basedon the polynomial reconstruction problem. In Eli Biham, editor, Advances inCryptology - EUROCRYPT 2003, number 2656 in Lecture Notes in ComputerScience, pages 229�240. Springer-Verlag, 2003.
6. Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. A family of fast syn-drome based cryptographic hash functions. In Ed Dawson and Serge Vau-denay, editors, Progress in Cryptology - Mycrypt 2005 : First InternationalConference on Cryptology in Malaysia, number 3715 in Lecture Notes in Com-puter Science, pages 64�83. Springer-Verlag, 2005.
7. Raghav Bhaskar, Daniel Augot, Valérie Issarny, and Daniele Sacchetti. Ane�cient group key agreement protocol for ad hoc networks. In WOWMOM'05. IEEE Workshop on Trust, Security and Privacy in Ubiquitous Computing,Taormina, Italy, 2005.
8. Daniel Augot, Mostafa El-Khamy, Robert J McEliece, Farzad Parvaresh, Mi-khail Stepanov, and Alexander Vardy. List decoding of reed-solomon product

A.3. Publications 109codes. In Proceedings of the Tenth International Workshop on Algebraic andCombinatorial Coding Theory, Zvenigorod, Russia, pages 210�213, September2006.
Résumés courts dans des conférences internationales avec comité de lec-ture
1. Daniel Augot, Pascale Charpin, and Nicolas Sendrier. On the minimum weightof some binary BCH codes. In IEEE Internation Symposium on InformationTheory, page 7, Budapest, Hungary, 1991.
2. Daniel Augot. Algebraic characterization of minimum weight codewords ofcyclic codes. In IEEE International Symposium on Information Theory 94,Trondheim, Norway, June 1994.
3. Daniel Augot and Françoise Lévy dit Véhel. Bounds on the minimum distanceof the duals of BCH codes. In IEEE International Symposium on InformationTheory, Trondheim, Norway, 1994.
4. Daniel Augot. Algebraic equations for minimum weight codewords of manycodes. In International Conference on Finite Field and Applications, Glasgow,Scotland, 1995.
5. Daniel Augot. Newton's identities for minimum codewords of a family ofalternant codes. In IEEE International Symposium on Information Theory(ISIT 95), Whistler, Canada, 1995.
6. Daniel Augot. Algebraic solutions of Newton's identities for cyclic codes.In Proceedings of the 1998 Information Theory Workshop, Killarney, Irland,1998.
7. Daniel Augot. A parallel version of a special case of the sudan decoding al-gorithm. In Information Theory, 2002. Proceedings. 2002 IEEE InternationalSymposium on, Lausanne, 2002.
8. Daniel Augot, Magali Bardet, and Jean-Charles Faugère. E�cient decoding of(binary) cyclic codes above the correction capacity of the code using Gröbnerbases. In IEEE International Symposium on Information Theory, Yokohama,Japan, 2003.
9. Daniel Augot, Magali Bardet, and Jean-Charles Faugère. On formulas fordecoding binary cyclic codes. In IEEE Internation Symposium on InformationTheory (ISIT 2007), Nice, France, 2007.
Conférences internationales1. Daniel Augot and Nicolas Sendrier. Idemptotents and the BCH bound. In
Sixth Joint Swedish -Russian International Workshop on Information Theory,Mölle, 1993.
2. Daniel Augot. Computing normal bases in �nite �elds. In Jacques Calmet,editor, Rhine Workshop on Computer Algebra, Karlsruhe, 1994.
3. Daniel Augot. Computing groebner bases for �nding codewords of smallweight. In The 2nd IMACS Conference on Applications of Computer Algebra,1996.
4. Daniel Augot. Protection des droits et marquage d'image. In ElectronicImaging and The Visual Arts (EVA'96), 1996.
5. Daniel Augot and Anne Canteaut. Cryptologie pour la sécurité des commu-nications. In CARI 98, colloque africain de recherche en informatique, Dakar,Sénégal, 1998.

110 Annexe A. Informations annexes
6. Nicolas Sendrier, Daniel Augot, Matthieu Finiasz, and Pierre Loidreau. Diver-sity in public key cryptography using coding theory and related problems. InSTORK cryptography workshop, Bruges, Belgium, november 2002. workshoppréparatoire du réseau d'excellence E-CRYPT.
7. Daniel Augot, Magali Bardet, and Jean-Charles Faugère. Decoding cycliccodes with algebraic systems. In Luxembourg Belgian (BMS), Dutch (KWG)and French (SMF) Mathematical Societies, editors, Joint BeNeLuxFra Confe-rence in Mathematics, May 2005.
8. Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. A family of fast syn-drome based cryptographic hash functions. In European Network of Excel-lence in Cryptology ECRYPT, editor, Ecrypt Conference on Hash Functions,Krakow, Poland, Krakow, Poland, 2005. http://www.ecrypt.eu.org/stvl/hfw/.
Rappors techniques et de recherche1. Daniel Augot, Pascale CHarpin, and Nicolas Sendrier. Studying the locator
polynomials of minimum weight codewords of BCH codes. Technical Report1488, INRIA, July 1991. http://www.inria.fr.
2. Daniel Augot and Paul Camion. The minimal polynomials, characteristicsubspaces, normal bases and the Frobenius from. Technical Report 2006,INRIA, 1993. http://www.inria.fr.
3. Daniel Augot and Caroline Fontaine. D5.4 : IPR protection for multimediaassets, 1997.
4. Daniel Augot and Lancelot Pecquet. An alternative to factorization : aspeedup for Sudan's decoding algorithm and its generalization to algebraic-geometric codes. Technical Report 3532, INRIA, Octobre 1998. http://www.inria.fr.
5. Daniel Augot, Magali Bardet, and Jean-Charles Faugère. E�cient decoding of(binary) cyclic codes beyond the correction capacity of the code using Gröbnerbases. Technical Report 4652, INRIA, Novembre 2002. http://www.inria.
fr.6. Daniel Augot, Matthieu Finiasz, and Pierre Loidreau. Using the trace ope-
rator to repair the polynomial reconstruction based cryptosystem, presen-ted at eurocrypt 2003. Cryptology ePrint Archive, Report 2003/209, 2003.http://eprint.iacr.org/.
7. Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. A fast provably securecryptographic hash function. eprint.iacr.org, 2003.
8. Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. A family of fast syn-drome based cryptographic hash functions. Technical Report 5592, INRIA,Juin 2005. http://www.inria.fr.
9. Daniel Augot, François Morain, Caroline Fontaine, Jean Leneutre, StéphaneMaag, Anna Cavalli, and Farid Naït-Abdesselam. Review of vulnerabilities inmobile ad-hoc networks : trust and routing protocols views. Technical report,ACI SERAC, 2005.
10. A. Canteaut (Ed.), D. Augot, A. Biryukov, A. Braeken, C. Cid, H. Dobber-tin, H. Englund, H. Gilbert, L. Granboulan, H. Handschuh, M. Hell, T. Jo-hansson, A. Maximov, M. Parker, T. Pornin, B. Preneel, M. Robshaw, andM.Ward. Open research areas in symmetric cryptography and technical trendsin lightweight cryptography. Technical report, Réseau d'excellence européenECRYPT, 2005.

A.4. Contrats de recherche 11111. Raghav Bhaskar, Paul Mühlethaler, Daniel Augot, Cédric Adjih, and Saadi
Boudjit. E�cient and dynamic group key agreement in Ad Hoc networks.Technical Report RR-5915, INRIA, 2006.
Colloques nationaux1. Daniel Augot. Introduction à la cryptologie des courbes elliptiques. In 27ème
École de printemps d'informatique théorique, Codage et cryptographie, Batz-sur-mer, France, 1999.
2. Daniel Augot. Algorithme de décodage de sudan et cryptanalyse. In Journéesnationales de calcul formel, CIRM, Luminy, 20-24 janvier 2003 2003.
3. Daniel Augot. Chi�rement et signature. In École des Jeunes Chercheurs anAlgorithmique et Calcul formel. Institut Gaspard Monge, laboratoire d'Infor-matique, 31 mars - 4 avril 2003.
Articles dans des revues sans comité de lecture1. Daniel Augot. Protection of intellectual property rights related to images.
ERCIM News, April 1998. http://www.ercim.org.2. Daniel Augot. Les travaux de M. Sudan sur les codes correcteurs d'erreurs.
Gazette des Mathematiciens, 98, octobre 2003.3. Daniel Augot. Madhu Sudan's work on error-correcting codes. European
Mathematical Society Newsletter, 51 :8�10, March 2004. http://www.emis.
de/.Édition de comptes rendus
1. Daniel Augot and Claude Carlet, editors. Workshop on Coding and Crypto-graphy, Paris, France, 1999. INRIA.
2. Daniel Augot and Claude Carlet, editors. Workshop on Coding and Crypto-graphy, Paris, France, January 2001. ESAT.
3. Daniel Augot, Pascale Charpin, and Grigory Kabatianski, editors. Workshopon Coding and Cryptography, Versailles, France, March 2003. ESAT.
Thèse1. Daniel Augot. Étude algébrique des mots de poids minimum des codes cy-
cliques, méthodes d'algèbre linéaire sur les corps �nis. PhD thesis, UniversitéPierre et Marie Curie, Paris 6, 1993.
A.4 Contrats de recherche
Projets industriels1. Aquarelle, 1995-1997, coordonné par Alain Michard. Aquarelle était un pro-
jet de Recherche et Développement soutenu par le programme � ApplicationsTélématiques � du cinquième PCRD de l'Union Européenne. Il s'agissait demettre un place un système de partage de l'information sur le patrimoineculturel. Il a été mis en place un consortium européen regroupant des institu-tions culturelles, des éditeurs, des entreprises industrielles technologiques, etdes laboratoires de recherche.Les partenaires culturels étaient très attentifs au problème de la protectiondes droits d'auteurs. J'ai contribué au livrable � IPR protection for multi-media assets �, et avec Caroline Fontaine, nous avons dé�ni un protocole degestion de clés pour le marquage d'images. Le groupe TELE (Benoit Macq)de l'université catholique de Louvain a été sous-contractant, en fournissant un

112 Annexe A. Informations annexes
algorithme de marquage. Nous avons réalisé un prototype intégrant la gestiondes clés et l'algorithme de Louvain.
2. Canal+, février-juin 2002. Expertise, avec Anne Canteaut, d'un algorithme dechi�rement symétrique développé en interne à Canal+.
3. Banque de France. décembre 2003-mars 2004. Étude de la possibilité de mettreun authenti�ant variable sur chaque billet, dépendant de données inscritesinvisibles.
Projets de recherche :1. Direction de l'Action de Recherche Concertée de l'INRIA � ARC courbes �,
1999-2001 : rassemblement du LIX (François Morain), de Limoges (IwanDuursma), et du projet CODES, en géométrie algébrique et théorie des nom-bres, pour le codage et la cryptographie.
2. ACI Polycrypt, 2001-2004 : avec le projet Spaces (Jean-Charles Faugère etGuillaume Hanrot) et le LACO de l'université de Limoges (Philippe Gabo-rit) : étude des systèmes polynomiaux intervenant dans les systèmes crypto-graphiques. C'est dans ce cadre que Jean-Charles Faugère a cassé le crypto-système HFE.
3. ACI SERAC, 2004-2007 : models and protocols for SEcuRity in wirelessAd hoC networks. Avec Farid Naït-Abdesselam de l'USTL (Université desSciences et Techniques de Lille), Jean Leneutre du GET (Groupe des Écolesdes Télécommunications) et managé par Caroline Fontaine. L'INRIA est pré-sente avec Codes, Tanc et Hipercom qui proposent des algorithmes et desprotocoles cryptographiques bien adaptés aux réseaux Ad Hoc. Je coordonnele pôle INRIA de ce projet.

Bibliographie
[ABD+99] Daniel Augot, Jean-Marc Boucqueau, Jean-François Delaigle, Caro-line Fontaine, and Eddy Goray. Secure delivery of images over opennetworks. Proceedings of the IEEE, 87(7) :2605�2614, November 1999.
[ABF02] Daniel Augot, Magali Bardet, and Jean-Charles Faugère. E�cientdecoding of (binary) cyclic codes beyond the correction capacity of thecode using Gröbner bases. Technical Report 4652, INRIA, Novembre2002. http://www.inria.fr.
[ABF03] Daniel Augot, Magali Bardet, and Jean-Charles Faugère. E�cient de-coding of (binary) cyclic codes above the correction capacity of thecode using Gröbner bases. In Proceedings of the 2003 IEEE Interna-tional Symposium on Information Theory, pages 362�362, 2003.
[ABF05] Daniel Augot, Magali Bardet, and Jean-Charles Faugère. Decodingcyclic codes with algebraic systems. In Luxembourg Belgian (BMS),Dutch (KWG) and French (SMF) Mathematical Societies, editors,Joint BeNeLuxFra Conference in Mathematics, May 2005.
[ABIS05] D. Augot, R. Bhaskar, V. Issarny, and D. Sacchetti. An e�cient groupkey agreement protocol for ad hoc networks. In World of WirelessMobile and Multimedia Networks, 2005. WoWMoM 2005. Sixth IEEEInternational Symposium on a, pages 576�580, 2005.
[ABIS07] Daniel Augot, Raghav Bhaskar, Valerie Issarny, and Daniele Sacchetti.A three round authenticated group key agreement protocol for adhocnetworks. Pervasive and Mobile Computing, 3(1) :36�52, 2007.
[ACS90] Daniel Augot, Pascale Charpin, and Nicolas Sendrier. Weights of somebinary cyclic codes throughout the Newton's identities. In GérardCohen and Pascale Charpin, editors, Eurocode 90. Springer-Verlag,1990.
[ADF98] Daniel Augot, Jean-Francois Delaigle, and Caroline Fontaine :. Ascheme for managing watermarking keys in the Aquarelle multimediadistributed system. In Jean-Jacques Quisquater, Yves Deswarte, Ca-therine Meadows, and Dieter Gollmann, editors, ESORICS, number1485 in Lecture Notes in Computer Science. Springer-Verlag, 1998.
[AEKM+06] Daniel Augot, Mostafa El-Khamy, Robert J McEliece, Farzad Parva-resh, Mikhail Stepanov, and Alexander Vardy. List decoding of reed-solomon product codes. In Proceedings of the Tenth InternationalWorkshop on Algebraic and Combinatorial Coding Theory, Zvenigo-rod, Russia, pages 210�213, September 2006.
[AF97] Daniel Augot and Caroline Fontaine. D5.4 : IPR protection for mul-timedia assets. Technical report, European Commission, 1997.
[AF98] Daniel Augot and Caroline Fontaine. Key issues for watermarking digi-tal images. In SPIE, EUROPTO - Conference on Electronic Imaging :
113

114 Bibliographie
Processing, Printing, and Publishing in Color, EUROPTO, pages 176�185, Zürich, Suisse, 1998.
[AF03] Daniel Augot and Matthieu Finiasz. A public key encryption schemebased on the polynomial reconstruction problem. In Advances incryptology�EUROCRYPT 2003, volume 2656 of Lecture Notes inComputer Science, pages 229�240. Springer, 2003.
[AFL03] Daniel Augot, Matthieu Finiasz, and Pierre Loidreau. Using the traceoperator to repair the polynomial reconstruction based cryptosystempresented at Eurocrypt 2003. Cryptology ePrint Archive, Report2003/209, 2003.
[AFS03] Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. A fast provablysecure cryptographic hash function. eprint.iacr.org, 2003.
[AFS05a] Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. A family of fastsyndrome based cryptographic hash functions. In European Networkof Excellence in Cryptology ECRYPT, editor, Ecrypt Conference onHash Functions, Krakow, Poland, Krakow, Poland, 2005. http://
www.ecrypt.eu.org/stvl/hfw/.[AFS05b] Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. A family of
fast syndrome based cryptographic hash functions. In Ed Dawsonand Serge Vaudenay, editors, Progress in Cryptology - Mycrypt 2005 :First International Conference on Cryptology in Malaysia, number3715 in Lecture Notes in Computer Science, pages 64�83. Springer-Verlag, 2005.
[AFS05c] Daniel Augot, Matthieu Finiasz, and Nicolas Sendrier. A family offast syndrome based cryptographic hash functions. Technical Report5592, INRIA, Juin 2005. http://www.inria.fr.
[AKS04] Arshad Ahmed Ahmed, Ralf Kötter, and Naresh R. Shanbhag. VLSIarchitectures for soft-decision decoding of Reed-Solomon codes. In2004 IEEE International Conference on Communications, volume 5,pages 2584�2590 Vol.5, 2004.
[Ale02] Michael Alekhnovich. Linear diophantine equations over polynomialsand soft decoding of Reed-Solomon codes. In Proceedings of the 43rdAnnual IEEE Symposium on Foundations of Computer Science, Van-couver, Canada, pages 439�448, 2002.
[Ale05] Michael Alekhnovich. Linear diophantine equations over polynomialsand soft decoding of Reed-Solomon codes. IEEE Transactions on In-formation Theory, 51(7) :2257�2265, 2005.
[AP98a] Daniel Augot and Lancelot Pecquet. An alternative to factorization :a speedup for Sudan decoding algorithm and its generalization toalgebraic-geometric codes. Technical Report 3532, INRIA, 1998. Ava-laible on http://www.inria.fr.
[AP98b] Daniel Augot and Lancelot Pecquet. An alternative to factorization :a speedup for Sudan's decoding algorithm and its generalization toalgebraic-geometric codes. Technical Report 3532, INRIA, Octobre1998. http://www.inria.fr.
[AP00a] Daniel Augot and Lancelot Pecquet. A Hensel lifting to replace fac-torization in list-decoding of Algebraic-Geometric and Reed-Solomoncodes. IEEE Transactions on Information Theory, 46(7) :2605�2614,November 2000.
[AP00b] Daniel Augot and Lancelot Pecquet. A Hensel lifting to replace fac-torization in list decoding of algebraic-geometric and Reed-Solomon

115codes. IEEE Transactions on Information Theory, 46(7) :2605�2613,Nov 2000.
[AST00] G. Ateniese, M. Steiner, and G. Tsudik. New multiparty authentica-tion services and key agreement protocols. Selected Areas in Commu-nications, IEEE Journal on, 18(4) :628�639, 2000.
[Aug93] Daniel Augot. Étude algébrique des mots de poids minimum des codescycliques, méthodes d'algèbre linéaire sur les corps �nis. PhD thesis,Université Pierre et Marie Curie, Paris 6, 1993.
[Aug94] Daniel Augot. Algebraic characterization of minimum weight code-words of cyclic codes. In IEEE International Symposium on Informa-tion Theory 94, Trondheim, Norway, June 1994.
[Aug96a] Daniel Augot. Description of minimum weight codewords of cycliccodes by algebraic systems. Finite Fields Appl., 2(2) :138�152, 1996.
[Aug96b] Daniel Augot. Protection des droits et marquage d'image. In Electro-nic Imaging and The Visual Arts (EVA'96), 1996.
[Aug98] Daniel Augot. Algebraic solutions of Newton's identities for cycliccodes. In Proceedings of the 1998 Information Theory Workshop,Killarney, Irland, 1998.
[Bar98] A. Barg. Complexity issues in coding theory. In V. S. Pless andW. C. Hu�man, editors, Handbook of Coding Theory, volume I. North-Holland, 1998.
[Bar04] Magali Bardet. Étude des systèmes algébriques surdéterminés. Ap-plications aux codes correcteurs et à la cryptographie. PhD thesis,Université Pierre et Marie Curie, Paris 6, 2004.
[BC04] Emmanuel Bresson and Dario Catalano. Constant round authentica-ted group key agreement via distributed computation. In Feng Bao,Robert Deng, and Jianying Zhou, editors, Public Key Cryptography�2013 PKC 2004, volume 2947 of Lecture Notes in Computer Science,pages 115�129, Berlin / Heidelberg, 2004. Springer.
[BCJ+05] Eli Biham, Ra� Chen, Antoine Joux, Patrick Carribault, ChristopheLemuet, and William Jalby. Collisions of SHA-0 and reduced SHA-1.In Ronald Cramer, editor, Advances in Cryptology - EUROCRYPT2005, Aarhus, Denmark, volume 3494 of Lectures Notes in ComputerScience, pages 36�57. Springer, 2005.
[BCP02] Emmanuel Bresson, Olivier Chevassut, and David Pointcheval. Dyna-mic group Di�e-Hellman key exchange under standard assumptions.In Lars Knudsen, editor, Advances in Cryptology - EUROCRYPT2002, Amsterdam, The Netherlands,, volume 2332 of Lecture Notesin Computer Science, pages 321�336. Springer, 2002.
[BCPQ01] Emmanuel Bresson, Olivier Chevassut, David Pointcheval, and Jean-Jacques Quisquater. Provably authenticated group Di�e-Hellman keyexchange. In CCS '01 : Proceedings of the 8th ACM conference onComputer and Communications Security, pages 255�264, New York,NY, USA, 2001. ACM Press.
[BD95] Mike V. D. Burmester and Yvo Desmedt. A secure and e�cient confe-rence key distribution system. In Alfredo De Santis, editor, Advancesin Cryptology �2014 EUROCRYPT'94, volume 950 of Lecture Notes inComputer Science, pages 275�286, Berlin / Heidelberg, 1995. Springer.
[Ber68] Elwyn R. Berlekamp. Algebraic coding theory. McGraw-Hill, 1968.

116 Bibliographie
[Bha06] Raghav Bhaskar. Protocoles Cryptographiques Pour Les Réseaux Mo-biles Ad Hoc. PhD thesis, École Polytechnique, June 2006.
[BM06] Emmanuel Bresson and Mark Manulis. Extended de�nitions of AKE-and MA-security for group key exchange protocols. Cryptology ePrintArchive, November 2006. http://eprint.iacr.org/.
[BMA+06] Raghav Bhaskar, Paul Mühlethaler, Daniel Augot, Cédric Adjih, andSaadi Boudjit. E�cient and dynamic group key agreement in Ad Hocnetworks. Technical Report RR-5915, INRIA, 2006.
[BMvT78] Elwyn R. Berlekamp, Robert J. McEliece, and Henk C. A. van Til-borg. On the inherent intractability of certain coding problems. IEEETransactions on Information Theory, 24(3) :384�386, 1978.
[BN90] J. Bruck and M. Naor. The hardness of decoding linear codes withpreprocessing. IEEE Transactions on Information Theory, 36(2) :381�385, 1990.
[BR94] Mihir Bellare and Phillip Rogaway. Entity authentication and keydistribution. In Douglas R. Stinson, editor, Advances in Cryptology- CRYPTO '93, volume 773 of Lecture Notes in Computer Science,pages 232�249, Berlin / Heidelberg, 1994. Springer.
[Bro98] A. E. Brouwer. Bounds on the size of linear codes. In V. S. Pless andW. C. Hu�man, editors, Handbook of Coding Theory, volume I, pages295�461. North-Holland, 1998.
[BS04] Andrew Brown and Amin Shokrollahi. Algebraic-geometric codes onthe erasure channel. In Proceedings of the International Workshop onInformation Theory, 2004, ISIT 2004, Chicago, page 76, 2004.
[BW98] Klaus Becker and Uta Wille. Communication complexity of group keydistribution. In Li Gong and Michael Reiter, editors, CCS '98 : Pro-ceedings of the 5th ACM conference on Computer and communicationssecurity, pages 1�6, New York, NY, USA, 1998. ACM Press.
[CDF06] Ingemar J. Cox, Gwenaël Doërr, and Teddy Furon. Watermarking isnot cryptography. In Digital Watermarking, volume 4283 of LectureNotes in Computer Science, pages 1�15, Berlin / Heidelberg, 2006.Springer.
[CFS01] Nicolas T. Courtois, Matthieu Finiasz, and Nicolas Sendrier. How toachieve a Mceliece-based digital signature scheme. In C. Boyd, editor,Advances in Cryptology - ASIACRYPT 2001, volume 2248 of LectureNotes in Computer Science, pages 157�174. Springer, 2001.
[Che05] Qi Cheng. Hard problems of algebraic geometry codes. http:
//arxiv.org/abs/cs.IT/0507026, July 2005.[Chi64] R. T. Chien. Cyclic decoding procedures for Bose-Chaudhuri-
Hocquenghem codes. IEEE Transactions on Information Theory,10(4) :357�363, 1964.
[CI90] A. B. Cooper III. Direct solution of bch syndrome equations. InE. Arkian, editor, Communications, Control, and Signal Processing,pages 281�286. Elsevier, 1990.
[CI91a] A. B. Cooper III. Finding BCH error locator polynomials in one step.Electronics Letters, 27(22) :2090�2091, 1991.
[CI91b] A. B. Cooper III. A one-step algorithm for �nding BCH error locatorpolynomials. In International Symposium ion Information Theory,ISIT 1991, pages 93�93, 1991.

117[CJ04] Jean-Sébastien Coron and Antoine Joux. Cryptanalysis of a provably
secure cryptographic hash function. Cryptology ePrint Archive, 2004.http://eprint.iacr.org/.
[CLO05] David A. Cox, John Little, and Donal O'Shea. Using Algebraic Geo-metry. Graduate Texts in Mathematics. Springer, March 2005.
[CLS06] Scott Contini, Arjen K. Lenstra, and Ron Steinfeld. VSH, an e�cientand provable collision-resistant hash function. In Serge Vaudenay,editor, Advances in Cryptology - EUROCRYPT 2006, volume 4004 ofLecture Notes in Computer Science, pages 165�182. Springer, 2006.
[CM02] Massimo Caboara and Teo Mora. The Chen-Reed-Helleseth-Truongdecoding algorithm and the Gianni-Kalkbrenner Gröbner shape theo-rem. Applicable Algebra in Engineering, Communication and Compu-ting, 13(3) :209�232, 2002.
[Cor03a] Jean-Sébastien Coron. Cryptanalysis of the repaired public-key en-cryption scheme based on the polynomial reconstruction problem.Cryptology ePrint Archive, Report 2003/219, October 2003.
[Cor03b] Jean-Sébastien Coron. Cryptanalysis of the repaired public-key en-cryption scheme based on the polynomial reconstruction problem.Cryptology ePrint Archive, 2003. eprint.iacr.org.
[Cor04] Jean-Sébastien Coron. Cryptanalysis of a public-key encryptionscheme based on the polynomial reconstrution problem. In Feng Bao,Robert Deng, and Jianying Zhou, editors, Public key cryptography�PKC 2004, Singapore, volume 2947 of Lecture Notes in ComputerScience, pages 14�27. Springer, 2004.
[Cov73] T. Cover. Enumerative source encoding. IEEE Transactions on In-formation Theory, 19(1) :73�77, 1973.
[CRHT94a] X. Chen, I. S. Reed, T. Helleseth, and T. K. Truong. General prin-ciples for the algebraic decoding of cyclic codes. IEEE Transactionson Information Theory, 40(5) :1661�1663, September 1994.
[CRHT94b] Xuemin Chen, I. S. Reed, T. Helleseth, and T. K. Truong. Algebraicdecoding of cyclic codes : a polynomial ideal point of view. In Gary L.Mullen and Peter J. Shiue, editors, Finite �elds : theory, applications,and algorithms, number 168 in Contemporary Mathematics, pages 15�22. American Mathematical Society, 1994.
[CRHT94c] Xuemin Chen, I. S. Reed, T. Helleseth, and T. K. Truong. Alge-braic decoding of cyclic codes : a polynomial ideal point of view. InFinite �elds : theory, applications, and algorithms (Las Vegas, NV,1993), volume 168 of Contemporary Mathematics, pages 15�22. Ame-rican Mathematical Society, 1994.
[CRHT94d] Xuemin Chen, I. S. Reed, T. Helleseth, and T. K. Truong. Use ofGröbner bases to decode binary cyclic codes up to the true minimumdistance. IEEE Transactions on Information Theory, 40(5) :1654�1661, 1994.
[CRT94] Xiaowei Chen, Irving S. Reed, and Trieu-Kien Truong. Decoding the(73, 37, 13) quadratic residue code. IEE Proceedings on Computersand Digital Techniques, 141(5) :253�258, 1994.
[CTR+03] Yaotsu Chang, Trieu-Kin Truong, Irving S. Reed, H. Y. Cheng, andC. D. Lee. Algebraic decoding of (71, 36, 11), (79, 40, 15), and (97, 49,15) quadratic residue codes. IEEE Transactions on Communications,51(9) :1463�1473, 2003.

118 Bibliographie
[DB05] R. Dutta and R. Barua. Dynamic group key agreement in tree-basedsetting. In C. Boyd and González J. M. Nieto, editors, Proc. 10thAustralasian Conference on Information Security and Privacy (ACISP2005), volume 3574 of Lecture Notes in Computer Science, pages 101�112, Berlin / Heidelberg, 2005. Springer.
[DH76] Whit�eld Di�e and Martin E. Hellman. New directions in cryptogra-phy. IEEE Transactions on Information Theory, IT-22(6) :644�654,1976.
[DN92] Stefan M. Dodunekov and Jan E. Nilsson. Algebraic decoding ofthe Zetterberg codes. IEEE Transactions on Information Theory,38(5) :1570�1573, 1992.
[DN93] Stefan M. Dodunekov and Jan E. Nilsson. Algebraic decoding ofZetterberg and Dumer-Zinoviev codes. In Proceedings of the 1993IEEE International Symposium on Information Theory, pages 306�306, 1993.
[DN94] Stefan M. Dodunekov and Jan E. Nilsson. Parallel decoding of the [23,12, 7] binary Golay code. IEE Proceedings on Computers and DigitalTechniques, 141(2) :119�122, 1994.
[Dr90] Ivan Bjerre Damgå rd. A design principle for hash functions. InG. Brassard, editor, Advances in cryptology�CRYPTO '89, volume435 of Lecture Notes in Computer Science, pages 416�427. Springer,1990.
[Eli57] Peter Elias. List decoding for noisy channels. Technical report, Re-search Lab. of Electronics, MIT, 1957.
[Fau99] Jean-Charles Faugère. A new e�cient algorithm for computing Gröb-ner bases (F4). Journal of Pure and Applied Algebra, 139(1-3) :61�88,June 1999.
[Fau02] Jean-Charles Faugère. A new e�cient algorithm for computing Gröb-ner bases without reduction to zero (F5). In Proceedings of the 2002 In-ternational Symposium on Symbolic and Algebraic Computation, Lille,France. ACM, 2002.
[Fed06] Sergei V. Fedorenko. A method for computation of the discrete Fouriertransform over a �nite �eld. Problems of Information Transmission,42(2) :139�151, June 2006.
[FGLM93] J. C. Faugère, P. Gianni, D. Lazard, and T. Mora. E�cient computa-tion of zero-dimensional Gröbner bases by change of ordering. Journalof Symbolic Computation, 16(4) :329�344, 1993.
[FGT01] Elisabetta Fortuna, Patrizia Gianni, and Barry Trager. Degree re-duction under specialization. Journal of Pure Applied Algebra, 164(1-2) :153�163, 2001.
[Fin04] Matthieu Finiasz. Nouvelles constructions utilisant des codes correc-teurs d'erreurs en cryptographie à clef publique,. PhD thesis, ÉcolePolytechnique, October 2004.
[FJ03] Jean-Charles Faugère and Antoine Joux. Algebraic cryptanalysis ofhidden �eld equation (HFE) cryptosystems using Gröbner bases. InDan Boneh, editor, Advances in cryptology�CRYPTO 2003, volume2729 of Lecture Notes in Computer Science, pages 44�60. Springer,2003.
[Fon98] Caroline Fontaine. Contribution à la recherche de fonctions booléenneshautement non linéaires, et au marquage d'images en vue de la protec-

119tion des droits d'auteur. PhD thesis, Université Paris VI, November1998.
[FT91] G. L. Feng and K. K. Tzeng. Decoding cyclic and BCH codes up toactual minimum distance using nonrecurrent syndrome dependencerelations. IEEE Transactions on Information Theory, 37(6) :1716�1723, 1991.
[Fur05] Teddy Furon. A survey of watermarking security. In Digital Water-marking, volume 3710 of Lecture Notes in Computer Science, pages201�215, Berlin/Heidelberg, 2005. Spinger.
[Gia89] Patrizia Gianni. Properties of Gröbner bases under specializations. InJames Davenport, editor, Eurocal '87 : European Conference on Com-puter Algebra, Leipzig GDR, volume 378 of Lecture Notes in ComputerScience, pages 293�297. Springer, 1989.
[GJ79] M. R. Garey and D. S. Johnson. Computers and Intractability : AGuide to the Theory of NP-Completeness. Series of Books in the Ma-thematical Sciences. W.H. Freeman & Company, January 1979.
[GLR+91] Peter Gemmell, Richard Lipton, Ronitt Rubinfeld, Madhu Sudan, andAvi Wigderson. Self-testing/correcting for polynomials and for ap-proximate functions. In Cris Koutsougeras and Je� Vitter, editors,STOC'91 : Proceedings of the twenty-third annual ACM symposiumon Theory of computing, New Orleans, United States, pages 33�42.ACM Press, 1991.
[Gop77] V. D. Goppa. Codes that are associated with divisors. ProblemyPereda ci Informacii, 13(1) :33�39, 1977.
[Gop81] V. D. Goppa. Codes on algebraic curves. Dokl. Akad. Nauk SSSR,259(6) :1289�1290, 1981.
[Gri86] Dima Grigoriev. Polynomial factoring over a �nite �eld and solvingsystems of algebraic equations. J. Soviet Math., 34 :1762�1803, 1986.
[GRS95] Oded Goldreich, Ronitt Rubinfeld, and Madhu Sudan. Learning poly-nomials with queries : the highly noisy case. In FOCS : 36th AnnualSymposium on Foundations of Computer Science, Milwaukee, UnitedStates, pages 294�303. IEEE Computer Society Press, 1995.
[GRS00] Oded Goldreich, Ronitt Rubinfeld, and Madhu Sudan. Learning poly-nomials with queries : the highly noisy case. SIAM Journal on DiscreteMathematics, 13(4), 2000.
[GS99] Venkatesan Guruswami and Madhu Sudan. Improved decoding ofReed-Solomon and algebraic-geometry codes. IEEE Transactions onInformation Theory, 45(6) :1757�1767, 1999.
[GS00] Shuhong Gao and Amin M. Shokrollahi. Computing roots of polyno-mials over function �elds of curves. In David Joyner, editor, Procee-dings of the Annapolis Conference on Number Theory, Coding Theory,and Cryptography 1999, pages 214�228. Springer, 2000.
[Gur04] Venkatesan Guruswami. List Decoding of Error-Correcting Codes -Winning Thesis of the 2002 ACM Doctoral Dissertation Competition,volume 3282 of Lectures Notes in Computer Science. Springer, De-cember 2004.
[GV05] Venkatesan Guruswami and Alexander Vardy. Maximum-likelihooddecoding of Reed-Solomon codes is NP-hard. IEEE Transactions onInformation Theory, 51(7) :2249�2256, 2005.

120 Bibliographie
[HH93] Russel J. Higgs and John F. Humphreys. Decoding the ternary Golaycode. IEEE Transactions on Information Theory, 39(3) :1043�1046,1993.
[HH95] Russel J. Higgs and John F. Humphreys. Decoding the ternary (23,12, 8) quadratic residue code. IEE Proceedings on Communications,142(3) :129�134, 1995.
[HH98] Russell J. Higgs and John F. Humphreys. Decoding the quintic(11, 6, 5) quadratic residue code. Mathematical Proceedings of theRoyal Irish Academy, 98A(1) :47�51, 1998.
[HN99] T. Hoeholdt and Refslund R. Nielsen. Decoding hermitian codes withsudan's algorithm. In M. Fossorier, H. Imai, S. Lin, and A. Poli,editors, Applied Algebra, Algebraic Algorithms and Error-CorrectingCodes : 13th International Symposium, AAECC-13, Honolulu, USA,volume 1719 of Lecture Notes in Computer Science, pages 260�269,Berlin, 1999. Springer.
[HP95] Tom Høholdt and Ruud Pellikaan. On the decoding of algebraic-geometric codes. IEEE Transactions on Information Theory,41(6) :1589�1614, 1995.
[HRTC01] Ruhua He, Irving S. Reed, Trieu-Kien Truong, and Xuemin Chen.Decoding the (47,24,11) quadratic residue code. IEEE Transactionson Information Theory, 47(3) :1181�1186, 2001.
[HT72] Carlos R. Hartmann and Kenneth K. Tzeng. Generalizations of theBCH bound. Information and Control, 20(5) :489�498, 1972.
[Hug94] E. Hughes. An encrypted key transport protocol. CRYPTO RumpSession, August 1994.
[Hum92] John F. Humphreys. Algebraic decoding of the ternary (13,7,5)quadratic residue code. IEEE Transactions on Information Theory,38(3) :1122�1125, 1992.
[ITW82] I. Ingemarsson, D. Tang, and C. Wong. A conference key distributionsystem. IEEE Transactions on Information Theory, 28(5) :714�720,1982.
[Jak98] Thomas Jakobsen. Cryptanalysis of block ciphers with probabilis-tic non-linear relations of low degree. In Advances in Cryptology,CRYPTO '98, volume 1462 of Lecture Notes in Computer Science,pages 212�222, 1998.
[JH04] Jom Justesen and Tom Høholdt. A Course in Error-Correcting Codes.EMS Textbooks in Mathematics. European Mathematical Society, Fe-bruary 2004.
[K�96] Ralf Kötter. On Algebraic Decoding of Algebraic-Geometric and CyclicCodes. PhD thesis, University of Linköping, 1996.
[Kal85] Erich Kaltofen. Polynomial-time reductions from multivariate to bi-and univariate integral polynomial factorization. SIAM Journal onComputing (SICOMP), 14(2) :469�489, 1985.
[KLL04] Hyun-Jeong Kim, Su-Mi Lee, and Dong H. Lee. Constant-round au-thenticated group key exchange for dynamic groups. In P. J. Lee,editor, Advances in Cryptology - ASIACRYPT 2004, volume 3329 ofLecture Notes in Computer Science, pages 245�259, Berlin / Heidel-berg, 2004. Springer.
[KLP68] T. Kasami, Shu Lin, and W. Peterson. New generalizations of theReed-Muller codes�I : Primitive codes. IEEE Transactions on Infor-mation Theory, 14(2) :189�199, 1968.

121[KPT00] Yongdae Kim, Adrian Perrig, and Gene Tsudik. Simple and fault-
tolerant key agreement for dynamic collaborative groups. In CCS'00 : Proceedings of the 7th ACM conference on Computer and com-munications security, pages 235�244, New York, NY, USA, 2000. ACMPress.
[KPT04] Y. Kim, A. Perrig, and G. Tsudik. Group key agreement e�cientin communication. IEEE Transactions on Computer, 53(7) :905�921,2004.
[KV03] Ralf Kötter and Alexander Vardy. Algebraic soft-decision decodingof Reed-Solomon codes. IEEE Transactions on Information Theory,49(11) :2809�2825, 2003.
[KY01a] Aggelos Kiayias and Moti Yung. Polynomial reconstruction basedcryptography (a short survey). In S. Vaudenay and A. M. Youssef,editors, Selected Areas in Cryptography : 8th Annual InternationalWorkshop, SAC 2001 Toronto, Canada, volume 2259 of Lecture Notesin Computer Science, pages 129�133, Berlin, 2001. Springer.
[KY01b] Aggelos Kiayias and Moti Yung. Secure games with polynomial expres-sions. In F. Orejas, P. G. Spirakis, and J. van Leeuwen, editors, Auto-mata, Languages and Programming : 28th International Colloquium,ICALP 2001, volume 2076 of Lecture Notes in Computer Science,pages 393�950. Springer, July 2001.
[KY02a] Aggelos Kiayias and Moti Yung. Cryptographic hardness based onthe decoding of Reed-Solomon codes. In P. Widmayer, F. Triguero,R. Morales, M. Hennessy, S. Eidenbenz, and R. Conejo, editors, Auto-mata, Languages and Programming : 29th International Colloquium,ICALP 2002, Malaga, Spain, volume 2380 of Lecture Notes in Com-puter Science, pages 232�243. Springer, July 2002.
[KY02b] Aggelos Kiayias and Moti Yung. Cryptographic hardness based onthe decoding of Reed-Solomon codes with applications. http://eccc.uni-trier.de/eccc-reports/2002/TR02-017/, 2002.
[KY03] Jonathan Katz and Moti Yung. Scalable protocols for authenticatedgroup key exchange. In Advances in Cryptology - CRYPTO 2003,volume 2729 of Lecture Notes in Computer Science, pages 110�125,Berlin / Heidelberg, 2003. Springer.
[KY04] Aggelos Kiayias and Moti Yung. Cryptanalyzing the polynomial-reconstruction based public-key system under optimal parameterchoice. In Pil J. Lee, editor, Advances in Cryptology - ASIACRYPT2004, volume 3329 of Lecture Notes in Computer Science, pages 401�416. Springer, December 2004.
[KY05] Aggelos Kiayias and Moti Yung. Cryptography and decoding Reed-Solomon codes as a hard problem. In IEEE Information Theory Work-shop on Theory and Practice in Information-Theoretic Security, pages48�54, 2005.
[Len85] Arjen K. Lenstra. Factoring multivariate polynomials over �nite �elds.Journal of Computer System Sciences, 30(2) :235�248, 1985.
[LN96] Rudolf Lidl and Harald Niederreiter. Finite Fields. Encyclopedia ofMathematics and its Applications. Cambridge University Press, Oc-tober 1996.
[LO06] Kwankyu Lee and Michael E. O'Sullivan. Sudan's list decoding ofReed-Solomon codes from a Groebner basis perspective. arxiv.org/abs/math.AC/0601022, Jan 2006.

122 Bibliographie
[LWCL95] Erl H. Lu, Hsiao P. Wuu, Y. C. Cheng, and P. C. Lu. Fast algorithmsfor decoding the (23,12) binary Golay code with four-error-correctingcapability. International Journal of Systems Science, 26(4) :937�945,1995.
[LY97] Philippe Loustaunau and Eric V. York. On the decoding of cycliccodes using Gröbner bases. Applicable Algebra in Engineering, Com-munication and Computation, 8(6) :469�483, 1997.
[Mas69] Jim Massey. Shift-register synthesis and BCH decoding. IEEE Tran-sactions on Information Theory, 15(1) :122�127, 1969.
[Mat94a] Mitsuru Matsui. The �rst experimental cryptanalysis of the data en-cryption standard. In Y. G. Desmedt, editor, Advances in Cryptology- CRYPTO '94, number 839 in Lecture Notes in Computer Science,pages 1�11. Springer-Verlag, 1994.
[Mat94b] Mitsuru Matsui. Linear cryptanalysis method for DES cipher. InT. Helleseth, editor, Advances in Cryptology - EUROCRYPT '93,number 765 in Lecture Notes in Computer Science, pages 386�397,Berlin-Heidelberg-New York, 1994. Springer-Verlag.
[Mat01] Gretchen L. Matthews. Weierstrass pairs and minimum distance ofGoppa codes. Designs, Codes and Cryptography, V22(2) :107�121,March 2001.
[McE78] Robert J. McEliece. A public-key cryptosystem based on algebraic co-ding theory. Technical report, Jet Propulsion Lab Deep Space NetworkProgress report, 1978.
[Mer90] Ralph C. Merkle. One way hash functions and DES. In G. Brassard,editor, Advances in cryptology�CRYPTO '89, volume 435 of LectureNotes in Computer Science, pages 428�446. Springer, 1990.
[MM05] Seiichi Mita and Hajime Matsui. An e�ective error correction using acombination of algebraic geometric codes and parity codes for HDD.IEEE Transactions on Magnetics, 41(10) :2992�2994, 2005.
[MS88] James L. Massey and Thomas Schaub. Linear complexity in codingtheory. In Gérard D. Cohen and Philippe Godlewski, editors, Pro-ceedings of the second Interpolation Colloquium on Coding Theoryand Applications, Cachan-Paris, France, 1986, volume 311 of LectureNotes in Computer Science, pages 19�32. Springer, 1988.
[MS03] Teo Mora and Massimiliano Sala. On the Gröbner bases of somesymmetric systems and their application to coding theory. Journal ofSymbolic Computation, 35(2) :177�194, 2003.
[MTV04] Jun Ma, Peter Trifonov, and Alexander Vardy. Divide-and-conquerinterpolation for list decoding of Seed-Solomon codes. In Proceedingsof the 2004 International Symposium on Information Theory, pages386�386, 2004.
[NH00] Rasmus R. Nielsen and Tom Høholdt. Decoding Reed-Solomon codesbeyond half the minimum distance. In Johannes Buchmann, TomHøholdt, Henning Stichtenoth, and Horacio Tapia-Recillas, editors,Coding Theory, Cryptography and Related Areas : Proceedings of anInternational Conference on Coding Theory, Cryptography and RelatedAreas, Guanajuato, 1998. Springer, 2000.
[NK93] Kaisa Nyberg and Lars R. Knudsen. Provable security against di�e-rential cryptanalysis. In E. F. Brickell, editor, Advances in Cryptology- CRYPTO '92, number 740 in Lecture Notes in Computer Science,pages 566�574, Berlin-Heidelberg-New York, 1993. Springer-Verlag.

123[NK95] Kaisa Nyberg and Lars R. Knudsen. Provable security against a di�e-
rential attack. Journal of Cryptology, V8(1) :27�37, December 1995.[NLKW04] J. Nam, J. Lee, S. Kim, and D. Won. Ddh-based group key agreement
for mobile computing. Cryptology ePrint Archive, 2004. http://
eprint.iacr.org/.[OF02] Henry O'Kee�e and Patrick Fitzpatrick. Gröbner basis solutions of
constrained interpolation problems. Linear Algebra and its Applica-tion, 351/352 :533�551, 2002.
[OS99] Vadim Olshevsky and Amin M. Shokrollahi. A displacement approachto e�cient decoding of algebraic-geometric codes. In STOC '99 : Pro-ceedings of the thirty-�rst annual ACM symposium on theory of com-puting, Atlanta, United States, pages 235�244. ACM Press, 1999.
[OS03a] Vadim Olshevksy and Amin M. Shokrollahi. A displacement approachto decoding algebraic codes. Contemporary Mathematics, 323, May2003.
[OS03b] Vadim Olshevsky and Amin M. Shokrollahi. E�cient list decodingof Reed-Solomon codes for message recovery in the presence of highnoise levels. US PATENT 6,631,172, 2003.
[Pec01] Lancelot Pecquet. Décodage en liste des codes géométriques. PhDthesis, Université Pierre et Marie Curie, Paris 6, November 2001.
[PEKMV] Farzad Parvaresh, Mostafa El-Khamy, Robert J. McEliece, andAlexander Vardy. Algebraic list decoding of Reed-Solomon productcodes. submitted to ISIT 2006.
[Per99] Adrian Perrig. E�cient collaborative key management protocols forsecure autonomous group communication. In International Workshopon Cryptographic Techniques and E-Commerce CrypTEC '99, pages192�202, 1999.
[PHB98] Vera S. Pless, Cary W. Hu�man, and Richard A. Brualdi. An intro-duction to algebraic codes. In Vera S. Pless and Cary W. Hu�man,editors, Handbook of Coding Theory, volume 1. Elsevier, 1998.
[PSvW91] R. Pellikaan, B. Z. Shen, and G. J. M. van Wee. Which linear codesare algebraic-geometric ? IEEE Transactions on Information Theory,,37(3) :583�602, 1991.
[PV05a] Farzad Parvaresh and Alexander Vardy. Correcting errors beyondthe Guruswami-Sudan radius in polynomial time. In FOCS 2005 :Proceedings of the 46th Annual IEEE Symposium on Foundations ofComputer Science, Pittsburgh, United States, pages 285�294, 2005.
[PV05b] Farzad Parvaresh and Alexander Vardy. Multivariate interpolationdecoding beyond the Guruswami-Sudan radius. In Allerton Confe-rence on Communication, Control and Computing. CDROM only,2005. available from authors.
[PW04a] Ruud Pellikaan and Xin-Wen Wu. List decoding of q-ary Reed-Mullercodes. preprint available form authors, 2004.
[PW04b] Ruud Pellikaan and Xin-Wen Wu. List decoding of q-ary Reed-Mullercodes. IEEE Transactions on Information Theory, 50(4) :679�682,2004.
[Roo83] Cornelis Roos. A new lower bound for the minimum distance of acyclic code. IEEE Transactions on Information Theory, 29(3) :330�332, 1983.

124 Bibliographie
[RR00] R. M. Roth and G. Ruckenstein. E�cient decoding of Reed-Solomoncodes beyond half the minimum distance. IEEE Transactions on In-formation Theory, 46(1) :246�257, 2000.
[RSA78] R. L. Rivest, A. Shamir, and L. Adleman. A method for obtainingdigital signatures and public-key cryptosystems. Commun. ACM,21(2) :120�126, February 1978.
[RTCY92] Irving S. Reed, Trieu-Kien Truong, Xuemin Chen, and Xiaowei Yin.The algebraic decoding of the (41, 21, 9) quadratic residue code. IEEETransactions on Information Theory, 38(3) :974�986, 1992.
[RYT90] Irving S. Reed, Xiaowei Yin, and Trieu-Kien Truong. Algebraic deco-ding of the (32, 16, 8) quadratic residue code. IEEE Transactions onInformation Theory, 36(4) :876�880, 1990.
[RYTH90] Irving S. Reed, Xiaowei Yin, Trieu-Kien Truong, and J. K. Holmes.Decoding the (24,12,8) golay code. Computers and Digital Techniques,IEE Proceedings-, 137(3) :202�206, 1990.
[Sak90] Shojiro Sakata. Extension of the Berlekamp-Massey algorithm to ndimensions. Information and Computation, 84(2) :207�239, 1990.
[Sak01] Shojiro Sakata. On fast interpolation method for Guruswami-Sudanlist decoding of one-point algebraic-geometry codes. In S. Boztaand I. Sphparlinski, editors, Applied algebra, algebraic algorithms anderror-correcting codes, AAECC-14, Melbourne, 2001, volume 2227 ofLecture Notes in Computer Science, pages 172�181. Springer, 2001.
[Sal02] Massimiliano Sala. Groebner bases and distance of cyclic codes.Applied Algebra in Engineering, Communications and Computing,13(2) :137�162, 2002.
[Sal03] Massimiliano Sala. Upper bounds on the dual distance of BCH(255,k). Designs Codes and Cryptography, 30(2) :159�168, September 2003.
[Sch80] J. T. Schwartz. Fast probabilistic algorithms for veri�cation of poly-nomial identities. Journal of the ACM, 27(4) :701�717, October 1980.
[Sch95] Bruce Schneier. Applied Cryptography : Protocols, Algorithms, andSource Code in C. Wiley, 2 edition, October 1995.
[SNF00] S. Sakata, Y. Numakami, and M. Fujisawa. A fast interpolation me-thod for list decoding of RS and algebraic-geometric codes. In Procee-dings of the IEEE International Symposium on Information Theory,Sorento, Italy, page 479, 2000.
[Sti93] Henning Stichtenoth. Algebraic Function Fields and Codes. Springer,1993.
[STW96] Michael Steiner, Gene Tsudik, and Michael Waidner. Di�e-Hellmankey distribution extended to group communication. In CCS '96 : Pro-ceedings of the 3rd ACM conference on Computer and communicationssecurity, pages 31�37, New York, NY, USA, 1996. ACM Press.
[STW00] M. Steiner, G. Tsudik, and M. Waidner. Key agreement in dynamicpeer groups. Parallel and Distributed Systems, IEEE Transactions on,11(8) :769�780, 2000.
[Sud97] Madhu Sudan. Decoding of Reed-Solomon codes beyond the error-correction bound. Journal of Complexity, 13(1) :180�193, March 1997.
[SW99] Mohammad A. Shokrollahi and Hal Wasserman. List decoding ofalgebraic-geometric codes. IEEE Transactions on Information Theory,45(2) :432�437, 1999.

125[Tav04] Cédric Tavernier. Testeurs, problèmes de reconstruction univariés et
multivariés, et application à la cryptanalyse du DES. PhD thesis, ÉcolePolytechnique, January 2004.
[TCCL05] Trieu-Kien Truong, Yaotsu Chang, Yan-Haw Chen, and C. D. Lee.Algebraic decoding of (103, 52, 19) and (113, 57, 15) quadratic residuecodes. IEEE Transactions on Communications, 53(5) :749�754, 2005.
[TVZ82] Michael A. Tsfasman, Serguei G. Vl�aduµ, and Th. Zink. Modularcurves, Shimura curves, and Goppa codes, better than Varshamov-Gilbert bound. Math. Nachr., 109 :21�28, 1982.
[UUC+05] UVIGO, UNIGE, CNIT, GAUSS, and CNRS. First summary reporton fundamentals. Technical report, ECRYPT Network of Excellence(NoE), March 2005.
[Val95] Annick Valibouze. Modules de cauchy, polynômes caractéristiques etrésolvantes. Technical Report 1995-131, LIAFA, 1995.
[Var97] Alexander Vardy. Algorithmic complexity in coding theory and theminimum distance problem. In STOC '97 : Proceedings of the twenty-ninth annual ACM symposium on Theory of computing, El Paso, Uni-ted States, pages 92�109. ACM Press, 1997.
[VK00] Alexander Vardy and Ralf Kötter. Algebraic soft-decision decoding ofReed-Solomon codes. http://www.comm.csl.uiuc.edu/~koetter/
publications/RSsoft.ps, May 2000.[Wag02] David Wagner. A generalized birthday problem. In Advances in
cryptology�CRYPTO 2002, volume 2442 of Lecture Notes in Com-puter Science, pages 288�303. Springer, 2002.
[WB86] Loyd R. Welch and Elwyn R. Berlekamp. Error correction for algebraicblock codes. US Patent 4 633 470, 1986.
[WFLY04] Xiaoyun Wang, Dengguo Feng, Xuejia Lai, and Hongbo Yu. Collisionsfor hash functions MD4, MD5, HAVAL-128 and RIPEMD. CryptologyePrint Archive, 2004. http://eprint.iacr.org/.
[WLF+05] Xiaoyun Wang, Xuejia Lai, Dengguo Feng, Hui Chen, and XiuyuanYu. Cryptanalysis of the hash functions MD4 and RIPEMD. In Ro-nald Cramer, editor, Advances in Cryptology�EUROCRYPT 2005,Aarhus, Denmark, volume 3494 of Lecture Notes in Computer Science,pages 1�18. Springer, 2005.
[Woz58] J. M. Wozencraft. List decoding. Technical report, MIT, Cambridge,MA, 1958.
[WS01] Xin-Wen Wu and P. H. Siegel. E�cient root-�nding algorithm withapplication to list decoding of algebraic-geometric codes. IEEE Tran-sactions on Information Theory, 47(6) :2579�2587, 2001.
[WY05] Xiaoyun Wang and Hongbo Yu. How to break MD5 and other hashfunctions. In Ronald Cramer, editor, Advances in Cryptology, EU-ROCRYPT 2005, Aarhus, Denmark, volume 3494 of Lecture Notes inComputer Science, pages 19�35. Springer, 2005.
[Xin01] Chaoping Xing. Algebraic-geometry codes with asymptotic parame-ters better than the Gilbert-Varshamov and the Tsfasman-Vl�aduµ-Zink bounds. IEEE Transactions on Information Theory, 47(1) :347�352, 2001.
[Xin05] Chaoping Xing. Goppa geometric codes achieving the Gilbert-Varshamov bound. IEEE Transactions on Information Theory,51(1) :259�264, January 2005.

126 Bibliographie
[Zip79] Richard Zippel. Probabilistic algorithms for sparse polynomials. InEdward W. Ng, editor, Symbolic and Algebraic Computation : EU-ROSM '79, An International Symposium on Symbolic and AlgebraicManipulation, Marseille, France, volume 72 of Lecture Notes in Com-puter Science, pages 216�226. Springer, 1979.





























