Embed Size (px)
Citation preview

Bart SteegmansDB2 for z/OS L2 PerformanceIBM
March23, 2017GSE DB2 for z/OS
DB2 as an In-Memory DBMS

Please Note
IBM’s statements regarding its plans, directions, and intent are subject to change orwithdrawal without notice at IBM’s sole discretion.
Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision.
The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any material, code or functionality. Information about potential future products may not be incorporated into any contract.
The development, release, and timing of any future features or functionality described for our products remains at our sole discretion.
Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual throughput or performance that any user will experience will vary depending upon many factors, including considerations such as the amount of multiprogramming in the user’s job stream, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here.
Many thanks to Jeff Josten !
2

Agenda
Overview of in-memory DB
Concepts
Examples
Benefits / tradeoffs
Transaction workloads considerations
Analytical workloads considerations
Feedback and discussion

In Memory Database: Overview

In-Memory DB Summary
In-Memory DB technology has been around for over a decade and served specific purposes
IMS MSDBs? OK, much more than a decade!
Technology trends have increased applicability of in-memory techniques, and vendor marketing has increased attention
In-Memory DB technology can be split into different categories:
1) Operational Systems
2) Warehouse Systems
3) Analytic Systems
4) Application caching
This presentation focuses primarily on #1 and #2

In-Memory DB Concepts
Basic ideas:
1. Operate on DB data in-memory to avoid I/O delays
2. Optimize structures for more efficient memory use
Compression can increase the amount of data that fits in memory
In-Memory DB is often associated with column stores, but it is also applicable for row stores
Column stores will usually achieve higher compression ratios
Column stores are optimized for fast scans and queries where fewer columns are returned
Row stores are optimized for fast updates and queries where more columns are returned
To service all of these workloads well, a hybrid approach is required
One storage format optimized for scans, another for updates
Many DBMS vendors are pursuing this hybrid strategy
DB2 for z/OS is in a leadership position
In-memory is applicable for both “sides” of the hybrid

Avoid Disk I/O and Cache Efficiency Is Important
Cache and memory latency on a hypothetical modern server
– L1 Cache – 1 machine cycle
– L2 Cache – 4 machine cycles
– L3 Cache – variable, 10’s of machine cycles
– L4 Cache – variable, 100’s of machine cycles
– Real memory – ~ 1000 machine cycles
Rough expected timing to read 4K data, normal use
– Coupling Facility short distance <10 mics
– High End DS8K using HPF, cache hit 150 mics
– Flash Express, 300 mics
– High End DS8K using Flash, cache miss 450 mics
– High End DS8K using rotating disk, cache miss 4000-8000 mics

8
Memory Access Times
CPU L1 L2/3 DRAM SSD HDD
Brussels
Louvain
Rome
4 times to the Moon and back
This room
6 - 20
100 - 400
5000
1000000
1 - 2
c y
c l e
sm
i l e s
(distances are not to scale)
1000
1
4-20
2M
20M
40 times to the Moon and back

In-Memory DB Benefits and Tradeoffs
Performance improvement by avoiding I/O and optimizing for cache efficiency (also easier admin)
Is In-Memory a panacea? No.
Many DBs do not fit in memory
Many DBs that fit in memory today may not tomorrow
Disk is still required for data persistence
Disk is still required for transactions
What about non-volatile memory?
Doesn’t help the DB recovery problem
A failed server with persistent memory won’t allow access
Lack of sw solutions to recover persistent memory on an OS or hypervisor failure: middleware must be given same page table mapping that were use on the previous IPL
Questionable value: very few system failures are caused by power loss. Other cases could be solved w/o non-volatile memory

Row-store vs. Column-store
Col1 Col2 Col3 Col4 Col5
Row Operations
Col1 Col2 Col3 Col4 Col5
Column Operations
Row1
Row2
Row3
Row4
Row1
Row2
Row3
Row4
Ro
w S
tore
Co
lum
n S
tore
Analytical
Queries
Transactional
Processing

DB2 Native
Processing
IBM
DB
2 A
naly
tics A
ccele
rato
r
OLTP Transactions
Operational analytics
Real time data ingestion
High concurrency
Advanced analytics
Standard reports
Complex queries
Historical queries
OLAP
DB2 for z/OS “Universal DB” Hybrid Architecture
z/OS LPAR
DB2 Member 1
z/OS LPAR
DB2 Member 2
Coupling
Facility
DB2 Data
Sharing
Group
• In-memory
technology
benefits both
these sides
• DB2 z/OS has
an industry
leadership
position for
integrated
transaction &
analytics
processing
(aka HTAP)
z/OS and Parallel Sysplex for
transaction and query workloads
with high security, availability,
scalability, recoverability
IDAA powered by Netezza for
cost effective high speed queries
and analytics

Transaction Workloads Considerations

In-Memory Opportunity for z/OS and CF LPARs
• zEC12 supports up to 3T of real memory
• z13 supports up to 10T of real memory
• This is expected to increase in future generation machines
• Memory prices are expected to continue to decrease
• DB2 10 and 11 can already take advantage of large real memory
• DB2 12 greatly expands DB2’s in-memory capabilities
Terabytes of
available storage


15
Problem: Translation Lookaside Buffer (TLB) coverage is
shrinking as % of memory size
Over the past few years application memory sizes have
dramatically increased due to support for 64-bit addressing
in both physical and virtual memory
TLB sizes have remained relatively small due to low access
time requirements and hardware space limitations
Therefore TLB coverage today represents a much smaller fraction of an
application’s working set size leading to a larger number of TLB misses
Applications can suffer a significant performance penalty resulting from an increased
number of TLB misses as well as the increased cost of each TLB miss
Solution: Increase TLB coverage without proportionally enlarging the TLB size by using
large pages
Large Pages allow for a single TLB entry to fulfill many more address translations
Large Pages will provide exploiters with better TLB coverage
Benefit:
Better performance by decreasing the number of TLB misses
DB2 10 uses large pages to back PGFIX(YES) buffer pools
DB2 11 introduced FRAMESIZE(2G) option
How to access large memory efficientlySolution: Large Page Frames 256 4K pages One 1M page

16
zEC12 / BC12: Extra Large Page Frames (2G)
256 4K pages One 1M page 2G page* – (512K x 4K pages), (2048 x 1M Pages)
*Not to scale

DB2 Buffer Pool - Frame size
Frame size
Page fix Supported DB2
H/W Requirement
Benefit
4K NO All N/A Most flexible configuration
4K YES All N/A CPU reduction during I/O
1M NO DB2 10 with APAR, or
DB2 11
Min. zEC12 and Flash Express
Backed by real or LFAREA
CPU reduction from TLB hit
1M YES Min. DB2 10 Min. z10
LFAREA 1M=xx
CPU reduction during I/O, CPU reduction from TLB hit
2G YES DB2 11 Min. zEC12
LFAREA 2G=xx
CPU reduction during I/O, CPU reduction from TLB hit
New in V11

18
All of buffer pools are backed by real storage
zEC12 16 CPs, 5000-6000 tps (simple to complex transactions)
120GB real storage with 70GB LFAREA configured for 1MB measurements
1MB Pageable frames are 1.9% better than 4KB pageable frames for this workload
70GB buffer pools are used, 8-10 sync I/O per transaction
1MB frames with PGFIX(YES) is the best performer in general
1,5
1,6
1,7
Mil
liseco
nd
s
Total DB2 CPU Time per Transaction
1M Fixed
1M Pageable
4K Fixed
4K Pageable
1 MB Large Frames –Example from IBM Brokerage Workload
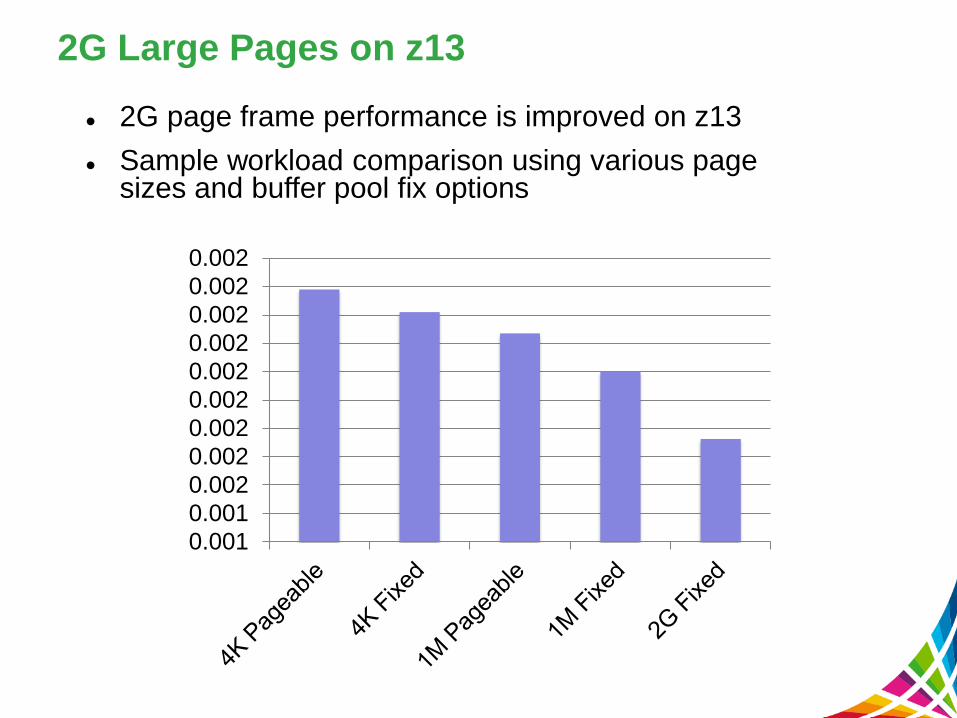
2G Large Pages on z13
0.001
0.001
0.002
0.002
0.002
0.002
0.002
0.002
0.002
0.002
0.002
2G page frame performance is improved on z13
Sample workload comparison using various page sizes and buffer pool fix options

DB2 incorporates extensive in-memory technology
DB2 for z/OS incorporates extensive in-memory technology since day #1 (> 30 years ago) and operates almost exclusively on in-memory data
Keeps frequently accessed data in memory (buffer pools)
Avoids disk I/O: > 90% of data accessed in memory without I/O
Prefetch mechanisms avoid I/O waits
Option to pin a table in memory (PGSTEAL(NONE) - new in DB2 10)
In a data sharing environment additional option to use GBP for caching
Writes all data changes (INSERT, UPDATE, DELETE) to memory
Persistently writes log records to disk (or CF) at commit time
Same behavior as In-Memory Databases
DB2 10 and 11 provide more opportunities to save CPU by adding memory (Trade memory for CPU)
DB2 12 provides even more
20

PGSTEAL(NONE) Buffer Pools in V10/V11
Buffer pool option for in-memory objects
Table space, partition, index space
Aimed at objects that can fit 100% in the buffer pool
Eliminates read I/Os by keeping the objects in memory after first access
Avoid page stealing overhead - no LRU chain maintenance
Disables wasteful prefetch scheduling
How it works
DB2 preloads the objects (table space, partition, index space) at the first access
If a buffer needs to be stolen for a new page, DB2 uses FIFO instead of LRU algorithm
Use for performance sensitive, frequently accessed objects
Static or predictable in size
Read only or in-place update
CLOSE(NO)21

Local Buffer Pools vs. Group Buffer Pools
Basics
Local buffer pool (LBP) caches both read-only and changed pages
Group buffer pool (GBP) by default only caches changed pages (GBPCACHE CHANGED)
Page written to GBP as changed, page becomes clean after castout
For most workloads, investing in larger LBP size is likely to show greater benefit provided the associated GBP is allocated with enough directory entries
May need to adjust GBP size or ratio when increasing LBP size to avoid GBP directory entry reclaims which can invalidate local buffers causing increased I/O
GBPCACHE ALL
Caches both the read-only and changed pages
GBP becomes a global cache for data sharing members to reduce I/O
Reads from CF are faster than reads from DASD
But reads from LBP are the fastest (see above)
May be an option to consider if DB2 members are memory constrained but CF has ample available memory22

Potential CPU Benefit of Larger LBPs
Larger size LBPs can reduce CPU by reducing sync I/Os
SVL Performance has measured approximately 20-40 usec. CPU per I/O on z13
Rough planning number, mileage will vary
The benefit depends on the size of active workload and access pattern
There may be no benefit for workloads with small working set and already achieving a high buffer pool hit ratio
A moderate increase in LBP size may not deliver significant benefit for workloads where there is a very large working set of pages
Varies depending on the configuration - CPU utilization, data sharing, etc.
Pages have to be re-referenced to get benefit – not for one time sequential read
Tools can model or simulate large local buffer pool size, but require expensive set of traces and intensive analysis
23

Large Local Buffer Pools-SAP Banking Day Posting
Banking (60M account) workload with 2 way data sharing : • 40% response time improvement and 11% CPU reduction from 30GB LBP to 236GB
LBP for both members with same GBP size (64GB)
http://www-03.ibm.com/support/techdocs/atsmastr.nsf/WebIndex/WP102461

Large Group Buffer Pools-SAP Banking Day Posting
Banking (60M account) workload with 2 way data sharing : • 11 % response time improvement and 6 % CPU reduction from 52 GB GBP to 398 GB for
both members with same LBP size (60GB)

DB2 Buffer Pool Simulation - Why?
Larger buffer pools can potentially reduce CPU usage and transaction response time by reducing sync I/Os
The benefit depends on the size of active workload and access pattern
IBM measurements demonstrate the value of large BPs for OLTP workloads
Up to 25% reduction in CPU time per transaction
Up to 70% response time improvements
Many customer environments are “memory starved” and could realize similar benefits
Try & validate may not work well with customer’s workload with high variations and memory limitations
Available tools require expensive traces and intensive analysis

Buffer Pool Simulation
Buffer pool simulation provides accurate benefit estimation of increasing buffer pool size (V12 but retrofit to V11 via PI22091)
Intended for production environments as well as test/dev
ALTER BUFFERPOOL command will support
SPSIZE (simulated pool size – how much larger you want to make it)
SPSEQT (sequential threshold for simulated pool)
DISPLAY BPOOL DETAIL and statistics trace(IFCID 2) will include:
Sync and Async DASD I/Os that could have been avoided
Sync I/O delay that could have been avoided
Cost of simulation
CPU cost : approximate 1-2% per buffer pool
Real storage cost : approximate 2% of simulated pool size (4K page size, less for larger page sizes)
For example, SPSIZE(1,000K) requires approx. 78MB additional real storage (4K page size)

DB2 10/11 : Tuning Opportunities with Larger Memory Large page frames (discussed before)
CPU reduction through better TLB efficiency
DB2 local and group buffer pools (discussed before)
Reduction of elapsed time and CPU time by avoiding I/Os
Thread reuse with IMS or CICS applications
Reduction of CPU time by avoiding thread allocation and deallocation
Thread reuse and RELEASE(DEALLOCATE)
Reduction of CPU time by avoiding package allocation and parent locks
DDF High performance DBATs support with DB2 10
Ability to break-in to persistent threads with DB2 11
Global dynamic statement cache
EDMSTMTC up to 4G with DB2 11, default 110MB
Reduction of CPU time by avoiding full prepare
Local statement cache
MAXKEEPD up to 200K statements with DB2 11, default 5000
Reduction of CPU time by avoiding short prepare
In-memory query runtime data cache
Reduce CPU/elapsed time with potentially better access path selection with DB2 11
MXDTCACH up to 512MB per thread, default 20MB

DB2 12: Benefits with Larger Memory
Reduce the CPU cost by utilizing more memory
Faster index access from OLTP, random select and insert
By creating in-memory index tree structure (FTB)
CPU reduction for in-memory buffer pools
Optimized in-memory buffer pool layout (contiguous BP)
Larger BP supported – up to 16 TB total
Faster insert through use of in-memory pipes for space search
In-memory techniques for query performance
Investigating other areas of memory optimization
Optimize more internal structures for CPU cache efficiency
Performance critical paths
In memory look up table
Dynamic statement cache pools (LC24 reduction)
Avoid EDM out of storage (using SMC to manage EDM storage)
Data compression improvements
More DB2 memory self-management (e.g. reduce Zparms)

DB2 12 Buffer Pool Related Enhancements
Larger buffer pool to reduce Sync I/Os
Improvement in In-Memory Buffer pools with PAGESTEAL (NONE)
Supporting > 1TB buffer pools
Sum of VPSIZE and SPSIZE can be up to 16TB
Still same restriction applies (2x of real storage)
Current z/OS limit is 4TB per LPAR
Buffer pool simulation (retrofitted to DB2 11 with PI22091)
Buffer pool page size Range for integer
4 KB 2000 - 4000000000
8 KB 1000 - 2000000000
16 KB 500 - 1000000000
32 KB 250 - 500000000

DB2 12 In-Memory Contiguous Buffer Pools
Greatly reduces GetPage overhead
Up to 8% CPU reduction measured for OLTP
PGSTEAL(NONE) – improved in DB2 12 to avoid LRU and hash chain overheads
Overflow area is used in case objects don’t fit
Allocated when the BP is allocated, but only backed when used
Automatically managed by DB2

DB2 12 In-Memory Index Optimization
A new Fast Index Traversal feature is introduced
Memory optimized structure –Fast Traverse Block (FTB) for fast index lookups
Resides in memory areas outside of the buffer pool
New zparm INDEX_MEMORY_CONTROL
Default=AUTO (min. of 500 MB or 20% of allocated BP storage)
(Currently) UNIQUE indexes only, key size 64 bytes or less
DB2 automatically determines which indexes would benefit from FTB
-DISPLAY STATS command shows which indexes are using FTBs
New SYSINDEXCONTROL catalog table
Specify time windows to control use of FTBs for an index
New IFCIDs 389 and 477 to track FTB usage

Fast Index Traversal : Faster & Cheaper
33
6%
11%
16%
23%
2 3 4 5
Index Levels
CPU Improvement (%) from Simple Lookup in DB2 12
Up to 23% CPU reduction for index look-up
using DB2 12 In-memory index tree

Classic IRWW: 2-Way Data Sharing Performance Measurements DB2 V12 vs V11 – RELEASE(COMMIT)
▪ Key Observations
▪ About 3.5% average DB2 CPU/transaction reduction in V12 BNFA
without enabling FTB
▪ Enabling FTB use improved CPU reduction to about 6% in both
BNFA and ANFA
▪ About 45% reduction in Getpages/txn with FTB
▪ DBM1 Real Storage increase by about 240 MB in BNFA mode
without using FTB (each member)
▪ Enabling FTB use increased real storage usage by an additional
110MB (each member)
550
570
590
610
630
650
670
V11 NFM V12 BNFA,FTB Disabled
V12 BNFA,FTB Enabled
(AUTO)
V12 ANFA,FTB Enabled
(AUTO)
CP
U/t
xn
(m
icro
seco
nd
s)
Classic IRWW 2-way: DB2 CPU/Transaction(Class2 + MSTR + DBM1 + IRLM)
0
10
20
30
40
50
60
70
80
90
V11 NFM V12 BNFA,FTB Disabled
V12 BNFA,FTB Enabled
(AUTO)
V12 ANFA,FTB Enabled
(AUTO)
Getp
ag
es/C
om
mit
Classic IRWW 2-way: Getpages/Commit
,0200,0400,0600,0800,0
1000,01200,01400,01600,01800,02000,0
V11 NFM V12 BNFA,FTB Disabled
V12 BNFA,FTB Enabled
(AUTO)
V12 ANFA,FTB Enabled
(AUTO)
Sto
rag
e (
MB
)
Classic IRWW 2-way: DBM1 Real StorageExcluding storage used by Local Buffer Pools
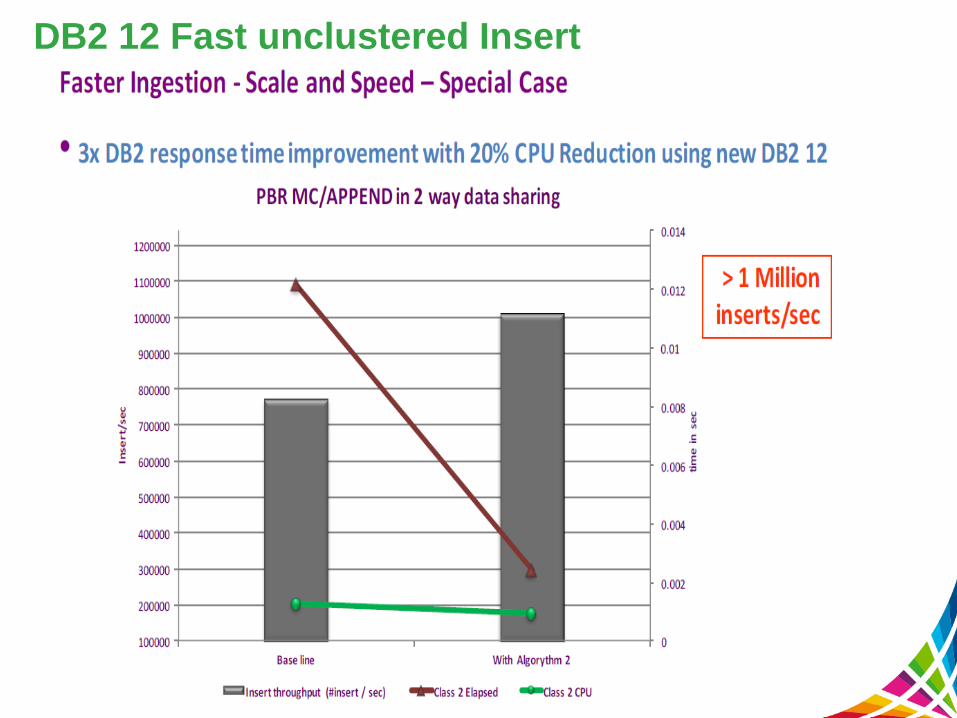
DB2 12 Fast unclustered Insert

DB2 12 Significant CPU Reduction in DB2 Query Workloads
36
CPU Reduction %
UNION ALL
w/View
Complex Outer
Join, UDF
Complex
reporting,
large sort
Simple
query or
large data
scan

Large memory means large REAL memory
Trade-off is CPU and ET improvements by doing more in-memory
No point in using larger memory for any of areas that were mentioned if it results in paging !
Make sure you have enough REAL storage!
If you have enough real storage, reduce need to micro manage it
Still need to monitor
If you have enough real storage, you can consider using
REALSTORAGE_MANAGEMENT=OFF
Will grow amount of real you need over time (but greatly depends on the workload)
Can save CPU time – freeing real at deallocation or every x commits
Monitor closely when you change to OFF

Analytical Workloads Considerations

HTAP = In-Memory Computing?
There is impression that having the data in memory is enough for delivering universal DBMS (handling both transactions and analytical workloads)
In-memory computing is a catchy phrase, everybody automatically assumes much better performance
But having the data in memory all the time is not enough, e.g. data intensive queries benefit even more from early filtering such as via columnar orientation, clever compression techniques, very high parallelism degree, …
It's regularly overlooked that most of traditional DBMSs already operate 'in-memory' more than 95% of time and the access pattern they are designed for (transactional processing) is not faster on 'true' in-memory DBMSs.

IDAA Customer Example
40
Customer Table ~ 5 Billion Rows
300 Mixed Workload Queries
Times
Faster
Query
Total
Rows
Reviewed
Total
Rows
Returned Hours Sec(s) Hours Sec(s)
Query 1 2,813,571 853,320 2:39 9,540 0.0 5 1,908
Query 2 2,813,571 585,780 2:16 8,220 0.0 5 1,644
Query 3 8,260,214 274 1:16 4,560 0.0 6 760
Query 4 2,813,571 601,197 1:08 4,080 0.0 5 816
Query 5 3,422,765 508 0:57 4,080 0.0 70 58
Query 6 4,290,648 165 0:53 3,180 0.0 6 530
Query 7 361,521 58,236 0:51 3,120 0.0 4 780
Query 8 3,425.29 724 0:44 2,640 0.0 2 1,320
Query 9 4,130,107 137 0:42 2,520 0.1 193 13
DB2 Only
DB2 with
IDAA
270 of the Mixed
Workload Queries
Executes in DB2 returning
results in seconds or sub-
seconds
30 of the Mixed Workload Queries took minutes to hours

LPAR CPU Utilization Effect
41
Without
accelerator
With
accelerator

HTAP: OLTP and analytics co-locationMeasurement results
Thousands of
complex, analytical
queries now
integrated with
operational workload
Baseline HTAP
First use case: operational priority(periodic data synchronization)
Operational
throughput
maintained with no
additional mainframe
capacity






























