Embed Size (px)
Citation preview

Three requirements for reducing performance issues and unplanned
downtime in any data center
DARRYL FUJITA TECHNICAL SOFTWARE SOLUTIONS
SPECIALIST HITACHI DATA SYSTEMS

How Big Is The Cost Of Unplanned IT Outages?
In 2010, the average revenue cost of an unplanned application outage was estimated to be nearly US$2.8 million dollars per hour, according to a report by IBM Global Services.
According to Dunn & Bradstreet, 59% of Fortune 500 companies experience a minimum of 1.6 hours of downtime per week.

How Big Is The Cost Of Unplanned IT Outages?

The Cost Of Unplanned Outages: A conservative estimate from Gartner pegs the hourly cost of downtime for computer networks at $42,000, so a company that suffers from worse than average downtime of 175 hours a year can lose more than $7 million per year.
The Scope Of Downtime Per Year Gartner has shown, downtime can reach an average of 87 hours a year. Obviously that's the sum of many outages - anywhere from a few minutes to hours. But at the end of the day, for an organization this becomes a staggering figure.
How Big Is The Cost Of Unplanned IT Outages?

Average Outage Period: According to the IT Process Institute, resolution time per outage is around 200 minutes. It's really interesting to see just how much time is being put in to resolve outages, when you consider what is happening to the customer experience and company reputation in this time.
How Big Is The Cost Of Unplanned IT Outages?

Majority Cause of Performance Errors Are Changes – Getting to the bottom of the matter, the Enterprise Management Association reports that 60% of unplanned availability and performance errors are the result of misconfigurations and changes.
How Big Is The Cost Of Unplanned IT Outages?

Increasingly Complex
More difficult to manage
New technologies - virtualization & cloud computing
Requirement to view and understand the infrastructure End to End
Today’s IT Environment

Heterogeneous platforms Hardware devices from a variety of vendors
Multiple monitoring tools; one for each device and/or manufacturer
Inconsistent reporting types make issue identification difficult and time-consuming
Various levels of expertise on staff Some broad and shallow
Others specialized and deep
Managing change Consolidations and acquisitions
Changes in management and staff
The Accidental Infrastructure

Primary pain points with IT
infrastructure management:
Lack of system-wide tools
Lack of proactive analysis
Lack of root cause analysis (RCA)
Top IT Infrastructure Management Challenges

Demands of IT…...
IT
Manager

Increased complexities in IT environment Proactive efforts
become challenge
Complexity adds significant time to get
to root cause
Virtualization Adds Complexity

Three things you must absolutely have to ensure
data center stability…
Comprehensive visibility across the data center through a single pane of glass Proactively monitor performance and changes across the entire infrastructure Intelligently automate root cause analysis to maximize efficiency
Essential Guidance

Monitoring your Data Center end-to-end
What is Comprehensive Visibility?
The Value of Visibility

Device specific monitoring tools lack sophistication to measure overall impact on data center
Device Level Visibility vs. Data Center Visibility

Give me a single console view of my data center…end-to-end
• Ability to see the bigger picture
• Know the relationships between devices and how they are impacting one another
• Ability to map virtual relationships
• Know what’s there, how it’s connected, if it’s available and how it’s performing against thresholds
Comprehensive Visibility…What Does it Look Like?

Value = I have visibility
into my IT environment
Comprehensive Visibility…What Does it Look Like?

“With the Hitachi IT Operations Analyzer solution we can achieve full visibility of our entire
infrastructure and be alerted to any issues in real time. This enables us to operate much more
efficiently and deliver an enhanced service to our patients.”
David Williams Director of Information
and Technology Aspen Healthcare
Hitachi IT Operations Analyzer: What Customers are Saying …

How can I keep an eye on changes and how they affect performance across the data center?
• Get proactive warnings of performance issues and capacity shortfalls before problems affect end users
• Real time metrics let you meet SLAs by pinpointing performance issues before end users notice
• Optimize your infrastructure for efficiency and minimize risk of performance degradations across your entire infrastructure
• View all hardware & software changes and see the impact of those changes across the data center
Getting Proactive

“Before Analyzer, we reacted. When a
problem occurred, we’d manually work to
diagnose issues. Analyzer takes the guesswork
out of managing devices and keeps us abreast
of what’s happening.”
Bryan Nash
Senior Vice President
McHenry Savings Bank
Hitachi IT Operations Analyzer: What Customers are Saying …

Help me reduce time and complexity associated with pinpointing and resolving critical issues in the data
center (and stop the finger pointing!)
Remove the troubleshooting step…get straight to fixing the real problem
Eliminate the finger pointing, improve team collaboration and reduce manual problem solving efforts by as much as 60% with automated root cause analysis
Why not automate the process of RCA rather than paying someone to manually perform tasks?
Faster diagnosis of issues = reduced MTTD & MTTR = reduced costs = enhanced productivity. Not too bad!
I Didn’t Know Root Cause Analysis Could be This Easy!

Quickly Identify the Root Cause through Automation
A unified end to end view of resource availability
and performance can help reduce the time required
to identify the business impact and root cause of problems
Cost Effective Path to Root Cause Analysis
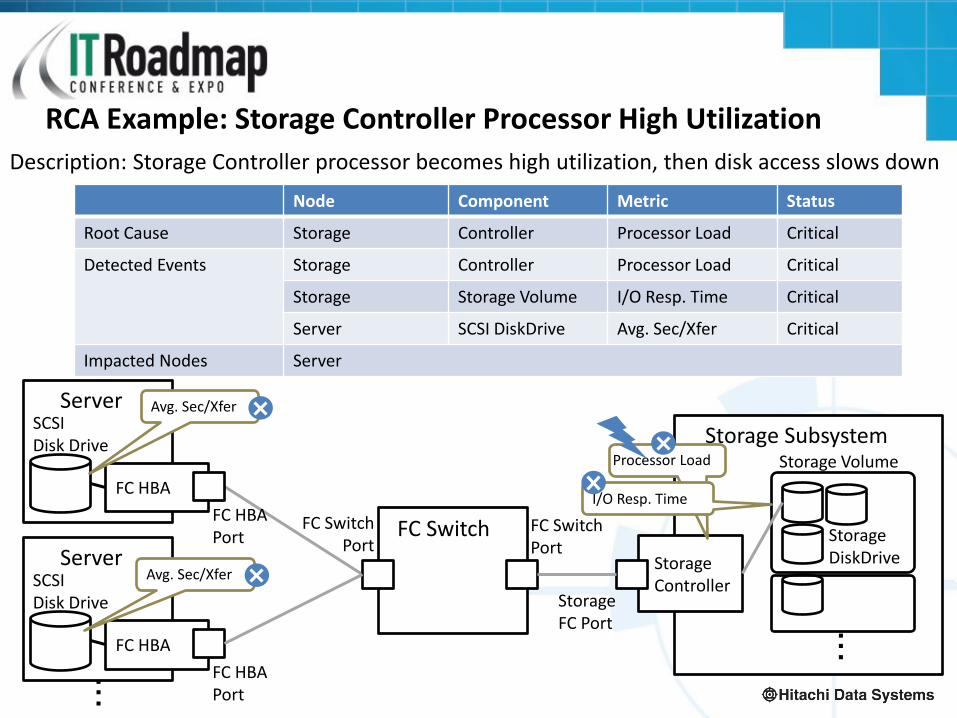
Description: Storage Controller processor becomes high utilization, then disk access slows down
Storage Subsystem
Storage Controller
Storage FC Port
FC Switch Port
FC Switch Server
FC Switch Port
FC HBA Port
FC HBA
SCSI Disk Drive
Server
FC HBA Port
FC HBA
SCSI Disk Drive
Storage DiskDrive
Storage Volume
・ ・ ・
・ ・ ・
Processor Load
I/O Resp. Time
Avg. Sec/Xfer
Avg. Sec/Xfer
Node Component Metric Status
Root Cause Storage Controller Processor Load Critical
Detected Events Storage Controller Processor Load Critical
Storage Storage Volume I/O Resp. Time Critical
Server SCSI DiskDrive Avg. Sec/Xfer Critical
Impacted Nodes Server
RCA Example: Storage Controller Processor High Utilization

End-to-End monitoring tool for heterogeneous environments
Visibility, Proactive Analysis, Automated Root Cause Analysis

Environment Over 3,000 devices in data center
30,000 employees
Problem Average 2-3 hours to diagnose critical performance
issues
Experiencing multiple critical events per month
600-900 hours in lost productivity per month
IT team performing manual correlation
Nothing in place to remediate and improve issues
Segmented IT teams finger pointing
Low visibility between Application, Server, SAN and Storage environments
Losing up to an estimated $50K per month directly
related to unplanned performance degradations
Case Study – City of Calgary

Solution Intelligently automate the process of pinpointing
root cause of all critical issues
Proactively manage performance across the complete infrastructure
Gain comprehensive visibility of the infrastructure and measure impact
Effect Reduction in mean time to diagnose (MTTD) by
over 60%
Saving lost productivity
Increased moral– no more finger pointing
IT moved from reactive to proactive
An estimated $500,000 savings per year
Case Study – City of Calgary

Three requirements for reducing performance issues and unplanned downtime in any data center





























